

-
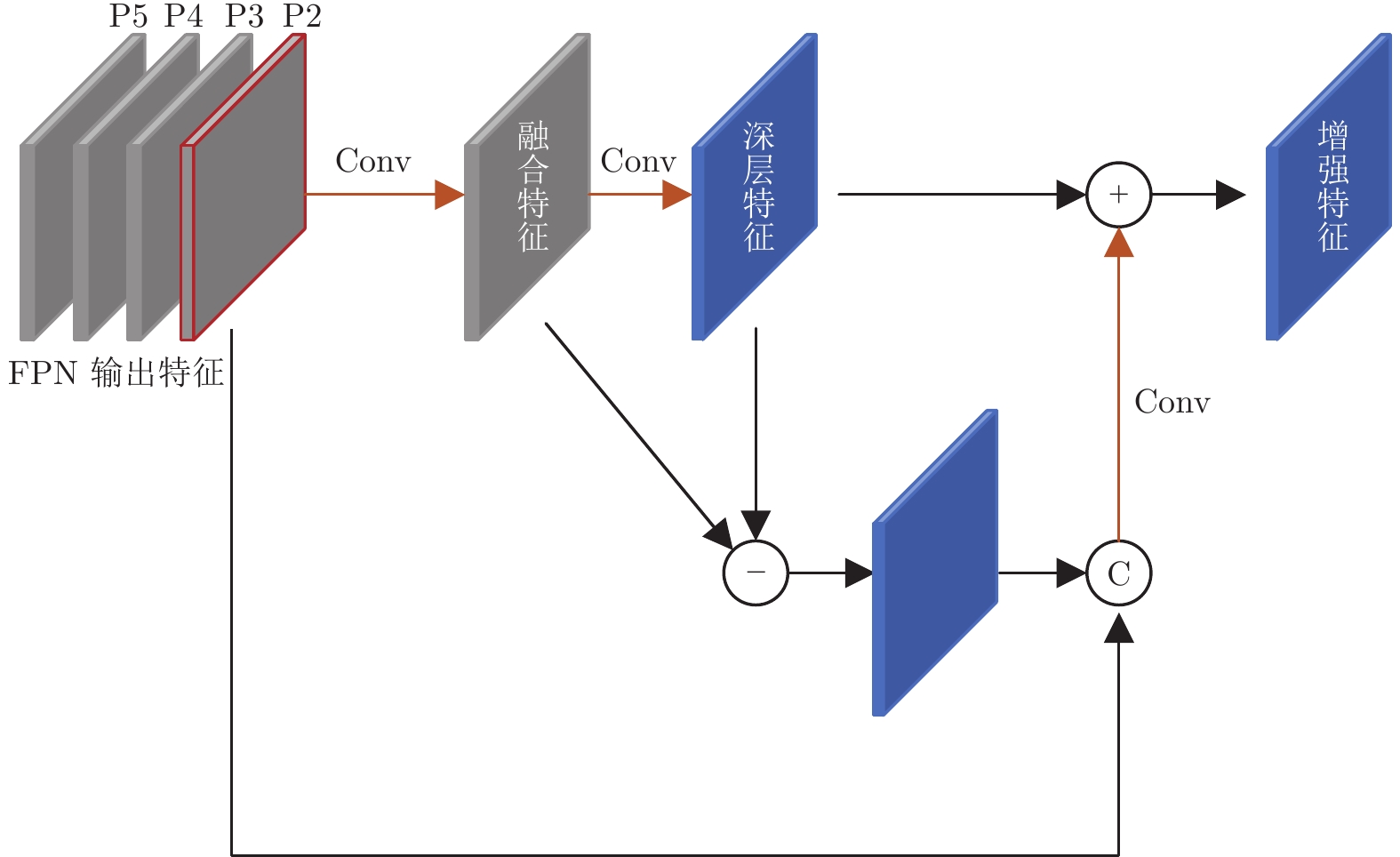
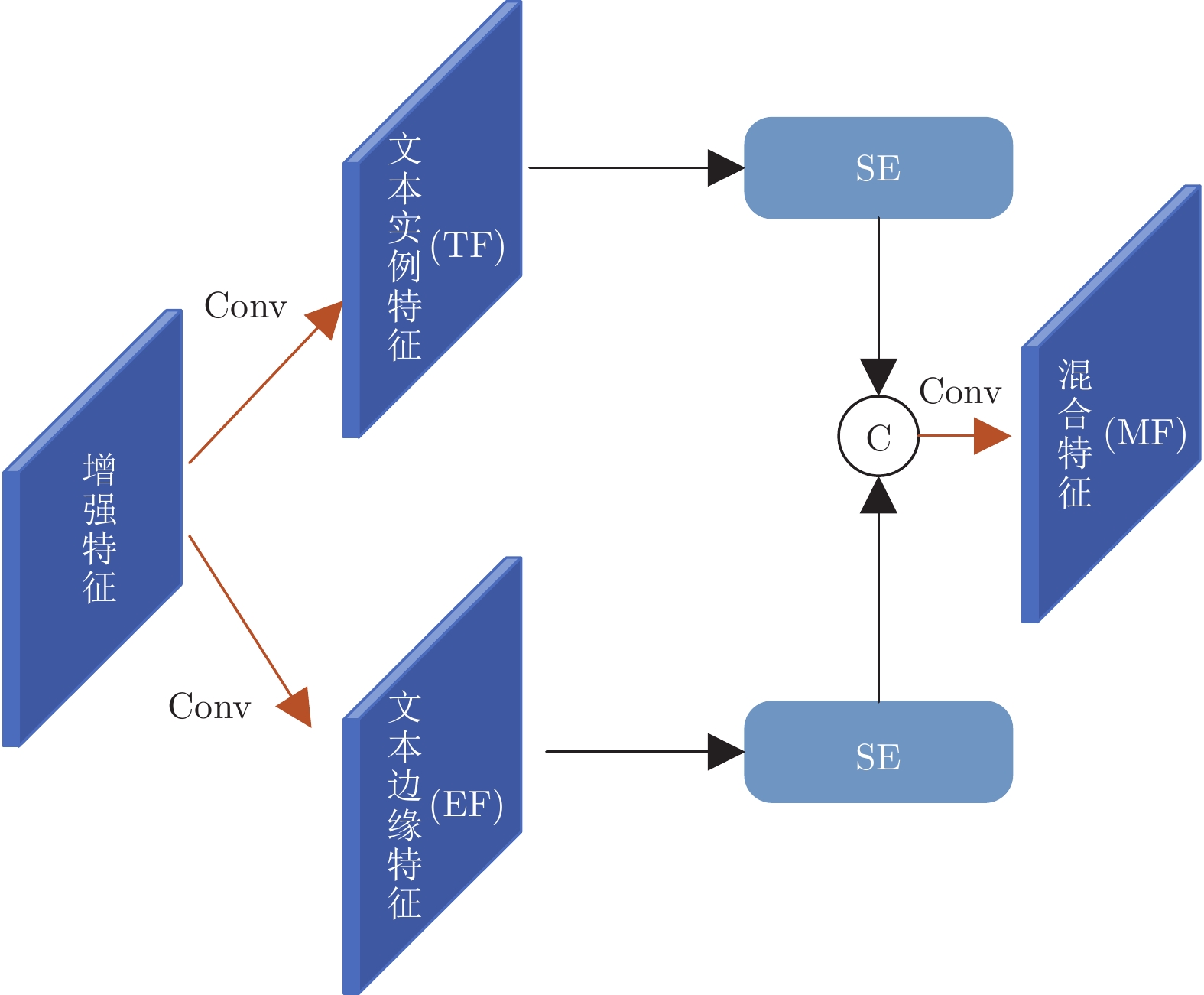
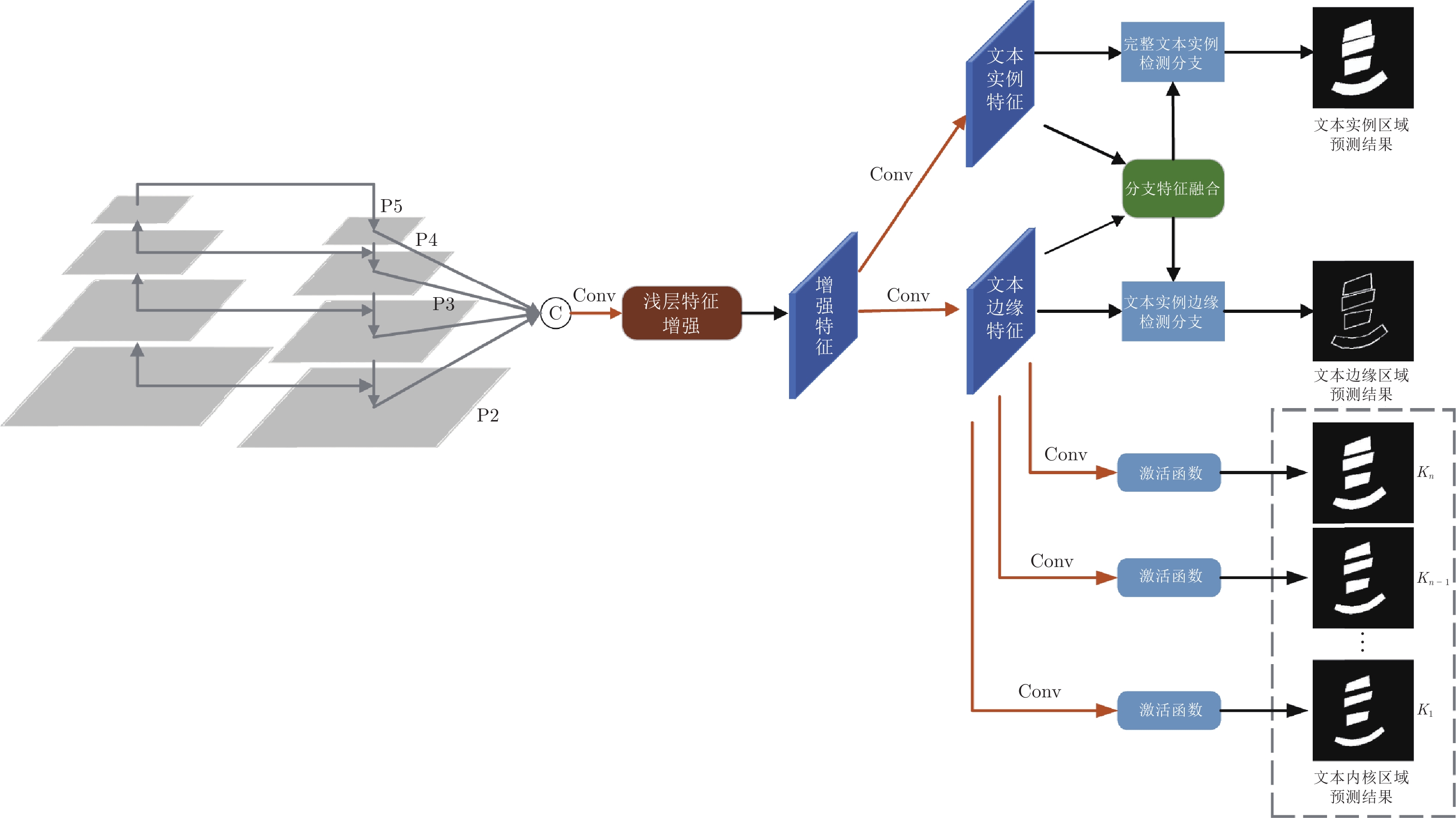
摘要: 在场景文本检测方法中, 文本实例的边缘特征与其他特征在大多数模型中都是以同样的方式进行处理, 而准确检测相邻文本边缘区域是正确识别任意形状文本区域的关键之一. 如果对边缘特征进行增强并使用独立分支进行建模, 必能有效提高模型的标识准确率. 为此, 提出了三个用以增强边缘特征的网络模块. 其中, 浅层特征增强模块可有效增强包含更多边缘特征的浅层特征; 边缘区域检测分支将普通特征和边缘特征进行区分以对目标的边缘特征进行显式建模; 而分支特征融合模块可将两种特征在识别过程进行更好的融合. 在将这三个模块引入渐进尺度扩张网络 (Progressive scale expansion network, PSENet) 之后, 相关消融实验表明这三个模块的单独使用及其组合均可进一步增加网络的预测准确率. 此外, 在三个常用公开数据集上与其他十个最新模型的比较结果表明, 改进后得到边缘特征增强网络 (Edge-oriented feature reinforcing network, EFRNet) 的识别结果具有较高的F1值.Abstract: In the detection of scene texts areas, the text instances' edge features are processed in the same way as other features. Nevertheless, the accurate detection of adjacent text edges is crucial in the correct identification of arbitrary-shaped text regions in natural scenes. Obviously, the identification accuracy increases if edge features can be enhanced and modeled through independent branches in the network. To this end, three network modules are proposed to enhance the edge features in this paper. These modules are the shallow feature enhancement module which effectively enhances the shallow features with more edge features, the edge region detection module which decouples the original features into edge features and text features to explicitly model the edge features of the object, and the branch feature fusion module which effectively fuses these two types of features in the recognition process. After the proposed modules are added to the progressive scale expansion network (PSENet), the ablation experiments show that both the independent application and the synthetic application of these modules increase the prediction accuracy. In addition, the comparison experiments on three commonly used public datasets with ten state-of-the-art methods show that the improved edge-oriented feature reinforcing network (EFRNet) has higher F1-measure accuracy.
-

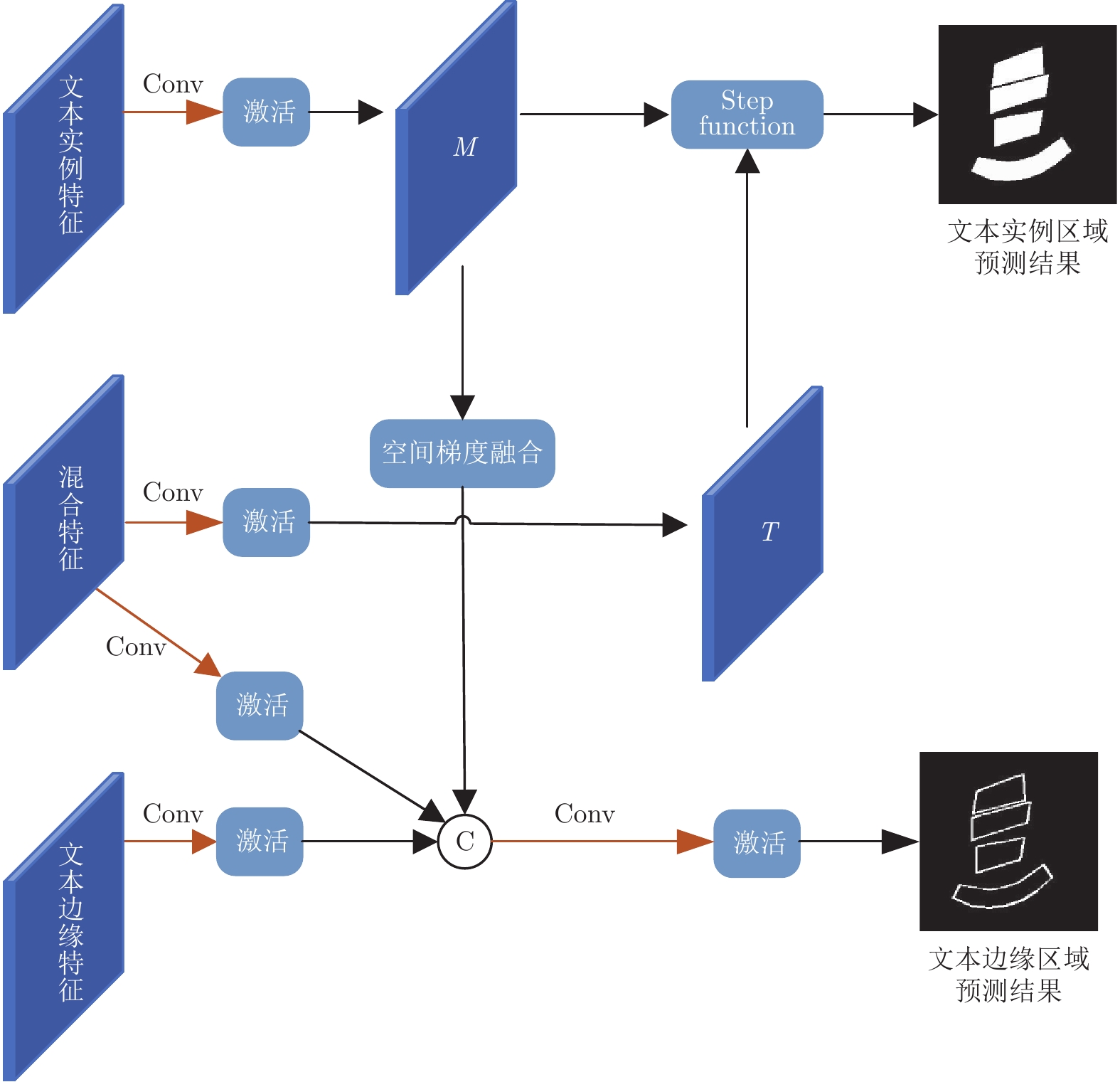
图 5 文本分割图空间梯度计算过程 ((a) 原始图像; (b) 初始检测结果; (c) 最大池化; (d) 探测到的边缘区域)
Fig. 5 Spatial gradient calculation for text segmentation graph ((a) Original images; (b) Initial detection results; (c) Max pool results; (d) Detected edges)

图 6 在数据集CTW1500上的预测结果比较 ((a) 原始图像; (b) 真实值; (c) PSENet; (d) EFRNet; (d) 边缘预测结果)
Fig. 6 Predicted results comparison on dataset CTW1500 ((a) Original image; (b) Ground truth; (c) PSENet; (d) EFRNet; (e) Predicted edge)
表 1 CTW1500、Total-Text和ICDAR 2015数据集上的消融实验结果, 其中P表示准确率, R表示召回率
Table 1 Ablation experimental on CTW1500, Total-Text and ICDAR 2015 datasets, P represents accuracy, R represents recall
浅层特征增强模块 分支特征融合模块 边缘检测分支 CTW1500 Total-Text ICDAR 2015 R (%) P (%) F1 (%) R (%) P (%) F1 (%) R (%) P (%) F1 (%) — — — 77.8 83.2 80.4 78.8 88.5 83.4 75.8 84.2 79.8 √ — — 78.1 83.9 80.8 79.3 88.6 83.7 75.8 85.3 80.3 — — √ 83.4 85.3 84.3 81.9 87.7 84.7 83.1 87.6 85.2 √ — √ 83.8 86.3 85.0 82.0 87.9 84.9 83.3 87.8 85.5 — √ √ 84.1 86.6 85.2 83.1 88.3 85.6 84.0 88.1 86.0 √ √ √ 85.9 86.8 86.3 84.0 88.9 86.4 85.7 89.5 87.6  下载: 导出CSV
下载: 导出CSV
表 2 CTW1500、Total-Text和ICDAR 2015数据集模型性能对比
Table 2 Performance comparison on CTW1500, Total-Text and ICDAR 2015 dataset with state-of-the-art models
方法 CTW1500 Total-Text ICDAR 2015 R (%) P (%) F1 (%) R (%) P (%) F1 (%) R (%) P (%) F1 (%) TextSnake[41] 85.3 67.9 75.6 74.5 82.7 78.4 80.4 84.9 82.6 PAN++[42] 81.2 86.4 83.7 81.0 89.3 85.0 81.9 84.0 82.9 PSENet[22] 75.6 80.6 78.0 75.1 81.8 78.3 79.7 81.5 80.6 DB[30] 80.2 86.9 83.4 82.5 87.1 84.7 83.2 91.8 87.3 DRRG[21] 83.0 85.9 84.5 84.9 86.5 85.7 84.7 88.5 86.6 ContourNet[43] 84.1 83.7 83.9 83.9 86.9 85.4 86.1 87.6 86.9 FCENet[18] 83.4 87.6 85.5 82.5 89.3 85.8 82.6 90.1 86.2 MOST[11] 79.4 83.6 81.4 80.0 86.7 83.2 87.3 89.1 88.2 PCR[12] 83.3 87.2 84.7 82.0 88.5 85.2 84.1 89.6 86.7 DBNet++[15] 82.8 87.9 85.3 83.2 88.9 86.0 83.9 90.0 87.3 EFRNet (ImageNet) 85.9 86.8 86.3 84.0 88.9 86.4 85.7 89.5 87.6 EFRNet (SynthText) 85.9 86.8 86.3 84.3 89.2 86.7 86.3 89.6 87.9
下载: 导出CSV
-
[1] Lyu P Y, Liao M H, Yao C, Wu W H, Bai X. Mask TextSpotter: An end-to-end trainable neural network for spotting text with arbitrary shapes. In: Proceedings of the 15th European Conference on Computer Vision. Munich, Germany: Springer, 2018. 71−88 [2] He T, Huang W L, Qiao Y, Yao J. Text-attentional convolutional neural network for scene text detection. IEEE Transactions on Image Processing, 2016, 25(6): 2529-2541 doi: 10.1109/TIP.2016.2547588 [3] Qin S Y, Manduchi R. Cascaded segmentation-detection networks for word-level text spotting. In: Proceedings of the 14th IAPR International Conference on Document Analysis and Recognition (ICDAR). Kyoto, Japan: IEEE, 2017. 1275−1282 [4] Cho H, Sung M, Jun B. Canny text detector: Fast and robust scene text localization algorithm. In: Proceedings of the International Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 3566−3573 [5] Tian S X, Pan Y F, Huang C, Lu S J, Yu K, Tan C L. Text flow: A unified text detection system in natural scene images. In: Proceedings of the International Conference on Computer Vision (ICCV). Santiago, Chile: IEEE, 2015. 4651−4659 [6] 王润民, 桑农, 丁丁, 陈杰, 叶齐祥, 高常鑫, 等. 自然场景图像中的文本检测综述. 自动化学报, 2018, 44(12): 2113-2141Wang Run-Min, Sang Nong, Ding Ding, Chen Jie, Ye Qi-Xiang, Gao Chang-Xin, et al. Text detection in natural scene image: A survey. Acta Automatica Sinica, 2018, 44(12): 2113-2141 [7] Liu Y L, Jin L W. Deep matching prior network: Toward tighter multi-oriented text detection. In: Proceedings of the International Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE, 2017. 3454−3461 [8] Zhang Z, Zhang C Q, Shen W, Yao C, Liu W Y, Bai X. Multi-oriented text detection with fully convolutional networks. In: Proceedings of the International Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 4159−4167 [9] Zhong Z Y, Jin L W, Huang S P. DeepText: A new approach for text proposal generation and text detection in natural images. In: Proceedings of the International Conference on Acoustics, Speech and Signal Processing (ICASSP). New Orleans, USA: IEEE, 2017. 1208−1212 [10] Tian Z, Huang W L, He T, He P, Qiao Y. Detecting text in natural image with connectionist text proposal network. In: Proceedings of the 14th European Conference on Computer vision. Amsterdam, The Netherlands: Springer, 2016. 56−72 [11] He M H, Liao M H, Yang Z B, Zhong H M, Tang J, Cheng W Q, et al. MOST: A multi-oriented scene text detector with localization refinement. In: Proceedings of the International Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, USA: IEEE, 2021. 8809−8818 [12] Dai P W, Zhang S Y, Zhang H, Cao X C. Progressive contour regression for arbitrary-shape scene text detection. In: Proceedings of the International Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, TN, USA: IEEE, 2021. 7389−7398 [13] He P, Huang W L, He T, Zhu Q L, Qiao Y, Li X L. Single shot text detector with regional attention. In: Proceedings of the International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017. 3066−3074 [14] Deng D, Liu H F, Li X L, Cai D. PixelLink: Detecting scene text via instance segmentation. In: Proceedings of the 32nd AAAI Conference on Artificial Intelligence. New Orleans, USA: AAAI, 2018. 6773−6780 [15] Liao M H, Zou Z S, Wan Z Y, Yao C, Bai X. Real-time scene text detection with differentiable binarization and adaptive scale fusion. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(1): 919-931. doi: 10.1109/TPAMI.2022.3155612 [16] Wang F F, Chen Y F, Wu F, Li X. TextRay: Contour-based geometric modeling for arbitrary-shaped scene text detection. In: Proceedings of the 28th ACM International Conference on Multimedia. Seattle, USA: ACM, 2020. 111−119 [17] Liu Y L, Chen H, Shen C H, He T, Jin L W, Wang L W. ABCNet: Real-time scene text spotting with adaptive Bezier-curve network. In: Proceedings of the International Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE, 2020. 9806−9815 [18] Zhu Y Q, Chen J Y, Liang L Y, Kuang Z H, Jin L W, Zhang W. Fourier contour embedding for arbitrary-shaped text detection. In: Proceedings of the International Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, USA: IEEE, 2021. 3122−3130 [19] Zhang C Q, Liang B R, Huang Z M, En M Y, Han J Y, Ding E R, et al. Look more than once: An accurate detector for text of arbitrary shapes. In: Proceedings of the International Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, USA: IEEE, 2019. 10544−10553 [20] Qin X G, Zhou Y, Guo Y H, Wu D Y, Tian Z H, Jiang N, et al. Mask is all you need: Rethinking mask R-CNN for dense and arbitrary-shaped scene text detection. In: Proceedings of the 29th ACM International Conference on Multimedia. Chengdu, China: ACM, 2021. 414−423 [21] Zhang S X, Zhu X B, Hou J B, Liu C, Yang C, Wang H F, et al. Deep relational reasoning graph network for arbitrary shape text detection. In: Proceedings of the International Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE, 2020. 9696−9705 [22] Wang W H, Xie E Z, Li X, Hou W B, Lu, T, Yu G, et al. Shape robust text detection with progressive scale expansion network. In: Proceedings of the International Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, USA: IEEE, 2019. 9328−9337 [23] Sheng T, Chen J, Lian Z H. CentripetalText: An efficient text instance representation for scene text detection. In: Proceedings of the 34th Advances in Neural Information Processing Systems. Cambridge, MA, USA: NIPS, 2021. 335−346 [24] Liu Z C, Lin G S, Yang S, Liu F Y, Lin W S, Goh W L. Towards robust curve text detection with conditional spatial expansion. In: Proceedings of the International Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, USA: IEEE, 2019. 7261−7270 [25] Tian Z T, Shu M, Lyu P, Li R Y, Zhou C, Shen X Y, et al. Learning shape-aware embedding for scene text detection. In: Proceedings of the International Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, USA: IEEE, 2019. 4229−4238 [26] Li J C, Lin Y, Liu R R, Ho C M, Shi H. RSCA: Real-time segmentation-based context-aware scene text detection. In: Proceedings of the International Conference on Computer Vision and Pattern Recognition (CVPRW). Nashville, USA: IEEE, 2021. 2349−2358 [27] He K M, Zhang X Y, Ren S Q, Sun J. Identity mappings in deep residual networks. In: Proceedings of the 14th European Conference on Computer Vision. Amsterdam, The Netherlands: Springer, 2016. 630−645 [28] Liu W, Liao S C, Ren W Q, Hu W D, Yu Y N. High-level semantic feature detection: A new perspective for pedestrian detection. In: Proceedings of the International Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, USA: IEEE, 2019. 5182−5191 [29] Hu J, Shen L, Sun G, Wu E. Squeeze-and-excitation networks. In: Proceedings of the International Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 7132−7141 [30] Liao M H, Wan Z Y, Yao C, Chen K, Bai X. Real-time scene text detection with differentiable binarization. In: Proceedings of the 34th AAAI Conference on Artificial Intelligence. New York, USA: AAAI, 2020. 11474−11481 [31] Zhen M M, Wang J L, Zhou L, Li S W, Shen T W, Shang J X, et al. Joint semantic segmentation and boundary detection using iterative pyramid contexts. In: Proceedings of the International Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE, 2020. 13663−13672 [32] Milletari F, Navab N, Ahmadi S A. V-Net: Fully convolutional neural networks for volumetric medical image segmentation. In: Proceedings of the 4th International Conference on 3D Vision (3DV). Stanford, USA: IEEE, 2016. 565−571 [33] Shrivastava A, Gupta A, Girshick R. Training region-based object detectors with online hard example mining. In: Proceedings of the International Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 761−769 [34] Karatzas D, Gomez-Bigorda L, Nicolaou A, Ghosh S, Bagdanov A, Iwamura M, et al. ICDAR 2015 competition on robust reading. In: Proceedings of the 13th International Conference on Document Analysis and Recognition (ICDAR). Tunis, Tunisia: IEEE, 2015. 1156−1160 [35] Ch'ng C K, Chan C S. Total-Text: A comprehensive dataset for scene text detection and recognition. In: Proceedings of the 14th IAPR International Conference on Document Analysis and Recognition (ICDAR). Kyoto, Japan: IEEE, 2017. 935−942 [36] Liu Y L, Jin L W, Zhang S T, Luo C J, Zhang S. Curved scene text detection via transverse and longitudinal sequence connection. Pattern Recognition, 2019, 90: 337-345 doi: 10.1016/j.patcog.2019.02.002 [37] Deng J, Wei D, Socher R, Li J, Kai L, Li F F. ImageNet: A large-scale hierarchical image database. In: Proceedings of the International Conference on Computer Vision and Pattern Recognition. Miami, USA: IEEE, 2009. 248−255 [38] He K M, Zhang X Y, Ren S Q, Sun J. Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification. In: Proceedings of the International Conference on Computer Vision (ICCV). Santiago, Chile: IEEE, 2015. 1026−1034 [39] Yin X C, Yin X W, Huang K Z, Hao H W. Robust text detection in natural scene images. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(5): 970-983 doi: 10.1109/TPAMI.2013.182 [40] Vatti B R. A generic solution to polygon clipping. Communications of the ACM, 1992, 35(7): 56-63 doi: 10.1145/129902.129906 [41] Long S B, Ruan J Q, Zhang W J, He X, Wu W H, Yao C. TextSnake: A flexible representation for detecting text of arbitrary shapes. In: Proceedings of the 15th European Conference on Computer Vision. Munich, Germany: Springer, 2018. 19−35 [42] Wang W H, Xie E Z, Li X, Liu X B, Liang D, Yang Z B, et al. PAN++: Towards efficient and accurate end-to-end spotting of arbitrarily-shaped text. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(9): 5349-5367 [43] Wang Y X, Xie H T, Zha Z J, Xing M T, Fu Z L, Zhang Y D. ContourNet: Taking a further step toward accurate arbitrary-shaped scene text detection. In: Proceedings of the International Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE, 2020. 11750−11759 [44] Gupta A, Vedaldi A, Zisserman A. Synthetic data for text localisation in natural images. In: Proceedings of the International Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 2315−2324 [45] Liao M H, Pang G, Huang J, Hassner T, Bai X. Mask TextSpotter v3: Segmentation proposal network for robust scene text spotting. In: Proceedings of the 16th European Conference on Computer Vision. Glasgow, UK: Springer, 2020. 706−722 -

 下载:
下载:

计量
- 文章访问数: 875
- HTML全文浏览量: 540
- PDF下载量: 232
- 被引次数: 0
