

-
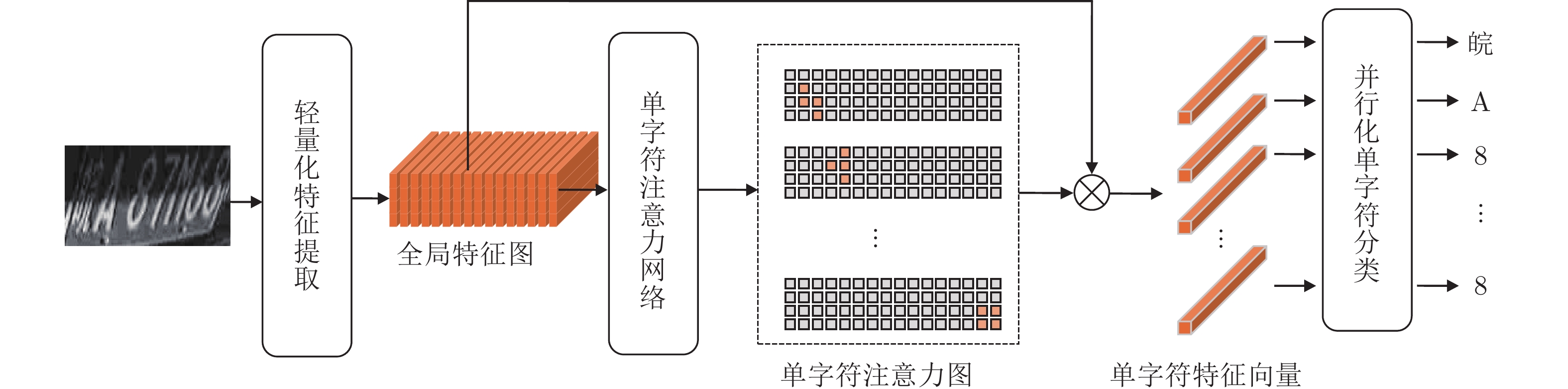
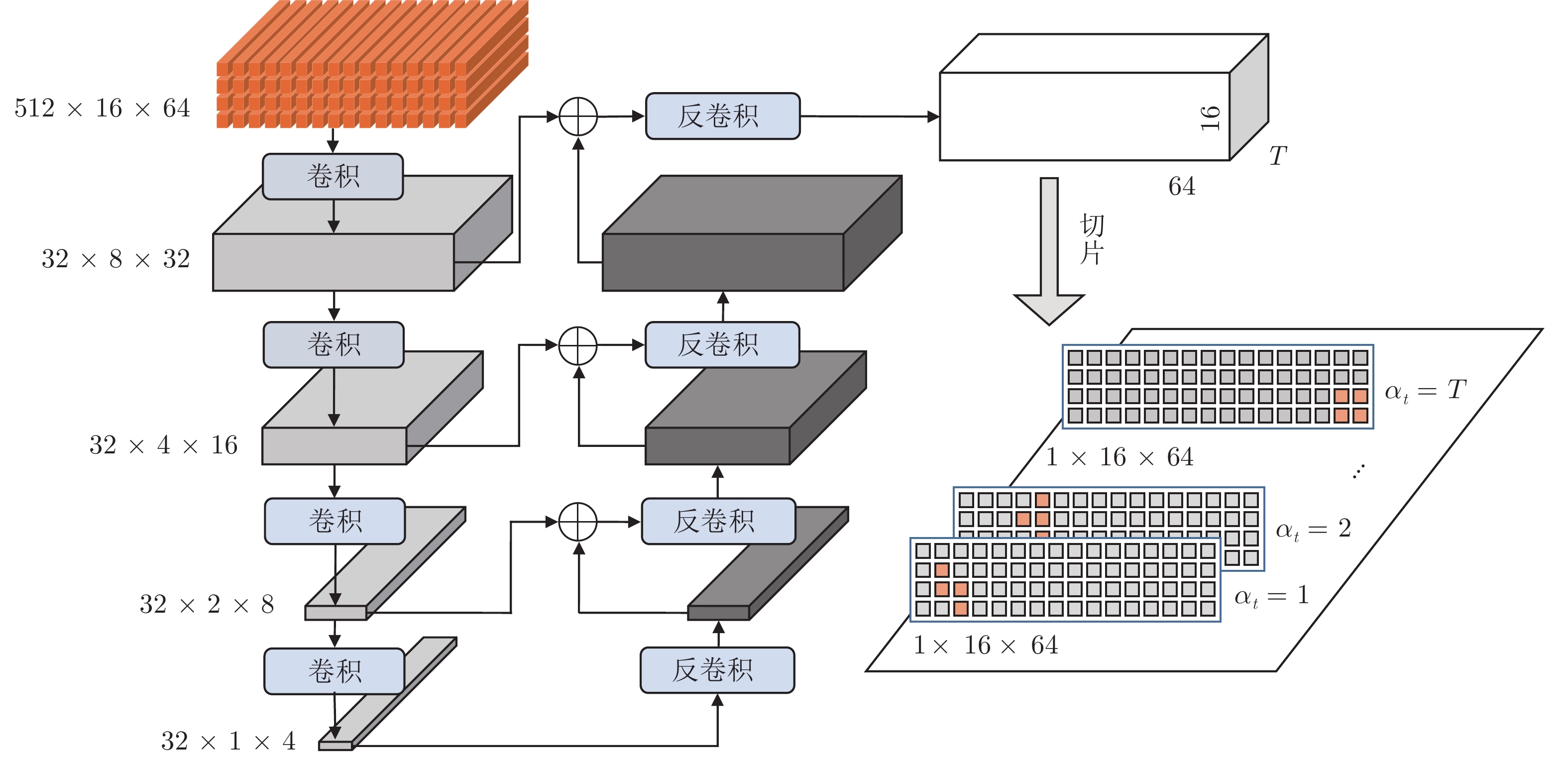
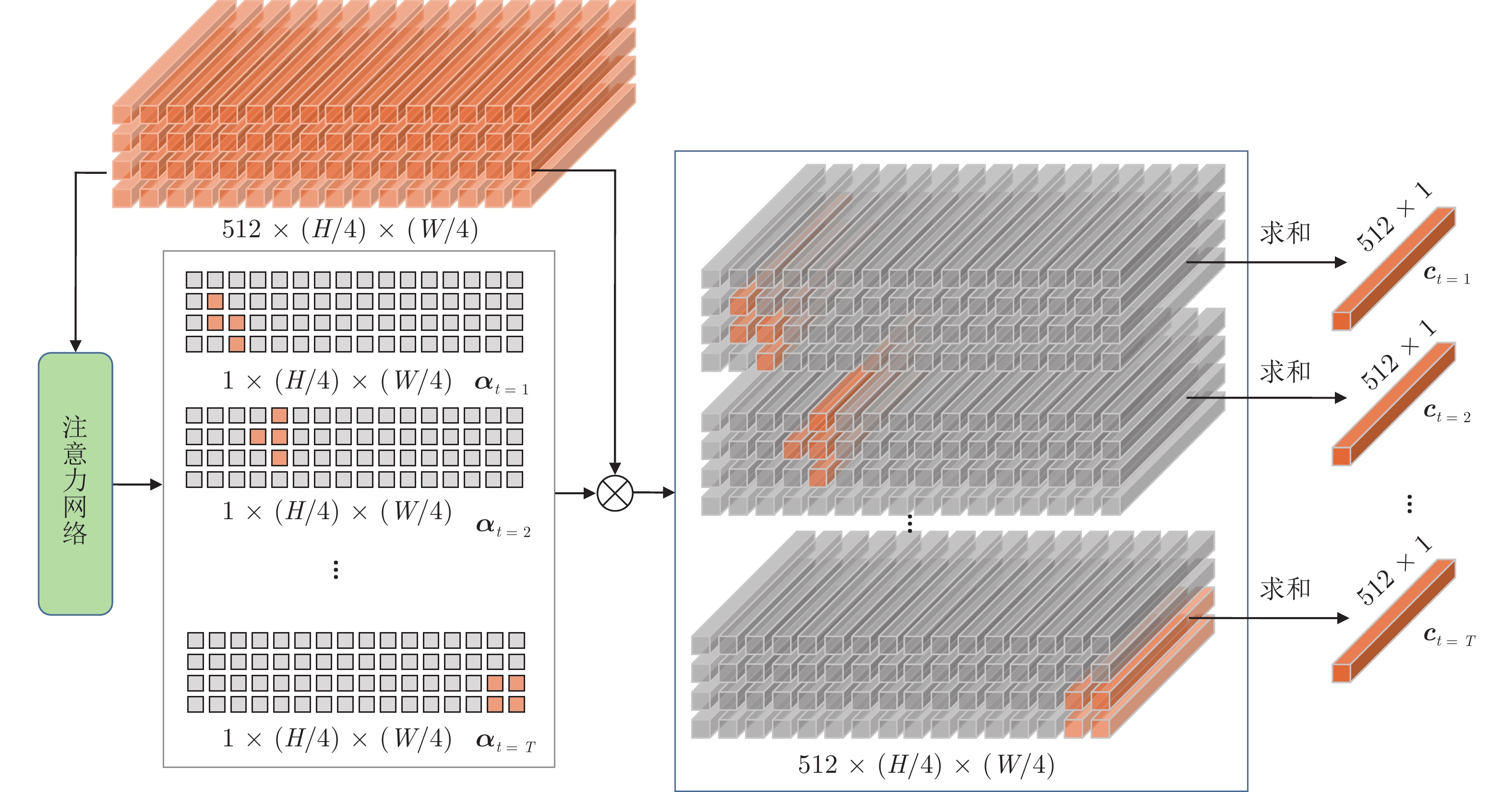
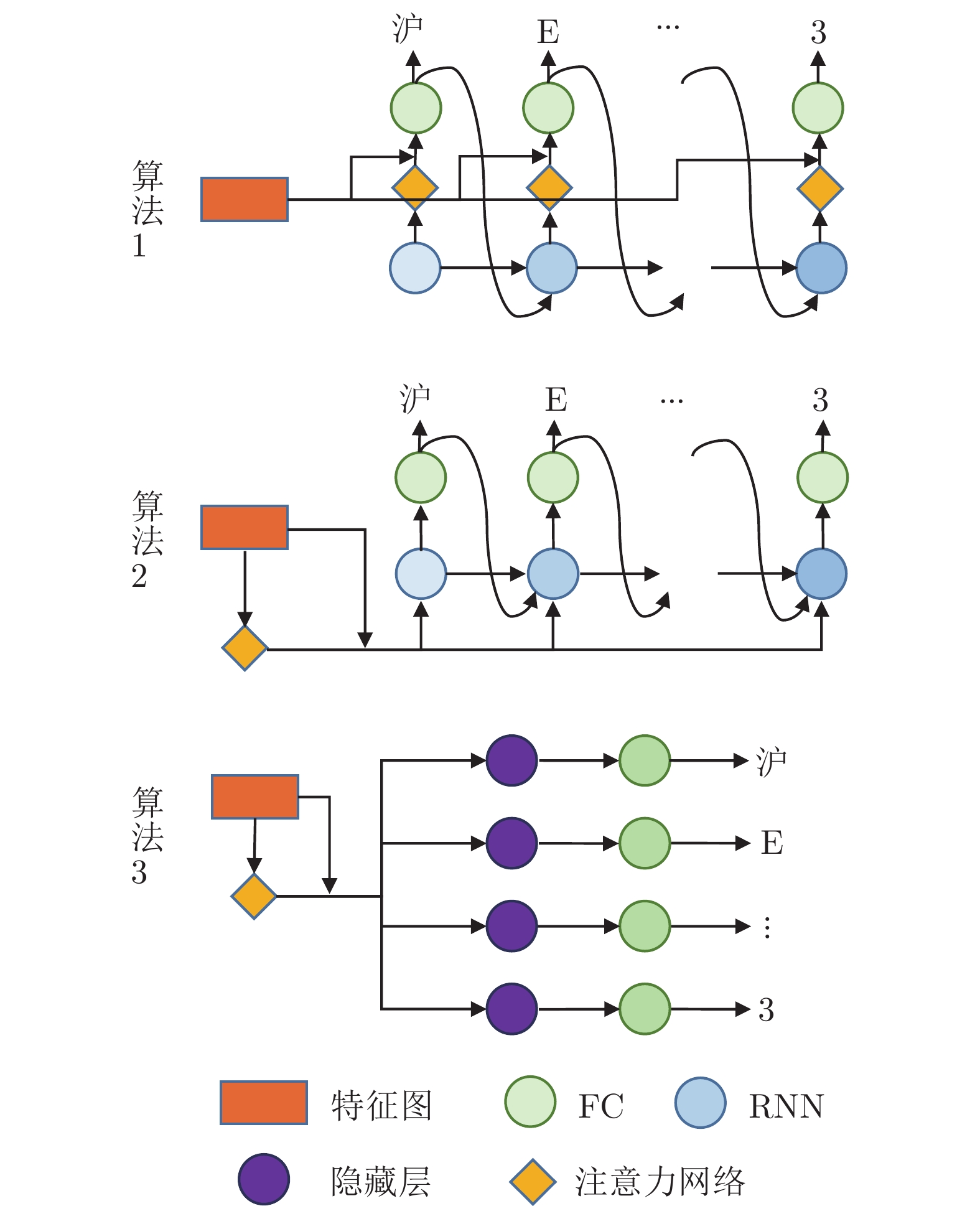
摘要: 复杂场景下的高精度车牌识别仍然存在着许多挑战, 除了光照、分辨率不可控和运动模糊等因素导致的车牌图像质量低之外, 还包括车牌品类多样产生的行数不一和字数不一等困难, 以及因拍摄角度多样出现的大倾角等问题. 针对这些挑战, 提出了一种基于单字符注意力的场景鲁棒的高精度车牌识别算法, 在无单字符位置标签信息的情况下, 使用注意力机制对车牌全局特征图进行单字符级特征分割, 以处理多品类车牌和倾斜车牌中的二维字符布局问题. 另外, 该算法通过使用共享参数的多分支结构代替现有算法的串行解码结构, 降低了分类头参数量并实现了并行化推理. 实验结果表明, 该算法在公开车牌数据集上实现了超越现有算法的精度, 同时具有较快的识别速度.Abstract: There are still many challenges for high-precision vehicle license plate recognition in complex scenarios. In addition to the low quality of license plate images caused by factors such as poor illumination, low resolution, and motion blur, challenges also include different variant numbers of characters and lines for different license plate categories, as well as large inclination caused by the various camera locations. In response to these challenges, this paper proposes a scene-robust high-precision license plate recognition algorithm based on character attention, which performs character level segmentation on the global feature map of the license plate images without character position label information. Such character level segmentation can deal with the 2D character layout problems in multi-category license plates and inclined license plates. In addition, this algorithm uses a shared weight classification header structure to replace the serial decoding structure used in existing algorithms, which reduces the number of classification header parameters and realizes parallel inference. The experimental results show that the algorithm achieves high accuracy which surpasses the existing algorithms on the public-domain data sets, and meanwhile has a faster recognition speed.
-

图 8 双行黄牌、新能源车牌及黑色车牌注意力图
Fig. 8 Attention maps of double-line and new energy and black plate licenses
表 1 在CCPD上的车牌识别准确率(%)
Table 1 License plate recognition accuracy on CCPD (%)
算法 平均 基础集 明暗集 远近集 旋转集 倾斜集 天气集 挑战集 Li 等[1] 94.4 97.8 94.8 94.5 87.9 92.1 86.8 81.2 Xu 等[27] 95.5 98.5 96.9 94.3 90.8 92.5 87.9 85.1 Wang 等[23] 96.6 98.9 96.1 96.4 91.9 93.7 95.4 83.1 Zou 等[8] 97.8 99.3 98.5 98.6 92.5 94.4 99.3 86.6 Yang 等[4] 97.5 99.1 96.9 95.9 97.1 98.0 97.5 85.9 Qin 等[33] 97.5 99.5 93.3 93.7 98.2 95.9 98.9 92.9 Qiao 等[34] 96.9 99.0 97.1 95.5 95.0 96.5 95.9 83.1 Zhang 等[20] 98.5 99.6 98.8 98.8 96.4 97.6 98.5 88.9 Liu 等[35] 98.74 99.73 99.05 99.23 97.62 98.40 98.89 88.51 GCN 98.79 99.70 99.07 98.96 98.33 98.82 98.66 89.42 CARNet 99.50
(0.02)99.89
(0.01)99.57
(0.08)99.56
(0.04)99.68
(0.04)99.80
(0.01)99.38
(0.06)94.92
(0.09) 下载: 导出CSV
下载: 导出CSV
表 2 本文算法有效性评估(%)
Table 2 Evaluation of the effectiveness of the algorithm of this paper (%)
评估指标 算法 平均 基础集 明暗集 远近集 旋转集 倾斜集 天气集 挑战集 $ {R_{LP}} $ GCN 98.79 99.70 99.07 98.96 98.33 98.82 98.66 89.42 (0.10) (0.03) (0.11) (0.11) (0.25) (0.19) (0.13) (0.54) CARNet 99.50 99.89 99.57 99.56 99.68 99.80 99.38 94.92 (0.02) (0.01) (0.08) (0.04) (0.04) (0.01) (0.06) (0.09) $ {R_{Char}} $ GCN 99.74 99.95 99.83 99.79 99.68 99.78 99.77 97.28 (0.02) (0.01) (0.02) (0.01) (0.05) (0.03) (0.02) (0.14) CARNet 99.90 99.98 99.94 99.93 99.95 99.97 99.90 98.89 (0.01) (0.01) (0.01) (0.01) (0.01) (0.01) (0.01) (0.01) $ {R_{C\_Char}} $ GCN 99.72 99.87 99.78 99.78 99.56 99.71 99.70 98.18 (0.02) (0.01) (0.02) (0.01) (0.06) (0.03) (0.06) (0.07) CARNet 99.92 99.99 99.93 99.89 99.95 99.98 99.95 99.13 (0.01) (0.01) (0.02) (0.02) (0.01) (0.01) (0.02) (0.01) $ {R_{W\_Char}} $ GCN 99.74 99.97 99.83 99.80 99.70 99.80 99.78 97.13 (0.02) (0.01) (0.02) (0.01) (0.05) (0.03) (0.01) (0.16) CARNet 99.90 99.98 99.94 99.93 99.95 99.97 99.89 98.85 (0.01) (0.01) (0.01) (0.01) (0.01) (0.01) (0.01) (0.01)
下载: 导出CSV
表 4 在混合品类车牌上的识别准确率
Table 4 Recognition accuracy on mixed types of license plates
车牌类别 数量 (张) GCN[22] (%) CARNet (%) 蓝牌车牌 1050 96.3 99.0 新能源绿牌 1010 41.9 78.5 大型车后牌 660 35.8 62.1 教练车牌 860 44.9 74.8 港澳车牌 1580 53.7 74.9 大型车前牌 980 63.2 75.8
下载: 导出CSV
表 5 各算法速度比较
Table 5 Comparison of algorithm speed
下载: 导出CSV
表 6 低功耗嵌入式硬件测试
Table 6 Low-power embedded device test
算法 硬件平台 推理引擎 耗时 (ms) Qin 等[9] Jetson Nano TensorFlow 68 CARNet Jetson Nano Pytorch 41 CARNet Jetson TX2 Pytorch 30 CARNet Hi3516DV300 NNIE 46
下载: 导出CSV
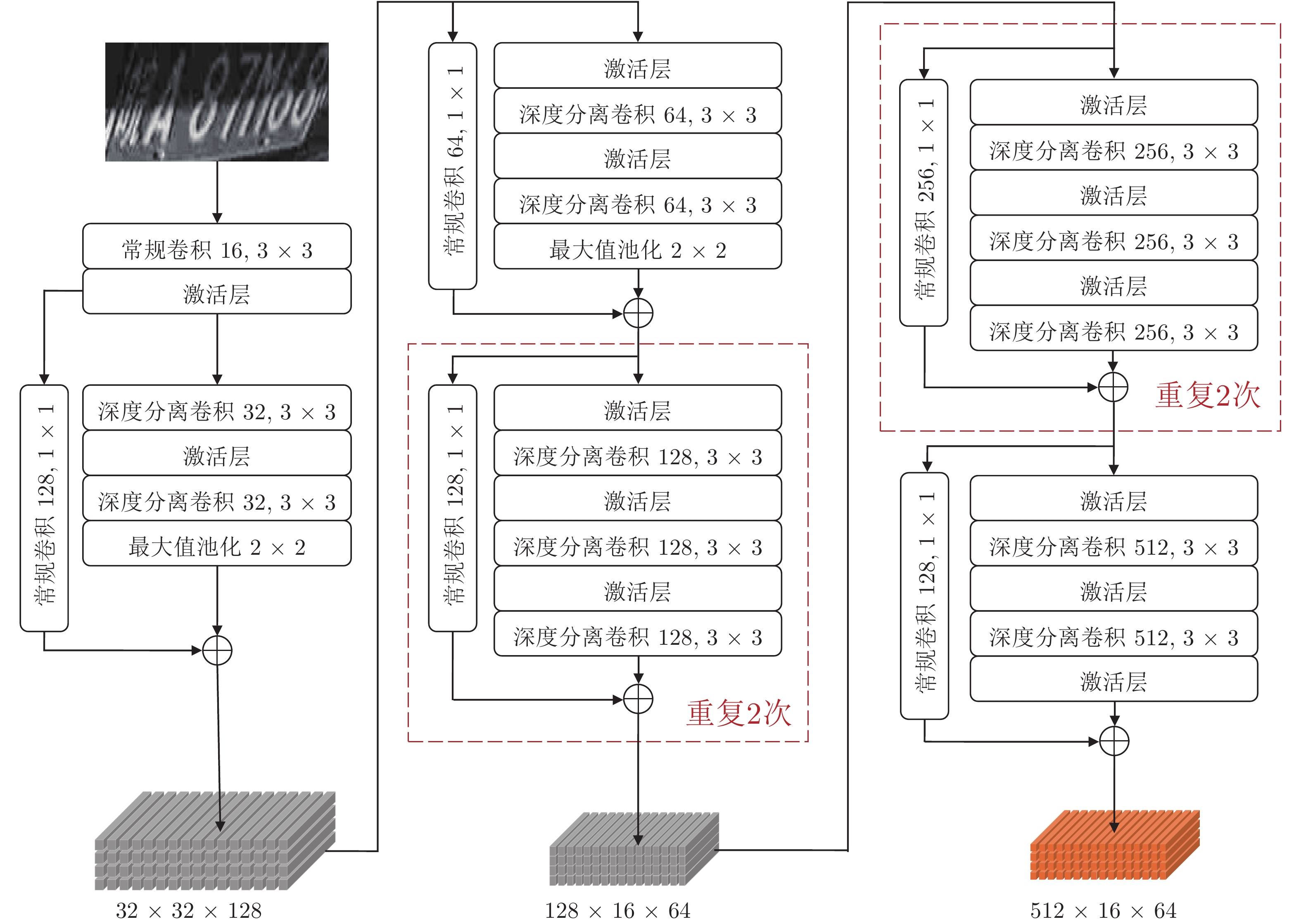
表 7 特征提取网络消融实验
Table 7 Feature extraction ablation experiment
特征提取 $ {R_{LP}} $(%) 参数量 计算复杂度 (GMacs) Resnet45[25] 99.5 13.94 M 14.66 Xception19 99.5 1.87 M 1.71
下载: 导出CSV
表 8 分类头参数共享消融实验
Table 8 Classification head weight sharing ablation experiment
参数共享 $ {R_{LP}} $(%) 参数量 计算复杂度 (GMacs) 是 99.5 1.87 M 1.71 否 99.4 3.82 M 1.71
下载: 导出CSV
表 9 单字符注意力消融实验
Table 9 Ablation experiments for single-character attention
单字符注意力 $ {R_{LP}} $(%) 参数量 计算复杂度 (GMacs) 有 99.5 1.87 M 1.71 无 99.1 3.04 M 1.02
下载: 导出CSV
-
[1] Li H, Wang P, You M Y, Shen C H. Reading car license plates using deep neural networks. Image and Vision Computing, 2018, 72: 14-23 doi: 10.1016/j.imavis.2018.02.002 [2] Wu C H, Xu S G, Song G C, Zhang S Q. How many labeled license plates are needed. In: Proceedings of the Chinese Conference on Pattern Recognition and Computer Vision. Guangzhou, China: 2018. 334−346 [3] Huang G, Liu Z, Maaten L V, Weinberger K Q. Densely connected convolutional networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017. 2261−2269 [4] Yang Y X, Xi W, Zhu C K, Zhao Y H. HomoNet: Unified license plate detection and recognition in complex scenes. In: Proceedings of the International Conference on Collaborative Computing: Networking, Applications and Worksharing. Shanghai, China: 2020. 268−282 [5] He M X, Hao P. Robust automatic recognition of Chinese license plates in natural scenes. IEEE Access, 2020, 8: 173804-173814 doi: 10.1109/ACCESS.2020.3026181 [6] Lee C Y, Osindero S. Recursive recurrent nets with attention modeling for ocr in the wild. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016. 2231−2239 [7] Cheng Z Z, Bai F, Xu Y L, Zheng G, Pu S L, Zhou S G. Focusing attention: Towards accurate text recognition in natural images. In: Proceedings of the IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 5086−5094 [8] Zou Y J, Zhang Y J, Yan J, Jiang X X, Huang T J, Fan H S, et al. A robust license plate recognition model based on bi-LSTM. IEEE Access, 2020, 8: 211630-211641 doi: 10.1109/ACCESS.2020.3040238 [9] Qin S X, Liu S J. Efficient and unified license plate recognition via lightweight deep neural network. IET Image Processing, 2020, 14(16): 4102-4109 doi: 10.1049/iet-ipr.2020.1130 [10] Guo J M, Liu Y F. License plate localization and character segmentation with feedback self-learning and hybrid binarization techniques. IEEE Transactions on Vehicular Technology, 2008, 57(3): 1417-1424 doi: 10.1109/TVT.2007.909284 [11] Silva S M, Jung C R. License plate detection and recognition in unconstrained scenarios. In: Proceedings of the European Conference on Computer Vision. Munich, Germany: 2018. 580−596 [12] Gou C, Wang K F, Yao Y J, Li Z X. Vehicle license plate recognition based on extremal regions and restricted boltzmann machines. IEEE Transactions on Intelligent Transportation Systems, 2016, 17(4): 1096-1107 doi: 10.1109/TITS.2015.2496545 [13] Park S H, Yu S B, Kim J, Yoon H. An all-in-one vehicle type and license plate recognition system using yolov4. Sensors, 2022, 22(3): 921-939 doi: 10.3390/s22030921 [14] Wang D, Tian Y M, Geng W H, Zhao L, Gong C. LPR-Net: Recognizing Chinese license plate in complex environments. Pattern Recognition Letters, 2020, 130: 148-156 doi: 10.1016/j.patrec.2018.09.026 [15] Luo C J, Jin L W, Sun Z H. Moran: A multi-object rectified attention network for scene text recognition. Pattern Recognition, 2019, 90: 109-118 doi: 10.1016/j.patcog.2019.01.020 [16] Jaderberg M, Simonyan K, Zisserman A, Kavukcuoglu K. Spatial transformer networks. In: Proceedings of the Annual Conference on Neural Information Processing Systems. Montreal, Can-ada: 2015. 2017−2025 [17] 周晓君, 高媛, 李超杰, 阳春华. 基于多目标优化多任务学习的端到端车牌识别方法. 控制理论与应用, 2021, 38(5): 676−688Zhou Xiao-Jun, Gao Yuan, Li Chao-Jie, Yang Chun-Hua. Multi-objective optimization based multi-task learning for end-to-end car license plates recognition. Control Theory and Applications. 2021, 38(5): 676−688 [18] Li H, Wang P, Shen C H, Zhang G Y. Show, attend and read: A simple and strong baseline for irregular text recognition. In: Proceedings of the 33rd AAAI Conference on Artificial Intelligence. Honolulu, USA: 2019. 8610−8617 [19] Xu H, Guo Z H, Wang D H, Zhou X D, Shi Y. 2D license plate recognition based on automatic perspective rectification. In: Proceedings of the 25th International Conference on Pattern Recognition. Milan, Italy: IEEE, 2021. 202−208 [20] Zhang L J, Wang P, Li H, Li Z, Shen C H. A robust attentional framework for license plate recognition in the wild. IEEE Transactions on Intelligent Transportation Systems, 2021, 22(11): 6967-6976 doi: 10.1109/TITS.2020.3000072 [21] Hu W Y, Cai X C, Hou J, Yi S, Lin Z P. GTC: Guided training of ctc towards efficient and accurate scene text recognition. In: Proceedings of the 34th AAAI Conference on Artificial Intelligence. New York, USA: 2020. 11005−11012 [22] Yan R J, Peng L R, Xiao S Y, Yao G. Primitive representation learning for scene text recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Nashville, USA: IEEE, 2021. 284−293 [23] Wang T W, Zhu Y Z, Jin L W, Luo C J, Chen X X, Wu Y Q, et al. Decoupled attention network for text recognition. In: Proceedings of the 34th AAAI Conference on Artificial Intelligence. New York, USA: AAAI, 2020. 12216−12224 [24] Chollet F. Xception: Deep learning with depthwise separable convolutions. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017. 1251−1258 [25] Shi B G, Yang M K, Wang X G, Lyu P Y, Yao C, Bai X. Aster: An attentional scene text recognizer with flexible rectification. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 41(9): 2035-2048 [26] Ronneberger O, Fischer P, Brox T. U-net: Convolutional networks for biomedical image segmentation. In: Proceedings of the International Conference on Medical Image Computing and Computer-assisted Intervention. Munich, Germany: 2015. 234− 241 [27] Xu Z B, Yang W, Meng A J, Lu N X, Huang H, Ying C C, et al. Towards end-to-end license plate detection and recognition: A large dataset and baseline. In: Proceedings of the European Conference on Computer Vision. Munich, Germany: 2018. 255− 271 [28] Zhao Y T, Yu Z, Li X Y. Evaluation methodology for license plate recognition systems and experimental results. IET Intelligent Transport Systems, 2018, 12(5): 375-385 doi: 10.1049/iet-its.2017.0138 [29] Sun M, Zhou F, Yang C, Yin X C. Image generation framework for unbalanced license plate data Set. In: Proceedings of the International Conference on Data Mining Workshops. Beijing, China: IEEE, 2019. 883−889 [30] Han B G, Lee J T, Lim K T, Choi D H. License plate image generation using generative adversarial networks for end-to-end license plate character recognition from a small set of real images. Applied Sciences, 2020, 10(8): 2780-2796 doi: 10.3390/app10082780 [31] Sun Y F, Liu Q, Chen S L, Zhou F, Yin X C. Robust Chinese license plate generation via foreground text and background separation. In: Proceedings of the 11th International Conference on Image and Graphics. Haikou, China: 2021. 290−302 [32] Goodfellow I J, Pouget-Abadie J, Mirza M, Xu B. Generative adversarial nets. In: Proceedings of the Advances in Neural Information Processing Systems. Montreal, Canada: 2014. 2672− 1680 [33] Qin S X, Liu S J. Towards end-to-end car license plate location and recognition in unconstrained scenarios. Neural Computing and Applications, to be published [34] Qiao L, Chen Y, Cheng Z Z, Xu Y L, Niu Y, Pu S L, et al. Mango: A mask attention guided one-stage scene text spotter. In: Proceedings of the 35th AAAI Conference on Artificial Intelligence. Virtual Event: 2021. 2467−2476 [35] Liu Q, Chen S L, Li Z J, Yang C, Chen F, Yin X C. Fast recognition for multidirectional and multi-type license plates with 2D spatial attention. In: Proceedings of the 16th International Conference on Document Analysis and Recognition. Lausanne, Swi-tzerland: 2021. 125−139 -

 下载:
下载:





计量
- 文章访问数: 1214
- HTML全文浏览量: 671
- PDF下载量: 277
- 被引次数: 0
