

-
摘要: 对于部分可观测环境下的多智能体交流协作任务, 现有研究大多只利用了当前时刻的网络隐藏层信息, 限制了信息的来源. 研究如何使用团队奖励训练一组独立的策略以及如何提升独立策略的协同表现, 提出多智能体注意力意图交流算法(Multi-agent attentional intention and communication, MAAIC), 增加了意图信息模块来扩大交流信息的来源, 并且改善了交流模式. 将智能体历史上表现最优的网络作为意图网络, 且从中提取策略意图信息, 按时间顺序保留成一个向量, 最后结合注意力机制推断出更为有效的交流信息. 在星际争霸环境中, 通过实验对比分析, 验证了该算法的有效性.Abstract: For multi-agent communication and cooperation tasks in partially observable environments, most of the existing studies only use the information of the hidden layer of the network at the current time, which limits the source of information. This paper studies how to use team rewards to train a set of independent policies and how to improve the collaborative performance of independent policies. A multi-agent attentional intention communication (MAAIC) algorithm is proposed to improve the communication mode, and an intention information module is added to expand the source of communication information. The network with the best performance in the history of an agent is taken as the intention network, from which the policy intention information is extracted. The historical intention information of the agent that performs best at all times is retained as a vector in chronological order, and combined with the attention mechanism and current observation history information to extract more effective information as input for decision-making. The effectiveness of the algorithm is verified by experimental comparison and analysis on StarCraft multi-agent challenge.
-
Key words:
- Multi-agent /
- reinforcement learning /
- intention communication /
- attention mechanism
-
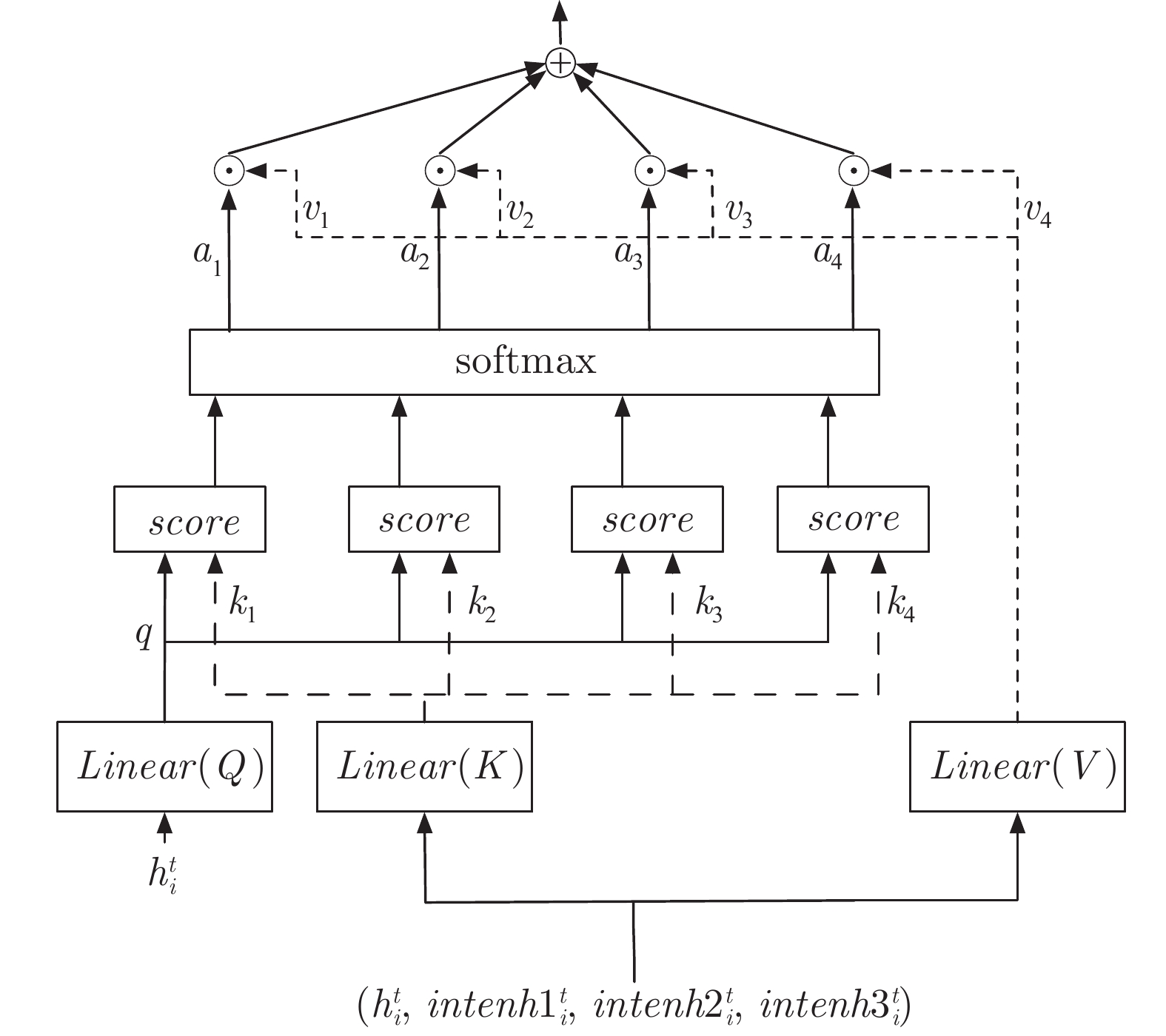
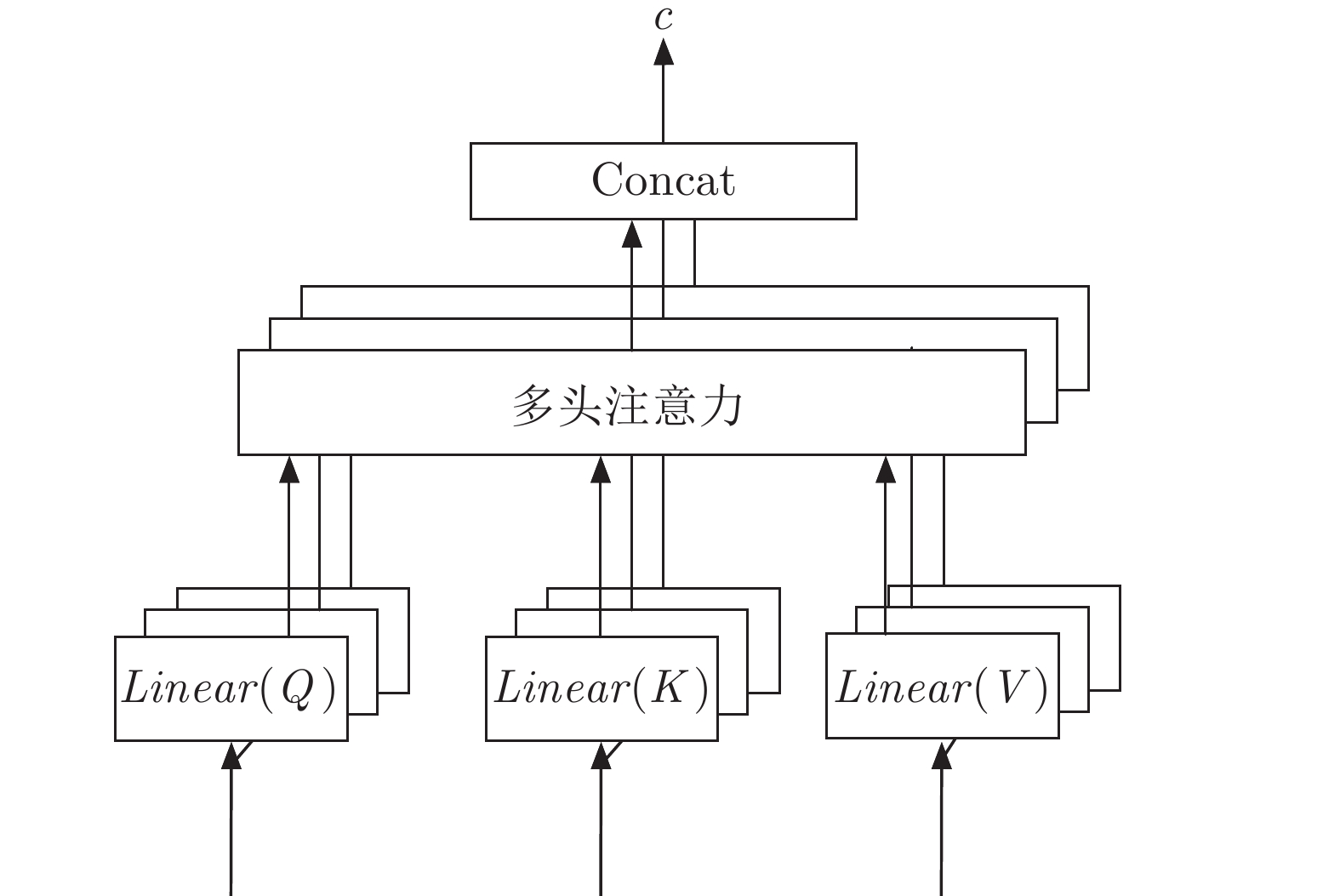
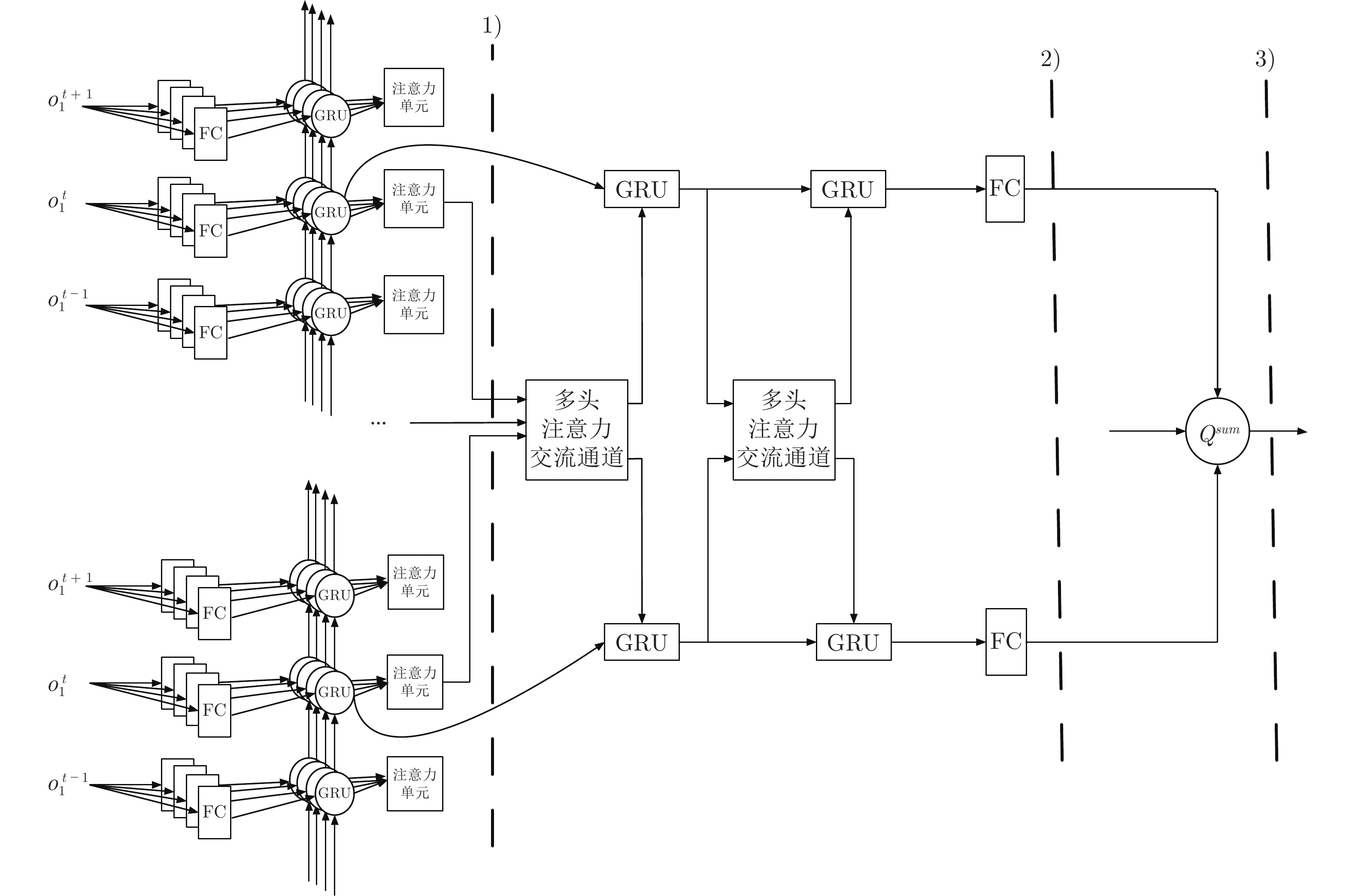
图 2 对意图网络进行自注意力信息的提取
Fig. 2 Extracting self attention information from intention network
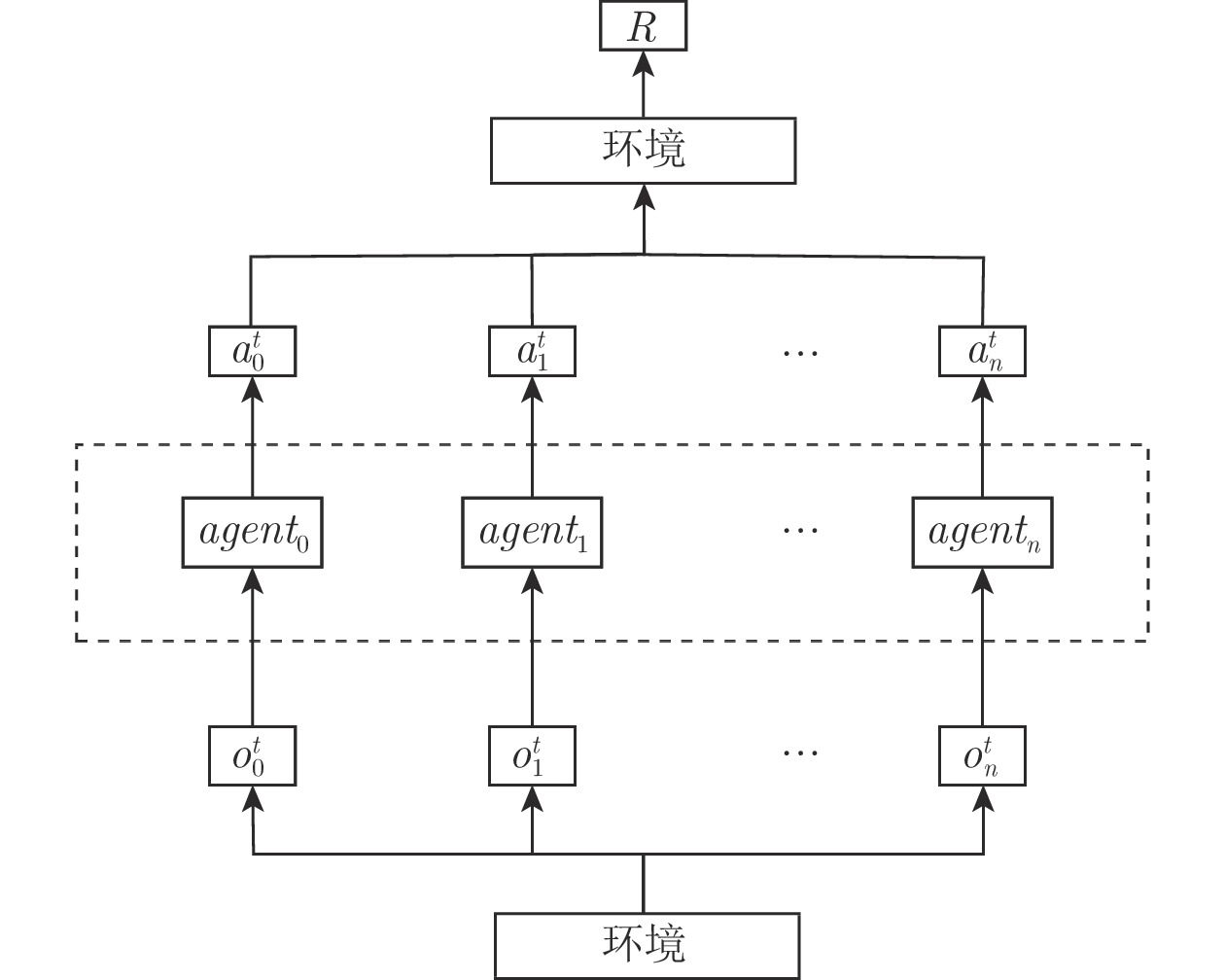
图 3 基于集中式训练分布式执行的多智能体同环境交互
Fig. 3 Multi-agent interaction with environment under centralized training and decentralized execution
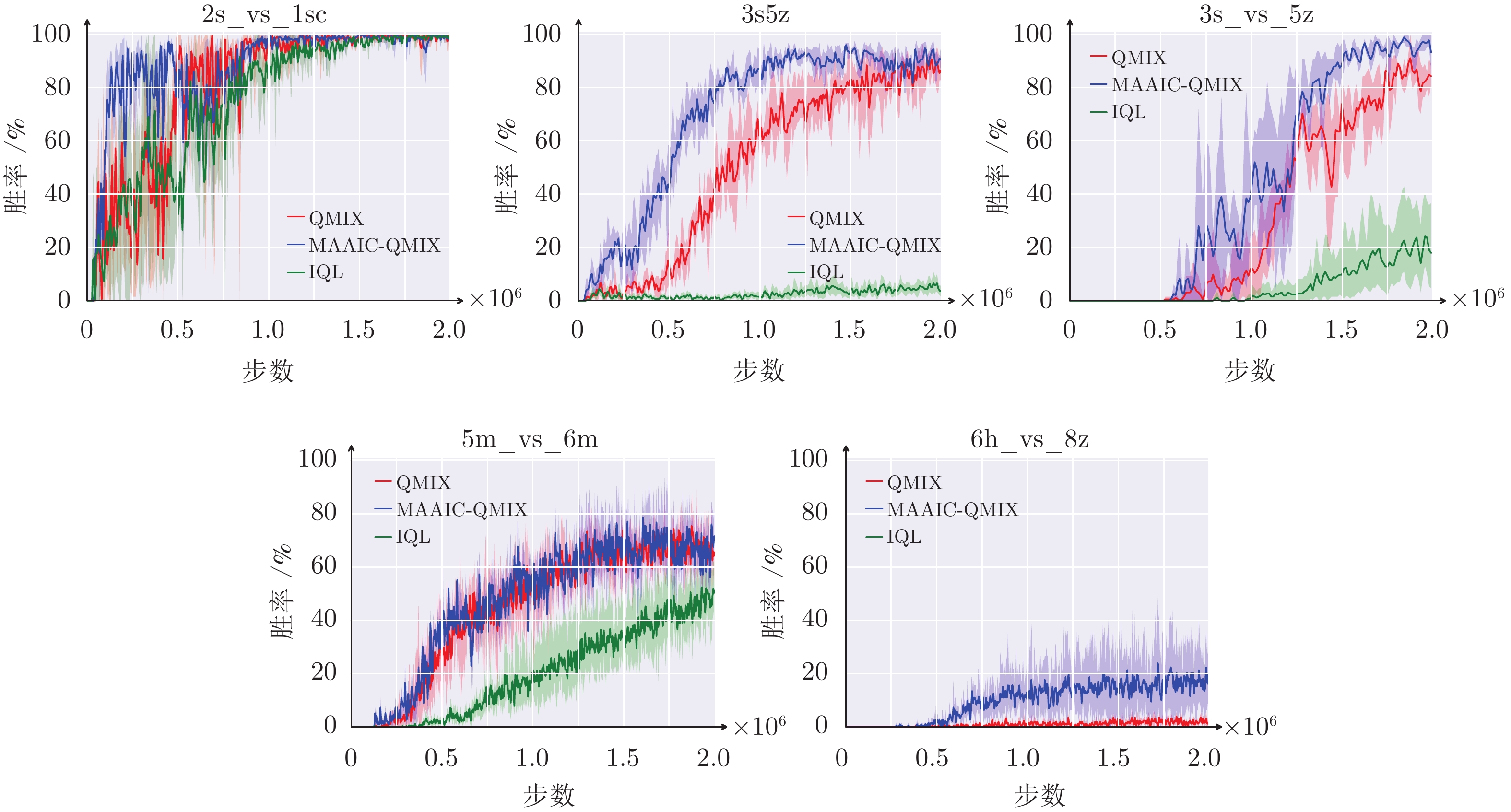
图 6 MAAIC-QMIX算法在SMAC上的实验结果
Fig. 6 Experimental results of MAAIC-QMIX algorithm on SMAC
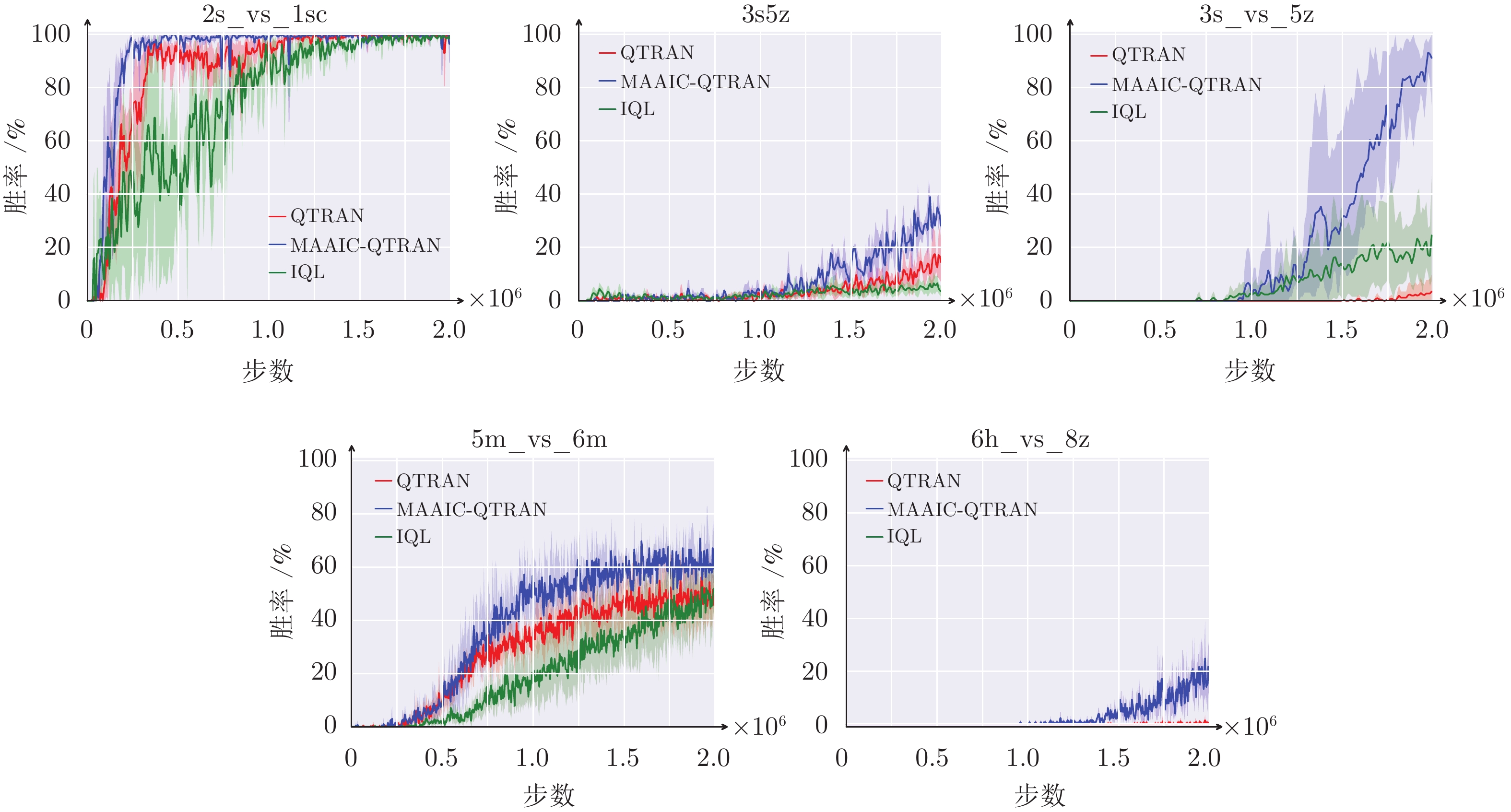
图 7 MAAIC-QTRAN算法在SMAC上的实验结果
Fig. 7 Experimental results of MAAIC-QTRAN algorithm on SMAC
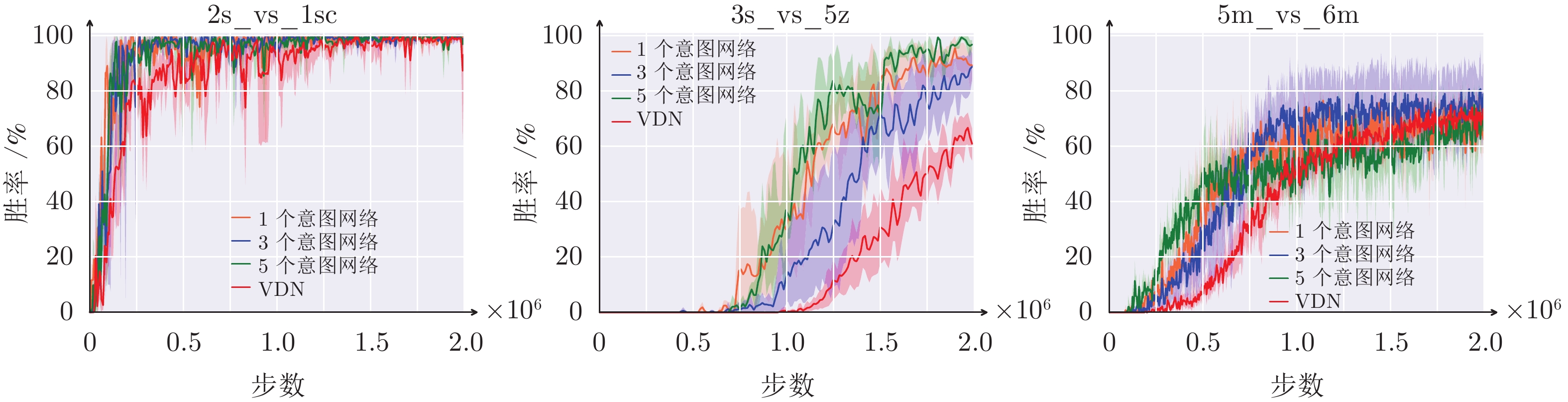
图 9 意图网络数的消融性实验结果
Fig. 9 Experimental ablation results of the number of intention networks

图 10 MAAIC-VDN算法在不同意图网络数的时间开销
Fig. 10 Time cost for different numbers of intention units based on MAAIC-VDN algorithm
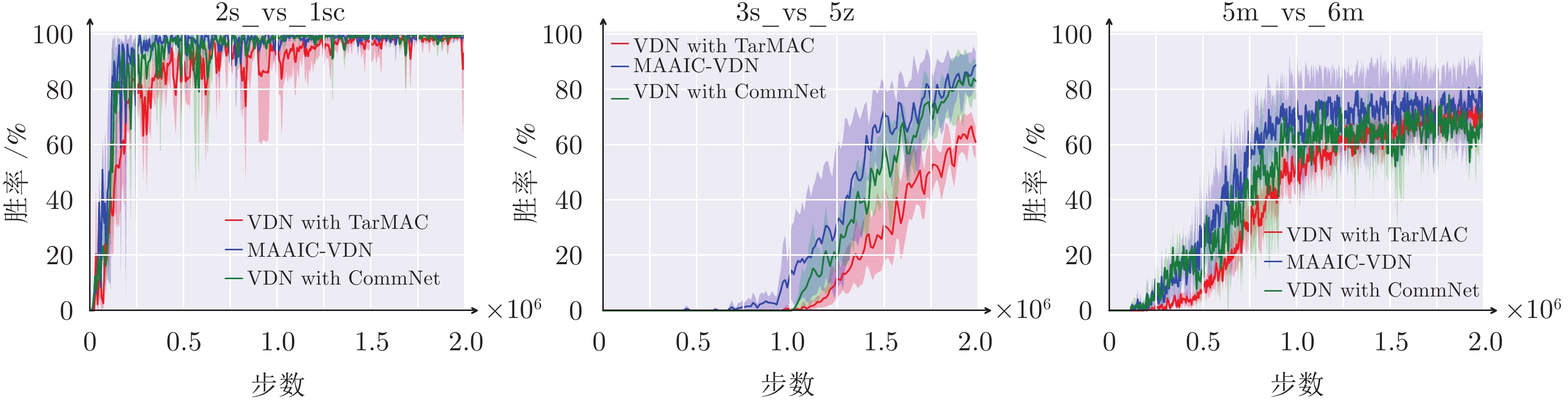
图 11 历史最优网络和最近邻网络作为MAAIC消融性实验结果
Fig. 11 Experimental ablation results of MAAIC with the best Q-network and the nearest Q-network
表 1 SMAC实验场景
Table 1 Experimental scenarios under SMAC
场景名称 我方单位 敌方单位 类型 5m_vs_6m 5名海军陆战队 6名海军陆战队 同构但不对称 3s_vs_5z 3潜行者 5 狂热者 微型技巧: 风筝 2s_vs_1sc 2缠绕者 1脊柱爬行者 微技巧交火 3s5z 3潜行者 & 5狂热者 3潜行者和
5狂热者异构且对称 6h_vs_8z 6蛇蝎 8狂热者 微招: 集中火力  下载: 导出CSV
下载: 导出CSV
表 2 测试算法的最大中值实验结果 (%)
Table 2 Maximum median performance of the algorithms tested (%)
场景 MAAIC-VDN VDN IQL MAAIC-QMIX QMIX Heuristic MAAIC-QTRAN QTRAN 2s_vs_1sc 100 100 100 100 100 0 100 100 3s5z 90 87 9 97 91 42 31 20 5m_vs_6m 87 78 59 74 75 0 67 58 3s_vs_5z 98 73 46 98 97 0 97 15 6h_vs_8z 55 0 0 31 3 0 22 0
下载: 导出CSV
表 3 MAAIC-VDN算法在不同意图网络数的GPU内存开销 (MB)
Table 3 GPU memory cost for different numbers of intention networks based on MAAIC-VDN algorithm (MB)
场景 5个意图网络 3个意图网络 1个意图网络 VDN with TarMAC VDN 2s_vs_1sc 1560 1510 1470 1120 680 5m_vs_6m 1510 1500 1500 1150 680 3s_vs_5z 2120 2090 2100 1480 730
下载: 导出CSV
B1 MAAIC算法网络参数
B1 Network parameters of MAAIC algorithm
参数名 设置值 说明 rnn_hidden_dim 64 对于局部观测的全连接特征编码维度, 循环网络的隐藏层维度 attention_dim1 64 意图信息的注意力编码维度 attention_dim2 $64\times 8$ 多头注意力机制的编码维度 n_intention 3 意图网络的个数
下载: 导出CSV
B2 SMAC环境下MAAIC算法训练参数
B2 Training parameters of MAAIC algorithm in SMAC
参数名 设置值 说明 Lr 0.0005 损失函数的学习率 Optim_eps 0.00001 RMSProp加到分母提升数值稳定性 Epsilon 1 探索的概率值 Min_epsilon 0.05 最低探测概率值 Anneal_steps 50000 模拟退火的步数 Epsilon_anneal_scale step 探索概率值的退火方式 N_epoch 20000 训练的总轮数 N_episodes 1 每轮的游戏局数目 Evaluate_cycle 100 评估周期间隔 Evaluate_epoch 20 评估次数 Batch_size 32 训练的批数据大小 Buffer_size 5000 内存池大小 Target_update_cycle 200 目标网络更新间隔 Grad_norm_clip 10 梯度裁剪, 防止梯度爆炸
下载: 导出CSV
C1 MPP环境下MAAIC算法训练参数
C1 Training parameters of MAAIC algorithm in MPP
参数名 设置值 说明 Training step 3000000 训练最大步数 Learning rate 0.0005 Adam优化的学习率 Replay buffer size 600000 最大的样本存储数量 Mini-batch size_epsilon 32 更新参数所用到的样本数量 Anneal_steps 500000 模拟退火的步数 $\alpha$ 1 外在奖励系数 $\beta $ 0.5 内在奖励系数
下载: 导出CSV
-
[1] Kurach K, Raichuk A, Stańczyk P, Zajac M, Bachem O, Espeholt L, et al. Google research football: A novel reinforcement learning environment. In: Proceedings of the AAAI Conference on Artificial Intelligence. New York, USA: 2020. 4501−4510 [2] Ye D, Liu Z, Sun M, Sun M, Shi B, Zhao P, et al. Mastering complex control in MOBA games with deep reinforcement learning. In: Proceedings of the AAAI Conference on Artificial Intelligence. New York, USA: 2020. 6672−6679 [3] Ohmer X, Marino M, Franke M, König P. Why and how to study the impact of perception on language emergence in artificial agents. In: Proceedings of the Annual Meeting of the Cognitive Science Society. Virtual Event: 2021. [4] 姚红革, 张玮, 杨浩琪, 喻钧. 深度强化学习联合回归目标定位. 自动化学报, 2020, 41: 1-10Yao Hong-Ge, Zhang Wei, Yang Hao-Qi, Yu Jun. Joint regression object localization based on deep reinforcement learning. Acta Automatica Sinica, 2020, 41: 1-10 [5] 吴晓光, 刘绍维, 杨磊, 邓文强, 贾哲恒. 基于深度强化学习的双足机器人斜坡步态控制方法. 自动化学报, 2020, 46: 1-12Wu Xiao-Guang, Liu Shao-Wei, Yang Lei, Deng Wen-Qiang, Jia Zhe-Heng. A gait control method for biped robot on slope based on deep reinforcement learning. Acta Automatica Sinica, 2020, 46: 1-12 [6] 孙长银, 穆朝絮. 多智能体深度强化学习的若干关键科学问题. 自动化学报, 2020, 46(7): 71-79Sun Chang-Yin, Mu Chao-Xu. Important scientific problems of multi-agent deep reinforcement learning. Acta Automatica Sinica. 2020, 46(7): 71-79. [7] Lillicrap T P, Hunt J J, Pritzel A, Heess N, Erez T, Tassa Y, et al. Continuous control with deep reinforcement learning. In: Proceedings of the International Conference on Learning Representations. San Juan, Puerto Rico: 2016. [8] Tampuu A, Matiisen T, Kodelja D, Kuzovkin I, Korjus K, Aru J, et al. Multi-agent cooperation and competition with deep reinforcement learning. Plos One, 2017, 12(4). Article No. e0172395 [9] Sunehag P, Lever G, Gruslys A, Czarnecki M W, Zambaldi V, Jaderberg M, et al. Value-decomposition networks for cooperative multiagent learning. In: Proceedings of the 17th International Conference on Autonomous Agents and MultiAgent Systems. Stockholm, Sweden: 2017. 2085−2087 [10] Rashid T, Samvelyan M, Schroeder C, Farquhar G, Foerster J, Whiteson S. QMIX: Monotonic value function factorization for deep multi-agent reinforcement learning. In: Proceedings of the International Conference on Machine Learning. Stockholm, Sweden: PMLR, 2018. 4295−4304 [11] Rashid T, Farquhar G, Peng B, Whiteson S. Weighted QMIX: Expanding monotonic value function factorization for deep multi-agent reinforcement learning. Advances in Neural Information Processing Systems, 2020, 33: 10199−10210 [12] Wang J H, Ren Z, Liu T, Yu Y, Zhang C. Qplex: Duplex dueling multi-agent Q-learning. In: Proceedings of the International Conference on Learning Representations. Virtual Event: 2021. [13] Cho K, Van Merriënboer B, Gulcehre C, Bahdanau D, Bougares F, Schwenk H, et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv preprint arXiv: 1406.1078, 2014. [14] Gupta J K, Egorov M, Kochenderfer M. Cooperative multi-agent control using deep reinforcement learning. In: Proceedings of the International Conference on Autonomous Agents and Multi-agent Systems. São Paulo, Brazil: Springer, 2017. 66−83 [15] Busoniu L, Babuska R, De Schutter B. Multi-agent reinforcement learning: A survey. In: Proceedings of the 9th International Conference on Control, Automation, Robotics and Vision. Singapore: IEEE, 2006. 1−6 [16] Hernandez-Leal P, Kartal B, Taylor M E. A survey and critique of multiagent deep reinforcement learning. Autonomous Agents and Multi-Agent Systems, 2019, 33(6): 750-797. doi: 10.1007/s10458-019-09421-1 [17] Tan M. Multi-agent reinforcement learning: Independent vs. cooperative agents. In: Proceedings of the 10th International Conference on Machine Learning. Amherst, USA: 1993. 330−337 [18] Hernandez-Leal P, Kartal B, Taylor M E. Is multiagent deep reinforcement learning the answer or the question? a brief survey. Learning, 2018, 21:22. [19] Oroojlooyjadid A, Hajinezhad D. A review of cooperative multi-agent deep reinforcement learning. arXiv preprint arXiv: 1810.05587, 2018. [20] Lowe R, Wu Y, Tamar A, Harb J, Abbeel P, Mordatch I. Multi-agent actor-critic for mixed cooperative-competitive environments. arXiv preprint arXiv: 1706.02275, 2017. [21] Pesce E, Montana G. Improving coordination in small-scale multi-agent deep reinforcement learning through memory-driven communication. Machine Learning, 2020, 1-21. [22] Kim W, Cho M, Sung Y. Message-dropout: An efficient training method for multi-agent deep reinforcement learning. In: Proceedings of the AAAI Conference on Artificial Intelligence. Hawaii, USA: 2019. 6079−6086 [23] Foerster J, Farquhar G, Afouras T, Nardelli N, Whiteson S. Counterfactual multi-agent policy gradients. In: Proceedings of the AAAI Conference on Artificial Intelligence. New Orleans, USA: 2018. 2974−2982 [24] Son K, Kim D, Kang W J, Hostallero D E, Yi Y. QTRAN: Learning to factorize with transformation for cooperative multi-agent reinforcement learning. In: Proceedings of the International Conference on Machine Learning. Long Beach, USA: PMLR, 2019. 5887−5896 [25] Yang Y, Hao J, Liao B, Shao K, Chen G, Liu W, et al. Qatten: A general framework for cooperative multi-agent reinforcement learning. CoRR, 2020, Article No. 03939 [26] Yang Y, Hao J, Chen G, Tang H, Chen Y, Hu Y, et al. Q-value path decomposition for deep multi-agent reinforcement learning. In: Proceedings of the International Conference on Machine Learning. Virtual Event: PMLR, 2020. 10706−10715 [27] Foerster J N, Assael Y M, De Freitas N, Whiteson S. Learning to communicate with deep multi-agent reinforcement learning. arXiv preprint arXiv: 1605.06676, 2016. [28] Sukhbaatar S, Szlam A, Fergus R. Learning multi-agent communication with back-propagation. In: Proceedings of the Annual Conference on Neural Information Processing Systems. Barcelona, Spain: 2016. 2244−2252 [29] Peng P, Wen Y, Yang Y, Yuan Q, Tang Z, Long H, et al. Multi-agent bidirectionally-coordinated nets: Emergence of human-level coordination in learning to play star-craft combat games. arXiv preprint arXiv: 1703.10069, 2017. [30] Singh A, Jain T, Sukhbaatar S. Learning when to communicate at scale in multi-agent cooperative and competitive tasks. arXiv preprint arXiv: 1812.09755, 2018. [31] Fu J, Li W, Du J, Huang Y. A multiscale residual pyramid attention network for medical image fusion. Biomedical Signal Processing and Control, 2021, 66: 102488. doi: 10.1016/j.bspc.2021.102488 [32] Locatello F, Weissenborn D, Unterthiner T, Mahendran A, Heigold G, Uszkoreit J, et al. Object-centric learning with slot attention. arXiv preprint arXiv: 2006.15055, 2020. [33] Jiang J, Lu Z. Learning attentional communication for multi-agent cooperation. arXiv preprint arXiv: 1805.07733, 2018. [34] Das A, Gervet T, Romoff J, Batra D, Parikh D, Rabbat M, et al. TarMAC: Targeted multi-agent communication. In: Proceedings of the International Conference on Machine Learning. Long Beach, USA: PMLR, 2019. 1538−1546 [35] Liu Y, Wang W, Hu Y, Hao J, Chen X, Gao Y. Multi-agent game abstraction via graph attention neural network. In: Proceedings of the AAAI Conference on Artificial Intelligence. New York, USA: 2020, 34. 7211−7218 [36] Raileanu R, Denton E, Szlam A, Fergus R. Modeling others using oneself in multi-agent reinforcement learning. In: Proceedings of the International Conference on Machine Learning. Stockholm, Sweden: 2018. 4257−4266 [37] Jaques N, Lazaridou A, Hughes E, Gulcehre C, Ortega P, Strouse D, et al. Social influence as intrinsic motivation for multi-agent deep reinforcement learning. In: Proceedings of the International Conference on Machine Learning. Long Beach, USA: PMLR, 2019. 3040−3049 [38] Littman M L. Markov games as a framework for multi-agent reinforcement learning. In: Proceedings of the Machine Learning Proceedings. New Brunswick, USA: 1994. 157−163 [39] Samvelyan M, Rashid T, De Witt C S, Farquhar G, Nardelli N, Rudner T G, et al. The star-craft multi-agent challenge. In: Proceedings of the Autonomous Agents and Multi-agent Systems. Montreal, Canada: 2019. 2186−2188 [40] Yu W W, Wang R, Li R Y, Gao J, Hu X H. Historical best Q-networks for deep reinforcement learning. In: Proceedings of the IEEE 30th International Conference on Tools With Artificial Intelligence. Volos, Greece: IEEE, 2018. 6−11 [41] Anschel O, Baram N, Shimkin N. Averaged-DQN: Variance reduction and stabilization for deep reinforcement learning. In: Proceedings of the International Conference on Machine Learning. Sydney, Australia: PMLR, 2017. 176−185 -

 下载:
下载:


计量
- 文章访问数: 2114
- HTML全文浏览量: 1353
- PDF下载量: 423
- 被引次数: 0
