

-
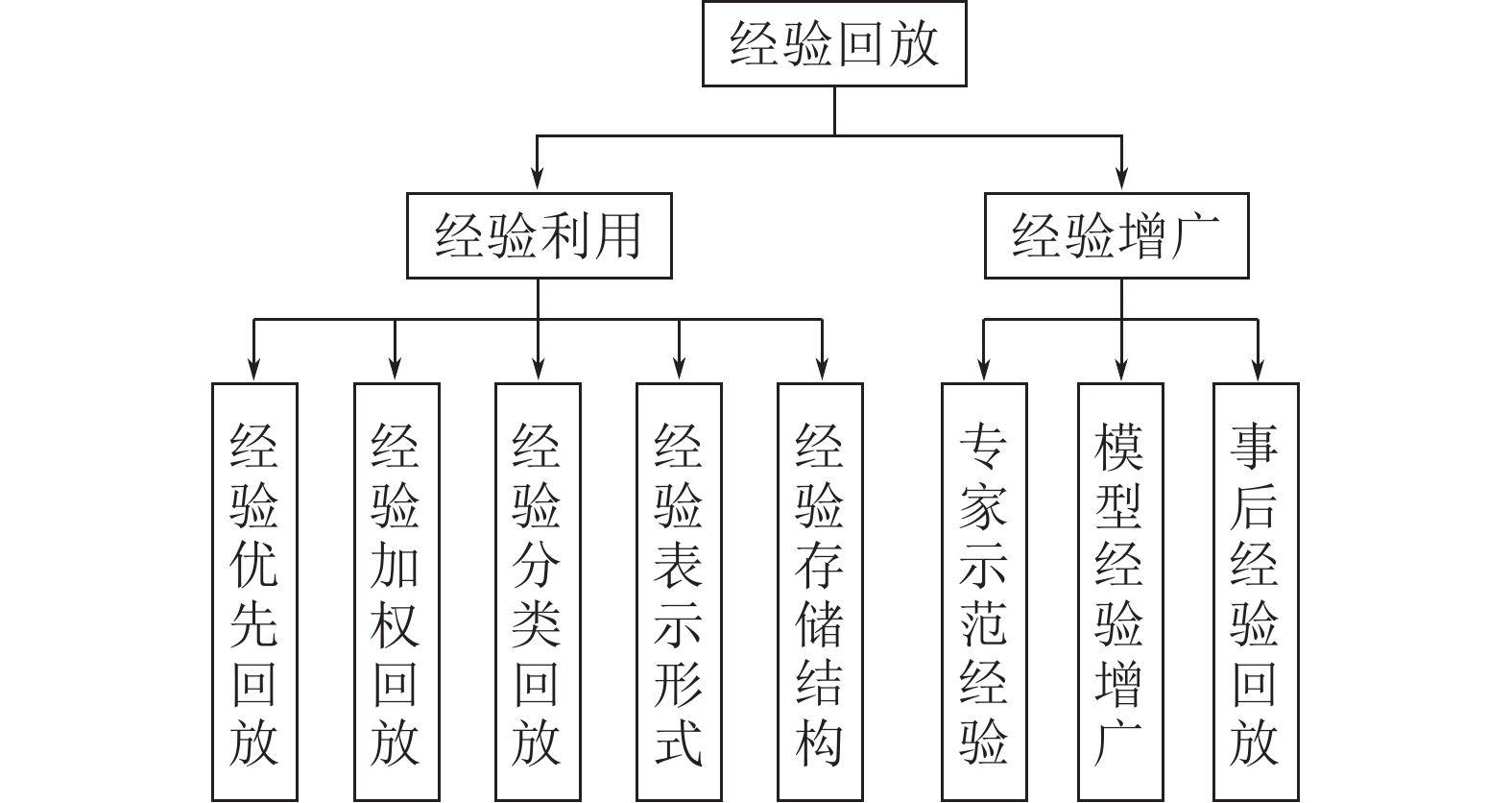
摘要: 作为一种不需要事先获得训练数据的机器学习方法, 强化学习(Reinforcement learning, RL)在智能体与环境的不断交互过程中寻找最优策略, 是解决序贯决策问题的一种重要方法. 通过与深度学习(Deep learning, DL)结合, 深度强化学习(Deep reinforcement learning, DRL)同时具备了强大的感知和决策能力, 被广泛应用于多个领域来解决复杂的决策问题. 异策略强化学习通过将交互经验进行存储和回放, 将探索和利用分离开来, 更易寻找到全局最优解. 如何对经验进行合理高效的利用是提升异策略强化学习方法效率的关键. 首先对强化学习的基本理论进行介绍; 随后对同策略和异策略强化学习算法进行简要介绍; 接着介绍经验回放(Experience replay, ER)问题的两种主流解决方案, 包括经验利用和经验增广; 最后对相关的研究工作进行总结和展望.Abstract: As a machine learning method that does not need to obtain training data in advance, reinforcement learning (RL) is an important method to solve the sequential decision-making problem by finding the optimal strategy in the continuous interaction between the agent and the environment. Through the combination of deep learning (DL), deep reinforcement learning (DRL) has both powerful perception and decision-making capabilities, and is widely used in many fields to solve complex decision-making problems. Off-policy reinforcement learning separates exploration and utilization by storing and replaying interactive experience, making it easier to find the global optimal solution. How to make reasonable and efficient use of experience is the key to improve the efficiency of off-policy reinforcement learning methods. First, this paper introduces the basic theory of reinforcement learning. Then, the on-policy and off-policy reinforcement learning algorithms are briefly introduced. Next, two mainstream solutions of experience replay (ER) problem are introduced, including experience utilization and experience expansion. Finally, the relevant research work is summarized and prospected.
-
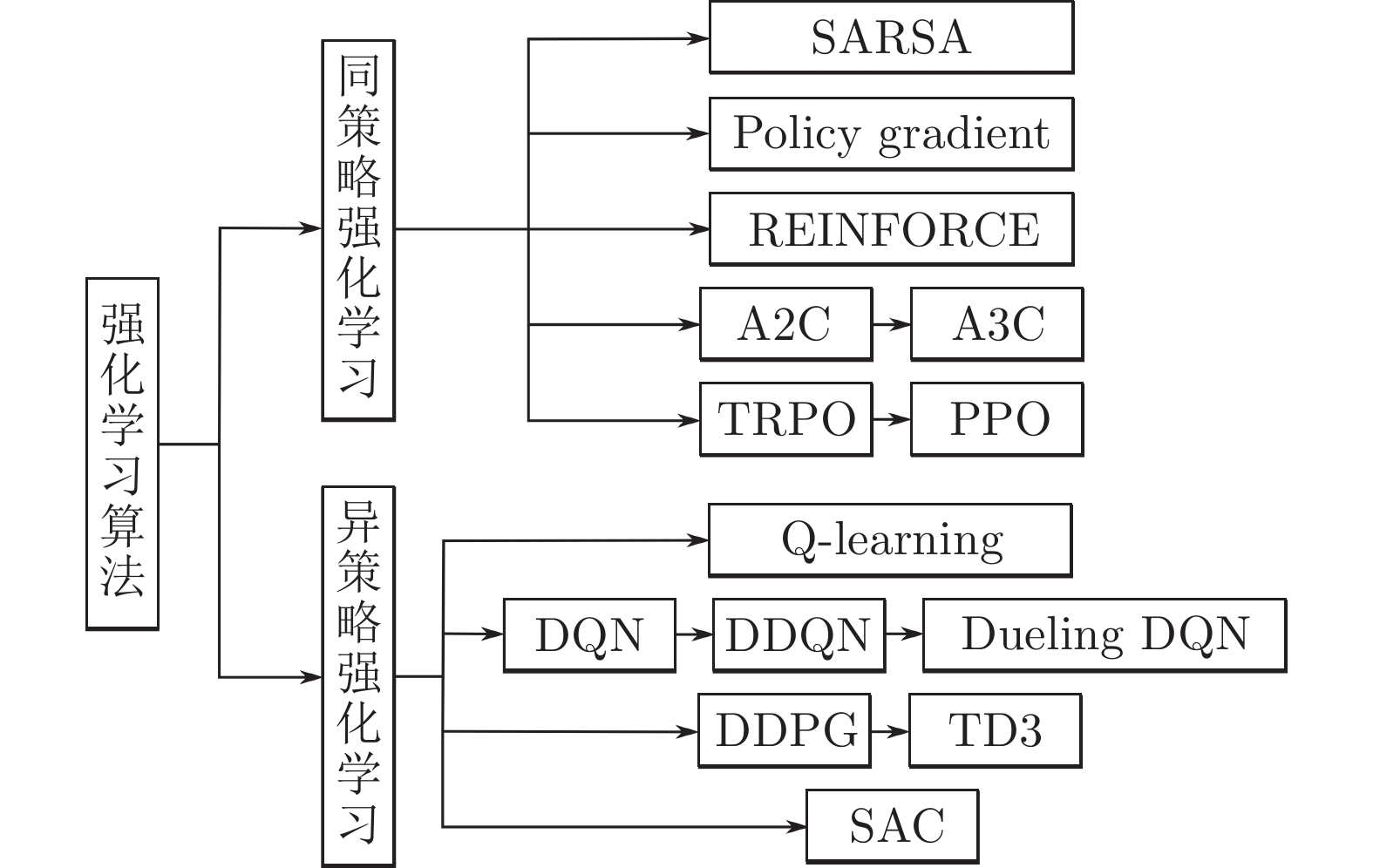
表 1 同策略与异策略算法的优势对比
Table 1 Comparison of advantages of on-policy and off-policy algorithms
算法优势 同策略RL 异策略RL 收敛速度更快 √ 训练过程更稳定 √ 超参数对算法影响更小 √ 可以平衡探索和利用的问题 √ 更易收敛到最优解 √ 经验来源更广 √ 经验的利用率更高 √ 算法的适用范围更广 √  下载: 导出CSV
下载: 导出CSV
表 4 经验存储结构算法的优化途径
Table 4 Optimization approaches of experience storage structure algorithms
下载: 导出CSV
-
[1] 高阳, 陈世福, 陆鑫. 强化学习研究综述. 自动化学报, 2004, 30(1): 86-100Gao Yang, Chen Shi-Fu, Lu Xin. Research on reinforcement learning technology: A review. Acta Automatica Sinica, 2004, 30(1): 86-100 [2] Sutton R S, Barto A G. Reinforcement Learning: An Introduction. Cambridge: MIT Press, 1998. [3] 李晨溪, 曹雷, 张永亮, 陈希亮, 周宇欢, 段理文. 基于知识的深度强化学习研究综述. 系统工程与电子技术, 2017, 39(11): 2603-2613 doi: 10.3969/j.issn.1001-506X.2017.11.30Li Chen-Xi, Cao Lei, Zhang Yong-Liang, Chen Xi-Liang, Zhou Yu-Huan, Duan Li-Wen. Knowledge-based deep reinforcement learning: A review. Systems Engineering and Electronics, 39(11): 2603-2613 doi: 10.3969/j.issn.1001-506X.2017.11.30 [4] Bellman R. Dynamic Programming. Princeton: Princeton University Press, 1957. [5] Mnih V, Kavukcuoglu K, Silver D, Rusu A A, Veness J, Bellemare M G, et al. Human-level control through deep reinforcement learning. Nature, 2015, 518(7540): 529-533 doi: 10.1038/nature14236 [6] 刘全, 翟建伟, 章宗长, 钟珊, 周倩, 章鹏, 等. 深度强化学习综述. 计算机学报, 2018, 48(1): 1-27 doi: 10.11897/SP.J.1016.2019.00001Liu Quan, Zhai Jian-Wei, Zhang Zong-Chang, Zhong Shan, Zhou Qian, Zhang Peng, et al. A survey on deep reinforcement learning. Chinese Journal of Computers, 2018, 48(1): 1-27 doi: 10.11897/SP.J.1016.2019.00001 [7] Mnih V, Kavukcuoglu K, Silver D, Graves A, Antonoglou I, Wierstra D, et al. Playing Atari with deep reinforcement learning. arXiv preprint arXiv: 1312.5602, 2013. [8] Cheng Y H, Chen L, Chen C L P, Wang X S. Off-policy deep reinforcement learning based on Steffensen value iteration. IEEE Transactions on Cognitive and Developmental Systems, 2021, 13(4): 1023-1032 doi: 10.1109/TCDS.2020.3034452 [9] Silver D, Huang A, Maddison C J, Guez A, Sifre L, Driessche G V D, et al. Mastering the game of Go with deep neural networks and tree search. Nature, 2016, 529(7587): 484-489 doi: 10.1038/nature16961 [10] Chen P Z, Lu W Q. Deep reinforcement learning based moving object grasping. Information Sciences, 2021, 565: 62-76. doi: 10.1016/j.ins.2021.01.077 [11] Jin Z H, Wu J H, Liu A D, Zhang W A, Yu L. Policy-based deep reinforcement learning for visual servoing control of mobile robots with visibility constraints. IEEE Transactions on Industrial Electronics, 2022, 69(2): 1898-1908 doi: 10.1109/TIE.2021.3057005 [12] Li X J, Liu H S, Dong M H. A general framework of motion planning for redundant robot manipulator based on deep reinforcement learning. IEEE Transactions on Industrial Informatics, 2022, 18(8): 5253-5263 doi: 10.1109/TII.2021.3125447 [13] Chen S Y, Wang M L, Song W J, Yang Y, Li Y J, Fu M Y. Stabilization approaches for reinforcement learning-based end-to-end autonomous driving. IEEE Transactions on Vehicular Technology, 2020, 69(5): 4740-4750 doi: 10.1109/TVT.2020.2979493 [14] Qi Q, Zhang L X, Wang J Y, Sun H F, Zhuang Z R, Liao J X, et al. Scalable parallel task scheduling for autonomous driving using multi-task deep reinforcement learning. IEEE Transactions on Vehicular Technology, 2020, 69(11): 13861-13874 doi: 10.1109/TVT.2020.3029864 [15] Kiran B R, Sobh I, Talpaert V, Mannion P, Sallab A A A, Yogamani S, et al. Deep reinforcement learning for autonomous driving: A survey. IEEE Transactions on Intelligent Transportation Systems, 2022, 23(6): 4909-4926 doi: 10.1109/TITS.2021.3054625 [16] Taghian M, Asadi A, Safabakhsh R. Learning financial asset-specific trading rules via deep reinforcement learning. Expert Systems with Applications, 2022, 195: Article No. 116523 doi: 10.1016/j.eswa.2022.116523 [17] Tsantekidis A, Passalis N, Tefas A. Diversity-driven knowledge distillation for financial trading using Deep Reinforcement Learning. Neural Networks, 2021, 140: 193-202 doi: 10.1016/j.neunet.2021.02.026 [18] Park H, Sim M K, Choi D G. An intelligent financial portfolio trading strategy using deep Q-learning. Expert Systems with Applications, 2020, 158: Article No. 113573 doi: 10.1016/j.eswa.2020.113573 [19] Tan W S, Ryan M L. A single site investigation of DRLs for CT head examinations based on indication-based protocols in Ireland. Journal of Medical Imaging and Radiation Sciences, DOI: 10.1016/j.jmir.2022.03.114 [20] Allahham M S, Abdellatif A A, Mohamed A, Erbad A, Yaacoub E, Guizani M. I-SEE: Intelligent, secure, and energy-efficient techniques for medical data transmission using deep reinforcement learning. IEEE Internet of Things Journal, 2021, 8(8): 6454-6468 doi: 10.1109/JIOT.2020.3027048 [21] Lin L J. Self-improving reactive agents based on reinforcement learning, planning and teaching. Machine Learning, 1992, 8: 293-321 [22] Bellman R. A Markovian decision process. Indiana University Mathematics Journal, 1957, 6(4): 679-684 doi: 10.1512/iumj.1957.6.56038 [23] Rummery G A, Niranjan M. On-line Q-learning Using Connectionist Systems, Technical Report GUED/F-INFENG/TR 166, Engineering Department, Cambridge University, England, 1994. [24] Sutton R, Mcallester D A, Singh S, Mansour Y. Policy gradient methods for reinforcement learning with function approximation. In: Proceedings of the Advances in Neural Information Processing Systems (NIPS). Denver, Colorado, USA: MIT Press, 1999. 1057−1063 [25] Williams R J. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine Learning, 1992, 8: 229-256 [26] Mnih V, Badia A P, Mirza M, Graves A, Harley T, Lillicrap P T, et al. Asynchronous methods for deep reinforcement learning. In: Proceedings of the 33rd International Conference on Machine Learning (ICML). New York, USA: ACM, 2016. 1928−1937 [27] Babaeizadeh M, Frosio I, Tyree S, Clemons J, Kautz J. Reinforcement learning through asynchronous advantage actor-critic on a GPU. arXiv preprint arXiv: 1611.06256, 2017. [28] Schulman J, Levine S, Moritz P, Jordan M I, Abbeel P. Trust region policy optimization. arXiv preprint arXiv: 1502.05477, 2015. [29] Schulman J, Wolski F, Dhariwal P, Radford A, Klimov O. Proximal policy optimization algorithms. arXiv preprint arXiv: 1707.06347, 2017. [30] Watkins C J C H, Dayan P. Q-learning. Machine Learning, 1992, 8(3): 279-292 [31] Hasselt H V, Guez A, Silver D. Deep reinforcement learning with double Q-learning. arXiv preprint arXiv: 1509.06461, 2015. [32] Wang Z Y, Tom S, Matteo H, Hado V H, Marc L, Nando D F. Dueling network architectures for deep reinforcement learning. In: Proceedings of the 33rd International Conference on Machine Learning (ICML). New York, USA: ACM, 2016. 1995−2003 [33] Lillicrap T P, Hunt J J, Pritzel A, Heess N, Erez T, Tassa Y, et al. Continuous control with deep reinforcement learning. arXiv preprint arXiv: 1509.02971, 2015. [34] Fujimoto S, Hoof V H, Meger D. Addressing function approximation error in actor-critic methods. arXiv preprint arXiv: 1802.09477, 2018. [35] Haarnoja T, Zhou A, Abbeel P, Levine S. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. arXiv preprint arXiv: 1801.01290, 2018. [36] Nair A, Srinivasan P, Blackwell S, Alcicek C, Fearon R, Maria A D, et al. Massively parallel methods for deep reinforcement learning. arXiv preprint arXiv: 1507.04296, 2015. [37] Hausknecht M, Stone P. Deep recurrent Q-learning for partially observable MDPs. arXiv preprint arXiv: 1507.06527, 2015. [38] Plappert M, Houthooft R, Dhariwal P, Sidor S, Chen R Y, Chen X, et al. Parameter space noise for exploration. arXiv preprint arXiv: 1706.01905, 2018. [39] Hessel M, Modayil J, Hasselt H V, Schaul T, Ostrovski G, Dabney W, et al. Rainbow: Combining improvements in deep reinforcement learning. arXiv preprint arXiv: 1710.02298, 2017. [40] 刘建伟, 高峰, 罗雄麟. 基于值函数和策略梯度的深度强化学习综述. 计算机学报, 2019, 42(6): 1406-1438 doi: 10.11897/SP.J.1016.2019.01406Liu Jian-Wei, Gao Feng, Luo Xiong-Lin. Survey of deep reinforcement learning based on value policy gradient. Chinese Journal of Computers, 2019, 42(6): 1406-1438 doi: 10.11897/SP.J.1016.2019.01406 [41] Haarnoja T, Zhou A, Hartikainen K, Tucker G, Ha S, Tan J, et al. Soft actor-critic algorithms and applications. arXiv preprint arXiv: 1812.05905, 2018. [42] Jang E, Gu S X, Poole B. Categorical reparameterization with Gumbel-Softmax. arXiv preprint arXiv: 1611.01144, 2017. [43] Schaul T, Quan J, Antonoglou I, Silver D. Prioritized experience replay. arXiv preprint arXiv: 1511.05952, 2016. [44] Brittain M, Bertram J, Yang X X, Wei P. Prioritized sequence experience replay. arXiv preprint arXiv: 1905.12726, 2019. [45] Lee S, Lee J, Hasuo I. Predictive PER: Balancing priority and diversity towards stable deep reinforcement learning. arXiv preprint arXiv: 2011.13093, 2020. [46] Cao X, Wan H Y, Lin Y F, Han S. High-value prioritized experience replay for off-policy reinforcement learning. In: Proceedings of the IEEE 31st International Conference on Tools With Artificial Intelligence (ICTAI). Portland, OR, USA: IEEE, 2019. 1510−1514 [47] 赵英男, 刘鹏, 赵巍, 唐降龙. 深度 Q 学习的二次主动采样方法. 自动化学报, 2019, 45(10): 1870-1882Zhao Ying-Nan, Liu Peng, Zhao Wei, Tang Jiang-Long. Twice sampling method in deep Q-network. Acta Automatica Sinica, 2019, 45(10): 1870-1882 [48] Sun P Q, Zhou W G, Li H Q. Attentive experience replay. In: Proceedings of the 34th AAAI Conference on Artificial Intelligence. New York, USA: AAAI Press, 2020. 5900−5907 [49] Hu Z J, Gao X G, Wan K F, Zhai Y W, Wang Q L. Relevant experience learning: A deep reinforcement learning method for UAV autonomous motion planning in complex unknown environments. Chinese Journal of Aeronautics, 2021, 34(12): 187-204 doi: 10.1016/j.cja.2020.12.027 [50] Cicek D C, Duran E, Saglam B, Mutlu F B, Kozat S S. Off-policy correction for deep deterministic policy gradient algorithms via batch prioritized experience replay. In: Proceedings of the 33rd IEEE International Conference on Tools With Artificial Intelligence (ICTAI). Washington, DC, USA: IEEE, 2021. 1255−1262 [51] Ren Z P, Dong D Y, Li H X, Chen C L. Self-paced prioritized curriculum learning with coverage penalty in deep reinforcement learning. IEEE Transactions on Neural Networks and Learning Systems, 2018, 29(6): 2216-2226 doi: 10.1109/TNNLS.2018.2790981 [52] Bengio Y, Louradour J, Collobert R, Weston J. Curriculum learning. In: Proceedings of the 26th Annual International Conference on Machine Learning (ICML). Montreal, Quebec, Canada: ACM, 2009. 41−48 [53] Wang X, Chen Y D, Zhu W W. A survey on curriculum learning. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(9): 4555-4576 [54] Hu Z J, Gao X G, Wan K F, Wang Q L, Zhai Y W. Asynchronous curriculum experience replay: A deep reinforcement learning approach for UAV autonomous motion control in unknown dynamic environments. arXiv preprint arXiv: 2207.01251, 2022. [55] Kumar A, Gupta A, Levine S. DisCor: Corrective feedback in reinforcement learning via distribution correction. arXiv preprint arXiv: 2003.07305, 2020. [56] Lee K, Laskin M, Srinivas A, Abbeel P. SUNRISE: A simple unified framework for ensemble learning in deep reinforcement learning. arXiv preprint arXiv: 2007.04938, 2020. [57] Sinha S, Song J M, Garg A, Ermon S. Experience replay with likelihood-free importance weights. arXiv preprint arXiv: 2006.13169, 2020. [58] Liu X H, Xue Z H, Pang J C, Jiang S Y, Xu F, Yu Y. Regret minimization experience replay in off-policy reinforcement learning. arXiv preprint arXiv: 2105.07253, 2021. [59] Zhang S T, Sutton R S. A deeper look at experience replay. arXiv preprint arXiv: 1712.01275, 2018. [60] Novati G, Koumoutsakos P. Remember and forget for experience replay. arXiv preprint arXiv: 1807.05827, 2019. [61] 时圣苗, 刘全. 采用分类经验回放的深度确定性策略梯度方法. 自动化学报, 2022, 48(7): 1816-1823 doi: 10.16383/j.aas.c190406Shi Sheng-Miao, Liu Quan. Deep deterministic policy gradient with classified experience replay. Acta Automatica Sinica, 2022, 48(7): 1816-1823 doi: 10.16383/j.aas.c190406 [62] 刘晓宇, 许驰, 曾鹏, 于海斌. 面向异构工业任务高并发计算卸载的深度强化学习方法. 计算机学报, 2021, 44(12): 2367-2380Liu Xiao-Yu, Xu Chi, Zeng Peng, Yu Hai-Bin. Deep reinforcement learning-based high concurrent computing offloading for heterogeneous industrial tasks. Chinese Journal of Computers, 2021, 44(12): 2367-2380 [63] 朱斐, 吴文, 伏玉琛, 刘全. 基于双深度网络的安全深度强化学习方法. 计算机学报, 2019, 42(8): 1812-1826 doi: 10.11897/SP.J.1016.2019.01812Zhu Fei, Wu Wen, Fu Yu-Chen, Liu Quan. A dual deep network based secure deep reinforcement learning method. Chinese Journal of Computers, 2019, 42(8): 1812-1826 doi: 10.11897/SP.J.1016.2019.01812 [64] Wei Q, Ma H L, Chen C L, Dong D Y. Deep reinforcement learning with quantum-inspired experience replay. IEEE Transactions on Cybernetics, 2022, 52(9): 9326-9338 doi: 10.1109/TCYB.2021.3053414 [65] Li Y J, Aghvami A H, Dong D Y. Path planning for cellular-connected UAV: A DRL solution with quantum-inspired experience replay. IEEE Transactions on Wireless Communications, 2022, 21(10): 7897-7912 doi: 10.1109/TWC.2022.3162749 [66] Chen X C, Yao L N, Wang X Z, McAuley J. Locality-sensitive experience replay for online recommendation. arXiv preprint arXiv: 2110.10850, 2021. [67] Bruin T D, Kober J, Tuyls K, Babuska R. Improved deep reinforcement learning for robotics through distribution-based experience retention. In: Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Daejeon, South Korea: IEEE, 2016. 3947−3952 [68] Li M Y, Kazemi A, Laguna A F, Hu X S. Associative memory based experience replay for deep reinforcement learning. arXiv preprint arXiv: 2207.07791, 2022. [69] Schaal S. Is imitation learning the route to humanoid robots? Trends in Cognitive Sciences, 1999, 3(6): 233-242 doi: 10.1016/S1364-6613(99)01327-3 [70] Attia A, Dayan S. Global overview of imitation learning. arXiv preprint arXiv: 1801.06503, 2018. [71] Hester T, Vecerik M, Pietquin O, Lanctot M, Schaul T, Piot B, et al. Deep Q-learning from demonstrations. arXiv preprint arXiv: 1704.03732, 2017. [72] Vecerik M, Hester T, Scholz J, Wang F M, Pietquin O, Piot B, et al. Leveraging demonstrations for deep reinforcement learning on robotics problems with sparse rewards. arXiv preprint arXiv: 1707.08817, 2017. [73] Guillen-Perez A, Cano M. Learning from Oracle demonstrations — a new approach to develop autonomous intersection management control algorithms based on multiagent deep reinforcement learning. IEEE Access, 2022, 10: 53601-53613 doi: 10.1109/ACCESS.2022.3175493 [74] Huang Z Y, Wu J D, Lv C. Efficient deep reinforcement learning with imitative expert priors for autonomous driving. IEEE Transactions on Neural Networks and Learning Systems, DOI: 10.1109/TNNLS.2022.3142822 [75] Hu Z J, Wan K F, Gao X G, Zhai Y W, Wang Q L. Deep reinforcement learning approach with multiple experience pools for UAV's autonomous motion planning in complex unknown environments. Sensors, 2020, 20(7): Article No. 1890 doi: 10.3390/s20071890 [76] Wan K F, Wu D W, Li B, Gao X G, Hu Z J, Chen D Q. ME-MADDPG: An efficient learning-based motion planning method for multiple agents in complex environments. International Journal of Intelligent Systems, 2022, 37(3): 2393-2427 doi: 10.1002/int.22778 [77] Lowe R, Wu Y, Tamar A, Harb J, Abbeel P, Mordatch I. Multi-agent actor-critic for mixed cooperative-competitive environments. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach, CA, USA: Curran Associates Inc., 2017. 6382−6393 [78] Zhang T Z, Miao X H, Li Y B, Jia L, Zhuang Y H. AUV surfacing control with adversarial attack against DLaaS framework. IEEE Transactions on Computers, DOI: 10.1109/TC.2021.3072072 [79] Sutton R S. Integrated architectures for learning, planning, and reacting based on approximating dynamic programming. In: Proceedings of the 7th International Conference on Machine Learning (ICML). Austin, Texas, USA: ACM, 1990. 216−224 [80] Silver D, Sutton R S, Müller M. Sample-based learning and search with permanent and transient memories. In: Proceedings of the 25th International Conference on Machine Learning (ICML). Helsinki, Finland: ACM, 2008. 968−975 [81] Santos M, Jose A, Lopez V, Botella G. Dyna-H: A heuristic planning reinforcement learning algorithm applied to role-playing-game strategy decision systems. Knowledge-Based Systems, 2012, 32: 28-36 doi: 10.1016/j.knosys.2011.09.008 [82] Pan Y C, Yao H S, Farahmand A, White M. Hill climbing on value estimates for search-control in Dyna. In: Proceedings of the 28th International Joint Conference on Artificial Intelligence (IJCAI). Macao, China: AAAI Press, 2019. 3209−3215 [83] Pan Y C, Zaheer M, White A, Patterson A, White M. Organizing experience: A deeper look at replay mechanisms for sample-based planning in continuous state domains. In: Proceedings of the 27th International Joint Conference on Artificial Intelligence (IJCAI). Stockholm, Sweden: AAAI Press, 2018. 4794−4800 [84] Andrychowicz M, Wolski F, Ray A, Schneider J, Fong R, Welinder P, et al. Hindsight experience replay. In: Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS). Long Beach, CA, USA: Curran Associates Inc., 2017. 5055–5065 [85] Schaul T, Horgan D, Gregor K, Silver D. Universal value function approximators. In: Proceedings of the 32nd International Conference on Machine Learning (ICML). Lille, France: JMLR.org, 2015. 1312−1320 [86] Luu T M, Yoo C D. Hindsight goal ranking on replay buffer for sparse reward environment. IEEE Access, 2021, 9: 51996-52007 doi: 10.1109/ACCESS.2021.3069975 [87] Fang M, Zhou C, Shi B, Gong B Q, Xu J, Zhang T. DHER: Hindsight experience replay for dynamic goals. In: Proceedings of the 7th International Conference on Learning Representations (ICLR). New Orleans, LA, USA: OpenReview.net, 2019. 1−12 [88] Hu Z J, Gao X G, Wan K F, Evgeny N, Li J L. Imaginary filtered hindsight experience replay for UAV tracking dynamic targets in large-scale unknown environments. Chinese Journal of Aeronautics, DOI: 10.1016/j.cja.2022.09.008 [89] Fang M, Zhou T Y, Du Y L, Han L, Zhang Z Y. Curriculum-guided hindsight experience replay. In: Proceedings of the 33rd International Conference on Neural Information Processing Systems (NIPS). Vancouver, BC, Canada: MIT Press, 2019. 12623−12634 [90] Yang R, Fang M, Han L, Du Y L, Luo F, Li X. MHER: Model-based hindsight experience replay. arXiv preprint arXiv: 2107.00306, 2021. -

 下载:
下载:
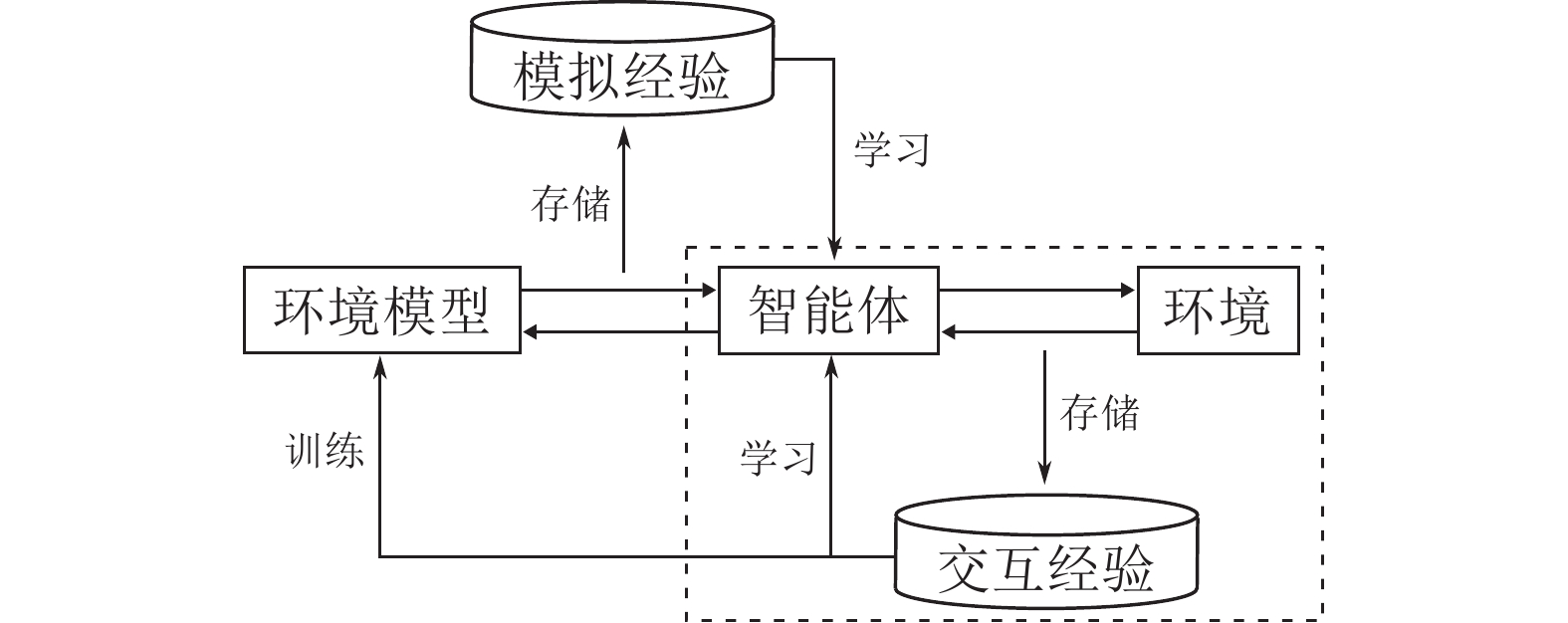


图(10) / 表(5)
计量
- 文章访问数: 4448
- HTML全文浏览量: 2182
- PDF下载量: 789
- 被引次数: 0
