

Privacy-preserving Average Consensus Control forMulti-agent Systems Under Deception Attacks
-
摘要: 针对通信网络遭受欺骗攻击的离散时间多智能体系统, 研究其均值趋同和隐私保护问题. 首先, 考虑链路信道存在窃听者的情形, 提出一种基于状态分解思想的分布式网络节点值重构方法, 以阻止系统初始信息的泄露. 其次, 针对所构建的欺骗攻击模型, 利用重构后节点状态信息并结合现有的安全接受广播算法, 提出一种适用于无向通信网络的多智能体系统均值趋同控制方法. 理论分析表明, 该方法能够有效保护节点初始状态信息的隐私, 并能消除链路中欺骗攻击的影响, 实现分布式系统中所有节点以初始值均值趋同. 最后, 通过数值仿真实验验证了该方法的有效性.Abstract: This paper investigates the average consensus and privacy-preserving problem for discrete-time multi-agent systems with deception attacks. First, considering the situation where there are eavesdroppers on the link channel, a distributed node value reconstruction method based on the idea of state decomposition is proposed to prevent the leakage of the initial information of the system. Then, under the constructed deception attack model, a novel average consensus control method for multi-agent systems with undirected communication networks is proposed, which uses the reconstructed node status information and combines with the secure acceptance and broadcast algorithm. Theoretical analysis shows that the proposed method can effectively protect the privacy of the initial state information of the nodes, and eliminate the influence of deception attacks in the links, and reach a consensus. Finally, numerical simulation experiments verify the effectiveness of the proposed method.
-
Key words:
- Multi-agent systems /
- average consensus /
- deception attack /
- privacy-preserving /
- cyber security
-
在现代化生产过程中, 有效的故障检测方法能够保障生产安全和提高生产效率.由于生产过程中多变量数据可以由分布式控制系统进行采集, 因此, 许多基于数据驱动的多变量统计过程控制(Multivariate statistical process control, MSPC)方法已经得到了广泛应用并取得了可喜的成果[1-2].
主元分析(Principal component analysis, PCA)作为一种典型的MSPC方法已经成功地被应用到生产过程的故障检测领域中并取得良好的效果[3-4]. PCA通过对监控变量实施线性变换并依据累积百分比方差(Cumulative percent variance, CPV)将输入空间分解为主元子空间(Principal component subspace, PCS)和残差子空间(Residual subspace, RS).在PCS和RS中, 分别应用$ T^2 $和平方预测误差(Square prediction error, SPE)两个统计量实现对样本状态(正常或故障)的监控[4].近年来, 基于PCA的不同故障检测策略已经被提出, 如核主元分析(Kernel PCA, KPCA)[5]和动态主元分析(Dynamic PCA, DPCA)[6]. KPCA是指首先通过非线性变换将输入空间映射至高维特征空间(Feature space, FS), 然后在FS中执行PCA方法进行故障检测[7].由于KPCA能够捕获过程的非线性特征, 故它更适合非线性过程的故障检测[8]. DPCA是考虑到过程的动态特征而被提出的.在DPCA方法中, 首先通过增广过程时间序列的方法将样本的动态特征转换为变量静态特征, 然后应用静态PCA实现对过程动态和静态特征的同步提取[9].需要注意的是上述基于PCA的不同方法首先对样本数据进行适当处理, 然后执行PCA故障检测.故障检测过程仍然应用$ T^2 $和$ SPE $两个统计量对过程进行监控. $ T^2 $和$ SPE $适用于单模态过程故障检测, 并且在故障检测过程中通常假设过程变量是独立同分布[10].当得分变量存在多模态结构或非线性相关时, $ T^2 $和$ SPE $控制图通常具有较低的故障检测率(Fault detection rate, FDR)或较高的误报率(False alarm rate, FAR)[11].
针对非线性和多模态过程故障检测问题, He等提出应用k近邻规则的故障检测(Fault detection using the k-nearest neighbor rule, FD-kNN)方法[12]. FD-kNN首先在训练集中依据欧氏距离查找样本的k近邻集, 然后以样本与其k近邻的距离之和作为统计指标进行过程监控.该方法能够降低过程的非线性和多模态等特征对故障检测的影响, 相比传统的基于PCA的不同方法具有较高的故障检测性能[12].与传统多模型方法相比[13-14], FD-kNN在多模态过程中只需要建立一个模型即可完成过程的故障检测, 它是一种更加适合多模态过程故障检测的单模型方法.考虑到FD-kNN中查找k近邻计算的复杂度, 一种基于主元的k近邻规则(Principal component-based k nearest neighbor rule, PC-kNN)被提出[15].该方法只在主元空间执行k近邻规则进行故障检测.由于少量主元参与查找样本k近邻的计算, 因此相比FD-kNN, PC-kNN具有高效性.然而, FD-kNN和PC-kNN方法具有相应的局限性[16].首先, 在多模态过程中如果模态方差结构差异明显, 即存在密集模态和稀疏模态, 这时密集模态的小尺度故障通常不能被上述方法检测.其次, PC-kNN方法只监视了样本在PCS中的变化, 一旦故障完全发生在RS中该方法是无效的.
针对具有非线性和多模态特征过程的故障检测问题, 本文提出一种基于k近邻主元得分差分的故障检测策略(Fault detection strategy based on principal component score difference of k nearest neighbors, kDiff-PCA).在kDiff-PCA中, 首先在训练集中查找样本的k近邻集并计算该集合的均值样本; 然后, 应用PCA计算训练集的主元负载矩阵, 同时计算样本与其均值样本的主元得分向量; 接下来, 计算每个样本的得分差分向量并获得过程的差分子空间; 最后, 在差分子空间计算新的统计量进行过程监控.在样本残差的计算中, 本文应用上述均值样本的得分对测试样本进行重构, 该过程区别于传统的残差计算方法.
1. 主元分析
假设$ {{{X}}_{m \times n}} $为训练集合, 其中$ m $和$ n $分别为样本数和监控变量数.在PCA中, 首先通过式(1)计算$ {X} $的协方差矩阵$ {C} $.
$$ \begin{equation} {{C}} = \frac{1}{{m - 1}}{{{X}}^{\rm{T}}}{{X}} \end{equation} $$ (1) 接下来, 将协方差矩阵$ {C} $进行特征值分解, 记$ {\lambda _1}, {\lambda _2}, \cdots , {\lambda _n} $为按照降序排列的特征值, $ {{P}} = [{{\pmb{p}}_1}, {{\pmb{p}}_2}, \cdots , {{\pmb{p}}_n}] $为与特征值相对应的特征向量矩阵.然后, 通过CPV确定主元数$ r $同时获得主元负载矩阵$ {{{P}}_r} = [{{\pmb{p}}_1}, {{\pmb{p}}_2}, \cdots , {{\pmb{p}}_r}] $.于是, $ {X} $的得分矩阵可表示为$ { T} = {\ {XP}}_r $且$ { X} $可以被分解为以下形式:
$$ \begin{equation} {{X}} = {{TP}}_r^{\rm{T}} + {{E}} \end{equation} $$ (2) 其中, $ E $为残差矩阵.
在故障检测过程中, PCA方法应用$ T^2 $和$ SPE $统计量分别监控样本在PCS和RS中的状态(正常或故障).
$$ \begin{equation} {{{T}}^2} = {\mathit{\boldsymbol{t}}}{{{\Lambda }}^{ - 1}}{{\mathit{\boldsymbol{t}}}^{\rm{T}}} \end{equation} $$ (3) $$ \begin{equation} SPE = {\mathit{\boldsymbol{e}}}{{\mathit{\boldsymbol{e}}}^{\rm{T}}} \end{equation} $$ (4) 其中, $ {\mathit{\boldsymbol{t}}} = {\mathit{\boldsymbol{x}}P}_r $为样本$ {\mathit{\boldsymbol{x}}} $的得分向量; $ {\Lambda} $为前$ r $个特征值构成的对角矩阵; $ {\mathit{\boldsymbol{e}}} = {\mathit{\boldsymbol{x}}}-{\mathit{\boldsymbol{t}}P}_r^{\rm T} $为样本$ {\mathit{\boldsymbol{x}}} $的残差向量.当变量服从多元高斯分布时, $ T^2 $和$ SPE $的控制限可以由式(5)和式(6)确定[17].
$$ \begin{equation} {{T}}_{\rm UCL}^2 = \frac{{r(m - 1)(m + 1)}}{{m(m - r)}}{{{F}}_{r, m - r;\alpha }} \end{equation} $$ (5) $$ \begin{equation} {{SPE}}_{\rm UCL} = g \cdot \chi _{h;\alpha }^2 \end{equation} $$ (6) 2. 基于$ \pmb k $近邻主元得分差分的故障检测策略
由于PCA方法通常不能有效捕获过程的非线性和多模态特征, 因此其在具有上述特征的过程中进行故障检测时, 通常不能获得令人满意的检测结果.当主元子空间中存在非线性或多模态结构时, 传统的$ T^2 $统计量具有较低的故障检测率.主要原因是在高维子空间中$ T^2 $统计量的控制限具有超椭圆结构, 这种超椭圆结构虽然能够准确检测过程的正常样本, 但是其对过程部分故障会产生误判.此外, 由式(4)可知$ SPE $用于监控样本残差的变化, 而式(4)可整理成如下形式:
$$ \begin{align} SPE = \, & ({\mathit{\boldsymbol{x}}P}{{{P}}^{\rm{T}}}{\rm{ - }}{\mathit{\boldsymbol{t}}P}_r^{\rm{T}}{\rm{)(}}{\mathit{\boldsymbol{x}}P}{{{P}}^{\rm{T}}}{\rm{ - }}{\mathit{\boldsymbol{t}}P}_r^{\rm{T}})^{\rm{T}} = \\ &{ [{\mathit{\boldsymbol{t}}}\;{{\mathit{\boldsymbol{t}}}_R}]{{[{\mathit{\boldsymbol{t}}}\;{{\mathit{\boldsymbol{t}}}_R}]}^{\rm{T}}} - 2{\mathit{\boldsymbol{t}}}{{\mathit{\boldsymbol{t}}}^{\rm{T}}} + {\mathit{\boldsymbol{t}}}{{\mathit{\boldsymbol{t}}}^{\rm{T}} = { {{\mathit{\boldsymbol{t}}}_R}{\mathit{\boldsymbol{t}}}_R^{\rm{T}}}}} \end{align} $$ (7) 其中, $ \bm t_R $为样本的残差得分向量.由式(7)可知, 从本质上看, $ SPE $计算的是样本残差得分到中心的平方欧氏距离.当样本残差得分分布平稳时, 使用这种距离对过程监控是有效的.然而, 如果残差得分分布差异较大且故障由分布平稳得分的异常变化引起, 那么这种故障通常不能被$ SPE $控制图检测.
为了降低非线性和多模态特征对PCA故障检测的影响和提高PCA的过程故障检测率, 本节提出一种基于k近邻主元得分差分的故障检测方法.
首先, 计算样本$ \bm x $的主元得分向量$ \bm t $.其次, 在训练集$ X $中应用k近邻规则查找$ \bm x $的k近邻样本$ {\mathit{\boldsymbol{x}}}^{(1)}, {\mathit{\boldsymbol{x}}}^{(2)}, \cdots , {\mathit{\boldsymbol{x}}}^{(k)} $, 并计算k近邻样本均值$ \bm m $的得分向量$ { \mathit{\boldsymbol{t}}^{[{\bm m}]}} $.
$$ \begin{equation} {\mathit{\boldsymbol{m}}} = \frac{1}{k}\sum\limits_{i = 1}^k {{{\mathit{\boldsymbol{x}}}^{(i)}}} \end{equation} $$ (8) $$ \begin{equation} {{\mathit{\boldsymbol{t}}}^{[\mathit{\boldsymbol{{m}}}]}} = {\mathit{\boldsymbol{m}}}{{{P}}_r} \end{equation} $$ (9) 接下来, 计算$ \bm x $的主元得分$ \bm t $与k近邻估计得分$ {\mathit{\boldsymbol{t}}^{[{\bm m}]}} $的差分向量$ \bm s $, 如式(10)所示.
$$ \begin{equation} \begin{array}{*{20}{l}} {\mathit{\boldsymbol{s}}}{ = {\mathit{\boldsymbol{t}}} - {{\mathit{\boldsymbol{t}}}^{[{\mathit{\boldsymbol{m}}}]}{ = ({\mathit{\boldsymbol{x}}} - {\mathit{\boldsymbol{m}}}){{P}}_r}}}\\ \end{array} \end{equation} $$ (10) 由式(10)可以看出, $ \bm s $本质上在衡量样本$ \bm x $与其近邻中心$ \bm m $的差异.由几何知识可知, 向量$ \bm x $与$ \bm m $的差$ {\bm x}-{\bm m} $表达的是一个起点为$ \bm m $终点为$ \bm x $的向量.这种差运算能够消除样本相对于坐标原点的差异, 同时可以获得样本相对于近邻的变化信息[12, 15].综上, 通过差分方法得到的差分向量$ \bm s $不包含过程的结构信息.换句话说, 差分方法能够降低多模态或非线性结构对过程故障检测的影响.
最后, 根据式(11)计算统计量$ {{T}}^2_{\rm {diff}} $,
$$ \begin{equation} {{T}}_{\rm diff}^2 = {\mathit{\boldsymbol{s}}}\;{{\Sigma }}_{\mathit{\boldsymbol{s}}}^{ - 1}\, {{\mathit{\boldsymbol{s}}}^{\rm{T}}} \end{equation} $$ (11) 其中, $ {{\Sigma_{\bm s}}} $为训练样本得分差分矩阵$ S $的协方差矩阵.在残差子空间建立如下统计量:
$$ \begin{equation} {{{q}}_{\rm {diff}}} = ({\mathit{\boldsymbol{x}}} - {{\mathit{\boldsymbol{t}}}^{[{\mathit{\boldsymbol{m}}}]}}{{P}}_r^{\rm{T}}){{\Sigma }}_{\mathit{\boldsymbol{e}}}^{ - 1}{({\mathit{\boldsymbol{x}}} - {{\mathit{\boldsymbol{t}}}^{[{\mathit{\boldsymbol{m}}}]}}{{P}}_r^{\rm{T}})^{\rm{T}}} \end{equation} $$ (12) 其中, $ {{\Sigma_{\bm e}}} $是残差矩阵$ {E = X-T^{[{\bm m}]}}{ P}_r^{\rm T} $的协方差矩阵.
由式(10)可知, 数据集$ S $具有中心在差分子空间坐标原点的单模态结构, 若假设得分差分向量满足多元高斯分布, 则$ {{T}}^2_{\rm {diff}} $的控制限可依据式(5)进行确定.对于$ {q}_{\rm {diff}} $, 式(12)可以改写成如下形式:
$$ \begin{equation} {{{q}}_{\rm {diff}}} = [({\mathit{\boldsymbol{x}}} - {\mathit{\boldsymbol{m}}}) + {{\mathit{\boldsymbol{e}}}_{\mathit{\boldsymbol{m}}}}]{{\Sigma }}_{\mathit{\boldsymbol{e}}}^{ - 1}{[({\mathit{\boldsymbol{x}}} - {\mathit{\boldsymbol{m}}}) + {{\mathit{\boldsymbol{e}}}_{\mathit{\boldsymbol{m}}}}]^{\rm{T}}} \end{equation} $$ (13) 其中, $ {\bm e}_m $为样本近邻均值的残差.若假设$ {\bm e} = ({\pmb x}-{\pmb m})+{\bm e}_m $近似服从多元高斯分布, 同样$ {q}_{\rm {diff}} $的控制限也可以由式(5)进行确定.为了方便, $ {T}_{\rm {diff}}^2 $和$ {q}_{\rm {diff}} $的控制限也可以应用核密度方法(Kernel density estimation, KDE)进行确定[18]. KDE方法在控制限的确定过程中已经得到了广泛的应用[19-21].
本文方法故障检测过程包含两步:离线建模和在线检测.
1) 离线建模
步骤1. 第一步:应用式(1)和式(2)计算训练数据的得分矩阵$ T $及负载矩阵$ P_r $;
步骤2. 应用式(8)计算训练样本$ {\bm x} $的k近邻均值向量$ {\bm m} $, 记训练集的k近邻均值矩阵为$ { M} $; 应用式(9)计算训练集的得分估计矩阵$ { {T^{[{\bm m}]}} = { MP_r}} $;
步骤3. 应用式(10)计算训练集得分差分矩阵$ { {S = T-T^{[{\bm m}]}}} $, 并计算$ S $的协方差矩阵$ { {\Sigma_{\bm s}}} $;
步骤4. 应用式(11)和式(12)计算训练样本的$ { T}_{\rm {diff}}^2 $和$ { q}_{\rm {diff}} $并确定控制限$ {T}_{\rm {diffUCL}}^2 $和$ {q}_{\rm {diffUCL}} $.
2) 在线检测
对于测试样本$ \bm x $,
步骤1. 计算$ \bm x $的得分向量$ \bm t $;
步骤2. 应用式(8)计算$ \bm x $的k近邻均值向量$ \bm m $并应用式(9)计算$ \bm x $的估计得分$ {\boldsymbol{t}^{[m]}} $;
步骤3. 应用式(10)计算$ \bm x $的得分差分向量$ \bm s $并应用式(11)和式(12)计算$ { T}_{\rm {diff}}^2 $和$ {q}_{\rm {diff}} $;
步骤4. 若$ {T}_{\rm {diff}}^2>{ T}_{\rm {diffUCL}}^2 $或$ { q}_{\rm {diff}}>{ q}_{\rm {diffUCL}} $, $ \bm x $为故障样本; 否则, $ \bm x $为正常样本.
需要注意的是本文方法中$ { T}_{\rm {diff}}^2 $统计量不同于PC-kNN和PCA中的$ D^2 $ (式(14))与$ { T^2} $统计量.
$$ \begin{equation} {{{D}}^2} = \sum\limits_{i = 1}^k {({\mathit{\boldsymbol{t}}} - {{\mathit{\boldsymbol{t}}}^{(i)}}){{({\mathit{\boldsymbol{t}}} - {{\mathit{\boldsymbol{t}}}^{(i)}})}^{\rm{T}}}} \end{equation} $$ (14) 与PC-kNN相比, 本文方法虽然同样应用k近邻规则, 但只是应用该规则进行样本主元得分的估计.由式(11)和式(14)可以看出, 本文方法应用$ {T}_{\rm {diff}}^2 $监控样本在得分差分子空间中的变化, 而PC-kNN应用$ D^2 $监控样本在主元子空间中的变化.同样, 虽然$ {T}_{\rm {diff}}^2 $与$ T^2 $具有相似结构, 但两者在不同的子空间(差分子空间和主元子空间)监控样本的变化.另外, 本文方法中的残差统计量$ { q}_{\rm {diff}} $不同于$ SPE $统计量.由式(4)和式(13)可以看出$ {q}_{\rm {diff}} $和$ SPE $分别通过$ {\bm t^{[{\bm m}]}} $和$ \bm t $对样本进行重构.
3. 仿真实验
3.1 非线性例子
在本节中, 通过一个非线性数值例子[12, 22]证明kDiff-PCA的有效性.该例共包含6个监控变量, 其中前两个变量$ x $和$ y $满足如下关系:
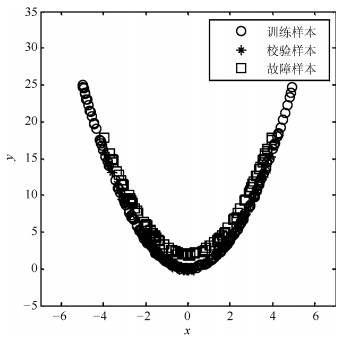
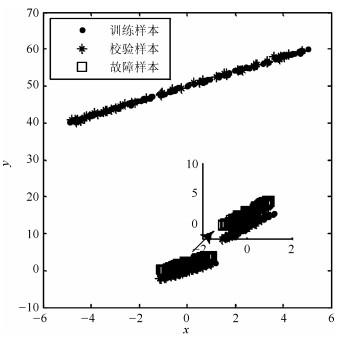
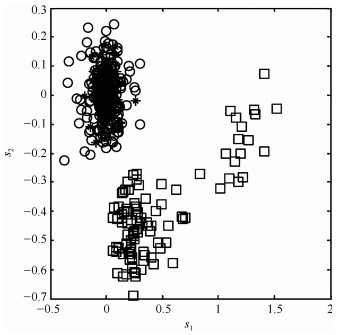
$$ \begin{equation} {y = {x^2} + e} \end{equation} $$ (15) 其中, 变量$ x $在$ [-5, 5] $服从均匀分布, $ e $是[0, 2]上的均匀噪声序列.余下变量为均值为0和方差为0.1的高斯白噪声.本例中, 200个正常样本用于模型训练.测试集同样包含200个样本, 其中前100个为在正常条件下采集的校验样本, 余下的为通过对变量$ y $增加扰动生成的故障点, 样本散点图如图 1所示.
为了验证本文方法的有效性, 在本节中将基于PCA的方法, 如PCA-$ T^2 $、PCA-$ SPE $、KPCA-$ T^2 $和KPCA-$ SPE $等对本例进行测试.同时, 适用于非线性和多模态过程故障检测的方法FD-kNN在本例中也被测试.通过CPV = 85%确定PCA和KPCA的主元数分别为2和6, 其中KPCA中核函数选择高斯核函数$ K({\mathit{\boldsymbol{x, y}}}) = \exp ( - {\left\| {\mathit{\boldsymbol{x - y}}} \right\|^2}/\beta ) $且窗宽参数$ \beta = 30 $.通过寻优测试, FD-kNN和本文方法中的近邻数$ k = 3 $.以上方法均采用99%的控制限进行故障检测.
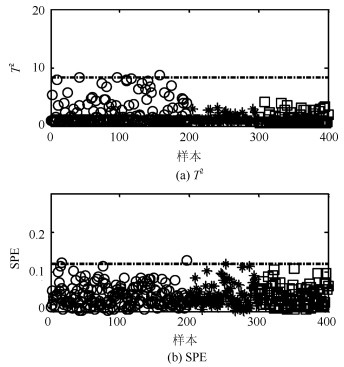
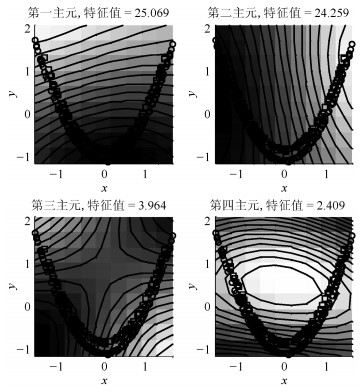
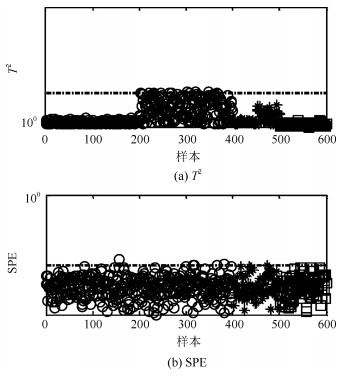
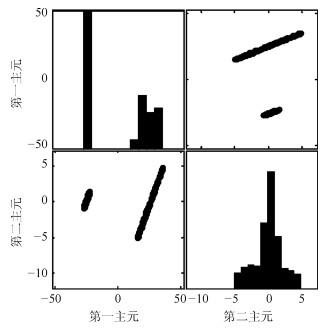
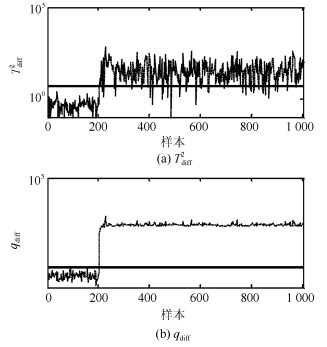
图 2给出PCA-$ T^2 $和PCA-$ SPE $的故障检测结果.虽然PCA能够捕获过程方差变化最大的方向, 但是其使用的统计量$ T^2 $并不适用于具有非线性结构过程的故障检测.因此, PCA-$ T^2 $和PCA-$ SPE $的故障检测率为0.适用于非线性过程故障检测的KPCA方法在本例中故障检测结果如图 3所示. 图 4给出KPCA中前4个主元得分的等高线及训练样本和故障样本的分布.由图 4可以看出, KPCA应用非线性映射能够捕获训练数据的非线性结构.但是由于故障样本具有较小的偏离尺度且具有训练数据的非线性结构, 因此从主元得分的角度观察仍然不能将训练样本与故障样本分离.综上, KPCA在本例中的故障检测率为0.
图 5给出FD-kNN方法在本例中的故障检测结果.可以看出, FD-kNN方法并不能有效识别过程故障且故障检测率为0.主要原因是FD-kNN方法适用于非线性过程大尺度故障的检测, 其对过程的小尺度故障检测通常具有较高的漏报率.本文方法的故障检测结果如图 6所示.综合检测结果分析, 本文方法的故障检测率达到99%且高于其他的传统方法.在本文方法中, 由于差分方法既能够消除主元空间的非线性结构, 又能够增大过程离群点偏离训练样本轨迹的尺度, 因此本文方法具有最高的故障检测率.
3.2 多模态例子
本节引用的多模态例子[22]包含两个模态, 每个样本包含4个监控变量.主要模型如下:
$$ \begin{equation} \begin{array}{*{20}{l}} {{M_1}\;\left\{ {\begin{array}{*{20}{l}} {x = t + e}, \\ {y = 2t + e}, \end{array}} \right.}&{t \sim {{U(}} - 1, 1)}\\ {{M_2}\;\left\{ {\begin{array}{*{20}{l}} {x = t + e}, \\ {y = 50 + 2t + e}, \end{array}} \right.}&{t \sim {{U(}} - 5, 5)} \end{array} \end{equation} $$ (16) 其中, $ x $和$ y $为过程主要变量, 余下变量为随机噪声.训练集包含200个样本, 其中前100个由模态1 ($ M_1 $)产生, 余下的由模态2 ($ M_2 $)产生.校验集包含100个样本, 其中前50个由$ M_1 $随机生成, 余下的由$ M_2 $生成.在模态$ M_1 $中, 通过对变量$ y $增加扰动, 生成100个故障样本.训练样本($ \circ $), 校验样本($ * $)和故障样本(□)关于变量$ x $和$ y $的散点图如图 7所示.
在该例中, 传统的PCA方法, PC-kNN方法及本文方法被测试.各种方法的参数设置和故障检测率和误报率见表 1.
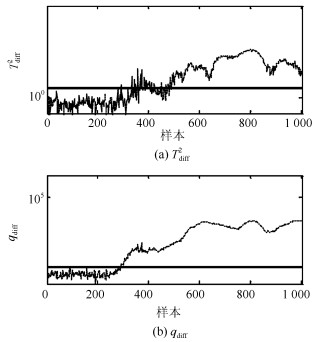
表 1 参数设置, 故障检测率和误报率Table 1 Setting of parameters, FDR and FAR方法 PCs k FDR FAR PCA 2 - 0 0 PC-kNN 2 3 85 0 本文方法 2 5 100 0 图 8给出PCA方法对本例的故障检测结果.可以看出, PCA方法对本例的故障检测是无效的.主要原因是在PCA方法中确定统计量$ T^2 $控制限时通常假设过程的得分变量服从独立高斯分布, 而由于本例中存在明显的多模态结构, 因此过程得分变量并不满足上述假设条件(如图 9所示), 从而降低了PCA方法的故障检测率.
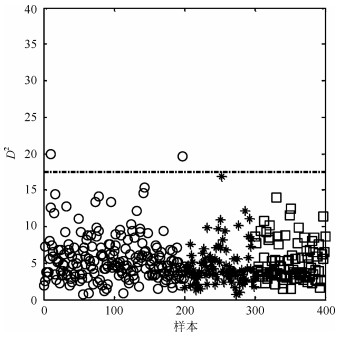
考虑到主元子空间仍然存在多模态结构, 因此基于主元的k近邻方法即PC-kNN在本例中进行了测试, 检测结果见图 10.可以看出, 相比PCA方法, PC-kNN方法的故障检测率大幅度提高.由于本例中两个模态数据的方差结构差异明显, 即第二个模态的分散程度明显高于第一模态, 因此第二模态样本的$ D^2 $值显著大于第一模态的$ D^2 $.为了更好地监控过程变化, $ D^2 $的控制限完全由第二模态的$ D^2 $值所决定且其明显大于第一模态的$ D^2 $值.综上, 当第一模态发生故障且故障尺度较小时, 故障样本的$ D^2 $值被第二模态的$ D^2 $值所淹没.因此, $ D^2 $控制图中依旧存在故障漏报情形, 其漏报率为15%.
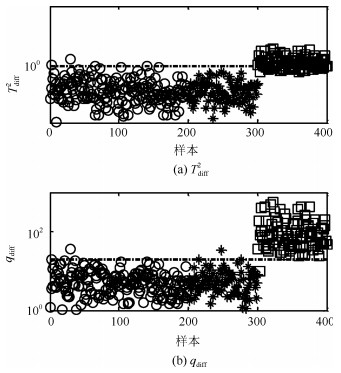
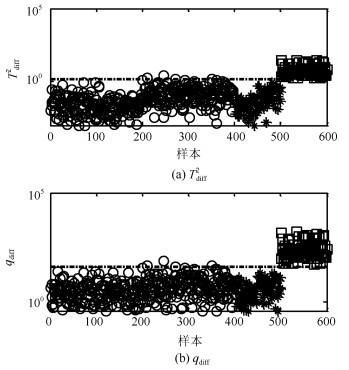
本文方法的故障检测结果见图 11.可以看出, 本文方法的故障检测率达到100%. 图 12给出本文方法中样本在差分子空间的分布.可以看出, 本文方法中的差分处理方式能够消除过程多模态的分布特征, 同时使得故障点偏离正常轨迹的特征得到保持且被强化.因此, 本文方法具有最优的检测性能.
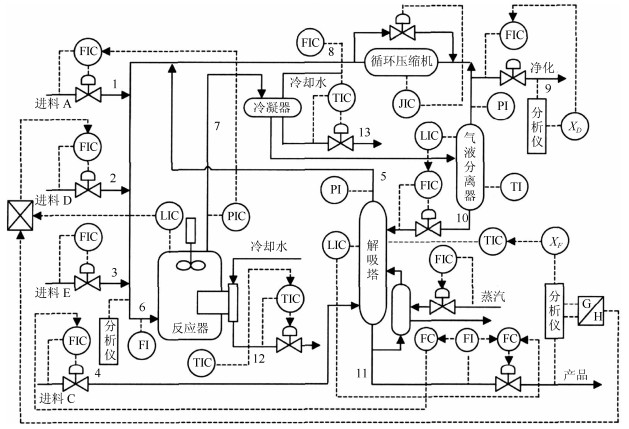
4. TE过程
TE (Tennessee Eastman)过程是Downs等人基于Tennessee Eastman化学公司实际化工生产过程提出的一个仿真模型[21].由于该过程能够较好地模拟实际化工过程的典型特征, 因此其被作为仿真例子广泛应用于过程监控与故障诊断的研究中[21-23]. 图 13给出TE过程所包含的5个操作单元. TE数据集包含22个连续测量变量, 19个成分测量变量及11个控制变量.在本节中, 依据文献[21]选取33个变量(22个连续测量变量和11个控制变量)对故障进行分析. TE仿真器可以模拟两种工作环境, 即模态1和模态3[24].在本节中, 训练数据集由模态1和模态3的2 000个正常样本构成, 其中前1 000个来自于模态1, 余下的来自模态3.应用本文方法及传统方法分别对模态1的故障8 (本节记为F$ _1 $)和10 (F$ _2 $)及模态3的故障5 (F$ _3 $), 8 (F$ _4 $)与10 (F$ _5 $)进行了故障检测, 各种故障均包含1 000个样本且故障由200时刻引入并持续到过程结束.
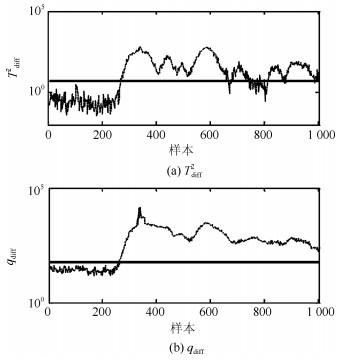
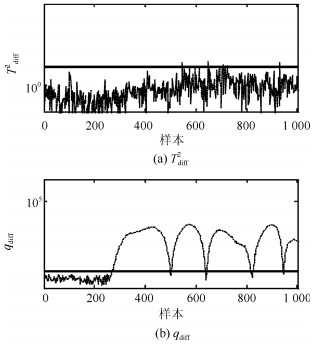
在本例中, 基于PCA不同方法的主元数均通过CPV = 85%进行确定.在KPCA中, 核函数选取为高斯核函数; 在DPCA中, 如文献[21]中所述, 参数lag = 2.各种方法对上述故障的故障检测率和误报率见表 2和3. 图 14~18给出本文方法关于上述故障的故障检测控制图, 注意为了便于观察检测结果, 部分图中数据进行了取对数处理.
表 2 各种方法的故障检测率Table 2 FDRs using different methods方法 F1 F2 F3 F4 F5 PCA-T2 54.6 0.1 89.4 67.8 3.4 PCA-SPE 79.8 0.6 98.8 76.5 1.4 KPCA-T2 69.6 1.4 6.1 67.6 0.5 KPCA-SPE 83.5 1.4 65.5 83.5 2 DPCA-T2 84.1 0 93.5 75.9 4.5 DPCA-SPE 65.8 0.1 88.1 76.6 1.5 Tdiff2 87.3 1.5 92.5 72.5 4.8 qdiff 92.5 90.3 100 92.5 95.1 表 3 各种方法的故障误报率Table 3 FARs using different methods方法 F1 F2 F3 F4 F5 PCA-T2 0 0 1.5 1.5 1.5 PCA-SPE 0 0 2.5 2.5 2.5 KPCA-T2 0.5 0.5 2 2 2 KPCA-SPE 0 0 2.5 2.5 2.5 DPCA-T2 0 0 3 3 3 DPCA-SPE 0 0 2.5 2.5 2.5 Tdiff2 0 0 0.5 0.5 0.5 qdiff 0 0 1 1 1 由表 2和检测控制图可以看出, 本文方法能够有效识别上述5种故障, 故障检测率达到90%以上.特别是对故障F$ _3 $的检测率达到100%.综合分析, 本文方法在TE多模态例子中的故障检测率高于传统的方法.此外, $ q_{\rm {diff}} $的故障检测率高于$ T^2_{\rm {diff}} $和传统的$ SPE $.这说明本文应用样本k近邻均值得分重构样本的方法能够有效地分离故障且强化故障尺度, 使得上述故障能够被准确检测.通过本例的检测结果可以看出, 传统的基于PCA的不同方法适用于单模态过程检测, 同时这些方法对多模态过程大尺度故障检测是有效的, 如本例中的故障F$ _1 $、F$ _3 $和F$ _4 $.本文方法的k近邻得分差分策略适用于具有非线性和多模态过程的故障检测; 同时, 相比传统的KPCA和DPCA方法, 本文方法具有较低的计算复杂度和较高的运算效率.综上, 本文方法是一种适用于多模态过程故障检测的单模型方法.
5. 结论
为了更好地对非线性和多模态过程进行故障检测, 本文提出一种基于主元得分差分的故障检测策略.得分差分方法能够降低过程数据多模态或变量非线性特征的影响, 能够提高故障检测率.通过模拟测试与对比分析, 本文方法的有效性得到验证.由于本文方法应用k近邻规则进行得分估计, 因此近邻数的选择问题是接下来研究的一个方向; 同时, 本文方法在间歇生产过程中的应用也是未来的一个研究问题.
-
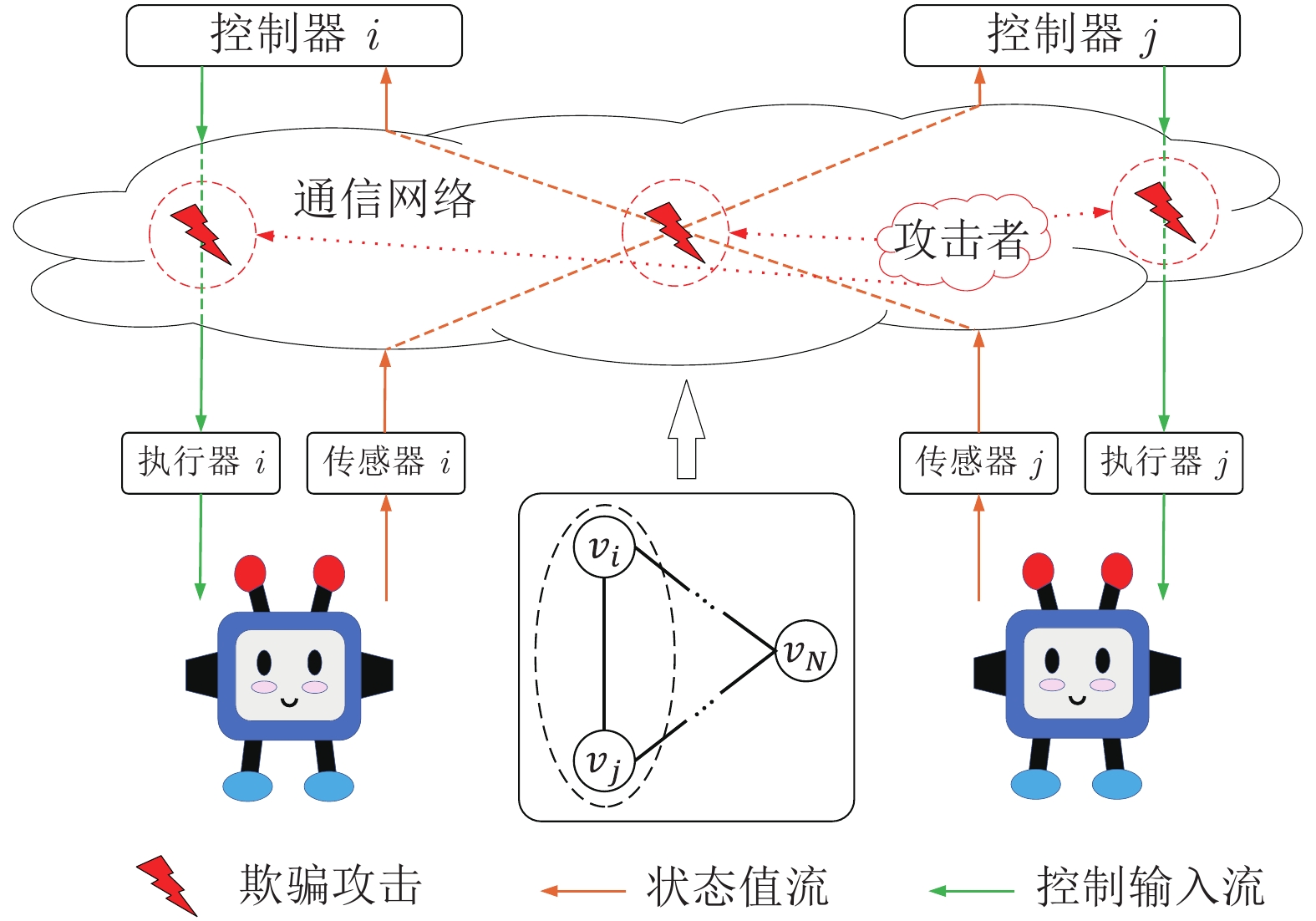
图 2 欺骗攻击下多智能体系统分布式网络示意图
Fig. 2 The diagram of the multi-agent system distributed network under deception attacks

图 4 系统不满足强(2f + 1)-链路鲁棒图下各节点的状态量测值变化轨迹
Fig. 4 State trajectory of each node with system that does not meet the strong (2f + 1)-links robustness

图 5 系统外部通信链路遭受欺骗攻击下各节点的状态量测值变化轨迹
Fig. 5 State trajectory of each node under deception attack on the external communication link of the system
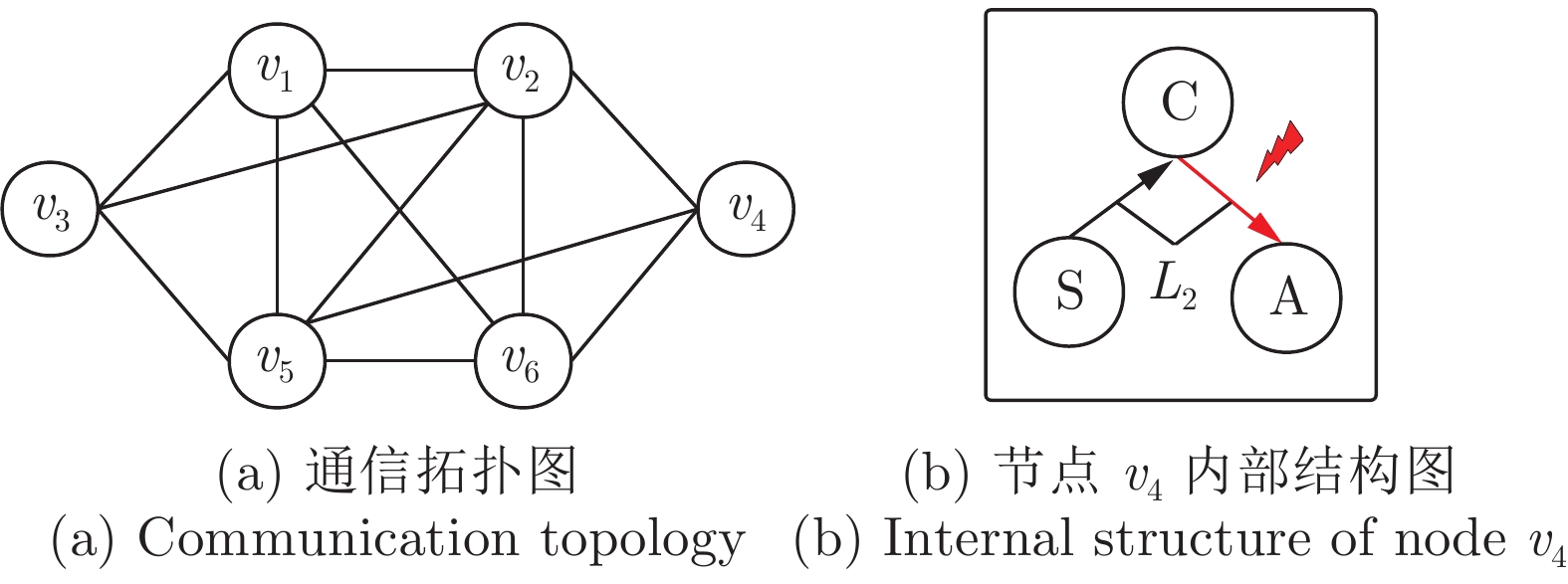
图 6 节点
$ v_4 $ 内部遭受欺骗攻击的通信拓扑及攻击示意图Fig. 6 Communication topology and attack diagram of the deception attack inside node
$ v_4 $ 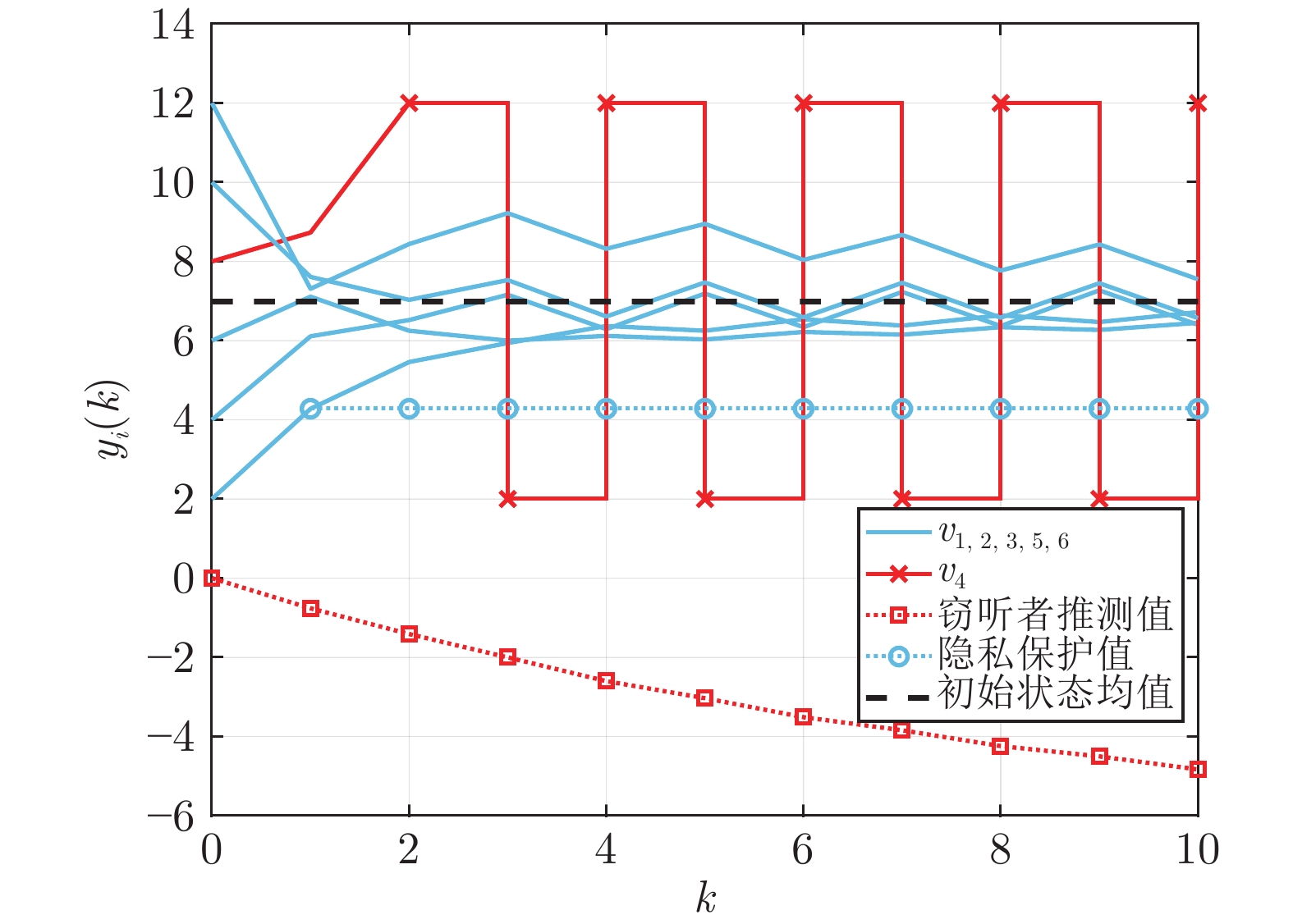
图 7 系统内部通信链路遭受欺骗攻击下使用状态分解算法各节点的状态量测值变化轨迹
Fig. 7 State trajectory of each node under deceptionattack on the internal communication link of thesystem by using the statedecomposition algorithm
-
[1] 丁俐夫, 颜钢锋. 多智能体系统安全性问题及防御机制综述. 智能系统学报, 2020, 15(3): 425-434Ding Li-Fu, Yan Gang-Feng. A survey of the security issues and defense mechanisms of multi-agent systems. CAAI Transactions on Intelligent Systems, 2020, 15(3): 425-434 [2] 李韬, 孟杨, 张纪锋. 多自主体量化趋同与有限数据率趋同综述. 自动化学报, 2013, 39(11): 1805-1811 doi: 10.3724/SP.J.1004.2013.01805Li Tao, Meng Yang, Zhang Ji-Feng. An overview on quantized consensus and consensus with limited data rate of multi-agent systems. Acta Automatica Sinica, 2013, 39(11): 1805-1811 doi: 10.3724/SP.J.1004.2013.01805 [3] 王祥科, 李迅, 郑志强. 多智能体系统编队控制相关问题研究综述. 控制与决策, 2013, 28(11): 1601-1613Wang Xiang-Ke, Li Xun, Zheng Zhi-Qiang. Survey of developments on multi-agent formation control related problems. Control and Decision, 2013, 28(11): 1601-1613 [4] 孙秋野, 滕菲, 张化光. 能源互联网及其关键控制问题. 自动化学报, 2017, 43(2): 176-194Sun Qiu-Ye, Teng Fei, Zhang Hua-Guang. Energy internet and its key control issues. Acta Automatica Sinica, 2017, 43(2): 176-194 [5] Huang Z, Mitra S, Dullerud G. Differentially private iterative synchronous consensus. In: Proceedings of the ACM Workshop on Privacy in the Electronic Society. New York, USA: 2012. 81−90 [6] Huang Z, Mitra S, Vaidya N. Differentially private distributed optimization. In: Proceedings of the International Conference on Distributed Computing and Networking. New York, USA: 2015. 1−10 [7] Nozari E, Tallapragada P, Cortes J. Differentially private average consensus: obstructions, trade-offs, and optimal algorithm design. Automatica, 2017, 81(7): 221-231 [8] Katewa V, Pasqualetti F, Gupta V. On privacy vs cooperation in multi-agent systems. International Journal of Control, 2018, 91(7): 1693-1707 doi: 10.1080/00207179.2017.1326632 [9] Manitara N, Hadjicostis C. Privacy-preserving asymptotic average consensus. In: Proceedings of the European Control Conference. Zurich, Switzerland: IEEE, 2013. 760−765 [10] Kia S, Cortes J, Martinez S. Dynamic average consensus under limited control authority and privacy requirements. International Journal of Robust and Nonlinear Control, 2015, 25(13): 1941-1966 doi: 10.1002/rnc.3178 [11] Pequito S, Kar S, Sundaram S, Aguiar A P. Design of communication networks for distributed computation with privacy guarantees. In: Proceedings of the 54th IEEE Conference on Decision and Control. Osaka, Japan: IEEE, 2015. 1370−1376 [12] Alaeddini A, Morgansen K, Mesbahi M. Adaptive communication networks with privacy guarantees. In: Proceedings of the American Control Conference. Seattle, USA: IEEE, 2017. 4460− 4465 [13] Hendriks R C, Erkin Z, Gerkmann T. Privacy preserving distributed beamforming based on homomorphic encryption. In: Proceedings of the 21st European Signal Processing Conference. Marrakech, Morocco: IEEE, 2013. 1−5 [14] Hendriks R C, Erkin Z, Gerkmann T. Privacy-preserving distributed speech enhancement forwireless sensor networks by processing in the encrypted domain. In: Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing. Vancouver, Canada: IEEE, 2013. 7005−7009 [15] Li Q, Cascudo I, Christensen M G. Privacy-preserving distributed average consensus based on additive secret sharing. In: Proceedings of the 27th European Signal Processing Conference. Coruna, Spain: IEEE, 2019. 1−5 [16] Li Q, Christensen M G. A privacy-preserving asynchronous averaging algorithm based on shamir's secret sharing. In: Proceedings of the 27th European Signal Processing Conference. Coruna, Spain: IEEE, 2019. 1−5 [17] Wang Y. Privacy-preserving average consensus via state decomposition. IEEE Transactions on Automatic Control, 2019, 64(11): 4711-4716 doi: 10.1109/TAC.2019.2902731 [18] Zhang D, Liu L, Feng G. Consensus of heterogeneous linear multiagent systems subject to aperiodic sampled-data and dos attack. IEEE Transactions on Cybernetics, 2019, 49(4): 1501-1511 doi: 10.1109/TCYB.2018.2806387 [19] Feng Z, Hu G. Secure cooperative event-triggered control of linear multiagent systems under dos attacks. IEEE Transactions on Control Systems Technology, 2020, 28(3): 741-752 doi: 10.1109/TCST.2019.2892032 [20] Yang Y, Xu H, Yue D. Observer-based distributed secure consensus control of a class of linear multi-agent systems subject to random attacks. IEEE Transactions on Circuits and Systems I: Regular Papers, 2019, 66(8): 3089-3099 doi: 10.1109/TCSI.2019.2904747 [21] Xu W, Hu G, Ho D W C, Feng Z. Distributed secure cooperative control under denial-of-service attacks from multiple adversaries. IEEE Transactions on Cybernetics, 2020, 50(8): 3458-3467 doi: 10.1109/TCYB.2019.2896160 [22] Zhu M, Martínez S. On distributed constrained formation control in operator–vehicle adversarial networks. Automatica, 2013, 49(12): 3571-3582 doi: 10.1016/j.automatica.2013.09.031 [23] Ding D, Wang Z, Ho D W C, Wei G. Observer-based event-triggering consensus control for multiagent systems with lossy sensors and cyber-attacks. IEEE Transactions on Cybernetics, 2016, 47(8): 1936-1947 [24] He W, Gao X, Zhong W, Qian F. Secure impulsive synchronization control of multi-agent systems under deception attacks. Information Sciences, 2018, 459: 354-368 doi: 10.1016/j.ins.2018.04.020 [25] Fu W, Qin J, Shi Y, Zheng W X, Kang Y. Resilient consensus of discrete-time complex cyber-physical networks under deception attacks. IEEE Transactions on Industrial Informatics, 2019, 16(7): 4868-4877 [26] He W, Mo Z, Han Q L, Qian F. Secure impulsive synchronization in Lipschitz-type multi-agent systems subject to deception attacks. IEEE/CAA Journal of Automatica Sinica, 2020, 7(5): 1326-1334 [27] Li H, Liao X, Huang T, Zhu W, Liu Y. Second-order global consensus in multiagent networks with random directional link failure. IEEE Transactions on Neural Networks and Learning Systems, 2014, 26(3): 565-575 [28] Li H, Chen G, Huang T, Dong Z. High-performance consensus control in networked systems with limited bandwidth communication and time-varying directed topologies. IEEE Transactions on Neural Networks and Learning Systems, 2016, 28(5): 1043-1054 [29] Lu Q, Liao X, Xiang T, Li H, Huang T. Privacy masking stochastic subgradient-push algorithm for distributed online optimization. IEEE Transactions on Cybernetics, 2020, 51(6): 3224-3237 [30] Fiore D, Russo G. Resilient consensus for multi-agent systems subject to differential privacy requirements. Automatica, 2019, 106: 18-26 doi: 10.1016/j.automatica.2019.04.029 [31] Zhang H, Sundaram S. Robustness of information diffusion algorithms to locally bounded adversaries. In: Proceedings of the American Control Conference. Montréal, Canada: IEEE, 2012. 5855−5861 [32] Dibaji S M, Safi M, Ishii H. Resilient distributed averaging. In: Proceedings of the American Control Conference. Philadelphia, USA: 2019. 96−101 [33] Hale M T, Egerstedty M. Differentially private cloud-based multi-agent optimization with constraints. In: Proceedings of the American Control Conference. Chicago, USA: 2015. 1235−1240 [34] LeBlanc H J, Zhang H, Koutsoukos X, Sundaram S. Resilient asymptotic consensus in robust networks. IEEE Journal on Selected Areas in Communications, 2013, 31(4): 766-781 doi: 10.1109/JSAC.2013.130413 期刊类型引用(4)
1. 伍益明,张润荣,徐宏,朱晨睿,郑宁. 基于隐写术的分布式隐私保护一致性控制方法. 自动化学报. 2025(01): 221-232 .  本站查看
本站查看2. 金增旺,刘茵,刁靖东,王震,孙长银,刘志强. 针对信息物理系统远程状态估计的隐蔽虚假数据注入攻击. 自动化学报. 2025(02): 356-365 . 本站查看3. 杨梅芳. 基于大数据技术的5G通信链路故障检测方法. 长江信息通信. 2024(05): 159-161 . 百度学术4. 陆洁. DDoS攻击下无线传感网络安全访问细粒度控制. 现代计算机. 2024(23): 133-136+141 . 百度学术其他类型引用(10)
-

 下载:
下载:



 下载:
下载:





计量
- 文章访问数: 1258
- HTML全文浏览量: 321
- PDF下载量: 359
- 被引次数: 14
