

-
摘要: 现有基于学习的单幅透射图像恢复方法常需要大量成对的标签数据来训练模型, 因缺乏成对图像集的监督约束, 致使透射图像恢复效果欠佳, 限制了其实用性. 提出了一种基于自监督学习的单幅透射图像恢复方法, 利用循环一致性生成对抗网络的循环结构和约束转移学习能力实现非成对图像的模型训练, 通过设计自学习模块, 从大规模的无监督数据中挖掘自身的监督信息对网络进行训练, 以此形成有效的从浅层到深层的特征提取, 提高透射图像正面内容的纹理、边缘等细节信息恢复质量, 实现单幅图像的透射去除. 实验结果表明, 该方法在合成图像数据集、公共图像数据集以及真实图像数据集上都取得了较好的透射图像恢复结果.Abstract: The existing single bleed-through image restorations based on learning methods often need a large number of paired images to train the model, due to the lack of paired images supervision constraints, the restoration effect of bleed-through image is not well, which limits their practicability. In this paper, a single bleed-through image restoration method based on self-supervised learning is proposed, the method uses the circulatory structure and constraint transfer learning ability of cycle-consistent generative adversarial networks to realize self-supervised single bleed-through image removal of unpaired images. Through the design of self-learning module, mining self-supervised information from large-scale unsupervised data are used to train the network, so as to form an effective feature extraction module from shallow layer to deep layer, which improve the restoration quality of texture, edge and other detail information of the front content of the bleed-through image. Finally, the bleed-through content has been removed for a single image. The experimental results show that this method achieves good results for bleed-through image restoration on synthetic image datasets, public image datasets and real image datasets.
-
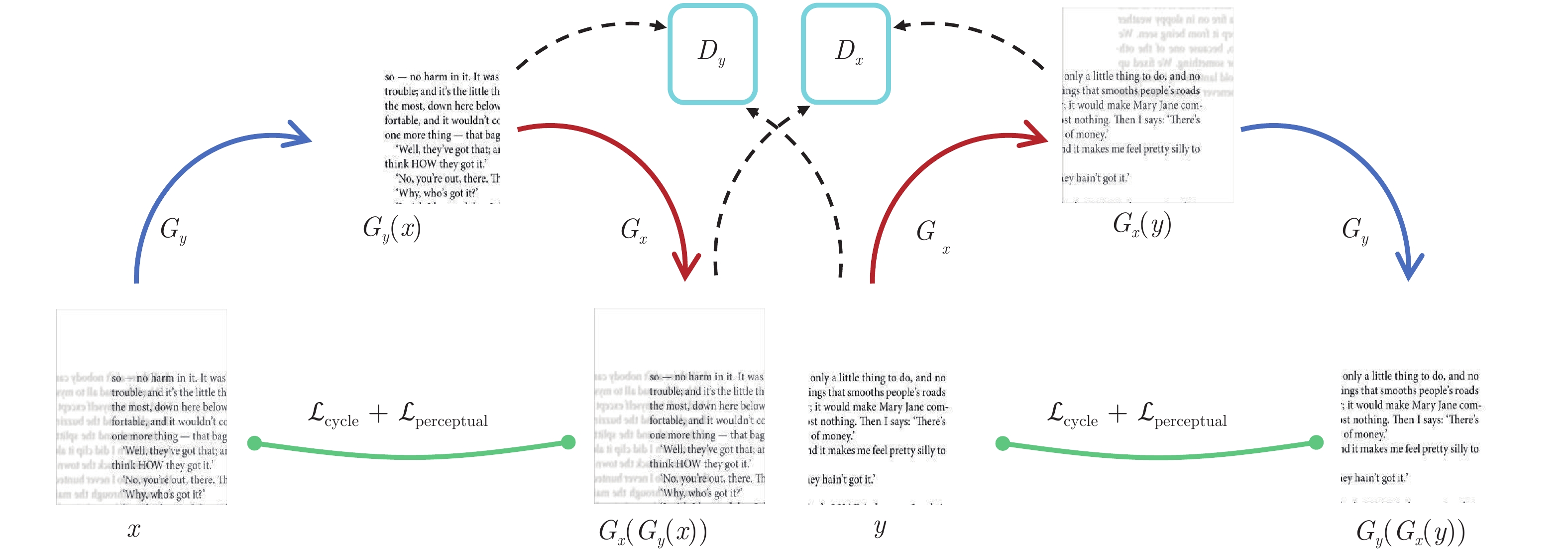
图 1 S-CycleGAN的网络结构 (
${G_y}$ 和$G_x$ 表示生成器,$D_y$ 和$D_x$ 表示判别器.$x$ 和$y$ 分别表示输入的透射图像和无透射图像,${\cal{L}}_{ {\rm{cycle}}}$ 和${\cal{L}}_{ {\rm{perceptual}}}$ 分别表示循环一致性损失和感知损失)Fig. 1 Structure of S-CycleGAN (
$G_y$ and$G_x$ are generators while$D_y$ and$D_x$ are discriminators,$x$ and$y$ represent the input bleed-through image and non-bleed-through image respectively,${\cal{L}}_{ {\rm{cycle}}}$ and${\cal{L}}_{ {\rm{perceptual}}}$ represent cycle consistency loss and perceptual loss respectively)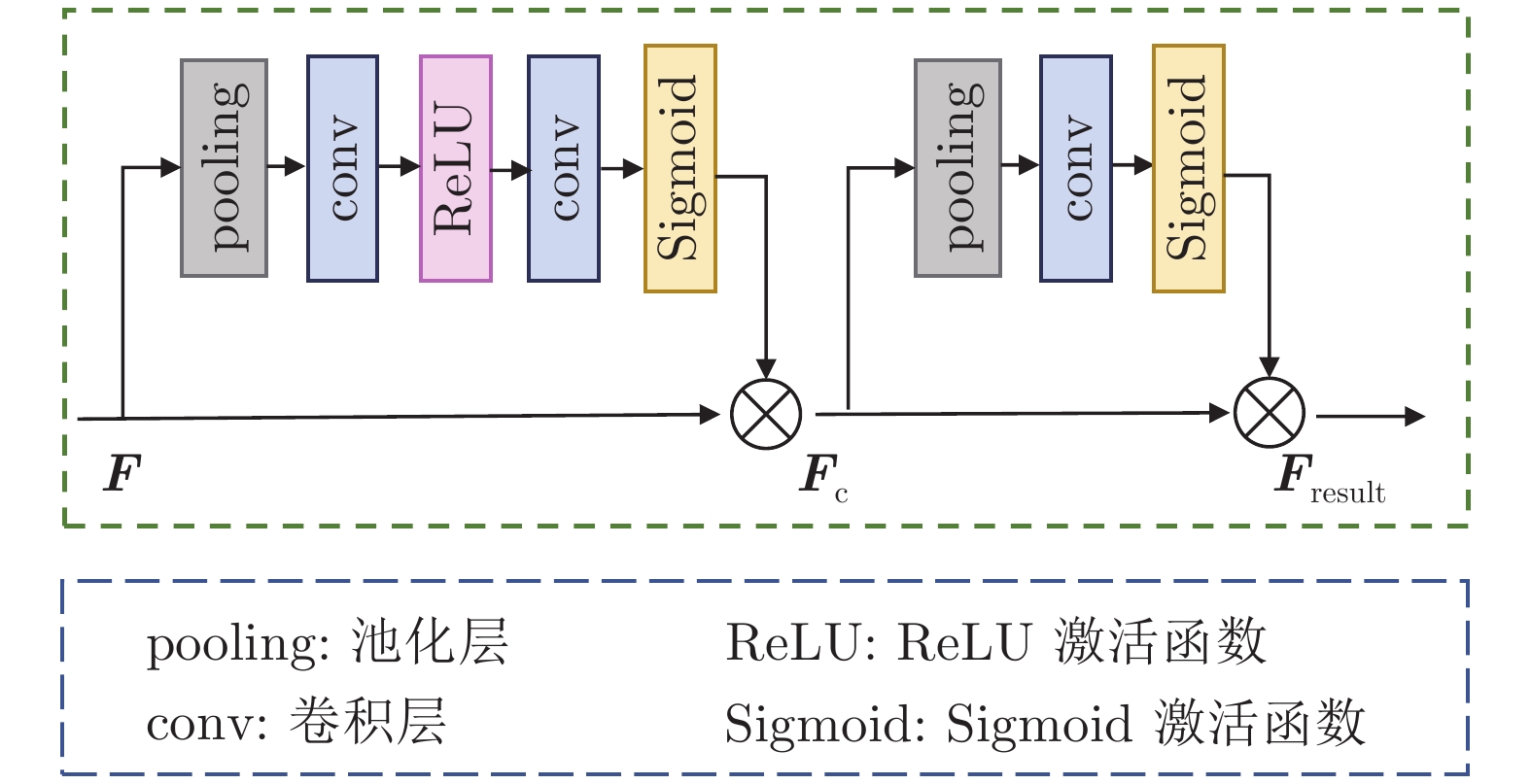
图 4 SLM的网络结构 (
$F$ 表示自学习模块的输入,$F_ {\rm{c}}$ 表示自学习模块的中间输出,$F_{ {\rm{result}}}$ 表示自学习模块的输出)Fig. 4 The network structure of SLM (
$F$ is the input to the self-learning module.$F_ {\rm{c}}$ is the intermediate output of the self-learning module.$F_{ {\rm{result}}}$ is the output of the self-learning module)
图 7 不同权重系数
$\omega$ 对FM和pFM评价指标的影响Fig. 7 Influence of different weight coefficient
$\omega$ for FM and pFM
图 8 各方法在DIBCO 2011数据集内一个样本的恢复结果
Fig. 8 Experiment results of one sample in DIBCO 2011 datasets by different methods

图 9 各方法在H-DIBCO 2016数据集的一个样本恢复结果
Fig. 9 Experiment results of one sample in H-DIBCO 2016 datasets by different methods

图 10 各方法在合成数据集的一个样本恢复结果
Fig. 10 Experiment results of one sample on synthetic document bleed-through datasets by different methods

图 11 不同方法在全国大学英语六级试卷透射图像的恢复结果
Fig. 11 Experiment results of CET-6 bleed-through datasets by different methods

图 12 不同方法在某初中数学试卷透射图像上的恢复结果
Fig. 12 Experiment results of test papers bleed-through datasets by different methods

图 13 不同网络结构在合成数据集上的消融实验
Fig. 13 Ablation experiments of different network structures on synthetic datasets
表 1 DIBCO数据集的文档透射图像恢复定量评价
Table 1 Quantitative evaluation of document bleed-through image restoration of DIBCO datasets
数据集 方法 PSNR (dB) FM (%) pFM (%) DRD Otsu 18.52 67.81 74.08 17.45 Ntirogiannis 16.34 85.34 86.06 8.18 SAGAN 21.55 87.47 92.28 5.97 DIBCO DD-GAN 22.67 88.90 91.19 5.53 2011 Castellanos 22.95 89.40 91.78 5.62 Sungho 23.54 89.67 91.03 5.59 S-CycleGAN 24.36 89.71 91.62 5.49 Otsu 14.90 72.57 73.51 23.67 Ntirogiannis 14.30 84.60 88.40 6.34 SAGAN 19.64 89.75 90.85 6.35 DIBCO DD-GAN 21.14 92.53 92.59 4.86 2009 Castellanos 21.95 90.00 91.68 6.03 Sungho 22.56 87.73 92.09 5.35 S-CycleGAN 22.83 90.98 92.65 4.54 Otsu 15.52 70.44 73.03 20.45 Ntirogiannis 18.14 83.72 87.49 10.98 SAGAN 20.35 91.64 92.71 5.64 DIBCO DD-GAN 21.54 90.48 93.63 3.17 2016 Castellanos 22.30 91.13 92.28 3.05 Sungho 21.96 90.27 92.69 2.63 S-CycleGAN 22.35 91.90 93.79 3.53  下载: 导出CSV
下载: 导出CSV
表 2 合成数据集的文档透射图像恢复定量评价
Table 2 Quantitative evaluation of document bleed-through image restoration of synthetic datasets
数据集 方法 PSNR (dB) FM (%) pFM (%) DRD Otsu 16.35 88.37 89.59 4.94 Ntirogiannis 19.30 89.21 90.68 8.87 SAGAN 16.05 87.61 91.28 5.21 合成数据集 DD-GAN 20.45 90.51 90.01 4.73 Castellanos 19.95 90.65 93.78 4.06 Sungho 21.03 90.53 92.67 3.86 S-CycleGAN 22.66 92.99 95.10 2.93
下载: 导出CSV
表 3 S-CycleGAN模块有效性客观评价指标对比
Table 3 Objective evaluation indexes comparison for the modules in S-CycleGAN
数据集 方法 PSNR (dB) FM (%) pFM (%) DRD CycleGAN 12.48 62.42 65.51 20.95 合成数据集 无SLM 19.75 88.80 92.50 3.95 S-CycleGAN 22.66 92.99 95.10 2.93 CycleGAN 11.41 69.71 71.33 16.31 H-DIBCO 无SLM 18.21 86.60 88.80 4.36 2016 S-CycleGAN 22.35 91.90 93.79 3.53
下载: 导出CSV
-
[1] Rasyidi H, Khan S. Historical document image binarization via style augmentation and atrous convolutions. Neural Computing and Applications, 2020, 33: 7339-7352 [2] Gupta N, Goyal N. Machine learning tensor flow based platform for recognition of hand written text. In: Proceedings of the International Conference on Computer Communication and Informatics. Coimbatore, India: IEEE, 2021. 1−6 [3] Han Y H, Wang W L, Liu H M, Wang Y Q. A combined approach for the binarization of historical tibetan document images. International Journal of Pattern Recognition and Artificial Intelligence, 2019, 33(14): 1954038. doi: 10.1142/S0218001419540387 [4] Otsu N. A threshold selection method from gray-level histograms. IEEE Transactions on Systems Man Cybernetics-Systems, 2007, 9(1): 62-66 [5] Ntirogiannis K, Gatos B, Pratikakis I. Performance evaluation methodology for historical document image binarization. IEEE Transactions on Image Processing, 2013, 22(2): 595-609 doi: 10.1109/TIP.2012.2219550 [6] Su B, Lu S, Tan C L. Binarization of historical document images using the local maximum and minimum. In: Proceedings of the International Work-shop on Document Analysis Systems. Boston, USA: Work-shop on Document Analysis Systems, 2010. 154−160 [7] Tensmeyer C, Martinez T. Document image binarization with fully convolutional neural networks. In: Proceedings of the International Conference on Document Analysis and Recognition. Kyoto, Japan: IEEE, 2017. 99−104 [8] Wu Y, Rawls S, Abdalmageed W, Natarajan P. Learning document image binarization from data. In: Proceedings of the IEEE International Conference on Image Processing. Phoenix, USA: IEEE, 2016. 3763−3767 [9] He S, Schomaker L. Deepotsu: document enhancement and binarization using iterative deep learning. Pattern Recognition, 2019, 91: 379-390 doi: 10.1016/j.patcog.2019.01.025 [10] Kang S, Iwana B K, Uchida S. Complex image processing with less data-document image binarization by integrating multiple pre-trained u-net modules. Pattern Recognition, 2020, 109: 107577 [11] Mondal R, Chakraborty D, Chanda B. Learning 2d morphological network for old document image binarization. In: Proceedings of the International Conference on Document Analysis and Recognition. Sydney, Australia: IEEE, 2019. 65−70 [12] Goodfellow I J, Pouget-Abadie J, Mirza M, et al. Generative adversarial networks. Advances in Neural Information Processing Systems, 2014, 3: 2672-2680 [13] Reed S, Akata Z, Mohan S, Tenka S, Schiele B, Lee H. Learning what and where to draw. In: Proceedings of the Neural Information Processing Systems. Barcelona, Spain: Curran Associates, 2016. 217−225 [14] Konwer A, Bhunia A K, Bhowmick A, et al. Staff line removal using generative adversarial networks. In: Proceedings of the International Conference on Pattern Recognition. Beijing, China: IEEE, 2018. 1103−1108 [15] De R, Chakraborty A, Sarkar R. Document image binarization using dual discriminator generative adversarial networks. IEEE Signal Processing Letters, 2020, 27: 1090-1094 doi: 10.1109/LSP.2020.3003828 [16] Castellanos F J, Gallego A J, Jorge C Z. Unsupervised neural domain adaptation for document image binarization. Pattern Recognition, 2020, 119: 108099 [17] Zhu J Y, Park T, Isola P. Unpaired image-to-image translation using cycle-consistent adversarial networks. In: Proceedings of the IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 2223−2232 [18] Sajjadi M, Scholkopf B, Hirsch M. EnhanceNet: single image super-resolution through automated texture synthesis. In: Proceedings of the IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 4501−4510 [19] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. In: Proceedings of the International Conference on Learning Representations. California, USA, 2015. 1−14 [20] Jia D, Dong W, Socher R, Li L J, Kai L, Li F F. Imagenet: A large-scale hierarchical image database. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Miami, USA: IEEE, 2009. 248−255 [21] Pratikakis I, Gatos B, Ntirogiannis K. Icdar 2013 document image binarization contest. In: Proceedings of the International Conference on Document Analysis and Recognition. Washington, USA: IEEE, 2013. 1471−1476 [22] Pratikakis I, Gatos B, Ntirogiannis K. Icfhr 2012 competition on handwritten document image binarization. In: Proceedings of the International Conference on Frontiers in Handwriting Recognition. Bari, Italy: IEEE, 2012. 817−822 [23] Ntirogiannis K, Gatos B, Pratikakis I. Icfhr 2014 competition on handwritten document image binarization. In: Proceedings of the International Conference on Frontiers in Handwriting Recognition. Hersonissos, Greece: IEEE, 2014. 809−813 [24] Pratikakis I, Zagoris K, Barlas G, Gatos B. Icdar2017 competition on document image binarization. In: Proceedings of the International Conference on Document Analysis and Recognition. Kyoto, Japan: IEEE, 2017. 2379−2140 [25] Pratikakis I, Gatos B, Ntirogiannis K. Icdar 2011 document image binarization contest. In: Proceedings of the International Conference on Document Analysis and Recognition. Beijing, China: IEEE, 2011. 1506−1510 [26] Gatos B, Ntirogiannis K, Pratikakis I. Icdar 2009 document image binarization contest. In: Proceedings of the International Conference on Document Analysis and Recognition. Barcelona, Spain: IEEE, 2009. 1375−1382 [27] Pratikakis I, Zagoris K, Barlas G, Gatos B. Icfhr 2016 Handwritten document image binarization contest. In: Proceedings of the International Conference on Frontiers in Handwriting Recognition. Shenzhen, China: IEEE, 2016. 2167−6445 [28] Zhang X, Goodfellow I, Metaxas D, Odena A. Self-attention generative adversarial networks. In: Proceedings of the International Conference on Machine Learning. California, USA, 2019. 7354−7363 [29] Suh S, Kim J, Lukowicz P, Lee Y O. Two-stage generative adversarial networks for document image binarization with color noise and background removal. 2020, arXiv: 2010.10103 -

















 下载:
下载:













计量
- 文章访问数: 1277
- HTML全文浏览量: 225
- PDF下载量: 263
- 被引次数: 0
