

-
摘要: 考虑到运动目标跟踪系统机动、隐身等人为对抗特征以及非视距、干扰、遮挡等环境因素, 其系统建模、估计与辨识过程中越来越无法回避非线性、非高斯以及参数未知等复杂系统特征的影响. 针对过程噪声先验信息不准确以及量测噪声非高斯环境下运动目标的非线性状态估计问题, 提出一种基于自然梯度的噪声自适应变分贝叶斯(Variational Bayes, VB)滤波算法. 首先, 利用指数族分布具有统一表达形式的优势, 构建参数化逆威沙特(Inverse-Wishart, IW)分布作为状态一步预测误差协方差的共轭先验分布, 同时选取学生t分布重构因量测随机缺失导致的具有非高斯特点的似然函数; 其次, 在变分贝叶斯优化框架下采用平均场理论将状态变量联合后验分布近似分解为独立的变分分布, 在此基础上, 结合坐标上升方法更新各变量的变分分布参数; 进而, 结合 Fisher 信息矩阵推导置信下界最大化关于状态估计及其估计误差协方差的自然梯度, 使非线性状态后验分布的近似分布沿梯度下降, 以实现对状态后验概率密度函数(Probability density function, PDF)的“紧密”逼近. 理论分析和仿真实验表明: 相对传统的非线性滤波方法, 本文算法对噪声不确定问题具有较好的自适应能力, 并且能够获得较高的状态估计精度.
-
关键词:
- 非线性滤波 /
- 自适应滤波 /
- 变分贝叶斯推断 /
- 自然梯度 /
- Fisher 信息矩阵
Abstract: Considering the increasing complexity and changeability of characteristics such as maneuvering and stealth in moving target tracking system and the influence of adverse factors such as non-line-of-sight, interference and occlusion in measurement environment. State estimation is likely to be confronted with complex system characteristics such as nonlinearity, non-Gaussian noise and unknown parameters. Aiming at nonlinear adaptive state estimation of moving target in a system with unknown process noise and non-Gaussian measurement noise, a novel noise adaptive variational Bayesian (VB) filter using natural gradient is proposed. Firstly, a parameterized inverse-Wishart (IW) distribution and a student's t distribution are constructed as the conjugate prior distribution of predicted state error covariance and measurement likelihood respectively. Then, in the framework of variational Bayesian optimization, the joint a posteriori distribution of estimation variables is approximately decomposed into independent variational distributions by using mean-field theory. On this basis, the variational distribution parameters of each variable are updated by combining coordinate ascend method and the characteristics of exponential distributions. Furthermore, under the condition of maximizing evidence lower bound, the natural gradients with respect to state estimation and its error covariance are derived by combining with Fisher information matrix. So that the variational distribution of nonlinear state gradually approaches the posteriori probability density function (PDF) of state along the natural gradient direction. Finally, simulation results show that the proposed algorithm has better adaptive ability to the problem of noise uncertainty and can obtain higher estimation accuracy compared to traditional algorithms. -
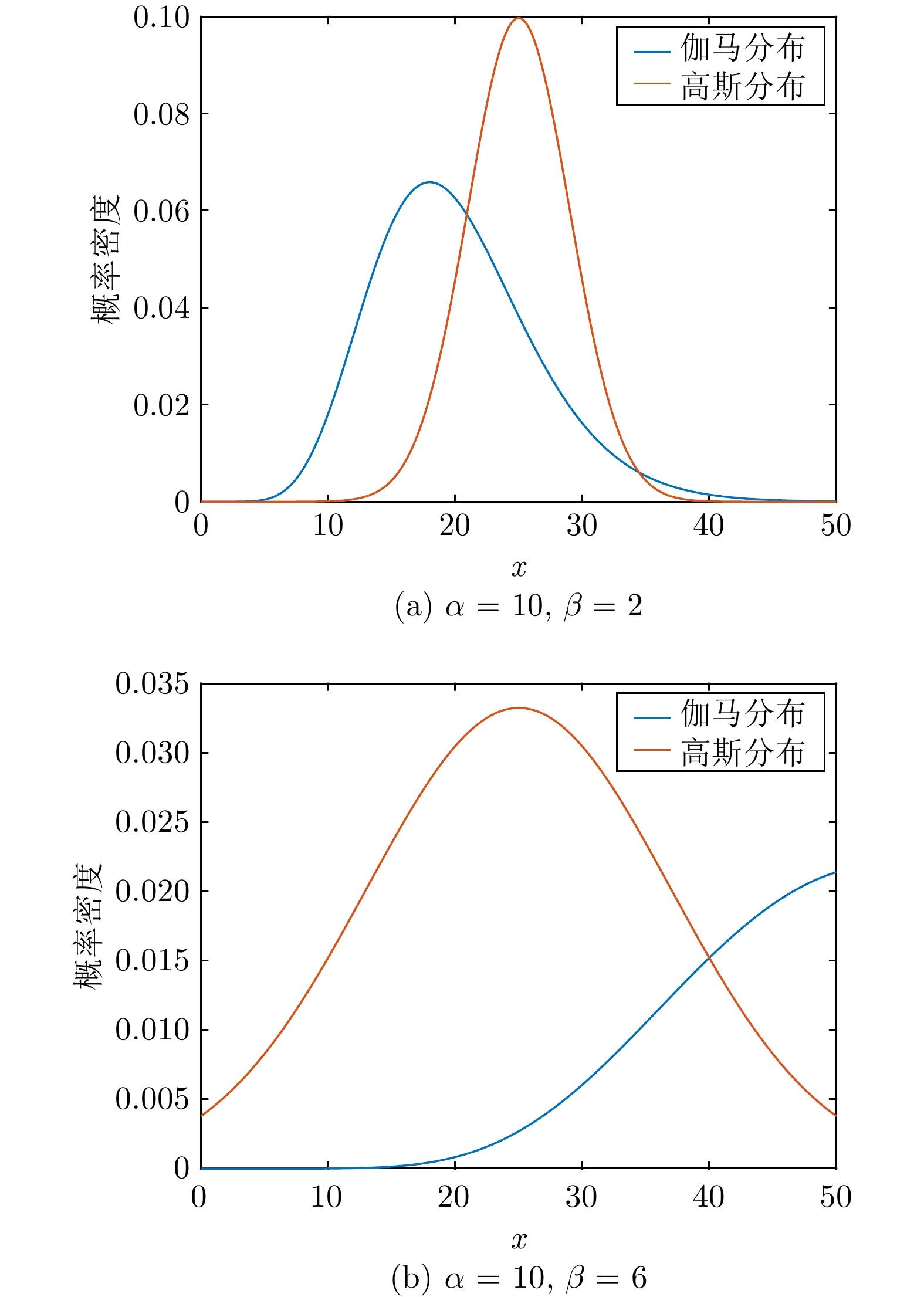
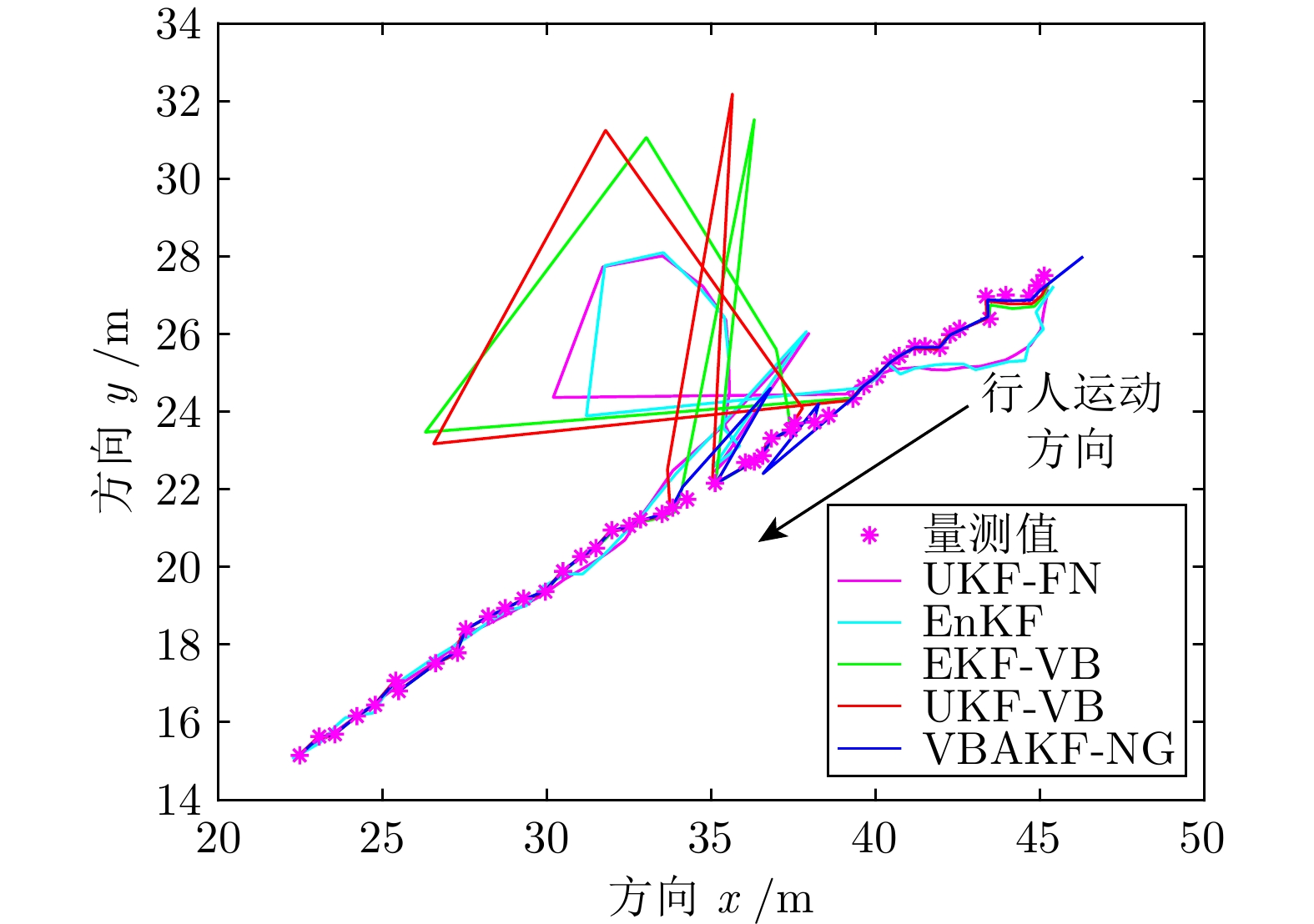
图 1 伽马分布参数对量测似然函数的影响示意图
Fig. 1 The diagram of the influence of Gamma distribution parameters on likelihood
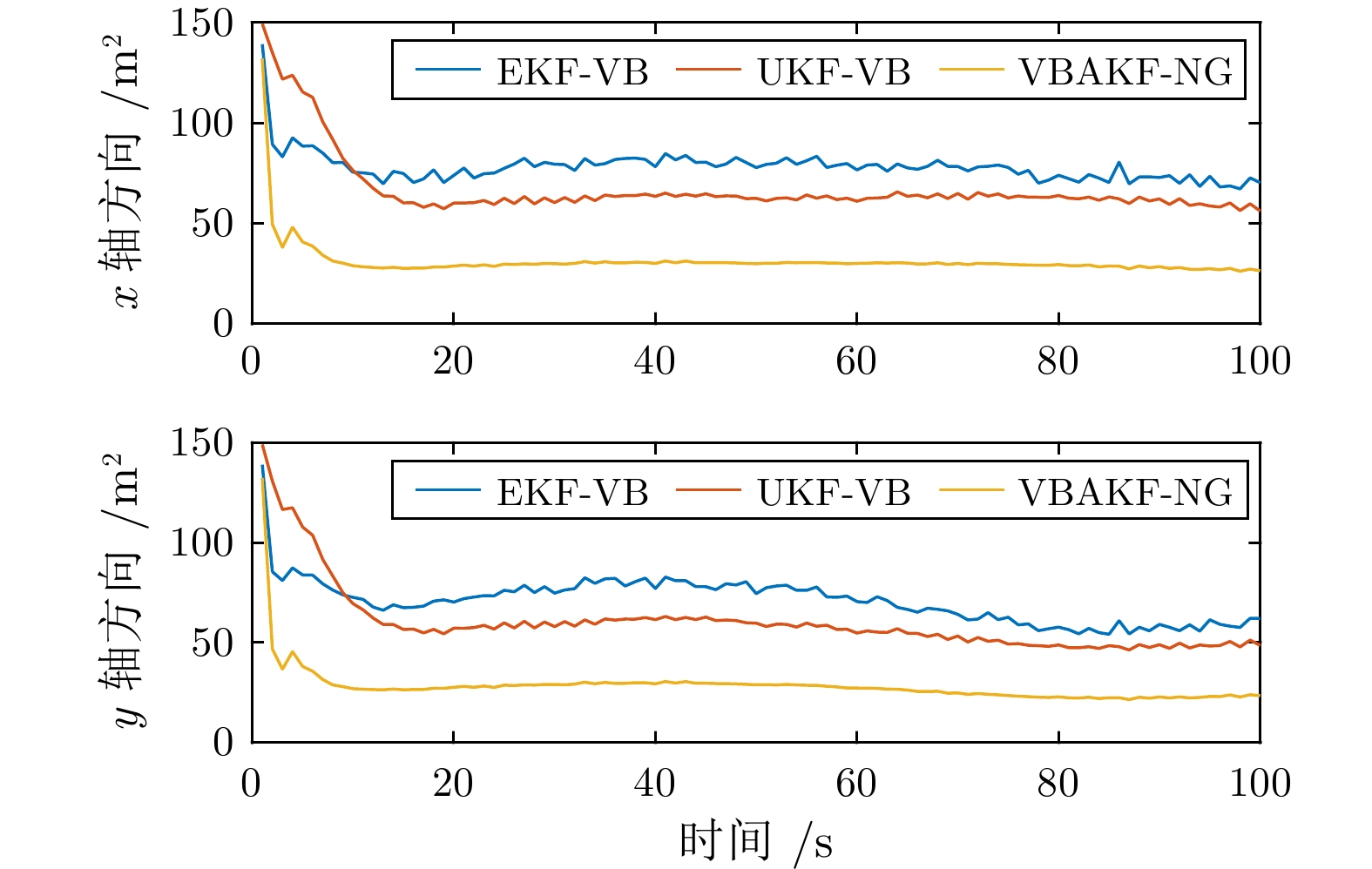
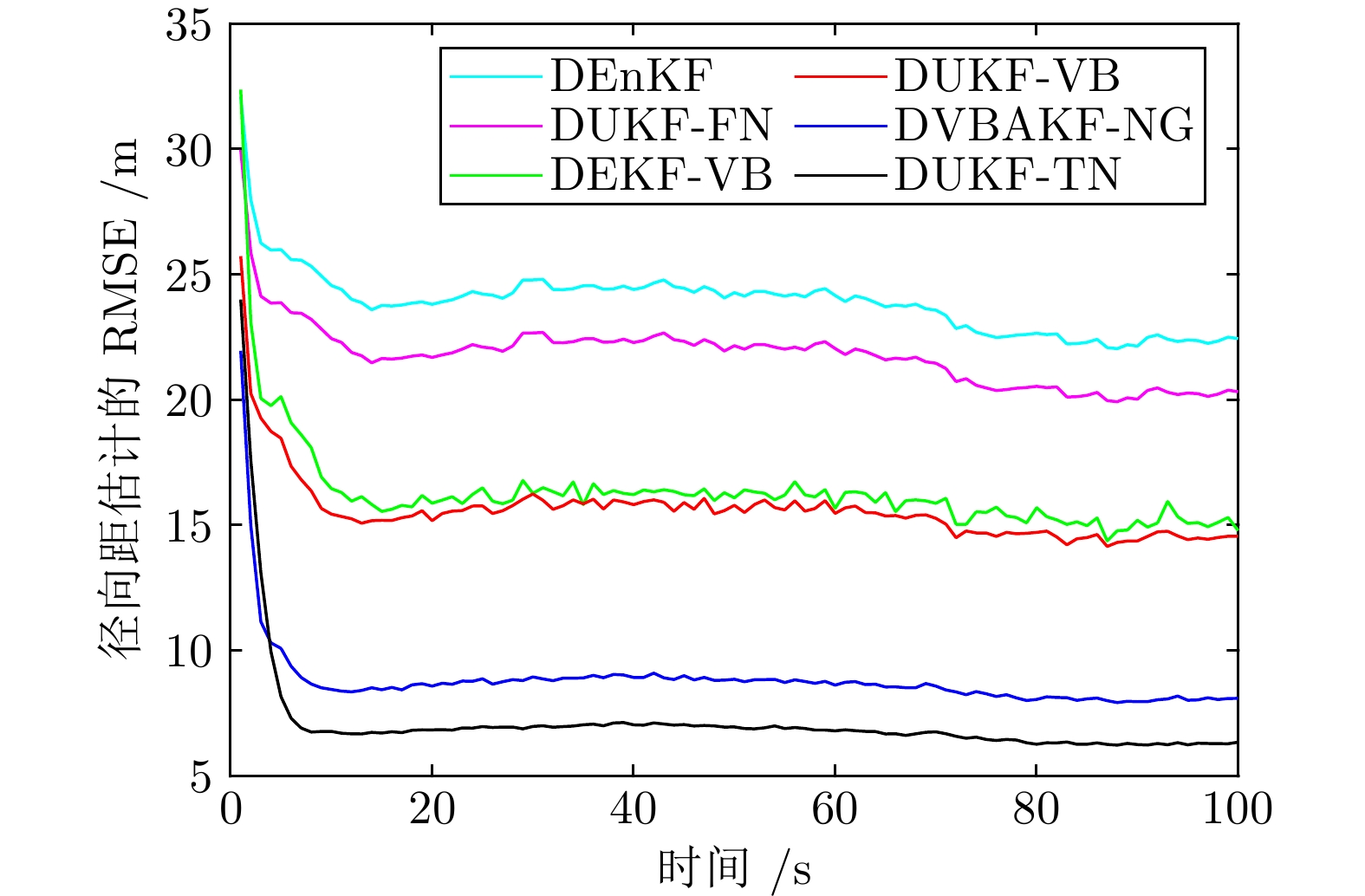
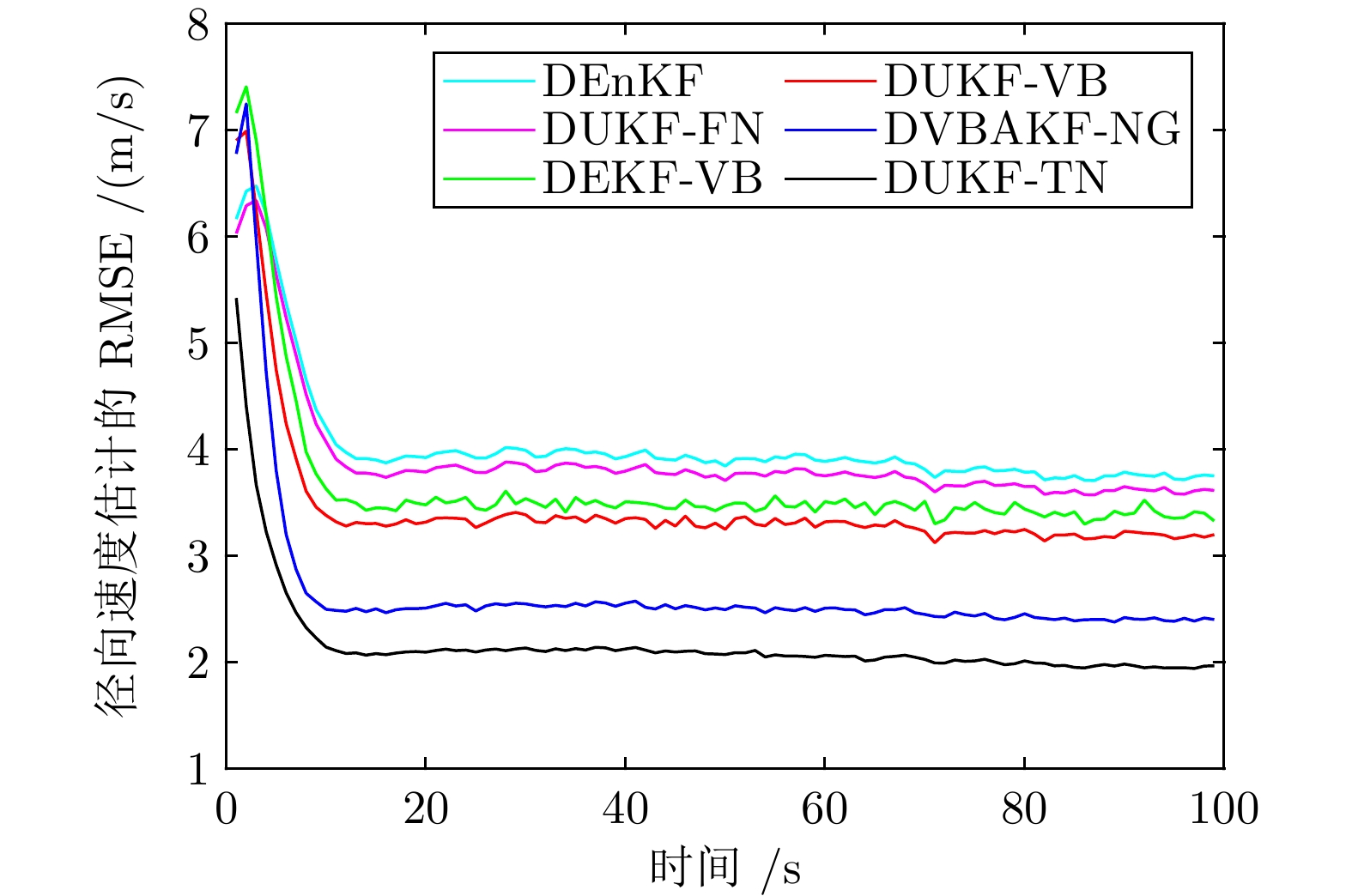
图 2 传感器1 位置状态预测误差协方差的估计值
Fig. 2 The expectation of the position state prediction error covariance from Sensor 1
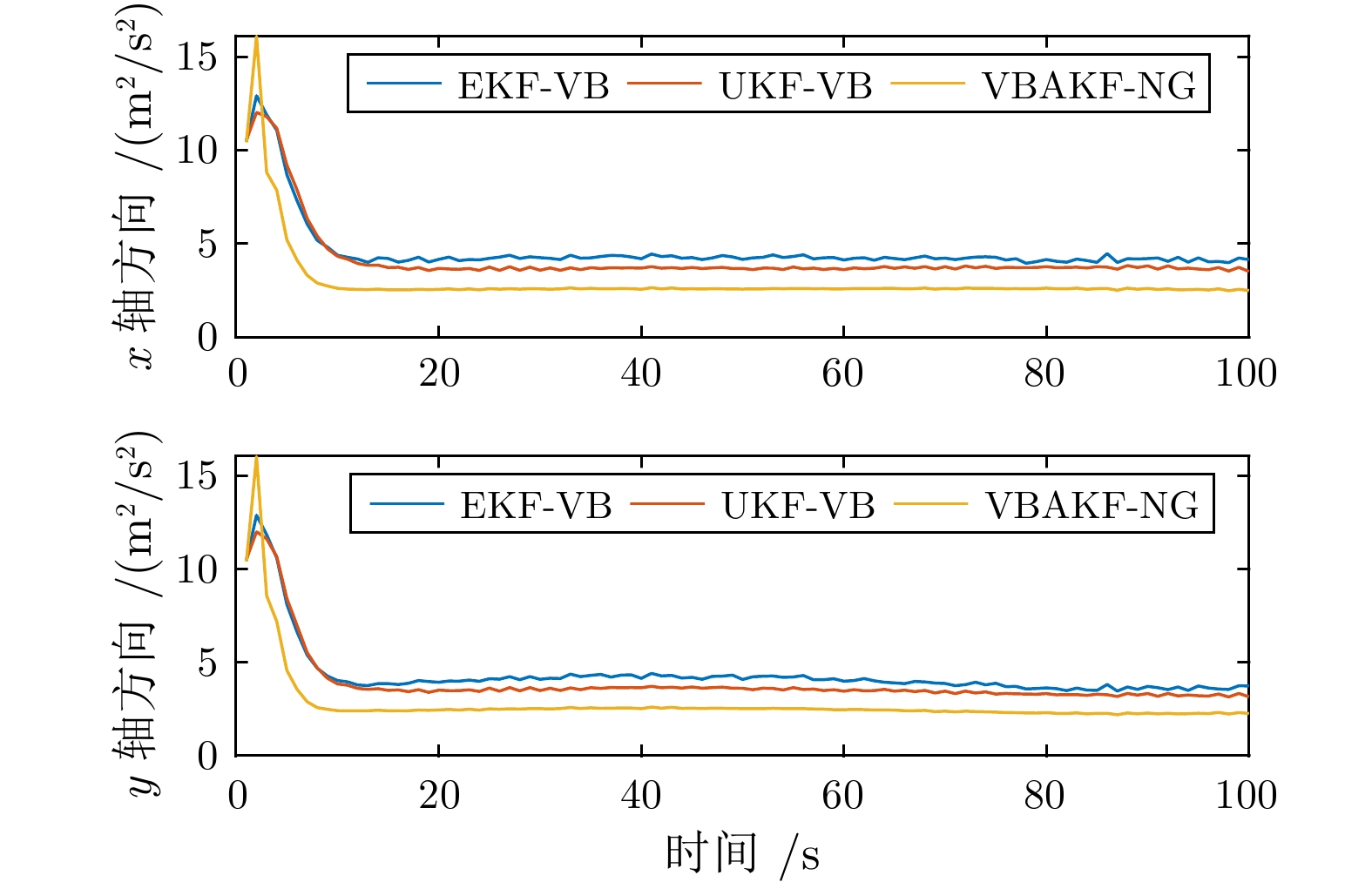
图 3 传感器1 速度状态预测误差协方差的估计值
Fig. 3 The expectation of the velocity state prediction error covariance from Sensor 1

图 4 传感器2 位置状态预测误差协方差的估计值
Fig. 4 The expectation of the position state prediction error covariance from Sensor 2
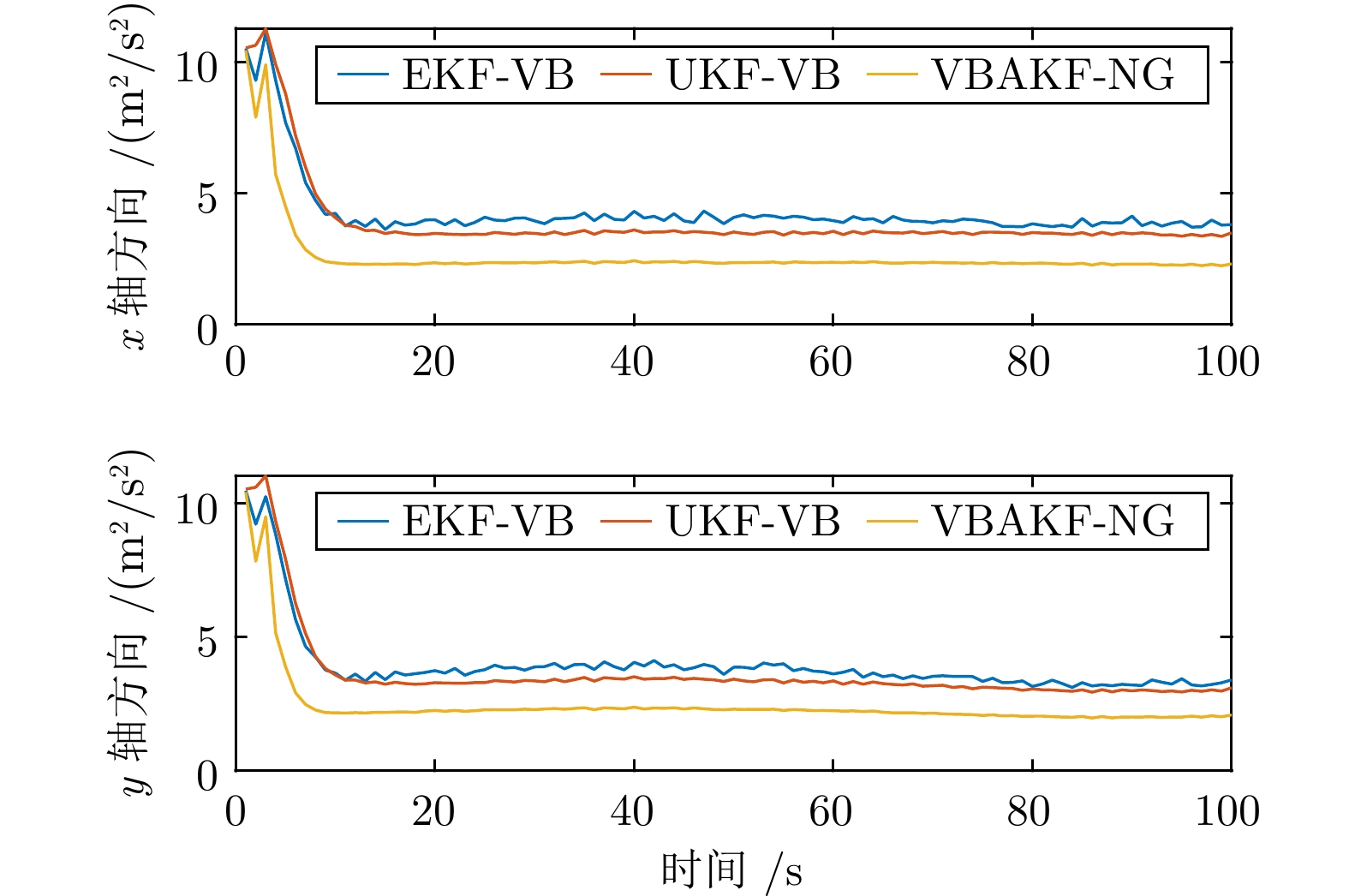
图 7 传感器3 速度状态预测误差协方差的估计值
Fig. 7 The expectation of the velocity state prediction error covariance from Sensor 3
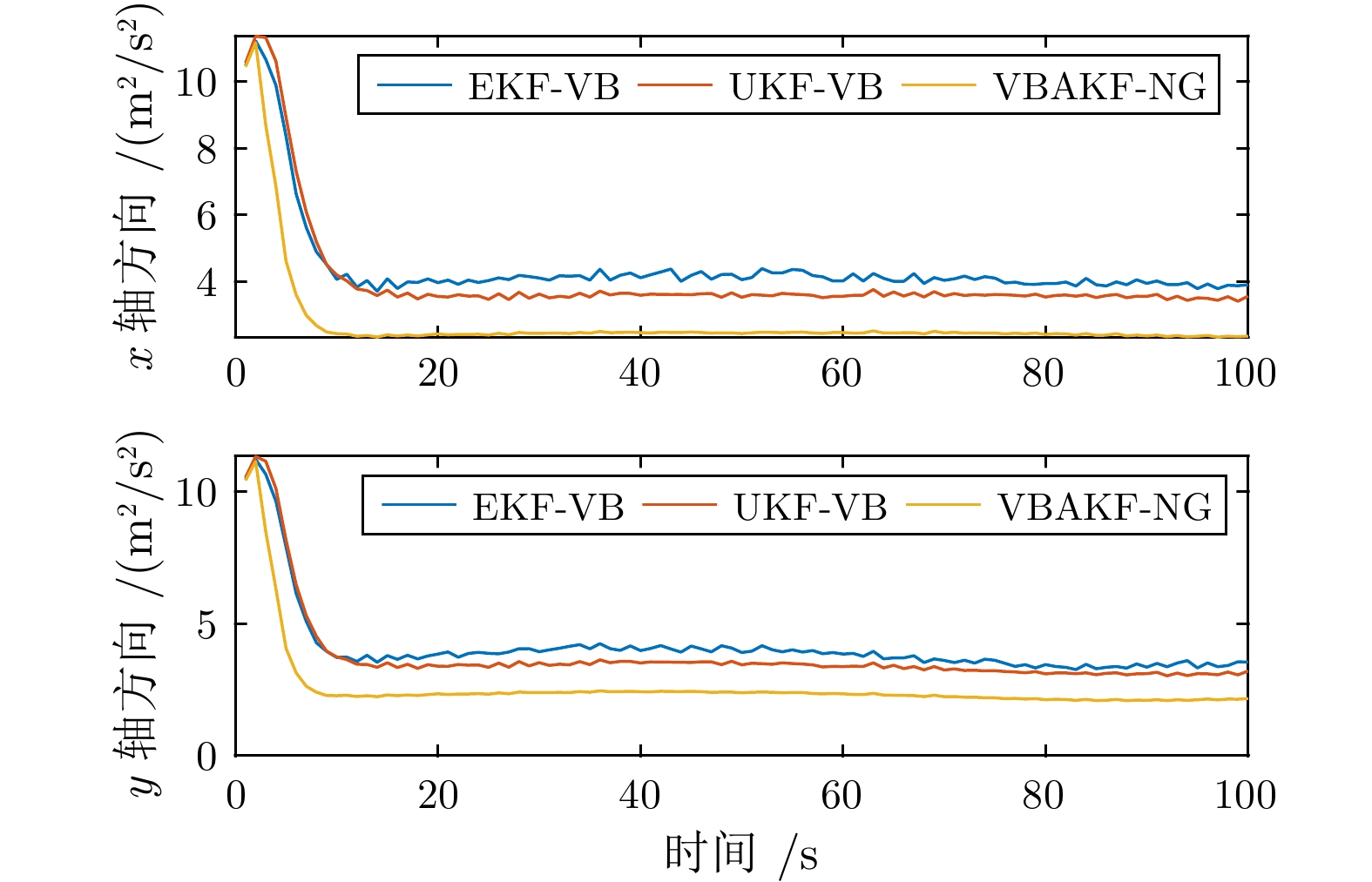
图 5 传感器2 速度状态预测误差协方差的估计值
Fig. 5 The expectation of the velocity state prediction error covariance from Sensor 2
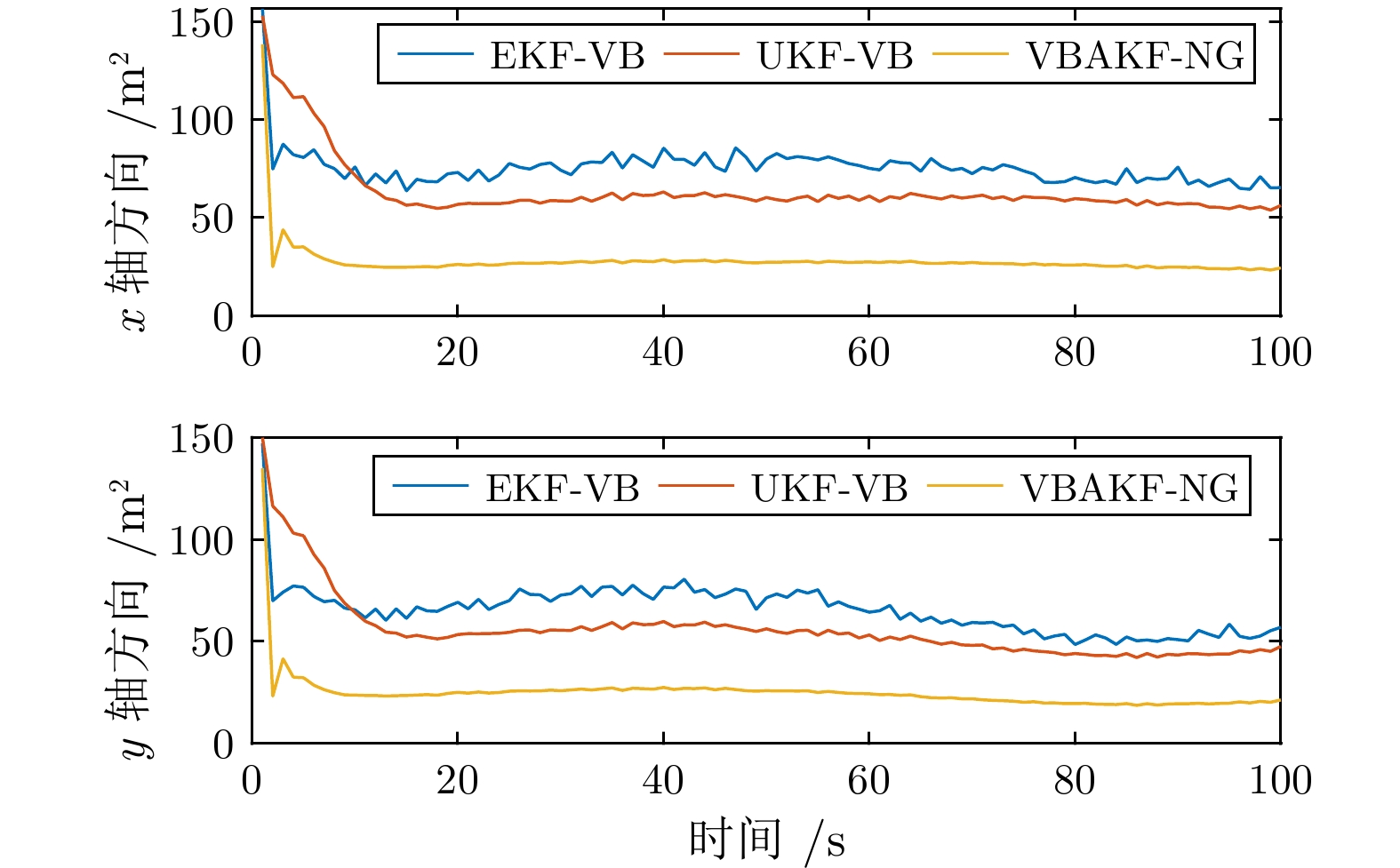
图 6 传感器3 位置状态预测误差协方差的估计值
Fig. 6 The expectation of the position state prediction error covariance from Sensor 3
图 8 传感器1 量测噪声方差的估计值
Fig. 8 The expectation of the measurement noise variance from Sensor 1

图 9 传感器2 量测噪声方差的估计值
Fig. 9 The expectation of the measurement noise variance from Sensor 2
图 10 传感器3 量测噪声方差的估计值
Fig. 10 The expectation of the measurement noise variance from Sensor 3
表 1 仿真参数
Table 1 Simulation parameters
参数 参数值 $ \alpha_0 $ 1 $ \beta_0 $ 2 $ t_s $ 100 $ {\tau} $ 10 $ v $ 5 $ n $ 4  下载: 导出CSV
下载: 导出CSV
-
[1] Shnitzer T, Talmon R, Slotine J J. Diffusion maps Kalman filter for a class of systems with gradient flows. IEEE Transactions on Signal Processing, 2020, 68: 2739-2753 doi: 10.1109/TSP.2020.2987750 [2] Wang X X, Liang Y, Pan Q, Zhao C H, Yang F. Nonlinear Gaussian smoothers with colored measurement noise. IEEE Transactions on Automatic Control, 2015, 60(3): 870-876 doi: 10.1109/TAC.2014.2337991 [3] Copp B, Subbarao K. Nonlinear adaptive filtering in terrain-referenced navigation. IEEE Transactions on Aerospace and Electronic Systems, 2015, 51(4): 3461-3469 doi: 10.1109/TAES.2015.140826 [4] 潘泉, 胡玉梅, 兰华, 孙帅, 王增福, 杨峰. 信息融合理论研究进展: 基于变分贝叶斯的联合优化. 自动化学报, 2019, 45(7): 1207-1223Pan Quan, Hu Yu-Mei, Lan Hua, Sun Shuai, Wang Zeng-Fu, Yang Feng. Information fusion progress: Joint optimization based on variational Bayesian theory. Acta Automatica Sinica, 2019, 45(7): 1207-1223 [5] Huang Y L, Zhang Y G, Zhao Y X, Chambers J A. A novel robust Gaussian-Student's t mixture distribution based Kalman filter. IEEE Transactions on Signal Processing, 2019, 67(13): 3606-3620 doi: 10.1109/TSP.2019.2916755 [6] Särkkä S, Nummenmaa A. Recursive noise adaptive Kalman filtering by variational Bayesian approximations. IEEE Transactions on Automatic Control, 2009, 54(3): 596-600 doi: 10.1109/TAC.2008.2008348 [7] Särkkä S, Hartikainen J. Non-linear noise adaptive Kalman filtering via variational Bayes. In: Proceedings of the IEEE International Workshop on Machine Learning for Signal Processing. Southampton, UK: IEEE, 2013. 1−6 [8] Agamennoni G, Nieto J I, Nebot E M. Approximate inference in state-space models with heavy-tailed noise. IEEE Transactions on Signal Processing, 2012, 60(10): 5024-5037 doi: 10.1109/TSP.2012.2208106 [9] Li W L, Sun S H, Jia Y M, Du J P. Robust unscented Kalman filter with adaptation of process and measurement noise covariances. Digital Signal Processing, 2016, 48: 93-103 doi: 10.1016/j.dsp.2015.09.004 [10] Dong P, Jing Z L, Leung H, Shen K, Li M Z. The labeled multi-Bernoulli filter for multitarget tracking with glint noise. IEEE Transactions on Aerospace and Electronic Systems, 2019, 55(5): 2253-2268 doi: 10.1109/TAES.2018.2884183 [11] Zhang W Y, Liang Y, Yang F, Xu L F. A robust Student's t-based labeled multi-Bernoulli filter. In: Proceedings of the 22th International Conference on Information Fusion. Ottawa, Canada: IEEE, 2019. 1−6 [12] Ardeshiri T, Özkan E, Orguner U, Gustafsson F. Approximate Bayesian smoothing with unknown process and measurement noise covariances. IEEE Signal Processing Letters, 2015, 22(12): 2450-2454 doi: 10.1109/LSP.2015.2490543 [13] Huang Y L, Zhang Y G, Wu Z M, Li N, Chambers J. A novel adaptive Kalman filter with inaccurate process and measurement noise covariance matrices. IEEE Transactions on Automatic Control, 2018, 63(2): 594-601 doi: 10.1109/TAC.2017.2730480 [14] Turner R, Bottone S, Stanek C. Online variational approximations to non-exponential family change point models: With application to radar tracking. In: Proceedings of the 26th International Conference on Neural Information Processing Systems. Lake Tahoe, USA: Curran Associates Inc., 2013. 306−314 [15] Tronarp F, García-Fernández Á F, Särkkä S. Iterative filtering and smoothing in nonlinear and non-Gaussian systems using conditional moments. IEEE Signal Processing Letters, 2018, 25(3): 408-412 doi: 10.1109/LSP.2018.2794767 [16] Nurminen H, Ardeshiri T, Piché R, Gustafsson F. Skew- t filter and smoother with improved covariance matrix approximation. IEEE Transactions on Signal Processing, 2018, 66(21): 5618-5633 doi: 10.1109/TSP.2018.2865434 [17] Gultekin S, Paisley J. Nonlinear Kalman filtering with divergence minimization. IEEE Transactions on Signal Processing, 2017, 65(23): 6319-6331 doi: 10.1109/TSP.2017.2752729 [18] Piché R, Särkkä S, Hartikainen J. Recursive outlier-robust filtering and smoothing for nonlinear systems using the multivariate Student-t distribution. In: Proceedings of the IEEE International Workshop on Machine Learning for Signal Processing. Santander, Spain: IEEE, 2012. 1−6 [19] Nurminen H, Ardeshiri T, Piché R, Gustafsson F. Robust inference for state-space models with skewed measurement noise. IEEE Signal Processing Letters, 2015, 22(11): 1898-1902 doi: 10.1109/LSP.2015.2437456 [20] Huang Y L, Zhang Y G, Li N, Wu Z M, Chambers J A. A novel robust Student's t-based Kalman filter. IEEE Transactions on Aerospace and Electronic Systems, 2017, 53(3): 1545-1554 doi: 10.1109/TAES.2017.2651684 [21] 胡振涛, 杨诗博, 胡玉梅, 周林, 金勇, 杨琳琳. 基于变分贝叶斯的分布式融合目标跟踪. 电子学报, 2022, 50(5): 1058-1065Hu Zhen-Tao, Yang Shi-Bo, Hu Yu-Mei, Zhou Lin, Jin Yong, Yang Lin-Lin. Distributed fusion target tracking based on variational Bayes. Acta Electronica Sinica, 2022, 50(5): 1058-1065 [22] Brooks S. Markov chain Monte Carlo method and its application. Journal of the Royal Statistical Society: Series D (The Statistician), 1998, 47(1): 69-100 [23] Geyer C J. Practical Markov chain Monte Carlo. Statistical Science, 1992, 7(4): 473-483 [24] Salimans T, Kingma D P, Welling M. Markov chain Monte Carlo and variational inference: Bridging the gap. In: Proceedings of the 32nd International Conference on International Conference on Machine Learning. Lille, France: JMLR.org, 2015. 1218−1226 [25] Humpherys J, West J. Kalman filtering with Newton's method[Lecture Notes]. IEEE Control Systems Magazine, 2010, 30(6): 101-106 doi: 10.1109/MCS.2010.938485 [26] Alessandri A, Gaggero M. Moving-horizon estimation for discrete-time linear and nonlinear systems using the gradient and Newton methods. In: Proceedings of the 55th IEEE Conference on Decision and Control. Las Vegas, USA: IEEE, 2016. 2906−2911 [27] Akyildiz Ö D, Chouzenoux É, Elvira V, Míguez J. A probabilistic incremental proximal gradient method. IEEE Signal Processing Letters, 2019, 26(8): 1257-1261 doi: 10.1109/LSP.2019.2926926 [28] Amari S I. Natural gradient works efficiently in learning. Neural Computation, 1998, 10(2): 251-276 doi: 10.1162/089976698300017746 [29] Ollivier Y. Online natural gradient as a Kalman filter. Electronic Journal of Statistics, 2018, 12(2): 2930-2961 [30] Cheng Y Q, Wang X Z, Morelande M, Moran B. Information geometry of target tracking sensor networks. Information Fusion, 2013, 14(3): 311-326 doi: 10.1016/j.inffus.2012.02.005 [31] Schmitt L, Fichter W. Globally valid posterior Cramér-Rao bound for three-dimensional bearings-only filtering. IEEE Transactions on Aerospace and Electronic Systems, 2018, 55(4): 2036-2044 -

 下载:
下载:

计量
- 文章访问数: 962
- HTML全文浏览量: 415
- PDF下载量: 273
- 被引次数: 0
