

Knowledge-based and Data-driven Integrating Methodologies for Collective Intelligence Decision Making: A Survey
-
摘要: 群体智能(Collectire intelligence, CI)系统具有广泛的应用前景. 当前的群体智能决策方法主要包括知识驱动、数据驱动两大类, 但各自存在优缺点. 本文指出, 知识与数据协同驱动将为群体智能决策提供新解法. 本文系统梳理了知识与数据协同驱动可能存在的不同方法路径, 从知识与数据的架构级协同、算法级协同两个层面对典型方法进行了分类, 同时将算法级协同方法进一步划分为算法的层次化协同和组件化协同, 前者包含神经网络树、遗传模糊树、分层强化学习等层次化方法; 后者进一步总结为知识增强的数据驱动、数据调优的知识驱动、知识与数据的互补结合等方法. 最后, 从理论发展与实际应用的需求出发, 指出了知识与数据协同驱动的群体智能决策中未来几个重要的研究方向.Abstract: Collective intelligence (CI) shows promising application prospects. Current research methodologies of intelligent decision making for CI systems can be categorized as knowledge-based and data-driven methods, both showing inherent advantages and disadvantages. Therefore, we claim that integrating knowledge-based and data-driven paradigms offers a new and prospective research direction. In this paper, possible methods of this integration are systematically introduced, and all of these methods are classified into a framework level and an algorithm level. Specifically, the methods integrated in the algorithm level are further categorized as hierarchical and componentized methods. In the hierarchical taxonomy, neural network tree, genetic fuzzy tree, and hierarchical reinforcement learning are included. In the componentized taxonomy, knowledge enhanced data-driven, data optimized knowledge-driven, and complementary knowledge and data driven methods are introduced. Finally, several future research priorities on the knowledge-based and data-driven integrating paradigms are proposed for the considerations of theoretical development and application requirement.
-

图 1 知识驱动和数据驱动各自优缺点
Fig. 1 Advantages and disadvantages of knowledge- based and data-driven methodologies

图 2 知识与数据协同驱动总体框架
Fig. 2 Overall framework of knowledge-based and data-driven methods integration
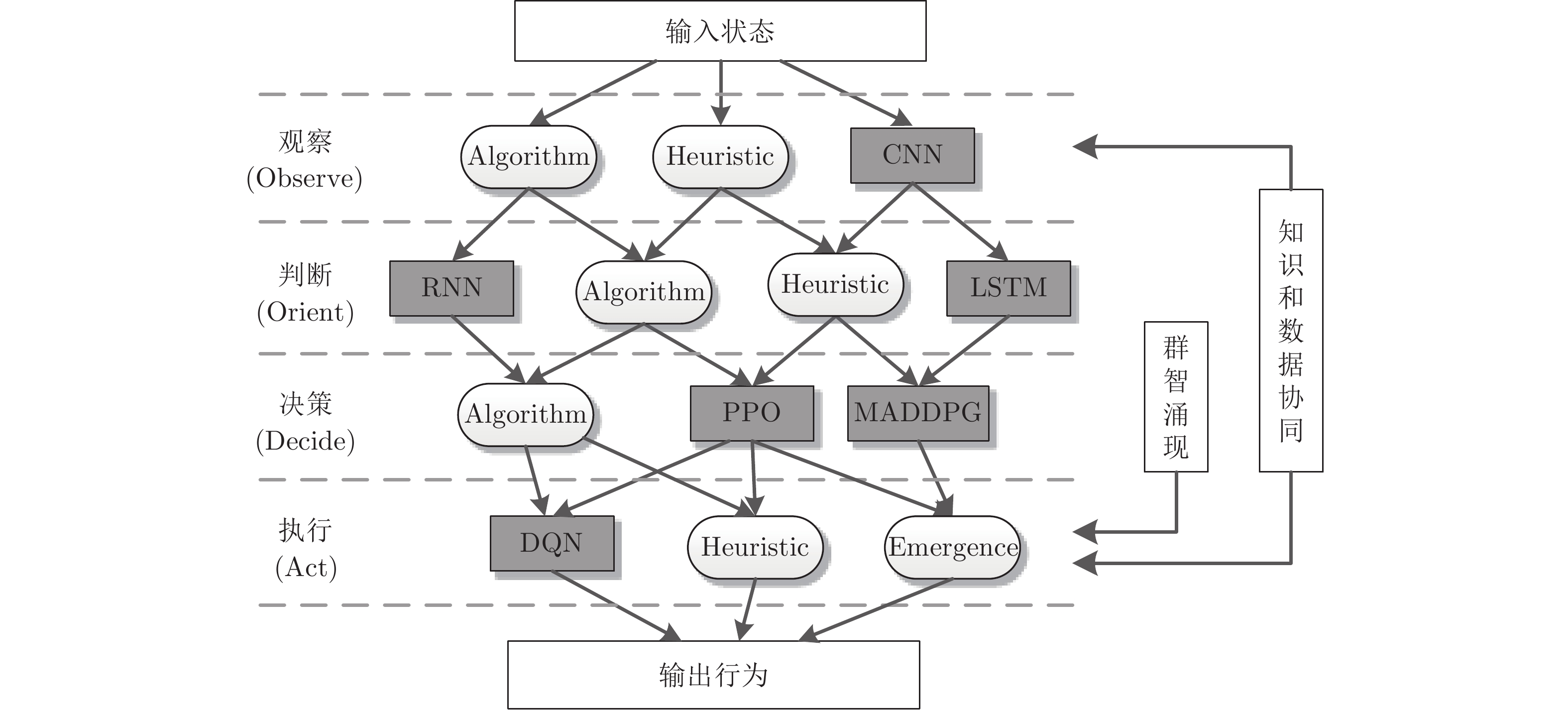
图 3 知识和数据架构级协同概念模型
Fig. 3 Conceptual model for framework-level integration of knowledge-based and data-driven methods
-
[1] Li W, Wu W J, Wang H M, Cheng X Q, Chen H J, Zhou Z H, et al. Crowd intelligence in AI 2.0 era. Frontiers of Information Technology and Electronic Engineering, 2017, 18(1): 15-43 [2] Chung S J, Paranjape A A, Dames P, Shen S J, Kumar V. A survey on aerial swarm robotics. IEEE Transactions on Robotics, 2018, 34(4): 837-855 doi: 10.1109/TRO.2018.2857475 [3] 杜永浩, 邢立宁, 蔡昭权. 无人飞行器集群智能调度技术综述. 自动化学报, 2020, 46(2): 222-241Du Yong-Hao, Xing Li-Ning, Cai Zhao-Quan. Survey on intelligent scheduling technologies for unmanned flying craft clusters. Acta Automatica Sinica, 2020, 46(2): 222-241 [4] Nguyen T T, Nguyen N D, Nahavandi S. Deep reinforcement learning for multiagent systems: A review of challenges, solutions, and applications. IEEE Transactions on Cybernetics, 2020, 50(9): 3826-3839 doi: 10.1109/TCYB.2020.2977374 [5] 孙长银, 穆朝絮. 多智能体深度强化学习的若干关键科学问题. 自动化学报, 2020, 46(7): 1301-1312Sun Chang-Yin, Mu Chao-Xu. Important scientific problems of multi-agent deep reinforcement learning. Acta Automatica Sinica, 2020, 46(7): 1301-1312 [6] He F J, Pan Y D, Lin Q K, Miao X L, Chen Z G. Collective intelligence: A taxonomy and survey. IEEE Access, 2019, 7: 170213-170225 doi: 10.1109/ACCESS.2019.2955677 [7] Krause J, Ruxton G D, Krause S. Swarm intelligence in animals and humans. Trends in Ecology and Evolution, 2010, 25(1): 28-34 [8] Wu T, Zhou P, Liu K, Yuan Y L, Wang X M, Huang H W, et al. Multi-agent deep reinforcement learning for urban traffic light control in vehicular networks. IEEE Transactions on Vehicular Technology, 2020, 69(8): 8243-8256 doi: 10.1109/TVT.2020.2997896 [9] 陈杰, 方浩, 辛斌. 多智能体系统的协同群集运动控制. 北京: 科学出版社, 2017.Chen Jie, Fang Hao, Xin Bin. Cooperative Flocking Control of Multi-Agent Systems. Beijing: Science Press, 2017. [10] Zhu B, Zaini A H B, Xie L H. Distributed guidance for interception by using multiple rotary-wing unmanned aerial vehicles. IEEE Transactions on Industrial Electronics, 2017, 64(7): 5648-5656 doi: 10.1109/TIE.2017.2677313 [11] Qin J H, Gao H J, Zheng W X. Exponential synchronization of complex networks of linear systems and nonlinear oscillators: A unified analysis. IEEE Transactions on Neural Networks and Learning Systems, 2015, 26(3): 510-521 doi: 10.1109/TNNLS.2014.2316245 [12] 王祥科, 刘志宏, 丛一睿, 李杰, 陈浩. 小型固定翼无人机集群综述和未来发展. 航空学报, 2020, 41(4): 023732Wang Xiang-Ke, Liu Zhi-Hong, Cong Yi-Rui, Li Jie, Chen Hao. Miniature fixed-wing UAV swarms: Review and outlook. Acta Aeronautica et Astronautica Sinica, 2020, 41(4): 023732 [13] 段海滨, 邱华鑫. 基于群体智能的无人机集群自主控制. 北京: 科学出版社, 2018.Duan Hai-Bin, Qiu Hua-Xin. Unmanned Aerial Vehicle Swarm Autonomous Control Based on Swarm Intelligence. Beijing: Science Press, 2018. [14] Watts D J, Strogatz S H. Collective dynamics of $‘$small-world$’$ networks. Nature, 1998, 393(6684): 440-442 doi: 10.1038/30918 [15] Barabasi A L, Albert R. Emergence of scaling in random networks. Science, 1999, 286(5439): 509-512 doi: 10.1126/science.286.5439.509 [16] Su Q, McAvoy A, Wang L, Nowak M A. Evolutionary dynamics with game transitions. Proceedings of the National Academy of Sciences of the United States of America, 2019, 116(51): 25398-25404 doi: 10.1073/pnas.1908936116 [17] 邢立宁, 陈英武. 基于知识的智能优化引导方法研究进展. 自动化学报, 2011, 37(11): 1285-1289Xing Li-Ning, Chen Ying-Wu. Research progress on intelligent optimization guidance approaches using knowledge. Acta Automatica Sinica, 2011, 37(11): 1285-1289 [18] Xu J X, Hou Z S. Notes on data-driven system approaches. Acta Automatica Sinica, 2009, 35(6): 668-675 [19] Xu Z B, Sun J. Model-driven deep-learning. National Science Review, 2018, 5(1): 22-24 doi: 10.1093/nsr/nwx099 [20] 李晨溪, 曹雷, 张永亮, 陈希亮, 周宇欢, 段理文. 基于知识的深度强化学习研究综述. 系统工程与电子技术, 2017, 39(11): 2603-2613 doi: 10.3969/j.issn.1001-506X.2017.11.30Li Chen-Xi, Cao Lei, Zhang Yong-Liang, Chen Xi-Liang, Zhou Yu-Huan, Duan Li-Wen. Knowledge-based deep reinforcement learning: A review. Systems Engineering and Electronics, 2017, 39(11): 2603-2613 doi: 10.3969/j.issn.1001-506X.2017.11.30 [21] Agarwal M. Combining neural and conventional paradigms for modelling, prediction and control. International Journal of Systems Science, 1997, 28(1): 65-81 doi: 10.1080/00207729708929364 [22] Hsiao Y T, Lee W P, Yang W, Muller S, Flamm C, Hofacker I, et al. Practical guidelines for incorporating knowledge-based and data-driven strategies into the inference of gene regulatory networks. IEEE/ACM Transactions on Computational Biology and Bioinformatics, 2016, 13(1): 64-75 doi: 10.1109/TCBB.2015.2465954 [23] Zhang J, Xiao W D, Li Y J. Data and knowledge twin driven integration for large-scale device-free localization. IEEE Internet of Things Journal, 2021, 8(1): 320-331 doi: 10.1109/JIOT.2020.3005939 [24] Reynolds C W. Flocks, herds and schools: A distributed behavioral model. ACM SIGGRAPH Computer Graphics, 1987, 21(4): 25-34 doi: 10.1145/37402.37406 [25] Vicsek T, Czirok A, Ben-Jacob E, Cohen I, Shochet O. Novel type of phase transition in a system of self-driven particles. Physical Review Letters, 1995, 75(6): 1226-1229 doi: 10.1103/PhysRevLett.75.1226 [26] Couzin I D, Krause J, James R, Ruxton G D, Franks N R. Collective memory and spatial sorting in animal groups. Journal of Theoretical Biology, 2002, 218(1): 1-11 doi: 10.1006/jtbi.2002.3065 [27] Cucker F, Smale S. Emergent behavior in flocks. IEEE Transactions on Automatic Control, 2007, 52(5): 852-862 doi: 10.1109/TAC.2007.895842 [28] Frazzoli E, Dahleh M A, Feron E. Real-time motion planning for agile autonomous vehicles. Journal of Guidance, Control, and Dynamics, 2002, 25(1): 116-129 doi: 10.2514/2.4856 [29] Choi H L, Brunet L, How J P. Consensus-based decentralized auctions for robust task allocation. IEEE Transactions on Robotics, 2009, 25(4): 912-926 doi: 10.1109/TRO.2009.2022423 [30] Sui Z Z, Pu Z Q, Yi J Q. Optimal UAVs formation transformation strategy based on task assignment and particle swarm optimization. In: Proceedings of the 2017 IEEE International Conference on Mechatronics and Automation (ICMA). Takamatsu, Japan: IEEE, 2017. 1804−1809 [31] Huang J. The cooperative output regulation problem of discrete-time linear multi-agent systems by the adaptive distributed observer. IEEE Transactions on Automatic Control, 2017, 62(4): 1979-1984 doi: 10.1109/TAC.2016.2592802 [32] Jiang H, He H B. Data-driven distributed output consensus control for partially observable multiagent systems. IEEE Transactions on Cybernetics, 2019, 49(3): 848-858 doi: 10.1109/TCYB.2017.2788819 [33] Tian B L, Lu H C, Zuo Z Y, Yang W. Fixed-time leader-follower output feedback consensus for second-order multiagent systems. IEEE Transactions on Cybernetics, 2019, 49(4): 1545-1550 doi: 10.1109/TCYB.2018.2794759 [34] Gao F, Chen W S, Li Z W, Li J, Xu B. Neural network-based distributed cooperative learning control for multiagent systems via event-triggered communication. IEEE Transactions on Neural Networks and Learning Systems, 2020, 31(2): 407-419 doi: 10.1109/TNNLS.2019.2904253 [35] Dong X W, Shi Z Y, Lu G, Zhong Y S. Output containment analysis and design for high-order linear time-invariant swarm systems. International Journal of Robust and Nonlinear Control, 2015, 25(6): 900-913 doi: 10.1002/rnc.3118 [36] Zhang Y H, Sun J, Liang H J, Li H Y. Event-triggered adaptive tracking control for multiagent systems with unknown disturbances. IEEE Transactions on Cybernetics, 2020, 50(3): 890-901 doi: 10.1109/TCYB.2018.2869084 [37] Lee M, Tarokh M, Cross M. Fuzzy logic decision making for multi-robot security systems. Artificial Intelligence Review, 2010, 34(2): 177-194 doi: 10.1007/s10462-010-9168-8 [38] Burgin G H, Sidor L B. Rule-Based Air Combat Simulation, NASA Contractor Report 4160, Titan Systems Inc., USA, 1988. [39] 刘源. 兵棋与兵棋推演. 北京: 国防大学出版社, 2013.Liu Yuan. War Game and War-Game Deduction. Beijing: National Defense University Press, 2013. [40] Gao K Z, Cao Z G, Zhang L, Chen Z H, Han Y Y, Pan Q K. A review on swarm intelligence and evolutionary algorithms for solving flexible job shop scheduling problems. IEEE/CAA Journal of Automatica Sinica, 2019, 6(4): 904-916 doi: 10.1109/JAS.2019.1911540 [41] 黄刚, 李军华. 基于AC-DSDE进化算法多UAVs协同目标分配. 自动化学报, 2021, 47(1): 173-184Huang Gang, Li Jun-Hua. Multi-UAV cooperative target allocation based on AC-DSDE evolutionary algorithm. Acta Automatica Sinica, 2021, 47(1): 173-184 [42] LeCun Y, Bengio Y, Hinton G. Deep learning. Nature, 2015, 521(7553): 436-444 doi: 10.1038/nature14539 [43] Littman M L. Reinforcement learning improves behaviour from evaluative feedback. Nature, 2015, 521(7553): 445-451 doi: 10.1038/nature14540 [44] Mnih V, Kavukcuoglu K, Silver D, Rusu A A, Veness J, Bellemare M G, et al. Human-level control through deep reinforcement learning. Nature, 2015, 518(7540): 529-533 doi: 10.1038/nature14236 [45] Silver D, Huang A, Maddison C J, Guez A, Sifre L, van den Driessche G, et al. Mastering the game of Go with deep neural networks and tree search. Nature, 2016, 529(7587): 484-489 doi: 10.1038/nature16961 [46] Silver D, Schrittwieser J, Simonyan K, Antonoglou I, Huang A, Guez A, et al. Mastering the game of Go without human knowledge. Nature, 2017, 550(7676): 354-359 doi: 10.1038/nature24270 [47] Schwartz H M. Multi-agent Machine Learning: A Reinforcement Approach. Hoboken: Wiley, 2014. [48] 梁星星, 冯旸赫, 马扬, 程光权, 黄金才, 王琦, 等. 多Agent深度强化学习综述. 自动化学报, 2020, 46(12): 2537-2557Liang Xing-Xing, Feng Yang-He, Ma Yang, Cheng Guang-Quan, Huang Jin-Cai, Wang Qi, et al. Deep multi-agent reinforcement learning: A survey. Acta Automatica Sinica, 2020, 46(12): 2537-2557 [49] Vinyals O, Babuschkin I, Czarnecki W M, Mathieu M, Dudzik A, Chung J, et al. Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature, 2019, 575(7782): 350-354 doi: 10.1038/s41586-019-1724-z [50] Lowe R, Wu Y, Tamar A, Harb J, Abbeel P, Mordatch I. Multi-agent actor-critic for mixed cooperative-competitive environments. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach, USA: MIT Press, 2017. 6382−6393 [51] Berner C, Brockman G, Chan B, Cheung V, Debiak P, Dennison C, et al. Dota 2 with large scale deep reinforcement learning. arXiv: 1912.06680, 2019. [52] 颜跃进, 李舟军, 陈跃新. 多Agent系统体系结构. 计算机科学, 2001, 28(5): 77-80 doi: 10.3969/j.issn.1002-137X.2001.05.020Yan Yue-Jin, Li Zhou-Jun, Chen Yue-Xin. Multi-agent system architecture. Computer Science, 2001, 28(5): 77-80 doi: 10.3969/j.issn.1002-137X.2001.05.020 [53] Brooks R. A robust layered control system for a mobile robot. IEEE Journal on Robotics and Automation, 1986, 2(1): 14-23 doi: 10.1109/JRA.1986.1087032 [54] Lawton J R T, Beard R W, Young B J. A decentralized approach to formation maneuvers. IEEE Transactions on Robotics and Automation, 2003, 19(6): 933-941 doi: 10.1109/TRA.2003.819598 [55] Bratman M E, Israel D J, Pollack M E. Plans and resource-bounded practical reasoning. Computational Intelligence, 1988, 4(3): 349-355 doi: 10.1111/j.1467-8640.1988.tb00284.x [56] Lieto A, Bhatt M, Oltramari A, Vernon D. The role of cognitive architectures in general artificial intelligence. Cognitive Systems Research, 2018, 48: 1-3 doi: 10.1016/j.cogsys.2017.08.003 [57] Li D Y, Ge S S, He W, Li C J, Ma G F. Distributed formation control of multiple Euler-Lagrange systems: A multilayer framework. IEEE Transactions on Cybernetics, 2020, DOI: 10.1109/TCYB.2020.3022535 [58] Amduka M, Russo J, Jha K, DeHon A, Lethin R, Springer J, et al. The Design of A Polymorphous Cognitive Agent Architecture (PCCA), Final Technical Report AFRL-RI-RS-TR-2008-137, Lockheed Martin Advanced Technology Laboratories, USA, 2008. [59] Keller J. DARPA to develop swarming unmanned vehicles for better military reconnaissance. Military & Aerospace Electronics, 2017, 28(2): 4-6 [60] 孙瑞, 王智学, 姜志平, 蒋鑫. 外军指挥控制过程模型剖析. 舰船电子工程, 2012, 32(5): 12-14, 42 doi: 10.3969/j.issn.1627-9730.2012.05.004Sun Rui, Wang Zhi-Xue, Jiang Zhi-Ping, Jiang Xin. Analysis of the foreign military command and control process model. Ship Electronic Engineering, 2012, 32(5): 12-14, 42 doi: 10.3969/j.issn.1627-9730.2012.05.004 [61] Fusano A, Sato H, Namatame A. Multi-agent based combat simulation from OODA and network perspective. In: Proceedings of the UkSim 13rd International Conference on Computer Modelling and Simulation. Cambridge, UK: IEEE, 2011. 249−254 [62] Huang Y Y. Modeling and simulation method of the emergency response systems based on OODA. Knowledge-Based Systems, 2015, 89: 527-540 doi: 10.1016/j.knosys.2015.08.020 [63] Zhao Q. Training and retraining of neural network trees. In: Proceedings of the 2001 International Joint Conference on Neural Networks. Washington, USA: IEEE, 2001. 726−731 [64] Brent R P. Fast training algorithms for multilayer neural nets. IEEE Transactions on Neural Networks, 1991, 2(3): 346-354 doi: 10.1109/72.97911 [65] Schmitz G P J, Aldrich C, Gouws F S. ANN-DT: An algorithm for extraction of decision trees from artificial neural networks. IEEE Transactions on Neural Networks, 1999, 10(6): 1392-1401 doi: 10.1109/72.809084 [66] Utkin L V, Zhuk Y A, Zaborovsky V S. An anomalous behavior detection of a robot system by using a hierarchical Siamese neural network. In: Proceedings of the 21st International Conference on Soft Computing and Measurements (SCM). St. Petersburg, Russia: IEEE, 2017. 630−634 [67] Bromley J, Bentz J W, Bottou L, Guyon I, Lecun Y, Moore C, et al. Signature verification using a “Siamese” time delay neural network. International Journal of Pattern Recognition and Artificial Intelligence, 1993, 7(4): 669-688 doi: 10.1142/S0218001493000339 [68] Calvo R, Figueiredo M. Reinforcement learning for hierarchical and modular neural network in autonomous robot navigation. In: Proceedings of the 2003 International Joint Conference on Neural Networks. Portland, USA: IEEE, 2003. 1340−1345 [69] Roy D, Panda P, Roy K. Tree-CNN: A hierarchical deep convolutional neural network for incremental learning. Neural Networks, 2020, 121: 148-160 doi: 10.1016/j.neunet.2019.09.010 [70] Zheng Y, Chen Q Y, Fan J P, Gao X B. Hierarchical convolutional neural network via hierarchical cluster validity based visual tree learning. Neurocomputing, 2020, 409: 408-419 doi: 10.1016/j.neucom.2020.05.095 [71] Yang Y X, Morillo I G, Hospedales T M. Deep neural decision trees. In: Proceedings of the 2018 ICML Workshop on Human Interpretability in Machine Learning. Stockholm, Sweden: ACM, 2018. 34−40 [72] Fei H, Ren Y F, Ji D H. A tree-based neural network model for biomedical event trigger detection. Information Sciences, 2020, 512: 175-185 doi: 10.1016/j.ins.2019.09.075 [73] Ren X M, Gu H X, Wei W T. Tree-RNN: Tree structural recurrent neural network for network traffic classification. Expert Systems with Applications, 2021, 167: Article No. 114363 doi: 10.1016/j.eswa.2020.114363 [74] Ernest N D. Genetic Fuzzy Trees for Intelligent Control of Unmanned Combat Aerial Vehicles [Ph.D. dissertation], University of Cincinnati, USA, 2015. [75] Ernest N, Carroll D, Schumacher C, Clark M, Cohen K, Lee G. Genetic fuzzy based artificial intelligence for unmanned combat aerial vehicle control in simulated air combat missions. Journal of Defense Management, 2016, 6(1): Article No. 1000144 [76] Ernest N, Cohen K, Kivelevitch E, Schumacher C, Casbeer D. Genetic fuzzy trees and their application towards autonomous training and control of a squadron of unmanned combat aerial vehicles. Unmanned Systems, 2015, 3(3): 185-204 doi: 10.1142/S2301385015500120 [77] Kang Y M, Pu Z Q, Liu Z, Li G, Niu R Y, Yi J Q. Air-to-air combat tactical decision method based on SIRMs fuzzy logic and improved genetic algorithm. In: Proceedings of the 2020 International Conference on Guidance, Navigation and Control. Tianjin, China: Springer, 2020. 3699−3709 [78] Botvinick M M. Hierarchical reinforcement learning and decision making. Current Opinion in Neurobiology, 2012, 22(6): 956-962 doi: 10.1016/j.conb.2012.05.008 [79] Bradtke S J, Duff M O. Reinforcement learning methods for continuous-time Markov decision problems. In: Proceedings of the 7th International Conference on Neural Information Processing Systems. Denver, USA: ACM, 1994. 393−400 [80] Dayan P, Hinton G E. Feudal reinforcement learning. In: Proceedings of the 5th International Conference on Neural Information Processing Systems. Denver, USA: ACM, 1993. 271−278 [81] Sutton R S, Precup D, Singh S. Between MDPs and semi-MDPs: A framework for temporal abstraction in reinforcement learning. Artificial Intelligence, 1999, 112(1-2): 181-211 doi: 10.1016/S0004-3702(99)00052-1 [82] Parr R, Russell S. Reinforcement learning with hierarchies of machines. In: Proceedings of the 10th International Conference on Neural Information Processing Systems. Denver, USA: ACM, 1997. 1043−1049 [83] Dietterich T G. Hierarchical reinforcement learning with the MAXQ value function decomposition. Journal of Artificial Intelligence Research, 2000, 13: 227-303 doi: 10.1613/jair.639 [84] Jaderberg M, Czarnecki W M, Dunning I, Marris L, Lever G, Castaneda A G, et al. Human-level performance in 3D multiplayer games with population-based reinforcement learning. Science, 2019, 364(6443): 859-865 doi: 10.1126/science.aau6249 [85] Yang J C, Borovikov I, Zha H Y. Hierarchical cooperative multi-agent reinforcement learning with skill discovery. In: Proceedings of the 19th International Conference on Autonomous Agents and Multiagent Systems. Auckland, New Zealand: ACM, 2020. 1566−1574 [86] Tang H Y, Hao J Y, Lv T J, Chen Y F, Zhang Z Z, Jia H T, et al. Hierarchical deep multiagent reinforcement learning with temporal abstraction. arXiv: 1809.09332, 2019. [87] 郑延斌, 李波, 安德宇, 李娜. 基于分层强化学习及人工势场的多Agent路径规划方法. 计算机应用, 2015, 35(12): 3491-3496 doi: 10.11772/j.issn.1001-9081.2015.12.3491Zheng Yan-Bin, Li Bo, An De-Yu, Li Na. Multi-agent path planning algorithm based on hierarchical reinforcement learning and artificial potential field. Journal of Computer Applications, 2015, 35(12): 3491-3496 doi: 10.11772/j.issn.1001-9081.2015.12.3491 [88] 王冲, 景宁, 李军, 王钧, 陈浩. 一种基于多Agent强化学习的多星协同任务规划算法. 国防科技大学学报, 2011, 33(1): 53-58 doi: 10.3969/j.issn.1001-2486.2011.01.012Wang Chong, Jing Ning, Li Jun, Wang Jun, Chen Hao. An algorithm of cooperative multiple satellites mission planning based on multi-agent reinforcement learning. Journal of National University of Defense Technology, 2011, 33(1): 53-58 doi: 10.3969/j.issn.1001-2486.2011.01.012 [89] Pierre B L, Harb J, Precup D. The option-critic architecture. In: Proceedings of the 31st AAAI Conference on Artificial Intelligence. San Francisco, USA: AAAI, 2017. 1726−1734 [90] Vezhnevets A S, Osindero S, Schaul T, Heess N, Jaderberg M, Silver D, et al. Feudal networks for hierarchical reinforcement learning. In: Proceedings of the 34th International Conference on Machine Learning. Sydney, Australia: PMLR, 2017. 3540−3549 [91] Piot B, Geist M, Pietquin O. Bridging the Gap between imitation learning and inverse reinforcement learning. IEEE Transactions on Neural Networks and Learning Systems, 2017, 28(8): 1814-1826 doi: 10.1109/TNNLS.2016.2543000 [92] 周志华. 机器学习. 北京: 清华大学出版社, 2016. 390-393Zhou Zhi-Hua. Machine Learning. Beijing: Tsinghua University Press, 2016. 390–393 [93] Argall B D, Chernova S, Veloso M, Browning B. A survey of robot learning from demonstration. Robotics and Autonomous Systems, 2009, 57(5): 469-483 doi: 10.1016/j.robot.2008.10.024 [94] Wu B. Hierarchical macro strategy model for MOBA game AI. In: Proceedings of the 33rd AAAI Conference on Artificial Intelligence. Honolulu, USA: AAAI, 2019. 1206−1213 [95] Sui Z Z, Pu Z Q, Yi J Q, Wu S G. Formation control with collision avoidance through deep reinforcement learning using model-guided demonstration. IEEE Transactions on Neural Networks and Learning Systems, 2021, 32(6): 2358-2372 doi: 10.1109/TNNLS.2020.3004893 [96] Ng A Y, Russell S J. Algorithms for inverse reinforcement learning. In: Proceedings of the 17th International Conference on Machine Learning. Stanford, USA: ACM, 2000. 663−670 [97] Shao Z F, Er M J. A review of inverse reinforcement learning theory and recent advances. In: Proceedings of the 2012 IEEE Congress on Evolutionary Computation. Brisbane, Australia: IEEE, 2012. 1−8 [98] 陈希亮, 曹雷, 何明, 李晨溪, 徐志雄. 深度逆向强化学习研究综述. 计算机工程与应用, 2018, 54(5): 24-35 doi: 10.3778/j.issn.1002-8331.1711-0289Chen Xi-Liang, Cao Lei, He Ming, Li Chen-Xi, Xu Zhi-Xiong. Overview of deep inverse reinforcement learning. Computer Engineering and Applications, 2018, 54(5): 24-35 doi: 10.3778/j.issn.1002-8331.1711-0289 [99] Finn C, Levine S, Abbeel P. Guided cost learning: Deep inverse optimal control via policy optimization. In: Proceedings of the 33rd International Conference on Machine Learning. New York, USA: JMLR, 2016. 49−58 [100] Wulfmeier M, Ondruska P, Posner I. Maximum entropy deep inverse reinforcement learning. arXiv: 1507.04888, 2015. [101] Choi S, Kim E, Lee K, Oh S. Leveraged non-stationary Gaussian process regression for autonomous robot navigation. In: Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA). Seattle, USA: IEEE, 2015. 473−478 [102] Reddy T S, Gopikrishna V, Zaruba G, Huber M. Inverse reinforcement learning for decentralized non-cooperative multiagent systems. In: Proceedings of the 2012 IEEE International Conference on Systems, Man, and Cybernetics (SMC). Seoul, Korea (South): IEEE, 2012. 1930−1935 [103] Lin X M, Beling P A, Cogill R. Multiagent inverse reinforcement learning for two-person zero-sum games. IEEE Transactions on Games, 2018, 10(1): 56-68 doi: 10.1109/TCIAIG.2017.2679115 [104] 王雪松, 朱美强, 程玉虎. 强化学习原理及其应用. 北京: 科学出版社, 2014. 15-16Wang Xue-Song, Zhu Mei-Qiang, Cheng Yu-Hu. Principle and Applications of Reinforcement Learning. Beijing: Science Press, 2014. 15−16 [105] Laud A D. Theory and Application of Reward Shaping in Reinforcement Learning [Ph.D. dissertation], University of Illinois, USA, 2004. [106] Wu S G, Pu Z Q, Liu Z, Qiu T H, Yi J Q, Zhang T L. Multi-target coverage with connectivity maintenance using knowledge- incorporated policy framework. In: Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA). Xi'an, China: IEEE, 2021. 8772−8778 [107] Wang J J, Zhang Q C, Zhao D B, Chen Y R. Lane change decision-making through deep reinforcement learning with rule-based constraints. In: Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN). Budapest, Hungary: IEEE, 2019. 1−6 [108] Khooban M H, Gheisarnejad M. A novel deep reinforcement learning controller based type-II fuzzy system: Frequency regulation in Microgrids. IEEE Transactions on Emerging Topics in Computational Intelligence, 2021, 5(4): 689-699 doi: 10.1109/TETCI.2020.2964886 [109] Ng A Y, Harada D, Russell S J. Policy invariance under reward transformations: Theory and application to reward shaping. In: Proceedings of the 16th International Conference on Machine Learning (ICML). Bled, Slovenia: ACM, 1999. 278−287 [110] Wiewiora E. Potential-based shaping and Q-value initialization are equivalent. Journal of Artificial Intelligence Research, 2003, 19: 205-208 doi: 10.1613/jair.1190 [111] Hussein A, Elyan E, Gaber M M, Jayne C. Deep reward shaping from demonstrations. In: Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN). Anchorage, USA: IEEE, 2017. 510−517 [112] Wiewiora E, Cottrell G W, Elkan C. Principled methods for advising reinforcement learning agents. In: Proceedings of the 20th International Conference on Machine Learning (ICML). Washington, USA: AAAI, 2003. 792−799 [113] Devlin S, Kudenko D. Dynamic potential-based reward shaping. In: Proceedings of the 11th International Conference on Autonomous Agents and Multiagent Systems. Valencia, Spain: ACM, 2012. 433−440 [114] Harutyunyan A, Devlin S, Vrancx P, Nowe A. Expressing arbitrary reward functions as potential-based advice. In: Proceedings of the 29th AAAI Conference on Artificial Intelligence. Austin, USA: AAAI, 2015. 2652−2658 [115] Singh S, Barto A G, Chentanez N. Intrinsically motivated reinforcement learning. In: Proceedings of the 17th International Conference on Neural Information Processing Systems. Vancouver, Canada: ACM, 2004. 1281−1288 [116] Singh S, Lewis R L, Barto A. Where do rewards come from? In: Proceedings of the 31st Annual Conference of the Cognitive Science Society. Amsterdam, the Netherlands: Cognitive Science Society, 2009. 2601−2606 [117] Zhang T J, Xu H Z, Wang X L, Wu Y, Keutzer K, Gonzalez J E, et al. BeBold: Exploration beyond the boundary of explored regions. arXiv: 2012.08621, 2020. [118] Burda Y, Edwards H, Pathak D, Storkey A J, Darrell T, Efros A A. Large-scale study of curiosity-driven learning. In: Proceedings of the 7th International Conference on Learning Representations. New Orleans, USA: ACM, 2019. 1−17 [119] Yang D, Tang Y H. Adaptive inner-reward shaping in sparse reward games. In: Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN). Glasgow, United Kingdom: IEEE, 2020. 1−8 [120] Kasabov N. Evolving fuzzy neural networks for supervised/unsupervised online knowledge-based learning. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 2001, 31(6): 902-918 doi: 10.1109/3477.969494 [121] Zhao D B, Yi J Q. GA-based control to swing up an acrobot with limited torque. Transactions of the Institute of Measurement and Control, 2006, 28(1): 3-13 doi: 10.1191/0142331206tm158oa [122] Zhou M L, Zhang Q. Hysteresis model of magnetically controlled shape memory alloy based on a PID neural network. IEEE Transactions on Magnetics, 2015, 51(11): Article No. 7301504 [123] Lutter M, Ritter C, Peters J. Deep Lagrangian networks: Using physics as model prior for deep learning. In: Proceedings of the 7th International Conference on Learning Representations. New Orleans, USA: ACM, 2019. [124] Raissi M, Perdikaris P, Karniadakis G E. Physics informed deep learning (Part I): Data-driven solutions of nonlinear partial differential equations. arXiv: 1711.10561, 2017. [125] Ledezma F D, Haddadin S. First-order-principles-based constructive network topologies: An application to robot inverse dynamics. In: Proceedings of the 17th International Conference on Humanoid Robotics (Humanoids). Birmingham, UK: IEEE, 2017. 438−445 [126] Sanchez-Gonzalez A, Heess N, Springenberg J T, Merel J, Riedmiller M A, Hadsell R, et al. Graph networks as learnable physics engines for inference and control. In: Proceedings of the 35th International Conference on Machine Learning. Stockholm, Sweden: PMLR, 2018. 4467−4476 [127] Jiang J C, Dun C, Huang T J, Lu Z Q. Graph convolutional reinforcement learning. In: Proceedings of the 2020 International Conference on Learning Representation (ICLR). 2020. [128] Velickovic P, Cucurull G, Casanova A, Romero A, Lio P, Bengio Y. Graph attention networks. In: Proceedings of the 6th International Conference on Learning Representations. Vancouver, Canada: ACM, 2018. 1−12 [129] Nagabandi A, Clavera I, Liu S M, Fearing R S, Abbeel P, Levine S, et al. Learning to adapt in dynamic, real-world environments through meta-reinforcement learning. In: Proceedings of the 7th International Conference on Learning Representations. New Orleans, USA: ACM, 2019. 1−17 [130] Liu D R, Xue S, Zhao B, Luo B, Wei Q L. Adaptive dynamic programming for control: A survey and recent advances. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2021, 51(1): 142-160 doi: 10.1109/TSMC.2020.3042876 [131] 陈鑫, 魏海军, 吴敏, 曹卫华. 基于高斯回归的连续空间多智能体跟踪学习. 自动化学报, 2013, 39(12): 2021-2031Chen Xin, Wei Hai-Jun, Wu Min, Cao Wei-Hua. Tracking learning based on Gaussian regression for multi-agent systems in continuous space. Acta Automatica Sinica, 2013, 39(12): 2021-2031 [132] Desouky S F, Schwartz H M. Q(λ)-learning fuzzy logic controller for a multi-robot system. In: Proceedings of the 2010 IEEE International Conference on Systems, Man and Cybernetics. Istanbul, Turkey: IEEE, 2010. 4075−4080 [133] Xiong T Y, Pu Z Q, Yi J Q, Sui Z Z. Adaptive neural network time-varying formation tracking control for multi-agent systems via minimal learning parameter approach. In: Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN). Budapest, Hungary: IEEE, 2019. 1−8 [134] Xiong T Y, Pu Z Q, Yi J Q, Tao X L. Fixed-time observer based adaptive neural network time-varying formation tracking control for multi-agent systems via minimal learning parameter approach. IET Control Theory & Applications, 2020, 14(9): 1147-1157 [135] 杨彬, 周琪, 曹亮, 鲁仁全. 具有指定性能和全状态约束的多智能体系统事件触发控制. 自动化学报, 2019, 45(8): 1527-1535Yang Bin, Zhou Qi, Cao Liang, Lu Ren-Quan. Event- triggered control for multi-agent systems with prescribed performance and full state constraints. Acta Automatica Sinica, 2019, 45(8): 1527-1535 [136] Yu J L, Dong X W, Li Q D, Ren Z. Practical time-varying formation tracking for second-order nonlinear multiagent systems with multiple leaders using adaptive neural networks. IEEE Transactions on Neural Networks and Learning Systems, 2018, 29(12): 6015-6025 doi: 10.1109/TNNLS.2018.2817880 [137] Patino D, Carelli R, Kuchen B. Stability analysis of neural networks based adaptive controllers for robot manipulators. In: Proceedings of the 1994 American Control Conference. Baltimore, USA: IEEE, 1994. 609−613 [138] Lin X B, Yu Y, Sun C Y. Supplementary reinforcement learning controller designed for quadrotor UAVs. IEEE Access, 2019, 7: 26422-26431 doi: 10.1109/ACCESS.2019.2901295 [139] Alshiekh M, Bloem R, Ehlers R, Konighofer B, Niekum S, Topcu U. Safe reinforcement learning via shielding. In: Proceedings of the 32nd AAAI Conference on Artificial Intelligence. New Orleans, USA: AAAI, 2018. 2669−2678 [140] Ye D H, Liu Z, Sun M F, Shi B, Zhao P L, Wu H, et al. Mastering complex control in MOBA games with deep reinforcement learning. In: Proceedings of the 34th AAAI Conference on Artificial Intelligence. New York, USA: AAAI, 2020. 6672−6679 [141] Shoham Y, Powers R, Grenager T. If multi-agent learning is the answer, what is the question? Artificial Intelligence, 2007, 171(7): 365-377 doi: 10.1016/j.artint.2006.02.006 [142] Tuyls K, Parsons S. What evolutionary game theory tells us about multiagent learning. Artificial Intelligence, 2007, 171(7): 406-416 doi: 10.1016/j.artint.2007.01.004 [143] Molnar C. Interpretable machine learning — a guide for making black box models explainable [Online], available: https://christophm.github.io/interpretable-ml-book/, June 24, 2021 [144] Albrecht S V, Stone P. Autonomous agents modelling other agents: A comprehensive survey and open problems. Artificial Intelligence, 2018, 258: 66-95 doi: 10.1016/j.artint.2018.01.002 -

 下载:
下载:




图(7)
计量
- 文章访问数: 7696
- HTML全文浏览量: 8431
- PDF下载量: 3187
- 被引次数: 0
