

Resource Scheduling Method of Multi-sensor Cooperative Detection for Flying Targets
-
摘要: 针对飞行目标机动性带来的多传感器协同探测资源调度动态性需求, 提出一种新的基于近端策略优化(Proximal policy optimization, PPO)与全连接神经网络结合的多传感器协同探测资源调度算法. 首先, 分析影响多传感器协同探测资源调度的复杂约束条件, 形成评价多传感器协同探测资源调度过程指标; 然后, 引入马尔科夫决策过程(Markov decision process, MDP)模拟多传感器协同探测资源调度过程, 并为提高算法稳定性, 将Adam算法与学习率衰减算法结合, 控制学习率调整步长; 最后, 基于改进近端策略优化与全卷积神经网络结合算法求解动态资源调度策略, 并通过对比实验表明该算法的优越性.Abstract: Aiming at the dynamic demand of multi-sensor cooperative detection resource scheduling brought by the maneuverability of flying targets, a new multi-sensor cooperative detection resource scheduling algorithm based on proximal policy optimization (PPO) and fully connected neural network is proposed. In this paper, we first build a constraint index model that affects the scheduling of multi-sensor cooperative detection resources. Next, we introduce the Markov decision process (MDP) to simulate the multi-sensor cooperative detection resource scheduling process, and in order to improve the stability of the algorithm, the Adam algorithm is combined with the learning rate attenuation algorithm to control the up-to-date step of learning rate. Finally, the optimal resource scheduling strategy is solved based on the improved proximal policy optimization and fully connected neural network algorithm, and the comparative experiment shows the superiority of the algorithm proposed in this paper.
-
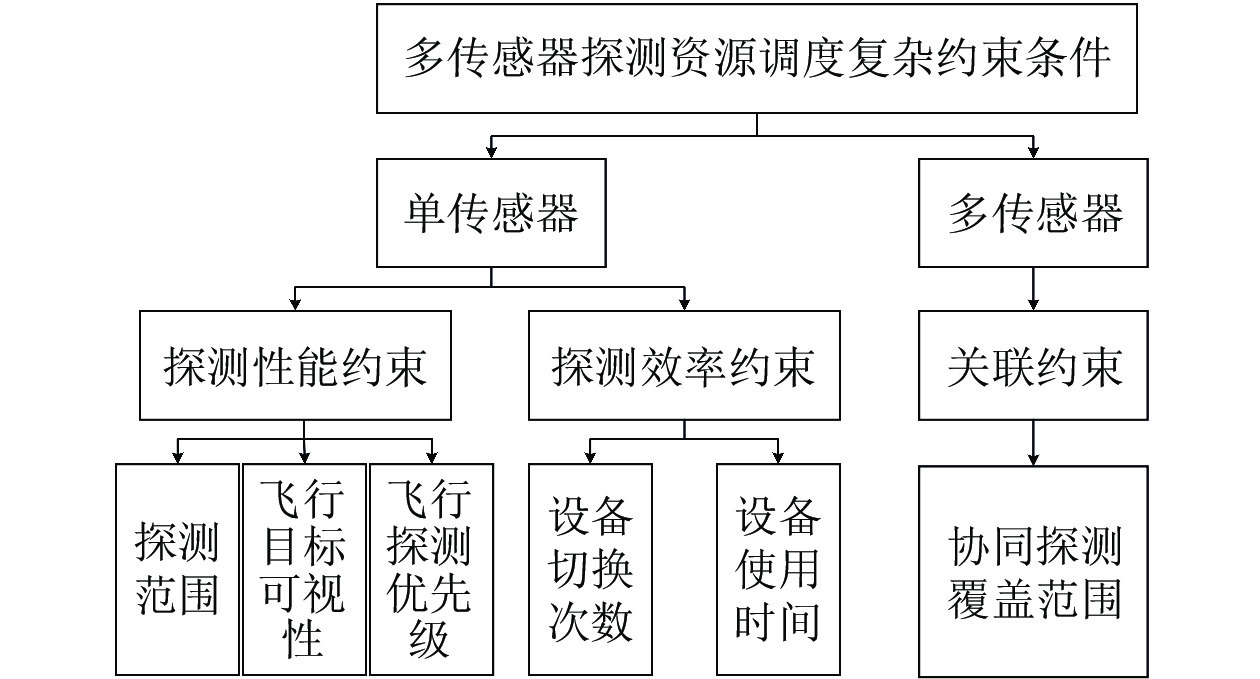
图 1 多传感器探测资源调度过程中复杂约束条件
Fig. 1 Complex constraints in the process of multi-sensor resources schedule

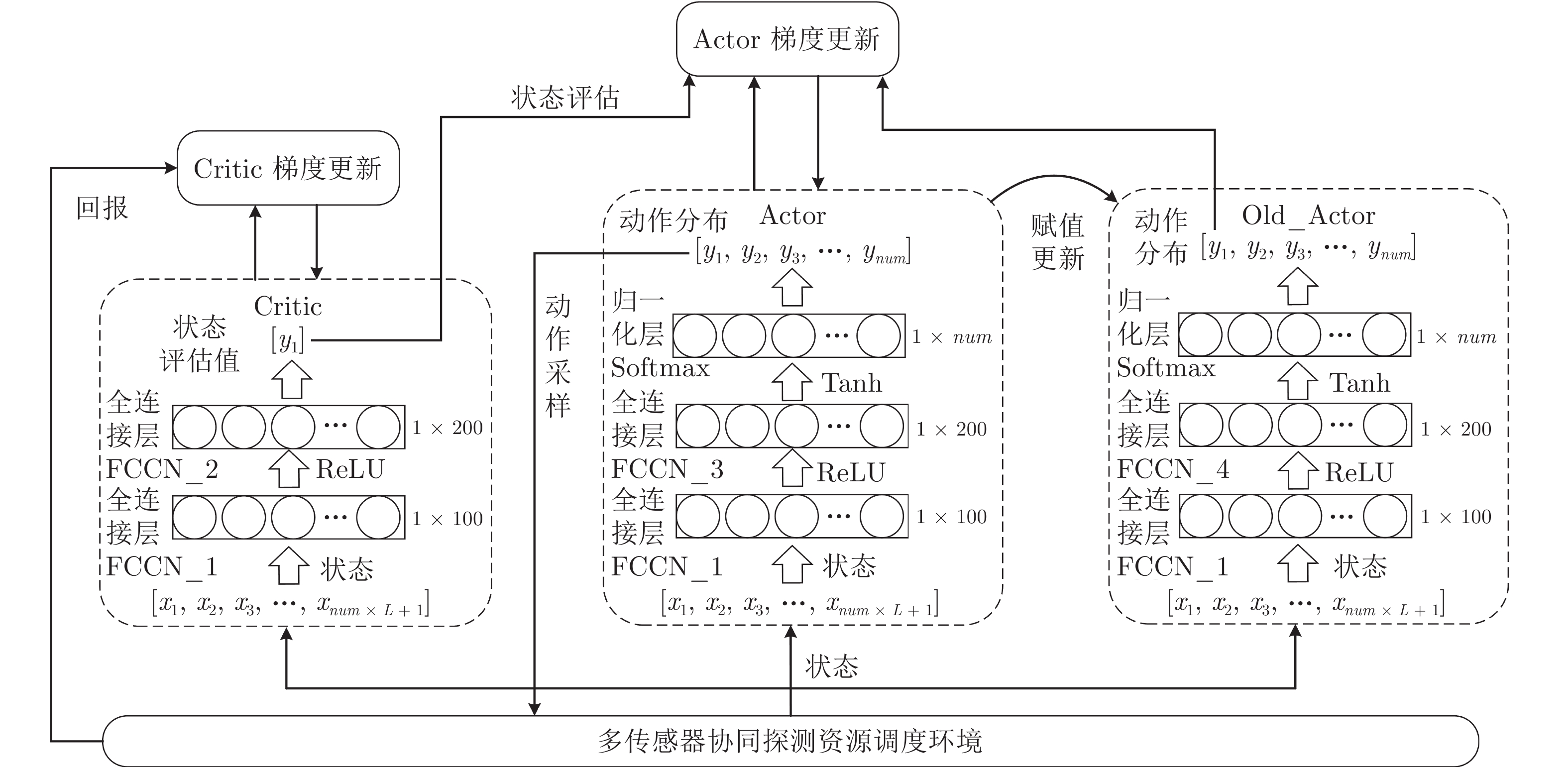
图 5 基于改进PPO-FCNN的多传感器协同探测资源调度算法训练示意图
Fig. 5 Training algorithm for multi-sensor cooperative detection resource scheduling based on improved PPO-FCNN

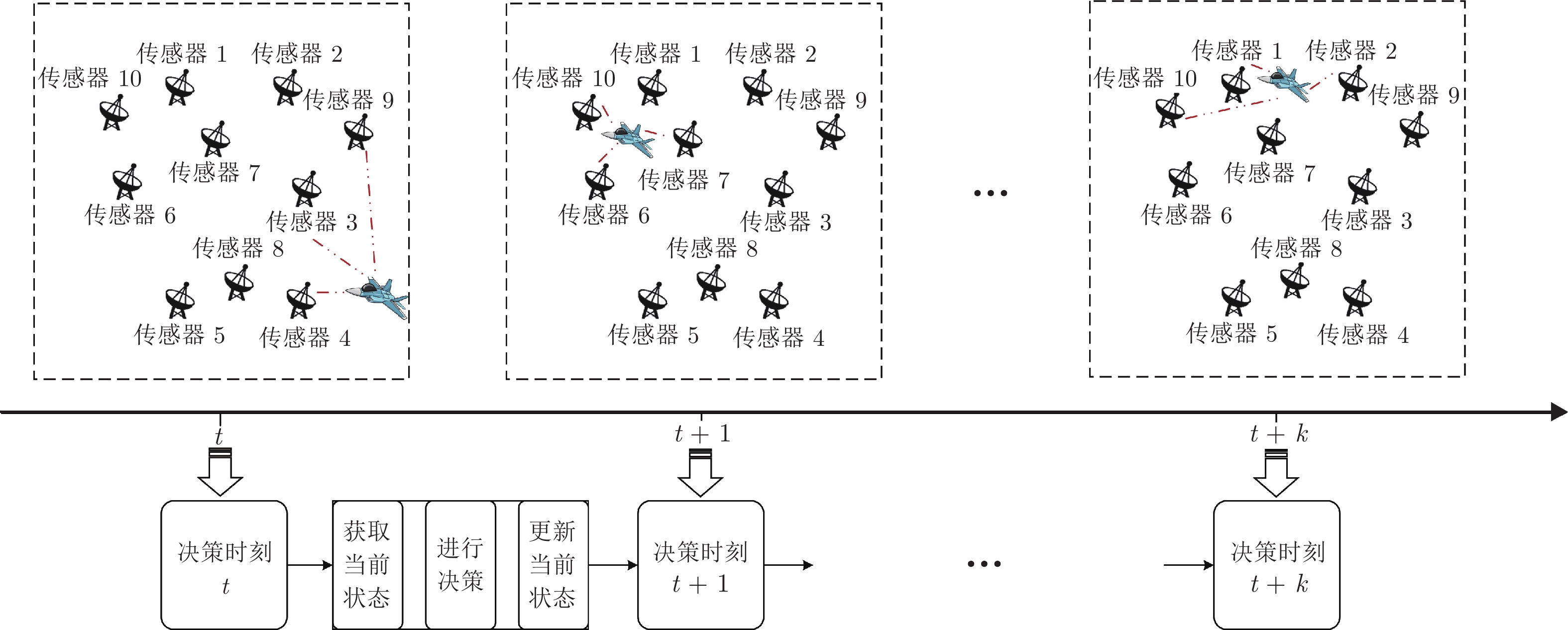
图 6 基于改进PPO-FCNN的多传感器协同探测资源动态调度算法流程
Fig. 6 Process of multi-sensor cooperative detection dynamic scheduling based on improved PPO-FCNN
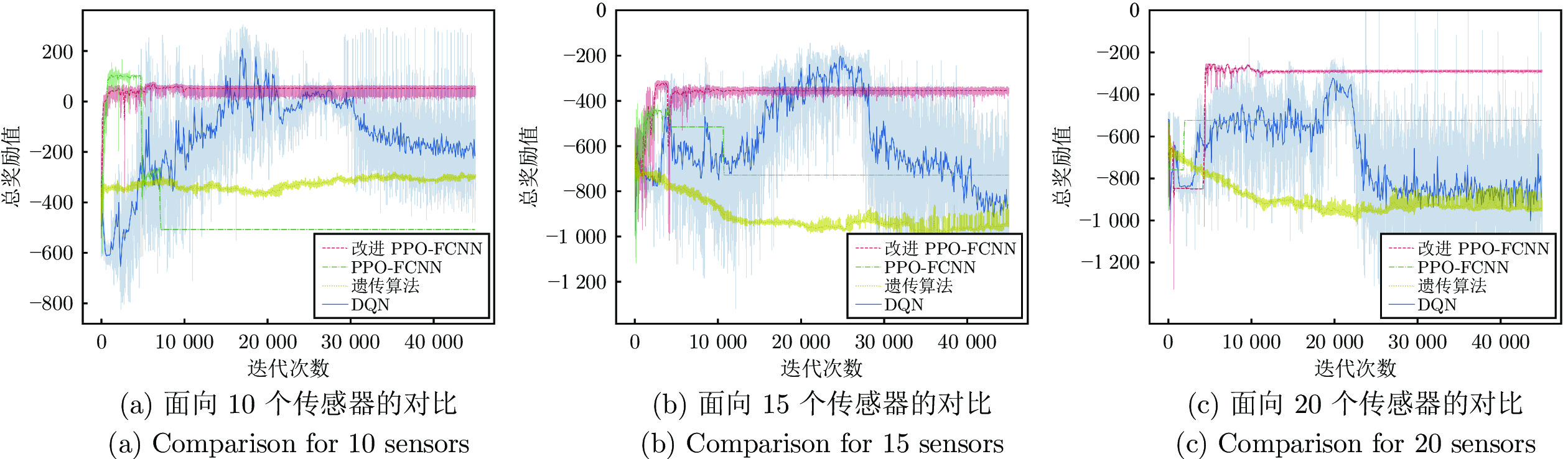
图 8 面向不同传感器数量的不同算法训练效果
Fig. 8 Training effects of different algorithms for different sensor numbers

图 9 面向不同传感器数量的收敛时间对比
Fig. 9 Comparison of convergence time for different sensor numbers
表 1 各层次神经网络参数
Table 1 Parameters of neural network at various layers
层次名 隐元个数 激活函数 FCCN_1 100 ReLU FCCN_2 200 ReLU FCCN_3 200 Tanh FCCN_4 200 Tanh Softmax $num$ Softmax  下载: 导出CSV
下载: 导出CSV
表 2 仿真参数设置
Table 2 Simulation parameters
参数配置 数值 Actor学习率 0.0001 Critic学习率 0.0002 衰减因子 0.9 最小样本数 64 更新间隔 10 次 裁剪函数参数$\varepsilon$ 0.2
下载: 导出CSV
表 3 飞行目标状态参数
Table 3 Parameters of flight target status
飞行目标参数 取值范围 横坐标$x_2^{(t)}$ 97 ~ 30 纵坐标$y_2^{(t)}$ 814 ~ 348 高度$z_2^{(t)}$ 168 ~ 400
下载: 导出CSV
表 4 第$i$号探测设备状态参数
Table 4 Status parameters of No. $i$ detection equipment
第$i$号探测设备参数 取值 通视性$vis_{i,t}$ 1或0 最大探测范围$Dis_i^{Max}$ 0 ~ 400 最大可工作时长$Store_i^{Max}$ 20 最大切换次数$ht$ 12 优先级$pre_{i,t}$ 1或0
下载: 导出CSV
表 5 传感器约束层次总排序表
Table 5 Hierarchical sorting summary for constraints of sensors
约束分类 权重 复杂约束 权重 $ {\alpha _1} $ $ {\alpha _2} $ $ {\beta _1} $ $ {\beta _2} $ $ {\beta _3} $ $ {\beta _4} $ $ {\beta _5} $ 单传感器约束 0.5 探测性能约束 0.5 0.4 0.4 0.2 0 0 0 探测效率约束 0.5 0 0 0.5 0.5 0 0 多传感器约束 0.5 关联约束 1.0 0 0 0 0 0 1.0 层次总排序 0.1 0.1 0.05 0.125 0.125 0.5
下载: 导出CSV
表 6 随机一致性指标
Table 6 Random consistent index
$ n $ ${\rm{RI}}$ 1 0 2 0 3 0.58 4 0.90 5 1.12 6 1.24 7 1.32 8 1.41 9 1.45
下载: 导出CSV
表 7 不同算法训练至收敛的迭代次数
Table 7 Iteration numbers of training to convergence for different algorithms
场景 改进PPO-FCNN PPO-FCNN DQN 遗传算法 面向10个传感器 10300 7133 38000 29000 面向15个传感器 10000 10712 42000 33000 面向20个传感器 10418 1935 26000 28000
下载: 导出CSV
表 8 改进PPO-FCNN面向不同传感器数量的收敛时间幅度对比(%)
Table 8 Comparison of convergence time amplitude of improved PPO-FCNN for different sensor numbers (%)
场景 PPO-FCNN DQN 遗传算法 面向10个传感器 39.00 –68.90 –59.10 面向15个传感器 –0.06 –72.30 –62.90 面向20个传感器 4.10 –54.15 –56.30
下载: 导出CSV
-
[1] 韩志钢, 卿利. 多节点传感器协同探测技术综述与展望. 电讯技术, 2020, 60(3): 358—364 doi: 10.3969/j.issn.1001-893x.2020.03.020Han Zhi-Gang, Qing Li. Overview and prospect of cooperative detection technology for multi-node's sensors. Telecommunication Engineering, 2020, 60(3): 358—364 doi: 10.3969/j.issn.1001-893x.2020.03.020 [2] 范成礼, 付强, 宋亚飞. 临空高速目标多传感器自主协同资源调度算法. 军事运筹与系统工程, 2018, 32(4): 45—50 doi: 10.3969/j.issn.1672-8211.2018.04.010Fan Cheng-Li, Fu Qiang, Song Ya-Fei. Multi sensor autonomous collaborative resource scheduling algorithm for high-speed target in the air. Military Operations Research and Systems Engineering, 2018, 32(4): 45—50 doi: 10.3969/j.issn.1672-8211.2018.04.010 [3] 高嘉乐, 邢清华, 梁志兵. 空天高速目标探测跟踪传感器资源调度模型与算法. 系统工程与电子技术, 2019, 41(10): 2243—2251 doi: 10.3969/j.issn.1001-506X.2019.10.13Gao Jia-Le, Xing Qing-Hua, Liang Zhi-Bing. Multiple sensor resources scheduling model and algorithm for high speed target tracking in aerospace. System Engineering and Electronics, 2019, 41(10): 2243—2251 doi: 10.3969/j.issn.1001-506X.2019.10.13 [4] 徐伯健, 李昌哲, 卜德锋, 符京杨. 基于多目标规划的GNSS地面站任务资源优化. 无线电工程, 2016, 46(7): 45—48 doi: 10.3969/j.issn.1003-3106.2016.07.12Xu Bo-Jian, Li Chang-Zhe, Bu De-Feng, Fu Jing-Yang. Optimization of GNSS ground station task resources based on multi-objective programming. Radio Engineering, 2016, 46(07): 45—48 doi: 10.3969/j.issn.1003-3106.2016.07.12 [5] 陈明, 周云龙, 刘晋飞, 靳文瑞. 基于MDP的多Agent生产线动态调度策略. 机电一体化, 2017, 23(11): 15—19, 56 doi: 10.16413/j.cnki.issn.1007-080x.2017.11.003Chen Ming, Zhou Yun-Long, Liu Jin-Fei, Jin Wen-Rui. Dynamic scheduling strategy of multi-agent productionLine based on MDP. Mechatronics, 2017, 23(11): 15—19, 56 doi: 10.16413/j.cnki.issn.1007-080x.2017.11.003 [6] Wei W, Fan X, Song H, Fan X, Yang J. Imperfect information dynamic stackelberg game based resource allocation using hidden Markov for cloud computing. IEEE Transactionson Services Computing, 2018, 11(99): 78—89 [7] Afzalirad M, Shafipour M. Design of an efficient genetic algorithm for resource constrained unrelated parallel machine scheduling problem with machine eligibility restrictions. Journal of Intelligent Manufacturing, 2018: 1—15 [8] Asghari A, Sohrabi M K, Yaghmaee F. Task scheduling, resource provisioning and load balancing on scientific workflows using parallel SARSA reinforcement learning agents and genetic algorithm. The Journal of Supercomputing, 2020: 1—29 [9] 孙长银, 穆朝絮. 多智能体深度强化学习的若干关键科学问题. 自动化学报, 2020, 46(7): 1301—1312 doi: 10.16383/j.aas.c200159Sun Chang-Yin, Mu Chao-Xu. Important scientific problems of multi-agent deep reinforcement learning. Acta Automatica Sinica, 2020, 46(7): 1301—1312 doi: 10.16383/j.aas.c200159 [10] 梁星星, 冯旸赫, 马扬, 程光权, 黄金才, 王琦, 等. 多Agent深度强化学习综述. 自动化学报, 2020, 46(12): 2537—2557 doi: 10.16383/j.aas.c180372Liang Xing-Xing, Feng Yang-He, Ma Yang, Cheng Guang-Quan, Huang Jin-Cai, Wang Qi, et al. Deep multi-agent reinforcement learning: A survey. Acta Automatica Sinica, 2020, 46(12): 2537—2557 doi: 10.16383/j.aas.c180372 [11] Mnih V, Kavukcuoglu K, Silver D, Rusu A A, Veness J, Bellemare M G, et al. Human-level control through deep reinforcement learning. Nature, 2015, 518(7540): 529—533 doi: 10.1038/nature14236 [12] Volodymyr M, Koray K, David S, Alex G, Ioannis A, Daan W, et al. Playing Atari with deep reinforcement learning [Online], available: https://arxiv.org, December 19, 2013 [13] Hado V H, Arthur G, David S. Deep reinforcement learning with double Q-learning [Online], available: https://arxiv.org, December 8, 2015 [14] John S, Sergey L, Philipp M, Michael I J, Pieter A. Trust region policy optimization [Online], available: https://arxiv.org, April 20, 2017 [15] Wu Y H, Elman M, Shun L, Roger G, Jimmy B. Scaleable trust-region method for deep reinforcement learning using Kronecker-factored approximate [Online], available: https://arxiv.org, August 18, 2017 [16] Nicolas H, Dhruva T B, Srinivasan S, Jay L, Josh M, Greg W, et al. Emergence of locomotion behaviours in rich environments [Online], available: http://www.arXiv.org, July 10, 2017 [17] Gao J L, Ye W J, Guo J, Li Z J. Deep reinforcement learning for indoor mobile robot path planning. Sensors, 2020, 20(19): 5493 doi: 10.3390/s20195493 [18] Shi X G, Timothy L, Ilya S, Sergey L. Continuous deep Q-learning with model-based acceleration [Online], available: http://www.arXiv.org, May 2, 2016 [19] Timothy P L, Jonathan J H, Alexander P, Nicolas H, Tom E, Yuval T, et al. Continuous control with deep reinforcement learning [Online], available: http://www.arXiv.org, July 5, 2019 [20] Zhan Y F, Guo S, Li P, Zhang J. A Deep reinforcement learning based offloading game in edge computing. IEEE Transactions on Computers, 2020, 69(6): 883—893 doi: 10.1109/TC.2020.2969148 [21] Gaudet B, Linares R, Furfaro R. Deep reinforcement learning for six degree-of–freedom planetary landing. Advances in Space Research, 2020, 65(7): 1723—1741 doi: 10.1016/j.asr.2019.12.030 [22] Tang F, Zhou Y, Kato N. Deep reinforcement learning for dynamic uplink/downlink resource allocation in high mobility 5G hetnet. IEEE Journal on Selected Areas in Communications, 2020, 38(12): 2773—2782 doi: 10.1109/JSAC.2020.3005495 [23] 周飞燕, 金林鹏, 董军. 卷积神经网络研究综述. 计算机学报, 2017, 40(06): 1229—251 doi: 10.11897/SP.J.1016.2017.01229Zhou Fei-Yan, Jin Lin-Peng, Dong Jun. A review of convolutional neural networks. Journal of Computer Science, 2017, 40(06): 1229—251 doi: 10.11897/SP.J.1016.2017.01229 [24] 马丁 T. 哈根, 霍华德 B. 德姆斯, 马克 H. 比乐. 神经网络设计. 北京: 机械工业出版社, 2002. 78−89Martin T. Hagen, Howard B. Demuth, Mark H. Beale. Neural Network Design. Beijing: China Machine Press, 2002. 78−89 [25] 董晨, 刘兴科, 周金鹏, 陆志沣. 导弹防御多传感器协同探测任务规划. 现代防御技术, 2018, 46(6): 57—63 doi: 10.3969/j.issn.1009-086x.2018.06.009Dong Chen, Liu Xing-Ke, Zhou Jin-Peng, Lu Zhi-Pei. Cooperative detection task programming of multi sensor for ballistic missile defense. Modern Defense Technology, 2018, 46(6): 57—63 doi: 10.3969/j.issn.1009-086x.2018.06.009 [26] 倪鹏, 王刚, 刘统民, 孙文. 反导作战多传感器任务规划技术. 火力与指挥控制, 2017, 42(8): 1—5 doi: 10.3969/j.issn.1002-0640.2017.08.001Ni Peng, Wang Gang, Liu Tong-Min, Sun Wen. Research on layered decision-making of multi-sensors planning based on heterogeneous MAS in anti-TBM combat. Fire Control and Command Control, 2017, 42(8): 1—5 doi: 10.3969/j.issn.1002-0640.2017.08.001 [27] 李志汇, 刘昌云, 倪鹏, 于洁, 李松. 反导多传感器协同任务规划综述. 宇航学报, 2016, 37(1): 29—38Li Zhi-Hui, Liu Chang-Yun, Ni Peng, Yu Jie, Li song. Review on multisensor cooperative mission planning in anti-TBM System. Joumal of Astronautics, 2016, 37(1): 29—38 [28] 唐俊林, 张栋, 王玉茜, 刘莉. 防空作战多传感器任务规划算法设计. 无人系统技术, 2019, 2(5): 46—55 doi: 10.19942/j.issn.2096-5915.2019.05.007Tang Jun-Lin, Zhang Dong, Wang Yu-Qian, Liu Li. Research on multi-sensor task planning algorithms for air defense operations. Unmanned System Technology, 2019, 2(5): 46—55 doi: 10.19942/j.issn.2096-5915.2019.05.007 [29] 谢红卫, 张明. 航天测控系统. 北京: 国防科技大学出版社, 2000. 100−109Xie Hong-Wei, Zhang Ming. Space TT&C System. Beijing: National University of Defense Technology Press, 2000. 100−109 [30] 郭茂耘. 航天发射安全控制决策的空间信息分析与处理研究 [博士论文], 重庆大学, 中国, 2011Guo Mao-Yun. Study on Spatial Information Analysis and Processing of the Dicision-making for Launching Safety Control [Ph.D. dissertation], Chongqing University, China, 2011 [31] 梁皓星. 基于深度强化学习的飞行目标探测传感器资源调度方法研究 [硕士论文], 重庆大学, 中国, 2020Liang Hao-Xing. Research on Flight Target Detection Sensor Resource Scheduling Method Based on Deep Reinforcement Learning [Master thesis], Chongqing University, China, 2020 [32] 刘建伟, 高峰, 罗雄麟. 基于值函数和策略梯度的深度强化学习综述. 计算机学报, 2019, 42(6): 1406—1438 doi: 10.11897/SP.J.1016.2019.01406Liu Jian-Wei, Gao Feng, Luo Xiong-Lin. Survey of deep reinforcement learning based on value function and policy gradient. Chinese Journal of Computers, 2019, 42(6): 1406—1438 doi: 10.11897/SP.J.1016.2019.01406 [33] John S, Filip W, Prafulla D, Alec R, Oleg K. Proximal policy optimization algorithms [Online], available: http://www.arXiv.org, August 28, 2017 [34] Kingma D, Ba J. Adam: A method for stochastic optimization [Online], available: http://www.arXiv.org, January 30, 2017 [35] Sun R Y. Optimization for deep learning: An overview. Journal of the Operations Research Society of China, 2020, 8(2): 249—294 doi: 10.1007/s40305-020-00309-6 [36] Tuomas H, Aurick Z, Pieter A, Sergey L. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor [Online], available: http://www.arXiv.org, August 8, 2018 [37] Wang H J, Yang Z, Zhou W G, Li D L. Online scheduling of image satellites based on neural networks and deep reinforcement learning. Chinese Journal of Aeronautics, 2019, 32(4): 1011—1019 doi: 10.1016/j.cja.2018.12.018 [38] 王肖宇. 基于层次分析法的京沈清文化遗产廊道构建 [博士论文], 西安建筑科技大学, 中国, 2009Wang Xiao-Yu. Creation of Beijing-Shenyang Qing (Dynasty) Cultural Heritage Corridor Based on Analytic Hierarchy Process [Ph.D. dissertation], Xi'an University of Architecture and Technology, China, 2009 -

 下载:
下载:



计量
- 文章访问数: 1239
- HTML全文浏览量: 517
- PDF下载量: 316
- 被引次数: 0
