

A Class Incremental Learning and Memory Fusion Method Using Random Weight Neural Networks
-
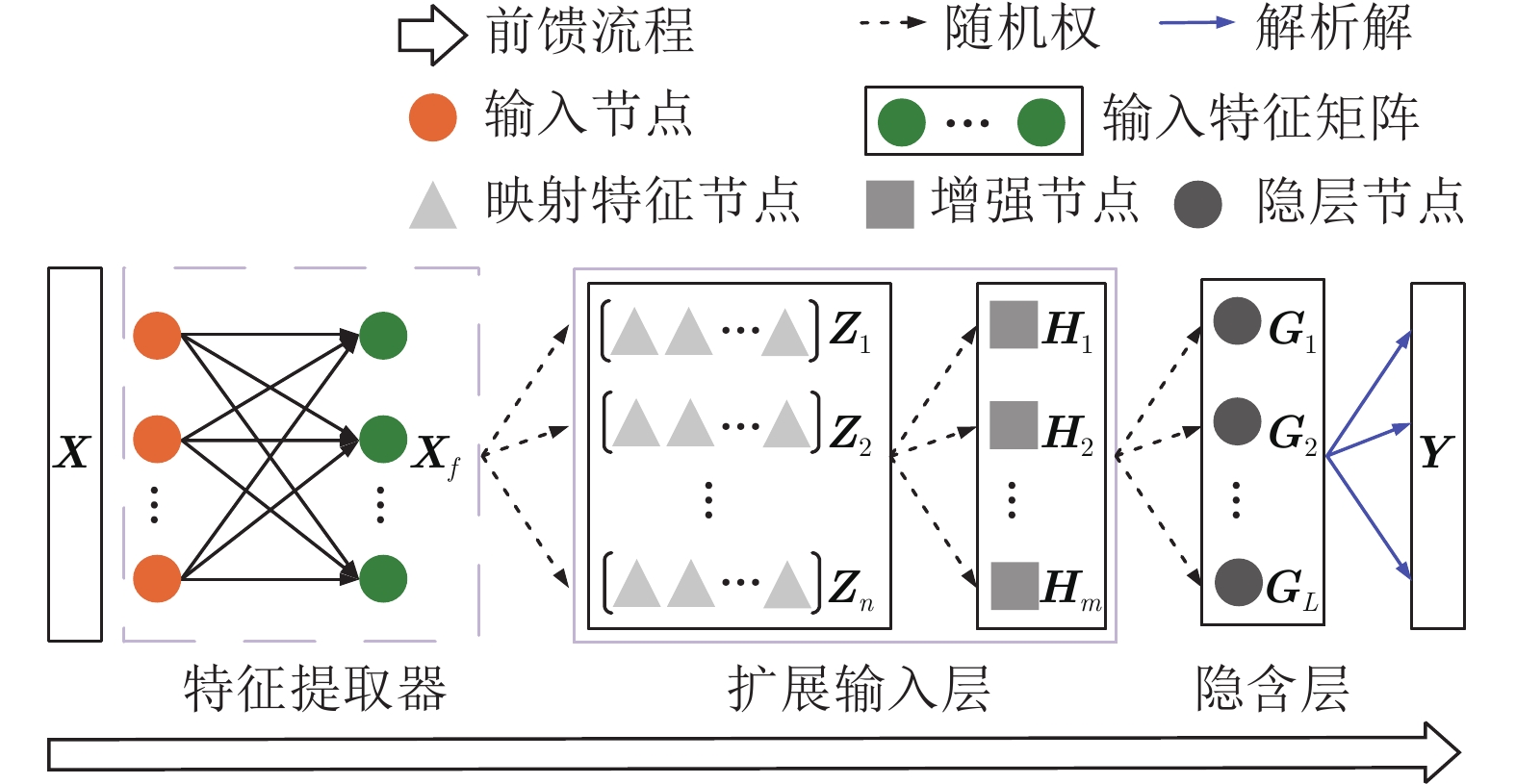
摘要: 连续学习(Continual learning, CL)多个任务的能力对于通用人工智能的发展至关重要. 现有人工神经网络(Artificial neural networks, ANNs)在单一任务上具有出色表现, 但在开放环境中依次面对不同任务时非常容易发生灾难性遗忘现象, 即联结主义模型在学习新任务时会迅速地忘记旧任务. 为了解决这个问题, 将随机权神经网络(Random weight neural networks, RWNNs)与生物大脑的相关工作机制联系起来, 提出一种新的再可塑性启发的随机化网络(Metaplasticity-inspired randomized network, MRNet)用于类增量学习(Class incremental learning, Class-IL)场景, 使得单一模型在不访问旧任务数据的情况下能够从未知的任务序列中学习与记忆融合. 首先, 以前馈方式构造具有解析解的通用连续学习框架, 用于有效兼容新任务中出现的新类别; 然后, 基于突触可塑性设计具备记忆功能的权值重要性矩阵, 自适应地调整网络参数以避免发生遗忘; 最后, 所提方法的有效性和高效性通过5个评价指标、5个基准任务序列和10个比较方法在类增量学习场景中得到验证.Abstract: The ability to continual learning (CL) on multiple tasks is crucial for the development of artificial general intelligence. Existing artificial neural networks (ANNs) performing well on a single task are prone to suffer from catastrophic forgetting when sequentially fed with different tasks in an open-ended environment, that is, the connectionist models trained on a new task could rapidly forget what was learned previously. To solve the problem, this paper proposes a new metaplasticity-inspired randomized network (MRNet) for the class incremental learning (Class-IL) scenario by relating random weight neural networks (RWNNs) with the relevant working mechanism of biological brain, which enables a single model to learn and remember the unknown task sequence without accessing old task data. First, a general continual learning framework with the closed-form solution is constructed in a feed-forward manner to effectively accommodate new categories emerging in new tasks; Second, a memory-related weight importance matrix is formed by referring to the property of synapses, which adaptively adjusts network parameters to avoid forgetting; Finally, effectiveness and efficiency of the proposed method are demonstrated in the class incremental learning scenario with 5 evaluation metrics, 5 benchmark task sequences, and 10 comparison methods.
-
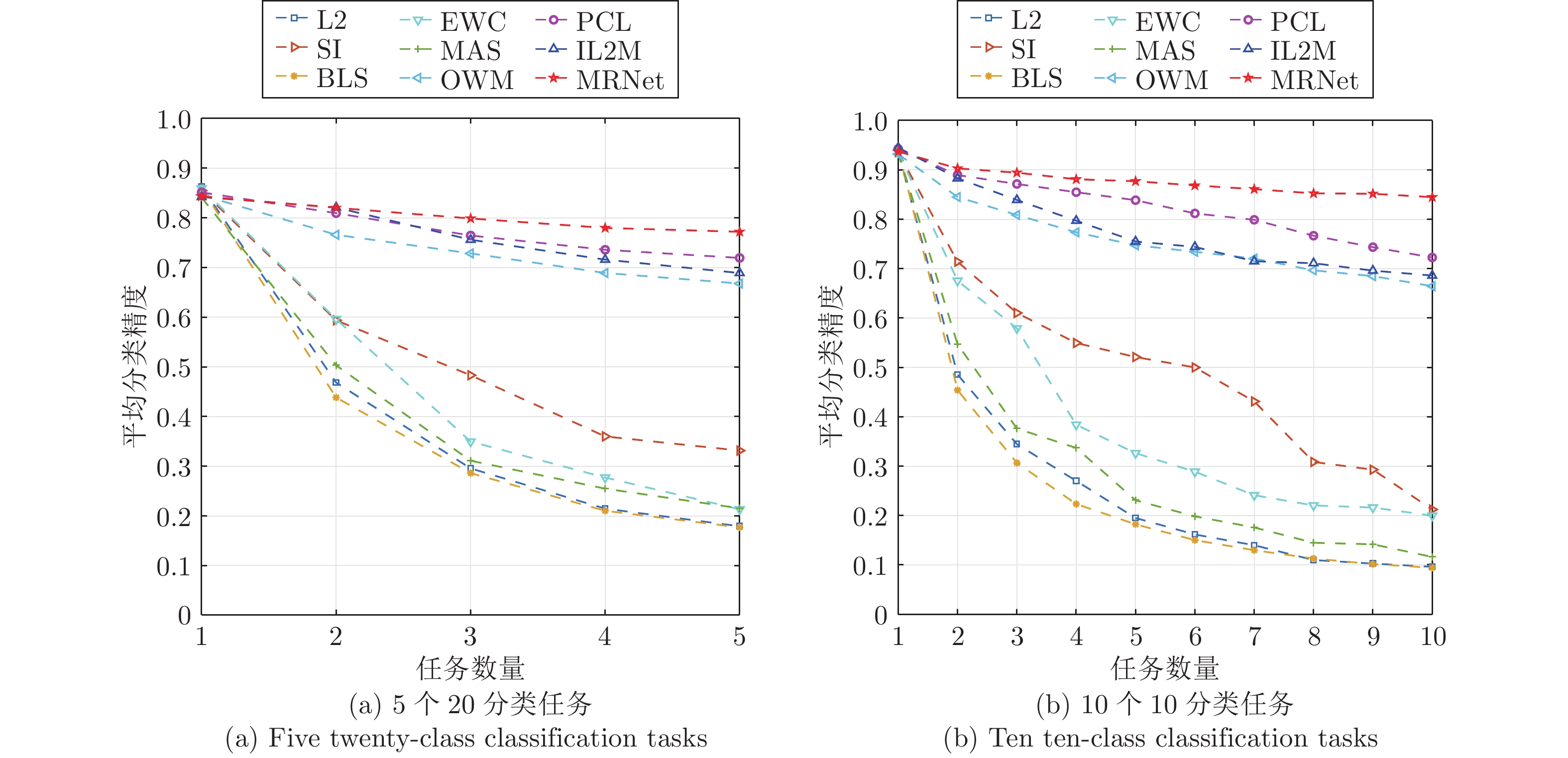
图 5 不同方法在CIFAR-100任务序列上的分类精度曲线
Fig. 5 Classification accuracy curves of different methods on CIFAR-100 task sequence
表 1 不同类增量学习方法的特性
Table 1 Characteristics of different Class-IL methods
方法 无需多次访问 无需逐层优化 无需数据存储 无需网络扩展 重放 × × × √ 扩展 × × √ × 正则化 × × √ √ MRNet √ √ √ √  下载: 导出CSV
下载: 导出CSV
表 2 连续学习FashionMNIST-10/5任务序列对比实验
Table 2 Comparative experiments on continuously learning FashionMNIST-10/5 task sequence
方法 指标 ACC (%) BWT FWT Time (s) No. Para. (MB) 非CL方法 BLS 19.93±0.22 — — 8.17±0.24 0.25 L2 26.55±6.27 — — 59.12±2.73 1.28 JT ~ 96.61 — — — — CL方法 EWC 34.96±7.62 −0.7248±0.0953 −0.0544±0.0300 69.21±4.10 11.48 MAS 38.54±3.49 −0.4781±0.0561 −0.2576±0.0548 110.26±1.74 3.83 SI 56.19±3.21 −0.3803±0.0631 −0.1329±0.0504 67.67±2.25 5.11 OWM 79.16±1.11 −0.1844±0.0197 −0.0635±0.0078 40.38±7.09 3.18 GEM 81.98±2.80 −0.0586±0.0654 −0.1093±0.0510 45.73±1.17 1.28 PCL 82.13±0.61 −0.1385±0.0413 −0.0647±0.0172 348.75±9.83 1.28 IL2M 84.61±2.95 −0.0712±0.0273 −0.0258±0.0248 44.18±1.34 1.28 MRNet 93.07±0.74 −0.0458±0.0069 −0.0261±0.0035 11.38±0.29 0.83
下载: 导出CSV
表 3 连续学习ImageNet-200任务序列对比实验
Table 3 Comparative experiments on continuously learning ImageNet-200 task sequence
方法 任务序列 ImageNet-200/10 ImageNet-200/50 IL2M 54.13±11.30 47.84±18.85 OWM 55.93±14.29 49.67±20.98 PCL 56.41±9.75 52.46±8.95 MRNet 56.50±9.13 55.93±11.51
下载: 导出CSV
表 4 权衡系数灵敏度分析
Table 4 Sensitivity analysis on the trade-off coefficients
保护程度 评价指标 ${A}_1$ (%) ${A}_2$ (%) ${A}_3$ (%) ${A}_4$ (%) ${A}_5$ (%) BWT FWT 1 84.45 42.88 28.20 20.51 17.45 −0.8420 0.0001 $10^2$ 84.45 75.48 68.57 61.54 55.65 −0.3629 −0.0015 $10^4$ 84.45 82.33 80.90 78.46 77.86 −0.0615 −0.0253 $10^6$ 84.45 71.48 61.37 49.81 41.11 −0.0199 −0.5263 $10^8$ 84.45 44.35 31.05 23.29 18.62 0.0003 −0.8270
下载: 导出CSV
表 5 MRNet结构分析
Table 5 Analysis on MRNet architecture
有无直连 评价指标 ${A}_1$ (%) ${A}_2$ (%) ${A}_3$ (%) ${A}_4$ (%) ${A}_5$ (%) BWT FWT × 98.20 92.58 93.98 93.34 92.61 −0.0199 −0.0560 √ 99.87 34.14 33.83 32.01 28.40 −0.1304 −0.1883
下载: 导出CSV
-
[1] McCloskey M, Cohen N J. Catastrophic interference in connectionist networks: The sequential learning problem. Psychology of Learning and Motivation. Elsevier, 1989. [2] French R M. Catastrophic forgetting in connectionist networks. Trends in Cognitive Sciences, 1999, 3(4): 128-135 doi: 10.1016/S1364-6613(99)01294-2 [3] McClelland J L, McNaughton B L, O'Reilly R C. Why there are complementary learning systems in the hippocampus and neocortex: insights from the successes and failures of connectionist models of learning and memory. Psychological Review, 1995, 102(3): 419-457 doi: 10.1037/0033-295X.102.3.419 [4] Aljundi R, Babiloni F, Elhoseiny M, Rohrbach M, Tuytelaars T. Memory aware synapses: Learning what (not) to forget. In: Proceedings of the European Conference on Computer Vision (ECCV). Munich, Germany: Springer, 2018. 139−154 [5] Li Z Z, Hoiem D. Learning without forgetting. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 40(12): 2935-2947 [6] Parisi G I, Kemker R, Part J L, Kanan C, Wermter S. Continual lifelong learning with neural networks: A review. Neural Networks, 2019, 113: 54-71 doi: 10.1016/j.neunet.2019.01.012 [7] Li Z Z, Hoiem D. A continual learning survey: Defying forgetting in classification tasks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(7): 3366-3385 [8] Perkonigg M, Hofmanninger J, Herold C J, Brink J A, Pianykh O, Prosch H, et al. Dynamic memory to alleviate catastrophic forgetting in continual learning with medical imaging. Nature Communications, 2021, 12(1): 1-12 doi: 10.1038/s41467-020-20314-w [9] Mallya A, Lazebnik S. Packnet: Adding multiple tasks to a single network by iterative pruning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City, USA: IEEE, 2018. 7765−7773 [10] Rosenfeld A, Tsotsos J K. Incremental learning through deep adaptation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 42(3): 651-663 [11] Hu W P, Qin Q, Wang M Y, Ma J W, Liu B. Continual learning by using information of each class holistically. Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2021, 35(9): 7797−7805 [12] Yang B Y, Lin M B, Zhang Y X, Liu B H, Liang X D, Ji R R, et al. Dynamic support network for few-shot class incremental learning. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(3): 2945−2951 [13] Shin H, Lee J K, Kim J, Kim J. Continual learning with deep generative replay. In: Proceedings of the 31st Conference on Neural Information Processing Systems (NeurIPS). Long Beach, USA: Curran Associates, Inc., 2017. 2990−2999 [14] Ven van de G M, Siegelmann H T, Tolias A S. Brain-inspired replay for continual learning with artificial neural networks. Nature Communications, 2020, 11(1): 1-14 doi: 10.1038/s41467-019-13993-7 [15] Belouadah E, Popescu A. IL2M: Class incremental learning with dual memory. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Seoul, South Korea: IEEE, 2019. 583−592 [16] Lopez-Paz D, Ranzato M. Gradient episodic memory for continual learning. In: Proceedings of the 31st Conference on Neural Information Processing Systems (NeurIPS). Long Beach, USA: Curran Associates, Inc., 2017. 6470−6479 [17] Chaudhry A, Marc'Aurelio R, Rohrbach M, Elhoseiny M. Efficient lifelong learning with A-GEM. In: Proceedings of the International Conference on Learning Representations (ICLR). New Orleans, USA: 2019. [18] Tang S X, Chen D P, Zhu J G, Yu S J, Ouyang W L. Layerwise optimization by gradient decomposition for continual learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, USA: IEEE, 2021. 9634−9643 [19] Zhang X Y, Zhao T F, Chen J S, Shen Y, Li X M. EPicker is an exemplar-based continual learning approach for knowledge accumulation in cryoEM particle picking. Nature Communications, 2022, 13(1): 1-10. doi: 10.1038/s41467-021-27699-2 [20] Schwarz J, Czarnecki W, Luketina J, Grabska-Barwinska A, Teh Y W, Pascanu R, et al. Progress & compress: A scalable framework for continual learning. In: Proceedings of the International Conference on Machine Learning (ICML). Stockholm, Sweden: JMLR, 2018. 4528−4537 [21] Zhang J T, Zhang J, Ghosh S, Li D W, Tasci S, Heck L, et al. Class-incremental learning via deep model consolidation. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). Snowmass, USA: IEEE, 2020. 1131−1140 [22] Liu X B, Wang W Q. GopGAN: Gradients orthogonal projection generative adversarial network with continual learning. IEEE Transactions on Neural Networks and Learning Systems, 2023, 34(1): 215−227 [23] Kirkpatrick J, Pascanu R, Rabinowitz N, Veness J, Desjardins G, Rusu A A, et al. Overcoming catastrophic forgetting in neural network. Proceedings of the National Academy of Sciences (PNAS), 2017, 114(13): 3521-3526 doi: 10.1073/pnas.1611835114 [24] Zenke F, Poole B, Ganguli S. Continual learning through synaptic intelligence. In: Proceedings of the International Conference on Machine Learning (ICML). Sydney, Australia: JMLR, 2017. 3987−3995 [25] Zeng G X, Chen Y, Cui B, Yu S. Continual learning of context-dependent processing in neural networks. Nature Machine Intelligence, 2019, 1(8): 364-372 doi: 10.1038/s42256-019-0080-x [26] Gao J Q, Li J Q, Shan H M, Qu Y Y, Wang J Z, Zhang J P. Forget less, count better: A domain-incremental self-distillation learning benchmark for lifelong crowd counting. arXiv preprint arXiv: 2205.03307, 2022. [27] 蒙西, 乔俊飞, 韩红桂. 基于类脑模块化神经网络的污水处理过程关键出水参数软测量. 自动化学报, 2019, 45(5): 906-919 doi: 10.16383/j.aas.2018.c170497Meng X, Qiao J F, Han H G. Soft measurement of key effluent parameters in wastewater treatment process using brain-like modular neural networks. Acta Automatica Sinica, 2019, 45(5): 906-919 doi: 10.16383/j.aas.2018.c170497 [28] Nadji-Tehrani M, Eslami A. A brain-inspired framework for evolutionary artificial general intelligence. IEEE Transactions on Neural Networks and Learning Systems, 2020, 31(12): 5257-5271 doi: 10.1109/TNNLS.2020.2965567 [29] Hu B, Guan Z H, Chen G R, Chen C L P. Neuroscience and network dynamics toward brain-inspired intelligence. IEEE Transactions on Cybernetics, 2022, 52(10): 10214−10227 [30] LeCun Y, Bottou L, Bengio Y, Haffner P. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 1998, 86(11): 2278-2324 doi: 10.1109/5.726791 [31] Pao Y H, Takefji Y. Functional-link net computing: Theory, system architecture, and functionalities. Computer, 1992, 25(5): 76-79 doi: 10.1109/2.144401 [32] Schmidt W F, Kraaijveld M A, Duin R P W. Feedforward neural networks with random weights. In: Proceedings of the 11th IAPR International Conference on Pattern Recognition. IEEE Computer Society, 1992. 1−4 [33] Igelnik B, Pao Y H. Stochastic choice of basis functions in adaptive function approximation and the functional-link net. IEEE Transactions on Neural Networks, 1995, 6(6): 1320-1329 doi: 10.1109/72.471375 [34] Cao W P, Wang X Z, Ming Z, Gao J Z. A review on neural networks with random weights. Neurocomputing, 2011, 275: 278-287 [35] Zhang L, Suganthan P N. Visual tracking with convolutional random vector functional link network. IEEE Transactions on Cybernetics, 2016, 47(10): 3243-3253 [36] Dai W, Li D P, Zhou P, Chai T Y. Stochastic configuration networks with block increments for data modeling in process industries. Information Sciences, 2019, 484: 367-386 doi: 10.1016/j.ins.2019.01.062 [37] 邹伟东, 夏元清. 基于压缩因子的宽度学习系统的虚拟机性能预测. 自动化学报, 2022, 48(3): 724-734 doi: 10.16383/j.aas.c190307Zou W D, Xia Y Q. Virtual machine performance prediction using broad learning system based on compression factor. Acta Automatica Sinica, 2022, 48(3): 724-734 doi: 10.16383/j.aas.c190307 [38] Huang G B, Zhu QY, Siew C K. Extreme learning machine: theory and applications. Neurocomputing, 2006, 70(1-3): 489-501 doi: 10.1016/j.neucom.2005.12.126 [39] Wang D H, Li M. Stochastic configuration networks: Fundamentals and algorithms. IEEE Transactions on Cybernetics, 2017, 47(10): 3466-3479 doi: 10.1109/TCYB.2017.2734043 [40] Chen C L P, Liu Z L. Broad learning system: An effective and efficient incremental learning system without the need for deep architecture. IEEE Transactions on Neural Networks and Learning Systems, 2017, 29(1): 10-24 [41] 代伟, 李德鹏, 杨春雨, 马小平. 一种随机配置网络的模型与数据混合并行学习方法. 自动化学报, 2021, 47(10): 2427-2437 doi: 10.16383/j.aas.c190411Dai W, Li D P, Yang C Y, Ma X P. A model and data hybrid parallel learning method for stochastic configuration networks. Acta Automatica Sinica, 2021, 47(10): 2427-2437 doi: 10.16383/j.aas.c190411 [42] Gong X R, Zhang T, Chen C L P, Liu Z L. Research review for broad learning system: Algorithms, theory, and applications. IEEE Transactions on Cybernetics, 2022, 52(9): 8922−8950 [43] Abraham W C, Bear M F. Metaplasticity: the plasticity of synaptic plasticity. Trends in Neurosciences, 1996, 19(4): 126-130 doi: 10.1016/S0166-2236(96)80018-X [44] 王韶莉, 陆巍. 再可塑性在学习记忆中作用的研究进展. 生理学报, 2016, 68(4): 475-482 doi: 10.13294/j.aps.2016.0032Wang S L, Lu W. Progress on metaplasticity and its role in learning and memory. Acta Physiologica Sinica, 2016, 68(4): 475-482 doi: 10.13294/j.aps.2016.0032 [45] Jedlicka P, Tomko M, Robins A, Abraham W C. Contributions by metaplasticity to solving the catastrophic forgetting problem. Trends in Neurosciences, 2022, 45(9): 656-666 doi: 10.1016/j.tins.2022.06.002 [46] Sussmann H J. Uniqueness of the weights for minimal feedforward nets with a given input-output map. Neural Networks, 1992, 5(4): 589-593 doi: 10.1016/S0893-6080(05)80037-1 [47] Lancaster P, Tismenetsky M. The Theory of Matrices: With Applications. Elsevier, 1985. [48] Kay S M. Fundamentals of statistical signal processing: Estimation theory. Traces and Emergence of Nonlinear Programming. Prentice-Hall, Inc, 1993. [49] Kuhn H W, Tucker A W. Nonlinear programming. Traces and Emergence of Nonlinear Programming. Springer, 2014. [50] Pan P, Swaroop S, Immer A, Eschenhagen R, Turner R, Khan M, et al. Continual deep learning by functional regularisation of memorable past. In: Proceedings of the 34th Conference on Neural Information Processing Systems (NeurIPS). Vancouver, Canada: 2020. 4453−4464 [51] Verma V K, Liang K J, Mehta N, Rai P, Carin L. Efficient feature transformations for discriminative and generative continual learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, USA: IEEE, 2021. 13865−13875 -

 下载:
下载:



计量
- 文章访问数: 2194
- HTML全文浏览量: 830
- PDF下载量: 428
- 被引次数: 0
