

Offline Data Driven Evolutionary Optimization Based on Pruning Stacked Generalization
-
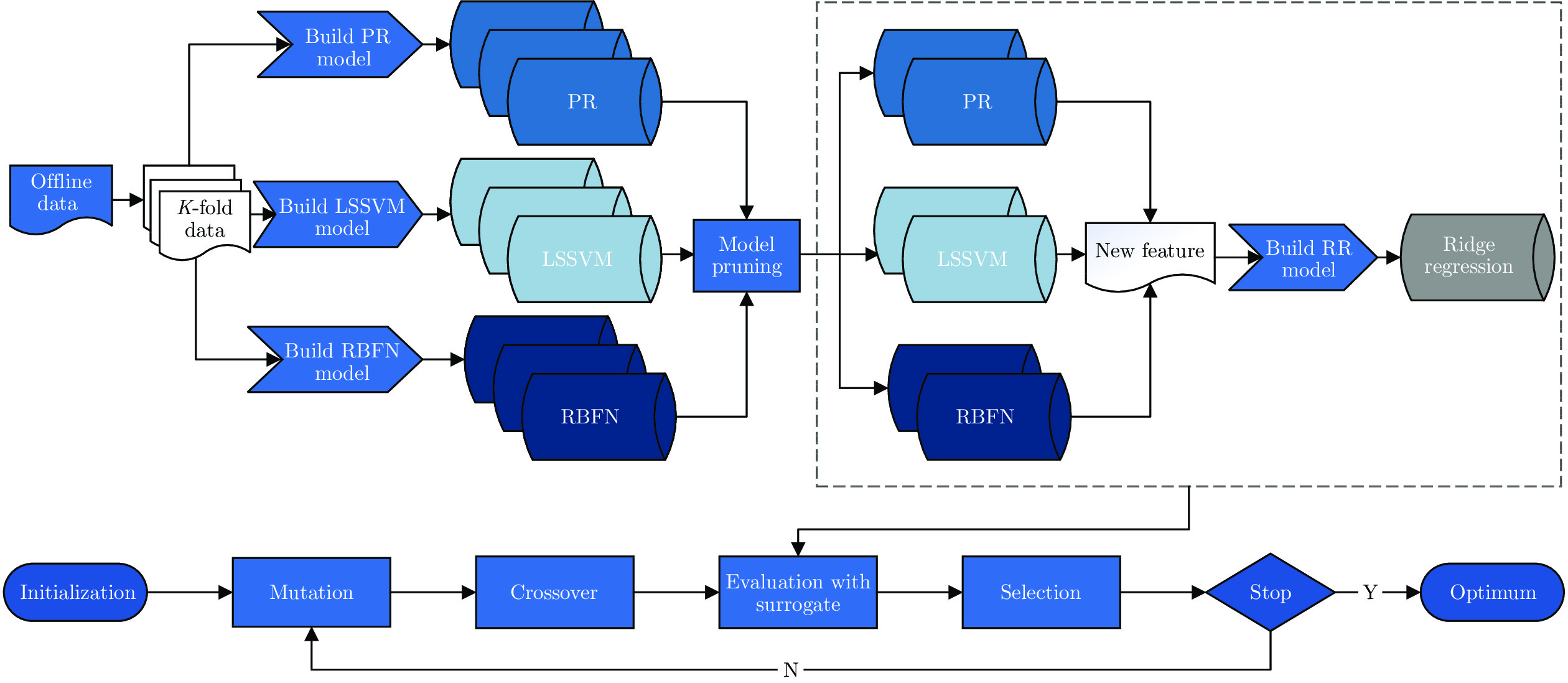
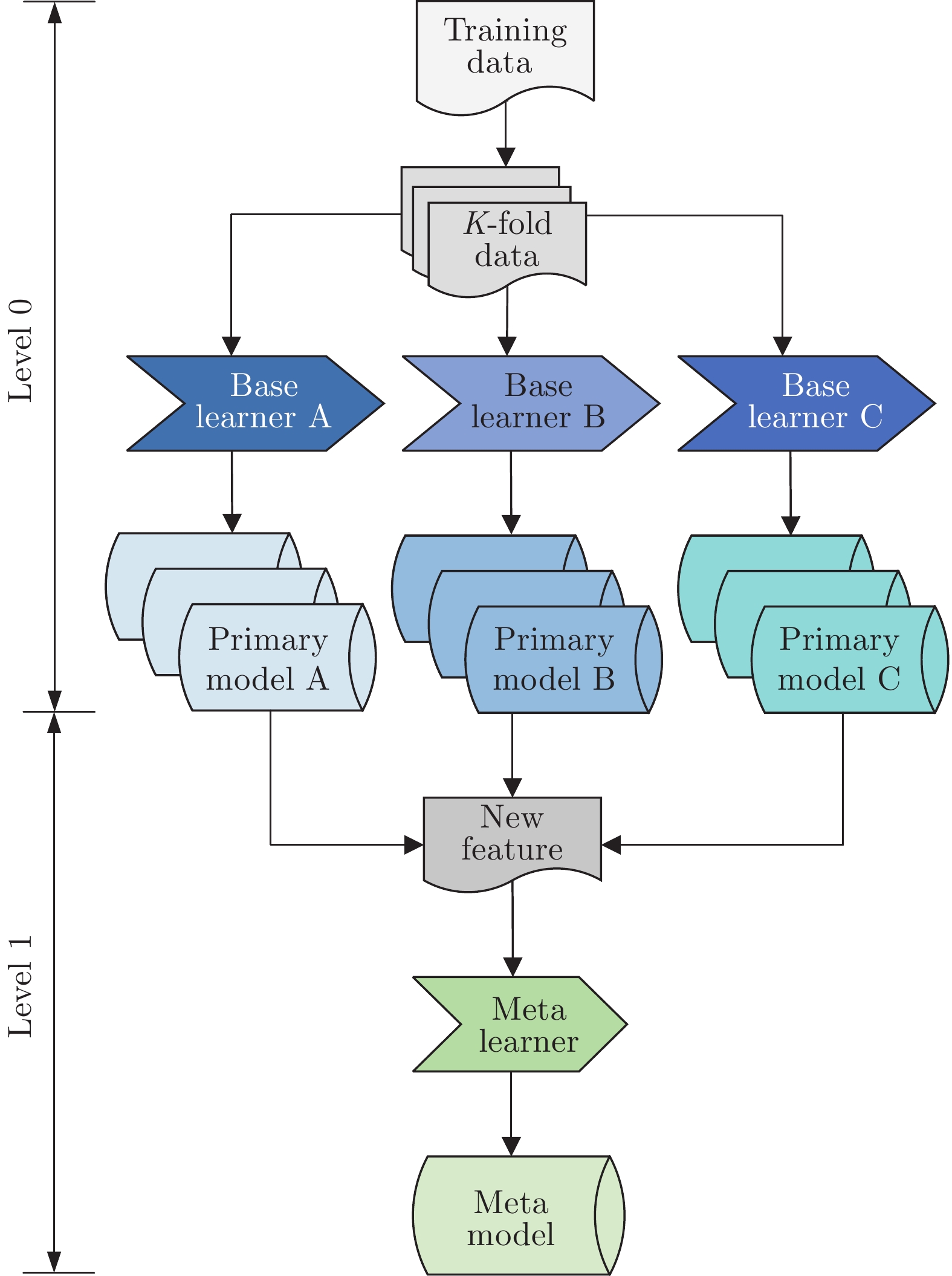
摘要: 现实世界中存在很多目标函数的计算非常昂贵, 甚至目标函数难以建模的复杂优化问题. 常规优化方法在解决此类问题时要么无从入手, 要么效率低下. 离线数据驱动的进化优化方法不需对真实目标函数进行评估, 跳出了传统优化方法的固铚, 极大推动了昂贵优化问题和不可建模优化问题的求解. 但离线数据驱动进化优化的效果严重依赖于所采用代理模型的质量. 为提升离线数据驱动进化优化的性能, 提出了一个基于剪枝堆栈泛化(Stacked generalization, SG)代理模型构建方法. 具体而言, 一方面基于异构的基学习器建立初级模型池, 再采用学习方式对各初级模型进行组合, 以提升代理模型的通用性和准确率. 另一方面基于等级保护指标对初级模型进行剪枝, 在提高初级模型集成效率的同时进一步提升最终代理模型的准确率, 并更好地指导种群的搜索. 为验证所提方法的有效性, 与7个最新的离线数据驱动的进化优化算法在12个基准测试问题上进行对比, 实验结果表明所提出的方法具有明显的优势.Abstract: In the real world, there are many complex optimization problems in which the objective function is time-consuming or even unavailable. Traditional optimization methods are either unable to start or inefficient in solving such problems. Offline data driven evolutionary optimization method is no need to evaluate the real objective function in the process of evolutionary, which greatly promotes the solution of expensive optimization problems and unmodeled optimization problems. However, the effectiveness of offline data driven evolutionary optimization depends heavily on surrogate model. In order to improve the quality of surrogate model, this paper proposes a surrogate model construction method based on pruning stack generalization (SG). Specifically, on the one hand, the primary model pool is established based on heterogeneous base learners, and then the primary models are conducted by learning methods to improve the generality and accuracy of surrogate model. On the other hand, the primary models are pruned based on the ranking preservation indicator, which can not only improve the ensemble efficiency of the primary models, but also further improve the accuracy of the final surrogate model, and better guide the evolutionary search. In order to verify the effectiveness of the proposed method, it is compared with 7 state-of-the-arts offline data driven evolutionary optimization algorithms on 12 benchmark problems. The experimental results demonstrate the superior performance of proposed method over compared algorithms.
-
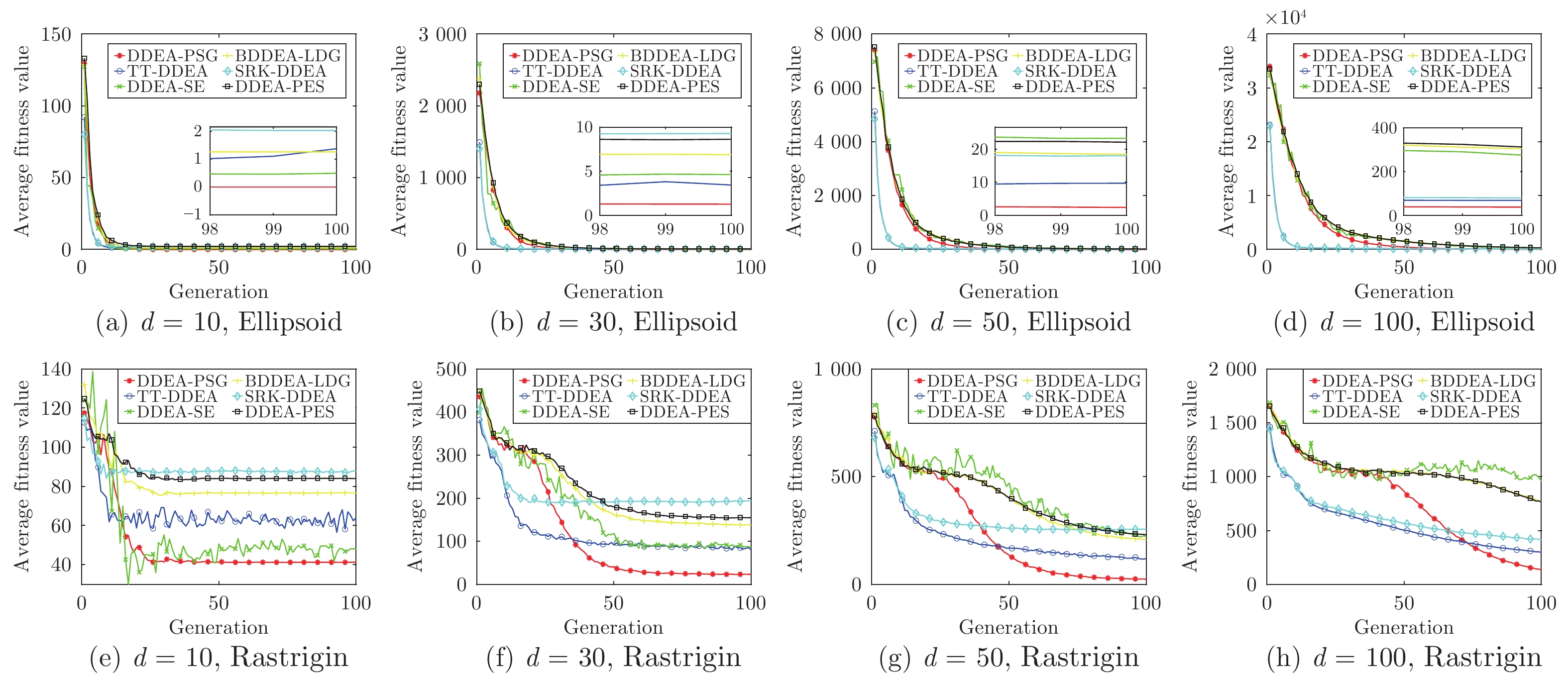
图 3 DDEA-SE, BDDEA-LDG, DDEA-PES, SRK-DDEA, TT-DDEA和DDEA-PSG在10, 30, 50, 100维Ellipsoid和Rastrigin上的收敛图
Fig. 3 Convergence profiles of DDEA-SE, BDDEA-LDG, DDEA-PES, SRK-DDEA, TT-DDEA and DDEA-PSG over 30 independent runs on Ellipsoid and Rastrigin of 10, 30, 50 and 100 dimensions
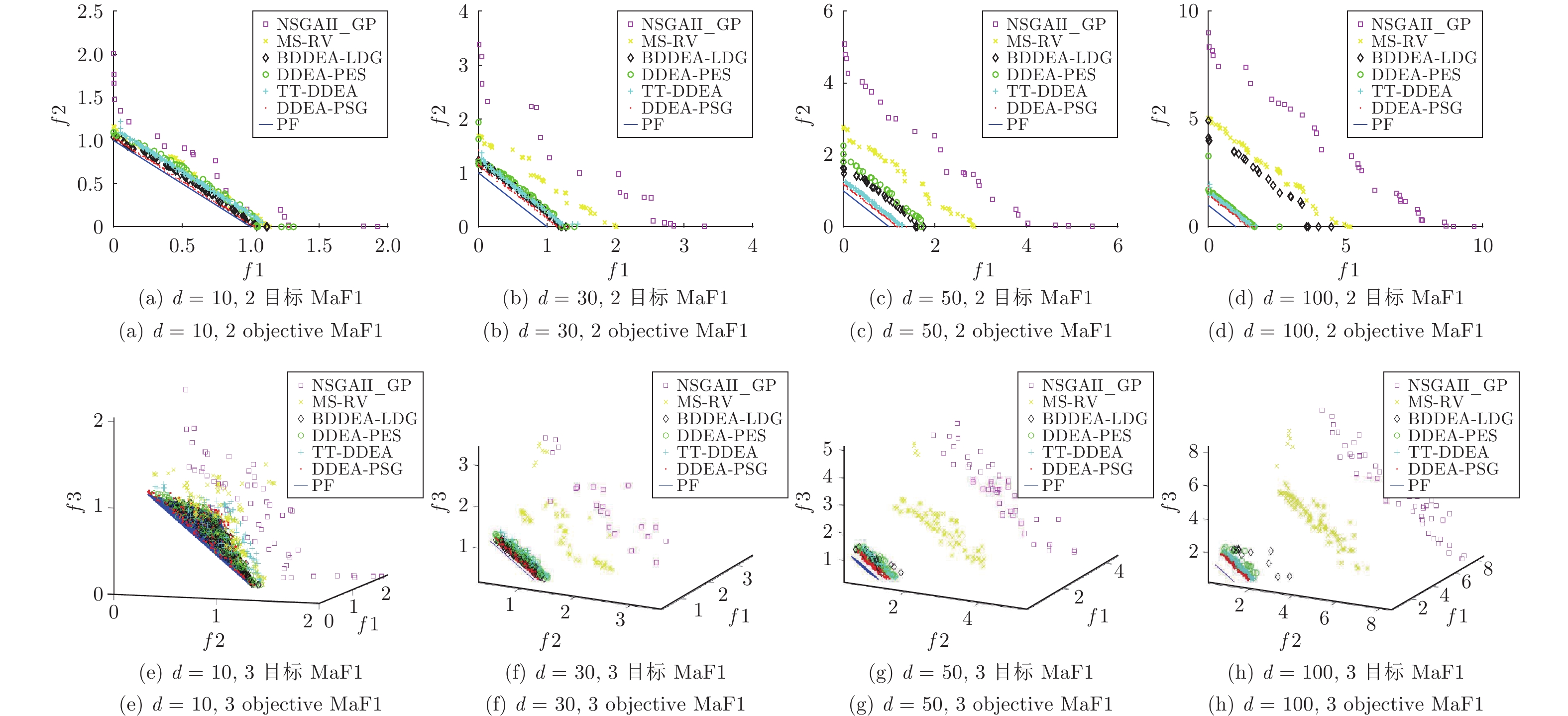
图 4 DDEA-PSG和NSGAII_GP, MS-RV, BDDEA-LDG, DDEA-PES, TT-DDEA在决策变量维度为10, 30, 50和100, 2目标和3目标MaF1问题实例上, 30次独立运行获得的非支配解集
Fig. 4 Non-dominated solutions of NSGAII_GP, MS-RV, BDDEA-LDG, DDEA-PES, TT-DDEA and DDEA-PSG over 30 independent runs on 2-objective MaF1 and 3-objective MaF1 of 10, 30, 50 and 100 dimensions
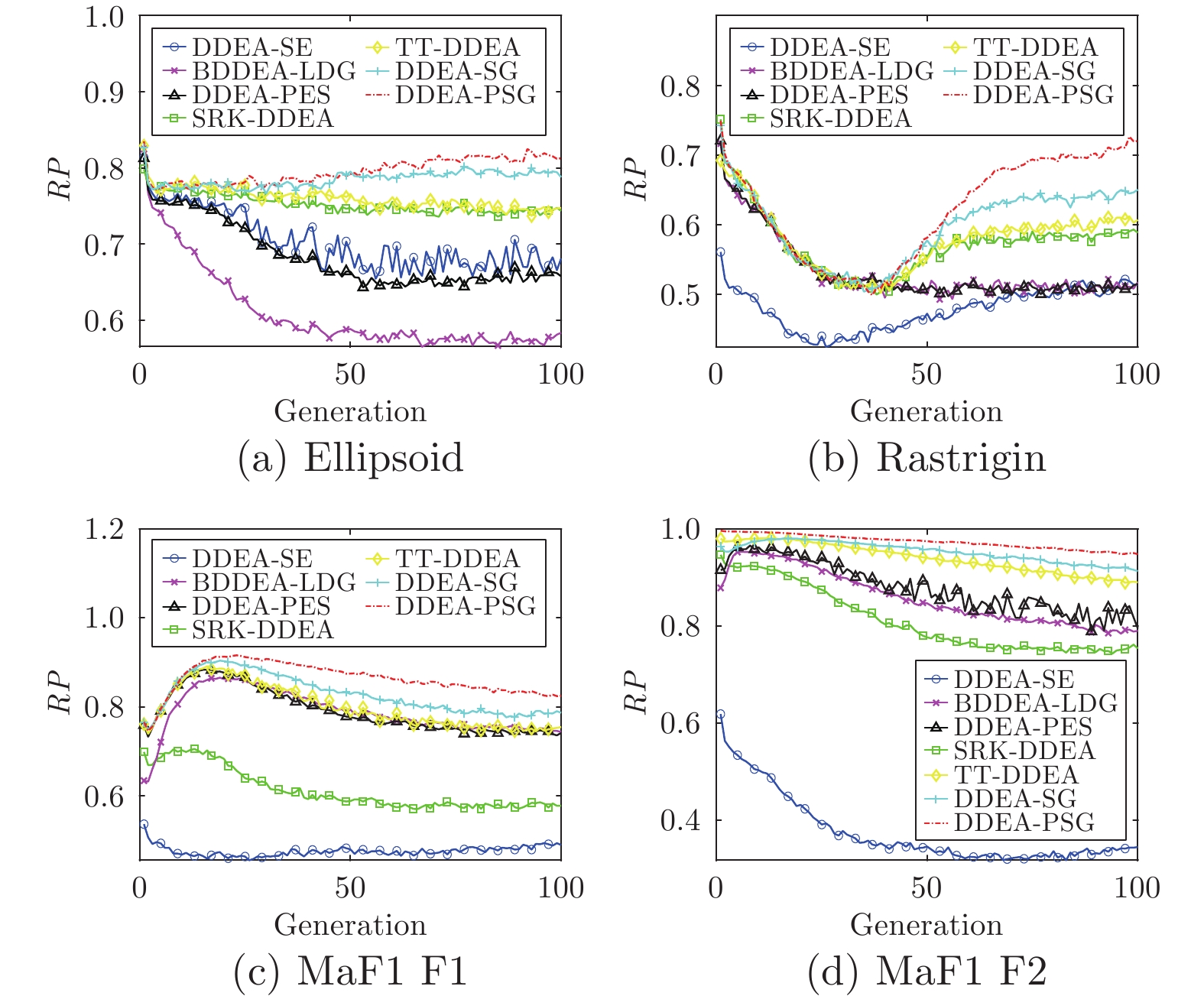
图 5 DDEA-PSG和各对比算法在100维Ellipsoid和Rastrigin测试实例, 以及100维2目标MaF1测试实例的2个目标函数上, 30次独立运行, 每次迭代过程中各算法代理模型的平均预测误差
Fig. 5 The average prediction error of surrogate model of DDEA-PSG and all comparison algorithms over 30 independent runs on 100 dimensions Ellipsoid, Rastrigin and two objective function of 2-objctive MaF1
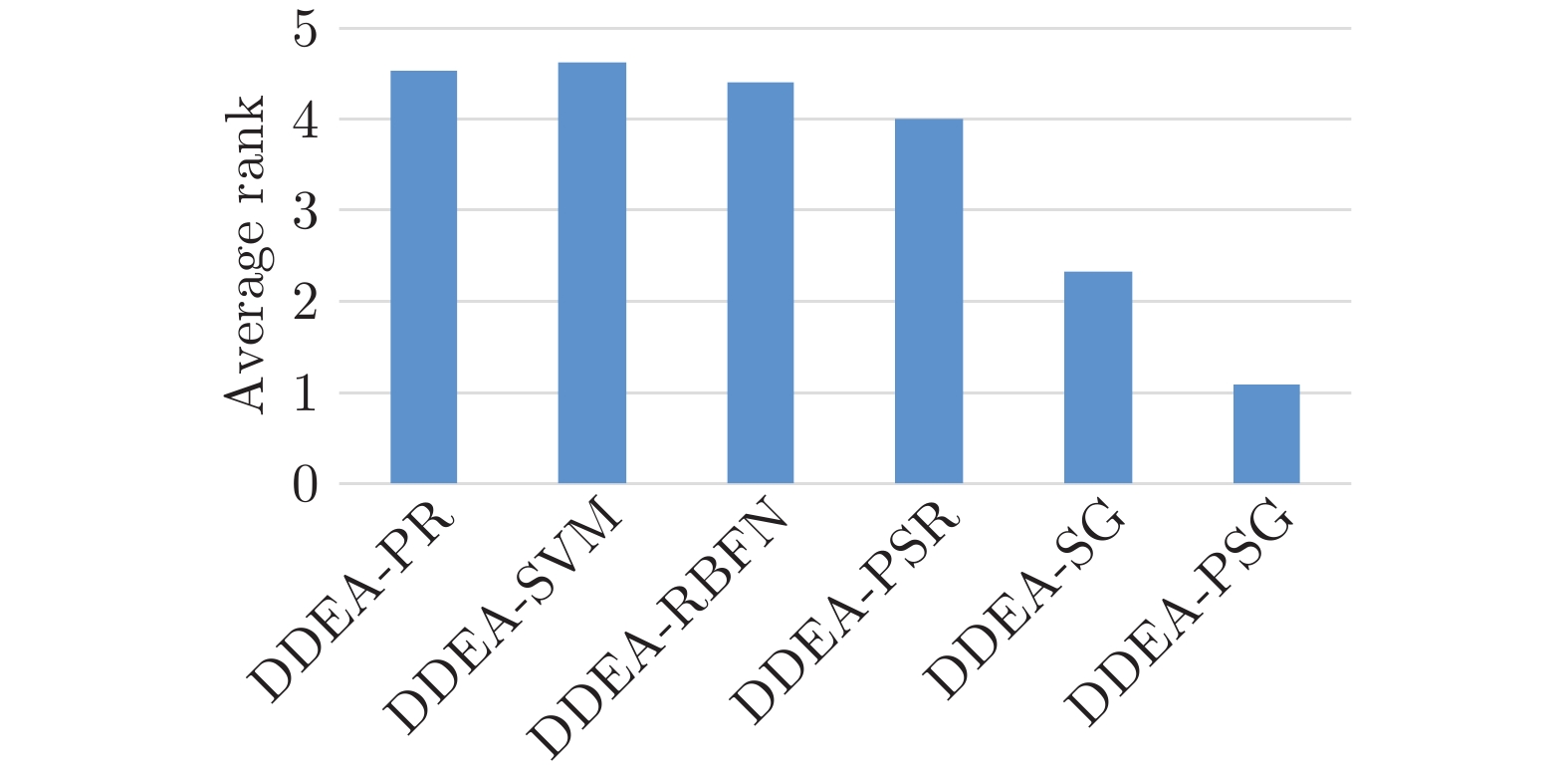
图 6 DDEA-PR, DDEA-SVM, DDEA-RBFN,DDEA-PSR, DDEA-SG和DDEA-PSG在所有测试实例上30次独立运行的平均性能排名
Fig. 6 Average performance ranking of DDEA-PR, DDEA-SVM, DDEA-RBFN, DDEA-PSR, DDEA-SG and DDEA-PSG over 30 independent runs on all test cases

图 7 参数$ k $取值不同时, DDEA-PSG在10, 50和100维Ellipsoid, Rastrigin和3目标MaF1, MaF7测试实例上, 30次独立运行的平均性能变化曲线图
Fig. 7 Average performance of DDEA-PSG over 30 independent runs on 10, 50 and 100 dimensions Ellipsoid, Rastrigin and 3-objective MaF1 and MaF7 with different values of parameter $ k $
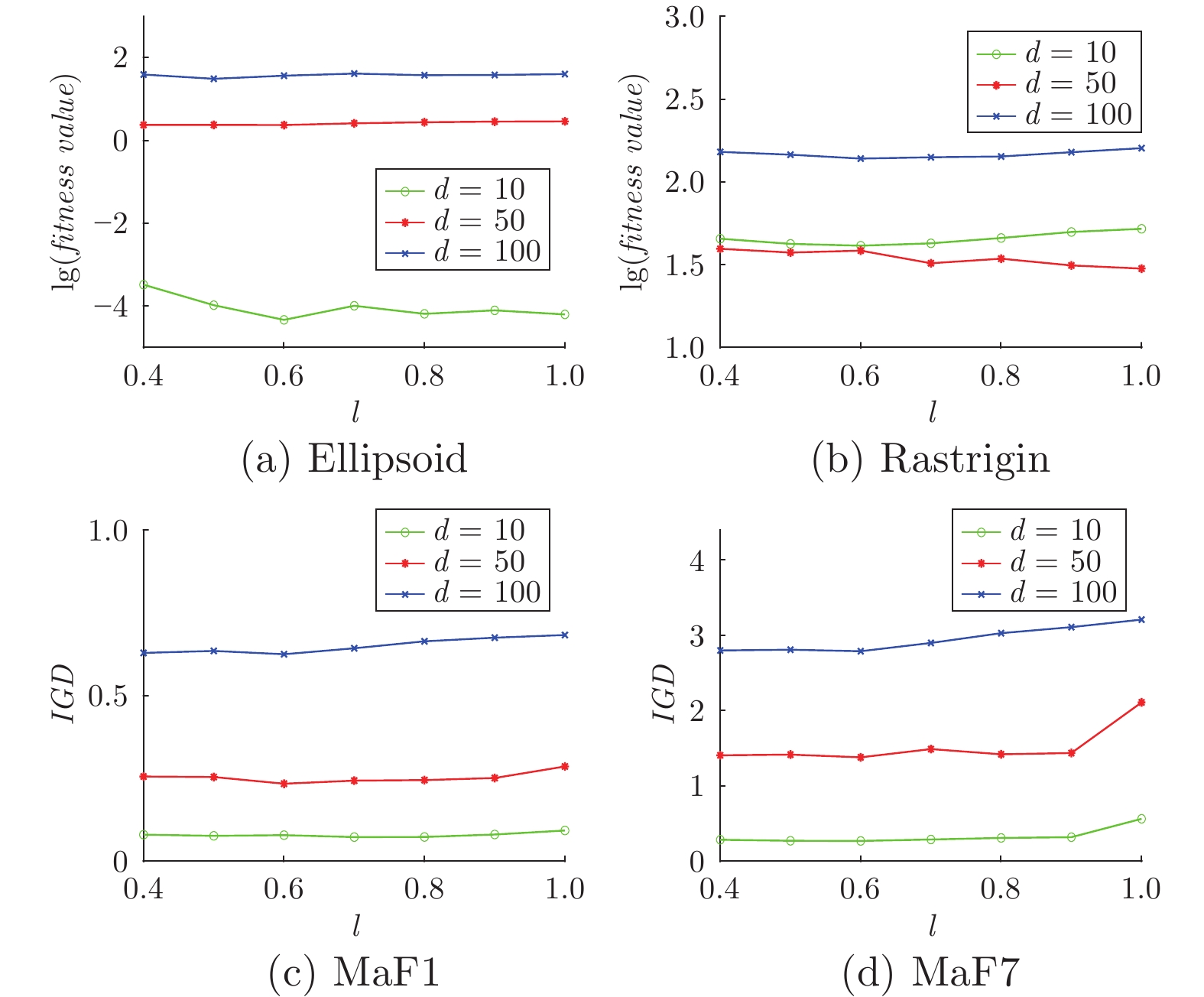
图 8 参数$ l $取值不同时, DDEA-PSG在10, 50和100维Ellipsoid, Rastrigin和3目标MaF1, MaF7测试实例上, 30次独立运行的平均性能变化曲线图
Fig. 8 Average performance of DDEA-PSG over 30 independent runs on 10, 50 and 100 dimensions Ellipsoid, Rastrigin and 3-objective MaF1 and MaF7 with different values of parameter $ l $
表 1 DDEA-SE, BDDEA-LDG, DDEA-PES, SRK-DDEA, TT-DDEA和DDEA-PSG在5个单目标测试问题上, 决策变量维度分别为10, 30, 50和100, 30次独立运行的平均值和标准差
Table 1 The mean and standard deviation of optimum solution of DDEA-SE, BDDEA-LDG, DDEA-PES, SRK-DDEA, TT-DDEA and DDEA-PSG over 30 independent runs on 5 single objective test problems of 10, 30, 50 and 100 dimensions
问题 维度 DDEA-SE BDDEA-LDG DDEA-PES SRK-DDEA TT-DDEA DDEA-PSG Ellipsoid 10 9.89×10−1− 1.22×100− 2.22×100− 6.60×100− 1.38×100− 4.67×10−5 (3.52×10−1) (3.79×10−1) (6.38×10−1) (5.22×10−1) (4.91×10−1) (5.41×10−5) 30 4.73×100− 6.60×100− 8.72×100− 9.29×100− 3.43×100− 1.26×100 (1.96×100) (1.30×100) (2.44×100) (1.65×100) (1.33×100) (1.19×100) 50 1.47×101− 1.90×101− 2.27×101− 1.81×101− 9.72×100− 2.38×100 (4.13×100) (3.37×100) (4.95×100) (3.40×100) (2.75×100) (2.20×100) 100 3.21×102− 3.00×102− 3.16×102− 7.91×101− 6.79×101− 3.71×101 (7.56×101) (6.13×101) (7.51×101) (1.72×101) (1.24×101) (9.81×100) Rosenbrock 10 2.69×101+ 3.44×101− 4.11×101− 6.05×101− 3.57×101− 3.18×101 (8.63×100) (6.04×100) (6.37×100) (1.61×101) (9.41×100) (1.32×101) 30 5.77×101+ 7.40×101− 8.01×101− 1.20×102− 5.85×101+ 6.94×101 (9.95×100) (6.57×100) (1.25×101) (1.04×101) (9.39×100) (1.31×101) 50 8.27×101− 9.82×101− 1.04×102− 1.45×102− 7.56×101− 6.11×101 (6.34×100) (4.83×100) (8.96×100) (6.96×100) (5.96×100) (4.59×100) 100 2.43×102− 2.54×102− 2.42×102− 2.36×102− 1.47×102− 1.13×102 (2.97×101) (3.76×101) (5.61×101) (1.71×101) (9.71×100) (3.13×100) Ackley 10 5.91×100− 7.24×100− 8.43×100− 8.30×100− 6.12×100− 5.61×100 (1.19×100) (1.09×100) (1.52×100) (1.24×100) (1.10×100) (1.43×100) 30 4.77×100− 5.71×100− 6.13×100− 6.54×100− 4.71×100− 2.91×100 (6.52×10−1) (4.13×10−1) (4.56×10−1) (6.14×10−1) (4.35×10−1) (5.78×10−1) 50 4.61×100− 5.41×100− 5.87×100− 5.61×100− 4.34×100− 2.49×100 (4.14×10−1) (3.09×10−1) (5.28×10−1) (3.97×10−1) (2.49×10−1) (4.22×10−1) 100 6.89×100− 7.19×100− 7.28×100− 5.34×100− 4.72×100− 3.85×100 (6.01×10−1) (4.01×10−1) (4.56×10−1) (5.46×10−1) (2.86×10−1) (2.52×10−1) Griewank 10 1.25×100− 1.36×100− 2.34×100− 7.07×10−1− 1.13×100− 2.07×10−2 (1.72×10−1) (1.55×10−1) (1.98×10−1) (2.28×10−1) (1.58×10−1) (2.53×10−2) 30 1.23×100≈ 1.36×100− 2.67×100− 1.05×100+ 1.14×100≈ 1.20×100 (1.30×10−1) (6.37×10−2) (1.18×10−1) (6.79×10−2) (6.41×10−2) (1.70×10−1) 50 1.77×100− 2.05×100− 4.16×100− 1.38×100+ 1.55×100− 1.44×100 (2.43×10−1) (1.96×10−1) (2.01×10−1) (1.73×10−1) (1.14×10−1) (2.05×10−1) 100 1.80×101− 1.83×101− 2.20×101− 4.47×100− 4.40×100− 3.54×100 (4.12×100) (3.91×100) (4.96×100) (1.14×100) (7.23×10−1) (4.09×10−1) Rastrigin 10 6.51×101− 8.13×101− 8.65×101− 7.89×101− 6.39×101− 4.12×101 (2.87×101) (2.62×101) (4.19×101) (2.50×101) (2.21×101) (2.64×101) 30 1.15×102− 1.41×102− 1.59×102− 1.94×102− 8.06×101− 2.36×101 (2.94×101) (2.57×101) (2.98×101) (3.51×101) (2.11×101) (2.30×101) 50 2.04×102− 2.08×102− 2.36×102− 2.57×102− 1.20×102− 3.85×101 (3.14×101) (3.10×101) (5.36×101) (2.78×101) (2.40×101) (1.64×101) 100 8.57×102− 7.61×102− 7.64×102− 4.16×102− 2.98×102− 1.39×102 (9.44×101) (1.12×102) (1.31×102) (5.81×101) (4.54×101) (3.06×101) +/≈/− 2/1/17 0/0/20 0/0/20 2/0/18 1/1/18  下载: 导出CSV
下载: 导出CSV
表 2 NSGAII_GP, MS-RV, BDDEA-LDG, DDEA-PES, TT-DDEA和DDEA-PSG在决策变量维度为10, 30, 50和100, 2目标MaF测试实例上, 30次独立运行的IGD平均值和标准差
Table 2 The mean and standard deviation of IGD of NSGAII_GP, MS-RV, BDDEA-LDG, DDEA-PES, TT-DDEA and DDEA-PSG over 30 independent runs on 2-objective MaF of 10, 30, 50 and 100 dimensions
问题 目标数 维度 NSGAII_GP MS-RV BDDEA-LDG DDEA-PES TT-DDEA DDEA-PSG MaF1 2 10 3.19×101− 2.79×101− 7.94×102− 2.42×101− 1.17×101− 4.11×102 (3.81×102) (3.91×102) (2.03×102) (7.91×102) (2.35×102) (4.09×102) 30 1.23×100− 1.12×100− 2.59×101− 2.87×101− 2.52×101− 1.44×101 (1.19×101) (8.53×102) (8.89×102) (8.76×102) (6.78×102) (6.35×102) 50 2.32×100− 2.25×100− 8.01×101− 8.12×101− 2.88×101− 1.71×101 (1.67×101) (1.43×101) (1.12×101) (2.16×101) (8.34×102) (3.97×102) 100 5.10×100− 8.44×101− 2.74×100− 8.24×101− 6.98×101− 4.43×101 (2.48×101) (8.50×102) (5.00×102) (3.55×101) (4.30×102) (1.04×101) MaF2 2 10 6.15×102− 5.78×10−3≈ 1.92×102− 4.50×102− 6.96×10−3− 5.33×10−3 (4.79×10−3) (1.37×10−3) (6.10×10−3) (1.90×102) (1.20×10−3) (8.71×10−4) 30 2.19×101− 7.81×102− 4.01×102− 4.85×102− 1.03×102+ 1.67×102 (1.49×102) (8.35×10−3) (1.06×102) (1.67×102) (5.38×10−3) (3.52×10−3) 50 3.86×101− 2.01×101− 8.89×102− 1.14×101− 2.96×102+ 3.27×102 (2.12×102) (1.80×102) (5.65×10−3) (4.92×102) (1.25×102) (7.95×10−3) 100 8.58×101− 1.86×101− 3.51×101− 1.07×101− 5.56×102≈ 4.90×102 (2.16×102) (1.80×102) (4.90×102) (6.98×10−3) (8.13×10−3) (9.72×10−3) MaF3 2 10 6.77×105− 2.38×105+ 6.39×105− 3.03×105− 3.86×105− 3.53×105 (2.71×105) (1.03×105) (9.00×104) (1.82×105) (6.24×104) (2.34×105) 30 1.74×107− 5.64×106≈ 9.17×106− 7.12×106− 6.20×106− 5.37×106 (9.77×106) (1.16×106) (9.94×105) (2.42×105) (1.75×106) (2.17×106) 50 1.57×108− 1.89×107+ 2.25×107− 2.07×107− 2.96×107− 1.97×107 (1.94×108) (2.77×106) (6.26×106) (9.46×106) (3.29×106) (3.40×106) 100 2.15×109− 1.64×107+ 3.32×108− 9.80×107− 7.17×107− 1.80×107 (2.75×109) (4.27×106) (3.23×107) (3.46×106) (3.80×107) (3.97×106) MaF4 2 10 6.65×102− 4.91×102≈ 7.04×102− 5.24×102− 5.53×102− 4.36×102 (1.62×102) (8.03×101) (8.53×101) (2.62×102) (1.18×102) (1.25×102) 30 2.87×103− 2.49×103≈ 3.21×103− 3.33×103− 3.01×103− 2.36×103 (2.70×102) (2.36×102) (7.60×101) (3.87×102) (3.81×102) (2.52×102) 50 5.29×103≈ 4.62×103+ 5.20×103≈ 5.00×103≈ 5.05×103≈ 5.14×103 (2.50×102) (2.36×102) (1.24×102) (1.97×102) (4.13×102) (3.33×102) 100 1.12×104≈ 4.61×103+ 1.10×104≈ 1.20×104− 1.07×104≈ 1.08×104 (4.37×102) (3.48×102) (3.19×102) (5.11×102) (7.62×102) (4.45×102) MaF5 2 10 2.69×100− 1.90×100+ 2.01×100≈ 2.02×100≈ 2.01×100≈ 2.04×100 (4.02×101) (3.76×101) (4.51×10−4) (4.04×10−3) (1.42×10−3) (2.66×102) 30 6.83×100− 1.81×100≈ 2.03×100− 2.06×100− 2.02×100− 1.86×100 (1.61×100) (3.66×101) (6.91×10−3) (3.22×102) (9.57×10−3) (7.55×101) 50 1.19×101− 4.33×100− 2.09×100− 2.51×100− 2.04×100− 1.75×100 (1.57×100) (5.12×101) (7.47×10−3) (3.01×101) (6.73×10−3) (9.65×101) 100 2.40×101− 5.46×100− 2.44×100− 3.19×100− 2.18×100− 5.45×101 (5.19×100) (3.09×101) (2.16×101) (4.24×101) (7.56×102) (1.37×101) MaF6 2 10 3.08×101− 2.85×101− 1.13×100− 2.81×100− 2.65×100− 1.65×100 (7.17×100) (7.47×100) (8.33×102) (1.55×100) (1.54×100) (1.08×100) 30 1.61×102− 1.55×102− 2.22×101− 1.80×101− 8.69×100− 8.08×100 (1.05×101) (1.30×101) (5.34×100) (4.15×100) (2.79×100) (2.00×100) 50 2.98×102− 2.87×102− 6.77×101− 7.18×101− 1.81×101− 1.73×101 (1.88×101) (2.50×101) (5.31×100) (1.66×101) (4.30×100) (3.52×100) 100 6.74×102− 1.46×102− 3.34×102− 1.63×102− 7.61×101− 4.99×101 (3.10×101) (1.43×101) (9.68×100) (6.79×101) (9.76×100) (5.94×100) MaF7 2 10 5.40×100− 3.84×101− 5.82×100− 4.46×100− 1.14×100− 1.56×102 (5.33×101) (6.70×102) (8.45×102) (1.11×101) (4.24×101) (1.23×10−3) 30 6.78×100− 2.38×100− 5.55×100− 5.12×100− 2.93×100− 2.26×101 (4.36×101) (3.39×101) (1.76×101) (6.22×102) (9.83×102) (1.45×101) 50 6.98×100− 3.61×100− 5.80×100− 5.32×100− 3.33×100− 8.91×101 (3.69×101) (4.17×101) (6.82×101) (1.75×101) (3.95×101) (3.14×101) 100 7.48×100− 3.63×100− 5.66×100− 6.19×100− 3.57×100− 1.51×100 (2.24×101) (3.33×101) (2.89×101) (6.13×101) (4.26×101) (2.07×101) +/≈/− 0/2/26 6/5/17 0/3/25 0/2/26 2/4/22
下载: 导出CSV
表 3 NSGAII_GP, MS-RV, BDDEA-LDG, DDEA-PES, TT-DDEA和DDEA-PSG在决策变量维度为10, 30, 50和100, 3目标MaF测试实例上, 30次独立运行的IGD平均值和标准差
Table 3 The mean and standard deviation of IGD of NSGAII_GP, MS-RV, BDDEA-LDG, DDEA-PES, TT-DDEA and DDEA-PSG over 30 independent runs on 3-objective MaF of 10, 30, 50 and 100 dimensions
问题 目标数 维度 NSGAII_GP MS-RV BDDEA-LDG DDEA-PES TT-DDEA DDEA-PSG MaF1 3 10 8.91×101− 4.44×101− 9.62×101− 1.18×100− 5.46×101− 7.86×10−2 (3.14×101) (5.14×10−2) (6.62×10−2) (7.41×10−2) (2.30×101) (1.01×10−2) 30 1.99×100− 1.48×100− 1.56×101≈ 1.81×101− 1.68×101− 1.49×101 (2.23×101) (1.76×101) (3.09×10−2) (2.38×10−2) (2.39×10−2) (1.84×10−2) 50 3.72×100− 2.57×100− 4.42×101− 4.86×101− 2.53×101− 2.34×101 (2.26×101) (2.71×101) (1.94×10−2) (7.53×10−2) (2.35×10−2) (2.11×10−2) 100 8.26×100− 5.63×100− 2.00×100− 1.33×100− 1.44×100− 6.25×101 (3.65×101) (1.78×101) (1.91×101) (3.41×101) (7.85×10−2) (5.62×10−2) MaF2 3 10 7.52×10−2− 4.03×10−2+ 6.31×10−2− 1.22×101− 4.53×10−2− 4.89×10−2 (1.64×103) (2.79×103) (8.54×103) (1.32×10−2) (5.58×103) (3.12×103) 30 1.78×101− 1.04×101− 8.56×10−2− 9.73×10−2− 8.40×10−2− 6.78×10−2 (2.93×103) (8.61×103) (2.49×10−2) (1.13×10−2) (6.39×103) (2.54×103) 50 2.91×101− 1.99×101− 1.33×101− 1.16×101− 1.15×100− 8.55×10−2 (6.63×103) (1.23×10−2) (3.42×10−2) (9.67×103) (1.68×10−2) (6.87×103) 100 5.96×101− 2.21×101− 2.59×101− 2.12×101− 7.49×101− 1.63×101 (2.14×10−2) (1.56×10−2) (2.52×10−2) (2.58×10−2) (2.83×10−2) (1.20×10−2) MaF3 3 10 8.27×105− 8.92×104+ 1.11×105− 2.63×105− 5.12×105− 2.66×105 (3.35×104) (4.67×104) (4.56×104) (4.30×104) (8.40×104) (1.64×104) 30 1.36×107− 4.58×106+ 2.55×107− 4.91×106− 3.85×107− 8.78×106 (1.22×107) (7.28×105) (3.52×106) (1.10×105) (3.75×106) (2.35×105) 50 1.06×108− 1.54×107+ 2.61×107− 5.21×107− 8.29×107− 2.86×107 (1.38×108) (1.44×106) (7.54×106) (5.00×108) (1.11×109) (3.53×106) 100 2.42×108− 1.61×107+ 1.30×108− 6.65×108− 2.65×108− 7.86×107 (3.21×106) (2.79×106) (7.09×106) (7.93×106) (5.15×106) (1.05×106) MaF4 3 10 1.61×103− 9.52×102+ 1.62×103− 1.60×103− 1.94×103− 1.37×103 (3.16×102) (2.83×102) (6.54×102) (4.54×102) (2.54×102) (3.05×102) 30 7.18×103≈ 6.32×103+ 7.43×103− 8.23×103− 7.02×103≈ 7.04×103 (5.30×102) (6.04×102) (9.58×102) (2.62×102) (1.33×103) (8.79×102) 50 1.32×104≈ 1.21×104+ 1.15×104− 1.26×104≈ 1.23×104− 1.32×104 (9.63×102) (8.51×102) (9.32×102) (9.87×102) (1.52×103) (1.09×103) 100 2.81×104− 1.17×104+ 4.07×104− 3.05×104− 2.81×104− 1.85×104 (1.72×103) (1.02×103) (2.83×102) (2.19×103) (1.78×103) (1.08×103) MaF5 3 10 5.08×100− 8.89×101− 4.90×100− 4.92×100− 4.92×100− 7.86×10−2 (1.54×100) (2.72×101) (5.72×103) (1.23×10−2) (2.63×10−2) (1.01×10−2) 30 1.45×101− 3.19×100− 5.00×100− 5.30×100− 4.96×100− 1.57×100 (3.60×100) (2.42×101) (3.00×10−2) (1.76×101) (5.25×10−2) (6.27×101) 50 2.39×101− 6.00×100− 5.27×100− 5.59×100− 5.00×100− 2.28×100 (5.24×100) (4.15×101) (5.27×10−2) (2.85×101) (6.13×10−2) (1.40×100) 100 4.09×101− 6.90×100− 7.36×100− 9.14×100− 5.56×100− 1.96×100 (1.21×101) (1.44×100) (1.84×100) (9.93×101) (5.66×101) (6.27×101) MaF6 3 10 2.34×101− 2.29×101− 6.24×101− 1.09×100− 3.39×101− 4.89×10−2 (3.82×100) (5.85×100) (2.44×101) (8.98×101) (9.68×10−2) (3.12×103) 30 1.54×102− 1.43×102− 1.37×101− 1.86×101− 1.28×101− 9.05×100 (1.87×101) (1.62×101) (1.69×100) (2.30×100) (4.69×1014) (1.60×100) 50 2.91×102− 2.91×102− 4.36×101− 3.76×101− 3.96×101− 3.50×101 (1.90×101) (1.86×101) (1.02×101) (9.97×100) (7.44×100) (1.09×101) 100 6.72×102− 1.57×102− 1.93×102− 2.97×102− 1.91×102− 1.20×102 (1.92×101) (1.86×101) (4.08×101) (6.88×101) (2.27×101) (2.05×101) MaF7 3 10 7.23×100− 5.53×101− 7.78×100− 6.04×100− 1.85×100− 2.69×101 (1.36×100) (1.67×101) (2.49×100) (1.82×100) (2.10×101) (2.60×101) 30 9.75×100− 3.64×100− 8.46×100− 7.86×100− 4.80×100− 7.51×101 (5.76×101) (8.02×101) (9.23×101) (7.07×10−2) (4.21×101) (7.58×10−2) 50 1.05×101− 5.50×100− 8.40×100− 7.43×100− 5.68×100− 1.38×100 (6.66×101) (6.48×101) (3.43×101) (2.57×101) (7.08×101) (1.82×101) 100 1.13×101− 5.73×100− 9.57×100− 8.77×100− 5.88×100− 2.79×100 (2.68×101) (5.92×101) (7.87×101) (5.57×101) (1.16×100) (3.62×101) +/≈/− 0/2/26 9/0/19 0/1/27 0/1/27 0/1/27
下载: 导出CSV
表 4 DDEA-PR, DDEA-SVM, DDEA-RBFN, DDEA-PSR, DDEA-SG和DDEA-PSG在Ellipsoid和Rastrigin上, 决策变量维度分别为10, 50和100, 30次独立运行的最优解的平均值和标准差
Table 4 The mean and standard deviation of optimum solution of DDEA-PR, DDEA-SVM, DDEA-RBFN, DDEA-PSR, DDEA-SG and DDEA-PSG over 30 independent runs on Ellipsoid and Rastirgin of 10, 50 and 100 dimensions
问题 维度 DDEA-PR DDEA-SVM DDEA-RBFN DDEA-PSR DDEA-SG DDEA-PSG Ellipsoid 10 5.03×10−5− 1.70×100− 1.39×100− 1.35×100− 6.32×10−5− 4.67×10−5 (4.75×10−5) (6.57×10−1) (4.61×10−1) (4.09×10−1) (1.44×10−5) (5.41×10−5) 50 1.91×104− 1.26×102− 4.84×100− 1.69×101− 2.92×100− 2.38×100 (2.09×103) (3.01×101) (1.85×100) (1.05×101) (6.24×10−1) (2.20×100) 100 9.18×104− 6.43×102− 8.94×101− 1.47×102− 4.05×101− 3.71×101 (4.36×103) (8.56×101) (1.13×101) (3.59×101) (7.26×100) (9.81×100) Rastrigin 10 2.25×102− 1.06×102− 5.51×101− 1.01×102− 5.22×101− 4.12×101 (3.29×101) (2.44×101) (2.18×101) (2.45×101) (1.47×101) (2.64×101) 50 1.30×103− 5.11×102− 8.23×101− 2.51×102− 3.00×101+ 3.85×101 (5.27×101) (5.60×101) (2.88×101) (7.96×101) (1.39×101) (1.64×101) 100 2.53×103− 9.97×102− 2.64×102− 4.72×102− 1.60×102− 1.39×102 (7.35×101) (7.29×101) (6.05×101) (1.22×102) (3.19×101) (3.06×101) +/≈/− 0/0/6 0/0/6 0/0/6 0/0/6 1/0/5
下载: 导出CSV
表 5 DDEA-PR, DDEA-SVM, DDEA-RBFN, DDEA-PSR, DDEA-SG和DDEA-PSG在决策变量维度分别为10, 50和100, 2目标和3目标MaF1和MaF7上, 30次独立运行的IGD平均值和标准差
Table 5 The mean and standard deviation of IGD of DDEA-PR, DDEA-SVM, DDEA-RBFN, DDEA-PSR, DDEA-SG and DDEA-PSG over 30 independent runs on 2-objective 3-objective MaF1 and MaF7 of 10, 50 and 100 dimensions
问题 目标数 维度 DDEA-PR DDEA-SVM DDEA-RBFN DDEA-PSR DDEA-SG DDEA-PSG MaF1 2 10 4.74×10−2− 7.95×10−2− 1.57×10−1− 5.52×10−2− 3.20×10−2+ 4.11×10−2 (1.26×10−3) (1.16×10−3) (5.05×10−2) (3.82×10−3) (1.62×10−3) (4.09×10−2) 50 4.40×100− 4.43×10−1− 2.79×10−1− 2.78×10−1− 2.19×10−1− 1.71×10−1 (4.00×10−1) (3.94×10−3) (2.94×10−2) (1.10×10−2) (3.59×10−2) (3.97×10−2) 100 1.05×101− 6.53×10−1− 5.19×10−1− 5.62×10−1− 5.02×100− 4.43×10−1 (6.03×10−1) (7.76×10−3) (2.95×10−1) (3.50×10−2) (4.23×10−1) (1.04×10−1) 3 10 9.42×10−2− 9.80×10−2− 3.06×10−1− 9.70×10−2− 6.26×10−2+ 7.86×10−2 (1.26×10−2) (1.46×10−2) (6.44×10−2) (1.52×10−2) (2.82×10−3) (1.01×10−2) 50 5.93×100− 3.16×10−1− 3.29×10−1− 3.19×10−1− 2.86×10−1− 2.34×10−1 (6.78×10−1) (1.42×10−2) (1.98×10−2) (1.30×10−2) (1.89×10−2) (2.11×10−2) 100 1.37×101− 8.47×10−1− 7.28×10−1− 7.60×10−1− 6.83×10−1− 6.25×10−1 (5.92×10−1) (4.10×10−2) (1.90×10−1) (2.65×10−2) (7.66×10−2) (5.62×10−2) MaF7 2 10 3.34×10−1− 4.11×100− 7.40×100− 1.69×100− 3.90×10−1− 1.56×10−2 (4.65×10−1) (4.74×10−1) (6.25×10−1) (1.28×100) (5.01×10−1) (1.23×10−3) 50 3.23×100− 4.26×100− 8.77×100− 6.11×100− 1.25×100− 8.91×10−1 (1.06×100) (4.56×10−2) (2.86×10−1) (1.83×10−1) (7.72×10−1) (3.14×10−1) 100 4.03×100− 3.29×100− 2.51×100− 7.10×100− 2.21×100− 1.51×100 (6.11×10−1) (7.66×10−1) (1.32×100) (2.55×100) (4.34×10−1) (2.07×10−1) 3 10 5.46×10−1− 6.23×100− 9.26×100− 1.40×100− 5.63×10−1− 2.69×10−1 (6.23×10−1) (5.87×10−1) (1.01×100) (6.98×10−1) (1.21×10−1) (2.60×10−1) 50 3.82×100− 6.31×100− 1.26×101− 8.84×100− 2.11×100− 1.38×100 (8.01×10−1) (3.78×10−1) (9.94×10−1) (1.44×100) (3.00×10−1) (1.82×10−1) 100 4.55×100− 1.27×101− 3.23×101− 1.18×101− 3.21×100− 2.79×100 (3.97×10−1) (3.88×10−1) (4.42×10−1) (1.02×100) (5.23×10−1) (3.62×10−1) +/≈/− 0/0/12 0/0/12 0/0/12 0/0/12 2/0/10
下载: 导出CSV
表 6 DDEA-SG和DDEA-PSG在决策变量维度为10, 50和100的Ellipsoid, Rastrigin, 以及2目标和3目标MaF1和MaF7上, 30次独立运行的运行时间平均值和标准差
Table 6 The mean and standard deviation of run time of DDEA-SG and DDEA-PSG over 30 independent runs on Ellipsoid, Rastrigin, 2-objctive/3-objective MaF1 and MaF7 of 10, 50 and 100 dimensions
问题 目标数 维度 DDEA-SG DDEA-PSG Ellipsoid 1 10 7.65×101− 4.55×101 (2.50×100) (1.30×100) 50 1.20×102− 7.44×101 (7.73×10−1) (6.20×10−1) 100 2.22×102− 1.39×102 (2.83×100) (8.23×10−1) Rastrigin 1 10 7.70×101− 4.55×101 (2.05×100) (1.21×100) 50 1.22×102− 7.39×101 (2.78×100) (9.38×10−1) 100 2.24×102− 1.41×102 (2.65×100) (3.72×10−1) MaF1 2 10 8.77×101− 5.34×101 (2.37×10−1) (1.45×10−1) 50 1.51×102− 9.22×101 (1.11×100) (6.76×10−1) 100 7.39×102− 4.51×102 (1.35×101) (8.24×100) 3 10 1.05×102− 6.43×101 (2.68×10−1) (1.63×10−1) 50 2.05×102− 1.25×102 (1.19×101) (7.25×100) 100 1.14×103− 6.94×102 (5.85×101) (3.57×101) MaF7 2 10 8.95×101− 5.46×101 (1.50×10−1) (9.15×10−2) 50 1.55×102− 9.46×101 (7.64×100) (4.66×100) 100 7.75×102− 4.73×102 (2.33×101) (1.42×101) 3 10 1.03×102− 6.31×101 (4.83×10−1) (2.94×10−1) 50 2.10×102− 1.28×102 (1.24×101) (7.58×100) 100 1.13×103− 6.89×102 (5.25×101) (3.20×101) +/≈/− 0/0/18
下载: 导出CSV
表 7 不同训练数据场景下, DDEA-PSG在Ellipsoid和Rastrigin上, 决策变量维度分别为10, 50和100, 30次独立运行的最优解的平均值和标准差
Table 7 The mean and standard deviation of optimum solution of DDEA-PSG over 30 independent runs on different offline data of Ellipsoid and Rastrigin of 10, 50 and 100 dimensions
问题 维度 5$ d $ rand 11$ d $ rand 5$ d $ LHS 11$ d $ LHS Ellipsoid 10 4.36×100− 6.86×10−5− 1.20×100− 4.67×10−5 (2.56×100) (5.32×10−5) (1.33×100) (5.41×10−5) 50 4.19×101− 1.78×101− 5.73×100− 2.38×100 (7.79×100) (3.65×100) (1.93×100) (2.20×100) 100 1.35×102− 7.82×101− 4.97×101− 3.71×101 (2.60×101) (1.17×101) (1.32×101) (9.81×100) Rastrigin 10 9.93×101− 8.00×101− 7.01×101− 4.12×101 (2.26×101) (2.07×101) (2.99×101) (2.64×101) 50 2.50×102− 1.45×102− 6.14×101− 3.85×101 (3.56×101) (2.45×101) (1.96×101) (1.64×101) 100 4.26×102− 2.56×102− 1.75×102− 1.39×102 (5.55×101) (3.59×101) (3.43×101) (3.06×101) +/≈/− 0/0/6 0/0/6 0/0/6
下载: 导出CSV
表 8 不同训练数据场景下, DDEA-PSG在决策变量维度分别为10, 50和100, 2目标和3目标MaF1和MaF7上, 30次独立运行的IGD平均值和标准差
Table 8 The mean and standard deviation of IGD of DDEA-PSG over 30 independent runs on different offline data of 2-objective/3-objective MaF1 and MaF7 of 10, 50 and 100 dimensions
问题 目标数 维度 5$ d $ rand 11$ d $ rand 5$ d $ LHS 11$ d $ LHS MaF1 2 10 5.95×10−2− 3.12×10−2− 4.37×10−2− 4.11×10−2 (3.18×10−2) (1.43×10−2) (2.32×10−2) (4.09×10−2) 50 2.43×10−1− 1.77×10−1≈ 1.81×10−1− 1.71×10−1 (2.11×10−2) (2.98×10−2) (5.34×10−2) (3.97×10−2) 100 5.28×10−1− 4.53×10−1≈ 5.74×10−1− 4.43×10−1 (6.93×10−2) (5.16×10−2) (1.76×10−1) (1.04×10−1) 3 10 1.09×10−1− 9.66×10−2− 1.23×10−1− 7.86×10−2 (1.53×10−2) (9.51×10−3) (3.45×10−2) (1.01×10−2) 50 3.38×10−1− 2.82×10−1− 3.23×10−1− 2.34×10−1 (3.36×10−2) (2.32×10−2) (3.23×10−2) (2.11×10−2) 100 8.22×10−1− 6.87×10−1− 7.34×10−1− 6.25×10−1 (1.02×10−1) (4.39×10−2) (8.14×10−2) (5.62×10−2) MaF7 2 10 2.26×10−2− 3.63×10−1− 1.92×10−1− 1.56×10−2 (2.24×10−3) (7.56×10−1) (3.71×10−1) (1.23×10−3) 50 1.05×100− 9.65×10−1− 1.56×100− 8.91×10−1 (1.81×10−1) (4.42×10−1) (1.65×100) (3.14×10−1) 100 1.72×100− 1.66×100− 1.92×10−1− 1.51×100 (1.74×10−1) (1.78×10−1) (3.71×10−1) (2.07×10−1) 3 10 4.49×10−1− 2.89×10−1− 3.85×10−1− 2.69×10−1 (6.60×10−2) (3.28×10−2) (7.30×10−2) (2.60×10−1) 50 3.05×100− 2.40×100− 2.73×100− 1.38×100 (7.24×10−1) (1.96×10−1) (1.54×10−1) (1.82×10−1) 100 2.92×100− 2.85×100≈ 2.90×100− 2.79×100 (2.06×10−1) (2.93×10−1) (4.27×10−1) (3.62×10−1) +/≈/− 0/0/12 0/3/9 0/0/12
下载: 导出CSV
-
[1] Eiben A E, Smith J. From evolutionary computation to the evolution of things. Nature, 2015, 521(7553): 476-482 doi: 10.1038/nature14544 [2] Zhan Zhi-Hui, Shi Lin, Tan K C, Zhang Jun. A survey on evolutionary computation for complex continuous optimization, Artificial Intelligence Review, 2022, 55:59-110 doi: 10.1007/s10462-021-10042-y [3] 封文清, 巩敦卫. 基于在线感知Pareto前沿划分目标空间的多目标进化优化. 自动化学报, 2020, 46(08): 1628-1643 doi: 10.16383/j.aas.2018.c180323Feng Wen-Qing, Gong Dun-Wei. Multi-objective evolutionary optimization with objective space partition based on online perception of pareto front, Acta Electronica Sinica, 2020, 46(08): 1628-1643 doi: 10.16383/j.aas.2018.c180323 [4] Liang J, Yue C T, Qu B Y. Multimodal multi-objective optimization: A preliminary study. In: Proceedings of the 18th IEEE Congress on Evolutionary Computation (CEC). Vancouver, Canada: IEEE, 2016. 2454−2461 [5] Tian Ye, Si Lang-Chun, Zhang Xing-Yi, Cheng Ran. Evolutionary large-scale multi-objective optimization: a survey. ACM computing surveys. 2022, 54(8): 1-34 [6] 王峰, 张衡, 韩孟臣, 邢立宁. 基于协同进化的混合变量多目标粒子群优化算法求解无人机协同多任务分配问题. 计算机学报, 2021, 44(10): 1967-1983 doi: 10.11897/SP.J.1016.2021.01967Wang Feng, Zhang Heng, Han Meng-Chen, Xing Li-Ning. Co-evolution based mixed-variable multi-objective particle swarm optimization for UAV cooperative multi-task allocation problem. Chinese Journal of Computers, 2021, 44(10): 1967-1983 doi: 10.11897/SP.J.1016.2021.01967 [7] Li Jian-Yu, Zhan Zhi-Hui, Zhang Jun. Evolutionary computation for expensive optimization: a survey. Machine Intelligence Research, 2022, 19:3–23 doi: 10.1007/s11633-022-1317-4 [8] He Cheng, Tian Ye, Wang Han-Ding, Jin Yao-Chu. A repository of real-world datasets for data-driven evolutionary multiobjective optimization. Complex & Intelligent Systems, 2020, 6(1):189-197 [9] Cheng Ran, He Cheng, Jin Yao-Chu, Yao Xin. Model-based evolutionary algorithms: a short survey. Complex & Intelligent Systems, 2018, 4:283-292 [10] 孙超利, 李贞, 金耀初. 模型辅助的计算费时进化高维多目标优化. 自动化学报 doi: 10.16383j.aas.c200969Sun Chao-Li, Li Zhen, Jin Yao-Chu. Surrogate-assisted expensive evolutionary many-objective optimization. Acta Electronica Sinica. doi: 10.16383j.aas.c200969 [11] McDonald D, Grantham W, Tabor W, Murphy M. Global and local optimization using radial basis function response surface models. Applied Mathematical Modelling, 2007, 31(10): 2095−2110. [12] Liu Bo, Zhang Qing-Fu, Gielen G G E. A Gaussian process surrogate model assisted evolutionary algorithm for medium scale expensive optimization problems. IEEE Transactions on Evolutionary Computation, 2013, 18(2): 180-192 [13] Jin Yao-Chu, Olhofer M, Sendhoff B. A framework for evolutionary optimization with approximate fitness functions. IEEE Transactions on evolutionary computation, 2002, 6(5): 481-494 doi: 10.1109/TEVC.2002.800884 [14] Regis R G. Evolutionary programming for high-dimensional constrained expensive black-box optimization using radial basis functions. IEEE Transactions on Evolutionary Computation, 2013, 18(3): 326-347 [15] Loshchilov I, Schoenauer M, Sebag M. A mono surrogate for multiobjective optimization. In: Proceedings of the 12th Annual Conference on Genetic and Evolutionary Computation. Portland, USA: ACM, 2010. 471−478 [16] Jin Yao-Chu, Wang Han-Ding, Chugh T, et al. Data-driven evolutionary optimization: An overview and case studies. IEEE Transactions on Evolutionary Computation, 2018, 23(3): 442-458 [17] Chugh T, Jin Yao-Chu, Miettinen K, Hakanen J, Sindhya K. A surrogate-assisted reference vector guided evolutionary algorithm for computationally expensive many-objective optimization. IEEE Transactions on Evolutionary Computation, 2016, 22(1): 129-142 [18] Wang Han-Ding, Jin Yao-Chu, Sun Chao-Li, et al. Offline data-driven evolutionary optimization using selective surrogate ensembles. IEEE Transactions on Evolutionary Computation, 2018, 23(2): 203-216 [19] Ding Jin-Liang, Chai Tian-You, Wang Hong, Chen Xin-Kai. Knowledge-based global operation of mineral processing under uncertainty. IEEE Transactions on Industrial Informatics, 2012, 8(4): 849-859 doi: 10.1109/TII.2012.2205394 [20] Chugh T, Chakraborti N, Sindhya K, Jin Yao-Chu. A data-driven surrogate-assisted evolutionary algorithm applied to a many-objective blast furnace optimization problem. Materials and Manufacturing Processes, 2017, 32(10): 1172-1178 doi: 10.1080/10426914.2016.1269923 [21] Guo D, Chai T Y, Ding J L, Jin Y C. Small data driven evolutionary multi-objective optimization of fused magnesium furnaces. In: Proceedings of the 2nd IEEE Symposium Series on Computational Intelligence (SSCI). Nashville, USA: IEEE, 2016. 1−8 [22] Wang Han-Ding, Jin Yao-Chu, Jansen J O. Data-driven surrogate-assisted multiobjective evolutionary optimization of a trauma system. IEEE Transactions on Evolutionary Computation, 2016, 20(6): 939-952 doi: 10.1109/TEVC.2016.2555315 [23] Li Jian-Yu, Zhan Zhi-Hui, Wang Chuan, Jin Hu, Zhang Jun. Boosting data-driven evolutionary algorithm with localized data generation. IEEE Transactions on Evolutionary Computation, 2020, 24(5): 923-937 doi: 10.1109/TEVC.2020.2979740 [24] Li Jian-Yu, Zhan Zhi-Hui, Wang Hua, Zhang Jun. Data-driven evolutionary algorithm with perturbation-based ensemble surrogates. IEEE Transactions on Cybernetics, 2020, 51(8): 3925-3937 [25] Goel T, Haftka R T, Wei S, Queipo N V. Ensemble of surrogates. Structural and Multidisciplinary Optimization, 2007, 33(3): 199-216 doi: 10.1007/s00158-006-0051-9 [26] Wolpert D H. Stacked generalization. Neural networks, 1992, 5(2): 241-259 doi: 10.1016/S0893-6080(05)80023-1 [27] Breiman L. Stacked regressions. Machine learning, 1996, 24(1): 49-64 [28] Ting K M, Witten I H. Issues in stacked generalization. Journal of artificial intelligence research, 1999, 10: 271-289 doi: 10.1613/jair.594 [29] Van der Laan M J, Polley E C, Hubbard A E. Super learner. Statistical applications in genetics and molecular biology, 2007, 6(1): 1-23 [30] Suykens J A K, Vandewalle J. Least squares support vector machine classifiers. Neural processing letters, 1999, 9(3): 293-300 doi: 10.1023/A:1018628609742 [31] Díaz-Manríquez A, Toscano G, Coello C A C. Comparison of metamodeling techniques in evolutionary algorithms. Soft Computing, 2017, 21(19): 5647-5663 doi: 10.1007/s00500-016-2140-z [32] Hoerl A E, Kennard R W. Ridge regression: Biased estimation for nonorthogonal problems. Technometrics, 1970, 12(1): 55-67 doi: 10.1080/00401706.1970.10488634 [33] Deb K, Beyer H G. Self-adaptive genetic algorithms with simulated binary crossover. Evolutionary computation, 2001, 9(2): 197-221 doi: 10.1162/106365601750190406 [34] Deb K, Pratap A, Agarwal S, Meyarivan K. A fast and elitist multiobjective genetic algorithm: NSGA-Ⅱ. IEEE Transactions on Evolutionary Computation, 2002, 6(2):182-197 doi: 10.1109/4235.996017 [35] Cheng Ran, Li Mi-Qing, Tian Ye, et al. A benchmark test suite for evolutionary many-objective optimization. Complex & Intelligent Systems, 2017, 3(1):67-81 [36] Rokach L. Taxonomy for characterizing ensemble methods in classification tasks: A review and annotated bibliography. Computational Statistics & Data Analysis, 2009, 53(12):4046-4072 [37] Garcia-Pedrajas N, Hervas-Martinez C, Ortiz-Boyer D. Cooperative coevolution of artificial neural network ensembles for pattern classification. IEEE Transactions on Evolutionary Computation, 2005, 9(3):271-302 doi: 10.1109/TEVC.2005.844158 [38] Breiman L. Bagging predictors. Machine learning, 1996, 24(2): 123-140 [39] Schapire R E, Freund Y. Boosting: Foundations and algorithms. Kybernetes, 2013, 42(1): 164−166 [40] Zhou Z H. Ensemble Methods: Foundations and Algorithms. Florida: CRC Press, 2012. 99−133 [41] Guo Dan, Jin Yao-Chu, Ding Jin-Liang, Chai Tian-You. Heterogeneous ensemble-based infill criterion for evolutionary multiobjective optimization of expensive problems, IEEE Transactions on Cybernetics, 2019, 49(3): 1012-1025 doi: 10.1109/TCYB.2018.2794503 [42] Zhou Y, Xu Z X. Multi-model stacking ensemble learning for dropout prediction in MOOCs. Journal of Physics Conference Series, 2020, 1607: Article No. 012004 [43] Gu Ke, Xia Zhi-Fang, Qiao Jun-Fei. Stacked selective ensemble for PM2.5 forecast. IEEE Transactions on Instrumentation and Measurement, 2020, 69(3):660-671. doi: 10.1109/TIM.2019.2905904 [44] Huang P F, Wang H D, Ma W P. Stochastic ranking for offline data-driven evolutionary optimization using radial basis function networks with multiple kernels. In: Proceedings of the 5th IEEE Symposium Series on Computational Intelligence (SSCI). Xiamen, China: IEEE, 2019. 2050−2057 [45] Runarsson T P, Yao Xin. Stochastic ranking for constrained evolutionary optimization. IEEE Transactions on evolutionary computation, 2000, 4(3): 284-294 doi: 10.1109/4235.873238 [46] Yang Cui-E, Ding Jin-Liang, Jin Yao-Chu, Chai Tian-You. Offline data-driven multiobjective optimization: Knowledge transfer between surrogates and generation of final solutions. IEEE Transactions on Evolutionary Computation, 2019, 24(3): 409-423 [47] Shan Y W, Hou Y J, Wang M Z, Xu F. Trimmed data-driven evolutionary optimization using selective surrogate ensembles. In: Proceedings of the 15th International Conference on Bio-Inspired Computing: Theories and Applications. Singapore: Springer, 2020. 106−116 [48] Huang P F, Wang H D, Jin Y C. Offline data-driven evolutionary optimization based on tri-training. Swarm and Evolutionary Computation, 2021, 60: Article No. 100800 [49] Zhou Zhi-Hua, Li Ming. Tri-training: Exploiting unlabeled data using three classifiers. IEEE Transactions on knowledge and Data Engineering, 2005, 17(11): 1529-1541 doi: 10.1109/TKDE.2005.186 [50] Wolpert D H, Macready W G. No free lunch theorems for optimization. IEEE transactions on evolutionary computation, 1997, 1(1): 67-82 doi: 10.1109/4235.585893 [51] Gelly S, Ruette S, Teytaud O. Comparison-based algorithms are robust and randomized algorithms are anytime. Evolutionary Computation, 2007, 15(4):411 doi: 10.1162/evco.2007.15.4.411 [52] Makridakis S. Accuracy measures: theoretical and practical concerns. International journal of forecasting, 1993, 9(4): 527-529 doi: 10.1016/0169-2070(93)90079-3 [53] Hyndman R J, Koehler A B. Another look at measures of forecast accuracy. International journal of forecasting, 2006, 22(4): 679-688 doi: 10.1016/j.ijforecast.2006.03.001 [54] Du K L, Swamy M N S. Neural Networks and Statistical Learning. London: Springer, 2014. 299−335 [55] Jin Yao-Chu, Sendhoff B. Pareto-based multiobjective machine learning: An overview and case studies. IEEE Transactions on Systems, Man, and Cybernetics, 2008, 38(3): 397-415 doi: 10.1109/TSMCC.2008.919172 [56] Mendes-Moreira J, Soares C, Jorge A M, Sousa J F D. Ensemble approaches for regression: a survey. ACM computing surveys, 2012, 45(1): 1-40 [57] Wu Sheng-Hao, Zhan Zhi-Hui, Zhang Jun. SAFE: Scale-adaptive fitness evaluation method for expensive optimization problems, IEEE Transactions on Evolutionary Computation, 2021, 25(3): 478-491 doi: 10.1109/TEVC.2021.3051608 -

 下载:
下载:

计量
- 文章访问数: 595
- HTML全文浏览量: 320
- PDF下载量: 158
- 被引次数: 0
