

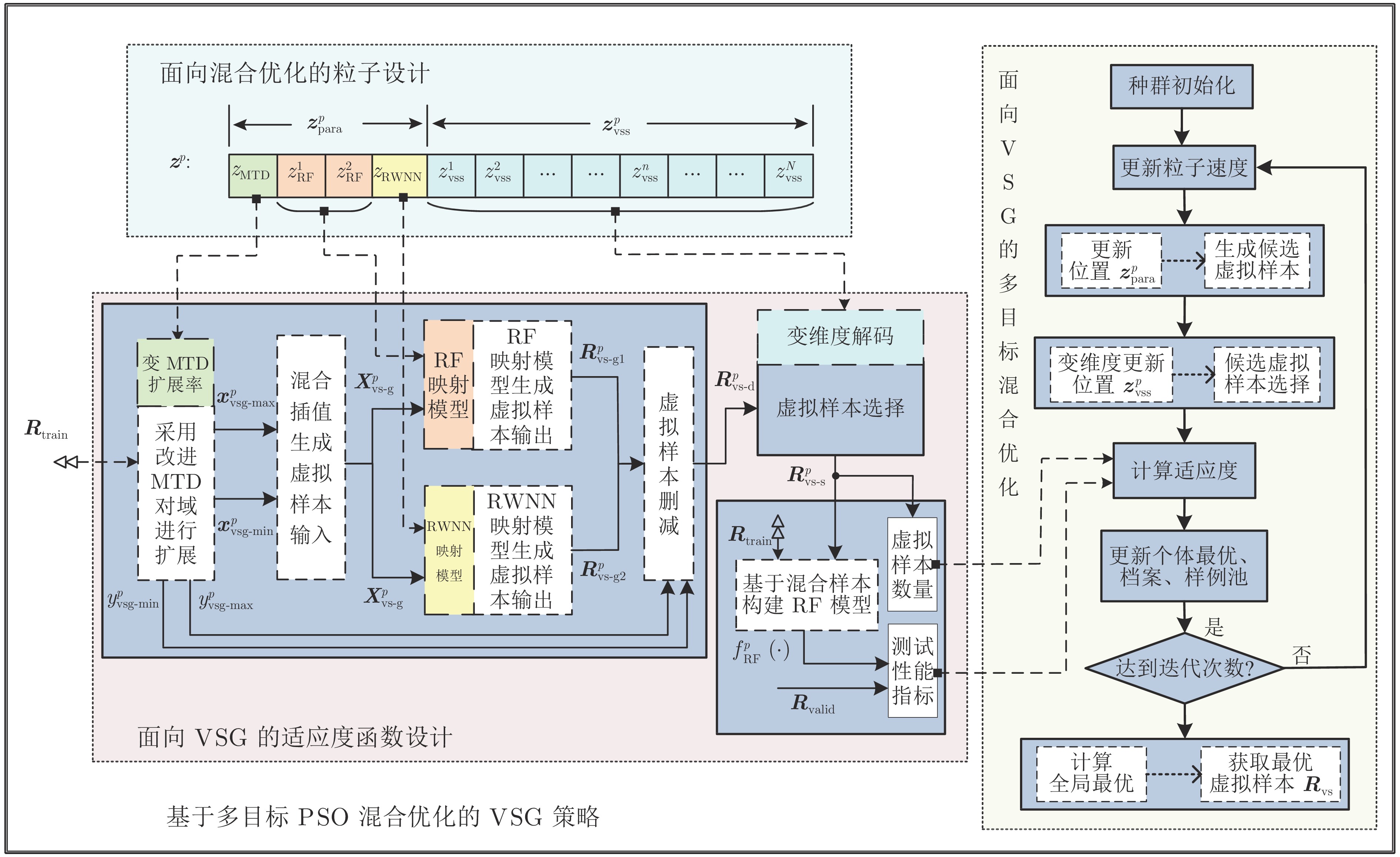
Virtual Sample Generation Method Based on Hybrid Optimization With Multi-objective PSO
-
摘要: 受限于检测技术难度、高时间与经济成本等原因, 难测参数的软测量模型建模样本存在数量少、分布稀疏与不平衡等问题, 严重制约了数据驱动模型的泛化性能. 针对以上问题, 提出一种基于多目标粒子群优化(Multi-objective particle swarm optimization, MOPSO)混合优化的虚拟样本生成(Virtual sample generation, VSG)方法. 首先, 设计综合学习粒子群优化算法的种群表征机制, 使其能够同时编码用于连续变量和离散变量; 然后, 定义具有多阶段多目标特性的综合学习粒子群优化算法适应度函数, 使其能够在确保模型泛化性能的同时最小化虚拟样本数量; 最后, 提出面向虚拟样本生成的多目标混合优化任务以改进综合学习粒子群优化算法, 使其能够适应虚拟样本优选过程的变维特性并提高收敛速度. 同时, 首次借鉴度量学习提出用于评价虚拟样本质量的综合评价指标和分布相似指标. 利用基准数据集和真实工业数据集验证了所提方法的有效性和优越性.Abstract: Due to the difficulty of detection technology, and high time and economic cost, the modeling samples of soft-sensing model with difficult parameters have some problems, such as small numbers, sparse distribution, and imbalance, which seriously restrict the generalization performance of data-driven models. To solve the above problems, a virtual sample generation (VSG) method based on multi-objective particle swarm optimization (MOPSO) hybrid optimization is proposed. First, the population representation mechanism of the integrated learning particle swarm optimization algorithm is designed, so that it can simultaneously encode the continuous and the discrete variables. Then, the fitness function of the integrated learning particle swarm optimization algorithm with multi-stage and multi-objective characteristics is defined to minimize the number of virtual samples while ensuring the generalization performance of the model. Finally, a multi-objective hybrid optimization task is generated for virtual samples to improve the integrated learning particle swarm optimization algorithm, so that it can adapt to the variable dimension characteristics of the virtual sample optimization process and improve the convergence speed. At the same time, the comprehensive evaluation index and distribution similarity index are proposed for evaluating the quality of virtual samples by referring to metric learning for the first time. In this paper, two benchmark datasets and an actual industrial dataset are used to verify the effectiveness and superiority of the proposed method.
-
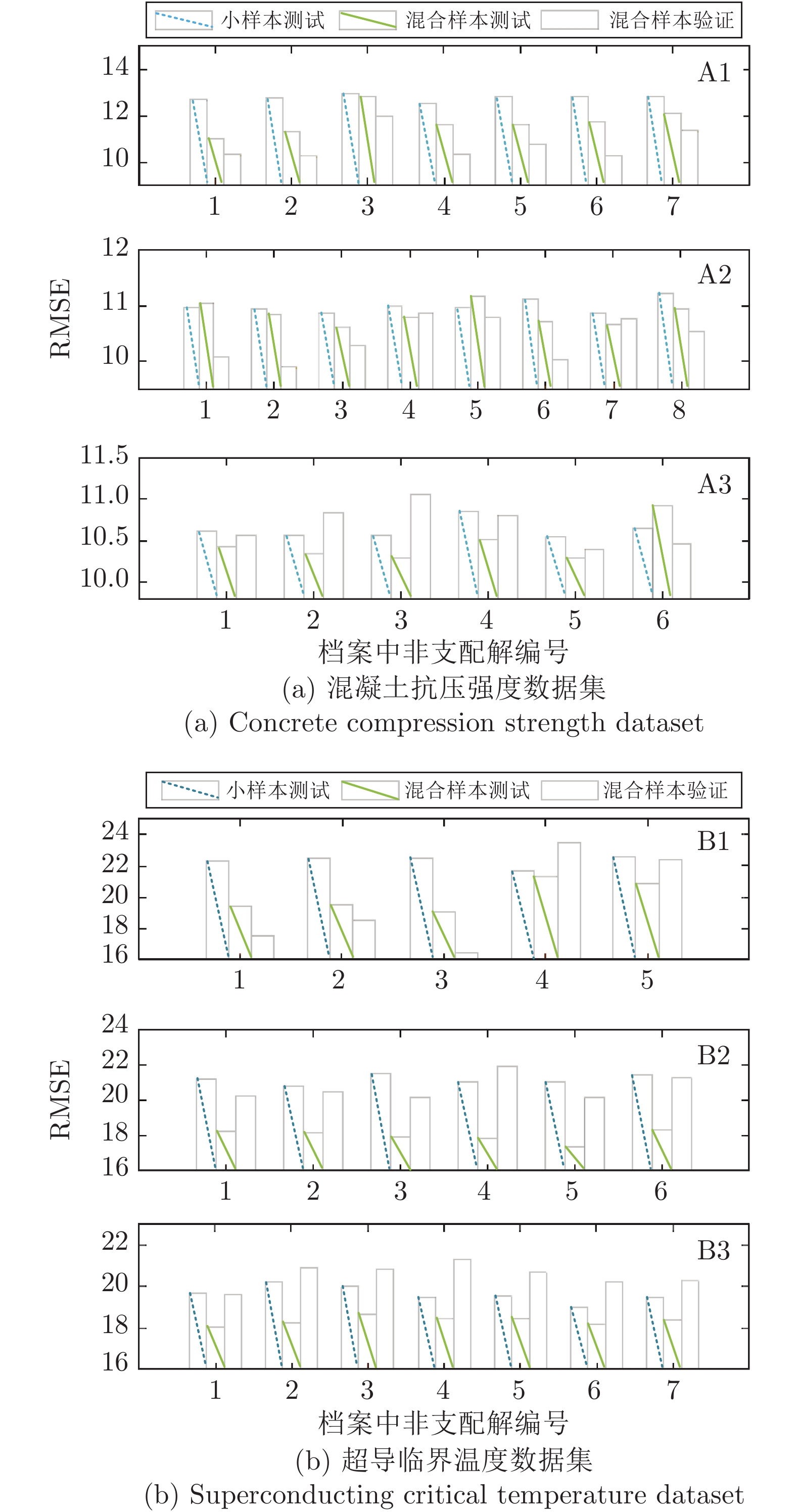
图 5 非支配解的建模性能指标对比
Fig. 5 Comparison of modeling performance indexes of non-dominant solutions
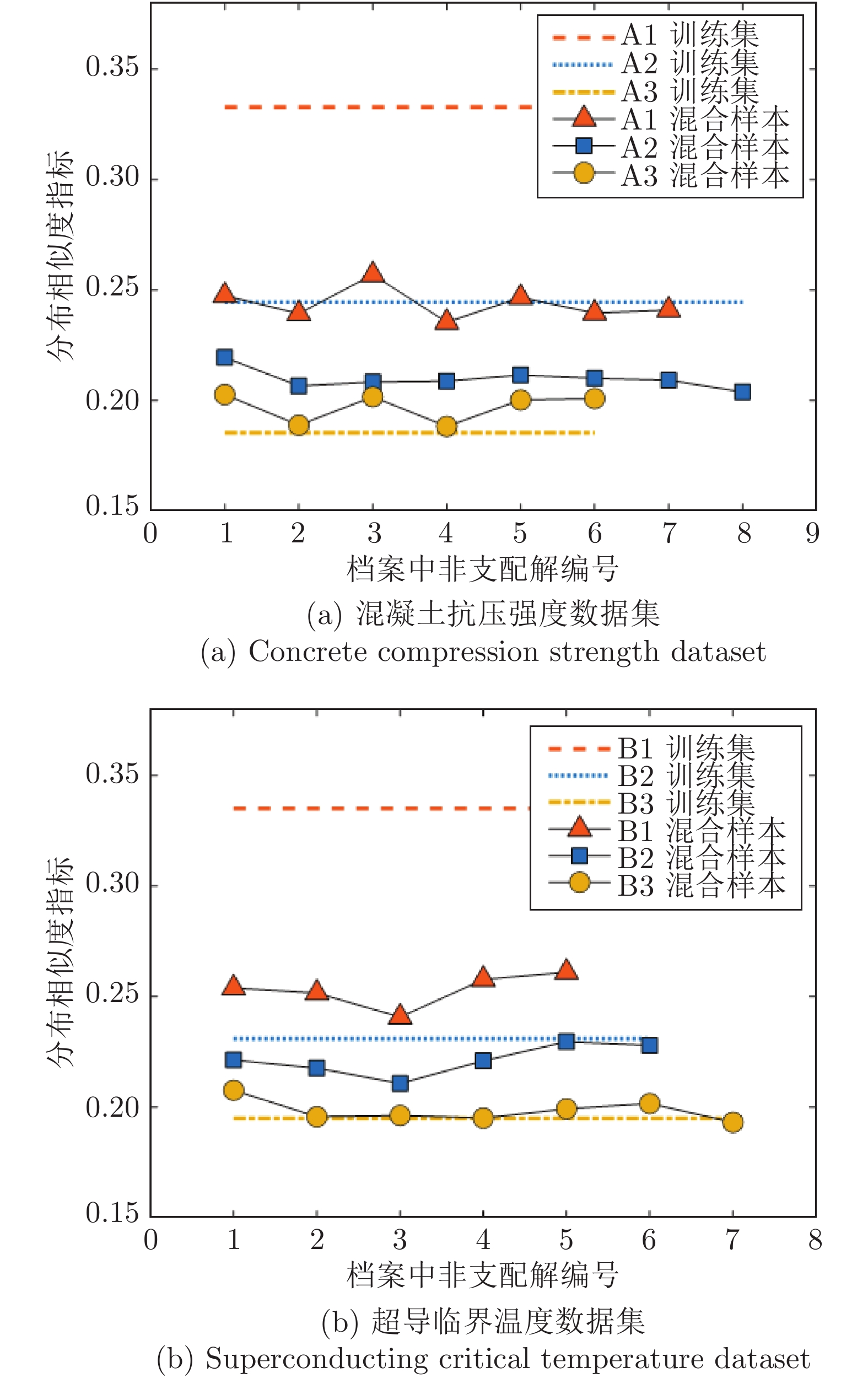
图 7 非支配解的分布相似度对比
Fig. 7 Comparison of distribution similarity of non-dominant solutions
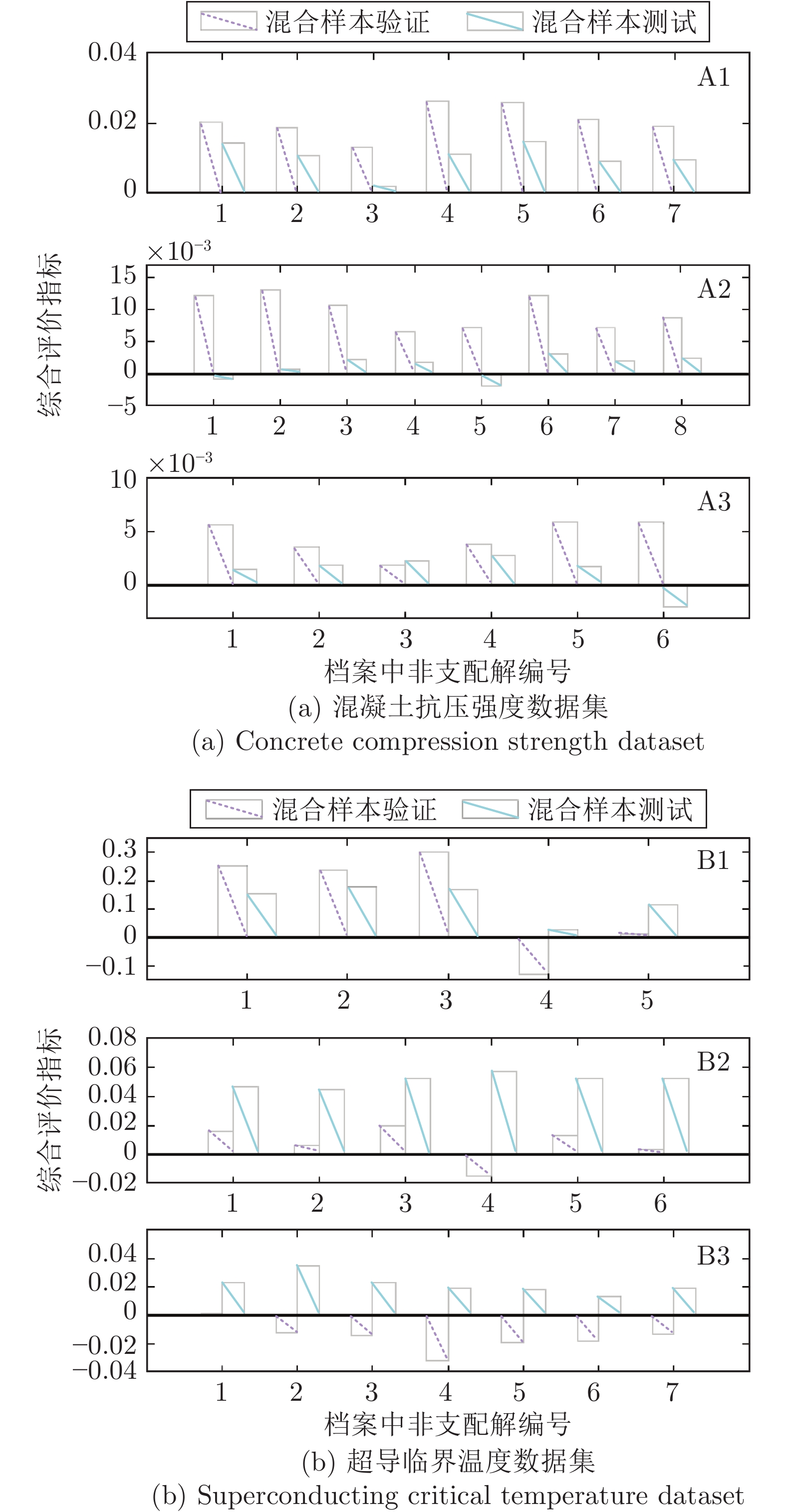
图 6 非支配解的综合评价指标对比
Fig. 6 Comparison of comprehensive evaluation indexes of non-dominant solutions
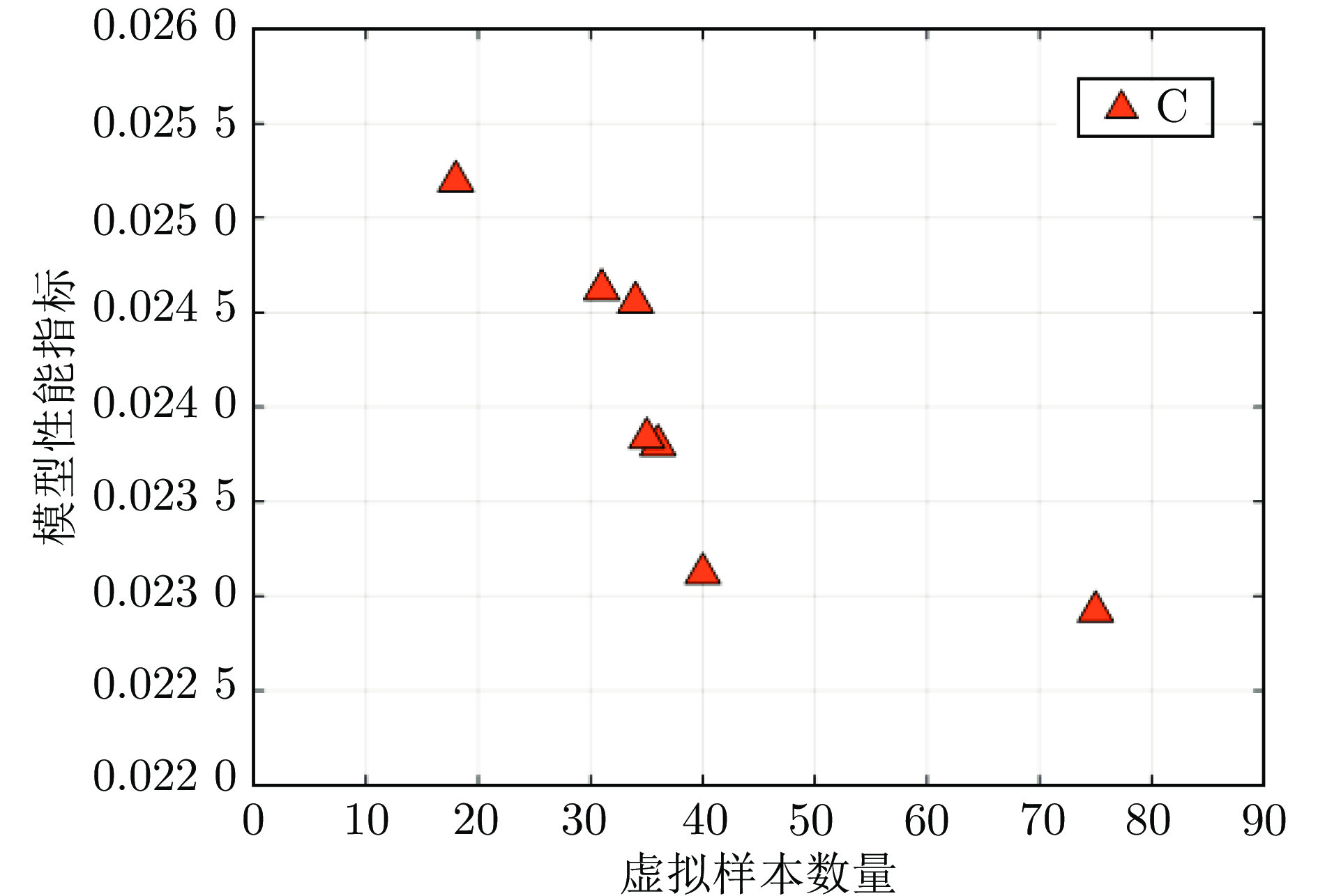
图 10 非支配解的Pareto前沿 —— DXN排放浓度
Fig. 10 Pareto front of non-dominated solutions ——DXN emission concentration
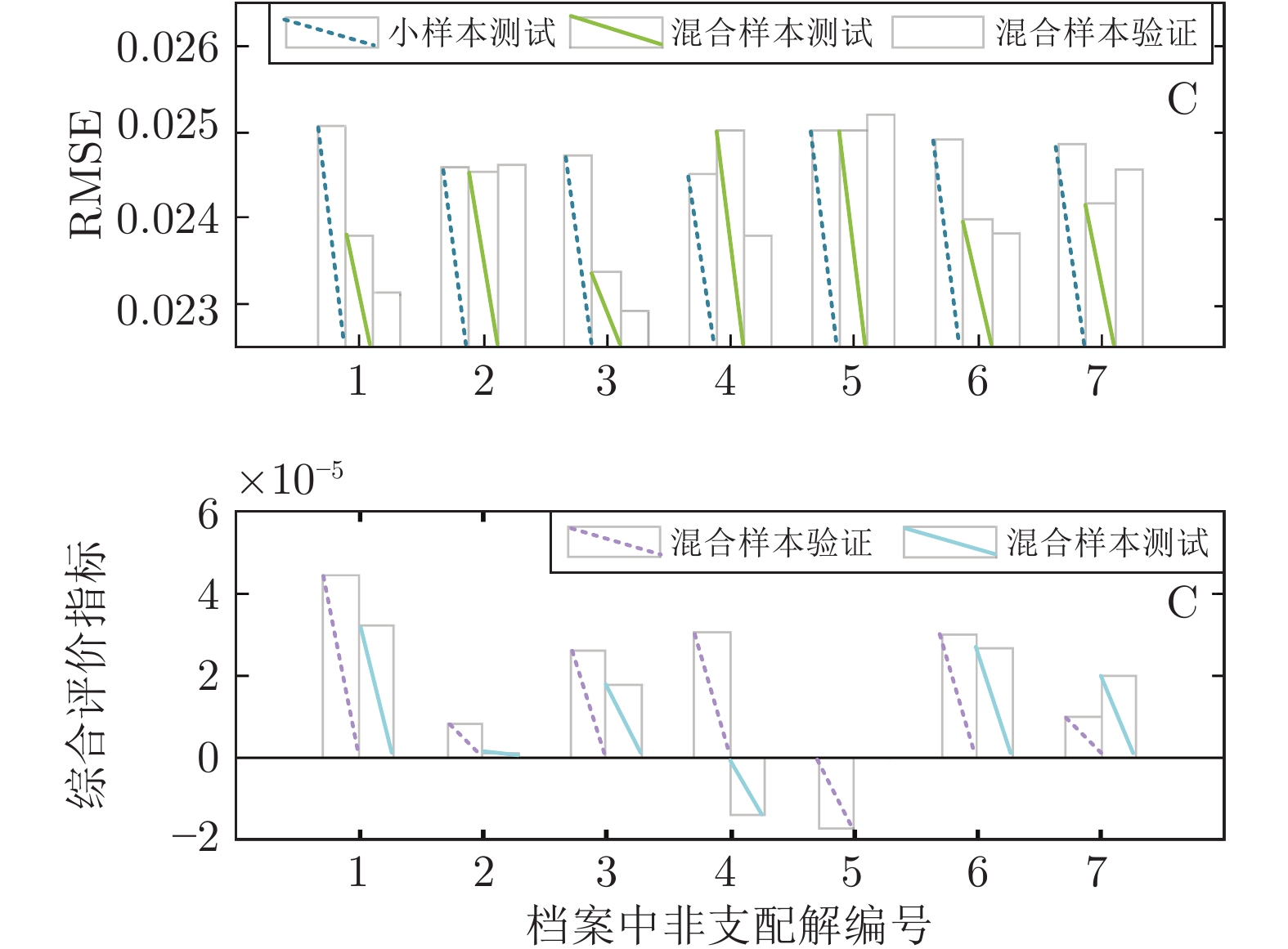
图 11 非支配解的建模性能和综合评价指标对比
Fig. 11 Comparison of modeling performance indexes and comprehensive evaluation indexes of non-dominant solutions
表 1 本文采用符号的含义
Table 1 The meaning of the symbols used in this article
序号 符号 含义 1 ${\rho _i}$ 全局最优粒子选择指标 2 ${\rho _j}$ 虚拟样本综合评价指标 3 $\eta $ 数据分布相似度 4 ${{\boldsymbol{F}}}\left( {{\boldsymbol{z}}} \right)$ 多目标优化问题的目标函数集 5 ${ {\boldsymbol{z} } }, {\boldsymbol{z}}_n^p\left( {t + 1} \right)$ 优化问题决策变量(粒子的位置矢量), 表示第$t + 1$次迭代时, 粒子$p$的第$n$维位置值 6 ${ {\boldsymbol{v} } }, {\boldsymbol{v} }_n^p( {t + 1} )$ 粒子的速度矢量, 表示第$t + 1$次迭代时, 粒子$p$的第$n$维速度值 7 ${w_{{{\rm{inertia}}}}}$ 粒子速度更新的惯性权重 8 ${{{\boldsymbol{d}}}^p}\left( {t + 1} \right)$ 第$t + 1$次迭代时, 粒子$p$的个体最优 9 $E_n^p$ 粒子$p$的第$n$维的学习样例值 10 ${N_{{{\rm{refresh}}}}}$ 个体最优未更新阈值, 用于控制学习样例的更新 11 $P_c^p$ 粒子$p$的学习概率, 用于控制学习样例的更新概率 12 $ran{k^p}$ 粒子$p$个体最优的适应度在种群中排名 13 $K$ RF模型中决策树数量 14 ${L_F}$ RF模型中切分特征数 15 ${\theta _{{{\rm{leaf}}}}}$ RF模型中决策树的叶节点包含样本数量的阈值 16 $F_{_{{{\rm{sel}}}}}^q$ RF模型中决策树的节点$q$最佳切分特征 17 ${s^q}$ RF模型中决策树的节点$q$最佳分裂点取值 18 $f_{_{{{\rm{tree}}}}}^k\left( \cdot \right)$ RF模型中第$k$个决策树模型 19 $f_{_{{{\rm{RF}}}}}^{}\left( \cdot \right)$ RF 模型 20 ${{\boldsymbol{z}}}_{_{{{\rm{para}}}}}^{}$ 指导候选虚拟样本生成的参数决策变量 21 ${{\boldsymbol{z}}}_{_{{{\rm{vss}}}}}^{}$ 筛选候选虚拟样本选择决策变量 22 $\mathop {{\boldsymbol{R}}}\nolimits_{_{{{\rm{train}}}}} $ 原始小样本训练集 23 ${ { {\boldsymbol{x} } }_{ { {\rm{vsg\text{-}min} } } }}, { { {\boldsymbol{x} } }_{ { {\rm{vsg\text{-}max} } } }}$ 采用改进MTD进行扩展后的输入扩展域的上限和下限 24 ${y_{ { {\rm{vsg\text{-}min} } } }}, {y_{ { {\rm{vsg\text{-}max} } } }}$ 采用改进MTD进行扩展后的输出扩展域的上限和下限 25 $\mathop { {\boldsymbol{X} } }\nolimits_{_{ { {\rm{vs\text{-}g} } } }}$ 混合插值生成的虚拟样本输入 26 $\mathop {{\boldsymbol{X}}}\nolimits_{_{{{\rm{equal}}}}} , \mathop {{\boldsymbol{X}}}\nolimits_{_{{{\rm{rand}}}}} $ 等间隔插值、随机插值生成的虚拟样本输入 27 $\mathop { {\boldsymbol{y} } }\nolimits_{_{ { {\rm{vs\text{-}g1} } } } } , \mathop { {\boldsymbol{y} } }\nolimits_{_{ { {\rm{vs\text{-}g2} } } } }$ 基于虚拟样本输入, 结合RF、RWNN映射模型生成的虚拟样本输出 28 ${ {\boldsymbol{R} } }_{ { {\rm{vs\text{-}g1} } } }^p, { {\boldsymbol{R} } }_{ { {\rm{vs\text{-}g2} } } }^p$ 基于虚拟样本输入, 结合RF、RWNN 映射模型生成的虚拟样本 29 $\mathop { {\boldsymbol{R} } }\nolimits_{_{ { {\rm{vs\text{-}g} } } }}$ 生成的混合虚拟样本 30 $\mathop { {\boldsymbol{R} } }\nolimits_{_{ { {\rm{vs\text{-}d} } } } }$ 对$\mathop { {\boldsymbol{R} } }\nolimits_{_{ { {\rm{vs\text{-}g} } } }}$进行删减后的候选虚拟样本 31 $\mathop { {\boldsymbol{R} } }\nolimits_{_{ { {\rm{vs\text{-}s} } } }}$ 对候选虚拟样本进行选择后获得的虚拟样本 32 $\mathop {{\boldsymbol{R}}}\nolimits_{_{{{\rm{valid}}}}} $ 原始小样本验证集 33 $\mathop {{\boldsymbol{R}}}\nolimits_{_{{{\rm{vs}}}}} $ 最优虚拟样本 34 ${f_{{{\rm{num}}}}}({{\boldsymbol{z}}})$ 多目标优化问题的目标之一, 筛选后的虚拟样本数量 35 ${f_{{{\rm{mod}}}}}({{\boldsymbol{z}}})$ 多目标优化问题的目标之一, 筛选后的虚拟样本与原始训练集构建RF模型的性能指标 36 $z_{{\rm{MTD}}}$ 粒子的参数决策变量之一, 对应基于MTD方法的扩展率${\gamma _{{{\rm{extend}}}}}$ 37 $z_{{{\rm{RF}}}}^{{\rm{1}}}$ 粒子的参数决策变量之一, 对应RF映射模型的切分特征数${L_F}$ 38 $z_{{{\rm{RF}}}}^{{\rm{2}}}$ 粒子的参数决策变量之一, 对应RF映射模型中决策树的中叶节点包含样本数量的阈值${\theta _{{{\rm{leaf}}}}}$ 39 ${z_{{{\rm{RWNN}}}}}$ 粒子的参数决策变量之一, 对应RWNN映射模型的隐含层神经元数量$I$ 40 ${\gamma _{{{\rm{extend}}}}}$ 基于MTD方法的扩展率 41 $I$ RWNN映射模型的隐含层神经元数量 42 $\mathop {{\boldsymbol{X}}}\nolimits_{_{{{\rm{train}}}}} $ 原始小样本训练集输入 43 ${{{\boldsymbol{y}}}_{{{\rm{train}}}}}$ 原始小样本训练集输出 44 ${y_{{{\rm{ave}}}}}$ ${{{\boldsymbol{y}}}_{{{\rm{train}}}}}$的均值 45 ${{{\boldsymbol{y}}}_{{{\rm{high}}}}}, {{{\boldsymbol{y}}}_{{{\rm{low}}}}}$ $\mathop {{\boldsymbol{X}}}\nolimits_{_{{{\rm{train}}}}} $中大于/小于${y_{{{\rm{ave}}}}}$的输出集合 46 ${y_{{{\rm{max}}}}}, {y_{{{\rm{min}}}}}$ ${{{\boldsymbol{y}}}_{{{\rm{train}}}}}$中最大值、最小值 47 ${y_{ { {\rm{H\text{-}ave} } } } }, {y_{ { {\rm{L\text{-}ave} } } } }$ ${{{\boldsymbol{y}}}_{{{\rm{high}}}}}, {{{\boldsymbol{y}}}_{{{\rm{low}}}}}$的均值 48 $\mathop N\nolimits_{_{{{\rm{equal}}}}} , \mathop N\nolimits_{_{{{\rm{rand}}}}} $ 等间隔插值、随机插值倍数 49 ${{\boldsymbol{W}}}, {{\boldsymbol{b}}}$ RWNN模型输入层与隐含层间神经元的连接权重与偏置 50 ${{\boldsymbol{H}}}_{}^{_{{{\rm{ori}}}}}$ RWNN模型隐含层输出矩阵 51 ${{\boldsymbol{\beta}}}$ RWNN模型隐含层与输出层神经元的连接权重 52 $\mathop N\nolimits_{_{ { {\rm{vs\text{-}g} } } } } \mathop {, N}\nolimits_{{ { {\rm{vs\text{-}d} } } } } , \mathop N\nolimits_{_{ { {\rm{vs\text{-}s} } } } }$ 生成、候选、选择后虚拟样本的数量 53 ${\theta _{{{\rm{select}}}}}$ 虚拟样本的选择阈值 54 ${{{\boldsymbol{\tilde z}}}_{{{\rm{vss}}}}}$ 对${{{\boldsymbol{z}}}_{{{\rm{vss}}}}}$进行变维度处理后获得 55 $F$ 使用虚拟样本集$\mathop { {\boldsymbol{R} } }\nolimits_{_{ { {\rm{vs\text{-}s} } } }}$的建模性能指标 56 $\mathop {{\boldsymbol{R}}}\nolimits_{_{{{\rm{mix}}}}} $ 原始训练集$\mathop {{\boldsymbol{R}}}\nolimits_{_{{{\rm{train}}}}} $与$\mathop { {\boldsymbol{R} } }\nolimits_{_{ { {\rm{vs\text{-}s} } } }}$的混合样本集 57 ${P_{{{\rm{num}}}}}$ 种群中粒子数量 58 ${N_{{{\rm{iter}}}}}$ 种群迭代次数 59 ${{\boldsymbol{A}}}$ 种群的外部档案, 保存非支配解  下载: 导出CSV
下载: 导出CSV
表 2 基准数据集划分
Table 2 Benchmark data set partitioning
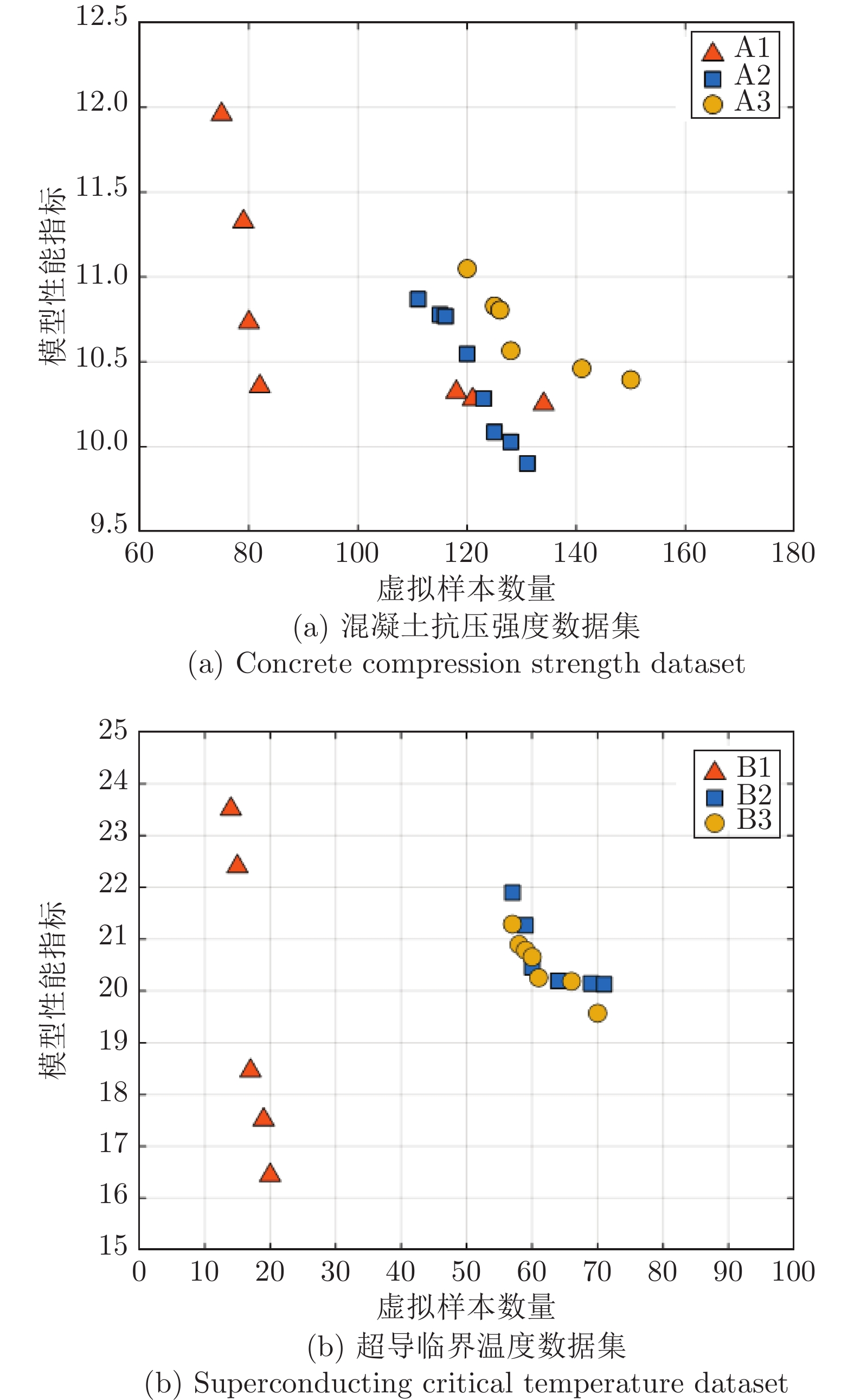
数据集 特征数 训练集 验证集 测试集 数据集编号 数量 $\eta $ 数量 $\eta $ 数量 $\eta $ 混凝土抗压强度 8 20 0.3327 20 0.3598 100 0.1255 A1 40 0.2444 40 0.2628 A2 60 0.1853 60 0.2070 A3 超导临界温度 81 20 0.3351 20 0.3388 100 0.1538 B1 40 0.2309 40 0.2423 B2 60 0.1949 60 0.1966 B3
下载: 导出CSV
表 3 基准数据基于多目标PSO混合优化的VSG参数设定
Table 3 Parameter setting of VSG based on hybrid optimization with multi-objective PSO for benchmark data
数据集 ${P_{{{\rm{num}}}}}$ ${N_{{{\rm{iter}}}}}$ ${N_{{{\rm{refresh}}}}}$ $K$ ${z_{{{\rm{MTD}}}}}$ $z_{{{\rm{RF}}}}^{{\rm{1}}}$ $z_{{{\rm{RF}}}}^{{\rm{2}}}$ ${z_{{{\rm{RWNN}}}}}$ 混凝土抗压强度 30 30 3 30 (0, 1) (1, 6) (2, 10) (3, 20) 超导临界温度 30 30 3 50 (0, 1) (1, 30) (2, 10) (3, 20)
下载: 导出CSV
表 4 基准数据基于多目标PSO混合优化获得的最优虚拟样本
Table 4 Optimal virtual samples obtained based on multi-objective PSO hybrid optimization for benchmark data
数据集 ${\mathop {{\boldsymbol{X}}}\nolimits_{_{{{\rm{vs}}}}} }$ ${y_{{{\rm{vs}}}}}$ A1 396.50 117.40 0 176.40 11.42 876.70 796.90 60.23 58.83 200.50 16.35 115.80 161.60 8.27 1071.70 809.90 17.23 29.23 240.90 0 100.30 183.50 5.87 977.30 852.40 14.00 18.25 272.40 56.58 0 199.00 0 965.00 786.90 37.38 12.62 347.40 0 0 190.80 0 1116.40 718.20 15.08 3.42 B1 5.69 95.64 60.78 69.89 36.85 1.48 1.41 182.20 26.79 4.08 77.39 51.82 60.19 35.09 1.22 1.27 121.40 95.32 4.00 76.44 50.35 59.37 34.71 1.20 1.29 121.30 80.12 4.46 82.72 56.99 64.52 36.03 1.30 1.09 131.20 51.89 3.54 83.97 60.06 66.37 43.11 1.07 0.97 99.90 6.38
下载: 导出CSV
表 5 基准数据原始样本输入/输出范围
Table 5 Input/output range of original samples for benchmark data
数据集 输入 输出 A1 最小值 102.0 0 0 121.8 0 801.0 594.0 1.0 2.3 最大值 540.0 359.4 200.1 247.0 32.2 1145.0 992.6 365.0 82.6 B1 最小值 1.0 6.9 6.4 5.3 2.0 0 0 0 0 最大值 9.0 209.0 209.0 209.0 209.0 2.0 2.0 208.0 185.0
下载: 导出CSV
表 6 基准数据基于多目标PSO混合优化的全局最优解的统计结果
Table 6 Statistical results of global optimal solution based on hybrid optimization with multi-objective PSO for benchmark data
数据集 超参数 虚拟样本数量 验证集 测试集 混合样本$\eta $ ${\gamma _{{{\rm{extend}}}}}$ ${L_F}$ ${\theta _{{{\rm{leaf}}}}}$ $I$ 平均${\rm{RMSE}}$ 平均$\rho $ 平均${\rm{RMSE}}$ 平均$\rho $ A1 0.6033 3 9 18 82 10.36 0.026 11.59 0.012 0.2354 A2 0.6245 6 5 19 128 10.03 0.012 10.73 0.003 0.2099 A3 0.6528 6 9 20 150 10.40 0.006 10.28 0.002 0.2002 B1 0.3951 5 5 16 20 16.44 0.300 19.07 0.169 0.2407 B2 0.4892 8 6 14 69 20.14 0.019 17.86 0.051 0.2118 B3 0.6775 19 6 15 70 19.57 0 18.05 0.023 0.2076
下载: 导出CSV
表 7 基准数据不同VSG方法的对比统计结果
Table 7 Comparative statistical results of different VSG methods for benchmark data
数据集 方法 虚拟样本数量 混合样本$\eta $ 测试${\rm{RMSE} }$ 测试$\rho $ 均值 方差 最优 均值$(\times{10^{ - 3} })$ 方差$(\times{10^{ - 4} })$ 最优$(\times{10^{ - 3} })$ A1 N-VSG 219 0.2770 16.47 8.785 14.11 4.09 15.44 4.62 M-VSG 238 0.3018 17.08 8.575 13.65 2.26 19.73 4.55 PSO-VSG 55 0.4235 16.35 3.822 12.75 3.76 30.20 5.88 MP-VSG 165 0.2641 14.03 4.525 12.93 6.04 9.93 7.19 MoHo-VSG 82 0.2354 11.59 0.107 9.67 12.46 1.34 14.72 B1 N-VSG 176 0.2945 24.38 10.541 21.96 13.87 17.96 14.25 M-VSG 281 0.3100 25.33 12.786 20.12 12.63 56.11 14.12 PSO-VSG 36 0.3317 26.11 17.710 20.38 1.69 71.20 8.23 MP-VSG 134 0.2513 20.84 3.452 19.47 17.43 4.37 18.89 MoHo-VSG 20 0.2076 18.05 0.062 17.84 169.26 1.57 178.69
下载: 导出CSV
表 8 DXN数据基于多目标PSO混合优化的VSG算法参数设定
Table 8 Parameter setting of VSG algorithm based on multi-objective PSO hybrid optimization for DXN data
参数 ${P_{{{\rm{num}}}}}$ ${N_{{{\rm{iter}}}}}$ ${N_{{{\rm{refresh}}}}}$ $K$ ${z_{{{\rm{MTD}}}}}$ $z_{{{\rm{RF}}}}^{{\rm{1}}}$ $z_{{{\rm{RF}}}}^{{\rm{2}}}$ ${z_{{{\rm{RWNN}}}}}$ 数据 30 30 3 50 (0, 1) (1, 35) (2, 10) (3, 20)
下载: 导出CSV
表 9 DXN数据基于多目标PSO混合优化获得的最优虚拟样本
Table 9 Optimal virtual samples obtained based on multi-objective PSO hybrid optimization for DXN data
${\mathop {{\boldsymbol{X}}}\nolimits_{_{{{\rm{vs}}}}} }$ ${y_{{{\rm{vs}}}}}$ 4.366 1.54 68.78 27.31 241.4 3.96 334.7 0.0289 4.206 0 68.94 28.15 222.5 3.77 306.8 0.0458 4.449 7.69 72.48 30.23 222.8 3.98 315.8 0.0685 4.432 10.00 71.83 30.00 225.9 3.99 319.5 0.0163 4.461 17.69 74.65 30.77 228.5 3.99 321.8 0.0029
下载: 导出CSV
表 10 DXN数据面向VSG的多目标PSO混合优化全局最优解
Table 10 DXN data for VSG-oriented multi-objective PSO hybrid optimization global optimal solution
性能指标 最优解 超参数${\gamma _{{{\rm{extend}}}}}$ 0.1206 超参数${L_F}$ 2 超参数${\theta _{{{\rm{leaf}}}}}$ 5 超参数$I$ 15 虚拟样本数量 40 验证集的平均${\rm{RMSE}}$ 0.0231 验证集的平均$\rho $ 4.41 ×${10^{ - 5}}$ 测试集的平均${\rm{RMSE}}$ 0.0238 测试集的平均$\rho $ 3.18 ×${10^{ - 5}}$ 验证集, 小样本建模的${\rm{RMSE}}$ 0.0259 测试集, 小样本建模的${\rm{RMSE}}$ 0.0251
下载: 导出CSV
表 11 DXN数据的不同VSG方法对比统计结果
Table 11 Comparative statistical results of different VSG methods based on DXN dataset
方法 虚拟样本
数量测试集的${\rm{RMSE} }$ 测试集的$\rho $ 均值 方差$(\times {10^{ - 4} })$ 最优 均值$(\times {10^{ - 5} })$ 方差 最优$(\times{10^{ - 5} })$ N-VSG 129 0.0406 0.695 0.0262 0.19 1.94 ×${10^{ - 5}}$ 0.36 M-VSG 116 0.0403 1.331 0.0231 0.26 8.83 ×${10^{ - 5}}$ 0.53 PSO-VSG 27 0.0328 0.519 0.0245 0.56 8.44 ×${10^{ - 5}}$ 1.02 MP-VSG 68 0.0377 1.208 0.0218 1.04 5.16 ×${10^{ - 7}}$ 1.78 MoHo-VSG 40 0.0231 0.691 0.0220 3.18 4.47 ×${10^{ - 9}}$ 3.45
下载: 导出CSV
-
[1] 乔俊飞, 郭子豪, 汤健. 面向城市固废焚烧过程的二噁英排放浓度检测方法综述. 自动化学报, 2020, 46(6): 1063−1089 doi: 10.16383/j.aas.c190005Qiao Jun-Fei, Guo Zi-Hao, Tang Jian. A review on the determination of dioxin emission concentration in municipal solid waste incineration process. Acta Automatica Sinica, 2020, 46(6): 1063−1089 doi: 10.16383/j.aas.c190005 [2] 柴天佑. 工业过程控制系统研究现状与发展方向. 中国科学: 信息科学, 2016, 46(8): 1003−1015 doi: 10.1360/N112016-00062Chai Tian-You. Industrial process control systems: Research status and development direction. Scientia Sinica Informationis, 2016, 46(8): 1003−1015 doi: 10.1360/N112016-00062 [3] Arafat H A, Jijakli K, Ahsan A. Environmental performance and energy recovery potential of five processes for municipal solid waste treatment. Journal of Cleaner Production, 2015, 105: 233−240 doi: 10.1016/j.jclepro.2013.11.071 [4] Zhou H, Meng A, Long Y Q, Li Q H, Zhang Y G. A review of dioxin-related substances during municipal solid waste incineration. Waste Management, 2015, 36(8): 106−118 [5] Jones P H, Degerlache J, Marti E, Mischer G, Niessen H J. The global exposure of man to dioxins: A perspective on industrial-waste incineration. Chemosphere, 1993, 26: 1491−1497 doi: 10.1016/0045-6535(93)90216-R [6] 汤健, 乔俊飞. 基于选择性集成核学习算法的固废焚烧过程二噁英排放浓度软测量. 化工学报, 2019, 70(2): 696−706 doi: 10.11949/j.issn.0438-1157.20181354Tang Jian, Qiao Jun-Fei. Soft sensor of dioxin emission concentration in solid waste incineration process based on selective ensemble kernel learning algorithm. Journal of Chemical Engineering and Technology, 2019, 70(2): 696−706 doi: 10.11949/j.issn.0438-1157.20181354 [7] He A, Li T, Li N, Wang K, Fu H. CABNet: Category attention block for imbalanced diabetic retinopathy grading. IEEE Transactions on Medical Imaging, 2021, 40(1): 143−153 doi: 10.1109/TMI.2020.3023463 [8] Wang Q, Wang K, Li Q, Yang Z, Jin G, Wang H. MBNN: A multi-branch neural network capable of utilizing industrial sample unbalance for fast inference. IEEE Sensors Journal, 2021, 21(2): 1809−1819 doi: 10.1109/JSEN.2020.3017686 [9] 汤健, 乔俊飞, 柴天佑, 刘卓, 吴志伟. 基于虚拟样本生成技术的多组分机械信号建模. 自动化学报, 2018, 44(9): 1569−1589 doi: 10.16383/j.aas.2017.c170204Tang Jian, Qiao Jun-Fei, Chai Tian-You, Liu Zhuo, Wu Zhi-Wei. Multi-component mechanical signal modeling based on virtual sample generation technology. Acta Automatica Sinica, 2018, 44(9): 1569−1589 doi: 10.16383/j.aas.2017.c170204 [10] Lin Y S, Li D C. The generalized-trend-diffusion modeling algorithm for small data sets in the early stages of manufacturing systems. European Journal of Operational Research, 2010, 207(1): 121−130 doi: 10.1016/j.ejor.2010.03.026 [11] Zhu Q X, Chen Z, Zhang X H, Rajabifard A, Chen Y. Dealing with small sample size problems in process industry using virtual sample generation: A Kriging-based approach. Soft Computing, 2020, 24(9): 6889−6902 doi: 10.1007/s00500-019-04326-3 [12] Zhang T, Chen J, Xie J, Pan T. SASLN: Signals augmented self-taught learning networks for mechanical fault diagnosis under small sample condition. IEEE Transactions on Instrumentation and Measurement, 2021, 70: 1−11 [13] Poggio T, Vetter T. Recognition and structure from one 2D model view: Observations on-prototypes, object classes and symmetries. Laboratory Massachusetts Institute of Technology, 1992: Article No. 1347 [14] Li D C, Lin L S, Chen C C, Yu W H. Using virtual samples to improve learning performance for small datasets with multi-modal distributions. Soft Computing, 2019, 23(22): 11883−11900 doi: 10.1007/s00500-018-03744-z [15] Niyogi P, Girosi F, Poggio T. Incorporating prior information in machine learning by creating virtual examples. Proceedings of the IEEE, 1998, 86(11): 2196−2209 doi: 10.1109/5.726787 [16] Li D C, Hsu H C, Tsai T I, Te J L, Susan C H. A new method to help diagnose cancers for small sample size. Expert Systems With Applications, 2007, 33(2): 420−424 doi: 10.1016/j.eswa.2006.05.028 [17] Zhu Y, Yao J. A novel reliability assessment method based on virtual sample generation and failure physical model. In: Proceedings of the 12th International Conference on Reliability, Maintainability, and Safety. Shanghai, China: 2018. 99−102 [18] Schlkopf B, Simard P, Smola A J, Vapnik V. Prior knowledge in support vector kernels. In: Proceedings of Neural Information Processing Systems. Denver, USA: 1997. 640−646 [19] Cai W D, Ma B, Zhang L, Han Y M. A pointer meter recognition method based on virtual sample generation technology. Measurement, 2020, 163: Article No. 107962 doi: 10.1016/j.measurement.2020.107962 [20] Gang H, Yuan X, Wei Z, Shi Y. An effective method for face recognition by creating virtual training samples based on pixel processing. In: Proceedings of the 10th International Conference on Intelligent Human-Machine Systems and Cybernetics. Hangzhou, China: 2018. 177−180 [21] Luo J, Tjahjadi T. Multi-set canonical correlation analysis for 3D abnormal gait behaviour recognition based on virtual sample generation. IEEE Access, 2020, 8: 32485−32501 doi: 10.1109/ACCESS.2020.2973898 [22] Li D C, Lin Y S. Using virtual sample generation to build up management knowledge in the early manufacturing stages. European Journal of Operational Research, 2006, 175(1): 413− 434 doi: 10.1016/j.ejor.2005.05.005 [23] Li D C, Lin L S. A new approach to assess product lifetime performance for small data sets. European Journal of Operational Research, 2013, 230(2): 290−298 doi: 10.1016/j.ejor.2013.04.016 [24] Lin L S, Li D C, Yu W H, Hsueh Y M. Generating multi-modality virtual samples with soft DBSCAN for small dataset learning. In: Proceedings of the 3rd International Conference on App-lied Computing and Information Technology/2nd International Conference on Computational Science and Intelligence. Okaya-ma, Japan: 2015. 363−368 [25] Zhang X H, Xu Y, He Y L, Zhu Q X. Novel manifold learning based virtual sample generation for optimizing soft sensor with small data. ISA Transactions, 2021, 109: 229−241 doi: 10.1016/j.isatra.2020.10.006 [26] Chen Z S, Zhu Q X, Xu Y, He Y L, Nagy Z K. Integrating virtual sample generation with input-training neural network for solving small sample size problems: Application to purified terephthalic acid solvent system. Soft Computing, 2021, 25(8): 6489−6504 [27] Li D C, Chen C C, Chang C J, Lin W K. A tree-based-trend-diffusion prediction procedure for small sample sets in the early stages of manufacturing systems. Expert Systems With Applications, 2012, 39(1): 1575−1581 doi: 10.1016/j.eswa.2011.08.071 [28] Zhu B, Chen Z S, Yu L A. A novel small sample mage-trend-diffusion technology. Journal of Chemical Industry and Technology, 2016, 67(3): 820−826 [29] He Y L, Wang P J, Zhang M Q, Zhu Q X, Xu Y A. A novel and effective nonlinear interpolation virtual sample generation method for enhancing energy prediction and analysis on small data problem: A case study of ethylene industry. Energy, 2018, 147: 418−427 doi: 10.1016/j.energy.2018.01.059 [30] 朱宝, 乔俊飞. 基于AANN特征缩放的虚拟样本生成方法及其过程建模应用. 计算机与应用化学, 2019, 36(4): 304−307 doi: 10.16866/j.com.app.chem201904002Zhu Bao, Qiao Jun-Fei. Virtual sample generation method based on AANN feature scaling and its process modeling application. Computer and Applied Chemistry, 2019, 36(4): 304−307 doi: 10.16866/j.com.app.chem201904002 [31] Qiao J F, Guo Z H, Tang J. Virtual sample generation method based on improved megatrend diffusion and hidden layer interpolation and its application. Journal of Chemical Industry and Engineering, 2020, 71(12): 5681−5695 [32] Tang J, Jia M, Liu Z, Chai T Y, Yu W. Modeling high dimensional frequency spectral data based on virtual sample generation technique. In: Proceedings of the International Conference on Information and Automation. Lijiang, China: 2015. 1090− 1095 [33] Li D C, Wen I. A genetic algorithm-based virtual sample generation technique to improve small data set learning. Neurocomputing, 2014, 143: 222−230 doi: 10.1016/j.neucom.2014.06.004 [34] Chen Z S, Zhu B, He Y L, Yu L A. A PSO based virtual sample generation method for small sample sets: Applications to regression datasets. Engineering Applications of Artificial Intelligence, 2016, 59: 236−243 [35] 汤健, 王丹丹, 郭子豪, 乔俊飞. 基于虚拟样本优化选择的城市固废焚烧过程二噁英排放浓度预测. 北京工业大学学报, 2021, 47(5): 431−443Tang Jian, Wang Dan-Dan, Guo Zi-Hao, Qiao Jun-Fei. Prediction of dioxin emission concentration in urban solid waste incineration process based on virtual sample optimization selection. Journal of Beijing University of Technology, 2021, 47(5): 431−443 [36] 汤健, 夏恒, 乔俊飞, 郭子豪. 深度集成森林回归建模方法及应用研究. 北京工业大学学报, 2021, 47(11): 1219−1229Tang Jian, Xia Heng, Qiao Jun-Fei, Guo Zi-Hao. Research on deeply integrated forest regression modeling method and its application. Journal of Beijing University of Technology, 2021, 47(11): 1219−1229 [37] Liang J J, Qin A K, Suganthan P N, Baskar S. Comprehensive learning particle swarm optimizer for global optimization of multi-modal functions. IEEE Transactions on Evolutionary Computation, 2006, 10(3): 281−295 doi: 10.1109/TEVC.2005.857610 [38] Tang J, Zhang J, Yu G, Zhang W P, Yu W. Multi-source latent feature selective ensemble modeling approach for small-sample high-dimension process data in application. IEEE Access, 2020, 8: 148475−148488 doi: 10.1109/ACCESS.2020.3015875 [39] 林越, 刘廷章, 王哲河. 具有两类上限条件的虚拟样本生成数量优化. 广西师范大学学报(自然科学版), 2019, 37(1): 142−148 doi: 10.16088/j.issn.1001-6600.2019.01.016Lin Yue, Liu Ting-Zhang, Wang Zhe-He. Optimization of virtual sample generating quantity with two kinds of upper limit conditions. Journal of Guangxi Normal University (Natural Science Edition), 2019, 37(1): 142−148 doi: 10.16088/j.issn.1001-6600.2019.01.016 [40] Vallejo M, Espriella C, Gómez-Santamaría J, Ramírez-Barrera A F, Delgado-Trejos E. Soft metrology based on machine learning: A review. Measurement Science and Technology, 2020, 31(3): Article No. 32001 doi: 10.1088/1361-6501/ab4b39 [41] 汤健, 乔俊飞, 徐喆, 郭子豪. 基于特征约简与选择性集成算法的城市固废焚烧过程二噁英排放浓度软测量. 控制理论与应用, 2021, 38(1): 110−120Tang Jian, Qiao Jun-Fei, Xu Zhe, Guo Zi-Hao. Soft measurement of dioxin emission concentration in municipal solid waste incineration process based on feature reduction and selective integration algorithm. Control Theory & Applications, 2021, 38(1): 110−120 [42] Zhong K, Han M, Han B. Data-driven based fault prognosis for industrial systems: A concise overview. IEEE/CAA Journal of Automatica Sinica, 2020, 7(2): 330−345 doi: 10.1109/JAS.2019.1911804 [43] 朱宝. 虚拟样本生成技术及建模应用研究[博士论文], 北京化工大学, 中国, 2017.Zhu Bao. Virtual Sample Generation Technology and Modeling Application [Ph.D. dissertation], Beijing University of Chemical Technology, China, 2017. [44] Li D C, Lin L S, Peng L J. Improving learning accuracy by using synthetic samples for small datasets with non-linear attribute dependency. Decision Support Systems, 2014, 59: 286−295 doi: 10.1016/j.dss.2013.12.007 [45] Chen Z S, Zhu B, He Y L, Yu L A. A PSO based virtual sample generation method for small sample sets: Applications to regression datasets. Engineering Applications of Artificial Intelligence, 2017, 59: 236−243 doi: 10.1016/j.engappai.2016.12.024 [46] Wang Y Q, Wang Z Y, Sun J Y, Zhang J J, Zissimos M. Gray bootstrap method for estimating frequency-varying random vibration signals with small samples. Chinese Journal of Aeronautics, 2014, 27(2): 383−389 doi: 10.1016/j.cja.2013.07.023 [47] Hong W C, Li M W, Geng J, Zhang Y. Novel chaotic bat algorithm for forecasting complex motion of floating platforms. Applied Mathematical Modelling, 2019, 72: 425−443 doi: 10.1016/j.apm.2019.03.031 [48] Bloch G, Lauer F, Colin G, Chamaillard Y. Support vector regression from simulation data and few experimental samples. Information Sciences, 2008, 178(20): 3813−3827 doi: 10.1016/j.ins.2008.05.016 [49] Thomas P T, Edward A P. Small sample reliability growth modeling using a grey systems model. Grey Systems Theory and Application, 2018, 8(3): 246−271 doi: 10.1108/GS-02-2018-0011 [50] Shapiai M I, Ibrahim Z, Khalid M, Jau L W, Pavlovic V, Watada J. Function and surface approximation based on enhanced kernel regression for small sample set. International Journal of Innovative Computing, Information & Control: IJICIC, 2011, 7(10): 5947−5960 [51] Dai Z, Wei H, Li X, Lv M. Validation of issile simulation model based on Bayesian theory with extreme small sample. In: Proceedings of the 3rd International Conference on Electron Device and Mechanical Engineering. Suzhou, China: 2020. 683−686 [52] Hou Y, Zheng E, Guo W, Xiao Q, Xu Z. Learning Bayesian network parameters with small data set: A parameter extension under constraints method. IEEE Access, 2020, 8: 24979−24989 doi: 10.1109/ACCESS.2020.2971099 [53] 于旭, 杨静, 谢志强. 虚拟样本生成技术研究. 计算机科学, 2011, 38(3): 16−19 doi: 10.3969/j.issn.1002-137X.2011.03.004Yu Xu, Yang Jing, Xie Zhi-Qiang. Research on virtual sample generation technology. Computer Science, 2011, 38(3): 16−19 doi: 10.3969/j.issn.1002-137X.2011.03.004 [54] Bunsan S, Chen W Y, Chen H W, Grisdanurak N. Modeling the dioxin emission of a municipal solid waste incinerator using neural networks. Chemosphere, 2013, 92: 258−264 doi: 10.1016/j.chemosphere.2013.01.083 [55] Xiao X D, Lu J W, Hai J. Prediction of dioxin emissions in flue gas from waste incineration based on support vector regression. Renewable Energy Resources, 2017, 35(8): 1107−1114 [56] 乔俊飞, 郭子豪, 汤健. 基于多层特征选择的固废焚烧过程二噁英排放浓度软测量. 信息与控制, 2021, 50(1): 75−87 doi: 10.13976/j.cnki.xk.2021.9663Qiao Jun-Fei, Guo Zi-Hao, Tang Jian. Soft sensing of dioxin emission concentration in solid waste incineration process based on multi-layer feature selection. Information and Control, 2021, 50(1): 75−87 doi: 10.13976/j.cnki.xk.2021.9663 -

 下载:
下载:




计量
- 文章访问数: 1417
- HTML全文浏览量: 347
- PDF下载量: 234
- 被引次数: 0
