

-
摘要: 图像密集描述旨在为复杂场景图像提供细节描述语句. 现有研究方法虽已取得较好成绩, 但仍存在以下两个问题: 1)大多数方法仅将注意力聚焦在网络所提取的深层语义信息上, 未能有效利用浅层视觉特征中的几何信息; 2)现有方法致力于改进感兴趣区域间上下文信息的提取, 但图像内物体空间位置信息尚不能较好体现. 为解决上述问题, 提出一种基于多重注意结构的图像密集描述生成方法—MAS-ED (Multiple attention structure-encoder decoder). MAS-ED通过多尺度特征环路融合(Multi-scale feature loop fusion, MFLF) 机制将多种分辨率尺度的图像特征进行有效集成, 并在解码端设计多分支空间分步注意力(Multi-branch spatial step attention, MSSA)模块, 以捕捉图像内物体间的空间位置关系, 从而使模型生成更为精确的密集描述文本. 实验在Visual Genome数据集上对MAS-ED进行评估, 结果表明MAS-ED能够显著提升密集描述的准确性, 并可在文本中自适应加入几何信息和空间位置信息. 基于长短期记忆网络(Long-short term memory, LSTM)解码网络框架, MAS-ED方法性能在主流评价指标上优于各基线方法.
-
关键词:
- 图像密集描述 /
- 多重注意结构 /
- 多尺度特征环路融合 /
- 多分支空间分步注意力
Abstract: Dense captioning aims to provide detailed description sentences for complex scenes. Although the existing research methods have achieved good results, there are still the following two problems: 1) Most methods only focus on the deep semantic information extracted by the network, and fail to effectively utilize the geometric information in the shallow visual features. 2) Existing methods are dedicated to improving the extraction of contextual information between regions of interest, but the spatial location information of objects in images cannot be well represented. To solve the above problems, this paper proposes a dense captioning generation method based on multiple attention structure-encoder decoder (MAS-ED). MAS-ED effectively integrates image features of multiple resolution scales through a multi-scale feature loop fusion (MFLF) mechanism, and designs a multi-branch spatial step attention (MSSA) at the decoding end to capture the spatial relationship between objects in the image, this enables the method model to generate more accurate dense description text. In this paper, MAS-ED is evaluated on the Visual Genome dataset. The experimental results show that MAS-ED can significantly improve the accuracy of dense captions, and can adaptively add geometric information and spatial location information to the text. Based on the long-short term memory (LSTM) decoding network framework, the performance of the MAS-ED method in this paper outperforms all baseline methods in mainstream evaluation indicators. -
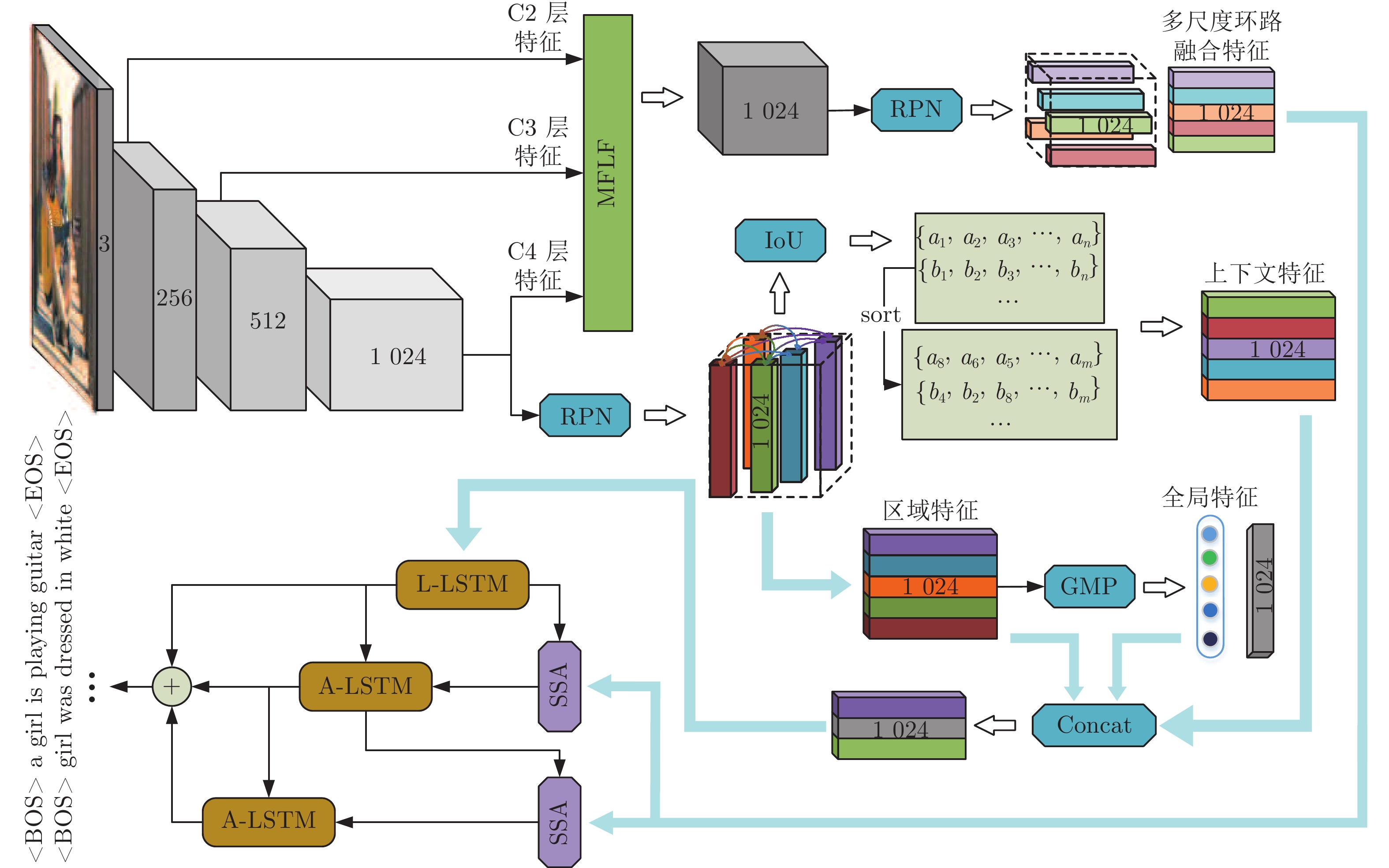
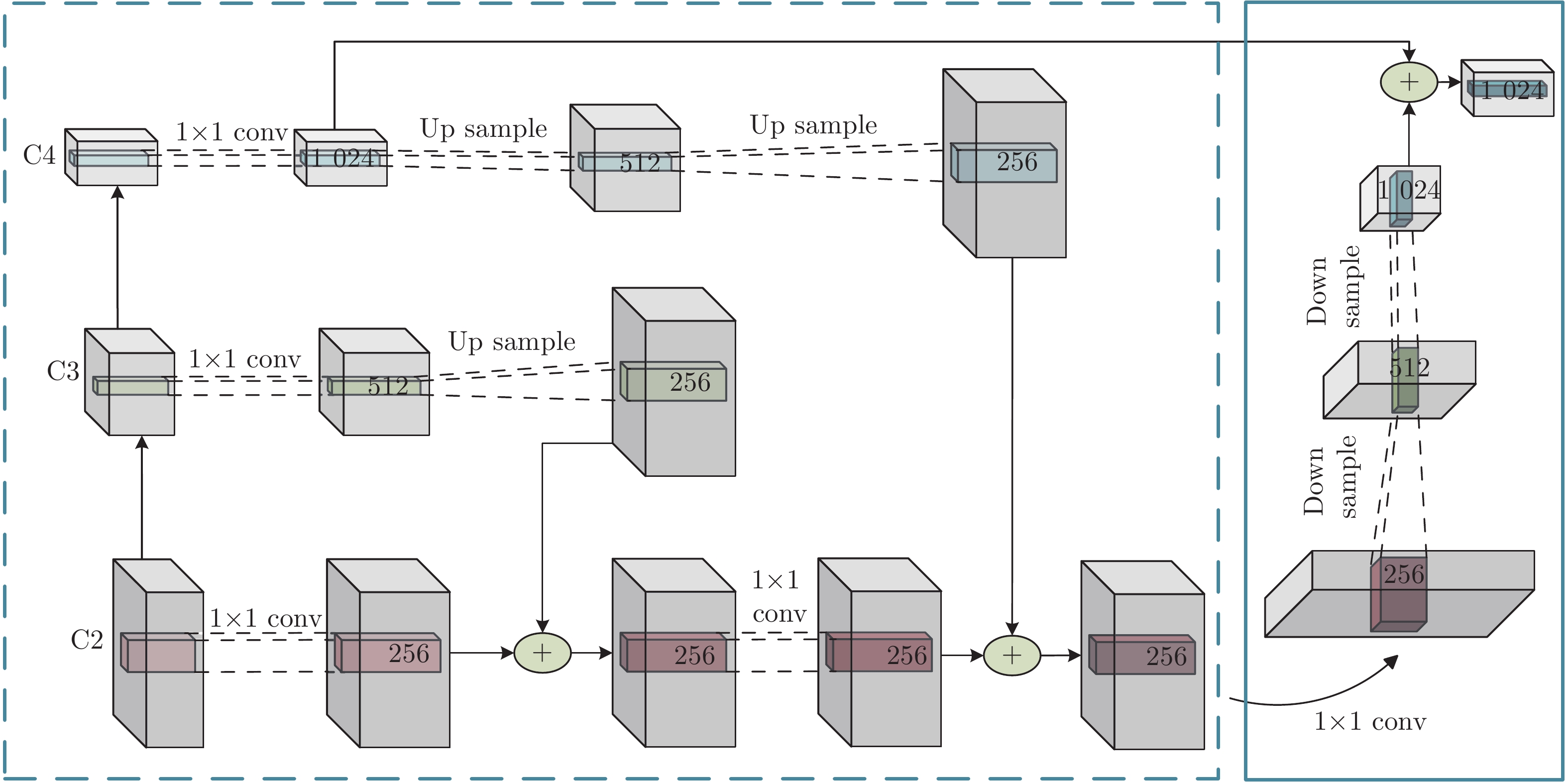
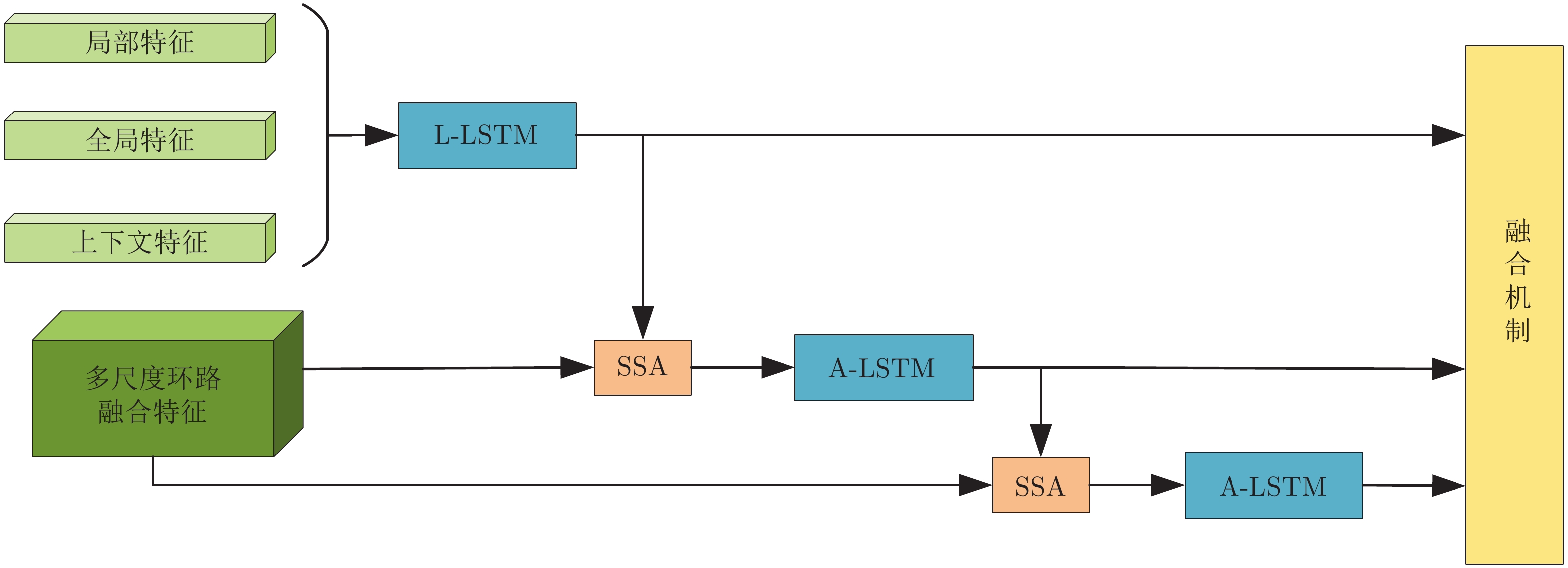
图 1 基于多重注意结构的图像密集描述生成方法
Fig. 1 Dense captioning method based on multi-attention structure

图 5 不同分支组合模型结果可视化(图中每行上面“[·]”表示语义流, 下面“[·]”表示几何流)
Fig. 5 Visualization of results of different semantic flow branching models (The upper “[·]” of each line in the figure represents the semantic flow, and the lower “[·]” represents the geometric flow)
表 1 基于LSTM解码网络密集描述算法mAP性能
Table 1 mAP performance of dense caption algorithms based on LSTM decoding network
 下载: 导出CSV
下载: 导出CSV
表 2 基于非LSTM解码网络密集描述算法mAP性能
Table 2 mAP performance of dense caption algorithms based on non-LSTM decoding network
模型 V1.0 V1.2 TDC 10.64 10.33 TDC + ROCSU 11.49 11.90 MAS-ED 10.68 11.04
下载: 导出CSV
表 3 VG数据集上密集描述模型mAP性能
Table 3 mAP performance of dense caption models on VG dataset
模型 VGG16 ResNet-152 Baseline[17] 9.31 9.96 MFLF-ED 10.29 10.65 MSSA-ED 10.42 11.87 MAS-ED 10.68 11.04
下载: 导出CSV
表 4 不同分支组合模型的mAP性能比较
Table 4 Comparison of mAP performance of different branch combination models
语义流 几何流 C2-C4 C2-C3 & C3-C4 C2-C4 + (C3-C4) C2-C4 + (C2-C3 & C3-C4) C3-C2 9.924 10.245 10.268 7.122 C4-C2 10.530 10.371 9.727 8.305 C4-C3 & C3-C2 10.125 10.349 10.474 10.299 C4-C2+(C3-C2) 10.654 10.420 10.504 10.230 C4-C2+(C4-C3&C3-C2) 10.159 10.242 10.094 7.704
下载: 导出CSV
表 5 SSA模块支路模型的mAP性能
Table 5 mAP performance of SSA module branch model
模型 Up-ED Down-ED MSSA-ED mAP 10.751 10.779 10.867
下载: 导出CSV
表 6 不同支路数对多分支解码器性能的影响
Table 6 Effects of different branch numbers on the performance of multi-branch decoders
模型 单支路 两支路 三支路 Up-ED 10.043 10.751 10.571 Down-ED 10.168 10.779 10.686 MSSA-ED 10.347 10.867 10.638
下载: 导出CSV
-
[1] Miao Y Q, Lin Z J, Ma X, Ding G G, Han J G. Learning transformation-invariant local descriptors with low-coupling binary codes. IEEE Transactions on Image Processing, 2021, 30: 7554-7566 doi: 10.1109/TIP.2021.3106805 [2] Khavas Z R, Ahmadzadeh S R, Robinette P. Modeling trust in human-robot interaction: A survey. In: Proceedings of the 2020 International Conference on Social Robotics. Berlin, Germany: Springer, 2020. 529−541 [3] Cao J L, Pang Y W, Han J G, Li X L. Hierarchical regression and classification for accurate object detection. IEEE Transactions on Neural Networks and Learning Systems, DOI: 10.1109/TNNLS.2021.3106641 [4] 蒋弘毅, 王永娟, 康锦煜. 目标检测模型及其优化方法综述. 自动化学报, 2021, 47(6): 1232-1255Jiang Hong-Yi, Wang Yong-Juan, Kang Jin-Yu. A survey of object detection models and its optimization methods. Acta Automatica Sinica, 2021, 47(6): 1232-1255 [5] 储珺, 束雯, 周子博, 缪君, 冷璐. 结合语义和多层特征融合的行人检测. 自动化学报, 2022, 48(1): 282-291Chu Jun, Shu Wen, Zhou Zi-Bo, Miao Jun, Leng Lu. Combining semantics with multi-level feature fusion for pedestrian detection. Acta Automatica Sinica, 2022, 48(1): 282-291 [6] Xu X, Wang T, Yang Y, Zuo L, Shen F M, Shen H T. Cross-modal attention with semantic consistence for image–text matching. IEEE Transactions on Neural Networks and Learning Systems, 2020, 31(12): 5412-5425 doi: 10.1109/TNNLS.2020.2967597 [7] 包希港, 周春来, 肖克晶, 覃飙. 视觉问答研究综述. 软件学报, 2021, 32(8): 2522-2544Bao Xi-Gang, Zhou Chun-Lai, Xiao Ke-Jing, Qin Biao. Survey on visual question answering. Journal of Software, 2021, 32(8): 2522-2544 [8] Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate. arXiv: 1409.0473, 2016. [9] Kulkarni G, Premraj V, Ordonez V, Dhar S, Li S M, Choi Y, et al. Babytalk: Understanding and generating simple image descriptions. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(12): 2891-2903 doi: 10.1109/TPAMI.2012.162 [10] You Q Z, Jin H L, Wang Z W, Fang C, Luo J B. Image captioning with semantic attention. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. NewYork, USA: IEEE, 2016. 4651−4659 [11] 王鑫, 宋永红, 张元林. 基于显著性特征提取的图像描述算法. 自动化学报, 2022, 48(3): 745-756Wang Xin, Song Yong-Hong, Zhang Yuan-Lin. Salient feature extraction mechanism for image captioning. Acta Automatica Sinica, 2022, 48(3): 745-756 [12] Girshick R, Donahue J, Darrell T, Malik J. Rich feature hierarchies for accurate object detection and semantic segmentation. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. NewYork, USA: IEEE, 2014. 580−587 [13] Hochreiter S, Schmidhuber J. Long short-term memory. Neural Computation, 1997, 9(8): 1735-1780 doi: 10.1162/neco.1997.9.8.1735 [14] Karpathy A, Li F F. Deep visual-semantic alignments for generating image descriptions. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. NewYork, USA: IEEE, 2015. 3128−3137 [15] Johnson J, Karpathy A, Li F F. Densecap: Fully convolutional localization networks for dense captioning. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2016. 4565−4574 [16] Jia X, Gavves E, Fernando B, Tuytelaars T. Guiding the long-short term memory model for image caption generation. In: Proceedings of the 2015 IEEE International Conference on Computer Vision. New York, USA: IEEE, 2015. 2407−2415 [17] Yang L J, Tang K, Yang J C, Li L J. Dense captioning with joint inference and visual context. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2017. 2193−2202 [18] Yin G J, Sheng L, Liu B, Yu N H, Wang X G, Shao J. Context and attribute grounded dense captioning. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2019. 6241−6250 [19] Li X Y, Jiang S Q, Han J G. Learning object context for dense captioning. In: Proceedings of the 2019 AAAI Conference on Artificial Intelligence. Menlo Park, California: AAAI, 2019. 8650−8657 [20] Shao Z, Han J G, Marnerides D, Debattista K. Region-object relation-aware dense captioning via transformer. IEEE Transactions on Neural Networks and Learning Systems, DOI: 10.1109/TNNLS.2022.3152990 [21] Lin T Y, Dollár P, Girshick R, He K M, Hariharan B, Belongie S. Feature pyramid networks for object detection. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2017. 2117−2125 [22] He K M, Zhang X Y, Ren S Q, Sun J. Deep residual learning for image recognition. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2016. 770−778 [23] Lu J S, Xiong C M, Parikh D, Socher R. Knowing when to look: Adaptive attention via a visual sentinel for image captioning. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2017. 375−383 [24] Anderson P, He X D, Buehler C, Teney D, Johnson M, Gould S, et al. Bottom-up and top-down attention for image captioning and visual question answering. In: Proceedings of the 2018 IEEE Conference on Computer Vsion and Pattern Recognition. New York, USA: IEEE, 2018. 6077−6086 [25] Zhang Z Z, Lan W J, Zeng W J, Jin X, Chen Z B. Relation-aware global attention for person re-identification. In: Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2020. 3183−3192 [26] Woo S, Park J, Lee J Y, Kweon I S. Cbam: Convolutional block attention module. In: Proceedings of the 2018 European Conference on Computer Vision. Berlin, Germany: Springer, 2018. 3−19 [27] Hu J, Shen L, Albanie S, Sun G, Wu E H. Squeeze-and-excitation networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(8): 2011-2023 doi: 10.1109/TPAMI.2019.2913372 [28] Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez A N, et al. Attention is all you need. In: Proceedings of the 2017 Advances in Neural Information Processing Systems. California, USA: Curran Associates Inc, 2017. 6000−6010 [29] Banerjee S, Lavie A. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In: Proceedings of the 2005 ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization. Stroudsburg, PA, USA: ACL, 2005. 65−72 -

 下载:
下载:





计量
- 文章访问数: 983
- HTML全文浏览量: 279
- PDF下载量: 187
- 被引次数: 0
