

-
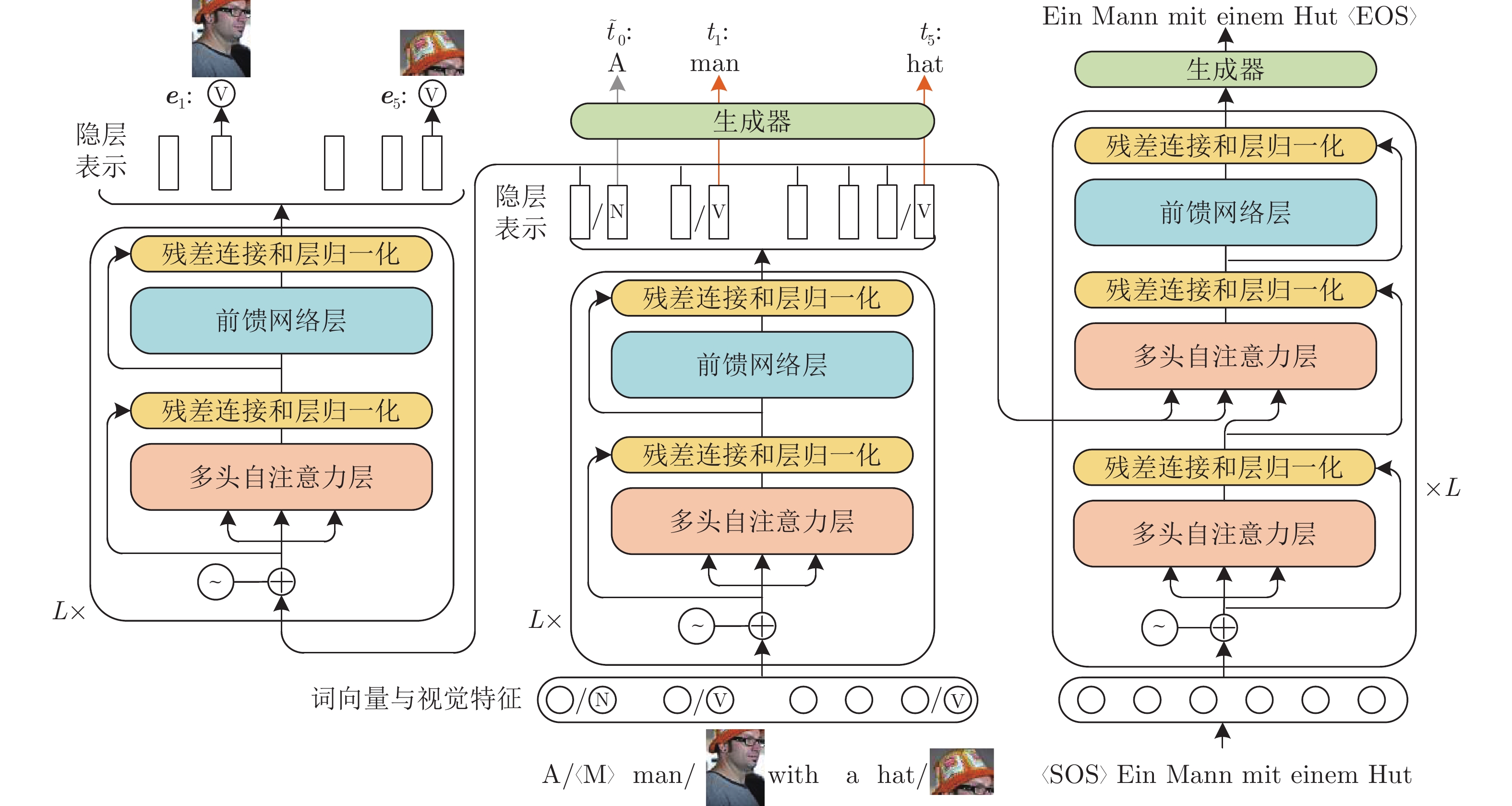
摘要: 现有多模态机器翻译(Multi-modal machine translation, MMT)方法将图片与待翻译文本进行句子级别的语义融合. 这些方法存在视觉信息作用不明确和模型对视觉信息不敏感等问题, 并进一步造成了视觉信息与文本信息无法在翻译模型中充分融合语义的问题. 针对这些问题, 提出了一种跨模态实体重构(Cross-modal entity reconstruction, CER)方法. 区别于将完整的图片输入到翻译模型中, 该方法显式对齐文本与图像中的实体, 通过文本上下文与一种模态的实体的组合来重构另一种模态的实体, 最终达到实体级的跨模态语义融合的目的, 通过多任务学习方法将CER模型与翻译模型结合, 达到提升翻译质量的目的. 该方法在多模态翻译数据集的两个语言对上取得了最佳的翻译准确率. 进一步的分析实验表明, 该方法能够有效提升模型在翻译过程中对源端文本实体的忠实度.Abstract: Existing multi-modal machine translation (MMT) methods perform the sentence-level semantic fusion of images and text to be translated. These methods have problems such as the unclear role of visual information played in the translation procedure and the insensitivity of the model to visual information, and further cause the problem that visual information and text information cannot be fully semantically integrated into the translation models. To solve these problems, a cross-modal entity reconstruction (CER) method has been proposed. Different from incorporating the complete image into the translation model, this method explicitly aligns the entities in the text and the image, reconstructs the entity of one modality through the combination of the text context and the entity of the other modality, and finally achieves the purpose of entity-level cross-modal semantic fusion. Through the multi-task learning method, the CER model is combined with the translation model to improve the translation quality. The method achieves the best translation accuracy on the two language pairs of the multi-modal translation dataset. Further analysis experiments show that this method can effectively improve the fidelity to the source-end textual entities in the translation procedure.1)
1 1https://spacy.io -

图 3 超参数$\omega $对CER-NMT翻译性能的影响
Fig. 3 Effect of hyperparameter $\omega $ on translation performance of CER-NMT
表 1 MMT模型在Multi30K以及Ambiguous MSCOCO上的英译德和英译法的翻译结果
Table 1 Results of MMT models on the English-German Multi30K and English-French Ambiguous MSCOCO
模型 英译德 英译法 Test2016 Test2017 MSCOCO Test2016 B M B M B M B M 句子级融合方法 IMGD 37.3 55.1 — — — — — — VMMTC 37.5 55.7 26.1 45.4 21.8 41.2 — — SerAttTrans 38.7 57.2 — — — — 60.8 75.1 GumAttTrans 39.2 57.8 31.4 51.2 26.9 46.0 — — 视觉实体融合方法 Parallel RCNNs 36.5 54.1 — — — — — — DelMMT 38.0 55.6 — — — — 59.8 74.4 GMMT 39.8 57.6 32.2 51.9 28.7 47.6 60.9 74.9 增强 NMT 方法 Imagination 36.8 55.8 — — — — — — VMMTF 37.7 56.0 30.1 49.9 25.5 44.8 — — EMMT 39.7 57.5 32.9 51.7 29.1 47.5 61.1 75.8 本文方法 Base 38.5 57.5 31.0 51.9 27.5 47.4 60.5 75.6 CER-NMT 40.2 57.8 32.5 52.0 28.3 47.1 61.6 76.1  下载: 导出CSV
下载: 导出CSV
表 2 在Multi30K Test2016英译德翻译任务上的消融实验
Table 2 Ablation study on the English-German Multi30K Test2016
序号 NMT VER TER TNER B $\omega$ $(1-\omega )\times \alpha$ $(1-\omega) \times \beta$ $(1-\omega) \times \gamma$ 0 0.70 0.12 0.12 0.06 40.2 1 0.76 0.12 0.12 — 40.0 2 0.82 0.12 — 0.06 39.5 3 0.82 — 0.12 0.06 39.6 4 0.70 0.15 0.15 — 39.9 5 0.70 0.20 — 0.10 39.2 6 0.70 — 0.20 0.10 39.3 7 0.88 0.12 — — 38.8 8 0.88 — 0.12 — 38.8 9 0.94 — — 0.06 39.0 10 0.70 0.30 — — 39.2 11 0.70 — 0.30 — 39.4 12 0.70 — — 0.30 39.0
下载: 导出CSV
-
[1] Barrault L, Bougares F, Specia L, Lala C, Elliott D, Frank S. Findings of the third shared task on multimodal machine translation. In: Proceedings of the 3rd Conference on Machine Translation: Shared Task Papers. Brussels, Belgium: Association for Computational Linguistics, 2018. 304−323 [2] Elliott D, Frank S, Barrault L, Bougares F, Specia L. Findings of the second shared task on multimodal machine translation and multilingual image description. In: Proceedings of the 2nd Conference on Machine Translation. Copenhagen, Denmark: Association for Computational Linguistics, 2017. 215−233 [3] Elliott D, Frank S, Sima'an K, Specia L. Multi30K: Multilingual English-German image descriptions. In: Proceedings of the 5th Workshop on Vision and Language. Berlin, Germany: Association for Computational Linguistics, 2016. 70−74 [4] Calixto I, Liu Q. Incorporating global visual features into attention-based neural machine translation. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing. Copenhagen, Denmark: Association for Computational Linguistics, 2017. 992−1003 [5] Elliott D, Kádár Á. Imagination improves multimodal translation. In: Proceedings of the 8th International Joint Conference on Natural Language Processing. Taipei, China: Asian Federation of Natural Language Processing, 2017. 130−141 [6] Zhou M Y, Cheng R X, Lee Y J, Yu Z. A visual attention grounding neural model for multimodal machine translation. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing. Brussels, Belgium: Association for Computational Linguistics, 2018. 3643−3653 [7] Toyama J, Misono M, Suzuki M, Nakayama K, Matsuo Y. Neural machine translation with latent semantic of image and text [Online], available: https://arxiv.org/pdf/1611.08459.pdf, November 25, 2016 [8] Calixto I, Rios M, Aziz W. Latent variable model for multi-modal translation. In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Florence, Italy: Association for Computational Linguistics, 2019. 6392−6405 [9] Calixto I, Liu Q, Campbell N. Doubly-attentive decoder for multi-modal neural machine translation. In: Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. Vancouver, Canada: Association for Computational Linguistics, 2017. 1913−1924 [10] Libovický J, Helcl J. Attention strategies for multi-source sequence-to-sequence learning. In: Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. Vancouver, Canada: Association for Computational Linguistics, 2017. 196−202 [11] Libovický J, Helcl J, Mareček D. Input combination strategies for multi-source transformer decoder. In: Proceedings of the 3rd Conference on Machine Translation: Research Papers. Brussels, Belgium: Association for Computational Linguistics, 2018. 253−260 [12] Yao S W, Wan X J. Multimodal transformer for multimodal machine translation. In: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Seattle, USA: Association for Computational Linguistics, 2020. 4346−4350 [13] Huang P Y, Liu F, Shiang S R, Oh J, Dyer C. Attention-based multimodal neural machine translation. In: Proceedings of the 1st Conference on Machine Translation. Berlin, Germany: Association for Computational Linguistics, 2016. 639−645 [14] Elliott D. Adversarial evaluation of multimodal machine translation. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing. Brussels, Belgium: Association for Computational Linguistics, 2018. 2974−2978 [15] Wu Z Y, Kong L P, Bi W, Li X, Kao B. Good for misconceived reasons: An empirical revisiting on the need for visual context in multimodal machine translation. In: Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing. Association for Computational Linguistics, 2021. 6153−6166 [16] Li J D, Ataman D, Sennrich R. Vision matters when it should: Sanity checking multimodal machine translation models. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing. Punta Cana, Dominican Republic: Association for Computational Linguistics, 2021. 8556−8562 [17] Caglayan O, Madhyastha P, Specia L, Barrault L. Probing the need for visual context in multimodal machine translation. In: Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Minneapolis, Minnesota, USA: Association for Computational Linguistics, 2019. 4159−4170 [18] Huang X, Zhang J J, Zong C Q. Entity-level cross-modal learning improves multi-modal machine translation. In: Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2021. Punta Cana, Dominican Republic: Association for Computational Linguistics, 2021. 1067−1080 [19] Long Q Y, Wang M X, Li L. Generative imagination elevates machine translation. In: Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics, 2021. 5738−5748 [20] Wang S N, Zhang J J, Zong C Q. Associative multichannel autoencoder for multimodal word representation. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing. Brussels, Belgium: Association for Computational Linguistics, 2018. 115−124 [21] Wang S N, Zhang J J, Zong C Q. Learning multimodal word representation via dynamic fusion methods. In: Proceedings of the 32nd AAAI Conference on Artificial Intelligence and the 30th Innovative Applications of Artificial Intelligence Conference and the 8th AAAI Symposium on Educational Advances in Artificial Intelligence. New Orleans, USA: AAAI, 2018. Article No. 733 [22] Agrawal A, Lu J S, Antol S, Mitchell M, Zitnick C L, Parikh D, et al. VQA: Visual question answering. International Journal of Computer Vision, 2017, 123(1): 4-31 doi: 10.1007/s11263-016-0966-6 [23] Li H R, Zhu J N, Ma C, Zhang J J, Zong C Q. Multi-modal summarization for asynchronous collection of text, image, audio and video. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing. Copenhagen, Denmark: Association for Computational Linguistics, 2017. 1092−1102 [24] Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez A N, et al. Attention is all you need. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach, USA: Curran Associates Inc., 2017. 6000−6010 [25] Wang D X, Xiong D Y. Efficient object-level visual context modeling for multimodal machine translation: Masking irrelevant objects helps grounding. In: Proceedings of the 35th AAAI Conference on Artificial Intelligence, the 33rd Conference on Innovative Applications of Artificial Intelligence, IAAI 2021, the 11th Symposium on Educational Advances in Artificial Intelligence. AAAI, 2021. 2720−2728 [26] Yin Y J, Meng F D, Su J S, Zhou C L, Yang Z Y, Zhou J, et al. A novel graph-based multi-modal fusion encoder for neural machine translation. In: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Seattle, USA: Association for Computational Linguistics, 2020. 3025−3035 [27] He K M, Zhang X Y, Ren S Q, Sun J. Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 770−778 [28] Yang Z Y, Gong B Q, Wang L W, Huang W B, Yu D, Luo J B. A fast and accurate one-stage approach to visual grounding. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Seoul, South Korea: IEEE, 2019. 4682−4692 [29] Koehn P, Hoang H, Birch A, Callison-Burch C, Federico M, Bertoldi N, et al. Moses: Open source toolkit for statistical machine translation. In: Proceedings of the 45th Annual Meeting of the Association for Computational Linguistics Companion Volume Proceedings of the Demo and Poster Sessions. Prague, Czech Republic: Association for Computational Linguistics, 2007. 177−180 [30] Sennrich R, Haddow B, Birch A. Neural machine translation of rare words with subword units. In: Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Berlin, Germany: Association for Computational Linguistics, 2016. 1715−1725 [31] Kingma D P, Ba J. Adam: A method for stochastic optimization [Online], available: https://arxiv.org/pdf/1412.6980.pdf, July 23, 2015 [32] Papineni K, Roukos S, Ward T, Zhu W J. Bleu: A method for automatic evaluation of machine translation. In: Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics. Philadelphia, USA: Association for Computational Linguistics, 2002. 311−318 [33] Denkowski M, Lavie A. Meteor universal: Language specific translation evaluation for any target language. In: Proceedings of the 9th Workshop on Statistical Machine Translation. Baltimore, USA: Association for Computational Linguistics, 2014. 376−380 [34] Cho K, van Merriënboer B, Gulcehre C, Bahdanau D, Bougares F, Schwenk H, et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP). Doha, Qatar: Association for Computational Linguistics, 2014. 1724−1734 [35] Hochreiter S, Schmidhuber J. Long short-term memory. Neural Computation, 1997, 9(8): 1735-1780 doi: 10.1162/neco.1997.9.8.1735 [36] Liu P B, Cao H L, Zhao T J. Gumbel-attention for multi-modal machine translation [Online], available: https://arxiv.org/pdf/2103.08862.pdf, March 16, 2021 [37] Ive J, Madhyastha P, Specia L. Distilling translations with visual awareness. In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Florence, Italy: Association for Computational Linguistics, 2019. 6525−6538 [38] Dyer C, Chahuneau V, Smith N A. A simple, fast, and effective reparameterization of IBM model 2. In: Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Atlanta, Georgia, USA: Association for Computational Linguistics, 2013. 644−648 -

 下载:
下载:



图(4) / 表(2)
计量
- 文章访问数: 2483
- HTML全文浏览量: 469
- PDF下载量: 290
- 被引次数: 0
