

A Multi-correlated Time-delay Estimation Method in the Blast Furnace Ironmaking Process Based on Time-series Correlation Matrix
-
摘要: 高炉冶炼过程由炉料传输反应时间和冶炼单元在空间和时间分布上的差异带来的变量时延影响了数据的准确性和真实因果关系, 因此有效地估计过程变量间的时延信息, 并在时序上配准数据, 是后续过程建模、优化控制与性能评估的核心. 考虑到变量间时延的多重关联性, 提出了一种基于时序关联矩阵的时延参数估计方法. 首先, 根据过程变量的时延参数在时空上重构对应的时序关联矩阵, 并引入灰色关联分析量化时序矩阵的多重关联相关性; 接着, 考虑到穷举所有时序关联矩阵的时间复杂度, 提出了一种双尺度协同搜索策略的动态多群粒子群算法用于快速寻找最优的时延参数, 提出的粒子群算法能兼顾全局探索能力和局部探测能力并跳出局部最优解; 最后, 基于一个数值仿真和某钢铁厂2# 高炉的工业实验验证了所提时延参数估计方法的可行性和有效性, 且通过所提方法在时序上重构的数据能有效提高后续硅含量软测量模型性能.Abstract: Variable time-delay is brought by transportation and reaction time of materials and the different distributions of smelting units in spatial and temporal, which affects the accuracy and the actual causal relationship of collected data. Therefore, the estimation of variable time-delay information and the reconstruction of data in time series effectively are the key points of subsequent process modeling, optimal control, and performance evaluation. Considering the multiple correlations characteristic of variable time-delay, an estimation method based on a time-series correlation matrix is proposed. First, the time-series correlation matrix is reconstructed in time and space according to the time-delay parameters, where grey correlation analysis is used to quantify the multi-correlated correlation. Then, considering the number of time-series correlation matrices and the time complexity of the exhaustive method, a dynamic multi-swarm particle swarm optimization based on a double-scale collaborative search strategy is proposed to search for the optimal time-delay parameters. The proposed optimization algorithm can consider both global exploration and local exploitation ability and escape local optimal solutions. Finally, the feasibility and effectiveness of the proposed time-delay estimation method are verified by a numerical simulation and an industrial experiment of 2# blast furnace in a steel plant. In addition, a significant improvement can be observed in the performance of the soft-sensor model of silicon content with the reconstruction of data in time series.
-
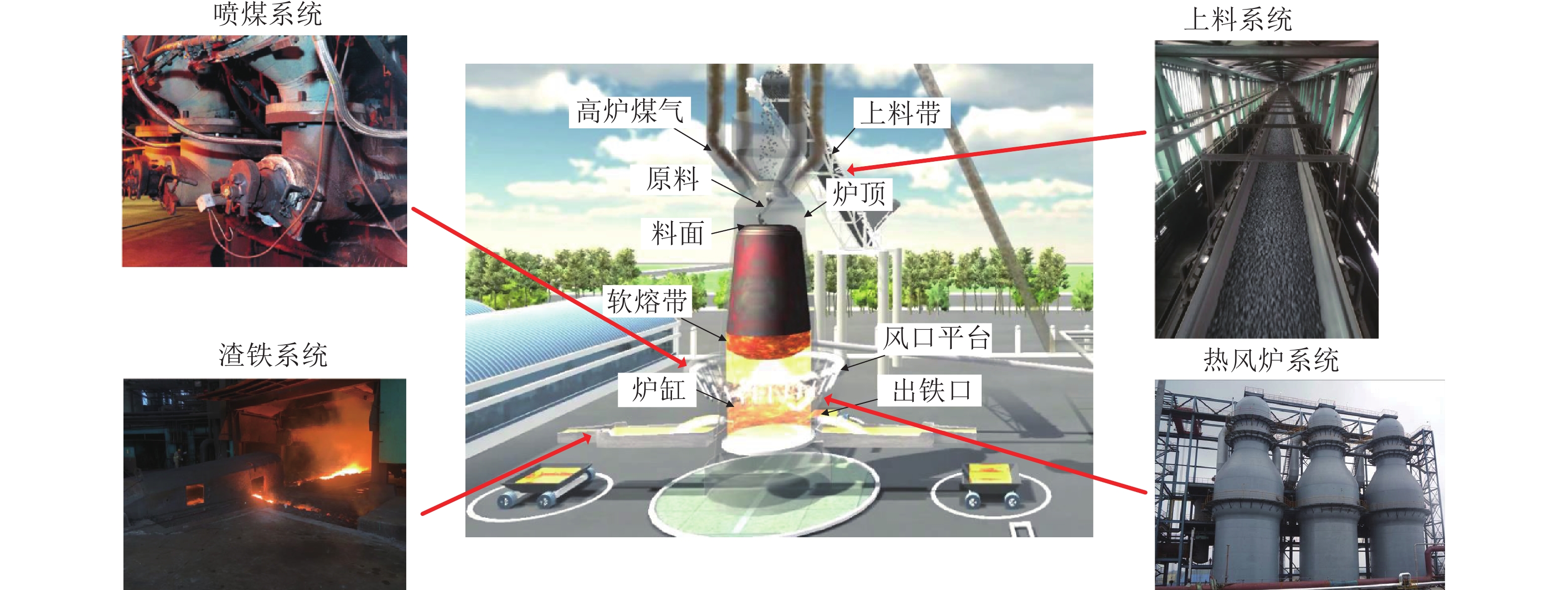
图 1 高炉三维仿真模拟图
Fig. 1 Three-dimensional simulation diagram of the blast furnace cast field

图 2 高炉炼铁过程中变时滞问题描述
Fig. 2 Illustration of variable time-delay problem in the blast furnace ironmaking process
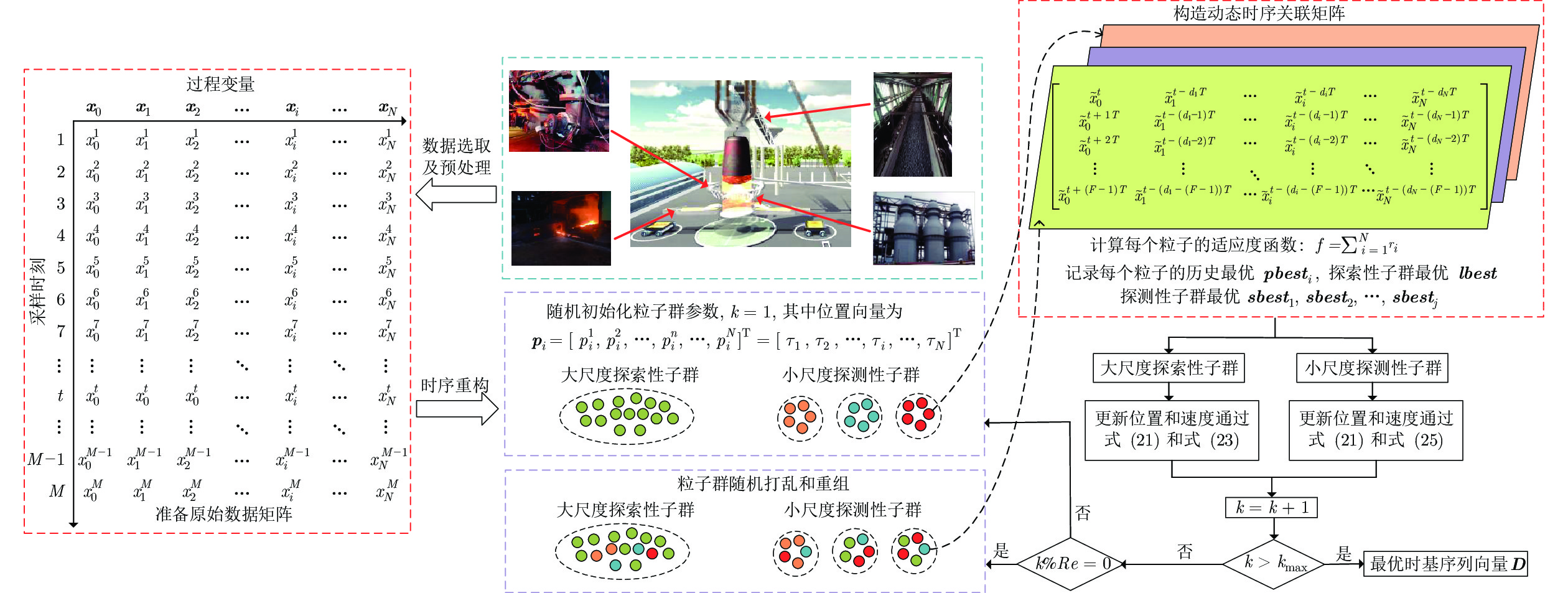
图 3 基于DMS-PSO-CS算法的时延参数估计框架
Fig. 3 Time-delay parameter estimation framework based on DMS-PSO-CS algorithm

图 4 基于DMS-PSO-CS算法时延估计的铁水硅含量预测结果
Fig. 4 The prediction details of silicon content in molten iron with time-delay estimation based on DMS-PSO-CS algorithm
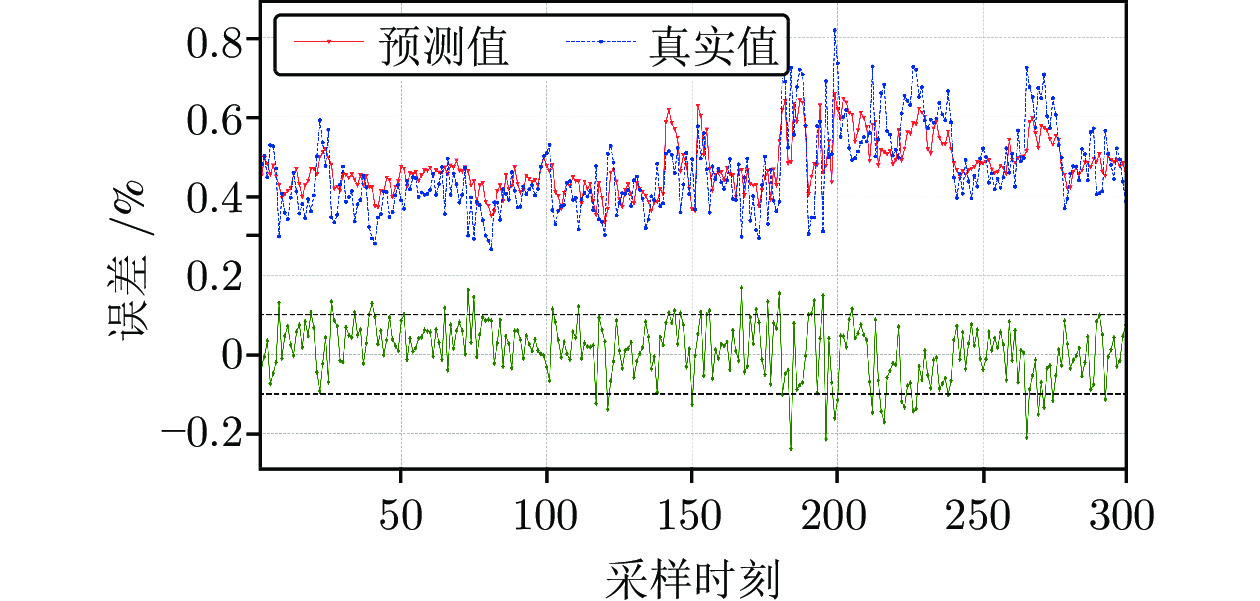
图 5 基于PSO算法时延估计的铁水硅含量预测结果
Fig. 5 The prediction details of silicon content in molten iron with time-delay estimation based on PSO algorithm
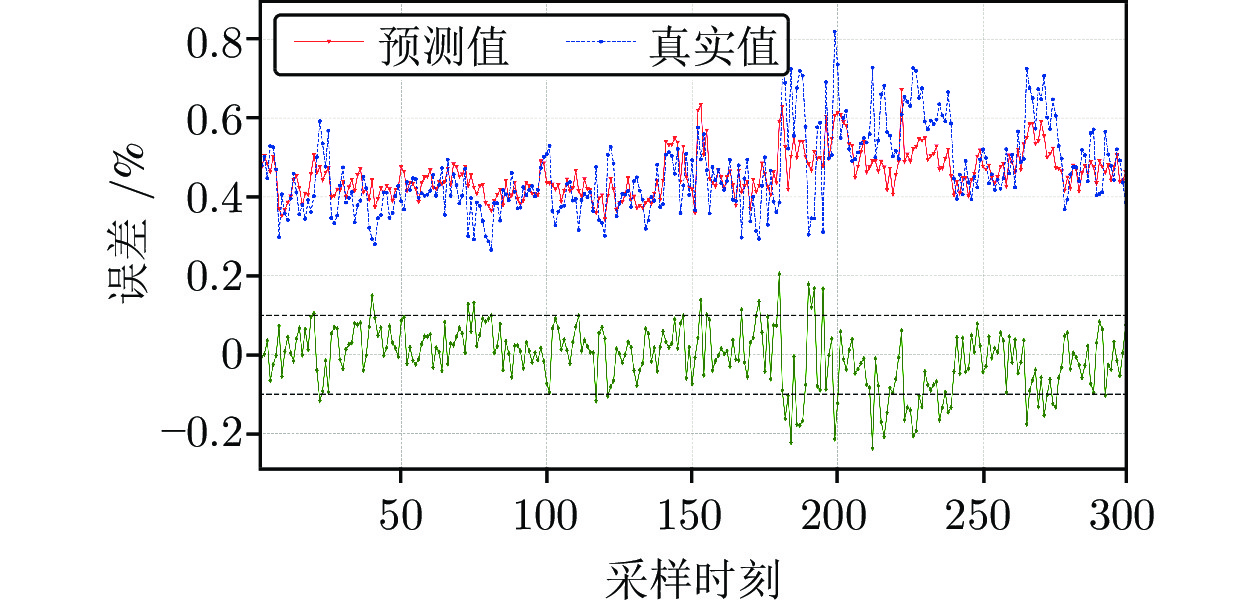
图 6 基于MIC算法时延估计的铁水硅含量预测结果
Fig. 6 The prediction details of silicon content in molten iron with time-delay estimation based on MIC algorithm
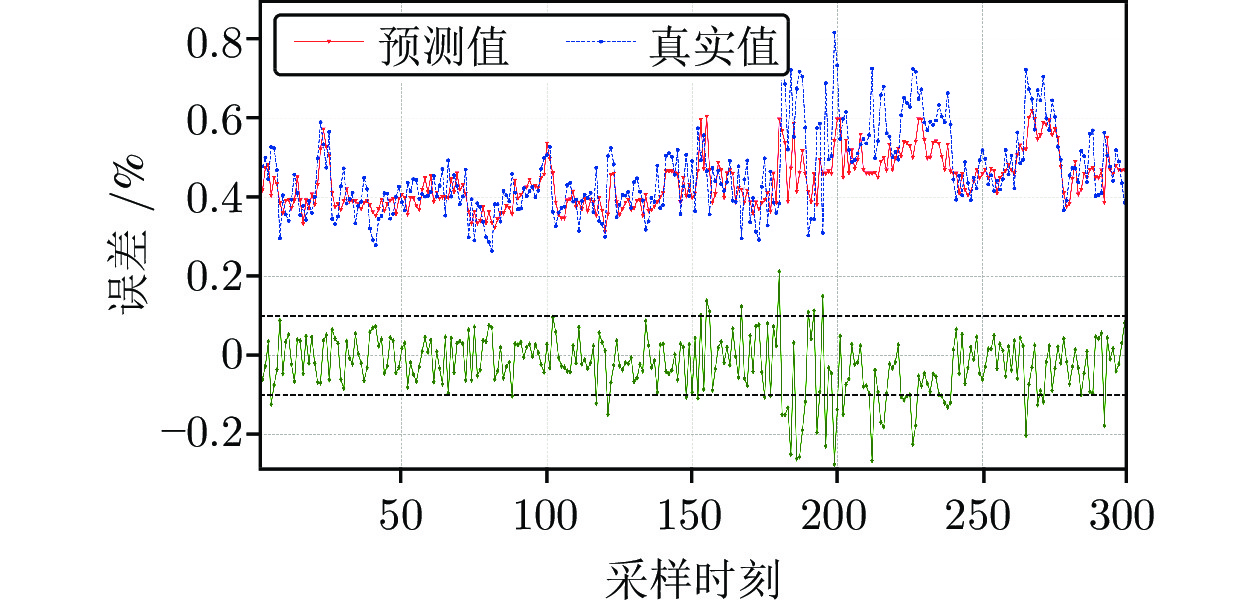
图 7 基于PCC算法时延估计的铁水硅含量预测结果
Fig. 7 The prediction details of silicon content in molten iron with time-delay estimation based on PCC algorithm
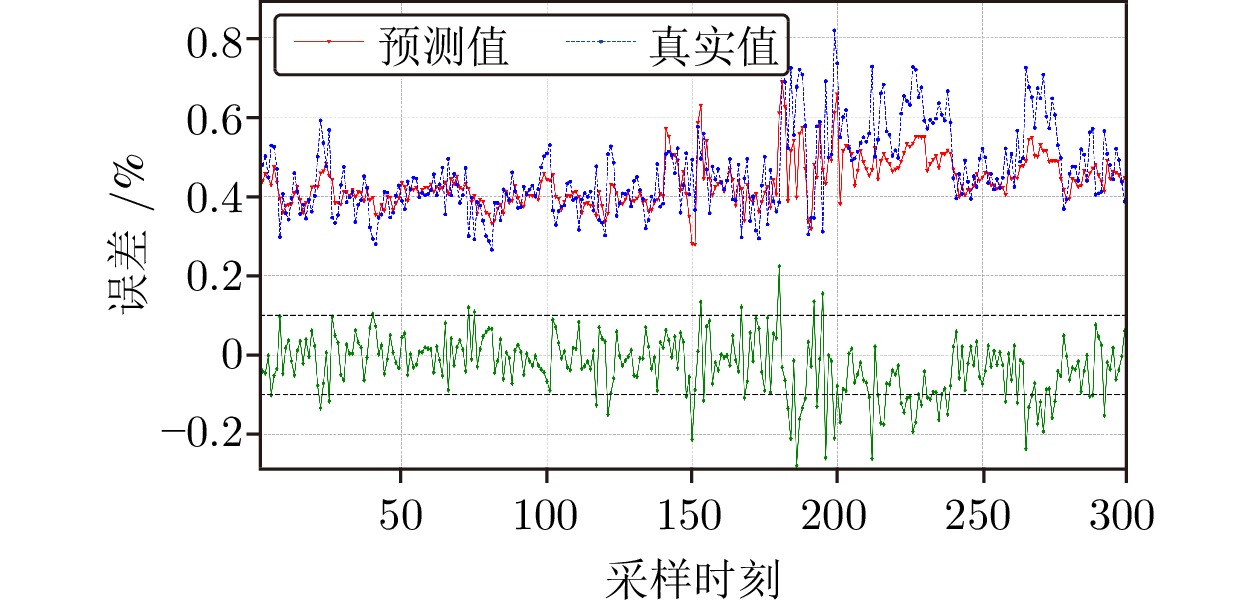
图 8 无时延估计的铁水硅含量预测结果
Fig. 8 The prediction details of silicon content in molten iron without time-delay estimation
表 1 数值仿真中基于不同方法估计的过程变量时延值
Table 1 The estimated variable time-delay values based on different methods in numerical simulation
变量 PCC MIC PSO DMS-PSO-CS $ \tau ' $ $ {x_1} $ 1 1 1 1 1 $ {x_2} $ 0 2 2 2 2 $ {x_3} $ 2 0 3 3 3 $ {x_4} $ 1 3 3 4 4  下载: 导出CSV
下载: 导出CSV
表 2 基于不同方法估计的过程变量时延参数
Table 2 The estimated process variable time-delayvalues based on different methods
变量 (单位) PCC MIC PSO DMS-PSO-CS 富氧率(wt%) 1 5 5 5 透气性指数$(\rm m^{3}/min \cdot kPa)$ 1 1 1 2 一氧化碳(wt%) 1 2 1 1 二氧化碳(wt%) 1 1 1 1 标准风速(m/s) 6 6 2 1 富氧流量$(\rm m^{3}/s)$ 1 3 6 1 冷风流量$(\rm m^{3}/min)$ 6 2 2 2 鼓风动能(J/s) 1 2 2 3 炉腹煤气量 (t) 6 1 2 2 炉腹煤气指数 6 2 2 2 顶压 (kPa) 1 3 1 4 富氧压力(kPa) 2 3 6 6 冷风压力 (kPa) 1 1 6 2 全压差(kPa) 1 2 2 2 热风压力(kPa) 1 1 5 2 实际风速 (m/s) 1 3 2 2 冷风温度 (°C) 1 6 1 1 热风温度 (°C) 1 6 2 2 顶温(°C) 1 5 1 2 顶温下降管 (°C) 1 1 2 6 阻力系数 1 1 2 1 鼓风湿度 ($ \rm g/m^{3} $) 3 6 1 1 本小时实际喷煤量(t/h) 2 1 1 3 上小时实际喷煤量 (t/h) 1 1 5 5 铁水温度 (°C) 1 1 1 1
下载: 导出CSV
表 3 基于不同建模策略下的铁水硅含量软测量模型性能
Table 3 Soft-sensor model performance of silicon content in molten iron based on different modeling strategies
序号 建模策略 TrRMSE TrMAE TsRMSE TsMAE 训练时间 (s) 1 SDAE + DM-PSO-CS 0.0715 0.0530 0.0723 0.0542 12.2 $ \times $ 60 + 8 2 SDAE + PSO 0.0748 0.0565 0.0759 0.0574 12.4 $ \times $ 60 + 10 3 SDAE + MIC 0.0752 0.0562 0.0765 0.0575 12.3 $ \times $ 60 + 12 4 SDAE + PCC 0.0763 0.0561 0.0776 0.0573 12.2 $ \times $ 60 + 10 5 SVR + DM-PSO-CS 0.0775 0.0572 0.0792 0.0588 7 6 RVFLN + DM-PSO-CS 0.0769 0.0573 0.0782 0.0585 3 7 SDAE + 无时延估计 0.0826 0.0605 0.0840 0.0613 12.3 $ \times $ 60 + 9
下载: 导出CSV
-
[1] Zhou H, Zhang H F, and Yang C J. Hybrid model based intelligent optimization of ironmaking process. IEEE Transaction on Industrial Electronics, 2020, 67(3): 2469-247 doi: 10.1109/TIE.2019.2903770 [2] 蒋朝辉, 许川, 桂卫华, 蒋珂. 基于最优工况迁移的高炉铁水硅含量预测方法. 自动化学报, 2021, 48(1): 207-219Jiang Zhao-Hui, Xu Chuang, Gui Wei-Hua, Jiang Ke. Prediction method of hot metal silicon content in blast furnace based on optimal smelting condition migration. Acta Automatica Sinica, 2021, 48(1): 207-219 [3] 李温鹏, 周平. 高炉铁水质量鲁棒正则化随机权神经网络建模. 自动化学报, 2020, 46(4): 721-733Li Wen-Peng, Zhou Ping. Blast furnace hot metal quality robust regularization random weight neural network modeling. Acta Automatica Sinica, 2020, 46(4): 721-733 [4] Chen S H, Gao C H. Linear priors mined and integrated for transparency of blast furnace black-Box SVM model. IEEE Transactions on Industrial Informatics, 2020, 16(6): 3862-3870 doi: 10.1109/TII.2019.2940475 [5] Li J P, Hua C C, Yang Y N, Zhang L M, Guan X P. Output space transfer based multi-input multi-output Takagi–Sugeno fuzzy modeling for estimation of molten iron quality in blast furnace. Knowledge-Based Systems, 2021, 219: 106906 doi: 10.1016/j.knosys.2021.106906 [6] Saxen H, Gao C H, and Gao Z W. Data-driven time discrete models for dynamic prediction of the hot metal silicon content in the blast furnace—A review. IEEE Transactions on Industrial Informatics, 2013, 9(4): 2213-2225 doi: 10.1109/TII.2012.2226897 [7] Tang X L, Zhuang L, Jiang C J. Prediction of silicon content in hot metal using support vector regression based on chaos particle swarm optimization. Expert Systems with Applications, 2009, 36(9): 11853-11857 doi: 10.1016/j.eswa.2009.04.015 [8] 周平, 张丽, 李温鹏, 戴鹏, 柴天佑. 集成自编码与PCA的高炉多元铁水质量随机权神经网络建模. 自动化学报, 2018, 44(10): 1799-1811Zhou Ping, Zhang Li, Li Wen-Peng, Dai Peng, Chai Tian-You. Modeling of blast furnace multi-element molten iron quality with random weight neural network based on self-encoding and PCA. Acta Automatica Sinica, 2018, 44(10): 1799-1811 [9] Zhou P, Li W P, Wang H, Li M J, Chai T Y. Robust online sequential RVFLNs for data modeling of dynamic time-varying systems with application of an ironmaking blast furnace. IEEE Transactions on Cybernetics, 2019, 50(11): 4783-4795 [10] Pan D, Jiang Z H, Chen Z P, Gui W H, Xie Y F, Yang C H. Temperature measurement and compensation method of blast furnace molten iron based on infrared computer vision. IEEE Transactions on Instrumentation and Measurement, 2018, 68(10): 3576-3588 [11] Pan D, Jiang Z H, Chen Z P, Jiang K, Gui W H. Compensation method for molten iron temperature measurement based on heterogeneous features of infrared thermal images. IEEE Transactions on Industrial Informatics, 2020, 16(11): 7056-7066 doi: 10.1109/TII.2020.2972332 [12] 蒋朝辉, 董梦林, 桂卫华, 阳春华, 谢永芳. 基于Bootstrap的高炉铁水硅含量二维预报. 自动化学报, 2016, 42(5): 715-723Jiang Zhao-Hui, Dong Meng-Lin, Gui Wei-Hua, Yang Chun-Hua, Xie Yong-Fang. Two-dimensional prediction for silicon content of hot metal of blast furnace based on bootstrap. Acta Automatica Sinica, 2016, 42(5): 715-723 [13] 蒋珂, 蒋朝辉, 谢永芳, 潘冬, 桂卫华. 基于动态注意力深度迁移网络的高炉铁水硅含量在线预测方法. 自动化学报, 2021, DOI:10. 16383/j.aas.c210524Jiang Ke, Jiang Zhao-Hui, Xie Yong-Fang, Dong Pan, Gui Wei-Hua. Online prediction method for silicon content of molten iron in blast furnace based on dynamic attention deep transfer network. Acta Automatica Sinica, 2021, DOI:10. 16383/j.aas.c210524 [14] Jiang K, Jiang Z H, Xie Y F, Chen Z P, Pan D, Gui W H. Classification of silicon content variation trend based on fusion of multilevel features in blast furnace ironmaking. Information Sciences, 2020, 521: 32-45 doi: 10.1016/j.ins.2020.02.039 [15] 阮宏镁, 田学民, 王平. 基于联合互信息的动态软测量方法. 化工学报, 2014, 65(11): 4497-4502 doi: 10.3969/j.issn.0438-1157.2014.11.040Ruan Hong-Mei, Tian Xue-Min, Wang Ping. Dynamic soft sensor method based on joint mutual information. CIESC Journal, 2014, 65(11): 4497-4502 doi: 10.3969/j.issn.0438-1157.2014.11.040 [16] Zhai L Y, Khoo L P, Zhong Z W. Design concept evaluation in product development using rough sets and grey relation analysis. Expert Systems with Applications, 2009, 36(3): 7072-7079 doi: 10.1016/j.eswa.2008.08.068 [17] Singh T, Patnaik A, Chauhan R. Optimization of tribological properties of cement kiln dust-filled brake pad using grey relation analysis. Materials & Design, 2016, 89: 1335-1342 [18] Patel M T. Multi optimization of process parameters by using grey relation analysis-a review. International Journal of Advanced Research in IT and Engineering, 2015, 4(6): 1-15 [19] Poli R, Kennedy J, Blackwell T. Particle swarm optimization. Swarm Intelligence, 2007, 1(1): 33-57 doi: 10.1007/s11721-007-0002-0 [20] Banks A, Vincent J, Anyakoha C. A review of particle swarm optimization. Part I: background and development. Natural Computing, 2007, 6(4): 467-484 doi: 10.1007/s11047-007-9049-5 [21] Van den Bergh F, Engelbrecht A P. A cooperative approach to particle swarm optimization. IEEE Transactions on Evolutionary Computation, 2004, 8(3): 225-239 doi: 10.1109/TEVC.2004.826069 [22] Komulainen T, Sourander M, Jämsä-Jounela S L. An online application of dynamic PLS to a dearomatization process. Computers and Chemical Engineering, 2004, 28(12): 2611-2619 doi: 10.1016/j.compchemeng.2004.07.014 [23] Curreri F, Graziani S, Xibilia M G. Input selection methods for data-driven Soft sensors design: Application to an industrial process. Information Sciences, 2020, 537: 1-17 doi: 10.1016/j.ins.2020.05.028 [24] Williamson D F, Parker R A, Kendrick J S. The box plot: a simple visual method to interpret data. Annals of Internal Medicine, 1989, 110(11): 916-921 doi: 10.7326/0003-4819-110-11-916 [25] Vincent P, Larochelle H, Lajoie I, Bengio Y, and Manzagol P. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. Journal of Machine Learning Research, 2010, 11: 3371-3408 -

 下载:
下载:


计量
- 文章访问数: 871
- HTML全文浏览量: 369
- PDF下载量: 249
- 被引次数: 0
