

A Meta-evolutionary Learning Algorithm for Opponent Adaptation in Two-player Zero-sum Games
-
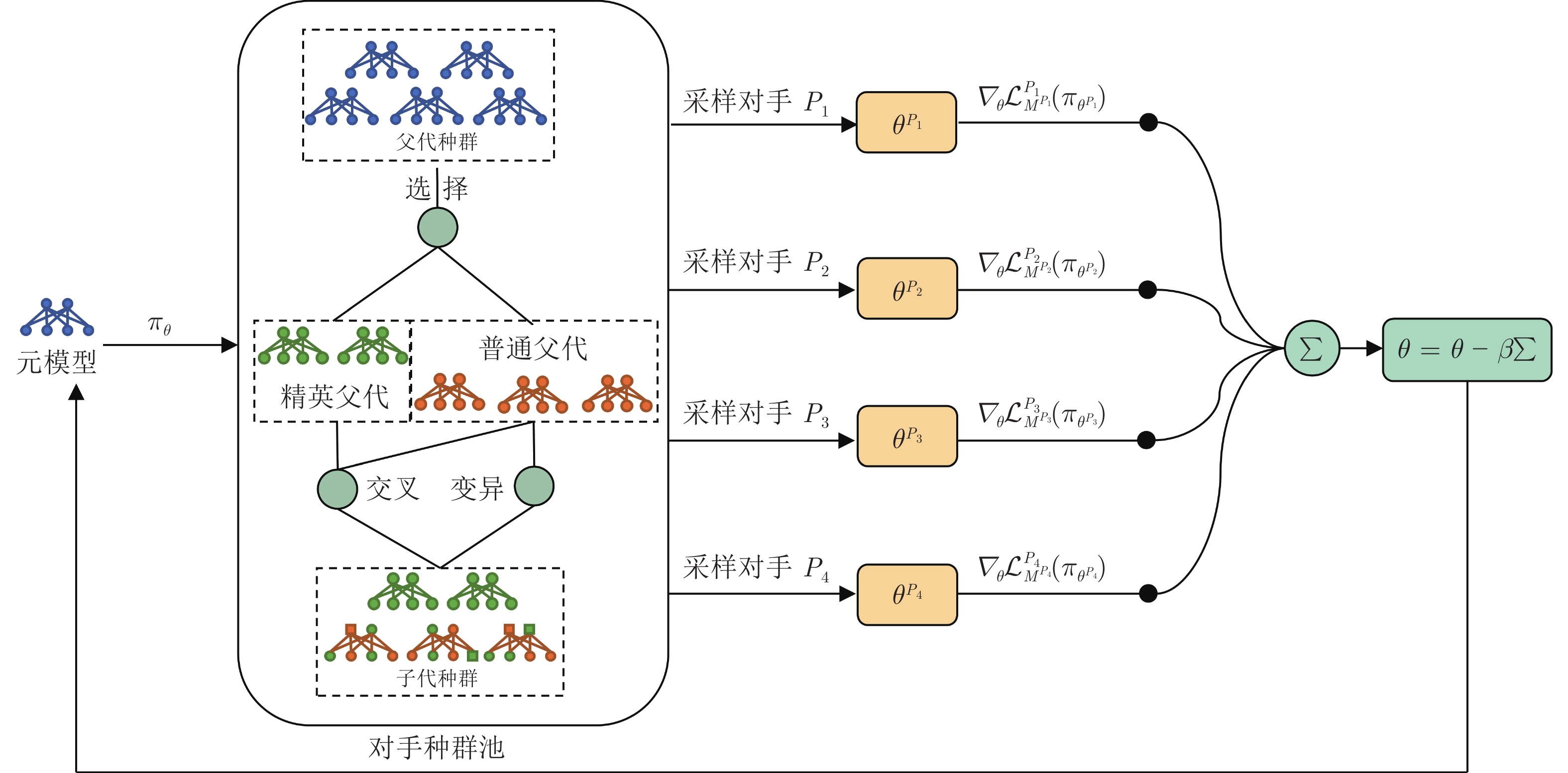
摘要: 围绕两人零和博弈所开展的一系列研究, 近年来在围棋、德州扑克等问题中取得了里程碑式的突破. 现有的两人零和博弈求解方案大多在理性对手的假设下围绕纳什均衡解开展, 是一种力求不败的保守型策略, 但在实际博弈中由于对手非理性等原因并不能保证收益最大化. 对手建模为最大化博弈收益提供了一种新途径, 但仍存在建模困难等问题. 结合元学习的思想提出了一种能够快速适应对手策略的元策略演化学习求解框架. 在训练阶段, 首先通过种群演化的方法不断生成风格多样化的博弈对手作为训练数据, 然后利用元策略更新方法来调整元模型的网络权重, 使其获得快速适应的能力. 在Leduc扑克、两人有限注德州扑克(Heads-up limit Texas Hold'em, LHE)和RoboSumo上的大量实验结果表明, 该算法能够有效克服现有方法的弊端, 实现针对未知风格对手的快速适应, 从而为两人零和博弈收益最大化求解提供了一种新思路.Abstract: Recently, two-player zero-sum games have made impressive breakthroughs in the Go and Texas Hold'em. Most of the existing two-player zero-sum game solutions are based on the assumption of rational opponents to approximate the Nash equilibrium solutions, which is a conservative strategy of trying to be undefeated but does not guarantee maximum payoffs in practice due to the opponents' irrationality. The opponent modeling provides a new way to maximize the payoff, but modeling has difficulties. This paper proposes a meta-evolutionary learning framework that can quickly adapt to the opponents. In the training phase, we first generate opponents with different styles as training data through the population evolution method, and then use the meta-strategy update method to adjust the network weights of the meta-model so that it can gain the ability to adapt quickly. Extensive experiments on Leduc poker, heads-up limit Texas Hold'em (LHE), and RoboSumo have shown that the algorithm can effectively overcome the drawbacks of existing methods and achieve fast adaptation to unknown style of opponents, thus providing a new way of solving two-player zero-sum games with maximum payoff.
-
Key words:
- Two-player zero-sum games /
- Nash equilibrium /
- opponent modeling /
- meta learning /
- population evolution
-

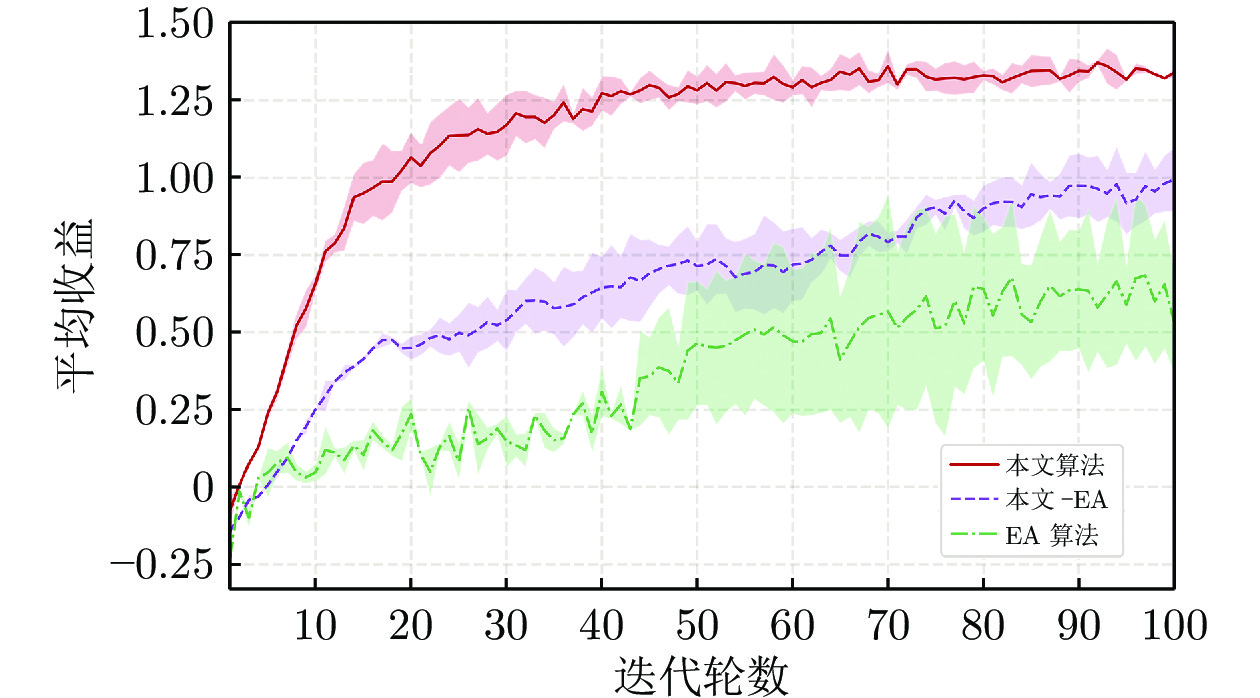
图 2 本文算法与基线算法在RoboSumo中的对比
Fig. 2 Comparison of our method with the baseline algorithm in RoboSumo
表 1 不同环境下的实验参数设置
Table 1 Hyperparameters settings
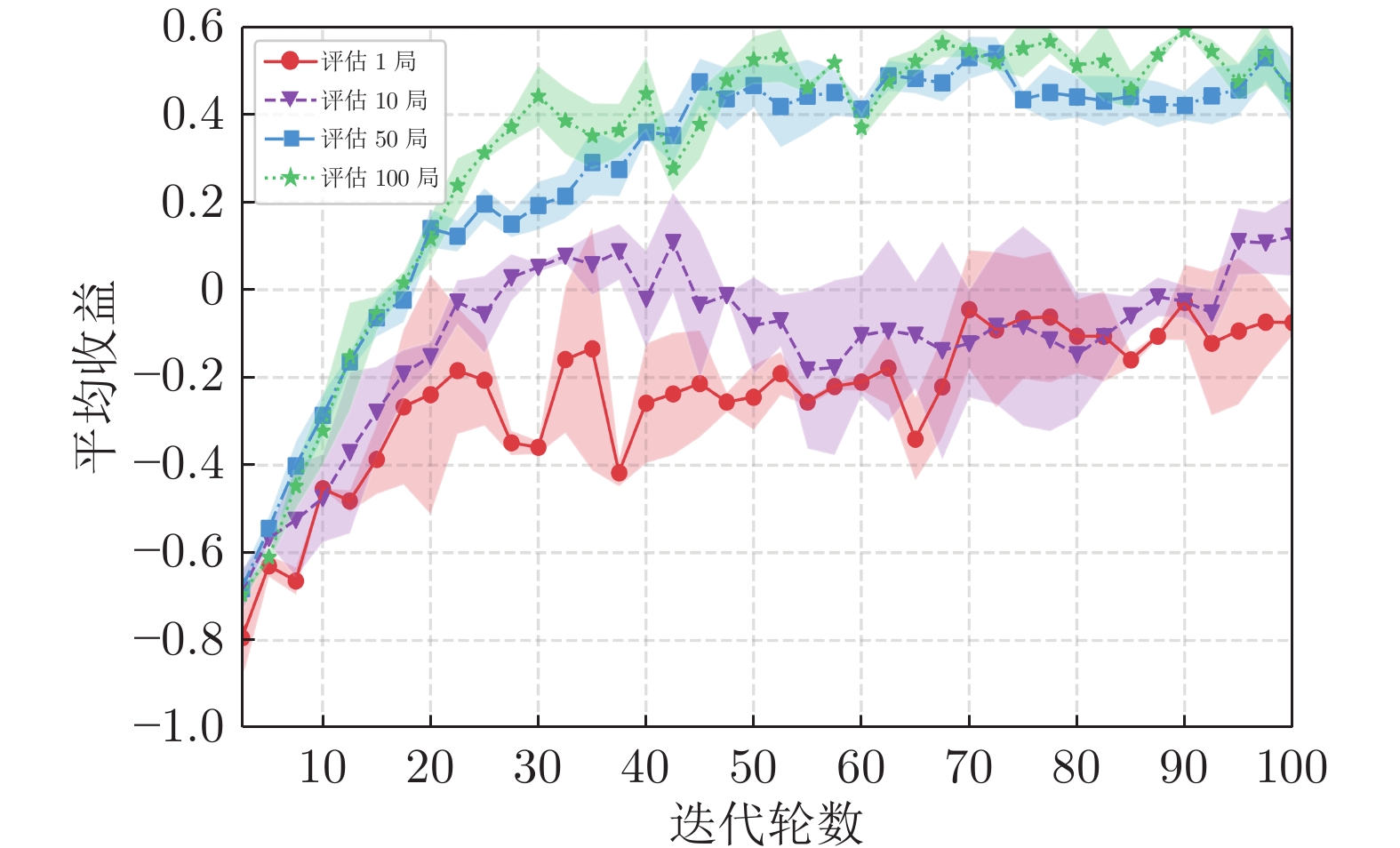
参数 Leduc LHE RoboSumo 状态空间 36 72 120 动作空间 4 4 8 网络尺寸 [64, 64] [128, 128] [128, 128] 训练步长$\alpha$ 0.100 0.050 0.003 训练步长$\beta$ 0.0100 0.0100 0.0006 折扣系数$\gamma$ 0.990 0.995 0.995 梯度更新步数 1 1 1 种群规模 10 10 10 精英比例$\vartheta$ 0.2 0.4 0.4 变异率 0.3 0.1 0.2 变异强度 0.1 0.1 0.1 测试更新步长 0.100 0.050 0.001 测试更新步数 3 3 3 评估局数 50 100 50 存储资源 (GB) ~ 0.3 ~ 2.0 ~ 1.5 迭代次数 (T) 100 400 300  下载: 导出CSV
下载: 导出CSV
表 2 本文算法与基线算法在Leduc环境中的对比
Table 2 The average return of our method and baseline methods in Leduc
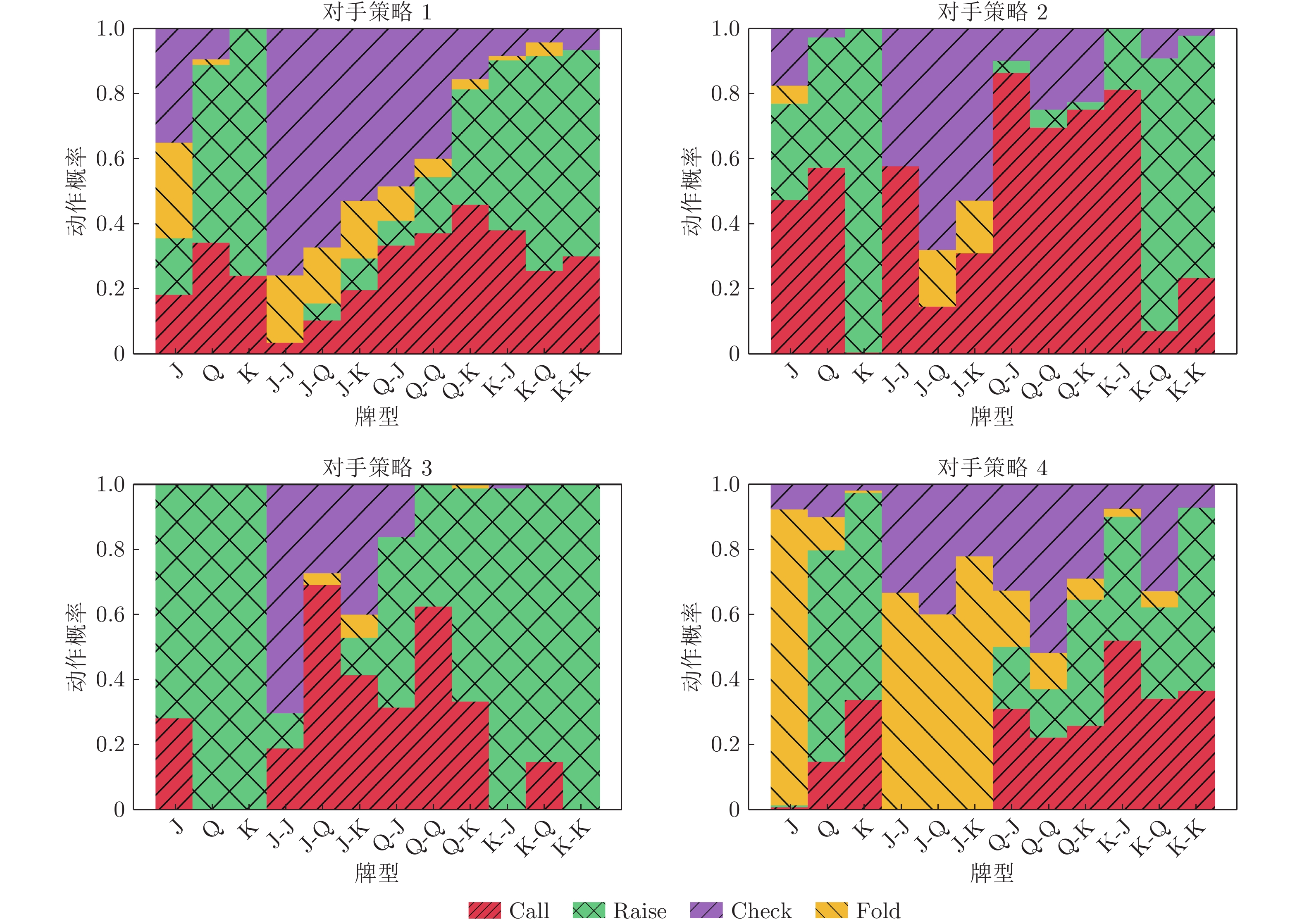
方法 Random 对手 Call 对手 Bluff 对手 CFR 对手 NFSP 对手 本文算法 1.359 ± 0.023 0.646 ± 0.069 0.576 ± 0.043 − 0.162 ± 0.032 0.325 ± 0.096 CFR 算法 0.749 ± 0.014 0.364 ± 0.010 0.283 ± 0.028 0.010 ± 0.024 0.144 ± 0.007 DRON 算法 1.323 ± 0.014 0.418 ± 0.011 0.409 ± 0.052 − 0.347 ± 0.031 0.212 ± 0.080 EOM 算法 1.348 ± 0.015 0.635 ± 0.007 0.444 ± 0.024 − 0.270 ± 0.042 − 0.012 ± 0.023 NFSP 算法 0.780 ± 0.019 0.132 ± 0.024 0.029 ± 0.022 − 0.412 ± 0.040 0.011 ± 0.027 MAML 算法 1.372 ± 0.028 0.328 ± 0.013 0.323 ± 0.044 − 0.409 ± 0.010 0.089 ± 0.051 本文算法 +PPO 1.353 ± 0.011 0.658 ± 0.005 0.555 ± 0.017 − 0.159 ± 0.041 0.314 ± 0.012 本文算法 −EA 0.994 ± 0.042 0.611 ± 0.021 0.472 ± 0.038 − 0.224 ± 0.016 0.203 ± 0.029 EA 算法 0.535 ± 0.164 0.422 ± 0.108 0.366 ± 0.113 − 0.365 ± 0.094 0.189 ± 0.102 Oracle 1.373 ± 0.007 0.662 ± 0.014 0.727 ± 0.012 − 0.089 ± 0.016 0.338 ± 0.041
下载: 导出CSV
表 3 本文算法与基线算法在LHE环境中的对比
Table 3 The average return of our method and baseline methods in LHE
方法 Random 对手 LA 对手 TA 对手 LP 对手 本文算法 2.594 ± 0.089 0.335 ± 0.012 0.514 ± 0.031 0.243 ± 0.102 DRON 算法 2.131 ± 0.672 − 0.609 ± 0.176 0.294 ± 0.057 0.022 ± 0.028 EOM 算法 2.555 ± 0.020 − 0.014 ± 0.013 0.237 ± 0.023 0.144 ± 0.128 NFSP 算法 1.342 ± 0.033 − 0.947 ± 0.012 − 0.352 ± 0.094 0.203 ± 0.089 MAML 算法 2.633 ± 0.035 0.037 ± 0.047 0.231 ± 0.057 0.089 ± 0.051 本文算法 +PPO 2.612 ± 0.058 0.327 ± 0.011 0.478 ± 0.042 0.246 ± 0.070 本文算法 −EA 2.362 ± 0.023 0.185 ± 0.049 0.388 ± 0.012 0.119 ± 0.015 EA 算法 2.193 ± 0.158 0.096 ± 0.087 0.232 ± 0.097 0.091 ± 0.009 Oracle 2.682 ± 0.033 0.513 ± 0.009 0.624 ± 0.011 0.270 ± 0.026
下载: 导出CSV
-
[1] LeCun Y, Bengio Y, Hinton G. Deep learning. Nature, 2015, 521(7553): 436-444 doi: 10.1038/nature14539 [2] Hinton G E, Salakhutdinov R R. Reducing the dimensionality of data with neural networks. Science, 2006, 313(5786): 504-507 doi: 10.1126/science.1127647 [3] Silver D, Huang A, Maddison C J, Guez A, Sifre L, Van Den Driessche, et al. Mastering the game of Go with deep neural networks and tree search. Nature, 2016, 529(7587): 484-489 doi: 10.1038/nature16961 [4] Silver D, Schrittwieser J, Simonyan K, Antonoglou I, Huang A, Guez A, et al. Mastering the game of go without human knowledge. Nature, 2017, 550(7676): 354-359 doi: 10.1038/nature24270 [5] Silver D, Hubert T, Schrittwieser J, Antonoglou I, Lai M, Guez A, et al. A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play. Science, 2018, 362(6419): 1140-1144 doi: 10.1126/science.aar6404 [6] 赵冬斌, 邵坤, 朱圆恒, 李栋, 陈亚冉, 王海涛, 等. 深度强化学习综述: 兼论计算机围棋的发展. 控制理论与应用, 2016, 33(6): 701-717 doi: 10.7641/CTA.2016.60173Zhao Dong-Bin, Shao Kun, Zhu Yuan-Heng, Li Dong, Chen Ya-Ran, Wang Hai-Tao, et al. Review of deep reinforcement learning and discussions on the development of computer Go. Control Theory and Applications, 2016, 33(6): 701-717 doi: 10.7641/CTA.2016.60173 [7] 周志华. AlphaGo专题介绍. 自动化学报, 2016, 42(5): 670Zhou Zhi-Hua. AlphaGo special session: An introduction. Acta Automatica Sinica, 2016, 42(5): 670 [8] Sandholm T. Solving imperfect-information games. Science, 2015, 347(6218): 122-123 doi: 10.1126/science.aaa4614 [9] Bowling M, Burch N, Johanson M, Tammelin O. Heads-up limit hold'em poker is solved. Science, 2015, 347(6218): 145-149 doi: 10.1126/science.1259433 [10] 郭潇逍, 李程, 梅俏竹. 深度学习在游戏中的应用. 自动化学报, 2016, 42(5): 676-684Guo Xiao-Xiao, Li Cheng, Mei Qiao-Zhu. Deep learning applied to games. Acta Automatica Sinica, 2016, 42(5): 676-684 [11] Brown G W. Iterative solution of games by fictitious play. Activity Analysis of Production and Allocation, 1951, 13(1): 374-376 [12] 沈宇, 韩金朋, 李灵犀, 王飞跃. 游戏智能中的AI-从多角色博弈到平行博弈. 智能科学与技术学报, 2020, 2(3): 205-213 doi: 10.11959/j.issn.2096-6652.202023Shen Yu, Han Jin-Peng, Li Ling-Xi, Wang Fei-Yue. AI in game intelligence—from multi-role game to parallel game. Chinese Journal of Intelligent Science and Technology, 2020, 2(3): 205-213 doi: 10.11959/j.issn.2096-6652.202023 [13] Tammelin O. Solving large imperfect information games using CFR+. arXiv preprint arXiv: 1407.5042, 2014. [14] Moravcík M, Schmid M, Burch N, Lisý V, Morrill D, Bard N, et al. Deepstack: Expert-level artificial intelligence in heads-up no-limit poker. Science, 2017, 356(6337): 508-513 doi: 10.1126/science.aam6960 [15] Brown N, Sandholm T. Superhuman AI for heads-up no-limit poker: Libratus beats top professionals. Science, 2018, 359(6374): 418-424 doi: 10.1126/science.aao1733 [16] Albrecht S V, Stone P. Autonomous agents modelling other agents: A comprehensive survey and open problems. Artificial Intelligence, 2018, 258: 66-95 doi: 10.1016/j.artint.2018.01.002 [17] He H, Boyd-Graber J, Kwok K, DauméIII H. Opponent modeling in deep reinforcement learning. In: Proceedings of the 33rd International Conference on Machine Learning. New York, USA: PMLR, 2016. 1804−1813 [18] Foerster J N, Chen R Y, Al-Shedivat M, Whiteson S, Abbeel P, Mordatch I. Learning with opponent-learning awareness. In: Proceedings of the 17th International Conference on Autonomous Agents and Multiagent Systems. Richland, USA: ACM, 2018. 122−130 [19] Nash J. Non-cooperative games. Annals of Mathematics, 1951, 54: 286-295 doi: 10.2307/1969529 [20] Neumann J V, Morgenstern O. The Theory of Games and Economic Behaviour. New Jersey: Princeton University Press, 1944. [21] Heinrich J, Silver D. Deep reinforcement learning from self-play in imperfect-information games. arXiv preprint arXiv: 1603.01121, 2016. [22] Lanctot M, Zambaldi V, Gruslys A, Lazaridou A, Tuyls K, Pérolat J, et al. A unified game-theoretic approach to multiagent reinforcement learning. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach, USA: Curran Associates Inc, 2017. 4193−4206 [23] Zinkevich M, Johanson M, Bowling M, Piccione C. Regret minimization in games with incomplete information. In: Proceedings of the 21st International Conference on Neural Information Processing Systems. Vancouver, Canada: Curran Associates Inc, 2007. [24] Brown N, Sandholm T. Solving imperfect-information games via discounted regret minimization. In: Proceedings of the 33rd AAAI Conference on Artificial Intelligence. Honolulu, USA: AAAI Press, 2019. 1829−1836 [25] Johanson M, Bard N, Burch N, Bowling M. Finding optimal abstract strategies in extensive form games. In: Proceedings of the 26th AAAI Conference on Artificial Intelligence. Toronto, Canada: AAAI Press, 2012. 1371−1379 [26] Heinrich J, Lanctot M, Silver D. Fictitious self-play in extensive-form games. In: Proceedings of the 32nd International Conference on Machine Learning. Lille, France: PMLR, 2015. 805−813 [27] Lanctot M, Waugh K, Zinkevich M, Bowling M. Monte Carlo sampling for regret minimization in extensive games. In: Proceedings of the 23rd Advances in Neural Information Processing Systems. Vancouver, Canada: Curran Associates Inc, 2009. 1078−1086 [28] Brown N, Lerer A, Gross S, Sandholm T. Deep counterfactual regret minimization. In: Proceedings of the 36th International Conference on Machine Learning. Long Beach, USA: PMLR, 2019. 793−802 [29] Hernandez-Leal P, Rosman B, Taylor M E, Sucar L E, Munoz De Cote E. A Bayesian approach for learning and tracking switching, non-stationary opponents. In: Proceedings of the 2016 International Conference on Autonomous Agents & Multiagent Systems. Singapore: ACM, 2016. 1315−131 [30] Rosman B, Hawasly M, Ramamoorthy S. Bayesian policy reuse. Machine Learning, 2016, 104(1): 99-127 doi: 10.1007/s10994-016-5547-y [31] Letcher A, Foerster J, Balduzzi D, Rocktäschel T, Whiteson S. Stable opponent shaping in differentiable games. In: Proceedings of the 7th International Conference on Learning Representations. New Orleans, USA: OpenReview.net, 2019. [32] Finn C, Abbeel P, Levine S. Model-agnostic meta-learning for fast adaptation of deep networks. In: Proceedings of the 34th International Conference on Machine Learning. Sydney, Australia: PMLR, 2017. 1126−1135 [33] Al-Shedivat M, Bansal T, Burda Y, Sutskever I, Mordatch I, Abbeel P. Continuous adaptation via meta-learning in nonstationary and competitive environments. In: Proceedings of the 6th International Conference on Learning Representations. Vancouver, Canada: OpenReview.net, 2018. [34] Vinyals O, Blundell C, Lillicrap T, Wierstra D. Matching networks for one shot learning. In: Proceedings of the 30th International Conference on Neural Information Processing Systems. Barcelona, Spain: Curran Associates Inc, 2016. 3630−3638 [35] Ravi S, Larochelle H. Optimization as a model for few-shot learning. In: Proceedings of the 5th International Conference on Learning Representations. Toulon, France: OpenReview.net, 2017. [36] Drugan M M. Reinforcement learning versus evolutionary computation: A survey on hybrid algorithms. Swarm and Evolutionary Computation, 2019, 44: 228-246 doi: 10.1016/j.swevo.2018.03.011 [37] Jaderberg M, Dalibard V, Osindero S, Czarnecki W M, Donahue J, Razavi A, et al. Population based training of neural networks. arXiv preprint arXiv: 1711.09846, 2017. [38] Jaderberg M, Czarnecki W M, Dunning I, Marris L, Lever G, Castaneda A G, et al. Human-level performance in 3D multiplayer games with population-based reinforcement learning. Science, 2019, 364(6443): 859-865 doi: 10.1126/science.aau6249 [39] Liu S, Lever G, Merel J, Tunyasuvunakool S, Heess N, Graepel T. Emergent coordination through competition. In: Proceedings of the 7th International Conference on Learning Representations. New Orleans, USA: OpenReview.net, 2019. [40] Khadka S, Tumer K. Evolution-guided policy gradient in reinforcement learning. In: Proceedings of the 32nd International Conference on Neural Information Processing Systems. Montréal, Canada: Curran Associates Inc, 2018. 1196−1208 [41] Conti E, Madhavan V, Petroski Such F, Lehman J, Stanley K, Clune J. Improving exploration in evolution strategies for deep reinforcement learning via a population of novelty-seeking agents. In: Proceedings of the 32nd International Conference on Neural Information Processing Systems. Montréal, Canada: Curran Associates Inc, 2018. 5032−5043 [42] Elman J L. Learning and development in neural networks: The importance of starting small. Cognition, 1993, 48(1): 71-99 doi: 10.1016/0010-0277(93)90058-4 [43] 梁星星, 冯旸赫, 马扬, 程光权, 黄金才, 王琦, 等.多Agent深度强化学习综述.自动化学报, 2020, 46(12): 2537-2557Liang Xing-Xing, Feng Yang-He, Ma Yang, Cheng Guang-Quan, Huang Jin-Cai, Wang Qi, et al. Deep multi-agent reinforcement learning: A survey. Acta Automatica Sinica, 2020, 46(12): 2537-2557 [44] 孙长银, 穆朝絮. 多智能体深度强化学习的若干关键科学问题. 自动化学报, 2020, 46(7): 1301-1312Sun Chang-Yin, Mu Chao-Xu. Important scientific problems of multi-agent deep reinforcement learning. Acta Automatica Sinica, 2020, 46(7): 1301-1312 [45] Finn C B. Learning to Learn With Gradients [Ph.D. dissertation], University of California, Berkeley, 2018 [46] Paszke A, Gross S, Massa F, Lerer A, Bradbury J, Chanan G, et al. Pytorch: An imperative style, high-performance deep learning library. In: Proceedings of the 33rd International Conference on Neural Information Processing Systems. Vancouver, Canada: Curran Associates Inc, 2019. 8024−8035 [47] Schulman J, Levine S, Abbeel P, Jordan M, Moritz P. Trust region policy optimization. In: Proceedings of the 32nd International Conference on Machine Learning. Lille, France: PMLR, 2015. 1889−1897 [48] Schulman J, Wolski F, Dhariwal P, Radford A, Klimov O. Proximal policy optimization algorithms. arXiv preprint arXiv: 1707.06347, 2017. [49] Schulman J, Moritz P, Levine S, Jordan M, Abbeel P. High-dimensional continuous control using generalized advantage estimation. In: Proceedings of the 4th International Conference on Learning Representations. San Juan, Puerto Rico: OpenReview.net, 2016. [50] Glorot X, Bordes A, Bengio Y. Deep sparse rectifier neural networks. In: Proceedings of the 4th International Conference on Artificial Intelligence and Statistics. Fort Lauderdale, USA: JMLR, 2011. 315−323 [51] Bansal T, Pachocki J, Sidor S, Sutskever I, Mordatch I. Emergent complexity via multi-agent competition. In: Proceedings of the 6th International Conference on Learning Representations. Vancouver, Canada: OpenReview.net, 2018. -

 下载:
下载:

计量
- 文章访问数: 1550
- HTML全文浏览量: 634
- PDF下载量: 337
- 被引次数: 0
