

-
摘要: 视觉语言导航, 即在一个未知环境中, 智能体从一个起始位置出发, 结合指令和周围视觉环境进行分析, 并动态响应生成一系列动作, 最终导航到目标位置. 视觉语言导航有着广泛的应用前景, 该任务近年来在多模态研究领域受到了广泛关注. 不同于视觉问答和图像描述生成等传统多模态任务, 视觉语言导航在多模态融合和推理方面, 更具有挑战性. 然而由于传统模仿学习的缺陷和数据稀缺的现象, 模型面临着泛化能力不足的问题. 系统地回顾了视觉语言导航的研究进展, 首先对于视觉语言导航的数据集和基础模型进行简要介绍; 然后全面地介绍视觉语言导航任务中的代表性模型方法, 包括数据增强、搜索策略、训练方法和动作空间四个方面; 最后根据不同数据集下的实验, 分析比较模型的优势和不足, 并对未来可能的研究方向进行了展望.Abstract: Vision-and-language navigation means that an agent in an unknown environment, starting from a starting location, dynamically generates a series of actions by making analysis with language instructions and the visual environment, and finally navigates to the goal location. And due to the widespread application prospect, in recent years, it has received increasing attention from researchers especially in multi-modal research. It is different from traditional multi-modal tasks such as vision question answer and image captioning, vision-and-language navigation is more challenging in terms of dynamic reasoning and multi-modal fusion. However, with the limitations of imitation learning and the phenomenon of data scarcity, the model is faced with the problem of insufficient generalization. In this paper, we review the current advances in the research of vision-and-language navigation. Firstly, we briefly introduce data sets in visual-and-language navigation. Then, we comprehensively introduce the representative models in vision-and-language navigation, including data augmentation, search strategies, training methods and action spaces. Finally, from the experiments under different data sets, we analyze the advantages and disadvantages of the existing models, and prospect some future and possible research directions.
-
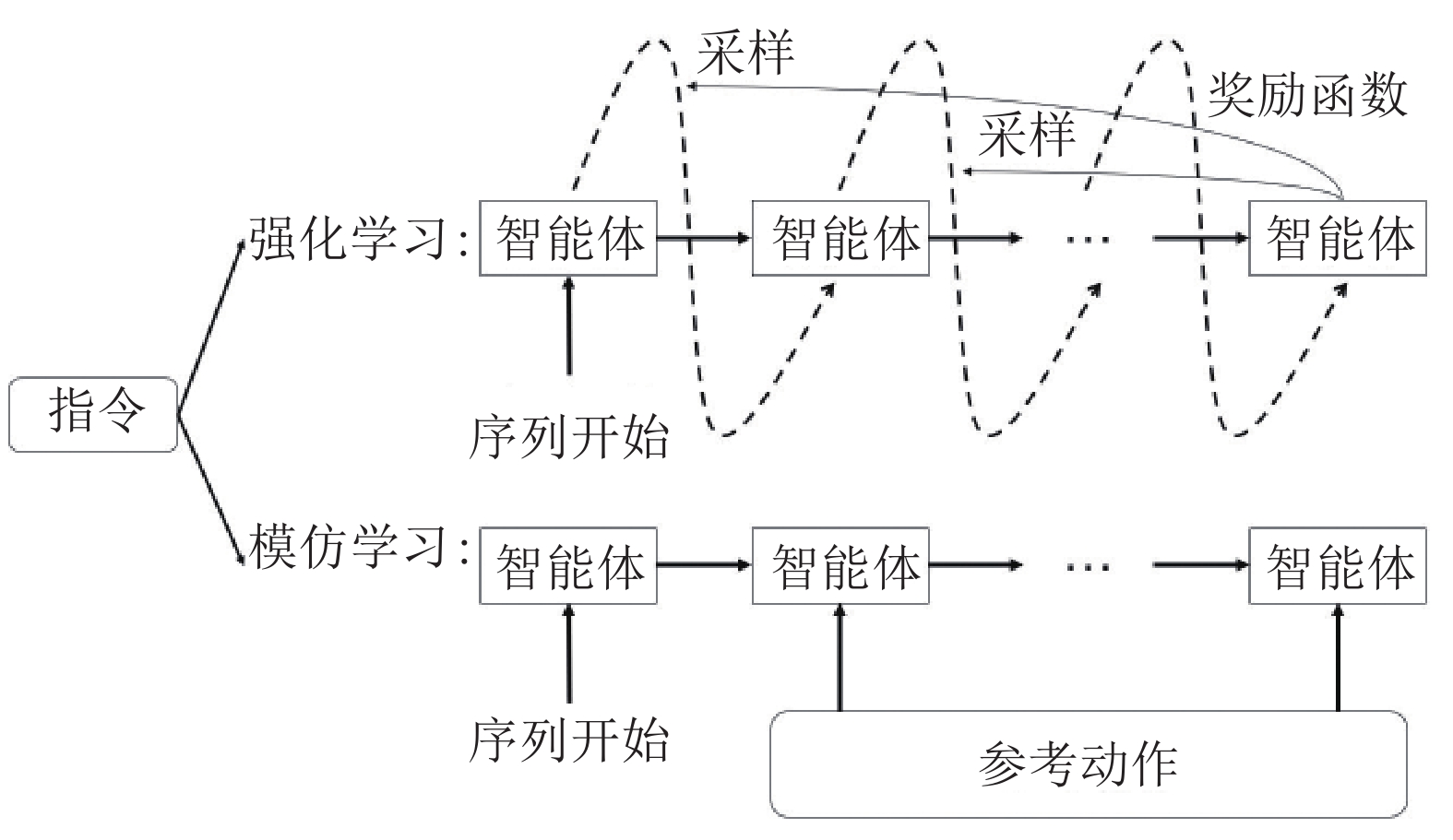
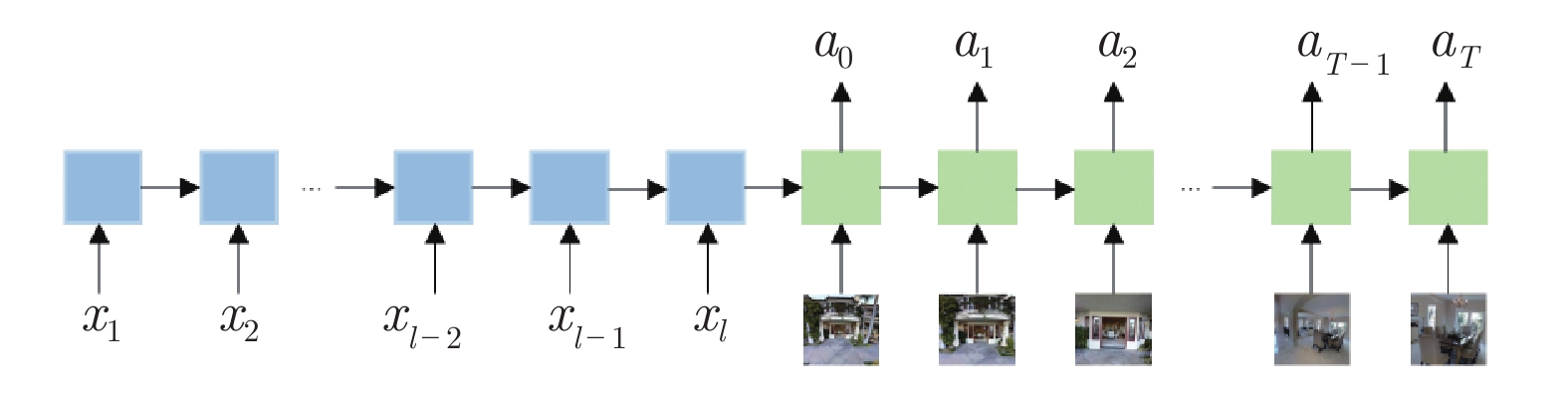
图 6 融合强化学习和模仿学习的过程
Fig. 6 The mixture of reinforcement learning and imitation learning
表 1 视觉语言导航不同数据集的对比
Table 1 The comparison of different datasets in vision-and-language navigation
数据集 训练集 (条) 可见验证集 (条) 不可见验证集 (条) 测试集 (条) 平均指令长度 (单词个数) 语言种类 FGR2R[7] 51 377 3 775 8 481 15 385 7.2 英语 REVERIE[4] 10 466 4 944 3 573 6 292 18.0 英语 BL-R2R[12] 14 025 1 020 2 349 4 188 20.6 英语/中文 R2R[1] 14 039 1 021 2 349 4 173 29.4 英语 R4R[8] 233 613 1 035 45 162 — 58.4 英语 R6R[9] 89 632 — 35 777 — 91.2 英语 R8R[9] 94 731 — 43 273 — 121.6 英语 RxR[10] 79 467 8 813 13 625 24 164 77.8 英语/印地语/泰卢固语 Landmark-RxR[11] 133 602 13 591 19 547 — 21.0 英语  下载: 导出CSV
下载: 导出CSV
表 2 视觉语言导航任务中的评价指标
Table 2 The metrics of vision-and-language navigation
评价指标 定义 公式 路径长度 起始位置到停止位置的导航轨迹长度 $\mathop {\displaystyle\sum d }\limits_{ { {\boldsymbol{v} }_i} \in V} \left( { { {\boldsymbol{v} }_i},{ {\boldsymbol{v} }_{i + 1} } } \right)$ 导航误差 预测路径终点和参考路径终点的距离 $d\left({\boldsymbol{v}}_{t},{\boldsymbol{v}}_{e}\right)$ 理想成功率 预测路径中任意节点距离参考路径终点的阈值距离内的概率 ${\mathbb{I}}\left[ {\left( {\mathop {\min }\limits_{{{\boldsymbol{v}}_i} \in V} d\left( {{{\boldsymbol{v}}_i},{{\boldsymbol{v}}_e}} \right)} \right) \le {d_{th}}} \right]$ 导航成功率 停止位置与参考路径终点的距离不大于 3 米的概率 ${\mathbb{I}}\left[ {NE({{\boldsymbol{v}}_t},{{\boldsymbol{v}}_e}) \le {d_{th}}} \right]$ 基于路径加权的成功率 基于路径长度加权的导航成功率 ${SR}({\boldsymbol{v} }_t, {\boldsymbol{v} }_e) \cdot \dfrac{d_{gt} }{\max \left\{ {PL}({ V}), d_{gt}\right\} }$ 长度加权的覆盖分数[59] 预测路径相对于参考路径的路径覆盖率和长度分数 ${PC}\left(P, R\right)\cdot LS\left( P, R\right)$ 基于动态时间规整加权成功率[59] 由成功率加权的预测路径和参考路径的时空相似性 $SR({ {\boldsymbol{v} }_t},{ {\boldsymbol{v} }_e}) \cdot \exp \left( { - \dfrac{ {\mathop {\min }\limits_{ {\boldsymbol{w} } \in W} \sum\nolimits_{\left( { {i_k},{j_k} } \right) \in {\boldsymbol{w} } } d \left( { { {\boldsymbol{r} }_{ {i_k} } },{ {\boldsymbol{q} }_{ {j_k} } } } \right)} }{ {|R| \cdot {d_{th} } } }} \right)$
下载: 导出CSV
表 3 在 R2R 测试数据集上的视觉语言导航方法对比
Table 3 The comparison of vision-and-language navigation methods on the R2R test dataset
方法 路径长度 (米) SR (%) SPL (%) seq2seq[1] 8.13 20.0 18.0 RPA[48] 9.15 25 23.0 SF[13] 14.82 35 28.0 SMNA[31] 18.04 48 35 PTA[29] 10.17 40.0 36.0 RCM[30] 11.97 43.0 38.0 Regretful[23] 13.69 48.0 40.0 FAST[22] 22.08 54.0 41.0 EGP[26] — 53.0 42.0 PRESS[52] 10.77 49.0 45.0 SSM[28] 22.10 61.0 46.0 Envdrop[17] 11.66 51.0 47.0 SERL[49] — 53.0 49.0 OAAM[32] 10.40 53.0 50.0 AuxRN[44] — 55.0 51.0 PREVALENT[54] 10.51 54.0 51.0 RelGraph[27] 10.29 55.0 52.0 RecBERT[57] 12.35 63.0 57.0 HAMT[58] 12.27 65.0 60.0
下载: 导出CSV
表 4 在 R4R 测试数据集上的视觉语言导航方法对比
Table 4 The comparison of vision-and-language navigation methods on the R4R test dataset
下载: 导出CSV
表 5 视觉语言导航中的不同方法改进的对比
Table 5 The comparison of different improvements in vision-and-language navigation
方法 数据
增强导航
策略动作
空间训练
方法R2R
SR (%)R4R
SR (%)Seq2seq[1] — — — √ 20.0 25.7 RPA[48] — — — √ 25.0 — SF[13] √ √ √ — 35.0 23.8 SMNA[31] — √ — √ 48.0 — Regretful[23] — √ — — 48.0 30.1 FAST[22] — √ — — 54.0 — PTA[29] — — √ — 40.0 24.0 PRESS[52] — — — √ 49.0 29.0 RCM[30] — √ — √ 43.0 29.0 Envdrop[17] √ — — √ 51.0 — SERL[49] — — — √ 53.0 — OAAM[32] — — — √ 53.0 31.0 PREVALENT[54] — — — √ 54.0 — EGP[26] — √ √ — 53.0 30.2 SSM[28] — √ — √ 61.0 — RecBERT[57] — √ — √ 63.0 43.6 HAMT[58] — √ — √ 65.0 44.6
下载: 导出CSV
-
[1] Anderson P, Wu Q, Teney D, Bruce J, Johnson M, Sünderhauf N, et al. Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 3674−3683 [2] Chang A, Dai A, Funkhouser T, Halber M, Niebner M, Savva M, et al. Matterport3D: Learning from rgb-d data in indoor environments. In: Proceedings of the International Conference on 3D Vision. Qingdao, China: IEEE, 2017. 667−676 [3] Chen H, Suhr A, Misra D, Snavely N, Artzi Y. Touchdown: Natural language navigation and spatial reasoning in visual street environments. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 12538−12547 [4] Qi Y K, Wu Q, Anderson P, Wang X, Wang W, Shen C H, et al. Reverie: Remote embodied visual referring expression in real indoor environments. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, USA: IEEE, 2020. 9979−9988 [5] Gao C, Chen J Y, Liu S, Wang L T, Zhang Q, Wu Q. Room-and-object aware knowledge reasoning for remote embodied referring expression. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville, USA: IEEE, 2021. 3064−3073 [6] Thomason J, Murray M, Cakmak M, Zettlemoyer L. Vision-and-dialog navigation. In: Proceedings of the Conference on Robot Learning. Cambridge, USA: 2021. 394−406 [7] Hong Y C, Rodriguez C, Wu Q, Gould S. Sub-instruction aware vision-and-language navigation. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing. Virtual Event: 2020. 3360−3376 [8] Jain V, Magalhaes G, Ku A, Vaswani A, Ie E, Baldridge J. Stay on the path: Instruction fidelity in vision-and-language navigation. In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Florence, Italy: 2019. 1862− 1872 [9] Zhu W, Hu H X, Chen J C, Deng Z W, Jain V, Ie E, et al. Babywalk: Going farther in vision-and-language navigation by taking baby steps. In: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Virtual Event: 2020. 2539−2556 [10] Ku A, Anderson P, Patel R, Ie E, Baldridge J. Room-across-room: Multilingual vision-and-language navigation with dense spatiotemporal grounding. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing. Virtual Event: 2020. 4392−4412 [11] He K J, Huang Y, Wu Q, Yang J H, An D, Sima S L, et al. Landmark-rxr: Solving vision-and-language navigation with fine-grained alignment supervision. In: Proceedings of the 35th International Conference on Neural Information Processing Systems. Virtual Event: 2021. 652−663 [12] Yan A, Wang X, Feng J, Li L, Wang W. Cross-lingual vision-language navigation [Online], available, https://arxiv.org/abs/1910.11301, December 6, 2020 [13] Fried D, Hu R H, Cirik V, Rohrbach A, Andreas J, Morency LP, et al. Speaker-follower models for vision-and-language navigation. In: Proceedings of the 32nd International Conference on Neural Information Processing Systems. Montreal Canada: MIT Press, 2018. 3318−3329 [14] Fu T, Wang X, Peterson MF, Grafton ST, Eckstein MP, Wang W. Counterfactual vision-and-language navigation via adversarial path sampler. In: Proceedings of the 16th European Conference on Computer Vision. Virtual Event: 2020. 71−86 [15] Huang H S, Jain V, Mehta H, Ku A, Magalhaes G, Baldridge J, et al. Transferable representation learning in vision-and-language navigation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul, South Korea: IEEE, 2019. 7404−7413 [16] Zhao M, Anderson P, Jain V, Wang S, Ku A, Baldridge J, et al. On the evaluation of vision-and-language navigation instructions. In: Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics. Virtual Event: 2021. 1302−1316 [17] Tan H, Yu L C, Bansal M. Learning to navigate unseen environments: Back translation with environmental dropout. In: Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics. Minneapolis, Minnesota: 2019. 2610−2621 [18] An D, Qi Y K, Huang Y, Wu Q, Wang L, Tan T N. Neighbor-view enhanced model for vision and language navigation. In: Proceedings of the 29th ACM International Conference on Multimedia. Chengdu, China: 2021. 5101−5109 [19] Yu F, Deng Z W, Narasimhan K, Russakovsky O. Take the scenic route: Improving generalization in vision-and-language navigation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Seattle, USA: IEEE, 2020. 920−921 [20] Rennie SJ, Marcheret E, Mroueh Y, Ross J, Goel V. Self-critical sequence training for image captioning. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017. 7008−7224 [21] Sutskever I, Vinyals O, Le QV. Sequence to sequence learning with neural networks. In: Proceedings of the 27th International Conference on Neural Information Processing Systems. Montr-eal, Canada: IEEE, 2014. 3104−3112 [22] Ke L, Li X J, Bisk Y, Holtzman A, Gan Z, Liu J J, et al. Tactical rewind: Self-correction via backtracking in vision-and-language navigation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 6741−6749 [23] Ma C, Wu Z X, AlRegib G, Xiong C M, Kira Z. The regretful agent: Heuristic-aided navigation through progress estimation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 6732−6740 [24] Wang H Q, Wang W G, Shu T M, Liang W, Shen J B. Active visual information gathering for vision-language navigation. In: Proceedings of the 16th European Conference on Computer Vision. Virtual Event: 2020. 307−322 [25] Chi T, Shen M M, Eric M, Kim S, Hakkani-tur D. Just ask: An interactive learning framework for vision and language navigation. In: Proceedings of the 34th AAAI Conference on Artificial Intelligence. California, USA: 2020. 2459−2466 [26] Deng Z W, Narasimhan K, Russakovsky O. Evolving graphical planner: Contextual global planning for vision-and-language navigation. In: Proceedings of the 34th International Conference on Neural Information Processing Systems. Virtual Event: 2020. 20660−20672 [27] Hong Y C, Rodriguez C, Qi Y K, Wu Q, Gould S. Language and visual entity relationship graph for agent navigation. In: Proceedings of the 34th International Conference on Neural Information Processing Systems. Virtual Event: 2020. 7685−7696 [28] Wang H Q, Wang W G, Liang W, Xiong C M, Shen J B. Structured scene memory for vision-language navigation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville, USA: IEEE, 2021. 8455−8464 [29] Landi F, Baraldi L, Cornia M, Corsini M, Cucchiara R. Perceive, transform and act: Multi-modal attention networks for vision-and-language navigation [Online], available: http://arxiv. org/abs/1911.12377, July 30, 2021 [30] Wang X, Huang Q Y, Celikyilmaz A, Gao J F, Shen D H, Wang Y F, et al. Reinforced cross-modal matching and self-supervised imitation learning for vision-language navigation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 6629−6638 [31] Ma C, Lu J S, Wu Z X, AlRegib G, Kira Z, Socher R, et al. Self-monitoring navigation agent via auxiliary progress estimation. In: Proceedings of the 7th International Conference on Learning Representations. New Orleans, USA: 2019 [32] Qi Y K, Pan Z Z, Zhang S P, Hengel A V, Wu Q. Object-and-action aware model for visual language navigation. In: Proceedings of the 16th European Conference on Computer Vision. Gla-sgow, UK: 2020. 303−317 [33] Thomason J, Gordon D, Bisk Y. Shifting the baseline: Single modality Performance on visual navigation & QA. In: Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics. Minneapolis, Minne-sota: 2019. 1977−1983 [34] Hu R H, Fried D, Rohrbach A, Klein D, Darrell T, Saenko K. Are you looking? grounding to multiple modalities in vision-and-language navigation. In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Florence, Italy: 2019. 6551−6557 [35] Zhang Y B, Tan H, Bansal M. Diagnosing the environment bias in vision-and-language navigation. In: Proceedings of the 29th International Conference on International Joint Conferences on Artificial Intelligence. Yokohama, Japan: 2021. 890−897 [36] Anderson P, Shrivastava A, Truong J, Majumdar A, Parikh D, Batra D, et al. Sim-to-real transfer for vision-and-language navigation. In: Proceedings of the Conference on Robot Learning. Cambridge, USA: 2021. 671−681 [37] Hochreiter S, Schmidhuber J. Long short-term memory. Neural computation, 1997, 9(8): 1735-1780 doi: 10.1162/neco.1997.9.8.1735 [38] Landi F, Baraldi L, Corsini M, Cucchiara R. Embodied vision-and-language navigation with dynamic convolutional filters. In: Proceedings of the 30th British Machine Vision Conference. Cardiff, UK: 2019. 18 [39] Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez A N, et al. Attention is all you need. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach, USA: 2017. 6000−6010 [40] Savva M, Kadian A, Maksymets O, Zhao Y L, Wijmans E, Jain B, et al. Habitat: A platform for embodied ai research. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul, South Korea: IEEE, 2019. 9338−9346 [41] Shen B K, Xia F, Li C S, Martín-Martín R, Fan L X, Wang G Z, et al. Igibson 1.0: A simulation environment for interactive tasks in large realistic scenes. In: Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems. Prague, Czech Republic: IEEE, 2021. 7520−7527 [42] Krantz J, Wijmans E, Majumdar A, Batra D, Lee S. Beyond the nav-graph: Vision-and-language navigation in continuous environments. In: Proceedings of the 16th European Conference on Computer Vision. Glasgow, UK: 2020. 104−120 [43] Chen K, Chen JK, Chuang J, Vázquez M, Savarese S. Topological planning with transformers for vision-and-language navigation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville, USA: IEEE, 2021. 11276−11286 [44] Zhu F D, Zhu Y, Chang X J, Liang X D. Vision-language navigation with self-supervised auxiliary reasoning tasks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, USA: IEEE, 2020. 10009−10019 [45] Xia Q L, Li X J, Li C Y, Bisk Y, Sui Z F, Gao J F, et al. Multi-view learning for vision-and-language navigation [Online], available, https://arxiv.org/abs/2003.00857, March 2, 2020 [46] Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate. In: Proceedings of the 3rd International Conference on Learning Representations. San Die-go, USA: 2015. [47] Bengio S, Vinyals O, Jaitly N, Shazeer N. Scheduled sampling for sequence prediction with recurrent Neural networks. In: Proceedings of the 29th International Conference on Neural Information Processing Systems. Montreal, Canada: 2015. 1171−1179 [48] Wang X, Xiong W H, Wang H M, Wang W Y. Look before you leap: Bridging model-free and model-based reinforcement learning for planned-ahead vision-and-language navigation. In: Proceedings of the 15th European Conference on Computer Vision. Munich, Germany: 2018. 38−55 [49] Wang H, Wu Q, Shen C H. Soft expert reward learning for vision-and-language navigation. In: Proceedings of the 16th Euro-pean Conference on Computer Vision. Glasgow, UK: 2020. 126− 141 [50] Lamb A, Goyal A, Zhang Y, Zhang S Z, Courville A, Bengio Y. Professor forcing: A new algorithm for training recurrent networks. In: Proceedings of the 30th International Conference on Neural Information Processing Systems. Barcelona, Spain: 2016. 4601−4609 [51] Ranzato M, Chopra S, Auli M, Zaremba W. Sequence level training with recurrent neural networks. In: Proceedings of the 4th International Conference on Learning Representations. San Juan, Puerto Rico: 2016 [52] Li X J, Li C Y, Xia Q L, Bisk Y, Celikyilmaz A, Gao J F, et al. Robust navigation with language pretraining and stochastic sampling. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Hong Kong, China: 2019. 1494−1499 [53] Devlin J, Chang M W, Lee K, Toutanova K. Bert: Pre-training of deep bidirectional transformers for language understanding. In: Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistic. Minneapolis, USA: 2018. 4171−4186 [54] Hao W T, Li C Y, Li X J, Carin L, Gao J F. Towards learning a generic agent for vision-and-language navigation via pre-training. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, USA: IEEE, 2020. 13134− 13143 [55] Huang J T, Huang B, Zhu L Q, Ma L Y, Liu J, Zeng G H, et al. Real-time vision-language-navigation based on a lite pre-training model. In: Proceedings of the International Conferences on Internet of Things and IEEE Green Computing and Communications and IEEE Cyber, Physical and Social Computing and IEEE Smart Data and IEEE Congress on Cybermatics. Rhodes, Greece: IEEE, 2020. 399−404 [56] Majumdar A, Shrivastava A, Lee S, Anderson P, Parikh D, Batra D. Improving vision-and-language navigation with image-text pairs from the web. In: Proceedings of the 16th European Conference on Computer Vision. Glasgow, UK: 2020. 259−274 [57] Hong Y C, Wu Q, Qi Y K, Rodriguez-Opazo C, Gould S. Vln bert: A recurrent vision-and-language bert for navigation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville, USA: IEEE, 2021. 1643− 1653 [58] Chen S Z, Guhur P, Schmid C, Laptev I. History aware multimodal transformer for vision-and-language navigation. In: Proceedings of the 35th International Conference on Neural Information Processing Systems. Virtual Event: 2021. 5834−5847 [59] Ilharco G, Jain V, Ku A, Ie E, Baldridge J. General evaluation for instruction conditioned navigation using dynamic time warping. In: Proceedings of the 33rd International Conference on Neural Information Processing Systems Workshops. Vancouver, Canada: 2019. -

 下载:
下载:


计量
- 文章访问数: 3428
- HTML全文浏览量: 1847
- PDF下载量: 1080
- 被引次数: 0
