

-
摘要: 现有多视图子空间聚类算法通常先进行张量表示学习, 进而将学习到的表示张量融合为统一的亲和度矩阵. 然而, 因其独立地学习表示张量和亲和度矩阵, 忽略了两者之间的高度相关性. 为了解决此问题, 提出一种基于一步张量学习的多视图子空间聚类方法, 联合学习表示张量和亲和度矩阵. 具体地, 该方法对表示张量施加低秩张量约束, 以挖掘视图的高阶相关性. 利用自适应最近邻法对亲和度矩阵进行灵活重建. 使用交替方向乘子法对模型进行优化求解, 通过对真实多视图数据的实验表明, 较于最新的多视图聚类方法, 提出的算法具有更好的聚类准确性.Abstract: A surge of the existing multi-view subspace clustering algorithms generally learn the third-order tensor representation first and then fuse the learned representation tensor into a unified affinity matrix. However, since they learn the representation tensor and the affinity matrix independently, they cannot seamlessly capture their high-order correlation. To address this challenge, we propose a novel multi-view subspace clustering method based on one-step tensor learning (OTSC) to jointly learn the representation tensor and affinity matrix. Specifically, we impose the low-rank tensor constraint on the representation tensor to explore the correlation of high-order cross-views dexterously, utilize the adaptive nearest neighbor strategy to reconstruct a flexible affinity matrix, and adopt the alternating direction method of multipliers (ADMM) to optimize our model. Extensive experiments on real multi-view data demonstrated the superiority of OTSC compared to the state-of-the-art methods.
-
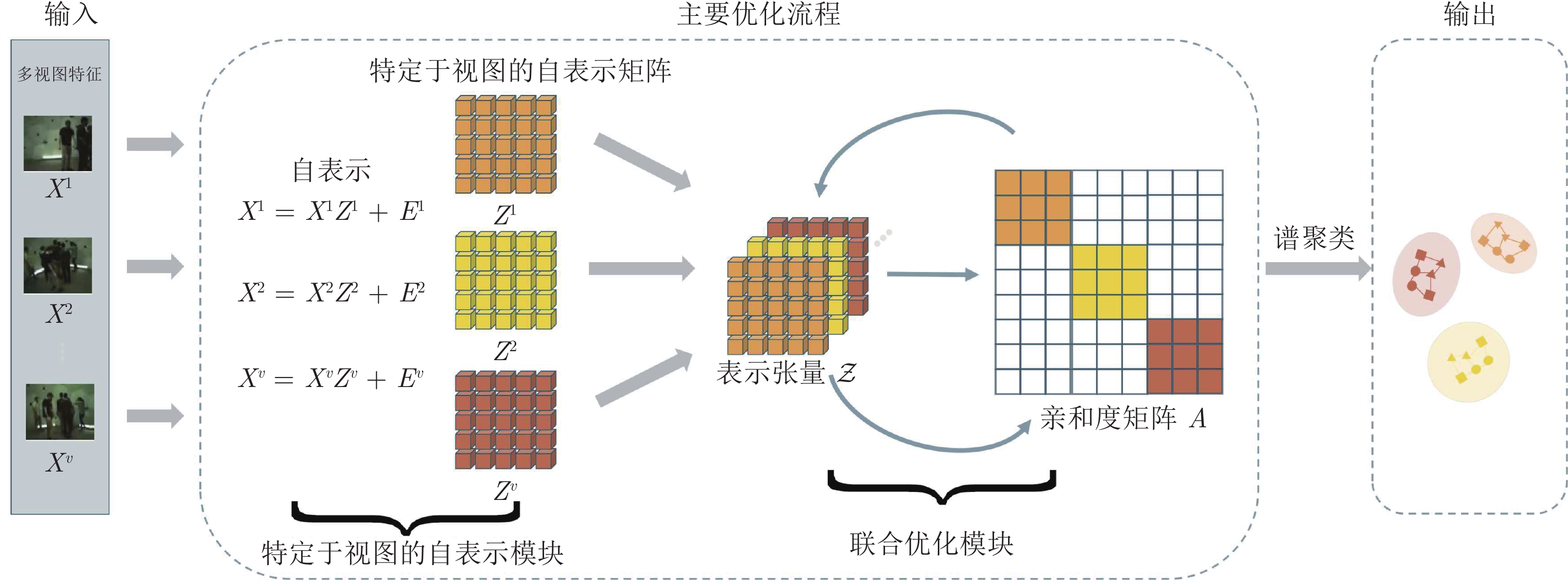
图 3 基于一步张量学习的多视图子空间聚类结构图
Fig. 3 The framework of the one-step tensor learning for multi-view subspace clustering (OTSC)

图 5 根据
$ACC$ 和$NMI$ 调整数据集ORL参数$\alpha$ 与$\gamma$ Fig. 5 Parameters tuning in terms of
$ACC$ and$NMI$ on ORL
图 7 收敛性曲线 ((a) BBCSport; (b) Extended YaleB)
Fig. 7 The convergence curves and ACC versus iterations on ((a) BBCSport; (b) Extended YaleB)
表 1 符号与定义
Table 1 Notations and definitions
符号 定义 $\boldsymbol{x}, X, {\cal{X}}$ 向量, 矩阵, 张量 1 单位向量 $I$ 单位矩阵 ${\cal{I}}$ 单位张量 $n$ 样本个数 $V$ 视图个数 $d_v$ 第$v$个视图的特征维度 $X^v\in {\bf{R}}^{d_v \times n}$ 第$v$个视图的特征矩阵 ${\cal{Z}}\in{\bf{R}}^{n\times n\times V}$ 表示张量 $A\in {\bf{R}}^{n \times n}$ 亲和度矩阵 $E^v\in {\bf{R}}^{n \times n}$ 噪声矩阵 $\|\cdot\|_{2,1}$ $l_{2,1}$范数 $\|\cdot\|_{\rm{F}}$ Frobenius范数 $\|\cdot\|_\infty$ 无穷范数 $\|\cdot\|_{*}$ 矩阵核范数 $\|\cdot\|_{\circledast}$ 张量核范数 ${\rm{FFT}}$ 快速傅里叶分解  下载: 导出CSV
下载: 导出CSV
表 2 真实多视图数据集信息
Table 2 Summary of all real-world multi-view databases
数据集 样本数量 类别 视图 种类 Extended YaleB 640 38 3 面部图像 ORL 400 40 3 面部图像 3Sources 169 6 3 新闻故事 BBCSport 544 5 2 新闻故事 UCI-Digits 2000 10 3 手写数字 COIL_20 1440 20 3 通用对象
下载: 导出CSV
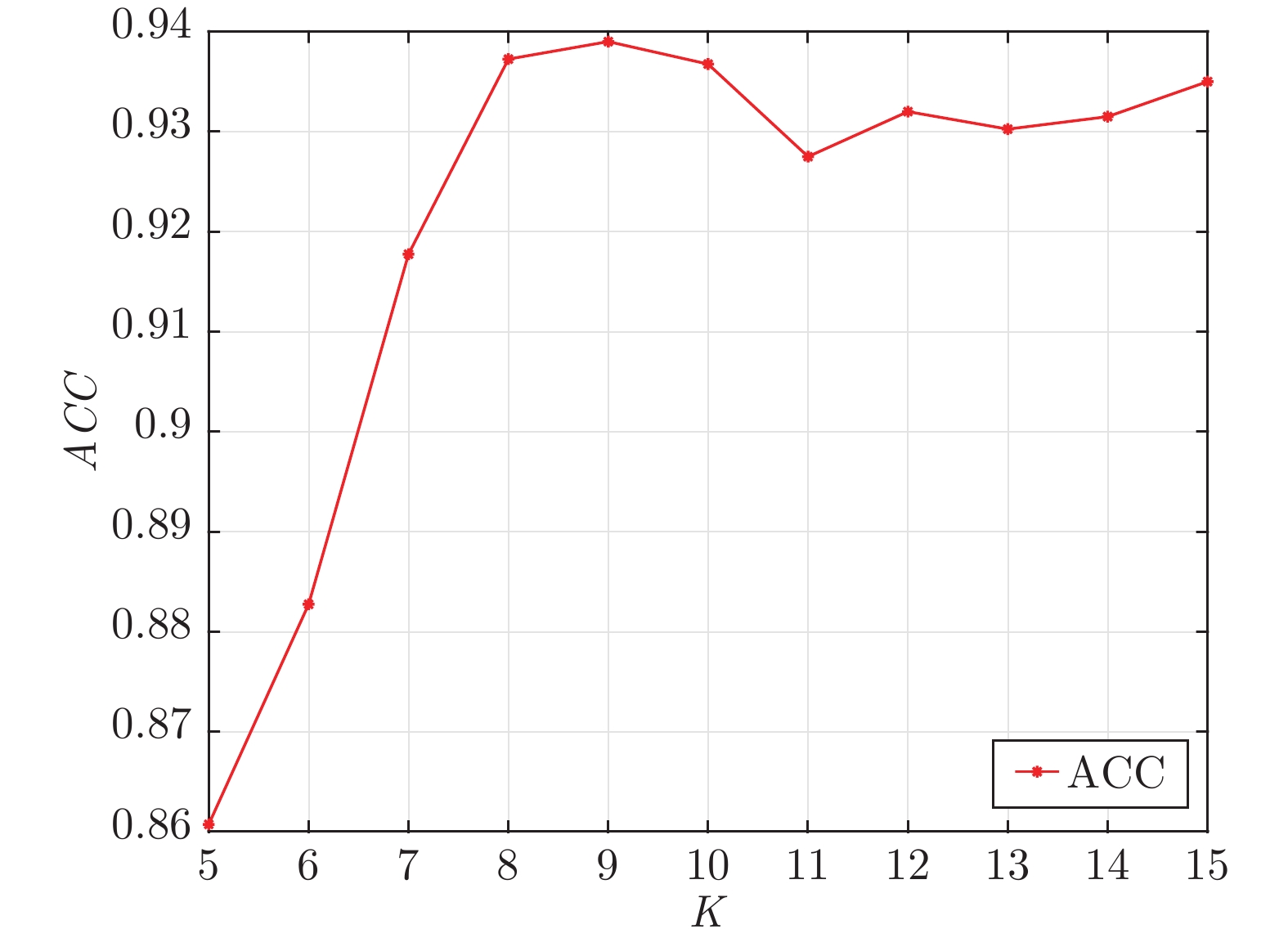
表 3 参数设置
Table 3 Parameter setting
数据集 $\alpha$ $\gamma$ $K$ Extended YaleB 1 0.005 5 ORL 0.1 0.05 12 3Sources 0.1 50 8 BBCSport 0.05 5 8 UCI-Digits 0.2 2 15 COIL_20 0.05 1 5
下载: 导出CSV
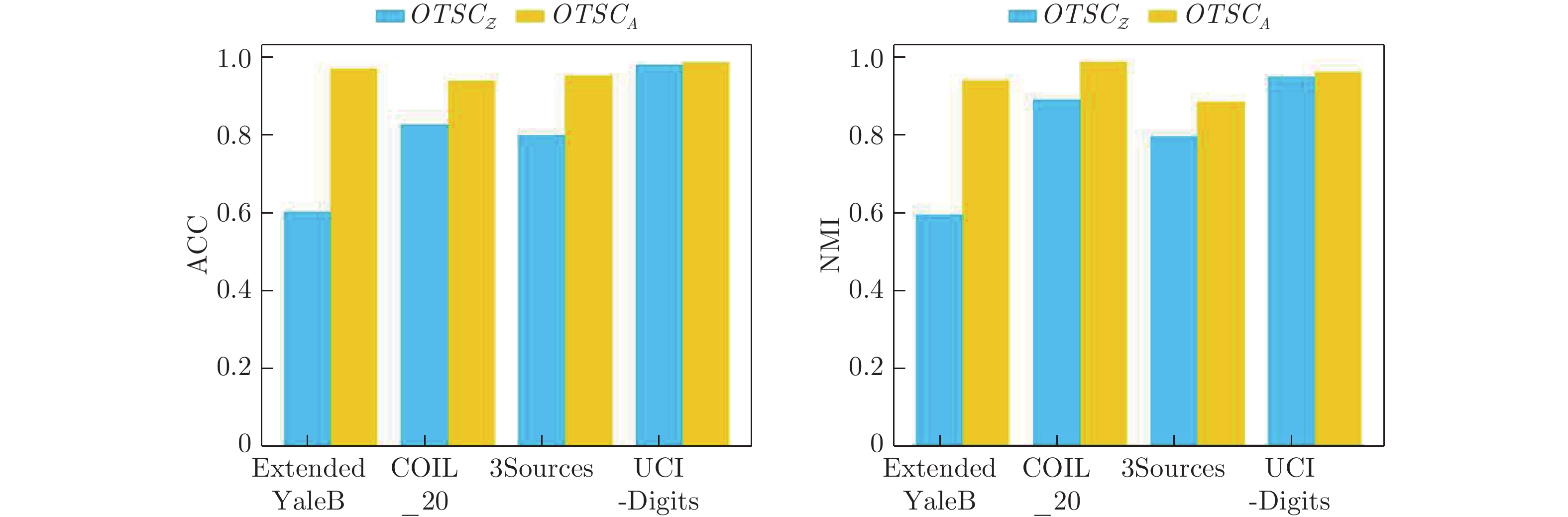
表 4 数据集Extended YaleB、ORL的聚类结果
Table 4 Clustering results (mean
$ \pm $ standard deviation) on Extended YaleB and ORL数据 类型 方法 $ACC$ $NMI$ $AR$ $F$-$score$ $Precision$ $Recall$ Extended YaleB 单视图方法 SSCbest 0.587±0.003 0.534±0.003 0.430±0.005 0.487±0.004 0.451±0.002 0.509±0.007 LRRbest 0.615±0.013 0.627±0.040 0.451±0.002 0.508±0.004 0.481±0.002 0.539±0.001 RSSbest 0.742±0.001 0.787±0.000 0.685±0.001 0.717±0.001 0.704±0.001 0.730±0.000 多视图方法 RMSC 0.210±0.013 0.157±0.019 0.060±0.014 0.155±0.012 0.151±0.012 0.159±0.013 DiMSC 0.615±0.003 0.636±0.002 0.453±0.005 0.504±0.006 0.481±0.004 0.534±0.004 LT-MSC 0.626±0.010 0.637±0.003 0.459±0.030 0.521±0.006 0.485±0.001 0.539±0.002 MLAN 0.346±0.011 0.352±0.015 0.093±0.009 0.213±0.023 0.159±0.018 0.321±0.013 t-SVD 0.652±0.000 0.667±0.004 0.500±0.003 0.550±0.002 0.514±0.004 0.590±0.004 GMC 0.434±0.000 0.449±0.000 0.157±0.000 0.265±0.000 0.204±0.000 0.378±0.000 LMSC 0.598±0.005 0.568±0.004 0.354±0.007 0.423±0.006 0.390±0.006 0.463±0.005 SCMV-3DT 0.410±0.001 0.413±0.002 0.185±0.002 0.276±0.001 0.244±0.002 0.318±0.001 LRTG 0.954±0.000 0.905±0.000 0.899±0.000 0.909±0.000 0.908±0.000 0.911±0.000 WTNNM 0.648±0.005 0.661±0.002 0.501±0.000 0.552±0.000 0.533±0.000 0.573±0.000 GLTA 0.571±0.002 0.630±0.005 0.510±0.005 0.560±0.004 0.544±0.004 0.576±0.006 本方法 OTSC 0.969±0.001 0.934±0.001 0.931±0.002 0.937±0.002 0.935±0.002 0.939±0.002 WOTSC 0.972±0.000 0.943±0.000 0.938±0.000 0.944±0.000 0.942±0.000 0.946±0.000 ORL 单视图方法 SSCbest 0.765±0.008 0.893±0.007 0.694±0.013 0.682±0.012 0.673±0.007 0.764±0.005 LRRbest 0.773±0.003 0.895±0.006 0.724±0.020 0.731±0.004 0.701±0.001 0.754±0.002 RSSbest 0.846±0.024 0.938±0.007 0.798±0.023 0.803±0.023 0.759±0.030 0.852±0.017 多视图方法 RMSC 0.723±0.007 0.872±0.012 0.645±0.003 0.654±0.007 0.607±0.009 0.709±0.004 DiMSC 0.838±0.001 0.940±0.003 0.802±0.000 0.807±0.003 0.764±0.012 0.856±0.004 LT-MSC 0.795±0.007 0.930±0.003 0.750±0.003 0.768±0.004 0.766±0.009 0.837±0.005 MLAN 0.705±0.02 0.854±0.018 0.384±0.010 0.376±0.015 0.254±0.021 0.721±0.020 t-SVD 0.970±0.003 0.993±0.002 0.967±0.002 0.968±0.003 0.946±0.004 0.991±0.003 GMC 0.633±0.000 0.857±0.000 0.337±0.000 0.360±0.000 0.232±0.000 0.801±0.000 LMSC 0.877±0.024 0.949±0.006 0.839±0.022 0.843±0.021 0.806±0.027 0.884±0.017 SCMV-3DT 0.839±0.012 0.908±0.007 0.763±0.018 0.769±0.017 0.747±0.020 0.792±0.016 LRTG 0.933±0.003 0.970±0.002 0.905±0.005 0.908±0.005 0.888±0.004 0.928±0.007 WTNNM 0.967±0.000 0.992±0.000 0.960±0.000 0.952±0.000 0.946±0.000 0.968±0.000 GLTA 0.976±0.002 0.994±0.006 0.958±0.024 0.963±0.019 0.952±0.035 0.989±0.012 本方法 OTSC 0.983±0.002 0.988±0.001 0.964±0.003 0.965±0.003 0.958±0.004 0.972±0.001 WOTSC 0.938±0.000 0.972±0.000 0.907±0.000 0.909±0.000 0.885±0.000 0.936±0.000
下载: 导出CSV
表 5 数据集3Sources、UCI-Digits的聚类结果
Table 5 Clustering results (mean
$ \pm $ standard deviation) on 3Sources and UCI-Digits数据 类型 方法 $ACC$ $NMI$ $AR$ $F$-$score$ $Precision$ $Recall$ 3Sources 单视图方法 SSCbest 0.762±0.003 0.694±0.003 0.658±0.004 0.743±0.003 0.769±0.001 0.719±0.005 LRRbest 0.647±0.033 0.542±0.018 0.486±0.028 0.608±0.033 0.594±0.031 0.636±0.096 RSSbest 0.722±0.000 0.601±0.000 0.533±0.000 0.634±0.000 0.679±0.000 0.595±0.000 多视图方法 RMSC 0.583±0.022 0.630±0.011 0.455±0.031 0.557±0.025 0.635±0.029 0.497±0.028 DiMSC 0.795±0.004 0.727±0.010 0.661±0.005 0.748±0.004 0.711±0.005 0.788±0.003 LT-MSC 0.781±0.000 0.698±0.003 0.651±0.003 0.734±0.002 0.716±0.008 0.754±0.005 MLAN 0.775±0.015 0.676±0.005 0.580±0.008 0.666±0.007 0.756±0.003 0.594±0.009 t-SVD 0.781±0.000 0.678±0.000 0.658±0.000 0.745±0.000 0.683±0.000 0.818±0.000 GMC 0.693±0.000 0.622±0.000 0.443±0.000 0.605±0.000 0.484±0.000 0.804±0.000 LMSC 0.912±0.006 0.826±0.007 0.842±0.011 0.887±0.008 0.873±0.007 0.877±0.012 SCMV-3DT 0.440±0.020 0.386±0.009 0.226±0.012 0.411±0.009 0.399±0.012 0.425±0.016 LRTG 0.947±0.000 0.865±0.000 0.881±0.000 0.909±0.000 0.911±0.000 0.906±0.000 WTNNM 0.793±0.000 0.692±0.000 0.679±0.000 0.761±0.010 0.693±0.000 0.845±0.000 GLTA 0.859±0.008 0.753±0.015 0.713±0.014 0.775±0.011 0.827±0.009 0.730±0.013 本方法 OTSC 0.953±0.000 0.880±0.000 0.893±0.000 0.918±0.000 0.914±0.000 0.922±0.000 WOTSC 0.947±0.000 0.867±0.000 0.888±0.000 0.914±0.000 0.909±0.000 0.920±0.000 UCI-Digits 单视图方法 SSCbest 0.815±0.011 0.840±0.001 0.770±0.005 0.794±0.004 0.747±0.010 0.848±0.004 LRRbest 0.871±0.001 0.768±0.002 0.736±0.002 0.763±0.002 0.759±0.002 0.767±0.002 RSSbest 0.819±0.000 0.863±0.000 0.787±0.000 0.810±0.000 0.756±0.000 0.872±0.000 多视图方法 RMSC 0.915±0.024 0.822±0.008 0.789±0.014 0.811±0.012 0.797±0.017 0.826±0.006 DiMSC 0.703±0.010 0.772±0.006 0.652±0.006 0.695±0.006 0.673±0.005 0.718±0.007 LT-MSC 0.803±0.001 0.775±0.001 0.725±0.001 0.753±0.001 0.739±0.001 0.767±0.001 MLAN 0.874±0.000 0.910±0.000 0.847±0.000 0.864±0.000 0.797±0.000 0.943±0.000 t-SVD 0.955±0.000 0.932±0.000 0.924±0.000 0.932±0.000 0.930±0.000 0.934±0.000 GMC 0.736±0.000 0.815±0.000 0.678±0.000 0.713±0.000 0.644±0.000 0.799±0.000 LMSC 0.893±0.000 0.815±0.000 0.783±0.000 0.805±0.000 0.798±0.000 0.812±0.000 SCMV-3DT 0.930±0.001 0.861±0.001 0.846±0.001 0.861±0.001 0.859±0.001 0.864±0.001 LRTG 0.981±0.000 0.953±0.000 0.957±0.000 0.961±0.000 0.961±0.000 0.962±0.000 WTNNM 0.998±0.000 0.993±0.000 0.994±0.000 0.995±0.010 0.998±0.000 0.995±0.000 GLTA 0.997±0.000 0.992±0.000 0.993±0.000 0.994±0.000 0.994±0.000 0.994±0.000 本方法 OTSC 0.983±0.001 0.958±0.001 0.962±0.001 0.966±0.001 0.965±0.000 0.966±0.002 WOTSC 0.983±0.000 0.958±0.000 0.962±0.000 0.966±0.000 0.965±0.000 0.966±0.000
下载: 导出CSV
表 6 数据集BBCSport、COIL-20的聚类结果
Table 6 Clustering results (mean
$ \pm $ standard deviation) on BBCSport and COIL-20数据 类型 方法 $ACC$ $NMI$ $AR$ $F$-$score$ $Precision$ $Recall$ BBCSport 单视图方法 SSCbest 0.627±0.003 0.534±0.008 0.364±0.007 0.565±0.005 0.427±0.004 0.834±0.004 LRRbest 0.836±0.001 0.698±0.002 0.705±0.001 0.776±0.001 0.768±0.001 0.784±0.001 RSSbest 0.878±0.000 0.714±0.000 0.717±0.000 0.784±0.000 0.787±0.000 0.782±0.000 多视图方法 RMSC 0.826±0.001 0.666±0.001 0.637±0.001 0.719±0.001 0.766±0.001 0.677±0.001 DiMSC 0.922±0.000 0.785±0.000 0.813±0.000 0.858±0.000 0.846±0.000 0.872±0.000 LT-MSC 0.460±0.046 0.222±0.028 0.167±0.043 0.428±0.014 0.328±0.028 0.629±0.053 MLAN 0.721±0.000 0.779±0.000 0.591±0.000 0.714±0.000 0.567±0.000 0.962±0.000 t-SVD 0.879±0.000 0.765±0.000 0.784±0.000 0.834±0.000 0.863±0.000 0.807±0.000 GMC 0.807±0.000 0.760±0.000 0.722±0.000 0.794±0.000 0.727±0.000 0.875±0.000 LMSC 0.847±0.003 0.739±0.001 0.749±0.001 0.810±0.001 0.799±0.001 0.822±0.001 SCMV-3DT 0.980±0.000 0.929±0.000 0.935±0.000 0.950±0.000 0.959±0.000 0.942±0.000 LRTG 0.943±0.005 0.869±0.009 0.840±0.012 0.879±0.000 0.866±0.006 0.892±0.014 WTNNM 0.963±0.000 0.900±0.000 0.908±0.000 0.930±0.000 0.950±0.000 0.911±0.000 GLTA 1.000±0.000 1.000±0.000 1.000±0.000 1.000±0.000 1.000±0.000 1.000±0.000 本方法 OTSC 0.970±0.000 0.914±0.000 0.911±0.000 0.933±0.000 0.928±0.000 0.937±0.000 WOTSC 0.985±0.000 0.950±0.000 0.957±0.000 0.967±0.000 0.963±0.000 0.971±0.000 COIL-20 单视图方法 SSCbest 0.803±0.022 0.935±0.009 0.798±0.022 0.809±0.013 0.734±0.027 0.804±0.028 LRRbest 0.761±0.003 0.829±0.006 0.720±0.020 0.734±0.006 0.717±0.003 0.751±0.002 RSSbest 0.837±0.012 0.930±0.006 0.789±0.005 0.800±0.005 0.717±0.012 0.897±0.017 多视图方法 RMSC 0.685±0.045 0.800±0.017 0.637±0.044 0.656±0.042 0.620±0.057 0.698±0.026 DiMSC 0.778±0.022 0.846±0.002 0.732±0.005 0.745±0.005 0.739±0.007 0.751±0.003 LT-MSC 0.804±0.011 0.860±0.002 0.748±0.004 0.760±0.007 0.741±0.009 0.776±0.006 MLAN 0.862±0.011 0.961±0.004 0.835±0.006 0.844±0.013 0.758±0.008 0.953±0.007 t-SVD 0.830±0.000 0.884±0.005 0.786±0.003 0.800±0.004 0.785±0.007 0.808±0.001 GMC 0.791±0.001 0.941±0.000 0.782±0.000 0.794±0.000 0.694±0.000 0.929±0.000 LMSC 0.806±0.013 0.862±0.007 0.765±0.014 0.776±0.013 0.770±0.013 0.783±0.013 SCMV-3DT 0.701±0.028 0.810±0.009 0.635±0.003 0.654±0.029 0.614±0.039 0.702±0.018 LRTG 0.927±0.000 0.976±0.000 0.928±0.000 0.932±0.000 0.905±0.000 0.961±0.000 WTNNM 0.902±0.000 0.945±0.000 0.893±0.000 0.898±0.010 0.897±0.000 0.900±0.000 GLTA 0.903±0.006 0.946±0.001 0.891±0.007 0.897±0.006 0.893±0.013 0.900±0.001 本方法 OTSC 0.936±0.004 0.983±0.004 0.938±0.006 0.941±0.006 0.906±0.007 0.979±0.006 WOTSC 0.960±0.026 0.976±0.004 0.934±0.025 0.938±0.024 0.918±0.042 0.959±0.004
下载: 导出CSV
-
[1] Du G W, Zhou L H, Yang Y D, Lü K, Wang L Z. Deep multiple auto-encoder-based multi-view clustering. Data Science and Engineering, 2021, 6(3): 323-338 doi: 10.1007/s41019-021-00159-z [2] Fu L L, Chen Z L, Chen Y Y, Wang S P. Unified low-rank tensor learning and spectral embedding for multi-view subspace clustering. IEEE Transactions on Multimedia, DOI: 10.1109/TMM.2022.3185886 [3] Wang X Y, Han T X, Yan S C. An HOG-LBP human detector with partial occlusion handling. In: Proceedings of the IEEE 12th International Conference on Computer Vision (ICCV). Kyoto, Japan: IEEE, 2009. 32−39 [4] Lades M, Vorbruggen J C, Buhmann J, Lang J, von der Malsburg C, Wurtz R P, et al. Distortion invariant object recognition in the dynamic link architecture. IEEE Transactions on Computers, 1993, 42(3): 300-311 doi: 10.1109/12.210173 [5] Dalal N, Triggs B. Histograms of oriented gradients for human detection. In: Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05). San Diego, USA: IEEE, 2005. 886−893 [6] Zhang C Q, Fu H Z, Liu S, Liu G C, Cao X C. Low-rank tensor constrained multiview subspace clustering. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV). Santiago, Chile: IEEE, 2015. 1582−1590 [7] Xie Y, Tao D C, Zhang W S, Liu Y, Zhang L, Qu Y Y. On unifying multi-view self-representations for clustering by tensor multi-rank minimization. International Journal of Computer Vision, 2018, 126(11): 1157-1179 doi: 10.1007/s11263-018-1086-2 [8] Shi D, Zhu L, Li J J, Cheng Z Y, Zhang Z. Flexible multiview spectral clustering with self-adaptation. IEEE Transactions on Cybernetics, DOI: 10.1109/TCYB.2021.3131749 [9] 赵博宇, 张长青, 陈蕾, 刘新旺, 李泽超, 胡清华. 生成式不完整多视图数据聚类. 自动化学报, 2021, 47(8): 1867-1875 doi: 10.16383/j.aas.c200121Zhao Bo-Yu, Zhang Chang-Qing, Chen Lei, Liu Xin-Wang, Li Ze-Chao, Hu Qing-Hua. Generative model for partial multi-view clustering. Acta Automatica Sinica, 2021, 47(8): 1867-1875 doi: 10.16383/j.aas.c200121 [10] Qin Y L, Wu H Z, Zhang X P, Feng G R. Semi-supervised structured subspace learning for multi-view clustering. IEEE Transactions on Image Processing, 2022, 31: 1-14 doi: 10.1109/TIP.2021.3128325 [11] Han Z B, Zhang C Q, Fu H Z, Zhou J Y. Trusted multi-view classification with dynamic evidential fusion. IEEE Transactions on Pattern Analysis and Machine Intelligence, DOI: 10.1109/TPAMI.2022.3171983 [12] An J F, Luo H Y, Zhang Z, Zhu L, Lu G M. Cognitive multi-modal consistent hashing with flexible semantic transformation. Information Processing & Management, 2022, 59(1): Article No. 102743 [13] Peng Z H, Liu H, Jia Y H, Hou J H. Adaptive attribute and structure subspace clustering network. IEEE Transactions on Image Processing, 2022, 31: 3430-3439 doi: 10.1109/TIP.2022.3171421 [14] Huang Z Y, Zhou J T, Zhu H Y, Zhang C, Lv J C, Peng X. Deep spectral representation learning from multi-view data. IEEE Transactions on Image Processing, 2021, 30: 5352-5362 doi: 10.1109/TIP.2021.3083072 [15] Liang Y W, Huang D, Wang C D, Yu P S. Multi-view graph learning by joint modeling of consistency and inconsistency. IEEE Transactions on Neural Networks and Learning Systems, DOI: 10.1109/TNNLS.2022.3192445 [16] Wang H, Yang Y, Liu B. GMC: Graph-based multi-view clustering. IEEE Transactions on Knowledge and Data Engineering, 2020, 32(6): 1116-1129 doi: 10.1109/TKDE.2019.2903810 [17] Patel V M, Vidal R. Kernel sparse subspace clustering. In: Proceedings of the IEEE International Conference on Image Processing (ICIP). Paris, France: IEEE, 2014. 2849−2853 [18] Yin M, Guo Y, Gao J B, He Z S, Xie S L. Kernel sparse subspace clustering on symmetric positive definite manifolds. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 5157−5164 [19] Wang S Q, Chen Y Y, Zhang L N, Cen Y G, Voronin V. Hyper-laplacian regularized nonconvex low-rank representation for multi-view subspace clustering. IEEE Transactions on Signal and Information Processing over Networks, 2022, 8: 376-388 doi: 10.1109/TSIPN.2022.3169633 [20] Li Z L, Tang C, Zheng X, Liu X W, Zhang W, Zhu E. High-order correlation preserved incomplete multi-view subspace clustering. IEEE Transactions on Image Processing, 2022, 31: 2067-2080 doi: 10.1109/TIP.2022.3147046 [21] Liu G C, Lin Z C, Yan S C, Sun J, Yu Y, Ma Y. Robust recovery of subspace structures by low-rank representation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(1): 171-184 doi: 10.1109/TPAMI.2012.88 [22] Elhamifar E, Vidal R. Sparse subspace clustering: Algorithm, theory, and applications. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(11): 2765-2781 doi: 10.1109/TPAMI.2013.57 [23] 尹明, 吴浩杨, 谢胜利, 杨其宇. 基于自注意力对抗的深度子空间聚类. 自动化学报, 2022, 48(1): 271-281Yin Ming, Wu Hao-Yang, Xie Sheng-Li, Yang Qi-Yu. Self-attention adversarial based deep subspace clustering. Acta Automatica Sinica, 2022, 48(1): 271-281 [24] Gao H C, Nie F P, Li X L, Huang H. Multi-view subspace clustering. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV). Santiago, Chile: IEEE, 2015. 4238−4246 [25] Chen Y Y, Xiao X L, Zhou Y C. Multi-view subspace clustering via simultaneously learning the representation tensor and affinity matrix. Pattern Recognition, 2020, 106: 107441 doi: 10.1016/j.patcog.2020.107441 [26] Zhang G Y, Zhou Y R, Wang C D, Huang D, He X Y. Joint representation learning for multi-view subspace clustering. Expert Systems with Applications, 2021, 166: 113913 doi: 10.1016/j.eswa.2020.113913 [27] Wu J L, Xie X Y, Nie L Q, Lin Z C, Zha H B. Unified graph and low-rank tensor learning for multi-view clustering. Proceedings of the AAAI Conference on Artificial Intelligence, 2020, 34(4): 6388-6395 doi: 10.1609/aaai.v34i04.6109 [28] Carroll J D, Chang J J. Analysis of individual differences in multidimensional scaling via an n-way generalization of “eckart-young” decomposition. Psychometrika, 1970, 35(3): 283-319 doi: 10.1007/BF02310791 [29] Tucker L R. Some mathematical notes on three-mode factor analysis. Psychometrika, 1966, 31(3): 279-311 doi: 10.1007/BF02289464 [30] Kilmer M E, Braman K, Hao N, Hoover R C. Third-order tensors as operators on matrices: A theoretical and computational framework with applications in imaging. SIAM Journal on Matrix Analysis and Applications, 2013, 34(1): 148-172 doi: 10.1137/110837711 [31] Liu X W, Wang L, Zhang J, Yin J P, Liu H. Global and local structure preservation for feature selection. IEEE Transactions on Neural Networks and Learning Systems, 2014, 25(6): 1083-1095 doi: 10.1109/TNNLS.2013.2287275 [32] Chen G L, Lerman G. Spectral curvature clustering (SCC). International Journal of Computer Vision, 2009, 81(3): 317-330 doi: 10.1007/s11263-008-0178-9 [33] Liu G C, Lin Z C, Yu Y. Robust subspace segmentation by low-rank representation. In: Proceedings of the 27th International Conference on Machine Learning (ICML). Haifa, Israel: Omnipress, 2010. 663−670 [34] 王卫卫, 李小平, 冯象初, 王斯琪. 稀疏子空间聚类综述. 自动化学报, 2015, 41(8): 1373-1384 doi: 10.16383/j.aas.2015.c140891Wang Wei-Wei, Li Xiao-Ping, Feng Xiang-Chu, Wang Si-Qi. A survey on sparse subspace clustering. Acta Automatica Sinica, 2015, 41(8): 1373-1384 doi: 10.16383/j.aas.2015.c140891 [35] You C, Robinson D P, Vidal R. Scalable sparse subspace clustering by orthogonal matching pursuit. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 3918−3927 [36] Vidal R, Favaro P. Low rank subspace clustering (LRSC). Pattern Recognition Letters, 2014, 43: 47-61 doi: 10.1016/j.patrec.2013.08.006 [37] Kheirandishfard M, Zohrizadeh F, Kamangar F. Deep low-rank subspace clustering. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Seattle, USA: IEEE, 2020. 864−865 [38] Nie F P, Wang X Q, Huang H. Clustering and projected clustering with adaptive neighbors. In: Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (SIGKDD). New York, USA: ACM, 2014. 977−986 [39] Yin M, Gao J B, Xie S L, Guo Y. Multiview subspace clustering via tensorial t-product representation. IEEE Transactions on Neural Networks and Learning Systems, 2019, 30(3): 851-864 doi: 10.1109/TNNLS.2018.2851444 [40] Xia R K, Pan Y, Du L, Yin J. Robust multi-view spectral clustering via low-rank and sparse decomposition. In: Proceedings of the 28th AAAI Conference on Artificial Intelligence (AAAI). Québec City, Canada: AAAI Press, 2014. 2149−2155 [41] Chen Y Y, Xiao X L, Peng C, Lu G M, Zhou Y C. Low-rank tensor graph learning for multi-view subspace clustering. IEEE Transactions on Circuits and Systems for Video Technology, 2022, 32(1): 92-104 doi: 10.1109/TCSVT.2021.3055625 [42] Guo X J. Robust subspace segmentation by simultaneously learning data representations and their affinity matrix. In: Proceedings of the 24th International Conference on Artificial Intelligence. Buenos Aires, Argentina: AAAI Press, 2015. 3547−3553 [43] 文杰, 颜珂, 张正, 徐勇. 基于低秩张量图学习的不完整多视角聚类. 自动化学报, DOI: 10.16383/j.aas.c200519Wen Jie, Yan Ke, Zhang Zheng, Xu Yong. Low-rank tensor graph learning based incomplete multi-view clustering. Acta Automatica Sinica, DOI: 10.16383/j.aas.c200519 [44] Cao X C, Zhang C Q, Fu H Z, Liu S, Zhang H. Diversity-induced multi-view subspace clustering. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, USA: IEEE, 2015. 586−594 [45] Nie F P, Cai G H, Li J, Li X L. Auto-weighted multi-view learning for image clustering and semi-supervised classification. IEEE Transactions on Image Processing, 2018, 27(3): 1501-1511 doi: 10.1109/TIP.2017.2754939 [46] Zhang C Q, Fu H Z, Hu Q H, Cao X C, Xie Y, Tao D C, et al. Generalized latent multi-view subspace clustering. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(1): 86-99 doi: 10.1109/TPAMI.2018.2877660 [47] Gao Q X, Xia W, Wan Z Z, Xie D Y, Zhang P. Tensor-SVD based graph learning for multi-view subspace clustering. Proceedings of the AAAI Conference on Artificial Intelligence, 2020, 34(4): 3930-3937 doi: 10.1609/aaai.v34i04.5807 -

 下载:
下载:















计量
- 文章访问数: 1608
- HTML全文浏览量: 1037
- PDF下载量: 466
- 被引次数: 0
