

-
摘要: 动态多目标优化问题(Dynamic multi-objective optimization problems, DMOPs)的目标函数发生变化时, 需要采取变化响应策略对种群进行重新初始化, 以快速追踪新环境中的最优解集. 现有动态多目标优化算法对不同个体、不同维度的决策变量缺乏针对性的变化响应, 导致重新初始化效果尚存在较大改进空间. 为此, 提出一种对不同个体、不同维度的决策变量分别进行自适应变化响应的动态多目标进化算法(Dynamic multi-objective evolutionary algorithm with adaptive change response, DMOEA-ACR). 该算法包括两个核心部分: 1)对$t $时间步最优种群和$t-1 $时间步最优种群中对应个体各维度决策变量之间的差异进行计算, 自适应选择变异策略或预测策略重新初始化不同个体、不同维度的决策变量; 2)在每轮迭代或重新初始化后, 对非支配个体进行存档, 基于存档中心构建预测策略. 为验证DMOEA-ACR的有效性, 在最新测试问题集SDP和DF上, 将其与动态多目标优化领域的6种先进算法进行对比. 实验结果表明, DMOEA-ACR在求解动态多目标优化问题时, 具有明显优势.Abstract: When the objective functions of dynamic multi-objective optimization problems (DMOPs) change, it is necessary to adopt a correspondent response strategy to reinitialize the population so that an optimal solution set in the new environment can be quickly tracked. The reinitialization effect of existing dynamic multi-objective optimization algorithms still leaves much room for improvement due to the lack of customized change response to different decision variables of different individuals. This paper proposes a dynamic multi-objective evolutionary algorithm with adaptive change response (DMOEA-ACR), which can adaptively reinitialize different decision variables of different individuals. DMOEA-ACR consists of two essential components. One is the adaptive change response strategy, which can adaptively choose the mutation strategy or the prediction strategy to reinitialize different decision variables of different individuals based on the correspondent decision variable difference between the t time step optimal population and the $t-1 $ time step optimal population. The other is the prediction strategy based on the archive core of non-dominant individuals. In order to verify its effectiveness, DMOEA-ACR is compared with six state-of-the-art algorithms in dynamic multi-objective optimization on the latest test suites SDP and DF. The experimental results show that DMOEA-ACR has obvious advantages in solving dynamic multi-objective optimization problems.
-
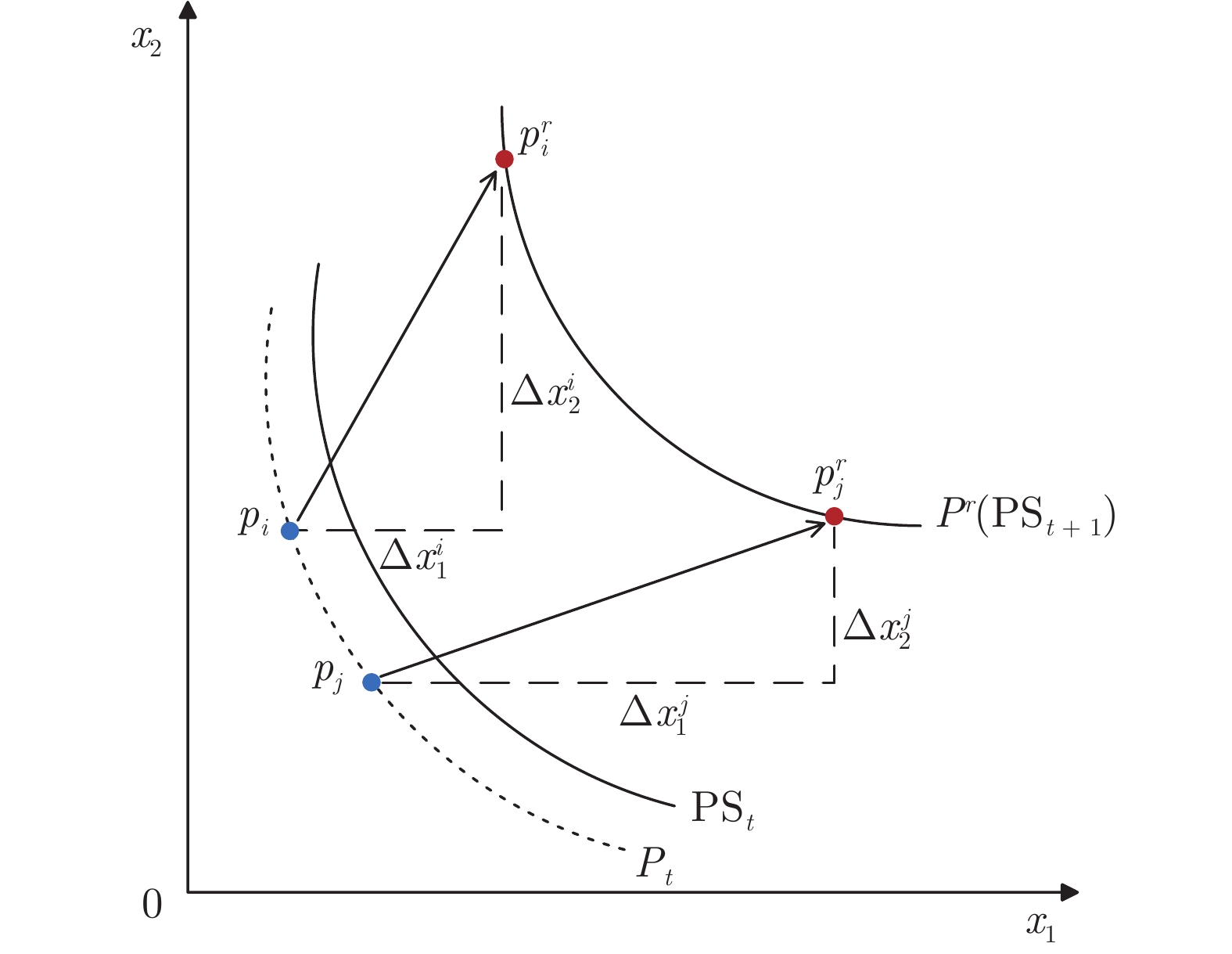
图 1 二维决策空间最理想情形下的重新初始化示意图
Fig. 1 Reinitialization illustration of the most ideal situation in 2D decision space
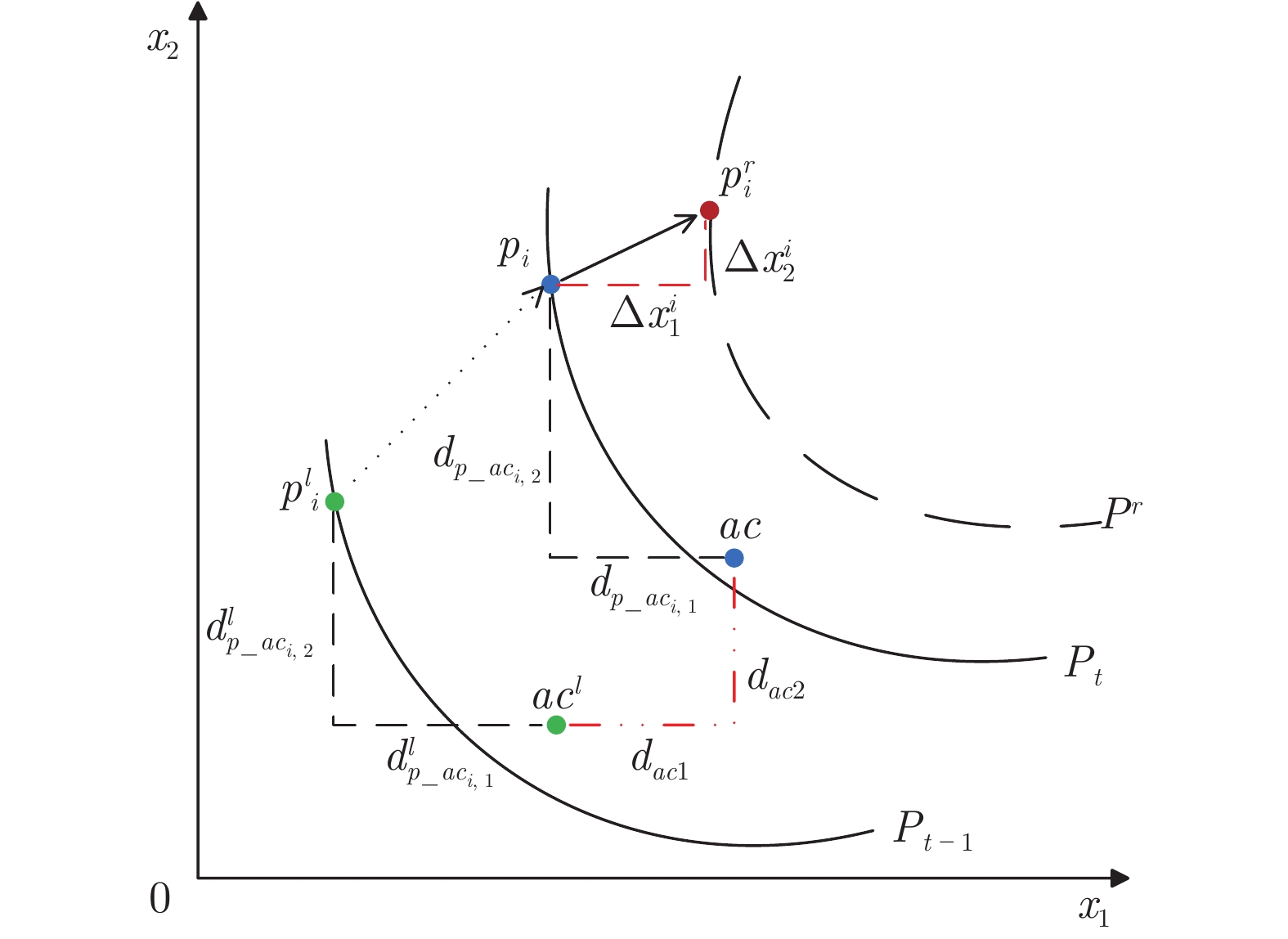
图 3 基于存档中心进行预测策略示意图
Fig. 3 Illustration of prediction strategy based on the central of archive
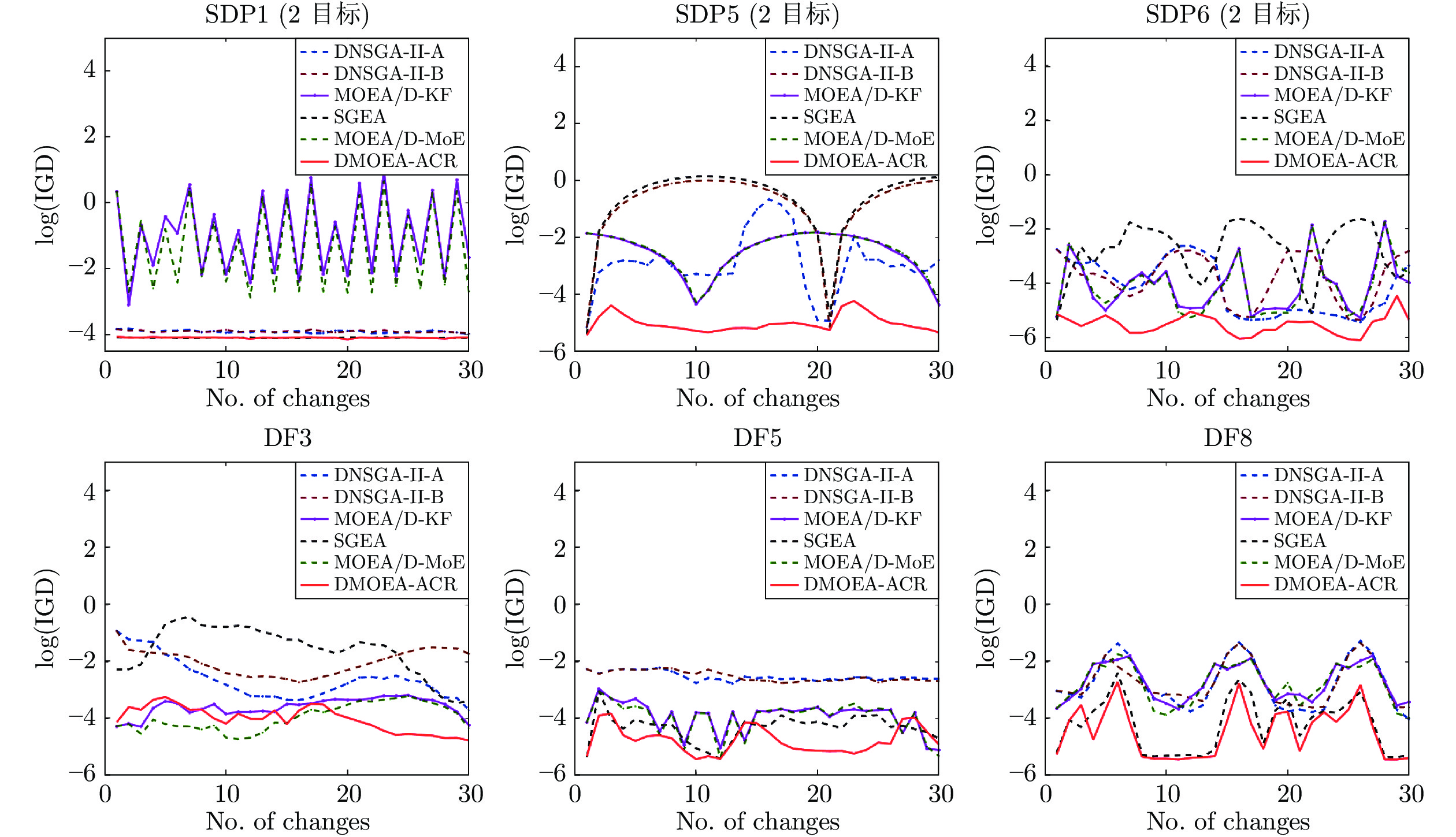
图 4 DNSGA-II-A、DNSGA-II-B、MOEA/D-KF、SGEA、MOEA/D-MoE和DMOEA-ACR在SDP1、SDP5、SDP6、DF3、DF5、DF8测试问题集上的log(IGD)均值变化比较
Fig. 4 Comparison of average log(IGD) trends of DNSGA-II-A, DNSGA-II-B, MOEA/D-KF, SGEA, MOEA/D-MoE, and DMOEA-ACR on SDP1, SDP5, SDP6, DF3, DF5, DF8

图 5 DNSGA-II-A、DNSGA-II-B、MOEA/D-KF和SGEA在SDP1、SDP6、DF3、DF8测试问题集上得到的PF图
Fig. 5 PF graph obtained by DNSGA-II-A, DNSGA-II-B, MOEA/D-KF, and SGEA on SDP1, SDP6, DF3, DF8

图 6 Tr-DMOEA、MOEA/D-MoE和DMOEA-ACR在SDP1、SDP6、DF3、DF8测试问题集上得到的PF图
Fig. 6 PF graph obtained by Tr-DMOEA, MOEA/D-MoE, and DMOEA-ACR on SDP1, SDP6, DF3, DF8
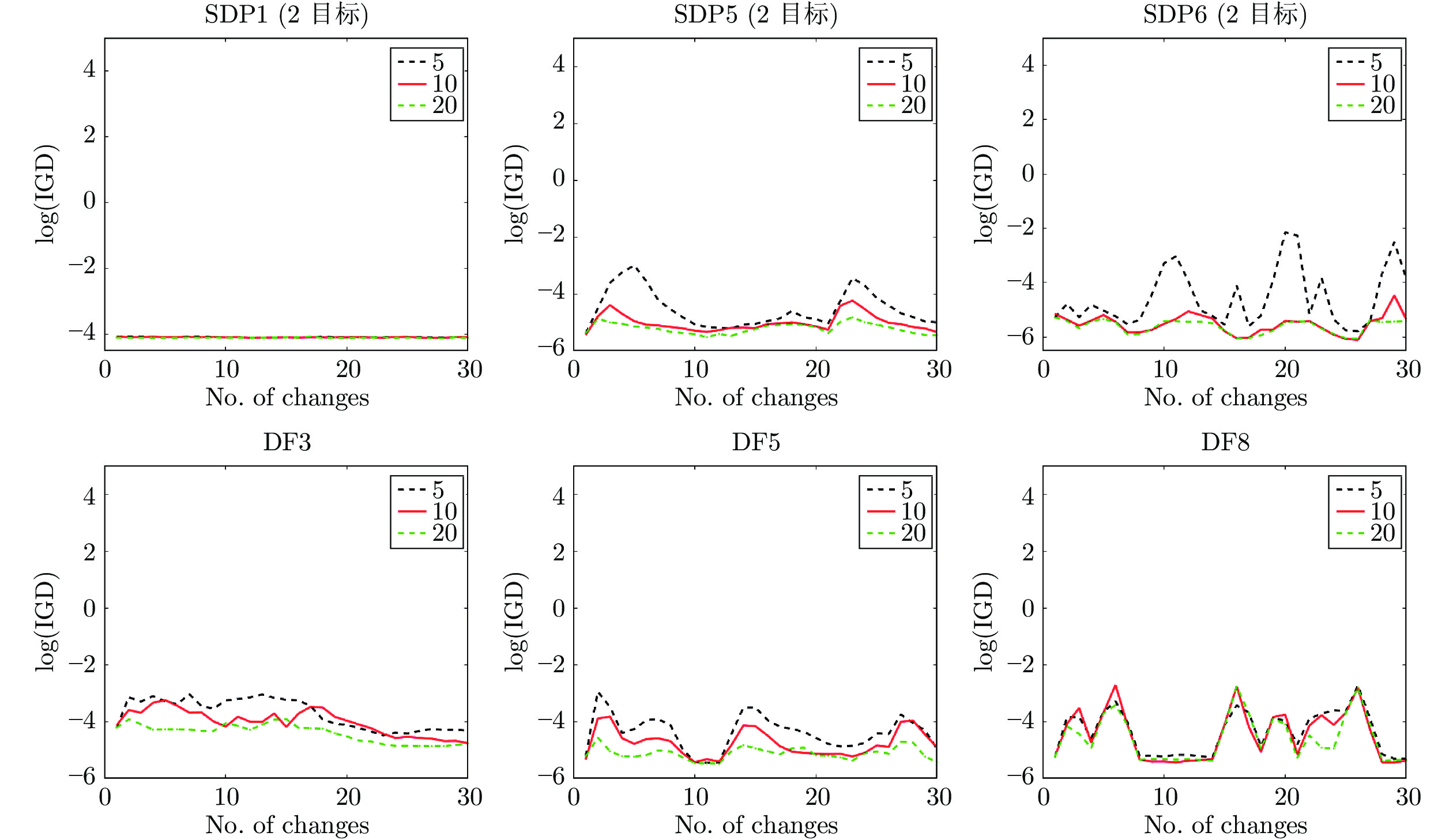
图 7 $ \tau t $分别为5、10、20时DMOEA-ACR在SDP1 (2目标)、SDP5 (2目标)、SDP6 (2目标)、DF3、DF5和DF8问题上的log(IGD)均值变化比较
Fig. 7 Comparison of average log(IGD) trends of DMOEA-ACR on SDP1 (2 goals), SDP5 (2 goals), SDP6 (2 goals), DF3, DF5, and DF8 where $\tau_t $ is 5, 10, 20, respectively
表 1 DNSGA-II-A、DNSGA-II-B、MOEA/D-KF、SGEA、Tr-DMOEA、MOEA/D-MoE和DMOEA-ACR在SDP上获得的MIGD均值和标准差
Table 1 The mean and standard deviation of MIGD of DNSGA-II-A, DNSGA-II-B, MOEA/D-KF, SGEA, Tr-DMOEA, MOEA/D-MoE, and DMOEA-ACR were obtained on SDP
问题集 评价指标 DNSGA-II-A DNSGA-II-B MOEA/D-KF SGEA Tr-DMOEA MOEA/D-MoE DMOEA-ACR SDP1 (2目标)
SDP1 (3目标)均值
标准差2.03 × 10−2
6.73 × 10−3 (−)2.01 × 10−2
5.34 × 10−3 (−)6.69 × 10−1
2.61 × 10−3 (−)1.66 × 10−2
5.12 × 10−3 (≈)2.53 × 10−1
2.65 × 10−2 (−)5.78 × 10−1
3.13 × 10−4 (−)1.65 × 10−2
3.67 × 10−3均值
标准差2.26 × 10−1
3.02 × 10−3 (−)2.32 × 10−1
6.78 × 10−3 (−)7.74 × 10−1
6.35 × 10−3 (−)1.40 × 10−1
4.74 × 10−3 (−)1.44 × 10−1
7.32 × 10−2 (−)7.46 × 10−1
2.14 × 10−3) (−)1.32 × 10−1
5.44 × 10−3SDP2 (2目标)
SDP2 (3目标)均值
标准差1.75 × 10−2
7.58 × 10−3 (+)1.74 × 10−2
7.05 × 10−3 (+)4.38 × 10−2
4.34 × 10−3 (+)1.00 × 100
3.17 × 10−3 (−)4.93 × 100
5.43 × 10−1 (−)3.23 × 10−2
8.38 × 10−3 (+)1.14 × 10−1
4.35 × 10−3均值
标准差2.87 × 10−1
7.18 × 10−3 (−)3.60 × 10−1
8.31 × 10−3 (−)3.36 × 10−1
7.67 × 10−4 (−)9.23 × 10−1
1.59 × 10−2 (−)4.80 × 10−1
6.61 × 10−2 (−)3.34 × 10−1
1.39 × 10−3 (−)2.42 × 10−1
7.12 × 10−3SDP3 (2目标)
SDP3 (3目标)均值
标准差1.76 × 100
6.74× 10−2 (+)1.81 × 10−1
3.97 × 10−2) (+)6.37 × 10−2
4.18 × 10−3 (+)2.07 × 10−1
2.04 × 10−3 (+)1.45 × 10+1
3.41 × 10−1 (+)4.58 × 10−1
1.30 × 10−3 (+)4.74 × 100
6.38 × 10−2均值
标准差7.01 × 100
8.34 × 10−2 (−)8.51 × 100
7.37 × 10−2 (−)8.54 × 10−1
1.43 × 10−2 (+)3.74 × 10−1
3.55 × 10−3 (+)2.36 × 10−1
3.67 × 10−2 (+)5.47 × 10−1
4.42 × 10−3 (+)3.33 × 100
8.53 × 10−2SDP4 (2目标)
SDP4 (3目标)均值
标准差1.14 × 10−1
6.19 × 10−3 (−)7.86 × 10−2
3.07 × 10−2 (−)5.63 × 10−2
1.01 × 10−3 (−)5.56 × 10−2
4.76 × 10−3 (−)3.65 × 100
4.09 × 10−1 (−)5.54 × 10−2
3.61 × 10−3 (−)5.08 × 10−2
5.03 × 10−3均值
标准差2.44 × 10−1
5.08 × 10−3 (−)2.26 × 10−1
7.48 × 10−2 (−)1.81 × 10−1
3.28 × 10−3 (−)1.95 × 10−1
2.43 × 10−3 (−)1.74 × 10−1
5.48 × 10−2 (−)1.79 × 10−1
2.71 × 10−2 (−)1.69 × 10−1
8.25 × 10−3SDP5 (2目标)
SDP5 (3目标)均值
标准差9.40 × 10−2
4.21 × 10−3 (−)6.27 × 10−1
8.05 × 10−3) (−)9.74 × 10−2
4.07 × 10−3 (−)7.19 × 10−1
2.79 × 10−2 (−)8.35 × 10−1
7.87 × 10−3 (−)9.86 × 10−2
4.37 × 10−4 (−)6.81 × 10−3
4.92 × 10−4均值
标准差1.41 × 10−1
6.08 × 10−2 (−)5.24 × 10−1
3.43 × 10−2 (−)1.54 × 10−1
7.81 × 10−3 (−)8.68 × 10−2
7.15 × 10−3 (−)1.46 × 10−1
6.43 × 10−2 (−)1.50 × 10−1
7.61 × 10−3 (−)6.38 × 10−2
6.06 ×10−3SDP6 (2目标)
SDP6 (3目标)均值
标准差2.47 × 10−2
1.53 × 10−3 (−)3.14 × 10−2
5.92 × 10−3 (−)2.45 × 10−2
3.69 × 10−3 (−)8.56 × 10−2
2.72 × 10−3 (−)4.28 × 10−1
5.97 × 10−3 (−)2.41 × 10−2
5.81 × 10−3 (−)4.26 × 10−3
7.43 × 10−4均值
标准差1.61 × 10−1
6.44 × 10−2 (−)1.79 × 10−1
6.45 × 10−2 (−)1.03 × 10−1
6.61 × 10−3 (−)5.38 × 10−2
6.05 × 10−3 (−)6.60 × 10−1
6.06 × 10−3 (−)5.33 × 10−2
3.86 × 10−2 (−)5.17 × 10−2
5.86 × 10−3SDP7 (2目标)
SDP7 (3目标)均值
标准差5.15 × 10−2
2.46 × 10−3 (+)2.96 × 10−2
7.28 × 10−3 (+)3.49 × 10−1
3.54 × 10−3 (−)2.67 × 10−1
6.73 × 10−3 (−)8.12 × 10−1
3.78 × 10−3 (−)3.11 × 10−1
6.65 × 10−3 (−)2.15 × 10−1
1.68 × 10−2均值
标准差2.41 × 10−1
3.12 × 10−3 (−)2.87 × 10−1
8.30 × 10−2 (−)3.76 × 10−1
5.71 × 10−3 (−)2.59 × 10−1
2.72 × 10−2 (−)3.71 × 10−1
4.97 × 10−2 (−)3.55 × 10−1
8.36 × 10−2 (−)2.24 × 10−1
5.11 × 10−3SDP8 (2目标)
SDP8 (3目标)均值
标准差1.40 × 10−1
6.12 × 10−2 (−)1.56 × 10−1
6.91 × 10−3 (−)1.15 × 10−1
1.31 × 10−3 (−)1.27 × 10−1
4.95 × 10−3 (−)2.77 × 10−1
5.62 × 10−2 (−)1.07 × 10−1
1.63 × 10−3 (−)3.14 × 10−2
4.26 × 10−3均值
标准差3.45 × 10−1
8.76 × 10−2 (−)2.97 × 10−1
3.58 × 10−3 (−)1.36 × 10−1
4.87 × 10−3 (−)1.21 × 10−1
6.82 × 10−3 (+)1.39 × 10−1
9.61 × 10−2 (−)1.03 × 10−1
4.73 × 10−3 (+)1.29 × 10−1
6.43 × 10−3SDP9 (2目标)
SDP9 (3目标)均值
标准差8.95 × 10−2
7.09 × 10−3 (−)6.67 × 10−1
5.94 × 10−3 (−)1.64 × 10−1
8.52 × 10−4 (−)2.45 × 10−1
2.06 × 10−3 (−)1.35 × 10−1
3.25 × 10−2 (−)1.56 × 10−1
6.23 × 10−3 (−)8.13 × 10−2
7.92 × 10−3均值
标准差4.01 × 10−1
8.98 × 10−3 (−)3.67 × 10−1
4.08 × 10−3 (−)4.93 × 10−1
6.03 × 10−3 (−)3.61 × 10−1
3.74 × 10−2 (≈)4.28 × 10−1
4.56 × 10−2 (−)4.45 × 10−1
9.13 × 10−3 (−)3.60 × 10−1
8.03 × 10−2SDP10 (2目标)
SDP10 (3目标)均值
标准差8.67 × 10−2
7.72 × 10−2 (−)1.15 × 10−1
8.31 × 10−2 (−)9.39 × 10−2
4.94 × 10−3 (−)2.23 × 10−1
1.75 × 10−2 (≈)2.35 × 100
3.74 × 10−1 (−)9.19 × 10−2
7.02 × 10−4 (−)2.21 × 10−2
1.67 × 10−3均值
标准差3.05 × 10−1
5.73 × 10−2 (−)2.56 × 10−1
9.76 × 10−2 (−)1.85 × 10−1
6.51 × 10−3 (−)4.51 × 10−1
8.06 × 10−2 (−)3.48 × 10−1
7.43 × 10−2 (−)1.79 × 10−1
3.63 × 10−3 (−)1.74 × 10−1
3.58 × 10−3SDP11 (2目标)
SDP11 (3目标)均值
标准差1.61 × 10−2
6.36 × 10−3 (−)7.40 × 10−3
7.67 × 10−4 (+)3.02 × 10−2
3.14 × 10−3 (−)3.36 × 10−2
6.91 × 10−3 (−)9.18 × 10−1
3.64 × 10−3 (−)2.43 × 10−2
3.26 × 10−3 (−)1.36 × 10−2
8.16 × 10−3均值
标准差1.49 × 10−1
7.48 × 10−3 (−)1.23 × 10−1
5.98 × 10−2 (−)9.77 × 10−2
2.81 × 10−2 (−)1.47 × 10−1
1.08 × 10−2 (−)8.98 × 10−2
6.05 × 10−3 (−)9.57 × 10−2
5.15 × 10−3 (−)8.77 × 10−2
9.65 × 10−3SDP12 (2目标)
SDP12 (3目标)均值
标准差2.20 × 10−2
4.03 × 10−3 (−)2.52 × 10−2
3.08 × 10−3 (−)9.16 × 10−3
2.78 × 10−3 (−)4.11 × 10−3
5.38 × 10−2 (−)8.09 × 10−2
4.65 × 10−2 (−)6.38 × 10−3
8.83 × 10−4 (−)4.04 × 10−3
2.17 × 10−4均值
标准差2.22 × 10−1
8.66 × 10−2 (−)2.15 × 10−1
6.79 × 10−2 (−)8.66 × 10−2
3.59 × 10−3 (−)9.97 × 10−2
7.02 × 10−2 (−)7.66 × 10−2
6.93 × 10−2 (−)8.13 × 10−2
4.16 × 10−3 (−)7.63 × 10−2
5.63 × 10−4“+/−/≈”合计 3/21/0 4/20/0 3/21/0 3/18/3 2/22/0 4/20/0  下载: 导出CSV
下载: 导出CSV
表 2 DNSGA-II-A、DNSGA-II-B、MOEA/D-KF、SGEA、Tr-DMOEA、MOEA/D-MoE和DMOEA-ACR在DF上获得的MIGD均值和标准差
Table 2 The mean and standard deviation of MIGD of DNSGA-II-A, DNSGA-II-B, MOEA/D-KF, SGEA, Tr-DMOEA, MOEA/D-MoE, and DMOEA-ACR were obtained on DF
问题集 评价指标 DNSGA-II-A DNSGA-II-B MOEA/D-KF SGEA Tr-DMOEA MOEA/D-MoE DMOEA-ACR DF1 (2目标) 均值
标准差3.31 × 10−2
8.35 × 10−3 (−)4.24 × 10−2
3.91 × 10−3 (−)1.85 × 10−2
4.47 × 10−3 (−)1.22 × 10−2
1.38 × 10−3 (−)6.42 × 10−2
3.34 × 10−3 (−)1.54 × 10−2
3.97 × 10−3 (−)9.15 × 10−3
3.67 × 10−3DF2 (2目标) 均值
标准差5.75 × 10−3
7.61 × 10−4 (+)5.76 × 10−3
2.08 × 10−4 (+)3.81 × 10−2
5.02 × 10−3 (+)1.22 × 10−1
2.76 × 10−2 (−)5.46 × 10−3
5.21 × 10−3 (+)3.10 × 10−2
5.23 × 10−3 (+)5.80 × 10−2
7.85 × 10−3DF3 (2目标) 均值
标准差9.48 × 10−2
5.32 × 10−3 (−)1.48 × 10−1
7.35 × 10−3 (−)2.85 × 10−2
3.32 × 10−3 (−)2.61 × 10−1
4.58 × 10−2 (−)3.90 × 10−1
7.31 × 10−3 (−)2.10 × 10−2
7.52 × 10−3 (−)1.99 × 10−2
3.20 × 10−3DF4 (2目标) 均值
标准差2.78 × 10−1
7.38 × 10−2 (−)3.81 × 10−1
2.79 × 10−2 (−)9.85 × 10−2
4.59 × 10−3 (−)5.56 × 10−2
7.88 × 10−3 (−)8.67 × 10−1
6.82 × 10−2 (−)9.09 × 10−2
2.81 × 10−3 (−)2.89 × 10−2
5.19 × 10−3DF5 (2目标) 均值
标准差8.05 × 10−2
6.39 × 10−2 (−)8.11 × 10−2
5.65 × 10−3 (−)2.20 × 10−2
4.03 × 10−3 (−)1.45 × 10−2
4.31 × 10−3 (−)2.99 × 10−2
4.34 × 10−3 (−)2.13 × 10−2
1.24 × 10−3 (−)9.32 × 10−3
6.01 × 10−4DF6 (2目标) 均值
标准差2.33 × 10−1
8.01 × 10−3 (+)2.40 × 10−1
8.18 × 10−3 (+)5.04 × 100
9.92 × 10−2 (−)1.51 × 100
8.39 × 10−2 (−)5.32 × 100
7.31 × 10−1 (−)2.98 × 100
7.68 × 10−1 (−)1.14 × 100
4.23 × 10−1DF7 (2目标) 均值
标准差1.56 × 10−2
4.33 × 10−3 (≈)1.85 × 10−2
6.02 × 10−3 (−)3.66 × 10−2
6.39 × 10−3 (−)2.08 × 10−1
5.04 × 10−3 (−)6.54 × 100
5.37 × 10−1 (−)3.72 × 10−2
2.29 × 10−3 (−)1.57 × 10−2
3.67 × 10−3DF8 (2目标) 均值
标准差8.82 × 10−2
7.13 × 10−2 (−)8.17 × 10−2
7.14 × 10−3 (−)7.94 × 10−2
3.68 × 10−3 (−)2.07 × 10−2
5.98 × 10−3 (−)2.85 × 10−1
6.81 × 10−2 (−)7.73 × 10−2
6.64 × 10−3 (−)1.70 × 10−2
5.68 × 10−3DF9 (2目标) 均值
标准差7.82 × 10−2
9.75 × 10−3 (−)8.69 × 10−2
9.98 × 10−3 (−)9.52 × 10−2
7.87 × 10−3 (−)2.57 × 10−1
6.30 × 10−2 (−)5.33 × 10−1
2.76 × 10−2 (−)7.09 × 10−2
5.31 × 10−2 (−)6.87 × 10−2
4.97 × 10−3DF10 (3目标) 均值
标准差2.88 × 10−1
8.10 × 10−3 (−)2.76 × 10−1
6.31 × 10−3 (−)1.80 × 10−1
3.51 × 10−2 (−)1.19 × 10−1
5.26 × 10−2 (−)8.51 × 10−1
8.61 × 10−2 (−)1.86 × 10−1
2.21 × 10−2 (−)1.05 × 10−1
8.18 × 10−2DF11 (3目标) 均值
标准差5.77 × 10−1
7.57 × 10−2 (−)5.80 × 10−1
3.59 × 10−3 (−)1.53 × 10−1
4.06 × 10−2) (−)8.20 × 10−2
3.14 × 10−2 (−)6.53 × 10−2
4.05 × 10−2 (−)1.50 × 10−1
(3.72 × 10−3) (−)6.38 × 10−2
5.07 × 10−3DF12 (3目标) 均值
标准差2.18 × 10−1
8.61 × 10−2 (−)2.34 × 10−1
2.36 × 10−2 (−)1.41 × 10−1
3.38 × 10−2 (−)1.47 × 10−1
2.78 × 10−2 (−)4.25 × 10−1
7.63 × 10−3 (−)1.00 × 10−1
6.98 × 10−2 (−)9.49 × 10−2
6.53 × 10−3DF13 (3目标) 均值
标准差1.80 × 10−1
5.32 × 10−2 (−)1.87 × 10−1
8.95 × 10−2 (−)2.79 × 10−1
5.72 × 10−2 (−)1.28 × 10−1
6.52 × 10−2 (−)1.37 × 100
2.71 × 10−1 (−)2.68 × 10−1
1.25 × 10−2 (−)1.15 × 10−1
4.38 × 10−2DF14 (3目标) 均值
标准差1.35 × 10−1
5.31 × 10−2 (−)1.22 × 10−1
4.32 × 10−2 (−)6.91 × 10−2
3.31 × 10−2 (−)5.19 × 10−2
4.06 × 10−2 (−)1.15 × 100
3.59 × 10−2 (−)6.88 × 10−2
5.81 × 10−2 (−)4.28 × 10−2
5.56 × 10−3“+/−/≈”合计 2/11/1 2/12/0 1/13/0 0/14/0 1/13/0 1/13/0
下载: 导出CSV
表 3 DNSGA-II-A、DNSGA-II-B、MOEA/D-KF、SGEA、Tr-DMOEA、MOEA/D-MoE和DMOEA-ACR在SDP (包括2目标和3目标)上的性能综合排名
Table 3 Performance comprehensive ranking of DNSGA-II-A, DNSGA-II-B, MOEA/D-KF, SGEA, Tr-DMOEA, MOEA/D-MoE, and DMOEA-ACR on SDP (including 2 goals and 3 goals)
算法 SDP1 SDP2 SDP3 SDP4 SDP5 SDP6 SDP7 SDP8 SDP9 SDP10 SDP11 SDP12 平均
排序DNSGA-II-A 3 1 7 7 2 5 2 6 2 4 5 7 4 DNSGA-II-B 4 3 4 6 7 6 3 5 5 5 2 6 6 MOEA/D-KF 7 5 1 4 5 3 6 4 7 3 4 4 5 SGEA 2 6 2 3 3 4 4 3 4 6 7 3 3 Tr-DMOEA 5 7 5 5 6 7 7 7 3 7 6 5 7 MOEA/D-MoE 6 4 3 2 4 2 5 1 6 2 3 2 2 DMOEA-ACR 1 2 6 1 1 1 1 2 1 1 1 1 1
下载: 导出CSV
表 4 DNSGA-II-A、DNSGA-II-B、MOEA/D-KF、SGEA、Tr-DMOEA、MOEA/D-MoE和DMOEA-ACR在DF的性能综合排名
Table 4 Performance comprehensive ranking of DNSGA-II-A, DNSGA-II-B, MOEA/D-KF, SGEA, Tr-DMOEA, MOEA/D-MoE, and DMOEA-ACR algorithms on DF
算法 DF1 DF2 DF3 DF4 DF5 DF6 DF7 DF8 DF9 DF10 DF11 DF12 DF13 DF14 平均
排序DNSGA-II-A 5 2 4 5 6 1 1 6 3 6 6 5 3 6 4 DNSGA-II-B 6 3 5 6 7 2 3 5 4 5 7 6 4 5 6 MOEA/D-KF 4 5 3 4 4 6 4 4 5 3 5 3 6 4 5 SGEA 2 7 6 2 2 4 6 2 6 2 3 4 2 2 3 Tr-DMOEA 7 1 7 7 5 7 7 7 7 7 2 7 7 7 7 MOEA/D-MoE 3 4 2 3 3 5 5 3 2 4 4 2 5 3 2 DMOEA-ACR 1 6 1 1 1 3 2 1 1 1 1 1 1 1 1
下载: 导出CSV
表 5 DMOEA-ACR-D1、DMOEA-ACR-D2、DMOEA-ACR-D3和DMOEA-ACR在DF上获得的MIGD均值和标准差
Table 5 The mean and standard deviation of MIGD of DMOEA-ACR-D1, DMOEA-ACR-D2, DMOEA-ACR-D3, and DMOEA-ACR were obtained on DF
问题集 评价指标 DMOEA-ACR-D1 DMOEA-ACR-D2 DMOEA-ACR-D3 DMOEA-ACR DF1 (2目标) 均值
标准差1.99 × 10−2
1.62 × 10−2 (−)2.58 × 10−2
1.51 × 10−2 (−)1.50 × 10−2
4.12 × 10−3 (−)9.15 × 10−3
3.67 × 10−3DF2 (2目标) 均值
标准差1.22 × 10−1
7.57 × 10−3 (−)2.54 × 10−2
4.08 × 10−3 (+)5.93 × 10−2
4.18 × 10−2 (−)5.80 × 10−2
7.85 × 10−3DF3 (2目标) 均值
标准差1.99 × 10−1
2.61 × 10−3 (−)2.33 × 10−1
4.52 × 10−3 (−)4.44 × 10−2
1.04 × 10−3 (−)1.99 × 10−2
3.20 × 10−3DF4 (2目标) 均值
标准差5.28 × 10−2
7.05 × 10−3 (−)2.70 × 10−2
6.82 × 10−3 (+)4.17 × 10−2
5.17 × 10−3 (−)2.89 × 10−2
5.19 × 10−3DF5 (2目标) 均值
标准差1.74 × 10−2
6.41 × 10−3 (−)5.05 × 10−2
3.69 × 10−3 (−)2.09 × 10−2
3.65 × 10−4 (−)9.32 × 10−3
6.01 × 10−4DF6 (2目标) 均值
标准差2.88 × 100
8.39 × 10−1 (−)6.44 × 100
5.07 × 10−1 (−)1.23 × 100
7.47 × 10−1 (−)1.14 × 100
4.23 × 10−1DF7 (2目标) 均值
标准差1.85 × 10−1
2.66 × 10−3 (−)1.42 × 10−2
7.06 × 10−3 (+)1.99 × 10−2
2.61 × 10−3 (−)1.57 × 10−2
3.67 × 10−3DF8 (2目标) 均值
标准差1.65 × 10−2
7.09 × 10−3 (+)1.56 × 10−2
5.13 × 10−3 (+)1.91 × 10−2
6.05 × 10−3 (−)1.70 × 10−2
5.68 × 10−3DF9 (2目标) 均值
标准差4.15 × 10−1
4.72 × 10−2 (−)1.21 × 10−1
4.81 × 10−3 (−)1.11 × 10−1
5.82 × 10−3 (−)6.87 × 10−2
4.97 × 10−3DF10 (3目标) 均值
标准差3.01 × 10−1
5.11 × 10−2 (−)1.48 × 10−1
1.42 × 10−2 (−)2.43 × 10−1
3.47 × 10−2 (−)1.05 × 10−1
8.18 × 10−2DF11 (3目标) 均值
标准差6.65 × 10−2
5.31 × 10−3 (−)7.76 × 10−2
6.37 × 10−3 (−)6.85 × 10−2
4.21 × 10−3 (−)6.38 × 10−2
5.07 × 10−3DF12 (3目标) 均值
标准差2.24 × 10−1
6.99 × 10−2 (−)2.62 × 10−1
8.70 × 10−2 (−)1.84 × 10−1
7.17 × 10−2 (−)9.49 × 10−2
6.53 × 10−3DF13 (3目标) 均值
标准差2.36 × 10−1
5.77 × 10−2 (−)1.62 × 10−1
3.91 × 10−2 (−)1.36 × 10−1
5.32 × 10−2 (−)1.15 × 10−1
4.38 × 10−2DF14 (3目标) 均值
标准差7.19 × 10−2
9.54 × 10−3 (−)6.25 × 10−2
4.32 × 10−3 (−)5.29 × 10−2
8.02 × 10−3 (−)4.28 × 10−2
5.56 × 10−3“+/−/≈”合计 1/13/0 4/10/0 0/14/0
下载: 导出CSV
表 6 DMOEA-ACR-D1、DMOEA-ACR-D2、DMOEA-ACR-D3和DMOEA-ACR在SDP上获得的MIGD均值和标准差
Table 6 The mean and standard deviation of MIGD of DMOEA-ACR-D1, DMOEA-ACR-D2, DMOEA-ACR-D3, and DMOEA-ACR were obtained on SDP
问题集 评价指标 DMOEA-ACR-D1 DMOEA-ACR-D2 DMOEA-ACR-D3 DMOEA-ACR SDP1 (2目标)
SDP1 (3目标)均值
标准差2.51 × 10−2
4.25 × 10−3 (−)1.78 × 10−2
3.03 × 10−3 (−)1.67 × 10−2
5.12 × 10−3 (≈)1.65 × 10−2
3.67 × 10−3均值
标准差1.68 × 10−1
5.34 × 10−2 (−)1.54 × 10−1
4.31 × 10−2 (−)1.41 × 10−1
4.08 × 10−2 (−)1.32 × 10−1
5.44 × 10−3SDP2 (2目标)
SDP2 (3目标)均值
标准差6.47 × 10−1
2.27 × 10−2 (−)1.12 × 10−1
6.26 × 10−2 (≈)2.15 × 10−1
3.38 × 10−2 (−)1.14 × 10−1
4.35 × 10−3均值
标准差4.05 × 10−1
3.15 × 10−2 (−)3.94 × 10−1
7.58 × 10−2 (−)5.64 × 10−1
4.15 × 10−2 (−)2.42 × 10−1
7.12 × 10−3SDP3 (2目标)
SDP3 (3目标)均值
标准差8.91 × 100
6.55 × 10−1 (−)4.81 × 100
1.06 × 10−2 (−)4.99 × 100
7.21 × 10−1 (−)4.74 × 100
6.38 × 10−2均值
标准差3.91 × 100
7.60 × 10−1 (−)4.40 × 100
4.96 × 10−1 (−)4.47 × 100
6.06 × 10−1 (−)3.33 × 100
8.53 × 10−2SDP4 (2目标)
SDP4 (3目标)均值
标准差6.96 × 10−2
6.16 × 10−3 (−)7.85 × 10−2
6.31 × 10−2 (−)1.60 × 10−1
5.51 × 10−2 (−)5.08 × 10−2
5.03 × 10−3均值
标准差2.10 × 10−1
4.01 × 10−2 (−)2.68 × 10−1
3.07 × 10−2 (−)1.89 × 10−1
4.19 × 10−2 (−)1.69 × 10−1
8.25 × 10−3SDP5 (2目标)
SDP5 (3目标)均值
标准差7.76 × 10−2
6.63 × 10−3 (−)7.40 × 10−3
2.25 × 10−3 (−)9.52 × 10−3
5.12 × 10−3 (−)6.81 × 10−3
4.92 × 10−4均值
标准差6.85 × 10−2
9.08 × 10−3 (−)6.71 × 10−2
6.91 × 10−3 (−)7.26 × 10−2
7.61 × 10−3 (−)6.38 × 10−2
6.06 × 10−3SDP6 (2目标)
SDP6 (3目标)均值
标准差7.98 × 10−3
4.37 × 10−3 (−)6.84 × 10−3
4.66 × 10−3 (−)6.83 × 10−3
2.03 × 10−3 (−)4.26 × 10−3
7.43 × 10−4均值
标准差6.05 × 10−2
8.12 × 10−3 (−)1.16 × 10−1
3.30 × 10−3 (−)5.14 × 10−2
4.60 × 10−3 (+)5.17 × 10−2
5.86 × 10−3SDP7 (2目标)
SDP7 (3目标)均值
标准差2.70 × 10−1
5.59 × 10−2 (−)2.34 × 10−1
7.57 × 10−2 (−)2.25 × 10−1
4.89 × 10−2 (−)2.15 × 10−1
1.68 × 10−2均值
标准差2.62 × 10−1
3.67 × 10−2 (−)1.14 × 100
3.86 × 10−2 (−)2.17 × 10−1
2.61 × 10−2 (+)2.24 × 10−1
5.11 × 10−3SDP8 (2目标)
SDP8 (3目标)均值
标准差9.54 × 10−2
6.63 × 10−3 (−)6.28 × 10−2
6.73 × 10−3 (−)4.53 × 10−2
5.15 × 10−3 (−)3.14 × 10−2
4.26 × 10−3均值
标准差3.46 × 10−1
3.10 × 10−2 (−)2.79 × 10−1
2.50 × 10−2 (−)3.21 × 10−1
2.07 × 10−2 (−)1.29 × 10−1
6.43 × 10−3SDP9 (2目标)
SDP9 (3目标)均值
标准差1.47 × 10−1
5.06 × 10−2 (−)1.28 × 10−1
4.65 × 10−2 (−)1.35 × 10−1
3.23 × 10−2 (−)8.13 × 10−2
7.92 × 10−3均值
标准差3.66 × 10−1
8.15 × 10−2 (−)4.01 × 10−1
4.08 × 10−2 (−)3.54 × 10−1
6.61 × 10−2 (+)3.60 × 10−1
8.03 × 10−2SDP10 (2目标)
SDP10 (3目标)均值
标准差6.36 × 10−2
2.03 × 10−3 (−)2.61 × 10−2
7.38 × 10−3 (−)3.75 × 10−2
2.25 × 10−3 (−)2.21 × 10−2
1.67 × 10−3均值
标准差1.68 × 10−1
6.22 × 10−2 (+)2.41 × 10−1
1.36 × 10−2 (−)3.86 × 10−1
5.46 × 10−2 (−)1.74 × 10−1
3.58 × 10−3SDP11 (2目标)
SDP11 (3目标)均值
标准差3.80 × 10−2
7.32 × 10−3 (−)4.83 × 10−2
5.21 × 10−3 (−)3.26 × 10−2
8.06 × 10−3 (−)1.36 × 10−2
8.16 × 10−3均值
标准差1.47 × 10−1
9.08 × 10−3 (−)9.68 × 10−2
6.52 × 10−3 (−)1.96 × 10−1
6.21 × 10−3 (−)8.77 × 10−2
9.65 × 10−3SDP12 (2目标)
SDP12 (3目标)均值
标准差4.53 × 10−3
3.18 × 10−3 (−)1.62 × 10−2
2.06 × 10−3 (−)1.40 × 10−2
1.32 × 10−3 (−)4.04 × 10−3
2.17 × 10−4均值
标准差1.62 × 10−1
5.34 × 10−2 (−)1.96 × 10−1
3.73 × 10−2 (−)1.02 × 10−1
2.17 × 10−2 (−)7.63 × 10−2
5.63 × 10−4“+/−/≈”合计 1/23/0 0/23/1 3/20/1
下载: 导出CSV
表 7 DMOEA-ACR-P1、DMOEA-ACR-P2、DMOEA-ACR-P3、DMOEA-ACR-P4和DMOEA-ACR在SDP上获得的MIGD的均值和标准差
Table 7 The mean and standard deviation of MIGD of DMOEA-ACR-P1, DMOEA-ACR-P2, DMOEA-ACR-P3, DMOEA-ACR-P4, and DMOEA-ACR were obtained on SDP
问题集 目标数 DMOEA-ACR-P1 DMOEA-ACR-P2 DMOEA-ACR-P3 DMOEA-ACR-P4 DMOEA-ACR SDP1 (2目标)
SDP1 (3目标)均值
标准差7.80 × 10−2
2.17 × 10−3 (−)1.87 × 10−2
7.05 × 10−3 (−)6.34 × 10−2
4.24 × 10−3 (−)1.73 × 10−2
5.76 × 10−3 (−)1.65 × 10−2
3.67 × 10−3均值
标准差6.69 × 10−1
4.82 × 10−3 (−)1.53 × 10−1
3.62 × 10−3 (−)5.50 × 10−1
4.01 × 10−3 (−)1.81 × 10−2
6.20 × 10−3 (−)1.32 × 10−1
5.44 × 10−3SDP2 (2目标)
SDP2 (3目标)均值
标准差1.78 × 10−1
3.16 × 10−3 (−)2.02 × 10−1
4.91 × 10−3 (−)2.25 × 10−1
3.97 × 10−3 (−)2.36 × 10−1
6.32 × 10−3 (−)1.14 × 10−1
4.35 × 10−3均值
标准差5.82 × 10−1
8.04 × 10−3 (−)3.25 × 10−1
6.51 × 10−3 (−)3.11 × 10−1
5.26 × 10−3 (−)3.21 × 10−1
4.58 × 10−3 (−)2.42 × 10−1
7.12 × 10−3SDP3 (2目标)
SDP3 (3目标)均值
标准差5.15 × 100
3.66 × 10−2 (−)4.85 × 100
1.35 × 10−2 (−)5.14 × 100
6.59 × 10−2 (−)4.83 × 100
4.76 × 10−2 (−)4.74 × 100
6.38 × 10−2均值
标准差1.99 × 100
5.14 × 10−2 (+)3.83 × 100
2.94 × 10−2 (−)3.88 × 100
5.68 × 10−2 (−)3.91 × 100
6.20 × 10−2 (−)3.33 × 100
8.53 × 10−2SDP4 (2目标)
SDP4 (3目标)均值
标准差4.67 × 10−2
5.16 × 10−3 (+)8.35 × 10−2
5.91 × 10−3 (−)1.02 × 10−1
4.85 × 10−3 (−)7.58 × 10−2
6.24 × 10−3 (−)5.08 × 10−2
5.03 × 10−3均值
标准差1.76 × 10−1
4.21 × 10−3 (−)2.13 × 10−1
3.89 × 10−3 (−)1.65 × 10−1
3.56 × 10−3 (+)2.02 × 10−1
5.81 × 10−3 (−)1.69 × 10−1
8.25 × 10−3SDP5 (2目标)
SDF5 (3目标)均值
标准差3.66 × 10−2
5.41 × 10−3 (−)7.63 × 10−3
3.00 × 10−4 (−)7.13 × 10−3
6.35 × 10−4 (−)8.08 × 10−3
6.10 × 10−4 (−)6.81 × 10−3
4.92 × 10−4均值
标准差3.96 × 10−1
8.79 × 10−2 (−)6.43 × 10−2
6.84 × 10−3 (−)6.49 × 10−2
2.96 × 10−3 (−)6.57 × 10−2
5.39 × 10−3 (−)6.38 × 10−2
6.06 × 10−3SDP6 (2目标)
SDP6 (3目标)均值
标准差6.48 × 10−3
5.61 × 10−4 (−)4.62 × 10−3
8.91 × 10−4 (−)4.36 × 10−3
6.03 × 10−4 (−)4.31 × 10−3
5.28 × 10−4 (−)4.26 × 10−3
7.43 × 10−4均值
标准差1.51 × 10−1
7.36 × 10−3 (−)5.27 × 10−2
7.18 × 10−3 (−)5.43 × 10−2
6.23 × 10−3 (−)5.20 × 10−2
5.98 × 10−3 (−)5.17 × 10−2
5.86 × 10−3SDP7 (2目标)
SDP7 (3目标)均值
标准差1.60 × 10−1
5.31 × 10−2 (+)3.26 × 10−1
6.94 × 10−2 (−)2.32 × 10−1
3.28 × 10−2 (−)2.46 × 10−1
4.51 × 10−2 (−)2.15 × 10−1
1.68 × 10−2均值
标准差5.98 × 10−2
6.60 × 10−3 (+)2.56 × 10−1
6.59 × 10−2 (−)2.43 × 10−1
4.67 × 10−3 (−)2.53 × 10−1
5.81 × 10−3 (−)2.24 × 10−1
5.11 × 10−3SDP8 (2目标)
SDP8 (3目标)均值
标准差1.23 × 10−1
6.57 × 10−2 (−)4.70 × 10−2
5.48 × 10−3 (−)2.70 × 10−2
4.90 × 10−3 (+)2.55 × 10−2
5.84 × 10−3 (+)3.14 × 10−2
4.26 × 10−3均值
标准差1.37 × 10−1
4.96 × 10−3 (−)1.81 × 10−1
3.69 × 10−3 (−)1.55 × 10−1
1.86 × 10−3 (−)1.40 × 10−1
7.82 × 10−3 (−)1.29 × 10−1
6.43 × 10−3SDP9 (2目标)
SDP9 (3目标)均值
标准差1.85 × 10−1
8.80 × 10−3 (−)1.29 × 10−1
7.61 × 10−3 (−)1.50 × 10−1
8.55 × 10−3 (−)1.32 × 10−1
6.27 × 10−3 (−)8.13 × 10−2
7.92 × 10−3均值
标准差4.94 × 10−1
9.43 × 10−2 (−)3.79 × 10−1
8.99 × 10−2 (−)3.67 × 10−1
9.08 × 10−2 (−)3.69 × 10−1
4.20 × 10−2 (−)3.60 × 10−1
8.03 × 10−2SDP10 (2目标)
SDP10 (3目标)均值
标准差1.12 × 10−1
3.13 × 10−3 (−)3.28 × 10−2
4.10 × 10−3 (−)2.23 × 10−2
2.15 × 10−3 (−)3.63 × 10−2
2.23 × 10−3 (−)2.21 × 10−2
1.67 × 10−3均值
标准差1.87 × 10−1
5.78 × 10−2 (−)2.80 × 10−1
3.65 × 10−2 (−)1.79 × 10−1
6.03 × 10−2 (−)1.92 × 10−1
2.65 × 10−3 (−)1.74 × 10−1
3.58 × 10−3SDP11 (2目标)
SDP11 (3目标)均值
标准差2.28 × 10−2
9.14 × 10−3 (−)3.60 × 10−2
7.61 × 10−3 (−)2.38 × 10−2
9.03 × 10−3 (−)3.34 × 10−2
8.16 × 10−3 (−)1.36 × 10−2
8.16 × 10−3均值
标准差8.83 × 10−2
8.87 × 10−3 (−)1.04 × 10−1
8.17 × 10−3 (−)8.79 × 10−2
5.96 × 10−3 (−)1.18 × 10−1
9.08×10−3 (−)8.77 × 10−2
9.65 × 10−3SDP12 (2目标)
SDP12 (3目标)均值
标准差4.52 × 10−3
3.75 × 10−3 (−)4.94 × 10−3
3.65 × 10−3 (−)4.37 × 10−3
7.29 × 10−3 (−)4.60 × 10−3
6.94 × 10−3 (−)4.04 × 10−3
2.17 × 10−4均值
标准差2.17 × 10−1
5.02 × 10−2 (−)2.65 × 10−1
4.10 × 10−2 (−)1.06 × 10−1
3.08 × 10−2 (−)3.23 × 10−1
5.24 × 10−2 (−)7.63 × 10−2
5.63 × 10−4“+/−/≈”合计 4/20/0 0/24/0 2/22/0 1/23/0
下载: 导出CSV
表 8 DMOEA-ACR-P1、DMOEA-ACR-P2、DMOEA-ACR-P3、DMOEA-ACR-P4和DMOEA-ACR在DF上获得的MIGD的均值和标准差
Table 8 The mean and standard deviation of MIGD of DMOEA-ACR-P1, DMOEA-ACR-P2, DMOEA-ACR-P3, DMOEA-ACR-P4, and DMOEA-ACR were obtained on DF
问题集 评价指标 DMOEA-ACR-P1 DMOEA-ACR-P2 DMOEA-ACR-P3 DMOEA-ACR-P4 DMOEA-ACR DF1 (2目标) 均值
标准差9.28 × 10−3
6.51 × 10−3 (−)1.82 × 10−2
1.39 × 10−2 (−)9.47 × 10−3
8.94 × 10−3 (−)1.73 × 10−2
5.06 × 10−3 (−)9.15 × 10−3
3.67 × 10−3DF2 (2目标) 均值
标准差1.01 × 10−1
3.16 × 10−2 (−)6.98 × 10−2
2.48 × 10−3 (−)1.16 × 10−1
3.90 × 10−2 (−)5.17 × 10−2
8.26 × 10−3 (+)5.80 × 10−2
7.85 × 10−3DF3 (2目标) 均值
标准差2.64 × 10−2
4.09 × 10−3 (−)2.89 × 10−2
6.71 × 10−3 (−)2.04 × 10−2
5.66 × 10−3 (≈)2.91 × 10−2
4.18 × 10−3 (−)1.99 × 10−2
3.20 × 10−3DF4 (2目标) 均值
标准差2.38 × 10−2
6.23 × 10−3 (+)3.99 × 10−2
4.20 × 10−3 (−)2.94 × 10−2
6.81 × 10−3 (−)2.77 × 10−2
7.11 × 10−3 (+)2.89 × 10−2
5.19 × 10−3DF5 (2目标) 均值
标准差8.51 × 10−3
8.38 × 10−3 (+)2.48 × 10−2
4.82 × 10−3 (−)8.83 × 10−3
6.22 × 10−4 (+)2.27 × 10−2
3.10 × 10−3 (−)9.32 × 10−3
6.01 × 10−4DF6 (2目标) 均值
标准差2.26 × 100
7.82 × 10−1 (−)1.46 × 100
6.33 × 10−1 (−)1.16 × 100
5.67 × 10−1 (−)1.60 × 100
4.28 × 10−1 (−)1.14 × 100
4.23 × 10−1DF7 (2目标) 均值
标准差1.62 × 10−2
4.61 × 10−3 (−)1.84 × 10−2
5.14 × 10−3 (−)1.45 × 10−2
7.12 × 10−3 (+)1.48 × 10−2
5.04 × 10−3 (+)1.57 × 10−2
3.67 × 10−3DF8 (2目标) 均值
标准差1.65 × 10−2
4.77 × 10−3 (+)2.87 × 10−2
4.00 × 10−3 (−)1.71 × 10−2
6.54 × 10−3 (≈)1.68 × 10−2
5.26 × 10−3 (+)1.70 × 10−2
5.68 × 10−3DF9 (2目标) 均值
标准差9.75 × 10−2
4.63 × 10−2 (−)9.32 × 10−2
3.91 × 10−3 (−)6.93 × 10−2
5.73 × 10−3 (−)1.10 × 10−1
6.05 × 10−3 (−)6.87 × 10−2
4.97 × 10−3DF10 (2目标) 均值
标准差1.92 × 10−1
9.39 × 10−2 (−)4.59 × 10−1
8.35 × 10−2 (−)2.37 × 10−1
3.07 × 10−2 (−)1.51 × 10−1
7.99 × 10−2 (−)1.05 × 10−1
8.18 × 10−2DF11 (2目标) 均值
标准差7.43 × 10−2
5.86 × 10−3 (−)8.51 × 10−2
4.81 × 10−3 (−)6.42 × 10−2
6.03 × 10−3 (−)6.57 × 10−2
5.87 × 10−3 (−)6.38 × 10−2
5.07 × 10−3DF12 (2目标) 均值
标准差1.75 × 10−1
3.23 × 10−2 (−)3.29 × 10−1
2.02 × 10−2 (−)2.60 × 10−1
6.17 × 10−2 (−)1.16 × 10−1
4.03 × 10−2 (−)9.49 × 10−2
6.53 × 10−3DF13 (2目标) 均值
标准差1.19 × 10−1
4.91 × 10−2 (−)2.57 × 10−1
2.68 × 10−2 (−)1.20 × 10−1
3.16 × 10−2 (−)2.48 × 10−1
4.82 × 10−2 (−)1.15 × 10−1
4.38 × 10−2DF14 (2目标) 均值
标准差4.43 × 10−2
6.09 × 10−3 (−)6.32 × 10−2
4.17 × 10−3 (−)4.59 × 10−2
3.21 × 10−3 (−)5.95 × 10−2
6.61 × 10−3 (−)4.28 × 10−2
5.56 × 10−3“+/−/≈”合计 3/11/0 0/14/0 2/10/2 4/10/0
下载: 导出CSV
表 9 $\tau_t$分别为5、10、20时DNSGA-II-A、DNSGA-II-B、MOEA/D-KF、SGEA、Tr-DMOEA、MOEA/D-MoE和DMOEA-ACR在SDP和DF上获得的显著差异统计结果
Table 9 Significant difference statistical results of DNSGA-II-A, DNSGA-II-B, MOEA/D-KF, SGEA, Tr-DMOEA, MOEA/D-MoE, and DMOEA-ACR were obtained on SDP and DF where$\tau_t $is 5, 10, 20, respectively
问题集 $\tau_t $ DNSGA-II-A DNSGA-II-B MOEA/D-
KFSGEA Tr-DMOEA MOEA/D-
MoEDMOEA-
ACRSDP 5 4/19/1 4/20/0 3/21/0 2/22/0 0/24/0 1/23/0 +/−/≈ 10 3/21/0 4/20/0 3/21/0 3/18/3 2/22/0 4/20/0 20 3/21/0 5/19/0 1/21/2 5/18/1 2/22/0 3/21/0 DF 5 2/12/0 2/11/1 1/13/0 1/13/0 0/14/0 1/13/0 +/−/≈ 10 2/11/1 2/12/0 1/13/0 0/14/0 1/13/0 1/13/0 20 2/12/0 2/12/0 1/13/0 2/12/0 1/12/1 1/12/1
下载: 导出CSV
-
[1] Cruz A R, Cardoso R T N, Takahashi R H C. Multi-objective dynamic optimization of vaccination campaigns using convex quadratic approximation local search. In: Proceedings of the 6th International Conference on Evolutionary Multi-Criterion Optimization. Ouro Preto, Brazil: 2011. 404−417 [2] Bui L T, Michalewicz Z, Parkinson E, Abello M B. Adaptation in dynamic environments: a case study in mission planning. IEEE Transactions on Evolutionary Computation, 2012, 16(2): 190-209. doi: 10.1109/TEVC.2010.2104156 [3] Zhong X, He Y, Du Z. Downlink power allocation in distributed satellite system based on dynamic multi-objective optimization. In: Proceedings of the International Conference on Wireless Communications & Signal Processing. Nanjing, China: 2015. 1−5 [4] Ding J L, Yang C, Xiao Q, Chai T Y, Jin Y C. Dynamic evolutionary multiobjective optimization for raw ore allocation in mineral processing. IEEE Transactions on Emerging Topics in Computational Intelligence, 2019, 3(1): 36-48. [5] Jiang S Y, Yang S X, Yao X, Tan K C, Kaiser M, Krasnogor N. Benchmark Functions for the CEC 2018 Competition on Dynamic Multiobjective Optimization, Technical Report, Institute of Artificial Intelligence, Newcastle University, UK, 2018 [6] Jiang S Y, Kaiser M, Yang S X, Kollias S D, Krasnogor N. A scalable test suite for continuous dynamic multiobjective optimization. IEEE Transactions on Cybernetics, 2020, 50(6): 2814-2826. doi: 10.1109/TCYB.2019.2896021 [7] Deb K, Agarwal S, Pratap A, Meyarivan T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Transactions on Evolutionary Computation, 2002, 6(2): 182-197. doi: 10.1109/4235.996017 [8] Zhang Q F, Li H. MOEA/D: A multiobjective evolutionary algorithm based on decomposition. IEEE Transactions on Evolutionary Computation, 2007, 11(6): 712-731. doi: 10.1109/TEVC.2007.892759 [9] Yang S, Yao X. Experimental study on population-based incremental learning algorithms for dynamic optimization problems. Soft Computing, 2005, 9(11): 815-834. doi: 10.1007/s00500-004-0422-3 [10] Deb K, Rao U B, Karthik S. Dynamic multi-objective optimization and decision-making using modified NSGA-II: A case study on hydro-thermal power scheduling. In: Proceedings of the 4th International Conference on Evolutionary Multi-Criterion Optim-ization. Matsushima, Japan: 2007. 803−817 [11] Zhou A M, Jin Y C, Zhang Q F. A population prediction strategy for evolutionary dynamic multiobjective optimization. IEEE Transactions on Cybernetics, 2014, 44(1): 40-53. doi: 10.1109/TCYB.2013.2245892 [12] 丁进良, 杨翠娥, 陈立鹏, 柴天佑等. 基于参考点预测的动态多目标优化算法. 自动化学报, 2017, 43(2): 313-320.Ding Jing-Liang, Yang Cui-er, Chen Li-Peng, Chai Tian-You. Dynamic multi-objective optimization algorithm based on reference point prediction. Acta Automatica Sinica, 2017, 43(2): 313-320 (in Chinese) [13] 陈美蓉, 郭一楠, 巩敦卫, 杨振. 一类新型动态多目标鲁棒进化优化方法. 自动化学报, 2017, 43(11): 2014-2032.Chen Mei-Rong, Guo Yi-Nan, Gong Dun-Wei, Yang Zhen. A novel dynamic multi-objective robust evolutionary optimization method. Acta Automatica Sinica, 2017, 43(11): 2014-2032 (in Chinese) [14] Zeng S Y, Chen G, Zheng L, Shi H, Garis H D, Ding L X X, et al. A dynamic multi-objective evolutionary algorithm based on an orthogonal design. In: Proceedings of the 6th IEEE Congress on Evolutionary Computation. Vancouver, Canada: 2006. 573− 580 [15] Goh C K, Tan K C. A competitive-cooperative coevolutionary paradigm for dynamic multiobjective optimization. IEEE Transactions on Evolutionary Computation, 2009, 13(1): 103-127. doi: 10.1109/TEVC.2008.920671 [16] Yen G G, Leong W F, Dynamic multiple swarms in multiobjective particle swarm optimization. IEEE Transactions on Systems, Man, and Cybernetics, Part A, 2009, 39(4): 890-911. doi: 10.1109/TSMCA.2009.2013915 [17] Shang R, Jiao L, Ren Y, Li L, Wang L. Quantum immune clonal co-evolutionary algorithm for dynamic multi-objective optimization. Soft Computing, 2014, 18(4): 743-756. doi: 10.1007/s00500-013-1085-8 [18] Liu R C, Li J X, Fan J, Mu C H, Jiao L C. A coevolutionary technique based on multi-swarm particle swarm optimization for dynamic multi-objective optimization. European Journal of Operational Research, 2017, 261(3): 1028-1051. doi: 10.1016/j.ejor.2017.03.048 [19] Zhang K, Shen C, Liu X, Yen G G. Multiobjective evolution strategy for dynamic multiobjective optimization. IEEE Transactions on Evolutionary Computation, 2020, 24(5): 974-988. doi: 10.1109/TEVC.2020.2985323 [20] Wang Y, Li B. Investigation of memory-based multi-objective optimization evolutionary algorithm in dynamic environment. In: Proceedings of the 9th IEEE Congress on Evolutionary Computation. Trondheim, Norway: 2009. 630−637 [21] Zhang Z, Qian S. Artificial immune system in dynamic environments solving time-varying non-linear constrained multi-objective problems. Soft Computing, 2011, 15(7): 1333-1349. doi: 10.1007/s00500-010-0674-z [22] Sahmoud S, Topcuoglu H R. A memory-based NSGA-II algo-rithm for dynamic multi-objective optimization problems. In: Proceedings of the 19th European Conference on Applications of Evolutionary Computation. Porto, Portugal: 2016. 296−310 [23] Hatzakis I, Wallace D. Dynamic multi-objective optimization with evolutionary algorithms: A forward-looking approach. In: Proceedings of the 8th Annual Conference on Genetic and Evolutionary Computation. Seattle, USA: 2006. 1201−1208 [24] 郑金华, 彭舟, 邹娟, 申瑞珉. 基于引导个体的预测策略求解动态多目标优化问题. 电子学报, 2015, 43(9): 1816-1825. doi: 10.3969/j.issn.0372-2112.2015.09.021Zheng Jin-Hua, Peng Zhou, Zou Juan, Shen Rrui-Min. A prediction strategy based on guide-individual for dynamic multi-objective optimization. Acta Electronica Sinic, 2015, 43(9): 1816-1825 (in Chinese) doi: 10.3969/j.issn.0372-2112.2015.09.021 [25] Liu R C, Niu X, Fan J, Mu C H, Jiao L C. An orthogonal predictive model-based dynamic multi-objective optimization algorithm. Soft Computing, 2015, 19(11): 3083-3107. doi: 10.1007/s00500-014-1470-y [26] Wu Y, Jin Y C, Liu X X. A directed search strategy for evolutionary dynamic multiobjective optimization, Soft Computing, 2015, 19(11): 3221-3235. doi: 10.1007/s00500-014-1477-4 [27] Muruganantham A, Tan K. C, Vadakkepat P. Evolutionary dynamic multiobjective optimization via Kalman filter prediction, IEEE Transactions on Cybernetics, 2016, 46(12): 2862-2873. doi: 10.1109/TCYB.2015.2490738 [28] Jiang S Y, Yang S X. A steady-state and generational evolutionary algorithm for dynamic multiobjective optimization, IEEE Transactions on Evolutionary Computation, 2017, 21(1): 65-82. doi: 10.1109/TEVC.2016.2574621 [29] Rong M, Gong D W, Zhang Y, Jin Y C, Pedrycz W. Multi-directional prediction approach for dynamic multi-objective optimization problems. IEEE Transactions on Cybernetics, 2018, 49(9): 3362-3374. [30] Cao L L, Xu L H, Goodman E D, Bao C T, Zhu S W. Evolutionary dynamic multiobjective optimization assisted by a support vector regression predictor, IEEE Transactions on Evolutionary Computation, 2019, 24(2): 305-319. [31] Rong M, Gong D W. A multi-model prediction method for dynamic multi-objective evolutionary optimization. IEEE Transactions on Evolutionary Computation, 2020, 24(2): 290-304. doi: 10.1109/TEVC.2019.2925358 [32] Wang C F, Yen G G, Jiang M, A grey prediction-based evolutionary algorithm for dynamic multiobjective optimization. Swarm and Evolutionary Computation, 2020, 56: 100695. doi: 10.1016/j.swevo.2020.100695 [33] Gee S B, Tan K C, Alippi C. Solving multi-objective optimization problems in unknown dynamic environments: an inverse modeling approach. IEEE Transactions on Cybernetics, 2017, 47(12): 4223-4234. doi: 10.1109/TCYB.2016.2602561 [34] Jiang M, Huang Z Q, Qiu L M, Huang W Z, Yen G G. Transfer learning-based dynamic multiobjective optimization algorithms, IEEE Transactions on Evolutionary Computation, 2018, 22(4): 501-514. doi: 10.1109/TEVC.2017.2771451 [35] Jiang M, Hu W Z, Qiu L M, Shi M H, Tan K C. Solving dynamic multi-objective optimization problems via support vector machine. In: Proceedings of the 10th International Conference on Advanced Computational Intelligence. Xiamen, China: 2018. 819−824 [36] Jiang M, Wang Z Z, Hong H K, Yen G G. Knee point based imbalanced transfer learning for dynamic multi-objective optimization. IEEE Transactions on Evolutionary Computation, to be published [37] Zhao Q, Yan B, Shi Y, Middendorf M. Evolutionary dynamic multi-objective optimization via learning from historical search process. IEEE Transactions on Cybernetics, 2021: Article No. 3059252 [38] Jiang M, Wang Z, Guo S, Gao X, Tan K C. Individual-based transfer learning for dynamic multi-objective optimization. IEEE Transactions on Cybernetics, doi: 10.1109/TCYB.2020.3017049. [39] Peng Z, Zheng J H, Zou J, Liu Min. Novel Prediction and memory strategies for dynamic multiobjective optimization. Soft Computing, 2015, 19(9): 2633-2653. doi: 10.1007/s00500-014-1433-3 [40] Azzouz R, Bechikh S, Said L B. A dynamic multi-objective evolutionary algorithm using a change severity-based adaptive population management strategy. Soft Computing, 2017, 21(4): 885-906. doi: 10.1007/s00500-015-1820-4 [41] Zou J, Li Q Y, Yang S X, Bai H, Zheng J H, A prediction strategy based on center points and knee points for evolutionary dynamic multi-objective optimization, Applied Soft Computing, 2017, 61: 806-818. doi: 10.1016/j.asoc.2017.08.004 [42] Liang Z P, Zheng S X, Zhu Z X, Yang S X. Hybrid of memory and prediction strategies for dynamic multiobjective optimization. Information Sciences, 2019, 485: 200-218. doi: 10.1016/j.ins.2019.01.066 [43] Rambabu R, Vadakkepat P, Tan K C, Jiang M. A mixture-of-experts prediction framework for evolutionary dynamic multiobjective optimization. IEEE Transactions on Cybernetics, 2019, 50(12): 5099-5112. [44] Zhang Q Y, Yang S X, Jiang S Y, Wang R G, Li X L. Novel prediction strategies for dynamic multiobjective optimization, IEEE Transactions on Evolutionary Computation, 2020, 24(2): 260-274. doi: 10.1109/TEVC.2019.2922834 [45] Gong D W, Xu B, Zhang Y, Guo Y N, Yang S X. A similarity-based cooperative co-evolutionary algorithm for dynamic interval multiobjective optimization problems. IEEE Transactions on Evolutionary Computation, 2020, 24(1): 142-156. doi: 10.1109/TEVC.2019.2912204 [46] Feng L, Zhou W, Liu W, Ong Y S, Tan K C. Solving dynamic multi-objective problem via autoencoding evolutionary search. IEEE Transactions on Cybernetics, 2020, 3017017 [47] Liang Z P, Wu T C, Ma X L, Zhu Z X, Yang S X. A dynamic multi-objective evolutionary algorithm based on decision variable classification. IEEE Transactions on Cybernetics, 2022, 52(3):1602−1615 [48] 刘若辰, 李建霞, 刘静, 焦李成. 动态多目标优化研究 综述. 计算机学报, 2020, 43(07): 1246-1278.Liu Ruo-Chen, Li Jian-Xia, Liu Jing, Jiao Li-Cheng. A survey on dynamic multi-objective optimization. Chinese Journal of Computers, 2020, 43(07): 1246-1278 (in Chinese) [49] 马永杰, 陈敏, 龚影, 程时升, 王甄延. 动态多目标优化进化算法研究进展. 自动化学报, 2020, 46(11): 2302-2318.Ma Yong-Jie, Chen Min, Gong Ying, Cheng Shi-Sheng, Wang Zeng-Yan. Research progress of dynamic multi-objective optimization evolutionary algorithm. Acta Automatica Sinica, 2020, 46(11): 2302-2318 (in Chinese) [50] Woldesenbet Y G, Yen G G. Dynamic evolutionary algorithm with variable relocation, IEEE Transactions on Evolutionary Computation, 2009, 13(3): 500-513. doi: 10.1109/TEVC.2008.2009031 [51] Koo, W T, Goh C K, Tan K C. A predictive gradient strategy for multi-objective evolutionary algorithms in a fast changing environment. Memetic Computing, 2010, 2(2): 87-110. doi: 10.1007/s12293-009-0026-7 [52] Sierra M R, Coello C A C. Improving PSO-based multi-objective optimization using cowding, mutation and epsilon-dominance. In: Proceedings of the 3rd International Conference on Evolutionary Multi-Criterion Optimization. Guanajuato, Mexico: 2005. 505−519 [53] Wilcoxon F. Individual comparisons by ranking methods. Breakthroughs in Statistics: Methodology and distribution. New York: Springer, 1992. 196−202 [54] Friedman M. The use of ranks to avoid the assumption of normality implicit in the analysis of variance. Journal of the American Statistical Association, 1937, 32(200): 675-701. doi: 10.1080/01621459.1937.10503522 -

 下载:
下载:


计量
- 文章访问数: 2085
- HTML全文浏览量: 1165
- PDF下载量: 376
- 被引次数: 0
