

Task Allocation and Reallocation for Heterogeneous Multiagent Systems Based on Potential Game
-
摘要: 针对异构多智能体系统, 基于势博弈理论提出一种新的任务分配和重分配算法. 考虑任务执行同步性和任务时效性的多重约束, 导致异构多智能体系统中各个体任务执行时间受到多种限制, 建立一个基于势博弈的算法结构, 使系统以分布式方式工作. 在此基础上, 基于势博弈理论设计任务分配算法, 保证在较低复杂度的同时, 可以得到近似最大化期望全局效用的良好分配方案, 并且随后将所提出的方法推广到任务重分配方案实现故障下的容错. 最后, 针对攻击任务场景对所提算法进行仿真验证, 结果表明, 在期望全局效用、容错能力和算法复杂度方面具有全面的性能.Abstract: This paper presents a novel task allocation and reallocation algorithm for heterogeneous multiagent systems based on potential game theory. Considering the multiple constraints of task execution synchronization and task timeliness, which lead to various restrictions on the execution time of each individual task in the heterogeneous multiagent systems, a potential game-based algorithm structure is established to make agents work in a distributed manner. On this basis, the task allocation algorithm is designed based on potential game theory, which produces a promising solution that nearly maximizes the expected global utility and guarantees lower complexity, and afterwards the fault tolerance is achieved by generalizing the proposed algorithm to task reallocation schemes. Finally, the proposed algorithm is verified by simulation of the attack task scenario, and results reveal the comprehensive performance in terms of the expected global utility, the fault tolerance and the algorithm complexity.
-
Key words:
- Task allocation /
- multiagent systems /
- potential game /
- constrained optimization /
- fault tolerance
-
肺癌是世界范围内发病率和死亡率最高的疾病之一, 占所有癌症病发症的18 %左右[1].美国癌症社区统计显示, 80 %到85 %的肺癌为非小细胞肺癌[2].在该亚型中, 大多数病人会发生淋巴结转移, 在手术中需对转移的淋巴结进行清扫, 现阶段通常以穿刺活检的方式确定淋巴结的转移情况.因此, 以非侵入性的方式确定淋巴结的转移情况对临床治疗具有一定的指导意义[3-5].然而, 基本的诊断方法在无创淋巴结转移的预测上存在很大挑战.
影像组学是针对医学影像的兴起的热门方法, 指通过定量医学影像来描述肿瘤的异质性, 构造大量纹理图像特征, 对临床问题进行分析决策[6-7].利用先进机器学习方法实现的影像组学已经大大提高了肿瘤良恶性的预测准确性[8].研究表明, 通过客观定量的描述影像信息, 并结合临床经验, 对肿瘤进行术前预测及预后分析, 将对临床产生更好的指导价值[9].
本文采用影像组学的方法来解决非小细胞肺癌淋巴结转移预测的问题.通过利用套索逻辑斯特回归(Lasso logistics regression, LLR)[10]模型得出基本的非小细胞肺癌淋巴结的转移预测概率, 并把组学模型的预测概率作为独立的生物标志物, 与患者的临床特征一起构建多元Logistics预测模型并绘制个性化诺模图, 在临床决策中的起重要参考作用.
1. 材料和方法
1.1 病人数据
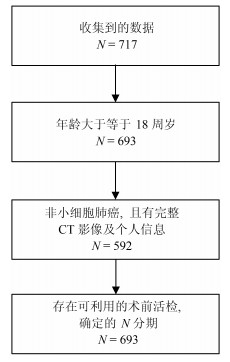
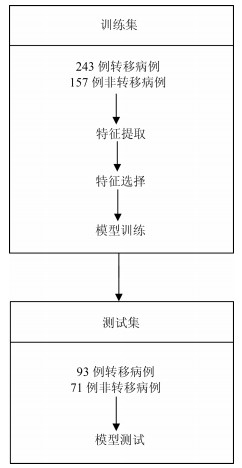
我们收集了广东省人民医院2007年5月至2014年6月期间的717例肺癌病例.这些病人在签署知情同意书后, 自愿提供自己的信息作为研究使用.为了充分利用收集到的数据对非小细胞肺癌淋巴结转移预测, 即对$N1-N3$与$N0$进行有效区分, 我们对收集的数据设置了三个入组标准: 1)年龄大于等于18周岁, 此时的肺部已经发育完全, 消除一定的干扰因素; 2)病理诊断为非小细胞肺癌无其他疾病干扰, 并有完整的CT (Computed tomography)增强图像及个人基本信息; 3)有可利用的术前病理组织活检分级用于确定N分期.经筛选, 共564例病例符合进行肺癌淋巴结转移预测研究的要求(如图 1).
为了得到有价值的结果, 考虑到数据的分配问题, 为了保证客观性, 防止挑数据的现象出现, 在数据分配上, 训练集与测试集将按照时间进行划分, 并以2013年1月为划分点.得到训练集: 400例, 其中, 243例正样本$N1-N3$, 157例负样本$N0$; 测试集: 164例, 其中, 93例正样本, 71例负样本.
1.2 病灶分割
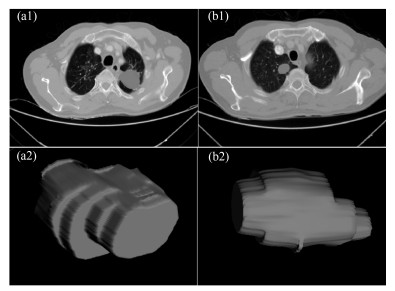
在进行特征提取工作前, 首先要对肿瘤病灶进行分割.医学图像分割的金标准是需要有经验的医生进行手动勾画的结果.但手动分割无法保证每次的分割结果完全一致, 且耗时耗力, 尤其是在数据量很大的情况下.因此, 手动分割不是最理想的做法.在本文中, 使用的自动图像分割算法为基于雪橇的自动区域生长分割算法[11], 该算法首先选定最大切片层的种子点, 这时一般情况下最大切片为中间层的切片, 然后估计肿瘤的大小即直径, 作为一个输入参数, 再自动进行区域生长得到每个切片的肿瘤如图 2(a1), (b1), 之后我们进行雪橇滑动到邻接的上下两个切面, 进行分割, 这样重复上述的区域生长即滑动切片, 最终分割得到多个切片的的肿瘤区域, 我们将肿瘤切面层进行组合, 得到三维肿瘤如图 2(a2), (b2).
1.3 特征的提取与筛选
利用影像组学处理方法, 从分割得到的肿瘤区域中总共提取出386个特征.这些特征可分为四组:三维形状特征, 表面纹理特征, Gabor特征和小波特征[12-13].形状特征通过肿瘤体积、表面积、体积面积比等特征描述肿瘤在空间和平面上的信息.纹理特征通过统计三维不同方向上像素的规律, 通过不同的分布规律来表示肿瘤的异质性. Gabor特征指根据特定方向, 特定尺度筛选出来的纹理信息.
小波特征是指原图像经过小波变换滤波器后的纹理特征.在模式识别范畴中, 高维特征会增加计算复杂度, 此外, 高维的特征往往存在冗余性, 容易造成模型过拟合.因此, 本位通过特征筛选方法首先对所有特征进行降维处理.
本文采用$L$1正则化Lasso进行特征筛选, 对于简单线性回归模型定义为:
$$ \begin{equation} f(x)=\sum\limits_{j=1}^p {w^jx^j} =w^\mathrm{T}x \end{equation} $$ (1) 其中, $x$表示样本, $w$表示要拟合的参数, $p$表示特征的维数.
要进行参数$w$学习, 应用二次损失来表示目标函数, 即:
$$ \begin{equation} J(w)=\frac{1}{n}\sum\limits_{i=1}^n{(y_i-f(x_i)})^2= \frac{1}{n}\vert\vert\ {{y}-Xw\vert\vert}^2 \end{equation} $$ (2) 其中, $X$是数据矩阵, $X=(x_1 , \cdots, x_n)^\mathrm{T}\in {\bf R}^{n\times p}$, ${y}$是由标签组成的列向量, ${y}=(y_1, \cdots, y_n )^\mathrm{T}$.
式(2)的解析解为:
$$ \begin{equation} \hat{w}=(X^\mathrm{T}X)^{-1}X^\mathrm{T}{y} \end{equation} $$ (3) 然而, 若$p\gg n$, 即特征维数远远大于数据个数, 矩阵$X^\mathrm{T}X$将不是满秩的, 此时无解.
通过Lasso正则化, 得到目标函数:
$$ \begin{equation} J_L(w)=\frac{1}{n} \vert\vert{y}-Xw\vert\vert^2+\lambda\vert\vert w\vert\vert _1 \end{equation} $$ (4) 目标函数最小化等价为:
$$ \begin{equation} \mathop {\min }\limits_w \frac{1}{n} \vert\vert{y}-Xw\vert\vert^2, \, \, \, \, \, \, \, \mathrm{s.t.}\, \, \vert \vert w\vert \vert _1 \le C \end{equation} $$ (5) 为了使部分特征排除, 本文采用$L$1正则方法进行压缩.二维情况下, 在$\mbox{(}w^1, w^2)$平面上可画出目标函数的等高线, 取值范围则为平面上半径为$C$的$L$1范数圆, 等高线与$L$1范数圆的交点为最优解. $L$1范数圆和每个坐标轴相交的地方都有"角''出现, 因此在角的位置将产生稀疏性.而在维数更高的情况下, 等高线与L1范数球的交点除角点之外还可能产生在很多边的轮廓线上, 同样也会产生稀疏性.对于式(5), 本位采用近似梯度下降(Proximal gradient descent)[14]算法进行参数$w$的迭代求解, 所构造的最小化函数为$Jl=\{g(w)+R(w)\}$.在每次迭代中, $Jl(w)$的近似计算方法如下:
$$ \begin{align} J_L (w^t+d)&\approx \tilde {J}_{w^t} (d)=g(w^t)+\nabla g(w^t)^\mathrm{T}d\, +\nonumber\\ &\frac{1} {2d^\mathrm{T}(\frac{I }{ \alpha })d}+R(w^t+d)=\nonumber\\ &g(w^t)+\nabla g(w^t)^\mathrm{T}d+\frac{{d^\mathrm{T}d} } {2\alpha } +\nonumber\\ &R(w^t+d) \end{align} $$ (6) 更新迭代$w^{(t+1)}\leftarrow w^t+\mathrm{argmin}_d \tilde {J}_{(w^t)} (d)$, 由于$R(w)$整体不可导, 因而利用子可导引理得:
$$ \begin{align} w^{(t+1)}&=w^t+\mathop {\mathrm{argmin}} \nabla g(w^t)d^\mathrm{T}d\, +\nonumber\\ &\frac{d^\mathrm{T}d}{2\alpha }+\lambda \vert \vert w^t+d\vert \vert _1=\nonumber\\ &\mathrm{argmin}\frac{1 }{ 2}\vert \vert u-(w^t-\alpha \nabla g(w^t))\vert \vert ^2+\nonumber\\ &\lambda \alpha \vert \vert u\vert \vert _1 \end{align} $$ (7) 其中, $S$是软阈值算子, 定义如下:
$$ \begin{equation} S(a, z)=\left\{\begin{array}{ll} a-z, &a>z \\ a+z, &a<-z \\ 0, &a\in [-z, z] \\ \end{array}\right. \end{equation} $$ (8) 整个迭代求解过程为:
输入.数据$X\in {\bf R}^{n\times p}, {y}\in {\bf R}^n$, 初始化$w^{(0)}$.
输出.参数$w^\ast ={\rm argmin}_w\textstyle{1 \over n}\vert \vert Xw-{y}\vert \vert ^2+\\ \lambda \vert\vert w\vert \vert _1 $.
1) 初始化循环次数$t = 0$;
2) 计算梯度$\nabla g=X^\mathrm{T}(Xw-{y})$;
3) 选择一个步长大小$\alpha ^t$;
4) 更新$w\leftarrow S(w-\alpha ^tg, \alpha ^t\lambda )$;
5) 判断是否收敛或者达到最大迭代次数, 未收敛$t\leftarrow t+1$, 并循环2)$\sim$5)步.
通过上述迭代计算, 最终得到最优参数, 而参数大小位于软区间中的, 将被置为零, 即被稀疏掉.
1.4 建立淋巴结转移影像组学标签与预测模型
本文使用LLR对组学特征进行降维并建模, 并使用10折交叉验证, 提高模型的泛化能力, 流程如图 3所示.
将本文使用的影像组学模型的预测概率(Radscore)作为独立的生物标志物, 并与临床指标中显著的特征结合构建多元Logistics模型, 绘制个性化预测的诺模图, 最后通过校正曲线来观察预测模型的偏移情况.
2. 结果
2.1 数据单因素分析结果
我们分别在训练集和验证集上计算各个临床指标与淋巴结转移的单因素P值, 计算方式为卡方检验, 结果见表 1, 发现吸烟与否和EGFR (Epidermal growth factor receptor)基因突变状态与淋巴结转移显著相关.
表 1 训练集和测试集病人的基本情况Table 1 Basic information of patients in the training set and test set基本项 训练集($N=400$) $P$值 测试集($N=164$) $P$值 性别 男 144 (36 %) 0.896 78 (47.6 %) 0.585 女 256 (64 %) 86 (52.4 %) 吸烟 是 126 (31.5 %) 0.030* 45 (27.4 %) 0.081 否 274 (68.5 %) 119 (72.6 %) EGFR 缺失 36 (9 %) 4 (2.4 %) 突变 138 (34.5 %) $ < $0.001* 67 (40.9 %) 0.112 正常 226 (56.5 %) 93 (56.7 %) 2.2 淋巴结转移影像组学标签
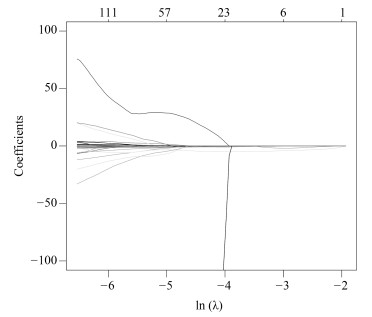
影像组学得分是每个病人最后通过模型预测后的输出值, 随着特征数的动态变化, 模型输出的AUC (Area under curve)值也随之变化, 如图 4所示, 使用R语言的Glmnet库可获得模型的参数$\lambda $的变化图.图中直观显示了参数$\lambda $的变化对模型性能的影响, 这次实验中模型选择了3个变量.如图 5所示, 横坐标表示$\lambda $的变化, 纵坐标表示变量的系数变化, 当$\lambda $逐渐变大时, 变量的系数逐渐减少为零, 表示变量选择的过程, 当$\lambda $越大表示模型的压缩程度越大.
 图 4 $\lambda $与变量数目对应走势Fig. 4 The trend of the parameters and the number of variables
图 4 $\lambda $与变量数目对应走势Fig. 4 The trend of the parameters and the number of variables通过套索回归方法, 自动的将变量压缩为3个, 其性能从图 4中也可发现, 模型的AUC值为最佳, 最终的特征如表 2所示. $V0$为截距项; $V179$为横向小波分解90度共生矩阵Contrast特征; $V230$为横向小波分解90度共生矩阵Entropy特征.
表 2 Lasso选择得到的参数Table 2 Parameters selected by LassoLasso选择的参数 含义 数值 $P$值 $V0$ 截距项 2.079115 $V179$ 横向小波分解90度共生矩阵Contrast特征(Contrast_2_90) 0.0000087 < 0.001*** $V230$ 横向小波分解90度共生矩阵Entropy特征(Entropy_3_180) $-$3.573315 < 0.001*** $V591$ 表面积与体积的比例(Surface to volume ratio) $-$1.411426 < 0.001*** $V591$为表面积与体积的比例; 将三个组学特征与$N$分期进行单因素分析, 其$P$值都是小于0.05, 表示与淋巴结转移有显著相关性.根据Lasso选择后的三个变量建立Logistics模型并计算出Rad-score, 详见式(9).并且同时建立SVM (Support vector machine)模型.
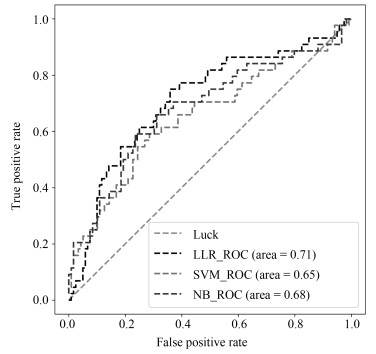
NB (Naive Bayesian)模型, 进行训练与预测, LLR模型训练集AUC为0.710, 测试集为0.712, 表现较优; 如表 3所示.将实验中使用的三个机器学习模型的结果进行对比, 可以发现, LLR的实验结果是最好的.
表 3 不同方法对比结果Table 3 Comparison results of different methods方法 训练集(AUC) 测试集(AUC) 召回率 LLR 0.710 0.712 0.75 SVM 0.698 0.654 0.75 NB 0.718 0.681 0.74 $$ \begin{equation} \begin{aligned} &\text{Rad-score}=2.328373+{\rm Contrast}\_2\_90\times\\ &\qquad 0.0000106 -{\rm entropy}\_3\_180\times 3.838207 +\\ &\qquad\text{Maximum 3D diameter}\times 0.0000002 -\\ &\qquad\text{Surface to volume ratio}\times 1.897416 \\ \end{aligned} \end{equation} $$ (9) 2.3 诺模图个性化预测模型
为了体现诺模图的临床意义, 融合Rad-score, 吸烟情况和EGFR基因因素等有意义的变量进行分析, 绘制出个性化预测的诺模图, 如图 7所示.为了给每个病人在最后得到一个得分, 需要将其对应变量的得分进行相加, 然后在概率线找到对应得分的概率, 从而实现非小细胞肺癌淋巴结转移的个性化预测.我们通过一致性指数(Concordance index, $C$-index)对模型进行了衡量, 其对应的$C$-index为0.724.
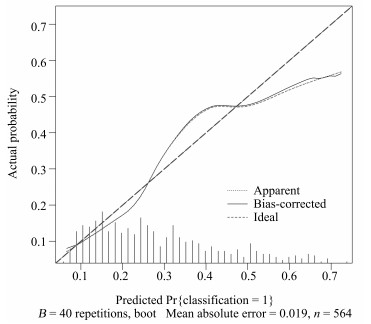
本文中使用校正曲线来验证诺模图的预测效果, 如图 8所示, 由校正曲线可以看出, 预测结果基本上没有偏离真实标签的结果, 表现良好, 因此, 该模型具有可靠的预测性能[15].
3. 结论
在构建非小细胞肺癌淋巴结转移的预测模型中, 使用LLR筛选组学特征并构建组学标签, 并与显著的临床特征构建多元Logistics模型, 绘制个性化预测的诺模图.其中LLR模型在训练集上的AUC值为0.710, 在测试集上的AUC值为0.712, 利用多元Logistics模型绘制个性化预测的诺模图, 得到模型表现能力$C$-index为0.724 (95 % CI: 0.678 $\sim$ 0.770), 并且在校正曲线上表现良好, 所以个性化预测的诺模图在临床决策上可起重要参考意义.[16].
-
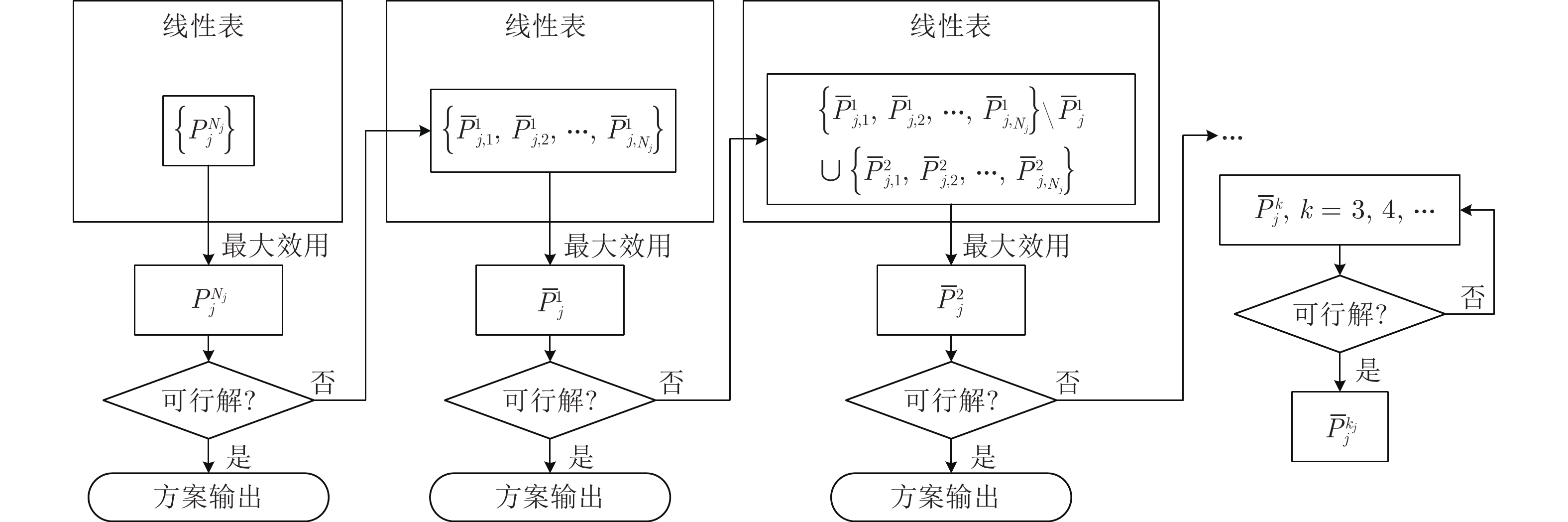
图 1 势博弈次优解的选择过程
Fig. 1 The process of selecting the suboptimal solution of the potential game
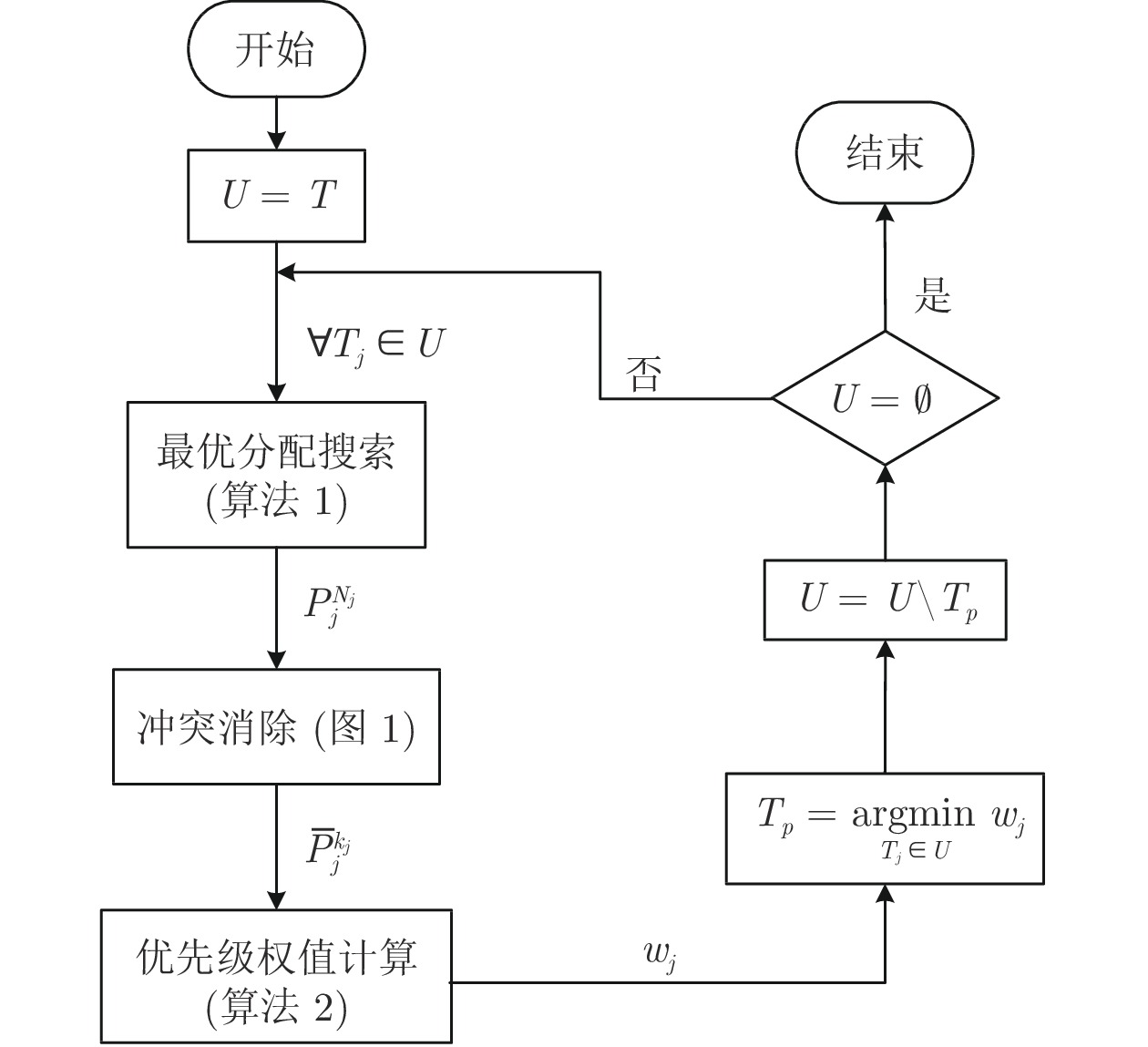
图 2 健康环境下的初始任务分配流程图
Fig. 2 The flow chart of the initial task allocation in the healthy environment
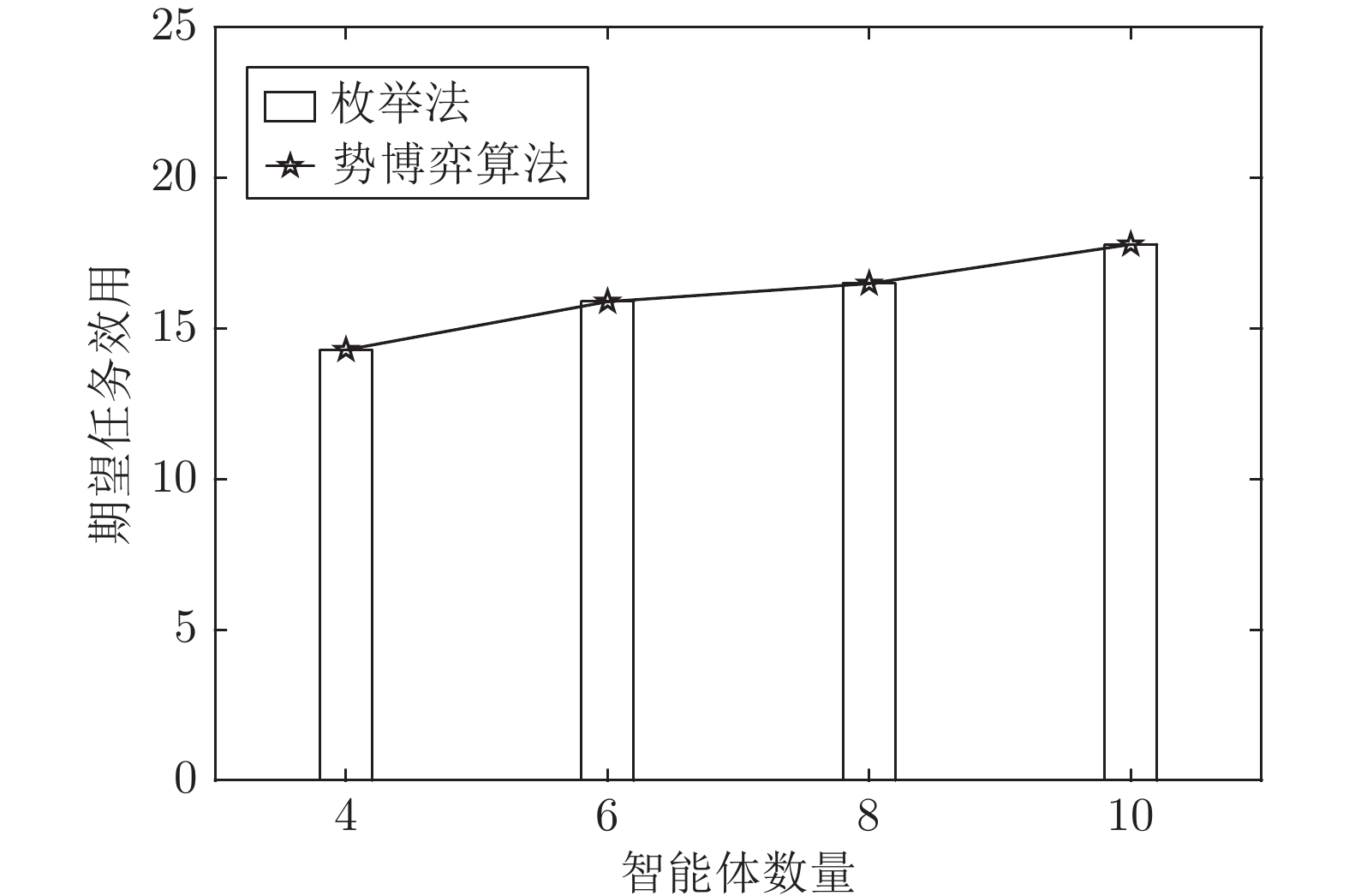
图 5 分配单项任务的最大期望效用对比
Fig. 5 Comparison of the maximum expected utilities for allocating a single task
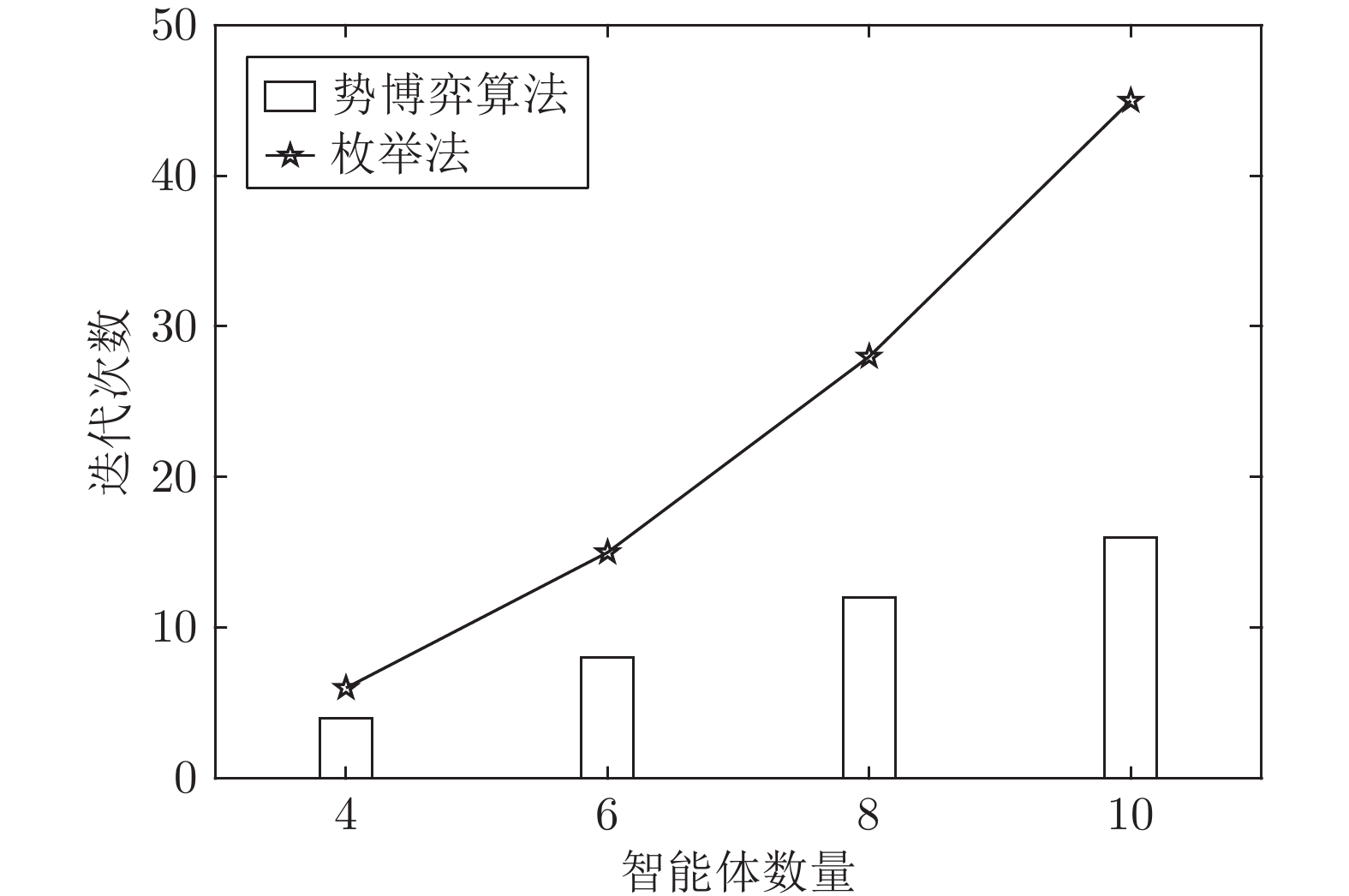
图 6 分配单项任务的所需迭代次数对比
Fig. 6 Comparison of the required number of iterations for allocating a single task
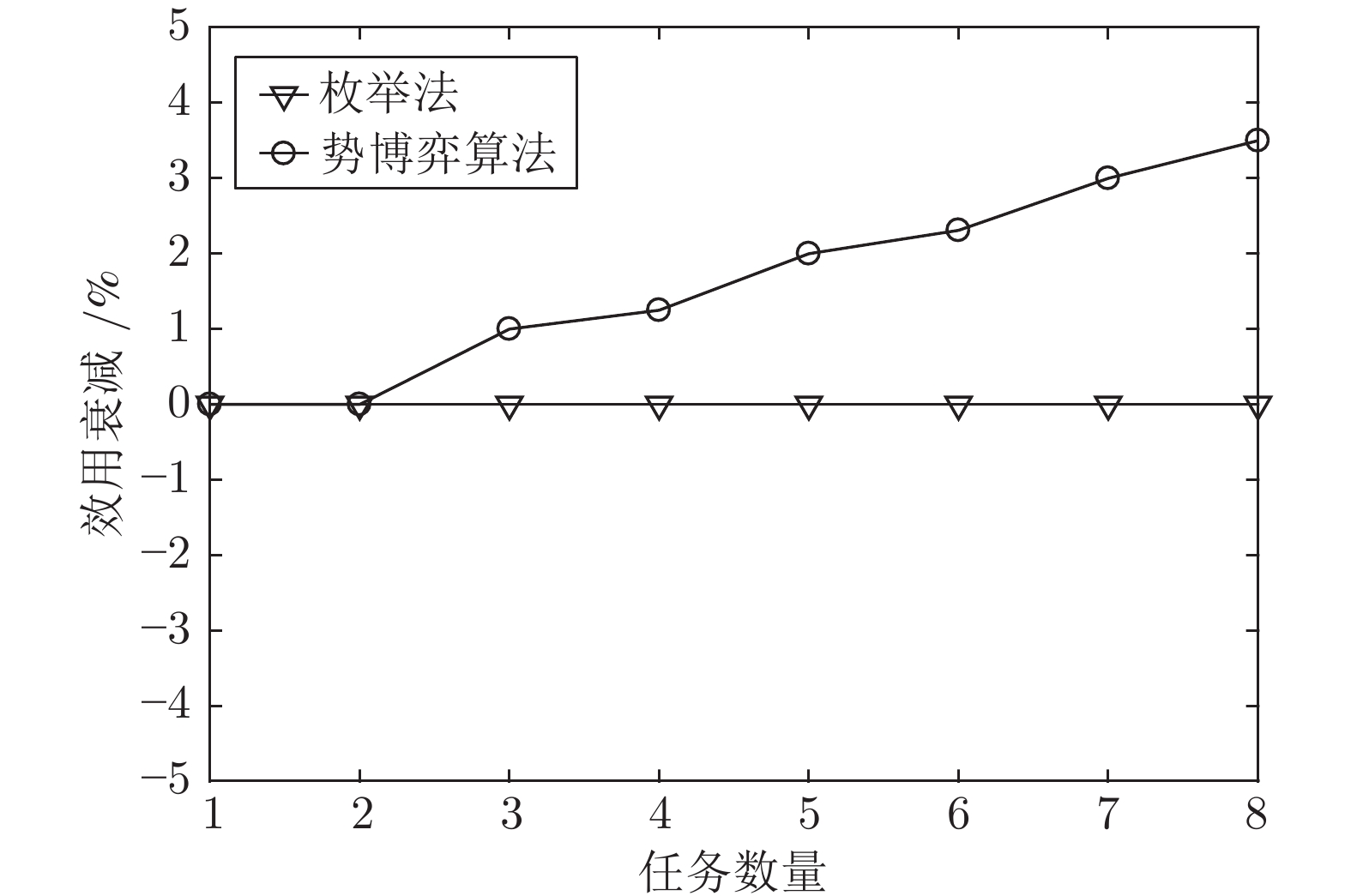
图 7 不同任务数量下的最大期望全局效用衰减
Fig. 7 Reductions of the maximum expected global utility under different number of tasks
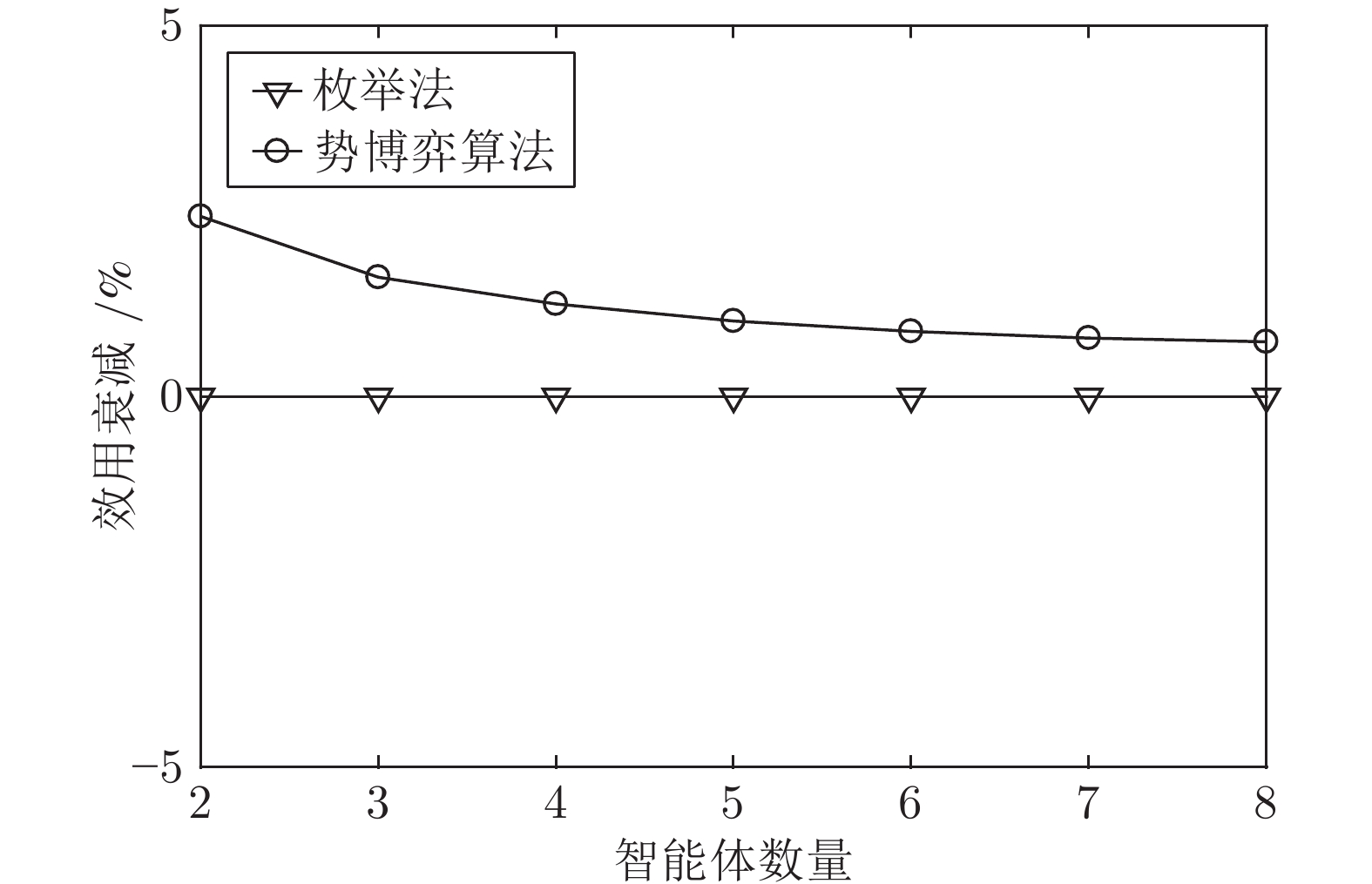
图 8 不同智能体数量下的最大期望全局效用衰减
Fig. 8 Reductions of the maximum expected global utility under different number of agents
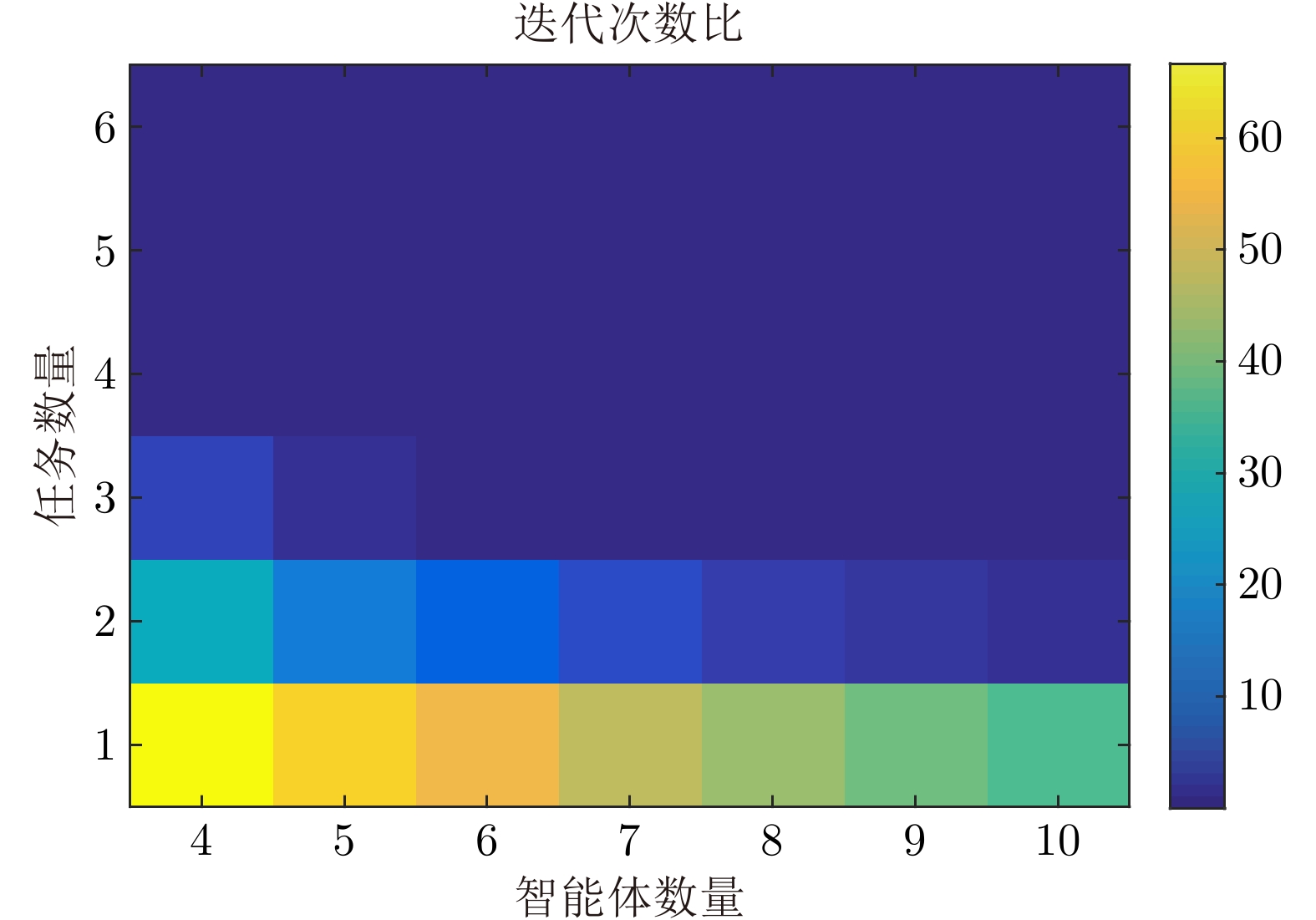
图 9 所提出算法与枚举法迭代次数的比值
Fig. 9 The ratio of the number of iterations between the proposed algorithm and the enumeration method
表 1 智能体初始信息
Table 1 Initial information of agents
智能体$A_i$ 位置 (m, m) 能力$(\lambda_{i1},\lambda_{i2},\lambda_{i3},\lambda_{i4})$ 最大速度 (m/s) 最大加速度 (m/s2) $A_1$ (0, 0) (0.5, 0.5, 1.0, 1.0) 10 0.25 $A_2$ (1000, 0) (1.0, 1.0, 0.5, 0.5) 20 0.25 $A_3$ (3000, 0) (0.5, 1.0, 1.0, 0.5) 10 0.25 $A_4$ (6000, 6000) (1.0, 0.5, 0.5, 1.0) 20 0.25  下载: 导出CSV
下载: 导出CSV
表 2 任务初始信息
Table 2 Initial information of tasks
任务$T_j$ 位置 (m, m) 基础效用$r_j$ 所需智能体数量$N_j$ 折扣系数$\mu_j$ $T_1$ (4000, 4000) 10 2 5$\times 10^{-4}$ $T_2$ (2000, 2000) 20 2 5$\times 10^{-4}$ $T_3$ (0, 2000) 10 2 5$\times 10^{-4}$ $T_4$ (2000, 4000) 10 2 5$\times 10^{-4}$
下载: 导出CSV
-
[1] Yang Y, Li Y F, Yue D, Tian Y C, Ding X H. Distributed secure consensus control with event-triggering for multiagent systems under DoS attacks. IEEE Transactions on Cybernetics, 2021, 51(6): 2916-2928 doi: 10.1109/TCYB.2020.2979342 [2] Zhang K, Jiang B, Shi P. Adjustable parameter-based distributed fault estimation observer design for multiagent systems with directed graphs. IEEE Transactions on Cybernetics, 2017, 47(2): 306-314 [3] 田磊, 董希旺, 赵启伦, 李清东, 吕金虎, 任章. 异构集群系统分布式自适应输出时变编队跟踪控制. 自动化学报, 2021, 47(10): 2386-2401Tian Lei, Dong Xi-Wang, Zhao Qi-Lun, Li Qing-Dong, Lv Jin-Hu, Ren Zhang. Distributed adaptive time-varying output formation tracking for heterogeneous swarm systems. Acta Automatica Sinica, 2021, 47(10): 2386-2401 [4] 黄刚, 李军华. 基于 AC-DSDE 进化算法多 UAVs 协同目标分配. 自动化学报, 2021, 47(1): 173-184Huang Gang, Li Jun-Hua. Multi-UAV cooperative target allocation based on AC-DSDE evolutionary algorithm. IEEE Transactions on Image Processing, 2021, 47(1): 173-184 [5] Li M C, Wang Z D, Li K L, Liao X K, Hone K, Liu X H. Task allocation on layered multiagent systems: When evolutionary many-objective optimization meets deep Q-learning. IEEE Transactions on Evolutionary Computation, 2021, 25(5): 842-855 doi: 10.1109/TEVC.2021.3049131 [6] 李勇, 李坤成, 孙柏青, 张秋豪, 王义娜, 杨俊友. 智能体 Petri 网融合的多机器人-多任务协调框架. 自动化学报, 2021, 47(8): 2029-2049Li Yong, Li Kun-Cheng, Sun Bai-Qing, Zhang Qiu-Hao, Wang Yi-Na, Yang Jun-You. Multi-robot-multi-task coordination framework based on the integration of intelligent agent and petri net. IEEE Transactions on Image Processing, 2021, 47(8): 2029-2049 [7] Gerkey B P, Mataric M J. A formal analysis and taxonomy of task allocation in multi-robot systems. International Journal of Robotics Research, 2004, 23(9): 939-954 doi: 10.1177/0278364904045564 [8] Alencar R C, Santana C J, Bastos-Filho C J A. Optimizing routes for medicine distribution using team ant colony system. Advances in Intelligent Systems and Computing, 2020, 923: 40-49 [9] Zhang F. Intelligent task allocation method based on improved QPSO in multi-agent system. Journal of Ambient Intelligence and Humanized Computing, 2020, 11: 655-662 doi: 10.1007/s12652-019-01242-0 [10] Rahman S M M, Wang Y. Mutual trust-based subtask allocation for human-robot collaboration in flexible lightweight assembly in manufacturing. Mechatronics, 2018, 54: 94-109 doi: 10.1016/j.mechatronics.2018.07.007 [11] Chen J X, Wu Q H, Xu Y H, Qi N, Guan X, Zhang Y L, et al. Joint task assignment and spectrum allocation in heterogeneous UAV communication networks: A coalition formation game-theoretic approach. IEEE Transactions on Wireless Communications, 2021, 20(1): 440-452 doi: 10.1109/TWC.2020.3025316 [12] Wang D, Li K M, Zhang Q, Lu X F, Luo Y. A cooperative task allocation game for multi-target imaging in radar networks. IEEE Sensors Journal, 2021, 21(6): 7541-7550 doi: 10.1109/JSEN.2021.3049899 [13] Sullivan N, Grainger S, Cazzolato B. Sequential single-item auction improvements for heterogeneous multi-robot routing. Robotics and Autonomous Systems, 2019, 115: 130-142 doi: 10.1016/j.robot.2019.02.016 [14] Lee D H. Resource-based task allocation for multi-robot systems. Robotics and Autonomous Systems, 2018, 103: 151-161 doi: 10.1016/j.robot.2018.02.016 [15] Huang X W, Gong S M, Yang J M, Zhang W J, Yang L W, Yeo C K. Hybrid market-based resources allocation in mobile edge computing systems under stochastic information. Future Generation Computer Systems, 2022, 127: 80-91 doi: 10.1016/j.future.2021.08.029 [16] Xu Y H, Jiang B, Yang H. Two-level game-based distributed optimal fault-tolerant control for nonlinear interconnected systems. IEEE Transactions on Neural Networks and Learning Systems, 2020, 31(11): 4892-4906 doi: 10.1109/TNNLS.2019.2958948 [17] 刘坤, 郑晓帅, 林业茗, 韩乐, 夏元清. 基于微分博弈的追逃问题最优策略设计. 自动化学报, 2021, 47(8): 1840-1854Liu Kun, Zheng Xiao-Shuai, Lin Ye-Ming, Han Le, Xia Yuan-Qing. Design of optimal strategies for the pursuit-evasion problem based on differential game. Acta Automatica Sinica, 2021, 47(8): 1840-1854 [18] Duan H B, Li P, Yu Y X. A predator-prey particle swarm optimization approach to multiple UCAV air combat modeled by dynamic game theory. IEEE/CAA Journal of Automatica Sinica, 2015, 2(1): 11-18 doi: 10.1109/JAS.2015.7032901 [19] Chapman A C, Micillo R A, Kota R, Jennings N R. Decentralised dynamic task allocation: A practical game theoretic approach. In: Proceedings of the 8th International Conference on Autonomous Agents and Multiagent Systems. Budapest, Hungary: IEEE, 2009. 915−922 [20] Wu H, Shang H L. Potential game for dynamic task allocation in multi-agent system. ISA Transactions, 2020, 102: 208-220 doi: 10.1016/j.isatra.2020.03.004 [21] Monderer D, Shapley L S. Potential games. Games and Economic Behavior, 1996, 14(1): 124-143 doi: 10.1006/game.1996.0044 [22] Xu X L, Mo R C, Dai F, Lin W M, Wan S H, Dou W C. Dynamic resource provisioning with fault tolerance for data-intensive meteorological workflows in cloud. IEEE Transactions on Industrial Informatics, 2020, 16(9): 6172-6181 doi: 10.1109/TII.2019.2959258 [23] Paul S, Chatterjee N, Ghosal P. A permanent fault tolerant dynamic task allocation approach for network-on-chip based multicore systems. Journal of Systems Architecture, 2019, 97: 287-303 doi: 10.1016/j.sysarc.2018.10.003 [24] Das G P, McGinnity T M, Coleman S A, Behera L. A fast distributed auction and consensus process using parallel task allocation and execution. In: Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems. San Francisco, CA, USA: IEEE, 2011. 4716−4721 [25] Farinelli A, Iocchi L, Nardi D. Distributed on-line dynamic task assignment for multi-robot patrolling. Autonomous Robots, 2017, 41(6): 1321-1345 doi: 10.1007/s10514-016-9579-8 [26] Guo S C, Huang H Z, Wang Z L, Xie M. Grid service reliability modeling and optimal task scheduling considering fault recovery. IEEE Transactions on Reliability, 2011, 60(1): 263-274 doi: 10.1109/TR.2010.2104190 [27] Shatz S M, Wang J P. Models and algorithms for reliability-oriented task-allocation in redundant distributed-computer systems. IEEE Transactions on Reliability, 1989, 38(1): 16-27 doi: 10.1109/24.24570 [28] Shoham Y, Brown K L. Multiagent Systems: Algorithmic, Game-theoretic, and Logical Foundations. Cambridge: Cambridge University Press, 2008. 174−177 [29] 唐嘉钰, 李相民, 代进进, 薄宁. 复杂约束条件下异构多智能体联盟任务分配. 控制理论与应用, 2020, 37(11): 2413-2422 doi: 10.7641/CTA.2020.90868Tang Jia-Yu, Li Xiang-Min, Dai Jin-Jin, Bo Ning. Coalition task allocation of heterogeneous multiple agents with complex constraints. Control Theory & Applications, 2020, 37(11): 2413-2422 doi: 10.7641/CTA.2020.90868 [30] Elhoseny M, Tharwat A, Hassanien A E. Bezier curve based path planning in a dynamic field using modified genetic algorithm. Journal of Computational Science, 2018, 25: 339-350 doi: 10.1016/j.jocs.2017.08.004 [31] Mellinger D, Kumar V. Minimum snap trajectory generation and control for quadrotors. In: Proceedings of the 2011 IEEE International Conference on Robotics and Automation. Shanghai, China: IEEE, 2011. 2520−2525 期刊类型引用(20)
1. 许家昌,郭佳,苏树智. 基于扩展型活性膜系统的彩色图像分割方法. 深圳大学学报(理工版). 2025(01): 59-67 .  百度学术
百度学术2. 姜煜. 基于混合算法OLPSOG的负载均衡优化分析. 集成电路应用. 2025(02): 104-106 . 百度学术3. 葛泉波,程惠茹,张明川,郑瑞娟,朱军龙,吴庆涛. 基于PCA和ICA模式融合的非高斯特征检测识别. 自动化学报. 2024(01): 169-180 . 本站查看4. 李大海,李鑫,王振东. 融合小生境机制的增强麻雀搜索算法及其应用. 计算机应用研究. 2024(04): 1077-1085 . 百度学术5. 李大海,刘晓峰,王振东. 基于动态双种群的黏菌和花粉混合算法. 计算机应用研究. 2024(07): 2052-2060 . 百度学术6. 李大海,詹美欣,王振东. 混合策略改进的麻雀搜索算法及其应用. 计算机应用研究. 2023(02): 404-412 . 百度学术7. 刘威,郭直清,姜丰,刘光伟,靳宝,王东. 协同围攻策略改进的灰狼算法及其PID参数优化. 计算机科学与探索. 2023(03): 620-634 . 百度学术8. 陶新民,郭文杰,李向可,陈玮,吴永康. 基于密度峰值的依维度重置多种群粒子群算法. 软件学报. 2023(04): 1850-1869 . 百度学术9. 王钦甜,沈艳军. 多阶段的郊狼优化算法. 广西师范大学学报(自然科学版). 2023(03): 105-117 . 百度学术10. 李大海,詹美欣,王振东. 基于多个改进策略的增强麻雀搜索算法. 计算机应用. 2023(09): 2845-2854 . 百度学术11. 李大海,李鑫,王振东. 融合多策略的增强麻雀搜索算法及其应用. 计算机应用研究. 2023(10): 3032-3039 . 百度学术12. 卢磊,贺智明,黄志成. 基于多策略改进的麻雀搜索算法. 计算机与现代化. 2023(10): 23-31 . 百度学术13. 史国宏,刘钊. 联合黏菌—乌鸦算法及其在机械设计中的应用. 工程机械. 2023(12): 48-62+8-9 . 百度学术14. 张新明,陈海燕,窦育强,王善侠,刘国奇,窦智,张贝. 改进的堆优化算法及其宫颈细胞数据聚类优化. 计算机应用研究. 2023(12): 3584-3591 . 百度学术15. 张新明,杨方圆,刘国奇. 多策略的郊狼优化算法. 计算机应用研究. 2022(04): 1124-1131 . 百度学术16. 李大海,詹美欣,王振东. 求解多峰目标函数的改进阴阳对算法. 计算机应用研究. 2022(05): 1402-1409 . 百度学术17. 石彪,王海燕,焦品博. 基于改进GWO-LSTM的船舶主机性能预测模型. 上海海事大学学报. 2022(02): 96-102 . 百度学术18. 赵金金,鲁海燕,徐杰,卢梦蝶,侯新宇. 双策略学习和自适应混沌变异的郊狼优化算法. 计算机应用研究. 2022(07): 2000-2006 . 百度学术19. 刘宇凇,刘升. 成败历史存档的融合龙格库塔-黏菌算法. 计算机工程与应用. 2022(17): 61-71 . 百度学术20. 李大海,刘庆腾,艾志刚,王振东. 基于动态D向分割和混沌扰动的阴阳对优化算法. 计算机应用. 2022(09): 2788-2799 . 百度学术其他类型引用(23)
-

 下载:
下载:

计量
- 文章访问数: 1358
- HTML全文浏览量: 337
- PDF下载量: 492
- 被引次数: 43
