

Anchor-free Based Object Detection Methods and Its Application Progress in Complex Scenes
-
摘要: 基于深度学习的目标检测方法是目前计算机视觉领域的热点, 在目标识别、跟踪等领域发挥了重要的作用. 随着研究的深入开展, 基于深度学习的目标检测方法主要分为有锚框的目标检测方法和无锚框的目标检测方法, 其中无锚框的目标检测方法无需预定义大量锚框, 具有更低的模型复杂度和更稳定的检测性能, 是目前目标检测领域中较前沿的方法. 在调研国内外相关文献的基础上, 梳理基于无锚框的目标检测方法及各场景下的常用数据集, 根据样本分配方式不同, 分别从基于关键点组合、中心点回归、Transformer、锚框和无锚框融合等4个方面进行整体结构分析和总结, 并结合COCO (Common objects in context)数据集上的性能指标进一步对比. 在此基础上, 介绍了无锚框目标检测方法在重叠目标、小目标和旋转目标等复杂场景情况下的应用, 聚焦目标遮挡、尺寸过小和角度多等关键问题, 综述现有方法的优缺点及难点. 最后对无锚框目标检测方法中仍存在的问题进行总结并对未来发展的应用趋势进行展望.Abstract: The object detection method based on deep learning is a hot spot in the field of computer vision currently, which plays an important role in object recognition and tracking. With the in-depth development of research, object detection method are mainly divided into anchor-based object detection method and anchor-free object detection method, the anchor-free object detection method is state-of-the-art method currently, which can reduces model complexity and reaches higher detection ability, owing to the fact that there is no need to predefine a large number of anchor boxes for it. Firstly, this paper summarizes the anchor-free object detection method and analyzes the performance on the common objects in context (COCO) dataset for further comparison in recent years, which are divided into keypoints combination, center point regression, Transformer, anchor-based fusing with anchor-free methods respectively, according to different sampling methods of anchor points. On the basis, in order to solve the above key problems, this paper focuses the applications of anchor-free object detection method in complex scenes. Finally, discusses the problems and the application trends of the anchor-free object detection method in the future development.
-
Key words:
- Anchor-free /
- keypoints /
- center point /
- Transformer /
- complex scenes /
- object detection
-
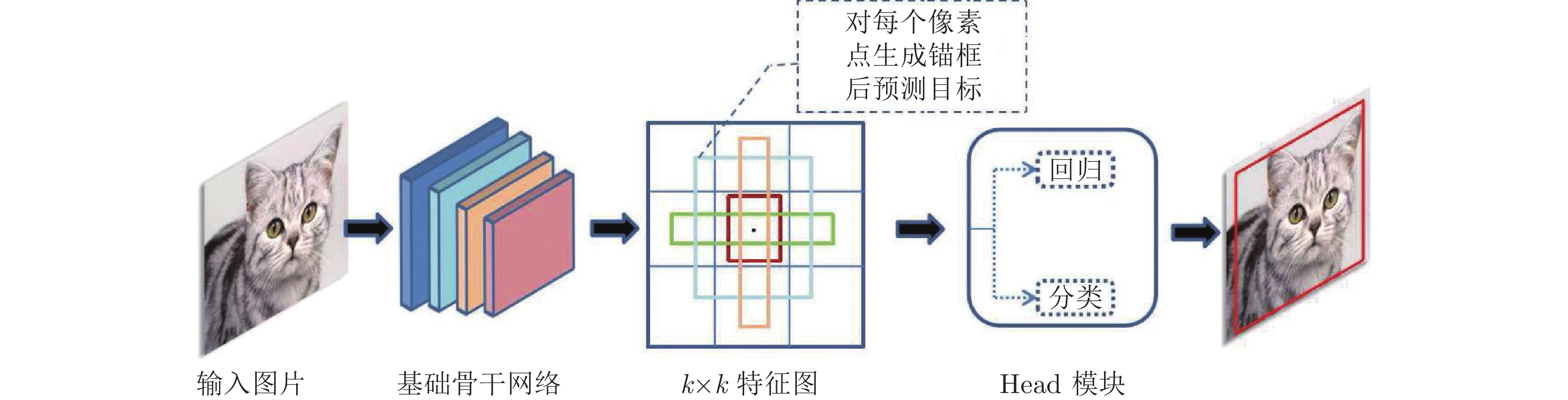
图 1 基于锚框的目标检测方法整体框架
Fig. 1 The overall framework of anchor-based object detection method
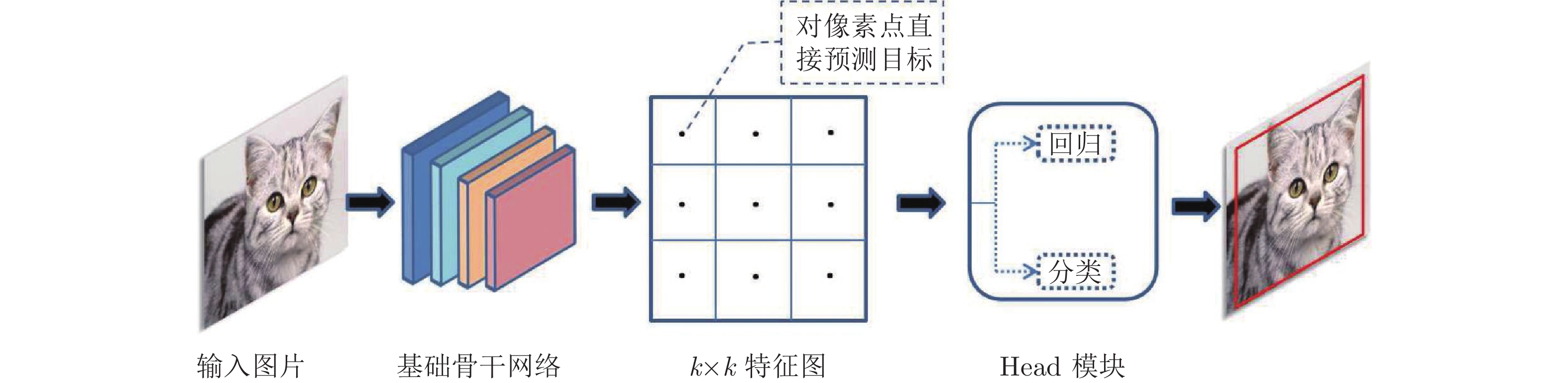
图 2 基于无锚框的目标检测方法整体框架
Fig. 2 The overall framework of anchor-free object detection method
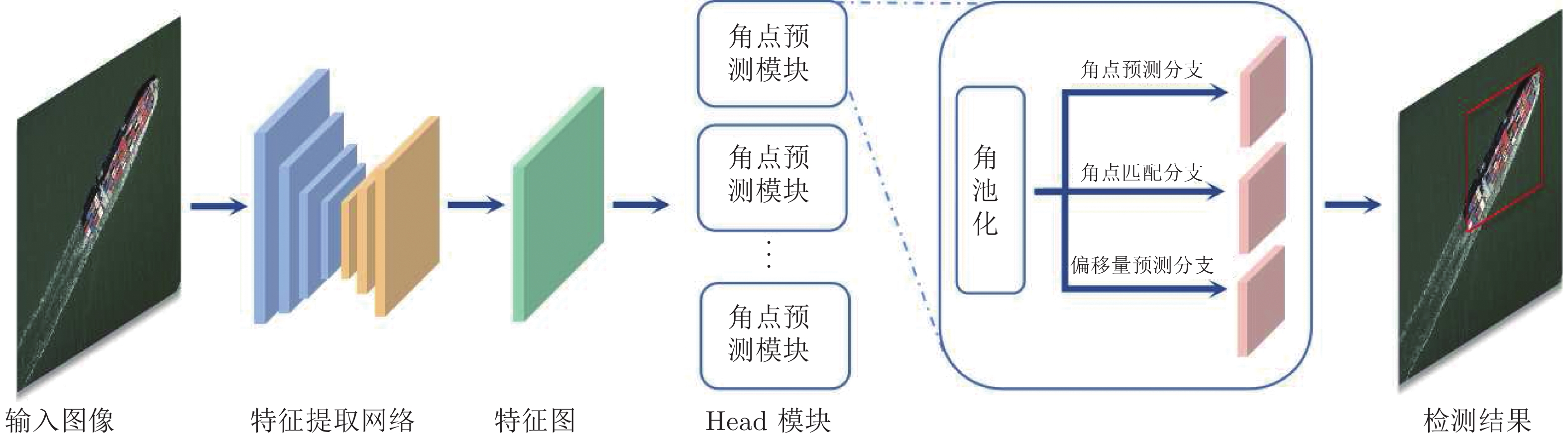
图 3 基于角点组合的CornerNet目标检测方法
Fig. 3 CornerNet framework of object detection method based on corner points combination

图 5 基于中心点回归的无锚框目标检测方法整体框架
Fig. 5 The overall framework of anchor-free object detection method based on center point regression
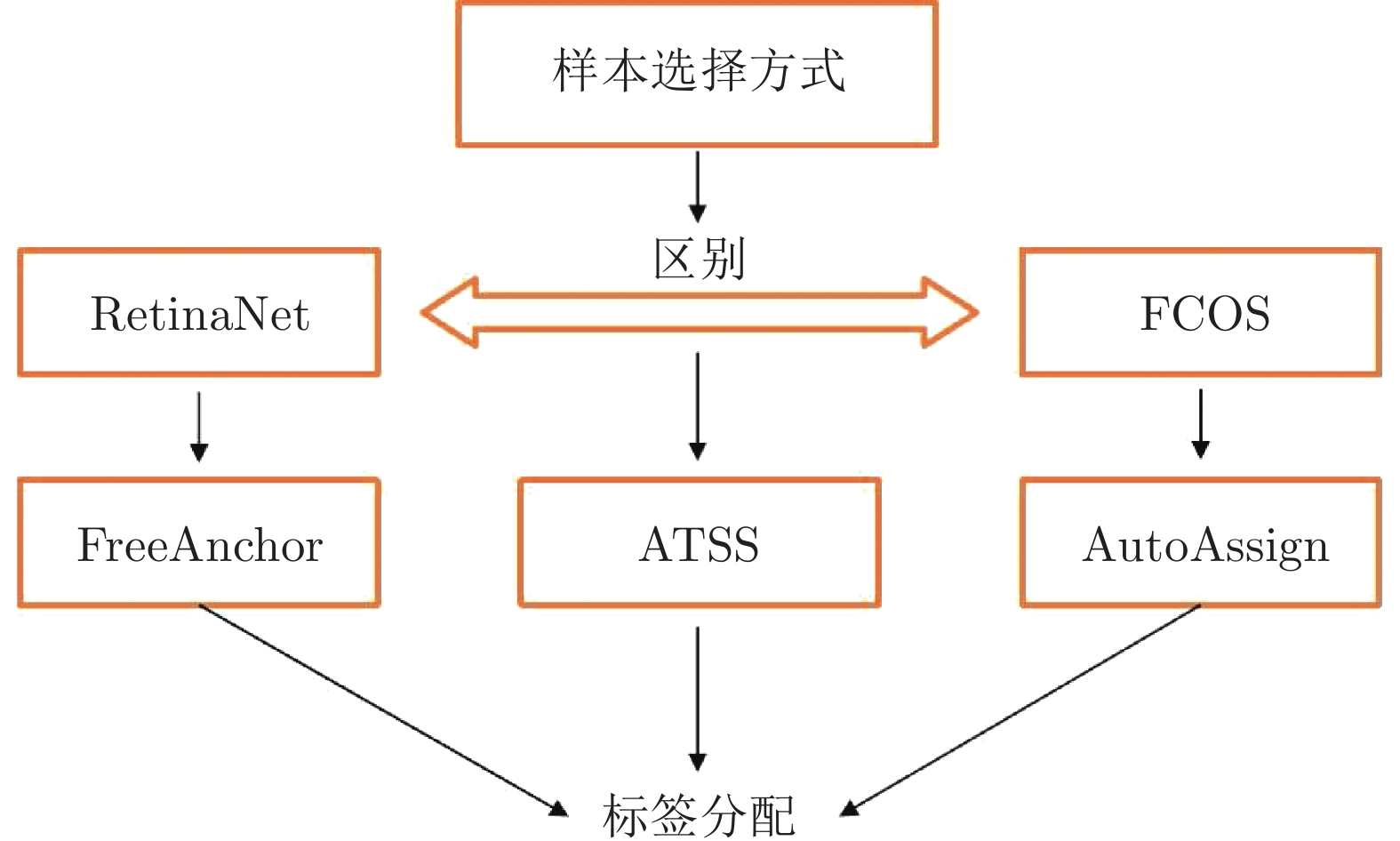
图 7 基于优化标签分配算法的关系
Fig. 7 The relationship between label assignment optimization algorithms
表 1 目标检测公共数据集对比
Table 1 Comparison of public datasets for object detection
数据集 类别数 图片数量 实例数量 图片尺寸 (像素) 标注方式 使用场景 发表年份 Pascal VOC[10] 20 ~23 k ~55 k 800 × 800 水平框 综合 2010 COCO[11] 80 ~123 k ~896 k — 水平框 综合 2014 DOTA[12] 15 ~2.8 k ~188 k 800 ~ 4000 水平框/旋转框 综合 2018 UCAS-AOD[13] 2 ~1 k ~6 k 1280 × 1280 旋转框 汽车、飞机 2015 ICDAR2015[14] 1 1.5 k — 720 × 1280 旋转框 文本 2015 CUHK-SYSU[15] 1 ~18 k ~96 k 50 ~ 4000 水平框 行人 2017 PRW[16] 1 ~12 k ~43 k — 水平框 行人 2017 CrowdHuman[17] 1 ~24 k ~470 k 608 × 608 水平框 行人 2018 HRSC2016[18] 1 ~1.1 k ~3 k ~1000 × 1000 旋转框 船舰 2017 SSDD[19] 1 1.16 k ~2.5 k 500 × 500 水平框 船舰 2017 HRSID[20] 1 ~5.6 k ~17 k 800 × 800 水平框 船舰 2020  下载: 导出CSV
下载: 导出CSV
表 2 基于无锚框的目标检测方法对比
Table 2 Comparison of anchor-free object detection method
方法类型 基于关键点组合 基于中心点回归 基于Transformer 基于锚框和无锚框融合 方法动机 无需设计锚框, 减少锚框带来的超参数, 简化模型 方法思想 组合关键点并检测 中心点回归预测框位置 Transformer的编码和解码直接预测 优化样本标签分配策略 方法优点 充分利用边界和内部信息 减少回归超参数数量 实现端到端, 简化流程 缓解正负样本不均衡 方法难点 不同类别关键点的误配对 中心点重叠目标的漏检 小目标检测性能较差 自适应标签分配不连续 计算速度 检测速度相对较慢 检测速度相对较快 收敛速度相对较慢 检测速度相对较慢
下载: 导出CSV
表 3 基于关键点组合的无锚框目标检测算法在COCO数据集上的性能及优缺点对比
Table 3 Comparison of the keypoints combination based anchor-free object detection methods on the COCO dataset
算法 特征提取网络 输入尺寸
(像素)处理器配置及检测速度(帧/s) mAP (%) 优点 缺点 收录来源 发表年份 PLN[21] Inception-V2 512 × 512 GTX 1080
—28.9 重叠及特殊形状目标的检测效果好 感受野范围较小 arXiv 2017 CornerNet[22] Hourglass-104 511 × 511 TitanX × 10
4.142.1 使用角池化来精确定位目标 同类别的角点匹配易出错 ECCV 2018 CornerNet-Saccade[23] Hourglass-54 255 × 255 GTX 1080Ti × 4
5.242.6 无需对每个像素点进行类别检测 小目标的误检率较高 BMVC 2020 CornerNet-Squeeze[23] Hourglass-54 255 × 255 GTX 1080Ti × 4
3334.4 大幅提升检测速度 角点类别的判断较易出错 BMVC 2020 ExtremeNet[24] Hourglass-104 511 × 511 TitanX × 10
3.143.7 极值点和中心点充分获取目标信息 容易产生假阳性样本 CVPR 2019 CenterNet-Triplets[25] Hourglass-104 511 × 511 Tesla V100 × 8
2.9447.0 用角点和中心点获取充分目标信息 中心点遗漏时位置偏移量大 ICCV 2019 CentripetalNet[26] Hourglass-104 511 × 511 Tesla V100 × 16
—48.0 改进CornerNet的角点误匹配问题 中心区域的缩放依赖超参数 CVPR 2020 SaccadeNet[27] DLA-34-DCN 512 × 512 RTX 2080Ti
2840.4 获取局部和整体特征, 提高特征利用率 需要平衡检测精度与速度 CVPR 2020 CPNDet[28] Hourglass-104 511 × 511 Tesla V100 × 8
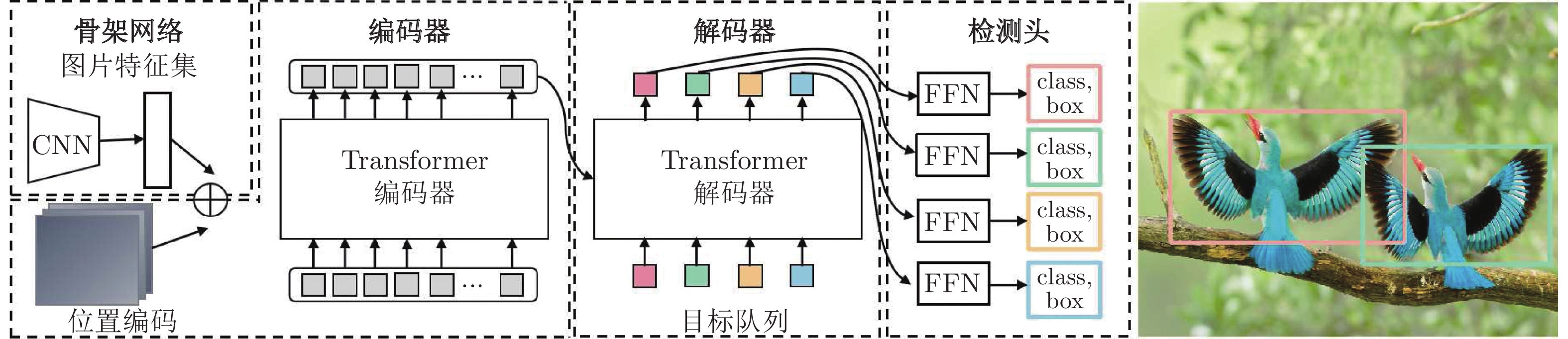
—49.2 多种分类器提升角点类别判断准确率 检测头计算效率较低 ECCV 2020
下载: 导出CSV
表 4 基于中心点回归的无锚框目标检测算法在COCO数据集上的性能及优缺点对比
Table 4 Comparison of the center point regression based anchor-free object detection methods on the COCO dataset
算法 特征提取网络 输入尺寸
(像素)处理器配置及检测速度(帧/s) mAP (%) 优点 缺点 收录来源 发表年份 YOLO v1[31] — — — — 用网格划分法提高中心点搜寻效率 目标中心点在同
网格内的漏检CVPR 2016 FCOS[33] ResNet-101 800 × $\le 1333$ —
9.341.5 用中心度降低远离中心点的预测框得分 同尺度特征层中
出现目标误检ICCV 2019 CenterNet[35] Hourglass-104 511 × 511 Titan X
7.845.1 用中心点定位目标减少角点匹配操作 目标中心点重合,
产生漏检arXiv 2019 Grid R-CNN[40] ResNet-101 800 × 800 Titan Xp × 32
3.4541.5 用网格定位机制精准定位边界框 特征采样区域
范围过于广泛CVPR 2019 Grid R-CNN Plus[41] ResNet-101 800 × 800 Titan Xp × 32
7.6942.0 缩小特征表达区域尺寸, 减少计算量 非代表性特征
区域存在遗漏arXiv 2019 HoughNet[37] Hourglass-104 512 × 512 Tesla V100 × 4
—46.4 用投票机制改进全局信息缺失的问题 投票机制使
计算量增大ECCV 2020 YOLOX[32] Darknet53 640 × 640 Tesla V100 × 8
90.147.4 解耦分类和回归分支, 提升收敛速度 难分类样本的
检测精度较低arXiv 2021 OneNet[34] ResNet-101 512 × $\le 853$ Tesla V100 × 8
5037.7 用最小匹配损失提升预测框和标签的匹配 单像素点检测单
目标, 产生漏检ICML 2021 CenterNet2[36] Res2Net-101-DCN-BiFPN 1280 × 1280 Titan Xp
—56.4 清晰区分目标特征和背景区域的特征 分步分类、回归的
效率较低arXiv 2021
下载: 导出CSV
表 5 基于Transformer的无锚框目标检测算法在COCO数据集上的性能及优缺点对比
Table 5 Comparison of the Transformer based anchor-free object detection methods on the COCO dataset
算法 特征提取
网络输入尺寸
(像素)处理器配置及
检测速度(帧/s)mAP (%) 浮点计算量(FLOPs/G) 优点 缺点 收录
来源发表
年份DETR[42] ResNet-50 (480, 800)×
(800, 1333)Tesla V100 × 16
2842.0 86 用Transformer减少手工设计参数数量 收敛速度慢, 小
目标检测性能较差ECCV 2020 TSP-FCOS[43] ResNet-50 (640, 800)×
(800, 1333)Tesla V100 × 8
1543.1 189 添加辅助子网来提高多尺度特征的提取 模型计算量、
复杂度较高ICCV 2021 Deformable DETR[44] ResNet-50 (480, 800)×
(800, 1333)Tesla V100
1943.8 173 有效关注稀疏空间的目标位置 模型计算量、
复杂度较高ICLR 2021 Dynamic DETR[45] ResNet-50 — Tesla V100 × 8
—47.2 — 用动态注意力机制加速收敛 未说明模型的
计算量、复杂度ICCV 2021 YOLOS[47] DeiT-base (480, 800)×
(800, 1333)—
2.742.0 538 不依赖卷积骨干网络, 性能良好 检测速度较低,
计算量较高NeurlPS 2021 SAM-DETR[46] ResNet-50 (480, 800)×
(800, 1333)Tesla V100 × 8
—41.8 100 利用语义对齐加速模型收敛速度 检测精度有待
进一步提升CVPR 2022 ViDT[49] Swin-base (480, 800)×
(800, 1333)Tesla V100 × 8
11.649.2 — 用新的骨干网络和检测颈减少计算开销 浅层难以直接获取
目标的有用信息ICLR 2022 DN-DETR[50] ResNet-50 — Tesla A100 × 8
—44.1 94 利用去噪训练法大幅提升检测性能 仅使用均匀
分布的噪声CVPR 2022
下载: 导出CSV
表 6 基于锚框和无锚框融合的目标检测算法在COCO数据集上的性能及优缺点对比
Table 6 Comparison of the anchor-based and anchor-free fusion object detection methods on the COCO dataset
算法 特征提取网络 输入尺寸
(像素)处理器配置及检测速度(帧/s) mAP (%) 优点 缺点 收录来源 发表年份 FSAF[52] ResNeXt-101 800 × 800 Tesla V100 × 8
2.7644.6 动态选择最适合目标的特征层 未区分不同特征
的关注程度CVPR 2019 SAPD[54] ResNeXt-101 800 × 800 GTX 1080Ti
4.547.4 能筛选出有代表性的目标特征 未能真正将有锚框和
无锚框分支融合ECCV 2020 ATSS[56] ResNeXt-101 800 ×
(800, 1333)Tesla V100
—50.7 能根据统计特性自动训练样本 未完全实现无需参数
调节的样本分配CVPR 2020 AutoAssign[57] ResNeXt-101 800 × 800 — 52.1 无需手动调节的动态样本分配 样本的的权重分配
机制相对较复杂arXiv 2020 LSNet[58] ResNeXt-101 800 ×
(800, 1333)Tesla V100 × 8
5.150.4 用位置敏感网络大幅提高定位精度 小目标的定位和
分类精度较低arXiv 2021 DW[59] ResNeXt-101 800 × 800 GPU × 8
—49.8 有效获取分类和回归置信度高的框 小目标的检测性能
仍需进一步提升CVPR 2022
下载: 导出CSV
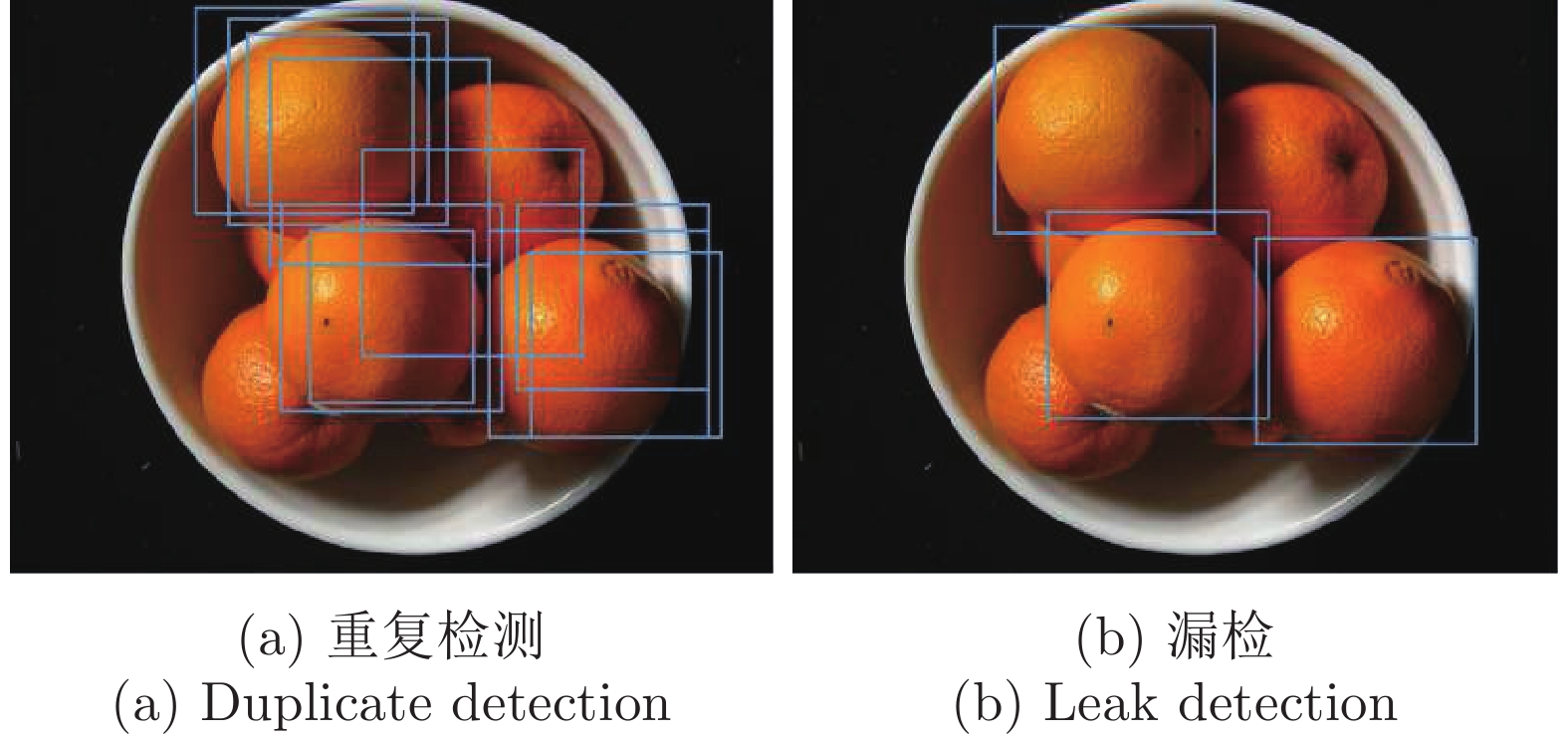
表 7 解决目标重叠排列问题的不同检测方法的性能对比
Table 7 Performance comparison of detection methods to solve the problem that objects are densely arranged
问题 算法 数据集 输入尺寸
(像素)骨干网络 处理器配置 检测速度
(帧/s)mAP (%) 收录来源 发表年份 目标重叠排列 VarifocalNet[75] COCO (480, 960)×
1333ResNeXt-101 Tesla V100 × 8 6.7 50.8 TMI 2019 WSMA-Seg[77] COCO — MSP-Seg — — 38.1 arXiv 2019 FCOS v2[73] COCO CrowdHuman 800×$\le$1333 ResNeXt-101 ResNet-50 GTX 1080Ti — 50.4
87.3TPAMI 2022 BorderDet[76] COCO 800×$\le$1333 ResNeXt-101 GPU × 8 — 50.3 ECCV 2020 AlignPS[71] CUHK-SYSU
PRW900 × 1500 ResNet-50 Tesla V100 16.4 94.0
46.1CVPR 2021 OTA-FCOS[78] COCO CrowdHuman (640, 800) ×$\le$
1333ResNeXt-101
ResNet-50GPU × 8 — 51.5
88.4CVPR 2021 LLA-FCOS[79] CrowdHuman 800×$\le$1400 ResNet-50 GPU × 8 — 88.1 Neuro-
computing2021 LTM[80] COCO 800×$\le$1333 ResNeXt-101 Tesla V100 × 8 1.7 46.3 TPAMI 2022 Efficient DETR[81] COCO CrowdHuman — ResNet-101
ResNet-50— — 45.7
90.8arXiv 2021 PSTR[72] CUHK-SYSU
PRW900×1500 ResNet-50 Tesla V100 — 94.2
50.1CVPR 2022 COAT[82] CUHK-SYSU
PRW900×1500 ResNet-50 Tesla A100 11.1 94.2
53.3CVPR 2022 Progressive
DETR[83]COCO CrowdHuman (480, 800)×$\le$1333 ResNet-50 GPU × 8 — 46.7
92.1CVPR 2022
下载: 导出CSV
表 8 解决目标重叠排列问题的不同检测方法优缺点对比
Table 8 Feature comparison of detection methods to solve the problem that objects are densely arranged
问题 算法 方法 优点 缺点/难点 目标重叠排列 CSP[70] 增加中心点偏移量预测分支和尺度预测分支 解决行人检测任务中漏检问题 特征与框间的关联度较低 VarifocalNet[75] 预测IACS分类得分、提出Varifocal Loss损失函数 有效抑制同目标重叠框 小目标检测效果需提升 WSMA-Seg[77] 利用分割模型构建无需NMS后处理的目标检测模型 准确利用重叠目标边缘特征 分割算法的模型复杂度较高 FCOS v2[73] 将中心度子分支加入回归分支, 并修正中心度计算方式 减少类别判断错误数量 针对不同尺度特征仅使用相同
检测头, 限制模型性能BorderDet[76] 用边界对齐的特征提取操作自适应地提取边界特征 高效获取预测框的位置 边界点选取数量较多 AlignPS[71] 使用特征对齐和聚合模块 解决区域、尺度不对齐的问题 未扩展到通用目标检测任务 OTA-FCOS[78] 用最优传输理论寻找全局高置信度样本分配方式 有助于选择信息丰富区域 模型的计算复杂度较高 LLA-FCOS[79] 使用基于损失感知的样本分配策略 锚点和真实框对应性更好 仅在密集人群中的效果较好 LTM[80] 目标与特征的匹配定义为极大似然估计问题 提高目标遮挡和不对齐的精度 检测速度有待进一步提高 Efficient DETR[81] 用密集先验知识初始化来简化模型结构 减少编码器和解码器数量 检测精度有待进一步提升 PSTR[72] 使用Transformer构成首个行人搜索网络 提高特征的可判别性和关联性 未扩展到通用目标检测任务 COAT[82] 用三段级联设计来检测和完善目标的检测和重识别 更清晰地区分目标和背景特征 部分阶段过度关注ReID特征,
牺牲部分检测性能Progressive
DETR[83]设计关联信息提取模块和队列更新模块 加强低置信点的复用 检测精度有待进一步提升
下载: 导出CSV
表 9 解决目标尺寸过小问题的不同检测方法性能对比
Table 9 Performance comparison of detection methods to solve the problem that object pixels are too few
问题 算法 数据集 输入尺寸
(像素)骨干网络 处理器配置 检测速度
(帧/s)mAP (%) 收录来源 发表年份 目标尺寸过小 RepPoints[89] COCO (480, 960) ×$\le$960 ResNet-101 GPU × 4 — 46.5 ICCV 2019 DuBox[92] COCO
VOC 2012800 × 800
500 × 500ResNet-101 VGG-16 NVIDIA P40 × 8 — 39.5
82.0arXiv 2019 PPDet[87] COCO 800 × 1300 ResNet-101 Tesla V100 × 4 — 45.2 BMVC 2020 RepPoints v2[90] COCO (800, 1333) × $\le$1333 ResNet-101 GPU × 8 — 48.1 NeurlPS 2020 FoveaBox[93] COCO
VOC 2012800 × 800 ResNet-101
ResNet-50GPU × 4 —
16.442.1
76.6TIP 2020 FBR-Net[94] SSDD 448 × 448 ResNet-50 RTX 2080Ti 25.0 92.8 TGRS 2021 FCOS (AFE-GDH)[88] HRSID
SSDD800 × 800 ResNet-50 NVIDIA Titan Xp 15.2
28.567.4
56.2Remote Sensing 2022 Oriented RepPoints [91] DOTA HRSC2016 1024 × 1024
(300, 900)×
(300, 1500)ResNet-101
ResNet-50RTX 2080Ti × 4 — 76.5
97.3CVPR 2022 QueryDet[95] COCO — ResNet-50 RTX 2080Ti × 8 14.4 39.5 CVPR 2022
下载: 导出CSV
表 10 解决目标尺寸过小问题的不同检测方法优缺点对比
Table 10 Feature comparison of detection methods to solve the problem that object pixels are too few
问题 算法 方法 优点 缺点/难点 目标尺寸过小 RepPoints[89] 使用点集形式表征目标的特征 自适应地学习极值点和语义信息 过度依赖回归分支 DuBox[92] 使用有多尺度特性的双尺度残差单元 减少小目标边缘和内部信息的漏检 分割模型的复杂度较高 PPDet[87] 使用框内部为正样本点的新标记策略 提高判别性目标特征的贡献程度 小目标特征信息不足 RepPoints v2[90] 增加角点验证分支来判断特征映射点 获得更具目标内部和边缘信息的特征 预测框定位准确度低 FoveaBox[93] 在多层特征图上检测多尺度目标特征 对目标形状和分布有很强的适应能力 难以区分目标和背景区域 FBR-Net[94] 用多尺度注意力机制选择特征重要性 减少背景区域与小目标间的强关联性 检测精度仍需进一步提升 FCOS (AFE-GDH)[88] 使用自适应特征编码策略(AFE)和构造高斯引导检测头 有效增强小目标表达能力 仅说明船舰目标有效性 Oriented RepPoints[91] 提出质量评估、样本分配方案和空间约束 提升非轴对齐小目标特征的捕获能力 仅涉及空域小目标检测 QueryDet[95] 使用基于级联稀疏查询机制进行动态预测 减少检测头计算开销、提高小目标的
位置精确度提高分辨率导致误判概率提高
下载: 导出CSV
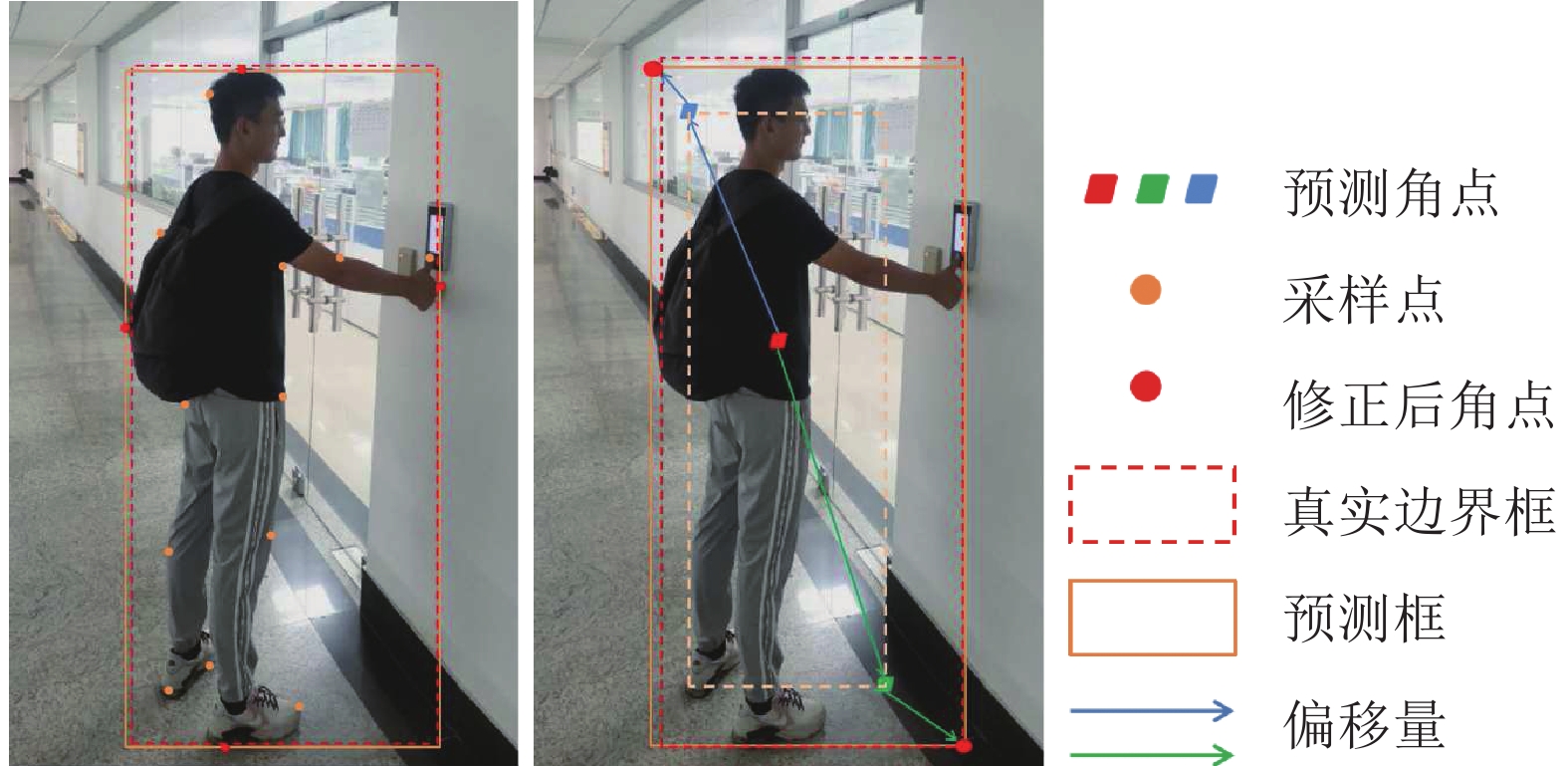
表 11 解决目标方向变化问题的不同检测方法性能对比
Table 11 Performance comparison of detection methods to solve the problem that object direction changeable
问题 算法 数据集 输入尺寸
(像素)骨干网络 处理器配置 检测速度
(帧/s)mAP (%) 收录来源 发表年份 目标方向
变化SARD[102] DOTA HRSC2016 800 × 800 ResNet-101 Tesla P100 —
1.572.9
85.4IEEE Access 2019 P-RSDet[97] DOTA
UCAS-AOD512 × 512 ResNet-101 Tesla V100 × 2 — 72.3
90.0IEEE Access 2020 O2-DNet[101] DOTA ICDAR2015 800 × 800 ResNet-101 Tesla V100 × 2 — 71.0
85.6P&RS 2020 DRN[106] DOTA HRSC2016 1024 × 1024
768 × 768Hourglass-104 Tesla V100 — 73.2
92.7CVPR 2020 BBAVectors[96] DOTA HRSC2016 608 × 608 ResNet-101 GTX 1080Ti × 4 —
11.775.4
88.6WACV 2021 FCOSR[98] DOTA HRSC2016 1024 × 1024
800 × 800ResNeXt-101 Tesla V100 × 4 7.9
—77.4
95.7arXiv 2021 DARDet[103] DOTA HRSC2016 1024 × 1024 ResNet-50 RTX 2080Ti 12.6
—71.2
78.9GRSL 2021 DAFNe[105] DOTA HRSC2016 1024 × 1024 ResNet-101 Tesla V100 × 4 — 76.9
89.5arXiv 2021 CHPDet[107] UCAS-AOD HRSC2016 1024 × 1024 DLA-34 RTX 2080Ti — 89.6
88.8TGRS 2021 AOPG[99] DOTA HRSC2016 1024 × 1024
(800, 1333) ×
(800, 1333)ResNet-101
ResNet-50RTX 2080Ti 10.8
—80.2
96.2TGRS 2022 GGHL[100] DOTA SSDD+ 800 × 800
—Darknet53 RTX 3090 × 2 42.3
44.176.9
90.2TIP 2022
下载: 导出CSV
表 12 解决目标方向变化问题的不同检测方法优缺点对比
Table 12 Feature comparison of detection methods to solve the problem that object direction changeable
问题 算法 方法 优点 缺点/难点 目标方向变化 SARD[102] 用尺度感知方法融合深层和
浅层特征信息对大尺度变化和多角度变化目标适应度好 整体检测效率较低 P-RSDet[97] 回归一个极半径和两个极角,
实现多角度物体的检测避免角度周期性及预测框的顶点排序问题 极坐标的后处理操作相关复杂度较高 O2-DNet[101] 用横纵比感知方向中心度的
方法, 学习判别性特征网络从复杂背景中学习更具判别性的特征 特征融合方法的实际融合效果较差 DRN[106] 使用自适应的特征选择模块和
动态优化的检测头缓解目标特征和坐标轴之间的不对齐问题 检测精度有待进一步提升 BBAVectors[96] 使用边缘感知向量来替代原回归参数 在同坐标系中回归所有参数, 减少计算量 向量的类型转化过程处理较复杂 FCOSR[98] 使用基于高斯分布的椭圆中心采样策略 修正样本分配方法在航空场景下漏检问题 未实现标签分配方案的自适应 DARDet[103] 设计高效对齐卷积模块来提取对齐特征 可一次性预测出所有的预测框相关参数 损失函数的角度预测偏移量较大 DAFNe[105] 使用基于方向感知的边界框中心度函数 降低低质量框的权重并且提高定位精度 损失函数仍存在部分旋转敏感度误差 CHPDet[107] 使用方位不变模块OIM生成
方位不变特征映射确定旋转目标的朝向(如车头、船头等) 存在目标预测框的位置偏移量 AOPG[99] 使用区域标签分配模块和粗定位模块 缓解标签分配不均衡、目标特征不对齐的问题 未实现标签分配方案的自适应 GGHL[100] 使用二维定向高斯热力图进行
定向框标签分配实现动态标签分配对齐回归和分类任务 检测精度有待进一步提升
下载: 导出CSV
-
[1] 聂光涛, 黄华. 光学遥感图像目标检测算法综述. 自动化学报, 2021, 47(8): 1749-1768 doi: 10.16383/j.aas.c200596Nie Guang-Tao, Huang Hua. A survey of object detection in optical remote sensing images. Acta Automatica Sinica, 2021, 47(8): 1749-1768 doi: 10.16383/j.aas.c200596 [2] Neubeck A, Van Gool L. Efficient non-maximum suppression. In: Proceedings of the 18th International Conference on Pattern Recognition (ICPR'06). Hong Kong, China: IEEE, 2006. 850−855 [3] Liu W, Anguelov D, Erhan D, Szegedy C, Reed S, Fu C Y, et al. SSD: Single shot multibox detector. In: Proceedings of the 14th European Conference on Computer Vision. Amsterdam, The Netherlands: Springer, 2016. 21−37 [4] Girshick R. Fast R-CNN. In: Proceedings of the IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015. 1440−1448 [5] Ren S Q, He K M, Girshick R, Sun J. Faster R-CNN: Towards real-time object detection with region proposal networks. In: Proceedings of the 29th International Conference on Neural Information Processing Systems. Montreal, Canada: 2015. 91−99 [6] Redmon J, Farhadi A. YOLO9000: Better, faster, stronger. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017. 6517−6525 [7] Redmon J, Farhadi A. YOLOv3: An incremental improvement. arXiv preprint arXiv: 1804.02767, 2018. [8] 肖雨晴, 杨慧敏. 目标检测算法在交通场景中应用综述. 计算机工程与应用, 2021, 57(6): 30-41 doi: 10.3778/j.issn.1002-8331.2011-0361Xiao Yu-Qing, Yang Hui-Min. Research on application of object detection algorithm in traffic scene. Computer Engineering and Applications, 2021, 57(6): 30-41 doi: 10.3778/j.issn.1002-8331.2011-0361 [9] Huang L C, Yang Y, Deng Y F, Yu Y N. DenseBox: Unifying landmark localization with end to end object detection. arXiv preprint arXiv: 1509.04874, 2015. [10] Everingham M, Van Gool L, Williams C K I, Winn J, Zisserman A. The PASCAL visual object classes (VOC) challenge. International Journal of Computer Vision, 2010, 88(2): 303-338 doi: 10.1007/s11263-009-0275-4 [11] Lin T Y, Maire M, Belongie S, Hays J, Perona P, Ramanan D, et al. Microsoft COCO: Common objects in context. In: Proceedings of the 13th European Conference on Computer Vision. Zurich, Switzerland: Springer, 2014. 740−755 [12] Xia G S, Bai X, Ding J, Zhu Z, Belongie S, Luo J B, et al. DOTA: A large-scale dataset for object detection in aerial images. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 3974−3983 [13] Zhu H G, Chen X G, Dai W Q, Fu K, Ye Q X, Jiao J B. Orientation robust object detection in aerial images using deep convolutional neural network. In: Proceedings of the IEEE International Conference on Image Processing (ICIP). Quebec City, Canada: IEEE, 2015. 3735−3739 [14] Karatzas D, Gomez-Bigorda L, Nicolaou A, Ghosh S, Bagdanov A, Iwamura M, et al. ICDAR 2015 competition on robust reading. In: Proceedings of the 13th International Conference on Document Analysis and Recognition (ICDAR). Tunis, Tunisia: IEEE, 2015. 1156−1160 [15] Xiao T, Li S, Wang B C, Lin L, Wang X G. Joint detection and identification feature learning for person search. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017. 3376−3385 [16] Zheng L, Zhang H H, Sun S Y, Chandraker M, Yang Y, Tian Q. Person re-identification in the wild. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017. 3346−3355 [17] Shao S, Zhao Z J, Li B X, Xiao T T, Yu G, Zhang X Y, et al. CrowdHuman: A benchmark for detecting human in a crowd. arXiv preprint arXiv: 1805.00123, 2018. [18] Liu Z K, Yuan L, Weng L B, Yang Y P. A high resolution optical satellite image dataset for ship recognition and some new baselines. In: Proceedings of the 6th International Conference on Pattern Recognition Applications and Methods. Porto, Portugal: SciTePress, 2017. 324−331 [19] Li J W, Qu C W, Shao J Q. Ship detection in SAR images based on an improved faster R-CNN. In: Proceedings of the SAR in Big Data Era: Models, Methods and Applications (BIGSARDATA). Beijing, China: IEEE, 2017. 1−6 [20] Wei S J, Zeng X F, Qu Q Z, Wang M, Su H, Shi J. HRSID: A high-resolution SAR images dataset for ship detection and instance segmentation. IEEE Access, 2020, 8: 120234-120254 doi: 10.1109/ACCESS.2020.3005861 [21] Wang X G, Chen K B, Huang Z L, Yao C, Liu W Y. Point linking network for object detection. arXiv preprint arXiv: 1706.03646, 2017. [22] Law H, Deng J. CornerNet: Detecting objects as paired keypoints. In: Proceedings of the 15th European Conference on Computer Vision (ECCV). Munich, Germany: Springer, 2018. 765−781 [23] Law H, Teng Y, Russakovsky O, Deng J. Cornernet-lite: Efficient keypoint based object detection. In: Proceedings of the 31st British Machine Vision Conference. BMVC, 2020. [24] Zhou X Y, Zhuo J C, Krähenbühl P. Bottom-up object detection by grouping extreme and center points. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 850−859 [25] Duan K W, Bai S, Xie L X, Qi H G, Huang Q M, Tian Q. CenterNet: Keypoint triplets for object detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul, South Korea: IEEE, 2019. 6568−6577 [26] Dong Z W, Li G X, Liao Y, Wang F, Ren P J, Qian C. CentripetalNet: Pursuing high-quality keypoint pairs for object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, USA: IEEE, 2020. 10516−10525 [27] Lan S Y, Ren Z, Wu Y, Davis L S, Hua G. SaccadeNet: A fast and accurate object detector. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, USA: IEEE, 2020. 10394−10403 [28] Duan K W, Xie L X, Qi H G, Bai S, Huang Q M, Tian Q. Corner proposal network for anchor-free, two-stage object detection. In: Proceedings of the 16th European Conference on Computer Vision. Glasgow, UK: Springer, 2020. 399−416 [29] 王彦情, 马雷, 田原. 光学遥感图像舰船目标检测与识别综述. 自动化学报, 2011, 37(9): 1029-1039Wang Yan-Qing, Ma Lei, Tian Yuan. State-of-the-art of ship detection and recognition in optical remotely sensed imagery. Acta Automatica Sinica, 2011, 37(9): 1029-1039 [30] Yu J H, Jiang Y N, Wang Z Y, Cao Z M, Huang T. UnitBox: An advanced object detection network. In: Proceedings of the 24th ACM International Conference on Multimedia. Amsterdam, The Netherlands: ACM, 2016. 516−520 [31] Redmon J, Divvala S, Girshick R, Farhadi A. You only look once: Unified, real-time object detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016. 779−788 [32] Ge Z, Liu S T, Wang F, Li Z M, Sun J. YOLOX: Exceeding YOLO series in 2021. arXiv preprint arXiv: 2107.08430, 2021. [33] Tian Z, Shen C H, Chen H, He T. FCOS: Fully convolutional one-stage object detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul, South Korea: IEEE, 2019. 9626−9635 [34] Sun P Z, Jiang Y, Xie E Z, Shao W Q, Yuan Z H, Wang C H, et al. What makes for end-to-end object detection? In: Proceedings of the 38th International Conference on Machine Learning. PMLR, 2021. 9934−9944 [35] Zhou X Y, Wang D Q, Krahenbuhl P. Objects as points. arXiv preprint arXiv: 1904.07850, 2019. [36] Zhou X Y, Koltun V, Krähenbühl P. Probabilistic two-stage detection. arXiv preprint arXiv: 2103.07461, 2021. [37] Samet N, Hicsonmez S, Akbas E. HoughNet: Integrating near and long-range evidence for bottom-up object detection. In: Proceedings of the 16th European Conference on Computer Vision. Glasgow, UK: Springer, 2020. 406−423 [38] Chu C, Zhmoginov A, Sandler M. CycleGAN, a master of steganography. arXiv preprint arXiv: 1712.02950, 2017. [39] Isola P, Zhu J Y, Zhou T H, Efros A A. Image-to-image translation with conditional adversarial networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017. 5967−5976 [40] Lu X, Li B Y, Yue Y X, Li Q Q, Yan J J. Grid R-CNN. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 7355−7364 [41] Lu X, Li B Y, Yue Y X, Li Q Q, Yan J J. Grid R-CNN plus: Faster and better. arXiv preprint arXiv: 1906.05688, 2019. [42] Carion N, Massa F, Synnaeve G, Usunier N, Kirillov A, Zagoruyko S. End-to-end object detection with transformers. In: Proceedings of the 16th European Conference on Computer Vision. Glasgow, UK: Springer, 2020. 213−229 [43] Sun Z Q, Cao S C, Yang Y M, Kitani K. Rethinking transformer-based set prediction for object detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. Montreal, Canada: IEEE, 2021. 3591−3600 [44] Zhu X Z, Su W J, Lu L W, Li B, Wang X G, Dai J F. Deformable DETR: Deformable transformers for end-to-end object detection. In: Proceedings of the 9th International Conference on Learning Representations. ICLR, 2021. [45] Dai X Y, Chen Y P, Yang J W, Zhang P C, Yuan L, Zhang L. Dynamic DETR: End-to-end object detection with dynamic attention. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. Montreal, Canada: IEEE, 2021. 2968−2977 [46] Zhang G J, Luo Z P, Yu Y C, Cui K W, Lu S J. Accelerating DETR convergence via semantic-aligned matching. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans, USA: IEEE, 2022. 939−948 [47] Fang Y X, Liao B C, Wang X G, Fang J M, Qi J Y, Wu R, et al. You only look at one sequence: Rethinking transformer in vision through object detection. In: Proceedings of the 35th International Conference on Neural Information Processing Systems. 2021. 26183−26197 [48] Dosovitskiy A, Beyer L, Kolesnikov A, Weissenborn D, Zhai X H, Unterthiner T, et al. An image is worth 16×16 words: Transformers for image recognition at scale. In: Proceedings of the 9th International Conference on Learning Representations. ICLR, 2021. [49] Song H, Sun D Q, Chun S, Jampani V, Han D, Heo B, et al. ViDT: An efficient and effective fully transformer-based object detector. In: Proceedings of the 10th International Conference on Learning Representations. ICLR, 2022. [50] Li F, Zhang H, Liu S L, Guo J, Ni L M, Zhang L. DN-DETR: Accelerate DETR training by introducing query DeNoising. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans, USA: IEEE, 2022. 13609−13617 [51] Wang J F, Yuan Y, Li B X, Yu G, Jian S. SFace: An efficient network for face detection in large scale variations. arXiv preprint arXiv: 1804.06559, 2018. [52] Zhu C C, He Y H, Savvides M. Feature selective anchor-free module for single-shot object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 840−849 [53] Lin T Y, Goyal P, Girshick R, He K M, Dollár P. Focal loss for dense object detection. In: Proceedings of the IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 2999−3001 [54] Zhu C C, Chen F Y, Shen Z Q, Savvides M. Soft anchor-point object detection. In: Proceedings of the 16th European Conference on Computer Vision. Glasgow, UK: Springer, 2020. 91−107 [55] Zhang X S, Wan F, Liu C, Ji R R, Ye Q X. FreeAnchor: Learning to match anchors for visual object detection. In: Proceedings of the 33rd International Conference on Neural Information Processing Systems. Vancouver, Canada: Curran Associates Inc., 2019. Article No. 14 [56] Zhang S F, Chi C, Yao Y Q, Lei Z, Li S Z. Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, USA: IEEE, 2020. 9756−9765 [57] Zhu B J, Wang J F, Jiang Z K, Zong F H, Liu S T, Li Z M, et al. AutoAssign: Differentiable label assignment for dense object detection. arXiv preprint arXiv: 2007.03496, 2020. [58] Duan K W, Xie L X, Qi H G, Bai S, Huang Q M, Tian Q. Location-sensitive visual recognition with cross-IOU loss. arXiv preprint arXiv: 2104.04899, 2021. [59] Li S, He C H, Li R H, Zhang L. A dual weighting label assignment scheme for object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans, USA: IEEE, 2022. 9377−9386 [60] 刘小波, 刘鹏, 蔡之华, 乔禹霖, 王凌, 汪敏. 基于深度学习的光学遥感图像目标检测研究进展. 自动化学报, 2021, 47(9): 2078-2089 doi: 10.16383/j.aas.c190455Liu Xiao-Bo, Liu Peng, Cai Zhi-Hua, Qiao Yu-Lin, Wang Ling, Wang Min. Research progress of optical remote sensing image object detection based on deep learning. Acta Automatica Sinica, 2021, 47(9): 2078-2089 doi: 10.16383/j.aas.c190455 [61] 龚浩田, 张萌. 基于关键点检测的无锚框轻量级目标检测算法. 计算机科学, 2021, 48(8): 106-110 doi: 10.11896/jsjkx.200700161Gong Hao-Tian, Zhang Meng. Lightweight anchor-free object detection algorithm based on KeyPoint detection. Computer Science, 2021, 48(8): 106-110 doi: 10.11896/jsjkx.200700161 [62] 邵晓雯, 帅惠, 刘青山. 融合属性特征的行人重识别方法. 自动化学报, 2022, 48(2): 564-571Shao Xiao-Wen, Shuai Hui, Liu Qing-Shan. Person re-identification based on fused attribute features. Acta Automatica Sinica, 2022, 48(2): 564-571 [63] 刘洋, 战荫伟. 基于深度学习的小目标检测算法综述. 计算机工程与应用, 2021, 57(2): 37-48 doi: 10.3778/j.issn.1002-8331.2009-0047Liu Yang, Zhan Yin-Wei. Survey of small object detection algorithms based on deep learning. Computer Engineering and Applications, 2021, 57(2): 37-48 doi: 10.3778/j.issn.1002-8331.2009-0047 [64] Bodla N, Singh B, Chellappa R, Davis L S. Soft-NMS: Improving object detection with one line of code. In: Proceedings of the IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 5562−5570 [65] Liu S T, Huang D, Wang Y H. Adaptive NMS: Refining pedestrian detection in a crowd. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 6452−6461 [66] Huang X, Ge Z, Jie Z Q, Yoshie O. NMS by representative region: Towards crowded pedestrian detection by proposal pairing. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, USA: IEEE, 2020. 10747−10756 [67] Zhang S F, Wen L Y, Bian X, Lei Z, Li S Z. Occlusion-aware R-CNN: Detecting pedestrians in a crowd. In: Proceedings of the 15th European Conference on Computer Vision (ECCV). Munich, Germany: Springer, 2018. 657−674 [68] 阳珊, 王建, 胡莉, 刘波, 赵皓. 改进RetinaNet的遮挡目标检测算法研究. 计算机工程与应用, 2022, 58(11): 209-214 doi: 10.3778/j.issn.1002-8331.2107-0277Yang Shan, Wang Jian, Hu Li, Liu Bo, Zhao Hao. Research on occluded object detection by improved RetinaNet. Computer Engineering and Applications, 2022, 58(11): 209-214 doi: 10.3778/j.issn.1002-8331.2107-0277 [69] Luo Z K, Fang Z, Zheng S X, Wang Y B, Fu Y W. NMS-Loss: Learning with non-maximum suppression for crowded pedestrian detection. In: Proceedings of the International Conference on Multimedia Retrieval. Taipei, China: ACM, 2021. 481−485 [70] Liu W, Hasan I, Liao S C. Center and scale prediction: A box-free approach for pedestrian and face detection. arXiv preprint arXiv: 1904.02948, 2019. [71] Yan Y C, Li J P, Qin J, Bai S, Liao S C, Liu L, et al. Anchor-free person search. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville, USA: IEEE, 2021. 7686−7695 [72] Cao J L, Pang Y W, Anwer R M, Cholakkal H, Xie J, Shah M, et al. PSTR: End-to-end one-step person search with transformers. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans, USA: IEEE, 2022. 9448−9457 [73] Tian Z, Shen C H, Chen H, He T. FCOS: A simple and strong anchor-free object detector. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(4): 1922-1933 [74] Rezatofighi H, Tsoi N, Gwak J Y, Sadeghian A, Reid I, Savarese S. Generalized intersection over union: A metric and a loss for bounding box regression. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 658−666 [75] Qin Y L, Wen J, Zheng H, Huang X L, Yang J, Song N, et al. Varifocal-Net: A chromosome classification approach using deep convolutional networks. IEEE Transactions on Medical Imaging, 2019, 38(11): 2569-2581 doi: 10.1109/TMI.2019.2905841 [76] Qiu H, Ma Y C, Li Z M, Liu S T, Sun J. BorderDet: Border feature for dense object detection. In: Proceedings of the 16th European Conference on Computer Vision. Glasgow, UK: Springer, 2020. 549−564 [77] Cheng Z H, Wu Y X, Xu Z H, Lukasiewicz T, Wang W Y. Segmentation is all you need. arXiv preprint arXiv: 1904.13300, 2019. [78] Ge Z, Liu S T, Li Z M, Yoshie O, Sun J. OTA: Optimal transport assignment for object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville, USA: IEEE, 2021. 303−312 [79] Ge Z, Wang J F, Huang X, Liu S T, Yoshie O. LLA: Loss-aware label assignment for dense pedestrian detection. Neurocomputing, 2021, 462: 272-281 doi: 10.1016/j.neucom.2021.07.094 [80] Zhang X S, Wan F, Liu C, Ji X Y, Ye Q X. Learning to match anchors for visual object detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(6): 3096-3109 doi: 10.1109/TPAMI.2021.3050494 [81] Yao Z Y, Ai J B, Li B X, Zhang C. Efficient DETR: Improving end-to-end object detector with dense prior. arXiv preprint arXiv: 2104.01318, 2021. [82] Yu R, Du D W, LaLonde R, Davila D, Funk C, Hoogs A, et al. Cascade transformers for end-to-end person search. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans, USA: IEEE, 2022. 7257−7266 [83] Zheng A L, Zhang Y, Zhang X Y, Qi X J, Sun J. Progressive end-to-end object detection in crowded scenes. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans, USA: IEEE, 2022. 847−856 [84] Zhu Y S, Zhao C Y, Wang J Q, Zhao X, Wu Y, Lu H Q. CoupleNet: Coupling global structure with local parts for object detection. In: Proceedings of the IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 4146−4154 [85] Li Y Z, Pang Y W, Shen J B, Cao J L, Shao L. NETNet: Neighbor erasing and transferring network for better single shot object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, USA: IEEE, 2020. 13346−13355 [86] Zhong Z Y, Sun L, Huo Q. An anchor-free region proposal network for Faster R-CNN-based text detection approaches. International Journal on Document Analysis and Recognition (IJDAR), 2019, 22(3): 315-327 doi: 10.1007/s10032-019-00335-y [87] Samet N, Hicsonmez S, Akbas E. Reducing label noise in anchor-free object detection. In: Proceedings of the 31st British Machine Vision Conference. BMVC, 2020. [88] He B K, Zhang Q Y, Tong M, He C. An anchor-free method based on adaptive feature encoding and Gaussian-guided sampling optimization for ship detection in SAR imagery. Remote Sensing, 2022, 14(7): 1738 doi: 10.3390/rs14071738 [89] Yang Z, Liu S H, Hu H, Wang L W, Lin S. RepPoints: Point set representation for object detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul, South Korea: IEEE, 2019. 9656−9665 [90] Chen Y H, Zhang Z, Cao Y, Wang L W, Lin S, Hu H. RepPoints v2: Verification meets regression for object detection. In: Proceedings of the 34th International Conference on Neural Information Processing Systems. 2020. Article No. 33 [91] Li W T, Chen Y J, Hu K X, Zhu J K. Oriented RepPoints for aerial object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans, USA: IEEE, 2022. 1819−1828 [92] Chen S, Li J P, Yao C Q, Hou W B, Qin S, Jin W Y, et al. DuBox: No-prior box objection detection via residual dual scale detectors. arXiv preprint arXiv: 1904.06883, 2019. [93] Kong T, Sun F C, Liu H P, Jiang Y N, Li L, Shi J B. FoveaBox: Beyound anchor-based object detection. IEEE Transactions on Image Processing, 2020, 29: 7389-7398 doi: 10.1109/TIP.2020.3002345 [94] Fu J M, Sun X, Wang Z R, Fu K. An anchor-free method based on feature balancing and refinement network for multiscale ship detection in SAR images. IEEE Transactions on Geoscience and Remote Sensing, 2021, 59(2): 1331-1344 doi: 10.1109/TGRS.2020.3005151 [95] Yang C, Huang Z H, Wang N Y. QueryDet: Cascaded sparse query for accelerating high-resolution small object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans, USA: IEEE, 2022. 13658−13667 [96] Yi J R, Wu P X, Liu B, Huang Q Y, Qu H, Metaxas D. Oriented object detection in aerial images with box boundary-aware vectors. In: Proceedings of the IEEE Winter Conference on Applications of Computer Vision. Waikoloa, USA: IEEE, 2021. 2149−2158 [97] Zhou L, Wei H R, Li H, Zhao W Z, Zhang Y, Zhang Y. Arbitrary-oriented object detection in remote sensing images based on polar coordinates. IEEE Access, 2020, 8: 223373-223384 doi: 10.1109/ACCESS.2020.3041025 [98] Li Z H, Hou B, Wu Z T, Jiao L C, Ren B, Yang C. FCOSR: A simple anchor-free rotated detector for aerial object detection. arXiv preprint arXiv: 2111.10780, 2021. [99] Cheng G, Wang J B, Li K, Xie X X, Lang C B, Yao Y Q, et al. Anchor-free oriented proposal generator for object detection. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: Article No. 5625411 [100] Huang Z C, Li W, Xia X G, Tao R. A general Gaussian heatmap label assignment for arbitrary-oriented object detection. IEEE Transactions on Image Processing, 2022, 31: 1895-1910 doi: 10.1109/TIP.2022.3148874 [101] Wei H R, Zhang Y, Chang Z H, Li H, Wang H Q, Sun X. Oriented objects as pairs of middle lines. ISPRS Journal of Photogrammetry and Remote Sensing, 2020, 169: 268-279 doi: 10.1016/j.isprsjprs.2020.09.022 [102] Wang Y S, Zhang Y, Zhang Y, Zhao L J, Sun X, Guo Z. SARD: Towards scale-aware rotated object detection in aerial imagery. IEEE Access, 2019, 7: 173855-173865 doi: 10.1109/ACCESS.2019.2956569 [103] Zhang F, Wang X Y, Zhou S L, Wang Y Q. DARDet: A dense anchor-free rotated object detector in aerial images. IEEE Geoscience and Remote Sensing Letters, 2021, 19: Article No. 8024305 [104] Chen Z M, Chen K, Lin W Y, See J, Yu H, Ke Y, et al. PIoU loss: Towards accurate oriented object detection in complex environments. In: Proceedings of the 16th European Conference on Computer Vision. Glasgow, UK: Springer, 2020. 195−211 [105] Lang S, Ventola F, Kersting K. DAFNe: A one-stage anchor-free approach for oriented object detection. arXiv preprint arXiv: 2109.06148, 2021. [106] Pan X J, Ren Y Q, Sheng K K, Dong W M, Yuan H L, Guo X W, et al. Dynamic refinement network for oriented and densely packed object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, USA: IEEE, 2020. 11204−11213 [107] Zhang F, Wang X Y, Zhou S L, Wang Y Q, Hou Y. Arbitrary-oriented ship detection through center-head point extraction. IEEE Transactions on Geoscience and Remote Sensing, 2021, 60: Article No. 5612414 [108] Yang X, Yan J C, Ming Q, Wang W T, Zhang X P, Tian Q. Rethinking rotated object detection with Gaussian wasserstein distance loss. In: Proceedings of the 38th International Conference on Machine Learning. PMLR, 2021. 11830−11841 [109] Yang X, Yang X J, Yang J R, Ming Q, Wang W T, Tian Q, et al. Learning high-precision bounding box for rotated object detection via Kullback-Leibler divergence. In: Proceedings of the 35th International Conference on Neural Information Processing Systems. 2021. 18381−18394 [110] Qian W, Yang X, Peng S L, Zhang X J, Yan J C. RSDet++: Point-based modulated loss for more accurate rotated object detection. IEEE Transactions on Circuits and Systems for Video Technology, 2022, 32(11): 7869-7879 doi: 10.1109/TCSVT.2022.3186070 [111] Yang X, Yang J R, Yan J C, Zhang Y, Zhang T F, Guo Z, et al. SCRDet: Towards more robust detection for small, cluttered and rotated objects. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul, South Korea: IEEE, 2019. 8231−8240 [112] Milan A, Leal-Taixé L, Reid I, Roth S, Schindler K. MOT16: A benchmark for multi-object tracking. arXiv preprint arXiv: 1603.00831, 2016. [113] Zhang Y F, Wang C Y, Wang X G, Zeng W J, Liu W Y. FairMOT: On the fairness of detection and re-identification in multiple object tracking. International Journal of Computer Vision, 2021, 129(11): 3069-3087 doi: 10.1007/s11263-021-01513-4 [114] Howard A G, Zhu M L, Chen B, Kalenichenko D, Wang W J, Weyand T, et al. MobileNets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv: 1704.04861, 2017. [115] Zhang X Y, Zhou X Y, Lin M X, Sun J. ShuffleNet: An extremely efficient convolutional neural network for mobile devices. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 6848−6856 [116] Wang R J, Li X, Ling C X. Pelee: A real-time object detection system on mobile devices. In: Proceedings of the 32nd International Conference on Neural Information Processing Systems. Montréal, Canada: Curran Associates Inc., 2018. 1967−1976 -

 下载:
下载:




计量
- 文章访问数: 2205
- HTML全文浏览量: 1996
- PDF下载量: 624
- 被引次数: 0
