

-
摘要: 随着信息技术的发展, 复杂系统越来越多地呈现出社会、物理、信息相融合的特征. 因为这些系统涉及到了人和社会的因素, 其设计、分析、管理、控制和综合等问题正面临前所未有的挑战. 在这种背景下, 计算实验应运而生, 通过“反事实”的算法化, 为量化分析复杂系统提供了一种数字化和计算化方法. 对于计算实验方法的发展现状与未来挑战进行了全面梳理: 首先介绍了计算实验方法的概念起源与应用特征; 然后详细阐述了计算实验的方法框架与关键步骤; 接着展示了计算实验方法的典型应用, 包括现象解释、趋势预测与策略优化; 最后给出了计算实验方法所面临的一些关键问题与挑战. 旨在梳理出计算实验方法的技术框架, 为其快速发展与跨学科应用提供支撑.Abstract: With the development of information technology, more and more complex systems show the characteristics of the integration of society, physics and information. Because these systems involve human and social factors, their design, analysis, management, control and synthesis are facing unprecedented challenges. In this context, the computational experiment emerged. It algorithmizes “counterfactuals” as a digital and computational method for quantitative analysis of complex systems. This article reviews the development status and future challenges of computational experiment method. Firstly, it introduces the conceptual origin and application characteristics of computational experiment method; then elaborates on the method framework and key steps of computational experiments; then shows typical applications of computational experiment methods, including phenomenon explanation, trend forecast and strategy optimization; finally, some key problems and challenges faced by computational experiment method are given. The purpose of this paper is to provide the technical framework of computational experiment method, which will facilitate its rapid development and interdisciplinary application.
-
Key words:
- Computational experiments /
- artificial society /
- multi-agent modeling /
- experiment design /
- road map
-

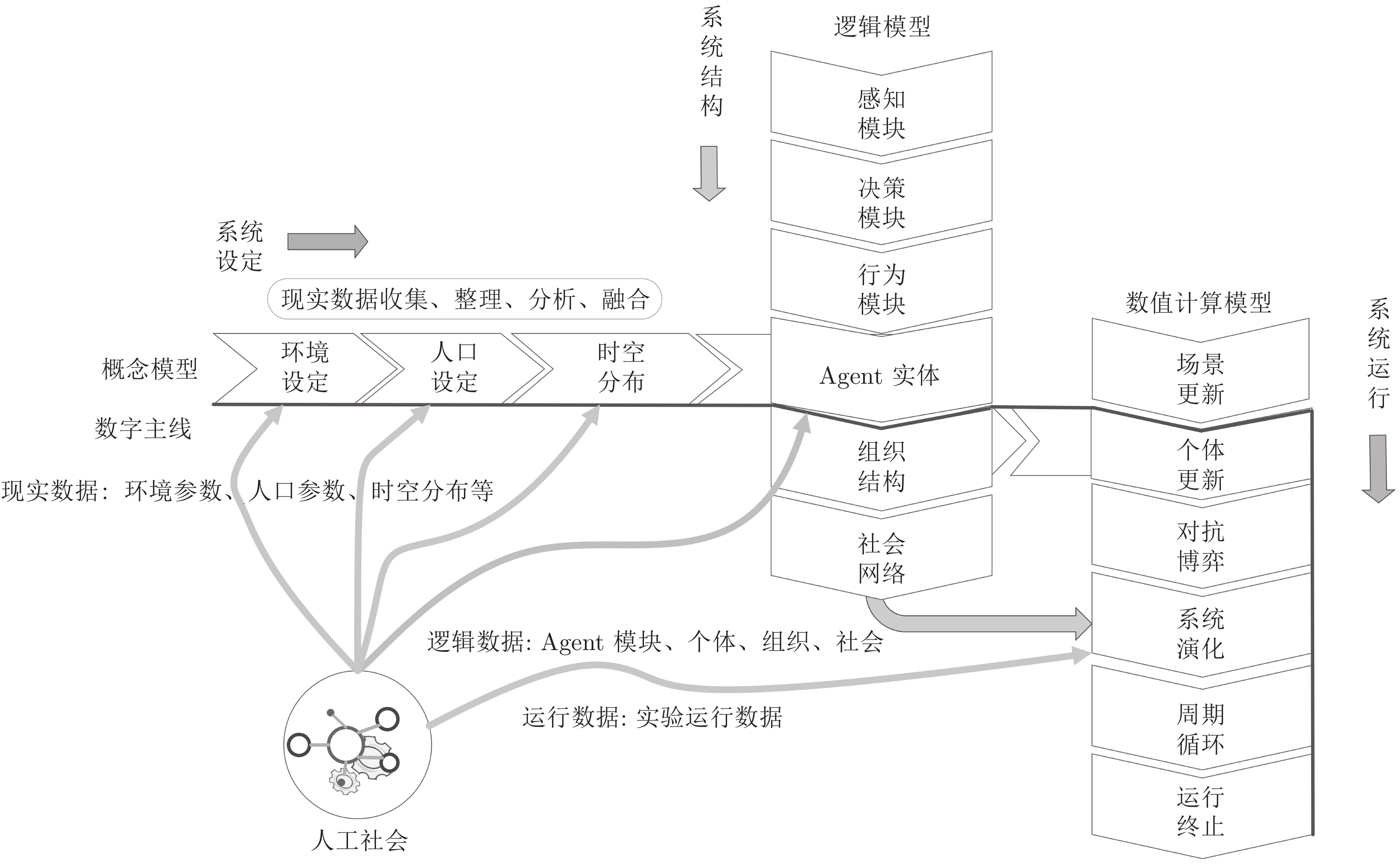
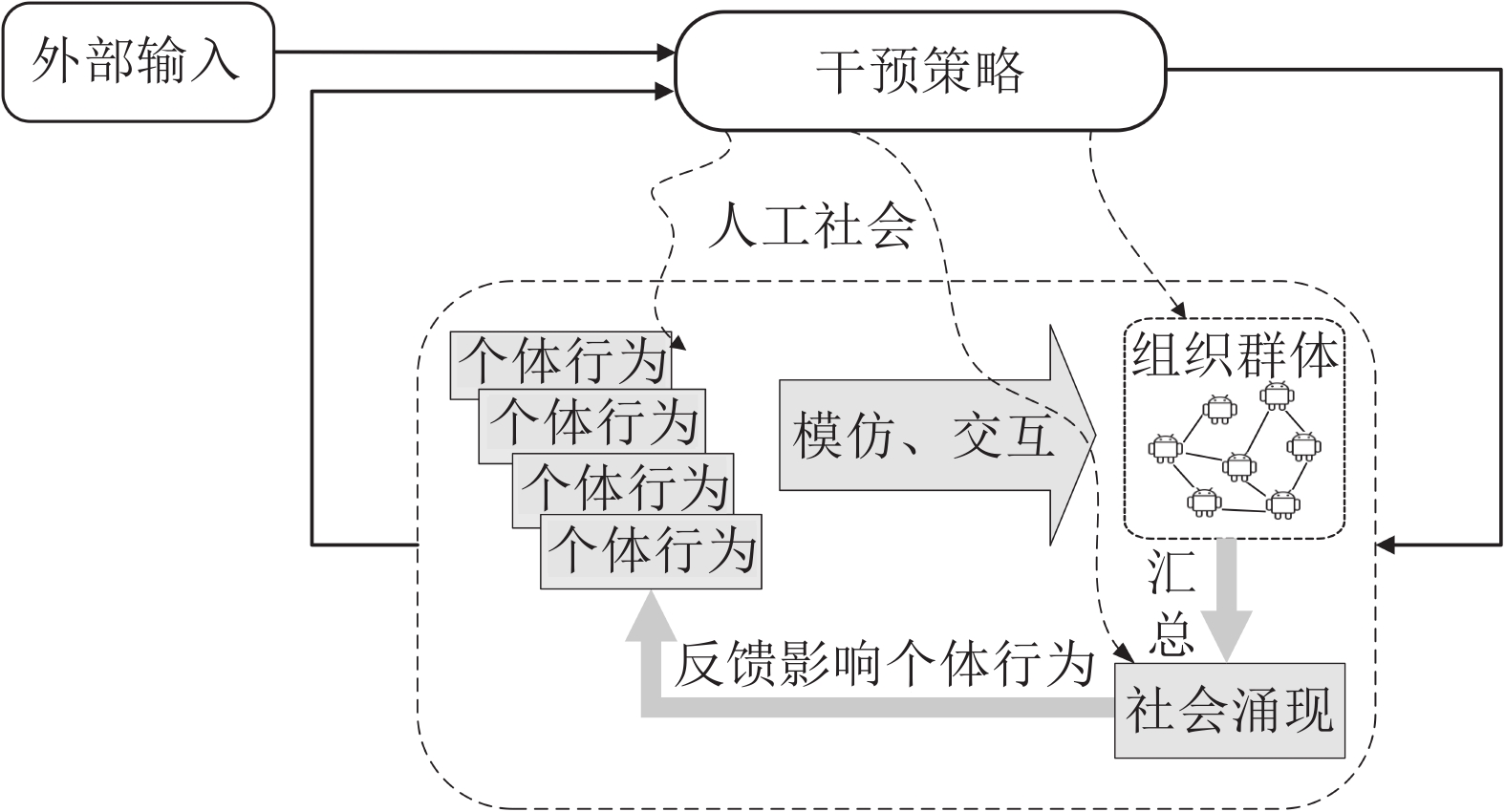
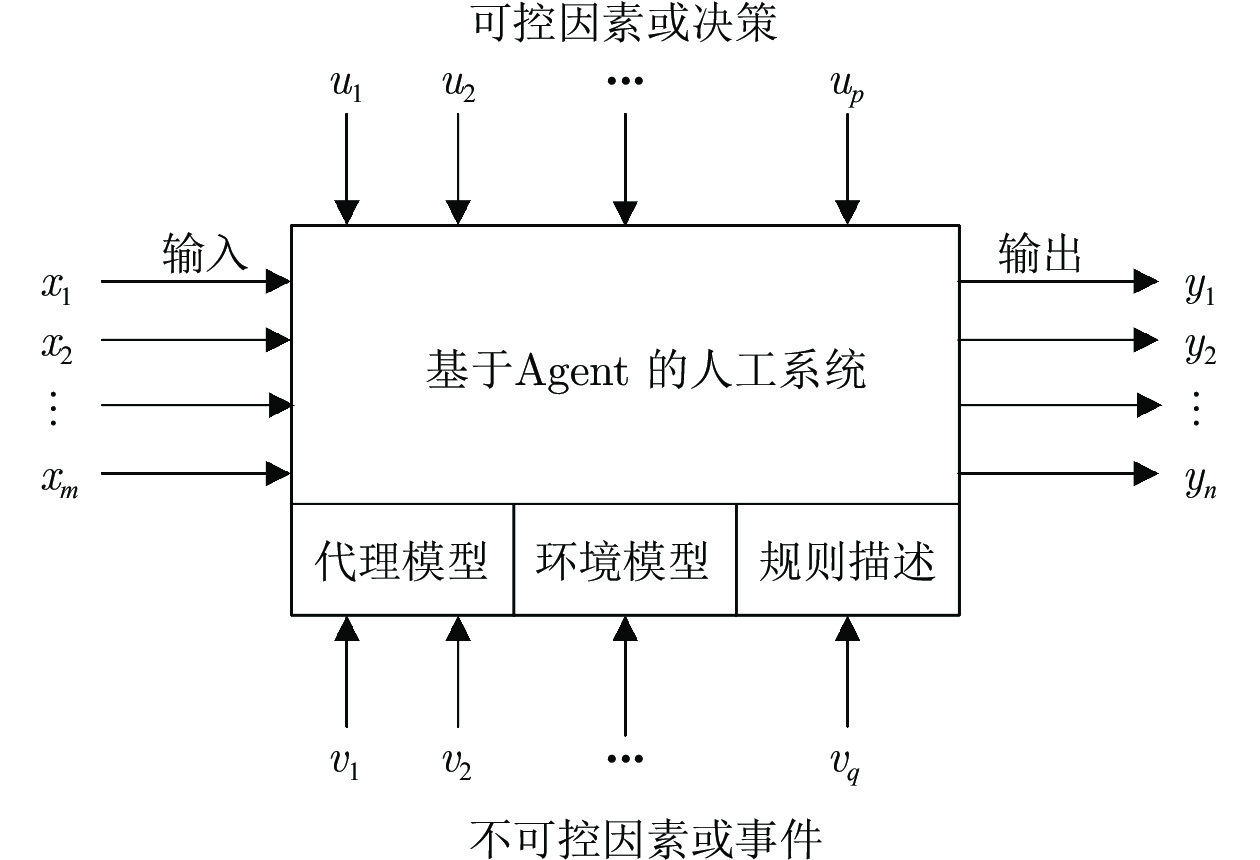
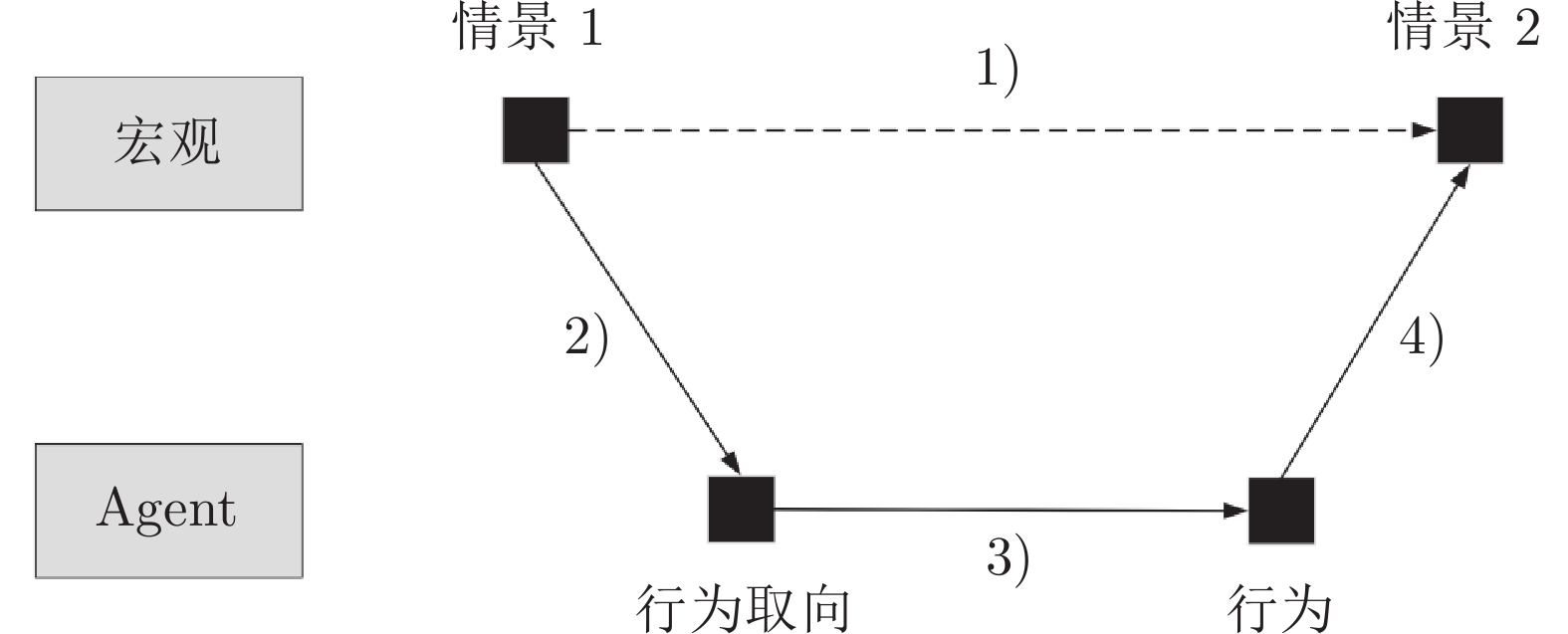
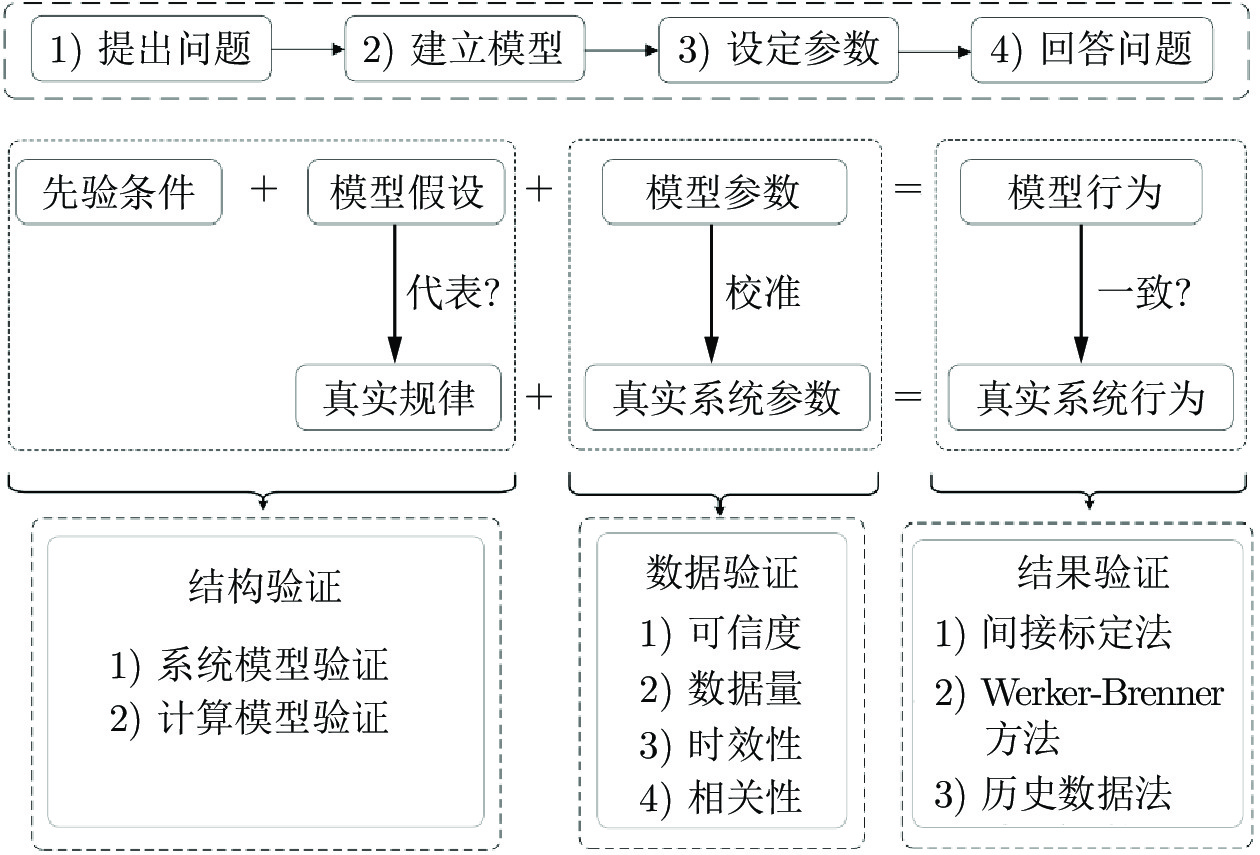
图 7 计算实验系统的运行流程图
Fig. 7 The operation flow chart of the computational experimental system
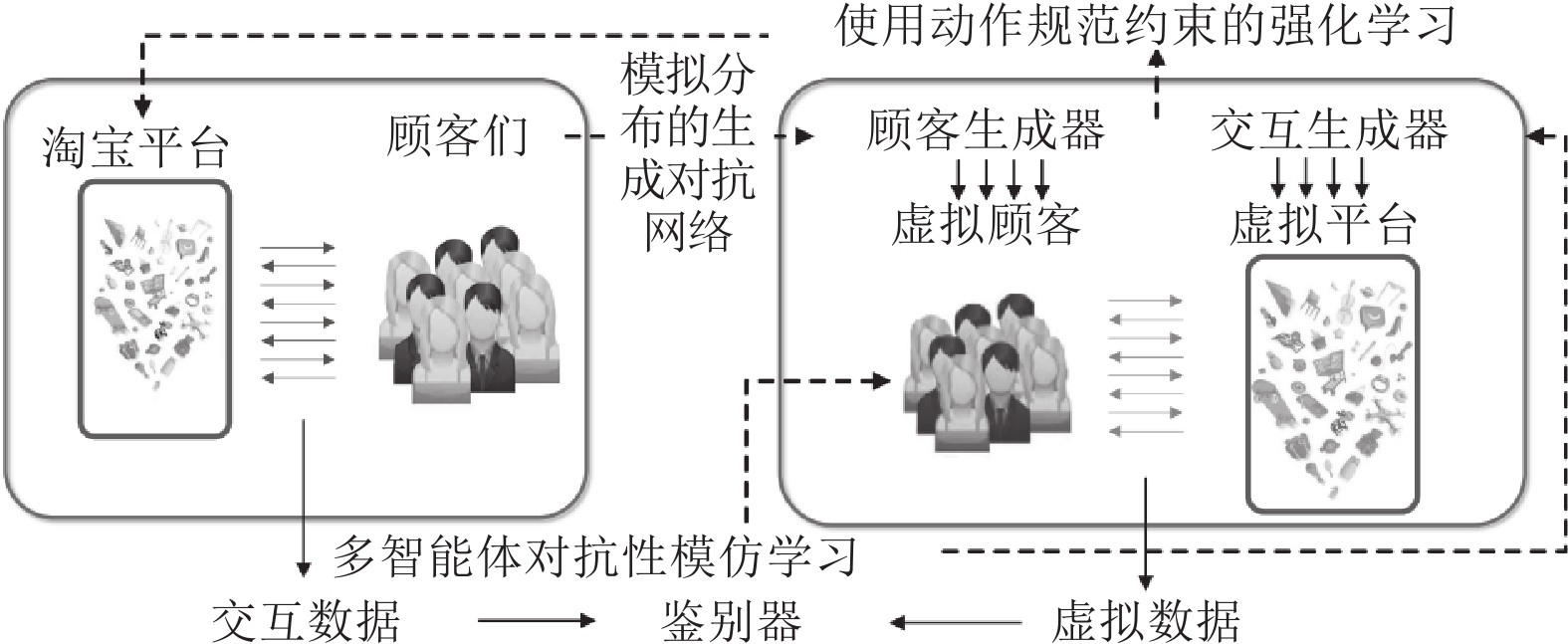
图 23 使用强化学习的虚拟淘宝架构
Fig. 23 The architecture of virtual Taobao using reinforcement learning

图 25 腾讯TAD Sim仿真系统场景演示
Fig. 25 The scene demonstration of Tencent TAD Sim simulation system
表 1 计算实验与相关概念的区别
Table 1 Differences between computational experiments and similar concepts
概念 实物实验 自然实验 (田野实验) 计算机仿真 计算实验 研究对象 在物理空间中实际进行的实验 在社会空间中实际进行的实验 在虚拟空间中对物理系统进行实验 在虚拟空间中对社会复杂系统进行实验 研究手段 通常在实验室、工厂或农场里进行, 通过控制实验条件, 进行观察实验 将受试群体暴露在自然条件或者某种特定的控制条件下, 通过观察实验组与控制组的指标变化进行实验 基于相似性原理, 采用自上而下、还原分解的方式建立与实际或设想系统之间具有同态关系的数学模型. 计算机以数值计算的方法执行求解过程, 输出与物理系统相同的结果 基于知识与学习机制, 采用自下而上的方式建立实际系统的计算模型, 能够对从未发生过的场景进行模拟推演 研究目标 构建理论与事实的桥梁, 不仅促进了理论到技术方法的转换, 也使得理论研究更加具有目的性 自己无法控制实验条件, 但通过某个意外事件, 正好创造出了符合要求的实验条件, 用以验证社会中的因果关系 关注建模的保真度, 即是否能准确反映物理对象的特性和状态, 从而指导实际物理系统的设计与优化 为实际社会复杂系统的设计、分析、管理、控制和综合提供科学决策和指导 应用领域 广泛应用于如农业、工业、制造业等领域 广泛应用于医学和社会科学的研究中, 也是心理学研究的一种重要方法 已经渗透到了各个领域, 包括交通运输、航空航天、工业制造、气象预测、电子信息产业等 与众多学科交叉融合, 成为诸多领域的重要工具, 例如计算社会学、计算经济学、计算金融学、计算组织学、计算流行病学等 局限性 实验时间较长, 由于伦理、道德、经济、社会等因素有时难以顺利开展 情境上比较真实, 而在干扰变数的处理上则比较差 由于缺乏充分可用的理论和先验知识, 自顶向下的建模方法难于对复杂系统进行准确描述并深入分析 如何证明计算模型的有效性与等价性没有取得共识, 容易遭受实验能否反映现实的质疑  下载: 导出CSV
下载: 导出CSV
表 2 典型的大规模流行病传播模拟系统特征对比
Table 2 Comparison of characteristics of typical large-scale epidemic spread simulation systems
特点 BIoWar[15] EpiSimS[68] GSAM[113] CovidSim[114] ASSOCC[115] SIsaR[116] 疾病类型 飞沫传播、物理
接触传播天花、流感 新型冠状病毒肺炎、
其他呼吸道病毒新型冠状病毒肺炎 新型冠状病毒肺炎 新型冠状病毒肺炎 主要用途 影响评估策略优化 影响评估策略优化 研究传染病的蔓延与控制 影响评估策略优化 影响评估政策权衡 评估不同干预政策的成本和收益 模拟尺度 美国中等城市 美国中等城市 全球 国家 国家 国家 模拟方法 多智能体 多智能体 多智能体 地理空间单元 多智能体 多智能体 开发语言 C++ − Java C++ Netlogo、R语言 Netlogo 可视化 否 是 是 是 是 是 开源 否 否 否 是 是 是 (可在网上运行)
下载: 导出CSV
-
[1] 王飞跃. 人工社会, 计算实验, 平行系统—关于复杂社会经济系统计算研究的讨论. 复杂系统与复杂性科学, 2004(4): 25-35 doi: 10.3969/j.issn.1672-3813.2004.04.002Wang Fei-Yue. Artificial society, computational experiments, parallel systems — a discussion on computational research of complex socio-economic systems. Complex Systems and Complexity Science, 2004(4): 25-35 doi: 10.3969/j.issn.1672-3813.2004.04.002 [2] 王飞跃, 史帝夫 $\cdot $ 兰森. 从人工生命到人工社会: 复杂社会系统研究的现状和展望. 复杂系统与复杂性科学, 2004, 1(1): 33-41 doi: 10.3969/j.issn.1001-9596.2004.05.024Wang Fei-Yue, Lansing J S. From artificial life to artificial societies——new methods for studies of complex social systems. Complex Systems and Complexity Science, 2004, 1(1): 33-41 doi: 10.3969/j.issn.1001-9596.2004.05.024[3] Prigogine I, Stengers I. Order Out of Chaos. New York: Bantam Books Inc, 1984. [4] Xue X, Wang S F, Gui B, Hou Z W. A computational experiment-based evaluation method for context-aware services in complicated environment. Information Sciences, 2016, 373: 269-286 doi: 10.1016/j.ins.2016.09.003 [5] Pearl J, Mackenzie D. Why: The New Science of Cause and Effect. New York: Basic Books, 2018. [6] Boschert S, Rosen R. Mechatronic Futures, Digital Twin: The Simulation Aspect. Cham: Springer, 2016. 59−74 [7] 王飞跃. 情报5.0: 平行时代的平行情报体系. 情报学报, 2015, 34(6): 563-574 doi: 10.3772/j.issn.1000-0135.2015.006.001Wang Fei-Yue. Intelligence 5.0: Parallel intelligence in parallel age. Journal of Information, 2015, 34(6): 563-574 doi: 10.3772/j.issn.1000-0135.2015.006.001 [8] 薛霄. 复杂系统的计算实验方法: 原理、模型与案例. 北京: 科学出版社, 2020.Xue Xiao. Computational Experiment Methods for Complex Systems: Principles, Models and Cases. Beijing: Science Press, 2020. [9] 王飞跃. 计算实验方法与复杂系统行为分析和决策评估. 系统仿真学报, 2004, 16(5): 893-897 doi: 10.3969/j.issn.1004-731X.2004.05.009Wang Fei-Yue. Computational experimental methods and complex system behavior analysis and decision evaluation. Journal of System Simulation, 2004, 16(5): 893-897 doi: 10.3969/j.issn.1004-731X.2004.05.009 [10] Li L, Wang X, Wang K. Parallel testing of vehicle intelligence via virtual-real interaction. Science Robotics, 2019, 4(28): eaaw4106 doi: 10.1126/scirobotics.aaw4106 [11] Li L, Huang W L, Liu Y. Intelligence testing for autonomous vehicles: A new approach. IEEE Transactions on Intelligent Vehicles, 2017, 1(2): 158-166 [12] Hu X F, Li Z Q, Yang J Y, Si G Y, Pi L. Some key issues of war gaming & simulation, Journal of System Simulation. 2010, 22(3): 549-553 [13] 吴江. 社会网络的动态分析与仿真实验. 武汉: 武汉大学出版社, 2012.Wu Jiang. Theory and Application of Social Network Dynamic Analysis and Simulation Experiments. Wuhan: Wuhan University Press, 2012. [14] Acevedo M F, Callicott J B, Monticino M. Models of natural and human dynamics in forest landscapes: Giorgio-site and cross-cultural synthesis. Geoforum, 2008, 39(2): 846-866 doi: 10.1016/j.geoforum.2006.10.008 [15] Carley K M, Fridsma D B, Casman E. BioWar: Scalable agent-based model of bioattacks. IEEE Transactions on Systems, Man, and Cybernetics - Part A: Systems and Humans, 2006, 36(2): 252-265 doi: 10.1109/TSMCA.2005.851291 [16] Huang C Y, Sun C T, Hsieh J L, Lin H. Simulating SARS: Small-world epidemiological modeling and public health policy assessments. Journal of Artificial Societies and Social Simulation, 2004, 7(4): 2 [17] Cioffi R C, Rouleau M. Mason rebeland: An agent-based model of politics, environment, and insurgency. International Studies Review, 2010, 12(1): 31-52 doi: 10.1111/j.1468-2486.2009.00911.x [18] Mitchell W. Complexity: The Emerging Science at the Edge of Order and Chaos. New York: Touchstone, 1992. [19] Bertalanffy L V. General System Theory. New York: Braziller, 1968. [20] Bertalanffy L V. Problems of Life: An Evaluation of Modern Biological and Scientific Thought. New York: Harper, 1952. [21] Norbert W. Cybernetics: Or Control and Communication in the Animal and the Machine. Massachusetts: MIT Press, 1961. [22] Shannon C E. A mathematical theory of communication. Bell System Technical Journal, 1948, 27(3): 379-423 doi: 10.1002/j.1538-7305.1948.tb01338.x [23] Prigogine J. Structure, dissipation and life, theoretical physics and biology. Theoretical Physics and Biology, 1969: 23-52 [24] Thom R. Structural Stability and Morphogenesis. Boca Raton: CRC Press, 2018. [25] Haken H P J. Synergetics. IEEE Circuits & Devices Magazine, 1977, 28(9): 412-414 [26] Li T Y, Yorke J A. Period three implies chaos. The American Mathematical Monthly, 1975, 82(10): 985-992 doi: 10.1080/00029890.1975.11994008 [27] Mandelbrot B B. Fractals, form, chance and dimension. The Mathematical Gazette, 1978, 62(420): 130-132 doi: 10.2307/3617679 [28] Bak P, Tang C, Wiesenfeld K. Self-organized criticality: An explanation of noise. Physical Review Letters, 1987, 59(4): 381-384 doi: 10.1103/PhysRevLett.59.381 [29] Holland J H. Adaptation in Natural and Artificial Systems: An Introductory Analysis with Applications to Biology, Control, and Artificial Intelligence. New York: MIT press, 1992. [30] Watts D J, Strogatz S H. Collective dynamics of ‘small-world’ networks. Nature, 1998, 393(6684): 440 doi: 10.1038/30918 [31] Barabási A L, Albert R. Emergence of scaling in random networks. Science, 1999, 286(5439): 509-512 doi: 10.1126/science.286.5439.509 [32] Neumann J. Theory of Self-reproducing Automata. Urbana: University of Illinois Press, 1966. [33] John Conway. Conway's game of life [Online], available: https://conwaylife.com/wiki/Conway%27s_Game_of_Life, June 25, 2022 [34] Langton C G. Artificial life in 1991 lectures in complex systems. Addison-Wesley Reading, 1992: 189-241 [35] Wolfram S. Random sequence generation by cellular automata. Advances in Applied Mathematics, 1986, 7(2): 123-169 doi: 10.1016/0196-8858(86)90028-X [36] Teruyam, Nakao Z, Chen Y W. A boid-like example of adaptive complex systems. In: Proceedings of the IEEE International Conference on Systems. Hawaii, USA: IEEE, 1999. 1−5 [37] Dorigo M, Birattari M, Stutzle T. Ant colony optimization. IEEE Computational Intelligence Magazine, 2006, 1(4): 28-39 doi: 10.1109/MCI.2006.329691 [38] Gilbert N, Troitzsch K G. Simulation for the Social Scientist 2nd Edition. Berkshire: Open University Press, 2005. [39] Swarm main page [Online], available: http://www.swarm.org, April 3, 2021 [40] Repastsource [Online], available: https://repast.github.io/index.html, April 1, 2021 [41] Parker M T. What is ascape and why should you care. Journal of Artificial Societies and Social Simulation, 2001, 4(1): 5 [42] Tisue S, Wilensky U. Netlogo: A simple environment for modeling complexity. In: Proceedings of the International conference on Complex Systems. Shanghai, China: 2004. 16−21 [43] Carl H, Steven C B. Artificial Societies: A Concept for Basic Research on the Societal Impacts of Information Technology. Santa Monica: RAND Corporation, 1991. [44] Nigel G. Rosaria Conte: Artificial Societies, the Computer Simulation of Social Life. London: University College London Press, 1995. [45] Epstein J M, Axtell R. Growing Artificial Societies: Social Science From the Bottom Up. Washington: Brookings Institution Press, 1996. [46] Arthur W B, Holland J, LeBaron B, Palmer R, Tayler P. Asset pricing under endogenous expectations in an artificial stock market. The Economy as an Evolving Complex System II. 1997: 15−44 [47] Basu N, Pryor R, Quint T. ASPEN: A microsimulation model of the economy. Computational Economics, 1998, 12: 223-241 doi: 10.1023/A:1008691115079 [48] Wang F Y. Shadow Systems: A New Concept for Nested and Embedded Co-simulation for Intelligent Systems. Tucson: University of Arizona, 1994. [49] Grieves M W. Virtually intelligent product systems: Digital and physical twins. Complex Systems Engineering: Theory and Practice, 2019. [50] Farsi M, Daneshkhah A, Hosseinian F A, Jahankhani H. Digital Twin Technologies and Smart Cities. Cham: Springer, 2020. [51] Wang F Y. Parallel system approach and management and control of complex systems. The Journal of Control and Decision, 2004, 19(5): 485-489 [52] Wang F Y. Toward a paradigm shift in social computing: The ACP approach. IEEE Intelligent Systems, 2007, 22(5): 65-67 doi: 10.1109/MIS.2007.4338496 [53] Wang F Y, Li X, Mao W. An ACP-based approach to intelligence and security informatics. Studies in Computational Intelligence, 2015, 563(1): 69-86 [54] Mei H. Understanding ‘software-defined’ from an OS perspective: Technical challenges and research issues. Science China Information Sciences, 2017, 60(12): 126101 doi: 10.1007/s11432-017-9240-4 [55] Busoniu L, Babuska R, Schutter B. A comprehensive survey of multiagent reinforcement learning. IEEE Transactions on Systems, Man, and Cybernetics, 2008, 38(2): 156-172 doi: 10.1109/TSMCC.2007.913919 [56] Xue X, Wang S F, Zhang L J, Feng Z Y, Guo Y D. Social learning evolution (SLE): Computational experiment-based modeling framework of social manufacturing. IEEE Transactions on Industrial Informatics, 2019, 15(6): 3343-3355 doi: 10.1109/TII.2018.2871167 [57] Wilensky U. Netlogo heatbugs model [Online], available: ht-tp://ccl.northwestern.edu/netlogo/models/Heatbugs. Novemb-er 16, 2020 [58] Schelling T C. Dynamic models of segregation. Journal of Mathematical Sociology, 1971, 1(2): 143-186 doi: 10.1080/0022250X.1971.9989794 [59] 张维. 计算实验金融研究. 北京: 科学出版社, 2010.Zhang Wei. Agent-based Computational Finance: An Alternative Way to Understand the Markets. Beijing: Science Press, 2010. [60] Carley K M, Gasser L. Multiagent Systems: A Modern Approach to Distributed Artificial Intelligence. Cambridge: MIT Press, 1999. [61] Marathe M, Vullikanti A K S. Computational epidemiology. Communications of the ACM, 2013, 56(7): 88-96 doi: 10.1145/2483852.2483871 [62] 盛昭瀚. 社会科学计算实验理论与应用. 上海: 上海三联书店, 2009.Sheng Zhao-Han. Experimental Theory and Application of Co-mputing in Social Sciences. Shanghai: Shanghai Sanlian Book-store, 2009. [63] Lazer D, Pentland A, Adamic L. Social science. Computational social science. Science, 2009, 323(5915): 721-723 doi: 10.1126/science.1167742 [64] Lazer D M J, Pentland A, Watts D J. Computational social science: Obstacles and opportunities. Science, 2020, 369(6507): 1060-1062 doi: 10.1126/science.aaz8170 [65] Goodfellow I J, Pouget A J, Mirza M. Generative adversarial networks. Advances in Neural Information Processing Systems, 2014, 3:2672-2680. [66] Nigel G, Rosaria C. Artificial Societies: The Computer Simulation of Social Life. London: University College London Press, 1995. [67] Xue X, Chen F Y, Zhou D Y, Wang X, Lu M, Wang F Y. Computational experiments for complex social systems part I: The customization of computational model, IEEE Transactions on Computational Social Systems, 2021. [68] Mniszewski S M, Del Valle S Y. EpiSimS: Large-scale Agent-based Modeling of the Spread of Disease, LA-UR-13-23236, Los Alamos National Laboratory, United States Department of Energy, USA, 2013 [69] 邱晓刚, 陈彬, 张鹏. 面向应急管理的人工社会构建与计算实验. 北京: 科学出版社, 2017.Qiu Xiao-Gang, Chen Bin, Zhang Peng. Artificial Society Construction and Computational Experiment for Emergency Management. Beijing: Science Press, 2017. [70] Jain A K, Mao J, Mohiuddin K M. Artificial neural networks: A tutorial. Computer, 1996, 29(3): 31-44 doi: 10.1109/2.485891 [71] Whitley D. A genetic algorithm tutorial. Statistics and Computing, 1994, 4(2): 65-85 [72] Alavi M, Henderson J C. An evolutionary strategy for implementing a decision support system. Management Science, 1981, 27(11): 1309-1323 doi: 10.1287/mnsc.27.11.1309 [73] Kennedy J, Eberhart R. Particle swarm optimization. In: Proceedings of the ICNN International Conference on Neural Networks. Perth, Australia: 1995. 1942−1948 [74] Karaboga D, Akay B. A comparative study of artificial bee colony algorithm. Mathematics and Computation, 2009, 214(1), 108-132 doi: 10.1016/j.amc.2009.03.090 [75] Dodds P S, Watts D J. A generalized model of social and biological contagion. Journal of Theoretical Biology, 2005, 232(4): 587-604 doi: 10.1016/j.jtbi.2004.09.006 [76] Chen W, Yuan Y, Zhang L. Scalable influence maximization in social networks under the linear threshold model. In: Proceedings of the IEEE International Conference on Data Mining. Sydney, Australia: IEEE, 2010. 88−97 [77] Hoppitt W, Laland K N. Social Learning: An Introduction to Mechanisms, Methods, and Models. Washington: Princeton Uni-versity Press, 2013. [78] Bachelor G, Brusa E, Ferretto D, Mitschke A. Model-based design of complex aeronautical systems through digital twin and thread concepts. IEEE Systems Journal, 2020, 14(2): 1568-1579 doi: 10.1109/JSYST.2019.2925627 [79] Wang F Y, Zheng N N, Cao D. Parallel driving in CPSS: A unified approach for transport automation and vehicle intelligence. IEEE / CAA Journal of Automatica Sinica, 2017, 4(4): 577-587 doi: 10.1109/JAS.2017.7510598 [80] Li L, Lin Y L, Zheng N N. Artificial intelligence test: A case study of intelligent vehicles. Artificial Intelligence Review, 2018, 50(3): 441-465 doi: 10.1007/s10462-018-9631-5 [81] Montgomery D C. Design and Analysis of Experiments. Hobo-ken: John Wiley & Sons, 2017. [82] 崔凯楠, 郑晓龙, 文丁, 赵学亮. 计算实验研究方法及应用. 自动化学报, 2013, 39(8): 1157-1169Cui Kai-Nan, Zheng Xiao-Long, Wen Ding, Zhao Xue-Liang. Researches and applications of computational experiments. Acta Automatica Sinica, 2013, 39(8): 1157-1169 [83] Fang K T, Lin D K J, Winker P, Zhang Y. Uniform design: Theory and application. Technometrics, 2000, 42(3): 237-248 doi: 10.1080/00401706.2000.10486045 [84] Marcos L P. Machine Learning for Asset Managers. Cambridge: Cambridge University Press, 2020. [85] Xue X, Feng Z Y, Chen S Z, Zhou Z B, Qin C Z, Li B, et al. Service ecosystem: A lens of smart digital society. IEEE International Conference on Services Computing (SCC 2021), p263−273 [86] Xue X, Zhou D Y, Chen F Y, Yu X N, Feng Z Y, Duan Y C, et al. From SOA to VOA: A shift in understanding the operation and evolution of service ecosystem. IEEE Transactions on Services Computing, 2021. [87] Frow P, McColl-Kennedy J R, Hilton T, McColl-Kennedy J, Hilton T, Davidson A, et al. Value propositions-a service ecosystem perspective. Marketing Theory, 2014, 14(3): 327-351 doi: 10.1177/1470593114534346 [88] Vargo, S L, Maglio, P P, Akaka, M A. On value and value co-creation: A service systems and service logic perspective. European Management Journal, 2008, 26: 145-152 [89] Kil H, Oh S, Elmacioglu E, Nam W, Lee D. Graph theoretic topological analysis of web service networks, World Wide Web, 2009, (12): 321-343 [90] Huang K, Fan Y, Tan W. An empirical study of programmable web: A network analysis on a service-mashup system. In: Proceedings of the 19th International Conference on Web Services. Honolulu, USA: IEEE, 2012. 552−559 [91] 马于涛, 何克清, 李兵, 刘婧. 网络化软件的复杂网络特性实证. 软件学报, 2011, 22(3): 381-407 doi: 10.3724/SP.J.1001.2011.03934Ma Yu-Tao, He Ke-Qing, Li Bin, Liu Jing. Empirical evidence of complex network characteristics of networked software. Journal of Software, 2011, 22(3): 381-407 doi: 10.3724/SP.J.1001.2011.03934 [92] Grieves M. Digital twin: Manufacturing excellence through virtual factory replication. White paper, 2014, 1: 1-7 [93] Burt R S. Structural Holes: The Social Structure of Competition. Cambridge: Harvard university press, 2009. [94] Fischer R, Scholten U, Scholten S. A reference architecture for feedback-based control of service ecosystems. In: Proceedings of the 4th IEEE International Conference on Digital Ecosystems and Technologies. Dubai, United Arab Emirates: IEEE, 2010, 1−6 [95] Diao Y. Using control theory to improve productivity of service systems. In: Proceedings of the IEEE International Conference on Services Computing. Salt Lake City, USA: 2007. 435− 442 [96] Kahn H, Wiener A J. The next thirty-three years: A framework for speculation. Daedalus, 1967: 705-732 [97] Douglas H J. Time Series Analysis. Princeton: Princeton University Press, 2020. [98] 李大宇, 米加宁, 徐磊. 公共政策仿真方法: 原理, 应用与前景. 公共管理学报, 2011, 8(4): 8-20Li Da-Yu, Mi Jia-Ning, Xu Lei. Simulation methods for public policy: Principles, applications and prospects. Journal of Public Administration, 2011, 8(4): 8-20 [99] Bar-Yam Y. From big data to important information. Complexity, 2016, 21(S2): 73-98 doi: 10.1002/cplx.21785 [100] Zenil H, Kiani N A, Zea A A, J. Tegnér. Causal deconvolution by algorithmic generative models. Nature Machine Intelligence, 2019, 1(1): 58-66 doi: 10.1038/s42256-018-0005-0 [101] Yang M, Xiong Z J. Model validation – methodological problems in agent-based modeling, System Engineering – Theory & Practice, 2013, 33(6): 1458-1470 [102] Gao J, Zhang Y C, Zhou T. Computational socioeconomics. Physics Reports, 2019, 817: 1-104 doi: 10.1016/j.physrep.2019.05.002 [103] Lu M, Chen S Z, Xue X, Wang X, Zhang Y F, Wang F Y. Computational experiments for complex social system part II: The evaluation of computational model, IEEE Transactions on Computational Social Systems, 2021. [104] Sundberg R. Multivariate calibration-direct and indirect regression methodology. Scandinavian Journal of Statistics, 1999, 26(2): 161-207 doi: 10.1111/1467-9469.00144 [105] Werker C, Brenner T. Empirical Calibration of Simulation Models, Report No.0410. Papers on Economics and Evolution, Philipps University of Marburg, Germany, 2004 [106] Malerba F, Nelson R, Orsenigo L. ‘History-friendly’ models of industry evolution: The computer industry. Industrial and Corporate Change, 1999, 8(1): 3-40 doi: 10.1093/icc/8.1.3 [107] Markisic S, Neumann M, Lotzmann U. Simulation of ethnic conflicts in former jugoslavia. In: Proceedings of the Internati-onal Conference on Energy, Chemical, Materials Science. Kobl-enz, Germany: 2012. 37−43 [108] Ravi B, Miodownik D, Nart J. Rescape: An agent-based framework for modeling resources, ethnicity, and conflict. The Journal of Artificial Societies and Social Simulation, 2008, 11(27) [109] Laver M, Sergenti E. Party Competition: An Agent-based Mo-del. Princetion: Princeton University Press, 2012. [110] Paul E J. Agent-based modeling: What I learned from the artificial stock market. Social Science Computer Review, 2002, 20(2): 174-186 doi: 10.1177/089443930202000207 [111] Yeh C H, Yang C Y. Examining the effectiveness of price limits in an artificial stock market. Journal of Economic Dynamics and Control, 2010, 34(10): 2089-2108 doi: 10.1016/j.jedc.2010.05.015 [112] Xue X, Gao J J, Wang S F, Feng Z Y. Service bridge: Transboundary impact evaluation method of internet. IEEE Transactions on Computational Social Systems, 2018, 5(3): 758-772 doi: 10.1109/TCSS.2018.2858565 [113] Epstein J M. Modelling to contain pandemics. Nature, 2009, 460(7256): 687-687 doi: 10.1038/460687a [114] Schneider K A, Ngwa G A, Schwehm M. The COVID-19 pandemic preparedness simulation tool: CovidSIM. BMC Infectious Diseases, 2020, 20(1): 1-11 doi: 10.1186/s12879-019-4717-5 [115] Ghorbani A, Lorig F, Bruin B. The ASSOCC simulation model: A response to the community call for the Covid-19 pandemic [Online], available: https://rofasss.org/2020/04/25/the-asso-cc-simulation-model, April 1, 2021 [116] Pescarmona G, Terna P, Acquadro A, Pescarmona P, Russo G, Terna S. How can ABM models become part of the policy-making process in times of emergencies — The S.I.S.A.R. epidemic model [Online], available: https://rofasss.org/2020/10/20/sisar/, April 1, 2022 [117] Shi J C, Yu Y, Da Q. Virtual-taobao: Virtualizing real-world online retail environment for reinforcement learning. In: Proce-edings of the AAAI Conference on Artificial Intelligence. Haw-aii, USA: 2019. 4902−4909 [118] Zheng S, Trott A, Srinivasa S. The AI economist: Improving equality and productivity with ai-driven tax policies. arXiv pr-eprint arXiv: 2004.13332v1. 2004 [119] Peter D, Emmanuel S. The case for a progressive tax: From basic research to policy recommendations. Journal of Economic Perspectives, 2011, 25(4): 165-190 doi: 10.1257/jep.25.4.165 [120] Robert E, Kelli L. Decision making in a virtual environment: Effectiveness of a semi-immersive ‘Decision Theater’ in understanding and assessing human-environment interactions. AutoCarto. 2006, 8: 1922 [121] The decision theather. Arizona State University. [Online]. ava-ilable: http://dt.asu.edu/, April 1,2022 -

 下载:
下载:















计量
- 文章访问数: 3752
- HTML全文浏览量: 3131
- PDF下载量: 2146
- 被引次数: 0
