

Data-driven Model-free Adaptive Control Method for High-speed Electric Multiple Unit
-
摘要: 针对动车组的速度跟踪控制问题, 同时考虑到现有基于模型的控制方法对系统动力学模型的依赖性, 以及传统无模型自适应控制时变参数估计算法的复杂性, 将改进的多输入多输出(Multiple-input multiple-output, MIMO)偏格式动态线性化无模型自适应控制(Partial form dynamic linearization-improved model-free adaptive control, PFDL-iMFAC)方法引入到动车组自动驾驶系统中. 该控制方法在无模型自适应控制的基础上, 考虑滑动时间窗口, 增加了可调自由度和设计灵活性, 并在输入准则函数中加上对能量函数的惩罚项, 减少能量损耗, 为动车组的跟踪精度和节能运行提供了一种优化的方法, 在满足动车组速度跟踪效果好的前提下实现节能运行. 最后以CRH380A动车组为对象进行仿真实验, 通过与传统无模型自适应控制对比: 所提出的控制算法各动力单元速度跟踪误差在 ±0.2 km/h以内, 加速度在 ±0.65 m/s2以内且变化平稳, 比传统无模型自适应控制方法节约9.86%的能量.Abstract: For the speed tracking control problem of electric multiple unit, the dependence of the existing model-based control methods on the system dynamic model and the complexity of the time-varying parameter estimation algorithm of the traditional model-free adaptive control are both considered. The improved multiple-input multiple-output (MIMO) partial format dynamic linearization-improved model-free adaptive control (PFDL-iMFAC) method is introduced into the automatic train operation system. On the basis of model-free adaptive control, this control method considers the sliding time window, increases the adjustable degree of freedom and design flexibility, and adds the penalty term to the energy function in the input criterion function to reduce the energy loss. It provides a compromise method for the tracking accuracy and energy-saving operation of electric multiple unit, and realizes energy-saving operation under the premise of satisfying the good speed tracking effect of electric multiple unit. Finally, CRH380A electric multiple unit is taken as the object for simulation experiment. Compared with the traditional model-free adaptive control, the speed tracking error of each power unit in the proposed control algorithm is within ±0.2 km/h, and the acceleration one is within ±0.65 m/s2 and the change is stable, saving 9.86% of energy compared with the traditional model-free adaptive control method.
-
制造业是国民经济的主体, 是立国之本, 兴国之器, 强国之基. 为了提升中国的综合国力和影响力, 有必要大力提升我国制造业在世界上的竞争能力. 然而, 与世界先进水平相比, 中国制造业仍然大而不强, 在资源利用效率、信息化利用水平、产品质量能效等方面具有显著的差距, 迫切需要进行转型升级, 从而实现制造业的跨越式发展. 2014年中国政府工作报告指出: “我们追求的发展, 是提高质量效益, 推进转型升级 ··· 从国际产业分工中低端向中高端提升. ”间歇过程与连续过程作为现代制造业中的两种重要生产方式[1], 一直以来相辅相成. 自20世纪90年代以来, 工业生产向柔性生产方式转移, 要求其对外部环境变化和内部变化具有快速适应能力, 产品从单一化向多品种转化, 并且具备高附加值, 因此间歇过程操作在工业生产中的地位日趋重要, 涉及关系国计民生的不同行业领域, 包括钢铁、冶金、化工、制药等. 目前学术界公认的间歇过程的定义[1]是指输入的原材料在有限的时间周期内, 遵循预定的不同工序, 被加工生产转化成一个或一批期望的产品, 并通过过程重复获得更多同种产品的生产制造过程. 现代社会中, 市场需求瞬息万变, 对柔性生产方式提出了更迫切的需求, 间歇过程越来越发挥其主导作用.
促使粗放型制造到智能制造转变的关键是间歇生产系统的高效运行. 这也是事关制造业未来可持续发展的关键. 高效, 即在更短的时间内消耗更少的资源生产更多优质的产品. 欧美多位院士, 包括加拿大工程院院士 MacGregor J F[2], 美国工程院院士 Biegler L T[3], Grossmann I E[4], 英国皇家科学院院士 Morris J[5], 美国工程院院士 Edgar T F[6]先后撰文, 指出应对生产的多样性, 间歇过程是重要的发展方向, 呼吁开展系统性研究, 提高间歇过程的运行性能. 在追求个性、多变的现代社会, 市场竞争日趋激烈, 小批量、多品种、均质化的发展趋势愈发明显, 对间歇过程的高效运行提出了更迫切的需求.
间歇过程的高性能监控技术是指能灵敏感知生产过程的实际运行状态, 解析系统的整体或局部是否正常运行; 对影响产品质量的生产因素进行分析与追溯, 及早发现影响产品的异常生产状况; 针对不同的异常和扰动, 给出合适的处理对策. 这对于维护生产过程安全可靠运行, 保障产品高质量需求具有重要的作用. 这其中具体可分为状态监测与故障诊断两方面. 状态监测[7]是指感知、分析和评估生产过程运行状态, 包括基于收集到的各种数据进行解析, 了解系统的历史情况和运行现状, 并充分考虑外界因素包括环境、负荷等的影响, 判断其是否处于正常以及评估所处运行水平. 而故障诊断[7]则是针对检测到的异常状态进一步解析, 了解内在原因和影响因素, 并借助对历史故障及维修记录等的挖掘和了解, 一方面对已经发生的故障进行分析和判断, 另一方面提前对设备可能要发生的故障进行预报. 间歇过程的高性能监控能够有效应对产品生产的频繁切换, 及时发现生产异常, 诊断故障原因, 克服故障对质量影响. 因此, 实施间歇生产高性能监控是实现制造业生产过程高效运行的核心手段. 在Web of Science核心数据库中, 按照主题词batch process monitoring检索结果, 关于间歇过程监控的SCI科研文章数量呈现逐年上升趋势, 间歇过程监控的研究正在引起科研工作者的重视, 业已成为人们关注的焦点.
但是, 间歇过程监控的研究起步较晚, 前人往往将间歇过程和连续过程二者混为一谈, 最典型的做法是直接借用连续过程现成的方法应用到间歇过程, 没有真正解析间歇过程的固有特性. 但是, 连续过程生产同种产品通常运行在稳定工作状态下. 而间歇过程的生产方式具有其特殊性, 与连续过程相比区别明显, 其中的显著不同在于间歇生产的产品和工艺操作条件改变频繁. 间歇生产始终处于操作条件切换和非平稳运行中, 具体到同一批次运行周期内亦无稳态工作点, 并在同一装置上频繁切换生产不同产品; 产品切换后, 生产条件改变, 导致其过程特性也发生变化. 综上所述, 间歇过程显然是非平稳的, 即它的统计特性(包括均值和方差)会随着时间推移而发生变化[8-10]. 因此, 它所生产的产品质量更容易被诸多不确定性因素影响, 包括设备状况、原材料、外界环境等. 近年来, 为满足更多样化的产品需求与消费升级对产品质量更高的要求, 间歇过程需要更频繁地切换工艺操作条件, 更灵敏检测和精确诊断影响产品质量的微小波动. 已有监控方法缺少对间歇过程大范围非平稳特性的分析, 没有充分认识和理解间歇过程自身的特性和特殊问题, 导致对微小故障的漏报, 正常状态切换的误报以及故障根因的误诊等问题愈发明显. 迫切需要能够有效表征非平稳特性变化规律, 精细监测状态变化以及精确解析故障特征的高性能监控方法.
目前, 从过程历史数据中提取信息并据此进行建模监测的数据解析方法[11-14]已成为过程监控研究的一个热点. 与专家经验等定性知识相比, 数据解析方法可以理解为一种特殊的基于知识的方法, 其主要的不同在于这些知识是从大量的工业数据中提取得到的, 而无需系统的精确模型和先验知识. 随着工业互联网和物联网技术的迅猛发展, 工业智能化水平显著提高, 人们可以便利快捷地观测、采集和存储大量过程数据, 包括高频和低频的传感器测量信号, 工艺数据和产品质量等结构化和非结构化数据, 为深入的解析和过程理解提供了丰富的数据支持. 此外, 数据解析方法的发展也为过程监控研究提供了理论指导, 涵盖了统计分析、机器学习、深度学习等技术. 概括来说, 数据解析方法通过分析挖掘收集的工业数据, 提取数据内部隐含的信息, 从而揭示工业过程的运行状态和追溯故障原因[7]. 近年来, 数据解析方法不断发展完善, 基于数据解析的间歇过程监测与故障诊断技术日益成为人们的研究热点, 其理论和方法体系正在不断向深层次发展.
本文从分析间歇过程的本质特性出发, 揭示了其大范围非平稳运行特性, 在此基础上总结了间歇过程区别于连续过程的“多重时变”特性, 指出了研究间歇过程监控算法的必要性. 进而, 基于这些特性, 我们对数据驱动的间歇过程监控算法近30 年的发展进行回顾和分析. 从算法层面来讲, 我们把间歇过程控制算法的发展分为三个阶段: 连续监控算法阶段、多向展开算法阶段和多时段分析算法阶段; 从功能的层面来讲, 分为特征提取层、状态监测层与故障诊断层; 在此基础上, 梳理了目前存在的问题, 并进一步介绍了间歇过程高性能监控未来可能的发展方向.
1. 间歇过程描述
1.1 间歇过程的大范围非平稳特性
间歇生产的过程特性非常复杂, 与另外一种典型的制造业生产方式—连续生产相比, 具有特殊的大范围非平稳运行特点, 可以用“多重时变”[15] 来概括, 如图1所示, 即“多样产品”、“重复运行”、“时段切换”和“变换指标”.
1) 多样产品: 间歇过程在同一装置上频繁切换生产不同产品; 产品切换后, 生产操作条件改变, 潜在过程特性也随之发生相应变化.
2) 重复运行: 间歇生产重复执行相同的操作来获得更多同种产品, 即一个生产周期结束, 操作切换重新开始生产; 但是, 不同生产周期并非严格重复, 亦会呈现批次间的非平稳波动特性.
3) 时段切换: 在同一批次生产周期内多操作工序切换是间歇过程固有的一个本质特征. 以注塑成型过程为例[16], 一个批次周期可以划分为三个主要的操作阶段, 包括注射、保压和冷却; 发酵过程按细菌的生长周期也可分为多个操作阶段, 涵盖停滞期、指数生长期、静止期等.
4) 变换指标: 为了保证产品的高质量要求, 针对不同产品, 多个操作阶段都可能具有不同控制目标和采用不同的控制方案, 其中主导操作变量不同, 物理操作亦不同, 导致运行轨迹呈现不同的潜在动态特性.
“多重时变”特性是多数间歇过程所具有的共性, 也是间歇过程的典型特点. 间歇过程的运行轨迹在时间、批次、产品三轴上发生三重变化, 在不同的工序操作、批次周期、产品生产中呈现出不同的过程特性. 相对于连续过程的状态监测, 间歇过程受操作条件频繁切换影响, 状态变化在时间、批次、产品三维上复杂耦合, 具有其独特的难点问题. 由于间歇生产时段切换与产品切换的双重影响以及受设备老化, 未知扰动等影响所导致的批次波动, 多维扰动造成间歇过程对理想状态不同程度上的偏离, 产生许多典型问题, 包括批次间慢漂移, 批次不同步(即不等长), 批次数不足, 多工况, 非线性严重, 非平稳特性显著等, 异常变化极易被这些正常状态偏离所掩盖. 如何在频繁操作条件切换下大范围对非平稳特性进行精确表征, 以及如何在大范围非平稳运行中区分正常状态切换与异常, 并针对异常工况进行精确的故障诊断是其中的难点问题.
1.2 间歇过程的数据特征
间歇过程测量数据与连续过程数据不同, 具有典型的三维结构特征. 间歇过程具有
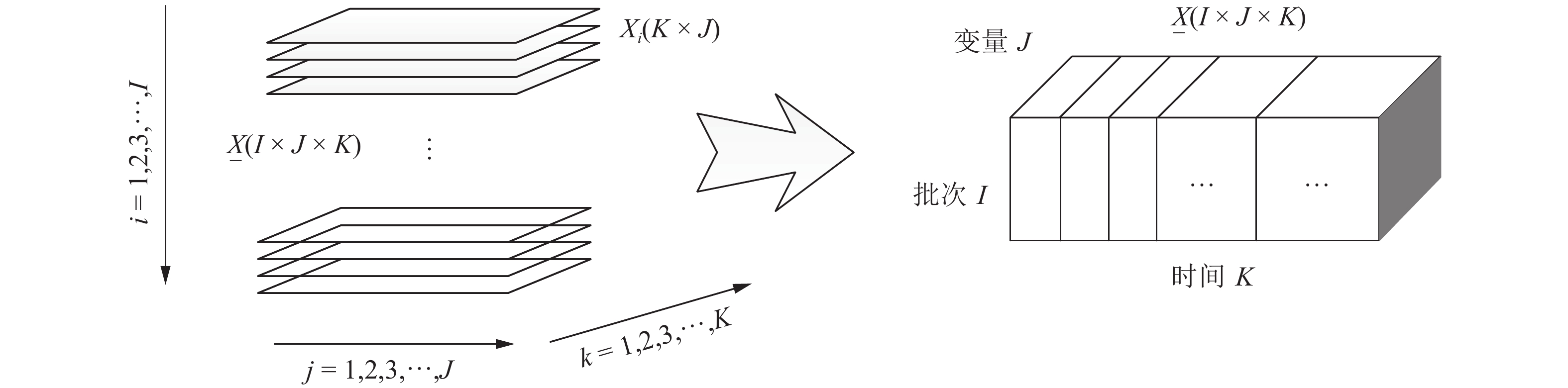
$ J $ 个测量变量, 针对每个变量在单个运行周期内都能采集$ K $ 个测量数据, 一次间歇操作则可以组成一个二维矩阵${{X}}(K\times J)$ . 其中行向量是某个采样点上的所有过程变量, 列向量则是每个变量沿时间轴的运行轨迹. 间歇操作往复运行$ I $ 次, 可以获得$ I $ 个二维矩阵${{X}}_i(K\times J)\ (i = 1,2,\cdots,I).$ 由此构成了间歇过程典型的三维数组$\underline{{{X}}}(I\times J\times K),$ 如图2所示. 三个维度分别代表间歇过程的操作周期$(i = 1,2,\cdots,I),$ 过程变量$(j = 1,2,\cdots,J)$ 以及测量时间$(k = 1, 2,\cdots,$ $K).$ 而间歇过程的产品质量往往离线测定, 每个批次对应其$ J_y $ 个产品质量指标, 形成一个行向量${{\pmb y}} = [y_1,y_2,\cdots,y_{Jy}],$ $ I $ 次批次则可构成一个二维的质量矩阵$Y(I\times J_y).$ 由此, 三维的过程变量数组$\underline{{{X}}}(I\times J\times K)$ 和二维的质量变量矩阵${{Y}}(I\times J_y)$ 构成了间歇过程的数据分析单元.除了数据分析单元具有典型的三维结构形式外, 受间歇生产本身反应的复杂性影响, 具有错综复杂的变量耦合关系. 以注塑成型为例[1], 从影响注塑制品质量的角度, 所有测量变量可以分为4类, 包括设备级、原材料级和过程变量级三种不同类别的变量以及外部和内部扰动. 过程变量能够揭示注塑成型过程中的实际运行状态, 注塑成型的典型过程变量有型腔中的熔体温度、压力分布、熔体注入量、模腔压力等. 此外, 生产过程亦受机器参数和材料参数等的影响. 这些不同级别, 不同性质的变量之间相互复杂耦合, 共同决定了最终制品的质量. 如何从数据中有效发掘出其中蕴含的统计特性与规律, 利用好这一座数据信息“金矿”, 发挥其重要价值, 成为间歇过程高性能监控的关键所在.
2. 数据驱动的间歇过程监控技术回顾
本节将概述面向间歇过程的数据驱动监控理论与方法发展的基本历程. 首先介绍传统的连续过程监控方法; 在此基础上, 基于批次展开的预处理方式, 从特性表征、 状态监测与故障诊断三个层面, 介绍间歇过程监控技术, 简略介绍以多向主元分析等为代表的面向间歇过程的监测理论方法以及所涉及的若干问题; 进而针对间歇生产的多时段运行特性进行了深入解析, 介绍了现有的多时段划分建模方法以及过程监测与故障诊断前人研究工作.
2.1 传统监控方法
随着传感器技术的进步, 电子和计算机应用技术的发展, 几乎所有的工业对象都配备了不同类别的传感测量装置, 包括光电、热敏、气敏、力敏、磁敏、声敏、湿敏等. 完备甚至冗余的工业传感器为我们提供了大量的数据, 其中蕴含了丰富信息有待挖掘, 从而能够指示生产过程的运行状态以及最终产品质量. 休哈特(Shewhart)控制图[17]方法首先应运而生, 并在此基础上提出和发展了累积和控制图(CUSUM)[18-19]以及指数加权滑动平均控制图(EWMA)[20]等新的控制图方法. 针对基于数据的统计分析和监测方法[17-21], 科研人员都在持续进行思考和实践. 但是, 由于当时缺乏相应的高效数据解析方法, 也没有考虑间歇过程的非平稳特性, 这些方法在工业过程尤其是间歇工业过程中并没有得到有效的实施. 自20世纪80 年代末以来, 多变量统计分析方法得到了重视和长足发展, 包括主元分析法(Principal component analysis, PCA)[22-23]、 偏最小二乘法(Partial least squares, PLS)[24-27]、独立成分分析(Independent component analysis, ICA)[28-31]等、为基于数据的过程监测与故障诊断奠定了基础, 并促进了其飞速发展. 多变量统计分析方法不需要获取过程的机理知识, 而只需要利用历史数据建立模型, 因此这类方法受到科研工作者的青睐和关注. 它们能够有效地提取数据中的关键信息, 剔除冗余量, 并能显著降低数据维度, 从而可以直接在二维的统计监视图中显示过程运行状态. 随着方法在多个连续生产过程中的成功应用, 相应的算法亦层出不穷, 从而极大地促进了基于多变量统计分析的过程监测、故障诊断、控制器设计、质量控制等. 20世纪90年代中期以前, 研究人员通常简单地将间歇过程当做有限时长的特殊的连续过程, 借用在连续过程中应用广泛的多变量统计建模方法, 而专门针对间歇过程监控的研究并未形成独立的理论体系. 由于间歇过程和连续过程特性的本质区别, 尤其是间歇过程的大范围非平稳特点, 直接借用连续过程的监控方法, 在间歇过程中很难取得令人满意的效果.
针对间歇过程的三维数据特点, 可以建立三线性分解模型直接针对其三维数据结构进行研究[32-38]. 采用三线性分解模型对数据进行存储和分析, 能够保留数据的结构信息. 譬如并行因子分析(PARAFAC)、Tucker-3模型以及N-PLS等. 但是这些模型计算起来非常复杂低效, 很难应用于实际工业过程. 另一种是将三维数组展开成二维数据后再进行数据解析[39-43]. 如图3所示, 总结起来, 有6种不同的二维矩阵展开方式[16], 主要体现在数据内部排列方式的不同. 而在这6种展开方式中, A和F, B和C, D和E这三组分别具有相同的维数特征. 其中, D方式得到的二维数据矩阵为
${{X}}(I\times KJ)$ , 称之为批次展开方式, 它保留了批次维度, 而融合了时间和变量两个维度上的数据, 其行向量涵盖了每一次批次生产周期内的所有变量和时间上的数据. 而A方式得到的二维数据矩阵为${{X}}(KI\times J)$ , 称之为变量展开方式, 其保留了过程变量维度不变, 而融合了间歇操作批次和采样时间两个维度上的数据, 其列向量涵盖了每一个变量在所有批次的所有采样时刻上的取值. 对于学术界进行理论研究和工业界的工程实践来说, 只有两种展开形式比较有意义, 即A变量展开方式和D批次展开方式. Nomikos等[39-41]于20世纪90年代提出了多向主元分析法(Multiway principal components analysis, MPCA)和多向偏最小二乘法(Multiway partial least squares, MPLS), 将分析的视角从不平稳的时间轴转变到平稳的批次角度, 着眼不同批次间的波动来定义正常变化, 从而创新性地将多元统计分析方法成功拓展应用于间歇过程中. 他们所提出的MPCA模型实际上采用了D批次展开方式. 他们的研究为后续基于多向统计分析进行间歇过程监控的研究拉开了序幕. 国际上不同的学术机构和团队, 包括瑞典Umea大学Wold教授[42-44]、美国Maryland大学McAvoy教授[45-46]、 Illinois工业学院的Üinar教授[47-49]、California大学的Seborg教授[50-51]、加拿大McMaster大学的MacGregor教授[37-39, 52]以及英国Newcastle大学的Martin和Morris教授[53-56]等, 大家各自提出了自己的理论方法体系, 包括不同的研究思路和手段, 对间歇过程监控的研究起到了促进作用. 和PCA/PLS等多元统计分析方法一样, 用于间歇生产的MPCA/MPLS等多向分析方法针对的是正常操作工况下的过程变量, 分析并定义其在批次方向上的正常波动, 并建立相应的模型和监测控制限表征其正常波动特性和范围. 因此, 多向分析模型解析的是正常工况下, 过程变量之间的潜在相关关系在各个不同批次间的变化规律和波动特征. 当受异常扰动影响, 过程变量相关关系随之改变, 从而偏离正常工况下的规律和特征; 调用事先建立的多向分析模型, 计算相应的多元统计量, 包括Hotelling-T2和SPE控制图[39], 并与其事先定义的监测控制限进行对比, 可以检测到这些异常工况的发生.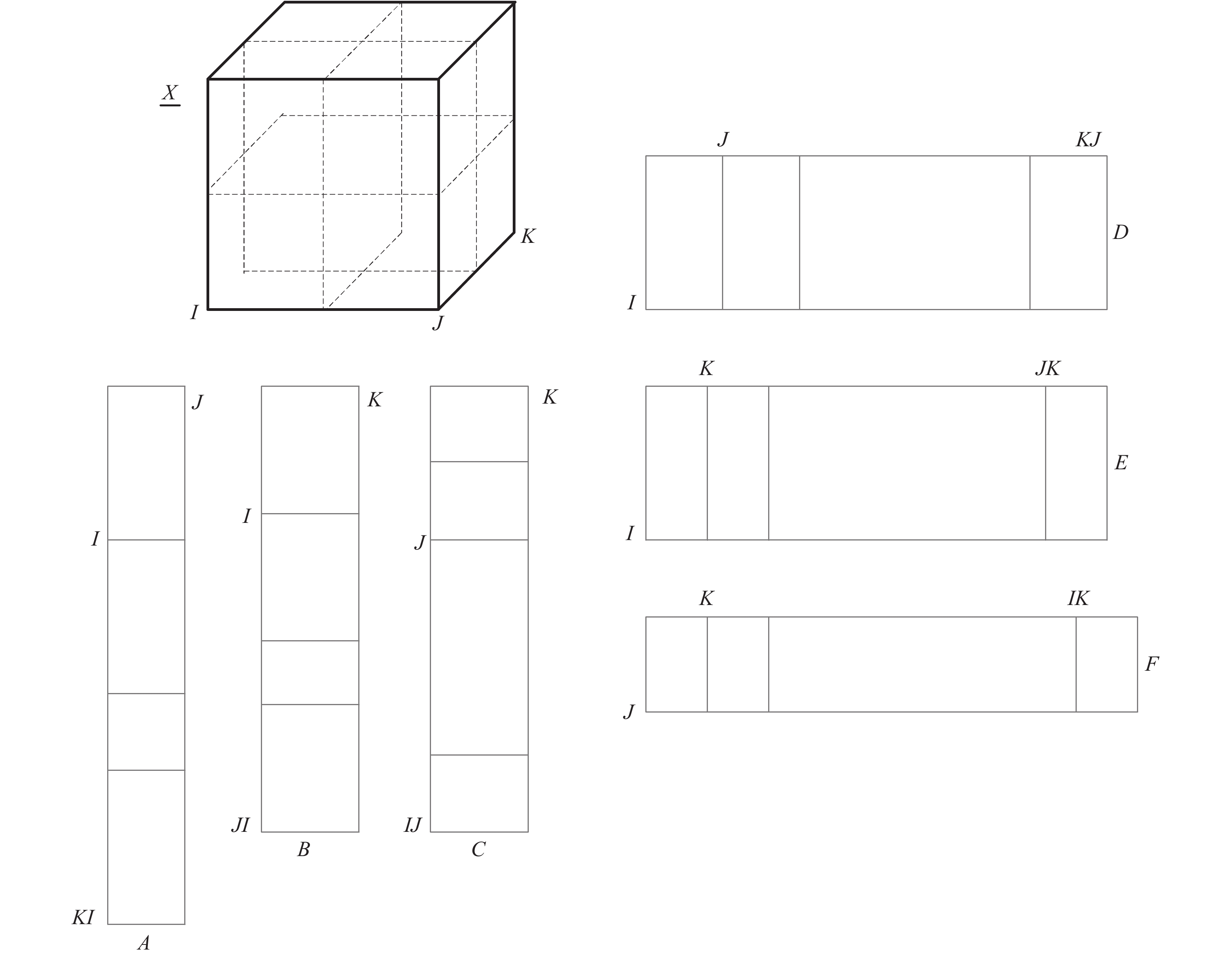 图 3 将三维数据展开成二维数据的6种方式Fig. 3 Unfold the three dimensions data into two dimensions using six different manners
图 3 将三维数据展开成二维数据的6种方式Fig. 3 Unfold the three dimensions data into two dimensions using six different manners很显然, MPCA/MPLS的建模思想和方法比较简单, 其在三维数据展开的基础上, 将每次批次生产周期内的所有变量和测点当作一个样本进行分析, 但却导致在线应用时未知测量数据预估成为必然[1], 而数据预估的精度也会影响在线监测的性能. 前人已经注意到其在线应用的局限和问题, 也从不同角度各自阐述了不同的解决思路和方法. 其中的一部分工作主要是针对数据预估方法做改进, 以期提高估计精度. 但是估计的数据和真实的数据实际总会有不同程度的差异, 导致对后续过程监测精度产生影响. 另外一种研究思路是改进间歇过程建模方法, 避免在线监测对数据的实时预估要求. Louwerse等[37]主观选取了多个时间点从而将间歇过程区分了不同时间区域, 建立了多个局部MPCA模型. Ündey等[47]则通过分析生产过程的实际演化进程, 分割不同进化度从而建立多个局部MPLS预测模型. 相较于Louwerse的方法提高了时间分割的合理性. 但是, 上述方法本质上都是借助D展开方式, 通过时间点分割将整个操作周期化整为零从而降低了数据预估的计算量, 实际上在线监测时仍旧需要在每个局部模型所涵盖的时间区域内进行数据预估. 另外一部分研究学者基于A展开方式进行分析. 1998年, Wold等[42]建立了一个统一的变量展开PCA模型用于间歇过程监测; Ündey等[49]将过程进化率作为响应变量, 将过程变量作为自变量, 建立了二者之间的回归关系, 在线应用时能够利用实时获取的每一个过程变量不断动态预测和更新当前批次生产的进度. 虽然基于变量展开的处理方式从形式上看解决了数据预估的问题, 但是其将运行批次上的正态波动和时间维度上的大范围非平稳波动融合到一起, 无法有效提取明确的统计分布规律定义其控制限. 对此, 一些研究工作[57-61]做了适当融合, 首先基于批次展开方式做数据预处理, 凸显每个时间点上批次维度上的波动信息, 然后将其按照变量展开方式进行分析, 这样可以凸显批次维度上的波动随时间的变化规律. 此外, 如果基于结合方式拓展进行回归建模, 为了保证自变量与因变量行维度的统一, 则需要对质量指标
${{Y}}(I\times J_y)$ 做相应的复制. 上述分析方法从不同的角度和思路对传统多向建模方法的局限性做了研究, 拓展了间歇过程监控方法.虽然间歇过程监控已经取得了一定的成绩, 但是, 考虑到间歇生产的复杂性和产品的多样性, 如何实现其高性能监控仍有许多难题和挑战, 需要从不同层面进行深入研究, 这也为我们带来无限的发展机遇.
2.2 间歇过程多时段监控方法
针对间歇过程的监控理论方法, 从分析逻辑的角度, 将从特性表征、状态监测与故障诊断三个层面进行阐述. 其中特性表征是基础, 状态监测是保障, 故障诊断是手段.
2.2.1 多时段表征方法
对于间歇过程分析, 主要难点在于频繁操作条件切换下大范围非平稳特性的表征问题, 这是高性能监控的重要基础. 前面我们提到过, 与连续生产制造过程相比, 间歇生产的过程特性更为复杂, 具有典型的大范围非平稳运行特点. 随着操作工序的切换, 多时段性是间歇过程的一个显著特点, 间歇过程特性在不同的时段中显著不同. 基于MPCA/MPLS的多向分析方法没有考虑多时段特性, 基于展开的二维数据矩阵简单的套用连续过程的分析思路, 很难反映时间上的变化规律以及凸显局部过程特性. 因此它们对局部时间段内发生的扰动通常不能灵敏检测, 尤其对于幅值较小的故障不能及时识别出来, 也无助于提高人们对过程的认识和理解.
在特性表征层, 针对间歇过程大范围非平稳变化特性无法深入刻画, 频繁状态切换问题缺少准确表征的问题, Lu等[62-64]和Zhao等[65-71]提出了非平稳特性变化规律解析与多时段表征的理论方法. 总结起来, 他们对多时段间歇过程具有如下认知[16]: 1)过程变化的规律: 间歇操作过程潜在特性并不是随着操作时间时刻变化, 而是跟随过程操作进程或过程机理特性的变化发生规律性的改变, 呈现出分时段性; 2)数据驱动的机制: 虽然很难直接获取过程运行的基本原理, 但是却可以非常容易地从过程数据中获取过程的统计特征, 由过程统计特征的变化来推断过程内部运行机制的变化; 3)时段划分的规则: 根据过程变量间相关关系或是过程变量与质量变量间相关关系的变化将间歇操作周期划分为若干子时段, 同一子时段内变量相关特性保持近似一致, 不同的子时段体现出显著不同的相关特性. 为了和间歇过程所具有的物理操作“阶段”区别开来, 这里的“时段”实际上指的是建模时段. 进一步, 在同一个物理操作阶段中, 如果过程变量相关性发生变化, 又可以将其划分为若干个建模“时段”. 除了不同的过程变量运行轨迹, 不同时段具有显著不同的过程潜在特性. 多时段表征理论方法从根本上克服了经典多向建模方法的保守性, 可以有效反映间歇生产操作条件频繁切换影响与非平稳变化特性, 增强了人们对间歇生产过程特性的理解; 有利于不同时段内关键信息的分析与提取, 显著提高了模型的精度. 目前, 多时段划分和表征方法已逐步成为间歇过程分析的有效方法[62-71]. 如何将一个操作周期合理地识别和划分成不同的子时段, 为间歇过程大范围非平稳运行条件下的高性能监控奠定了理论基础.
已有很多专家学者做了广泛和深入的研究, 提出了各种各样的时段识别和划分办法. 概括起来, 可分为过程机理方法、特征分析方法和自动划分方法三类[1], 如表1所示. 上述几种时段识别方法各有各的适用场合与优缺点. 一般来说, 需要综合考虑实际应用场景及各种方法的适用范围选用适合的算法. 在某些情况下, 为了达到更好的应用效果, 可能需要将几种手段方法做有效结合. 通过子时段划分, 在同一个时段内对于相似的过程特性可以建立一个统一的子时段模型; 不同的时段建立不同的模型, 从而可以更精细地揭示过程特性的变化规律. 相较于传统的多向建模方法, 子时段表征策略有其明显的优势, 也有利于促进人们对过程操作机理的理解和认识.
表 1 时段划分方法总结对比Table 1 The comparison of different phase partition methods时段划分方法 划分依据 优点 缺点 过程机理法[45, 48, 72] 利用实际间歇工业过程运行机理的变化来划分过程运行时段, 要求一定的专家经验和过程知识. 如果间歇生产过程相对简单或者工程师对此比较熟悉, 则可以比较容易地获取过程机理知识实现时段划分. 工业生产过程往往机理复杂, 很难在短时间内获取相关的知识和经验, 从而极大地限制和约束了其顺利实施施和推广应用. 特征分析方法[73—75] 时段的切换对应引起相应测量变量的变化. 对某些过程变量或从中提取的特征变量进行分析, 借助其沿时间轴上的变化判断时段信息. 指示变量方法是其中一种典型代表. 当时段发生切换或者变化, 过程特性变化, 相应的某些过程变量或是特征变量亦发生显著变化, 可用于指示不同时段. 算法较为简单. 并不是每个工业过程中都存在并能找到这样的“指示”变量. k-means[62—66] 通过相似度度量, 分析不同时间点上的潜在相关特性的相似与不同, 如果时间片具有相似特性则被归到同一类中, 具有显著差异则被分到不同类中. 该方法能够自动划分不同的多个时段, 不需借助任何过程机理和知识. 分类的结果决定于过程相关性在时间方向上的变化规律. 没有考虑间歇过程时段运行的时序性, 因此划分结果中会出现时间上不连续的具有相似过程相关性的时间片被分在同一个聚类中. 时段划分结果可读性有所欠缺, 需要针对划分结果进行进一步的后续处理. 此外, 该划分方法根据距离定义衡量过程相关特性的相似度, 聚类的结果受到相似性衡量指标的影响, 而该指标并不能与过程监测的目的直接相关. MPPCA[74—75] 一种优化策略, 通过对不同时间点进行不断尝试, 分析在该点的划分所得到的局部模型是否能够改善原有模型对数据的重构精度, 以此来确定该点的划分是否合适. 无需过程先验知识条件, 自动划分的各个时段时间连续, 解释性较强. 易陷入局部最优, 导致时段划分结果不能更好的反映过程特性变化. SSPP[76—77] 自动地按照间歇生产过程运行时间顺序捕捉潜在过程特性的发展变化, 通过评估时段划分对监测统计量的影响确定合适的时段划分点. 无需过程先验知识条件, 深入考虑了间歇过程潜在特性的时变性和实际过程运行的时序性以及时段划分结果对于之后监测性能的影响. 对过程时段特性变化的实时捕捉具有一定的时间延迟. 2.2.2 多时段状态监测方法
在时段概念提出后, 原有面向间歇过程监测的研究成果可以与时段表征手段结合起来, 建立一套完整的基于时段的过程监测与故障诊断理论方法体系. 从时段基本概念的萌芽, 到提出直至完善, 前后经历了10多年的发展历程. 1994年, Kosanovich等[72]分析了一个聚合物反应工业过程中两个具有明显不同特征的反应时段, 对其分别建立不同的MPCA模型进行过程监测, 当不同的监测模型指示异常, 可以具体定位到故障发生的阶段. Dong等[45]则通过建立多个非线性MPCA模型描述一个绝缘密封放热化学反应器, 侧重分析过程的非线性问题. 他们的工作可以认为是对多时段监测的研究做了初步尝试和探索. 此后, 英国的Martin等[78]研究团队提出了“group”的概念, 这是与时段相似的一种表达, 并建立了相应的监测策略. Lennox等[74]在时段基础上, 对如何更好地建立局部模型进行了进一步的分析和探索. 此外, 研究学者通过分析过程变量对于最终产品质量影响的变化, 提出了一种局部时间效应的理念, 分析并定义了影响质量的关键操作时段, 从而提高实时质量预测的精度. 譬如, Duchesne等[79]提出了一种路径多块PLS模型, 建立了不同时间段内过程变量与实时质量测量之间的相关关系. 但是由于质量变量的实时测量值很难获得, 该方法很难实现实际应用. 不管是“group”抑或“块”的理念, 都可认为是“时段”概念的另外一种表达. 但是他们都没有明确地提出时段的概念. 2002年, Ündey等[48]首次清晰地定义了操作时段的概念, 将发生在不同操作单元以及执行不同操作的步骤称之为“操作时段”, 并指出, 针对不同操作时段进行过程监测和控制是非常重要的. 但是, 这里的定义更侧重于物理操作时段, 而非从过程潜在特性层面的定义. 因此, 上述基于局部时段的监测工作基本上都是将各个局部时间段内的数据展开成二维数据矩阵作为分析单元, 直接套用了之前传统的多向统计分析方法的模式, 并未从根本上得到突破. Lu等[62-64]和Zhao 等[66-71]首次从过程潜在特性层面, 定义了建模子时段的概念. 为了与前面的工作进行区别, 这里的时段更多侧重建模时段, 即英文中的“phase”, 而非前面所说的物理操作时段, 即英文中的“stage”. 他们提出, 可由数据的统计特征反推过程特性的变化, 区分过程子时段, 建立基于时段自动划分的子PCA/PLS间歇过程监测方法. 在其研究工作中, 他们认为在同一个子时段中潜在变量相关关系具有相似性, 可以用一个统一的二维模型有效地表征和解析其特性. 在线监测时, 对于新的过程测量数据,
${\pmb{x}}_{\rm{new}}(J\times 1)$ , 首先调用该时刻的数据标准化信息进行数据预处理, 然后根据时间标签指示当前数据隶属于哪一个子时段, 从而判断应该使用哪一个子时段监测模型评估当前数据并计算监测统计量, 如果计算的监测统计量均位于正常范围内, 则当前数据指示正常状态; 否则任何一种监测统计量超限则判定该数据指示异常. 这种子时段模型结构简单, 而且对于每个时刻均可进行实时监测而无须数据预估. 这位后续基于时段的过程监控奠定了坚实的工作基础. 进一步, 考虑到这种硬性的时段划分方法虽然分析了不同时段过程特性的不同, 却忽视了时段切换期间的过渡问题. 在Zhao等[16, 65]的工作中, 对时段过渡做了明确定义: 相较于各个子时段内部稳定的运行模式, 即稳定的过程波动和相关关系, 不同时段切换期间, 过程相关特性更多呈现出一种渐变的模式, 即从一种模式逐渐向另一种模式过渡, 并不是“一蹴而就”的[16], 在过渡过程中非平稳特性更显著. 因此, 必须指出, 过渡模式和各个稳定子时段特性不同, 其监测手段也不应该一概而论. 对于多时段的过程监测, 需要综合考虑稳定子时段与动态过渡的不同特性, 并需要特别关注由此导致的两类典型监测问题, 即“误报”和“漏报”. 一方面, 将动态的过渡模式硬性归属到各个稳定子时段中, 必然会导致无法精确地对子时段进行表征和建模, 引发“漏报”的可能; 另一方面, 在线监测时如果简单利用子时段模型对时段过渡区域的样本进行分析, 必然会导致更多的虚警率, 即提高误报警的概率. Zhao等[65]首次揭示了时段过渡现象和规律, 并提出了一种软时段监测方法用于区分各时段及时段间过渡的不同变化并进行在线过程监测, 进一步提升了模型精度和监测性能. 相较于传统的多向监测方法, 子时段建模与基于时段的过程监测能够精细解析过程潜在特性的数据变化规律, 反过来促进了人们对复杂工业过程机理的认知和了解, 从而极大推动了间歇过程高性能监控的研究与发展. 表2中总结概括了相较于传统的多向分析方法, 基于时段的建模与监测研究的优势, 不仅包括建模复杂度的降低, 更重要的是其有助于加强人们对过程的理解和认识.表 2 多向分析方法与子时段分析方法对比Table 2 The comparison of multi-way methods and phase partition methods方法 优点 缺点 多向分析法 分析方法相对简单, 直接针对展开的二维数据矩阵进行分析, 可借用传统的连续过程方法. 针对整个过程只需要建立一个模型. 无法有效分析过程特性时间上的变化规律. 子时段分析方法 1)可以更细致地揭示过程运行的潜在特征, 更好地体现过程运行的局部特征, 促进对复杂工业过程的了解;
2)在每个子时段可以很容易建立统计分析模型, 结构简单, 模型实用;
3)基于子时段可以很容易建立过程监测模型并实现在线应用而无需预估未知数据;
4)可以提高在线故障检测的精度和灵敏度, 并有利于后续准确的故障隔离和诊断;
5)可以深入分析质量指标和每个时段的具体关系, 找出影响质量的关键时段和预测变量等关键性因素, 有利于产品质量的进一步改进.需要进行时段划分, 分析过程特性在同一个操作周次内的变化. 2.3 典型问题的状态监控方法
传统的间歇过程监测方法, 包括统计机器学习方法, 如高斯混合模型(GMM)、支持向量机(SVM)、慢特征分析方法、相对变化分析等[6, 80-85], 针对采集到的过程数据进行分析挖掘, 其中大部分为从工业现场采集到的传感数据等, 从中提取能够用于在线过程监测的模型. 一般来说, 这些学习方法所使用的样本通常要求具有完备性与代表性. 同时, 传统的多元统计分析方法往往是在一些基本假设的前提下对过程数据进行分析. 然而, 由于工业过程运行的复杂性, 理想化的假设条件, 包括高斯与静态分布、线性关系、单一模态等, 往往是不切实际的. 相对于连续过程的状态监测, 具有小批量生产特点的间歇过程受操作条件频繁切换影响, 状态变化在时间、批次、产品三维上复杂耦合. 由于间歇生产时段切换与产品切换的双重影响以及受设备老化, 未知扰动等影响所导致的批次波动, 多维扰动造成间歇过程对理想状态不同程度上的偏离, 产生许多典型问题, 包括批次间慢漂移, 批次运行不同步(即不等长), 批次数不足, 多工况, 非线性严重, 动态特性显著等[1], 异常变化极易被这些正常状态偏离所掩盖. 如何在大范围非平稳运行中区分正常状态切换与异常是其中的难点问题. 而传统方法忽视了指示状态变化的重要信息, 无法满足对故障检测的灵敏性要求, 无法区分正常状态切换与异常扰动, 直接或间接造成间歇过程状态监测的漏报率和误报率高的问题. 在对间歇过程进行监测时, 需要充分考虑这些实际问题以及相应的过程特征并对其进行分析. 下面重点介绍这5方面的特殊问题.
1) 不等长问题
按照预先设定好的多个工序往复生产, 这是间歇生产的典型特点. 理想情况下, 各个批次应该是相同运行时长的. 但是受气候差异, 原材料波动以及干扰等不同方面的影响, 间歇操作批次不可能严格按照相同的设定实现重复生产, 导致批次的长度也可能参差不齐. 针对这一问题, 过去几年出现了很多解决方法, 最常见的包括最短长度切割法[80-81]、最长批次补齐法[82], 以动态时间扭曲(Dynamic time warping, DTW)[83-85]和相关优化规整(COW)[86-87]为代表的轨迹对整方法等. 最短长度切割法和最长批次补齐法只适用于不等长不严重的情况并且要求在公共的时间段内大部分运行轨迹应该是重叠的. 而轨迹对整方法可能对过程变量的自相关及互相关关系产生扭曲. 如果存在一个变量, 能够代替采样时间, 将不等长批次统一成相同时长, 则可以进行后续的分析和研究. 对此, Nomikos等[41]定义了“指示”变量: a)当过程特性变化, 相应的某些变量亦发生显著变化, 具有一种单调变化特征, 可用于指示不同时段; b)该变量的起始点数值在不同批次上保持一致, 并且具有相同的终点值. 借助于该指示变量, 将批次长度统一等同于数据插值, 即根据“指示”变量对过程运行轨迹进行重新采样, 在其每个采样点上将对应过程变量的数值通过相关计算方法重新获得. 在实际过程中, 有时候很容易找到期望的”指示”变量, 譬如, 针对反应过程的某些累计进料量[88]以及反应程度[89-90]等可以作为“指示”变量. Kaistha等[91]提出了一种方法, 用于提取间歇过程中过程特性一致性发生变化的时刻. 一旦事件发生的时刻被提取出来, 则可以采用线性插值的方法对时间轴进行统一化处理或者填补(削减)批次数据. 然而, 该方法局限于间歇过程特性变化十分迅速的情况, 如阶跃变化、斜坡变化和峰值处, 此时事件发生时刻可以准确提取出来. 此外, 将原始过程变量通过稀疏采样或插值方法统一化成相同长度的曲线可能会扭曲和改变过程变量的相关性, 包括自相关及互相关等. 另外, 找到这样合适的“指示”变量也不是一件容易的事情, 一方面, 并非每个工业过程中都存在这样的变量; 另一方面, “指示”变量法也不适用于分析具有多时段特性的间歇生产. 考虑到间歇生产的多时段特性, 不等长批次的分析和解决需要考虑更多的因素和方面. 如图4所示, 不等长问题需要考虑不同的时段的具体表现, 在每个时段, 可能有不同的不等长现象, 具有不同的表征和影响; 此外, 不等长严重程度在不同时段中亦有所不同. 为了解决这些问题, 一些学者[92-97]针对不等长多时段问题做了进一步研究, 一方面能够自动在线判断各个不等的时段长度; 另一方面, 可以实现对各个不等长时段运行状态的在线监测, 区分正常的时段切换与当前时段的异常. Lu等[92]和Zhao等[93]提出的关于监测性能的连续不等长时段识别方法, 分别针对轻度不等长问题[92]和严重不等长问题[93]提出了解决思路; Wang等[98]结合了核主成分分析和自回归移动平均外因时间序列模型, 提出了三步特征点提取方法来对齐不同批次的长度进而对不等长间歇过程进行建模与监测; Luo等[99]在变形K-means 聚类方法的基础上利用对操作阶段敏感的轨迹变量将间歇过程划分成不同的阶段, 并提出一种阶段鉴定方法用来将新样本分配到对应的阶段; Zhang等[95] 提出的基于“变滑动窗口-k近邻策略”的处理方法, 构建了不规则时间片对不等长所造成的时段错位问题进行了分析. 不等长间歇过程分析由于受到时间的约束, 无法直接套用连续过程的相似样本搜索和学习, 其中需要考虑的难点则是如何在线识别各个不等长时段的界标, 区分正常的不等长时段切换与异常扰动.
2) 有限批次问题
大多间歇过程监测算法主要提取和分析批次间的波动作为正常工况的参考基准, 对此, 要求有充足的间歇操作批次数, 这是多元统计分析的前提和基础. 然而, 一些间歇生产操作时间漫长, 操作步骤复杂, 人们很难在一定时间内获取充足的批次; 此外, 由于生产成本昂贵, 获取建模数据往往要耗费大量的人力、物力. 对于这一类具有有限批次的间歇过程, 如何利用现有的少量批次, 构建新的分析单元, 提取它们蕴含的最大知识和信息, 是非常值得探讨的问题. Lu等[96]基于一个批次提出了子时段PCA建模方法, 利用时间滑动窗口扫描整个过程提取分析过程变量间的相关特性, 从而获取过程潜在特性在时间方向上的发展变化实现了时段划分与建模; 此外, 在状态监测执行过程中随着批次的增多实现了在线更新. Zhao等[97]对此作了拓展, 将有限批次问题拓展到批次数 ≥ 1 的情况, “一个建模批次”的情况只是本文算法的一个特例. 该研究将传统的时间滑动窗口泛化为批次 − 时间滑动窗口, 综合利用了不同批次的信息, 从中识别各个子时段并建立相应的子时段模型. Tulsyan等[100]为批次过程提出了一个贝叶斯非参数模型, 并利用该模型产生克隆过程数据扩充建模样本进而解决有限样本问题.
对于有限批次问题, 尽管可以建立初始模型, 但是由于数据样本的不充足性, 在线应用时实时的模型更新是必然的选择. 目前, 针对有限批次问题的研究工作仍有许多问题有待解决, 主要包括如何初始建模以及后续更新策略上. 相较于连续过程的小样本建模问题, 间歇过程的监测问题更为复杂, 需要从小样本中识别出时段特性并建立时段模型. 此外, 有限批次问题往往是伴随着新产品或者新操作条件而产生的, 机器学习领域的迁移学习[101-102]和增量学习策略[103-104]为有限批次问题的解决提供了新的办法和思路.
3) 多模态问题
大多数监测方法均假设多时段间歇过程在单一模态(工况)下运行. 实际上, 由于各种因素的影响, 如原料和组分的变更, 外部环境的变化以及不同的产品的要求, 制造过程往往在不同模态间转化(如图5所示). 尤其是为了满足日益变化的市场需求, 生产策略以及运行条件需要频繁地调整, 这也导致多模态问题的普遍存在. 另外, 由于外部扰动等影响, 间歇过程可能出现批次间慢时变问题, 这也是多模态存在的原因之一. 这样, 当所估测的运行模式并不是运行在参考模型的运行条件下时, 传统的建模策略往往会遇到模型失配的问题. 针对多模态过程的统计建模与监测是一个非常有挑战的问题, 尤其间歇过程本身具有多时段特性, 具有双重维度上的多模态特性. 如何兼顾批次间的工况变动信息以及时间方向上的时段切换, 分析不同模态下过程特性如何变化, 以及不同模态之间有什么样的关系, 都是非常有意义的研究问题. 目前针对此方面的研究还较少, 大多是针对于连续过程.
针对多模态间歇过程, 如果简单地针对每种模态分别进行单独分析与建模, 虽然可以对不同运行模态下的多时段信息进行分析和挖掘, 但是忽视了多模态间的关系[105]. 多模态运行情况下, 每种模态下过程特性如何变化, 揭示多时段特性, 以及不同模态间有什么样的关系, 它们之间的相似与不同, 都是非常有意义的研究问题. 浙江大学赵春晖团队[106-108]率先将间歇过程监控拓展到时间, 批次和模态三维系统中, 针对多模态问题建立了一种协同时段划分, 模态间相对关系建模和监测方法, 深入分析了多模态之间的关系. 图6为一个两模态间歇过程的多时段特性示意图. 其中一种模态包含三个过程时段, 另一种模态包含两个过程时段. 在不同模态中, 受不同运行条件和过程机理驱动, 过程特性的变化可能会有所不同, 每个时段开始和结束的时刻可能会有所不同. 通过同时考虑所有模态, 划分结果可以反映在一定时间区域内较快的特性变化. 譬如, 当第二种模态过程特性发生显著变化从第一时段切换到第二时段的时候, 第一模态的过程特性实际上仍旧保持在第一时段. 如果综合考虑这两种模态的特性变化, 可以将第一模态的第一时段进一步划分为两个子时段, 从而得到一个两模态间统一的时段划分结果. 这为基于时段进行模态间相关关系的分析奠定了基础.
4) 非线性问题
从严格意义上讲, 绝大多数的复杂工业过程变量之间都不具备线性关系. 特别是工业过程运行工况的多变, 导致非线性数据关系越来越显著, 无法使用传统的线性分析方法对其中的潜在过程特性进行有效的提取、分析和利用. 对此, 各种非线性方法[109-116]应运而生, 用于分析各种非线性问题. 基于核的方法是最先被采用的非线性方法, 用于解耦变量之间的非线性和训练非线性模型. 该方法只需要在高维特征空间进行相应的线性计算, 具有较高的运算效率. 该类方法中, 较为常用的包括核主成分分析(KPCA)、 核偏最小二乘、 核判别分析等. 实际工业过程中, 往往包含不同程度的非线性关系, 此外, 往往同时涵盖线性和非线性关系. 因此, 对于不同的工业过程, 有必要有针对性的进行分析并采用适当的监测方法. 然而, 传统的监测方法往往假设过程是单一线性或非线性的, 而这种假设没有严格依据支撑, 往往与实际不符. 这直接导致选择的方法可能并不适合所分析的过程, 从而降低了模型精度和在线监测性能. 因此, 考虑到假设的不可靠性或者难以获取的情况, 对实际过程线性和非线性关系的判断显得至关重要. Kruger 等[114]提出了一种基于PCA 模型误差方差估计的非线性度量方法. Zhang 等[115]通过结合皮尔森相关和互信息, 定义了一种非线性系数, 以此来判断系统的非线性度. 然而, 上述这些工作均采用单一的线性或非线性分析方法, 即: 如果判断大部分过程变量为非线性, 则采用非线性方法; 反之, 如果判断大部分过程变量为线性, 则采用线性方法. 实际上, 复杂工业过程变量之间往往线性和非线性相关关系同时存在, 不能简单地将其定义为纯线性或纯非线性的对象. 对于这种具有线性和非线性关系混合特征的工业过程, 一方面, 采用单一的线性分析方法不能有效解析非线性关系和捕捉状态变化; 另一方面, 单一的非线性方法无法有效解析其中隐藏的线性变量关系, 亦无法直观显示变量之间的关联性. 总而言之, 工业过程变量往往线性和非线性混合, 单一的线性或者非线性分析方法均无法实现数据潜在特性的全面解析. 因此, 如何有效区分具有线性和非线性变量成为其中的难点问题. 考虑到现实中混合变量相关性问题是普遍存在的, Li 等[116]提出了一种线性评估方法, 通过识别其中存在的线性变量关系实现了线性变量子组划分, 并区分了线性和非线性变量; 结合线性和非线性分析方法, 分别针对不同的变量关系进行建模, 实现了对复杂工业过程的精细监测. 但是基于核的方法受限于核函数的性质, 在线应用有些时候并不能取得较好的结果. 近些年, 随着深度学习的发展, 不少基于深度神经网络的方法也随之被提出. Yan等[117]首先将自编码网络(AE) 用于提取非线性特征, 并建立了相应的监测模型用于非线性过程监测. Yu等[112]进一步结合降噪自编码(DAE)和弹性网(EN) 鲁棒的监测含噪非线性过程并隔离出引起故障的关键变量.
对于间歇过程而言, 由于运行阶段的变化其非线性特性会更加显著. 一般来说, 在考虑多时段特性的基础上, 可以很好地将原有连续过程的非线性分析方法拓展到间歇过程中. 此外, 大量针对间歇过程的非线性过程监测方法也提了出来. Zhang等[118]基于核判别分析提出了一种非线性批次过程监测和故障鉴定方法. Zhao等[119]结合了核独立成分分析方法和主成分分析方法, 将批次过程分段之后对各阶段建立相应的监测模型. Rashid等[120]进一步结合了多向核独立成分分析和多维互信息, 在不相似度方法的基础上提出一种适用于非线性非高斯动态批次过程的监测方法. 近些年, 一些大数据方法也被应用于非线性批次过程监测中. 例如, Onel等[121]利用基于非线性支持向量机从海量数据中选择特征进而建立故障监测与诊断模型.
5) 动特性问题
受闭环反馈作用影响, 现代工业过程往往呈现明显的动态特性. 这里, 动态特性是指工业过程数据具有的与时间相关联的特性, 这与对象的内在机制关系紧密[122], 包括过程所处的操作阶段, 物理化学反应机理以及外界噪声, 扰动的干扰等. 此外, 过程动态性也受对象上施加的控制手段和作用影响. 传统的统计过程监测方法往往假设过程数据静态独立. 但实际过程变量前后的测量点往往相互关联, 体现出明显的时序相关性, 即过程动态特性. 这些动态特性亦包含了有利于过程监测的关键信息. 如果过程监测中不考虑到数据的动态性, 将难以准确描述数据的真实变动, 无法区分过程正常的动态波动与异常扰动, 往往得到粗糙甚至错误的结论. 此外, 故障特征受过程动态特性的影响, 或者受随机噪声和过程扰动的影响, 也会发生扭曲, 导致监测灵敏度下降等问题. 和非线性问题类似, 在考虑多时段特性的基础上, 可以很好的将原有连续过程的动特性分析方法拓展到间歇过程中. 对于动态过程进行信息提取和多元监测的方法主要包括下述的两类.
一类是多元统计分析方法的动态扩展[123-125], 譬如, 动态PCA (DPCA)[123-124]、动态偏最小二乘(DPLS)[125]等; 这类方法在连续过程中得到了很广泛的应用, 并向间歇过程做了成功的推广. Chen等[126]结合了动态PCA和动态PLS提出了一种动态批次过程在线监测方法. Hu等[127]提出了一种动态多向领域保持嵌入(NPE), 提取数据的局部领域结构来建立监测模型进行统计过程监测.
第二类是时序相关性分析方法[128-130], 譬如, 典型相关分析方法(CVA)[128-130], 慢特征分析方法(SFA)[131-132]等. Shang等[132]以及Zhao等[133-134]提出了动静特性协同分析的思想, 同时提取了动态信息和静态信息, 并分别建立不同的监测模型和定义不同的监测统计量. 该思想通过动态和静态信息变化的精细解析, 使状态变化的指示更加精细化. 此外, Zhao等[135-139]将经济学领域中针对非平稳时序信号分析的协整理论引入进来, 提取了频繁操作条件切换中的长期均衡关系, 实现了对大范围非平稳运行中微小故障信号的灵敏检测. 在批次过程的应用中, 时序相关性分析方法研究的这相对较少. Choi等[137]结合多变量自回归模型(AR)和多向主成分分析(PCA)提出了基于动态模型的批次过程监测. Zhang等[70]通过动静协同实现了对间歇生产工况间的正常切换, 新工况出现, 时段正常切换, 异常扰动这4种情况的准确区分, 从而为间歇过程复杂状态变化的精细分析和识别提供了一条新的研究思路.
第一类动态分析方法仅对时序相关性进行解析用于建模和监测, 缺乏对过程状态变化的充分解析和判断. 与之对应的, 第二类动态分析方法则结合了动静态信息进而更灵敏和精细地区分实际过程中发生的复杂的状态变化. 对于动态信息的分析, 更重要的是能结合其他信息用于精细识别当前的状态变化. 前人工作揭示了关于动静态信息的相辅相成作用[70, 138-140], 即: 静态特性主要针对稳定运行在某种工况下的过程模式, 与之相辅相成, 动态特性则主要揭示了在闭环反馈控制的作用下过程的波动情况. 如何将静动态信息有效综合利用, 对过程状态变化进行精准判断, 区分正常变化与异常扰动, 是动静协同监测的精髓所在. 总的来说, 上述工作均推动了间歇过程动态性分析和监测的研究. 后续针对动特性监测的研究, 可以考虑动态性的深入解析与特征提取, 并结合具体问题赋予所提特征实际物理意义.
2.4 间歇过程故障诊断技术
在发现监测统计量超限, 指示故障发生后, 人们希望可以快速识别异常原因并采取必要的调整或纠正措施使之回到正常的控制区域. 目前已有很多基于历史测量数据的故障诊断方法[129, 141-147], 比如Fisher判别分析、支持向量机、随机森林等方法, 主要用于故障分类的研究. 但是故障分类的方法要基于历史故障数据, 在实际过程中通常很难获得充足的故障历史数据. 在多元统计过程监测领域, 贡献图方法[148] 常用于隔离根源故障变量, 其基于的基本思想是这些故障变量对超限的监测统计量的贡献更显著. 因此, 该方法仅需要正常的统计监测模型, 不需要先验故障知识或故障数据. 但是, 由于过程变量之间的相关性, 一个变量的影响可能会传播到其他变量, 从而导致无法准确区分各个变量的不同贡献, 造成混乱的结果. Alcala等[149]证明了即使在处理传感器故障这种简单问题时, 传统贡献图也无法保证故障传感器具有最大贡献值. 如果知道了实际故障方向, 可以进一步分析故障, 包括恢复故障数据的正常部分并估计故障幅度大小. 基于PCA模型, Dunia等[150]提出了故障重构的思想, 即从故障数据提取故障子空间(即故障方向)作为重构模型来纠正故障数据. 其中, 实施数据纠正恢复其正常部分的过程称为故障重构; 通过故障重构识别故障原因的过程称为基于重构的故障诊断. 基于该方法, 从已知的故障集合中选取每一个故障子空间都进行一次故障重构; 如果被选的故障子空间恰好是真实的故障方向, 那么基于重构后的数据重新计算的监测统计量将落回在控制限制内, 由此可以确定故障原因. 该方法是在大量的统计数据的基础上完成的, 关键是获取不同故障下的子空间模型. 基于故障数据建模, 比不利用故障数据的方法能更有效地捕获故障波动信息, 从而实现更精确的故障诊断. 由于故障重构是借助于消除监测统计量的故障报警信号来判断故障原因, 从故障检测的角度看, 与失控监测统计量有关的显著故障波动(即故障影响)实际上与故障过程本身的波动大小是不同的. 传统的重构建模方法仅仅针对故障数据进行分析, 揭示故障波动的大小, 实际上并不能准确提取故障影响. Zhao等[151-153]提出了一种相对变化的方法, 其基本思想是: 把正常过程状态作为参考工况, 基于正常工况的充足批次建立监测模型, 它们代表了关注的过程波动监测方向; 考虑到相对过程波动对故障监测结果的影响, 将每种故障工况向这些监测方向上进行投影, 分别在PCA监测系统中的主元子空间和残差子空间中, 将故障工况在各监测方向上的过程波动与正常参考工况进行对比; 在每个监测方向上如果故障工况的过程波动明显大于正常工况的波动, 则为显著故障影响, 否则为正常波动. 其基于的原理为: 根据监测统计量的计算方式, 当用参考模型进行在线过程监测时, 报警信号是由故障工况下显著增大的过程波动造成的. 根据上述相对变化分析方法, 可以提取对超限报警起主要作用的故障偏差并用于建立故障重构模型, 这样可以更有效地恢复数据正常部分并识别故障原因. 这里需要强调的是, 相对分析不是针对每种故障工况分别独立建模, 而是分析正常工况和故障工况间的相对变化, 这样可以提取和利用更重要的故障信息. 故障重构的思想需要每个故障工况都能得到充足建模批次, 也就是要求统计意义上涵盖了充足的批次方向上的故障波动[153]. 但是, 大多数情况下, 要求每种故障工况下获得充足的故障建模批次往往并不现实. 此外, 从故障重构的角度, 其本质是希望能够更有效地消除超限的监测统计量, 因此需要充分分析和挖掘导致故障报警的关键故障波动来构建故障子空间. 基于上述分析, 如何基于有限批次有效提取精确的故障子空间是非常重要的问题. 基于相对变化的思想, Zhao等[154]实现了基于少量故障批次的间歇过程故障诊断, 能够充分挖掘利用少量故障批次中的异常波动信息. 而Sun等[155] 针对非平稳过程的实时故障诊断研究, 提出了一种基于协整分析的稀疏重构策略用于故障变量的隔离, 不需要任何历史故障信息. 该方法成功在高端发电装备的故障诊断中得到了验证. Peng等[157]利用模糊C-clustering将间歇过程划分成不同的阶段, 并利用改进的和偏最小二乘建立贡献率指标用于求解故障诊断问题. Zhao等[158] 考虑了过程时序相关性和动态性, 提出了一种基于张量动态邻域保持映射(NPE)用于解决间歇过程中的故障诊断问题. Yang等[159]结合了主成分分析(PCA)、递归特征消除(RFE)和支持向量机(SVM)提出一种适合于盘尼西林发酵的间歇过程故障诊断方法. 在没有更多故障信息的前提下, 传统的故障诊断技术常常在分析复杂故障时失灵, 而一些基于机器学习的智能诊断理论近年来开始初露端倪[159-161]. 但其大部分研究工作主要集中在稳态连续过程, 应用于间歇工业过程诊断领域的相关文献较少, 可能的原因是间歇过程故障数据的有限性, 大范围不平稳性, 本身状态变化的多样性, 动态时变性以及未知扰动的存在. 此外, 由于故障影响与间歇过程本身运行特性叠加耦合, 即使同种故障发生在不同阶段和不同时刻所造成的影响亦有所不同. 因此, 原有用于监测的间歇过程的批次重复特性无法直接套用于故障诊断分析. 目前, 针对连续过程的许多故障诊断方法无法有效应用于间歇过程, 间歇过程的故障诊断还有很多问题没有解决. 主要需要考虑在不平稳运行过程中如何对其中隐藏的故障特征和故障影响进行有效解析.
3. 展望与前景
过去近三十年, 学者们在间歇过程状态监控与故障诊断算法的研究上取得了丰硕的成绩, 间歇过程高性能监控也得到了更广泛的应用. 传统的研究工作将连续过程和间歇过程分立割裂进行, 如何搭建起沟通连续过程和间歇过程之间的桥梁, 将研究思路和方法相互借鉴, 获得更为有效的建模, 监测与诊断方法, 是后续需要考虑的一个重要方向. 针对间歇过程监控的研究仍存在着一些问题需要进一步的研究, 其中包括以下几个方面.
3.1 闭环反馈下的过程监控
目前针对间歇过程的状态监控与故障诊断研究都是针对开环系统进行的, 没有考虑在反馈控制律作用下, 过程潜在特性所受到的影响和响应的变化. 受闭环反馈的影响, 过程运行特性相较于开环系统下将有所不同, 变量间的相关关系也从不同程度上被更改, 因此, 直接套用传统开环系统的监控方法没有考虑闭环系统的特点和问题, 无法真正解决实际问题. 需要重新考虑和设计, 以符合实际的工业需求, 解决更实际的生产安全性问题. 周东华等[162]曾提出, 由于反馈控制作用, 外部扰动的影响受到抑制, 当异常扰动处于发展初期幅值较小时, 往往被控制效果抵消, 从而影响故障特征的及时发现和提取. 此外, 闭环系统中, 子系统间复杂耦合性导致故障影响传播路径复杂, 异常征兆多变以及变量关系发生扭曲. 而对于具有典型多时段特性的间歇过程来说, 闭环反馈下的状态监测与故障诊断更具有挑战性. 比如, 不同操作阶段具有不同的控制目标和控制方案, 主导操作变量亦可能不同, 呈现不同的动态特征; 不同阶段的控制性能可能有所不同, 并且随着阶段间的频繁变换, 控制性能可能发生动态变化; 被控变量可能并非设定点, 而是设定曲线等. 前面我们提到间歇过程监测的动特性问题, 闭环反馈下更需要对过程动态信息进行充分解析与利用, 用于有效指示控制器调控作用. 目前尚未有针对闭环系统下的间歇过程的监控与诊断的研究. 基于数据分析方法对闭环反馈下的间歇生产运行进行高性能状态监控与故障诊断的研究是非常有意义和挑战性的工作.
3.2 间歇过程的运行状态评价
针对间歇过程的状态监测不仅局限于对生产状态做出正常或异常的识别和判断, 还应对当前正常运行状态的优劣水平有进一步的分析. 状态评价是对运行状态优劣等级的评估, 可将其定义为广义上的状态监测[7]. 针对正常的运行过程, 状态评价是指通过深入的数据解析, 进一步区分和识别实际生产运行状态的优劣情况, 以便对生产操作能及时调整, 消除导致运行状态非优的不利因素, 从而保证生产过程的高效进行. 状态评价的覆盖面非常广泛, 但针对工业过程运行状态优劣等级的评价较少. 目前的评价研究主要集中在产品质量、控制器性能以及设备健康度等方面. 已有部分学者针对连续过程运行状态评价进行了初步的研究[131, 133, 163]. 由于间歇过程具有多时段, 过程批次运行, 质量信息无法实时获取等特性, 间歇过程的状态评价更具挑战性和难点. 目前, 间歇过程运行状态评价相关的研究工作还少有报道, 研究仍在摸索阶段. 间歇过程的状态评价有许多问题需要解决, 也是间歇过程监测的难点, 热点问题之一.
3.3 多故障并发的故障诊断
受间歇过程变操作点动态过渡运行和变工况影响, 很多参数都在变化, 同一故障其特征参数随间歇过程操作点, 工况变化较大, 很难确定故障特征参数正常参考值范围以及精确提取故障特征信息. 此外, 多个子系统间的强耦合性导致故障异常参数在子系统间传播, 给故障准确定位增加了困难. 已有故障诊断方法不能很好地适应间歇过程动态过渡运行的新常态, 其实用性受到很大限制. 另一方面, 实际生产过程中系统运行不正常往往是由多种原因引起的, 对准确地判定故障的性质、类别、位置和程度提出更高要求和考验. 目前的故障诊断系统都是建立在单一故障基础上, 对多故障并发条件下的故障诊断还缺乏分解能力[164]. 多故障的辨识是今后的研究重点, 这不仅是间歇过程故障诊断的需求, 也是故障诊断学中一个热门话题. 与单故障诊断不同, 多故障诊断侧重分析不同故障的耦合特性. 一方面, 间歇过程运行工况频繁切换, 复杂多变, 不同阶段或工况下故障影响因素都可能发生变化, 因此即使同一种故障其表征亦有不同, 这导致了故障的不确定性与多样性. 另一方面, 故障表征与故障源之间并非简单的单一映射关系, 受几种故障源相互影响相互关联影响, 导致当前的故障表征, 这形成了多种故障之间的复杂耦合特性. 上述问题导致了间歇过程故障诊断技术上的难点和挑战. 因此, 对于间歇过程的复合故障诊断, 需要考虑时段与工况的切换, 寻找一种非线性映射, 能够准确关联检测量与故障特征, 故障特征与故障源之间的关系.
3.4 非优状态与故障工况的自修复
对间歇过程实施运行状态监控和故障诊断, 最终是要实现间歇过程非优运行状态和故障工况的自修复[165], 意味着基于状态监测与故障诊断和早期预警, 其中一类非优状态和故障能够通过控制的调整手段实现修复, 即自愈调控. 运行状态非优和故障自愈调控是确保间歇过程安全可靠运行的重要手段. 这里非优是指针对间歇过程运行建立的综合评价指标偏离给定的理想区间. 考虑到间歇过程运行和故障工况的复杂性, 要有效实施自愈, 需要有丰富的专家经验和知识能够自动判断决策. 此外, 自愈方案在执行前需要反复检验和验证. 数字双胞胎技术为自愈方案的设计奠定了基础. 如何映射(模拟)、监控、 诊断、预测和控制产品在现实环境中的形成过程和行为, 联接数字虚体空间中的虚拟事物与物理实体空间中的实体事物, 相互传输数据和指令, 数字孪生作为智能制造中的一个基本要素, 逐渐走进了人们的视野, 已成为迈向工业4.0进程中极为重要的技术要素. 针对能通过控制手段进行自愈的非优状态和故障, 在发生故障之前或者故障出现显著影响之前, 研究如何利用积累的长期运行经验, 知识与工业大数据, 以定性和定量相结合的方式, 制定合适的调控手段, 结合强化学习[166-167]等智能方法, 通过数字双胞胎的反复验证, 将确认后的调控指令下发到实际物理世界, 在一个批次结束前或者经过少量几个批次及时准确地调整控制回路设定点, 使非优状态恢复最优运行, 消除和避免发生故障, 可以将故障带来的损失降到最低, 更有利于间歇过程的安全, 可靠运行, 具有重要研究价值.
4. 结语
本文针对间歇过程的非平稳特性和独特的数据特征, 总结了近三十年来间歇过程状态监控与故障诊断算法的发展. 从直接借用连续过程的监控算法, 到引入三维数据展开, 再到利用间歇过程多时段特性进行设计和分析, 以及针对几类实际问题的解决思路, 间歇过程状态监控与故障诊断在理论和应用方面都获得了丰硕的成果, 实现了从粗放式监测到精细化监测的跨越. 大数据分析、机器学习和云计算等新技术的涌现, 为增强间歇过程运行的智能能力提供了巨大的发展空间. 智能能力是指与人体中相似的三种功能: 感知、决策和行动. 随着当今传感和控制技术的迅速发展, 间歇制造系统中已不乏传感器或执行器. 目前间歇生产所面临的挑战是如何处理信息和知识, 以便使计算机能够在几乎没有人为干预的情况下, 在正确的时间和地点自动做出正确的决策. 近些年, 随着深度学习研究和应用的深入, 不少深度学习方法也被初步应用到了工业过程控制中, 包括卷积神经网络、生成多抗网络和长短记忆模型. 前人已经做了一些有意义的尝试, 包括Wu等和Yu等[168, 104]各自应用卷积结构提取工业过程的局部特征, 用于建立模型诊断异常样本的故障类别; Wang 等[169]结合降噪自编码(DAE)和生成对抗网络(GAN)尝试解决工业过程中的缺失数据问题; Yuan等[170]将监督长短记忆模型(LSTM)应用到解决非线性动态过程的软测量问题上. 随着人工智能最新理论尤其是近年流行的高级机器学习理论方法及其在工程科技领域的深入应用为解决间歇过程的状态监测与故障诊断问题提供了新的手段和新的思路. 推动人工智能基础理论研究成果向间歇过程高效运维的转化是实现场景人工智能需要发力的关键之一. 本文提出了间歇过程在高性能状态监控与故障诊断方面存在的几个问题和未来可能的发展方向, 供大家参考和进一步分析讨论.
-

图 1 动车组运行过程动力学描述
Fig. 1 Dynamic description of electric multiple unit operation process
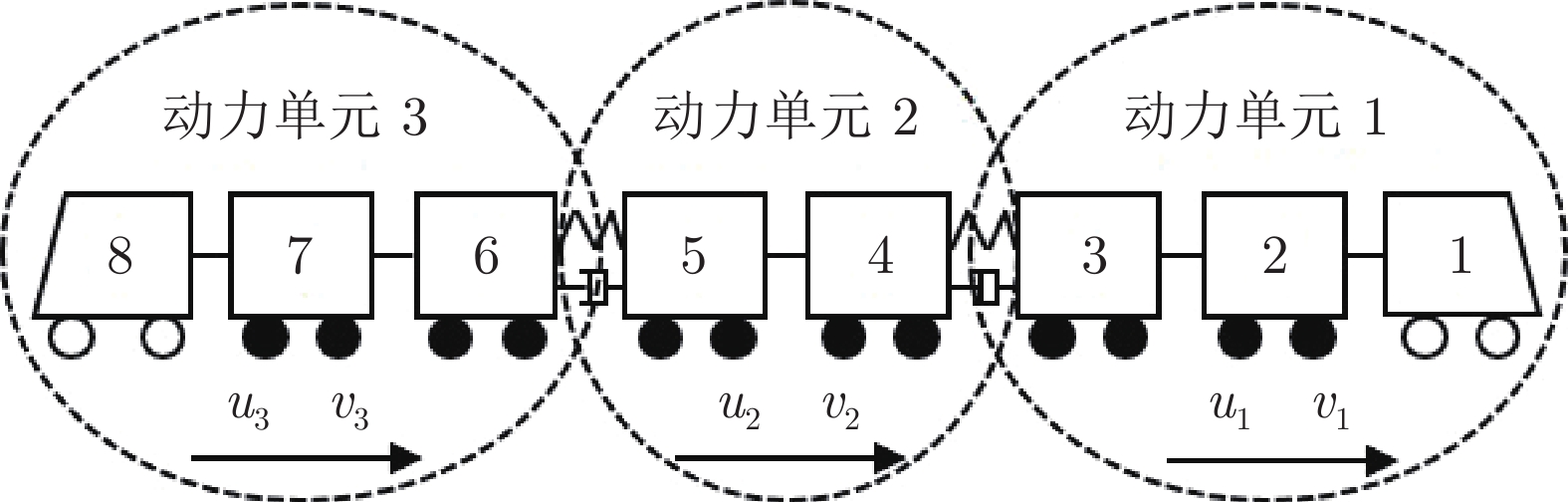
图 2 CRH380A型动车组动力单元分布
Fig. 2 Distribution of CRH380A electric multiple unit power unit

图 3 改进的动车组无模型自适应控制结构框图
Fig. 3 An improved block diagram of model-free adaptive control structure for electricmultiple unit
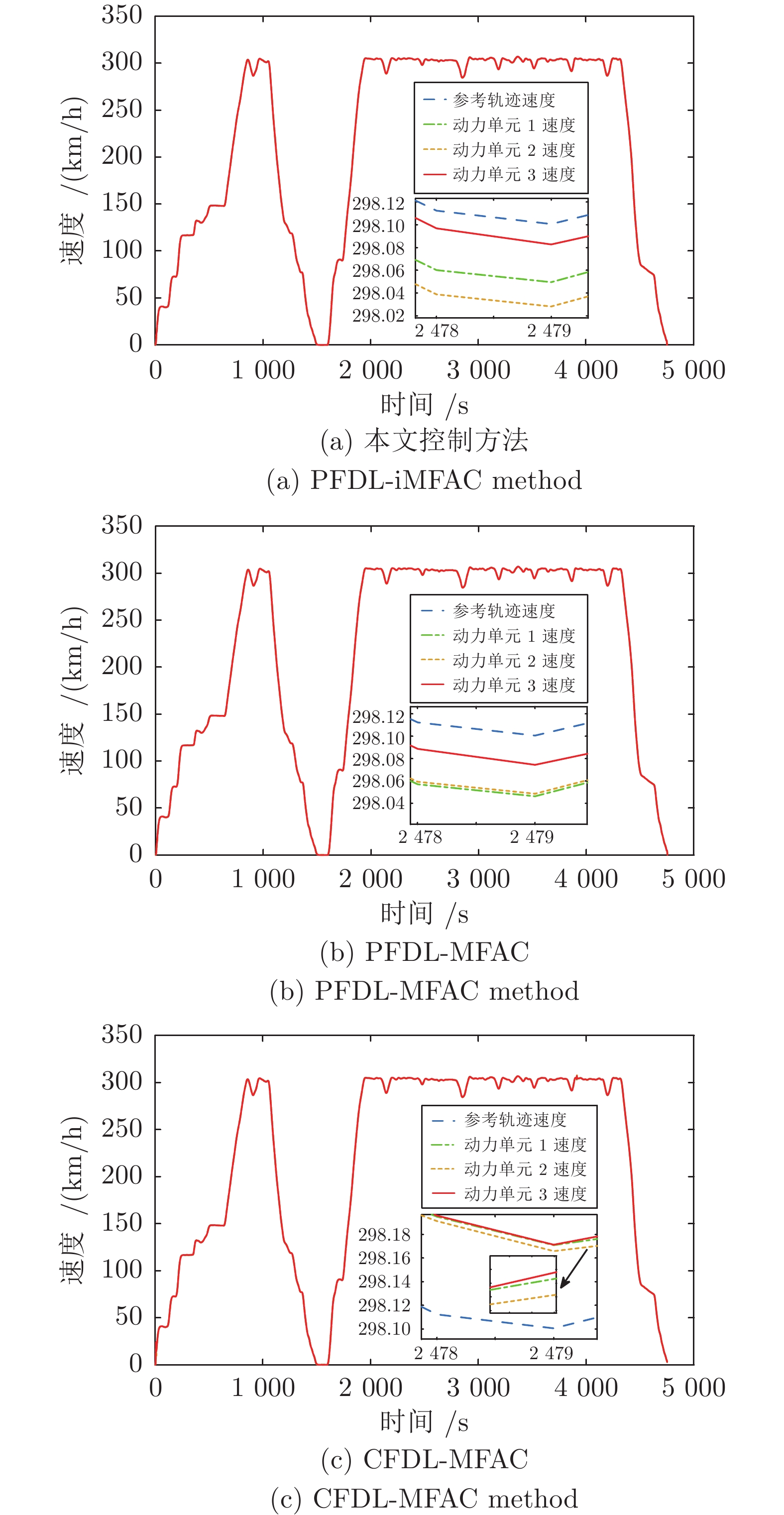
图 4 本文方法与其他方法速度跟踪曲线对比
Fig. 4 The velocity tracking curves of the proposed method are compared with those of other methods

图 5 本文方法与其他方法各动力单元速度跟踪误差对比
Fig. 5 The velocity tracking errors of the proposed method are compared with those of other methods
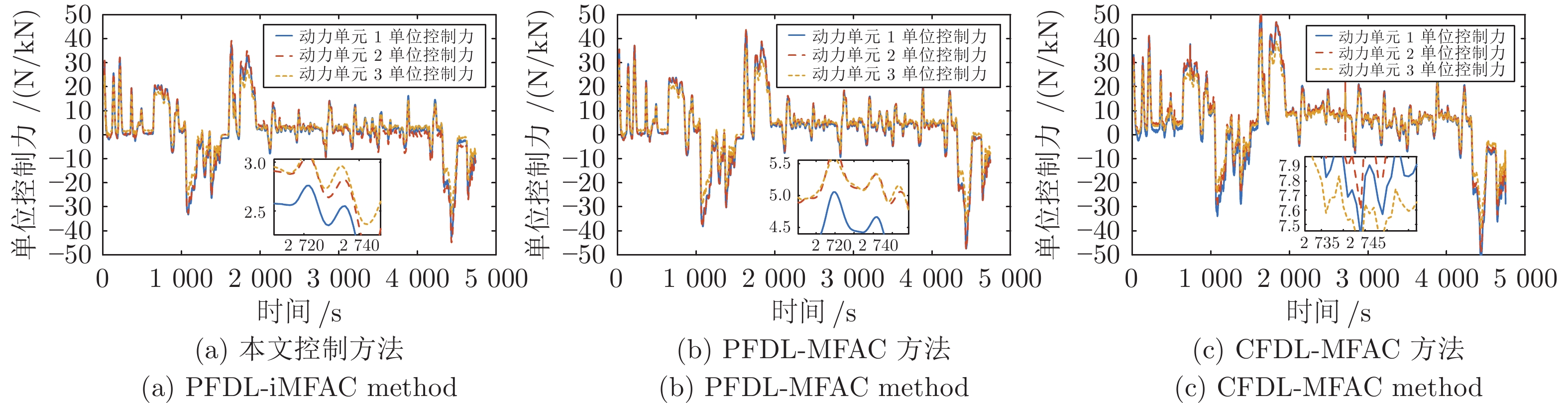
图 6 本文方法与其他方法单位控制力变化对比
Fig. 6 The variation of unit control force is compared with other methods
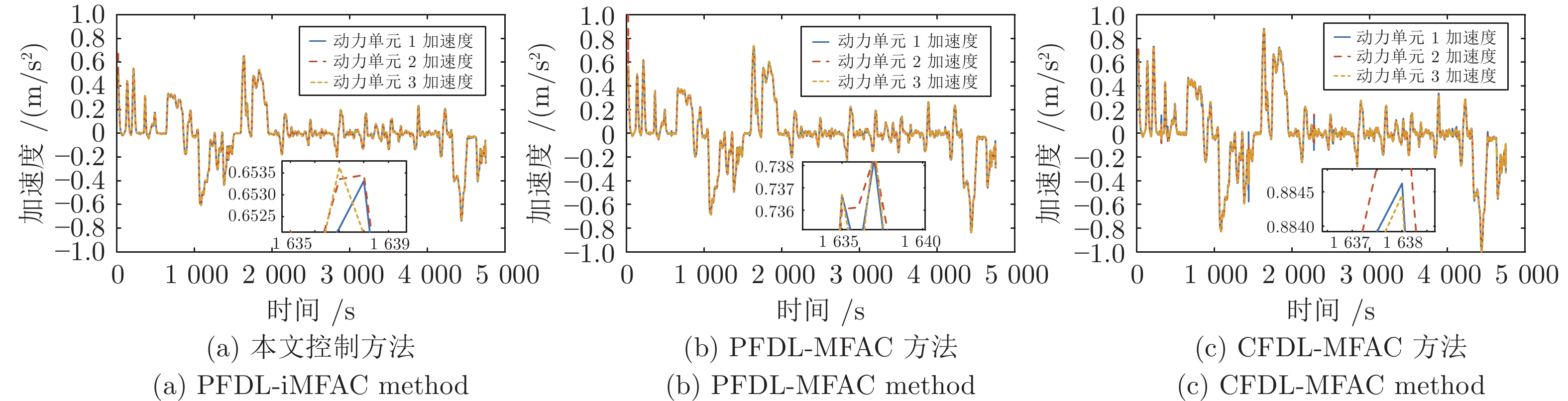
图 7 本文方法与其他方法加速度变化对比
Fig. 7 The acceleration changes of the proposed method are compared with other methods
表 1 CRH380A型动车组模型参数
Table 1 The CRH380A electric multiple unitmodel parameters
参数名称 参数值 单位 动力单元质量$M_1$ $ 1.836\times 10^5$ kg 动力单元质量$M_2$ $ 1.123\times 10^5 $ kg 动力单元质量$M_3$ $ 1.836\times 10^5 $ kg 列车阻力系数$a_r$ 5.2 N/kg 列车阻力系数$b_r$ $ 3.6\times 10^{-2} $ ${\rm{N} } \cdot {\rm{s} }^2/({\rm{kg} } \cdot {\rm{m} })$ 列车阻力系数$c_r$ $ 1.2\times 10^{-3} $ ${\rm{N} } \cdot {\rm{s} }^2/({\rm{kg} } \cdot {\rm{m}^2 })$ 车钩弹性系数$k$ $ 2\times 10^7 $ N/m 车钩阻尼系数$d$ $ 5\times 10^6 $ ${\rm{N}} \cdot {\rm{s/m} }$  下载: 导出CSV
下载: 导出CSV
表 2 各个控制方法的若干性能指标对比
Table 2 Comparison of several performance indexes of each control method
控制方法 均方误差 最大加减速度 (m/s2) 能量损耗 节约率 (%) 文献[19] $1.2\times 10^{-2} $ 1.0848 $ 2.41\times 10^6 $ — PFDL-MFAC $6.2\times 10^{-3} $ 0.7309 $2.29\times 10^6 $ $5.04$ PFDL-iMFAC $6.6\times 10^{-3} $ 0.6572 $2.17\times 10^6$ $9.86 $
下载: 导出CSV
-
[1] 汪仁智, 李德伟, 席裕庚. 采用预测控制的地铁节能优化控制算法. 控制理论与应用, 2017, 34(9): 1129-1135 doi: 10.7641/CTA.2017.60861Wang Ren-Zhi, Li De-Wei, Xi Yu-Geng.Metro energy saving optimization algorithm by using model predictive control. Control Theory & Applications, 2017, 34(9): 1129-1135 doi: 10.7641/CTA.2017.60861 [2] 杨辉, 张坤鹏, 王昕, 衷路生. 高速列车多模型广义预测控制方法. 铁道学报, 2011, 33(8): 80-87 doi: 10.3969/j.issn.1001-8360.2011.08.014Yang Hui, Zhang Kun-Peng, Wang Xin, Zhong Lu-Sheng. Generalized multiple model predictive control method of high-speed train. Journal of the China Railway Society, 2011, 33(8): 80-87 doi: 10.3969/j.issn.1001-8360.2011.08.014 [3] 衷路生, 李兵, 龚锦红, 张永贤, 祝振敏. 高速列车非线性模型的极大似然辨识. 自动化学报, 2014, 40(12): 2950-2958Zhong Lu-Sheng, Li Bing, Gong Jin-Hong, Zhang Yong-Xian, Zhu Zhen-Min. Maximum likelihood identification of nonlinear model for high-speed train. Acta Automatica Sinica, 2014, 40(12): 2950-2958 [4] Liu X Y, Xun J, Ning B, Wang C. Braking process identification of high-speed trains for automatic train stop control. ISA Transactions, 2020, doi: 10.1016/j.isatra.2020.10.059 [5] 贾超. 考虑安全约束的列车自动驾驶多质点非线性预测控制 [博士论文], 北京交通大学, 中国, 2020Jia Chao. Nonlinear Predictive Control for Automatic Train Operation With Consideration of Safety Constraints and Multi-Point Model [Ph.D. dissertation], Beijing Jiaotong University, China, 2020 [6] 李中奇, 金柏, 杨辉, 谭畅, 付雅婷. 高速动车组强耦合模型的分布式滑模控制策略. 自动化学报, 2020, 46(3): 495-508Li Zhong-Qi, Jin Bai, Yang Hui, Tang Chang, Fu Ya-Ting. Predictive control using a distributed model for electric multiple unit. Acta Automatica Sinica, 2020, 46(3): 495-508 [7] Wu X, Zhang K J, Cheng M. Adaptive numerical approach for optimal control of a single train. Journal of Systems Science & Complexity, 2019, 32(4): 1053-1071 [8] Yang Y Q, Mao B H, Wang M. Research on freight train operation control simulation on long steep downhill lines. ASCE-ASME Journal of Risk and Uncertainty in Engineering Systems, Part A: Civil Engineering, 2021, 7(3): 05021003 [9] 侯忠生. 非线性系统参数辩识、自适应控制及无模型学习自适应控制 [博士论文], 东北大学, 中国, 1994Hou Zhong-Sheng. Nonlinear System Parameter Identification, Adaptive Control and Model Free Adaptive Learning Control [Ph.D. dissertation], Northeastern University, China, 1994 [10] 温亮, 周平. 基于多参数灵敏度分析与遗传优化的铁水质量无模型自适应控制. 自动化学报, 2021, 47(11): 2600-2613Wen Liang, Zhou Ping. Model-free adaptive control of molten iron quality based on multi-parameter sensitivity analysis and GA optimization. Acta Automatica Sinica, 2021, 47(11): 2600-2613 [11] Ma Y S, Che W W, Deng C, Wu Z G. Distributed model-free adaptive control for learning nonlinear MASs under DoS attacks. IEEE transactions on neural networks and learning systems, 2021, doi: 10.1109/TNNLS.2021.3104978 [12] Wang H Z, Fang L J, Song T Z, Xu J Q, Shen H S. Model-free adaptive sliding mode control with adjustable funnel boundary for robot manipulators with uncertainties. The Review of scientific instruments, 2021, 92(6), 065101 doi: 10.1063/5.0037054 [13] 李醒, 王晓峰. 不确定机器人系统无模型自适应滑模控制方法. 南京理工大学学报, 2015, 39(6): 655-660Li Xing, Wang Xiao-Feng. Model-free adaptive sliding mode control method for uncertain robot system. Journal of Nanjing University of Science and Technology, 2015, 39(6): 655-660 [14] Li X S, Ren Y Y, Zheng X Li, Liu L. Model-free adaptive control for tank truck rollover stabilization. Mathematical Problems in Engineering, 2021, 2021(3): 1-16 [15] 姚文龙, 庞震, 池荣虎, 邵巍. 环卫车辆轨迹跟踪系统的无模型自适应迭代学习控制. 控制理论与应用, 2022, 39(1): 101-108 doi: 10.7641/CTA.2021.00797Yao Wen-Long, Pang Zhen, Chi Rong-Hu, Shao Wei. Track tracking control of sanitation vehicle based on model-free adaptive iterative learning control. Control Theory & Applications, 2022, 39(1): 101-108 doi: 10.7641/CTA.2021.00797 [16] 潘晓龙, 鲜斌. 小型无人直升机的无模型自适应鲁棒控制设计. 控制理论与应用, 2017, 34(9): 1171-1178 doi: 10.7641/CTA.2017.70029Pan Xiao-Long, Xian Bin. Model-free adaptive robust control design for a small unmanned helicopter. Control Theory & Applications, 2017, 34(9): 1171-1178 doi: 10.7641/CTA.2017.70029 [17] Yang W, Yin C K, Hou Z S. A novel energy efficient operation strategy for a train based on model-free adaptive predictive control. In: Proceedings of the 31st Chinese Control Conference. Hefei, China: 2012. 1523−1528 [18] Wang H J, Hou Z S, Jin S T. Model-free adaptive fault-tolerant control for multiple point-mass subway trains with speed and traction/braking force constraints. IFAC PapersOnLine, 2020, 53(2): 3916-3921 doi: 10.1016/j.ifacol.2020.12.2239 [19] 石卫师. 基于无模型自适应控制的城轨列车自动驾驶研究. 铁道学报, 2016, 38(3): 72-77 doi: 10.3969/j.issn.1001-8360.2016.03.010Shi Wei-Shi. Research on automatic train operation based on model-free adaptive control. Journal of the China Railway Society, 2016, 38(3): 72-77 doi: 10.3969/j.issn.1001-8360.2016.03.010 [20] 王海, 刘根锋, 侯忠生. 高速列车数据驱动无模型自适应容错控制. 控制与决策, 2022, 37(5): 1127-1136Wang Hai, Liu Gen-Feng, Hou Zhong-Sheng. Data-driven model-dree adaptive fault tolerant control for high-speed train. Control and Decision, 2022, 37(5): 1127-1136 [21] 李中奇. 高速动车组自适应速度跟踪控制 [博士论文], 南昌大学, 中国, 2015Li Zhong-Qi. Adaptive Speed Tracking Control for High-Speed EMU [Ph.D. dissertation], Nanchang University, China, 2015 [22] 李中奇, 杨辉, 刘明杰, 刘杰民. 高速动车组制动过程的建模及跟踪控制. 中国铁道科学, 2016, 37(5): 80-86 doi: 10.3969/j.issn.1001-4632.2016.05.11Li Zhong-Qi, Yang Hui, Liu Ming-Jie, Liu Jie-Min. Modeling and tracking control for braking process of high-speed electric multiple unit. China Railway Science, 2016, 37(5): 80-86 doi: 10.3969/j.issn.1001-4632.2016.05.11 [23] 丁盼. 基于多质点模型的高速列车自适应速度跟踪控制 [硕士论文], 华东交通大学, 中国, 2021Ding Pang. A Multiple Point-Mass Model based High-Speed Train Adaptive Dpeed Tracking Control Scheme [Master thesis], East China Jiaotong University, China, 2021 [24] Yang Y M, Yan F. Research on train dynamic coupling strategy based on distributed model predictive control. Journal of Physics: Conference Series, 2022, 2183(12029): 1-12 [25] 侯忠生. 无模型自适应控制的现状与展望. 控制理论与应用, 2006(4): 586-592 doi: 10.3969/j.issn.1000-8152.2006.04.017Hou Zhong-Sheng. On model-free adaptive control: the state of the art and perspective. Control Theory & Applications, 2006(4): 586-592 doi: 10.3969/j.issn.1000-8152.2006.04.017 [26] 侯忠生. 再论无模型自适应控制. 系统科学与数学, 2014, 34(10): 1182-1191Hou Zhong-Sheng. Highlight and perspective on model free adaptive control. Journal of Systems Science and Mathematical Sciences, 2014, 34(10): 1182-1191 [27] 金尚泰. 无模型学习自适应控制的若干问题研究及其应用 [博士论文], 北京交通大学, 中国, 2008Jin Shang-Tai. On Model Free Learning Adaptive Control and Applications [Ph.D. dissertation], Beijing Jiaotong University, China, 2008 [28] Hou Z S, Jin S T. Data-driven model-free adaptive control for a class of MIMO nonlinear discrete-time systems. IEEE transactions on neural networks, 2011, 22(12) : 2173-2188 doi: 10.1109/TNN.2011.2176141 [29] 李中奇, 丁俊英, 杨辉, 刘江. 基于控制器匹配的高速列车广义预测控制方法. 铁道学报, 2018, 40(9): 82-89 doi: 10.3969/j.issn.1001-8360.2018.09.012Li Zhong-Qi, Ding Jun-Ying, Yang Hui, Liu Jiang. Generalized predictive control tuning for high-speed train based on controller matching method. Journal of the China Railway Society, 2018, 40(9): 82-89 doi: 10.3969/j.issn.1001-8360.2018.09.012 [30] 冯增喜, 张聪, 李丙辉. 基于改进粒子群优化算法的MFAC参数寻优. 控制工程, 2021, 28(4): 766-773Feng Zeng-Xi, Zhang Cong, Li Bing-Hui. Optimization of MFAC parameters based on improved particle swarm optimization algorithm. Control Engineering of China, 2021, 28(4): 766-773 [31] 基于改进卡尔曼滤波器的扰动抑制无模型自适应控制方案. 控制理论与应用, to be publishedModel-free adaptive control with disturbance rejection based on modified Kalman filter. Control Theory & Applications, to be published 期刊类型引用(9)
1. 徐飞,姜新宇,李子欣,史黎明,李耀华. 高速直线感应电机自学习抗扰控制策略. 电工技术学报. 2025(06): 1771-1783 .  百度学术
百度学术2. 李中奇,周靓,杨辉. 高速动车组数据驱动无模型自适应积分滑模预测控制. 自动化学报. 2024(01): 194-210 . 本站查看3. 金龙,张凡,刘佰阳,郑宇. 基于数据驱动的冗余机器人末端执行器位姿控制方案. 自动化学报. 2024(03): 518-526 . 本站查看4. 谷小峰,马庆鲁,黄文杰,李国庆. 实时参数整定的无模型自适应控制算法及其在气体分馏装置的应用. 石油炼制与化工. 2024(03): 97-106 . 百度学术5. 周靓,夏金凤,李中奇. 改进的动车组速度跟踪系统的无模型自适应控制. 交通运输工程学报. 2024(02): 267-280 . 百度学术6. 岳丽丽,王一栋,肖宝弟,武晓春. 城轨列车自动驾驶积分反步线性自抗扰控制. 湖南大学学报(自然科学版). 2024(08): 78-90 . 百度学术7. 李中奇,黄琳静,周靓,杨辉,唐博伟. 高速列车滑模自抗扰黏着控制方法. 交通运输工程学报. 2023(02): 251-263 . 百度学术8. 伍文豪,李润梅,熊刚. 基于城轨列车单质点动力学模型的滑模自适应速度跟踪控制. 铁路计算机应用. 2023(08): 94-99 . 百度学术9. 李中奇,张俊豪,唐博伟. 高速列车精确停车的超扭曲非奇异终端滑模控制方法. 铁道学报. 2023(12): 83-91 . 百度学术其他类型引用(11)
-


 下载:
下载:






















计量
- 文章访问数: 1905
- HTML全文浏览量: 281
- PDF下载量: 348
- 被引次数: 20
