

-
摘要: 由于点云的非结构性和无序性, 目前已有的点云分类网络在精度上仍然需要进一步提高. 通过考虑局部结构的构建、全局特征聚合和损失函数改进三个方面, 构造一个有效的点云分类网络. 首先, 针对点云的非结构性, 通过学习中心点特征与近邻点特征之间的关系, 为不规则的近邻点分配不同的权重, 以此构建局部结构; 然后, 使用注意力思想, 提出加权平均池化(Weighted average pooling, WAP), 通过自注意力方式, 学习每个高维特征的注意力分数, 在应对点云无序性的同时, 可以有效地聚合冗余的高维特征; 最后, 利用交叉熵损失与中心损失之间的互补关系, 提出联合损失函数(Joint loss function, JL), 在增大类间距离的同时, 减小类内距离, 进一步提高了网络的分类能力. 在合成数据集ModelNet40、ShapeNetCore和真实世界数据集ScanObjectNN上进行实验, 与目前性能最好的多个网络相比较, 验证了该整体网络结构的优越性.Abstract: Due to the unstructured and disordered nature of point cloud, the classification accuracy is still needed to improve for the currently existed point cloud classification approaches. In this paper, an effective point cloud classification network is proposed by considering local structure construction, global feature aggregation, and loss function improvement. Firstly, in view of the unstructured nature of point cloud, the local structure is constructed via assigning different weights to those irregular neighborhood points, which are computed via the relationship between the center point feature and its neighbor feature. Moreover, a strategy of weighted average pooling (WAP) is designed to learn the attention score of each high-dimensional feature through self-attention mechanization, which can effectively aggregate redundant high-dimensional features while coping with point cloud disorder. In addition, a joint loss function (JL) is presented by utilizing the complementary relationship between the cross-entropy loss and the center loss, which increases the inter-class distance while reduces the intro-class distance, and further improves the classification ability of the network. Compared to several state-of-the-art networks, the experimental results on the synthetic dataset ModelNet40 and ShapeNetCore and the real-world dataset ScanObjectNN demonstrate the superiority of the overall network structure.
-
Key words:
- Deep learning /
- 3D point cloud /
- point cloud classification /
- attention mechanism /
- loss function
-
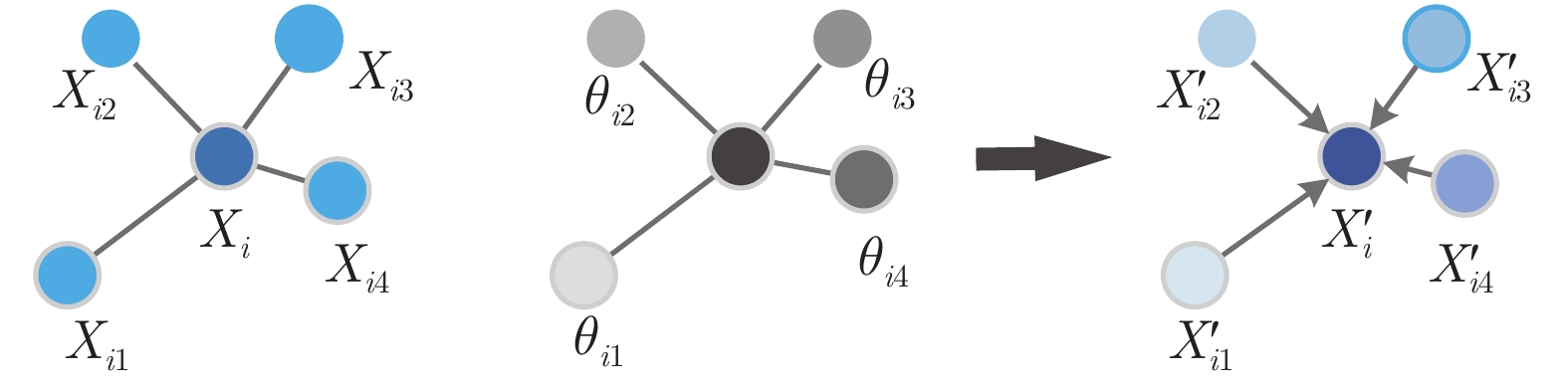
图 2 中心点和近邻点的局部结构图
Fig. 2 Diagram of local structure between the central point and its neighbors
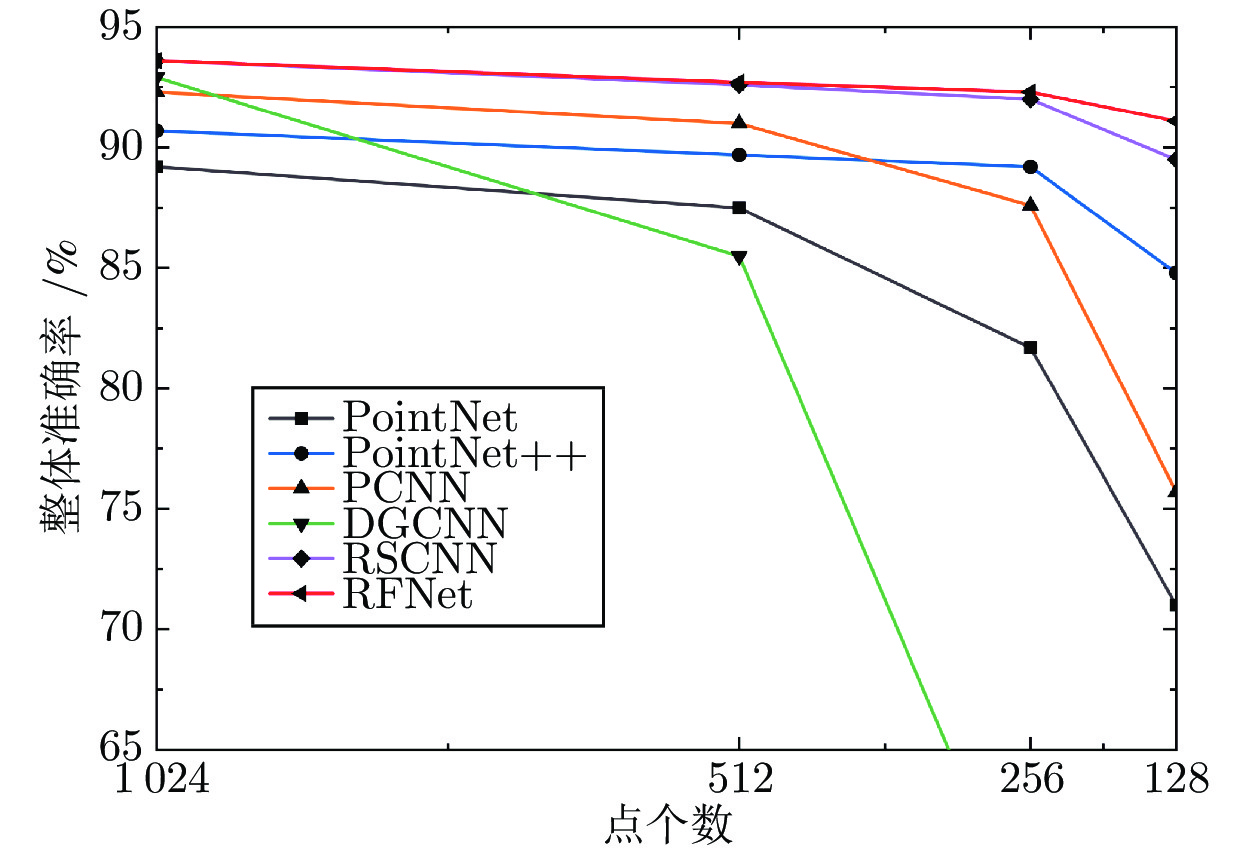
图 7 采样密度实验结果对比
Fig. 7 Comparison of experiment results with different sampling densities
表 1 实验配置
Table 1 Experimental configuration
项目 详情 操作系统 CentOS Linux7 GPU Tesla V100 32 GB CUDA 10.0 CUDNN 7.0 Python 3.6.0 Pytorch 1.3.0  下载: 导出CSV
下载: 导出CSV
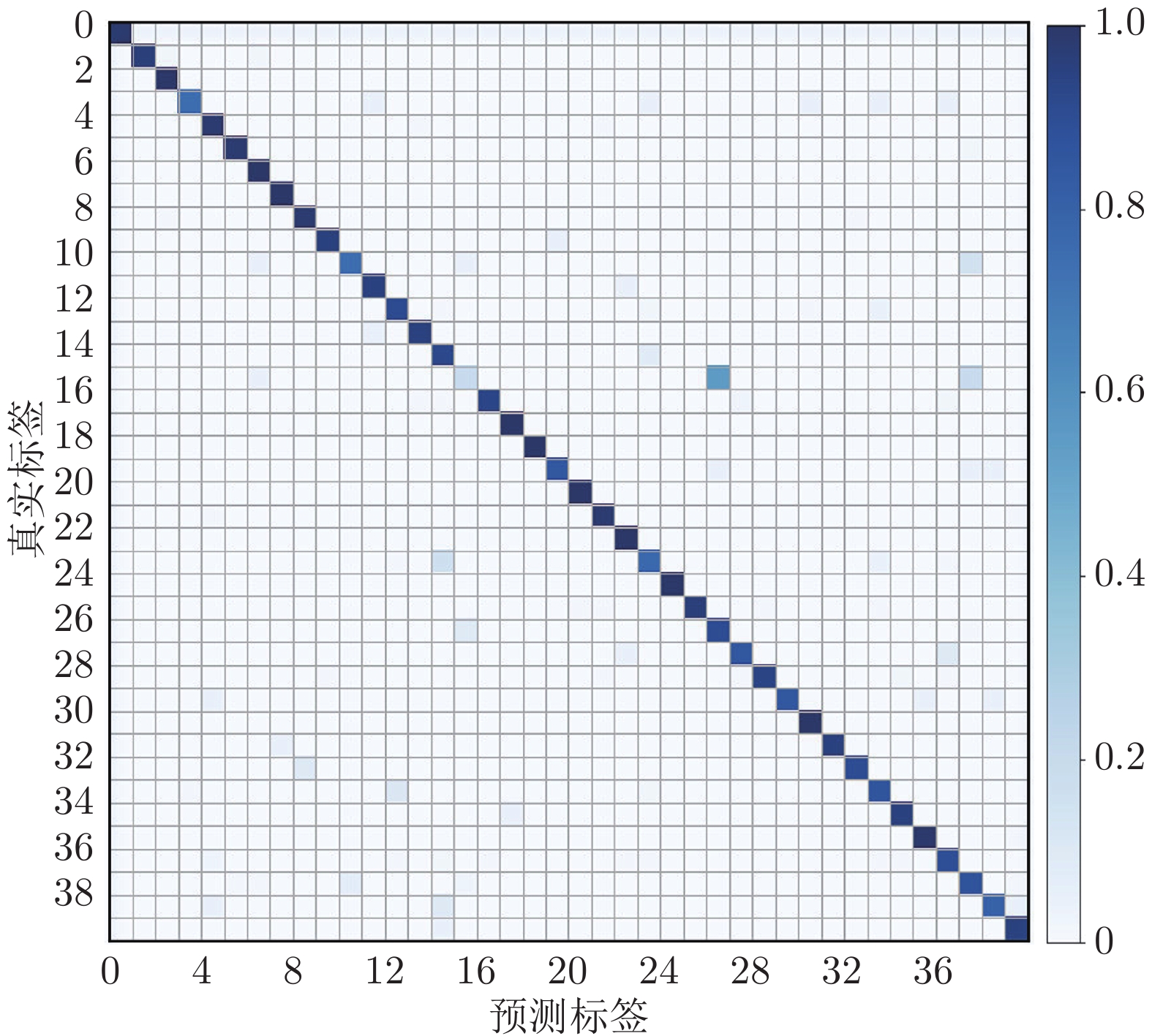
表 2 在ModelNet40数据集上的实验结果
Table 2 Experimental results on ModelNet40
方法 输入 mAcc (%) OA (%) PointNet 1 k 86.0 89.2 PointNet++ 1 k — 90.7 Spec-GCN 1 k — 91.5 DGCNN 1 k 90.2 92.9 RSCNN 1 k — 92.9 PCT 1 k — 93.2 ECC[22] 1 k 83.2 87.4 RMFP-DNN[23] 1 k 88.9 92.6 PointCNN[24] 1 k 88.1 92.2 Point2sequence[25] 1 k 90.4 92.6 Point Transformer [26] 1 k — 92.8 Octant-CNN[27] 1 k 88.7 91.9 DRNet[28] 1 k — 93.1 AdaptConv[29] 1 k 90.7 93.4 RFNet 1 k 91.2 93.6 PointNet++ 5 k + nor — 91.9 DGCNN 2 k 90.7 93.5 RSCNN 1 k + voting — 93.6 SpiderCNN 5 k + nor — 92.4 RFNet 2 k 91.4 94.0
下载: 导出CSV
表 3 不同网络的易错模型分类对比
Table 3 Classification comparison of error-prone models for different networks
易错模型 真实标签 PointNet DGCNN RFNet 
植物 植物 植物 植物 
花盆 植物 植物 植物 
花瓶 花盆 花瓶 花瓶 
花瓶 瓶子 花瓶 花瓶 
杯子 花盆 花盆 杯子
下载: 导出CSV
表 4 在ShapeNetCore数据集上的实验结果
Table 4 Experimental results on ShapeNetCore
方法 输入 OA (%) PointNet 1 k 83.7 PointNet++ 1 k 85.1 DGCNN 1 k 84.7 Point2sequence 1 k 85.2 SpiderCNN 1 k + nor 85.3 KPConv[30] 1 k 86.2 RFNet 1 k 88.3
下载: 导出CSV
表 5 在ScanObjectNN数据集上的实验结果 (%)
Table 5 Experimental results on ScanObjectNN (%)
方法 mAcc OA Bag Bin Box Sofa Desk Shelf Table Door Bed Cabinet Chair Display Pillow Sink Toilet PointNet 63.4 68.2 36.1 69.8 10.5 76.7 50.0 72.6 67.8 93.8 61.8 62.6 89.0 73.0 67.6 64.2 55.3 PointNet++ 75.4 77.9 49.4 84.4 31.6 90.5 74.0 72.6 72.6 85.2 75.5 77.4 91.3 79.4 81.0 80.8 85.9 DGCNN 73.6 78.1 49.4 82.4 33.1 91.4 63.3 79.3 77.4 89.0 64.5 83.9 91.8 77.0 77.1 75.0 69.4 PointCNN 75.1 78.5 57.8 82.9 33.1 91.9 65.3 84.2 67.4 84.8 80.0 83.6 92.6 78.4 80.0 72.5 71.8 SpiderCNN 69.8 73.7 43.4 75.9 12.8 90.5 65.3 78.0 65.9 91.4 69.1 74.2 89.0 74.5 80.0 65.8 70.6 RFNet 76.3 79.6 54.0 81.9 34.1 92.2 74.1 79.9 72.1 91.5 81.3 83.5 91.3 80.2 82.6 78.9 67.0
下载: 导出CSV
表 6 不同模块的消融实验 (%)
Table 6 Ablation experiment of different modules (%)
方法 RFConv WAP JL mAcc OA 网络0 × × × 90.2 92.9 网络1 √ × × 91.0 93.3 网络2 √ √ × 91.1 93.5 网络3 √ × √ 91.1 93.4 网络4 √ √ √ 91.2 93.6
下载: 导出CSV
表 7 高斯噪声鲁棒性实验 (%)
Table 7 Robustness experiment of Gaussian noise (%)
方法 无高斯噪声 有高斯噪声 mAcc OA mAcc OA PointNet 86.0 89.2 83.4 87.6 PointNet++ — 90.7 — 89.6 DGCNN 90.2 92.9 89.7 92.6 RSCNN — 92.9 — 92.3 RFNet 91.2 93.6 91.0 93.5
下载: 导出CSV
表 8 不同特征关系的消融实验 (%)
Table 8 Ablation studies about different relationships between features (%)
方法 ${e_{ij}}$ $di{s_{ij}}$ ${l_{ij}}$ ${s_{ij}}$ OA 网络1 √ × × × 93.3 网络2 √ × √ × 93.5 网络3 √ × √ √ 93.6 网络4 √ √ × × 93.1 网络5 × √ √ √ 93.5 网络6 √ √ √ √ 93.2
下载: 导出CSV
表 9 网络的复杂度对比
Table 9 Comparison of network complexity
方法 参数量(M) 浮点运算数(G) OA (%) PointNet 3.47 0.45 89.2 PointNet++ 1.74 4.09 91.9 DGCNN 1.81 2.43 92.9 PCT 2.88 2.32 93.2 KPConv 14.30 — 92.9 RFNet 2.36 2.95 93.6
下载: 导出CSV
-
[1] Guo Y, Bennamoun M, Sohel F, Min L, Wan J. 3D object recognition in cluttered scenes with local surface features: a survey. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2014, 36(11): 2270-2287 [2] 田永林, 沈宇, 李强, 王飞跃. 平行点云: 虚实互动的点云生成与三维模型进化方法. 自动化学报, 2020, 46(12): 2572-2582Tian Yong-Lin, Shen Yu, Li Qiang, Wang Fei-Yue. Parallel point clouds: point clouds generation and 3d model evolution via virtual-real interaction. Acta Automatica Sinica, 2020, 46(12): 2572-2582 [3] Qi C R, Su H, Mo K, Guibas L J. PointNet: Deep learning on point sets for 3D classification and segmentation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017. 77−85 [4] Guo Y, Wang H, Hu Q, Liu H, Bennamoun M. Deep learning for 3d point clouds: a survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020. 43(12): 4438-4364 [5] Su H, Maji S, Kalogerakis E, Learned-Miller E. Multi-view convolutional neural networks for 3D shape recognition. In: Proceedings of the IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015. 945−953 [6] Yang Z, Wang L. Learning relationships for multi-view 3D object recognition. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul, South Korea: IEEE, 2019. 7504−7513 [7] 徐思雨, 祝继华, 田智强, 李垚辰, 庞善民. 逐步求精的多视角点云配准方法. 自动化学报, 2019, 45(8): 1486-1494Xu Si-Yu, Zhu Ji-Hua, Tian Zhi-Qiang, Li Yao-Chen, Pang Shan-Min. Stepwise refinement approach for registration of multi-view point sets. Acta Automatica Sinica, 2019, 45(8): 1486-1494 [8] Maturana D, Scherer S. VoxNet: A 3D convolutional neural network for real-time object recognition. In: Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems. Hamburg, Germany: IEEE, 2015. 922−928 [9] Riegler G, Osman U A, Geiger A. OctNet: Learning deep 3D representations at high resolutions. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017. 6620−6629 [10] Qi C R, Yi L, Su H, Guibas L J. PointNet++: Deep hierarchical feature learning on point sets in a metric space. In: Proceedings of the Advances in Neural Information Processing Systems. Long Beach, USA: 2017. 5099−5108 [11] Wang C, Samari B, Siddiqi K. Local spectral graph convolution for point set feature learning. In: Proceedings of the European Conference on Computer Vision. Munich, Germany: 2018. 56−71 [12] Wang Y, Sun Y, Liu Z, Sarma S E, Bronstein M M, Solomon J M. Dynamic graph cnn for learning on point clouds. ACM Transactions on Graphics, 2019, 38(5): 1-12 [13] Liu Y, Fan B, Xiang S, Pan C. Relation-shape convolutional neural network for point cloud analysis. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 8895−8904 [14] Wang L, Huang Y, Hou Y, Zhang S, Shan J. Graph attention convolution for point cloud semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 10288−10297 [15] Chen C, Fragonara L Z, Tsourdos A. Gapointnet: graph attention based point neural network for exploiting local feature of point cloud. Neurocomputing, 2021, 438: 122-132 doi: 10.1016/j.neucom.2021.01.095 [16] Guo M H, Cai J X, Liu Z N, Mu T J, Martin R R, Hu S M. Pct: point cloud transformer. Computational Visual Media, 2021, 7(2): 187-299 doi: 10.1007/s41095-021-0229-5 [17] Wen Y, Zhang K, Li Z, Qiao Y. A discriminative feature learning approach for deep face recognition. In: Proceedings of the European Conference on Computer Vision. Amsterdam, Netherland: 2016. 499−515 [18] Wu Z, Song S, Khosla A, Yu F, Zhang L, Tang X, et al. 3D ShapeNets: A deep representation for volumetric shapes. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Boston, USA: IEEE, 2015. 1912−1920 [19] Yi L, Kim V G, Ceylan D, Shen I C, Yan M, Su H, et al. A scalable active framework for region annotation in 3d shape collections. ACM Transactions on Graphics, 2016, 35(6): 1-12 [20] Uy M A, Pham Q H, Hua B S, Nguyen T, Yeung S K. Revisiting point cloud classification: A new benchmark data-set and classification model on real-world data. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul, South Korea: IEEE, 2019. 1588−1597 [21] Xu Y, Fan T, Xu M, Long Z, Yu Q. SpiderCNN: Deep learning on point sets with parameterized convolutional filters. In: Proceedings of the European Conference on Computer Vision. Munich, Germany: 2018. 90−105 [22] Simonovsky M, Komodakis N. Dynamic edge-conditioned filters in convolutional neural networks on graphs. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017. 3693−3702 [23] 田钰杰, 管有庆, 龚锐. 一种鲁棒的多特征点云分类分割深度神经网络. 计算机工程, 2021, 47(11): 234-240Tian Yu-Jie, Guan You-Qing, Gong Rui. A robust deep neural network for multi-feature point cloud classification and segmentation. Computer Engineering, 2021, 47(11): 234-240 [24] Li Y, Bu R, Sun M, Chen B. PointCNN: Convolution on x-transformed points. In: Proceedings of the Advances in Neural Information Processing System. Montreal, Canada: 2018. 828− 838 [25] Liu X, Han Z, Liu Y, Zwicker M. Point2sequence: Learning the shape representation of 3D point clouds with an attention-based sequence to sequence network. In: Proceedings of the AAAI Conference on Artificial Intelligence. Honolulu, USA: AAAI, 2019. 8778−8785 [26] Engel N, Belagiannis V, Dietmayer K. Point transformer. IEEE Access, 2021, 9: 134826-134840 doi: 10.1109/ACCESS.2021.3116304 [27] 许翔, 帅惠, 刘青山. 基于卦限卷积神经网络的3D点云分析. 自动化学报, 2021, 47(12): 2791−2800Xu Xiang, Shuai Hui, Liu Qing-Shan. Octant convolutional neural network for 3D point cloud analysis. Acta Automatica Sinica, 2021, 47(12): 2791−2800 [28] Qiu S, Anwar S, Barnes N. Dense-resolution network for point cloud classification and segmentation. In: Proceedings of the IEEE Winter Conference on Applications of Computer Vision. Virtual Event: IEEE, 2021. 3812−3821 [29] Zhou H, Feng Y, Fang M, Wei M, Qin J, Lu T. Adaptive graph convolution for point cloud analysis. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. Montreal, Canada: IEEE, 2021. 4965−4974 [30] Thomas H, Qi C R, Deschaud J E, Marcotegui B, Goulette F, Guibas L. KPConv: Flexible and deformable convolution for point clouds. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul, South Korea: IEEE, 2020. 6420−6429 -

 下载:
下载:




计量
- 文章访问数: 1729
- HTML全文浏览量: 745
- PDF下载量: 325
- 被引次数: 0
