

-
摘要: 多元时间序列(Multivariate time series, MTS)分类是许多领域中的重要问题, 准确的分类结果可以有效地帮助决策. 当前的MTS分类算法在个体的表征学习阶段难以自动建模多元变量之间复杂的交互关系, 并且无法评估分类结果的可信度, 这会导致模型性能受限, 以及缺乏具备统计意义的可靠性解释. 本文提出了一种基于不确定性的多元时间序列分类算法, 变分贝叶斯共享图神经网络, 即VBSGNN (Variational Bayes shared graph neural network). 首先通过图神经网络(Graph neural network, GNN)提取多元变量之间的交互特征, 然后利用贝叶斯神经网络(Bayesian neural network, BNN)为预测过程引入了不确定性. 最后在10个公开MTS数据集上进行了算法实验, 并与当前提出的7类算法进行了比较, 结果表明VBSGNN可有效学习多元变量之间的交互关系, 提升了分类效果, 并使得模型具备一定的可靠性评估能力.Abstract: Multivariate time series (MTS) classification is an important problem in many fields. Accurate classification results can help realize effective decision-making. Current MTS classification algorithms fail to automatically capture the complex interactions among multiple variables in the representation learning stage, and lack confidence evaluation of the classification results. This causes limited model performance and a shortage of statistically meaningful model reliability explanation. In this paper, an uncertainty-aware multivariate time series classification algorithm, namely VBSGNN (Variational Bayes graph neural network), is proposed. First, the multivariate interaction features are extracted automatically via a graph neural network module. Then, the uncertainty is introduced into the prediction process based on the Bayesian neural network, which finally gives the prediction results some level of confidence. Finally, the algorithm experiments are carried out on 10 publicly available MTS datasets, and compared with seven state-of-the-art benchmarks. The results show that the proposed algorithm VBSGNN can efficiently learn the interactions between multiple variables, improve the classification results, and obtains confidence evaluation ability.1) 1 数据获取地址:
http://timeseriesclassification.com -
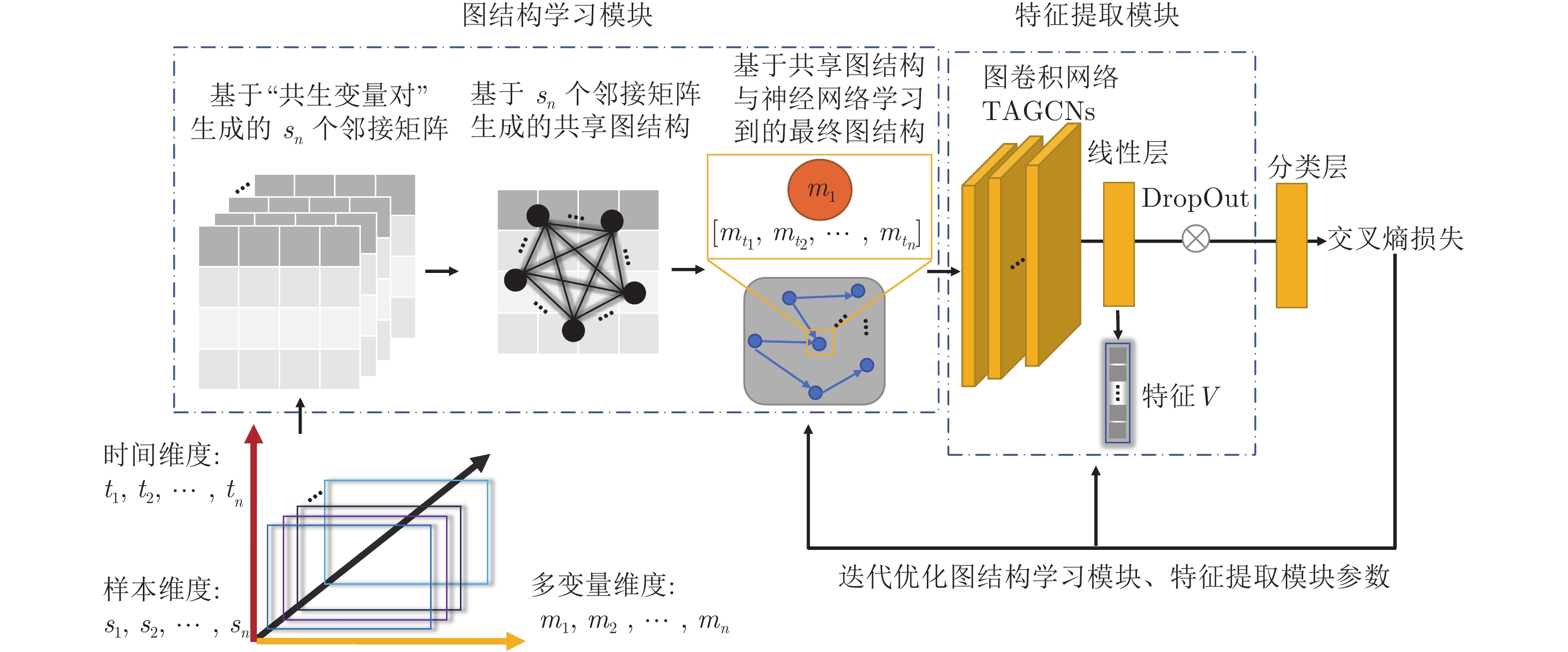
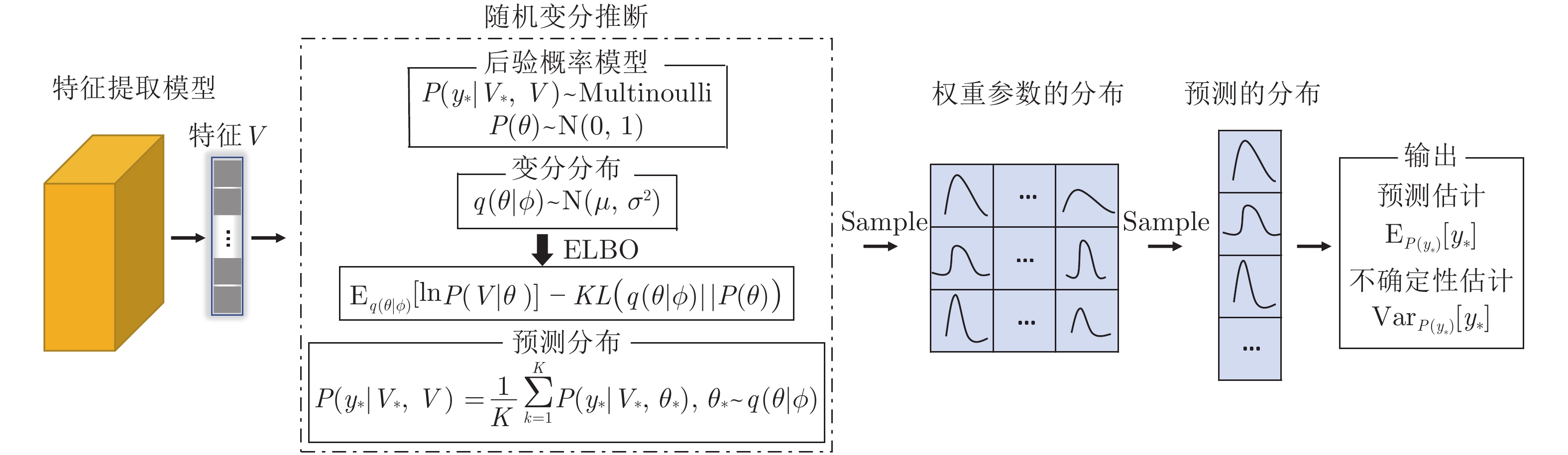
图 1 MTS数据特征提取模型架构与优化流程
Fig. 1 Feature extraction model architecture and optimization process of MTS data
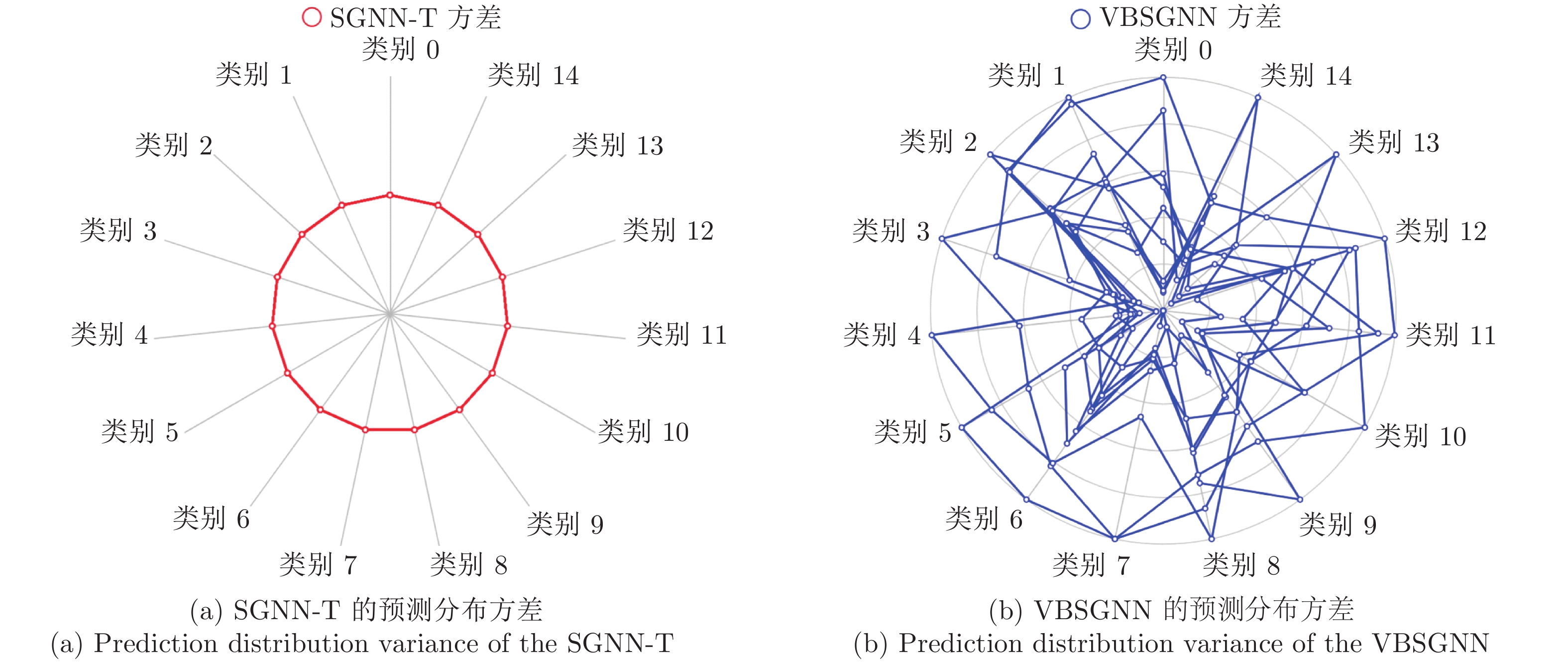
图 3 SGNN-T和VBSGNN的预测分布方差对比
Fig. 3 Variance comparison of prediction distribution between SGNN-T and VBSGNN

图 4 基于VBSGNN不确定得分改善预测效果评估
Fig. 4 Evaluation of improving prediction effect based on VBSGNN uncertainty score
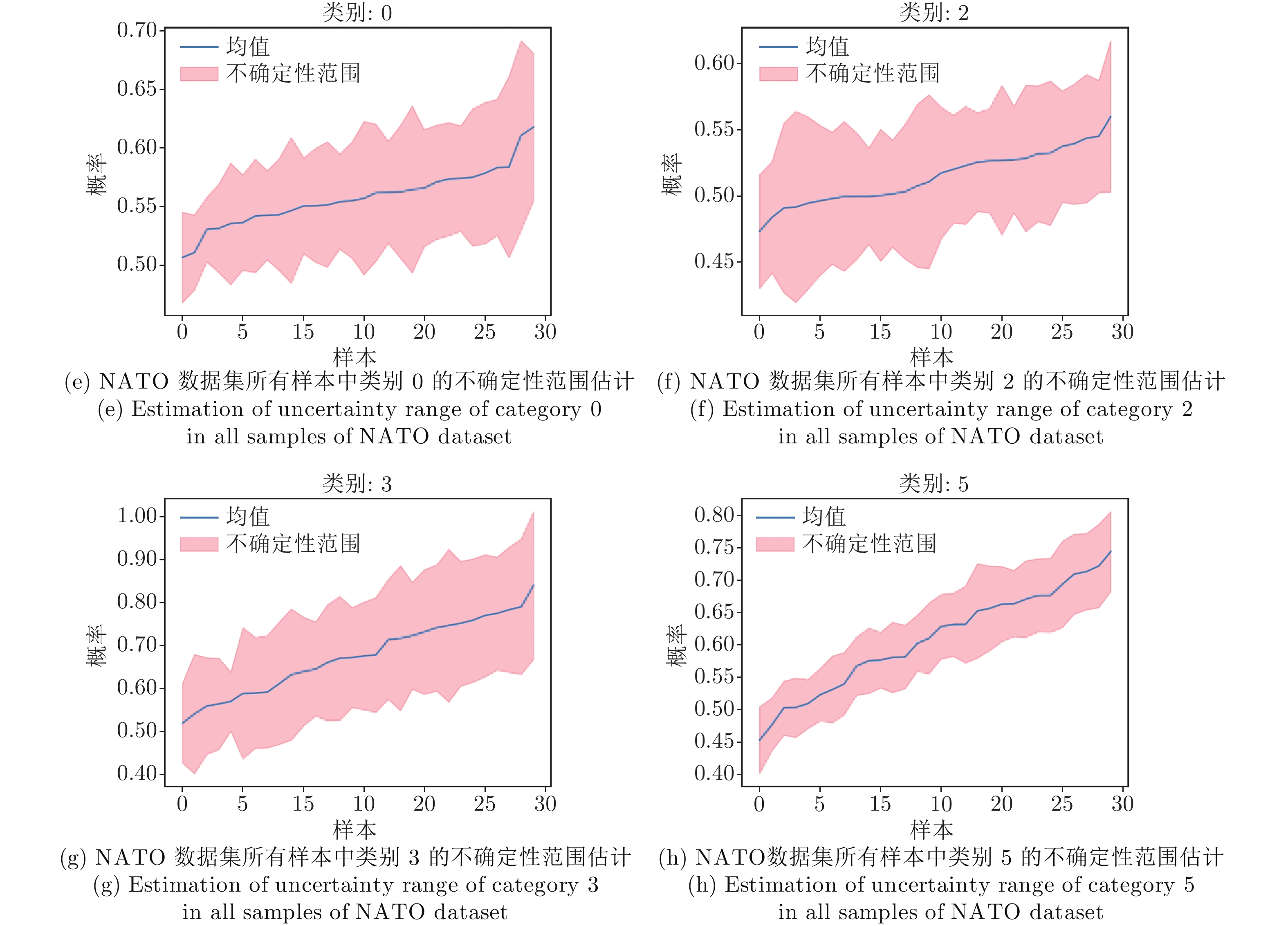
图 5 基于VBSGNN的模型不确定性估计 (NATO数据集)
Fig. 5 Model uncertainty estimation based on the VBSGNN (NATO dataset)

图 6 节点大小与边连接的关系 (NATO数据集)
Fig. 6 The relationship between node size and edge connection (NATO dataset)
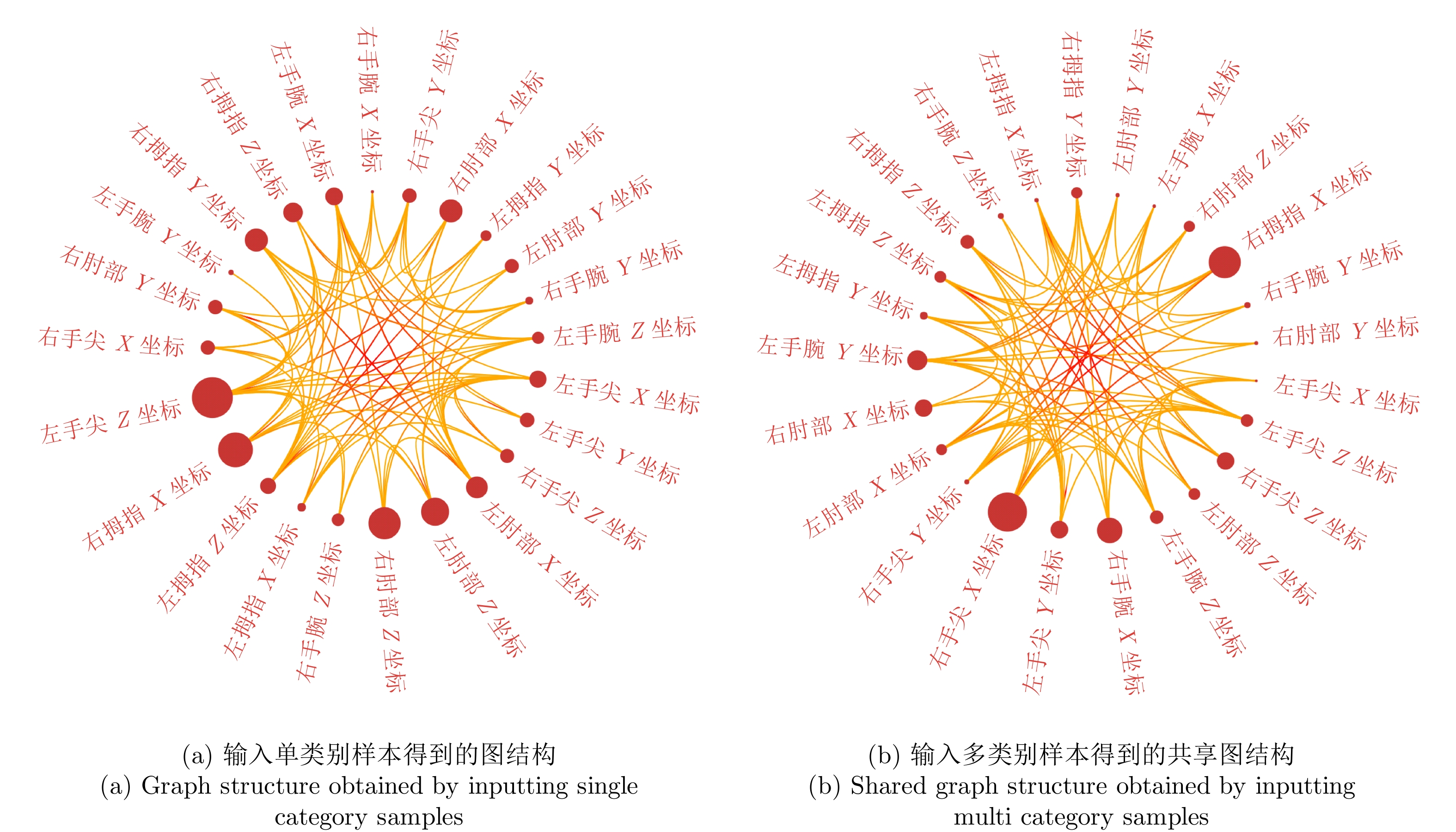
图 7 神经网络学习到的单类别与多类别共享图结构 (NATO数据集)
Fig. 7 Single class and multi class shared graph structures learned by neural networks (NATO dataset)
表 1 实验中使用的10个数据集概要
Table 1 Summary of the 10 UEA datasets used in experimentation
名称 训练集大小 测试集大小 多变量维度 时间维度 类别个数 AF AtrialFibrillation 15 15 2 640 3 FM FingerMovements 316 100 28 50 2 HMD HandMovementDirection 160 74 10 400 4 HB Heartbeat 204 205 61 405 2 LIB Libras 180 180 2 45 15 MI MotorImagery 278 100 64 3000 2 NATO NATOPS 180 180 24 51 6 PD PenDigits 7494 3498 2 8 10 SRS2 SelfRegulationSCP2 200 180 7 1152 2 SWJ StandWalkJump 12 15 4 2500 3  下载: 导出CSV
下载: 导出CSV
表 2 在10个公开数据集上的不同算法准确率对比
Table 2 Accuracy of different algorithms on 10 public datasets are compared
算法 数据集 AF FM HMD HB LIB MI NATO PD SRS2 SWJ Wins ED 0.267 0.519 0.279 0.620 0.833 0.510 0.850 0.973 0.483 0.333 0 DTWI 0.267 0.513 0.297 0.659 0.894 0.390 0.850 0.939 0.533 0.200 0 DTWD 0.267 0.529 0.231 0.717 0.872 0.500 0.883 0.977 0.539 0.200 0 ED(norm) 0.200 0.510 0.278 0.619 0.833 0.510 0.850 0.973 0.483 0.333 0 DTWI(norm) 0.267 0.520 0.297 0.658 0.894 0.390 0.850 0.939 0.533 0.200 0 DTWD(norm) 0.267 0.530 0.231 0.717 0.870 0.500 0.883 0.977 0.539 0.200 0 WEASEL+MUSE 0.400 0.550 0.365 0.727 0.894 0.500 0.870 0.948 0.460 0.267 0 HIVE-COTE 0.133 0.550 0.446 0.722 0.900 0.610 0.889 0.934 0.461 0.333 1 MLSTM-FCN 0.333 0.580 0.527 0.663 0.850 0.510 0.900 0.978 0.472 0.400 0 TapNet 0.333 0.470 0.338 0.751 0.878 0.590 0.939 0.980 0.550 0.133 0 MTPool-M 0.533 0.504 0.486 0.742 0.828 0.560 0.928 0.978 0.550 0.533 0 MTPool-D 0.400 0.530 0.459 0.737 0.811 0.600 0.944 0.977 0.550 0.533 0 MTPool-S 0.400 0.590 0.473 0.722 0.811 0.540 0.889 0.983 0.539 0.667 0 MTPool-One 0.400 0.570 0.405 0.717 0.833 0.540 0.889 0.970 0.539 0.600 0 MTPool-Corr 0.400 0.590 0.419 0.722 0.828 0.560 0.904 0.973 0.550 0.600 0 MTPool 0.467 0.620 0.432 0.742 0.861 0.630 0.904 0.983 0.600 0.667 0 SGNN-S 0.600 0.650 0.541 0.741 0.889 0.600 0.961 0.984 0.589 0.600 2 SGNN-I 0.533 0.550 0.514 0.741 0.883 0.640 0.933 0.974 0.572 0.600 1 SGNN-A 0.533 0.560 0.500 0.751 0.878 0.560 0.961 0.980 0.550 0.600 0 SGNN-T 0.600 0.640 0.608 0.756 0.889 0.630 0.978 0.985 0.600 0.733 7 VBSGNN 0.667 0.680 0.622 0.776 0.872 0.680 0.972 0.984 0.622 0.733 9
下载: 导出CSV
表 3 NATO图结构中24个节点对应的变量名称
Table 3 Corresponding variable names of 24 nodes in graph structure based on NATO dataset
手部传感器变量 肘部传感器变量 手腕传感器变量 拇指传感器变量 节点 0: 左手尖 X 坐标 节点 6: 左肘部 X 坐标 节点 12: 左手腕 X 坐标 节点 18: 左拇指 X 坐标 节点 1: 左手尖 Y 坐标 节点 7: 左肘部 Y 坐标 节点 13: 左手腕 Y 坐标 节点 19: 左拇指 Y 坐标 节点 2: 左手尖 Z 坐标 节点 8: 左肘部 Z 坐标 节点 14: 左手腕 Z 坐标 节点 20: 左拇指 Z 坐标 节点 3: 右手尖 X 坐标 节点 9: 右肘部 X 坐标 节点 15: 右手腕 X 坐标 节点 21: 右拇指 X 坐标 节点 4: 右手尖 Y 坐标 节点 10: 右肘部 Y 坐标 节点 16: 右手腕 Y 坐标 节点 22: 右拇指 Y 坐标 节点 5: 右手尖 Z 坐标 节点 11: 右肘部 Z 坐标 节点 17: 右手腕 Z 坐标 节点 23: 右拇指 Z 坐标
下载: 导出CSV
-
[1] 张熙来, 赵俭辉, 蔡波. 针对PM_2.5单时间序列数据的动态调整预测模型. 自动化学报, 2018, 44(10): 1790-1798Zhang Xi-Lai, Zhao Jian-Hui, Cai Bo. Prediction model with dynamic adjustment for single time series of PM_2.5. Acta Automatica Sinica, 2018, 44(10): 1790-1798 [2] 徐任超, 阎威武, 王国良, 杨健程, 张曦. 基于周期性建模的时间序列预测方法及电价预测研究. 自动化学报, 2020, 46(6): 1136-1144Xu Ren-Chao, Yan Wei-Wu, Wang Guo-Liang, Yang Jian-Cheng, Zhang Xi. Time series forecasting based on seasonality modeling and its application to electricity price forecasting. Acta Automatica Sinica, 2020, 46(6): 1136-1144 [3] Keogh E, Chu S, Hart D, Pazzani M. Segmenting time series: A survey and novel approach. Data Mining in Time Series Databases. Singapore: World Scientific, 2004. 1−21 [4] Zhang X C, Gao Y F, Lin J, Lu C T. TapNet: Multivariate time series classification with attentional prototypical network. In: Proceedings of the 34th AAAI Conference on Artificial Intelligence. New York, USA: AAAI, 2020. 6845−6852 [5] Wang X, Gao Y F, Lin J, Rangwala H, Mittu R. A machine learning approach to false alarm detection for critical arrhythmia alarms. In: Proceedings of the IEEE 14th International Conference on Machine Learning and Applications (ICMLA). Miami, USA: IEEE, 2015. 202−207 [6] Minnen D, Starner T, Essa I, Isbell C. Discovering characteristic actions from on-body sensor data. In: Proceedings of the 10th IEEE International Symposium on Wearable Computers. Montreux, Switzerland: IEEE, 2006. 11−18 [7] Rakthanmanon T, Keogh E. Fast shapelets: A scalable algorithm for discovering time series shapelets. In: Proceedings of the 2013 SIAM International Conference on Data Mining. Austin, USA: SIAM, 2013. 668−676 [8] Seto S, Zhang W Y, Zhou Y C. Multivariate time series classification using dynamic time warping template selection for human activity recognition. In: Proceedings of the 2015 IEEE Symposium Series on Computational Intelligence. Cape Town, South Africa: IEEE, 2015. 1399−1406 [9] Pei W J, Dibeklioğlu H, Tax D M J, Van Der Maaten L. Multivariate time-series classification using the hidden-unit logistic model. IEEE Transactions on Neural Networks and Learning Systems, 2018, 29(4): 920-931 doi: 10.1109/TNNLS.2017.2651018 [10] Karim F, Majumdar S, Darabi H, Harford S. Multivariate LSTM-FCNs for time series classification. Neural Networks, 2019, 116: 237-245 doi: 10.1016/j.neunet.2019.04.014 [11] Zheng Y, Liu Q, Chen E H, Ge Y, Zhao J L. Time series classification using multi-channels deep convolutional neural networks. In: Proceedings of the 15th International Conference on Web-Age Information Management. Macau, China: Springer, 2014. 298−310 [12] 毛文涛, 蒋梦雪, 李源, 张仕光. 基于异常序列剔除的多变量时间序列结构化预测. 自动化学报, 2018, 44(4): 619-634Mao Wen-Tao, Jiang Meng-Xue, Li Yuan, Zhang Shi-Guang. Structural prediction of multivariate time series through outlier elimination. Acta Automatica Sinica, 2018, 44(4): 619-634 [13] Wu Z H, Pan S R, Chen F W, Long G D, Zhang C Q, Yu P S. A comprehensive survey on graph neural networks. IEEE Transactions on Neural Networks and Learning Systems, 2021, 32(1): 4-24 doi: 10.1109/TNNLS.2020.2978386 [14] Scarselli F, Gori M, Tsoi A C, Hagenbuchner M, Monfardini G. The graph neural network model. IEEE Transactions on Neural Networks, 2009, 20(1): 61-80 doi: 10.1109/TNN.2008.2005605 [15] Cao D F, Wang Y J, Duan J Y, Zhang C, Zhu X, Huang C R, et al. Spectral temporal graph neural network for multivariate time-series forecasting. In: Proceedings of the 34th Advances in Neural Information Processing Systems. arXiv: 2103.07719 [16] Wu Z H, Pan S R, Long G D, Jiang J, Chang X J, Zhang C Q. Connecting the dots: Multivariate time series forecasting with graph neural networks. In: Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. Virtual Event: ACM, 2020. 753−763 [17] Duan Z H, Xu H Y, Wang Y Y, Huang Y D, Ren A N, Xu Z B, et al. Multivariate time-series classification with hierarchical variational graph pooling. arXiv preprint arXiv: 2010.05649, 2020. [18] Spadon G, Hong S D, Brandoli B, Matwin S, Rodrigues-Jr J F, Sun J M. Pay attention to evolution: Time series forecasting with deep graph-evolution learning. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, doi: 10.1109/TPAMI.2021.3076155 [19] Hamilton W L, Ying R, Leskovec J. Inductive representation learning on large graphs. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach, USA: Curran Associates Inc., 2017. 1025−1035 [20] Xu K, Hu W H, Leskovec J, Jegelka S. How powerful are graph neural networks. In: Proceedings of the 7th International Conference on Learning Representations. New Orleans, USA: ICLR, 2019. [21] Veličković P, Cucurull C, Casanova A, Romero A, Liò P, Bengio Y. Graph attention networks. In: Proceedings of the 6th International Conference on Learning Representations. Vancouver, Canada: ICLR, 2018. [22] Tran D, Dusenberry M W, Van Der Wilk M, Hafner D. Bayesian layers: A module for neural network uncertainty. In: Proceedings of the 33rd International Conference on Neural Information Processing Systems. Vancouver, Canada: Curran Associates Inc., 2019. 14660−14672 [23] Kendall A, Gal Y. What uncertainties do we need in Bayesian deep learning for computer vision. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach, USA: 2017. 5575−5585 [24] Zhang C, Bütepage J, Kjellström H, Mandt S. Advances in variational inference. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 41(8): 2008-2026 doi: 10.1109/TPAMI.2018.2889774 [25] Zhang X L, Qian B Y, Cao S L, Li Y, Chen H, Zheng Y F. INPREM: An interpretable and trustworthy predictive model for healthcare. In: Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. Virtual Event: ACM, 2020. 450−460 [26] Ranjan E, Sanyal S, Talukdar P P. ASAP: Adaptive structure aware pooling for learning hierarchical graph representations. In: Proceedings of the 34th AAAI Conference on Artificial Intelligence. New York, USA: AAAI, 2020. 5470−5477 [27] Du J, Zhang S H, Wu G H, Moura J M F, Kar S. Topology adaptive graph convolutional networks. arXiv: 1710.10370, 2018. [28] Szegedy C, Liu W, Jia Y Q, Sermanet P, Reed S, Anguelov D, et al. Going deeper with convolutions. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, USA: IEEE, 2015. 1−9 [29] Hinton G E, Srivastava N, Krizhevsky A, et al. Improving neural networks by preventing co-adaptation of feature detectors. Computer Science, 2012, 3(4): 212-223 [30] Kingma D P, Ba J. Adam: A method for stochastic optimization. In: Proceedings of the 3rd International Conference on Learning Representations. San Diego, USA: ICLR, 2015. 1−15 [31] 季文强. 基于深度学习和不确定性量化的数据驱动剩余寿命预测方法研究 [硕士学位论文], 中国科学技术大学, 中国, 2020Ji Wen-Qiang. Research on Data-driven Remaining Useful Life Prediction Method Based on Deep Learning and Uncertainty Quantification [Master thesis], University of Science and Technology of China, China, 2020 [32] Hoffman M D, Blei D M, Wang C, Paisley J W. Stochastic variational inference. Journal of Machine Learning Research, 2013, 14(1): 1303-1347 [33] Zhang A Y, Zhou H H. Theoretical and computational guarantees of mean field variational inference for community detection. The Annals of Statistics, 2020, 48(5): 2575-2598 [34] Shokoohi-Yekta M, Wang J, Keogh E J. On the non-trivial generalization of dynamic time warping to the multi-dimensional case. In: Proceedings of the 2015 SIAM International Conference on Data Mining. Vancouver, Canada: SIAM, 2015. 289−297 [35] Bagnall A , Flynn M , Large J. A tale of two toolkits, report the third: On the usage and performance of HIVE-COTE v1.0. arXiv preprint arXiv: 2004.06069, 2020. -

 下载:
下载:

计量
- 文章访问数: 1993
- HTML全文浏览量: 1912
- PDF下载量: 442
- 被引次数: 0
