

Research on T-DQN Intelligent Obstacle Avoidance Algorithm of Unmanned Surface Vehicle
-
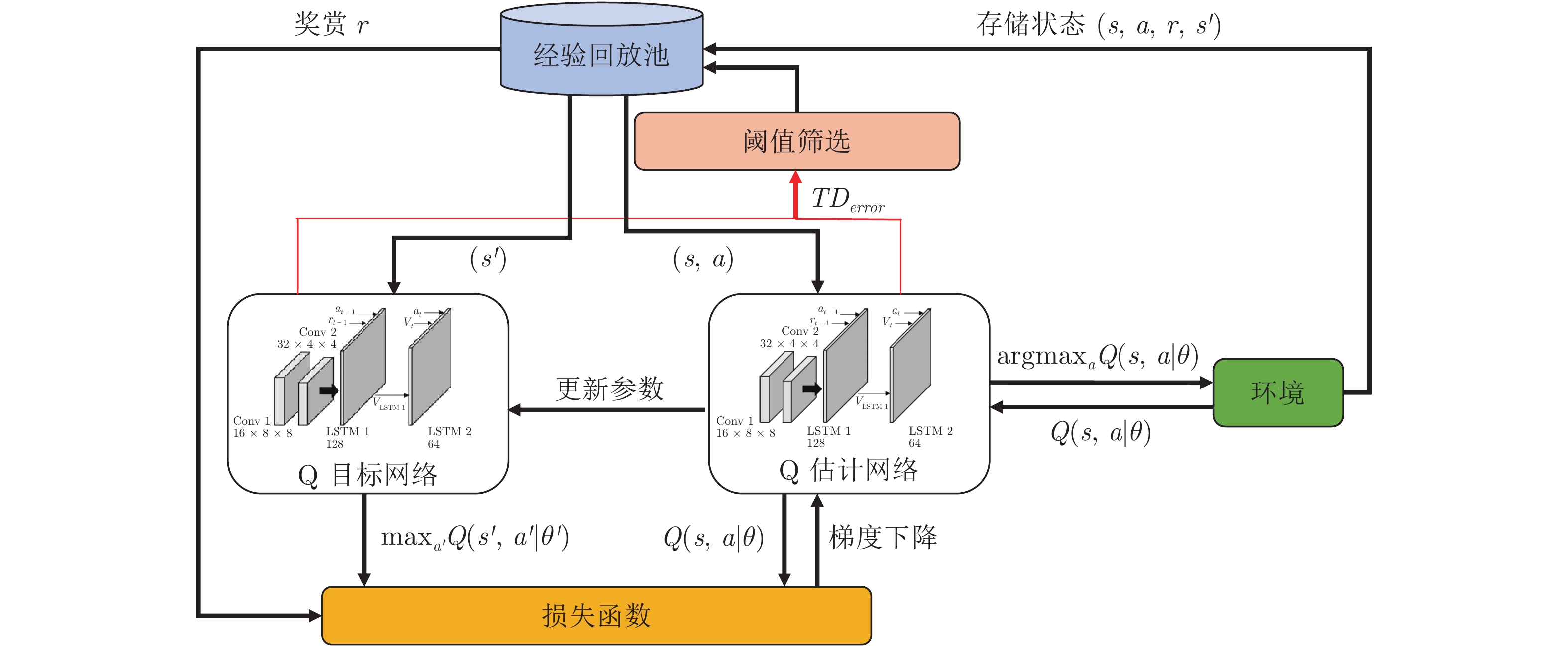
摘要: 无人艇(Unmanned surface vehicle, USV)作为一种具有广泛应用前景的无人系统, 其自主决策能力尤为关键. 由于水面运动环境较为开阔, 传统避障决策算法难以在量化规则下自主规划最优路线, 而一般强化学习方法在大范围复杂环境下难以快速收敛. 针对这些问题, 提出一种基于阈值的深度Q网络避障算法(Threshold deep Q network, T-DQN), 在深度Q网络(Deep Q network, DQN)基础上增加长短期记忆网络(Long short-term memory, LSTM)来保存训练信息, 并设定经验回放池阈值加速算法的收敛. 通过在不同尺度的栅格环境中进行实验仿真, 实验结果表明, T-DQN算法能快速地收敛到最优路径, 其整体收敛步数相比Q-learning算法和DQN算法, 分别减少69.1%和24.8%, 引入的阈值筛选机制使整体收敛步数降低41.1%. 在Unity 3D强化学习仿真平台, 验证了复杂地图场景下的避障任务完成情况, 实验结果表明, 该算法能实现无人艇的精细化避障和智能安全行驶.Abstract: Unmanned surface vehicle (USV) is a kind of unmanned system with wide application prospect, and it is important to train the autonomous decision-making ability. Due to the wide water surface motion environment, traditional obstacle avoidance algorithms are difficult to independently plan a reasonable route under quantitative rules, while the general reinforcement learning methods are difficult to converge quickly in large and complex environment. To solve these problems, we propose a threshold deep Q network (T-DQN) algorithm, by adding long short-term memory (LSTM) network on basis of deep Q network (DQN), to save training information, and setting proper threshold value of experience replay pool to accelerate convergence. We conducted simulation experiments in different sizes grid, and the results show T-DQN method can converge to optimal path quickly, compared with the Q-learning and DQN, the number of convergence episodes is reduced by 69.1%, and 24.8%, respectively. The threshold mechanism reduces overall convergence steps by 41.1%. We also verified the algorithm in Unity 3D reinforcement learning simulation platform to investigate the completion of obstacle avoidance tasks under complex maps, the experiment results show that the algorithm can realize detailed obstacle avoidance and intelligent safe navigation.
-
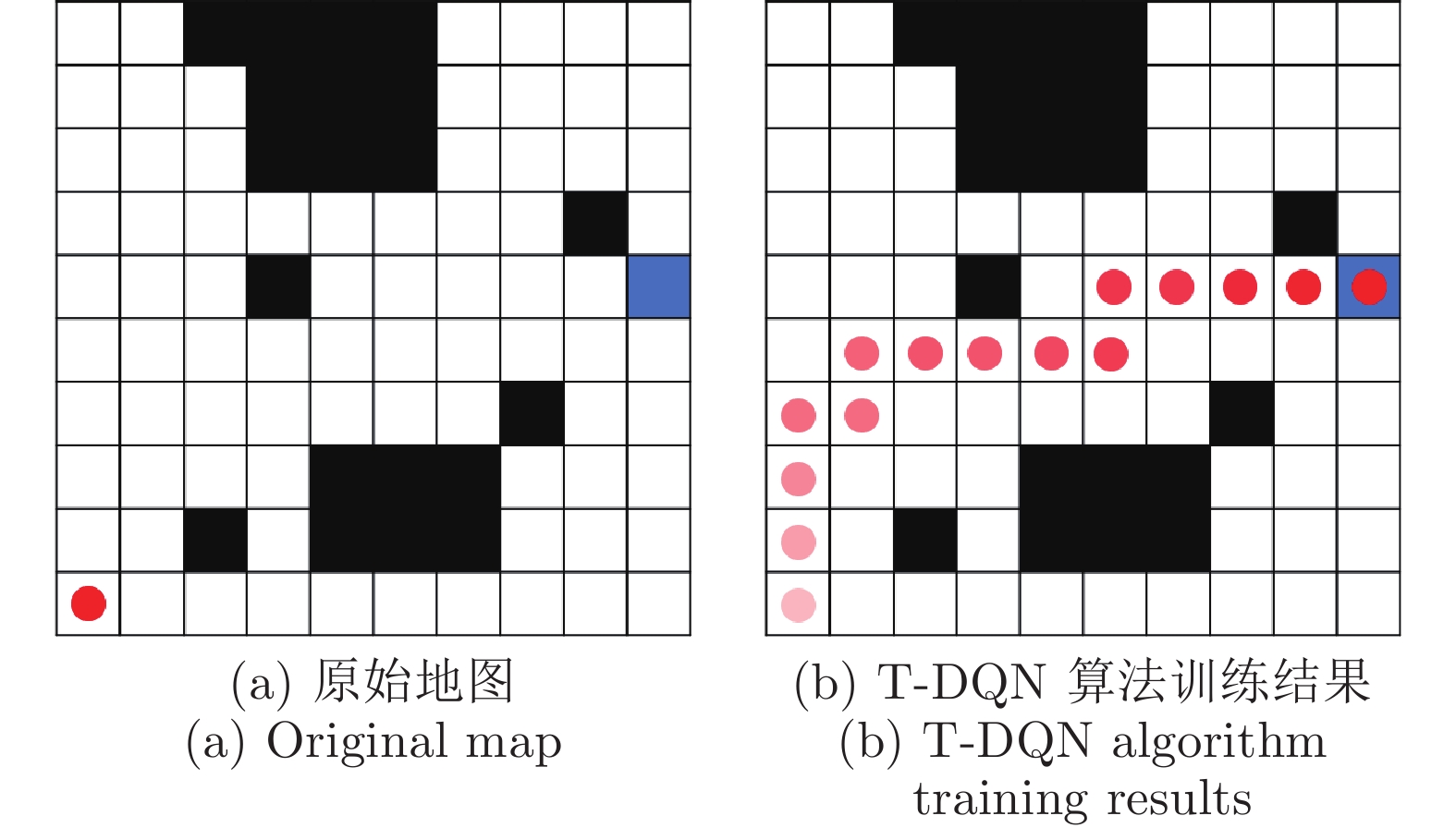
图 6 10 × 10栅格地图下采用T-DQN训练后的路径结果
Fig. 6 Path results after T-DQN training under 10 × 10 grid map
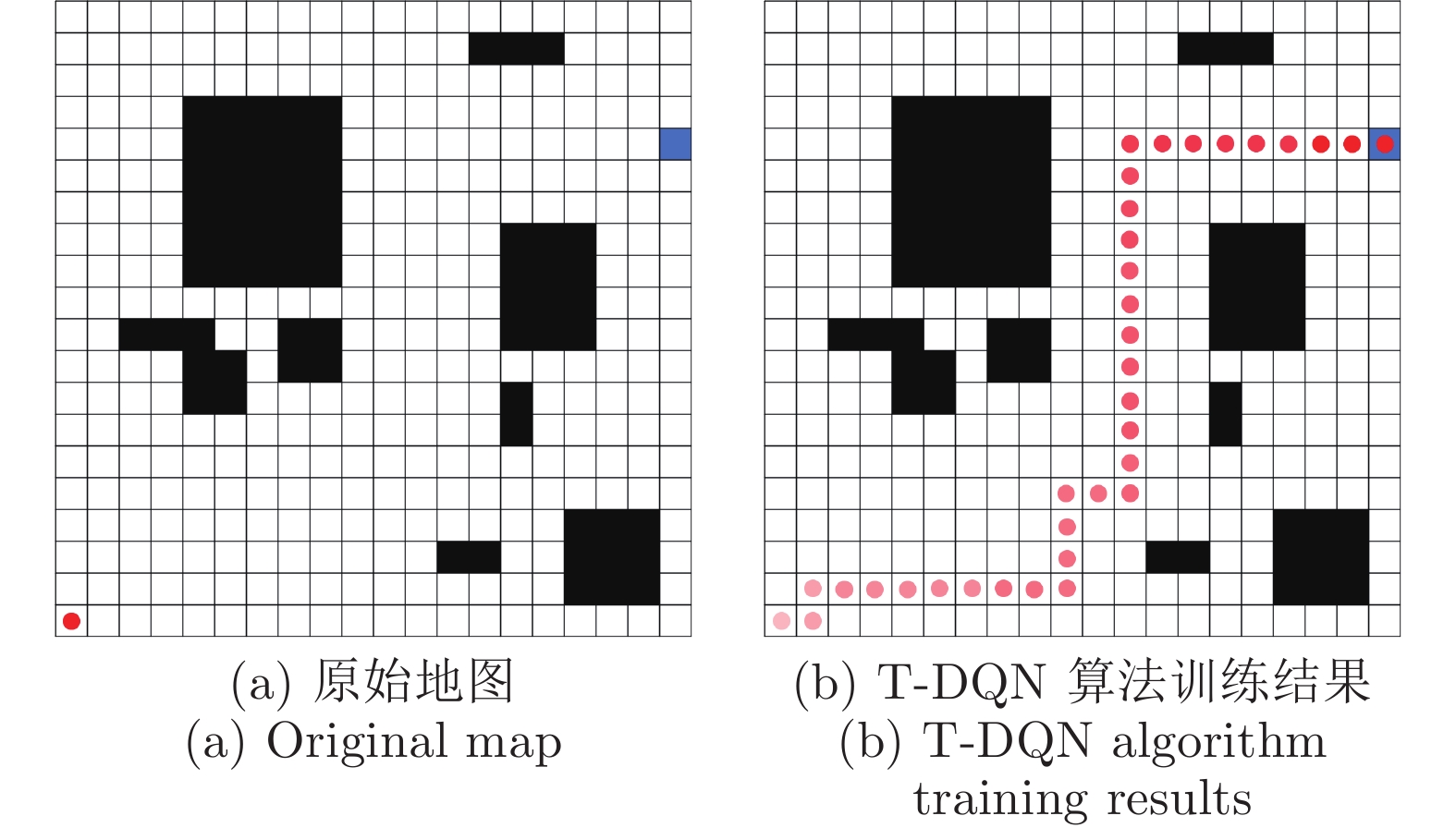
图 7 20 × 20栅格地图下采用T-DQN训练后的路径结果
Fig. 7 Path results after T-DQN training under 20 × 20 grid map
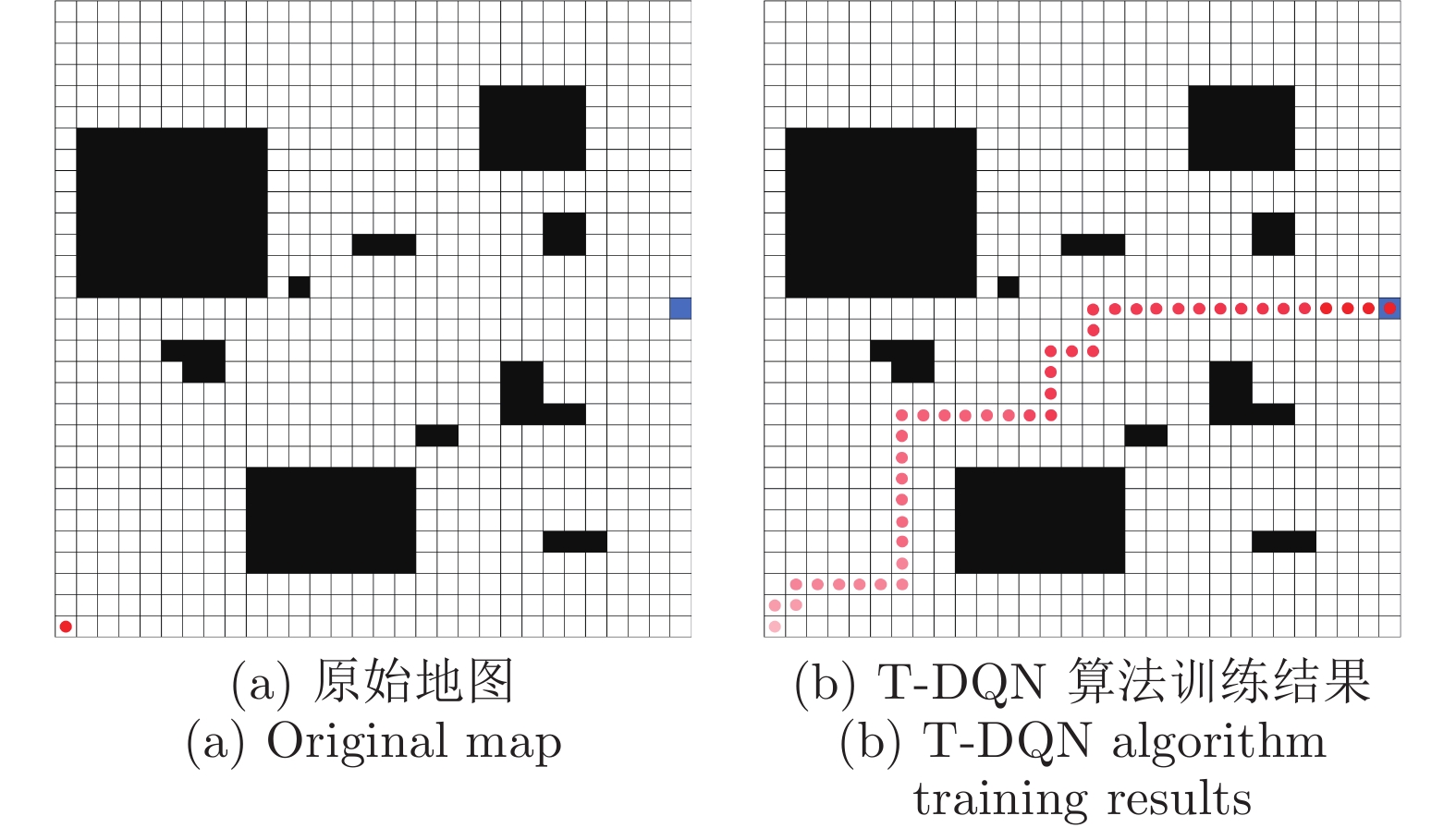
图 8 30 × 30栅格地图下采用T-DQN训练后的路径结果
Fig. 8 Path results after T-DQN training under 30 × 30 grid map
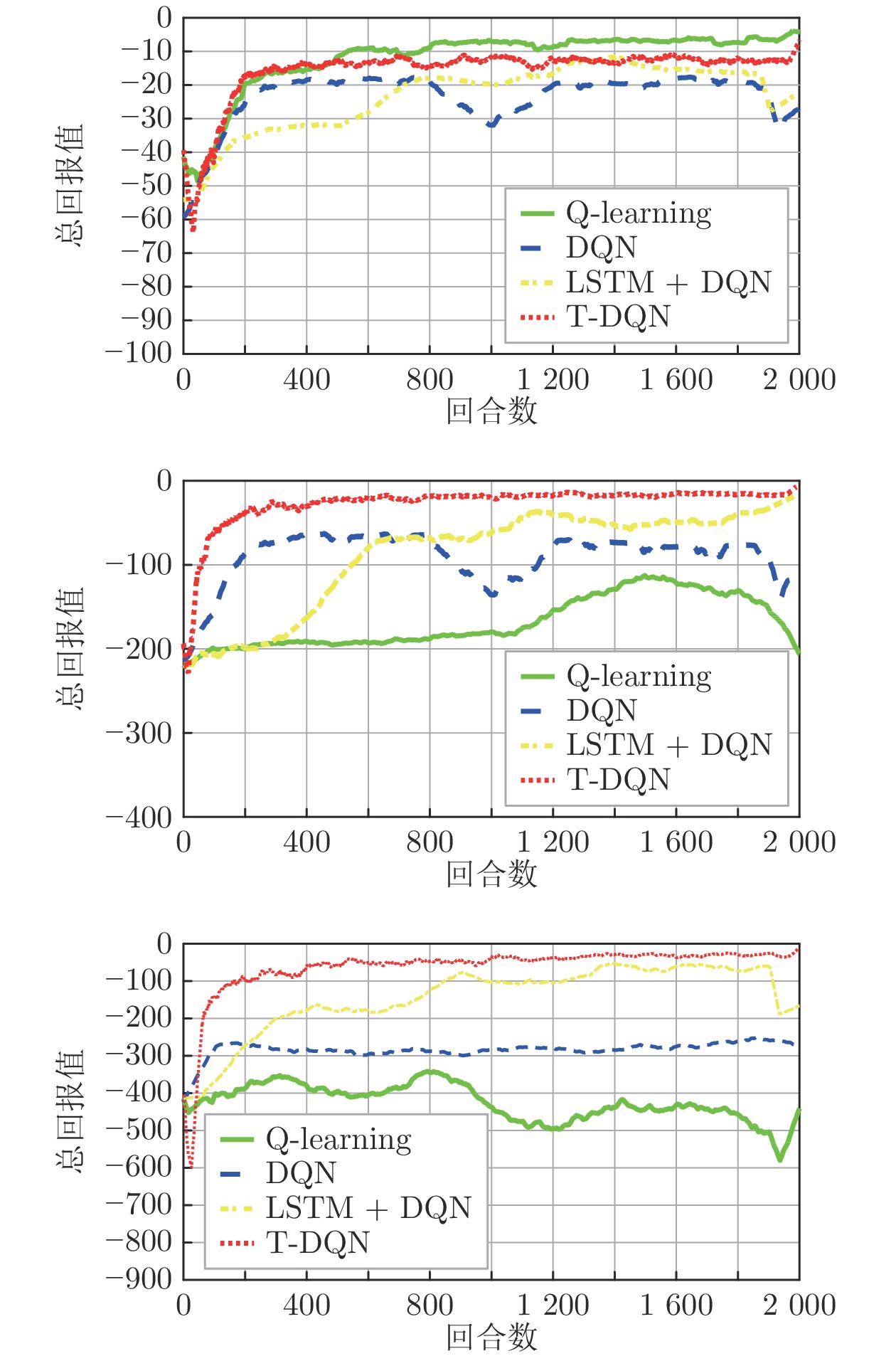
图 9 4种算法分别在10 × 10、20 × 20、30 × 30栅格地图下的平均回报值对比
Fig. 9 Comparison of the average return values of 4 algorithms under 10 × 10, 20 × 20, 30 × 30 grid maps
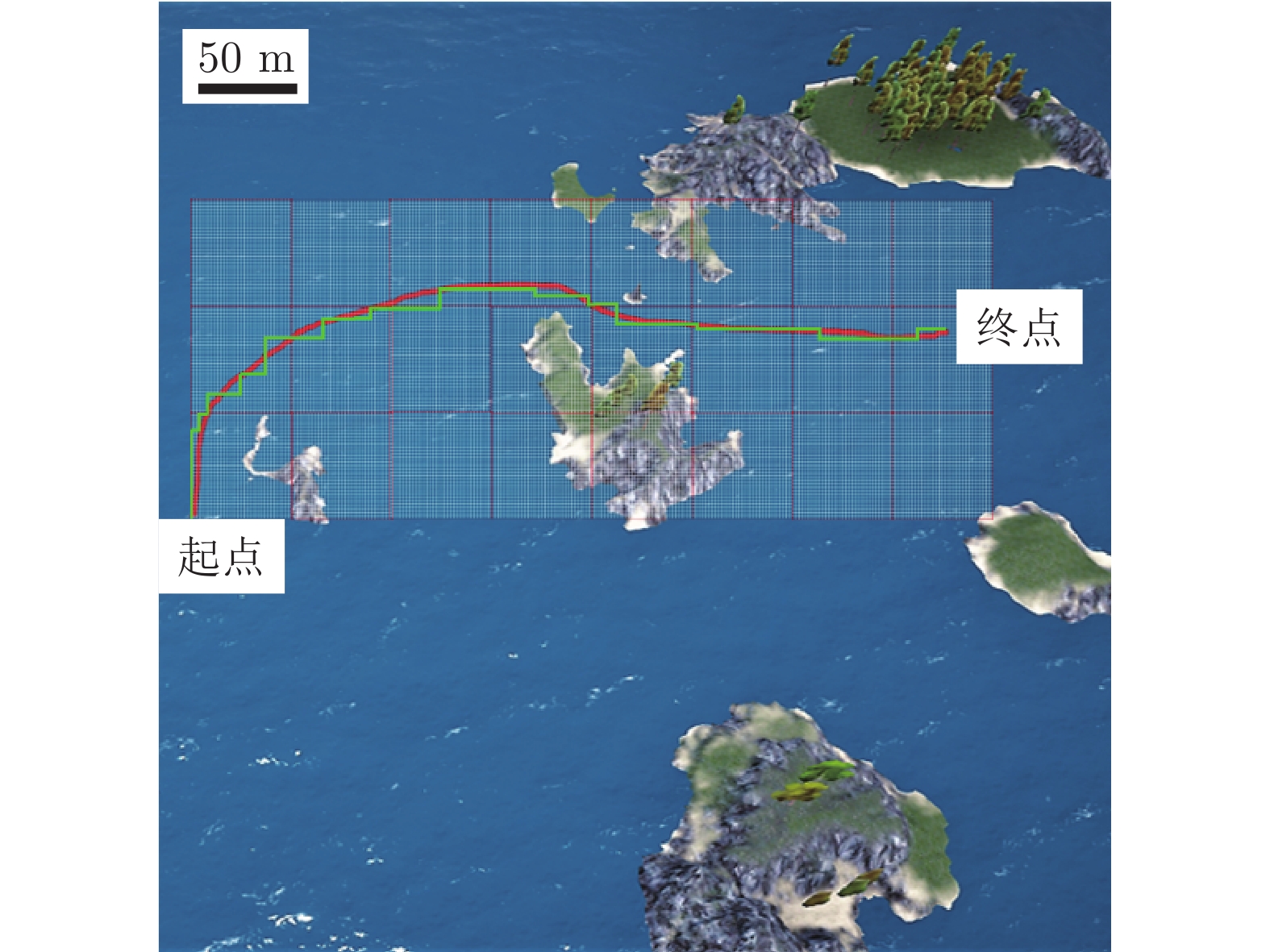
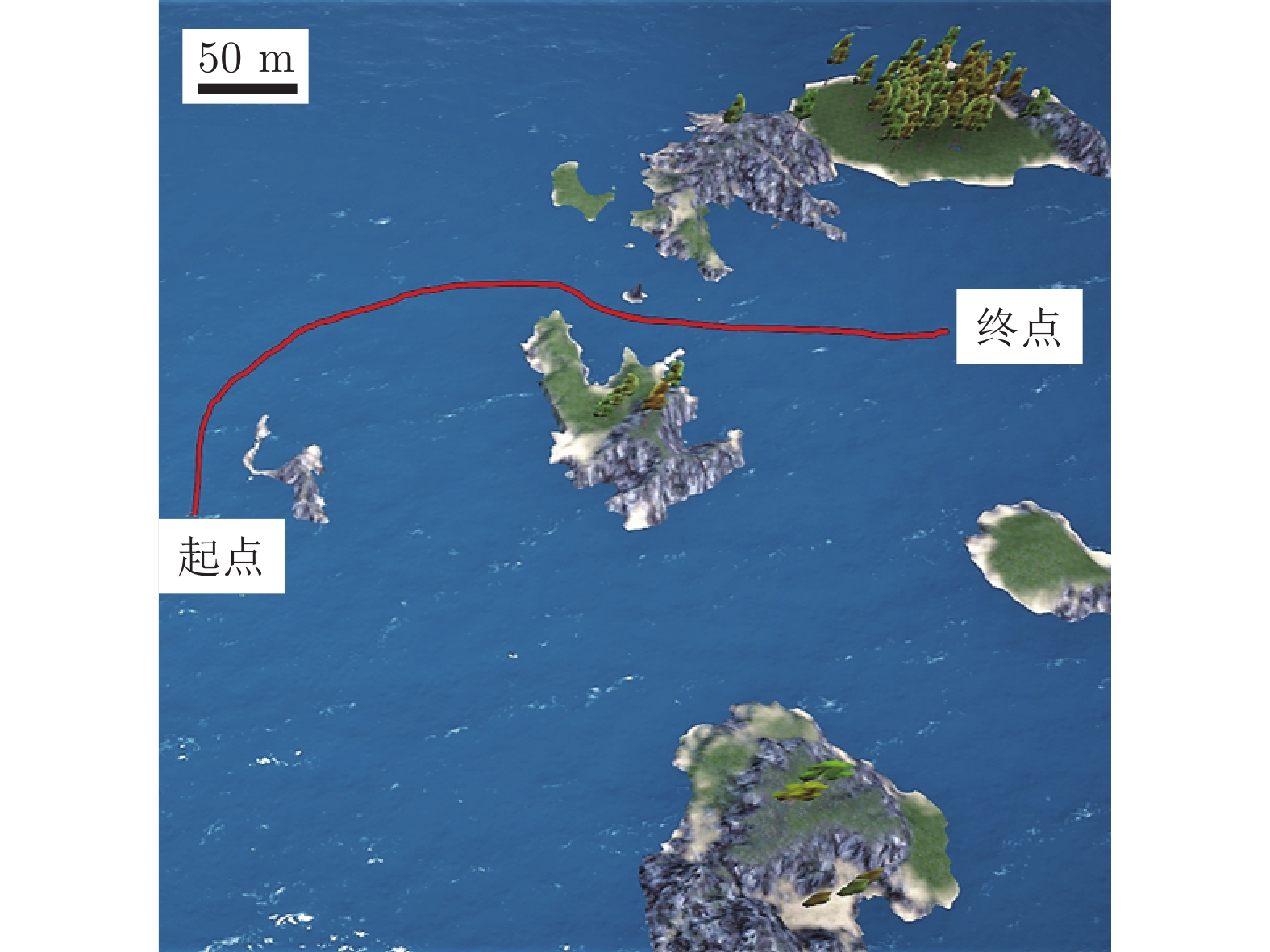
图 13 无人艇全局/局部路径规划仿真运动轨迹对比
Fig. 13 Comparison of global/local simulation trajectories of USV
表 1 4种算法收敛步数对比
Table 1 Comparison of convergence steps of 4 algorithms
算法 10 × 10
栅格地图20 × 20
栅格地图30 × 30
栅格地图Q-learning 888 > 2000 > 2000 DQN 317 600 > 2000 LSTM + DQN 750 705 850 T-DQN 400 442 517  下载: 导出CSV
下载: 导出CSV
-
[1] Tang PP, Zhang RB, Liu DL, Huang LH, Liu GQ, Deng TQ. Local reactive obstacle avoidance approach for high-speed unmanned surface vehicle. Ocean Engineering, 2015, 106: 128-140 doi: 10.1016/j.oceaneng.2015.06.055 [2] Campbell S, Naeem W, Irwin G W. A review on improving the autonomy of unmanned surface vehicles through intelligent collision avoidance manoeuvres. Annual Reviews in Control, 2012, 36(2): 267-283 doi: 10.1016/j.arcontrol.2012.09.008 [3] Liu ZX, Zhang YM, Yu X, Yuan C. Unmanned surface vehicles: An overview of developments and challenges. Annual Review in Control, 2016, 41: 71-93 doi: 10.1016/j.arcontrol.2016.04.018 [4] 张卫东, 刘笑成, 韩鹏. 水上无人系统研究进展及其面临的挑战. 自动化学报, 2020, 46(5): 847−857Zhang Wei-Dong, Liu Xiao-Cheng, Han Peng. Progress and challenges of overwater unmanned systems. Acta Automatica Sinica, 2020, 46(5): 847−857 [5] 范云生, 柳健, 王国峰, 孙宇彤. 基于异源信息融合的无人水面艇动态路径规划. 大连海事大学学报, 2018, 44(1): 9-16Fan Yun-Sheng, Liu Jian, Wang Guo-Feng, Sun Yu-Tong. Dynamic path planning for unmanned surface vehicle based on heterologous information fusion. Journal of Dalian Maritime University, 2018, 44(1): 9-16 [6] Zhan WQ, Xiao CS, Wen YQ, Zhou CH, Yuan HW, Xiu SP, Zhang YM, Zou X, Liu X, Li QL. Autonomous visual perception for unmanned surface vehicle navigation in an unknown environment. Sensors, 2019, 19(10): 2216 doi: 10.3390/s19102216 [7] Zhou CH, Gu SD, Wen YQ, Du Z, Xiao CS, Huang L, Zhu M. The review unmanned surface vehicle path planning: Based on multi-modality constraint. Ocean Engineering, 2020, 200: 107043 doi: 10.1016/j.oceaneng.2020.107043 [8] Yang X, Cheng W. AGV path planning based on smoothing A* algorithm. International Journal of Software Engineering and Applications, 2015, 6(5): 1-8 doi: 10.5121/ijsea.2015.6501 [9] Lozano-Pérez T, Wesley M A. An algorithm for planning collision-free paths among polyhedral obstacles. Communications of the ACM, 1979, 22(10): 560-570 doi: 10.1145/359156.359164 [10] 姚鹏, 解则晓. 基于修正导航向量场的AUV自主避障方法. 自动化学报, 2020, 46(08): 1670-1680Yao Peng, Xie Ze-Xiao. Autonomous obstacle avoidance for AUV based on modified guidance vector field. Acta Automatica Sinica, 2020, 46(08): 1670-1680 [11] 董瑶, 葛莹莹, 郭鸿湧, 董永峰, 杨琛. 基于深度强化学习的移动机器人路径规划. 计算机工程与应用, 2019, 55(13): 15-19+157 doi: 10.3778/j.issn.1002-8331.1812-0321Dong Yao, Ge Yingying, Guo Hong-Yong, Dong Yong-Feng, Yang Chen. Path planning for mobile robot based on deep reinforcement learning. Computer Engineering and Applications, 2019, 55(13): 15-19+157 doi: 10.3778/j.issn.1002-8331.1812-0321 [12] 吴晓光, 刘绍维, 杨磊, 邓文强, 贾哲恒. 基于深度强化学习的双足机器人斜坡步态控制方法. 自动化学报, 2020, 46(x): 1−12Wu Xiao-Guang, Liu Shao-Wei, Yang Lei, Deng Wen-Qiang, Jia Zhe-Heng. A gait control method for biped robot on slope based on deep reinforcement learning. Acta Automatica Sinica, 2020, 46(x): 1−12 [13] Szepesvári C. Algorithms for reinforcement learning. Synthesis Lectures on Artificial Intelligence and Machine Learning, 2010, 4(1): 1-103 [14] Sigaud O, Buffet O. Markov Decision Processes in Artificial Intelligence. Hoboken: John Wiley & Sons, 2013. 39−44 [15] 王子强, 武继刚. 基于RDC-Q学习算法的移动机器人路径规划. 计算机工程, 2014, 40(6): 211-214 doi: 10.3969/j.issn.1000-3428.2014.06.045Wang Zi-Qiang, Wu Ji-Gang. Mobile robot path planning based on RDC-Q learning algorithm. Computer Engineering, 2014, 40(6): 211-214 doi: 10.3969/j.issn.1000-3428.2014.06.045 [16] Silva Junior, A G D, Santos D H D, Negreiros A P F D, Silva J M V B D S, Gonçalves L M G. High-level path planning for an autonomous sailboat robot using Q-learning. Sensors, 2020, 20(6), 1550 doi: 10.3390/s20061550 [17] Kim B, Kaelbling L P, Lozano-Pérez T. Adversarial actor-critic method for task and motion planning problems using planning experience. In: Proceedings of the 33rd AAAI Conference on Artificial Intelligence. Honolulu, USA: 2019. 8017−8024 [18] Chen Y F, Liu M, Everett M, How J P. Decentralized non-communicating multi-agent collision avoidance with deep reinforcement learning. In: Proceedings of the IEEE international conference on robotics and automation. Singapore: IEEE, 2017. 285−292 [19] Tai L, Paolo G, Liu M. Virtual-to-real deep reinforcement learning: Continuous control of mobile robots for mapless navigation. In: Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems. Vancouver, Canada: IEEE, 2017. 31−36 [20] Zhang J, Springenberg J T, Boedecker J, Burgard W. Deep reinforcement learning with successor features for navigation across similar environments. In: Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems. Vancou-ver, Canada: IEEE, 2017. 2371−2378 [21] Matthew H, Stone P. Deep recurrent Q-learning for partially observable MDPs. arXiv preprint arXiv: 1507.06527, 2015. [22] Liu F, Chen C, Li Z, Guan Z, Wang H. Research on path planning of robot based on deep reinforcement learning. In: Proceedings of the 39th Chinese Control Conference. Shenyang, China: IEEE, 2020. 3730−3734 [23] Wang P, Chan C Y. Formulation of deep reinforcement learning architecture toward autonomous driving for on-ramp merge. In: Proceedings of the IEEE 20th International Conference on Intelligent Transportation Systems. Yokohama, Japan: IEEE, 2017. 1−6 [24] Deshpande N, Vaufreydaz D, Spalanzani A. Behavioral decision-making for urban autonomous driving in the presence of pedestrians using deep recurrent Q-network. In: Proceedings of the 16th International Conference on Control, Automation, Robotics and Vision. Shenzhen, China: IEEE, 2020. 428−433 [25] Peixoto M J P, Azim A. Context-based learning for autonomous vehicles. In: Proceedings of the IEEE 23rd International Symposium on Real-time Distributed Computing. Nashville, USA: IEEE, 2020. 150−151 [26] Degris T, Pilarski P M, Sutton R S. Model-free reinforcement learning with continuous action in practice. In: Proceedings of the American Control Conference. Montreal, Canada: IEEE, 2012. 2177−2182 [27] Gao N, Qin Z, Jing X, Ni Q, Jin S. Anti-Intelligent UAV jamming strategy via deep Q-Networks. IEEE Transactions on Communications, 2019, 68(1): 569-581 [28] Mnih V, Kavukcuoglu K, Silver D. Playing atari with deep reinforcement learning. arXiv preprint arXiv: 1312.5602, 2013. [29] Mnih V, Kavukcuoglu K, Silver D. Human-level control through deep reinforcement learning. Nature, 2015, 518(7540): 529-533 doi: 10.1038/nature14236 [30] Zhang CL, Liu XJ, Wan DC, Wang JB. Experimental and numerical investigations of advancing speed effects on hydrodynamic derivatives in MMG model, part I: X-vv, Y-v, N-v. Ocean Engineering, 2019, 179: 67-75 doi: 10.1016/j.oceaneng.2019.03.019 -

 下载:
下载:




计量
- 文章访问数: 4160
- HTML全文浏览量: 1457
- PDF下载量: 626
- 被引次数: 0
