

Hierarchical Granular Contrastive Network-based Knowledge Acquisition and Modeling for Gas Scheduling of Steel Industry
-
摘要: 对于钢铁燃气系统的实时有效调度是实现企业节能降耗的关键. 考虑燃气产消过程所包含的多工况特征, 提出了一种基于分层粒度对比网络的调度知识获取与建模方法. 鉴于深度对比学习对于语义信息的处理能力, 定义和描述了一系列信息粒度, 以建立能源数据的语义表示. 为初步提取多工况调度知识, 采用长短时记忆(Long and short-term memory, LSTM)网络学习具有时变特性的粒度变量特征. 在此基础上, 利用专家经验知识定性地划分对比学习样本, 建立基于粒度对比学习的知识表征网络. 为挖掘调度数据中所包含的深层次知识, 进一步提出了基于反馈机制的分层对比网络模型, 并通过网络输出层实现调度建模任务. 实验部分采用了国内某钢铁厂高炉煤气系统的实际数据进行了多组对比实验, 结果表明所提方法获得的知识表示能够有效提高燃气系统的建模精度, 帮助实现专家级别的调度表现.Abstract: A real-time effective scheduling for gas system of steel industry is important for achieving energy saving and consumption reduction. Considering that the gas generation and consumption processes are characterized by multiple operating conditions, a knowledge acquisition and modeling algorithm based on hierarchical granular contrastive network is proposed. In view of the capabilities of deep contrast learning for processing semantic information, a series of information granularities are defined and described to establish a semantic representation of the energy data. To extract multi-condition scheduling knowledge, a long and short-term memory (LSTM) network is used to learn the time-varying characteristics of granular variables. On top of this, a knowledge representation network based on granular contrastive learning is established, which takes advantage of the expert knowledge to partition the contrastive samples. For digging out deep-level knowledge involved in the scheduling data, a hierarchical contrastive network is further proposed by employing a closed-loop feedback mechanism, and then scheduling modeling tasks can be addressed with output layers. The practical operation data coming from the blast furnace gas system of a domestic steel plant are utilized to perform our experiments. The results show that the multi-condition knowledge representation obtained by the proposed method would help improve the modeling accuracy of the gas system and realize human-level scheduling performance.
-
Key words:
- Steel industry /
- gas system /
- knowledge acquisition /
- information granularity /
- contrastive learning
-
钢铁生产是高耗能和高排放的生产过程, 能源介质的发生与消耗在其中起到了至关重要的作用.随着煤炭、石油等一次能源的紧缺, 充分利用钢铁生产过程中产生的副产煤气不但可以提高企业节能降耗水平, 还可减少煤气放散对环境的污染[1]. 而在生产工艺和设备状态相对固定的情况下, 对于能源系统的优化调度逐渐成为实现节能降耗的重要手段.
一些现有的能源优化调度研究已经在文献中有所报道, 包括强化学习[2]、基于数学规划方法[3-4]、案例推理[5]以及因果关系建模[6]等. 其中, 文献[2]提出了一种结合专家经验和生产计划的能源动态调度策略. 文献[3]采用预测−调度两阶段方法, 首先利用高斯过程回归对不确定条件下的能源需求进行预测, 从而建立关于容量约束的优化调度模型. 文献[4]提出了一种新颖的数学规划模型, 研究了燃气系统缓冲用户中富余煤气的优化配置. 针对连续生产过程建模, 文献[5]设计了一种稀疏模糊推理方法, 用于推测具有动态特征的调度知识. 此外, 一种基于粒度因果关系的方法被用来挖掘间歇性生产特征下能源产消过程的因果关系, 进而建立基于因果推理调度模型[6]. 在智能学习与优化调控方面, 文献[7]针对离散时间最优控制设计, 介绍了集成学习逼近器和强化公式的评价智能方法. 文献[8]设计了一种基于折扣广义值迭代的智能算法, 有效解决了一类复杂非线性系统的最优跟踪控制问题. 文献[9]结合神经标识符学习和启发式动态规划算法, 解决了非仿射离散时间系统的最优跟踪控制问题. 上述方法在智能优化控制领域提出了创新性的思路. 然而, 由于生产工况的多样性, 能源系统的运行条件可能会实时变化, 需对能源发生、消耗和存储过程中所包含的多工况知识进行有效表示, 并衡量它们对调度模型的影响, 进而实现对于调整方向和调度量的有效判断.
针对包含多工况特性的建模方法, 文献[10]结合条件指示变量(专家知识) 和条件驱动聚类建立工况划分模型, 可将时间尺度的非平稳和瞬态过程巧妙地还原到不同的条件切片中, 在同一条件切片内揭示相似的过程特征. 文献[11]针对操作条件切换和生产产品变化, 提出一种条件判别自编码器来表征稳态模式, 并设计了基于注意力的评估器对暂态特征进行描述. 此外, 文献[12]提出了一种具有鲁棒性的指数平稳子空间分析算法, 探索用于非平稳过程监控的自适应策略. 上述研究可以有效结合专家经验和实际数据, 提出了面向多工况特性的精确建模方法. 然而其主要针对工业暂态特性和过程监控问题进行分析, 而本文方法侧重于研究工业能源产消变化的稳态过程.
近年来, 基于深度网络的表征学习技术受到广泛关注. 通过以低维向量的形式表达研究对象的语义信息, 可以提高知识获取、表示和推理的性能. 其中, 对比学习侧重于从大规模数据中挖掘潜在信息, 提高下游任务的数据表示能力. 例如, 文献[13]通过预先训练的教师模型学习知识表示, 并采用聚类方法将其简化为伪标签, 然后使用伪标签训练下游学生网络, 以提升图像分类精度. 文献[14]采用动量对比学习实现新冠病毒的CT图像快速诊断. 目前, 对比学习方法还被广泛应用于语义分析[15]、推荐系统[16]和视觉表示[17]等研究领域, 但在能源系统知识型工作中应用较少. 而由于能源系统优化调度过程需结合机理知识、专家领域知识和运行数据中的隐含知识, 包含复杂工况条件, 因此采用深度对比网络获取显性/隐性知识将是有益的尝试.
粒度计算理论是通过粒度化的方式对不同尺度和层级的数据进行统一描述, 促进了可用数据和存在性关系的知识组织方式[18]. 针对副产能源系统调度问题, 通过时间跨度、幅值和线型等三维特征构建能源数据的粒度知识表示, 提出了基于协同条件聚类的长期预测模型[19]. 针对工业实际对于建模可靠性的需求, 分层粒度计算方法[20]被用来建立区间形式的预测模型. 以设备变量信息粒为基本处理单元, 粒度计算还结合了模糊逻辑和强化学习来获得动态调度策略[21-22]. 考虑到目前对比学习主要应用于具有显式语义描述的领域, 因此对于工业能源系统的知识型工作, 可采用粒度计算方法从能源数据中提取语义特征, 为深度网络提供更为丰富的数据信息.
本文面向钢铁燃气产消过程的多工况特征, 提出了一种基于分层粒度对比网络的调度知识获取与建模方法. 首先通过粒度化的方式划分和描述能源数据, 形成多维度特征语义表示. 为了提取多工况调度知识, 利用专家经验数据划分样本, 构建基于粒度对比学习的知识表征网络, 并采用多层次的学习策略来学习经验数据具有的多工况类别特性. 为进一步挖掘出深层次的隐藏信息, 提出了一种基于闭环反馈机制的分层对比网络模型. 据我们所知, 本文工作是对比学习首次应用于钢铁工业能源系统的知识提取与优化调度领域. 实验部分结果表明了本文方法获得的知识表示可拟合出专家水平的调度策略, 并能够有效提高燃气系统的建模精度.
本文结构如下: 第1节就典型燃气系统结构和优化调度过程中涉及的知识型工作作出简单介绍及分析; 第2节描述基于分层粒度对比网络的知识获取及建模方法; 第3节给出大量的仿真实验, 充分验证所提方法的有效性; 第4节对全文进行了总结和展望.
1. 问题描述
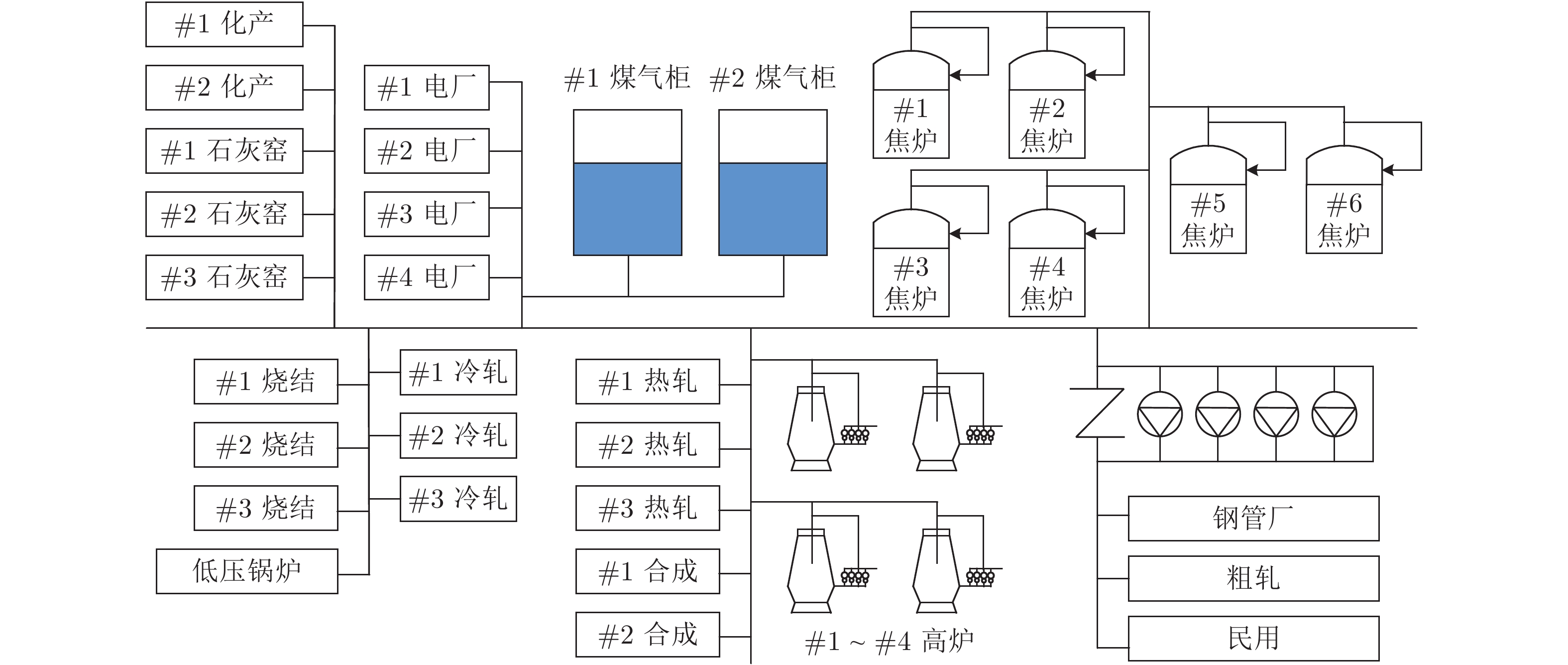
钢铁燃气系统是工业生产与能源消耗相互耦合的主体. 图1所示为一个典型能源系统(高炉煤气系统) 结构图, 主要由煤气发生用户(高炉) 、传输管网、煤气柜以及一系列煤气消耗用户4部分组成.其中, 4座高炉作为发生单元, 每小时可以向传输管网输送约180万立方米煤气. 传输系统包括管网、混合站和压力站. 消耗用户主要包括炼焦炉、热轧厂、冷轧厂、化工产品回收(Chemical product recycling, CPR) 、低压锅炉(Low pressure boiler, LPB) 、合成单元(Synthesis unit, SU) 和发电机. 由于4座高炉在产生高炉煤气的同时, 其自身配备的热风炉在切换过程中会消耗大量高炉煤气, 导致流入管网的煤气流量频繁波动. 此外, 在生产过程中还会出现诸多异常状态, 如高炉减风、设备参数变化等. 为维持能源系统的平衡稳定, 现场操作人员需要监控各能源用户的运行状态, 进而作出能源产消的工况判断, 在必要的情况下对一些可调整用户(如电厂、低压锅炉等) 的煤气消耗量做出调整(如图2所示), 以保证煤气柜的安全运行, 达到节能减排的目的.
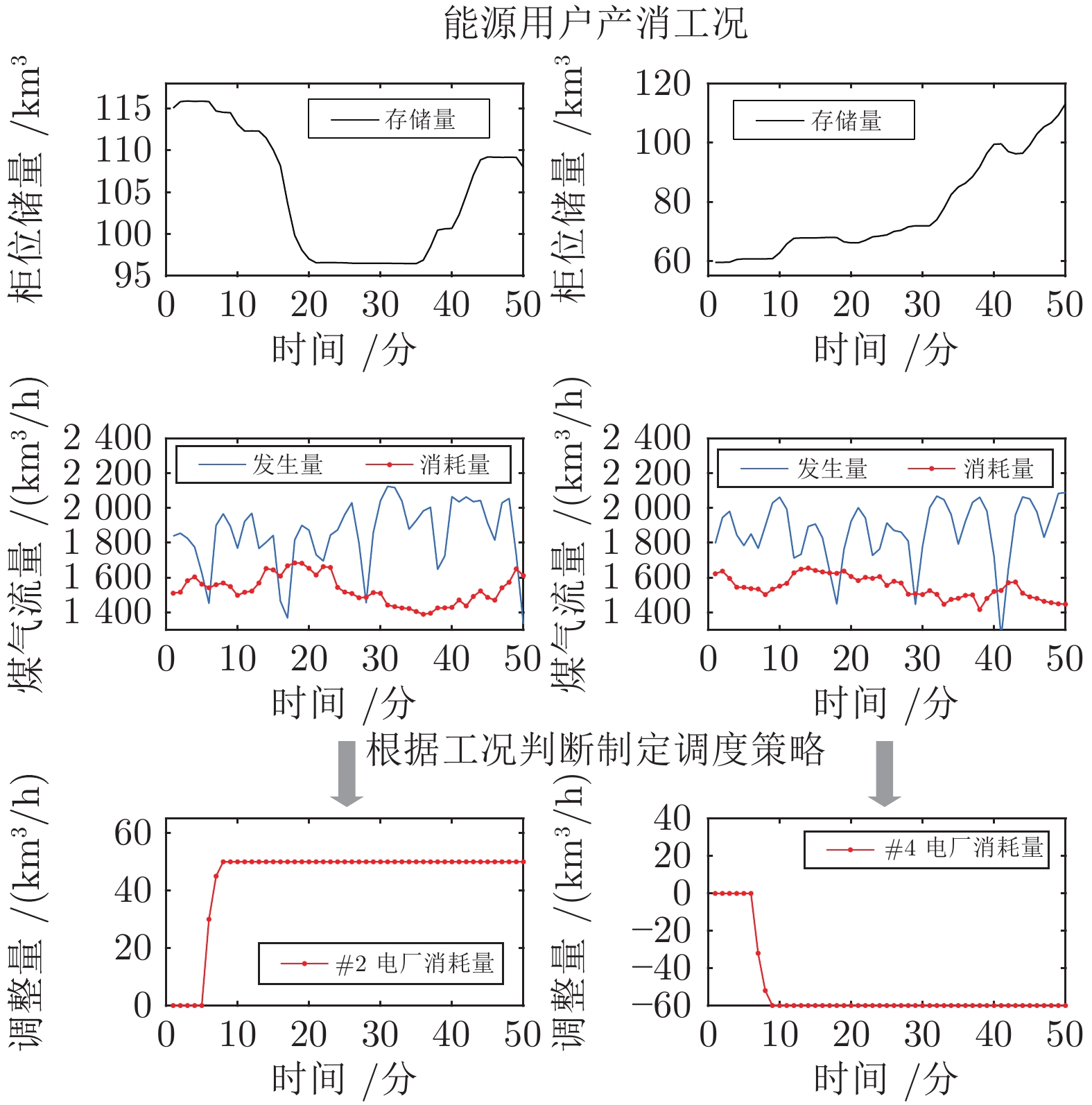 图 2 燃气产消多工况特征及调度过程Fig. 2 The multi-condition characteristics and their scheduling process of gas generation and consumption
图 2 燃气产消多工况特征及调度过程Fig. 2 The multi-condition characteristics and their scheduling process of gas generation and consumption考虑到燃气系统的复杂结构, 导致很难对整个系统的能源产消过程建立机理模型. 另一方面, 单纯基于数据的方法无法区分出不同调度工况下的系统运行状态及差异. 而知识型工作自动化能够将经验和数据紧密联系, 有针对性地提取不同工况条件下的深层次调度知识, 并通过知识的表示及处理方法实现精准的判断和创新性的决策任务[23]. 因此, 如何从数据中提取出与调度工况和系统状态相关的知识, 构建关于钢铁副产能源系统的知识获取及表示方法, 对于其优化调度工作具有重要意义.
2. 基于分层粒度对比网络知识获取与表示
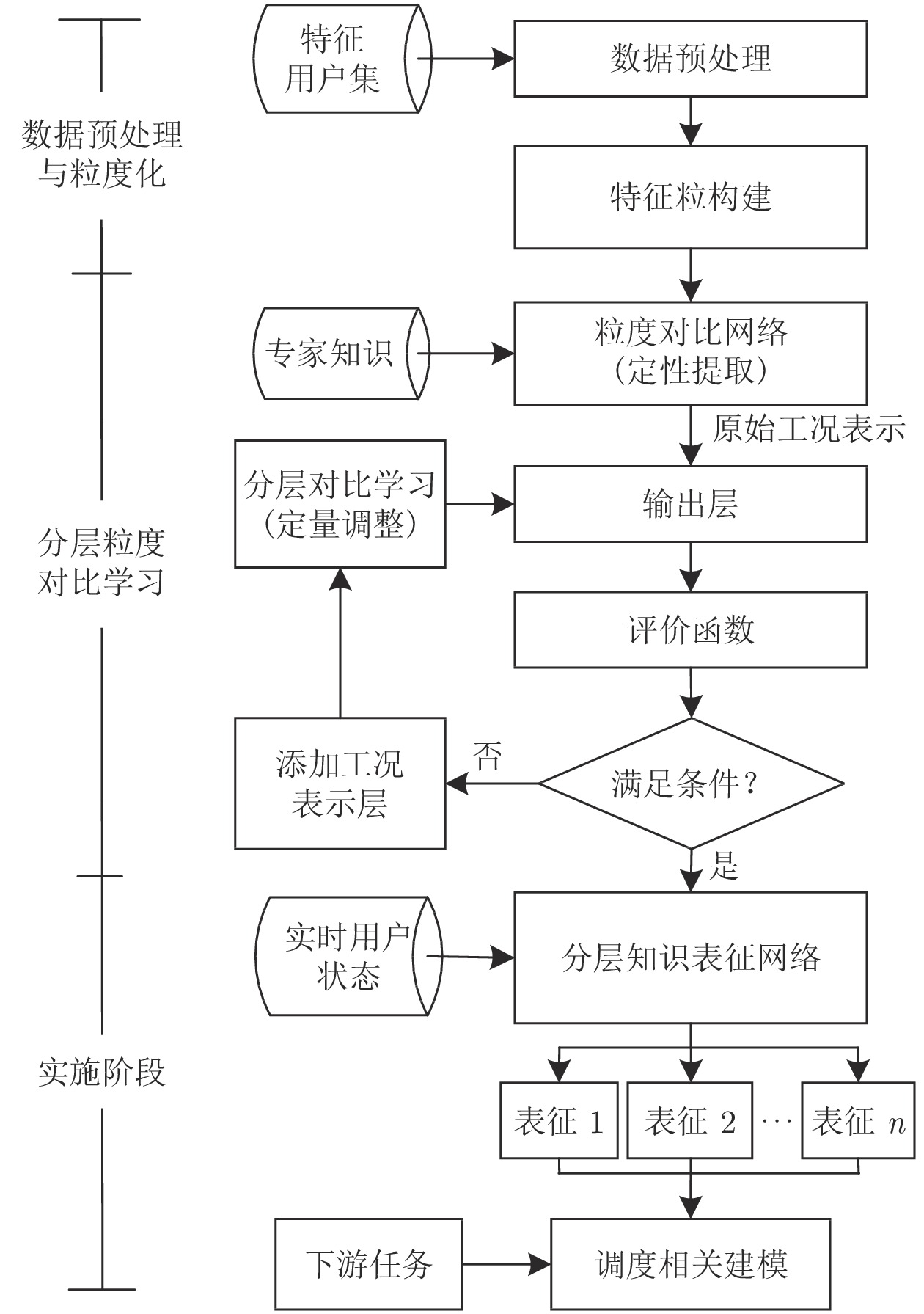
考虑到燃气产消过程的复杂工况及其对于调度决策的影响, 本文提出一种基于分层粒度对比网络的调度知识获取与表示方法. 整体架构如图3所示, 可分为三个阶段, 即数据预处理与粒度化、分层粒度对比网络构建及调度实施阶段.
第一阶段将主要用户数据进行滤波处理, 根据能源数据的波动语义构建特征信息粒. 第二阶段利用专家经验知识建立粒度对比网络, 形成定性的工况知识表示. 而后通过定义输出层得到现有知识表示的评价函数, 依据定量的评价反馈结果添加表示层, 并利用分层对比学习模型细化工况特征表示.
第三阶段, 首先根据能源用户的实时状态, 根据建立的分层对比网络获得多工况特征的组合向量, 而后根据不同的下游任务建立相关预测及调度模型, 获得完整的调度方案.
2.1 基于生产语义的数据粒度化
目前深度对比学习主要用于处理文本、图像等具有显式语义描述的领域, 通过对图片数据的增强(如随机剪切、随机颜色失真等) 来构建适用于处理图像信息的表示形式. 针对包含时变信息和多因素影响的工业能源系统数据, 采用粒度计算的方式提取语义信息, 形成适合于下游深度网络的数据表示形式. 考虑到能源数据的波动趋势包含丰富的生产实际意义, 不同的趋势特征往往对应不同的设备运行或能源产消工况, 本文首先根据数据的趋势特征划分数据粒, 并建立相对应的特征描述方式.
在一般情况下, 工业时间序列可以划分为时间维度上的一系列连续趋势片段(信息粒), 这些片段可由一组原型基底通过横向和纵向的伸缩变换进行近似[19]. 本文构建了1/4周期的正弦曲线作为基底(如式(1)所示), 每组基底可以代表一类典型的波动趋势(单调性和凹凸性). 此外, 采用直线来描述曲线为单调线性的特殊情况.
$$ y = \sin (x + \varphi ) $$ (1) 其中,
$ \varphi $ 代表不同的正弦周期. 这样一来, 可通过基底的横向和纵向的伸缩变换来近似任意的趋势片段, 如$y = A\sin ((2/\pi) Dx + \varphi )$ 表示对基底进行了横向伸缩尺度D (时间跨度) 和纵向伸缩尺度A (波动幅值) 之后的近似曲线.为了匹配原始时间序列并获得基于趋势的粒度, 本文根据单调和凹凸特性对数据序列进行划分. 借鉴文献[19]中的方式, 给定序列
$ X = \{ {x_1},{x_2},\cdots,{x_n}\} $ , 首先需要判断X中每个数据点$ {x_i} $ 领域内小段曲线的趋势特征(单调性、凹凸性), 记为数据点$ {x_i} $ 的标识$ {F_i} $ . 考虑时间序列的一阶和二阶动态特性, 命名为$ \{ {\Delta _2},{\Delta _3},\cdots,{\Delta _N}\} $ 和$\{ {E_3},{E_4},\cdots,{E_N}\}$ , 其中${\Delta _i} = {x_i} - {x_{i - 1}}$ ,$ {E_i} = {\Delta _i} - {\Delta _{i - 1}} $ . 根据单调性、凹凸性定义,$ {\Delta _i} $ 及$ {\Delta _i}{\Delta _{i - 1}} $ 分别表示数据点$ {x_i} $ 与$ {x_{i - 1}} $ 之间小段曲线的单调性及时间序列在点$ {x_{i - 1}} $ 处的单调性变化, 同时$ {E_i} $ 表示该段曲线的凹凸性. 具体的数据点标识判断标准如下所示, 其中$ i = 3,4,\cdots,N $ . 为了实现信息粒的语义划分, 依次检索X中每个数据点的标识$ {F_i} $ , 在数据点标识发生改变处划分数据.$$ \qquad{\begin{split} &1)\;{\rm{if}}\;{\Delta }_{i-1}{\Delta }_{i}\ge 0\cap {\Delta }_{i} > 0\cap {E}_{i} > 0,\;{\rm{then}}\;{F}_{i}\;{\rm{is}}\;\text{convex rise}\\ &2)\;{\rm{if}}\;{\Delta }_{i-1}{\Delta }_{i}\ge 0\cap {\Delta }_{i}\ge 0\cap {E}_{i} < 0,\;{\rm{then}}\;{F}_{i}\;{\rm{is}}\;\text{concave}\\ &\;\quad{\rm{rise}}\\ &3)\;{\rm{if}}\;{\Delta }_{i-1}{\Delta }_{i}\ge 0\cap {\Delta }_{i}\le 0\cap {E}_{i} > 0,\;{\rm{then}}\;{F}_{i}\;{\rm{is}}\;\text{convex}\\ &\;\quad{\rm{decline}}\\ & 4)\;{\rm{if}}\;{\Delta }_{i-1}{\Delta }_{i}\ge 0\cap {\Delta }_{i} < 0\cap {E}_{i} < 0,\;{\rm{then}}\;{F}_{i}\;{\rm{is}}\;\text{concave}\\ &\;\quad{\rm{decline}}\\ & 5)\;{\rm{if}}\;{\Delta }_{i-1}{\Delta }_{i} < 0\cap {\Delta }_{i}\le 0,\;{\rm{then}}\;{F}_{i}\;{\rm{is}}\;\text{concave decline}\\ &6)\;{\rm{if}}\;{\Delta }_{i-1}{\Delta }_{i} < 0\cap {\Delta }_{i} > 0,\;{\rm{then}}\;{F}_{i}\;{\rm{is}}\;\text{convex rise}\\ &7)\;{\rm{if}}\;{E}_{i}=0,\;{\rm{then}}\;{F}_{i}\;{\rm{is}}\;\text{straight}\end{split}} $$ 在实际应用中, 可根据运行过程中不断产生的能源数据判断当前序列的趋势特性是否发生变化, 以此来划分数据序列, 并构建在线样本的粒度化输入. 需要注意的是在信息粒划分之前, 本文采用经验模态分解(Empirical mode decomposition, EMD) 对原始的训练数据进行滤波. 由于EMD过程需要计算由各个极值点形成的包络线, 因此需等待数据到达极值之后再进行滤波. 若需要立即给出调度策略, 亦可将当前时刻作为极值点, 并结合历史数据来进行滤波计算.
为反映能源用户运行状态的语义特征, 划分后的数据粒G被进一步描述为三维特征向量的形式, 包括其对应的横向和纵向伸缩尺度D和A, 以及代表基底类型的线型特征L[19], 记为G = {D, A, L}.
2.2 基于粒度对比网络的知识粗获取
本文基于第2.1节中的信息粒的语义描述, 利用调度过程中的专家经验知识(如调整方向、调整量大小等) 划分潜在空间的对比学习样本, 提出粒度对比网络模型实现副产能源系统的调度知识粗提取.
对比学习通过潜在空间中的对比损失来最大化相似工况样本不同隐性特征之间的一致性, 从而学习知识的表示形式[17]. 传统对比学习方法通过吸引或排斥来构建类似于二分类的处理方式. 考虑到由专家经验知识带来多分类情况, 因此不同于传统方法, 本文对所建立的模型执行多个训练步骤. 在训练过程中首先根据调整方向进行二分类的对比学习, 之后通过构建具有不同调整量大小的输入样本再进行多次学习, 使得输出的表示向量能够区分多类别的专家知识.
对比网络模型的输入为能源发生、消耗以及存储等流量数据, 即
${{\boldsymbol{s}}_e} = \{ {\boldsymbol{s}}_e^{(1)},{\boldsymbol{s}}_e^{(2)},\cdots,{\boldsymbol{s}}_e^{(n)}\}$ , 其中e表示不同调度事件, n为输入因素个数. 该网络结构如图4所示, 可分为以下5个部分:1) 首先根据历史时刻的专家经验
$ \kappa $ (调整方向、调整量大小等) 将数据样本定性地划分为不同的子集 {${\boldsymbol{s}}_{i1}^{},{\boldsymbol{s}}_{i2}^{},\cdots$ }, {${\boldsymbol{s}}_{j1}^{},{\boldsymbol{s}}_{j2}^{},\cdots \},\cdots$ .2) 采用第2.1节中的粒度化方式对样本子集中的各输入因素数据进行语义增强, 即
$$ {G_e} = Aug({{\boldsymbol{s}}_e}) = \{ G_e^{(1)},G_e^{(2)},\cdots,G_e^{(n)}\} $$ (2) 3) 基于神经网络的编码器
$ f(\cdot) $ 从数据的粒度化特征描述中提取表示向量. 为了学习各输入因素粒度变量的时变特性, 本文采用长短时记忆(Long-short-term memory, LSTM)网络[24]来获得$ {h_{e,\tau }} = \{ h_{e,\tau }^{(1)},h_{e,\tau }^{(2)},\cdots,h_{e,\tau }^{(n)}\} $ , 其中$ \tau $ 为数据划分后信息粒序列的时间步.$h_{e,\tau }^{(m)} \in {{\bf{R}}^d}$ 为网络的隐藏表示, 计算为$$ \begin{split} {h}_{e,\tau }^{(m)}=\;&f({G}_{e,\tau }^{(m)})={\rm{LSTM}}({G}_{e,\tau }^{(m)})=\\ &{\rm{LSTM}}({G}_{e,\tau -T}^{(m)},{G}_{e,\tau -T+1}^{(m)},\cdots,{G}_{e,\tau }^{(m)})\end{split} $$ (3) 其中, T为LSTM时间步长. 在LSTM中, 采用门控机制调节内部记忆单元的输出以学习输入序列数据的复杂表示[25]. 其中存储单元可记忆任意时间间隔的信息, 并且由3种门管理出入单元的信息流. 输出
$ h_{e,\tau }^{(m)} $ (简化为$ {h_\tau } $ ) 可被看作为输入、隐层状态$ {h_{\tau {{ - }}1}} $ 以及存储单元状态$ {c_{\tau -1}} $ 的加权组合. 其中, 遗忘门$ {f_\tau } $ , 输入门$ {i_\tau } $ , 存储单元$ {c_\tau } $ , 输出门$ {o_\tau } $ 和隐层状态$ {h_\tau } $ 可被计算为$$ {f_\tau } = \sigma \left(\sum\limits_{{W_x}} {f{t_i}} + {W_{hf}}{h_{\tau - 1}}\right) = {F_f}\left(\sum\limits_{{W_x}} {f{t_i}} ,{h_{\tau - 1}}\right) $$ (4) $$ {i}_{\tau }=\sigma \left({\displaystyle \sum _{{W}_{x}}f{t}_{i}}+{W}_{hi}{h}_{\tau -1}\right) ={F}_{i}\left({\displaystyle \sum _{{W}_{x}}f{t}_{i}},{h}_{\tau -1}\right) $$ (5) $$ \begin{split} {c}_{\tau }=\;&{f}_{\tau }{c}_{\tau -1}+{i}_{\tau }\mathrm{tanh}\left({\displaystyle \sum _{{W}_{x}}f{t}_{i}}+{W}_{hc}{h}_{\tau -1}\right)=\\ &{F}_{f}\left({\displaystyle \sum _{{W}_{x}}f{t}_{i}},{h}_{\tau -1}\right){c}_{\tau -1}\;+\\ &{F}_{\tilde{c}}\left({F}_{i}\left({\displaystyle \sum _{{W}_{x}}f{t}_{i}},{h}_{\tau -1}\right),{\displaystyle \sum _{{W}_{x}}f{t}_{i}},{h}_{\tau -1}\right)=\\ &{F}_{c}\left({\displaystyle \sum _{{W}_{x}}f{t}_{i}},{h}_{\tau -1},{c}_{\tau -1}\right)\end{split} $$ (6) $$ {o_\tau } = \sigma \left(\sum\limits_{{W_x}} {f{t_i}} + {W_{ho}}{h_{\tau - 1}}\right) = {F_o}\left(\sum\limits_{{W_x}} {f{t_i}} ,{h_{\tau - 1}}\right) $$ (7) $$ {h_\tau } = {o_\tau }\tanh ({c_\tau }) = {F_h}\left({F_o}\left(\sum\limits_{{W_x}} {f{t_i}} ,{h_{\tau - 1}}\right),{c_\tau }\right)\;\;\;\; $$ (8) 其中,
$ f{t_i} $ 表示信息粒$ G $ 中的特征描述, 即{D, A, L}. 可以看出式(4) ~ 式(6)依赖于$ {h_{\tau - 1}} $ 和当前的输入, 并且式(6)中的$ {c_\tau } $ 和式(8)中的$ {h_\tau } $ 与它们前一时间步的值相关. 将式(6)代入式(8)得到关于历史值的加权形式, 即$$ {h_\tau } = {F_h}\left({h_{\tau - 1}},{c_{\tau - 1}},\sum\limits_{{W_x}} {f{t_i}} \right) $$ (9) 从式(9)可以看出,
$ {h_\tau } $ 不仅包含了先前时间步的信息, 还与各粒度特征的加权信息相关. 而传统神经网络的非线性预测器, 其输出是输入的简单加权组合, 使得权值未能随着序列而改变, 无法考虑到燃气系统产、消、储数据所包含的时序关联和粒度语义特征之间的协同关系. 因此, 本文采用LSTM可更为灵活地计算非线性权值, 将能源产消用户的时间依赖关系及特征语义关联反映到$ {h_\tau } $ 和$ {c_\tau } $ 中.4) 小型神经网络映射层
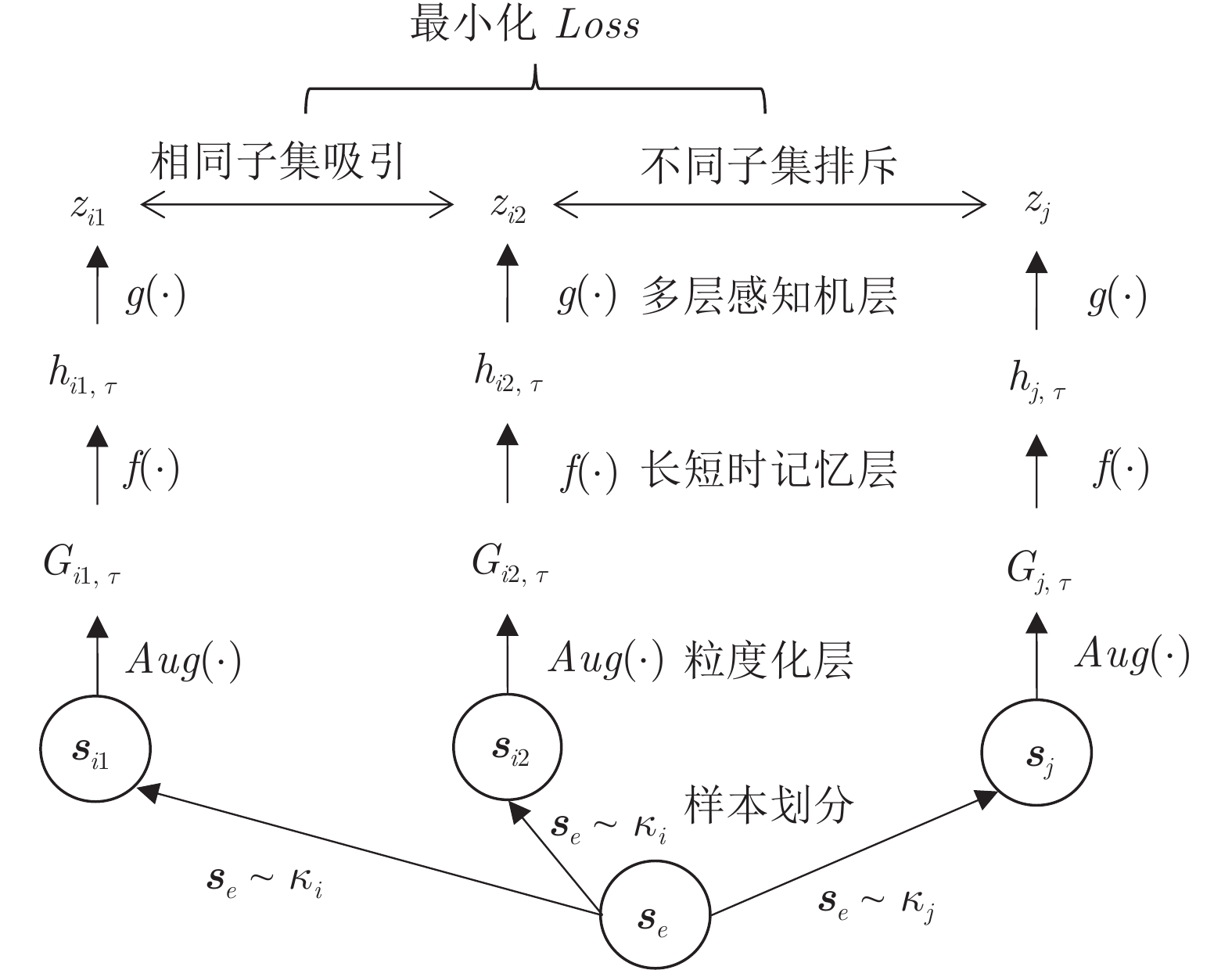
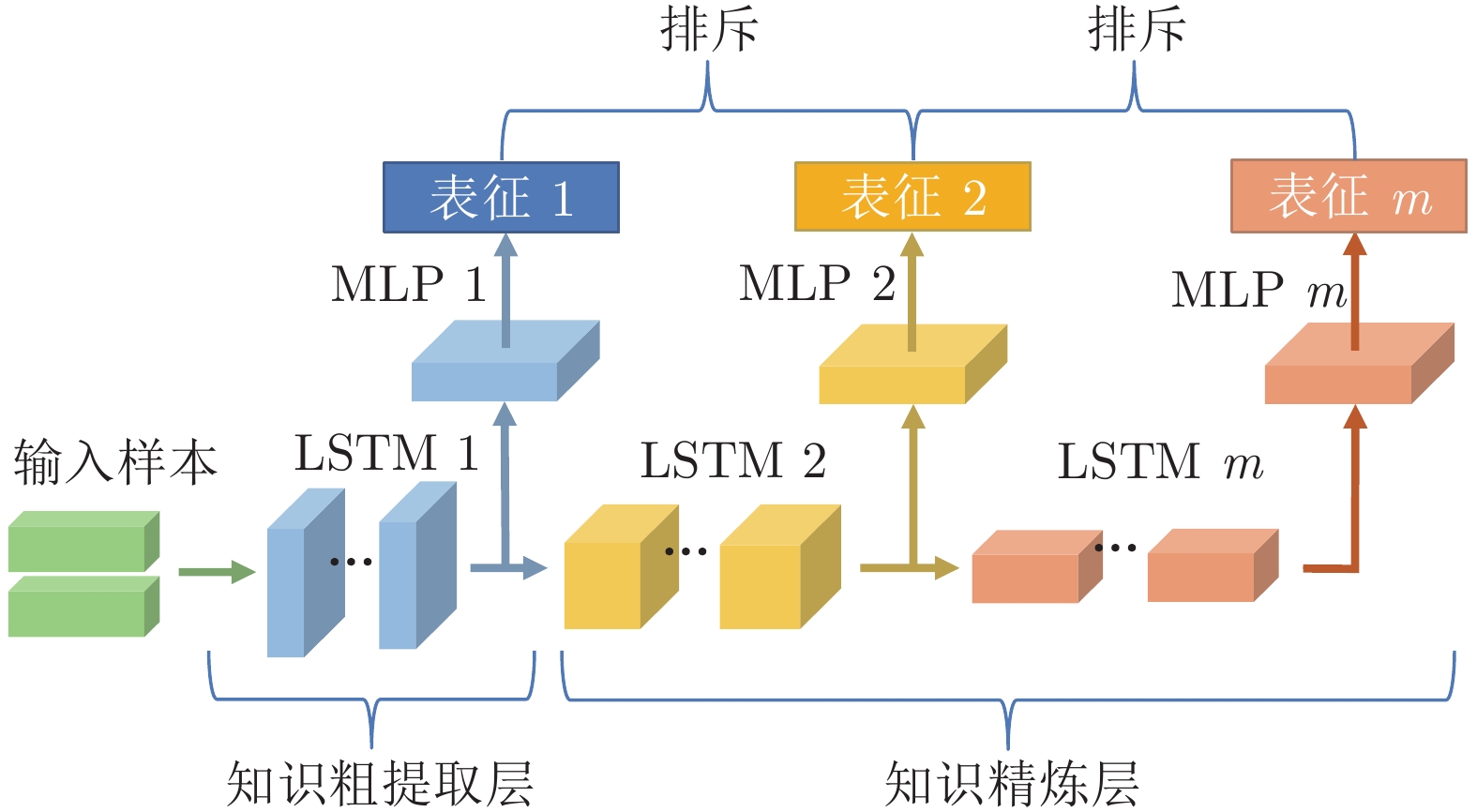
$g(\cdot)$ 将提取的表示向量映射到对比损失空间. 本文采用单隐藏层的多层感知机(Multilayer perceptron, MLP)来获得$ z_e^{(m)} = g(h_{e,\tau }^{(m)}) = {W^{(2)}}\sigma ({W^{(1)}}h_{e,\tau }^{(m)}) $ , 其中$ \sigma $ 为一个ReLU非线性变换. 该特征映射层得到的$ z_{ek}^{(m)} $ 相比于$ h_{e,\tau }^{(m)} $ 将更有助于定义对比损失. 将各个特征用户的$ z_e^{(m)} $ 合并以得到样本的工况知识表示, 即${{\boldsymbol{z}}_e} = [z_e^{(1)},z_e^{(2)},\cdots, z_e^{(n)}]$ . 以2个输入用户为例, 图5进一步展示了知识表示的计算过程, 其中表示空间的大小取决于专家经验对于调度过程中系统运行状态的分类个数.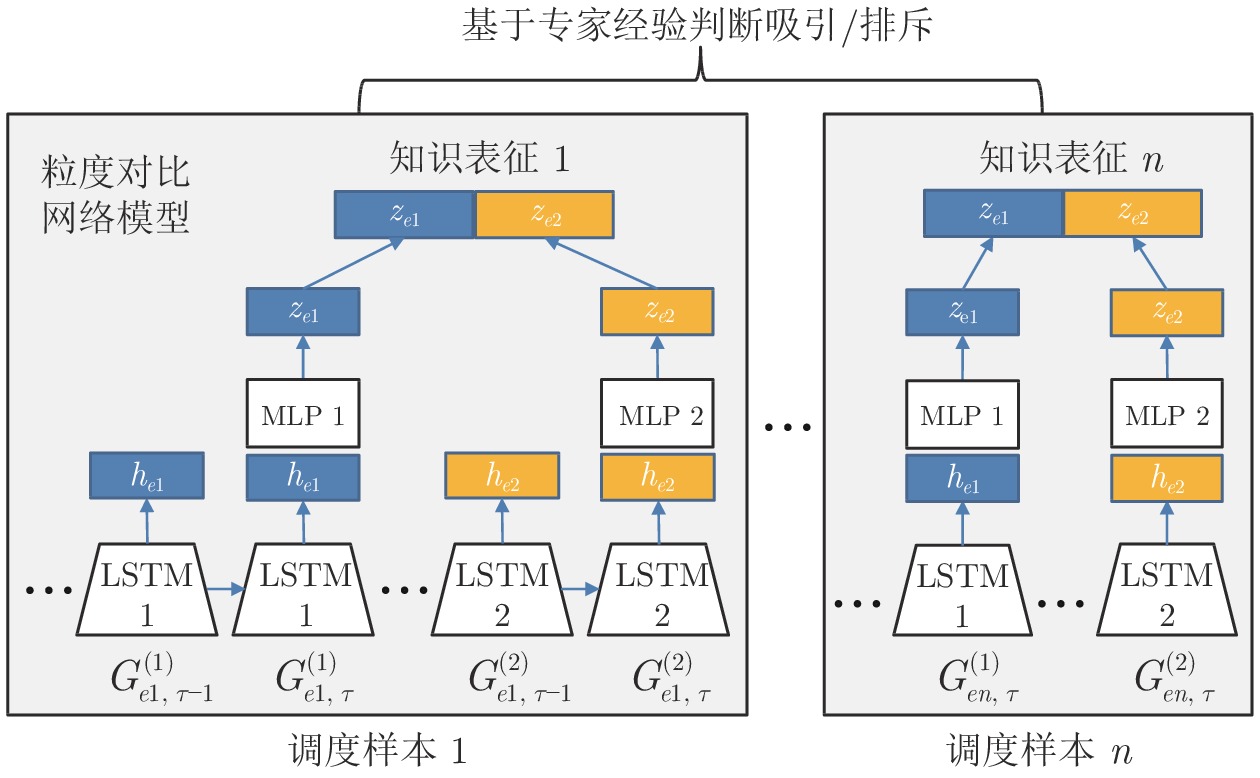 图 5 样本数据知识表征的计算过程描述Fig. 5 The calculation process of the knowledge representation of sample data
图 5 样本数据知识表征的计算过程描述Fig. 5 The calculation process of the knowledge representation of sample data5) 为对比学习任务定义损失函数. 给定输入样本集
$\{ {{\boldsymbol{s}}_e}\}$ , 假设样本集中包含属于不同潜在空间的样本${{\boldsymbol{s}}_i}$ 和${{\boldsymbol{s}}_k}$ , 粒度对比学习的任务旨在通过知识表示向量${{\boldsymbol{z}}_i}$ ,${{\boldsymbol{z}}_k}$ 对样本进行区分.损失函数使得同一潜在空间样本(i, j)的表示向量相近, 而区分不同空间样本(i, k)的表示. 本文定义损失函数如下
$$ Loss = - \sum\limits_i {\ln \left( {\frac{{\displaystyle\sum\limits_{j = 1}^p {{{\text{e}}^{d({{\boldsymbol{z}}_{i,}}{{\boldsymbol{z}}_j})}}} }}{{\displaystyle\sum\limits_{j = 1}^p {{{\text{e}}^{d({{\boldsymbol{z}}_{i,}}{{\boldsymbol{z}}_j})}}} + \displaystyle\sum\limits_{k = 1}^q {{{\text{e}}^{d({{\boldsymbol{z}}_{i,}}{{\boldsymbol{z}}_k})}}} }}} \right)} $$ (10) 其中, p表示与
$ {{\boldsymbol{z}}_i} $ 属于同一潜在空间的样本个数; q为不同空间样本个数;$d({\boldsymbol{u}},{\boldsymbol{v}})$ 表示向量间的距离, 这里采用余弦相似度来衡量. 从式(10)中可以看出, 假设样本数量为N, 若在训练模型时使用了所有可能的数据对, 则用于训练的数据信息量可达到N(N−1)/2. 也就是说相比于经典的有监督学习方法, 对比学习模型的训练过程要多出近似于(N−1)/2个样本, 因此能够更为高效地利用相对稀疏的专家调度数据.2.3 基于分层粒度对比学习的知识精炼
上述过程获得的工况表示虽然可以涵盖大部分系统运行情况, 但是无法获取经验数据中更深层次的隐性知识, 本节进一步提出一种分层粒度对比学习模型实现知识的细化表示.
定义验证集
$ \left\{ {{{\boldsymbol{s}}_1},{{\boldsymbol{s}}_2},\cdots,{{\boldsymbol{s}}_l}} \right\} $ , 根据第2.2节学习到的模型得到相应的工况表示$ \left\{ {{{\boldsymbol{z}}_1},{{\boldsymbol{z}}_2},\cdots,{{\boldsymbol{z}}_l}} \right\} $ . 在此基础上, 添加输出层来学习下游任务, 对获取的知识表示进行评价. 本文通过在工况表示的基础上增加MLP层来拟合能源系统调度时刻的调整量, 进而判断当前的工况表示是否能够满足实际应用条件. 若样本数据集$\{ {{{\boldsymbol{\tilde s}}}_1}, {{{\boldsymbol{\tilde s}}}_2},\cdots,{{{\boldsymbol{\tilde s}}}_r} \}$ 的误差高于某一设定的阈值, 即$$ |{y_e} - {\rm{Output}}(g(f({{\boldsymbol{\tilde s}}_{{e}}})))| > \theta ,{{e}} \in [1,r] $$ (11) 其中, ye为真实调整量. 说明当前的空间表示无法覆盖该样本集中所隐含的工况知识. 这种情况下需进一步采用对比学习的方式扩展空间表示, 以区分
$ \left\{ {{{{\boldsymbol{\tilde s}}}_1},{{{\boldsymbol{\tilde s}}}_2},\cdots,{{{\boldsymbol{\tilde s}}}_r}} \right\} $ 与验证集中的其他样本, 直到所有的样本均满足评价函数条件为止, 因此, 较小的阈值$ \theta $ 会增加对比网络的层数. 本文在知识粗提取的基础上, 通过选择合适的阈值, 使得模型能够有效覆盖隐含的调度工况和特征. 分层粒度对比学习网络的结构如图6所示.图6中最底层所示的网络为传统的LSTM网络, 在知识细化过程中LSTM的层数不断增多, 以提取更深层次的隐藏信息. 中间层为采用MLP的特征映射层, 用于获得工况知识的表示向量, 并在此基础上构建对比学习损失函数. 在实际应用过程中, 共增加了2层对比网络, 以权衡知识获取表现和网络模型复杂度. 需要注意的是, 由于多层网络中当前层级需要学习与上一层级不同的隐性特征, 因此损失函数中各个层级的特征表示均为相互排斥. 本文定义第i层粒度对比网络的损失函数如下
$$ Los{s_i} = - \ln \left(\frac{1}{{\displaystyle\sum\limits_{i = 1}^r {\displaystyle\sum\limits_{j = 1}^{l - r} {{{\text{e}}^{d({\boldsymbol{\tilde z}}_e^i,{\boldsymbol{z}}_e^j)}}} } }}\right) $$ (12) 其中, r为未满足条件的样本数, l为验证集样本总数.
在训练过程中, 采用一种批次训练方式, 从低层次到高层次依次训练LSTMi及MLPi, 即在完成低层级的网络训练后, 若根据判断条件需进一步增添对比学习层, 则在保持现有层级权值参数不变的情况下训练下一层级的网络模型. 因此, 本文提出的分层粒度对比网络在训练过程可有效避免由深层网络结构带来的梯度消失影响.
分层粒度对比网络的实施过程如图7所示, 输入样本
$ {{\boldsymbol{s}}_e} $ 到模型中得到多层级的工况知识表示$\{ {{\boldsymbol{z}}_1}, {{\boldsymbol{z}}_2},\cdots,{{\boldsymbol{z}}_n} \}$ , 将n个知识表示拼接为行向量$[{{\boldsymbol{z}}_1},{{\boldsymbol{z}}_2},\cdots, {{\boldsymbol{z}}_n}]$ 以整合不同层级的特征, 并定义输出层来实现知识表示的加权和选择. 图 7 分层粒度对比网络实施过程Fig. 7 The implement process of the hierarchical granular contrastive network
图 7 分层粒度对比网络实施过程Fig. 7 The implement process of the hierarchical granular contrastive network3. 实验与分析
3.1 实验设定
为了验证本文方法的有效性, 采用国内某钢铁企业高炉煤气系统2019年4月的实际运行数据, 从中选取了200组调度时刻(来自现场人工记录). 数据采样间隔为1分钟. 按照5 : 4 : 1的比例将样本随机划分为训练集、验证集和测试集. 训练集和验证集分别用于知识粗提取和知识精炼过程, 测试集用于测试模型效果. 每个数据集均包含煤气过剩和短缺情况(通过人工调度量进行区分), 代表不同的能源系统运行状态. 考虑由数据采集与监视控制系统(Supervisory control and data acquisition, SCADA)采集的工业数据本身包含异常点、噪声及缺失数据, 因此在建模之前需要进行数据预处理过程, 包括对原始数据进行异常点删除、缺失数据填补和滤波去噪. 此外, 在数据输入到分层对比网络之前, 需对粒度化的特征输入进行归一化处理, 以提升网络模型的收敛速度.
采用Tensorflow深度学习平台和NVIDIA TITAN Xp图形处理单元执行实验, 模型中LSTM单元和MLP均为单隐层结构(每层包含128个节点), 通过随机正态分布初始化网络权重, 并选取均方误差作为最小化的损失函数. 训练过程中采用Adam算法优化求解, 其他主要参数设置如下: 用于每次训练过程的数据批尺寸batch_size = 10; 训练回合数training_epoch = 40; 优化算法学习率learning_rate = 5 × 10−4.
3.2 能源调度量估计结果
钢铁燃气系统的调度过程需通过对能源存储量的实时估计来确定调整时刻, 并根据调度模型计算出系统调整量. 本文基于多层粒度对比学习训练得到的特征表示, 通过定义不同的输出层来实现对于系统调整量的估计任务.
图8(a)比较了不同学习阶段的调度量计算结果. 其中以人工调度数据作为基准参照, 对比了专家知识的二分类、多分类对比学习以及提出的分层网络模型结果. 调度量为正数表示煤气剩余, 此时操作员制定合理的调度方案, 通过增加一些可调用户的消耗量以降低柜位高度; 否则视为煤气短缺情况. 从图8(a)中可以看出, 基于专家知识的学习过程无法判断出第5个测试样本的系统运行状态(如图8(a)圆圈中所示), 给出了错误的调度方向. 而经过多层对比学习后, 这些状态可被所提出的模型准确辨识, 说明了本文方法对于深层次调度工况知识获取的有效性.
此外, 图9给出了各阶段对比模型的计算结果对于专家调整量的绝对误差. 以平均绝对误差(Mean absolute error, MAE), 平均绝对百分误差(Mean absolute percentage error, MAPE) 和均方根误差(Root mean square error, RMSE) 作为评价指标, 这些指标通过下式计算
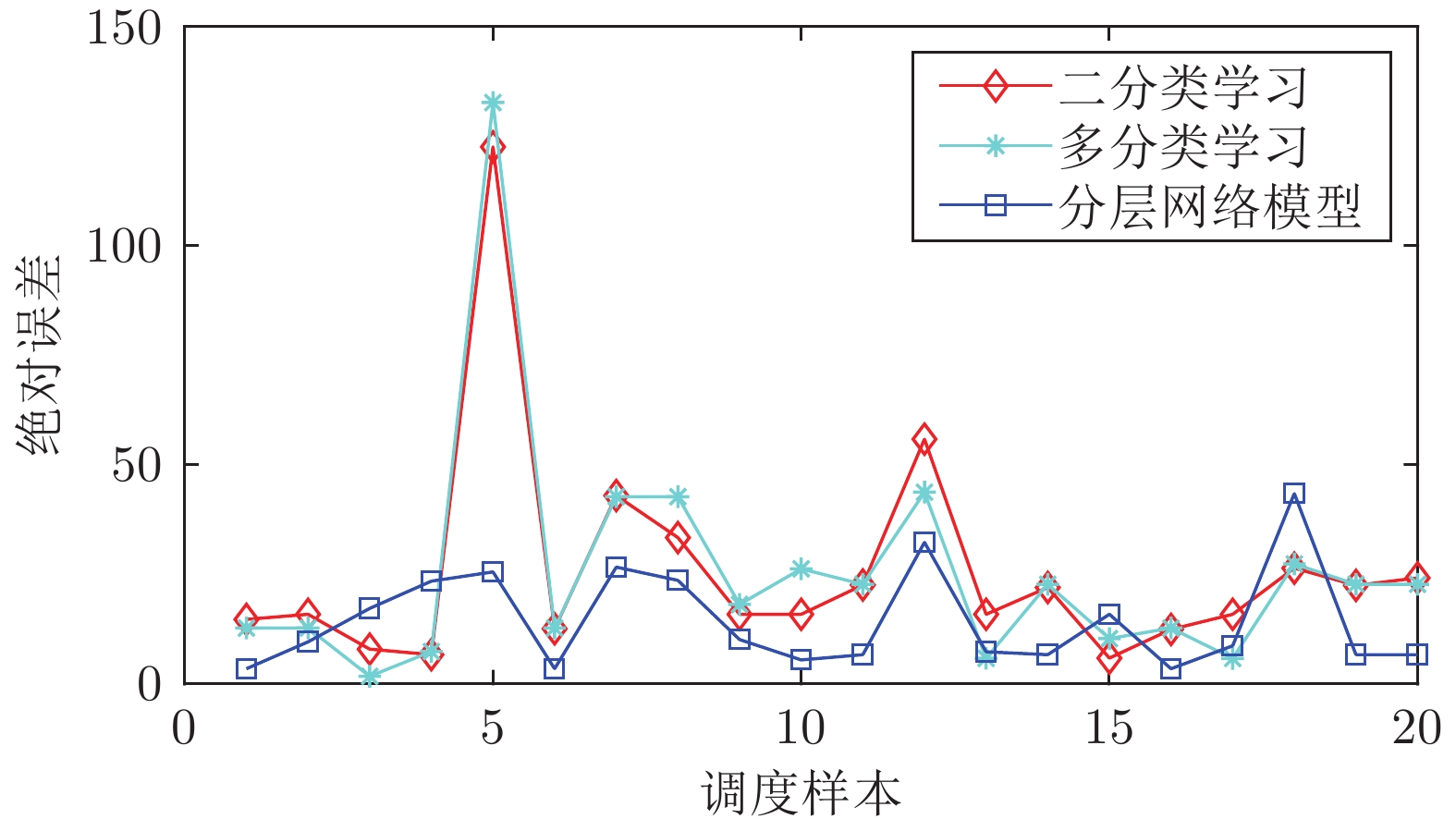 图 9 各阶段对比学习模型的误差比较Fig. 9 Absolute error of the scheduling amount during different contrastive learning phases
图 9 各阶段对比学习模型的误差比较Fig. 9 Absolute error of the scheduling amount during different contrastive learning phases$$ {\rm{MAE}} = \frac{1}{n}\sum\limits_{i = 1}^n {|{y_i} - {{\hat y}_i}|} $$ (13) $$ {\rm{MAPE}} = \frac{{100}}{n}\sum\limits_{i = 1}^n {\frac{{\left| {{y_i} - {{\hat y}_i}} \right|}}{{{y_i}}}} $$ (14) $$ {\text{RMSE}} = \sqrt {\frac{1}{n}\sum\limits_{i = 1}^n {{{({y_i} - {{\hat y}_i})}^2}} } $$ (15) 其中, n为测试样本数量,
$ {y_i} $ 为真实值,$ {\hat y_i} $ 为估计值. 此外, 表1列出了详细的误差统计结果. 从图9和表1中可以看出, 基于专家知识的多分类模型相比于二分类模型在拟合效果方面无明显提高, 这说明仅利用定性或显性知识构建的对比学习模型不足以覆盖隐含的调度工况或特征. 而进一步建立的分层次粒度对比网络可通过多层次的定量学习帮助模型达到与调度专家类似的水平, 表明所提分层次结构对于隐性调度知识具有学习能力.表 1 各对比学习阶段的误差统计Table 1 Error statistical results of different contrastive learning phases模型 MAE RMSE MAPE 二分类知识学习 25.5538 35.9038 47.8148 多分类知识学习 25.2805 37.3146 48.4387 分层次对比网络 (本文方法) 14.2621 18.0120 25.9330 为了说明本文所建立的多工况知识模型的有效性, 选取一些常见的数值拟合和调度方法, 即深度学习方法(LSTM)[26]、强化学习调度方法(Actor-critic)[22]和核函数方法(最小二乘支持向量机, Least-squares support-vector machine, LSSVM)[27]作为对比, 所用方法的参数均通过试错的方式进行优化调整. 类似地, 图8(b)、图10以及表2给出了各方法对于调整量的计算结果及误差和耗时比较. 如图8(b)中圆圈部分所示, LSSVM和LSTM方法对于调度方向的判断存在偏差, 这可能是因为这两种方法仅通过输入与输出数据的非线性关系进行建模和拟合, 无法考虑到能源系统多工况运行场景. 由于采用关于调度评价指标的优化模型, Actor-critic方法能够准确判断出测试样本的调度方向, 但从图10和表2中的结果可以看出, 其对于人工经验的拟合结果不及本文方法. 表2中还给出了提出方法与各对比方法的计算耗时(Time consumption, TC) 统计. 由于采用核学习的方式, LSSVM的计算耗时最短; 与传统有监督学习方式不同, Actor-critic需要从环境中学习相关特征, 因此其学习过程需要更长的时间; 而所提方法的训练过程包含了知识粗提取和知识精炼两部分且网络结构更为复杂, 因此相比于经典的LSTM方法更为耗时. 考虑到由于副产能源调度具有事件驱动特征, 相邻调度过程往往间隔数小时以上, 因此所提方法不足1分钟的训练代价能够满足工业现场的调度需求.
 图 10 不同方法获得的调度量绝对误差对比Fig. 10 Absolute error of the scheduling amount obtained by the comparative algorithms表 2 各对比方法的误差及耗时统计Table 2 Statistical results of error and time consumption of the comparative algorithms
图 10 不同方法获得的调度量绝对误差对比Fig. 10 Absolute error of the scheduling amount obtained by the comparative algorithms表 2 各对比方法的误差及耗时统计Table 2 Statistical results of error and time consumption of the comparative algorithms模型 MAE RMSE MAPE TC (s) LSSVM 30.8112 40.5874 58.3436 1.8990 Actor-critic 52.6542 62.4786 99.1213 195.1375 LSTM 25.4867 38.1860 48.6895 11.7582 本文方法 14.2621 18.0120 25.9330 39.0892 进一步地, 比较表1中二分类和多分类知识学习与表2中对比方法的拟合精度可以发现, 无论是否进行分层次学习, 采用专家经验知识构建表征学习模型相比于传统方法对于调度量估计方面具有优势, 这也说明了知识−数据协同建模相比于单纯的数据驱动方法在能源调度方面的优势.
3.3 能源存储量的预测建模比较
鉴于钢铁燃气调度属于一类事件驱动的决策过程, 因此对于调度时刻的准确判断亦十分重要. 现有的调度方法大多采用预测建模的方式来估计能源存储量的变化趋势, 进而作出调度判断和决策. 本文选取LSSVM作为柜位预测模型, 分别采用单工况建模和多工况模型(基于知识表示划分训练样本后, 建立组合预测模型) 来验证所获得调度知识的有效性. 根据生产现场的长期调研可知, 由于生产作业部门在日间需要进行方案制定、计划调整、检测分析等会议, 导致其生产频率比夜间的频率低, 因此柜位多接近于存储上限, 而夜间场景的柜位相对较低, 本文分别考虑了这两种场景下的预测建模精度.
图11所示为不同场景下的对比结果. 表3中进一步给出了结果的误差统计. 很显然根据所提出的调度知识网络对输入数据进行工况划分后, 所建立的组合模型相比于单工况模型具有更高的预测精度. 上述结果表明, 本文所提出的分层粒度对比网络能够对调度过程中包含的多工况知识进行认知和表示, 而对于知识的有效运用则有助于提高燃气系统的建模精度.
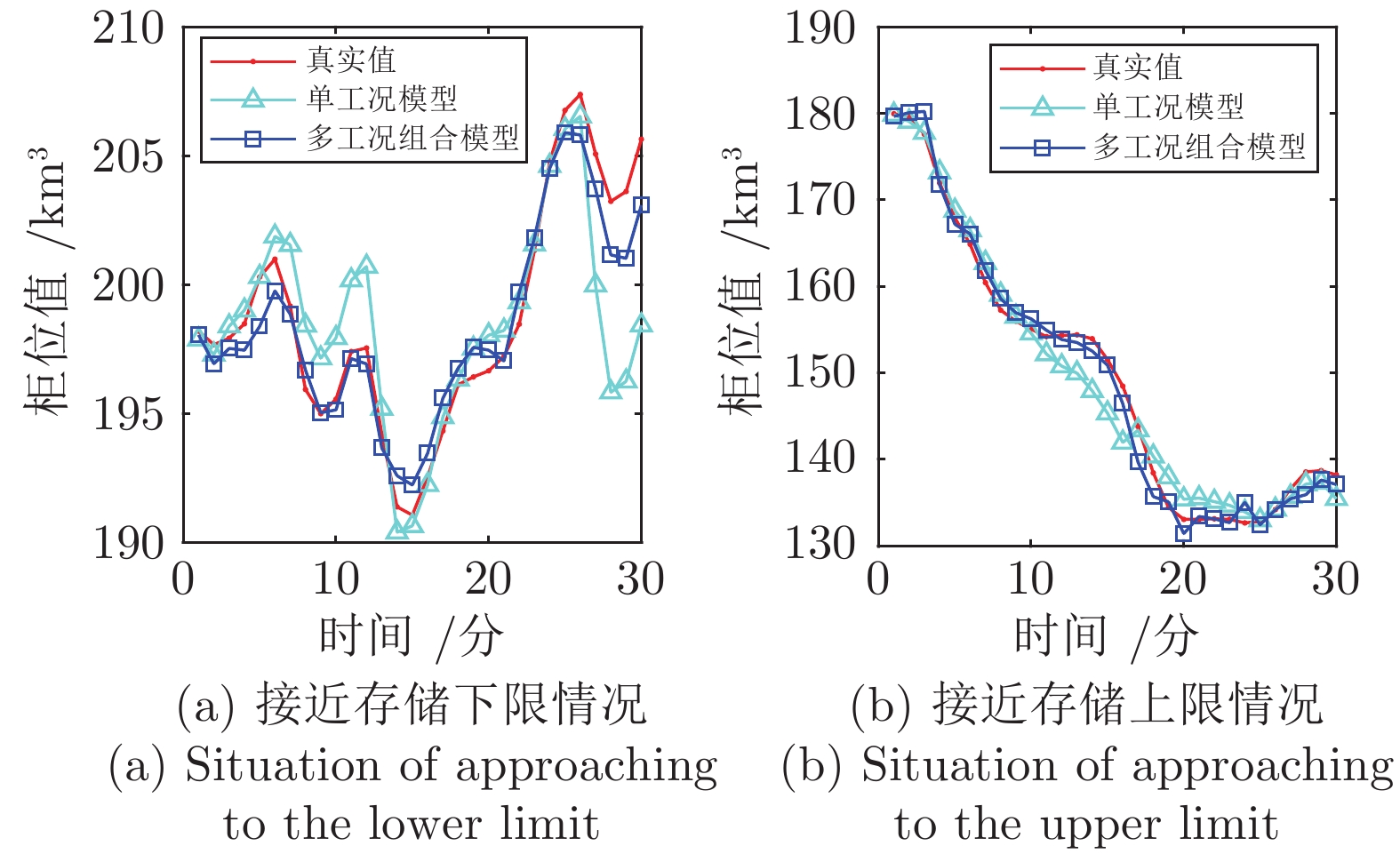 图 11 通过知识表示构建多工况组合模型与单一预测建模的结果对比Fig. 11 Prediction modeling results with and without using the granular contrastive learning model for extracting multiple working-condition knowledge表 3 不同场景下的煤气柜位预测误差统计Table 3 The error statistics of the gas tank level prediction under different situations
图 11 通过知识表示构建多工况组合模型与单一预测建模的结果对比Fig. 11 Prediction modeling results with and without using the granular contrastive learning model for extracting multiple working-condition knowledge表 3 不同场景下的煤气柜位预测误差统计Table 3 The error statistics of the gas tank level prediction under different situations统计误差 MAE RMSE MAPE 接近柜位存储上限 单工况 1.8248 2.8128 0.9093 多工况 0.9576 1.1646 0.4794 接近柜位存储下限 单工况 2.0187 2.6831 1.3711 多工况 1.1772 1.5033 0.7981 4. 结论
对于钢铁燃气系统的实时有效调度是实现企业节能降耗和智能制造的关键. 考虑到燃气产消过程包含多工况特征, 本文通过粒度计算的方式提取能源数据语义特征, 提出了一种基于多层粒度对比网络的知识获取与建模方法. 其优势在于能够有效获取多工况及深层次的调度知识, 从而有助于能源系统的建模过程和调度判断. 实验部分计算和对比了不同工况下的预测精度及调度策略, 结果表明提出方法获得的知识表示可进一步提高建模精度, 并达到与人类专家一致的决策水平.
另一方面, 由于所提方法尚无法实现基于调度评价的知识和策略优化过程, 因此一些相关的改进工作值得进一步关注. 首先, 可建立相关评估体系来指导对比学习中潜在空间的划分, 进一步实现知识发现、更新知识表示. 其次, 所提出的知识表示架构还可结合强化学习实现对于调度策略的优化过程, 将对比学习获得的知识表示作为强化学习状态来约束学习环境, 可简化状态空间, 以提升学习表现和收敛能力, 获得更优的调度策略.
-
图 2 燃气产消多工况特征及调度过程
Fig. 2 The multi-condition characteristics and their scheduling process of gas generation and consumption
图 5 样本数据知识表征的计算过程描述
Fig. 5 The calculation process of the knowledge representation of sample data
图 7 分层粒度对比网络实施过程
Fig. 7 The implement process of the hierarchical granular contrastive network
图 9 各阶段对比学习模型的误差比较
Fig. 9 Absolute error of the scheduling amount during different contrastive learning phases
图 10 不同方法获得的调度量绝对误差对比
Fig. 10 Absolute error of the scheduling amount obtained by the comparative algorithms
图 11 通过知识表示构建多工况组合模型与单一预测建模的结果对比
Fig. 11 Prediction modeling results with and without using the granular contrastive learning model for extracting multiple working-condition knowledge
表 1 各对比学习阶段的误差统计
Table 1 Error statistical results of different contrastive learning phases
模型 MAE RMSE MAPE 二分类知识学习 25.5538 35.9038 47.8148 多分类知识学习 25.2805 37.3146 48.4387 分层次对比网络 (本文方法) 14.2621 18.0120 25.9330  下载: 导出CSV
下载: 导出CSV
表 2 各对比方法的误差及耗时统计
Table 2 Statistical results of error and time consumption of the comparative algorithms
模型 MAE RMSE MAPE TC (s) LSSVM 30.8112 40.5874 58.3436 1.8990 Actor-critic 52.6542 62.4786 99.1213 195.1375 LSTM 25.4867 38.1860 48.6895 11.7582 本文方法 14.2621 18.0120 25.9330 39.0892
下载: 导出CSV
表 3 不同场景下的煤气柜位预测误差统计
Table 3 The error statistics of the gas tank level prediction under different situations
统计误差 MAE RMSE MAPE 接近柜位存储上限 单工况 1.8248 2.8128 0.9093 多工况 0.9576 1.1646 0.4794 接近柜位存储下限 单工况 2.0187 2.6831 1.3711 多工况 1.1772 1.5033 0.7981
下载: 导出CSV
-
[1] Wang T Y, Zhao J, Liu Q L, Wang W. Granular-based multi-layer spatiotemporal network with control gates for energy prediction of steel industry. IEEE Transactions on Instrumentation and Measurement, DOI: 10.1109/TIM.2021.3122173 [2] Wang T Y, Zhao J, Xu Q S, Pedrycz W, Wang W. A dynamic scheduling framework for byproduct gas system combining expert knowledge and production plan. IEEE Transactions on Automation Science and Engineering, DOI: 10.1109/TASE.2022.3162653 [3] Jiang S L, Peng G, Bogle I D L. A two-stage robust optimization approach for oxygen flexible distribution under uncertainty in iron and steel plants. arXiv preprint arXiv: 2106.11635, 2021. [4] . Yang J H, Cai J J, Sun W Q, Huang J. Optimal allocation of surplus gas and suitable capacity for buffer users in steel plant. Applied Thermal Engineering, 2017, 115: 586-596 doi: 10.1016/j.applthermaleng.2016.12.096 [5] . Zhai Y W, Lv Z, Zhao J, Wang W, Leung H. Data-driven inference modeling based on an on-line Wang-Mendel fuzzy approach. Information Sciences, 2021, 551: 113-127 doi: 10.1016/j.ins.2020.10.018 [6] . Jin F, Wang L Q, Zhao J, Wang W, Liu Q L. Granular-causality-based byproduct energy scheduling for energy-intensive enterprise. IEEE Transactions on Automation Science and Engineering, 2020, 17(4): 1662-1673 doi: 10.1109/TASE.2020.2969436 [7] . Wang D, Ha M M, Zhao M M. The intelligent critic framework for advanced optimal control. Artificial Intelligence Review, 2022, 55: 1-22 doi: 10.1007/s10462-021-10118-9 [8] 王鼎, 赵明明, 哈明鸣, 乔俊飞. 基于折扣广义值迭代的智能最优跟踪及应用验证. 自动化学报, 2022, 48(1): 182-193 doi: 10.16383/j.aas.c210658. Wang Ding, Zhao Ming-Ming, Ha Ming-Ming, Qiao Jun-Fei. Intelligent optimal tracking with application verifications via discounted generalized value iteration. Acta Automatica Sinica, 2022, 48(1): 182−193 doi: 10.16383/j.aas.c210658 [9] . Wang D, Zhao M M, Ha M M, Ren J. Neural optimal tracking control of constrained nonaffine systems with a wastewater treatment application. Neural Networks, 2021, 143: 121-132 doi: 10.1016/j.neunet.2021.05.027 [10] . Zhao C H, Chen J H, Jing H. Condition-driven data analytics and monitoring for wide-range nonstationary and transient continuous processes. IEEE Transactions on Automation Science and Engineering, 2020, 18(4): 1563-1574 [11] Chen X, Zhao C H. Conditional discriminative autoencoder and condition-driven immediate representation of soft transition for monitoring complex nonstationary processes. Control Engineering Practice, 2022, 122: Article No. 105090 [12] . Chen J H, Zhao C H. Exponential stationary subspace analysis for stationary feature analytics and adaptive nonstationary process monitoring. IEEE Transactions on Industrial Informatics, 2021, 17(12): 8345-8356 doi: 10.1109/TII.2021.3053308 [13] Chen T, Kornblith S, Swersky K, Norouzi M, Hinton G E. Big self-supervised models are strong semi-supervised learners. arXiv preprint arXiv: 2006.10029, 2020. [14] Chen X C, Yao L, Zhou T, Dong J M, Zhang Y. Momentum contrastive learning for few-shot COVID-19 diagnosis from chest CT images. Pattern Recognition, 2021, 113: Article No. 107826 [15] Marcheggiani D, Titov I. Encoding sentences with graph convolutional networks for semantic role labeling. arXiv preprint arXiv: 1703.04826, 2017. [16] Wu S, Tang Y Y, Zhu Y Q, Wang L, Xie X, Tan T N. Session-based recommendation with graph neural networks. In: Proceedings of the 2019 AAAI Conference on Artificial Intelligence. Palo Alto, USA: AAAI Press, 2019. [17] . Chen T, Kornblith S, Norouzi M, Hinton G. A simple framework for contrastive learning of visual representations. International Conference on Machine Learning, 2020, 119: 1597-1607 [18] . Pedrycz W. Granular computing for data analytics: A manifesto of human-centric computing. IEEE/CAA Journal of Automatica Sinica, 2018, 5(6): 1025-1034 doi: 10.1109/JAS.2018.7511213 [19] . Wang T Y, Han Z Y, Zhao J, Wang W. Adaptive granulation-based prediction for energy system of steel industry. IEEE Transactions on Cybernetics, 2018, 48(1): 127-138 doi: 10.1109/TCYB.2016.2626480 [20] Han Z Y, Pedrycz W, Zhao J, Wang W. Hierarchical granular computing-based model and its reinforcement structural learning for construction of long-term prediction intervals. IEEE Transactions on Cybernetics, DOI: 10.1109/TCYB.2020.2964011 [21] . Wang T Y, Zhao J, Sheng C Y, Wang W, Wang L Q. Multi-layer encoding genetic algorithm-based granular fuzzy inference for blast furnace gas scheduling. IFAC-PapersOnLine, 2016, 49(20): 132-137 doi: 10.1016/j.ifacol.2016.10.109 [22] Zhao J, Wang T Y, Pedrycz W, Wang W. Granular prediction and dynamic scheduling based on adaptive dynamic programming for the blast furnace gas system. IEEE Transactions on Cybernetics, DOI: 10.1109/TCYB.2019.2901268 [23] 桂卫华, 陈晓方, 阳春华, 谢永芳. 知识自动化及工业应用. 中国科学: 信息科学, 2016, 46(8): 1016-1034 doi: 10.1360/N112016-00065. Gui Wei-Hua, Chen Xiao-Fang, Yang Chun-Hua, Xie Yong-Fang. Knowledge automation and industrial application. Scientia Sinica informationis, 2016, 46(8): 1016-1034 doi: 10.1360/N112016-00065 [24] . Hochreiter S, Schmidhuber J. Long short-term memory. Neural Computation, 1997, 9(8): 1735-1780 doi: 10.1162/neco.1997.9.8.1735 [25] . Liu J, Shahroudy A, Xu D, Kot A C, Wang G. Skeleton-based action recognition using spatiotemporal LSTM network with trust gates. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 40(12): 3007-3021 [26] . Wang T Y, Leung H, Zhao J, Wang W. Multiseries featural LSTM for partial periodic time-Series prediction: A case study for steel industry. IEEE Transactions on Instrumentation and Measurement, 2020, 69(9): 5994-6003 doi: 10.1109/TIM.2020.2967247 [27] . Han Z Y, Liu Y, Zhao J, Wang W. Real time prediction for converter gas tank levels based on multi-output least square support vector regressor. Control Engineering Practice, 2012, 20(12): 1400-1409 doi: 10.1016/j.conengprac.2012.08.006 -

 下载:
下载:
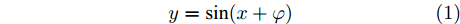
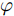
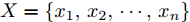
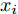
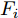
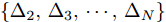
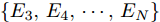
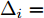
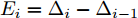

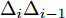
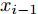
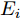
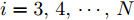
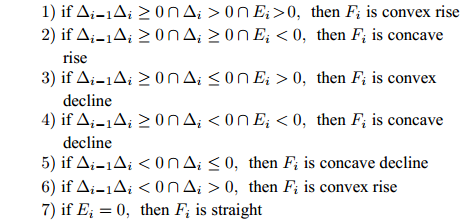
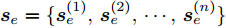
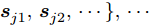
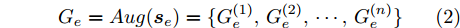
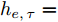

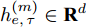
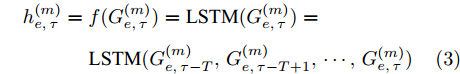
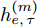
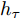
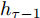
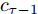
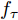
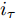
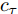
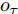
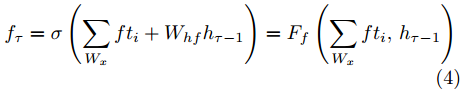
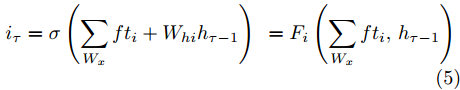
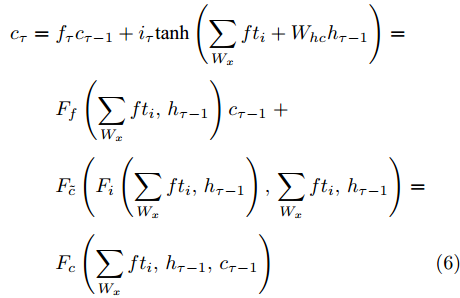
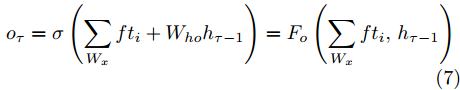
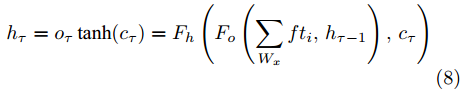
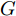
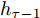
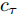
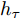
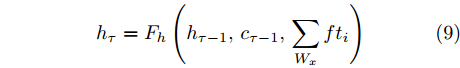
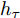
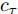
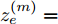
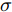
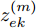
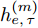
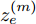
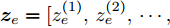
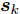
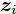
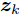
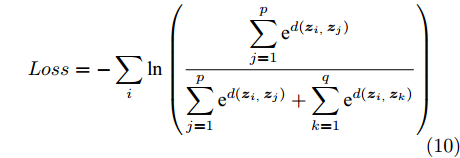
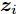
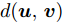
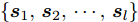
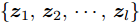
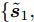
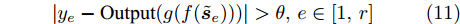
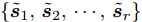
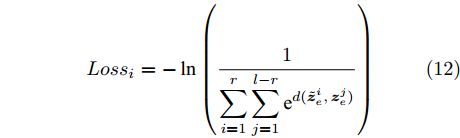
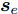
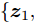
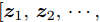

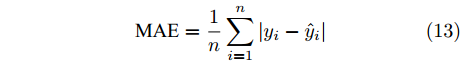
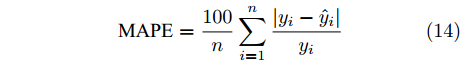
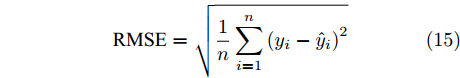
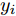
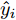
计量
- 文章访问数: 770
- HTML全文浏览量: 160
- PDF下载量: 190
- 被引次数: 0
