

On Imitation Learning of Robot Movement Trajectories: A Survey
Author Bio:
HUANG Yan-Long University academic fellow at the School of Computing, University of Leeds, Leeds, UK. His interest covers imitation learning, reinforcement learning and motion planning. Corresponding author of this paper
XU De Professor at the Institute of Automation, Chinese Academy of Sciences. He received his bachelor and master degrees from Shandong University of Technology in 1985 and 1990, respectively. He received his Ph. D. degree from Zhejiang University in 2001. His research interest covers robotics and automation, such as visual measurement, visual control, intelligent control, visual positioning, microscopic vision, and microassembly
TAN Min Professor at the State Key Laboratory of Management and Control for Complex Systems, Institute of Automation, Chinese Academy of Sciences. His research interest covers robotics and intelligent control systems







-
摘要: 作为机器人技能学习中的一个重要分支, 模仿学习近年来在机器人系统中得到了广泛的应用. 模仿学习能够将人类的技能以一种相对直接的方式迁移到机器人系统中, 其思路是先从少量示教样本中提取相应的运动特征, 然后将该特征泛化到新的情形. 本文针对机器人运动轨迹的模仿学习进行综述. 首先详细解释模仿学习中的技能泛化、收敛性和外插等基本问题; 其次从原理上对动态运动基元、概率运动基元和核化运动基元等主要的模仿学习算法进行介绍; 然后深入地讨论模仿学习中姿态和刚度矩阵的学习问题、协同和不确定性预测的问题以及人机交互中的模仿学习等若干关键问题; 最后本文探讨了结合因果推理的模仿学习等几个未来的发展方向.Abstract: As a promising direction in the community of robot learning, imitation learning has achieved great success in a myriad of robotic systems. Imitation learning is capable of providing a straightforward way to transfer human skills to robots by extracting motion features from few demonstrations and subsequently employing them to new scenarios. This paper will review literature on trajectory learning by imitation for robots. The basic problems in imitation learning are first described in detail, such as skill adaptation, convergence and extrapolation. After that, state-of-the-art approaches are introduced, including dynamical movement primitives, probabilistic movement primitives and kernelized movement primitives. Later, various key problems are explained at length, e.g., learning of orientations and stiffness matrices, synergy and uncertainty prediction, as well as imitation learning in human-robot interaction. Finally, the possible future directions of imitation learning, for instance, the combination of imitation learning and causal inference, are discussed.
-
Key words:
- Robot learning /
- imitation learning /
- movement primitive /
- trajectory learning
1) 1 在一些文献中轨迹的模仿学习被归类为BC, 然而考虑到其研究内容的差异, 本文采用不同的划分方式.2) 2 将式(2)中的$ \boldsymbol{{s}} $ 和$ \boldsymbol{{\xi}} $ 分别用$ \boldsymbol{{\xi}} $ 和$ \dot{\boldsymbol{{\xi}}} $ 进行替换即可.3) 3 该协方差可以控制自适应轨迹经过期望点$ \boldsymbol{{\mu}}_t^{*} $ 的误差:$ \boldsymbol{{\Sigma}}_t^{*} $ 越小则误差越小, 反之则误差变大.4 根据文献([35], 第3.6节), 固定基函数的数量常随输入变量维度的增加呈指数级增加.5 关于从GMM中采样的方法可以参考文献[59].4) 4 根据文献([35], 第3.6节), 固定基函数的数量常随输入变量维度的增加呈指数级增加.5) 5 关于从GMM中采样的方法可以参考文献[59].6) 6 对于期望点输入和参考轨迹存在重叠的情况, 可参考文献[6]中的轨迹更新策略.7) 7 在预测之前需要获得足够多的训练样本对$ \{\boldsymbol{{s}}, \tilde{\boldsymbol{{w}}}\} $ .8) 8 分割后的轨迹片段一般不等同于MP, 常常不同的轨迹片段可能对应相同的MP, 因此需要对轨迹片段进行聚类.9) 9 向量值GP通过恰当的可分离核函数可以表征多维轨迹之间的协同关系, 然而其未考虑轨迹本身的方差, 故这里未将其包括在内.10) 10 这里使用“协方差”是为了表明i)和ii)使用相同的预测模型.11 这些工作中对应的控制器被称作最小干涉控制(Minimal intervention control).11) 11 这些工作中对应的控制器被称作最小干涉控制(Minimal intervention control).12) 12 利用泛函梯度得到的导数为函数, 该导数用来对函数本身进行优化.13) 13 该更新同时也需要机器人的观测轨迹, 然而该轨迹恰是需要预测的, 因此文献[20]在更新$ \boldsymbol{{w}} $ 时将机器人的观测值设成零向量, 同时将拟合机器人轨迹的基函数设成零矩阵. -

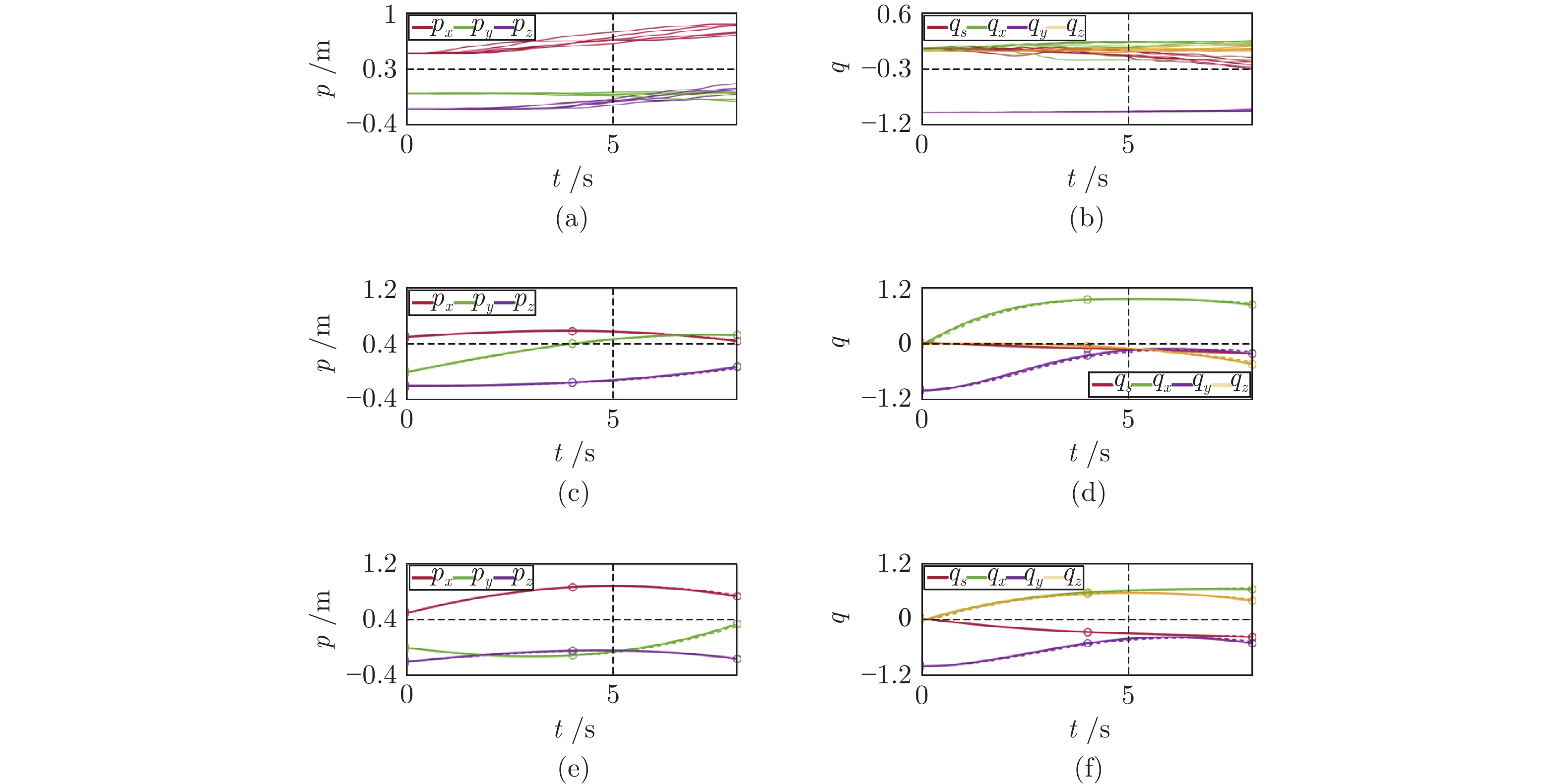
图 2 粉刷任务中的示教轨迹(a) ~ (b)以及泛化轨迹(c) ~ (f), 其中(c) ~ (d)和(e) ~ (f)对应不同情形下的泛化[30].
$[p_x \ p_y \ p_z]^{\rm{T}} $ 和$[q_s \ q_x \ q_y \ q_z]^{\rm{T}}$ 分别表示机器人末端的位置和四元数姿态. 圆圈为泛化时对应的期望路径点Fig. 2 Demonstrations (a) ~ (b) and adapted trajectories (c) ~ (f) in painting tasks, where (c) ~ (d) and (e) ~ (f) correspond to different adaptations.
$[p_x \ p_y \ p_z]^{\rm{T}} $ and$[q_s \ q_x \ q_y \ q_z]^{\rm{T}}$ denote Cartesian position and quaternion, respectively. Circles depict various desired points
图 3 DMP在书写字母中的应用. (a)表示技能的复现, (b) ~ (c)均表示技能的泛化, 其中实线对应DMP生成的轨迹, 虚线为示教轨迹并用 ‘*’ 和 ‘+’ 分别表示其起点和终点, 圆圈表示泛化轨迹需要经过的期望位置点
Fig. 3 The application of DMP in writing tasks. (a) corresponds to skill reproduction, (b) ~ (c) represent skill adaptations with different desired points. Solid curves are generated via DMP, while the dashed curves denote the demonstration with ‘*’ and ‘+’ respectively marking its starting and ending points. Circles depict desired points which the adapted trajectories should go through

图 4 KMP在书写字母中的应用. (a)对应二维轨迹, (b) ~ (e)分别表示轨迹的
$x,$ $y,$ $\dot{x}$ 和$\dot{y}$ 分量. 实线对应KMP生成的轨迹, 虚线为通过GMR对示教轨迹进行建模得到的均值, 圆圈表示不同的期望点Fig. 4 The application of KMP in a writing task. (a) plots the corresponding 2D trajectories, while (b) ~ (e) show the
$x,$ $y,$ $\dot{x}$ and$\dot{y}$ components of trajectories, respectively. Solid curves are planned via KMP while the dashed curves are retrieved by GMR after modelling demonstrations. Circles denote various desired points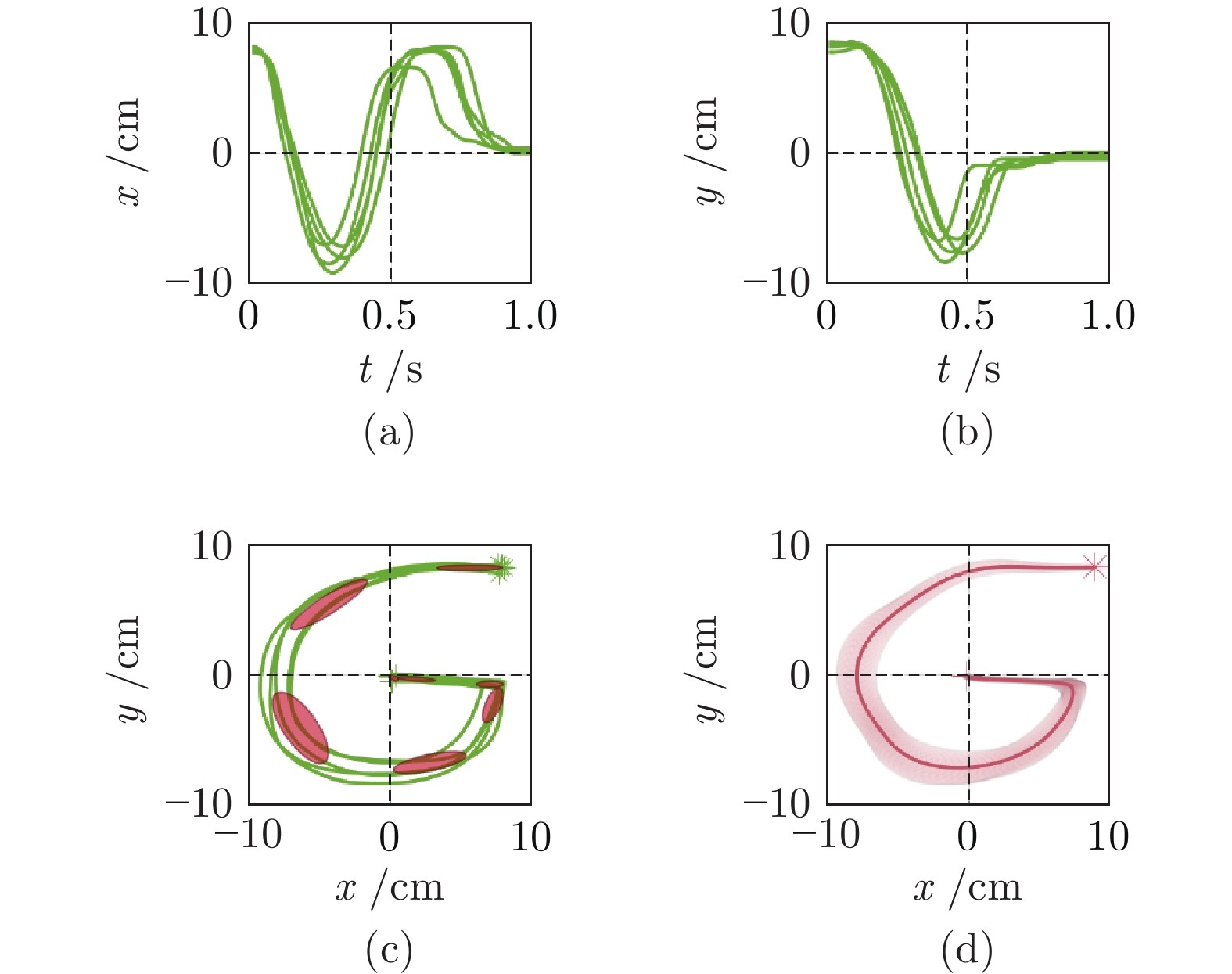
图 5 应用GMM和GMR对多条示教轨迹进行概率建模. (a) ~ (b)分别对应示教轨迹的
$x$ 和$y$ 分量, (c) ~ (d)表示GMM和GMR的建模结果, 其中(c)中椭圆表示GMM中的高斯成分, (d)中的实线和阴影部分分别表示多条轨迹的均值和方差Fig. 5 The modeling of multiple demonstrations using GMM and GMR. (a) ~ (b) plot the
$x$ and$y$ components of demonstrations. (c) ~ (d) depict the probabilistic features obtained via GMM and GMR, where the ellipses in (c) denote the Gaussian components in GMM, the solid curve and shaded area in (d) represent the mean and covariance of demonstrations, respectively
表 1 几种主要模仿学习方法的对比
Table 1 Comparison among the state-of-the-art approaches in imitation learning
 下载: 导出CSV
下载: 导出CSV
表 2 几种主要姿态学习方法的对比
Table 2 Comparison among the state-of-the-art approaches in orientation learning
单位范数 多轨迹概率 中间姿态 目标姿态 收敛性 时间输入 多维输入 单个基元 姿态 角速度 姿态 角速度 Pastor 等[62] — — — — — √ — √ √ — Silverio 等[63] — √ — — — √ — — √ √ Ude 等[64] √ — — — — √ — √ √ — Abu-Dakka 等[65] √ — — — — √ — √ √ — Ravichandar 等[66] √ √ — — — √ — √ — √ Zeestraten 等[67] √ √ — — — √ — — √ √ Huang 等[34] √ √ √ √ √ √ √ — √ √ Saveriano 等[68] √ — — √ √ √ √ √ √ —
下载: 导出CSV
-
[1] Schaal S. Is imitation learning the route to humanoid robots? Trends in Cognitive Sciences, 1999, 3(6): 233-242 doi: 10.1016/S1364-6613(99)01327-3 [2] Ijspeert A J, Nakanishi J, Hoffmann H, Pastor P, Schaal S. Dynamical movement primitives: Learning attractor models for motor behaviors. Neural Computation, 2013, 25(2): 328-373 doi: 10.1162/NECO_a_00393 [3] Khansari-Zadeh S M, Billard A. Learning stable nonlinear dynamical systems with gaussian mixture models. IEEE Transactions on Robotics, 2011, 27(5): 943-957 doi: 10.1109/TRO.2011.2159412 [4] Paraschos A, Daniel C, Peters J, Neumann G. Probabilistic movement primitives. In: Proceedings of the 26th International Conference on Neural Information Processing Systems. Nevada, USA: NIPS, 2013. 2616−2624 [5] Calinon S, Bruno D, Caldwell D G. A task-parameterized probabilistic model with minimal intervention control. In: Proceedings of the 2014 IEEE International Conference on Robotics and Automation. Hong Kong, China: IEEE, 2014. 3339−3344 [6] Huang Y L, Rozo L, Silverio J, Caldwell D G. Kernelized movement primitives. The International Journal of Robotics Research, 2019, 38(7): 833-852 doi: 10.1177/0278364919846363 [7] Muhlig M, Gienger M, Hellbach S, Steil J J, Goerick C. Task-level imitation learning using variance-based movement optimization. In: Proceedings of the 2009 IEEE International Conference on Robotics and Automation. Kobe, Japan: IEEE, 2009. 1177−1184 [8] Huang Y L, Buchler D, Koc O, Scholkopf B, Peters J. Jointly learning trajectory generation and hitting point prediction in robot table tennis. In: Proceedings of the 2016 IEEE-RAS 16th International Conference on Humanoid Robots. Cancun, Mexico: IEEE, 2016. 650−655 [9] Huang Y L, Silverio J, Rozo L, Caldwell D G. Hybrid probabilistic trajectory optimization using null-space exploration. In: Proceedings of the 2018 IEEE International Conference on Robotics and Automation. Brisbane, Australia: IEEE, 2018. 7226−7232 [10] Stulp F, Theodorou E, Buchli J, Schaal S. Learning to grasp under uncertainty. In: Proceedings of the 2011 IEEE International Conference on Robotics and Automation. Shanghai, China: IEEE, 2011. 5703−5708 [11] Mylonas G P, Giataganas P, Chaudery M, Vitiello V, Darzi A, Yang G Z. Autonomous eFAST ultrasound scanning by a robotic manipulator using learning from demonstrations. In: Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems. Tokyo, Japan: IEEE, 2013. 3251−3256 [12] Reiley C E, Plaku E, Hager G D. Motion generation of robotic surgical tasks: Learning from expert demonstrations. In: Proceedings of the 2010 Annual International Conference of the IEEE Engineering in Medicine and Biology. Buenos Aires, Argentina: IEEE, 2010. 967−970 [13] Colome A, Torras C. Dimensionality reduction in learning Gaussian mixture models of movement primitives for contextualized action selection and adaptation. IEEE Robotics and Automation Letters, 2018, 3(4): 3922-3929 doi: 10.1109/LRA.2018.2857921 [14] Canal G, Pignat E, Alenya G, Calinon S, Torras C. Joining high-level symbolic planning with low-level motion primitives in adaptive HRI: Application to dressing assistance. In: Proceedings of the 2018 IEEE International Conference on Robotics and Automation. Brisbane, Australia: IEEE, 2018. 3273−3278 [15] Joshi R P, Koganti N, Shibata T. A framework for robotic clothing assistance by imitation learning. Advanced Robotics, 2019, 33(22): 1156-1174 doi: 10.1080/01691864.2019.1636715 [16] Motokura K, Takahashi M, Ewerton M, Peters J. Plucking motions for tea harvesting robots using probabilistic movement primitives. IEEE Robotics and Automation Letters, 2020, 5(2): 3275-3282 doi: 10.1109/LRA.2020.2976314 [17] Ding J T, Xiao X H, Tsagarakis N, Huang Y L. Robust gait synthesis combining constrained optimization and imitation learning. In: Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems. Las Vegas, USA: IEEE, 2020. 3473−3480 [18] Zou C B, Huang R, Cheng H, Qiu J. Learning gait models with varying walking speeds. IEEE Robotics and Automation Letters, 2020, 6(1): 183-190 [19] Huang R, Cheng H, Guo H L, Chen Q M, Lin X C. Hierarchical interactive learning for a human-powered augmentation lower exoskeleton. In: Proceedings of the 2016 IEEE International Conference on Robotics and Automation. Stockholm, Sweden: IEEE, 2016. 257−263 [20] Maeda G, Ewerton M, Neumann G, Lioutikov R, Peters J. Phase estimation for fast action recognition and trajectory generation in human–robot collaboration. The International Journal of Robotics Research, 2017, 36(13-14): 1579-1594 doi: 10.1177/0278364917693927 [21] Silverio J, Huang Y L, Abu-Dakka F J, Rozo L, Caldwell D G. Uncertainty-aware imitation learning using kernelized movement primitives. In: Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems. Macau, China: IEEE, 2019. 90−97 [22] Pomerleau D A. ALVINN: An autonomous land vehicle in a neural network. In: Proceedings of the 1st International Conference on Neural Information Processing Systems. Denver, USA: NIPS, 1989. 305−313 [23] Ross S, Gordon G J, Bagnell D. A reduction of imitation learning and structured prediction to no-regret online learning. In: Proceedings of the 14th International Conference on Artificial Intelligence and Statistics. Fort Lauderdale, USA: JMLR.org, 2011. 627−635 [24] Abbeel P, Ng A Y. Apprenticeship learning via inverse reinforcement learning. In: Proceedings of the 21st International Conference on Machine Learning. Banff, Canada: 2004. 1−8 [25] Ho J, Ermon S. Generative adversarial imitation learning. In: Proceedings of the 30th International Conference on Neural Information Processing Systems. Barcelona, Spain: NIPS, 2016. 4572−4580 [26] Liu Nai-Jun, Lu Tao, Cai Ying-Hao, Wang Shuo. A review of robot manipulation skills learning methods. Acta Automatica Sinica, 2019, 45(3): 458-470 [27] Qin Fang-Bo, Xu De. Review of robot manipulation skill models. Acta Automatica Sinica, 2019, 45(8): 1401-1418 [28] Billard A, Epars Y, Cheng G, Schaal S. Discovering imitation strategies through categorization of multi-dimensional data. In: Proceedings of the 2003 IEEE/RSJ International Conference on Intelligent Robots and Systems. Las Vegas, USA: IEEE, 2003. 2398−2403 [29] Calinon S, Guenter F, Billard A. On learning, representing, and generalizing a task in a humanoid robot. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 2007, 37(2): 286-298 doi: 10.1109/TSMCB.2006.886952 [30] Huang Y L, Abu-Dakka F J, Silverio J, Caldwell D G. Generalized orientation learning in robot task space. In: Proceedings of the 2019 International Conference on Robotics and Automation. Montreal, Canada: IEEE, 2019. 2531−2537 [31] Matsubara T, Hyon S H, Morimoto J. Learning stylistic dynamic movement primitives from multiple demonstrations. In: Proceedings of the 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems. Taipei, China: IEEE, 2010. 1277−1283 [32] Giusti A, Zeestraten M J A, Icer E, Pereira A, Caldwell D G, Calinon S, et al. Flexible automation driven by demonstration: Leveraging strategies that simplify robotics. IEEE Robotics & Automation Magazine, 2018, 25(2): 18-27 [33] Huang Y L, Scholkopf B, Peters J. Learning optimal striking points for a ping-pong playing robot. In: Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems. Hamburg, Germany: IEEE, 2015. 4587−4592 [34] Huang Y L, Abu-Dakka F J, Silverio J, Caldwell D G. Toward orientation learning and adaptation in Cartesian space. IEEE Transactions on Robotics, 2021, 37(1): 82-98 doi: 10.1109/TRO.2020.3010633 [35] Bishop C M. Pattern Recognition and Machine Learning. Heidelberg: Springer, 2006. [36] Cohn D A, Ghahramani Z, Jordan M I. Active learning with statistical models. Journal of Artificial Intelligence Research, 1996, 4: 129-145 doi: 10.1613/jair.295 [37] Calinon S. A tutorial on task-parameterized movement learning and retrieval. Intelligent Service Robotics, 2016, 9(1): 1-29 doi: 10.1007/s11370-015-0187-9 [38] Guenter F, Hersch M, Calinon S, Billard A. Reinforcement learning for imitating constrained reaching movements. Advanced Robotics, 2007, 21(13): 1521-1544 doi: 10.1163/156855307782148550 [39] Peters J, Vijayakumar S, Schaal S. Natural actor-critic. In: Proceedings of the 16th European Conference on Machine Learning. Porto, Portugal: Springer, 2005. 280−291 [40] Rabiner L R. A tutorial on hidden Markov models and selected applications in speech recognition. Proceedings of the IEEE, 1989, 77(2):257-286 doi: 10.1109/5.18626 [41] Yu S Z. Hidden semi-Markov models. Artificial Intelligence, 2010, 174(2): 215-243 doi: 10.1016/j.artint.2009.11.011 [42] Calinon S, D’halluin F, Sauser E L, Caldwell D G, Billard A G. Learning and reproduction of gestures by imitation. IEEE Robotics & Automation Magazine, 2010, 17(2): 44-54 [43] Osa T, Pajarinen J, Neumann G, Bagnell J A, Abbeel P, Peters J. An algorithmic perspective on imitation learning. Foundations and Trends® in Robotics, 2018, 7(1-2): 1-79 doi: 10.1561/2300000053 [44] Zeestraten M J A, Calinon S, Caldwell D G. Variable duration movement encoding with minimal intervention control. In: Proceedings of the 2016 IEEE International Conference on Robotics and Automation. Stockholm, Sweden: IEEE, 2016. 497−503 [45] Rasmussen C E, Williams C K I. Gaussian Processes for Machine Learning. Cambridge: MIT Press, 2006. [46] Hofmann T, Scholkopf B, Smola A J. Kernel methods in machine learning. The Annals of Statistics, 2008, 36(3): 1171-1220 [47] Alvarez M A, Rosasco L, Lawrence N D. Kernels for vector-valued functions: A review. Foundations and Trends® in Machine Learning, 2012, 4(3): 195-266 doi: 10.1561/2200000036 [48] Solak E, Murray-Smith R, Leithead W E, Leith D J, Rasmussen C E. Derivative observations in Gaussian process models of dynamic systems. In: Proceedings of the 15th International Conference on Neural Information Processing Systems. Vancouver, Canada: MIT Press, 2002. 1057−1064 [49] Atkeson C G, Moore A W, Schaal S. Locally weighted learning. Artificial Intelligence Review, 1997, 11(1-5): 11-73 [50] Kober J, Mulling K, Kromer O, Lampert C H, Scholkopf B, Peters J. Movement templates for learning of hitting and batting. In: Proceedings of the 2010 IEEE International Conference on Robotics and Automation. Anchorage, USA: IEEE, 2010. 853−858 [51] Fanger Y, Umlauft J, Hirche S. Gaussian processes for dynamic movement primitives with application in knowledge-based cooperation. In: Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems. Daejeon, Korea : IEEE, 2016. 3913−3919 [52] Calinon S, Li Z B, Alizadeh T, Tsagarakis N G, Caldwell D G. Statistical dynamical systems for skills acquisition in humanoids. In: Proceedings of the 12th IEEE-RAS International Conference on Humanoid Robots. Osaka, Japan: IEEE, 2012. 323−329 [53] Stulp F, Sigaud O. Robot skill learning: From reinforcement learning to evolution strategies. Paladyn, Journal of Behavioral Robotics, 2013, 4(1): 49-61 [54] Kober J, Oztop E, Peters J. Reinforcement learning to adjust robot movements to new situations. In: Proceedings of the 22nd International Joint Conference on Artificial Intelligence. Barcelona, Spain: IJCAI/AAAI, 2011. 2650−2655 [55] Zhao T, Deng M D, Li Z J, Hu Y B. 2018. Cooperative manipulation for a mobile dual-arm robot using sequences of dynamic movement primitives. IEEE Transactions on Cognitive and Developmental Systems, 2020, 12(1): 18−29 [56] Li Z J, Zhao T, Chen F, Hu Y B, Su C Y, Fukuda T. Reinforcement learning of manipulation and grasping using dynamical movement primitives for a humanoidlike mobile manipulator. IEEE/ASME Transactions on Mechatronics, 2018, 23(1): 121-131 doi: 10.1109/TMECH.2017.2717461 [57] Paraschos A, Rueckert E, Peters J, Neumann G. Model-free probabilistic movement primitives for physical interaction. In: Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems. Hamburg, Germany: IEEE, 2015. 2860−2866 [58] Havoutis I, Calinon S. Supervisory teleoperation with online learning and optimal control. In: Proceedings of the 2017 IEEE International Conference on Robotics and Automation. Singapore: IEEE, 2017. 1534−1540 [59] Hershey J R, Olsen P A. Approximating the Kullback Leibler divergence between Gaussian mixture models. In: Proceedings of the 2007 IEEE International Conference on Acoustics, Speech and Signal Processing. Honolulu, USA: IEEE, 2007. IV-317−IV-320 [60] Goldberg P W, Williams C K I, Bishop C M. Regression with input-dependent noise: A Gaussian process treatment. In: Proceedings of the 10th International Conference on Neural Information Processing Systems. Denver, USA: NIPS, 1998. 493−499 [61] Kersting K, Plagemann C, Pfaff P, Burgard W. Most likely heteroscedastic Gaussian process regression. In: Proceedings of the 24th International Conference on Machine Learning. Corvalis, USA: ACM, 2007. 393−400 [62] Pastor P, Hoffmann H, Asfour T, Schaal S. Learning and generalization of motor skills by learning from demonstration. In: Proceedings of the 2009 IEEE International Conference on Robotics and Automation. Kobe, Japan: IEEE, 2009. 763−768 [63] Silverio J, Rozo L, Calinon S, Caldwell D G. Learning bimanual end-effector poses from demonstrations using task-parameterized dynamical systems. In: Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems. Hamburg, Germany: IEEE, 2015. 464−470 [64] Ude A, Nemec B, Petric T, Morimoto J. Orientation in cartesian space dynamic movement primitives. In: Proceedings of the 2014 IEEE International Conference on Robotics and Automation. Hong Kong, China: IEEE, 2014. 2997−3004 [65] Abu-Dakka F J, Nemec B, J\orgensen J A, Savarimuthu T R, Kruger N, Ude A. Adaptation of manipulation skills in physical contact with the environment to reference force profiles. Autonomous Robots, 2015, 39(2): 199-217 doi: 10.1007/s10514-015-9435-2 [66] Ravichandar H, Dani A. Learning position and orientation dynamics from demonstrations via contraction analysis. Autonomous Robots, 2019, 43(4): 897-912 doi: 10.1007/s10514-018-9758-x [67] Zeestraten M J A, Havoutis I, Silverio J, Calinon S, Caldwell D G. An approach for imitation learning on Riemannian manifolds. IEEE Robotics and Automation Letters, 2017, 2(3): 1240-1247 doi: 10.1109/LRA.2017.2657001 [68] Saveriano M, Franzel F, Lee D. Merging position and orientation motion primitives. In: Proceedings of the 2019 International Conference on Robotics and Automation. Montreal, Canada: IEEE, 2019. 7041−7047 [69] Abu-Dakka F J, Kyrki V. Geometry-aware dynamic movement primitives. In: Proceedings of the 2020 IEEE International Conference on Robotics and Automation. Paris, France: IEEE, 2020. 4421−4426 [70] Abu-Dakka F J, Huang Y L, Silverio J, Kyrki V. A probabilistic framework for learning geometry-based robot manipulation skills. Robotics and Autonomous Systems, 2021, 141: 103761. doi: 10.1016/j.robot.2021.103761 [71] Calinon S. Gaussians on Riemannian manifolds: Applications for robot learning and adaptive control. IEEE Robotics & Automation Magazine, 2020, 27(2): 33-45 [72] Kronander K, Billard A. Learning compliant manipulation through kinesthetic and tactile human-robot interaction. IEEE Transactions on Haptics, 2014, 7(3): 367-380 doi: 10.1109/TOH.2013.54 [73] Wu Y Q, Zhao F, Tao T, Ajoudani A. A framework for autonomous impedance regulation of robots based on imitation learning and optimal control. IEEE Robotics and Automation Letters, 2021, 6(1): 127-134 doi: 10.1109/LRA.2020.3033260 [74] Forte D, Gams A, Morimoto J, Ude A. On-line motion synthesis and adaptation using a trajectory database. Robotics and Autonomous Systems, 2012, 60(10): 1327-1339 doi: 10.1016/j.robot.2012.05.004 [75] Kramberger A, Gams A, Nemec B, Chrysostomou D, Madsen O, Ude A. Generalization of orientation trajectories and force-torque profiles for robotic assembly. Robotics and Autonomous Systems, 2017, 98: 333-346 doi: 10.1016/j.robot.2017.09.019 [76] Stulp F, Raiola G, Hoarau A, Ivaldi S, Sigaud O. Learning compact parameterized skills with a single regression. In: Proceedings of the 13th IEEE-RAS International Conference on Humanoid Robots. Atlanta, USA: IEEE, 2013. 417−422 [77] Huang Y L, Silverio J, Rozo L, Caldwell D G. Generalized task-parameterized skill learning. In: Proceedings of the 2018 IEEE International Conference on Robotics and Automation. Brisbane, Australia: IEEE, 2018. 5667−5474 [78] Kulic D, Ott C, Lee D, Ishikawa J, Nakamura Y. Incremental learning of full body motion primitives and their sequencing through human motion observation. The International Journal of Robotics Research, 2012, 31(3): 330-345 doi: 10.1177/0278364911426178 [79] Manschitz S, Gienger M, Kober J, Peters J. Learning sequential force interaction skills. Robotics, 2020, 9(2): Article No. 45 doi: 10.3390/robotics9020045 [80] Kober J, Gienger M, Steil J J. Learning movement primitives for force interaction tasks. In: Proceedings of the 2015 IEEE International Conference on Robotics and Automation. Seattle, USA: IEEE, 2015. 3192−3199 [81] Medina J R, Billard A. Learning stable task sequences from demonstration with linear parameter varying systems and hidden Markov models. In: Proceedings of the 1st Annual Conference on Robot Learning. Mountain View, USA: PMLR, 2017. 175−184 [82] Meier F, Theodorou E, Stulp F, Schaal S. Movement segmentation using a primitive library. In: Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems. San Francisco, USA: IEEE, 2011. 3407−3412 [83] Lee S H, Suh I H, Calinon S, Johansson R. Autonomous framework for segmenting robot trajectories of manipulation task. Autonomous Robots, 2015, 38(2): 107-141 doi: 10.1007/s10514-014-9397-9 [84] Stulp F, Schaal S. Hierarchical reinforcement learning with movement primitives. In: Proceedings of the 11th IEEE-RAS International Conference on Humanoid Robots. Bled, Slovenia: IEEE, 2011. 231−238 [85] Daniel C, Neumann G, Kroemer O, Peters J. Learning sequential motor tasks. In: Proceedings of the 2013 IEEE International Conference on Robotics and Automation. Karlsruhe, Germany: IEEE, 2013. 2626−2632 [86] Duan A Q, Camoriano R, Ferigo D, Huang Y L, Calandriello D, Rosasco L, et al. Learning to sequence multiple tasks with competing constraints. In: Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems. Macau, China: IEEE, 2019. 2672−2678 [87] Silverio J, Huang Y L, Rozo L, Calinon S, Caldwell D G. Probabilistic learning of torque controllers from kinematic and force constraints. In: Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems. Madrid, Spain: IEEE, 2018. 1−8 [88] Schneider M, Ertel W. Robot learning by demonstration with local Gaussian process regression. In: Proceedings of the 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems. Taipei, China: IEEE, 2010. 255-260 [89] Umlauft J, Fanger Y, Hirche S. Bayesian uncertainty modeling for programming by demonstration. In: Proceedings of the 2017 IEEE International Conference on Robotics and Automation. Singapore: IEEE, 2017. 6428−6434 [90] Wilson A G, Ghahramani Z. Generalised Wishart processes. In: Proceedings of the 27th Conference on Uncertainty in Artificial Intelligence. Barcelona, Spain: AUAI Press, 2011. 1−9 [91] Medina J R, Lee D, Hirche S. Risk-sensitive optimal feedback control for haptic assistance. In: Proceedings of the 2012 IEEE International Conference on Robotics and Automation. Saint Paul, USA: IEEE, 2012. 1025−1031 [92] Huang Y L, Silverio J, Caldwell D G. Towards minimal intervention control with competing constraints. In: Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems. Madrid, Spain: IEEE, 2018. 733−738 [93] Calinon S, Billard A. A probabilistic programming by demonstration framework handling constraints in joint space and task space. In: Proceedings of the 2008 IEEE/RSJ International Conference on Intelligent Robots and Systems. Nice, France: IEEE, 2008. 367−372 [94] Calinon S, Billard A. Statistical learning by imitation of competing constraints in joint space and task space. Advanced Robotics, 2009, 23(15): 2059-2076 doi: 10.1163/016918609X12529294461843 [95] Paraschos A, Lioutikov R, Peters J, Neumann G. Probabilistic prioritization of movement primitives. IEEE Robotics and Automation Letters, 2017, 2(4): 2294-2301 doi: 10.1109/LRA.2017.2725440 [96] Fajen B R, Warren W H. Behavioral dynamics of steering, obstable avoidance, and route selection. Journal of Experimental Psychology: Human Perception and Performance, 2003, 29(2): 343-362 doi: 10.1037/0096-1523.29.2.343 [97] Hoffmann H, Pastor P, Park D H, Schaal S. Biologically-inspired dynamical systems for movement generation: Automatic real-time goal adaptation and obstacle avoidance. In: Proceedings of the 2009 IEEE International Conference on Robotics and Automation. Kobe, Japan: IEEE, 2009. 2587−2592 [98] Duan A Q, Camoriano R, Ferigo D, Huang Y L, Calandriello D, Rosasco L, et al. Learning to avoid obstacles with minimal intervention control. Frontiers in Robotics and AI, 2020, 7: Article No. 60 doi: 10.3389/frobt.2020.00060 [99] Park D H, Hoffmann H, Pastor P, Schaal S. Movement reproduction and obstacle avoidance with dynamic movement primitives and potential fields. In: Proceedings of the 8th IEEE-RAS International Conference on Humanoid Robots. Daejeon, Korea: IEEE, 2008. 91−98 [100] Maciejewski A A, Klein C A. Obstacle avoidance for kinematically redundant manipulators in dynamically varying environments. The International Journal of Robotics Research, 1985, 4(3): 109-117 doi: 10.1177/027836498500400308 [101] Shyam R B, Lightbody P, Das G, Liu P C, Gomez-Gonzalez S, Neumann G. Improving local trajectory optimisation using probabilistic movement primitives. In: Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems. Macau, China: IEEE, 2019. 2666−2671 [102] Zucker M, Ratliff N, Dragan A D, Pivtoraiko M, Klingensmith M, Dellin C M, et al. CHOMP: Covariant hamiltonian optimization for motion planning. The International Journal of Robotics Research, 2013, 32(9-10): 1164-1193 doi: 10.1177/0278364913488805 [103] Huang Y L, Caldwell D G. A linearly constrained nonparametric framework for imitation learning. In: Proceedings of the 2020 IEEE International Conference on Robotics and Automation. Paris, France: IEEE, 2020. 4400−4406 [104] Saveriano M, Lee D. Learning barrier functions for constrained motion planning with dynamical systems. In: Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems. Macau, China: IEEE, 2019. 112−119 [105] Huang Y L. EKMP: Generalized imitation learning with adaptation, nonlinear hard constraints and obstacle avoidance. arXiv: 2103.00452, 2021. [106] Osa T, Esfahani A M G, Stolkin R, Lioutikov R, Peters J, Neumann G. Guiding trajectory optimization by demonstrated distributions. IEEE Robotics and Automation Letters, 2017, 2(2): 819-826 doi: 10.1109/LRA.2017.2653850 [107] Marinho Z, Boots B, Dragan A, Byravan A, Srinivasa S, Gordon G J. Functional gradient motion planning in reproducing kernel Hilbert spaces. In: Proceedings of the Robotics: Science and Systems XII. Ann Arbor, USA, 2016. 1−9 [108] Rana M A, Mukadam M, Ahmadzadeh S R, Chernova S, Boots B. Towards robust skill generalization: Unifying learning from demonstration and motion planning. In: Proceedings of the 1st Annual Conference on Robot Learning. Mountain View, USA: PMLR, 2017. 109−118 [109] Koert D, Maeda G, Lioutikov R, Neumann G, Peters J. Demonstration based trajectory optimization for generalizable robot motions. In: Proceedings of the 2016 IEEE-RAS 16th International Conference on Humanoid Robots. Cancun, Mexico: IEEE, 2016. 515−522 [110] Ye G, Alterovitz R. Demonstration-guided motion planning. Robotics Research. Cham: Springer, 2017. 291−307 [111] Englert P, Toussaint M. Learning manipulation skills from a single demonstration. The International Journal of Robotics Research, 2018, 37(1): 137-154 doi: 10.1177/0278364917743795 [112] Doerr A, Ratliff N D, Bohg J, Toussaint M, Schaal S. Direct loss minimization inverse optimal control. In: Proceedings of the Robotics: Science and Systems. Rome, Italy, 2015. 1−9 [113] Hansen N. The CMA evolution strategy: A comparing review. Towards a New Evolutionary Computation: Advances in the Estimation of Distribution Algorithms. Berlin, Heidelberg: Springer, 2006, 75−102 [114] Ewerton M, Neumann G, Lioutikov R, Amor H B, Peters J, Maeda G. Learning multiple collaborative tasks with a mixture of interaction primitives. In: Proceedings of the 2015 IEEE International Conference on Robotics and Automation. Seattle, USA: IEEE, 2015. 1535−1542 [115] Amor H B, Neumann G, Kamthe S, Kroemer O, Peters J. Interaction primitives for human-robot cooperation tasks. In: Proceedings of the 2014 IEEE International Conference on Robotics and Automation. Hong Kong, China: IEEE, 2014. 2831−2837 [116] Vogt D, Stepputtis S, Grehl S, Jung B, Amor H B. A system for learning continuous human-robot interactions from human-human demonstrations. In: Proceedings of the 2017 IEEE International Conference on Robotics and Automation. Singapore: IEEE, 2017. 2882−2889 [117] Silverio J, Huang Y L, Rozo L, Caldwell D G. An uncertainty-aware minimal intervention control strategy learned from demonstrations. In: Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems. Madrid, Spain: IEEE, 2018. 6065−6071 [118] Khoramshahi M, Billard A. A dynamical system approach to task-adaptation in physical human–robot interaction. Autonomous Robots, 2019, 43(4): 927-946 doi: 10.1007/s10514-018-9764-z [119] Kalakrishnan M, Chitta S, Theodorou E, Pastor P, Schaal S. STOMP: Stochastic trajectory optimization for motion planning. In: Proceedings of the 2011 IEEE International Conference on Robotics and Automation. Shanghai, China: IEEE, 2011. 4569−4574 [120] Schulman J, Duan Y, Ho J, Lee A, Awwal I, Bradlow H, et al. Motion planning with sequential convex optimization and convex collision checking. The International Journal of Robotics Research, 2014, 33(9): 1251-1270 doi: 10.1177/0278364914528132 [121] Osa T. Multimodal trajectory optimization for motion planning. The International Journal of Robotics Research, 2020, 39(8): 983-1001 doi: 10.1177/0278364920918296 [122] LaValle S M, Kuffner Jr J J. Randomized kinodynamic planning. The International Journal of Robotics Research, 2001, 20(5): 378-400 doi: 10.1177/02783640122067453 [123] Kavraki L E, Svestka P, Latombe J C, Overmars M H. Probabilistic roadmaps for path planning in high-dimensional configuration spaces. IEEE Transactions on Robotics and Automation, 1996, 12(4): 566-580 doi: 10.1109/70.508439 [124] Hsu D, Latombe J C, Kurniawati H. On the probabilistic foundations of probabilistic roadmap planning. The International Journal of Robotics Research, 2006, 25(7): 627-643 doi: 10.1177/0278364906067174 [125] Celemin C, Maeda G, Ruiz-del-Solar J, Peters J, Kober J. Reinforcement learning of motor skills using policy search and human corrective advice. The International Journal of Robotics Research, 2019, 38(14): 1560-1580 doi: 10.1177/0278364919871998 [126] Maeda G, Ewerton M, Osa T, Busch B, Peters J. Active incremental learning of robot movement primitives. In: Proceedings of the 1st Annual Conference on Robot Learning. Mountain View, USA: PMLR, 2017. 37−46 [127] Pearl J. Causality. Cambridge: Cambridge University Press, 2009. [128] Katz G, Huang D W, Hauge T, Gentili R, Reggia J. A novel parsimonious cause-effect reasoning algorithm for robot imitation and plan recognition. IEEE Transactions on Cognitive and Developmental Systems, 2018, 10(2): 177-193 doi: 10.1109/TCDS.2017.2651643 [129] Haan P, Jayaraman D, Levine S. Causal confusion in imitation learning. In: Proceedings of the 33rd Conference on Neural Information Processing Systems. Vancouver, Canada: NeurIPS, 2019. 11693−11704 -

 下载:
下载:

















计量
- 文章访问数: 6529
- HTML全文浏览量: 3885
- PDF下载量: 1929
- 被引次数: 0
