

-
摘要: 机器学习以强大的自适应性和自学习能力成为网络空间防御的研究热点和重要方向. 然而机器学习模型在网络空间环境下存在受到对抗攻击的潜在风险, 可能成为防御体系中最为薄弱的环节, 从而危害整个系统的安全. 为此科学分析安全问题场景, 从运行机理上探索算法可行性和安全性, 对运用机器学习模型构建网络空间防御系统大有裨益. 全面综述对抗机器学习这一跨学科研究领域在网络空间防御中取得的成果及以后的发展方向. 首先, 介绍了网络空间防御和对抗机器学习等背景知识; 其次, 针对机器学习在网络空间防御中可能遭受的攻击, 引入机器学习敌手模型概念, 目的是科学评估其在特定威胁场景下的安全属性; 然后, 针对网络空间防御的机器学习算法, 分别论述了在测试阶段发动规避攻击、在训练阶段发动投毒攻击、在机器学习全阶段发动隐私窃取的方法, 进而研究如何在网络空间对抗环境下, 强化机器学习模型的防御方法; 最后, 展望了网络空间防御中对抗机器学习研究的未来方向和有关挑战.Abstract: Machine learning has the ability to learn in various conditions, and becomes a research hotspot and an important direction for cyberspace defense. Unfortunately, machine learning models have potential risks of suffering adversarial attacks in the cyberspace and may become the weakest part of the defense system. Therefore, it is of great benefit to discuss cyberspace defense scenarios and the fundamental issues about the possibility and security of using machine learning algorithms, which is the basis of building cyberspace defense system with machine learning models later on. Adversarial machine learning for cyberspace defense is an interdisciplinary research field. In this paper, we provide a comprehensive review of works related to this filed. Firstly, we present the background and related works of cyberspace defense and adversarial machine learning. Secondly, we provide a model to describe the adversarial model of attack against machine learning in cyberspace defense systems, and thoroughly assess its security attributes under specific threat scenarios. Specifically, we discuss the methods of launching evasion attacks in the test phase, launching poisoning attacks in the training phase, and launching privacy violation in the whole phase for cyberspace defense systems. On the basis of this, we study how to strengthen the machine learning models with different defense mechanisms in cyberspace. Finally, we discuss the future works and challenges of research on adversarial machine learning in cyberspace defense.
-
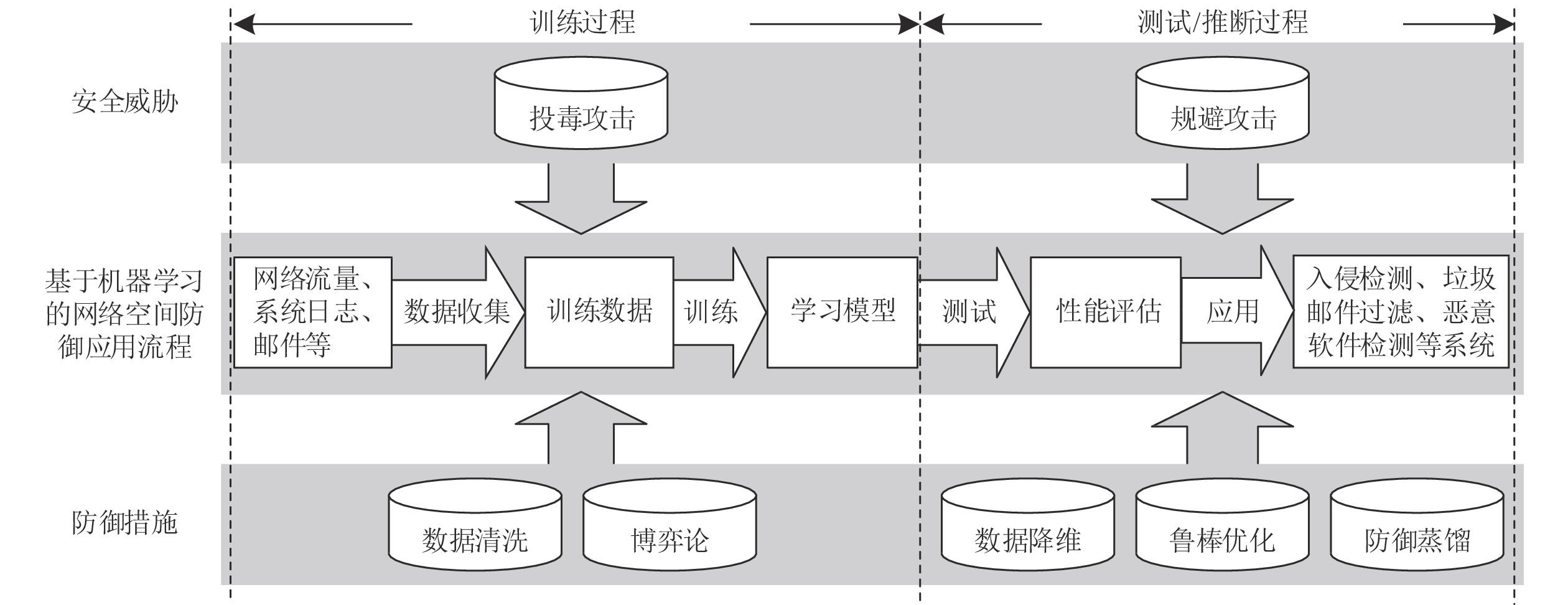
图 2 网络空间防御中的对抗攻击与防御措施
Fig. 2 Adversarial attack and defense methods for cyberspace defense
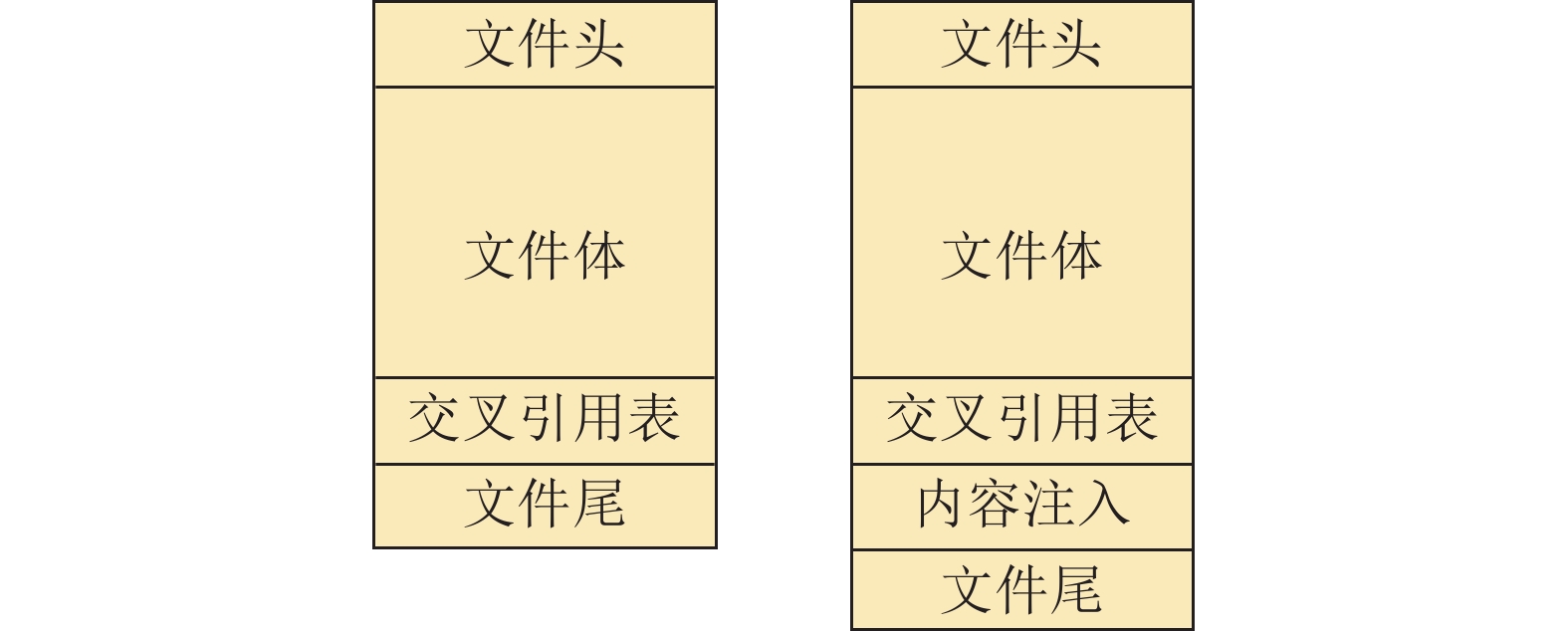
图 4 原始PDF 文件(左图)和修改后的PDF文件(右图)
Fig. 4 The original (left) and modified (right) PDF file
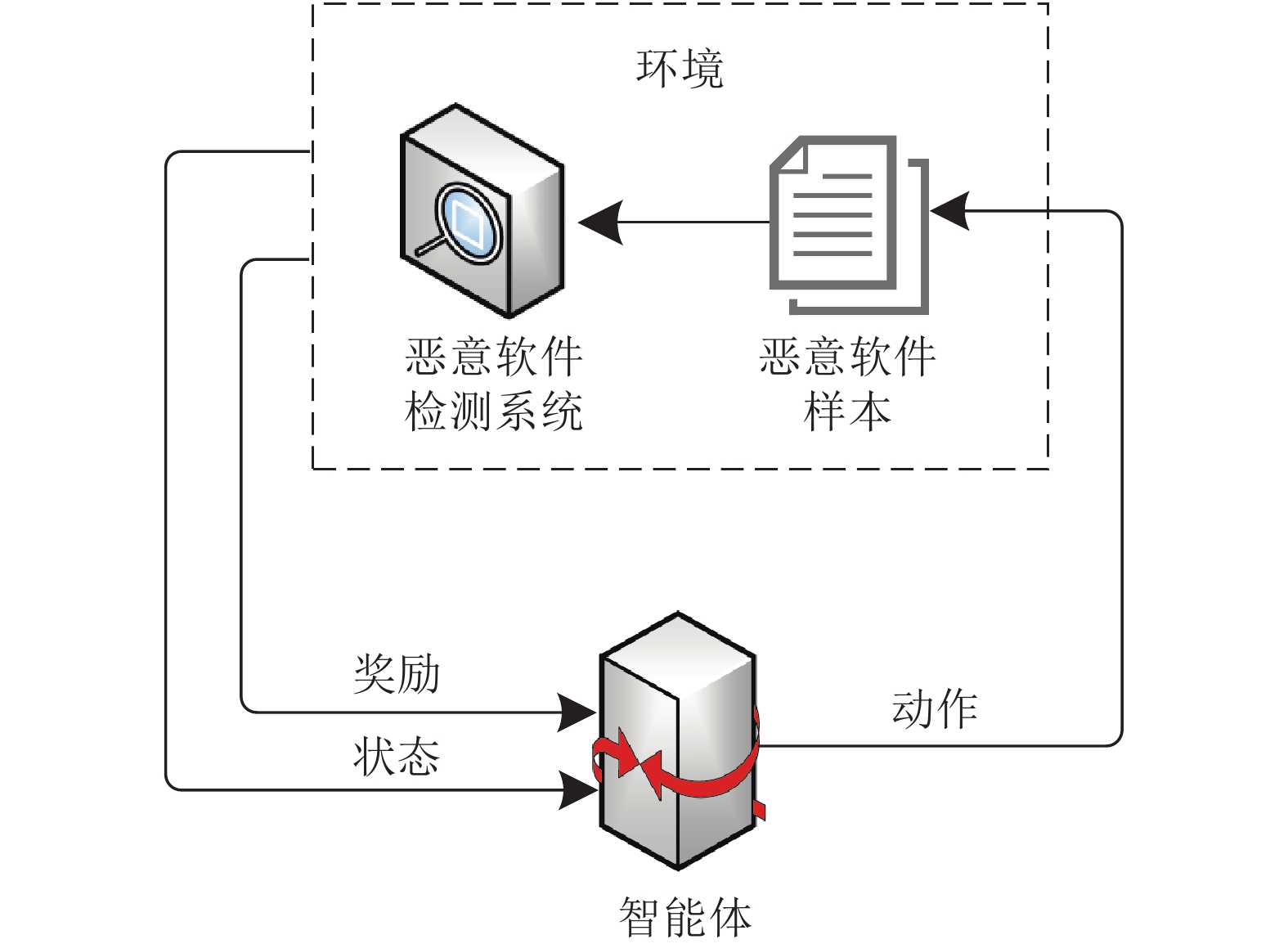
图 6 基于强化学习的恶意软件规避框架
Fig. 6 Framework of malware evasion based on reinforcement learning
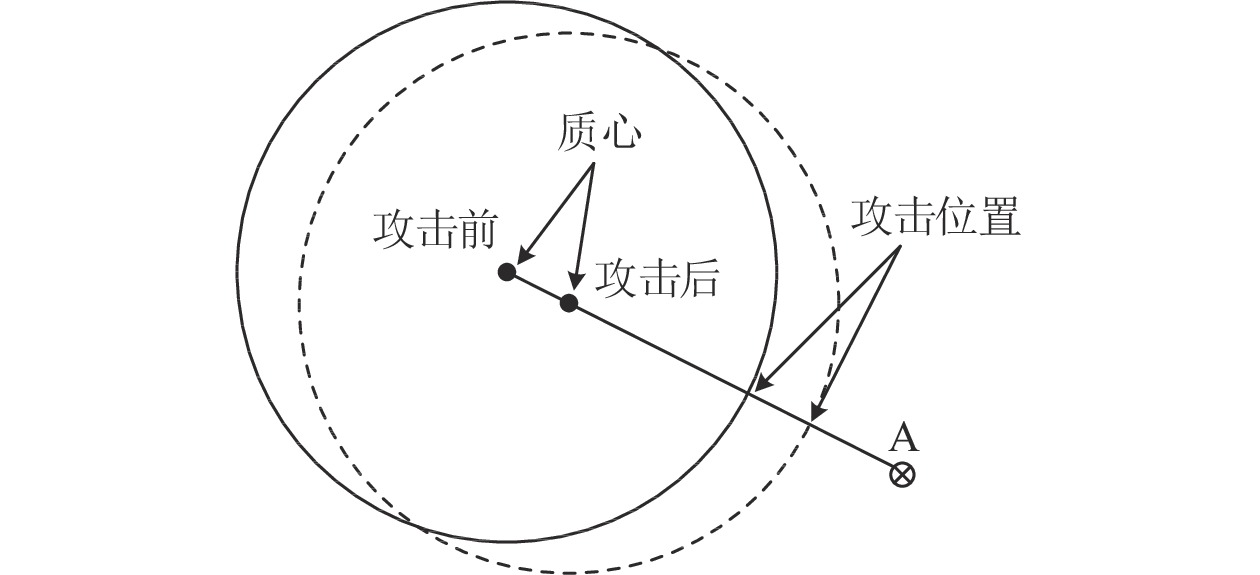
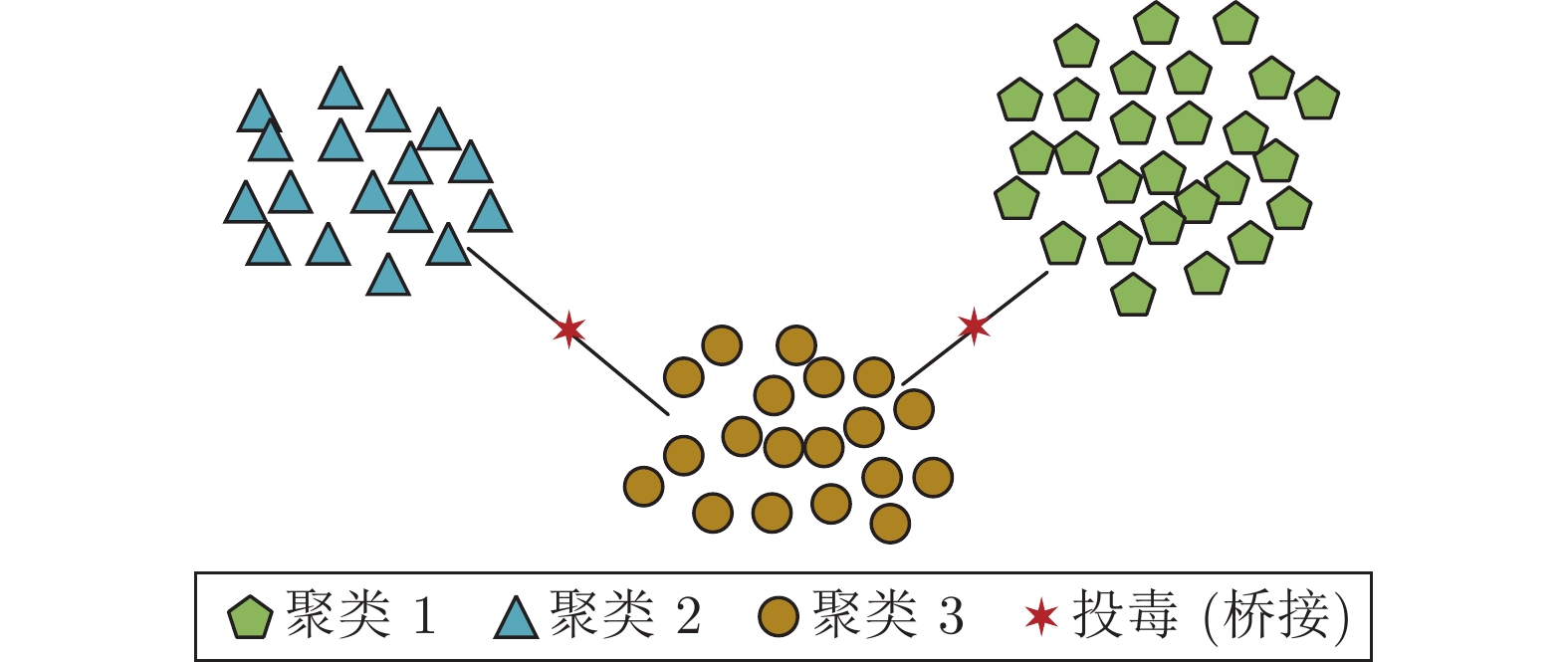
图 7 针对质心异常检测的投毒攻击
Fig. 7 The illustration of poisoning attack for centroid anomaly detection
表 1 对抗机器学习相关综述
Table 1 Related surveys about adversarial machine learning
类别 文献题目 主要内容 发表年份 机器学习模型 SoK: Security and privacy in machine learning[15] 分析机器学习模型的攻击面, 系统论述机器学习模型在训练和推断过程中可能遭受的攻击以及防御措施. 2018 Wild patterns: Ten years after the rise of adversarial machine learning[7] 系统揭示对抗机器学习演进路线, 内容涵盖计算机视觉以及网络安全等领域 2018 A survey on security threats and defensive techniques of machine learning: A data driven view[12] 从数据驱动视角论述机器学习的对抗攻击和防御问题. 2018 The security of machine learning in an adversarial setting: A survey[13] 论述对抗环境下, 机器学习在训练和推断/测试阶段遭受的攻击, 提出相应的安全评估机制和对应的防御策略 2019 A taxonomy and survey of attacks against machine learning[14] 论述机器学习应用于不同领域时的对抗攻击, 主要包括入侵检测、垃圾邮件过滤、视觉检测等领域. 2019 机器学习模型安全与隐私研究综述[16] 从数据安全、模型安全以及模型隐私三个角度对现有的攻击和防御研究进行系统总结和归纳 2021 机器学习安全攻击与防御机制研究进展和未来挑战[11] 基于攻击发生的位置和时序对机器学习安全和隐私攻击进行分类, 并对现有攻击方法和安全防御机制进行介绍 2021 深度学
习模型Survey of attacks and defenses on edge-deployed neural networks[18] 论述边缘神经网络的攻击与防御 2019 Adversarial examples in modern machine learning: A review[19] 论述对抗样本生成与防御技术 2019 A survey of safety and trustworthiness of deep neural networks: Verification, testing, adversarial attack and defence, and Interpretability[20] 论述深度神经网络(Deep neural network, DNN)的安全与可解释性 2020 对抗样本生成技术综述[21] 围绕前传、起源和发展三个阶段对对抗样本进行综述 2020 机器学习隐私 机器学习的隐私保护研究综述[17] 着重论述机器学习的隐私保护技术 2020 A survey of privacy attacks in machine learning[22] 论述机器学习中隐私攻击与保护技术 2020 机器学习隐私保护研究综述[23] 着重论述机器学习的隐私保护技术 2020 计算机视觉 Threat of adversarial attacks on deep learning in computer vision: A survey[24] 论述计算机视觉中深度学习模型的攻击与防御 2018 Adversarial machine learning in image classification: A survey towards the defender's perspective[25] 从防御角度研究计算机视觉分类问题中的对抗机器学习 2020 Adversarial examples on object recognition: A comprehensive survey[26] 论述神经网络在视觉领域应用时, 存在的对抗样本的攻防问题 2020 Adversarial attacks on deep learning models of computer vision: A survey[27] 论述计算机视觉中深度学习模型的对抗攻击 2020 自然语言处理 Adversarial attacks on deep-learning models in natural language processing[28] 论述自然语言处理领域中深度学习模型的对抗攻击与防御问题 2020 生物医疗领域 Adversarial biometric recognition: A review on biometric system security from the adversarial machine-learning perspective[29] 首次从对抗机器学习角度论述生物识别系统的安全问题 2015 Toward an understanding of adversarial examples in clinical trials[30] 论述基于深度学习模型的临床实验中的对抗样本问题 2018 Secure and robust machine learning for healthcare: A Survey[31] 从对抗机器学习的角度概述医疗保健领域中机器学习应用的现状、挑战及解决措施 2021 网络空间防御 Adversarial attacks against intrusion detection systems: Taxonomy, solutions and open issues[32] 论述入侵检测系统中的对抗攻击问题以及应对措施 2013 Towards adversarial malware detection: Lessons learned from PDF-based attacks[33] 论述基于机器学习的恶意便携式文档格式 (Portable document format, PDF)文件检测系统可能遭受的对抗攻击 2019  下载: 导出CSV
下载: 导出CSV
表 2 对抗机器学习时间线
Table 2 A timeline of adversarial machine learning history
年份 主要内容 2004 Dalvi 等[42] 和 Lowd 等[43-44] 研究了垃圾邮件检测中的对抗问题, 提出线性分类模型可能被精心设计的对抗样本所愚弄 2006 Barreno 等[8] 从更广泛的角度质疑机器学习模型在对抗环境中的适用性问题, 并提出一些可行措施来消除或降低这些威胁 2007 NeurIPS 举办 Machine Learning in Adversarial Environments for Computer Security研讨会. 2010年, Machine Learning期刊为该研讨会设立同名专题[54] 2008 CCS 举办首届人工智能与安全研讨会 AISec(Workshop on Artificial Intelligence and Security), 并且持续举办至2020年 2012 面向计算机安全的机器学习方法达堡展望研讨会 (Dagstuhl Perspectives Workshop on Machine Learning Methods for Computer Security), 探讨对抗学习和基于学习的安全技术面临的挑战和未来研究方向[55] 2014 KDD 举办安全与隐私特别论坛 2016 AAAI 举办面向网络空间安全的人工智能研讨会 AICS (Artificial Intelligence for Cyber Security), 此后至2019年每年举办一届 2017 为促进对抗样本的相关研究, 谷歌大脑 (Google Brain) 在 NeurIPS2017 上举办对抗攻击与防御挑战赛 2018 NeurIPS2018举办对抗视觉挑战赛, 目的是促进更加鲁棒的机器视觉模型和更为广泛可用的对抗攻击 Yevgeniy 等[6]撰写书籍 Adversarial Machine Learning, 并由 Morgan & Claypool 出版社发行 2019 Joseph 等[5]撰写书籍 Adversarial Machine Learning, 并由剑桥大学出版社发行 论文Adversarial attacks on medical machine learning[56] Science 期刊上发表, 指出医疗机器学习中出现新脆弱性问题, 需要新
举措论文 Why deep-learning AIs are so easy to fool[57] 在 Nature期刊上发表, 探讨深度学习遭受对抗攻击时的鲁棒性 KDD2019 举办首届面向机器学习和数据挖掘的对抗学习方法研讨会, 至今已连续举办两届 清华大学和阿里安全于天池竞赛平台联合举办安全 AI 挑战者计划, 至今已有 5 期. 同时, 每年底举办 AI 与安全研讨会, 至今已连续举办两届. 2020 KDD2020 举办首届面向安全防御的可部署机器学习国际研讨会 (Workshop on Deployable Machine Learning for Security Defense) 2021 AAAI2021 举办鲁棒、安全、高效的机器学习国际研讨会 (Towards Robust, Secure and Efficient Machine Learning) 注: 数据更新至2021年2月8日.
下载: 导出CSV
表 3 基于威胁建模的机器学习攻击分类
Table 3 Classfication of attacks against machine learning based on threat model
敌手能力 敌手目标 敌手知识 模型完整性 模型可用性 隐私窃取 测试数据 规避攻击 — 模型提取
模型反演
成员推断白盒攻击
黑盒攻击训练数据 投毒攻击(后门攻击) 投毒攻击(油蛙攻击) 模型反演
成员推断白盒攻击
黑盒攻击
下载: 导出CSV
表 4 网络空间防御中的典型对抗攻击
Table 4 Typical adversarial attacks for cyberspace defense
攻击方法 相关文献 应用领域 特点 规避攻击 基于模仿的规避攻击 [42, 44, 64−66] 垃圾邮件检测 模仿攻击采用启发式算法, 尝试向恶意文件中添加良性特征或者向良性文件中注入恶意特征, 从而实现规避 [67] 流量分析 [68] 恶意软件检测 [62, 69−75] 恶意 PDF 文件分类 基于梯度的规避攻击 [75−77] 恶意 PDF 文件分类 基于梯度的规避攻击利用梯度下降求解优化问题, 对输入样本执行细粒度的修改, 以最小化 (最大化) 样本被归类为恶意 (良性) 的概率 [9, 78−79] 恶意软件检测 [63, 80] 入侵检测 基于迁移的规避攻击 [70, 81] 恶意 PDF 文件分类 基于迁移的规避攻击主要利用了对抗样本的跨模型迁移性, 可以应用于无法获取模型梯度的各种攻击场景 [82−84] 入侵检测 [85] XSS 检测 [86] 域名生成 [87−89] 恶意软件检测 投毒攻击 可用性攻击 [8, 44, 90−92] 垃圾邮件检测 可用性攻击的目的是增加测试阶段的分类误差, 从而造成拒绝服务 [93−94] 入侵检测 完整性攻击 [95−96] 异常检测 完整性攻击的目的是使得恶意软件特定子集被模型误分类 [97−98] 恶意软件检测 隐私窃取 模型提取攻击 [99] — 隐私窃取主要目的是窃取机器学习模型或训练数据的信息 模型反演攻击 [100−101] 成员推断攻击 [102−103]
下载: 导出CSV
表 5 网络空间防御中用于对抗攻击的典型防御措施
Table 5 Typical defense against adversarial attacks for cyberspace defense
防御措施 相关文献 应用场景 简述 规避防御 数据降维 [117−118] 垃圾邮件检测 可以有效防御对抗攻击, 但模型对正常样本的精度可能降低 [118−119] 恶意软件检测 鲁棒优化 [120−124] 恶意软件检测 基本思想是模型在训练时存在“盲点”, 将构造的对抗样本注入训练集, 以提高模型的泛化能力 防御蒸馏 [125−129] 恶意软件检测 难以防御 C&W 攻击方法 投毒防御 数据清洗 [130] 异常检测 该方法将投毒攻击视为离群值进行处理 [131−136] — 博弈论 [137−141] 垃圾邮件检测 该方法将博弈论的思想用于处理垃圾邮件的投毒攻击 隐私保护 差分隐私 [142−149] — 该方法的难点在于如何平衡模型可用性与隐私保护效果 模型压缩 [109] 该方法可用于缓解成员推断攻击 模型集成 [150] 该方法的主要思想是将模型中低于特定阈值的损失梯度设为零, 可以用于防御模型提取攻击
下载: 导出CSV
-
[1] 搜狐. 美国东海岸断网事件主角Dyn关于DDoS攻击的后果. [Online], available: https://www.sohu.com/a/117078005_257305, October 25, 2016 [2] 搜狐. WannaCry勒索病毒事件分析. [Online], available: https://www.sohu.com/a/140863167_244641, May 15, 2017 [3] 彭志艺, 张衠, 惠志斌, 覃庆玲. 中国网络空间安全发展报告(2019版). 北京: 社会科学文献出版社, 2019.Peng Zhi-Yi, Zhang Zhun, Hui Zhi-Bin, Qin Qing-Ling. Annual Report on the Development of Cyberspace Security in China (2019). Beijing: Social Sciences Academic Press, 2019. [4] 张蕾, 崔勇, 刘静, 江勇, 吴建平. 机器学习在网络空间安全研究中的应用. 计算机学报, 2018, 41 (9): 1943-1975 doi: 10.11897/SP.J.1016.2018.01943Zhang Lei, Cui Yong, Liu Jing, Jiang Yong, Wu Jian-Ping. Application of machine learning in cyberspace security research. Chinese Journal of Computers, 2018, 41(9): 1943-1975 doi: 10.11897/SP.J.1016.2018.01943 [5] Joseph A D, Nelson B, Rubinstein B I P, Tygar J D. Adversarial Machine Learning. Cambridge: Cambridge University Press, 2019. [6] Yevgeniy V, Murat K. Adversarial Machine Learning. San Rafael: Morgan & Claypool Publishers, 2018. [7] Biggio B, Roli F. Wild patterns: Ten years after the rise of adversarial machine learning. Pattern Recognition, 2018, 84: 317-331 doi: 10.1016/j.patcog.2018.07.023 [8] Barreno M, Nelson B, Sears R, Joseph A D, Tygar J D. Can machine learning be secure? In: Proceedings of the 2006 ACM Symposium on Information, Computer and Communications Security. Taipei, China: ACM, 2006. 16–25 [9] Grosse K, Papernot N, Manoharan P, Backes M, Mcdaniel P. Adversarial examples for malware detection. In: Proceedings of the 22nd European Symposium on Research in Computer Security. Oslo, Norway: Springer, 2017. 62−79 [10] Biggio B, Fumera G, Roli F. Pattern recognition systems under attack: Design issues and research challenges. International Journal of Pattern Recognition and Artificial Intelligence, 2014, 28(7): Article No. 1460002 doi: 10.1142/S0218001414600027 [11] 李欣姣, 吴国伟, 姚琳, 张伟哲, 张宾. 机器学习安全攻击与防御机制研究进展和未来挑战. 软件学报, 2021, 32(2): 406-423Li Xin-Jiao, Wu Guo-Wei, Yao Lin, Zhang Wei-Zhe, Zhang Bin. Progress and future challenges of security attacks and defense mechanisms in machine learning. Journal of Software, 2021, 32(2): 406−423 [12] Liu Q, Li P, Zhao W, Cai W, Yu S, Leung V C M. A survey on security threats and defensive techniques of machine learning: A data driven view. IEEE Access, 2018, 6: 12103-12117 doi: 10.1109/ACCESS.2018.2805680 [13] Wang X, Li J, Kuang X, Tan Y-A. The security of machine learning in an adversarial setting: A survey. Journal of Parallel Distributed Computing, 2019, 130: 12-23 doi: 10.1016/j.jpdc.2019.03.003 [14] Pitropakis N, Panaousis E, Giannetsos T, Anastasiadis E, Loukas G. A taxonomy and survey of attacks against machine learning. Computer Science Review, 2019, 34: Article No. 100199 doi: 10.1016/j.cosrev.2019.100199 [15] Papernot N, Mcdaniel P, Sinha A, Wellman M P. Sok: Security and privacy in machine learning. In: Proceedings of the 3rd IEEE European Symposium on Security and Privacy. London, UK: IEEE, 2018. 399−414 [16] 纪守领, 杜天宇, 李进锋, 沈超, 李博. 机器学习模型安全与隐私研究综述. 软件学报, 2021, 32(1): 41-67Ji Shou-Ling, Du Tian-Yu, Li Jin-Feng, Shen Chao, Li Bo. Security and privacy of machine learning models: A survey. Journal of Software, 2021, 32(1): 41-67 [17] 刘俊旭, 孟小峰. 机器学习的隐私保护研究综述. 计算机研究与发展, 2020, 57(2): 346-362 doi: 10.7544/issn1000-1239.2020.20190455Liu Jun-Xu, Meng Xiao-Feng. Survey on privacy-preserving machine learning. Journal of Computer Research and Development, 2020, 57(2): 346-362. doi: 10.7544/issn1000-1239.2020.20190455 [18] Isakov M, Gadepally V, Gettings K, Kinsy M. Survey of attacks and defenses on edge-deployed neural networks. In: Proceedings of the 2019 IEEE High Performance Extreme Computing Conference. Waltham, MA, USA: IEEE, 2019. 1−8 [19] Wiyatno R, Xu A, Dia O, Berker A D. Adversarial examples in modern machine learning: A review. ArXiv: 1911.05268, 2019. [20] Huang X, Kroening D, Ruan W, Sun Y, Thamo E, Wu M, et al. A survey of safety and trustworthiness of deep neural networks: Verification, testing, adversarial attack and defence, and interpretability. Computer Science Review, 2020, 37: 100270 doi: 10.1016/j.cosrev.2020.100270 [21] 潘文雯, 王新宇, 宋明黎, 陈纯. 对抗样本生成技术综述. 软件学报, 2020, 31(1): 67-81Pan Wen-Wen, Wang Xin-Yu, Song Ming-Li, Chen Chun. Survey on generating adversarial examples. Journal of Software, 2020, 31(1): 67-81 [22] Rigaki M, García S. A survey of privacy attacks in machine learning. ArXiv: 2007.07646, 2020. [23] 谭作文, 张连福. 机器学习隐私保护研究综述. 软件学报, 2020, 31(7): 2127-2156Tan Zuo-Wen, Zhang Lian-Fu. Survey on privacy preserving techniques for machine learning. Journal of Software, 2020, 31(7): 2127-2156 [24] Akhtar N, Mian A. Threat of adversarial attacks on deep learning in computer vision: A survey. IEEE Access, 2018, 6: 14410-14430 doi: 10.1109/ACCESS.2018.2807385 [25] Machado G R, Silva E, Goldschmidt R R. Adversarial machine learning in image classification: A survey towards the defender's perspective. ArXiv: 2009.03728, 2020. [26] Serban A, Poll E, Visser J. Adversarial examples on object recognition: A comprehensive survey. ACM Computing Surveys, 2020, 53(3): Article No. 66 [27] Ding J, Xu Z. Adversarial attacks on deep learning models of computer vision: A survey. In: Proceedings of the 20th International Conference on Algorithms and Architectures for Parallel Processing. New York, NY, USA: Springer, 2020. 396−408 [28] Zhang W, Sheng Q Z, Alhazmi A, Li C. Adversarial attacks on deep-learning models in natural language processing. ACM Transactions on Intelligent Systems and Technology, 2020, 11(3): 1-41 [29] Biggio B, Fumera G, Russu P, Didaci L, Roli F. Adversarial biometric recognition: A review on biometric system security from the adversarial machine-learning perspective. IEEE Signal Processing Magazine, 2015, 32(5): 31-41 doi: 10.1109/MSP.2015.2426728 [30] Papangelou K, Sechidis K, Weatherall J, Brown G. Toward an understanding of adversarial examples in clinical trials. In: Proceedings of the 2018 European Conference on Machine Learning and Knowledge Discovery in Databases. Dublin, Ireland: Springer, 2018. 35−51 [31] Qayyum A, Qadir J, Bilal M, Al-Fuqaha A. Secure and robust machine learning for healthcare: A survey. IEEE Reviews in Biomedical Engineering, 2021, 14: 156-180 doi: 10.1109/RBME.2020.3013489 [32] Corona I, Giacinto G, Roli F. Adversarial attacks against intrusion detection systems: Taxonomy, solutions and open issues. Information Sciences, 2013, 239: 201-225 doi: 10.1016/j.ins.2013.03.022 [33] Maiorca D, Biggio B, Giacinto G. Towards adversarial malware detection: Lessons learned from PDF-based attacks. ACM Computing Surveys, 2019, 52(4): Article No. 78 [34] Army U S G U. Joint Publication 3−12: Cyberspace Operations. North Charleston: Create Space Independent Publishing Platform, 2018. [35] Gibson W. Neuronmancer. New York: Ace Books, 1984. [36] 罗军舟, 杨明, 凌振, 吴文甲, 顾晓丹. 网络空间安全体系与关键技术. 中国科学(信息科学), 2016, 46(8): 939−968Luo Jun-Zhou, Yang Ming, Ling Zhen, Wu Wen-Jia, Gu Xiao-Dan. Architecture and key technologies of cyberspace security. Scientia Sinica Informationis, 2016, 46(8): 939−968 [37] 方滨兴. 从层次角度看网络空间安全技术的覆盖领域. 网络与信息安全学报, 2015, 1(1): 2–7Fang Bin-Xing. A hierarchy model on the research fields of cyberspace security technology. Chinese Journal of Network and Information Security, 2015, 1(1): 2–7 [38] National Institute of Standards and Technology. Framework for improving critical infrastructure cybersecurity version 1.1. [Online], available: https://www.nist.gov/publications/framework-improving-critical-infrastructure-cybersecurity-version-11, April 16, 2018. [39] Turing A M. Computing machinery and intelligence. Mind, 1950, 59(236): 433-460 [40] Samuel A L. Some studies in machine learning using the game of checkers. IBM Journal of Research and Development, 1959, 3(3): 211-229 [41] Mohri M, Rostamizadeh A, Talwalkar A. Foundations of Machine Learning. London: MIT Press, 2012. [42] Dalvi N, Domingos P, Sumit M, Verma S D. Adversarial classification. In: Proceedings of the 10th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Seattle, USA: ACM, 2004. 99−108 [43] Lowd D, Meek C. Adversarial learning. In: Proceedings of the 11th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Chicago, USA: ACM, 2005. 641−647 [44] Lowd D, Meek C. Good word attacks on statistical spam filters. In: The 2nd Conference on Email and Anti-Spam. Stanford, CA, USA: 2005. [45] Barreno M, Nelson B, Joseph A D, Tygar J D. The security of machine learning. Machine Learning, 2010, 81(2): 121-148 doi: 10.1007/s10994-010-5188-5 [46] Dasgupta P, Collins J B. A survey of game theoretic approaches for adversarial machine learning in cybersecurity tasks. AI Magazine, 2019, 40(2): 31-43 doi: 10.1609/aimag.v40i2.2847 [47] Szegedy C, Zaremba W, Sutskever I, Bruna J, Erhan D, Goodfellow I, et al. Intriguing properties of neural networks. In: Proceedings of the 2nd International Conference on Learning Representations. Banff, Canada: 2014. [48] Goodfellow I J, Shlens J, Szegedy C. Explaining and harnessing adversarial examples. In: Proceedings of the 3rd International Conference on Learning Representations. San Diego, USA: 2015. [49] Li X, Li F. Adversarial examples detection in deep networks with convolutional filter statistics. In: Proceedings of the 2017 IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 5775−5783 [50] Lu J, Issaranon T, Forsyth D. Safetynet: Detecting and rejecting adversarial examples robustly. In: Proceedings of the 16th IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 446−454 [51] Meng D, Chen H. MagNet: A two-pronged defense against adversarial examples. In: Proceedings of the ACM SIGSAC Conference on Computer and Communications Security. Dallas, USA: ACM, 2017. 135−147 [52] Melis M, Demontis A, Biggio B, Brown G, Fumera G, Roli F. Is deep learning safe for robot vision? Adversarial examples against the icub humanoid. In: Proceedings of the 16th IEEE International Conference on Computer Vision Workshops. Venice, Italy: IEEE, 2017. 751−759 [53] Papernot N, Mcdaniel P, Wu X, Jha S, Swami A. Distillation as a defense to adversarial perturbations against deep neural networks. In: Proceedings of the 2016 IEEE Symposium on Security and Privacy. San Jose, USA: IEEE, 2016. 582−597 [54] Laskov P, Lippmann R. Machine learning in adversarial environments. Machine Learning, 2010, 81(2): 115-119 doi: 10.1007/s10994-010-5207-6 [55] Joseph A, Laskov P, Roli F, Tygar J, Nelson B. Machine learning methods for computer security. Dagstuhl Reports, 2012, 2: 109-130 [56] Finlayson S G, Bowers J D, Ito J, Zittrain J L, Beam A L, Kohane I S. Adversarial attacks on medical machine learning. Science, 2019, 363(6433): 1287-1289 doi: 10.1126/science.aaw4399 [57] Heaven D. Why deep-learning ais are so easy to fool. Nature, 2019, 574: 163-166 doi: 10.1038/d41586-019-03013-5 [58] 程琪芩, 万良. BiLSTM在跨站脚本检测中的应用研究. 计算机科学与探索, 2020, 14(8): 1338-1347 doi: 10.3778/j.issn.1673-9418.1909035Cheng Qi-Qian, Wan Liang. Application research of BiLSTM in cross-site scripting detection. Journal of Frontiers of Computer Science and Technology, 2020, 14(8): 1338-1347 doi: 10.3778/j.issn.1673-9418.1909035 [59] Biggio B, Fumera G, Roli F. Security evaluation of pattern classifiers under attack. IEEE Transactions on Knowledge and Data Engineering, 2014, 26: 984-996 doi: 10.1109/TKDE.2013.57 [60] Kerckhoffs A. La cryptographie militaire. Journal des Sciences Militaires, 1883, 9: 5-83 [61] 范苍宁, 刘鹏, 肖婷, 赵巍, 唐降龙. 深度域适应综述: 一般情况与复杂情况. 自动化学报, 2021, 47(3): 515-548Fan Cang-Ning, Liu Peng, Xiao Ting, Zhao Wei, Tang Xiang-Long. A review of deep domain adaptation: General situation and complex situation. Acta Automatica Sinica, 2021, 47(3): 515−548 [62] Smutz C, Stavrou A. Malicious PDF detection using metadata and structural features. In: Proceedings of the 28th Annual Computer Security Applications Conference. Orlando, Florida, USA: ACM, 2012. 239–248 [63] Clements J, Yang Y, Sharma A A, Hu H, Lao Y. Rallying adversarial techniques against deep learning for network security. ArXiv: 1903.11688, 2019. [64] Wittel G L, Wu S F. On attacking statistical spam filters. In: Proceedings of the 1st Conference on Email and Anti-spam. Mountain View, CA, USA: 2004. 1−7 [65] Liu C, Stamm S. Fighting unicode-obfuscated spam. In: Proceedings of the Anti-phishing Working Groups 2nd Annual eCrime Researchers Summit. Pittsburgh, PA, USA: ACM, 2007. 45−59 [66] Sculley D, Wachman G M, Brodley C E. Spam filtering using inexact string matching in explicit feature space with on-line linear classifiers. In: Proceedings of the 15th Text REtrieval Conference. Gaithersburg, USA: 2006. 1−10 [67] Wright C V, Coull S E, Monrose F. Traffic morphing: An efficient defense against statistical traffic analysis. In: Proceedings of the 16th Annual Network and Distributed System Security Symposium. San Diego, USA: ISOC, 2009. 237–250 [68] Rosenberg I, Shabtai A, Rokach L, Elovici Y. Generic black-box end-to-end attack against state of the art API call based malware classifiers. In: Proceedings of the 21st International Symposium on Research in Attacks, Intrusions and Defenses. Heraklion, Greece: 2018. 490−510 [69] Šrndić N, Laskov P. Detection of malicious PDF files based on hierarchical document structure. In: Proceedings of the 20th Annual Network and Distributed System Security Symposium. San Diego, USA: ISOC, 2013. 1−16 [70] Šrndić N, Laskov P. Practical evasion of a learning-based classifier: A case study. In: Proceedings of the 35th IEEE Symposium on Security and Privacy. San Jose, USA: IEEE, 2014. 197−211 [71] Suciu O, Coull S E, Johns J. Exploring adversarial examples in malware detection. In: Proceedings of the 2019 IEEE Security and Privacy Workshops. San Francisco, USA: IEEE, 2019. 8−14 [72] Corona I, Maiorca D, Ariu D, Giacinto G. Lux0R: Detection of malicious PDF-embedded javascript code through discriminant analysis of API references. In: Proceedings of the 2014 ACM Artificial Intelligent and Security Workshop. Scottsdale, USA: ACM, 2014. 47−57 [73] Maiorca D, Corona I, Giacinto G. Looking at the bag is not enough to find the bomb: An evasion of structural methods for malicious PDF files detection. In: Proceedings of the 8th ACM SIGSAC Symposium on Information, Computer and Communications Security. Hangzhou, China: ACM, 2013. 119–130 [74] Xu W, Qi Y, Evans D. Automatically evading classifiers: A case study on PDF malware classifiers. In: Proceedings of the 23rd Annual Network and Distributed System Security Symposium. San Diego, USA: ISOC, 2016. 1−15 [75] Biggio B, Corona I, Maiorca D, Nelson B, Srndic N, Laskov P, et al. Evasion attacks against machine learning at test time. In: Proceedings of the 2013 European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases. Prague, Czech: Springer, 2013. 387−402 [76] Smutz C, Stavrou A. When a tree falls: Using diversity in ensemble classifiers to identify evasion in malware detectors. In: Proceedings of the 23rd Annual Network and Distributed System Security Symposium. San Diego, USA: ISOC, 2016. 1−15 [77] Biggio B, Corona I, Nelson B, Rubinstein B I P, Maiorca D, Fumera G, et al. Security evaluation of support vector machines in adversarial environments. In: Proceedings of the Support Vector Machines Applications. Cham, Switzerland: Springer International Publishing, 2014. 105−153 [78] Kolosnjaji B, Demontis A, Biggio B, Maiorca D, Giacinto G, Eckert C, et al. Adversarial malware binaries: Evading deep learning for malware detection in executables. In: Proceedings of the 26th European Signal Processing Conference. Rome, Italy: EUSIPCO, 2018. 533−537 [79] Kreuk F, Barak A, Aviv-Reuven S, Baruch M, Pinkas B, Keshet J. Adversarial examples on discrete sequences for beating whole-binary malware detection. ArXiv: 1802.04528, 2018. [80] Huang C H, Lee T H, Chang L H, Lin J R, Horng G. Adversarial attacks on SDN-based deep learning IDS system. In: Proceedings of the 2018 International Conference on Mobile and Wireless Technology. Hong Kong, China: Springer, 2019. 181−191 [81] Dang H, Huang Y, Chang E-C. Evading classifiers by morphing in the dark. In: Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security. Dallas, USA: ACM, 2017. 119−133 [82] Lin Z, Shi Y, Xue Z. IDSGAN: Generative adversarial networks for attack generation against intrusion detection. ArXiv: 1809.02077, 2018. [83] Rigaki M, Garcia S. Bringing a GAN to a knife-fight: Adapting malware communication to avoid detection. In: Proceedings of the 2018 IEEE Symposium on Security and Privacy Workshops. San Francisco, USA: IEEE, 2018. 70−75 [84] Yan Q, Wang M, Huang W, Luo X, Yu F R. Automatically synthesizing DoS attack traces using generative adversarial networks. International Journal of Machine Learning and Cybernetics, 2019, 10(12): 3387-3396 doi: 10.1007/s13042-019-00925-6 [85] Fang Y, Huang C, Xu Y, Li Y. RLXSS: Optimizing XSS detection model to defend against adversarial attacks based on reinforcement learning. Future Internet, 2019, 11: 177 doi: 10.3390/fi11080177 [86] Anderson H S, Woodbridge J, Filar B. DeepDGA: Adversarially-tuned domain generation and detection. In: Proceedings of the 9th ACM Workshop Artificial Intelligence and Security. Vienna, Austria: ACM, 2016. 13−21 [87] Hu W, Tan Y. Generating adversarial malware examples for black-box attacks based on GAN. ArXiv: 1702.05983, 2017. [88] Anderson H S, Kharkar A, Filar B, Evans D, Roth P. Learning to evade static PE machine learning malware models via reinforcement learning. ArXiv: 1801.08917, 2018. [89] 唐川, 张义, 杨岳湘, 施江勇. DroidGAN: 基于DCGAN的Android对抗样本生成框架. 通信学报, 2018, 39(S1): 64-69Tang Chuan, Zhang Yi, Yang Yue-Xiang, Shi Jiang-Yong. DroidGAN: Android adversarial sample generation framework based on DCGAN. Journal on Communications, 2018, 39(S1): 64-69 [90] Nelson B, Barreno M, Chi F J, Joseph A D, Rubinstein B I P, Saini U, et al. Exploiting machine learning to subvert your spam filter. In: Proceedings of the 1st USENIX Workshop on Large-Scale Exploits and Emergent Threats: Botnets, Spyware, Worms, and More. San Francisco, CA, USA: USENIX Association, 2008. 1−9 [91] Newsome J, Karp B, Song D X. Paragraph: Thwarting signature learning by training maliciously. In: Proceedings of the 9th International Symposium on Recent Advances in Intrusion Detection. Hamburg, Germany: Springer, 2006. 81−105 [92] Huang L, Joseph A D, Nelson B, Rubinstein B I P, Tygar J D. Adversarial machine learning. In: Proceedings of the 4th ACM Workshop on Security and Artificial Intelligence. New York, USA: ACM, 2011. 43–58 [93] Kim H A, Karp B, Usenix. Autograph: Toward automated, distributed worm signature detection. In: Proceedings of the 13rd USENIX Security Symposium. San Diego, USA: USENIX Association, 2004. 271−286 [94] Rubinstein B I P, Nelson B, Huang L, Joseph A D, Lau S H, Rao S, et al. Antidote: Understanding and defending against poisoning of anomaly detectors. In: Proceedings of the 9th ACM SIGCOMM Conference on Internet Measurement. Chicago, IL, USA: ACM, 2009. 1−14 [95] Nelson B, Joseph A D. Bounding an attack's complexity for a simple learning model. In: Proceedings of the 1st USENIX Workshop on Tackling Computer Systems Problems with Machine Learning Techniques. Saint Malo, France: USENIX, 2006. 1−5 [96] Kloft M, Laskov P. Online anomaly detection under adversarial impact. In: Proceedings of the 13th International Conference on Artificial Intelligence and Statistics. Sardinia, Italy: Microtome, 2010. 405−412 [97] Biggio B, Pillai I, Rota Bulo S, Ariu D, Pelillo M, Roli F. Is data clustering in adversarial settings secure? In: Proceedings of the 6th Annual ACM Workshop on Artificial Intelligence and Security. Berlin, Germany: ACM, 2013. 87−97 [98] Biggio B, Rieck K, Ariu D, Wressnegger C, Corona I, Giacinto G, et al. Poisoning behavioral malware clustering. In: Proceedings of the 7th ACM Workshop Artificial Intelligence and Security. Scottsdale, USA: ACM, 2014. 27−36 [99] Tramèr F, Zhang F, Juels A, Reiter M K, Ristenpart T. Stealing machine learning models via prediction APIs. In: Proceedings of the 25th USENIX Security Symposium. Austin, USA: USENIX Association, 2016. 601−618 [100] Fredrikson M, Jha S, Ristenpart T. Model inversion attacks that exploit confidence information and basic countermeasures. In: Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security. Denver, USA: ACM, 2015. 1322−1333 [101] Papernot N, Mcdaniel P D, Goodfellow I J, Jha S, Celik Z B, Swami A. Practical black-box attacks against machine learning. In: Proceedings of the 2017 ACM Asia Conference on Computer and Communications Security. Abu Dhabi, UAE: ACM, 2017. 506−519 [102] Fredrikson M, Lantz E, Jha S, Lin S, Page D, Ristenpart T. Privacy in pharmacogenetics: An end-to-end case study of personalized warfarin dosing. In: Proceedings of the 23rd USENIX Security Symposium. San Diego, USA: USENIX Association, 2014. 17−32 [103] Shokri R, Stronati M, Song C, Shmatikov V. Membership inference attacks against machine learning models. In: Proceedings of the 2017 IEEE Symposium on Security and Privacy. San Jose, USA: IEEE, 2017. 3−18 [104] Maiorca D, Giacinto G, Corona I. A pattern recognition system for malicious PDF files detection. In: Proceedings of the 8th International Conference on Machine Learning and Data Mining in Pattern Recognition. Berlin, Germany: Springer, 2012. 510−524 [105] Papernot N, Mcdaniel P D, Jha S, Fredrikson M, Celik Z B, Swami A. The limitations of deep learning in adversarial settings. In: Proceedings of the 2016 IEEE European Symposium on Security and Privacy. Saarbruecken, Germany: IEEE, 2016. 372−387 [106] Carlini N, Wagner D A. Towards evaluating the robustness of neural networks. In: Proceedings of the 2017 IEEE Symposium on Security and Privacy. San Jose, USA: IEEE, 2017. 39−57 [107] Eykholt K, Evtimov I, Fernandes E, Li B, Rahmati A, Xiao C, et al. Robust physical-world attacks on deep learning visual classification. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 1625−1634 [108] Chen P Y, Sharma Y, Zhang H, Yi J F, Hsieh C J. EAD: Elastic-net attacks to deep neural networks via adversarial examples. In: Proceedings of the 32nd AAAI Conference on Artificial Intelligence. New Orleans, USA: AAAI, 2018. 10−17 [109] Papernot N, Mcdaniel P D, Goodfellow I J. Transferability in machine learning: From phenomena to black-box attacks using adversarial samples. ArXiv: 1605.07277, 2016. [110] Goodfellow I J, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, et al. Generative adversarial nets. In: Proceedings of the 28th Annual Conference on Neural Information Processing Systems. Montreal, Canada: MIT Press, 2014. 2672−2680 [111] 王坤峰, 苟超, 段艳杰, 林懿伦, 郑心湖, 王飞跃. 生成式对抗网络GAN的研究进展与展望. 自动化学报, 2017, 43(03): 321-332Wang Kun-Feng, Gou Chao, Duan Yan-Jie, Lin Yi-Lun, Zheng Xin-Hu, Wang Fei-Yue. Generative adversarial networks: The state of the art and beyond. Acta Automatica Sinica, 2017, 43(3): 321-332 [112] Kearns M, Li M. Learning in the presence of malicious errors. In: Proceedings of the 20th annual ACM Symposium on Theory of Computing. Chicago, USA: ACM, 1988. 267–280 [113] John Leyden. Kaspersky Lab denies tricking AV rivals into nuking harmless files. [Online], available: https://www.theregister.co.uk/2015/08/14/kasperskygate/, August 14, 2015. [114] Kloft M, Laskov P. Security analysis of online centroid anomaly detection. Journal of Machine Learning Research, 2012, 13: 3681-3724 [115] Liao C, Zhong H, Squicciarini A C, Zhu S, Miller D J. Backdoor embedding in convolutional neural network models via invisible perturbation. In: Proceedings of the 10th ACM Conference on Data and Application Security and Privacy. New Orleans, LA, USA: ACM, 2020. 97–108 [116] Hayes J, Melis L, Danezis G, Cristofaro E D. LOGAN: Membership inference attacks against generative models. Proceedings on Privacy Enhancing Technologies, 2019, 2019(1): 133-152 doi: 10.2478/popets-2019-0008 [117] Bhagoji A N, Cullina D, Sitawarin C, Mittal P. Enhancing robustness of machine learning systems via data transformations. In: Proceedings of the 52nd Annual Conference on Information Sciences and Systems. Princeton, USA: IEEE, 2018. 1−5 [118] Zhang F, Chan P P K, Biggio B, Yeung D S, Roli F. Adversarial feature selection against evasion attacks. IEEE Transactions on Cybernetics, 2016, 46(3): 766-77 doi: 10.1109/TCYB.2015.2415032 [119] Wang Q, Guo W, Zhang K, Ororbia A G, Xing X, Liu X, et al. Adversary resistant deep neural networks with an application to malware detection. In: Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Halifax, Canada: ACM, 2017. 1145–1153 [120] Al-Dujaili A, Huang A, Hemberg E, O'reilly U. Adversarial deep learning for robust detection of binary encoded malware. In: Proceedings of the 2018 IEEE Symposium on Security and Privacy Workshops. San Francisco, USA: IEEE, 2018. 76−82 [121] Demontis A, Melis M, Biggio B, Maiorca D, Arp D, Rieck K, et al. Yes, machine learning can be more secure! A case study on Android malware detection. IEEE Transactions on Dependable and Secure Computing, 2019, 16(4): 711-724 doi: 10.1109/TDSC.2017.2700270 [122] Yang W, Kong D, Xie T, Gunter C A. Malware detection in adversarial settings: Exploiting feature evolutions and confusions in Android apps. In: Proceedings of the 33rd Annual Computer Security Applications Conference. 2017. [123] Tramèr F, Kurakin A, Papernot N, Goodfellow I, Boneh D, Mcdaniel P. Ensemble adversarial training: Attacks and defenses. In: Proceedings of the 6th International Conference on Learning Representations. Vancouver, Canada: 2018. 1−20 [124] Li D, Li Q. Adversarial deep ensemble: Evasion attacks and defenses for malware detection. IEEE Transactions on Information Forensics and Security, 2020, 15: 3886-3900 doi: 10.1109/TIFS.2020.3003571 [125] Hinton G E, Vinyals O, Dean J. Distilling the knowledge in a neural network. ArXiv: 1503.02531, 2015. [126] Hosseini H, Chen Y, Kannan S, Zhang B, Poovendran R. Blocking transferability of adversarial examples in black-box learning systems. ArXiv: 1703.04318, 2017. [127] Papernot N, Mcdaniel P D. Extending defensive distillation. ArXiv: 1705.05264, 2017. [128] Grosse K, Papernot N, Manoharan P, Backes M, Mcdaniel P D. Adversarial perturbations against deep neural networks for malware classification. ArXiv: 1606.04435, 2016. [129] Stokes J W, Wang D, Marinescu M, Marino M, Bussone B. Attack and defense of dynamic analysis-based, adversarial neural malware detection models. In: Proceedings of the 2018 IEEE Military Communications Conference. Los Angeles, CA, USA: IEEE, 2018. 102−109 [130] Cretu G F, Stavrou A, Locasto M E, Stolfo S J, Keromytis A D. Casting out demons: Sanitizing training data for anomaly sensors. In: Proceedings of the 2008 IEEE Symposium on Security and Privacy. Oakland, USA: IEEE, 2008. 81−95 [131] Laishram R, Phoha V V. Curie: A method for protecting SVM classifier from poisoning attack. ArXiv: 1606.01584, 2016. [132] Steinhardt J, Koh P W, Liang P. Certified defenses for data poisoning attacks. In: Proceedings of the 31st Annual Conference on Neural Information Processing Systems. Long Beach, USA: MIT Press, 2017. 3518−3530 [133] Metzen J H, Genewein T, Fischer V, Bischoff B. On detecting adversarial perturbations. In: The 5th International Conference on Learning Representations. Toulon, France: 2017. [134] Feinman R, Curtin R R, Shintre S, Gardner A B. Detecting adversarial samples from artifacts. ArXiv: 1703.00410, 2017. [135] Cao Y, Yang J. Towards making systems forget with machine unlearning. In: Proceedings of the 36th IEEE Symposium on Security and Privacy. San Jose, USA: IEEE, 2015. 463−480 [136] Bourtoule L, Chandrasekaran V, Choquette-Choo C A, Jia H, Travers A, Zhang B, et al. Machine unlearning. In: The 42nd IEEE Symposium on Security and Privacy. Virtual Event: 2021. 141−159 [137] Brückner M, Scheffer T. Nash equilibria of static prediction games. In: Proceedings of the 23rd Annual Conference on Neural Information Processing Systems. Vancouver, Canada: MIT Press, 2009. 171−179 [138] Brückner M, Scheffer T. Stackelberg games for adversarial prediction problems. In: Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. San Diego, CA, USA: ACM, 2011. 547−555 [139] Brückner M, Kanzow C, Scheffer T. Static prediction games for adversarial learning problems. Journal of Machine Learning Research, 2012, 13: 2617-2654 [140] Sengupta S, Chakraborti T, Kambhampati S. MTDeep: Boosting the security of deep neural nets against adversarial attacks with moving target defense. In: Proceedings of the 10th International Conference on Decision and Game Theory for Security. Stockholm, Sweden: Springer, 2019. 479−491 [141] Biggio B, Fumera G, Roli F. Design of robust classifiers for adversarial environments. In: Proceedings of the 2011 IEEE International Conference on Systems, Man, and Cybernetics. Anchorage, USA: IEEE, 2011. 977−982 [142] Dwork C. Differential privacy. In: Proceedings of the 33rd International Colloquium on Automata, Languages and Programming. Venice, Italy: Springer, 2006. 1−12 [143] Dwork C, Mcsherry F, Nissim K, Smith A D. Calibrating noise to sensitivity in private data analysis. In: Proceedings of the 3rd Theory of Cryptography Conference. New York, USA: Springer, 2006. 265−284 [144] Mcsherry F, Talwar K. Mechanism design via differential privacy. In: Proceedings of the 48th Annual IEEE Symposium on Foundations of Computer Science. Providence, USA: IEEE, 2007. 94−103 [145] Dwork C, Roth A. The algorithmic foundations of differential privacy. Foundations and Trends in Theoretical Computer Science, 2014, 9: 211-407 [146] 张泽辉, 富瑶, 高铁杠. 支持数据隐私保护的联邦深度神经网络模型研究. 自动化学报, 2022, 48(5): 1153−1172Zhang Ze-Hui, Fu Yao, Gao Tie-Gang. Research on federated deep neural network model for data privacy protection. Acta Automatica Sinica, 2022, 48(5): 1153−1172 [147] Jayaraman B, Evans D. Evaluating differentially private machine learning in practice. In: Proceedings of the 28th USENIX Security Symposium. Santa Clara, USA: USENIX Association, 2019. 1895−1912 [148] Rahman M A, Rahman T, Laganière R, Mohammed N, Wang Y. Membership inference attack against differentially private deep learning model. Transactions on Data Privacy, 2018, 11(1): 61-79 [149] Mcmahan H B, Ramage D, Talwar K, Zhang L. Learning differentially private recurrent language models. In: Proceedings of the 6th International Conference on Learning Representations. Vancouver, Canada: 2018. 1−14 [150] Salem A, Zhang Y, Humbert M, Fritz M, Backes M. Ml-leaks: Model and data independent membership inference attacks and defenses on machine learning models. In: Proceedings of the 26th Annual Network and Distributed System Security Symposium. San Diego, USA: ISOC, 2019. 1−15 [151] Carlini N, Liu C, Erlingsson Ú, Kos J, Song D. The secret sharer: Evaluating and testing unintended memorization in neural networks. In: Proceedings of the 28th USENIX Security Symposium. Santa Clara, USA: USENIX Association, 2019. 267−284 [152] Melis L, Song C, Cristofaro E D, Shmatikov V. Exploiting unintended feature leakage in collaborative learning. In: Proceedings of the 2019 IEEE Symposium on Security and Privacy. San Francisco, USA: IEEE, 2019. 691−706 [153] Song L, Shokri R, Mittal P. Privacy risks of securing machine learning models against adversarial examples. In: Proceedings of the 26th ACM SIGSAC Conference on Computer and Communications Security. London, UK: ACM, 2019. 241−257 [154] Ganju K, Wang Q, Yang W, Gunter C A, Borisov N. Property inference attacks on fully connected neural networks using permutation invariant representations. In: Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security. New York, USA: ACM, 2018. 619–633 [155] Kipf T N, Welling M. Semi-supervised classification with graph convolutional networks. In: Proceedings of the 5th International Conference on Learning Representations. Toulon, France: 2017. [156] Kipf T, Welling M. Variational graph auto-encoders. ArXiv: 1611.07308, 2016. [157] Hamilton W L, Ying R, Leskovec J. Inductive representation learning on large graphs. In: Proceedings of the 31st Annual Conference on Neural Information Processing Systems. Long Beach, USA: MIT Press, 2017. 1025–1035 [158] Hou S, Ye Y, Song Y, Abdulhayoglu M. HinDroid: An intelligent Android malware detection system based on structured heterogeneous information network. In: Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Halifax, Canada: ACM, 2017. 1507–1515 [159] Ye Y, Hou S, Chen L, Lei J, Wan W, Wang J, et al. Out-of-sample node representation learning for heterogeneous graph in real-time Android malware detection. In: Proceedings of the 28th International Joint Conference on Artificial Intelligence. Macao, China: Morgan Kaufmann, 2019. 4150−4156 [160] Fan Y, Hou S, Zhang Y, Ye Y, Abdulhayoglu M. Gotcha-sly malware! Scorpion: A metagraph2vec based malware detection system. In: Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. London, UK: ACM, 2018. 253−262 [161] Zügner D, Akbarnejad A, Günnemann S. Adversarial attacks on neural networks for graph data. In: Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. London, UK: ACM, 2018. 2847−2856 [162] Zhu D, Cui P, Zhang Z, Zhu W. Robust graph convolutional networks against adversarial attacks. In: Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Anchorage, USA: ACM, 2019. 1399−1407 [163] Hou S F, Fan Y J, Zhang Y M, Ye Y F, Lei J W, Wan W Q, et al. αCyber: Enhancing robustness of Android malware detection system against adversarial attacks on heterogeneous graph based model. In: Proceedings of the 28th ACM International Conference on Information and Knowledge Management. Beijing, China: ACM, 2019. 609−618 [164] Sun L, Wang J, Yu P S, Li B. Adversarial attack and defense on graph data: A survey. ArXiv: 1812.10528, 2018. [165] Carlini N, Wagner D. Adversarial examples are not easily detected: Bypassing ten detection methods. In: Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security. Dallas, USA: ACM, 2017. 3−14 [166] Carlini N, Mishra P, Vaidya T, Zhang Y, Sherr M, Shields C, et al. Hidden voice commands. In: Proceedings of the 25th USENIX Security Symposium. Austin, USA: USENIX Association, 2016. 513−530 [167] Miller B, Kantchelian A, Afroz S, Bachwani R, Dauber E, Huang L, et al. Adversarial active learning. In: Proceedings of the 2014 ACM Artificial Intelligent and Security Workshop. Scottsdale, USA: ACM, 2014. 3−14 -

 下载:
下载:



计量
- 文章访问数: 4408
- HTML全文浏览量: 3118
- PDF下载量: 968
- 被引次数: 0
