

Event-triggered Control Design for Optimal Tracking of Unknown Nonlinear Zero-sum Games
-
摘要: 设计了一种基于事件的迭代自适应评判算法, 用于解决一类非仿射系统的零和博弈最优跟踪控制问题. 通过数值求解方法得到参考轨迹的稳定控制, 进而将未知非线性系统的零和博弈最优跟踪控制问题转化为误差系统的最优调节问题. 为了保证闭环系统在具有良好控制性能的基础上有效地提高资源利用率, 引入一个合适的事件触发条件来获得阶段性更新的跟踪策略对. 然后, 根据设计的触发条件, 采用Lyapunov方法证明误差系统的渐近稳定性. 接着, 通过构建四个神经网络, 来促进所提算法的实现. 为了提高目标轨迹对应稳定控制的精度, 采用模型网络直接逼近未知系统函数而不是误差动态系统. 构建评判网络、执行网络和扰动网络用于近似迭代代价函数和迭代跟踪策略对. 最后, 通过两个仿真实例, 验证该控制方法的可行性和有效性.Abstract: In this paper, an event-based iterative adaptive critic algorithm is designed to address optimal tracking control for a class of nonaffine zero-sum games. The steady control of the reference trajectory is obtained by numerical calculation. Then, the optimal tracking control problem of unknown nonlinear zero-sum games is transformed into the optimal regulation problem of corresponding error dynamics. In order to ensure that the closed-loop system possesses favourable control performance while can effectively improve the resource utilization, an appropriate event-triggering condition is introduced to obtain the tracking policy pair aperiodically. According to the designed triggering condition and the Lyapunov stability theory, the error system is proved to be asymptotically stable. In addition, four neural networks are constructed to promote the implementation of the proposed algorithm. In order to improve the accuracy of the steady control in target trajectory, the model network is used to approach the unknown system function directly instead of the error dynamic system. The critic network, the action network, and the disturbance network are constructed to obtain the approximate iterative cost function and the approximate iterative tracking policy pair. Finally, two examples are presented to demonstrate the feasibility and effectiveness of the proposed algorithm.
-
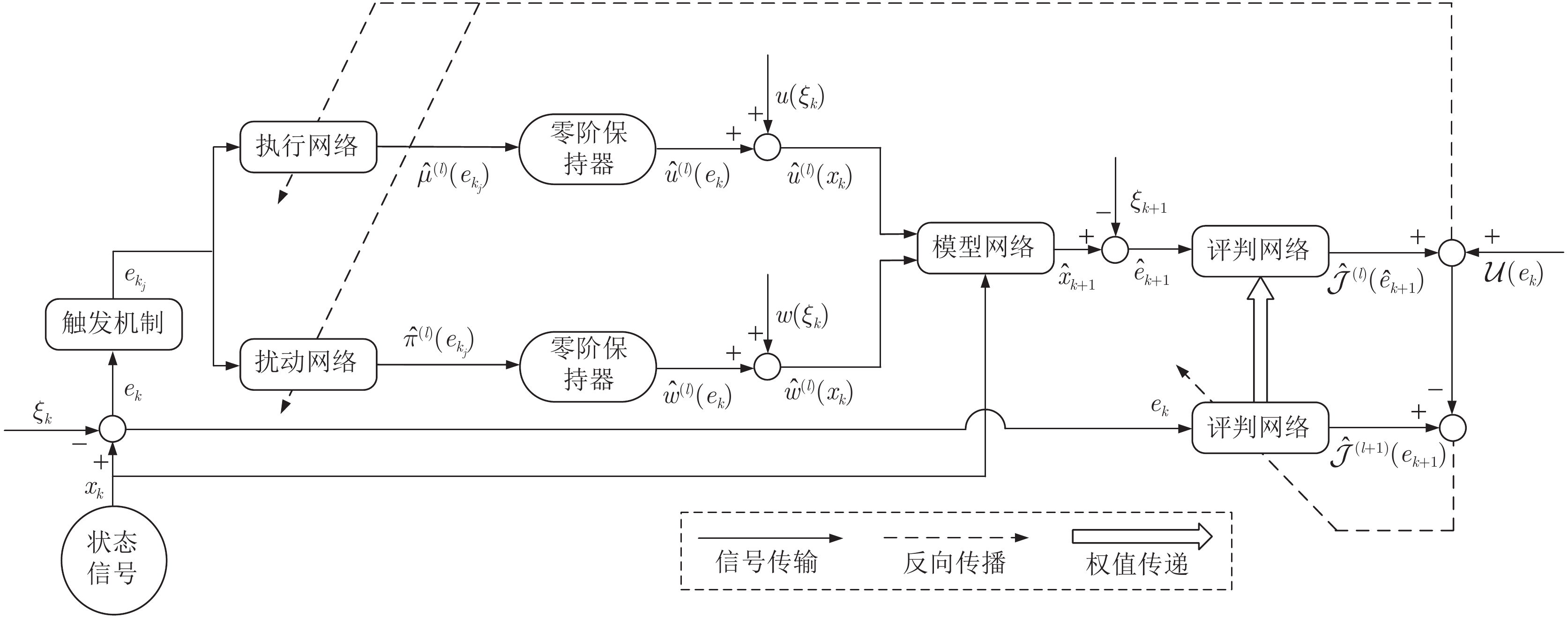
图 1 基于事件的零和博弈跟踪控制方法示意图
Fig. 1 The simple structure of the event-based zero-sum game tracking control method
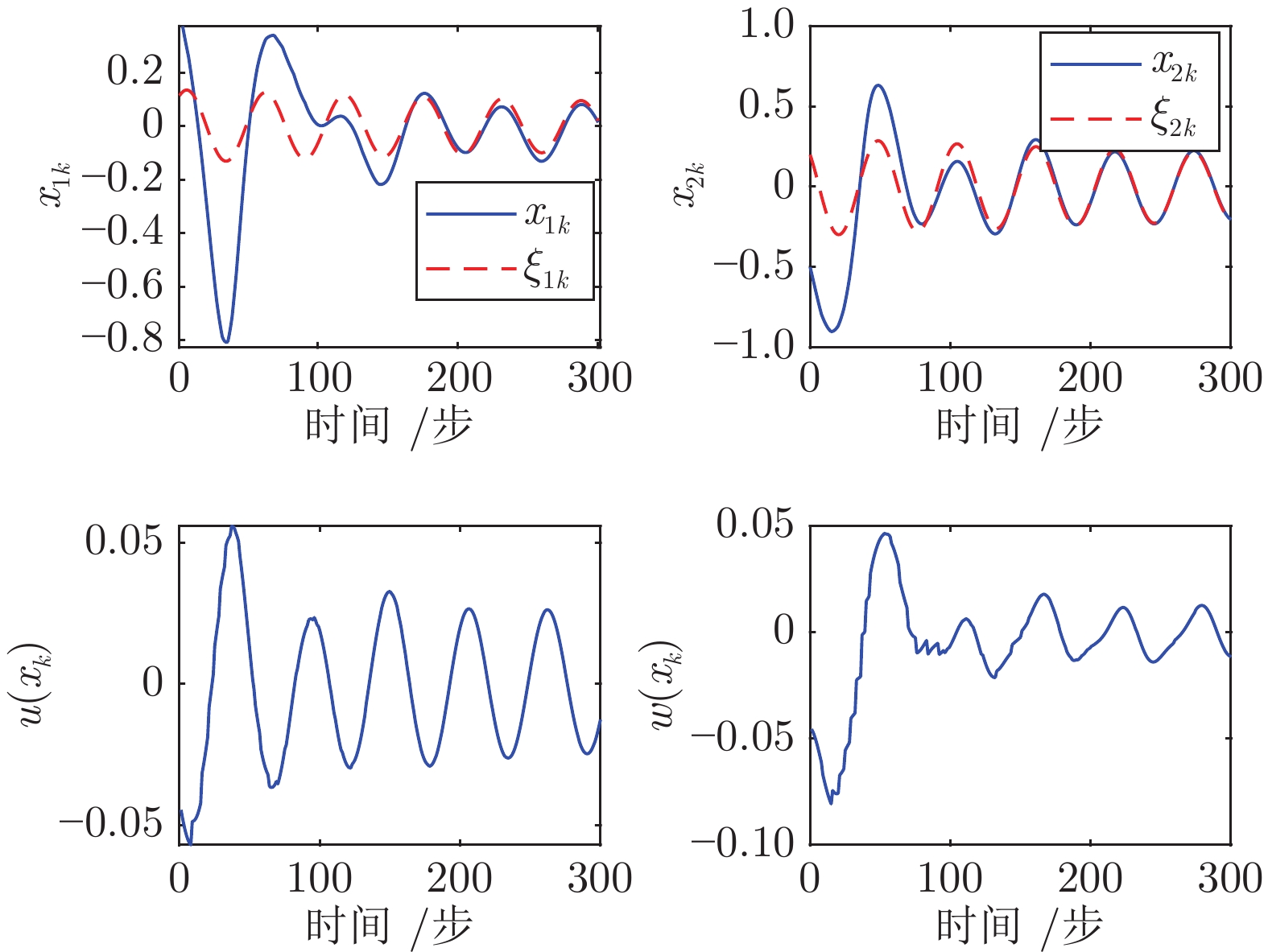
图 3 系统状态、控制律和扰动律轨迹(例1)
Fig. 3 Trajectories of the state, the control law, and the disturbance law (Example 1)
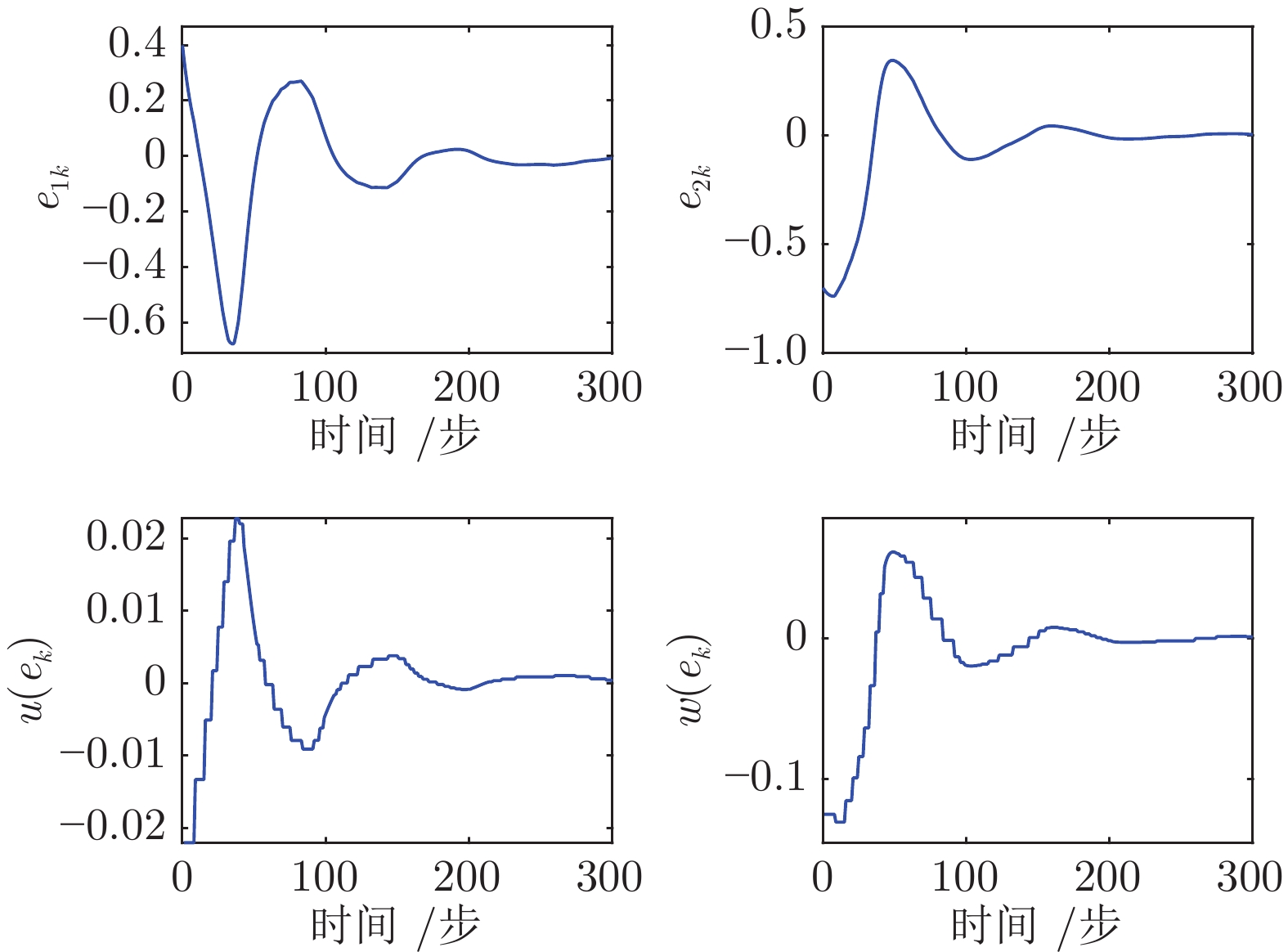
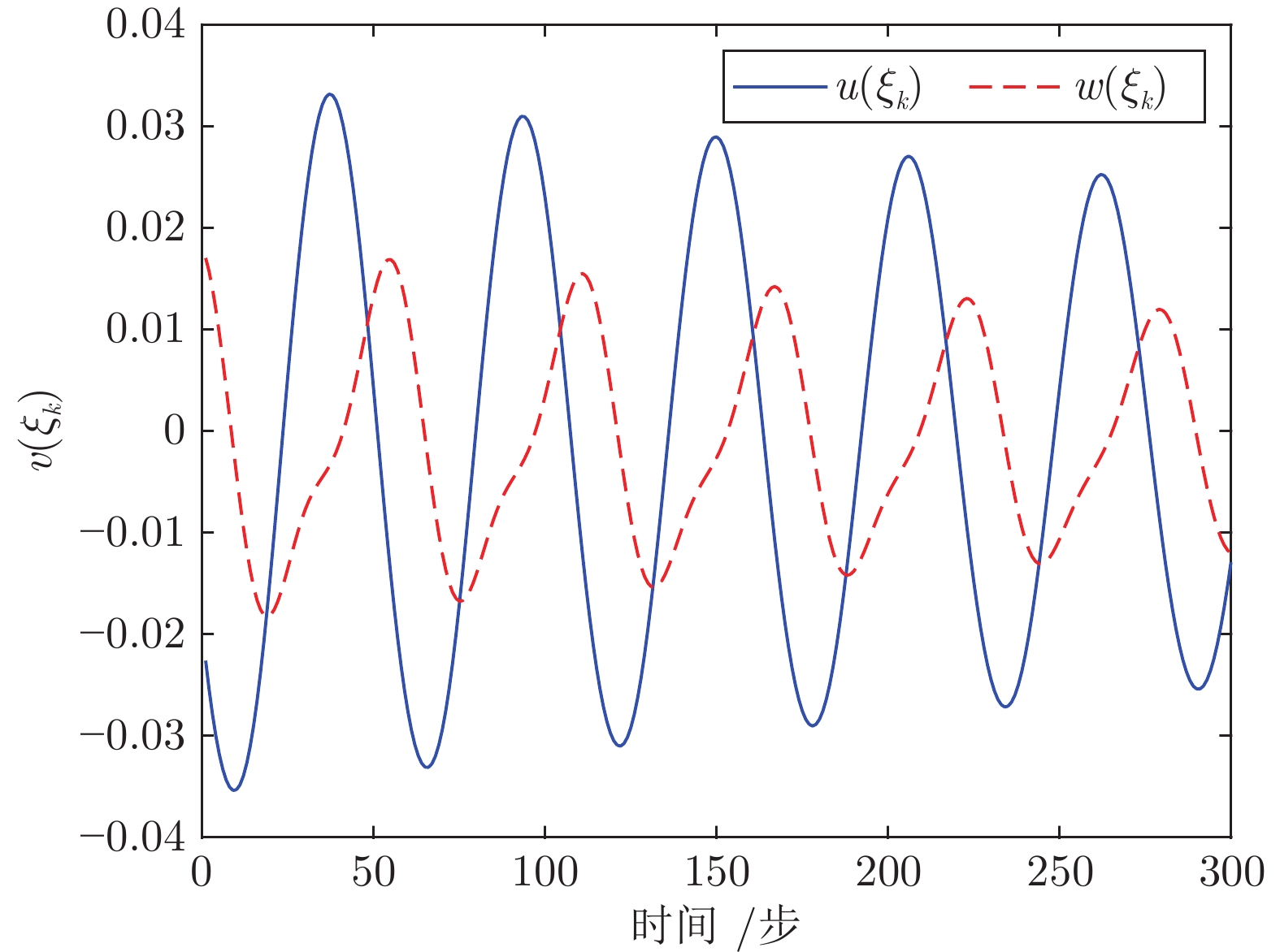
图 4 跟踪误差、跟踪控制律和跟踪扰动律轨迹(例1)
Fig. 4 Trajectories of the tracking error, the tracking control law, and the tracking disturbance law (Example 1)

图 8 系统状态、控制律和扰动律轨迹(例2)
Fig. 8 Trajectories of the state, the control law, and the disturbance law (Example 2)
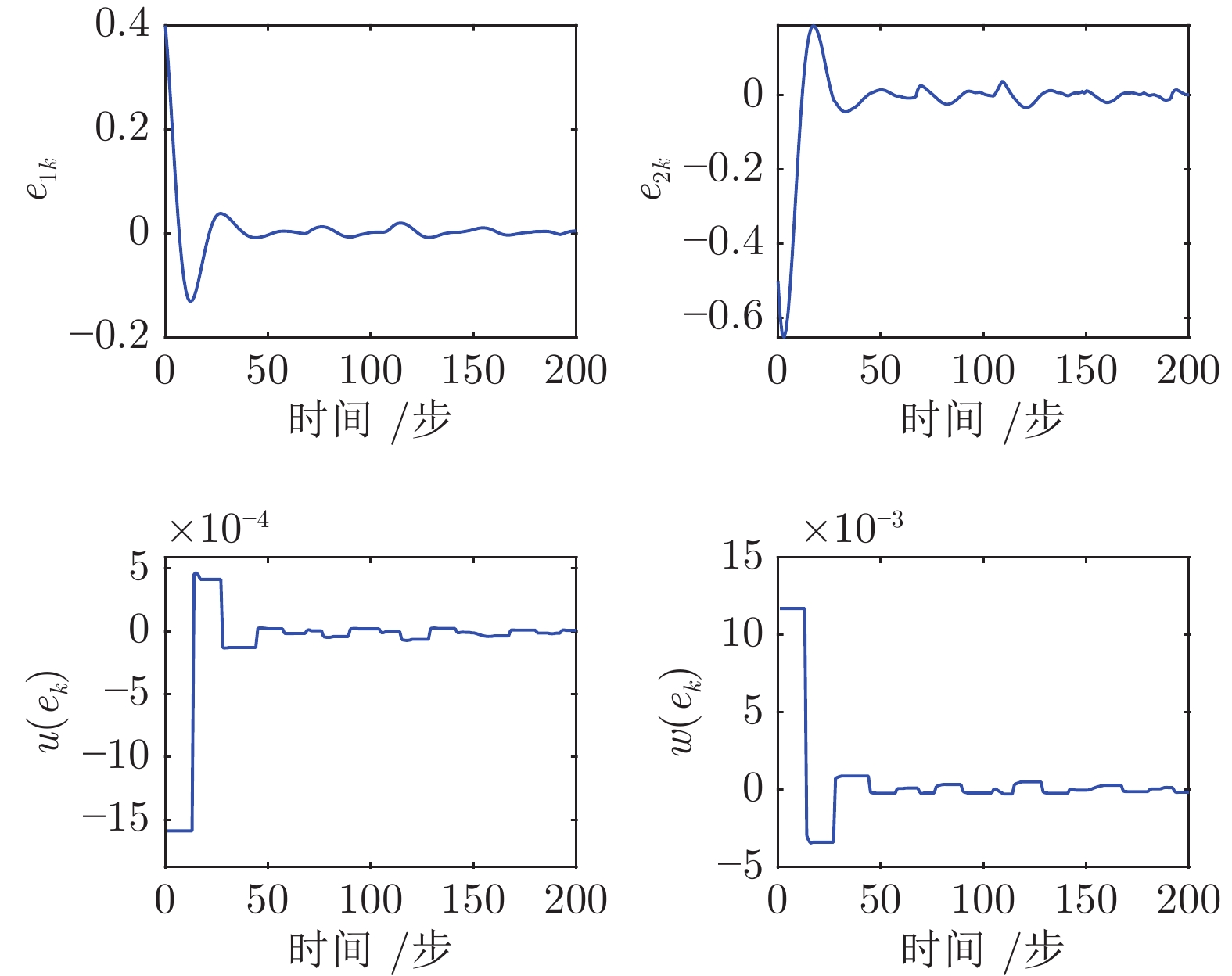
图 9 跟踪误差、跟踪控制律和跟踪扰动律轨迹(例2)
Fig. 9 Trajectories of the tracking error, the tracking control law, and the tracking disturbance law (Example 2)
表 1 两个仿真实验的主要参数
Table 1 Main parameters of two experimental examples
符号 例 1 例 2 $ {\cal{Q}} $ $ 0.01I_2 $ $ 0.1I_2 $ $ {\cal{R}} $ $ I $ $ I $ $ \gamma $ $ 0.01 $ $ 0.1 $ $ \Gamma $ $ 0.2 $ $ 0.35 $ $ \beta $ $ 1/6 $ $ 7/27 $ $ \epsilon $ $ 10^{-5} $ $ 10^{-5} $  下载: 导出CSV
下载: 导出CSV
-
[1] Li C D, Yi J Q, Lv Y S, Duan P Y. A hybrid learning method for the data-driven design of linguistic dynamic systems. IEEE/CAA Journal of Automatica Sinica, 2019, 6(6): 1487-1498 [2] Basar T, Bernhard P. $H_{\infty}$ optimal control and related minimax design problems: A dynamic game approach. IEEE Transactions on Automatic Control, 1996, 41(9): 1397-1399 doi: 10.1109/TAC.1996.536519[3] Dong J X, Hou Q H, Ren M M. Control synthesis for discrete-time T-S fuzzy systems based on membership function-dependent $H_{\infty}$ performance. IEEE Transactions on Fuzzy Systems, 2020, 28(12): 3360-3366 doi: 10.1109/TFUZZ.2019.2950879[4] Qian D W, Li C D, Lee S G, Ma C. Robust formation maneuvers through sliding mode for multi-agent systems with uncertainties. IEEE/CAA Journal of Automatica Sinica, 2018, 5(1): 342-351 [5] Mathiyalagan K, Su H Y, Shi P, Sakthivel R. Exponential $H_{\infty}$ filtering for discrete-time switched neural networks with random delays. IEEE Transactions on Cybernetics, 2015, 45(4): 676-687 doi: 10.1109/TCYB.2014.2332356[6] Werbos P J. Approximate dynamic programming for real-time control and neural modeling. In: Proceedings of the Handbook of Intelligent Control: Neural, Fuzzy, and Adaptive Approaches. New York, USA: 1992. [7] Heydari A. Stability analysis of optimal adaptive control under value iteration using a stabilizing initial policy. IEEE Transactions on Neural Networks and Learning Systems, 2018, 29(9): 4522-4527 doi: 10.1109/TNNLS.2017.2755501 [8] Al-Tamimi A, Lewis F L, Abu-Khalaf M. Discrete-time nonlinear HJB solution using approximate dynamic programming: Convergence proof. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 2008, 38(4): 943-949 doi: 10.1109/TSMCB.2008.926614 [9] Liu D R, Wei Q L. Generalized policy iteration adaptive dynamic programming for discrete-time nonlinear systems. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2015, 45(12): 1577-1591 doi: 10.1109/TSMC.2015.2417510 [10] Guo W T, Si J N, Liu F, Mei S W. Policy approximation in policy iteration approximate dynamic programming for discrete-time nonlinear systems. IEEE Transactions on Neural Networks and Learning Systems, 2018, 29(7): 2794-2807 [11] Modares H, Lewis F L, Naghibi-Sistani M-B. Adaptive optimal control of unknown constrained-input systems using policy iteration and neural networks. IEEE Transactions on Neural Networks and Learning Systems, 2013, 24(10): 1513-1525 doi: 10.1109/TNNLS.2013.2276571 [12] Kiumarsi B, Lewis F L. Actor-critic-based optimal tracking for partially unknown nonlinear discrete-time systems. IEEE Transactions on Neural Networks and Learning Systems, 2015, 26(1): 140-151 doi: 10.1109/TNNLS.2014.2358227 [13] 王鼎. 基于学习的鲁棒自适应评判控制研究进展. 自动化学报, 2019, 45(6): 1031-1043 doi: 10.16383/j.aas.c170701Wang Ding. Research progress on learning-based robust adaptive critic control. Acta Automatica Sinica, 2019, 45(6): 1031-1043 doi: 10.16383/j.aas.c170701 [14] Zhao F Y, Gao W N, Liu T F, Jiang Z P. Adaptive optimal output regulation of linear discrete-time systems based on event-triggered output-feedback. Automatica, 2022, 137: 10103 [15] Wang D, Qiao J F, Cheng L. An approximate neuro-optimal solution of discounted guaranteed cost control design. IEEE Transactions on Cybernetics, 2022, 52(1): 77-86 doi: 10.1109/TCYB.2020.2977318 [16] Niu B, Liu J D, Wang D, Zhao X D, Wang H Q. Adaptive decentralized asymptotic tracking control for large-scale nonlinear systems with unknown strong interconnections. IEEE/CAA Journal of Automatica Sinica, 2022, 9(1): 173-186 doi: 10.1109/JAS.2021.1004246 [17] Wang D, Ha M M, Zhao M M. The intelligent critic framework for advanced optimal control. Artificial Intelligence Review, 2022, 55(1): 1-22 [18] Zhang H G, Wei Q L, Luo Y H. A novel infinite-time optimal tracking control scheme for a class of discrete-time nonlinear systems via the greedy HDP iteration algorithm. IEEE Transactions on Systems, Man, and Cybernetics–Part B: Cybernetics, 2008, 38(4): 937-942 [19] Li C, Ding J L, Lewis F L, Chai T Y. A novel adaptive dynamic programming based on tracking error for nonlinear discrete-time systems. Automatica, 2021, 129: 109687 doi: 10.1016/j.automatica.2021.109687 [20] Wang D, Hu L Z, Zhao M M, Qiao J F. Adaptive critic for event-triggered unknown nonlinear optimal tracking design with wastewater treatment applications. IEEE Transactions on Neural Networks and Learning Systems, 2021. DOI: 10.1109/TNNLS.2021.3135405 [21] 王鼎, 赵明明, 哈明鸣, 乔俊飞. 基于折扣广义值迭代的智能最优跟踪及应用验证. 自动化学报, 2022, 48(1): 182-193 doi: 10.16383/j.aas.c210658Wang Ding, Zhao Ming-Ming, Ha Ming-Ming, Qiao Jun-Fei. Intelligent optimal tracking with application verifications via discounted generalized value iteration. Acta Automatica Sinica, 2022, 48(1): 182-193 doi: 10.16383/j.aas.c210658 [22] Postoyan R, Tabuada P, Nesic D, Anta A. A framework for the event-triggered stabilization of nonlinear systems. IEEE Transactions on Automatic Control, 2015, 60(4): 982-996 doi: 10.1109/TAC.2014.2363603 [23] Ha M M, Wang D, Liu D R. Event-triggered constrained control with DHP implementation for nonaffine discrete-time systems. Information Sciences, 2020, 519: 110–123 doi: 10.1016/j.ins.2020.01.020 [24] Sahoo A, Xu H, Jagannathan S. Near optimal event-triggered control of nonlinear discrete-time systems using neurodynamic programming. IEEE Transactions on Neural Networks and Learning Systems, 2016, 27(9): 1801-1815 doi: 10.1109/TNNLS.2015.2453320 [25] Wang D, Ha M M, Qiao J F. Self-learning optimal regulation for discrete-time nonlinear systems under event-driven formulation. IEEE Transactions on Automatic Control, 2020, 65(3): 1272-1279 doi: 10.1109/TAC.2019.2926167 [26] Dong L, Zhong X N, Sun C Y, He H B. Adaptive event-triggered control based on heuristic dynamic programming for nonlinear discrete-time systems. IEEE Transactions on Neural Networks and Learning Systems, 2017, 28(7): 1594-1605 doi: 10.1109/TNNLS.2016.2541020 [27] Dong L, Zhong X N, Sun C Y, He H B. Event-triggered adaptive dynamic programming for continuous-time systems with control constraints. IEEE Transactions on Neural Networks and Learning Systems, 2017, 28(8): 1941-1952 doi: 10.1109/TNNLS.2016.2586303 [28] Zhang H G, Luo Y H, Liu D R. Neural-network-based near-optimal control for a class of discrete-time affine nonlinear systems with control constraints. IEEE Transactions on Neural Networks, 2009, 20(9): 1490-1503 doi: 10.1109/TNN.2009.2027233 [29] Jiang Z P, Wang Y. Input-to-state stability for discrete-time nonlinear systems. Automatica, 2001, 37(6): 857-869 [30] Zhang Y W, Zhao B, Liu D R. Deterministic policy gradient adaptive dynamic programming for model-free optimal control. Neurocomputing, 2020, 387: 40–50 doi: 10.1016/j.neucom.2019.11.032 -

 下载:
下载:












计量
- 文章访问数: 2066
- HTML全文浏览量: 404
- PDF下载量: 430
- 被引次数: 0
