

-
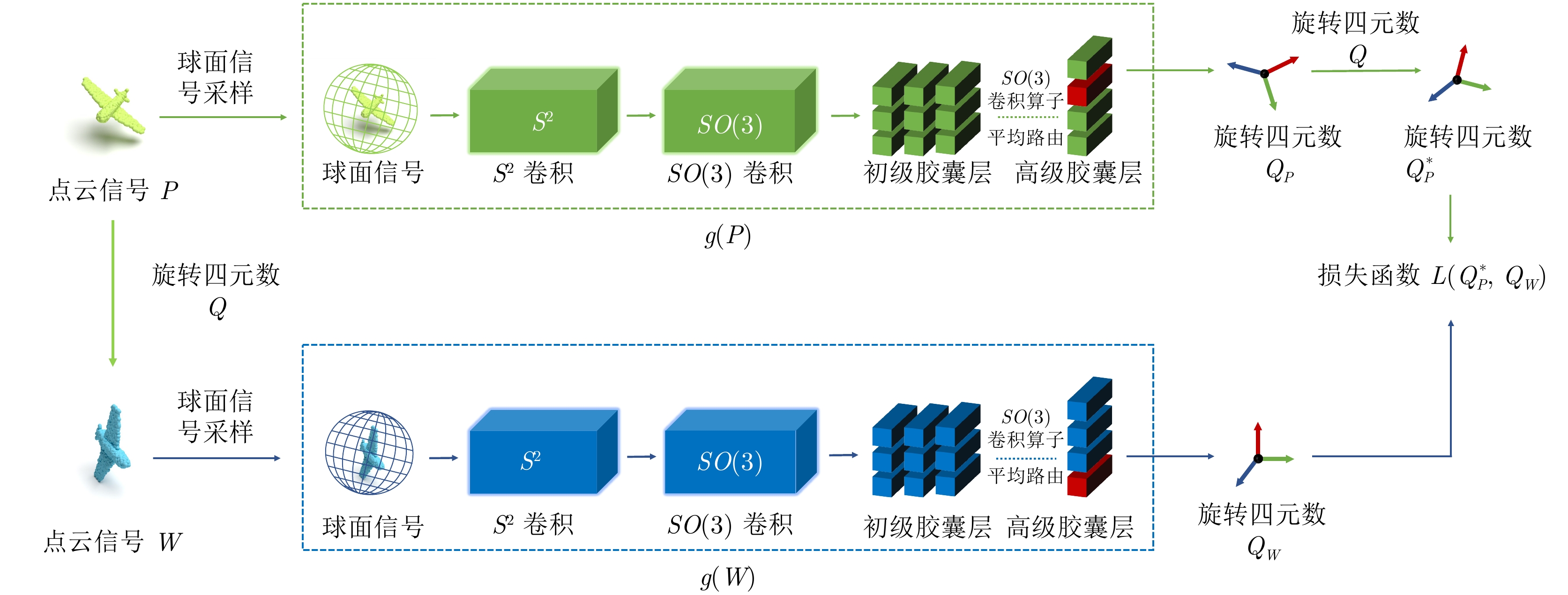
摘要: 在三维视觉任务中, 三维目标的未知旋转会给任务带来挑战, 现有的部分神经网络框架对经过未知旋转后的三维目标进行识别或分割较为困难. 针对上述问题, 提出一种基于自监督学习方式的矢量型球面卷积网络, 用于学习三维目标的旋转信息, 以此来提升分类和分割任务的表现. 首先, 对三维点云信号进行球面采样, 映射到单位球上; 然后, 使用矢量球面卷积网络提取旋转特征, 同时将随机旋转后的三维点云信号输入相同结构的矢量球面卷积网络提取旋转特征, 利用自监督网络训练学习旋转信息; 最后, 对随机旋转的三维目标进行目标分类实验和部分分割实验. 实验表明, 所设计的网络在测试数据随机旋转的情况下, 在ModelNet40数据集上分类准确率提升75.75%, 在ShapeNet数据集上分割效果显著, 交并比(Intersection over union, IoU)提升51.48%.Abstract: The unknown rotation of 3D objects can bring challenges to the 3D vision tasks. It is difficult for some existing neural networks to classify or segment the 3D model after the unknown rotation. Aiming at the above problems, this paper proposes a vector spherical convolutional network based on self-supervised for learning the rotation information of 3D objects. First, the 3D point cloud signal is spherically sampled and mapped to the unit sphere; then, the rotational features are extracted by the vector spherical convolution network, while the randomly rotated 3D point cloud is input into the vector spherical convolution network of the same structure to extract rotation features, and the self-supervised network is used to train and learn the rotation information; finally, target classification experiments and part segmentation experiments are performed on randomly rotated 3D objects. Experimental results show that the network designed in this paper has a 75.75% improvement in classification accuracy on the ModelNet40 dataset and a significant segmentation effect on the ShapeNet dataset with a 51.48% improvement in the intersection over union (IoU) under random rotation of the test data.
-

图 6 ModelNet40规范方向实验可视化结果
Fig. 6 ModelNet40 canonical orientation experiment visualization results
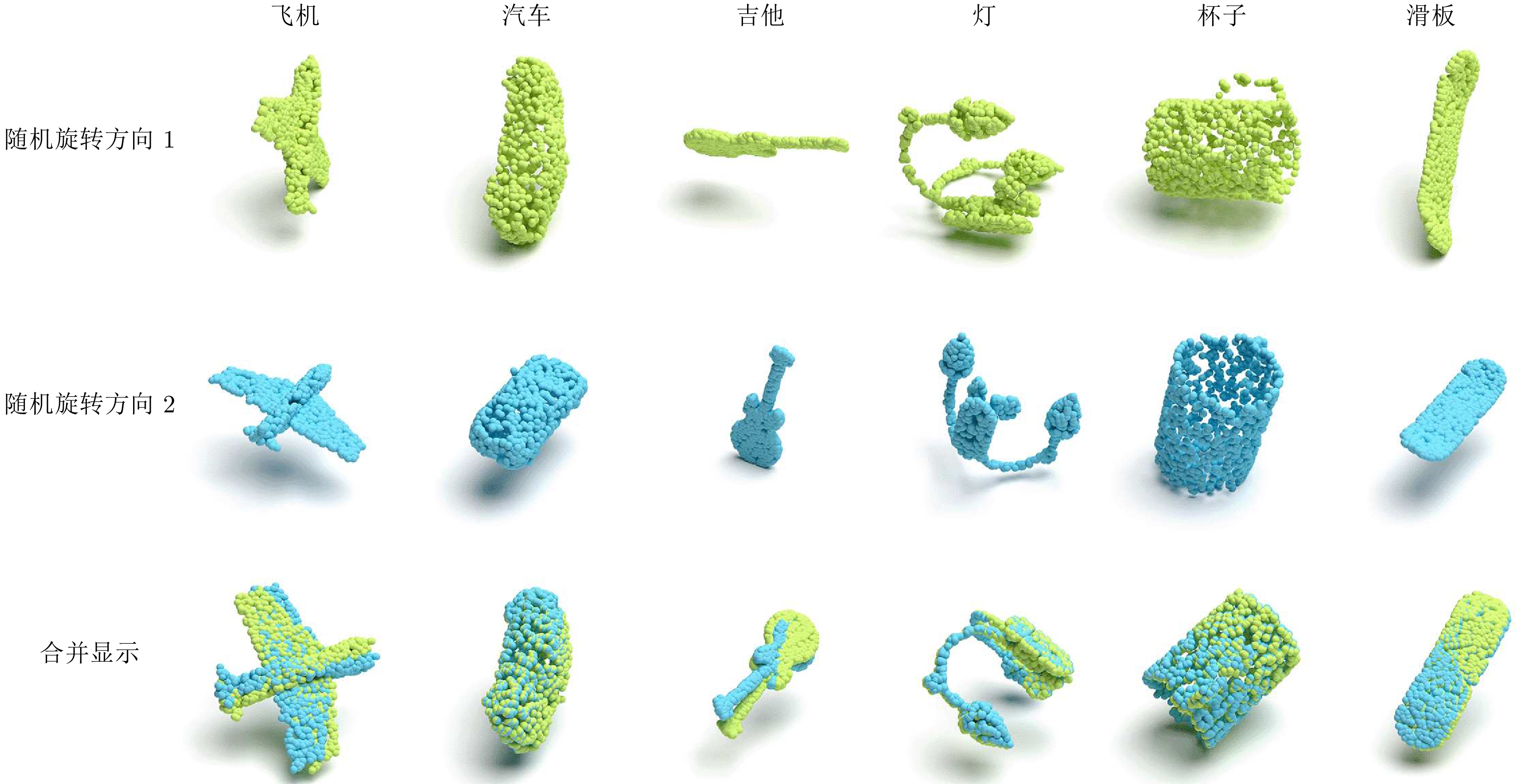
图 7 ShapeNet规范方向实验可视化结果
Fig. 7 ShapeNet canonical orientation experiment visualization results
表 1 常用符号表
Table 1 Table of common symbols
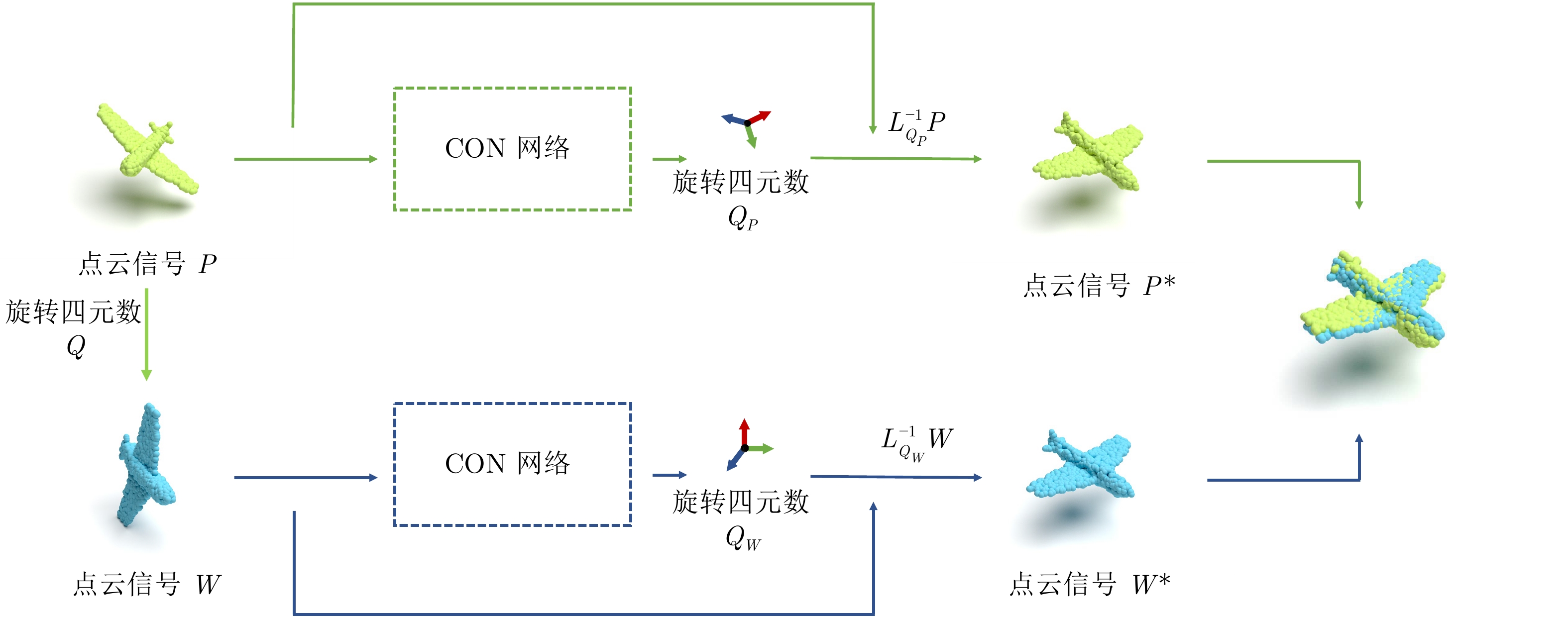
序号 符号 说明 1 $\left(a_i, b_j, c_k\right)$ 球面网格坐标 2 $\left(\alpha_n, \beta_n, h_n\right)$ 点云用球面坐标表示 3 $S^2$ 单位球面 4 $SO(3)$ 三维旋转群 5 $g$ 表示$\mathrm{CON}$网络运算过程 6 $f$ 指$S^2$或$SO(3)$信号 7 $L_R$ 旋转操作符 8 $\psi$ 卷积核 9 ${\boldsymbol{h}}$ 矢量神经元  下载: 导出CSV
下载: 导出CSV
表 3 部分分割实验结果IoUs (%)
Table 3 Part segmentation experimental results IoUs (%)
随机旋转 不旋转 avg.
inst.avg.
cls.飞机 包 帽子 汽车 椅子 耳机 吉他 刀 灯 笔记本
电脑摩托
车马克
杯手枪 火箭 滑板 桌子 avg.
inst.avg.
cls.PointNet[43] 31.30 29.38 19.90 46.25 43.27 20.81 27.04 15.63 34.72 34.64 42.10 36.40 19.25 49.88 33.30 22.07 25.71 29.74 83.15 78.95 PointNet++[46] 36.66 35.00 21.90 51.70 40.06 23.13 43.03 9.65 38.51 40.91 45.56 41.75 18.18 53.42 42.19 28.51 38.92 36.57 84.63 81.52 RS-Net[50] 50.38 32.99 38.29 15.45 53.78 33.49 60.83 31.27 9.50 43.48 57.37 9.86 20.37 25.74 20.63 11.51 30.14 66.11 84.92 81.41 PCNN[51] 28.80 31.72 23.46 46.55 35.25 22.62 24.27 16.67 32.89 39.80 52.18 38.60 18.54 48.90 27.83 27.46 27.60 24.88 85.13 81.80 SPLATNet[52] 32.21 38.25 34.58 68.10 46.96 19.36 16.25 24.72 88.39 52.99 49.21 31.83 17.06 48.56 21.20 34.98 28.99 28.86 84.97 82.34 DGCNN[53] 43.79 30.87 24.84 51.29 36.69 20.33 30.07 27.86 38.00 45.50 42.29 34.84 20.51 48.74 26.25 26.88 26.95 28.85 85.15 82.33 SO-Net[48] 26.21 14.37 21.08 8.46 1.87 11.78 27.81 11.99 8.34 15.01 43.98 1.81 7.05 8.78 4.41 6.38 16.10 34.98 84.83 81.16 SpiderCNN[54] 31.81 35.46 22.28 53.07 54.2 22.57 28.86 23.17 35.85 42.72 44.09 55.44 19.23 48.93 28.65 25.61 31.36 31.32 85.33 82.40 SHOT+PointNet[55] 32.88 31.46 37.42 47.30 49.53 27.71 28.09 16.34 9.79 27.66 37.33 25.22 16.31 50.91 25.07 21.29 43.10 40.27 32.75 31.25 CGF+PointNet[56] 50.13 46.26 50.97 70.34 60.44 25.51 59.08 33.29 50.92 71.64 40.77 31.91 23.93 63.17 27.73 30.99 47.25 52.06 50.13 46.31 RIConv[57] 79.31 74.60 78.64 78.70 73.19 68.03 86.82 71.87 89.36 82.95 74.70 76.42 56.58 88.44 72.16 51.63 66.65 77.47 79.55 74.43 Kim 等[58] 79.56 74.41 77.53 73.43 76.95 66.13 87.22 75.44 87.42 80.71 78.44 71.21 51.09 90.76 73.69 53.86 68.10 78.62 79.92 74.69 Li 等[59] 82.17 78.78 81.49 80.07 85.55 74.83 88.62 71.34 90.38 82.82 80.34 81.64 68.87 92.23 74.51 54.08 74.59 79.11 82.47 79.40 PRIN[49] 71.20 66.75 69.29 55.90 71.49 56.31 78.44 65.92 86.01 73.58 66.97 59.29 47.56 81.47 71.99 49.02 64.70 70.12 72.04 68.39 SPRIN[14] 82.67 79.50 82.07 82.01 76.48 75.53 88.17 71.45 90.51 83.95 79.22 83.83 72.59 93.24 78.99 58.85 74.77 80.31 82.59 79.31 CON+PointNet 84.39 80.86 82.27 79.14 85.88 76.44 90.42 73.24 90.96 82.81 82.99 95.64 69.51 91.93 79.74 55.60 75.33 81.81 84.06 81.22
下载: 导出CSV
表 4 与主流网络结合的分类准确度(%)
Table 4 Classification accuracy in combination with mainstream networks (%)
下载: 导出CSV
表 5 与主流网络结合的部分分割实验结果IoUs (%)
Table 5 Experimental results of part segmentation combined with mainstream networks IoUs (%)
随机旋转 不旋转 avg.
inst.avg.
cls.飞机 包 帽子 汽车 椅子 耳机 吉他 刀 灯 笔记本
电脑摩托
车马克
杯手枪 火箭 滑板 桌子 avg.
inst.avg.
cls.PointNet[43] 31.30 29.38 19.90 46.25 43.27 20.81 27.04 15.63 34.72 34.64 42.10 36.40 19.25 49.88 33.30 22.07 25.71 29.74 83.15 78.95 PointNet++[46] 36.66 35.00 21.90 51.70 40.06 23.13 43.03 9.65 38.51 40.91 45.56 41.75 18.18 53.42 42.19 28.51 38.92 36.57 84.63 81.52 DGCNN[53] 43.79 30.87 24.84 51.29 36.69 20.33 30.07 27.86 38.00 45.50 42.29 34.84 20.51 48.74 26.25 26.88 26.95 28.85 85.15 82.33 CON+PointNet 84.39 80.86 82.27 79.14 85.88 76.44 90.42 73.24 90.96 82.81 82.99 95.64 69.51 91.93 79.74 55.60 75.33 81.81 84.06 81.22 CON+PointNet++ 85.77 82.30 84.12 80.66 88.90 76.51 90.37 78.65 90.15 83.01 83.62 95.45 71.26 91.67 80.77 60.36 77.23 84.01 86.02 83.41 CON+DGCNN 85.21 81.36 83.71 79.02 86.91 74.21 93.22 74.43 91.90 82.31 84.24 96.53 70.22 90.86 81.37 58.28 76.96 83.27 85.73 82.62
下载: 导出CSV
-
[1] Piga N A, Onyshchuk Y, Pasquale G, Pattacini U, Natale L. ROFT: real-time optical flow-aided 6D object pose and velocity tracking. IEEE Robotics and Automation Letters, 2022, 7(1): 159-166 doi: 10.1109/LRA.2021.3119379 [2] Gao F, Sun Q, Li S, Li W, Li Y, Yu J, et al. Efficient 6D object pose estimation based on attentive multi-scale contextual information. IET Computer Vision, 2022, 16(7): 596-606 doi: 10.1049/cvi2.12101 [3] Peng W, Yan J, Wen H, Sun Y. Self-supervised category-level 6D object pose estimation with deep implicit shape representation. In: Proceedings of AAAI Conference on Artificial Intelligence. Palo Alto, USA: AAAI, 2022. 2082−2090 [4] Huang W L, Hung C Y, Lin I C. Confidence-based 6D object pose estimation. IEEE Transactions on Multimedia, 2022, 24: 3025-3035 doi: 10.1109/TMM.2021.3092149 [5] Li X, Weng Y, Yi L, Guibas L J, Abbott A L, Song S, et al. Leveraging SE(3) equivariance for self-supervised category-level object pose estimation from point clouds. In: Proceedings of Annual Conference on Neural Information Processing Systems. New York, USA: MIT Press, 2021. 15370−15381 [6] Melzi S, Spezialetti R, Tombari F, Bronstein M M, Stefano L D, Rodol E. Gframes: Gradient-based local reference frame for 3D shape matching. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, USA: IEEE, 2019. 4629−4638 [7] Gojcic Z, Zhou C, Wegner J D, Wieser A. The perfect match: 3D point cloud matching with smoothed densities. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, USA: IEEE, 2019. 5545−5554 [8] Hao Z, Zhang T, Chen M, Zhou K. RRL: Regional rotate layer in convolutional neural networks. In: Proceedings of AAAI Conference on Artificial Intelligence. Palo Alto, USA: AAAI, 2022. 826−833 [9] Esteves C, Allen-Blanchette C, Makadia A, Daniilidis K. Learning SO(3) equivariant representations with spherical CNNs. In: Proceedings of European Conference on Computer Vision. Berlin, DE: Springer, 2018. 52−68 [10] Chen Y, Zhao J Y, Shi C W. Mesh convolution: a novel feature extraction method for 3d nonrigid object classification. IEEE Transactions on Multimedia, 2021, 23: 3098-3111 doi: 10.1109/TMM.2020.3020693 [11] Cohen T S, Geiger M, Köhler J, Wellin M. Spherical CNNs. In: Proceedings of International Conference on Learning Representations. Vancouver, CA: 2018. 1−15 [12] Gerken J E, Carlsson O, Linander H, Ohlsson F, Petersson C, Persson D. Equivariance versus augmentation for spherical images. In: Proceedings of International Conference on Machine Learning. New York, USA: PMLR, 2022. 7404−7421 [13] Cohen T, Welling M. Group equivariant convolutional networks. In: Proceedings of International Conference on Machine Learning. New York, USA: PMLR, 2016. 2990−2999 [14] You Y, Lou Y, Shi R, Liu Q, Tai Y W, Ma L Z, et al. Prin/sprin: on extracting point-wise rotation invariant features. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(12): 9489-9502 doi: 10.1109/TPAMI.2021.3130590 [15] Mitchel T W, Aigerman N, Kim V G, Kazhdan M. Möbius convolutions for spherical CNNs. In: Proceedings of ACM SIGGRAPH Annual Conference. New York, USA: ACM, 2022. 1−9 [16] Mazzia V, Salvetti F, Chiaberge M. Efficient-capsnet: capsule network with self-attention routing. Scientific reports, 2021, 11(1): 1-13 doi: 10.1038/s41598-020-79139-8 [17] Hinton G E, Krizhevsky A, Wang S D. Transforming auto-encoders. In: Proceedings of International Conference on Artificial Neural Networks. Berlin, DE: Springer, 2011. 44−51 [18] Sabour S, Frosst N, Hinton G E. Dynamic routing between capsules. In: Proceedings of Annual Conference on Neural Information Processing Systems. New York, USA: MIT Press, 2017. 3856−3866 [19] Hinton G E, Sabour S, Frosst N. Matrix capsules with EM routing. In: Proceedings of International Conference on Learning Representations. Vancouver, CA: 2018. 16−30 [20] Zhang Z, Xu Y, Yu J, Gao S H. Saliency detection in 360 videos. In: Proceedings of European Conference on Computer Vision. Berlin, DE: Springer, 2018. 488−503 [21] Iqbal T, Xu Y, Kong Q Q, Wanfg W W. Capsule routing for sound event detection. In: Proceedings of European Signal Processing Conference. Piscataway, USA: IEEE, 2018. 2255−2259 [22] Gu J, Tresp V. Improving the robustness of capsule networks to image affine transformations. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, USA: IEEE, 2020. 7285−7293 [23] Gu J, Tresp V, Hu H. Capsule network is not more robust than convolutional network. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, USA: IEEE, 2021. 14309−14317 [24] Venkataraman S R, Balasubramanian S, Sarma R R. Building deep equivariant capsule networks. In: Proceedings of International Conference on Learning Representations. Vancouver, CA: 2020. 1−12 [25] 姚红革, 董泽浩, 喻钧, 白小军. 深度EM胶囊网络全重叠手写数字识别与分离. 自动化学报: 2022, 48(12): 2996-3005 DOI: 10.16383/j.aas.c190849Yao Hong-Ge, Dong Ze-Hao, Yu Jun, Bai Xiao-Jun. Fully overlapped handwritten number recognition and separation based on deep EM capsule network. Acta Automatica Sinica, 2022, 48(12): 2996-3005 doi: 10.16383/j.aas.c190849 [26] Saha S, Ebel P, Zhu X X. Self-supervised multisensor change detection. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 1-10 [27] Gong Y, Lai C I, Chung Y A, Glass J R. SSAST: Self-supervised audio spectrogram transformer. In: Proceedings of AAAI Conference on Artificial Intelligence. Palo Alto, USA: AAAI, 2022. 10699−10709 [28] Sun L, Zhang Z, Ye J, Peng H, Zhang J W, Su S, et al. A self-supervised mixed-curvature graph neural network. In: Proceedings of AAAI Conference on Artificial Intelligence. Palo Alto, USA: AAAI, 2022. 4146−4155 [29] Zbontar J, Jing L, Misra I, LeCun Y, Deny S. Barlow twins: Self-supervised learning via redundancy reduction. In: Proceedings of International Conference on Machine Learning. New York, USA: PMLR, 2021. 12310−12320 [30] Becker S, Hinton G E. Self-organizing neural network that discovers surfaces in random-dot stereograms. Nature, 1992, 355(6356): 161-163 doi: 10.1038/355161a0 [31] Goldberger J, Hinton G E, Roweis S, Salakhutdinov R. Neighbourhood components analysis. In: Proceedings of Annual Conference on Neural Information Processing Systems. New York, USA: MIT Press, 2004. 513−520 [32] Bromley J, Bentz J W, Bottou L, Guyon I, LeCun Y, Moore C, et al. Signature verification using a siamese time delay neural network. International Journal of Pattern Recognition and Artificial Intelligence, 1993, 07(04): 669-688 doi: 10.1142/S0218001493000339 [33] Hadsell R, Chopra S, Lecun Y. Dimensionality reduction by learning an invariant mapping. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, USA: IEEE, 2006. 1735−1742 [34] Chopra S, Hadsell R, Lecun Y. Learning a similarity metric discriminatively, with application to face verification. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, USA: IEEE, 2005. 539−546 [35] Spezialetti R, Salti S, Stefano L D. Learning an effective equivariant 3D descriptor without supervision. In: Proceedings of International Conference on Computer Vision. Piscataway, USA: IEEE, 2019. 6400−6409 [36] Driscoll J R, Healy D M. Computing fourier transforms and convolutions on the 2-sphere. Advances in applied mathematics, 1994, 15(2): 202-250 doi: 10.1006/aama.1994.1008 [37] Thomas F. Approaching dual quaternions from matrix algebra. IEEE Transactions on Robotics, 2014, 30(05): 1037-1048 doi: 10.1109/TRO.2014.2341312 [38] Busam B, Birdal T, Navab N. Camera pose filtering with local regression geodesics on the riemannian manifold of dual quaternions. In: Proceedings of International Conference on Computer Vision Workshops. Piscataway, USA: IEEE, 2017. 2436−2445 [39] Cohen T S, Geiger M, Weiler M. A general theory of equivariant CNNs on homogeneous spaces. In: Proceedings of Annual Conference on Neural Information Processing Systems. New York, USA: MIT Press, 2019. 9142−9153 [40] Zhao Y, Birdal T, Lenssen J E, Menegatti E, Guibas L J, Tombari F, et al. Quaternion equivariant capsule networks for 3D point clouds. In: Proceedings of European Conference on Computer Vision. Berlin, DE: Springer, 2020. 1−19 [41] Kondor R, Trivedi S. On the generalization of equivariance and convolution in neural networks to the action of compact groups. In: Proceedings of International Conference on Machine Learning. New York, USA: PMLR, 2018. 2747−2755 [42] Lenssen J E, Fey M, Libuschewski P. Group equivariant capsule networks. In: Proceedings of Annual Conference on Neural Information Processing Systems. New York, USA: MIT Press, 2018. 8858−8867 [43] Qi C R, Su H, Mo K, Guibas L J. PointNet: Deep learning on point sets for 3D classification and segmentation. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, USA: IEEE, 2017. 77−85 [44] Chang A X, Funkhouser T A, Guibas L J, Hanrahan P, Huang Q X, Li Z, et al. ShapeNet: An information-rich 3D model repository. arXiv preprint arXiv: 1512.03012, 2015. [45] Kingma D P, Ba J. Adam: A method for stochastic optimization. arXiv preprint arXiv: 1412.6980, 2014. [46] Qi C R, Yi L, Su H, Guibas L J. PointNet++: Deep hierarchical feature learning on point sets in a metric space. In: Proceedings of Annual Conference on Neural Information Processing Systems. New York, USA: MIT Press, 2017. 5099−5108 [47] Zhang K, Hao M, Wang J, Silva C W, Fu C L. Linked dynamic graph CNN: Learning on point cloud via linking hierarchical features. arXiv preprint arXiv: 1904.10014, 2019. [48] Li J, Chen B M, Lee G H. SO-Net: Self-organizing network for point cloud analysis. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, USA: IEEE, 2018. 9397−9406 [49] You Y, Lou Y, Liu Q, Tai Y W, Ma L Z, Lu C W, et al. Pointwise rotation-invariant network with adaptive sampling and 3D spherical voxel convolution. In: Proceedings of AAAI Conference on Artificial Intelligence. Palo Alto, USA: AAAI, 2020. 12717−12724 [50] Huang Q, Wang W, Neumann U. Recurrent slice networks for 3D segmentation of point clouds. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, USA: IEEE, 2018. 2626−2635 [51] Atzmon M, Maron H, Lipman Y. Point convolutional neural networks by extension operators. ACM Transactions on Graphics, 2018, 37(4): 71 [52] Su H, Jampani V, Sun D, Maji S, Kalogerakis E, Yang M H, et al. SPLATNet: Sparse lattice networks for point cloud processing. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, USA: IEEE, 2018. 2530−2539 [53] Wang Y, Sun Y, Liu Z, Sarma S E, Bronstein M M, Solomon J M. Dynamic graph CNN for learning on point clouds. ACM Transactions on Graphics, 2019, 38(5): 146:1-146:12 [54] Xu Y, Fan T, Xu M, Zeng L, Qiao Y. SpiderCNN: Deep learning on point sets with parameterized convolutional filters. In: Proceedings of European Conference on Computer Vision. Berlin, DE: Springer, 2018. 90−105 [55] Tombari F, Salti S, Stefano L D. Unique signatures of histograms for local surface description. In: Proceedings of European Conference on Computer Vision. Berlin, DE: Springer, 2010. 356−369 [56] Khoury M, Zhou Q Y, Koltun V. Learning compact geometric features. In: Proceedings of International Conference on Computer Vision. Piscataway, USA: IEEE, 2017. 153−161 [57] Zhang Z, Hua B S, Rosen D W, Yeung S K. Rotation invariant convolutions for 3D point clouds deep learning. In: Proceedings of International Conference on 3D Vision. Piscataway, USA: IEEE, 2019. 204−213 [58] Kim S, Park J, Han B. Rotation-invariant local-to-global representation learning for 3D point cloud. In: Proceedings of Annual Conference on Neural Information Processing Systems. New York, USA: MIT Press, 2020. 8174−8185 [59] Li X Z, Li R H, Chen G Y, Fu C W, Cohen-Or D, Heng P. A rotation-invariant framework for deep point cloud analysis. IEEE Transactions on Visualization and Computer Graphics, 2021, 28(12): 4503-4514 -

 下载:
下载:



计量
- 文章访问数: 802
- HTML全文浏览量: 367
- PDF下载量: 236
- 被引次数: 0
