

Data-driven Bayesian Optimization Method for Intermittent hypoxic Training Strategy Decision
-
摘要: 青藏地区快速的经济发展使得进入高原的群体数量日益增加, 随之而来的高原健康问题也愈发突出. 间歇性低氧训练(Intermittent hypoxic training, IHT)是急进高原前常使用的预习服方法, 一般针对不同个体均设置固定的开环策略, 存在方案制定无标准、系统化的理论指导缺乏、效果不明显等问题. 针对以上情况, 设计了一种小样本数据驱动的IHT策略贝叶斯闭环学习优化框架, 建立自回归结构的高斯过程血氧饱和度(Peripheral oxygen saturation, SpO2)预测模型, 并考虑高低风险事件对训练的影响, 设计与氧浓度变化方向和速率相关的风险不对称代价函数, 提出具有安全约束的贝叶斯优化方法, 实现IHT最优供氧浓度的优化决策. 考虑到现有仿真器无法反映个体动态变化过程, 依据“最优速率理论”设计了合理的模型自适应变化律. 所提出闭环干预方法通过该仿真器进行了可行性和有效性验证. 说明该学习框架能够指导个体提升高原适应能力, 减轻其在预习服阶段的非适应性不良反应, 为个性化IHT提供精准调控手段.Abstract: The rapid economic development of Qinghai-Tibet region has led to an increasing number of groups entering the plateau, and the consequent problem of high-altitude health has become increasingly prominent. Intermittent hypoxic training (IHT) is a commonly-used preacclimatization approach before rapidly going to the plateau. It is usually designed as fixed open-loop strategies for different individuals, which has several disadvantages such as no standard formulation, lack of systematic theoretical guidance and poor efficacy. In this paper, a data-driven Bayesian closed-loop learning optimization framework of IHT strategy is designed by using small samples, and a Gaussian process model with autoregressive structure of peripheral oxygen saturation (SpO2) is built for prediction. Based on the predictive model, a risk asymmetric cost function related to the oxygen concentration rate and its direction is developed. Finally, a Bayesian optimization method with safety constraints is proposed to enable the optimal decision of IHT oxygen concentration. Given that the existing simulator cannot reflect the process dynamics of individuals, a reasonable model adaptation law is designed according to the “optimal rate theory”. The feasibility and effectiveness of the proposed closed-loop intervention method are verified by the simulator. These results indicate that the proposed learning framework can help individuals to improve their adaptability to high-altitudes, reduce their non-adaptive adverse reactions in the pretraining stage, and provide precise control solution to personalized IHT.
-
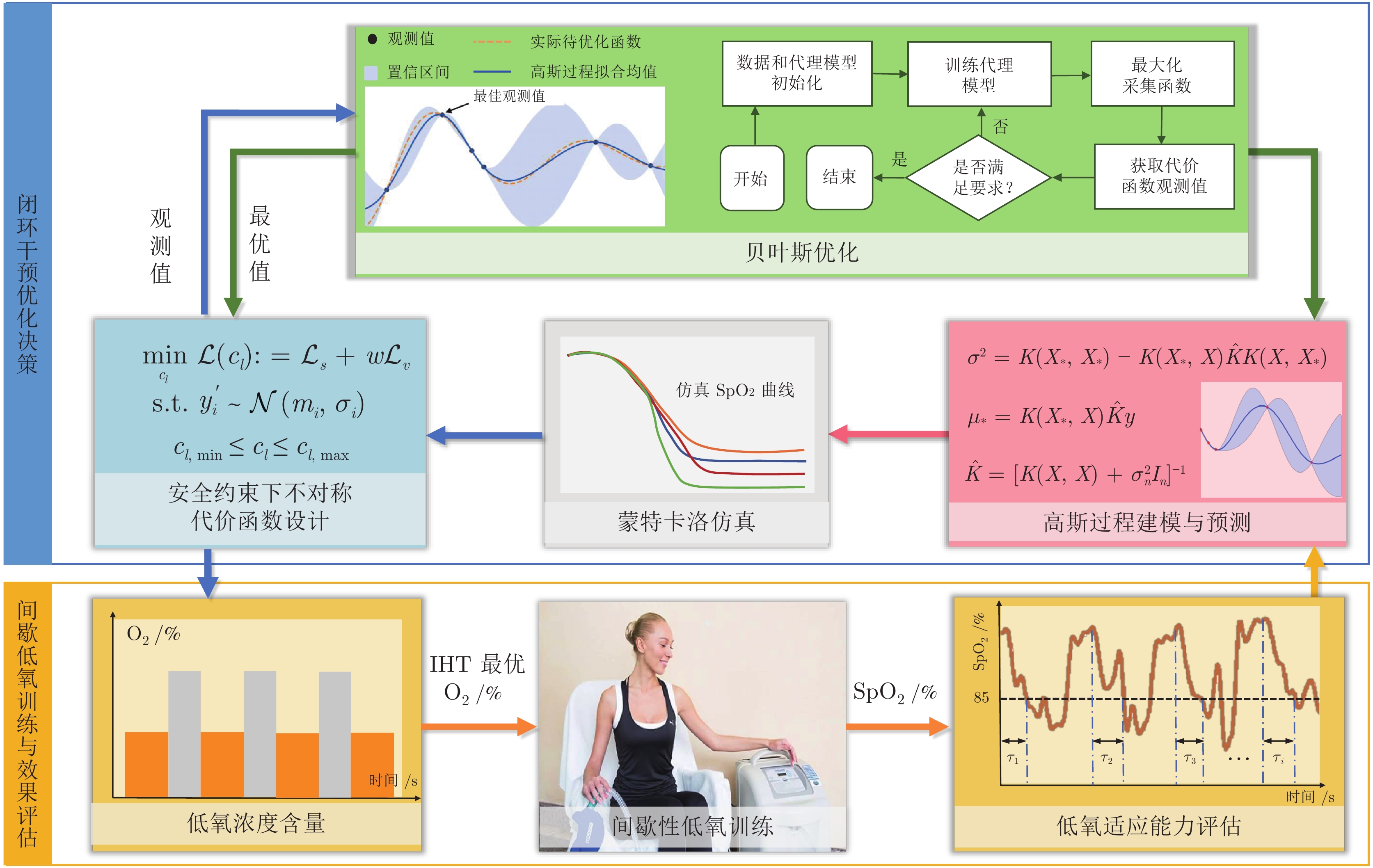
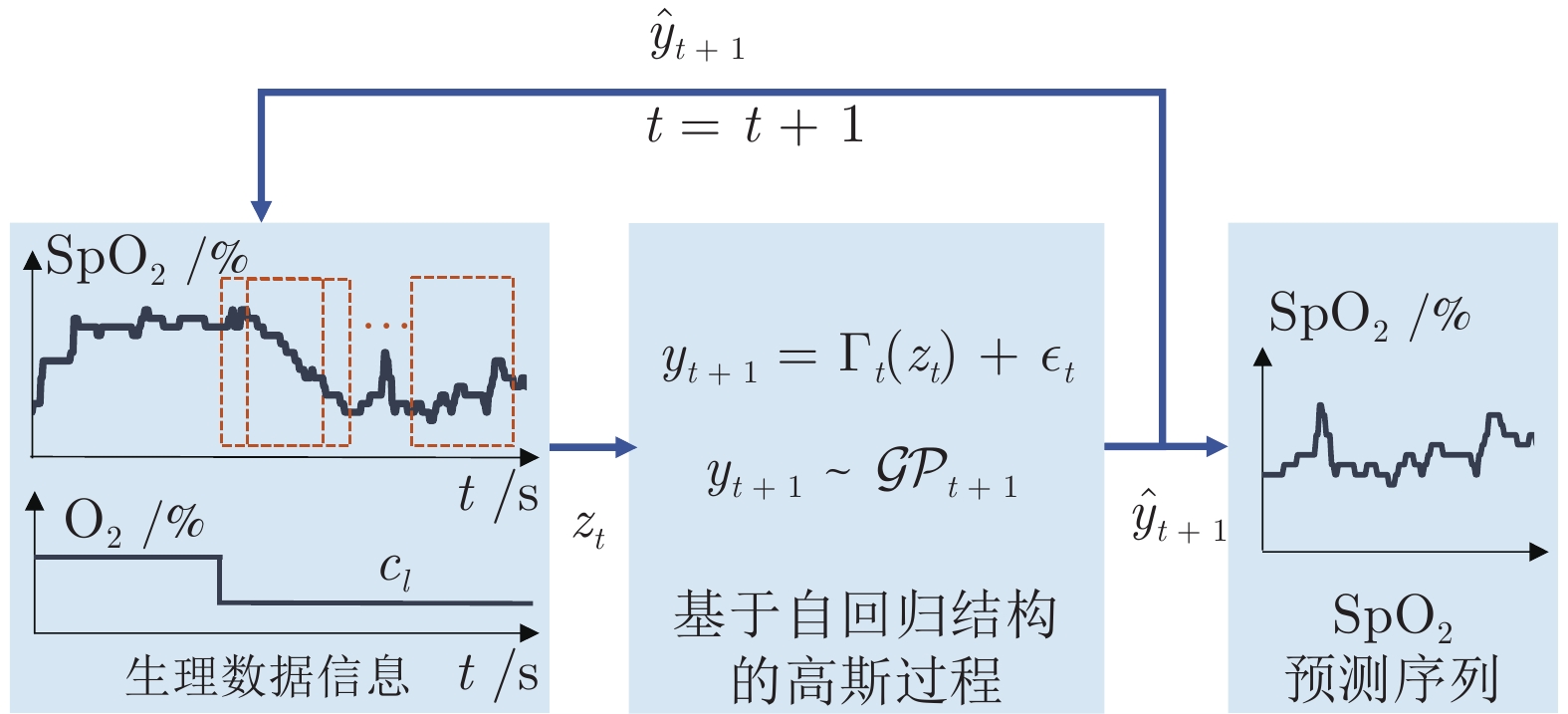
图 1 高原适应性能力提升的IHT策略优化决策算法流程图
Fig. 1 Flow chart of IHT optimization decision algorithm for high-altitude adaptability improvement
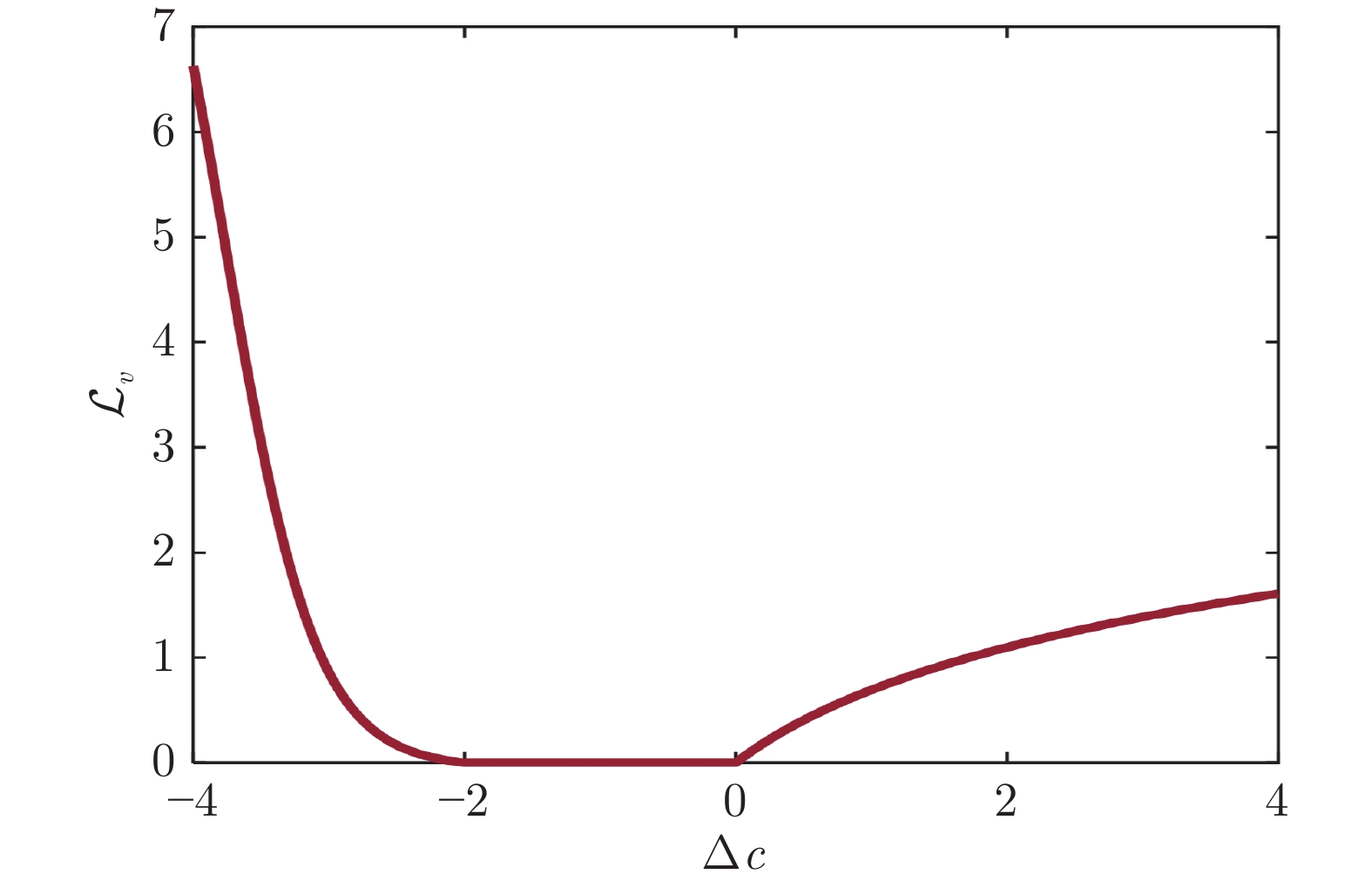
图 3 所设计代价函数$ {\cal{L}}_{v} $部分的惩罚强度在不同$ \Delta c $下的变化
Fig. 3 The penalty changes of designed $ {\cal{L}}_v $ term under different $ \Delta c $ values
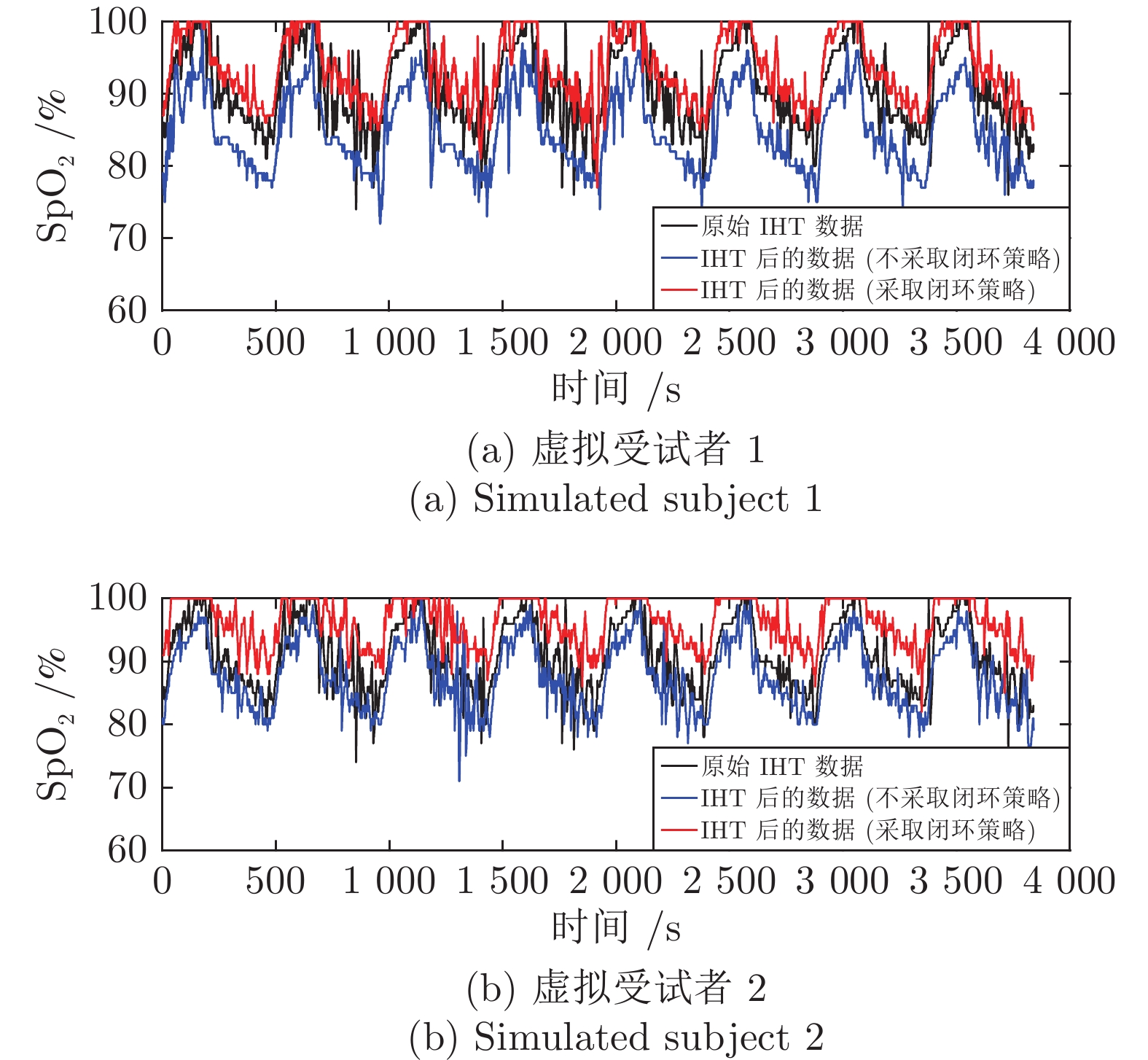
图 4 虚拟受试者1和2采取开环和闭环策略进行IHT的$ {\rm{ SpO}}_2 $曲线
Fig. 4 The $ {\rm{ SpO}}_2 $ curves of simulated subject 1 and 2 that perform IHT based on traditional open-loop strategy and proposed closed-loop strategy
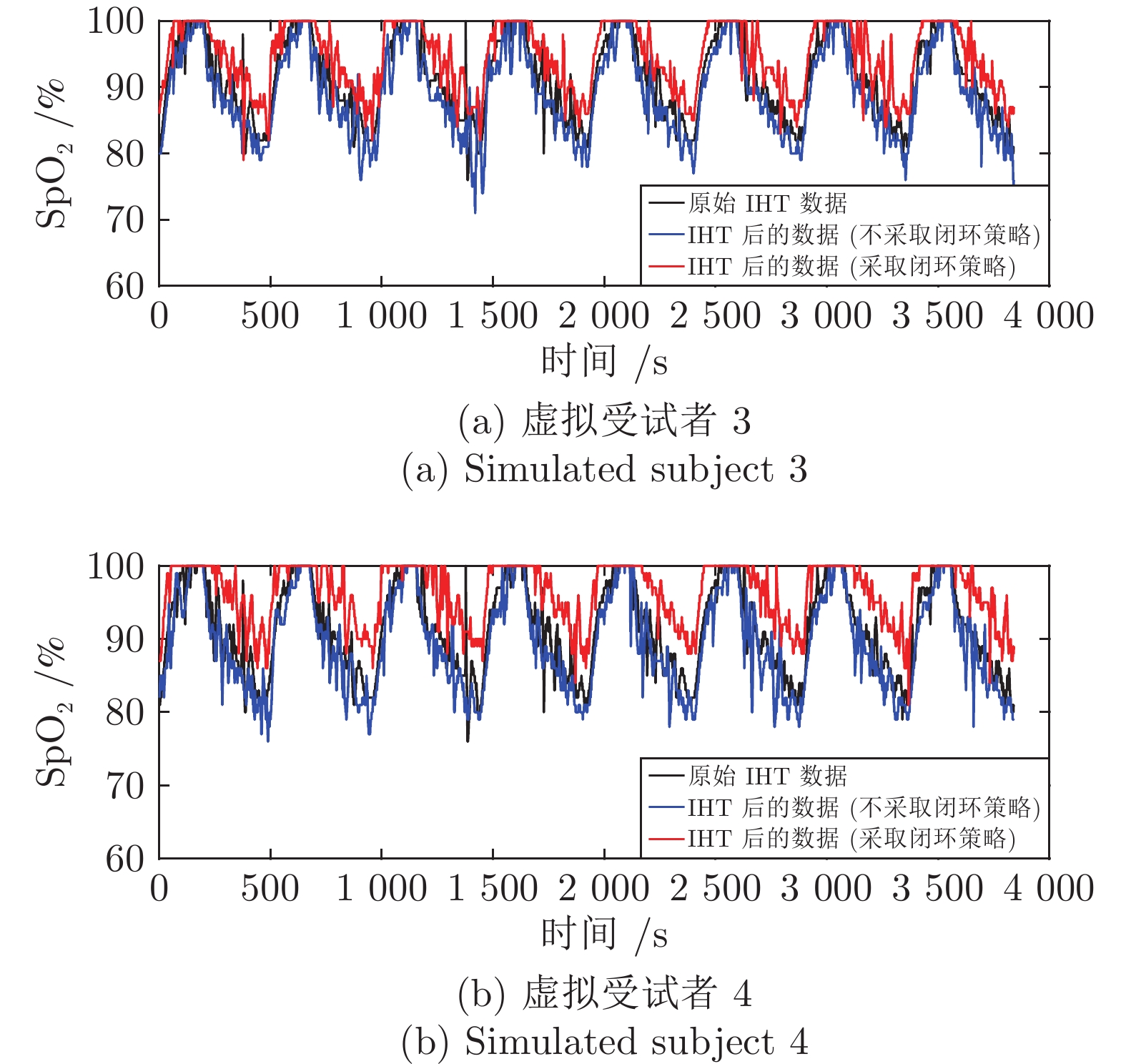
图 5 虚拟受试者3和4采取开环和闭环策略进行IHT的$ {\rm{ SpO}}_2 $曲线
Fig. 5 The $ {\rm{ SpO}}_2 $ curves of simulated subject 3 and 4 that perform IHT based on traditional open-loop strategy and proposed closed-loop strategy

图 6 10名虚拟受试者采取开环和闭环策略进行IHT的$ {\rm{ SpO}}_2 $曲线
Fig. 6 The $ {\rm{ SpO}}_2 $ curves of 10 simulated subjects that perform IHT based on traditional open-loop strategy and proposed closed-loop strategy
表 1 相关参数取值
Table 1 Related parameters
参数 含义 取值 $ n_s $ 一日IHT的低氧段总数 8 $ n_t $ 一段低氧段预测点总数 200 $ n_p $ 一段低氧段采样点总数 300 $ \sigma^{2} $ 平方指数核函数超参数 10 $ \ell $ 平方指数核函数超参数 10 $ \boldsymbol{y}_{r} $ 目标$ {\rm{ SpO}}_2 $向量 $ [95H_{50},90H_{50}, 85H_{100}]^\mathrm{T} $ $ Q $ 代价函数惩罚矩阵 136I $ w $ 代价函数权重系数 1000 $ c_{l,\min} $ 供氧浓度下阈值 (%) 10 $ c_{l,\max} $ 供氧浓度上阈值 (%) 15  下载: 导出CSV
下载: 导出CSV
表 2 虚拟受试者1和2采取开环策略进行IHT和采取闭环策略进行IHT的效果对比
Table 2 Comparison results of simulated subject 1 and 2 trained by using traditional open-loop strategy and proposed closed-loop strategy
个体设定 指标 初始状态 开环策略 闭环策略 $ c_{o}=13 $,
$ \Delta c_{op}=-1.5 $DSI (s) 137 84 256 SpO2平均值(%) 90.9 84.9 93.6 SpO2标准差(%) 5.5 5.4 4.8 $ c_{o}=12 $,
$ \Delta c_{op}=-1.5 $DSI (s) 137 90 300 SpO2平均值(%) 90.9 87.8 96.2 SpO2标准差(%) 5.5 5.4 3.6
下载: 导出CSV
表 3 虚拟受试者3和4采取开环策略进行IHT和采取闭环策略进行IHT的效果对比
Table 3 Comparison results of simulated subject 3 and 4 trained by using traditional open-loop strategy and proposed closed-loop strategy
个体设定 指标 初始状态 开环策略 闭环策略 $ c_{o}=12 $,
$ \Delta c_{op}=-1 $DSI (s) 154 136 203 SpO2平均值(%) 91.4 89.5 94.7 SpO2标准差(%) 6.1 6.5 5.0 $ c_{o}=12 $,
$ \Delta c_{op}=-1.5 $DSI (s) 154 81 300 SpO2平均值 (%) 91.4 89.5 96.4 SpO2标准差(%) 6.1 6.6 4.1
下载: 导出CSV
表 4 10名虚拟受试者采取开环策略进行IHT和采取闭环策略进行IHT的效果对比
Table 4 Comparison results of 10 simulated subjects trained by using traditional open-loop strategy and proposed closed-loop strategy
受试者 指标 初始状态 开环策略 闭环策略 1 DSI (s) 137 32 300 SpO2平均值(%) 90.9 84.9 96.4 SpO2标准差(%) 5.46 5.37 3.53 2 DSI (s) 140 53 300 SpO2平均值(%) 92.7 86.1 95.6 SpO2标准差(%) 4.72 4.85 3.73 3 DSI (s) 138 31 300 SpO2平均值(%) 92.3 84.8 97.4 SpO2标准差(%) 4.81 4.70 2.88 4 DSI (s) 271 153 300 SpO2平均值(%) 94.6 89.9 98.5 SpO2标准差(%) 4.04 4.10 2.29 5 DSI (s) 138 35 184 SpO2平均值(%) 92.3 87.1 96.3 SpO2标准差(%) 4.32 4.33 3.51 6 DSI (s) 138 20 279 SpO2平均值(%) 92.3 84.8 94.1 SpO2标准差(%) 4.81 4.79 4.34 7 DSI (s) 42 35 78 SpO2平均值(%) 89.0 85.1 91.5 SpO2标准差(%) 5.44 5.52 5.19 8 DSI (s) 91 84 176 SpO2平均值(%) 89.9 87.6 92.1 SpO2标准差(%) 6.17 6.16 5.63 9 DSI (s) 138 66 300 SpO2平均值(%) 91.3 88.2 95.1 SpO2标准差(%) 5.01 4.86 4.02 10 DSI (s) 138 44 300 SpO2平均值(%) 91.3 84.8 96.0 SpO2标准差(%) 4.94 4.78 3.64
下载: 导出CSV
表 5 10名虚拟受试者的对比结果
Table 5 Comparison results of 10 simulated subjects
指标 初始状态 开环策略 闭环策略 DSI (s) 137.1 56.3 251.7 SpO2平均值(%) 91.7 86.3 95.3 SpO2标准差(%) 4.97 4.95 3.88
下载: 导出CSV
-
[1] Andrew M L, Peter H H. Medical conditions and high-altitude travel. New England Journal of Medicine, 2022, 386(4): 364-373 doi: 10.1056/NEJMra2104829 [2] Joshua C T, Philip N A. Global and country-level estimates of human population at high altitude. Proceedings of the National Sciences, 2021, 118(18): e2102463118 doi: 10.1073/pnas.2102463118 [3] Cobb A B, Levett D Z H, Mitchell K, Aveling W, Hurlbut D, Gilbert-Kawai E, et.al. Physiological responses during ascent to high altitude and the incidence of acute mountain sickness. Physiological reports, 2021, 9(7): e14809 [4] Gudbjartsson T, Sigurdsson E, Gottfredsson M, Bjornsson O M, Gudmundsson G. High altitude illness and related diseases - A review. Laeknabladid, 2019, 105(11): 499-507 [5] Victor S, Jan C P, and Katarína K. Manifestation of intracranial lesions at high altitude: Case report and review of the literature. High Altitude Medicine & Biology, 2021, 22(1): 87-89 [6] Fulco C S, Beidleman B A, Muza S R. Effectiveness of preacclimatization strategies for highaltitude exposure. Exercise and Sport Sciences Reviews, 2013, 41(1): 55-63 doi: 10.1097/JES.0b013e31825eaa33 [7] Ambroży T, Maciejczyk M, Klimek A T, Wiecha S, Stanula A, Snopkowski P, et.al. The effects of intermittent hypoxic training on anaerobic and aerobic power in boxers. International Journal of Environmental Research and Public Health, 2020, 17(24): 9361 doi: 10.3390/ijerph17249361 [8] Wille M, Gatterer H, Mairer K, Philippe M, Schwarzenbacher H, Faulhaber M, et.al. Short-term intermittent hypoxia reduces the severity of acute mountain sickness. Medicine & Science in Sports, 2012, 22(5): e79-e85 [9] 刘园园. 高原健康理论框架下的渐进型间歇性低氧预习服训练研究 [博士学位论文], 山东大学, 中国, 2014Liu Yuan-Yuan. Short-Term Intermittent Hypoxia Reduces the Severity of Acute Mountain Sickness [Ph.D. dissertation], Shandong University, China, 2014 [10] Treml B, Kleinsasser A, Hell T, Knotzer H, Wille M, Burtscher M. Carry-over quality of pre-acclimatization to altitude elicited by intermittent hypoxia: A participant-blinded, randomized controlled trial on antedated acclimatization to altitude. Frontiers in Physiology, DOI: 10.3389/fphys.2020.00531 [11] Gangwar A, Pooja, Sharma M, Singh K, Patyal A, Bhaumik G, et.al. Intermittent normobaric hypoxia facilitates high altitude acclimatization by curtailing hypoxia-induced infammation and dyslipidemia. Pflugers Archiv, 2019, 471(7):949-959 doi: 10.1007/s00424-019-02273-4 [12] 杨军, 俞梦孙, 曹征涛, 吴峰, 张宏金, 王海涛, 等.间歇性递增式常压低氧暴露训练对高原习服效果的研究. 中华航空航天医学杂志, 2012, 3: 161-164Yang Jun, Yu Meng-Sun, Cao Zheng-Tao, Wu Feng, Zhang Hong-Jin, Wang Hai-Tao, et.al. Study on the effect of increasing intermittent hypoxia exposure on altitude acclimatization. Chinese Journal of Aerospace Medicine, 2012, 3: 161-164 [13] Kwiatkowska M, Atkins M S, Ayas N T, Ryan C F. Knowledge-based data analysis: First step toward the creation of clinical prediction rules using a new typicality measure. IEEE Transactions on Information Technology in Biomedicine, 2007, 11(6):651-660 doi: 10.1109/TITB.2006.889693 [14] Sakellarios A I, Räber L, Bourantas C V, Exarchos T P, Athanasiou L S, Pelosi G, et.al. Prediction of atherosclerotic plaque development in an In Vivo coronary arterial segment based on a multilevel modeling approach. IEEE Transactions on Biomedical Engineering, 2017, 64(8):1721-1730 doi: 10.1109/TBME.2016.2619489 [15] 喻勇, 司小胜, 胡昌华, 崔忠马, 李洪鹏. 数据驱动的可靠性评估与寿命预测研究进展:基于协变量的方法. 自动化学报, 2018, 44(2): 216-227Yu Yong, Si Xiao-Sheng, Hu Chang-Hua, Cui Zhong-Ma, Li Hong-Peng. Data driven reliability assessment and life-time prognostics: A review on covariate models. Acta Automatica Sinica, 2018, 44(2): 216-227 [16] 李天梅, 司小胜, 刘翔, 裴洪. 大数据下数模联动的随机退化设备剩余寿命预测技术. 自动化学报, 2022, 48(9): 2119-2141 doi: 10.16383/j.aas.c201068Li Tian-Mei, Si Xiao-Sheng, Liu Xiang, Pei Hong. Data-model interactive remaining useful life prediction technologies for stochastic degrading devices with big data. Acta Automatica Sinica, 2022, 48(9): 2119-2141 doi: 10.16383/j.aas.c201068 [17] 蒋珂, 蒋朝辉, 谢永芳, 潘冬, 桂卫华. 基于动态注意力深度迁移网络的高炉铁水硅含量在线预测方法. 自动化学报, DOI: 10.16383/j.aas.c210524"> 10.16383/j.aas.c210524 Jiang Ke, Jiang Zhao-Hui, Xie Yong-Fang, Pan Dong, Gui Wei-Hua. Online prediction method for silicon content of molten iron in blast furnace based on dynamic attention deep transfer network. Acta Automatica Sinica, DOI:10.16383/j.aas.c210524"> 10.16383/j.aas.c210524 [18] Box G E, Jenkins G M, Reinsel G C, Ljung G M. Time Series Analysis: Forecasting and Control. Hoboken: John Wiley & Sons, 2015. [19] Xie J, Wang Q. Benchmarking machine learning algorithms on blood glucose prediction for type I diabetes in comparison with classical time-series models. IEEE Transactions on Biomedical Engineering, 2020, 67(11): 3101-3124 doi: 10.1109/TBME.2020.2975959 [20] Moniri A, Terracina D, Rodriguez-Manzano J, Strutton P H, Georgiou P. Real-time forecasting of sEMG features for trunk muscle fatigue using machine learning. IEEE Transactions on Biomedical Engineering, 2021, 68(2): 718-727 doi: 10.1109/TBME.2020.3012783 [21] Michalis K T. Variational learning of inducing variables in sparse Gaussian processes. In: Proceedings of the 12th International Conference on Artificial Intelligence and Statistics. Florida, USA: PMLR, 2009. 567−574 [22] Beckers T, Hirche S. Prediction with approximated gaussian process dynamical models. IEEE Transactions on Automatic Control, 2022, 68: 6460-6473 [23] Lee S I, Mortazavi B, Hoffman H A, Lu D S, Li C, Paak B H, et.al. A prediction model for functional outcomes in spinal cord disorder patients using gaussian process regression. IEEE Transactions on Biomedical Engineering, 2016, 20(1): 91-99 [24] Huang H, Song Y, Peng X, Ding S X, Zhong W, Du W, et.al. A sparse nonstationary trigonometric gaussian process regression and its application on nitrogen oxide prediction of the diesel engine. IEEE Transactions on Industrial Informatics, 2021, 17(12): 8367-8377 doi: 10.1109/TII.2021.3068288 [25] 史大威, 蔡德恒, 刘蔚, 王军政, 纪立农. 面向智能血糖管理的餐前胰岛素剂量贝叶斯学习优化方法. 自动化学报, DOI: 10.16383/j.aas.c210067Shi Da-Wei, Cai De-Heng, Liu Wei, Wang Jun-Zheng, Ji Li-Nong. Bayesian learning based optimization of meal bolus dosage for intelligent glucose management. Acta Automatica Sinica, DOI: 10.16383/j.aas.c210067 [26] 金哲豪, 刘安东, 俞立. 基于GPR和深度强化学习的分层人机协作控制. 自动化学报, 2022, 48(9): 1-11Jin Zhe-Hao, Liu An-Dong, Yu Li. Hierarchical human-robot cooperative control based on GPR and DRL. Acta Automatica Sinica, 2022, 48(9): 1-11 [27] Rosolia U, Zhang X, Borrelli F. Data-driven predictive control for autonomous systems. Annual Review of Control, Robotics, and Autonomous Systems, 2018, 1(1): 259-286 doi: 10.1146/annurev-control-060117-105215 [28] Yu M. Human-performance engineering at high altitude. Science Supp, 2014: 7−8 [29] Chen J, Xiao R, Wang L, Zhu L, Shi D. Unveiling interpretable key performance indicators in hypoxic response: a system identification approach. IEEE Transactions on Industrial Electronics, 2022, 69(12): 13676-13685 doi: 10.1109/TIE.2021.3137618 [30] Chen J, Tian Y, Zhang G, Cao Z, Zhu L, Shi D. IoT-enabled intelligent dynamic risk assessment of acute mountain sickness: The role of event-triggered signal processing. IEEE Transactions on Industrial Informatics, 2023, 19(1): 730−738 [31] Williams C K I, Rasmussen C E. Gaussian Processes for Machine Learning. Cambridge: The MIT Press, 2006. [32] Hackett, Peter H. and Roach, Robert C. High-altitude llness. New England Journal of Medicine, 2001, 345(2): 107-114 doi: 10.1056/NEJM200107123450206 [33] Levine B D, Stray-Gundersen J. Dose-response of altitude training: how much altitude is enough? Advances in Experimental Medicine and Biology, 2006, 69: 233-247 -

 下载:
下载:

计量
- 文章访问数: 1310
- HTML全文浏览量: 413
- PDF下载量: 202
- 被引次数: 0
