

-
摘要: 张量主成分分析(Tensor principal component analysis, TPCA)在彩色图像低维表征领域得到广泛深入研究, 采用${\rm{F}}$范数平方作为低维投影的距离度量方式, 表征含离群数据和噪声图像的鲁棒性较弱. ${L}_{1}$范数能够抑制噪声的影响, 但所获的低维投影数据缺乏重构误差约束, 其局部表征能力也较弱. 针对上述问题, 利用${\rm{F}}$范数作为目标函数的距离度量方式, 提出一种基于$\rm{F}$范数的分块张量主成分分析算法(Block TPCA with $\rm{F}$-norm, BlockTPCA-F), 提高张量低维表征的鲁棒性. 考虑到同时约束投影距离与重构误差, 提出一种基于比例$\rm{F}$范数的分块张量主成分分析算法(Block TPCA with proportional F-norm, BlockTPCA-PF), 其最大化投影距离与最小化重构误差均得到了优化. 然后, 给出其贪婪的求解算法, 并对其收敛性进行理论证明. 最后, 对包含不同噪声块和具有实际遮挡的彩色人脸数据集进行实验, 结果表明, 所提算法在平均重构误差、图像重构与分类率等方面均得到明显提升, 在张量低维表征中具有较强的鲁棒性.Abstract: Tensor principal component analysis (TPCA) has been widely and deeply studied in the field of low-dimensional representation of color images. Using the square F-norm as the distance metric of low-dimensional projection, the robustness of representing the images with outliers and noise is weak. ${L}_{1}$ can suppress the influence of noise, but the obtained low-dimensional projection data lacks the constraint of reconstruction errors, and the local representation ability is also weak. To solve the above problems, using F-norm as the distance metric of the objective function, a block TPCA with F-norm (BlockTPCA-F) algorithm is proposed to improve the robustness of tensor representation with low dimension. Considering the constraints of projection distances and reconstruction errors at the same time, a block TPCA with proportional F-norm (BlockTPCA-PF) algorithm is presented. The maximum projection distance and the minimum reconstruction error in the objective function are optimized. Then, the greedy algorithms for BlockTPCA-F and BlockTPCA-PF are given respectively, and the convergence is proved theoretically. Finally, experiments are carried out on color face datasets with different artificial noise blocks or actual occluded faces. The results show that the proposed algorithms have been significantly improved in the average reconstruction error, the image reconstruction and the classification rate, and they have strong robustness in tensor low-dimensional representation.
-

图 3 ${{\cal{X}}_m}$, ${{\cal{Y}}_m}$与${{\cal{E}}_m}$之间的关系
Fig. 3 The relation between ${{\cal{X}}_m}$, ${{\cal{Y}}_m}$ and ${{\cal{E}}_m}$
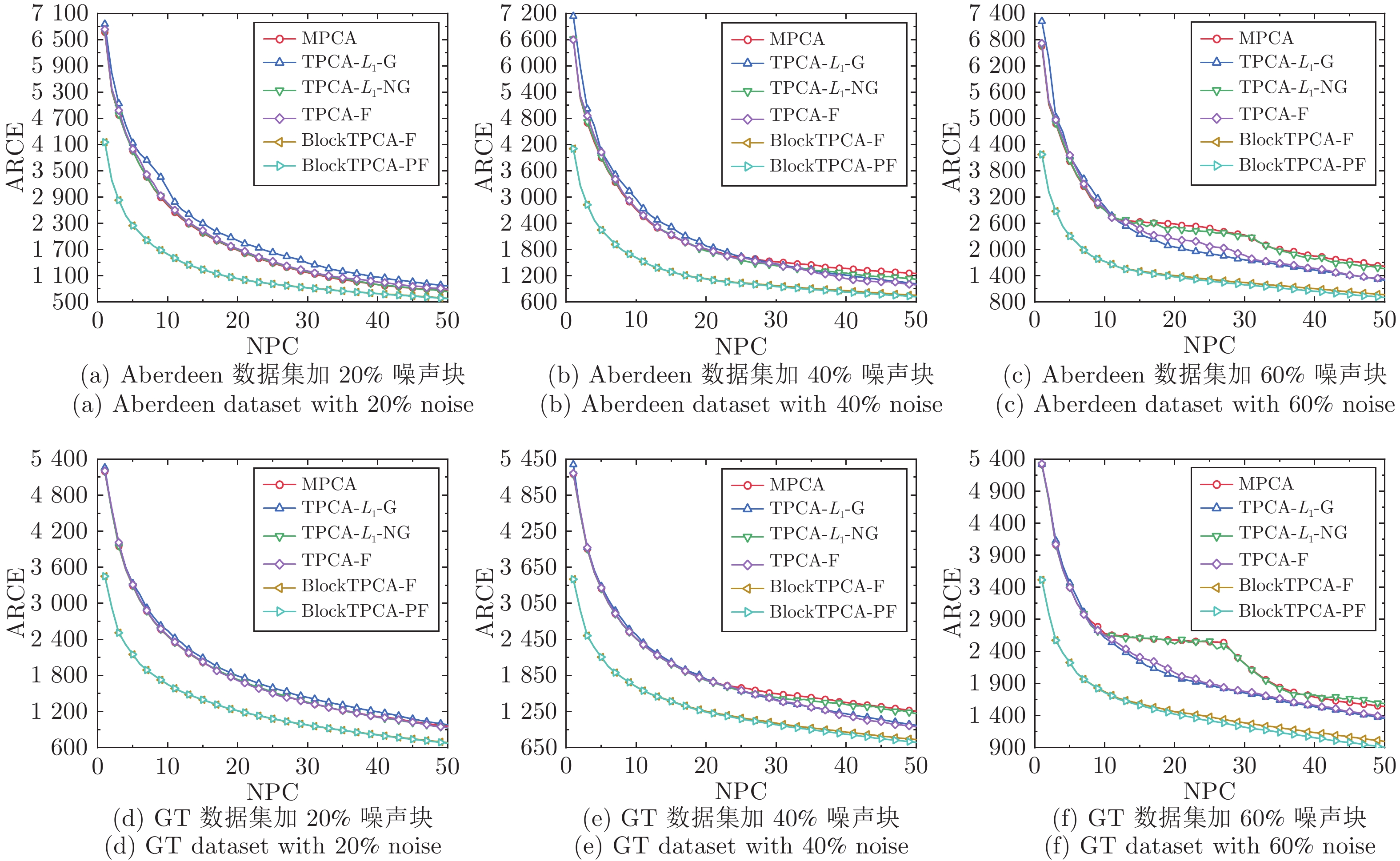
表 1 20%噪声下最优平均分类率
Table 1 Optimal average classification rate under 20% noise
NPC MPCA TPCA-$L _{1} $-G TPCA-$L _{1} $-NG TPCA-F BlockTPCA-F BlockTPCA-PF AB 10 0.9048 0.8974 0.9079 0.9153 0.9153 0.9143 20 0.9132 0.9111 0.9132 0.9101 0.9164 0.9175 30 0.9090 0.9069 0.9090 0.9069 0.9090 0.9101 40 0.9058 0.9048 0.9058 0.9026 0.9090 0.9090 50 0.9048 0.9058 0.9058 0.9005 0.9079 0.9058 GT 10 0.6940 0.7020 0.7055 0.7055 0.6900 0.6915 20 0.7015 0.6935 0.6935 0.6950 0.7070 0.7090 30 0.7005 0.6875 0.6880 0.6905 0.7020 0.7035 40 0.6900 0.6860 0.6850 0.6845 0.7010 0.7035 50 0.6855 0.6820 0.6850 0.6840 0.6970 0.7000  下载: 导出CSV
下载: 导出CSV
表 3 60%噪声下最优平均分类率
Table 3 Optimal average classification rate under 60% noise
NPC MPCA TPCA-$L _{1} $-G TPCA-$L _{1} $-NG TPCA-F BlockTPCA-F BlockTPCA-PF AB 10 0.7958 0.7958 0.7937 0.7915 0.8148 0.8116 20 0.7810 0.7810 0.7788 0.7779 0.7926 0.7947 30 0.7810 0.7746 0.7820 0.7757 0.7788 0.7799 40 0.7841 0.7746 0.7767 0.7799 0.7778 0.7799 50 0.7778 0.7757 0.7778 0.7799 0.7757 0.7757 GT 10 0.5354 0.5550 0.5690 0.5700 0.5690 0.5680 20 0.5344 0.5450 0.5665 0.5680 0.5580 0.5580 30 0.5238 0.5455 0.5590 0.5590 0.5510 0.5520 40 0.5101 0.5435 0.5470 0.5470 0.5500 0.5510 50 0.5048 0.5405 0.5450 0.5455 0.5470 0.5485
下载: 导出CSV
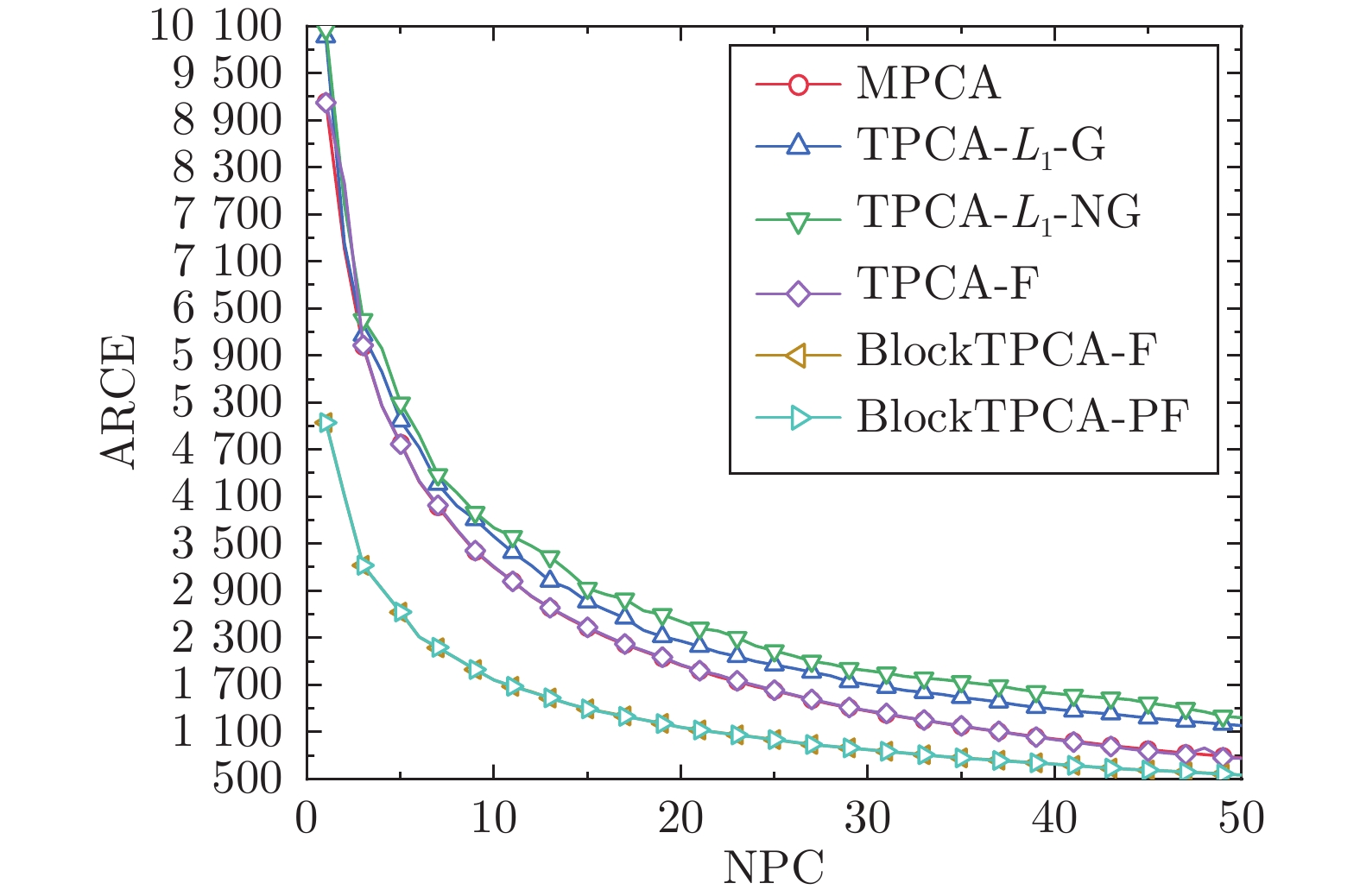
表 4 AR人脸数据集最优平均分类率
Table 4 Optimal average classification rate of AR face dataset
NPC MPCA TPCA-$L _{1} $-G TPCA-$L _{1} $-NG TPCA-F BlockTPCA-F BlockTPCA-PF AR 10 0.7692 0.7653 0.7692 0.7731 0.8077 0.8077 20 0.7654 0.7653 0.7654 0.7616 0.8001 0.8001 30 0.7654 0.7615 0.7653 0.7654 0.8039 0.8039 40 0.7654 0.7692 0.7692 0.7654 0.8038 0.8038 50 0.7692 0.7615 0.7654 0.7692 0.8039 0.8039
下载: 导出CSV
表 2 40%噪声下最优平均分类率
Table 2 Optimal average classification rate under 40% noise
NPC MPCA TPCA-$L _{1} $-G TPCA-$L _{1} $-NG TPCA-F BlockTPCA-F BlockTPCA-PF AB 10 0.8804 0.8794 0.8847 0.8772 0.8889 0.8889 20 0.8783 0.8772 0.8751 0.8709 0.8889 0.8889 30 0.8624 0.8571 0.8593 0.8635 0.8751 0.8730 40 0.8519 0.8497 0.8508 0.8614 0.8603 0.8571 50 0.8497 0.8476 0.8466 0.8519 0.8529 0.8497 GT 10 0.6243 0.6645 0.6650 0.6630 0.6690 0.6690 20 0.5788 0.6335 0.6300 0.6295 0.6590 0.6590 30 0.5556 0.6115 0.6115 0.6115 0.6455 0.6455 40 0.5471 0.6050 0.6070 0.6070 0.6320 0.6320 50 0.5439 0.6035 0.6070 0.6065 0.6220 0.6220
下载: 导出CSV
-
[1] Zare A, Ozdemir A, Iwen M A, Aviyente S. Extension of PCA to higher order data structures: An introduction to tensors, tensor decompositions, and tensor PCA. Proceedings of the IEEE, 2018, 106(8): 1341-1358 doi: 10.1109/JPROC.2018.2848209 [2] Chachlakis D G, Dhanaraj M, Prater-Bennette A, Markopoulos P P. Dynamic L1-norm tucker tensor decomposition. IEEE Journal of Selected Topics in Signal Processing, 2021, 15(3): 587-602 doi: 10.1109/JSTSP.2021.3058846 [3] Liu J X, Wang D, Chen J. Monitoring framework based on generalized tensor PCA for three-dimensional batch process data. Industrial & Engineering Chemistry Research, 2020, 59(22): 10493-10508 [4] Qing Y H, Liu W Y. Hyperspectral image classification based on multi-scale residual network with attention mechanism. Remote Sensing, 2021, 13(3): Article No. 335 doi: 10.3390/rs13030335 [5] Wu S X, Wai H T, Li L, Scaglione A. A review of distributed algorithms for principal component analysis. Proceedings of the IEEE, 2018, 106(8): 1321-1340 doi: 10.1109/JPROC.2018.2846568 [6] 夏志明, 赵文芝, 徐宗本. 张量主成分分析与高维信息压缩方法. 工程数学学报, 2017, 34(6): 571-590 doi: 10.3969/j.issn.1005-3085.2017.06.001Xia Zhi-Ming, Zhao Wen-Zhi, Xu Zong-Ben. Principle component analysis for tensors and compression theory for high-dimensional information. Chinese Journal of Engineering Mathematics, 2017, 34(6): 571-590 doi: 10.3969/j.issn.1005-3085.2017.06.001 [7] Yang J, Zhang D, Frangi A F, Yang J Y. Two-dimensional PCA: A new approach to appearance-based face representation and recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2004, 26(1): 131-137 doi: 10.1109/TPAMI.2004.1261097 [8] Wang H X. Block principal component analysis with L1-norm for image analysis. Pattern Recognition Letters, 2012, 33(5): 537-542 doi: 10.1016/j.patrec.2011.11.029 [9] Neumayer S, Nimmer M, Setzer S, Steidl G. On the robust PCA and Weiszfeld$’$s algorithm. Applied Mathematics & Optimization, 2020, 82(3): 1017-1048 [10] Kwak N. Principal component analysis based on L1-norm maximization. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2008, 30(9): 1672-1680 doi: 10.1109/TPAMI.2008.114 [11] Nie F P, Huang H, Ding C, Luo D J, Wang H. Robust principal component analysis with non-greedy $l_1$-norm maximization. In: Proceedings of the 22nd International Joint Conference on Artificial Intelligence. Barcelona, Spain: AAAI, 2011. 1433−1438 [12] Li X L, Pang Y W, Yuan Y. L1-norm-based 2DPCA. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 2010, 40(4): 1170-1175 doi: 10.1109/TSMCB.2009.2035629 [13] Wang R, Nie F P, Yang X J, Gao F F, Yao M L. Robust 2DPCA with non-greedy $\ell_1$-norm maximization for image analysis. IEEE Transactions on Cybernetics, 2015, 45(5): 1108-1112 [14] Kwak N. Principal component analysis by $L_p$-norm maximization. IEEE Transactions on Cybernetics, 2014, 44(5): 594-609 doi: 10.1109/TCYB.2013.2262936 [15] Wang J. Generalized 2-D principal component analysis by Lp-norm for image analysis. IEEE Transactions on Cybernetics, 2016, 46(3): 792-803 doi: 10.1109/TCYB.2015.2416274 [16] 李春娜, 陈伟杰, 邵元海. 鲁棒的稀疏$L_p$-模主成分分析. 自动化学报, 2017, 43(1): 142-151Li Chun-Na, Chen Wei-Jie, Shao Yuan-Hai. Robust sparse $L_p$ norm principal component analysis. Acta Automatica Sinica, 2017, 43(1): 204-211 [17] Xiao X L, Chen Y Y, Gong Y J, Zhou Y C. Low-rank preserving t-linear projection for robust image feature extraction. IEEE Transactions on Image Processing, 2021, 30: 108-120 doi: 10.1109/TIP.2020.3031813 [18] Lu H P, Plataniotis K N, Venetsanopoulos A N. MPCA: Multilinear principal component analysis of tensor objects. IEEE Transactions on Neural Networks, 2008, 19(1): 18-39 doi: 10.1109/TNN.2007.901277 [19] Hu W M, Li X, Zhang X Q, Shi X C, Maybank S, Zhang Z F. Incremental tensor subspace learning and its applications to foreground segmentation and tracking. International Journal of Computer Vision, 2011, 91(3): 303-327 doi: 10.1007/s11263-010-0399-6 [20] Han L, Wu Z, Zeng K, Yang X W. Online multilinear principal component analysis. Neurocomputing, 2018, 275: 888-896 doi: 10.1016/j.neucom.2017.08.070 [21] Wu J S, Qiu S J, Zeng R, Kong Y Y, Senhadji L, Shu H Z. Multilinear principal component analysis network for tensor object classification. IEEE Access, 2017, 5: 3322-3331 doi: 10.1109/ACCESS.2017.2675478 [22] Li X T, Ng M K, Xu X F, Ye Y M. Block principal component analysis for tensor objects with frequency or time information. Neurocomputing, 2018, 302: 12-22 doi: 10.1016/j.neucom.2018.02.014 [23] Zheng Y M, Xu A B. Tensor completion via tensor QR decomposition and $L_{2,1}$-norm minimization. Signal Processing, 2021, 189: Article No. 108240 [24] Du S Q, Xiao Q J, Shi Y Q, Cucchiara R, Ma Y D. Unifying tensor factorization and tensor nuclear norm approaches for low-rank tensor completion. Neurocomputing, 2021, 458: 204-218 doi: 10.1016/j.neucom.2021.06.020 [25] Yang J H, Zhao X L, Ji T Y, Ma T H, Huang T Z. Low-rank tensor train for tensor robust principal component analysis. Applied Mathematics and Computation, 2020, 367: Article No. 124783 doi: 10.1016/j.amc.2019.124783 [26] Zhang X Q, Wang D, Zhou Z Y, Ma Y. Robust low-rank tensor recovery with rectification and alignment. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 43(1): 238-255 doi: 10.1109/TPAMI.2019.2929043 [27] Lai Z H, Xu Y, Chen Q C, Yang J, Zhang D. Multilinear sparse principal component analysis. IEEE Transactions on Neural Networks and Learning Systems, 2014, 25(10): 1942-1950 doi: 10.1109/TNNLS.2013.2297381 [28] Sun W W, Yang G, Peng J T, Du Q. Lateral-slice sparse tensor robust principal component analysis for hyperspectral image classification. IEEE Geoscience and Remote Sensing Letters, 2020, 17(1): 107-111 doi: 10.1109/LGRS.2019.2915315 [29] Lu C Y, Feng J S, Chen Y D, Liu W, Lin Z C, Yan S C. Tensor robust principal component analysis with a new tensor nuclear norm. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(4): 925-938 doi: 10.1109/TPAMI.2019.2891760 [30] Zheng Y B, Huang T Z, Zhao X L, Jiang T X, Ma T H, Ji T Y. Mixed noise removal in hyperspectral image via low-fibered-rank regularization. IEEE Transactions on Geoscience and Remote Sensing, 2020, 58(1): 734-749 doi: 10.1109/TGRS.2019.2940534 [31] Pang Y W, Li X L, Yuan Y. Robust tensor analysis with L1-norm. IEEE Transactions on Circuits and Systems for Video Technology, 2010, 20(2): 172-178 doi: 10.1109/TCSVT.2009.2020337 [32] Zhao L M, Jia W M, Wang R, Yu Q. Robust tensor analysis with non-greedy $\ell_1$-norm maximization. Radioengineering, 2016, 25(1): 200-207 doi: 10.13164/re.2016.0200 [33] Li T, Li M Y, Gao Q X, Xie D Y. F-norm distance metric based robust 2DPCA and face recognition. Neural Networks, 2017, 94: 204-211 doi: 10.1016/j.neunet.2017.07.011 [34] Gao Q X, Ma L, Liu Y, Gao X B, Nie F P. Angle 2DPCA: A new formulation for 2DPCA. IEEE Transactions on Cybernetics, 2018, 48(5): 1672-1678 doi: 10.1109/TCYB.2017.2712740 [35] Zhou S S, Zhang D Q. Bilateral angle 2DPCA for face recognition. IEEE Signal Processing Letters, 2019, 26(2): 317-321 doi: 10.1109/LSP.2018.2889925 [36] Ge W M, Li J X, Wang X F. Robust tensor principal component analysis based on F-norm. In: Proceedings of the IEEE International Conference on Mechatronics and Automation (ICMA). Beijing, China: IEEE, 2020. 1077−1082 -

 下载:
下载:









计量
- 文章访问数: 1228
- HTML全文浏览量: 436
- PDF下载量: 184
- 被引次数: 0
