

-
摘要: 跨光谱人脸检测在活体人脸识别、体温筛查等领域有着重要的应用价值. 众所周知, 可见光人脸易于检测, 然而红外人脸难于检测, 因此借助可见光图像的人脸检测结果进而完成红外人脸检测是一种有效的解决方案. 但是跨光谱图像之间不可避免的存在偏差, 导致检测精度不高. 为了解决这一问题, 提出了一种弱对齐跨光谱图像的人脸检测算法, 该方法基于跨光谱图像之间的偏差设计了候选框布置策略, 并在此基础上提出了跨光谱特征表示方法用于选取最优候选框. 此外, 本文还构建了一个跨光谱人脸数据集. 最后, 在跨光谱人脸数据集和OTCBVS人脸数据集上的实验结果证明, 该方法能够较好地完成红外图像人脸检测任务.Abstract: Cross-spectral face detection has important application value in the field of face spoof detection and body temperature screening. It is known that it is easy to detect faces in visible light images. However, it is a challenge problem to localize faces accurately in infrared images. Therefore, it is an effective solution to complete infrared face detection based on the face detection results of visible light images. The result of above scheme is nevertheless unsatisfactory since there are unavoidable deviations between cross-spectral images. To solve this problem, this paper proposes a novel face detection algorithm based on weakly aligns cross-spectral images. This method designs the dispatch scheme of candidate box based on the deviation between cross-spectral images, and thus proposes a cross-spectral feature representation method to select the best candidate box. In addition, this paper also constructed a cross-spectral face dataset. Finally, the experimental results on the cross-spectral face and OTCBVS face datasets demontrate that the proposed method can complete the task of infrared image face detection well over the competed methods.
-
Key words:
- Weakly aligned /
- cross-spectral /
- face detection /
- computer vision
-
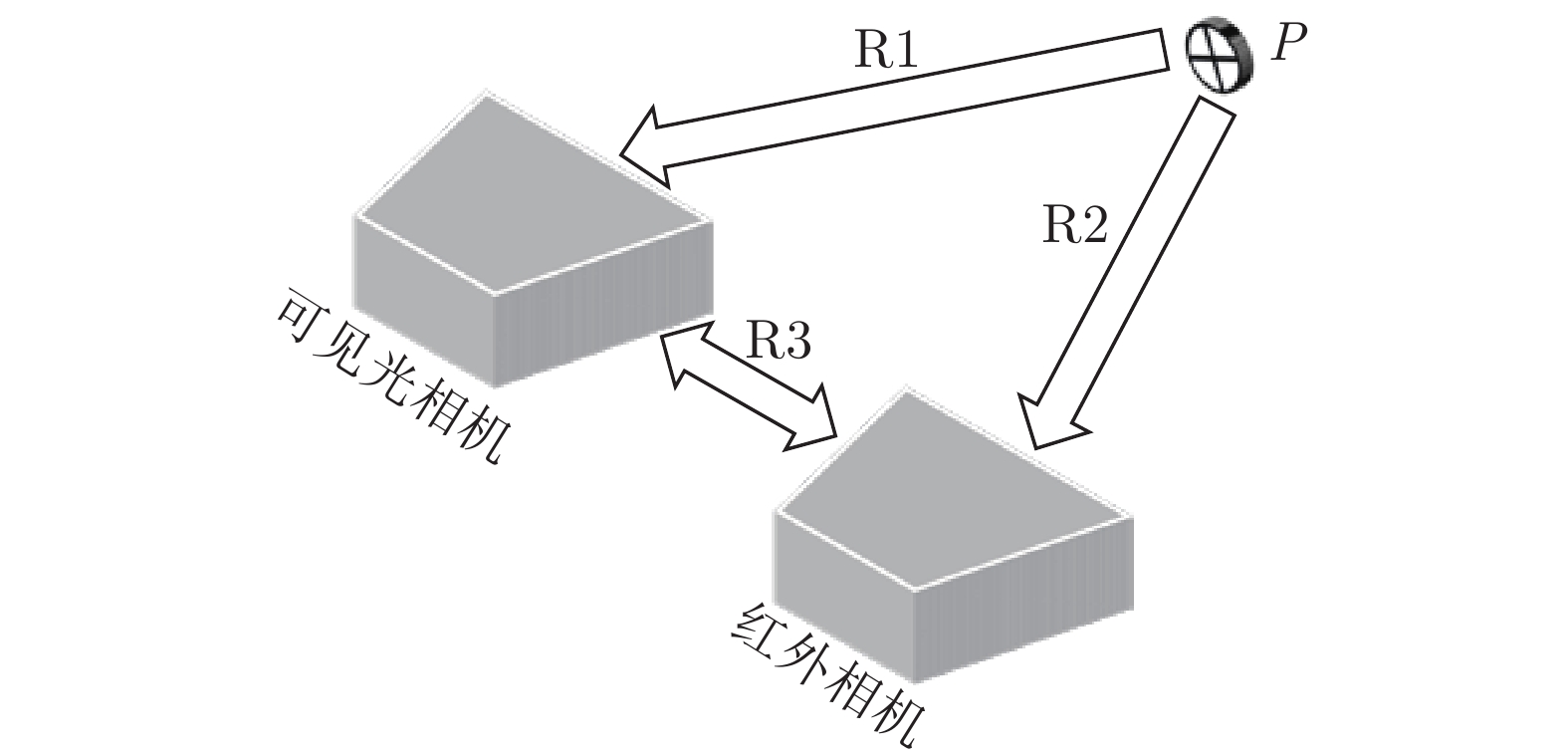
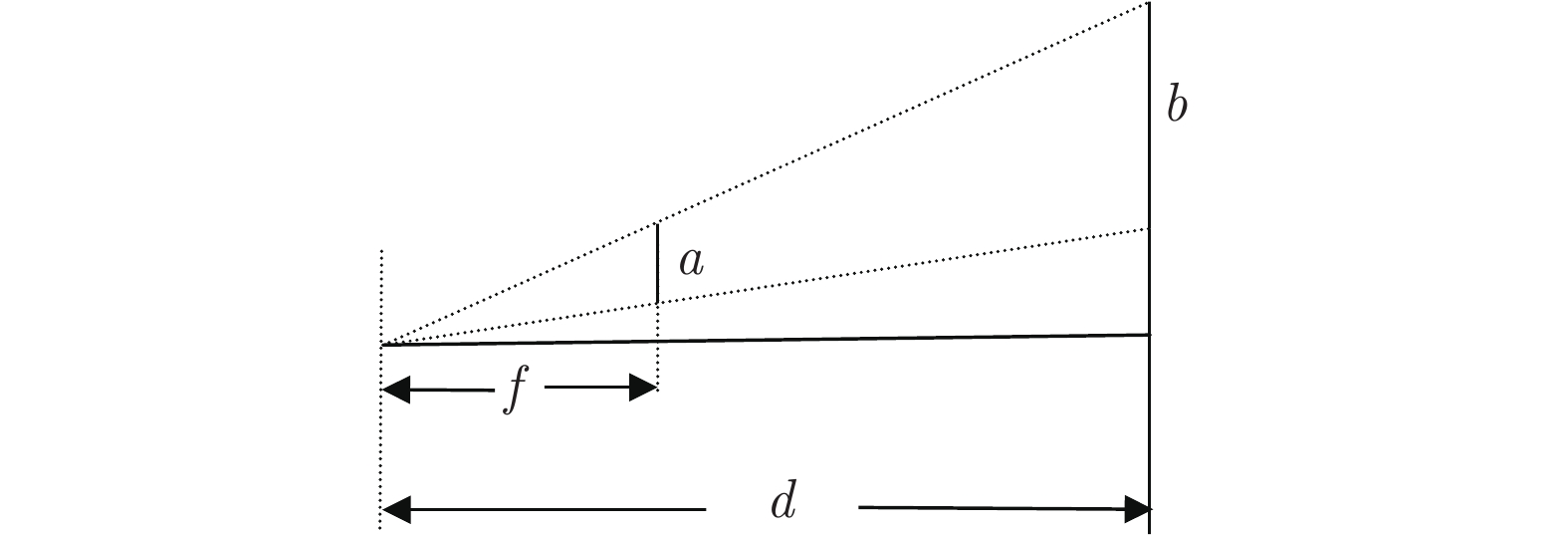
图 2 双相机与空间内任意一点的关系
Fig. 2 The relationship between dual cameras and any point in space
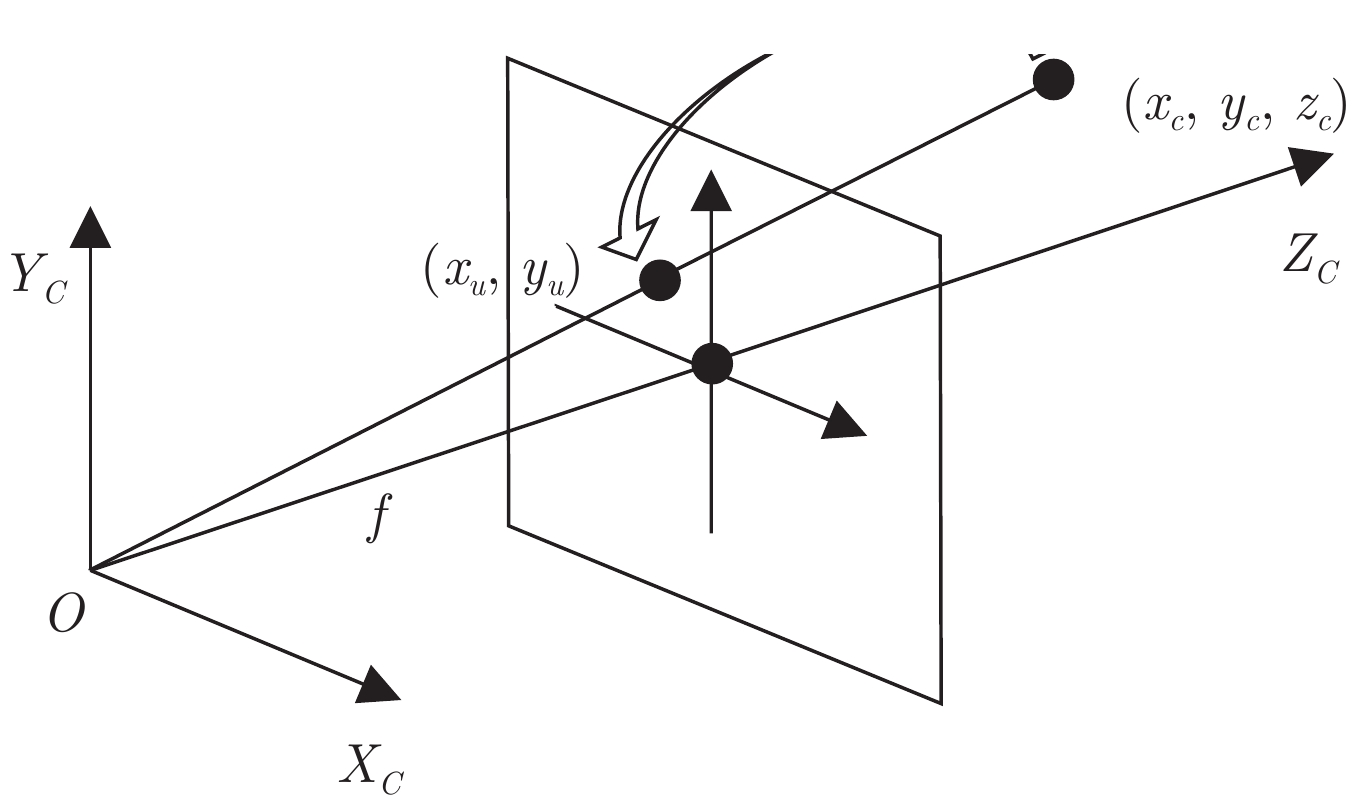
图 3 空间中任意一点在相机中的成像坐标
Fig. 3 The imaging coordinates of any point in space in the camera
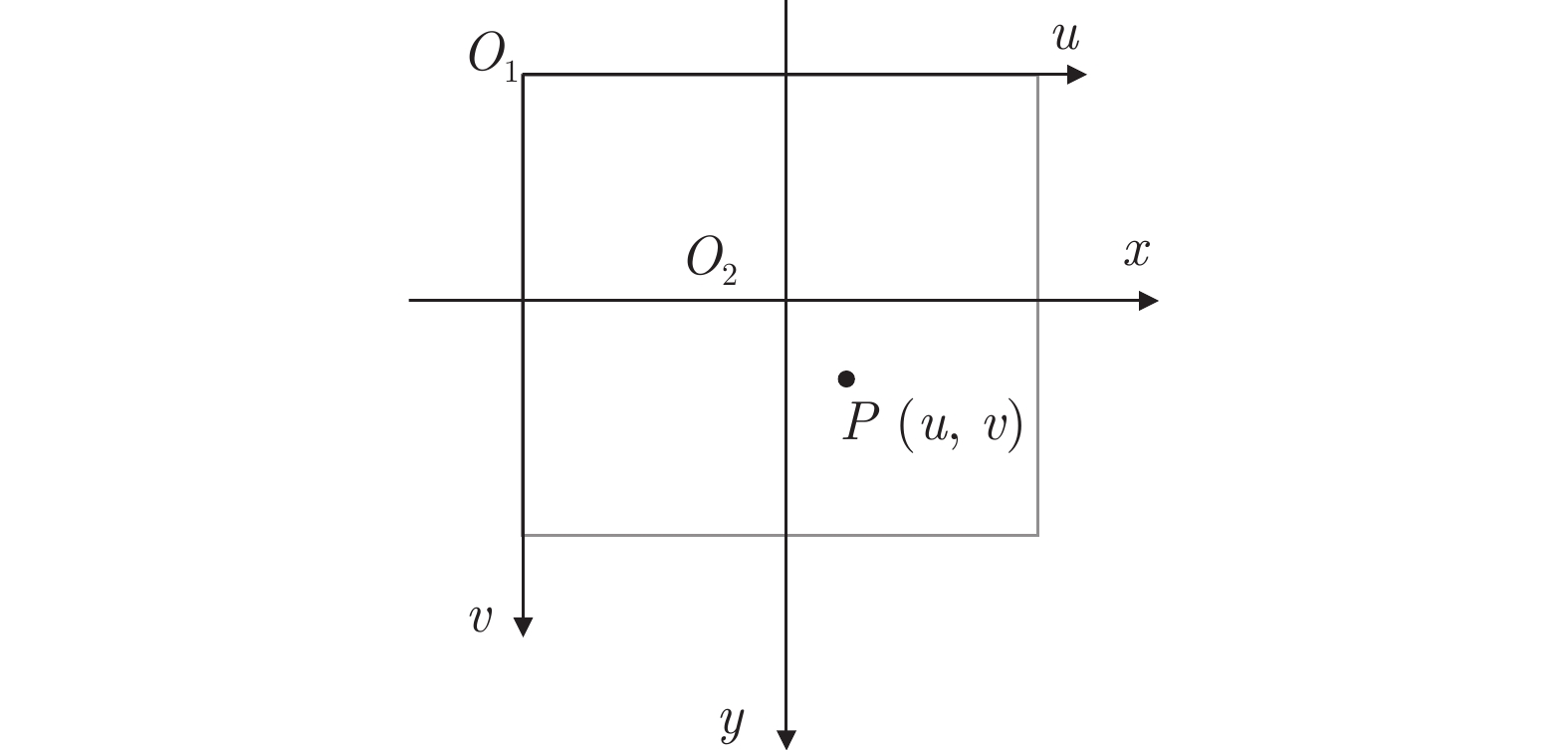
图 4 像素坐标系与图像坐标系的关系
Fig. 4 The relationship between pixel coordinate system and image coordinate system
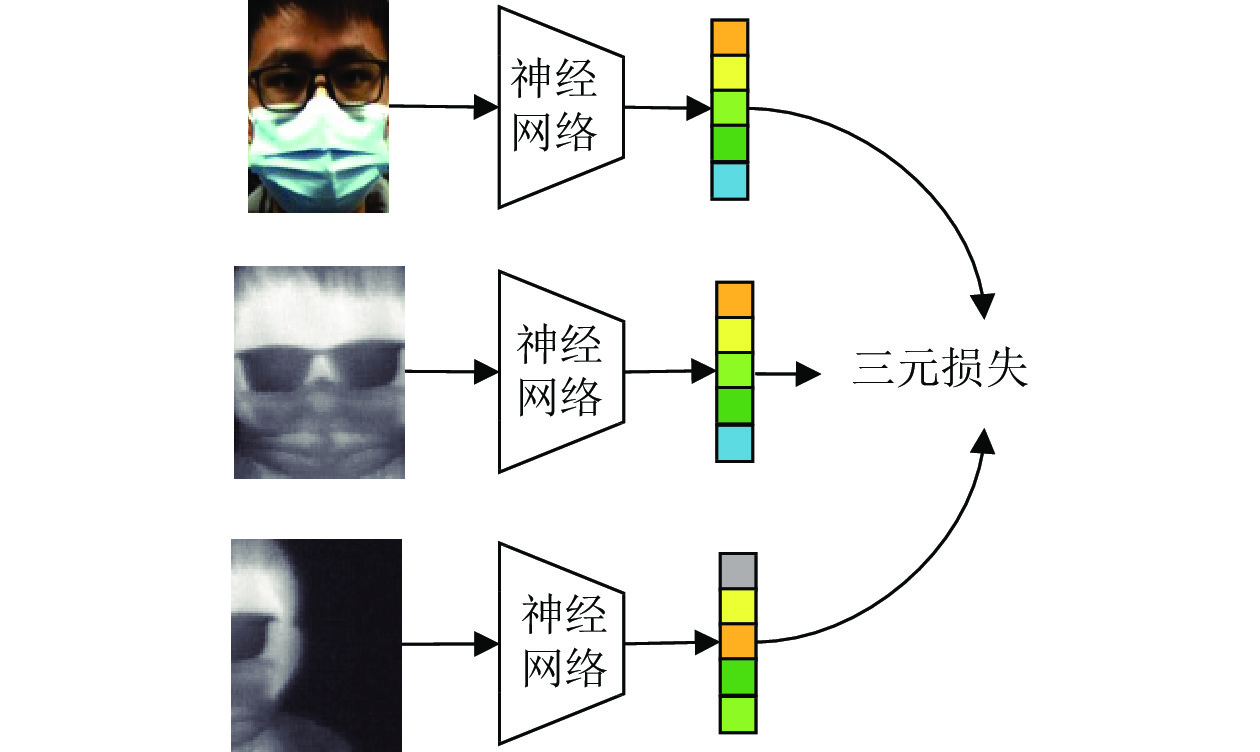
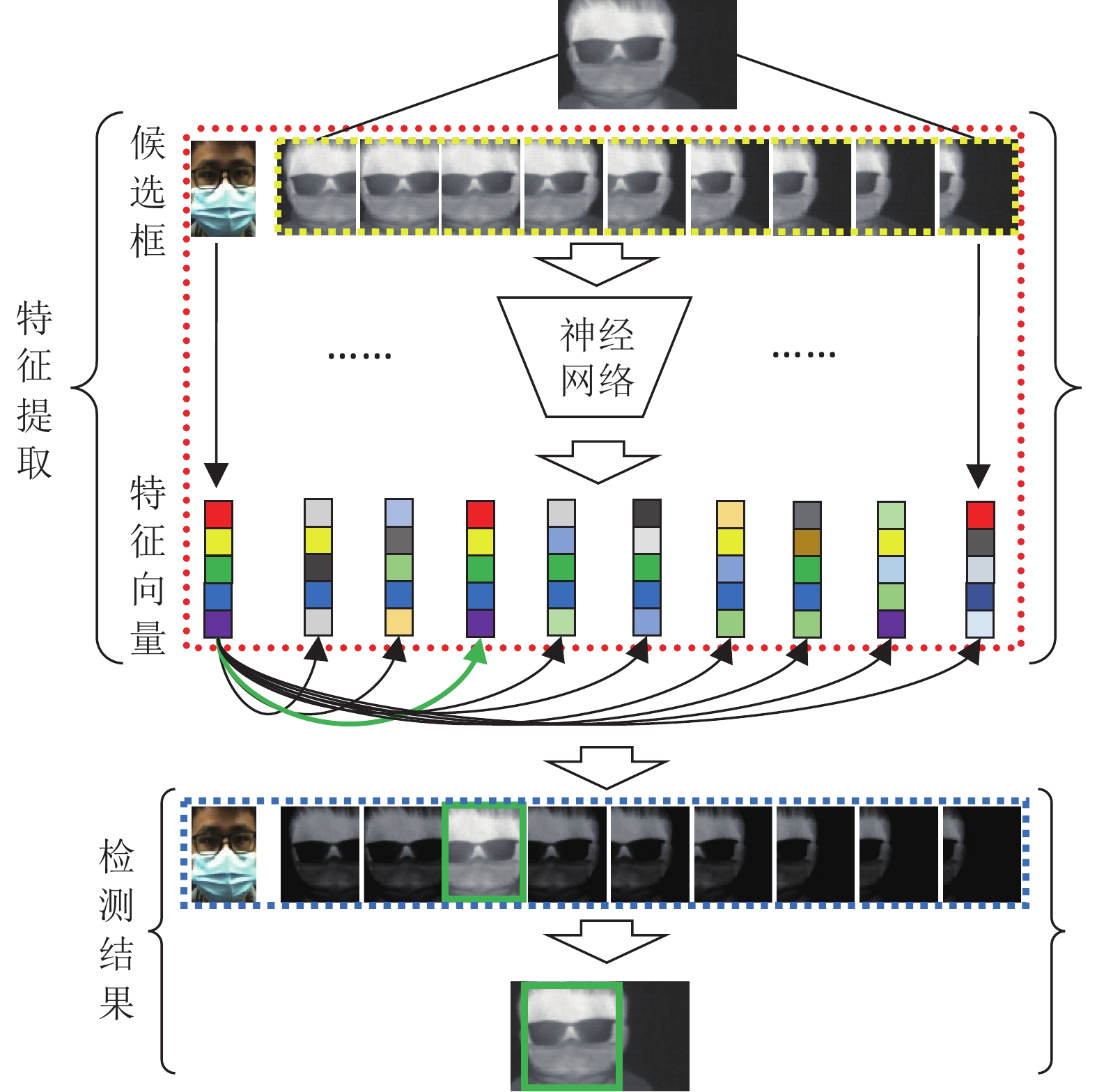
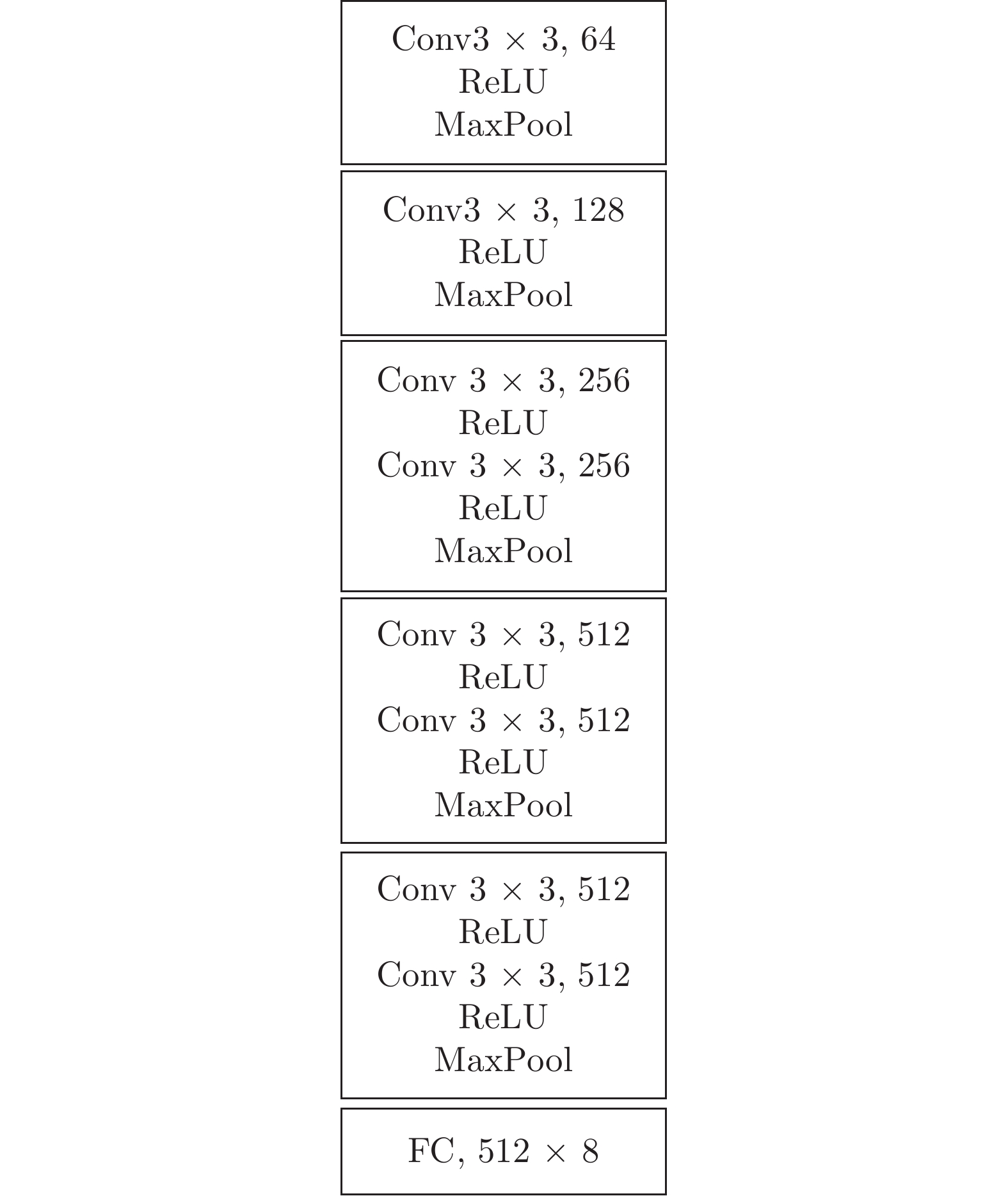
图 10 跨光谱特征表示网络训练方式
Fig. 10 Cross-spectral feature representation network training method
表 1 测试集为CSF-白天的实验结果
Table 1 Experiment results on CSF-day
算法 IoU > 0.5 时 AP (%) IoU > 0.3 时 AP (%) 坐标映射 44.6 88.4 粗略纠正 55.9 87.9 本文算法 87.5 89.6  下载: 导出CSV
下载: 导出CSV
表 2 测试集为CSF-夜间的实验结果
Table 2 Experiment results on CSF-night
算法 IoU > 0.5 时 AP (%) IoU > 0.3 时 AP (%) 坐标映射 36.9 82.7 粗略纠正 50.8 82.4 本文算法 81.8 84.1
下载: 导出CSV
表 3 测试集为OTCBVS的实验结果
Table 3 Experiment results on OTCBVS
算法 IoU > 0.5 时 AP (%) IoU > 0.3 时 AP (%) 坐标映射 16.4 46.8 粗略纠正 54.5 76.5 本文算法 74.4 86.6
下载: 导出CSV
表 5 CSF中候选框的选取对模型的影响
Table 5 Influence of the selection of the proposal on the model in CSF
候选框 IoU > 0.5 时 AP (%) 时间 (ms) 1/8 71.4 9 1/8, 2/8 84.8 16 1/8, 2/8, 3/8 86.3 23 1/8, $\cdots , 4/8$ 86.4 28
下载: 导出CSV
表 6 OTCBVS中候选框的选取对模型的影响
Table 6 Influence of the selection of the proposal on the model in OTCBVS
候选框 IoU > 0.5 时 AP (%) 时间 (ms) 1/8 70.5 10 1/8, 2/8 73.1 16 1/8, 2/8, 3/8 74.2 24 1/8, $\cdots, 4/8$ 74.4 30
下载: 导出CSV
表 7 负样本类型对模型精度的影响
Table 7 Effect of negative sample type on model accuracy
负样本类型 IoU > 0.5 时 AP (%) 0 46.1 4/8 70.5 5/8 69.7 6/8 47.1 7/8 21.5 0, 4/8, 5/8, 6/8, 7/8 86.4
下载: 导出CSV
表 8 CSF数据集上的对比实验结果
Table 8 Comparative experiment results on CSF dataset
算法 IoU > 0.5 时 AP (%) IoU > 0.3 时 AP (%) FaceBoxes 9.1 9.1 S3FD 9.1 9.1 Pyramidbox 35.9 36.3 DSFD 35.8 36.3 Tinyface 56.5 82.4 S3FD-IR 72.3 73.4 DSFD-IR 81.9 83.7 DSFD-本文算法 86.4 88.5
下载: 导出CSV
表 9 OTCBVS数据集上的对比实验结果
Table 9 Comparative experiment results on OTCBVS dataset
算法 IoU > 0.5 时 AP (%) IoU > 0.3 时 AP (%) FaceBoxes — — S3FD 9.1 9.1 Pyramidbox 36.1 36.1 DSFD 27.2 27.2 Tinyface 25.1 38.6 S3FD-IR 60.8 73.6 DSFD-IR 69.4 70.4 DSFD-本文算法 75.0 86.3
下载: 导出CSV
-
[1] Bilodeau G A, Torabi A, St-Charles P L, Riahi D. Thermal–visible registration of human silhouettes: A similarity measure performance evaluation. Infrared Physics & Technology, 2014, 64: 79-86. [2] Rowley H A, Baluja S, Kanade T. Neural network-based face detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1998, 20(1), 23-38. doi: 10.1109/34.655647 [3] Rowley H A, Baluja S, Kanade T. Rotation invariant neural network-based face detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Santa Barbara, USA: IEEE, 1998. 38−44 [4] Viola P, Jones M J. Robust Real-Time Face Detection. International Journal of Computer Vision, 2004, 57(2): 137-154. doi: 10.1023/B:VISI.0000013087.49260.fb [5] Li S Z, Zhu L, Zhang Z, Blake A, Zhang H, Shum H. Statistical learning of multi-view face detection. In: Proceedings of the 7th European Conference on Computer Vision. Berlin, Germany: 2002. 67−81 [6] Mathias M, Benenson R, Pedersoli M, Van Gool L. Face detection without bells and whistles. In: Proceedings of the 13rd European Conference on Computer Vision. Zurich, Switzerland: 2014. 720−735 [7] Li Q, Sun Z, He R, Tan T. Learning symmetry features for face detection based on sparse group lasso. In: Proceedings of the Chinese Conference on Biometric Recognition. Jinan, China: 2013. 162−169 [8] Li J, Wang Y, Wang C, Tai Y, Qian J, Yang J, et al. DSFD: Dual shot face detector. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Seattle, USA: IEEE, 2020. 5055−5064 [9] Zhang S, Zhu X, Lei Z, Shi H, Wang X, Li S Z, et al. S3FD: Single shot scale-invariant face detector. In: Proceedings of the IEEE International Conference on Computer Vision. Venice, Ita-ly: IEEE, 2017. 192−201 [10] Bai Y, Zhang Y, Ding M, Ghanem B. Finding tiny faces in the wild with generative adversarial network. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 21–30 [11] Zhang S, Wen L, Shi H, Lei Z, Lyu S, Li S Z. Single-Shot Scale-Aware Network for Real-Time Face Detection. International Journal of Computer Vision, 2019, 127(6-7): 537-559. doi: 10.1007/s11263-019-01159-3 [12] Zhang S, Zhu X, Lei Z, Shi H, Wang X, Li S Z. Faceboxes: A CPU real-time face detector with high accuracy. In: Proceedin-gs of the IEEE International Joint Conference on Biometrics. Denver, USA: IEEE, 2017. 1−9 [13] Tang X, Du D K, He Z, Liu J. Pyramidbox: A context-assisted single shot face detector. In: Proceedings of the 15th European Conference on Computer Vision. Munich, Germany: 2018. 797− 813 [14] Yang S, Luo P, Loy C C, Tang X. Wider face: A face detection benchmark. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016. 525−5533 [15] C. Ma, T Ngo, U Hideaki, N Hajime, S. Atsushi, T Rin-Ichiro. Adapting local features for face detection in thermal image. Sensors, 2017, 17(12): 2741-. [16] Kyal C K, Poddar H, Reza M. Detection of human face by thermal infrared camera using MPI model and feature extraction method. In: Proceedings of the 4th International Conference on Computing Communication and Automation. Greater Noida, India: IEEE, 2018. 1−5 [17] Budzan S, Wyżgolik R. Face and eyes localization algorithm in thermal images for temperature measurement of the inner canthus of the eyes. Infrared Physics & Technology, 2013, 60: 225-234. [18] Ribeiro R F, Fernandes J M, Neves A J R. Face detection on infrared thermal image. In: Proceedings of the 2nd International Conference on Advances in Signal Image and Video Processing. Barcelona, Spain: 2017. 38–42 [19] Goulart C, Valadão C, Delisle-Rodriguez D, Funayama D, Favarato A, Baldo G, et al. Visual and Thermal Image Processing for Facial Specific Landmark Detection to Infer Emotions in a Child-Robot Interaction. Sensors, 2019, 19(13): 2844. doi: 10.3390/s19132844 [20] Somboonkaew A, Prempree P, Vuttivong S, Wetcharungsri J, Porntheeraphat S, Chanhorm S, et al. Mobile-platform for automatic fever screening system based on infrared forehead temperature. In: Proceedings of the IEEE Opto-Electronics and Communications Conference and Photonics Global Conference. Sing-apore, Singapore: IEEE, 2017. 1−4 [21] Mallat K, Dugelay J L. A benchmark database of visible and thermal paired face images across multiple variations. In: Proceedings of the IEEE International Conference of the Biometrics Special Interest Group. Darmstadt, Germany: IEEE, 2018. 1−5 [22] Panetta K, Wan Q, Agaian S, Rajeev S, Kamath S, Rajendran R, et al. A comprehensive database for benchmarking imaging systems. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 42(3): 509-520. [23] Hwang S, Park J, Kim N, Choi Y, So Kweon I. Multispectral pedestrian detection: Benchmark dataset and baseline. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Boston, USA: IEEE, 2015. 1037−1045 [24] 张秀伟, 张艳宁, 杨涛, 等. 基于Co-motion的可见光--热红外图像序列自动配准算. 自动化学报, 2010, 36(009): 1220-1231. doi: 10.3724/SP.J.1004.2010.01220Zhang Xiu-Wei, Zhang Yan-Ning, Yang Tao, Zhang Xin-Gong, Shao Da-Pei. Automatic Visual-thermal Image Sequence Registration Based on Co-motion. Acta Automatica Sinica, 2010, 36(009): 1220-1231. doi: 10.3724/SP.J.1004.2010.01220 [25] 高雪琴, 刘刚, 肖刚, 等. 基于FPDE的红外与可见光图像融合算法[J]. 自动化学报, 2020, v. 46(04): 186-194.Gao Xue-Qin, Liu Gang, Xiao Gang, Bavirisetti Durga Prasad, SHI Kai-Lei. Fusion Algorithm of Infrared and Visible Images Based on FPDE. Acta Automatica Sinica, 2020, v. 46(04): 186-194. [26] 廉蔺, 李国辉, 张军, 涂丹. 基于边缘最优映射的红外和可见光图像自动配准算. 自动化学报, 2012, 38(04): 570-581. doi: 10.3724/SP.J.1004.2012.00570Lian Lin, Li Guo-Hui, Zhang Jun, Tu Dan. An Automatic Registration Algorithm of Infrared and Visible Images Based on Optimal Mapping of Edges. Acta Automatica Sinica, 2012, 38(04): 570-581. doi: 10.3724/SP.J.1004.2012.00570 [27] (刘松涛, 刘振兴, 姜宁. 基于融合显著图和高效子窗口搜索的红外目标分. 自动化学报, 2018, 44(012): 2210-2221).Liu Song-Tao, Liu Zhen-Xing, Jiang Ning. Target Segmentation of Infrared Image Using Fused Saliency Map and Efficient Subwindow Search. Acta Automatica Sinica, 2018, 44(012): 2210-2221. [28] (袁浩期, 李扬, 王俊影, 等. 基于红外热像的行人面部温度高精度检测技术. 红外技术, 2019, v. 41;No. 324(12): 94-99).Yuan Hao-qi, Li Yang, Wang Jun-Ying, Liu Hang. High Precision Detection Technology of Pedestrian Face Temperature Based on Infrared Thermal Imaging. Infrared Technology, 2019, v. 41;No. 324(12): 94-99. [29] Zhi T, Pires B R, Hebert M, Narasimhan S. G. Deep material-aware cross-spectral stereo matching. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 1916−1925 [30] Liang M, Guo X, Li H, Wang X, Song, Y. Unsupervised cross-spectral stereo matching by learning to synthesize. In: Proceedings of the AAAI Conference on Artificial Intelligence. Honolulu, USA: 2019. 8706−8713 [31] Zhang L, Zhu X, Chen X, Yang X, Lei Z, Liu Z. Weakly aligned cross-modal learning for multispectral pedestrian detection. In: Proceedings of the IEEE International Conference on Computer Vision. Seoul, South Korea: IEEE, 2019. 5127−5137 [32] Dwith Chenna Y N, Ghassemi P, Pfefer T J, Casamento J, Wang Q. Free-Form Deformation Approach for Registration of Visible and Infrared Facial Images in Fever Screening. Sensors, 2018, 18(2): 125. doi: 10.3390/s18010125 [33] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. arXiv preprint, 2014, arXiv: 1409.1556 [34] Schroff F, Kalenichenko D, Philbin J. FaceNet: A unified embedding for face recognition and clustering. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Boston, USA: IEEE, 2015. 815−823 -

 下载:
下载:








计量
- 文章访问数: 1708
- HTML全文浏览量: 496
- PDF下载量: 264
- 被引次数: 0
