

A Multi-correlated Time-delay Estimation Method in the Blast Furnace Ironmaking Process Based on Time-series Correlation Matrix
-
摘要: 高炉冶炼过程由炉料传输反应时间和冶炼单元在空间和时间分布上的差异带来的变量时延影响了数据的准确性和真实因果关系, 因此有效地估计过程变量间的时延信息, 并在时序上配准数据, 是后续过程建模、优化控制与性能评估的核心. 考虑到变量间时延的多重关联性, 提出了一种基于时序关联矩阵的时延参数估计方法. 首先, 根据过程变量的时延参数在时空上重构对应的时序关联矩阵, 并引入灰色关联分析量化时序矩阵的多重关联相关性; 接着, 考虑到穷举所有时序关联矩阵的时间复杂度, 提出了一种双尺度协同搜索策略的动态多群粒子群算法用于快速寻找最优的时延参数, 提出的粒子群算法能兼顾全局探索能力和局部探测能力并跳出局部最优解; 最后, 基于一个数值仿真和某钢铁厂2# 高炉的工业实验验证了所提时延参数估计方法的可行性和有效性, 且通过所提方法在时序上重构的数据能有效提高后续硅含量软测量模型性能.Abstract: Variable time-delay is brought by transportation and reaction time of materials and the different distributions of smelting units in spatial and temporal, which affects the accuracy and the actual causal relationship of collected data. Therefore, the estimation of variable time-delay information and the reconstruction of data in time series effectively are the key points of subsequent process modeling, optimal control, and performance evaluation. Considering the multiple correlations characteristic of variable time-delay, an estimation method based on a time-series correlation matrix is proposed. First, the time-series correlation matrix is reconstructed in time and space according to the time-delay parameters, where grey correlation analysis is used to quantify the multi-correlated correlation. Then, considering the number of time-series correlation matrices and the time complexity of the exhaustive method, a dynamic multi-swarm particle swarm optimization based on a double-scale collaborative search strategy is proposed to search for the optimal time-delay parameters. The proposed optimization algorithm can consider both global exploration and local exploitation ability and escape local optimal solutions. Finally, the feasibility and effectiveness of the proposed time-delay estimation method are verified by a numerical simulation and an industrial experiment of 2# blast furnace in a steel plant. In addition, a significant improvement can be observed in the performance of the soft-sensor model of silicon content with the reconstruction of data in time series.
-
蝴蝶种类的识别与鉴定在农林业生产与保护、艺术生活等方面均具有重要意义.蝴蝶种类极其丰富多样, 《世界蝴蝶分类名录》 [1]记录了世界蝴蝶17科、47亚科、1 690属、15 141种, 其中记载中国蝴蝶12科、33亚科、434属、2 153种.自2016年我国环境保护部启动了蝴蝶多样性观测工作[2], 全国蝴蝶观测数据库的数据量呈现海量增长.如何对生态蝴蝶及时且准确地检测, 这对昆虫分类学专家是一个很大的挑战.因此, 自然生态蝴蝶种类检测问题已成为促进蝴蝶相关领域研究与应用的关键问题之一.
随着机器学习发展与应用, 为实现蝴蝶自动、快速、准确地检测与识别创造了有利条件. 2013年Kang等[3]提出了一种基于分支长度相似熵的形状识别方法, 使用BLS熵谱(Branch length similarity, BLS)作为BP神经网络的输入特征训练网络来识别蝴蝶. 2014年Kaya等[4]先后尝试了Gabor特征、颜色和纹理特征与极限学习机、人工神经网络以及Logistic回归等方法相结合, 探讨蝴蝶自动识别方法. 2015年李凡[5]提出基于蝴蝶形态与纹理分布规律的特征提取与优化方法, 采用改进的K最近邻[6] (K-nearest neighbor, KNN)分类算法进行分类, 研究并实现了50种蝴蝶的自动分类方法.近年来, 基于深度学习的蝴蝶目标检测取得了良好的检测结果, 主要原因是卷积神经网络可直接从图像像素级提取具有更加强大表征力的特征[7-8]. 2016年Liu等[9]使用基于全局对比区域的方法来计算病虫害目标位置的显著性特征图, 再由深度卷积补缀网络(Deep convolution neural network, DCNN)对图像特征进行分类, 但此方法未考虑目标与背景相似等实例. 2017年周爱明等[10]使用CaffeNet模型在蝴蝶标本图像和180幅生态蝴蝶图像上, 通过训练不同的后验概率支持向量机做分类器来实现蝴蝶分类.以上算法大多是对标本模式照进行识别, 不能直接应用在生态蝴蝶的检测问题上. 2018年谢娟英等[11]构建基于Faster R-CNN [12]的蝴蝶自动检测系统, 采用蝴蝶模式照图像和生态照图像对其模型进行训练, 然后在蝴蝶生态照片中实现对94类蝴蝶的自动检测, 并使用ZF [13]、VGG_CNN_M_1024 [14]、VGG16 [15]三种预训练网络做算法自身对比实验, 并且均优于对比算法YOLO-v2 [16]、YOLO-v3 [17]模型.
综上所述, 现有的生态蝴蝶检测任务与相关算法目前仍存在以下三个问题: 1)算法基本以蝴蝶标本模式照图像进行识别研究, 偏向于单纯的分类任务, 而在生态照图像上的拓展能力较弱; 2)所使用的数据集中包含的蝴蝶类别偏少, 因此建立的识别模型泛化能力较低; 3)对蝴蝶的分类一般到科级, 而对亚科到种名的精细区分较为困难.
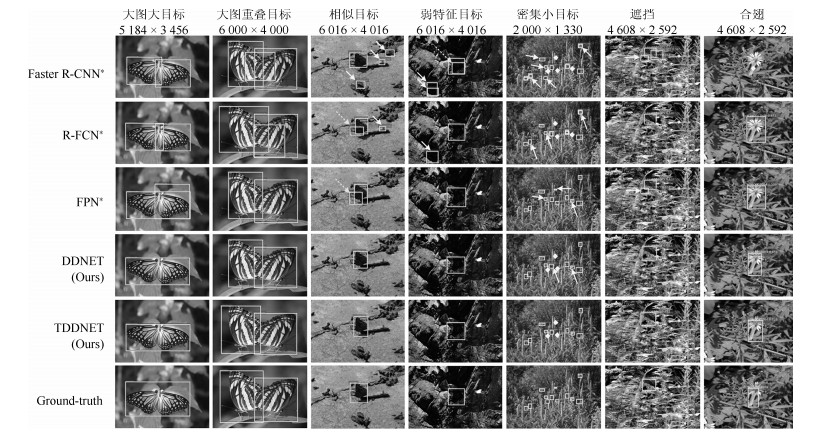
由于采集的蝴蝶生态照图像常会受到光照和观察点变化的影响, 多种类蝴蝶目标检测任务则成为了挑战性的视觉检测任务之一.在自然生态照蝴蝶检测任务数据集[11]上更具挑战性的因素有: 1)待检测的蝴蝶生态图像分辨率迥异(最大7 630像素~4 912像素与最小800像素~450像素), 且蝴蝶类别要求细分至种名; 2) 94类蝴蝶多特征与多尺度, 且形态变化较大; 3)背景复杂:蝴蝶与背景相似性高; 4)蝴蝶重叠、曝光不足进一步导致检测难等.如图 1所示为蝴蝶生态照示例.
针对上述问题和挑战, 本文提出了一种基于迁移学习和可变形卷积深度神经网络的蝴蝶检测算法(TDDNET), 可对蝴蝶自然生态照中不同种名的94类蝴蝶实现较高精度检测.
1. 本文所提算法
本文提出了一种基于迁移学习和可变形卷积深度神经网络的蝴蝶检测算法(TDDNET).主要包括底层特征学习和模型迁移两个阶段, 所提算法框架如图 2所示, 在第一阶段构建了二分类检测网络(DNET-base)强化特征学习能力; 第二阶段则由模型迁移方法优化TDDNET的检测性能.其中, 第一阶段又分为两个部分: 1)通过可变形卷积模型重建ResNet-101 [18]特征提取层; 2)结合RPN [12]网络构建一个二分类检测网络(DNET-base), 对蝴蝶目标和背景进行分离训练, 增强网络对蝴蝶特征学习能力, 使得网络对蝴蝶的检出率更高.而第二阶段则可分为三个部分: 1)以DNET-base网络模型为基础, 保持特征提取网络模块的参数不变; 2)重新构建RoI [12]池化模块, 以RPN网络指导敏感位置区域可变形RoI池化过程, 获得多尺度目标的评分特征图和精准位置信息; 3)通过Soft-max和Soft-NMS [19]进行多分类优化, 最终形成TDDNET模型.
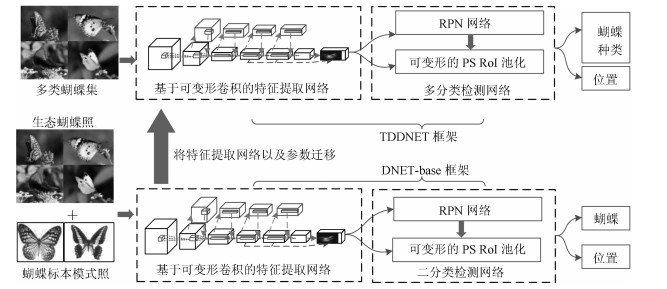 图 2 本文所提算法TDDNET的原理框架示意图Fig. 2 Schematic diagram of TDDNET's principle framework proposed in this paper
图 2 本文所提算法TDDNET的原理框架示意图Fig. 2 Schematic diagram of TDDNET's principle framework proposed in this paper在模型训练过程中:先将蝴蝶数据归为一类, 通过训练重构的可变形卷积ResNet-101使得DNET-base模型对蝴蝶特征的提取能力最大化; 而后将DNET-base特征提取网络和参数迁移至TDDNET模型, 再重新训练TDDNET的多分类器.这种方法可使TDDNET网络的收敛性变得更快更稳定.下面, 将本文所提算法详述如下.
1.1 可变形卷积
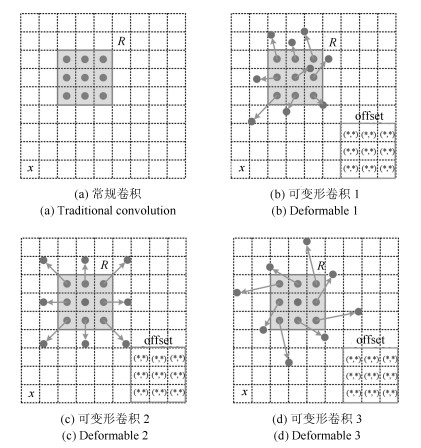
在蝴蝶的自然生态照中, 蝴蝶多姿多样, 色彩斑斓, 并且部分蝴蝶伪装能力极强.因此通过大量数据与数据增强使常规卷积网络完全"记忆"生态蝴蝶的多样变化较为困难.因为常规卷积网络在构建模型变换时被限制于固定的几何结构, 这种局限性决定了卷积单元在输入图像上只能在固定位置上采样, 造成卷积层提取的特征表征能力较弱.在类似卷积的池化过程也只能在固定的比例下降低特征空间分辨率, 致使特征丢失严重, 进一步导致损失函数的拟合能力弱和网络检测精度较差.为解决上述问题, 本文所提算法中采用Dai等[20]提出的可变形卷积模型, 重新构建ResNet [18]网络结构, 以及RoI兴趣区域池化模型来提升网络检测性能.如图 3所示, 为常规卷积与可变形卷积采样方式示例.
可变形的卷积模型引入了空间几何形变的学习能力, 从而更好地适应空间形变的目标特征提取与目标检测任务.如图 3 (b)~3 (d)所示, 在可变形卷积中将常规的网格拓展为拥有偏置量$ \{ \Delta {p_n}|n = 1, \cdots, N\} $的偏置矩阵Offset, 其中$ N = |R| $.对输入图像中的每一个在$ {p_0} $位置上的变形卷积如式(1)所示.
$ \begin{equation} y({p_n}) = \sum\limits_{{p_n} \in R } {\omega ({p_n})} x({p_0} + {p_n} + \Delta {p_n}) \end{equation} $
(1) 其中, $ \Delta {p_n} $为偏置量, 且是一个分数, $ \omega(*) $为采样点权重.然而, 这样的操作引入了一个新问题, 即需要对不连续的位置变量求导.借鉴Jaderberg等[21]的双线性插值的思想来求解.偏置矩阵通过一个同输入图像一样大小的卷积层学习而来, 如图 4所示, 即获得的偏置域的大小与输入图像的大小一致, 其中通道维度$ 2N $对应$ N $个二维的偏置矩阵.卷积核与现有的卷积一样具有相同的空间解析度和扩展度(如在图 4中$ 3 \times 3 $的核扩展度为1).同样, 将得到的特征图送入下一个卷积层时, 采用一样的可变形卷积模型提取特征.在训练时, 同时学习用于产生输出特征的卷积内核和偏置矩阵.
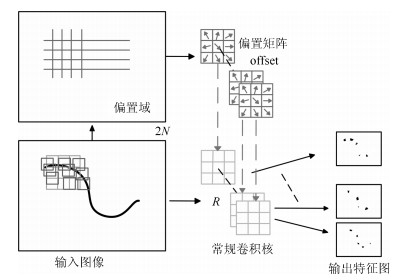 图 4 $3 \times 3$可变形卷积特征计算过程示例Fig. 4 An example of deformable convolution feature calculation process ($3 \times 3$)
图 4 $3 \times 3$可变形卷积特征计算过程示例Fig. 4 An example of deformable convolution feature calculation process ($3 \times 3$)因偏置矩阵使卷积的采样位置可自由变换, 偏置矩阵定义了$ R $接受域的大小和扩张量, 所以可变形卷积的偏置域指向的采样点对目标趋向性较强, 则输出特征信息就较多.这种自适应确定蝴蝶形变尺度和蝴蝶位置的方法在检测中是非常有效的.如图 5所示, 当可变形卷积效果堆叠时, 其模型的复合变形对特征提取能力的提升影响也较大.
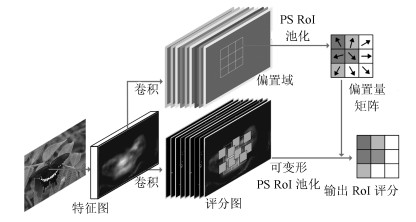
1.2 可变形的位置敏感兴趣区域池化
为了获得自然生态图像中蝴蝶的位置和分类, 所提算法采用了位置敏感兴趣区域[22] (Position sensitive RoI pooling, PS RoI)池化来构建TDDNE的分类器.随着网络的加深, 其平移旋转不变性越强, 这个性质对于保证分类模型的鲁棒性具有积极意义.然而, 在检测问题中, 过度的平移旋转不变性, 又使得网络对目标位置信息的感知能力削弱.因此, 在蝴蝶检测中考虑到特征提取和对小目标检测边框对齐问题, 采取与可变形卷积一样的结构策略来构建区域空间可变形的敏感位置RoI池化过程.同时, 取消特征聚集过程中的量化操作, 使用双线性插值的方法获得浮点数的像素坐标, 让整个特征聚集过程转换为一个连续量的操作, 最后进行均值池化.如图 6所示, 为可变形的位置敏感RoI池化.
首先, 利用卷积产生特征图的偏置域, 由于RoI池化将RoI区域分成$ k \times k $块($ k $为可调参数), 因此通过一个全卷积层可产生偏置量矩阵$ \left\{{\Delta {p_{ij}}|0 \le i, j < k} \right\} $, 它被附加在区域空间池化块(类似卷积核)的位置上, 即可得到可变形的PS RoI池化模型, 即第$ (i, j) $块的输出值是通过其对应的评分图$ {x_{i, j}} $ (替换常规特征图计算中的)而得到.因此, 可参照式(1)改写可变形的敏感位置RoI池化的计算式(2).
$ \begin{equation} y(i, j) = \sum\limits_{p \in bin(i, j)} \frac{x({p_0} + p + \Delta {p_{ij}})}{n_{ij}} \end{equation} $
(2) 其中, $ \Delta {p_{ij}} $仍是一个分数, $ {n_{ij}} $是区域块位置上的像素数且这个全卷积层是通过反向传播学习得来.因为在可变形的PS RoI池化后得到固定大小的$ k \times k $区域块特征, 直接用全连接层归一化即可得到$ k \times k $个偏置域$ \Delta {\hat p_{ij}} $.但是这些偏置域并不能直接使用, 因为RoI区域大小不一致, 而且输入特征图的宽$ w $和高$ h $也不一致, 故采用一个增益$ \gamma = 0.1 $加以矫正, 与$ (w, h) $点乘可得真值$ \Delta {p_{ij}} = \gamma \Delta {\hat p_{ij}} \cdot (w, h) $.
1.3 构建蝴蝶检测网络TDDNET框架
阶段1 (DNET-base).考虑到数据集中蝴蝶种类数量分布不均等性和蝴蝶种类形态之间的相似性, 本文先设计了一种基于可变形卷积模型的二分类检测网络(简称DNET-base), 强化网络对特征的学习能力.如图 8中的第一阶段参数与二分类过程所示, 所建网络包括两个部分:
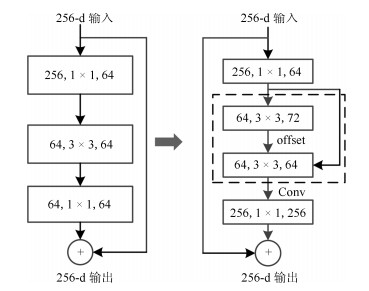 图 7 构建ResNet单元为可变形ResNet结构Fig. 7 Construct the ResNet unit as a deformable ResNet structure RoI
图 7 构建ResNet单元为可变形ResNet结构Fig. 7 Construct the ResNet unit as a deformable ResNet structure RoI 图 8 本文所提算法的网络模型与参数说明(TDDNET)Fig. 8 Network model and parameter description of the algorithm proposed in this paper (TDDNET)
图 8 本文所提算法的网络模型与参数说明(TDDNET)Fig. 8 Network model and parameter description of the algorithm proposed in this paper (TDDNET)1) 通过可变形卷积模型重建ResNet-101特征提取过程, 即把ResNet-101的全连接层和均值池化层都移除, 重新构建ResNet-101结构剩余层Conv2 (Res2c)、Conv3 (Res3b3)、Conv4 (Res4b 22)和Conv5 (Res5a、Res5b、Res5c)的卷积层重构为可变形的卷积网络层.具体构建方法如图 7所示, 通过对输入特征图进行全卷积获得相同维度的偏置域层Offset, 在Offset的偏置量指引作用下, 对输入特征进行可变形卷积操作获得输出特征.
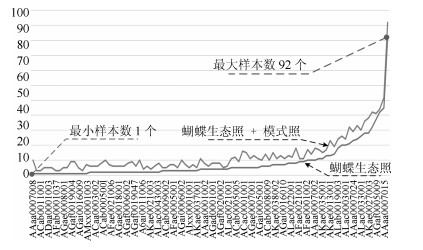
2) 结合RPN网络构建二分类检测网络, 通过RPN网络与PS RoI池化层后, 可获得分类得分图和目标边框.因为是二分类模型, 即类别只有蝴蝶和背景.通过Soft-max和Soft-NMS [19]在$ 1 000\times2 $的特征信息中获得准确的蝴蝶类别和位置信息.即将数据集中的全部蝴蝶种类归为一类"Butterfly".然后, 通过DNET-base网络对蝴蝶目标和背景进行分离训练.这种方法可有效避免部分种类数据匮乏与种类数据量不均衡(数据集中部分蝴蝶种类只有1个样本, 最多92个样本)造成的训练困难问题, 可有效强化"第一阶段"网络对蝴蝶特征的提取能力.
阶段2 (TDDNET).如图 8所示, 借鉴迁移学习的思想, 针对性地训练多分类器(94类+ 1背景), 即对第一阶段参数进行迁移, 将其作为第二阶段中提取特征的基层网络参数, 将其获得的聚集特征传递至第二阶段的多分类模型中进行训练, 以此提高分类精确度.首先, 基于DNET-base构建TDDNET框架的特征提取网络.然后, 结合可变形卷积模型, 构建以RPN网络指导敏感位置区域可变形RoI池化层部分, 以此获得多尺度目标的评分特征图和精准位置信息, 最后通过Soft-max和Soft-NMS进行多分类优化, 形成完整的TDDNET模型.并且在所提算法中使用在线难示例挖掘(Online hard example mining, OHEM)算法[23]优化训练PS RoI的卷积检测算子, 由此可获得最小的训练损失和较高的均值平均精度(Mean average precision, mAP).因为OHEM取消了人为设置的参数, 同时放宽了正负样本的约束, 以零阈值作为负样本下界, 并取消正负样本比例.其计算方法为OHEM对RPN提供的候选区域计算损失并排序, 挑选出损失最大的目标区域为难样例再加入网络训练.在所提算法中使用Soft-NMS方法提取目标边框.非极大值抑制NMS算法, 可获取目标的最佳坐标, 并移除目标的重复边界框, 如式(3)所示.
$ \begin{equation} {s_i} = \begin{cases} {{s_i}}, &{iou < {N_t}}\\ 0, &{iou \ge {N_t}} \end{cases} \end{equation} $
(3) 其中, $ {s_i} $为评分, $ {N_t} $为抑制阈值.由于NMS采用置信度最高的检测方法, 因其相邻目标检测框置信度强制为0, 所以对于区域重叠较大的目标(如图 1)会出现漏检, 从而导致算法的检出率降低. Soft-NMS [19]中将NMS算法进行改进, 使得$ {s_i} \leftarrow {s_i}f(iou(M, {b_i})) $, 由此可使用线性加权的方式改写NMS算法函数, 如式(4)所示.
$ \begin{equation} {s_i} = \begin{cases} {{s_i}}, &{iou < {N_t}}\\ {{s_i}(1 - iou(M, {b_i}))}, &{iou \ge {N_t}} \end{cases} \end{equation} $
(4) 其中, $ iou(M, {b_i}) $为最大评分的边界框$ M $与待处理边界框$ {b_i} $的交并比.在TDDNET框架中使用的损失函数与R-FCN和Faster R-CNN中的一样, 采用多目标检测损失函数, 即同时考虑分类损失和位置损失.在可变形的PSRoI池化后会得到$ {k^2} $个区域块, 对每一个区域块都有$ c + 1 $(为$ c $类+1背景)维的分类预测向量, 由此产生分类得分特征图, 如式(5)和(6)所示.
$ \begin{equation} {r_c}(\Theta ) = \sum\limits_{(x, y) \in bin(i, j)} \frac{{m_{i, j, c}}(\Phi |\Theta )} {n} \end{equation} $
(5) $ \begin{equation} \Phi = (x + {x_0} + \Delta {x_{bin(i, j)}}, y + {y_0} + \Delta {y_{bin(i, j)}}) \end{equation} $
(6) 其中, $ {m_{i, j, c}} $为$ {k^2}(c + 1) $个得分特征图之一, $ n $为区域块中的像素数量, $ ({x_0}, {y_0}) $表示RoI区域块的左上角位置. $ \Delta {x_{bin(i, j)}} $, $ \Delta {y_{bin(i, j)}} $为第$ (i, j) $区域块的偏置量, $ \Theta $为TDDNET的训练参数.所提算法中使用Soft-max来响应分类, 如式(7)所示.
$ \begin{equation} {S_c}(\Theta ) = \frac{{\rm e}^{{r_c}(\Theta )}}{\sum\limits_{c' = 0}^c {{{\rm e}^{{r_{c'}}(\Theta )}}}} \end{equation} $
(7) 由此, 可通过交叉熵损失和Soft-L1 [10, 22]边框回归定义TDDNET中的损失函数, 如式(8)所示.
$ \begin{equation} \begin{aligned} L(S, {b_{(x, y, w, h)}}) & = {L_{cls}}(S, {S_{{c^*}}}) +\\ &\lambda [{c^*} > 0]{L_{reg}}(b, {b^*}) \end{aligned} \end{equation} $
(8) 其中, $ {b_{(x, y, w, h)}} $为预测位置, $ {b^*} $为Ground-Truth目标位置标注值, $ {c^*} $为类别真值标签, 如果$ {c^*} = 0 $表示为背景, $ {L_{cls}}(S, {S_{{c^*}}}) = -{\rm ln}{_{cls}}(S|{S_{{c^*}}}) $表示交叉熵损失函数, $ {L_{reg}} $表示Soft-L1边框回归损失函数.
2. 实验结果与分析
为了验证所提算法的有效性, 在2018年第三届中国数据挖掘竞赛上提供的蝴蝶生态照数据集[11]上, 与现阶段一些主流目标检测算法做对比实验.对比算法分别为Faster R-CNN [12]、FPN [24]、R-FCN [22]、SSD [25]、YOLO-v3 [17], 其中还对比了由可变形卷积模型重建的Faster R-CNN、R-FCN、FPN网络模型的变体.通过定性和定量的实验对比, 验证所提算法在生态照上的蝴蝶目标检测效果较好.所提算法与对比实验评测平台信息为: 1) CPU为Intel Core i7 6700; 2)采用英伟达GTX 1070 8 GB显存GPU; 3)使用Ubuntu 16.04操作系统, 内存16 GB; 4)除了YOLO-v3网络实验外, 所提算法与对比实验均依赖于MXNET开发库框架, 其版本为0.12.0, OpenCV版本为3.4.1.
2.1 数据集
所提算法与对比算法使用数据包括:标准数据集和拓展数据集.其中, 标准数据集为2018年第三届中国数据挖掘竞赛所提供的蝴蝶图像数据集, 其中蝴蝶生态照数据集721张共94类蝴蝶(测试集暂未公开), 图像分辨率最大为7 630 $ \times $ 4 912与最小为800 $ \times $ 450, 且生态蝴蝶标注为种名类别, 如金裳凤蝶(编号AAaa0001002), 多姿麝凤蝶(编号AAaa0003011).生态蝴蝶数据集中目标特征多样、尺度变化较大, 些许蝴蝶类的伪装色与背景极为相似, 以及部分图像曝光不足等特点.数据集中有部分类别, 如西番翠凤蝶与克里翠凤蝶、云豹蛱蝶与伊诺小豹蛱蝶, 其在形态上基本一致, 但在纹理和颜色特征[26]上存在一定差异, 即一些细节纹理和颜色特征起到了主导作用, 具有一定细粒度特性[27].
标准数据集中, 每种蝴蝶至少1个样本, 最多包含92个样本, 呈现出典型的长尾分布; 另外, 蝴蝶标本模式照图像数据集中与94类一致的有480张.每种蝴蝶至少1个样本, 最多包含11个样本. 94类蝴蝶的整体数据分布如图 9所示.
拓展数据集, 根据标准数据集的统计信息(如图 9所示)进行再次收集, 将少于10个样本的蝴蝶种类进行数据扩充, 共扩充789张图像均来自于网络上的蝴蝶生态图像.最后的数据集样本分布如图 10所示.在实验中做了简单交叉验证, 即将数据按照各个类的数量进行对半划分, 确保每个类在测试集合和训练集中都有近似相等的数据量, 并做两者的交替实验, 其检测结果相差小于$ 1 \% $.因此, 为了确保数据充分驱动模型, 以及测试数据集公正性, 在全部蝴蝶生态照图像数据集中, 按照种类样本数量的20 %抽取相应图像作为最终测试集, 由此将蝴蝶生态照图像数据集划分为训练集1 215张, 测试集286张.
最后, 考虑到数据集中蝴蝶目标平移或旋转不变性, 对数据集进行增广, 包括水平翻转、旋转$ \pm {30^\circ} $, 得到蝴蝶训练数据集5 085张(生态照$ 1 215\times3 $张+模式照$ 480\times3 $张), 蝴蝶测试照854张.从不同角度采集数据, 对蝴蝶目标检测性能有一定的促进作用.所以, 旋转角度可以随意选择, 但角度选择不宜过多, 以免造成冗余训练, 拓展数据集分布情况如图 10所示.
2.2 主观结果分析
针对生态蝴蝶图像一些特点, 对所提算法与对比算法的改进变体在测试数据集上进行主观检测, 如图 11所示.在图 11中实线箭头为误检目标(分类错误)、虚箭头为目标重叠框、菱形为漏检目标.从图 11可看出, 对于大目标的图像, 本文算法和FPN*均获得了完整目标框, 然而FPN*检出重叠目标, R-FCN*和Faster R-CNN*出现目标割裂, 这说明蝴蝶形态(展翅正视与合翅侧视)在对比算法存在一定的影响.在对重叠目标中R-FCN*与Faster RCNN*均出现误检目标框, 因此在特征区分度上较弱于其他算法.在相似目标、弱特征目标以及密集小目标上对比算法均出现了误检、漏检以及重叠检测现象, 本文所提算法仅出现了对部分小目标漏检, 整体表现优于对比算法.在蝴蝶目标被遮挡和合翅正视情况下, 本文算法可以获得较为完整的目标边界框, Faster RCNN*出现了目标割裂和漏检情况, 其他算法检测到的蝴蝶边界框与标注边界框重合度存在相对较大的差值, 且在这两种情况下检测置信度都相对较低.因此, 本文算法在大目标与重叠目标上对特征的细微区分表现较好, 对背景相似目标与弱特征目标的检测也较为稳定, 且少误检和漏检.在图 11中, 所提算法检测结果与预检测目标(Ground-truth)较相符.
2.3 客观结果分析
评价标准采用$ mA{P_{0.5}} $和$ mA{P_{0.7}} $, 以及检出率(Detection rate, DR)和精确度(Accuracy, ACC).其中, DR与ACC来自2018年第三届中国数据挖掘大赛的评价标准.检出率DR为所有覆盖率的平均值, 其中覆盖率为交并比(Intersection over union, IoU)的值.精确度ACC为分类正确的数量与生态蝴蝶总数量的比值.
所提算法自身对比实验, 包括四种情况: 1)所提算法的完整模型验证; 2)所提算法中使用NMS算法的验证; 3)不采用迁移学习, 即摒弃DNET-base模型架构, 直接训练DDNET (NMS)模型架构验证, 此模型也是我们在第三届数据挖掘大赛上使用的模型; 4)所提算法中采用无可变形卷积的ResNet-101网络验证.如表 1所示, 所提算法检测效果表现较好.同时, 对比了可变形卷积网络在不同层时对所提算法的影响, 如表 2所示.
表 1 针对所提算法网络结构自身差异对比Table 1 Contrast the differences of the network structure of the proposed algorithm网络结构差异 mAP0.5 mAP0.7 DR ACC TDDNET (Soft-NMS) 0.9415 0.9235 0.9082 0.9370 TDDNET (NMS) 0.9358 0.9208 0.9004 0.9274 DDNET (NMS, 无迁移) 0.9137 0.9009 0.8503 0.9180 TDDNET(无可变形卷积) 0.8827 0.8506 0.8532 0.8728 表 2 针对所提算法中在不同层使用可变形卷积模型的差异Table 2 Aiming at the difference of using deformable convolution network in different layers of the proposed algorithm可变形卷积网络层 mAP0.5 mAP0.7 DR ACC TDDNET完整框架 0.9415 0.9235 0.9082 0.9370 TDDNET框架(除Res2c) 0.9402 0.9174 0.9004 0.9304 Res5 $(a, b, c)+$ PS RoI 0.9258 0.9076 0.8939 0.9186 PS RoI 0.9106 0.8902 0.8899 0.8960 Res5 $(a, b, c)$ 0.8802 0.8609 0.8693 0.8901 在表 1中的实验数据说明, 模型DDNET (NMS, 无迁移)的检测效果优于TDDNET (无可变形卷积), 即加入可变形卷积对网络影响较大.从测试数据中也表现出Soft-NMS的效果较优于NMS模型, 并且模型参数的迁移对网络也有积极的影响.因此, 可变形卷积网络和模型迁移学习方法均有利于提高网络的检测性能.
在表 2中实验数据说明, 可变形卷积层对网络的检测性能是非常有利的.然而随着可变形卷积网络层数的增加, 网络参数也是成倍地增长, 网络耗时也在递增, 需要按照实际问题需求设置可变形卷积网络层.
所提算法与主流检测算法对比实验, 如表 3所示, 对比算法包括Faster R-CNN [12]、FPN [24]、R-FCN [22]、SSD [25]、YOLO-v3 [17], 其中YOLO-v3的预训练网络模型分别为ResNet50和DarkNet.同时, 也对比了由可变形卷积模型构建的Faster R-CNN、R-FCN、FPN网络模型的变体, 用*表示.在表 3中实验数据说明, 所提算法优于对比算法.并且, Faster R-CNN、R-FCN、FPN在经过可变形卷积网络重建后, 相比原来算法检测性能上都有一定改善. FPN*与所提算法实验结果数值上非常接近, 然而, FPN*算法计算复杂度高于本文算法, 且耗时较长.从DR值和ACC的值上也说明, 所提算法对蝴蝶特征的位置敏感性较好, 分类准确性也较高.
表 3 所提算法与其他目标检测算法的实验结果Table 3 Experimental results of the proposed algorithm and other target detection algorithms对比算法 mAP0.5 mAP0.7 DR ACC Faster R-CNN [12] 0.7879 0.7418 0.8308 0.7845 Faster R-CNN* 0.8207 0.7932 0.8554 0.8144 R-FCN [22] 0.8650 0.8405 0.8650 0.8911 R-FCN* 0.8957 0.8594 0.8747 0.9087 FPN [24] 0.8926 0.8644 0.8994 0.9057 FPN* 0.9288 0.9261 0.8982 0.9206 SSD [25] 0.7794 0.7013 0.8648 0.7564 YOLO-v3 [17] (ResNet50) 0.7787 0.7785 0.8751 0.7956 YOLO-v3 [17] (DarkNet) 0.7889 0.7822 0.8746 0.8050 TDDNET 0.9415 0.9235 0.9082 0.9370 2.4 实验讨论
卷积网络对图像特征提取, 可理解卷积为滤波, 是对特征信息的筛选与叠加, 逐步让目标的特征转向语义特征, 而构建网络让这种多维特征语义化更加有效.然而, 常规的卷积模型被固定结构所限制, Yu等[28]尝试扩张卷积的感受野, 可以对目标的轮廓信息保留较好. Zhou等[29]对卷积核做了旋转操作, 让网络可以得到目标的角度信息. Jeon等[30]通过星形蔓延方式改变固定的卷积核, 让离散的输入空间变成一个连续的采样空间, 来提升网络对特征提取能力. Jaderberg等[21]则利用仿射变换的思想提出了空间变换网络, 可对各种形变的数据进行空间变换, 以此提高分类准确率.可变形卷积模型可以理解为卷积包含了上述模型的基本变换.可变形卷积让卷积过程变得更加灵活, 对特征提取也变得更强更准确.因此, 针对蝴蝶目标特征多样性、形态多变性等特点, 以及目标的细化分类与检测难问题, 在所提算法上有较大的改善, 并且获得了较好的检测效果.
因为生态蝴蝶图像与标本模式图像属于同源数据, 即存在较大的特征相似性.由DNET-base把蝴蝶模式照的蝴蝶特征与生态图像的蝴蝶特征变换至相同的特征空间, 使其具有同样的分布并训练学习网络参数, 最后将所得参数迁移至TDDNET, 再通过微调训练迅速地使TDDNET在蝴蝶检测任务上获得良好检测性能.迁移学习还有更出色的算法有待挖掘, 可通过样本迁移、特征迁移、参数或模型迁移、关系迁移等促进深度学习网络对多分类小样本检测任务获得更好的检测性能.此外, 因为蝴蝶数据[11]的测试集并未公开, 故训练与测试中使用的数据集为721张生态照+模式照, 以及部分扩充数据.在本文划分的测试集上, 使用DDNET (NMS, 无迁移)模型测试结果DR为0.8503和ACC为0.9180. DDNET也是我们在竞赛使用的算法模型, 竞赛测试结果DR为0.8368和ACC为0.8380.这也说明与TDDNET对比, 所提算法在生态蝴蝶检测性能上具有较大的提升.
本文骨干网络模型选择RCNN网络.因为目标检测过程中有很多不确定的因素, 如图像中的目标形状、姿态、数量以及成像时会有光照、遮挡等因素干扰、目标检测算法主要集中在两个方向: Twostage算法(如RCNN [11-12, 22, 24, 31]系列)和Onestage算法(如YOLO [16-17]、SSD [25]等).两者主要区别在于Twostage算法需要先生成预选框, 然后进行细粒度目标检测. Onestage算法会直接提取特征来预测目标分类和位置.因此, 采用第一种方式的算法偏向于检测精度, 采用第二种方式的算法偏向于检测速度.数据提供者要求每张图像检测时间在2秒内, 故本文算法的骨干网络模型选择RCNN网络, 并且所提算法实验检测效率约2张/秒至3张/秒.
因为在相同的任务上, 不同网络模型对目标学习的偏向性不同, 如检出率、精确性等.如对生态照中的小目标蝴蝶群体, 利用蝴蝶的群体习性, 故可借鉴李策等[32]的目标语义关联方法实现小目标检测.也可使用多网络协同检测方式[33]或者网络级联优化方式[34], 通过融合检测结果获得较好的检测效果.也可使用如Inception [35]、ResNext [36]等深度残差网络继续改进算法模型, 以及借鉴Mask R-CNN [31]中的RoI Align模型等解决"边框对齐问题", 以此提升目标检测网络的精确度.此外, 生态蝴蝶照图像中蝴蝶目标尺度变化也是非常大, 可以借鉴Zhou等[37]和Bharat等[38]的多尺度目标检测算法来改进生态蝴蝶目标检测.
3. 结论
在分析了部分主流目标检测算法的优势, 以及在生态蝴蝶检测问题上的局限性的基础上, 针对蝴蝶生态照图像中的蝴蝶检测问题, 本文提出了一种基于迁移学习和可变性卷积深度神经网络的蝴蝶检测算法.所提算法利用可变性卷积模型来增加特征网络的基层卷积层对特征的萃取能力, 结合RPN网络, 构建可变形的位置敏感区域池化模型进一步提升网络的检测精准性, 并利用迁移学习的思想, 在任务中有效地解决了数据样本不平衡与匮乏的问题.在对比实验中也取得了较好的检测结果.在未来的工作中将借鉴深监督学习思想, 结合迁移学习知识与可变形卷积模型理论继续改进目标检测模型.
致谢: 感谢2018年第三届中国数据挖掘大赛组委会组织的赛事以及提供的蝴蝶数据集. -
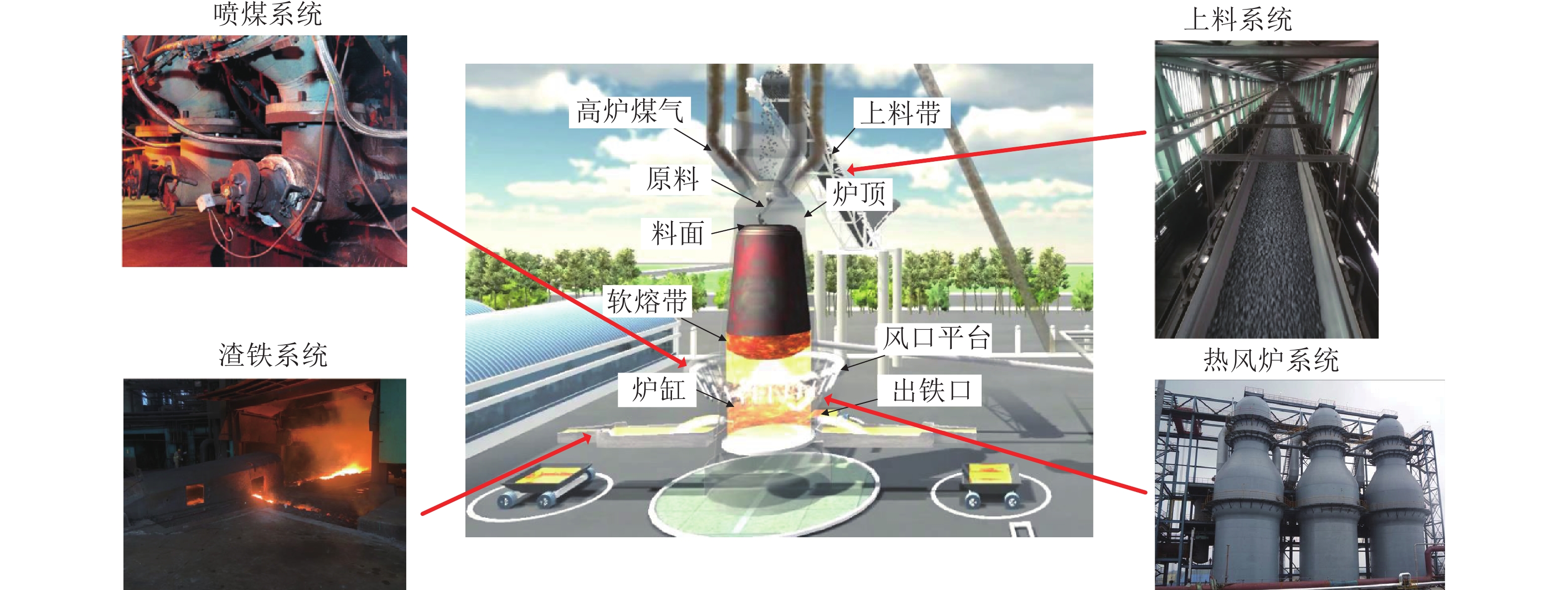
图 1 高炉三维仿真模拟图
Fig. 1 Three-dimensional simulation diagram of the blast furnace cast field

图 2 高炉炼铁过程中变时滞问题描述
Fig. 2 Illustration of variable time-delay problem in the blast furnace ironmaking process
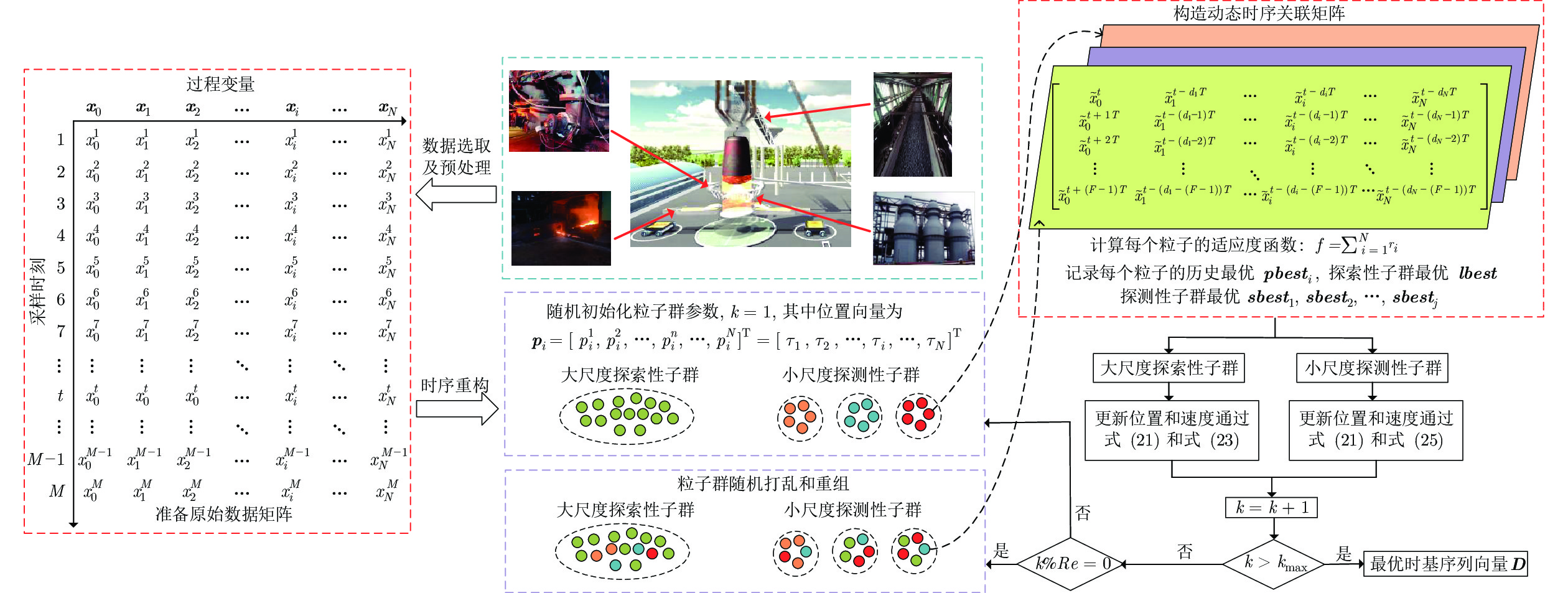
图 3 基于DMS-PSO-CS算法的时延参数估计框架
Fig. 3 Time-delay parameter estimation framework based on DMS-PSO-CS algorithm

图 4 基于DMS-PSO-CS算法时延估计的铁水硅含量预测结果
Fig. 4 The prediction details of silicon content in molten iron with time-delay estimation based on DMS-PSO-CS algorithm
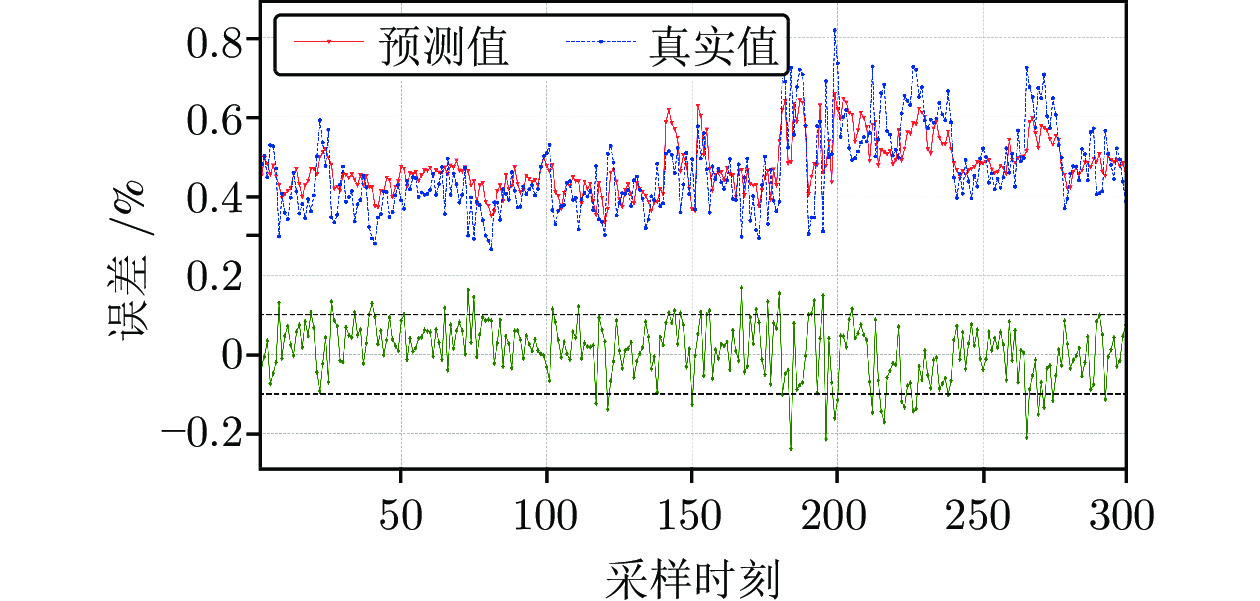
图 5 基于PSO算法时延估计的铁水硅含量预测结果
Fig. 5 The prediction details of silicon content in molten iron with time-delay estimation based on PSO algorithm
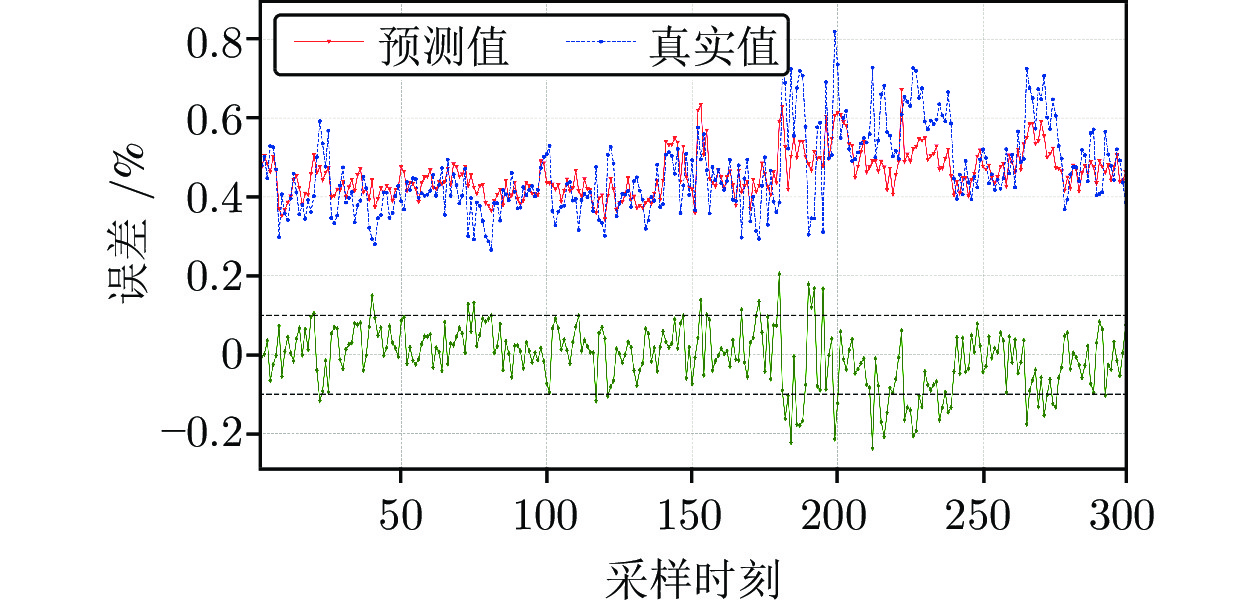
图 6 基于MIC算法时延估计的铁水硅含量预测结果
Fig. 6 The prediction details of silicon content in molten iron with time-delay estimation based on MIC algorithm
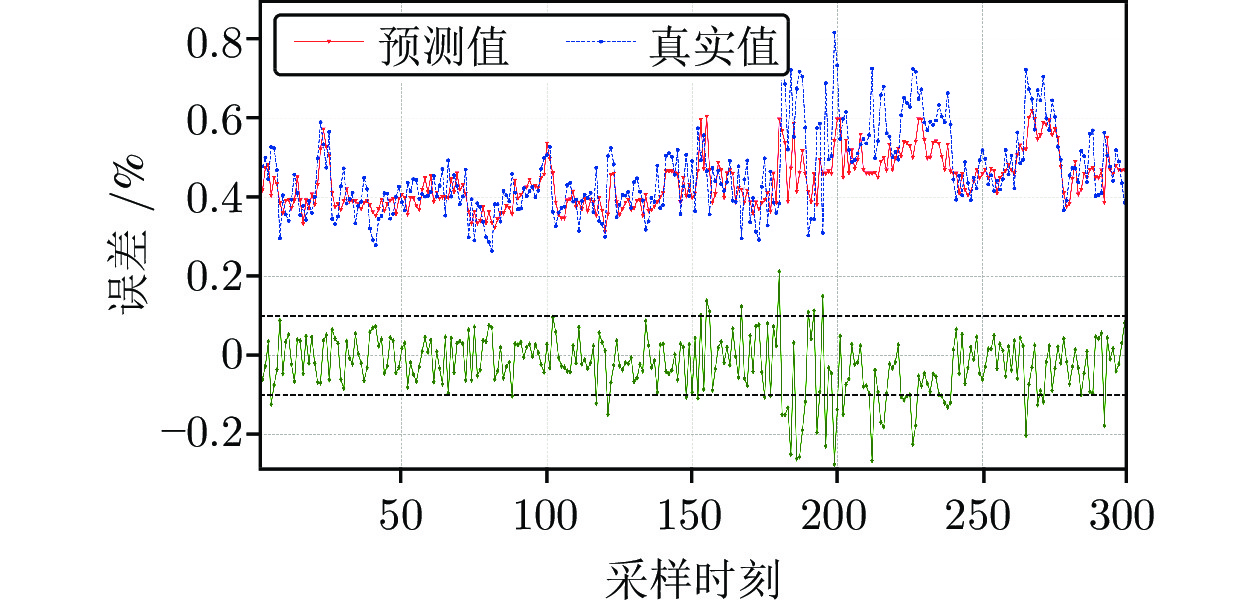
图 7 基于PCC算法时延估计的铁水硅含量预测结果
Fig. 7 The prediction details of silicon content in molten iron with time-delay estimation based on PCC algorithm
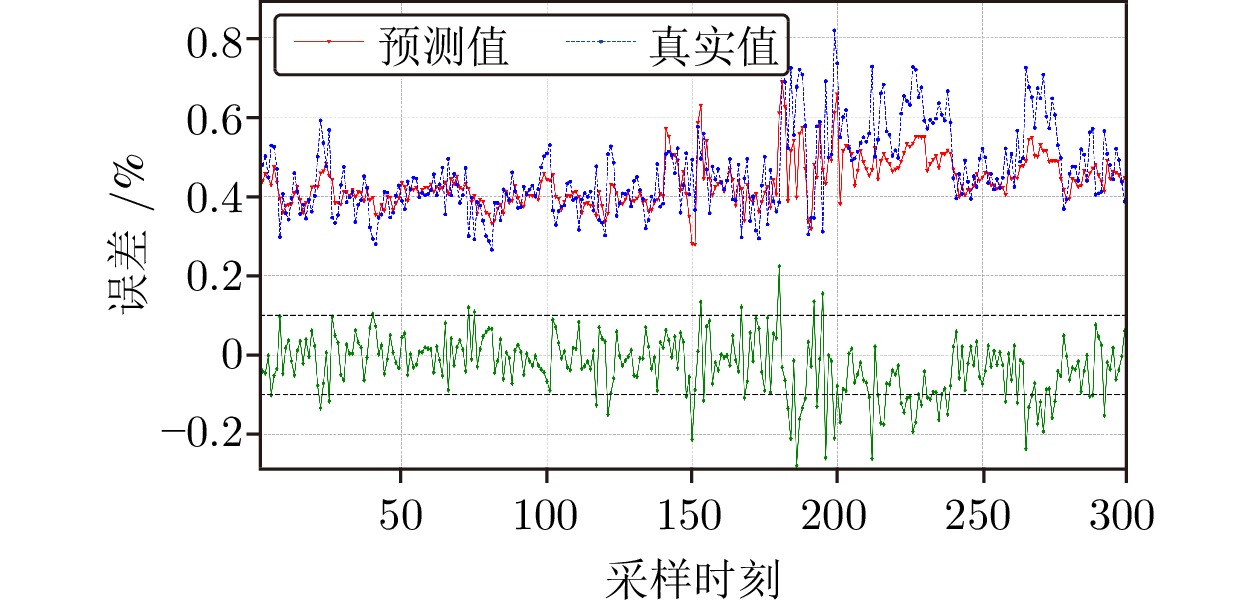
图 8 无时延估计的铁水硅含量预测结果
Fig. 8 The prediction details of silicon content in molten iron without time-delay estimation
表 1 数值仿真中基于不同方法估计的过程变量时延值
Table 1 The estimated variable time-delay values based on different methods in numerical simulation
变量 PCC MIC PSO DMS-PSO-CS $ \tau ' $ $ {x_1} $ 1 1 1 1 1 $ {x_2} $ 0 2 2 2 2 $ {x_3} $ 2 0 3 3 3 $ {x_4} $ 1 3 3 4 4  下载: 导出CSV
下载: 导出CSV
表 2 基于不同方法估计的过程变量时延参数
Table 2 The estimated process variable time-delayvalues based on different methods
变量 (单位) PCC MIC PSO DMS-PSO-CS 富氧率(wt%) 1 5 5 5 透气性指数$(\rm m^{3}/min \cdot kPa)$ 1 1 1 2 一氧化碳(wt%) 1 2 1 1 二氧化碳(wt%) 1 1 1 1 标准风速(m/s) 6 6 2 1 富氧流量$(\rm m^{3}/s)$ 1 3 6 1 冷风流量$(\rm m^{3}/min)$ 6 2 2 2 鼓风动能(J/s) 1 2 2 3 炉腹煤气量 (t) 6 1 2 2 炉腹煤气指数 6 2 2 2 顶压 (kPa) 1 3 1 4 富氧压力(kPa) 2 3 6 6 冷风压力 (kPa) 1 1 6 2 全压差(kPa) 1 2 2 2 热风压力(kPa) 1 1 5 2 实际风速 (m/s) 1 3 2 2 冷风温度 (°C) 1 6 1 1 热风温度 (°C) 1 6 2 2 顶温(°C) 1 5 1 2 顶温下降管 (°C) 1 1 2 6 阻力系数 1 1 2 1 鼓风湿度 ($ \rm g/m^{3} $) 3 6 1 1 本小时实际喷煤量(t/h) 2 1 1 3 上小时实际喷煤量 (t/h) 1 1 5 5 铁水温度 (°C) 1 1 1 1
下载: 导出CSV
表 3 基于不同建模策略下的铁水硅含量软测量模型性能
Table 3 Soft-sensor model performance of silicon content in molten iron based on different modeling strategies
序号 建模策略 TrRMSE TrMAE TsRMSE TsMAE 训练时间 (s) 1 SDAE + DM-PSO-CS 0.0715 0.0530 0.0723 0.0542 12.2 $ \times $ 60 + 8 2 SDAE + PSO 0.0748 0.0565 0.0759 0.0574 12.4 $ \times $ 60 + 10 3 SDAE + MIC 0.0752 0.0562 0.0765 0.0575 12.3 $ \times $ 60 + 12 4 SDAE + PCC 0.0763 0.0561 0.0776 0.0573 12.2 $ \times $ 60 + 10 5 SVR + DM-PSO-CS 0.0775 0.0572 0.0792 0.0588 7 6 RVFLN + DM-PSO-CS 0.0769 0.0573 0.0782 0.0585 3 7 SDAE + 无时延估计 0.0826 0.0605 0.0840 0.0613 12.3 $ \times $ 60 + 9
下载: 导出CSV
-
[1] Zhou H, Zhang H F, and Yang C J. Hybrid model based intelligent optimization of ironmaking process. IEEE Transaction on Industrial Electronics, 2020, 67(3): 2469-247 doi: 10.1109/TIE.2019.2903770 [2] 蒋朝辉, 许川, 桂卫华, 蒋珂. 基于最优工况迁移的高炉铁水硅含量预测方法. 自动化学报, 2021, 48(1): 207-219Jiang Zhao-Hui, Xu Chuang, Gui Wei-Hua, Jiang Ke. Prediction method of hot metal silicon content in blast furnace based on optimal smelting condition migration. Acta Automatica Sinica, 2021, 48(1): 207-219 [3] 李温鹏, 周平. 高炉铁水质量鲁棒正则化随机权神经网络建模. 自动化学报, 2020, 46(4): 721-733Li Wen-Peng, Zhou Ping. Blast furnace hot metal quality robust regularization random weight neural network modeling. Acta Automatica Sinica, 2020, 46(4): 721-733 [4] Chen S H, Gao C H. Linear priors mined and integrated for transparency of blast furnace black-Box SVM model. IEEE Transactions on Industrial Informatics, 2020, 16(6): 3862-3870 doi: 10.1109/TII.2019.2940475 [5] Li J P, Hua C C, Yang Y N, Zhang L M, Guan X P. Output space transfer based multi-input multi-output Takagi–Sugeno fuzzy modeling for estimation of molten iron quality in blast furnace. Knowledge-Based Systems, 2021, 219: 106906 doi: 10.1016/j.knosys.2021.106906 [6] Saxen H, Gao C H, and Gao Z W. Data-driven time discrete models for dynamic prediction of the hot metal silicon content in the blast furnace—A review. IEEE Transactions on Industrial Informatics, 2013, 9(4): 2213-2225 doi: 10.1109/TII.2012.2226897 [7] Tang X L, Zhuang L, Jiang C J. Prediction of silicon content in hot metal using support vector regression based on chaos particle swarm optimization. Expert Systems with Applications, 2009, 36(9): 11853-11857 doi: 10.1016/j.eswa.2009.04.015 [8] 周平, 张丽, 李温鹏, 戴鹏, 柴天佑. 集成自编码与PCA的高炉多元铁水质量随机权神经网络建模. 自动化学报, 2018, 44(10): 1799-1811Zhou Ping, Zhang Li, Li Wen-Peng, Dai Peng, Chai Tian-You. Modeling of blast furnace multi-element molten iron quality with random weight neural network based on self-encoding and PCA. Acta Automatica Sinica, 2018, 44(10): 1799-1811 [9] Zhou P, Li W P, Wang H, Li M J, Chai T Y. Robust online sequential RVFLNs for data modeling of dynamic time-varying systems with application of an ironmaking blast furnace. IEEE Transactions on Cybernetics, 2019, 50(11): 4783-4795 [10] Pan D, Jiang Z H, Chen Z P, Gui W H, Xie Y F, Yang C H. Temperature measurement and compensation method of blast furnace molten iron based on infrared computer vision. IEEE Transactions on Instrumentation and Measurement, 2018, 68(10): 3576-3588 [11] Pan D, Jiang Z H, Chen Z P, Jiang K, Gui W H. Compensation method for molten iron temperature measurement based on heterogeneous features of infrared thermal images. IEEE Transactions on Industrial Informatics, 2020, 16(11): 7056-7066 doi: 10.1109/TII.2020.2972332 [12] 蒋朝辉, 董梦林, 桂卫华, 阳春华, 谢永芳. 基于Bootstrap的高炉铁水硅含量二维预报. 自动化学报, 2016, 42(5): 715-723Jiang Zhao-Hui, Dong Meng-Lin, Gui Wei-Hua, Yang Chun-Hua, Xie Yong-Fang. Two-dimensional prediction for silicon content of hot metal of blast furnace based on bootstrap. Acta Automatica Sinica, 2016, 42(5): 715-723 [13] 蒋珂, 蒋朝辉, 谢永芳, 潘冬, 桂卫华. 基于动态注意力深度迁移网络的高炉铁水硅含量在线预测方法. 自动化学报, 2021, DOI:10. 16383/j.aas.c210524Jiang Ke, Jiang Zhao-Hui, Xie Yong-Fang, Dong Pan, Gui Wei-Hua. Online prediction method for silicon content of molten iron in blast furnace based on dynamic attention deep transfer network. Acta Automatica Sinica, 2021, DOI:10. 16383/j.aas.c210524 [14] Jiang K, Jiang Z H, Xie Y F, Chen Z P, Pan D, Gui W H. Classification of silicon content variation trend based on fusion of multilevel features in blast furnace ironmaking. Information Sciences, 2020, 521: 32-45 doi: 10.1016/j.ins.2020.02.039 [15] 阮宏镁, 田学民, 王平. 基于联合互信息的动态软测量方法. 化工学报, 2014, 65(11): 4497-4502 doi: 10.3969/j.issn.0438-1157.2014.11.040Ruan Hong-Mei, Tian Xue-Min, Wang Ping. Dynamic soft sensor method based on joint mutual information. CIESC Journal, 2014, 65(11): 4497-4502 doi: 10.3969/j.issn.0438-1157.2014.11.040 [16] Zhai L Y, Khoo L P, Zhong Z W. Design concept evaluation in product development using rough sets and grey relation analysis. Expert Systems with Applications, 2009, 36(3): 7072-7079 doi: 10.1016/j.eswa.2008.08.068 [17] Singh T, Patnaik A, Chauhan R. Optimization of tribological properties of cement kiln dust-filled brake pad using grey relation analysis. Materials & Design, 2016, 89: 1335-1342 [18] Patel M T. Multi optimization of process parameters by using grey relation analysis-a review. International Journal of Advanced Research in IT and Engineering, 2015, 4(6): 1-15 [19] Poli R, Kennedy J, Blackwell T. Particle swarm optimization. Swarm Intelligence, 2007, 1(1): 33-57 doi: 10.1007/s11721-007-0002-0 [20] Banks A, Vincent J, Anyakoha C. A review of particle swarm optimization. Part I: background and development. Natural Computing, 2007, 6(4): 467-484 doi: 10.1007/s11047-007-9049-5 [21] Van den Bergh F, Engelbrecht A P. A cooperative approach to particle swarm optimization. IEEE Transactions on Evolutionary Computation, 2004, 8(3): 225-239 doi: 10.1109/TEVC.2004.826069 [22] Komulainen T, Sourander M, Jämsä-Jounela S L. An online application of dynamic PLS to a dearomatization process. Computers and Chemical Engineering, 2004, 28(12): 2611-2619 doi: 10.1016/j.compchemeng.2004.07.014 [23] Curreri F, Graziani S, Xibilia M G. Input selection methods for data-driven Soft sensors design: Application to an industrial process. Information Sciences, 2020, 537: 1-17 doi: 10.1016/j.ins.2020.05.028 [24] Williamson D F, Parker R A, Kendrick J S. The box plot: a simple visual method to interpret data. Annals of Internal Medicine, 1989, 110(11): 916-921 doi: 10.7326/0003-4819-110-11-916 [25] Vincent P, Larochelle H, Lajoie I, Bengio Y, and Manzagol P. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. Journal of Machine Learning Research, 2010, 11: 3371-3408 期刊类型引用(7)
1. 董宏丽,孙桐,王闯,杨帆,商柔. 基于门控注意网络模型的天然气管道泄漏检测新方法. 天然气工业. 2025(01): 25-36 .  百度学术
百度学术2. 吕世玮,黄德镛,高聪,贾子月. PSO优化算法在尾矿库空间预测中的应用. 有色金属(矿山部分). 2024(01): 126-132 . 百度学术3. 李盛新,叶丰华,李道童,张秀波,韩红瑞. 基于IQPSO-GA优化ANFIS模型的服务器故障预警方法. 计算机测量与控制. 2024(04): 37-45 . 百度学术4. 董宏丽,商柔,汪涵博,王闯,陈双庆,管闯. 基于贝叶斯单源域领域泛化算法的天然气管道故障智能诊断. 天然气工业. 2024(09): 27-37 . 百度学术5. 马朱桐,向龙,闫珂. 基于APSO和SVM的滨海河网冲淤需水量预测模型研究——以斗龙港为例. 人民珠江. 2024(12): 114-121 . 百度学术6. 张勇,梁晓珂,陈志鹏,巩敦卫. 基于多代理辅助多目标进化优化的建筑节能智能设计方法. 控制与决策. 2023(11): 3057-3065 . 百度学术7. 郑路佳,管闯,李含阳,李航,董宏丽. 基于U型卷积神经网络的微地震信号降噪方法. 东北石油大学学报. 2023(05): 111-124+146 . 百度学术其他类型引用(5)
-


 下载:
下载:



计量
- 文章访问数: 719
- HTML全文浏览量: 244
- PDF下载量: 232
- 被引次数: 12
