

-
摘要: 事件相机对场景的亮度变化进行成像, 输出异步事件流, 具有极低的延时, 受运动模糊问题影响较少. 因此, 可以利用事件相机解决高速运动场景下的光流(Optical flow, OF)估计问题. 基于亮度恒定假设和事件产生模型, 利用事件相机输出事件流的低延时性质, 融合存在运动模糊的亮度图像帧, 提出基于事件相机的连续光流估计算法, 提升了高速运动场景下的光流估计精度. 实验结果表明, 相比于现有的基于事件相机的光流估计算法, 该算法在平均端点误差、平均角度误差和均方误差3个指标上, 分别提升11%、45% 和8%. 在高速运动场景下, 该算法能够准确重建出高速运动目标的连续光流, 保证了存在运动模糊情况时, 光流估计的精度.Abstract: Event camera encodes the brightness change of the scene and outputs asynchronous event data, with extremely low delay and few motion blur problem. Therefore, event camera can be used to solve the problem of optical flow (OF) estimation in high-speed motion scenes. In this paper, based on the assumption of constant brightness and event generation model, continuous optical flow estimation algorithm based on event camera is proposed by utilizing the low-delay property of event stream and fusing the brightness images with motion blur, which greatly improves the optical flow estimation accuracy in high-speed motion scenes. Experimental results show that the proposed algorithm improves the average endpoint error, the average angular error and the mean square error by 11%, 45% and 8%, respectively, comparing with the existing event-based optical flow estimation algorithms. In high-speed motion scenes, the proposed algorithm can accurately reconstruct the continuous optical flow of the high-speed moving target, thus guaranteeing the accuracy of optical flow estimation in the presence of motion blur.
-

图 1 基于传统相机和基于事件相机的光流估计效果对比 ((a)传统相机输出图像帧序列; (b)传统Horn-Schunck 算法的光流估计结果; (c)事件相机输出事件流; (d)本文EDI-CLG算法光流估计结果)
Fig. 1 Comparison of traditional camera and event camera based optical flow ((a) The samples of images acquired by traditional camera; (b) The results using Horn-Schunck algorithm; (c) The event data generated by event camera; (d) The results using the proposed EDI-CLG algorithm)

图 2 DAVIS240数据集的亮度图像和对应事件帧 ((a) TranslBoxes数据; (b) RotDisk数据; (c) TranslSin数据)
Fig. 2 Brightness image and corresponding event frame of DAVIS240 datasets ((a) TranslBoxes dataset; (b) RotDisk dataset; (c) TranslSin dataset)
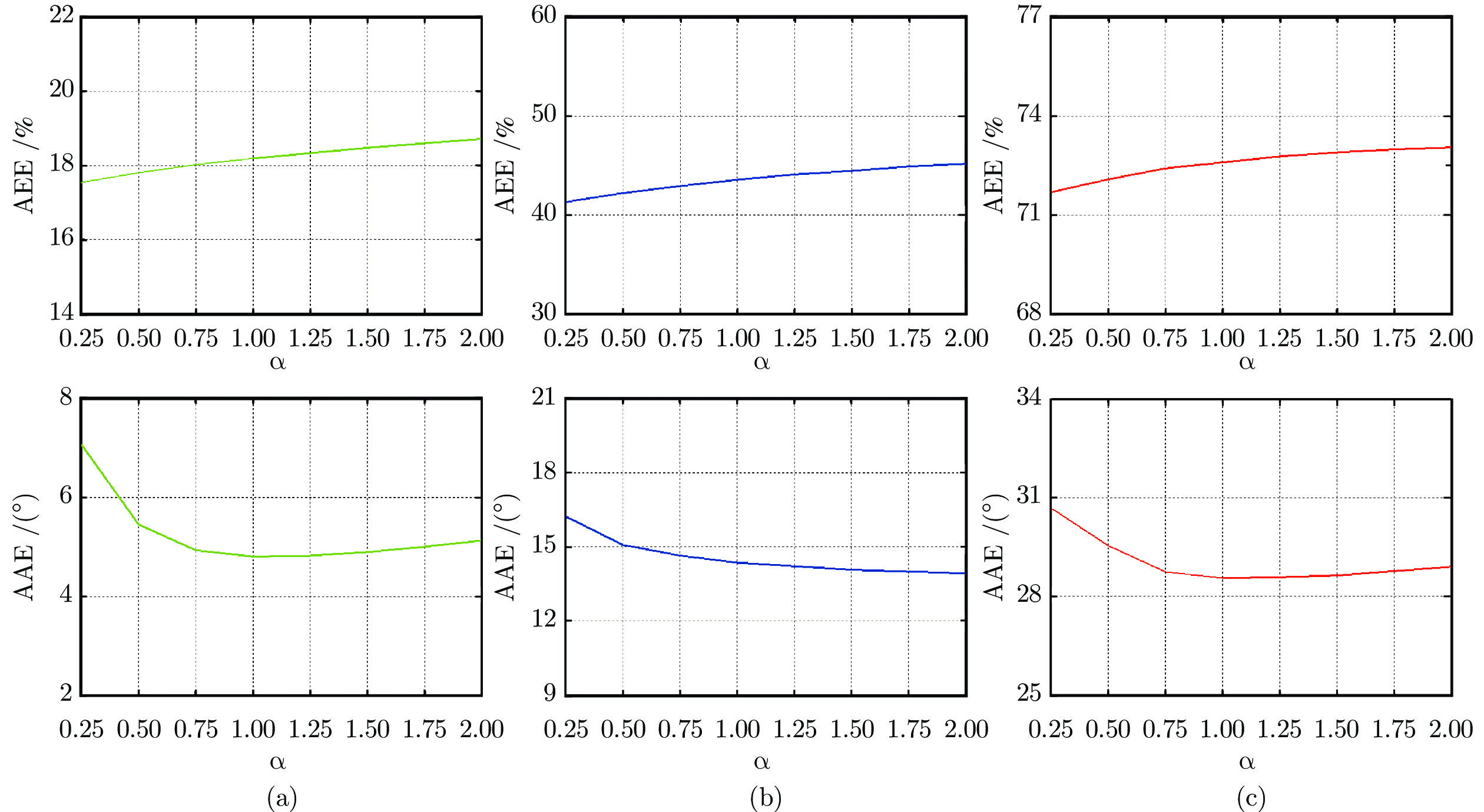
图 3 正则化参数$ \alpha $与光流误差的关系曲线 ((a) TranslBoxes数据; (b) RotDisk数据; (c) TranslSin数据)
Fig. 3 Relationship between optical flow error and regularization parameter $ \alpha $ ((a) TranslBoxes dataset; (b) RotDisk dataset; (c) TranslSin dataset)

图 4 DAVIS240数据集光流结果对比图 ((a)光流真实值; (b)本文EDI-HS方法; (c)本文EDI-CLG方法; (d) DAVIS-OF方法; (e) DVS-CM方法; (f) DVS-LP方法)
Fig. 4 Comparison of optical flow results on DAVIS240 datasets ((a) Ground truth; (b) The proposed EDI-HS method; (c) The proposed EDI-CLG method; (d) The DAVIS-OF method; (e) The DVS-CM method; (f) The DVS-LP method)

图 5 运动模糊数据集光流结果对比图 ((a)运动模糊亮度图像; (b) 使用EDI方法重建的清晰亮度图像; (c)本文EDI-HS 方法; (d)本文EDI-CLG方法; (e) DVS-CM方法; (f) DVS-LP方法)
Fig. 5 Comparison of optical flow results on motion blur datasets ((a) Brightness image with motion blur; (b) Reconstructed clear brightness image using EDI method; (c) The proposed EDI-HS method; (d) The proposed EDI-CLG method; (e) The DVS-CM method; (f) The DVS-LP method)

图 6 连续光流误差对比折线图 ((a) EDI-CLG算法改进前的平均端点误差; (b) EDI-CLG算法改进前的平均角度误差;(c) EDI-CLG算法改进后与DAVIS-OF算法的平均端点误差对比; (d) EDI-CLG算法改进后与DAVIS-OF算法的平均角度误差对比)
Fig. 6 Continuous optical flow error comparison ((a) The average endpoint error of EDI-CLG before improvement; (b) The average angular error of EDI-CLG before improvement; (c) Comparison of the average endpoint error between the improved EDI-CLG and DAVIS-OF; (d) Comparison of the average angular error between the improved EDI-CLG and DAVIS-OF)

图 7 EDI-CLG算法和DAVIS-OF算法连续光流结果对比图 ((a)光流真实值; (b) DAVIS-OF方法; (c)本文EDI-CLG方法在单帧图像曝光时间内连续4次进行光流计算的结果)
Fig. 7 Comparison of continuous optical flow results between EDI-CLG algorithm and DAVIS-OF algorithm ((a) Ground truth; (b) The DAVIS-OF method; (c) The results of four continuous optical flow calculations within the exposure time of a frame using the proposed EDI-CLG method)
表 1 DAVIS240数据集光流误差表
Table 1 Optical flow error on DAVIS240 datasets
数据 算法 AEE ($\%$) AAE (°) MSE TranslBoxes DVS-CM 43.65 ± 27.15 21.46 ± 32.86 39.94 DVS-LP 124.78 ± 92.05 19.66 ± 13.71 81.03 DAVIS-OF 31.20 ± 3.18 17.29 ± 7.18 15.57 EDI-HS 18.65 ± 2.92 5.13 ± 4.72 17.86 EDI-CLG 18.01 ± 2.65 4.79 ± 3.05 16.77 RotDisk DVS-CM 54.26 ± 28.30 34.39 ± 25.88 40.75 DVS-LP 104.63 ± 97.15 20.76 ± 14.17 77.25 DAVIS-OF 33.94 ± 17.02 13.07 ± 8.58 14.30 EDI-HS 42.93 ± 20.91 14.87 ± 12.83 33.10 EDI-CLG 42.44 ± 20.86 13.79 ± 10.52 33.02 TranslSin DVS-CM 91.96 ± 9.95 43.16 ± 39.09 85.41 DVS-LP 107.68 ± 70.04 69.53 ± 30.82 94.53 DAVIS-OF 84.78 ± 61.22 56.75 ± 41.53 62.61 EDI-HS 75.74 ± 51.69 30.14 ± 9.98 72.96 EDI-CLG 72.45 ± 44.12 28.53 ± 4.97 35.28  下载: 导出CSV
下载: 导出CSV
表 2 运行时间对比
Table 2 Comparison of running time
算法 平均每帧运行时间(s) DVS-CM 206.85 DVS-LP 5.29 DAVIS-OF 0.52 EDI-HS 0.61 EDI-CLG 0.63
下载: 导出CSV
-
[1] Mitrokhin A, Fermüller C, Parameshwara C, Aloimonos Y. Event-based moving object detection and tracking. In: Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems. Madrid, Spain: IEEE, 2019. 1−9 [2] 江志军, 易华蓉. 一种基于图像金字塔光流的特征跟踪方法. 武汉大学学报·信息科学版, 2007, 32(8): 680-683.Jiang Zhi-Jun, Yi Hua-Rong. A feature tracking method based on image pyramid optical flow. Journal of Wuhan University·Information Science Edition, 2007, 32(8): 680-683. [3] Liu X, Zhao G, Yao J, et al. Background subtraction based on low-rank and structured sparse decomposition. IEEE Transactions on Image Processing, 2015, 24(8): 2502-2514. doi: 10.1109/TIP.2015.2419084 [4] 祝轩, 王磊, 张超, 等. 基于连续性约束背景模型减除的运动目标检测. 计算机科学, 2019(6): 317-321.Zhu Xuan, Wang Lei, Zhang Chao, et al. Moving object detection based on continuous constraint background model subtraction. Computer Science, 2019(6): 317-321. [5] Vidal A R, Rebecq H, Horstschaefer T, et al. Ultimate SLAM? Combining events, images, and IMU for robust visual SLAM in HDR and high speed scenarios. IEEE Robotics and Automation Letters, 2018, 3(2): 994-1001. doi: 10.1109/LRA.2018.2793357 [6] Leutenegger S, Lynen S, Bosse M, et al. Keyframe-based visual–inertial odometry using nonlinear optimization. The International Journal of Robotics Research, 2014, 34(3): 314-334. [7] Antink C H, Singh T, Singla P, et al. Advanced Lucas Kanada optical flow for deformable image registration. Journal of Critical Care, 2012, 27(3): e14-e14. [8] H Kostler, Ruhnau K, Wienands R. Multigrid solution of the optical flow system using a combined diffusion and curvature based regularizer. Numerical Linear Algebra with Applications, 2010, 15(2-3): 201-218. [9] Ishiyama H, Okatani T, Deguchi K. High-speed and high-precision optical flow detection for real-time motion segmentation. In: Proceedings of the SICE Annual Conference. Sapporo, Japan: IEEE, 2004. 1202−1205 [10] Horn B, Schunck B G. Determining optical flow. Artificial Intelligence, 1981, 17(1-3): 185-203. doi: 10.1016/0004-3702(81)90024-2 [11] Delbruck T. Neuromorophic vision sensing and processing. In: Proceedings of the 46th European Solid State Device Research Conference. Lausanne, Switzerland: IEEE, 2016. 7−14 [12] 马艳阳, 叶梓豪, 刘坤华, 等. 基于事件相机的定位与建图算法: 综述. 自动化学报, 2020, 46: 1-11.Ma Yan-Yang, Ye Zi-Hao, Liu Kun-Hua, et al. Location and mapping algorithms based on event cameras: a survey. Acta Automatica Sinica, 2020, 46: 1-11. [13] Hu Y, Liu S C, Delbruck T. V2E: From video frames to realistic DVS events. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops. New York, USA: IEEE, 2021. [14] Benosman R, Ieng S H, Clercq C, et al. Asynchronous frameless event-based optical flow. Neural Networks: the official journal of the International Neural Network Society, 2012, 27(3): 32-37. [15] Gallego G, Rebecq H, Scaramuzza D. A unifying contrast maximization framework for event cameras, with applications to motion, depth, and optical flow estimation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 3867−3876 [16] Benosman R, Clercq C, Lagorce X, et al. Event-based visual flow. IEEE Transactions on Neural Networks and Learning Systems, 2014, 25(2): 407-417. doi: 10.1109/TNNLS.2013.2273537 [17] 江盟, 刘舟, 余磊. 低维流形约束下的事件相机去噪算法. 信号处理, 2019, 35(10): 1753-1761.Jiang Meng, Liu Zhou, Yu Lei. Event camera denoising algorithm with low dimensional manifold constraints. Signal Processing, 2019, 35(10): 1753-1761. [18] Berner R, Brandli C, Yang M, Liu S C, Delbruck T. A 240 × 180 10 mW 12 us latency sparse-output vision sensor for mobile applications. In: Proceedings of the Symposium on VLSI Circuits. Kyoto, Japan: IEEE, 2013. 186−187 [19] Lichtsteiner P, Posch C, Delbruck T. A 128×128 120 dB 15 μs latency asynchronous temporal contrast vision sensor. IEEE Journal of Solid-State Circuits, 2008, 43(2): 566-576. doi: 10.1109/JSSC.2007.914337 [20] Son B, Suh Y, Kim S, Jung H, Ryu H. A 640 × 480 dynamic vision sensor with a 9 μm pixel and 300 Meps address-event representation. In: Proceedings of the IEEE International Solid-state Circuits Conference. San Francisco, USA: IEEE, 2017. 66−67 [21] Almatrafi M, Hirakawa K. DAViS camera optical flow. IEEE Transactions on Computational Imaging, 2020, 6: 396-407. doi: 10.1109/TCI.2019.2948787 [22] Lucas B D, Kanade T. An iterative image registration technique with an application to stereo vision. In: Proceedings of the International Joint Conference on Artificial Intelligence. San Francisco, USA: IEEE, 1981. 674−679 [23] Black M J, Anandan P. The robust estimation of multiple motions: parametric and piecewise smooth flow fields. Computer Vision and Image Understanding, 1996, 3(1): 75-104. [24] 黄波, 杨勇. 一种自适应的光流估计方法. 电路与系统学报, 2001, 6(4): 92-96.Huang Bo, Yang Yong. An adaptive optical flow estimation method. Journal of Circuits and Systems, 2001, 6(4): 92-96. [25] Fortun D, Bouthemy P, Kervrann C. Optical flow modeling and computation: A survey. Computer Vision and Image Understanding, 2015, 134: 1-21. doi: 10.1016/j.cviu.2015.02.008 [26] Gong D, Yang J, Liu L, Zhang Y, Shi Q. From motion blur to motion flow: A deep learning solution for removing heterogeneous motion blur. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017. 2319−2328 [27] Jin M G, Hu Z, Favaro P. Learning to extract flawless slow motion from blurry videos. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Los Angeles, USA: IEEE, 2019. 8112−8121 [28] Liu P D, Janai J, et al. Self-supervised linear motion deblurring. IEEE Robotics and Automation Letters, 2020, 5(2): 2475-2482. doi: 10.1109/LRA.2020.2972873 [29] Maqueda A I, Loquercio A, Gallego G, Garcia N, Scaramuzza D. Event-based vision meets deep learning on steering prediction for self-driving cars. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 5419−5427 [30] Yang G, Ye Q, He W, Zhou L, Li W. Live demonstration: Real-time VI-SLAM with high-resolution event camera. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops. Los Angeles, USA: IEEE, 2019. 1707− 1708 [31] Bodo R, Tobi D. Evaluation of event-based algorithms for optical flow with ground-truth from inertial measurement sensor. Frontiers in Neuroscience, 2016, 10: 176-192. [32] Tobias B, Stephan T, Heiko N. On event-based optical flow detection. Frontiers in Neuroscience, 2015, 9: 137-151. [33] Liu M, Delbruck T. Block-matching optical flow for dynamic vision sensors: Algorithm and FPGA implementation. In: Proceedings of the IEEE International Symposium on Circuits and Systems. Baltimore, USA: IEEE, 2017. 1−4 [34] Liu M, Delbruck T. ABMOF: A novel optical flow algorithm for dynamic vision sensors. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 1805−1815 [35] Barranco F, Fermuller C, Aloimonos Y. Bio-inspired motion estimation with event-driven sensors. In: Proceedings of the International Work Conference on Artificial Neural Networks. Palma de Mallorca, Spain: IEEE, 2015. 309−321 [36] Bardow P, Davison A J, Leutenegger S. Simultaneous optical flow and intensity estimation from an event camera. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016. 884−892 [37] Gehrig D, Rebecq H, Gallego G, Scaramuzza D. Asynchronous, photo-metric feature tracking using events and frames. In: Proceedings of the Computer Vision. Munich, Germany: IEEE, 2018. 601−618 [38] Pan L, Scheerlinck C, Yu X, Hartley R, Dai Y. Bringing a blurry frame alive at high frame-rate with an event camera. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Los Angeles, USA: IEEE, 2019. 6813−6822 [39] Pan L, Liu M, Hartley R. Single image optical flow estimation with an event camera. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2020. 1669−1678 [40] Baker S, Matthews I. Lucas-Kanade 20 years on: A unifying framework. International Journal of Computer Vision, 2004, 56(3): 221-255. doi: 10.1023/B:VISI.0000011205.11775.fd [41] Bruhn A, Weickert J, Schnorr C. Lucas/Kanade meets Horn/Schunck: Combining local and global optic flow methods. International Journal of Computer Vision, 2005, 61(3): 211-231. [42] Niklaus S, Long M, Liu F. Video frame interpolation via adaptive separable convolution. In: Proceedings of the IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 261−270 -

 下载:
下载:

计量
- 文章访问数: 2597
- HTML全文浏览量: 1841
- PDF下载量: 401
- 被引次数: 0
