

Steganographer Detection via Multiple-instance Learning Graph Convolutional Networks
-
摘要: 隐写者检测通过设计模型检测在批量图像中嵌入秘密信息进行隐蔽通信的隐写者, 对解决非法使用隐写术的问题具有重要意义. 本文提出一种基于多示例学习图卷积网络 (Multiple-instance learning graph convolutional network, MILGCN) 的隐写者检测算法, 将隐写者检测形式化为多示例学习(Multiple-instance learning, MIL) 任务. 本文中设计的共性增强图卷积网络(Graph convolutional network, GCN) 和注意力图读出模块能够自适应地突出示例包中正示例的模式特征, 构建有区分度的示例包表征并进行隐写者检测. 实验表明, 本文设计的模型能够对抗多种批量隐写术和与之对应的策略.Abstract: Steganographer detection aims to solve the problem of illegal use of batch steganography by designing models to detect steganographers who embed secret information in images for covert communication. This paper proposes a novel steganographer detection algorithm called as multiple-instance learning graph convolutional network (MILGCN) to formalize steganography detection as a multiple-instance learning (MIL) task. The commonness enhancement graph convolutional network (GCN) and attention graph readout module designed in this paper can adaptively highlight the positive instance pattern and construct distinguishable bag representations for steganographer detection. Experiments show that the designed model can successfully attack a variety of batch steganography and the corresponding strategies.
-
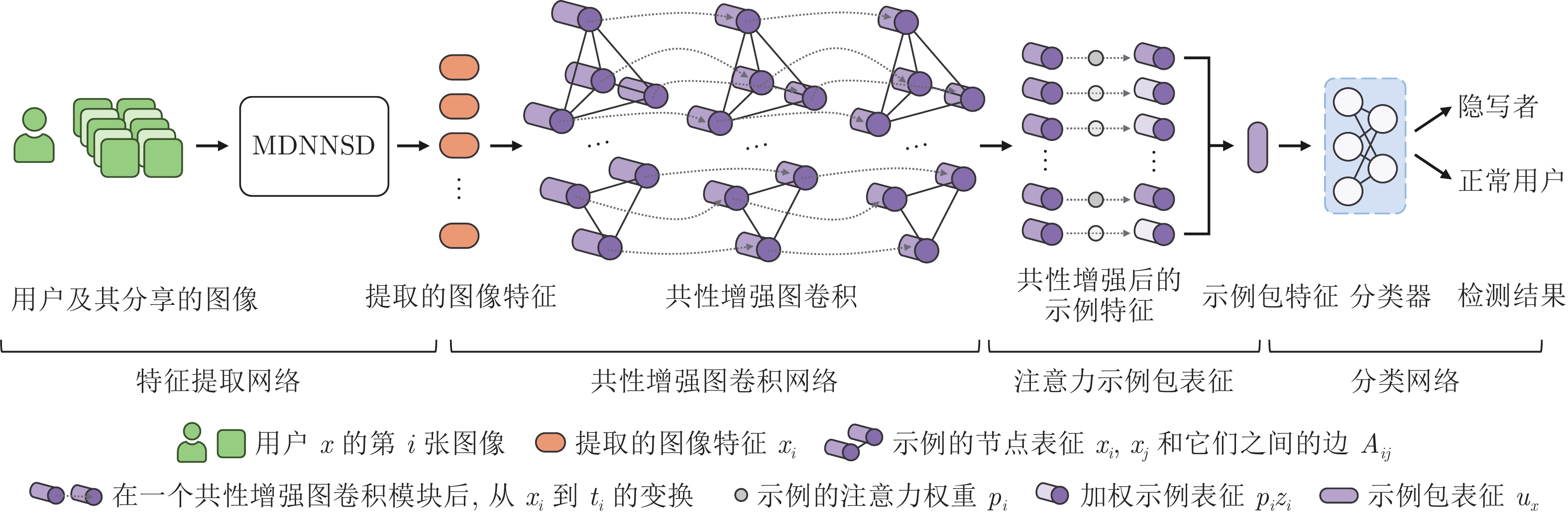
图 1 基于多示例学习图卷积网络的隐写者检测框架
Fig. 1 Steganographer detection framework based on multiple-instance learning graph convolutional network
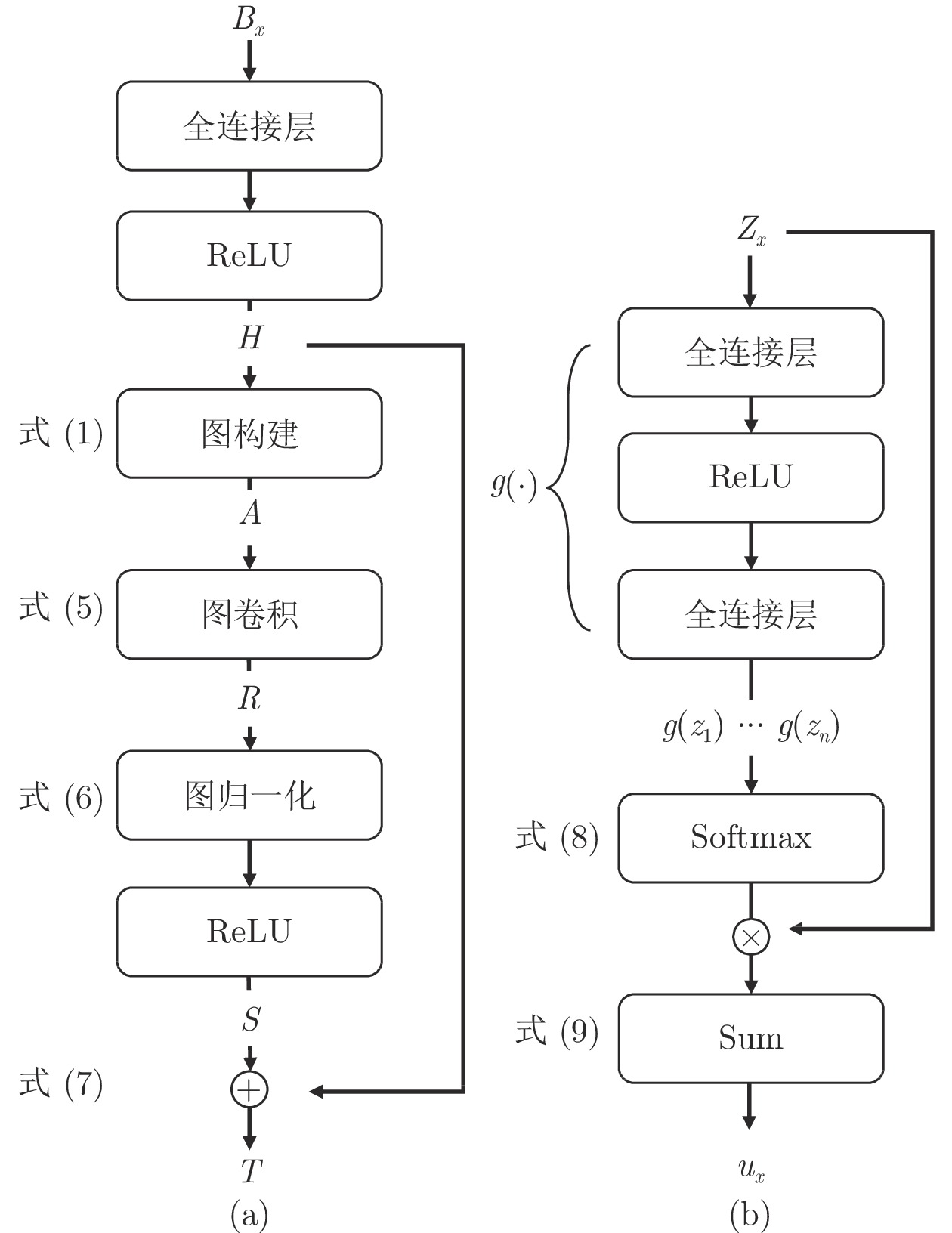
图 2 隐写者检测框架中两个模块((a) 共性增强图卷积模块; (b) 注意力读出模块)
Fig. 2 Two modules in steganographer detection framework ((a) The commonness enhancement graph convolutional network module; (b) The attention readout module)

图 3 当测试阶段隐写者使用不同隐写术、分享的载密图像数量占总图像数量的10%到100%时, 不同的基于图的隐写者检测方法检测准确率
Fig. 3 The accurate rate of different graph-based steganographer detection methods when the number of shared secret images is from 10% to 100% of the total number of images and the steganographer uses different steganography in test
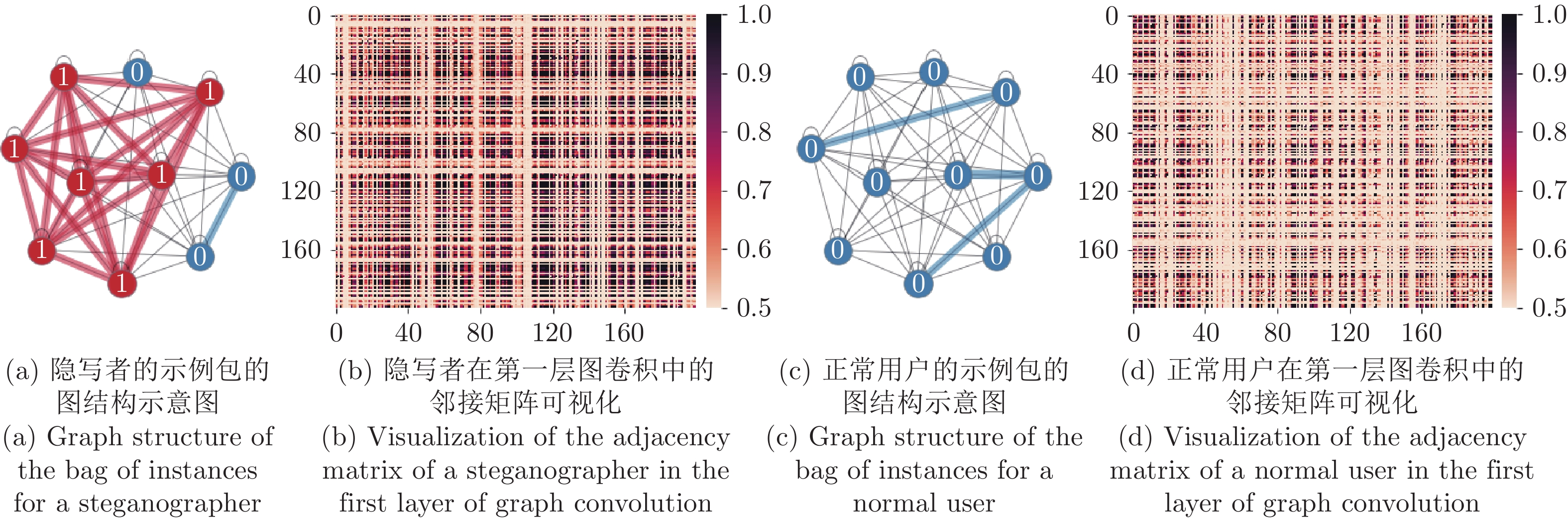
图 4 隐写者和正常用户所对应图结构的可视化
Fig. 4 Visualization of graph structures corresponding to steganographer and normal user
表 1 使用的变量符号及对应说明
Table 1 The variable symbols and their corresponding descriptions
变量 含义 $B_x$ 用户$x$对应的示例包 $x_i$ 示例包$B_x$内第$i$个示例 $m$ 当前数据集中示例包的总数量 $n$ 当前示例包中示例的总数量 $v_i$ 共性增强图卷积模块的第$i$个输入示例特征 $h_i$ 对$v_i$使用$f$函数进行特征提取后得到的示例特征向量 $H$ 由示例特征向量构成的示例包的矩阵表示 $H=[h_1,\cdots,h_n]^{\rm{T}}$ $A_{ij}$ 图中第$i$个与第$j$个示例节点之间边的权重 $N_i$ 图中第$i$个示例节点的所有邻居节点 $A$ 示例包$B_x$所构成图的邻接矩阵 $r_i$ 进行图卷积后$h_i$所对应的示例特征向量 $R$ 由示例特征向量构成的示例包的矩阵表示 $R=[r_1,\cdots,r_n]^{\rm{T}}$ $s_i$ 进行图归一化后$r_i$ 所对应的示例特征向量 $S$ 由示例特征向量构成的示例包的矩阵表示 $S=[s_1,\cdots,s_n]^{\rm{T}}$ $t_i$ 共性增强图卷积模块的第$i$个输出示例特征 $T$ 由示例特征向量构成的示例包的矩阵表示 $T=[t_1,\cdots,t_n]^{\rm{T}}$ $f$ 特征提取函数 $g$ 注意力计算函数 $z_i$ 共性增强图卷积模块的输出, 也是注意力读出模块的第$i$个输入示例特征 $Z_x$ 由共性增强图卷积模块得到的示例特征向量构成的用户$x$对应的示例包的矩阵表示 $u_x$ 用户$x$对应的示例包的特征向量表征 $p_i$ 当前示例包中第$i$个示例对示例包表征的贡献 ${\rho_i}$ 第$i$个示例包的预测结果 $Y_i$ 第$i$个示例包的真实标签 $L$ 本文设计的损失函数 $L_{\rm{bag}}$ 本文设计的多示例学习分类损失 $L_{\rm{entropy}}$ 本文设计的熵正则损失 $L_{\rm{contrastive}}$ 本文设计的对比学习损失 $\lambda_1, \lambda_2, \lambda_3$ 超参数, 用于调整$L_{\rm{bag}},$ $L_{\rm{entropy}},$ $L_{\rm{contrastive}}$的权重  下载: 导出CSV
下载: 导出CSV
表 2 已知隐写者使用相同图像隐写术(S-UNIWARD) 时的隐写者检测准确率(%), 嵌入率从0.05 bpp到0.4 bpp
Table 2 Steganography detection accuracy rate (%) when steganographers use the same image steganography (S-UNIWARD), while the embedding payload is from 0.05 bpp to 0.4 bpp
模型 嵌入率(bpp) 0.05 0.1 0.2 0.3 0.4 前沿 MDNNSD 4 54 100 100 100 XuNet_SD 2 2 71 100 100 基于GAN SSGAN_SD 0 1 1 2 4 基于GNN GAT 2 3 3 3 4 GraphSAGE 28 88 100 100 100 AGNN 24 99 100 100 100 GCN 19 96 100 100 100 SAGCN 72 100 100 100 100 基于MIL MILNN_self 15 87 100 100 100 MILNN_git 18 96 100 100 100 本文 MILGCN-MF 47 100 100 100 100 MILGCN 74 100 100 100 100
下载: 导出CSV
表 3 当测试阶段隐写者使用相同隐写术(S-UNIWARD) 和分享的载密图像数量占总图像数量为10%到100%时, SRNet-AVG和SRNet-MILGCN的检测成功率 (%)
Table 3 The accurate rate (%) of SRNet-AVG and SRNet-MILGCN when the number of shared secret images is from 10% to 100% of the total number of images and the steganographer uses the same steganography (S-UNIWARD) in test
方法 占比(%) 10 30 50 70 90 100 SRNet-AVG 26 100 100 100 100 100 SRNet-MILGCN 35 100 100 100 100 100
下载: 导出CSV
表 4 当用户分享不同数量的图像时, 使用MILGCN和SAGCN进行隐写者检测的准确率(%),嵌入率从0.05 bpp到0.4 bpp
Table 4 Steganography detection accuracy rate (%) of MILGCN and SAGCN when users share different numbers of images, while the embedding payload is from 0.05 bpp to 0.4 bpp
数量(张) 嵌入率 (bpp) 0.05 0.1 0.2 0.3 0.4 MILGCN 100 35 96 100 100 100 200 74 100 100 100 100 400 96 100 100 100 100 600 100 100 100 100 100 SAGCN 100 31 96 100 100 100 200 72 100 100 100 100 400 91 100 100 100 100 600 91 100 100 100 100
下载: 导出CSV
表 5 在隐写术错配情况下, 当分享的载密图像数量占比5%时, MILGCN取得的隐写者检测准确率(%)
Table 5 Steganography detection accuracy rate (%) in the case of steganography mismatch when the number of shared secret images is 5% of the total number of images
测试隐写术 HUGO-BD WOW HILL MiPOD 检测准确率 6 4 5 5
下载: 导出CSV
表 6 训练模型使用HILL作为隐写术, 分享的载密图像数量占比10%或30%, MILGCN取得的隐写者检测准确率(%)
Table 6 Steganography detection accuracy rate (%) when the steganography used for training is HILL and the number of shared secret images is 10% or 30% of the total number of images
载密图像比例 测试隐写术 HUGO-BD WOW HILL MiPOD 10% 9 6 7 4 30% 37 48 49 47
下载: 导出CSV
表 7 已知隐写者使用相同图像隐写术(J-UNIWARD)时的隐写者检测准确率(%), 嵌入率从0.05 bpnzAC到0.4 bpnzAC
Table 7 Steganography detection accuracy rate (%) when steganographer use the same image steganography (J-UNIWARD) and the embedding payload is from 0.05 bpnzAC to 0.4 bpnzAC
模型 嵌入率(bpnzAC) 0.05 0.1 0.2 0.3 0.4 JRM_SD 11 17 25 31 48 PEV_SD 0 0 1 1 5 GraphSAGE 13 68 100 100 100 AGNN 13 84 100 100 100 GCN 16 88 100 100 100 SAGCN 17 92 100 100 100 MILGCN 25 92 100 100 100
下载: 导出CSV
表 8 当测试阶段隐写者使用nsF5或UERD等图像隐写术嵌入秘密信息时, 不同方法的隐写者检测准确率(%),嵌入率从0.05 bpnzAC到0.4 bpnzAC
Table 8 Steganography detection accurate rate (%) of different methods when steganographer uses nsF5 or UERD as image steganography in the testing phase and the embedding payload is from 0.05 bpnzAC to 0.4 bpnzAC
隐写术 模型 嵌入率(bpnzAC) 0.05 0.1 0.2 0.3 0.4 nsF5 PEV_SD 0 1 9 52 93 GraphSAGE 21 91 100 100 100 AGNN 20 90 100 100 100 GCN 24 90 100 100 100 SAGCN 29 92 100 100 100 MILGCN 22 90 100 100 100 UERD GraphSAGE 25 91 100 100 100 AGNN 29 94 100 100 100 GCN 33 96 100 100 100 SAGCN 33 98 100 100 100 MILGCN 42 99 100 100 100
下载: 导出CSV
表 9 计算复杂度分析
Table 9 The analysis of computational complexity
方法名称 批次平均
运行时间(s)单个样本浮点
运算数(千兆次)参数量(千个) MILNN 0.001 0.003 12.92 GCN 0.830 2.480 67.97 SAGCN 2.210 7.410 67.94 MILGCN 0.020 0.070 74.18
下载: 导出CSV
-
[1] Ker A D, Pevný T. A new paradigm for steganalysis via clustering. In: Proceedings of the SPIE 7880, Media Watermarking, Security, and Forensics III. Bellingham, USA: SPIE, 2011. 312−324 [2] Pevný T, Feidrich J. Merging Markov and DCT features for multi-class JPEG steganalysis. In: Proceedings of the SPIE 6505, Security, Steganography, and Watermarking of Multimedia Contents IX. Bellingham, USA: SPIE, 2007. 1−13 [3] Ker A D, Pevný T. Identifying a steganographer in realistic and heterogeneous data sets. In: Proceedings of the SPIE 8303, Media Watermarking, Security, and Forensics. Bellingham, USA: SPIE, 2012. 1−13 [4] Ker A D, Pevný T. The steganographer is the outlier: Realistic large-scale steganalysis. IEEE Transactions on Information Forensics and Security, 2014, 9(9): 1424−1435 doi: 10.1109/TIFS.2014.2336380 [5] Li F Y, Wu K, Lei J S, Wen M, Bi Z Q, Gu C H. Steganalysis over large-scale social networks with high-order joint features and clustering ensembles. IEEE Transactions on Information Forensics and Security, 2016, 11(2): 344−357 doi: 10.1109/TIFS.2015.2496910 [6] Zheng M J, Zhong S H, Wu S T, Jiang J M. Steganographer detection via deep residual network. In: Proceedings of the IEEE International Conference on Multimedia and Expo (ICME). Piscataway, USA: IEEE, 2017. 235−240 [7] Zheng M J, Zhong S H, Wu S T, Jiang J M. Steganographer detection based on multiclass dilated residual networks. In: Proceedings of the ACM on International Conference on Multimedia Retrieval. New York, USA: ACM, 2018. 300−308 [8] Zhang Z, Zheng M J, Zhong S H, Liu Y. Steganographer detection via enhancement-aware graph convolutional network. In: Proceedings of the IEEE International Conference on Multimedia and Expo (ICME). Piscataway, USA: IEEE, 2020. 1−6 [9] Zhang Z, Zheng M J, Zhong S H, Liu Y. Steganographer detection via a similarity accumulation graph convolutional network. Neural Networks: The Official Journal of the International Neural Network Society, 2021, 136: 97−111 doi: 10.1016/j.neunet.2020.12.026 [10] Ning X, Tian W J, Yu Z Y, Li W J, Bai X, Wang Y B. HCFNN: High-order coverage function neural network for image classifican. Pattern Recognition, 2022, 131: Article No. 108873 doi: 10.1016/j.patcog.2022.108873 [11] Defferrard M, Bresson X, Vandergheynst P. Convolutional neural networks on graphs with fast localized spectral filtering. In: Proceedings of the 30th International Conference on Neural Information Processing Systems (NIPS). New York, USA: Curran Associates Inc., 2016. 3844−3852 [12] Kipf T N, Welling M. Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv: 1609.02907, 2016. [13] Hamilton W L, Ying R, Leskovec J. Inductive representation learning on large graphs. In: Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS). New York, USA: Curran Associates Inc., 2017. 1025−1035 [14] Ying R, You J X, Morris C, Ren X, Hamilton W L, Leskovec J. Hierarchical graph representation learning with differentiable pooling. In: Proceedings of the 32nd International Conference on Neural Information Processing Systems (NIPS). New York, USA: Curran Associates Inc., 2018. 4805−4815 [15] Veličković P, Cucurull G, Casanova A, Romero A, Liò P, Bengio Y. Graph attention networks. In: Proceedings of the 6th International Conference on Learning Representation. Vancouver, Canada: ICLR Press, 2018. 1−12 [16] Gao W, Wan F, Yue J, Xu S C, Ye Q X. Discrepant multiple instance learning for weakly supervised object detection. Pattern Recognition: The Journal of the Pattern Recognition Society, 2022, 122: Article No. 108233 doi: 10.1016/j.patcog.2021.108233 [17] Tang X C, Liu M Z, Zhong H, Ju Y Z, Li W L, Xu Q. MILL: Channel attention-based deep multiple instance learning for landslide recognition. ACM Transactions on Multimedia Computing, Communications, and Applications, 2021, 17(2s): 1−11 [18] Yuan M, Xu Y T, Feng R X, Liu Z M. Instance elimination strategy for non-convex multiple-instance learning using sparse positive bags. Neural Networks, 2021, 142: 509−521 doi: 10.1016/j.neunet.2021.07.009 [19] Su Z Y, Tavolara T E, Carreno-Galeano G, Lee S J, Gurcan M N, Niazi M K K. Attention2majority: Weak multiple instance learning for regenerative kidney grading on whole slide images. Medical Image Analysis, 2022, 79: Article No. 102462 doi: 10.1016/j.media.2022.102462 [20] Bas P, Filler T, Pevný T. “Break our steganographic system”: The ins and outs of organizing BOSS. In: Proceedings of the International Workshop on Information Hiding. Prague, Czech Republic: Springer, 2011. 59−70 [21] Holub V, Fridrich J. Low-complexity features for JPEG steganalysis using undecimated DCT. IEEE Transactions on Information Forensics and Security, 2015, 10(2): 219−228 doi: 10.1109/TIFS.2014.2364918 [22] Fridrich J, Kodovsky J. Rich models for steganalysis of digital images. IEEE Transactions on Information Forensics and Security, 2012, 7(3): 868−882 doi: 10.1109/TIFS.2012.2190402 [23] Shi H C, Dong J, Wang W, Qian Y L, Zhang X Y. SSGAN: Secure steganography based on generative adversarial networks. In: Proceedings of the Pacific Rim Conference on Multimedia. Harbin, China: Springer, 2017. 534−544 [24] Pevný T, Somol P. Using neural network formalism to solve multiple-instance problems. arXiv preprint arXiv: 1609.07257, 2016. [25] Thekumparampil K K, Wang C, Oh S, Li L J. Attention-based graph neural network for semi-supervised learning. arXiv preprint arXiv: 1803.03735, 2018. [26] Xu G S, Wu H Z, Shi Y Q. Structural design of convolutional neural networks for steganalysis. IEEE Signal Processing Letters, 2016, 23(5): 708−712 doi: 10.1109/LSP.2016.2548421 [27] Holub V, Fridrich J, Denemark T. Universal distortion function for steganography in an arbitrary domain. EURASIP Journal on Information Security, DOI: 10.1186/1687-417X-2014-1 [28] Filler T, Fridrich J. Gibbs construction in steganography. IEEE Transactions on Information Forensics and Security, 2010, 5(4): 705−720 doi: 10.1109/TIFS.2010.2077629 [29] Holub V, Fridrich J. Designing steganographic distortion using directional filters. In: Proceedings of the IEEE International Workshop on Information Forensics and Security (WIFS). Piscataway, USA: IEEE, 2012. 234−239 [30] Sedighi V, Cogranne R, Fridrich J. Content-adaptive steganography by minimizing statistical detectability. IEEE Transactions on Information Forensics and Security, 2016, 11(2): 221−234 doi: 10.1109/TIFS.2015.2486744 [31] Fridrich J, Pevný T, Kodovský J. Statistically undetectable JPEG steganography: Dead ends challenges, and opportunities. In: Proceedings of the 9th Workshop on Multimedia and Security. Dallas, USA: ACM, 2007. 3−14 [32] Guo L J, Ni J Q, Su W K, Tang C P, Shi Y Q. Using statistical image model for JPEG steganography: Uniform embedding revisited. IEEE Transactions on Information Forensics and Security, 2015, 10(12): 2669−2680 doi: 10.1109/TIFS.2015.2473815 [33] Qian Y L, Dong J, Wang W, Tan T N. Deep learning for steganalysis via convolutional neural networks. In: Proceedings of the SPIE 9409, Media Watermarking, Security, and Forensics. Bellingham, USA: SPIE, 2015. 1−10 [34] 卫星, 李佳, 孙晓, 刘邵凡, 陆阳. 基于混合生成对抗网络的多视角图像生成算法. 自动化学报, 2021, 47(11): 2623−2636Wei Xing, Li Jia, Sun Xiao, Liu Shao-Fan, Lu Yang. Cross-view image generation via mixture generative adversarial network. Acta Automatica Sinica, 2021, 47(11): 2623−2636 [35] 胡铭菲, 左信, 刘建伟. 深度生成模型综述. 自动化学报, 2022, 48(1): 40−74 doi: 10.16383/j.aas.c190866Hu Ming-Fei, Zuo Xin, Liu Jian-Wei. Survey on deep generative model. Acta Automatica Sinica, 2022, 48(1): 40−74 doi: 10.16383/j.aas.c190866 [36] 董胤蓬, 苏航, 朱军. 面向对抗样本的深度神经网络可解释性分析. 自动化学报, 2022, 48(1): 75−86Dong Yin-Peng, Su Hang, Zhu Jun. Interpretability analysis of deep neural networks with adversarial examples. Acta Automatica Sinica, 2022, 48(1): 75−86 [37] 余正飞, 闫巧, 周鋆. 面向网络空间防御的对抗机器学习研究综述. 自动化学报, 2022, 48(7): 1625−1649Yu Zheng-Fei, Yan Qiao, Zhou Yun. A survey on adversarial machine learning for cyberspace defense. Acta Automatica Sinica, 2022, 48(7): 1625−1649 [38] 赵博宇, 张长青, 陈蕾, 刘新旺, 李泽超, 胡清华. 生成式不完整多视图数据聚类. 自动化学报, 2021, 47(8): 1867−1875 doi: 10.16383/j.aas.c200121Zhao Bo-Yu, Zhang Chang-Qing, Chen Lei, Liu Xin-Wang, Li Ze-Chao, Hu Qing-Hua. Generative model for partial multi-view clustering. Acta Automatica Sinica, 2021, 47(8): 1867−1875 doi: 10.16383/j.aas.c200121 [39] 张博玮, 郑建飞, 胡昌华, 裴洪, 董青. 基于流模型的缺失数据生成方法在剩余寿命预测中的应用. 自动化学报, 2023, 49(1): 185−196Zhang Bo-Wei, Zheng Jian-Fei, Hu Chang-Hua, Pei Hong, Dong Qing. Missing data generation method based on flow model and its application in remaining life prediction. Acta Automatica Sinica, 2023, 49(1): 185−196 [40] Wei G, Guo J, Ke Y Z, Wang K, Yang S, Sheng N. A three-stage GAN model based on edge and color prediction for image outpainting. Expert Systems With Applications, 2023, 214: Article No. 119136 doi: 10.1016/j.eswa.2022.119136 [41] Wang Y F, Dong X S, Wang L X, Chen W D, Zhang X J. Optimizing small-sample disk fault detection based on LSTM-GAN model. ACM Transactions on Architecture and Code Optimization, 2022, 19(1): 1−24 [42] Boroumand M, Chen M, Fridrich J. Deep residual network for steganalysis of digital images. IEEE Transactions on Information Forensics and Security, 2019, 14(5): 1181−1193 doi: 10.1109/TIFS.2018.2871749 -

 下载:
下载:

计量
- 文章访问数: 882
- HTML全文浏览量: 465
- PDF下载量: 192
- 被引次数: 0
