

-
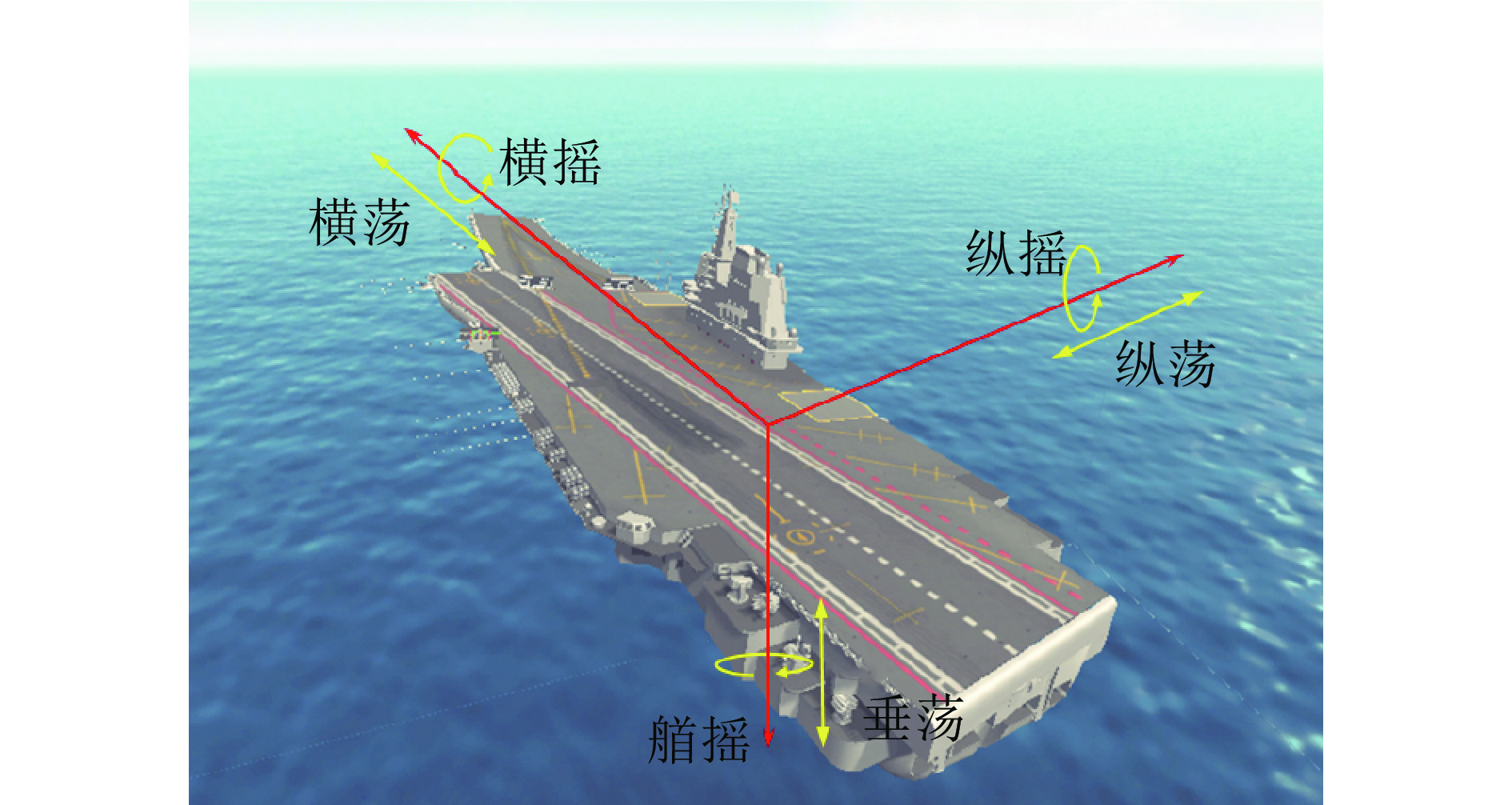
摘要: 航母甲板在风、浪、流等因素影响下做六自由度不规则运动, 影响舰载机着舰精度. 航母甲板运动预估与补偿是自动着舰系统的重要功能之一, 也是提高舰载机着舰安全性与成功率的关键技术之一. 为此, 提出一种面向甲板运动预估的鲁棒学习模型, 通过基本构建单元自适应演化出复杂学习系统. 构建单元的训练采用非梯度的伪逆学习策略, 提高了训练效率, 简化了学习控制超参数调优; 构建单元的架构设计采用数据驱动的策略, 简化了架构超参数调优; 采用图拉普拉斯正则化方法提高了模型对噪声和意外扰动的鲁棒性. 通过某型航母在中等海况条件下以典型航速巡航时的仿真实验, 验证了所提方法在甲板纵摇、横摇以及垂荡运动预估问题中的有效性及鲁棒性.Abstract: The irregular deck motion of the aircraft carrier in six-degree freedom is generally caused by wind, waves, and currents, which affects the precision of aircraft landings. Aircraft carrier deck motion prediction and compensation are important functions of automatic landing systems as well as key technologies improving the safety and success rate of aircraft landing. In this paper, a robust learning model for deck motion prediction was presented, which constructs complex learning systems through the adaptive evolution of basic building blocks. The training of these building blocks employs a non-gradient pseudoinverse learning strategy, which improves training efficiency and simplifies the tuning of learning control hyperparameters. The architecture design of the building blocks adopts a data-driven approach, simplifying architectural hyperparameter tuning. A graph Laplace regularization term was employed in order to enhance the robustness of the model against noise and unexpected perturbations. Through simulation experiments conducted on a specific aircraft carrier cruising at a typical speed under moderate sea conditions, the effectiveness and robustness of the proposed method in predicting the pitch, roll, and heave of the deck are verified.
-
Key words:
- Aircraft carrier /
- deck motion prediction /
- robustness /
- machine learning /
- simulation validation
-
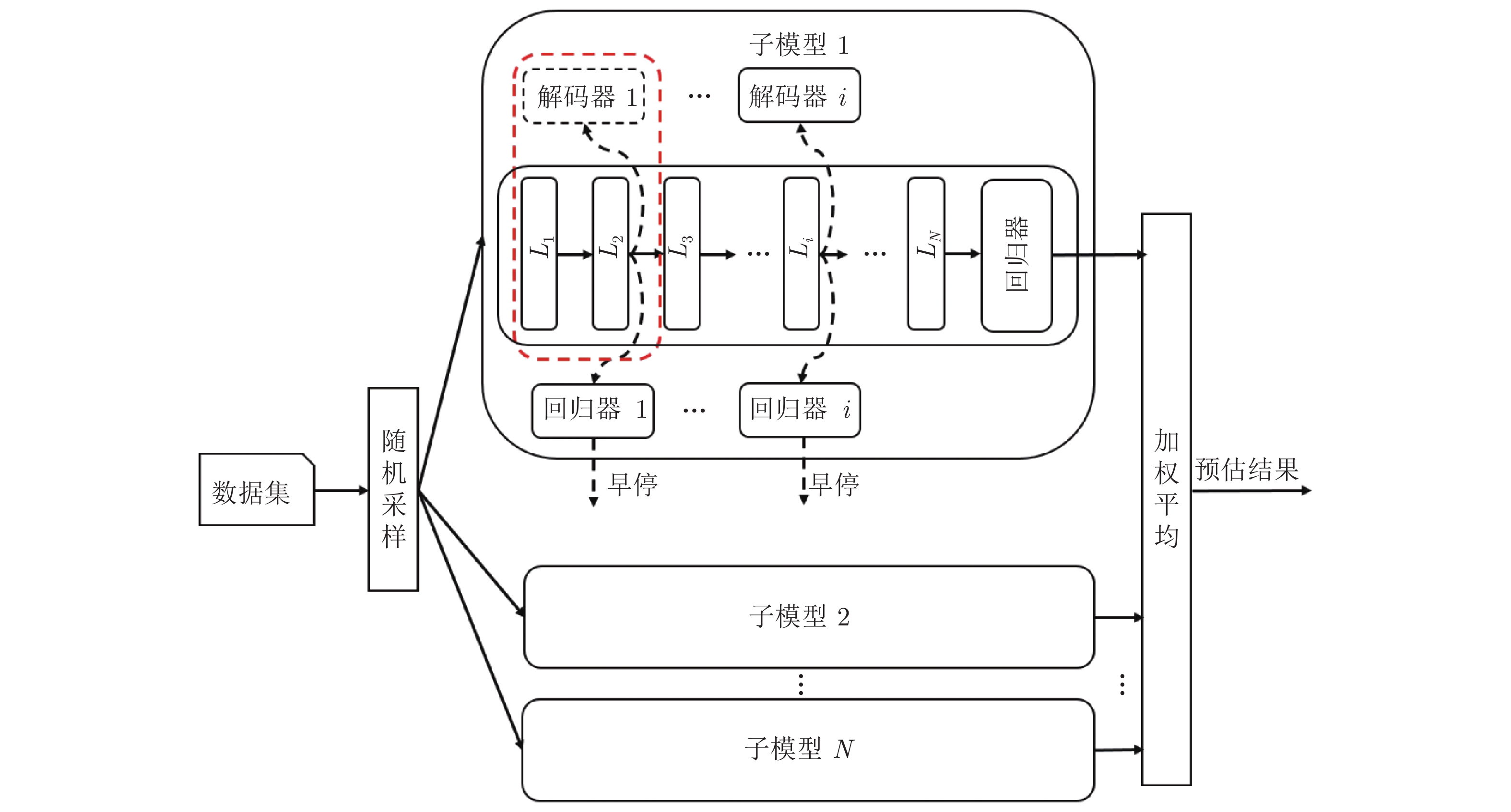
图 2 多个子模型集成学习系统架构
Fig. 2 The architecture of the ensemble learning system with multiple sub-models
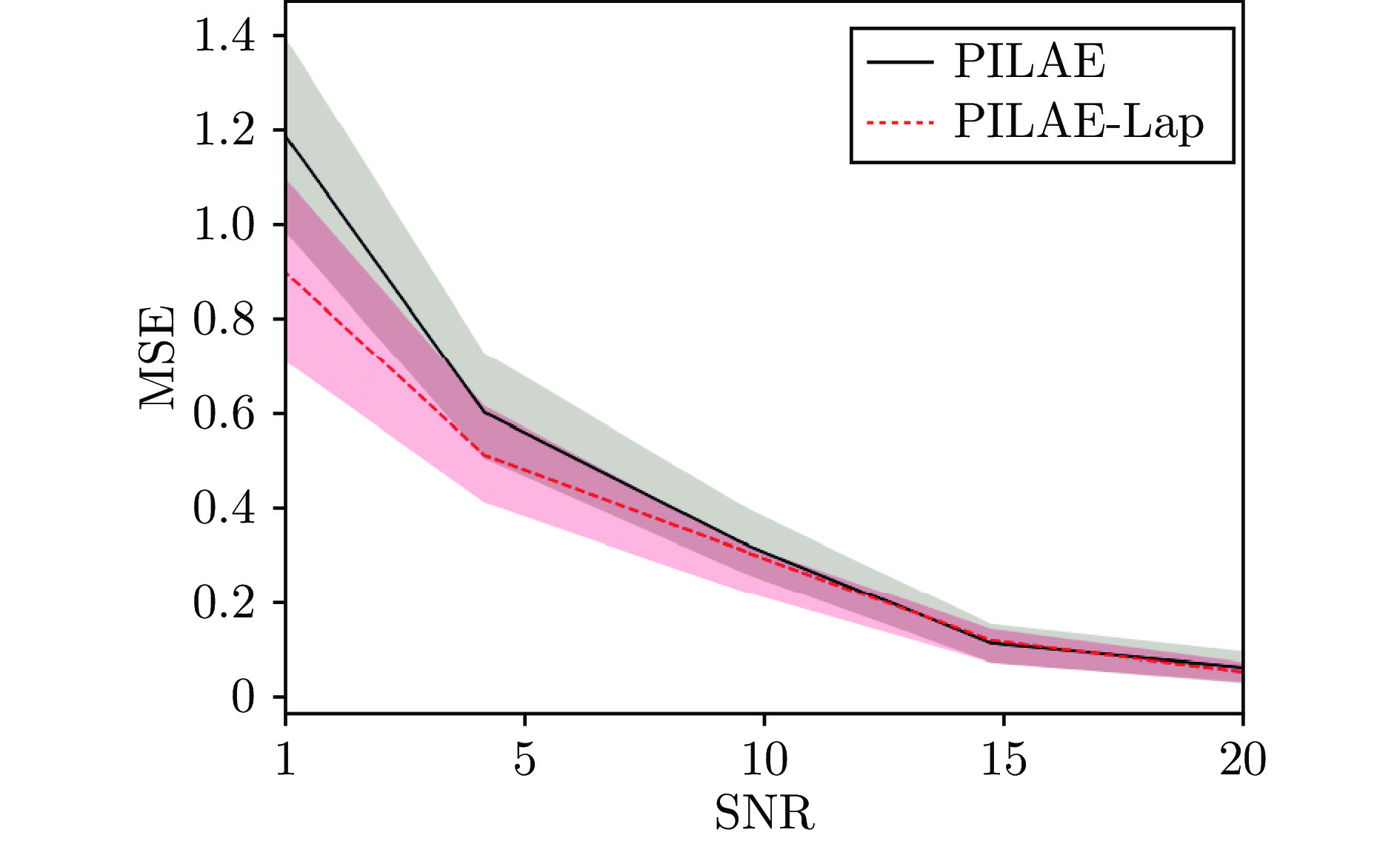
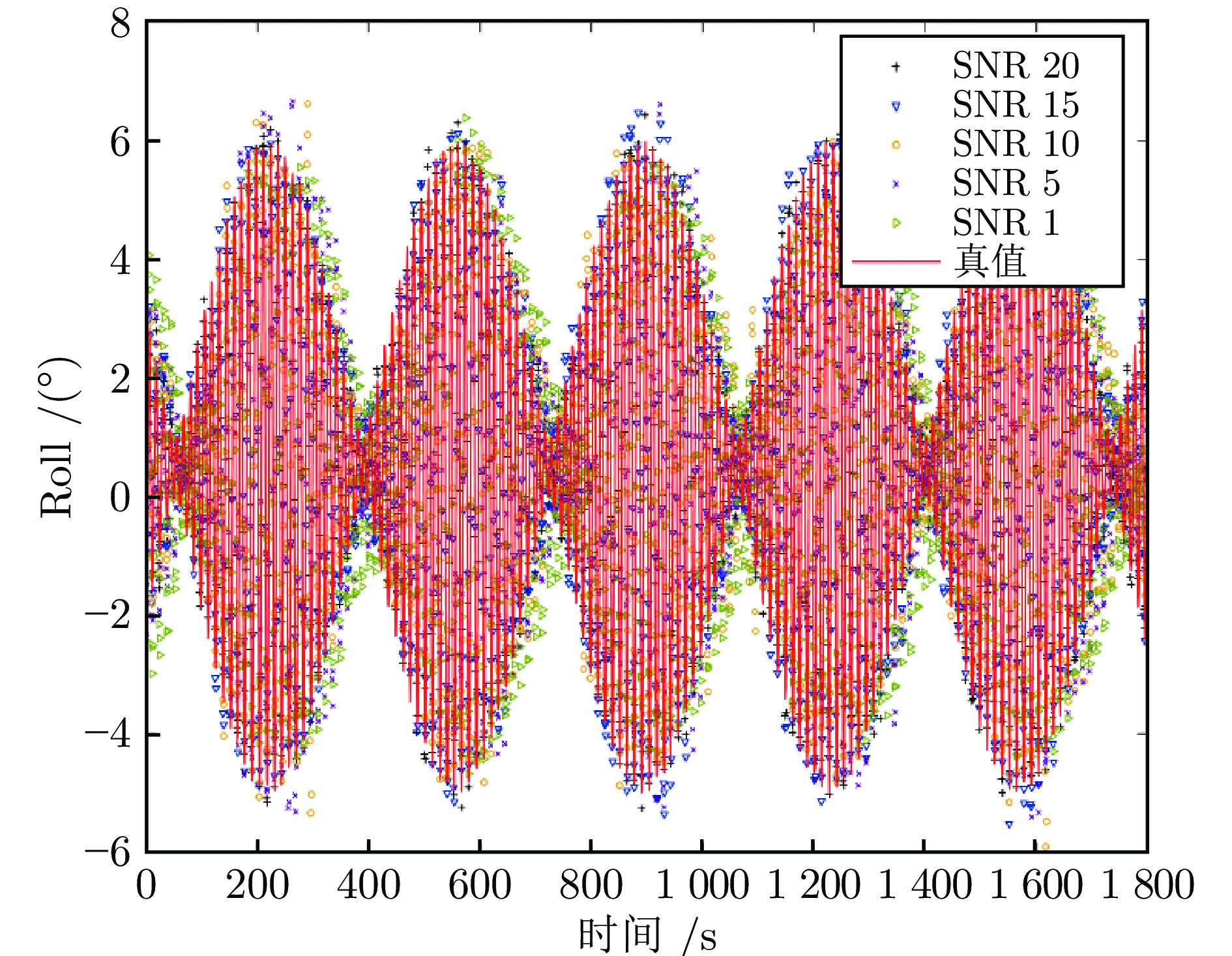
图 7 PILAE 与 PILAE-Lap 的甲板横摇预估结果对比
Fig. 7 The deck roll prediction results comparison between PILAE and PILAE-Lap
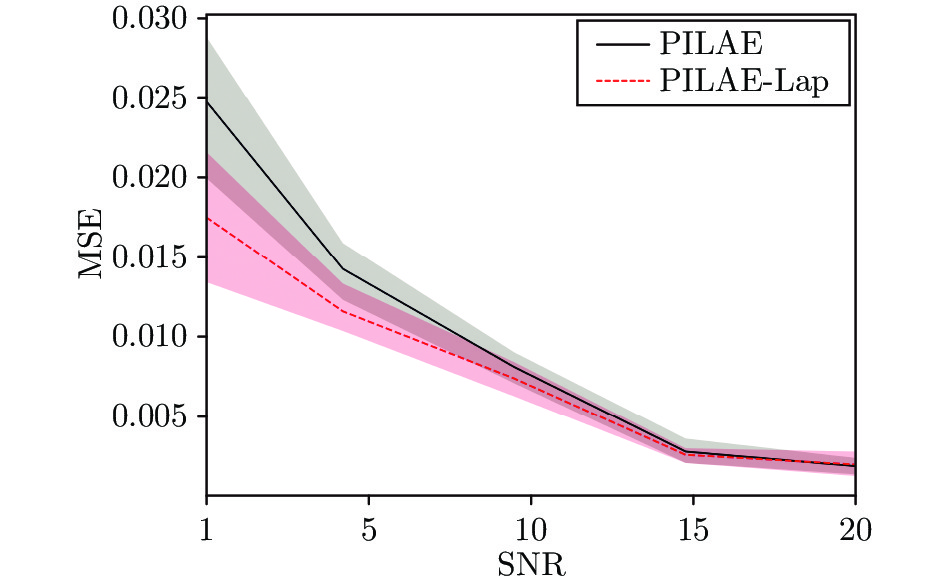
图 6 PILAE 与 PILAE-Lap 的甲板纵摇预估结果对比
Fig. 6 The deck pitch prediction results comparison between PILAE and PILAE-Lap
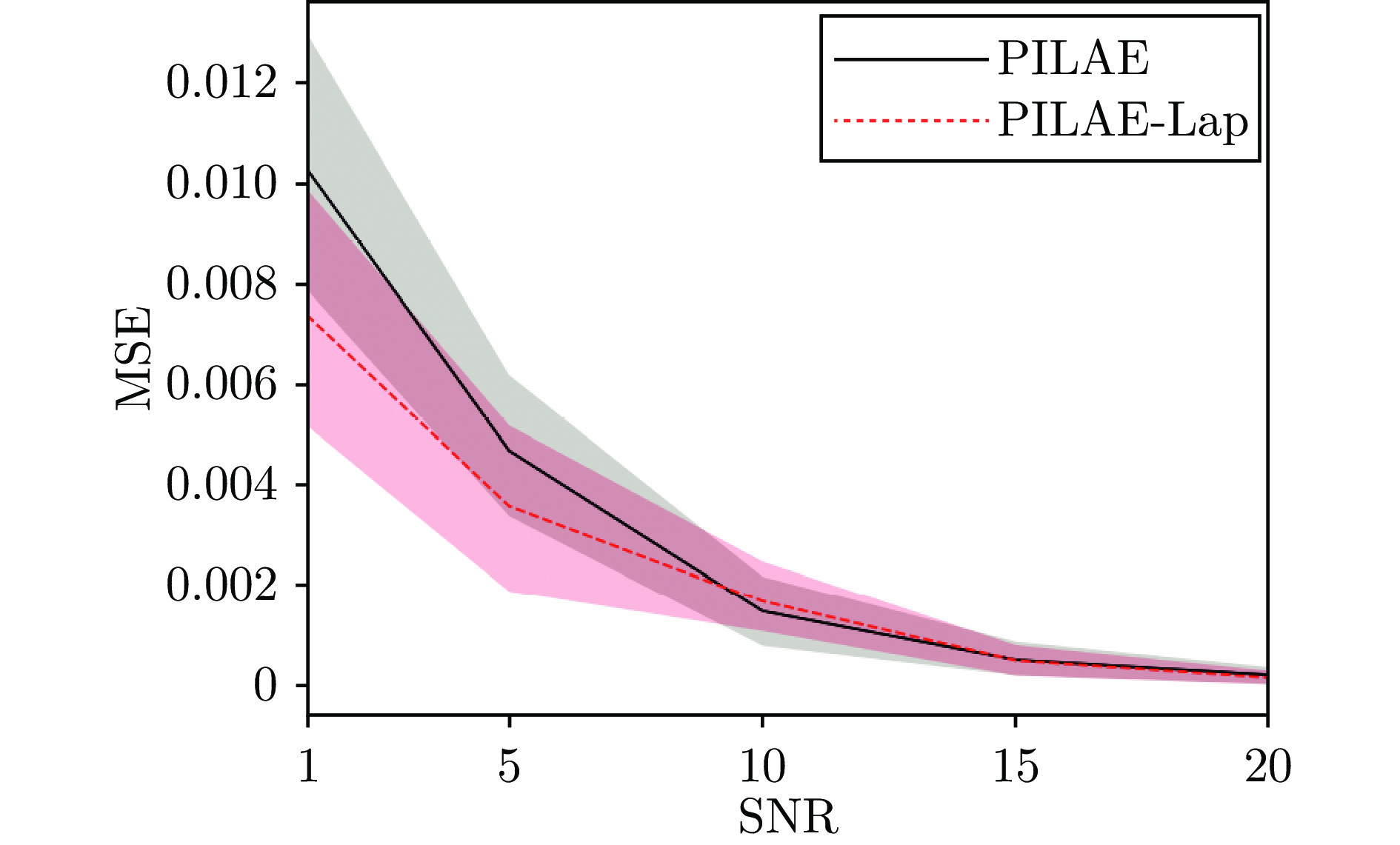
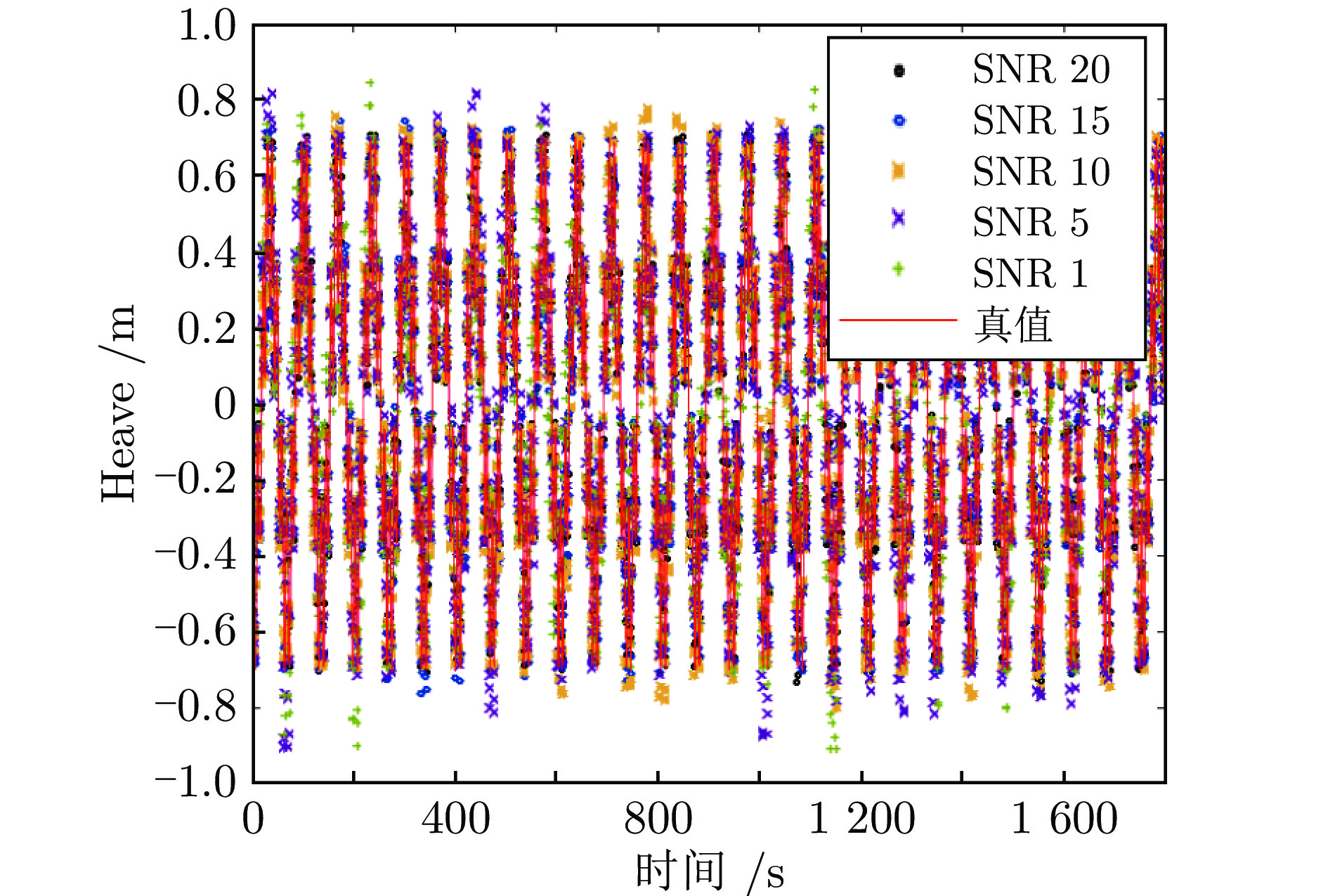
图 8 PILAE与PILAE-Lap的甲板垂荡预估结果对比
Fig. 8 The deck heave prediction results comparison between PILAE and PILAE-Lap
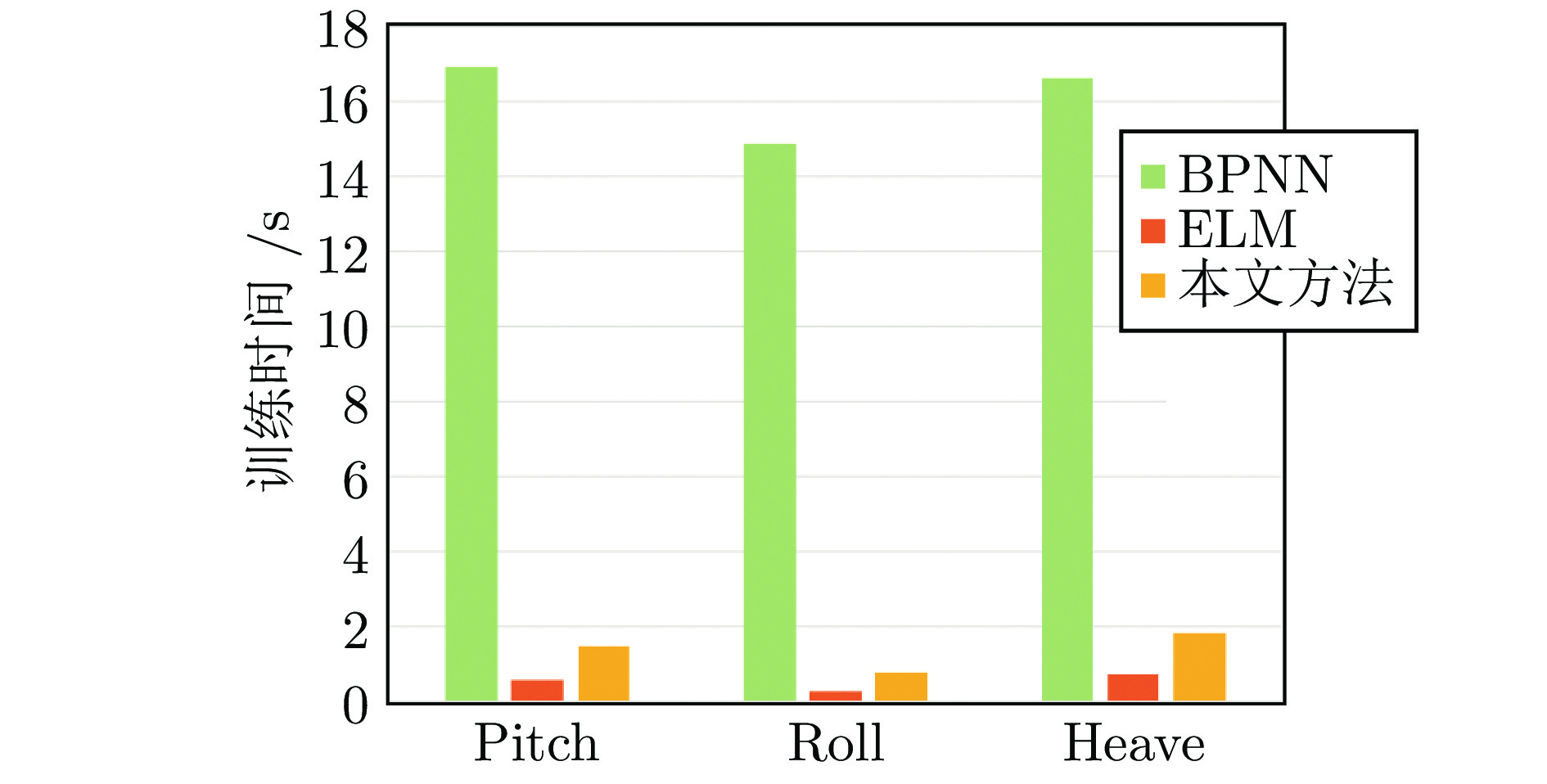
图 9 本文所提方法与其他方法的训练耗时对比
Fig. 9 Training time comparison between our proposed method and others
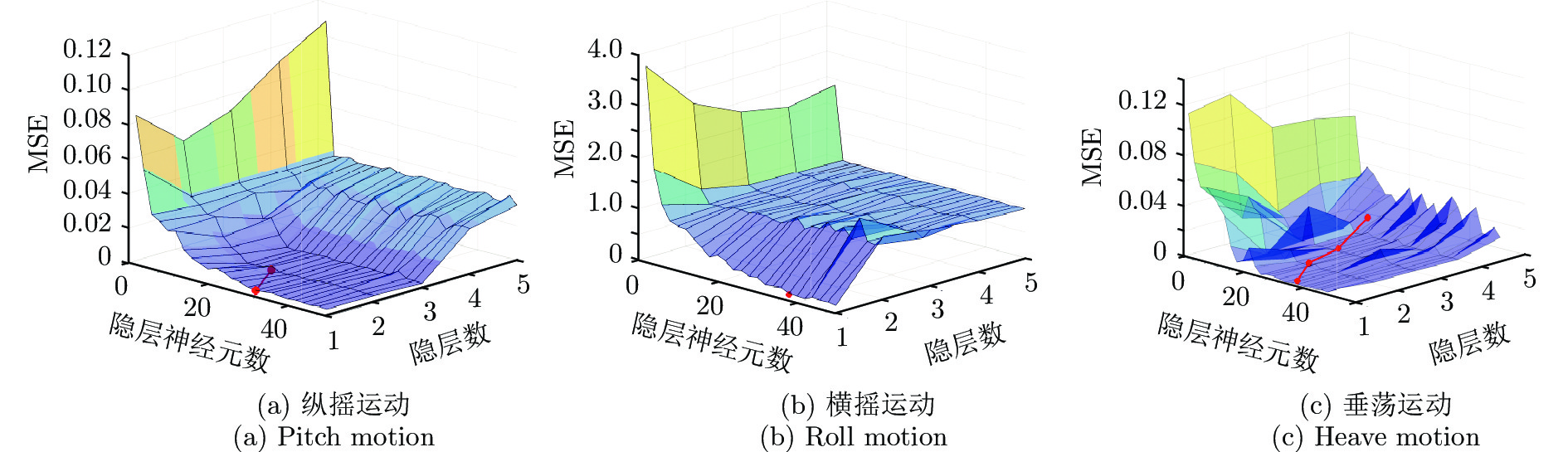
图 10 本文方法生成的网络架构及运动预估性能
Fig. 10 The network architectures generated by our proposed method and its motion prediction performance
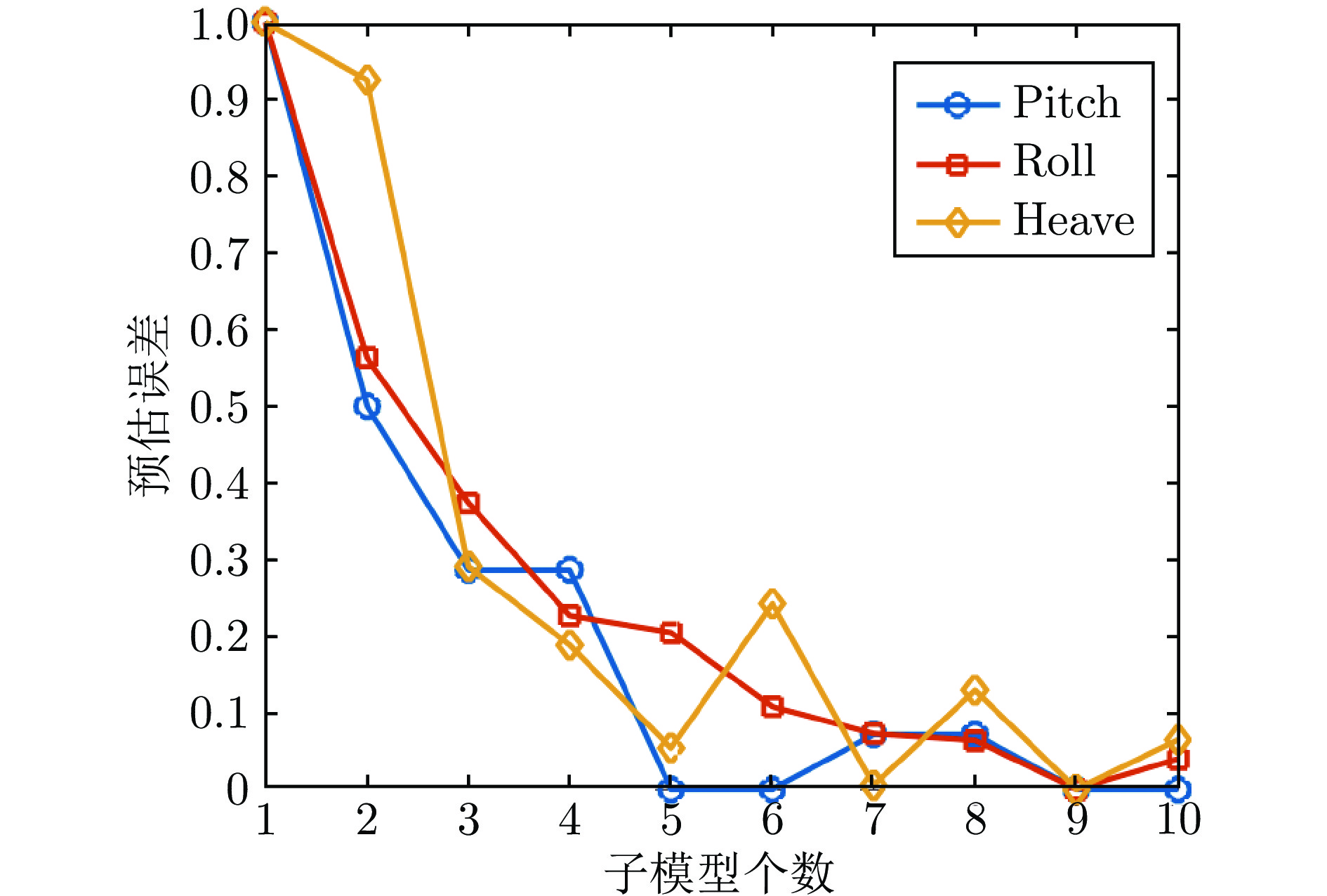
图 11 预估性能与子模型个数的关系
Fig. 11 The prediction performance with different number of sub-model
表 1 本文所提方法与其他方法的预测均方误差对比
Table 1 Comparison of prediction MSE between our proposed method with others
方法 Pitch Roll Heave BPNN 0.021 2 0.016 5 0.075 4 ELM 0.019 8 0.116 5 0.076 5 KELM-PSO 0.012 4 0.013 7 0.056 0 Kalman filter 0.022 4 0.573 7 0.026 1 Autoregression 0.006 6 0.016 8 0.020 8 本文方法 0.001 5 0.025 4 0.002 9 注: 加粗字体表示各列最优结果.  下载: 导出CSV
下载: 导出CSV
-
[1] 甄子洋. 舰载无人机自主着舰回收制导与控制研究进展. 自动化学报, 2019, 45(4): 669−681Zhen Zi-Yang. Research development in autonomous carrier-landing/ship-recovery guidance and control of unmanned aerial vehicles. Acta Automatica Sinica, 2019, 45(4): 669−681 [2] 石明, 屈香菊, 王萌辉. 甲板运动对舰载机人工着舰的影响和补偿. 飞行力学, 2006, 24(1): 5−8 doi: 10.3969/j.issn.1002-0853.2006.01.002Shi Ming, Qu Xiang-Ju, Wang Meng-Hui. The influence and compensation of deck motion in carrier landing approach. Flight Dynmics, 2006, 24(1): 5−8 doi: 10.3969/j.issn.1002-0853.2006.01.002 [3] 张志冰, 甄子洋, 江驹, 薛艺璇. 舰载机自动着舰引导与控制综述. 南京航空航天大学学报, 2018, 50(6): 734−744Zhang Zhi-Bing, Zhen Zi-Yang, Jiang Ju, Xue Yi-Xuan. Review on development in guidance and control of automatic carrier landing of carrier-based aircraft. Journal of Nanjing University of Aeronautics and Astronautics, 2018, 50(6): 734−744 [4] 江驹, 王新华, 甄子洋, 杨一栋, 袁锁中, 周鑫. 舰载机起飞着舰引导与控制. 北京: 科学出版社, 2019.Jiang Ju, Wang Xin-Hua, Zhen Zi-Yang, Yang Yi-Dong, Yuan Suo-Zhong, Zhou Xin. Guidance and Control of Carrier-Based Aircraft Launching and Landing. Beijing: Science Press, 2019. [5] 王能建, 刘钦辉, 李江, 商振. 舰载机出动回收能力仿真研究. 北京: 科学出版社, 2018.Wang Neng-Jian, Liu Qin-Hui, Li Jiang, Shang Zhen. Simulation on Ircraft Sortie Generation Rate. Beijing: Science Press, 2018. [6] 张永花, 周鑫. 舰载机着舰点垂直运动补偿技术仿真研究. 系统仿真学报, 2013, 25(4): 826−830Zhang Yong-Hua, Zhou Xin. Simulation study on landing point vertical motion in carrier landing. Journal of System Simulation, 2013, 25(4): 826−830 [7] 周鑫, 彭荣鲲, 袁锁中. 舰载机理想着舰点垂直运动的预估与补偿. 航空学报, 2013, 34(7): 1663−1669Zhou Xin, Peng Rong-Kun, Yuan Suo-Zhong. Prediction and compensation for vertical motion of ideal touchdown point in carrier landing. Acta Aeronautica ET Astronautica Sinica, 2013, 34(7): 1663−1669 [8] Xue Y X, Zhen Z Y, Yang L Q, Wen L D. Adaptive fault-tolerant control for carrier-based UAV with actuator failures. Aerospace Science and Technology, 2020, 107: Article No. 106227 doi: 10.1016/j.ast.2020.106227 [9] Nicolau V, Aiordachioaie D, Popa R. Neural network prediction of the wave influence on the yaw motion of a ship. In: Proceedings of the IEEE International Joint Conference on Neural Networks. Budapest, Hungary: IEEE, 2004. 2801−2806 [10] Liu X X, Wang Q M, Huang Y J, Song Q, Zhao L Y. A prediction method for deck motion of aircraft carrier based on particle swarm optimization and kernel extreme learning machine. Sensors and Materials, 2017, 29(9): 1291−1303 [11] Li G Y, Kawan B, Wang H, Zhang H X. Neural-network-based modelling and analysis for time series prediction of ship motion. Ship Technology Research, 2017, 64(1): 30−39 doi: 10.1080/09377255.2017.1309786 [12] Sidar M, Doolin B. On the feasibility of real-time prediction of aircraft carrier motion at sea. IEEE Transactions on Automatic Control, 1983, 28(3): 350−356 doi: 10.1109/TAC.1983.1103227 [13] 邢伯阳, 潘峰, 王位, 冯肖雪. 基于复合地标导航的动平台四旋翼飞行器自主优化降落技术. 航空学报, 2019, 40(6): Article No. 322601Xing Bo-Yang, Pan Feng, Wang Wei, Feng Xiao-Xue. Moving platform self-optimization landing technology for quadrotor based on hybrid landmark. Acta Aeronautica et Astronautica Sinica, 2019, 40(6): Article No. 322601 [14] Bhatia A K, Ju J, Kumar A, Shah S, Zhen Z Y. Adaptive preview control with deck motion compensation for autonomous carrier landing of an aircraft. International Journal of Adaptive Control Signal Processing, 2021, 35(5): 769−785 doi: 10.1002/acs.3228 [15] Zhen Z Y, Jiang S Y, Ma K. Automatic carrier landing control for unmanned aerial vehicles based on preview control and particle filtering. Aerospace Science and Technology, 2018, 81: 99−107 doi: 10.1016/j.ast.2018.07.039 [16] Zhen Z Y, Jiang S Y, Jiang J. Preview control and particle filtering for automatic carrier landing. IEEE Transactions on Aerospace and Electronic Systems, 2018, 54(6): 2662−2674 doi: 10.1109/TAES.2018.2826398 [17] 杨柳, 徐东昊. 基于极短期运动预报的舰载机着舰过程仿真分析. 中国舰船研究, 2018, 13(4): 99−103Yang Liu, Xu Dong-Hao. Aircraft carrier landing process simulation based on extremely short-term prediction of ship motion. Chinese Journal of Ship Research, 2018, 13(4): 99−103 [18] Yin J C, Zou Z J, Xu F, Wang N N. Online ship roll motion prediction based on grey sequential extreme learning machine. Neurocomputing, 2014, 129(10): 168−174 [19] Wang K, Guo P, Xin X, Ye Z B. Autoencoder, low rank approximation and pseudoinverse learning algorithm. In: Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics. Banff, Canada: IEEE, 2017. 948−953 [20] Guo P, Wang K, Zhou X L. PILAE: A non-gradient descent learning scheme for deep feedforward neural networks [Online], available: https://arxiv.org/abs/1811.01545v3, November 9, 2021 [21] Wang K, Guo P. An ensemble classification model with unsupervised representation learning for driving stress recognition using physiological signals. IEEE Transactions on Intelligent Transportation Systems, 2021, 22(6): 3303−3315 doi: 10.1109/TITS.2020.2980555 [22] Guo P, Lv M R. A pseudoinverse learning algorithm for feedforward neural networks with stacked generalization applications to software reliability growth data. Neurocomputing, 2004, 56(1): 101−121 [23] Rifai S, Vincent P, Muller X, Glorot X, Bengio Y. Contractive auto-encoders: Explicit invariance during feature extraction. In: Proceedings of the 28th International Conference on Machine Learning. Bellevue, Washington, USA: Omnipress, 2011. 833−840 [24] Wang K, Guo P. A robust automated machine learning system with pseudoinverse learning. Cognitive Computation, 2021, 13(3): 724−735 doi: 10.1007/s12559-021-09853-6 [25] Diallo B, Hu J, Li T R, Khan G A, Liang X Y, Zhao Y M. Deep embedding clustering based on contractive autoencoder. Neurocomputing, 2021, 433: 96−107 doi: 10.1016/j.neucom.2020.12.094 [26] Wu E Q, Peng X Y, Zhang C Z, Lin J X, Sheng R S F. Pilots' fatigue status recognition using deep contractive autoencoder network. IEEE Transactions on Instrumentation and Measurement, 2019, 68(10): 3907−3919 doi: 10.1109/TIM.2018.2885608 [27] 陈晓云, 陈媛. 子空间结构保持的多层极限学习机自编码器. 自动化学报, 2022, 48(4): 1091−1104Chen Xiao-Yun, Chen Yuan. Multi-layer extreme learning machine autoencoder with subspace structure preserving. Acta Automatica Sinica, 2022, 48(4): 1091−1104 [28] 张万栋, 李庆忠, 黎明, 武庆明. 基于最优误差自校正极限学习机的高频地波雷达RD谱图海面目标检测算法. 自动化学报, 2021, 47(1): 108−120Zhang Wan-Dong, Li Qing-Zhong, Li Ming, Q. M. Jonathan Wu. Sea surface target detection for RD images of HFSWR based on optimized error self-adjustment extreme learning machine. Acta Automatica Sinica, 2021, 47(1): 108−120 -

 下载:
下载:

计量
- 文章访问数: 1643
- HTML全文浏览量: 550
- PDF下载量: 192
- 被引次数: 0
