

Online Prediction Method for Silicon Content of Molten Iron in Blast Furnace Based on Dynamic Attention Deep Transfer Network
-
摘要: 铁水硅含量是反映高炉冶炼过程中热状态变化的灵敏指示剂, 但无法实时在线检测, 造成铁水质量调控盲目. 为此, 提出一种基于动态注意力深度迁移网络(Attention deep transfer network, ADTNet)的高炉铁水硅含量在线预测方法. 首先, 针对传统深度网络静态建模思路无法准确描述过程变量与铁水硅含量之间的关系, 提出一种基于注意力机制模块的输入过程变量与输出硅含量之间的动态关系描述方法; 其次, 为降低硅含量预测模型训练时对标签数据的依赖, 考虑到铁水温度与硅含量数据之间的正相关性, 利用小时级硅含量标签数据微调基于分钟级铁水温度数据预训练好的深度模型的结构, 进而提高基于动态注意力深度迁移网络的硅含量预测精度; 同时, 为增强预测网络的可解释性, 实时给出了基于动态注意力机制模块计算的每个样本各过程变量对铁水硅含量的贡献度; 最后, 基于某钢铁厂2号高炉的工业实验, 验证了该方法的准确性、有效性和先进性.Abstract: The molten iron silicon content, which can reflect the thermal state in blast furnace hearth during the ironmaking process, is difficult to detect in real time. This will cause blind adjustment to the quality of the molten iron. Hence, this paper proposes a data-driven model for the online prediction of the silicon content based on dynamic attention deep transfer network (ADTNet). First, considering that the deep network cannot accurately describe the relationship between process variables and the silicon content based on static modeling process, a dynamic attention module is designed to describe the dynamic relationship between the inputs and outputs. Then, to reduce the dependence of labeled silicon content samples during model training process, an online prediction model is established based on minute-level temperature data after considering the positive correlation between molten iron temperature and silicon content data. Subsequently, using the labeled silicon content data to fine tune the parameters of the well-trained deep model and improve the silicon content prediction performance based on dynamic attention deep transfer network. Furthermore, to enhance the interpret-ability of the deep black box model, the contribution of process variables of each sample to the silicon content is presented based on the dynamic attention module. Finally, industrial experiments of No. 2 blast furnace in a steel plant verify the accuracy, effectiveness and advancement of the proposed method.
-
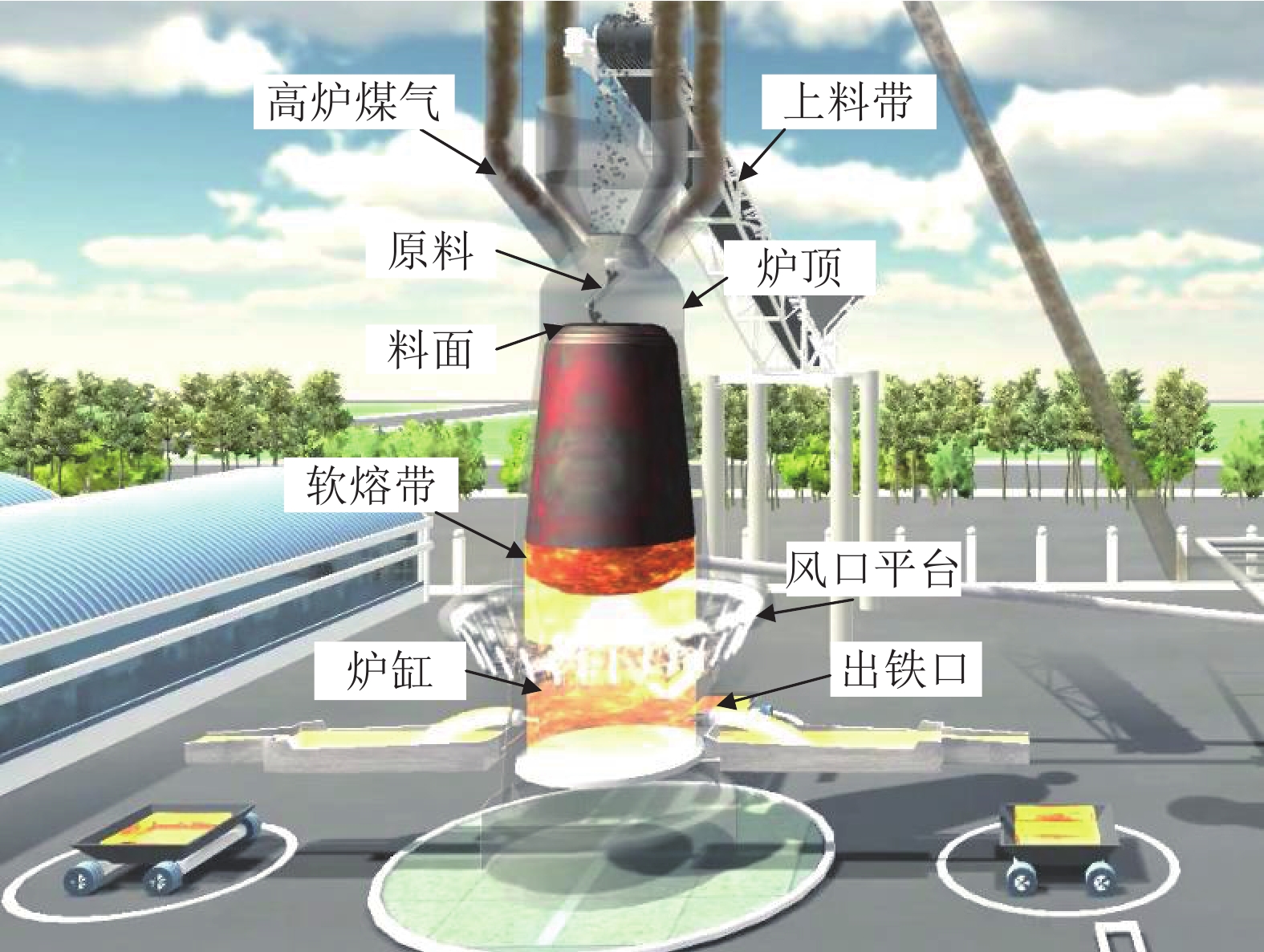
图 1 高炉三维仿真模拟图
Fig. 1 Three-dimensional simulation diagram ofthe blast furnace cast field
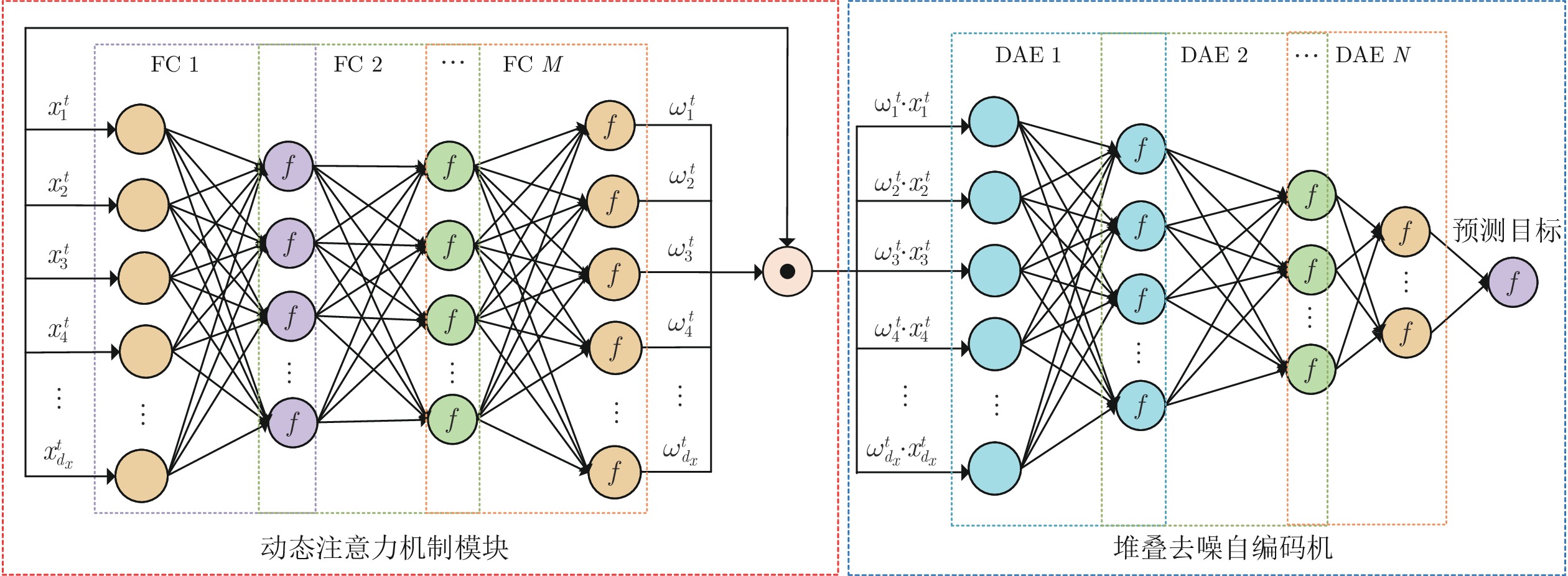
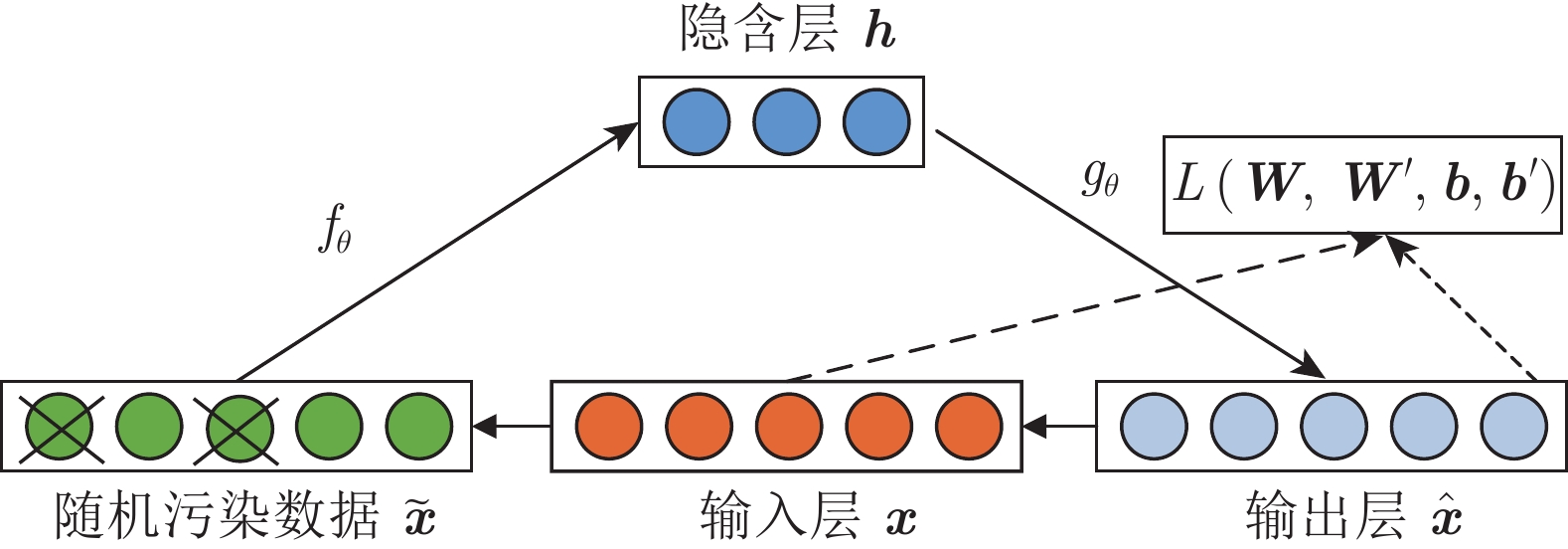
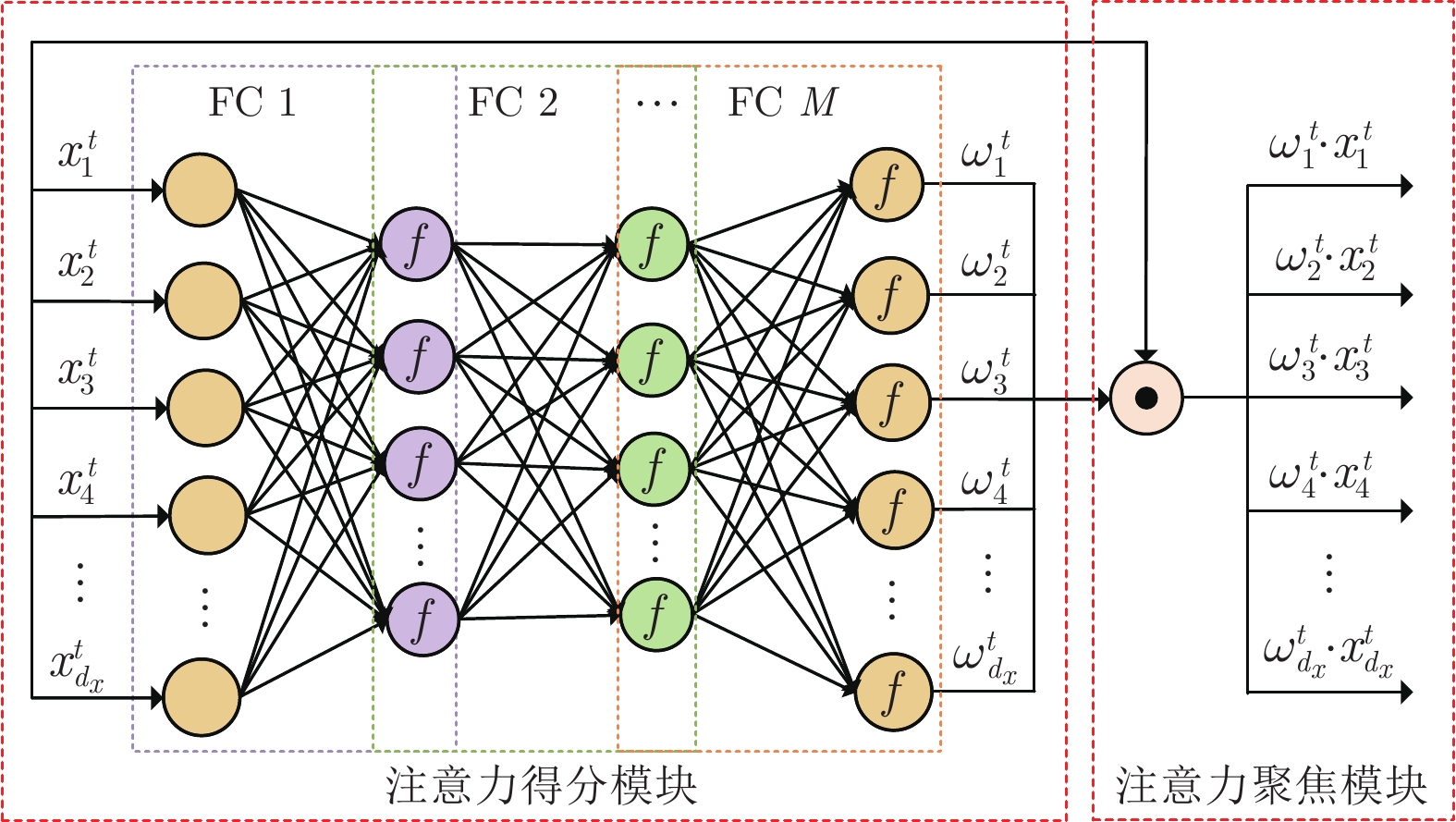
图 5 基于动态注意力机制模块的深度去噪自编码机网络
Fig. 5 Deep denoising autoencoders network based on dynamic attention mechanism module
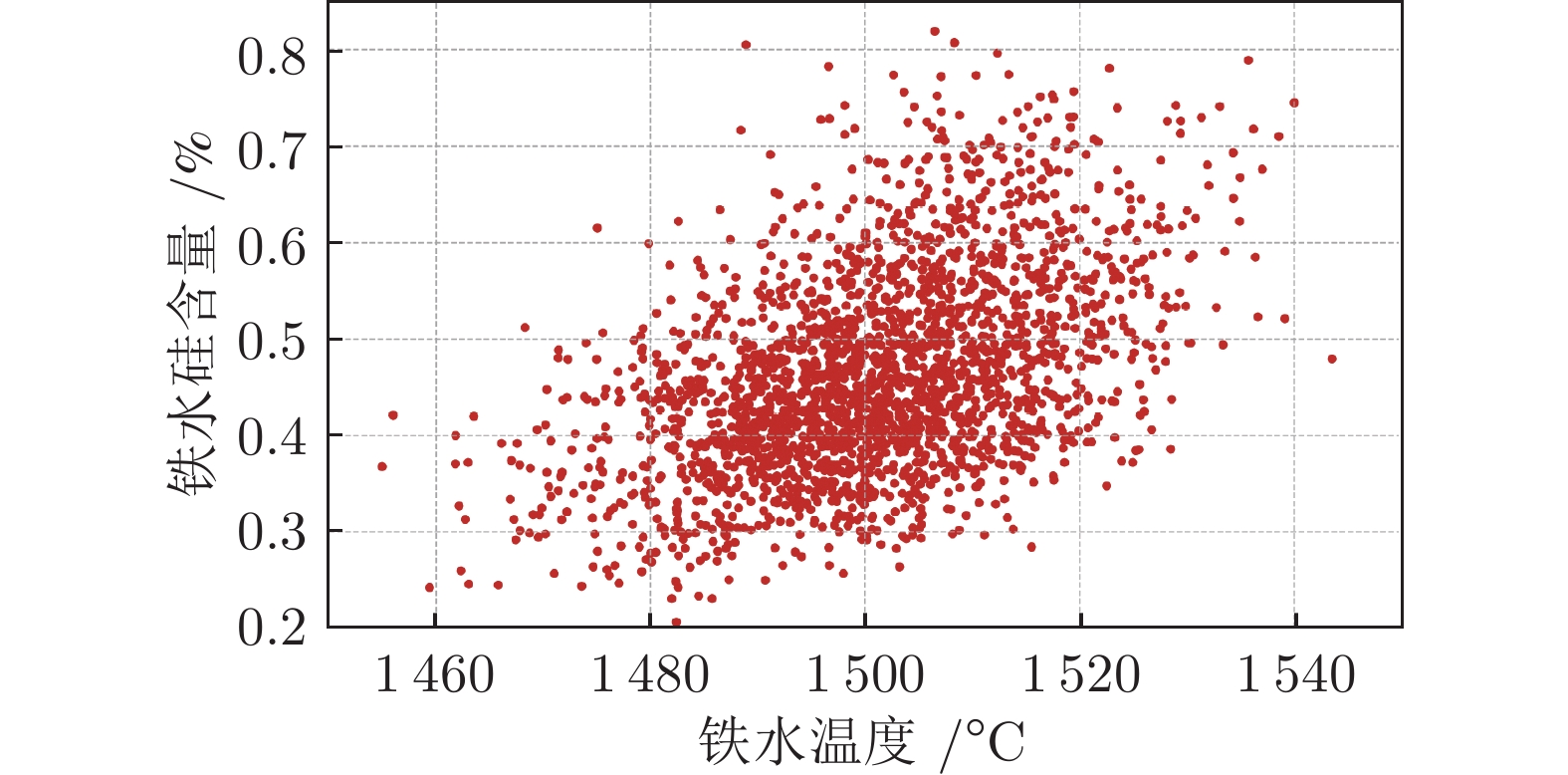
图 6 铁水温度与铁水硅含量的散点图
Fig. 6 The scatter plot of temperature and silicon content of molten iron
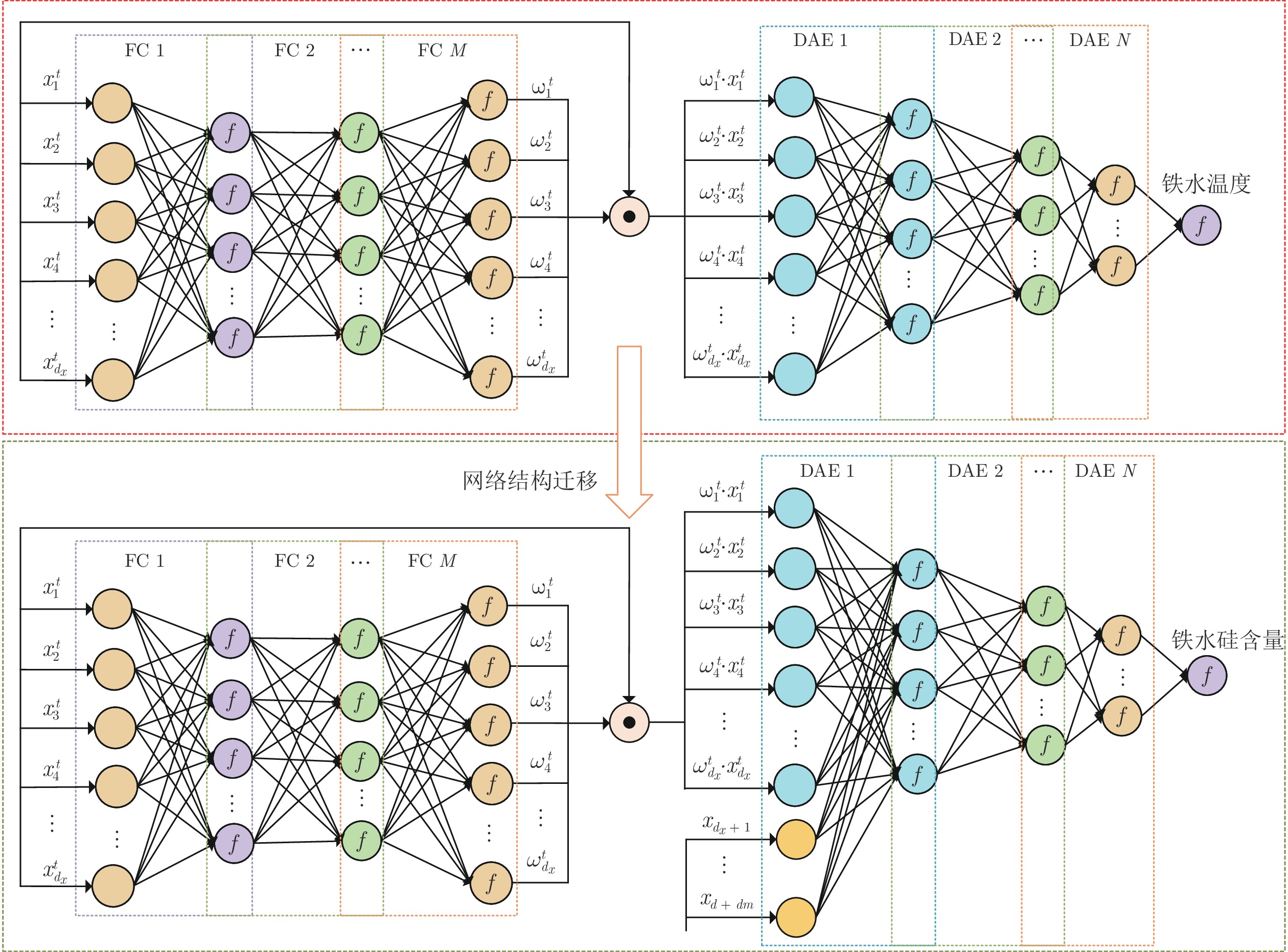
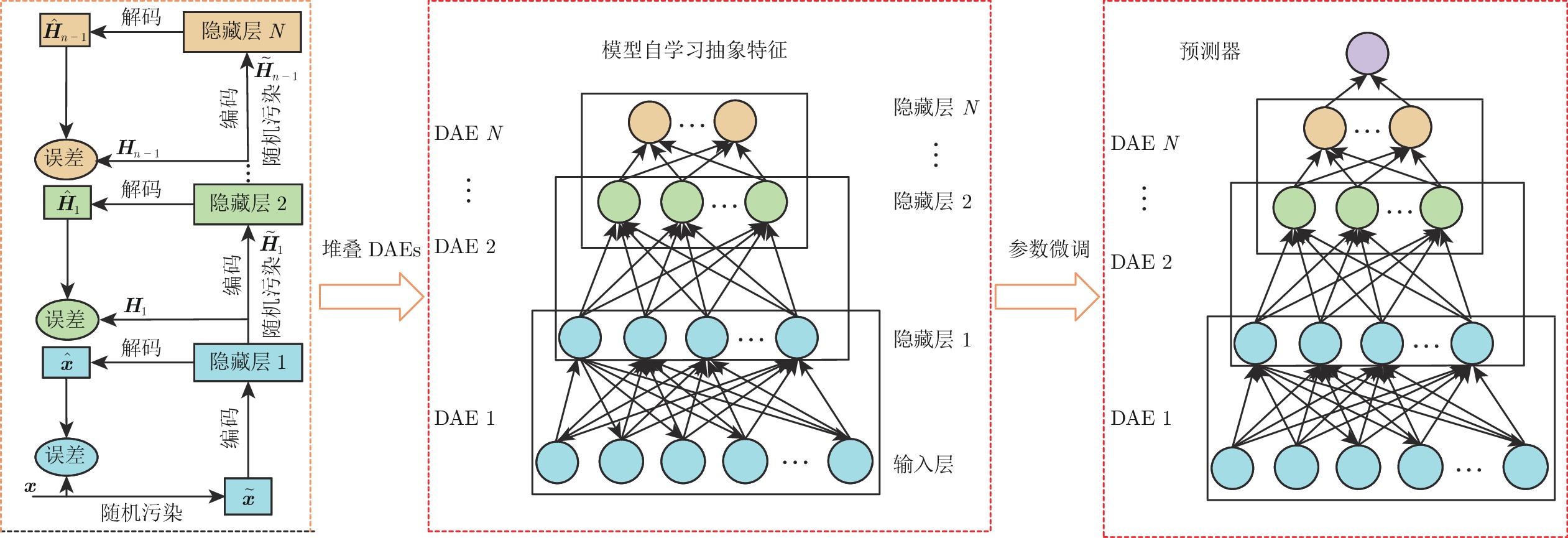
图 8 基于深度迁移网络的铁水硅含量在线预报模型
Fig. 8 Online prediction model of silicon content in molten iron based on deep transfer network
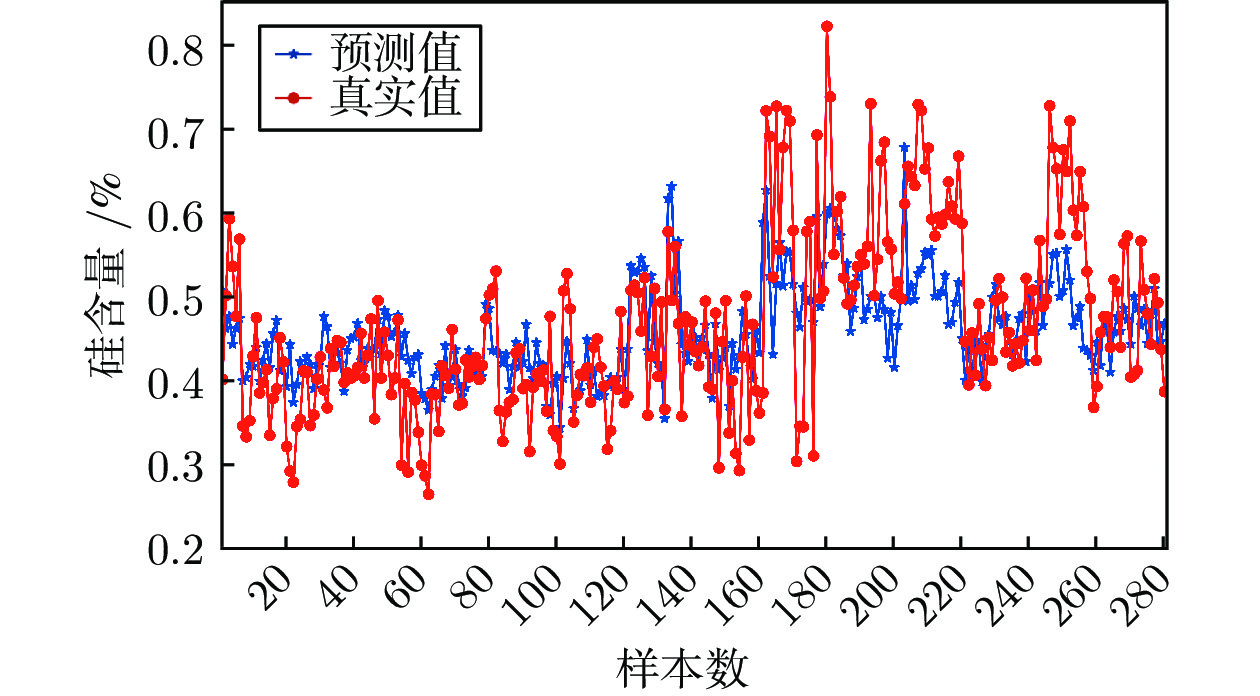
图 10 基于堆叠去噪自编码机的铁水硅含量预测结果
Fig. 10 Prediction results of silicon content based on S-DAE
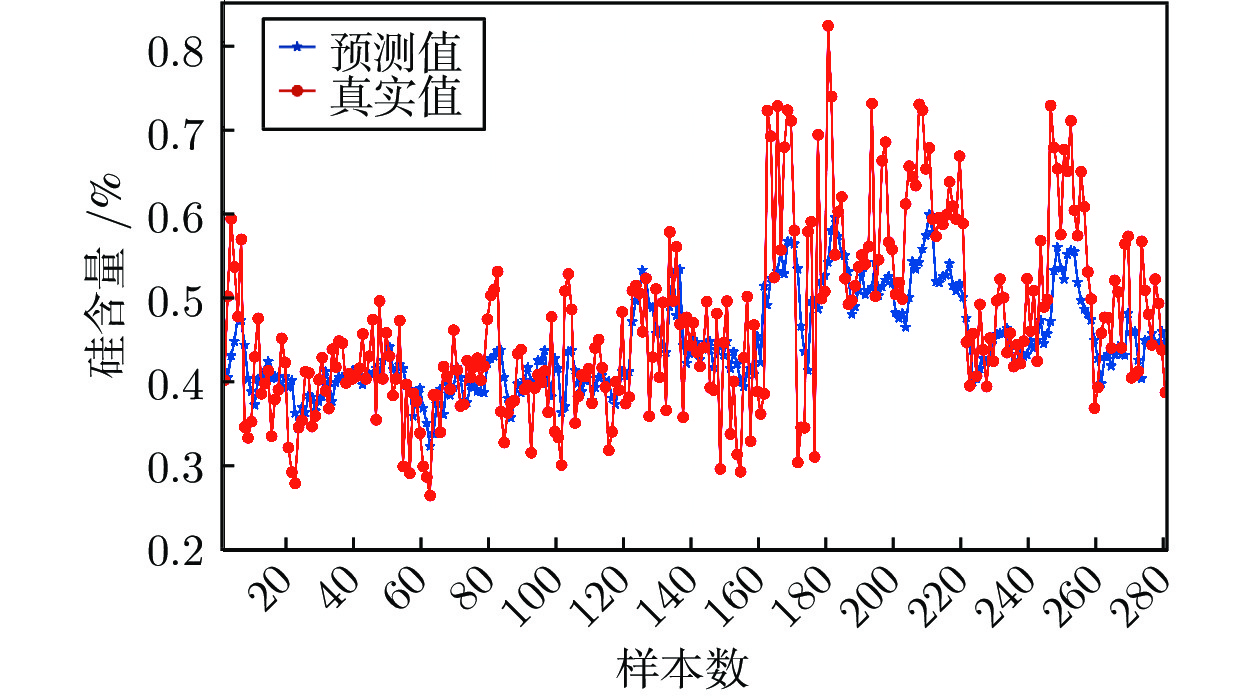
图 11 基于动态注意力机制深度网络的铁水硅含量预测结果
Fig. 11 Prediction results of silicon content based on ADNet
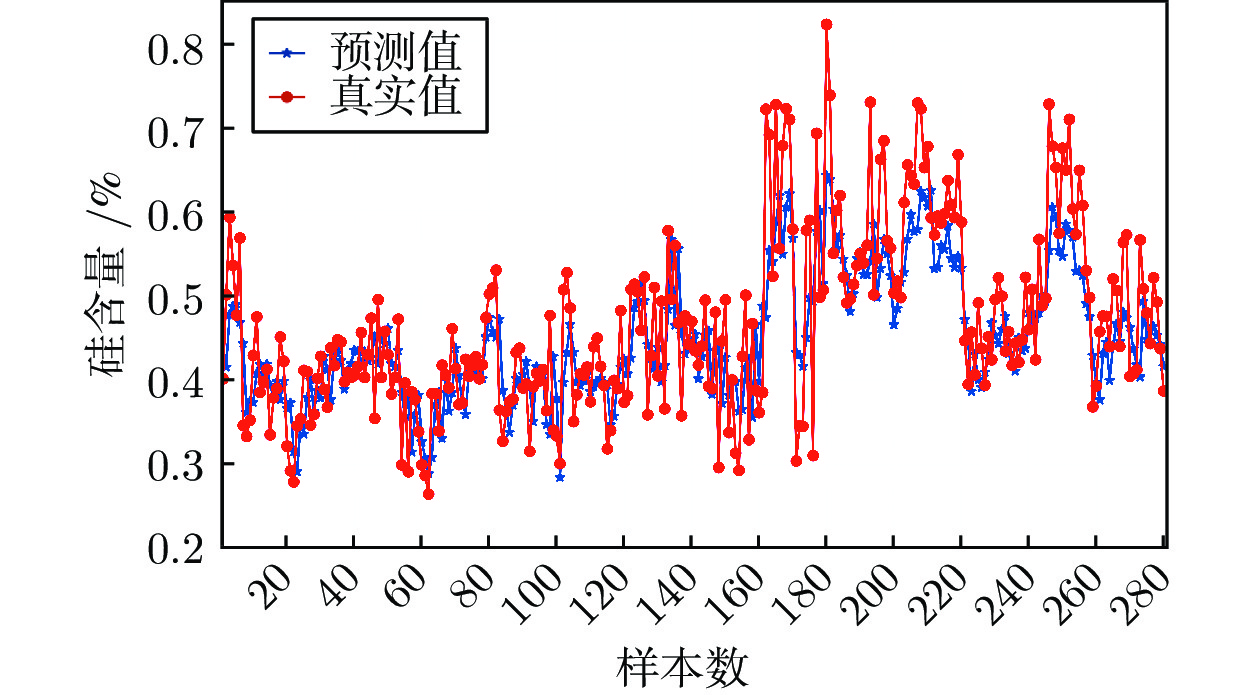
图 12 基于动态注意力深度迁移网络的铁水硅含量预测结果
Fig. 12 Prediction results of silicon content based on ADTNet
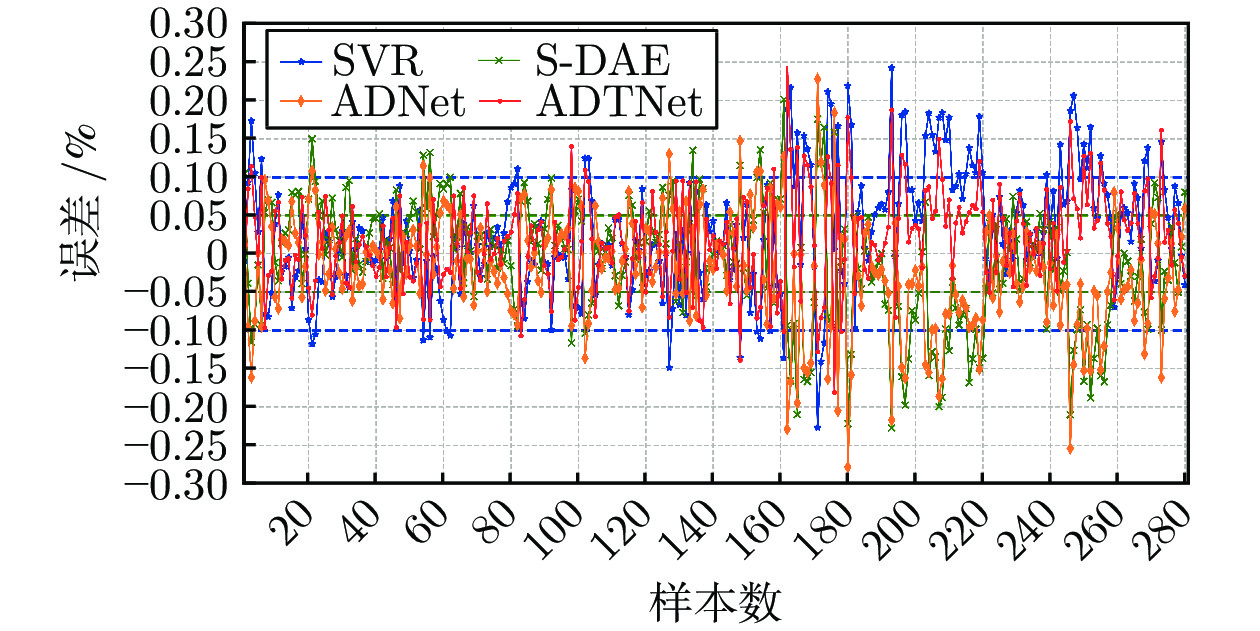
图 13 基于不同模型的铁水硅含量误差分布图
Fig. 13 Prediction errors of silicon content in molten iron based on different models
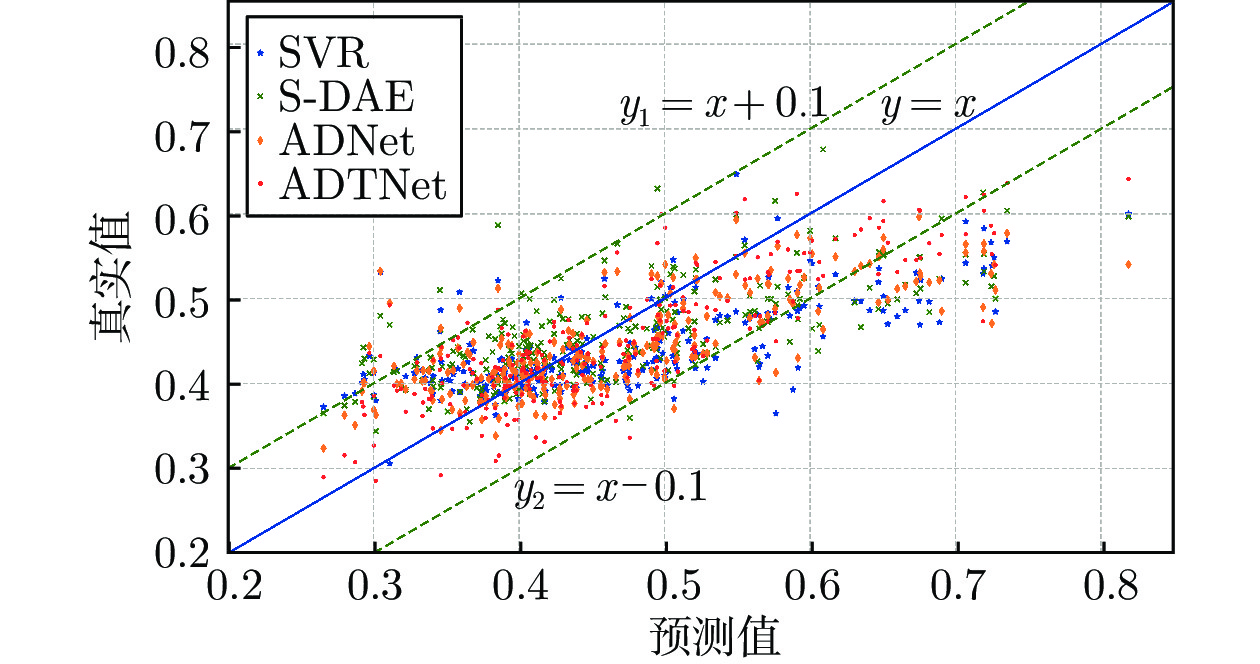
图 14 基于不同模型的预测和实际铁水硅含量分布散点图
Fig. 14 The scatter plot of predictive and observed silicon content based on different models
表 1 过程变量最大互信息系数
Table 1 Maximal information coefficient of process variables
过程变量 MICMIT MICSi 过程变量 MICMIT MICSi 富氧率 0.104 0.115 冷风压力 0.104 0.094 透气性指数 0.104 0.111 全压差 0.104 0.130 CO 0.103 0.104 热风压力 0.103 0.116 CO2 0.111 0.145 实际风速 0.100 0.113 标准风速 0.117 0.111 冷风温度 0.102 0.109 富氧流量 0.120 0.129 热风温度 0.101 0.115 冷风流量 0.117 0.111 顶温 0.120 0.162 鼓风动能 0.101 0.107 顶温下降管 0.111 0.155 炉腹煤气量 0.108 0.127 阻力系数 0.103 0.110 炉腹煤气指数 0.109 0.128 鼓风湿度 0.135 0.140 顶压 0.128 0.156 富氧压力 0.103 0.096 本小时实际
喷煤量0.100 0.136 上一小时
实际喷煤量0.110 0.165  下载: 导出CSV
下载: 导出CSV
表 2 基于不同模型的预测性能
Table 2 Prediction performance based on different models
模型 RMSE MAE HR (%) SVR 0.0832 0.0635 77.5 S-DAE 0.0794 0.0616 84.6 ADNet 0.0772 0.0583 86.4 ADTNet 0.0649 0.0509 90.0
下载: 导出CSV
-
[1] 周平, 张丽, 李温鹏, 戴鹏, 柴天佑. 集成自编码与PCA的高炉多元铁水质量随机权神经网络建模. 自动化学报, 2018, 44(10): 1799-1811Zhou Ping, Zhang Li, Li Wen-Peng, Dai Peng, Chai Tian-You. Modeling of blast furnace multi-element molten iron quality with random weight neural network based on self-encoding and PCA. Acta Automatica Sinica, 2018, 44(10): 1799-1811 [2] Zhou H, Zhang H F, and Yang C J. Hybrid model based intelligent optimization of ironmaking process. IEEE Transaction on Industrial Electronics, 2020, 67(3): 2469-247 doi: 10.1109/TIE.2019.2903770 [3] Jiang K, Jiang Z H, Xie Y F, Pan D, Gui W H. Abnormality monitoring in the blast furnace ironmaking process based on stacked dynamic target-driven denoising autoencoders. IEEE Transactions on Industrial Informatics, 2022, 18(3): 1854−1863 [4] 郜传厚, 渐令, 陈积明, 孙优贤. 复杂高炉炼铁过程的数据驱动建模及预测算法. 自动化学报, 2009, 35(06): 725-730 doi: 10.3724/SP.J.1004.2009.00725Gao Chuan-Hou, Jian Ling, Chen Jia-Ming, Sun You-Xian. Data-driven modeling and prediction algorithm for complex blast furnace ironmaking process. Acta Automatica Sinica, 2009, 35(6): 725-730 doi: 10.3724/SP.J.1004.2009.00725 [5] Chen S H, Gao C H. Linear priors mined and integrated for transparency of blast furnace black-Box SVM model. IEEE Transactions on Industrial Informatics, 2020, 16(6): 3862-3870 doi: 10.1109/TII.2019.2940475 [6] Zhou P, Lv Y B, Wang H, and Chai T Y. Data-driven robust RVFLNs modeling of a blast furnace iron-making process using Cauchy distribution weighted M-Estimation. IEEE Transaction on Industrial Electronics, 2017, 64(9): 7141–7151 doi: 10.1109/TIE.2017.2686369 [7] 宋贺达, 周平, 王宏, 柴天佑. 高炉炼铁过程多元铁水质量非线性子空间建模及应用. 自动化学报, 2016, 42(11): 1664-1679Song He-Da, Zhou Ping, Wang Hong, Chai Tian-You. Nonlinear subspace modeling of multivariate molten iron quality in blast furnace ironmaking and its application. Acta Automatica Sinica, 2016, 42(11): 1664-1679 [8] Spirin N A, Onorin O P, Istomin A S. Study of transition processes of blast-furnace smelting by the mathematical model me-thod. In: Proceedings of the IOP Conference Series, Materials Science and Engineering. Suzhou, China: Institute of Physics Pu-blishing, 2018. 12−73 [9] Spirin N, Onorin O, Alexander I. Prediction of blast furnace thermal state in real-time operation. Solid State Phenomena, 2020, 299: 518-523 doi: 10.4028/www.scientific.net/SSP.299.518 [10] Spirin N. A, Polinov A A, Gurin I A, Pishnograev SN. Information system for real-time prediction of the silicon content of iron in a blast furnace. Metallurgist, 2020, 63(9): 898-905 [11] Saxen H, Gao C H, and Gao Z W. Data-driven time discrete models for dynamic prediction of the hot metal silicon content in the blast furnace—A review. IEEE Transactions on Industrial Informatics, 2013, 9(4): 2213-2225 doi: 10.1109/TII.2012.2226897 [12] 李温鹏, 周平. 高炉铁水质量鲁棒正则化随机权神经网络建模. 自动化学报, 2020, 46(04): 721-733Li Wen-Peng, Zhou Ping. Blast furnace hot metal quality robust regularization random weight neural network modeling. Acta Automatica Sinica, 2020, 46(04): 721-733 [13] 蒋朝辉, 许川, 桂卫华, 蒋珂. 基于最优工况迁移的高炉铁水硅含量预测方法. 自动化学报Jiang Zhao-Hui, Xu Chuang, Gui Wei-Hua, Jiang Ke. Prediction method of hot metal silicon content in blast furnace based on optimal smelting condition migration. Acta Automatica Sinica, to be published. [14] Zhou P, Guo D W, Wang H, and Chai T Y. Data-driven robust M-LS-SVR-based NARX modeling for estimation and control of molten iron quality indices in blast furnace ironmaking. IEEE Transactions on Neural Networks and Learning Systems, 2018, 29(9): 4007-4021 doi: 10.1109/TNNLS.2017.2749412 [15] 蒋朝辉, 董梦林, 桂卫华, 阳春华, 谢永芳. 基于Bootstrap的高炉铁水硅含量二维预报. 自动化学报, 2016, 42(05): 715-723Jiang Zhao-Hui, Dong Meng-Lin, Gui Wei-Hua, Yang Chun-Hua, Xie Yong-Fang. Two-dimensional prediction for silicon content of hot metal of blast furnace based on bootstrap. Acta Automatica Sinica, 2016, 42(5): 715-723 [16] Li J P, Hua C C, Yang Y N, Guan X P. Bayesian block structure sparse based T–S fuzzy modeling for dynamic prediction of hot metal silicon content in the blast furnace. IEEE Transactions on Industrial Electronics, 2017, 65(6): 4933-4942 [17] Hinton G E, Osindero S, and Teh Y W. A fast learning algorithm for deep belief nets. Neural Computing, 2006, 18(7): 1527-1554 doi: 10.1162/neco.2006.18.7.1527 [18] Hinton G E, Deng L, Yu D, et al. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. IEEE Signal Process, 2012, 29(6): 82-97 doi: 10.1109/MSP.2012.2205597 [19] Ma J, Wu F, Zhu J, Xu D, and Kong D. A pre-trained convolutional neural network based method for thyroid nodule diagnosis. Ultrasonics, 2017, 73: 221 doi: 10.1016/j.ultras.2016.09.011 [20] Krizhevsky A, Sutskever I, and Hinton G E. Imagenet classification with deep convolutional neural networks. in Process Advance Neural Information Process System, 2012, 1097-1105 [21] Jiang K, Jiang Z H, Xie Y F, Chen Z P, Pan D, Gui W H. Classification of silicon content variation trend based on fusion of multilevel features in blast furnace ironmaking. Information Sciences, 2020, 521: 32-45 doi: 10.1016/j.ins.2020.02.039 [22] Wang Y L, Pan Z F, Yuan X F, Yang C H, and Gui W H. A novel deep learning based fault diagnosis approach for chemical process with extended deep belief network. ISA Transactions, 2020, 96: 457-467 doi: 10.1016/j.isatra.2019.07.001 [23] Pan D, Jiang Z H, Chen Z P, Jiang K, Gui W H. Compensation method for molten iron temperature measurement based on heterogeneous features of infrared thermal images. IEEE Transactions on Industrial Informatics, 2020, 16(11): 7056-7066. doi: 10.1109/TII.2020.2972332 [24] Pan D, Jiang Z H, Chen Z P, Gui W H, Xie Y F, Yang C H. Temperature measurement and compensation method of blast furnace molten iron based on infrared computer vision. IEEE Transactions on Instrumentation and Measurement, 2018, 68 (10): 3576-3588. [25] Vincent P, Larochelle H, Lajoie I, Bengio Y, and Manzagol P. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. Journal of Machine Learning Research, 2010, 11: 3371–3408 [26] Vincent P, Larochelle H, Bengio Y, Manzagol P A. Extracting and composing robust features with denoising autoencoders. In: Proceedings of the 25th International Conference Machine Lea-rning. Helsinki, Finland: 2008. 1096−1103 [27] Reshef D N, Reshef Y A. Detecting novel associations in large data sets. Science, 2011, 334(6062): 1518-1524 doi: 10.1126/science.1205438 [28] Agarap A F. Deep learning using rectified linear units (ReLU). arXiv preprint arXiv: 1803.08375, 2018. -

 下载:
下载:




计量
- 文章访问数: 2725
- HTML全文浏览量: 917
- PDF下载量: 558
- 被引次数: 0
