

Intelligent Forecasting Method of Caustic Concentration in Alumina Production Process Based on End-edge-cloud Coordination
-
摘要: 苛性碱溶液浓度是氧化铝生产过程中的重要运行指标, 由于苛性碱溶液的温度和浓度频繁波动, 导致目前的浓度检测仪表检测精度低, 只能采用人工化验获得苛性碱浓度值, 化验结果的严重滞后导致无法实现苛性碱浓度的自动控制, 影响氧化铝产品质量. 在分析苛性碱溶液浓度控制过程动态特性的基础上建立了由线性模型和未知非线性动态系统描述的苛性碱浓度预报模型, 将参数辨识与自适应深度学习相结合, 提出端边云协同的氧化铝生产过程苛性碱浓度智能预报方法, 并采用氧化铝生产企业的实际生产数据对本文所提方法进行应用验证. 应用结果表明, 所提的苛性碱浓度智能预报方法可以实时、准确预报苛性碱浓度, 为实现苛性碱浓度的闭环运行优化控制创造了条件.Abstract: Caustic concentration is an important operating indicator in alumina production process. Due to frequent fluctuations in terms of the temperature and concentration of caustic solution, the precision of current concentration meters can not be guaranteed. High precision caustic concentration can only be obtained through manual assay. However, the severe lag of assay results will lead to the failure of automatic control of caustic concentration, which affects the quality of alumina products. In this paper, the dynamic characteristics of caustic concentration are analysed, and a caustic concentration forecasting model described by a linear model and an unknown nonlinear dynamic system is established. Then a novel intelligent forecasting method for caustic concentration of alumina production process based on end-edge-cloud cooperation is established by incorporating parameter identification with adaptive deep learning. The application verification of the proposed method is performed on actual production data from an alumina manufacturer. The results show that the proposed intelligent forecasting method is able to forecast caustic concentration accurately in real time, providing conditions for achieving the closed-loop optimal control of caustic concentration.
-
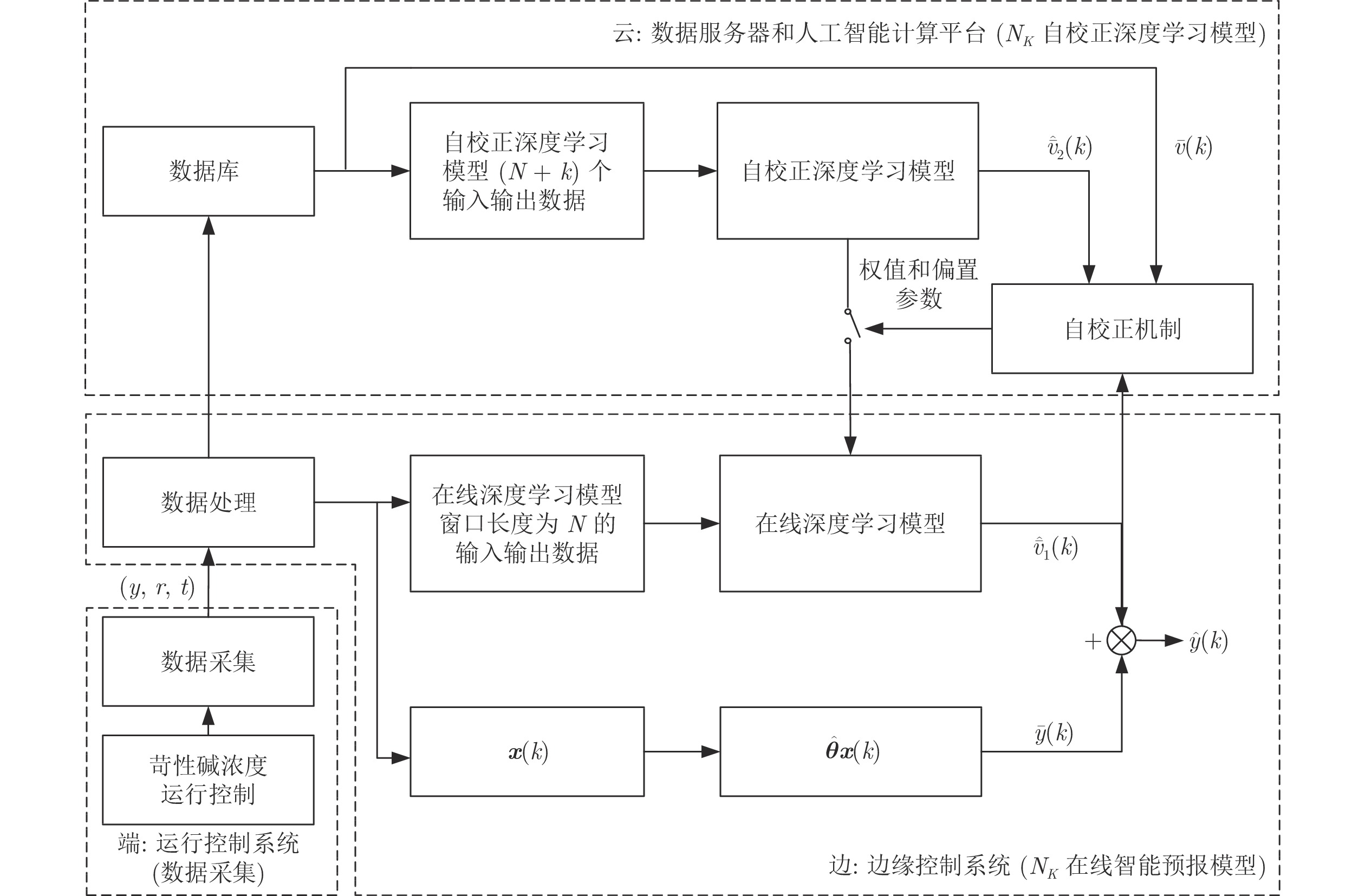
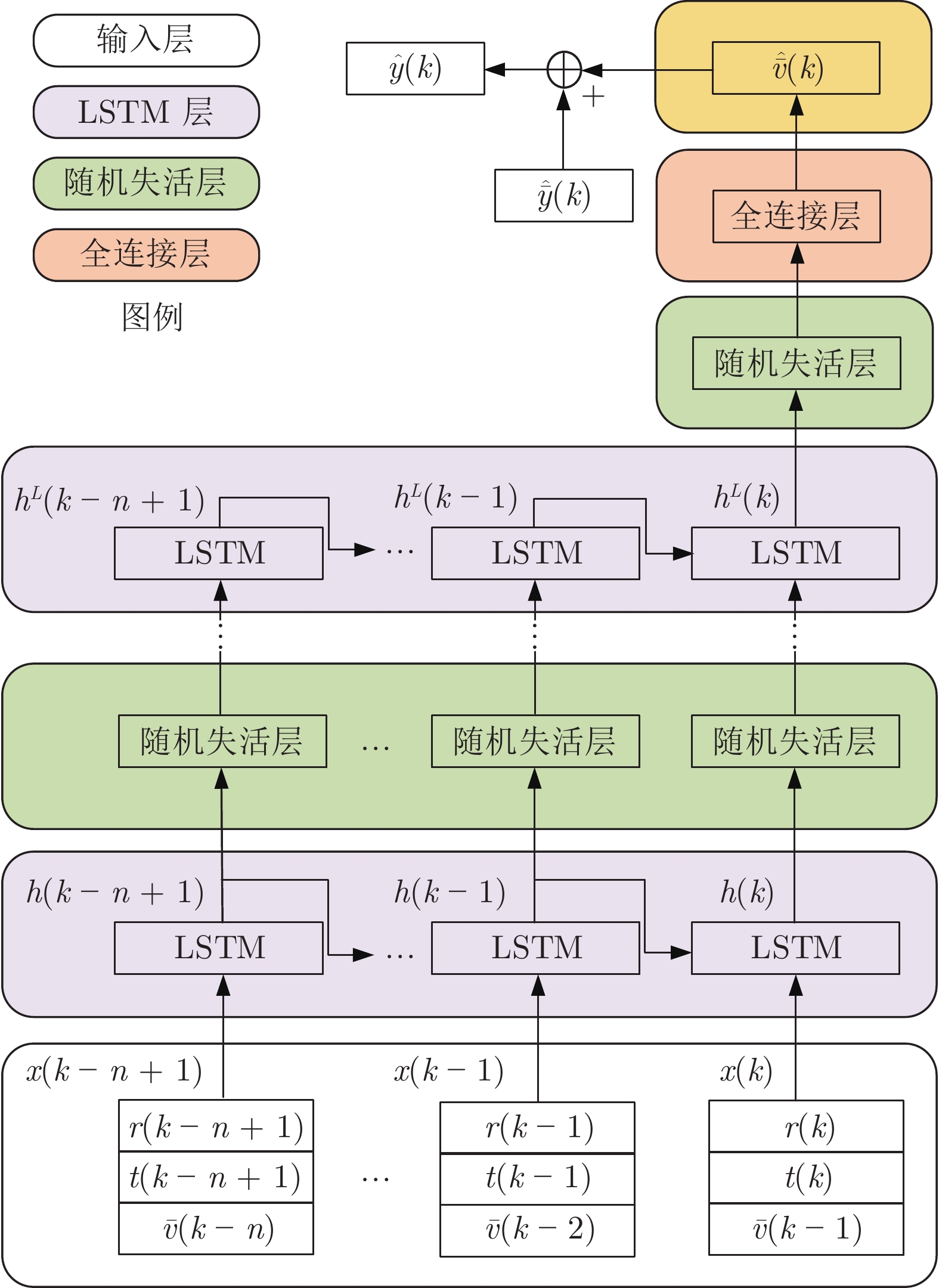
图 2 端边云协同的苛性碱浓度智能预报结构
Fig. 2 Intelligent forecasting structure of caustic concentration based on end-edge-cloud coordination
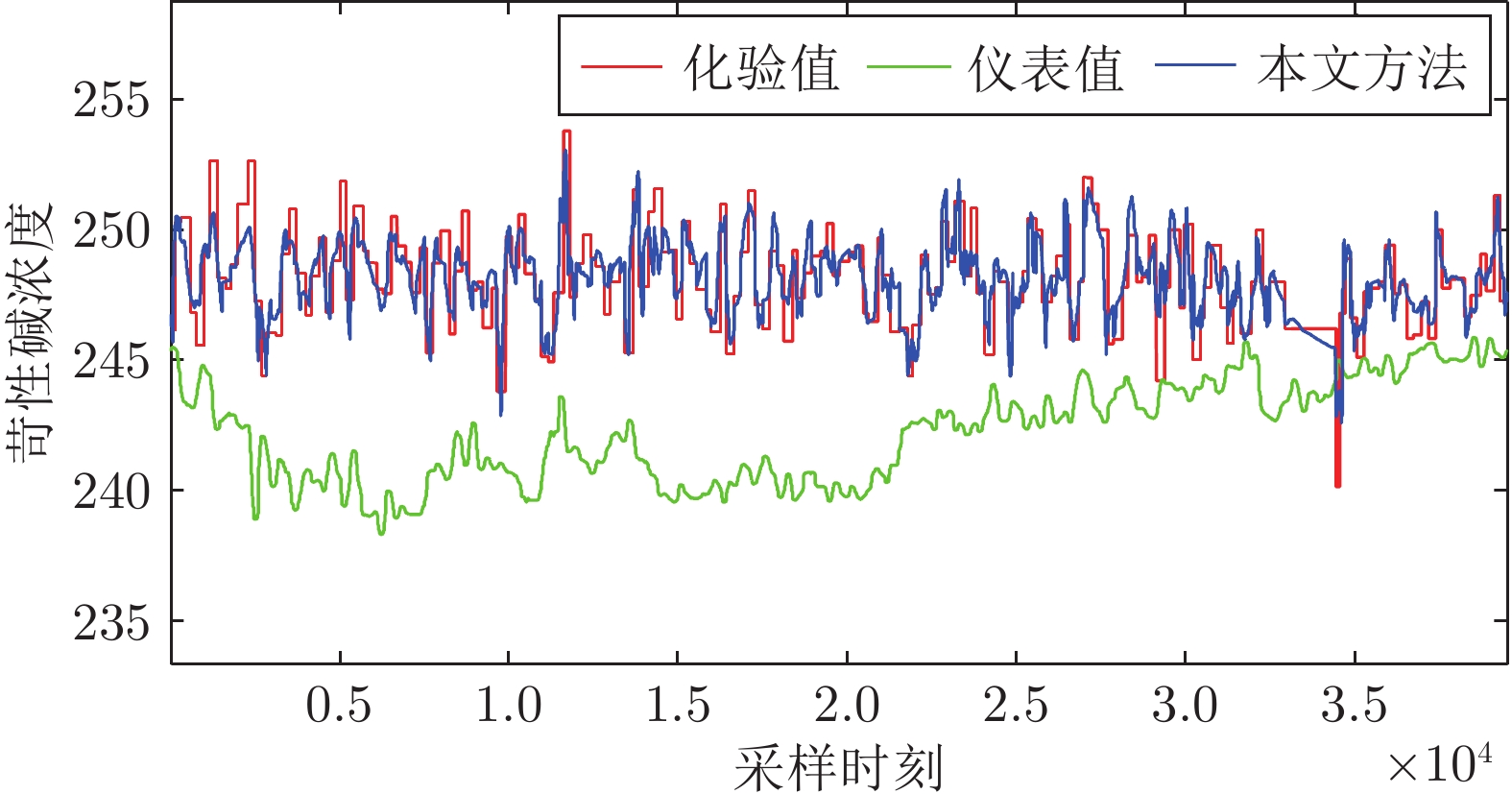
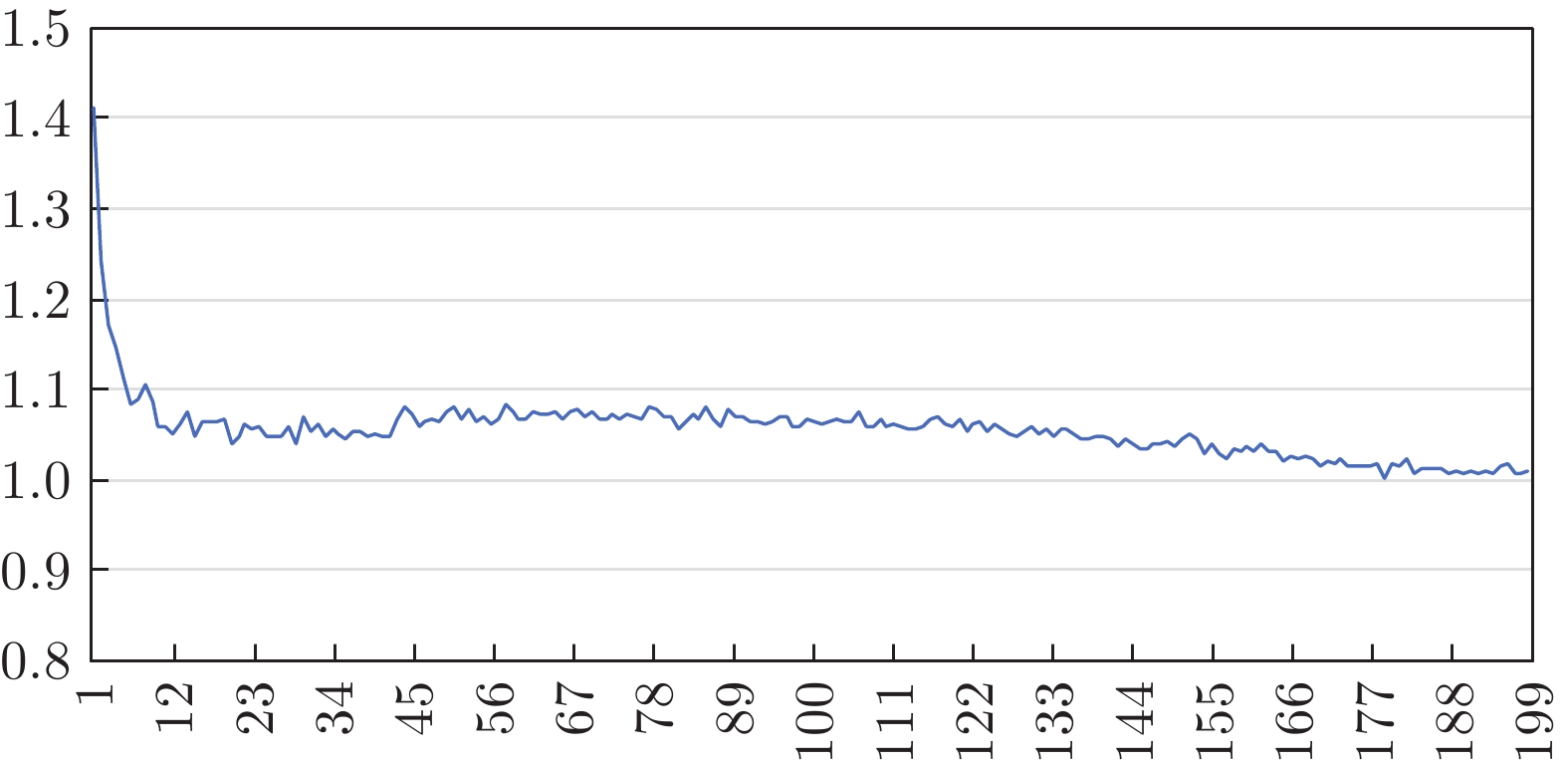
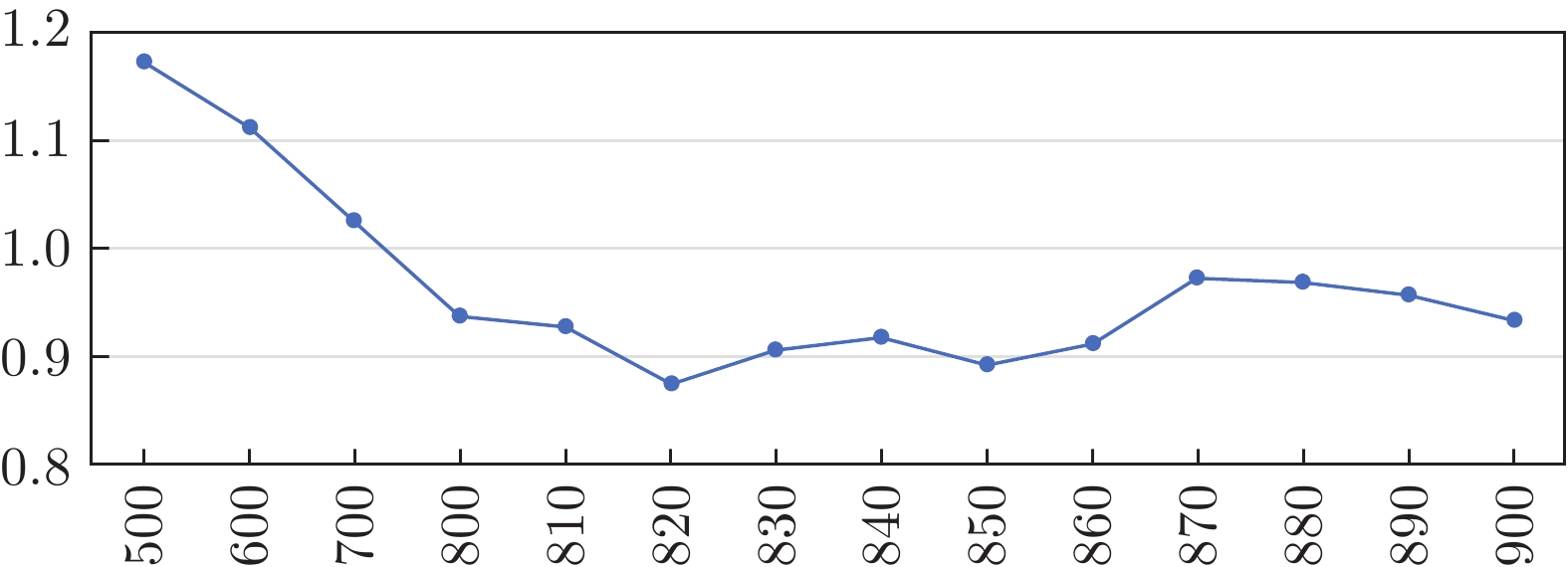
图 7 苛性碱浓度预报方法实验结果
Fig. 7 Experimental results of caustic concentration forecasting method
表 1 验证误差与深度神经网络中LSTM单元层数
Table 1 Validation error and the number of LSTM unit
LSTM单元层数 1 2 3 4 RMSE 1.28 1.14 1.17 1.20 MAE 1.00 0.82 0.83 0.91 MAPE 0.53 0.47 0.48 0.51  下载: 导出CSV
下载: 导出CSV
表 2
$ TP $ 、$ FP $ 、$ TN $ 和$ FN $ 的计算方式Table 2 Formula of
$ TP $ ,$ FP $ ,$ TN $ and$ FN $ 条件 $ \bar{v}(k) - \bar{v}(k - 1)\geq0 $ $ \bar{v}(k) - \bar{v}(k - 1)<0 $ $ \hat{\bar{v}}(k) - \hat{\bar{v}}(k - 1)\geq 0 $ $ TP(k)=1 $ $ FN(k)=1 $ $ \hat{\bar{v}}(k) - \hat{\bar{v}}(k - 1)< 0 $ $ FP(k)=1 $ $ TN(k)=1 $
下载: 导出CSV
表 3 苛性碱浓度预报效果
Table 3 Forecasting result for caustic concentration
方法 RMSE MAE 本文方法 0.89 0.58 线性模型 2.76 2.21 深度学习模型 1.21 0.97
下载: 导出CSV
表 4 苛性碱浓度预报方法的精度指标
Table 4 Accuracy index of forecasting method for caustic concentration
方法 RMSE MAE TPR (%) TNR (%) 浓度检测仪表 6.87 6.38 55.17 63.64 离线预报模型 1.14 0.82 76.04 92.86 在线预报模型 0.94 0.67 84.38 93.85 本文方法 0.89 0.58 88.54 94.05
下载: 导出CSV
-
[1] 符岩, 张阳春. 氧化铝厂设计. 北京: 冶金工业出版社, 2008.Fu Yan, Zhang Yang-Chun. Alumina Plant Design. Beijing: Metallurgical Industry Press, 2008. [2] Ma Y, Preveniou A, Kladis A, Pettersen J. Circular economy and life cycle assessment of alumina production: Simulation-based comparison of Pedersen and Bayer processes. Journal of Cleaner Production, 2022: Article No. 132807 [3] 郭万里. 氧化铝制取工. 太原: 山西人民出版社, 2006.Guo Wan-Li. Alumina Preparation. Taiyuan: Shanxi People's Publishing House, 2006. [4] 王永刚, 柴天佑. 蒸发过程的非线性控制仿真研究. 控制工程, 2010, 17(2): 127-130, 134 doi: 10.3969/j.issn.1671-7848.2010.02.001Wang Yong-Gang, Chai Tian-You. On nonlinear control of evaporation process via simulation. Control Engineering of China, 2010, 17(2): 127-130, 134 doi: 10.3969/j.issn.1671-7848.2010.02.001 [5] Li D, Jiang K, Jiang X, Zhao F, Wang S, Feng L, et al. Improving the A/S ratio of pretreated coal fly ash by a two-stage roasting for Bayer alumina production. Fuel, 2022, 310: Article No. 122478 [6] Wu Z, Lv H, Xie M, Li L, Zhao H, Liu F. Reaction behavior of quartz in gibbsite-boehmite bauxite in Bayer digestion and its effect on caustic consumption and alumina recovery. Ceramics International, 2022, 48(13): 18676-18686 doi: 10.1016/j.ceramint.2022.03.141 [7] Cheng L, Wang Y, Zhou Q, Qi T, Liu G, Peng Z, Li X. Scale formation during the Bayer process and a potential prevention strategy. Journal of Sustainable Metallurgy, 2021, 7(3): 1293-1303 doi: 10.1007/s40831-021-00417-4 [8] Jin Y, Chen J, Xu L, Wang P. Refractive index measurement for biomaterial samples by total internal reflection. Physics in Medicine and Biology, 2006, 51(20): 371-379 doi: 10.1088/0031-9155/51/20/N02 [9] Mahdieh M, Nazari T. Measurement of impurity and temperature variations in water by interferometry technique. Optik, 2013, 124(20): 4393-4396 doi: 10.1016/j.ijleo.2013.01.059 [10] 孙玉梅, 刘若晨, 王美春, 贾振江, 陈祥光. 基于折光法的发酵罐总糖含量在线自动测量系统. 光学精密工程, 2016, 24(10): 287-293Sun Yu-Mei, Liu Ruo-Chen, Wang Mei-Chun, Jia Zhen-Jiang, Chen Xiang-Guang. On-line automatic measuring system for total sugar content in chlortetracycline fermentation tank based on refraction method. Editorial Office of Optics and Precision Engineering, 2016, 24(10): 287-293 [11] Tan C, Huang Y. Dependence of refractive index on concentration and temperature in electrolyte solution, polar solution, nonpolar solution, and protein solution. Journal of Chemical and Engineering Data, 2015, 60(10): 2827-2833 doi: 10.1021/acs.jced.5b00018 [12] 白泽生, 刘竹琴, 徐红. 几种液体的折射率与其浓度关系的经验公式. 延安大学学报 (自然科学版), 2004(1): 33-34, 36Bai Ze-Sheng, Liu Zhu-Qin, Xu Hong. An experienced formula about the connection of refraction index and consistence of several liquid. Journal of Yanan University (Natural Science Edition), 2004(1): 33-34, 36 [13] 李伟, 袁红兵, 廉自生. 基于折光法检测乳化液浓度的研究. 煤炭技术, 2015, 34(4): 299-301 doi: 10.13301/j.cnki.ct.2015.04.116Li Wei, Yuan Hong-Bing, Lian Zi-Sheng. Study on detection of emulsion density based on refractive index method. Coal Technology, 2015, 34(4): 299-301 doi: 10.13301/j.cnki.ct.2015.04.116 [14] MPR E-SCAN [Online], avaliable: https://electronmachine.com, March 26, 2022 [15] Yang T, Yi X, Lu S, Johansson K, Chai T. Intelligent manufacturing for the process industry driven by industrial artificial intelligence. Engineering, 2021, 7(9): 1224-1230 doi: 10.1016/j.eng.2021.04.023 [16] 唐时健, 李晓莉. 氧化铝生产中不同母液蒸发流程的比较. 轻金属, 2013(4): 17-20 doi: 10.3969/j.issn.1002-1752.2013.04.004Tang Shi-Jian, Li Xiao-Li. The comparison of different spent liquor evaporation processes in alumina production. Light Metals, 2013(4): 17-20 doi: 10.3969/j.issn.1002-1752.2013.04.004 [17] 于力一, 贾瑶, 柴天佑. 基于规则推理的氧化铝蒸发过程智能设定控制. 第 31 届中国过程控制会议. 徐州, 中国: 2020. 40Yu Li-Yi, Jia Yao, Chai Tian-You. Intelligent setting control based on RBR for alumina evaporation process. In: Proceedings of the 31st Chinese Process Control Conference. Xuzhou, China: 2020. 40 [18] Chai T, Zhang J, Yang T. Demand forecasting of the fused magnesia smelting process with system identification and deep learning. IEEE Transactions on Industrial Informatics, 2021, 17(12): 8387-8396 doi: 10.1109/TII.2021.3065930 [19] 任俊超, 刘丁, 万银. 基于混合集成建模的硅单晶直径自适应非线性预测控制. 自动化学报, 2020, 46(5): 1004-1016 doi: 10.16383/j.aas.c190798Ren Jun-Chao, Liu Ding, Wan Yin. Hybrid integrated modeling based adaptive nonlinear predictive control of silicon single crystal diameter. Acta Automatica Sinica, 2020, 46(5): 1004-1016 doi: 10.16383/j.aas.c190798 [20] 柳长源, 李文强, 毕晓君. 基于RCNN-LSTM的脑电情感识别研究. 自动化学报, 2022, 48(3): 917-925Liu Chang-Yuan, Li Wen-Qiang, Bi Xiao-Jun. Research on EEG emotion recognition based on RCNN-LSTM. Acta Automatica Sinica, 2022, 48(3): 917-925 [21] Krizhevsky A, Sutskever I, Hinton G. Imagenet classification with deep convolutional neural networks. In: Proceedings of the 25th Advances in Neural Information Processing Systems (NIPS). Lake Tahoe, Nevada, USA: 2012. 1097−1105 [22] Srivastava N, Hinton G, Krizhevsky A, Sutskever I, Salakhutdinov R. Dropout: A simple way to prevent neural networks from overfitting. Journal of Machine Learning Research, 2014, 15(1): 1929-1958 [23] Ren L, Wang T, Laili Y, Zhang L. A data-driven self-supervised LSTM-deepfm model for industrial soft sensor. IEEE Transactions on Industrial Informatics, 2021, 18(9): 5859-5869 [24] Quan R, Zhu L, Wu Y, Yang Y. Holistic LSTM for pedestrian trajectory prediction. IEEE transactions on image processing, 2021, 30: 3229-3239 doi: 10.1109/TIP.2021.3058599 [25] Han Y, Qi W, Ding N, Geng Z. Short-time wavelet entropy integrating improved LSTM for fault diagnosis of modular multilevel converter. IEEE Transactions on Cybernetics, DOI: 10.1109/TCYB.2020.3041850 [26] Kong F, Li J, Jiang B, Wang H, Song H. Integrated generative model for industrial anomaly detection via bi-directional LSTM and attention mechanism. IEEE Transactions on Industrial Informatics, DOI: 10.1109/TⅡ.2021.3078192 [27] Klaus G, Rupesh K, Jan K, Bas R, Jürgen S. LSTM: A search space odyssey. IEEE Transactions on Neural Networks and Learning systems, 2016, 28(10): 2222-2232 [28] Rumelhart D, Hinton G, Williams R. Learning representations by back-propagating errors. Nature, 1986, 323(6088): 533-536 doi: 10.1038/323533a0 [29] Yang J, Chai T, Luo C, Yu W. Intelligent demand forecasting of smelting process using data driven and mechanism model. IEEE Transactions on Industrial Electronics, 2018, 66(12): 9745-9755 [30] Basheer I, Hajmeer M. Artificial neural networks: Fundamentals, computing, design, and application. Journal of Microbiological Methods, 2000, 43(1): 3-31 doi: 10.1016/S0167-7012(00)00201-3 [31] Simon R, Mark G. A First Course in Machine Learning. Boca Raton: CRC Press, 2011. [32] Rahmatian M, Chen Y, Dunford W, Rahmatian F. Incorporating goodness-of-fit metrics to improve synchrophasor-based fault location. IEEE Transactions on Power Delivery, 2018, 33(4): 1944-1953 doi: 10.1109/TPWRD.2018.2790410 -

 下载:
下载:


















计量
- 文章访问数: 1273
- HTML全文浏览量: 640
- PDF下载量: 405
- 被引次数: 0
