

A Synonym Mining Algorithm Based on Pair-wise Character Embedding andNoisy Robust Learning
-
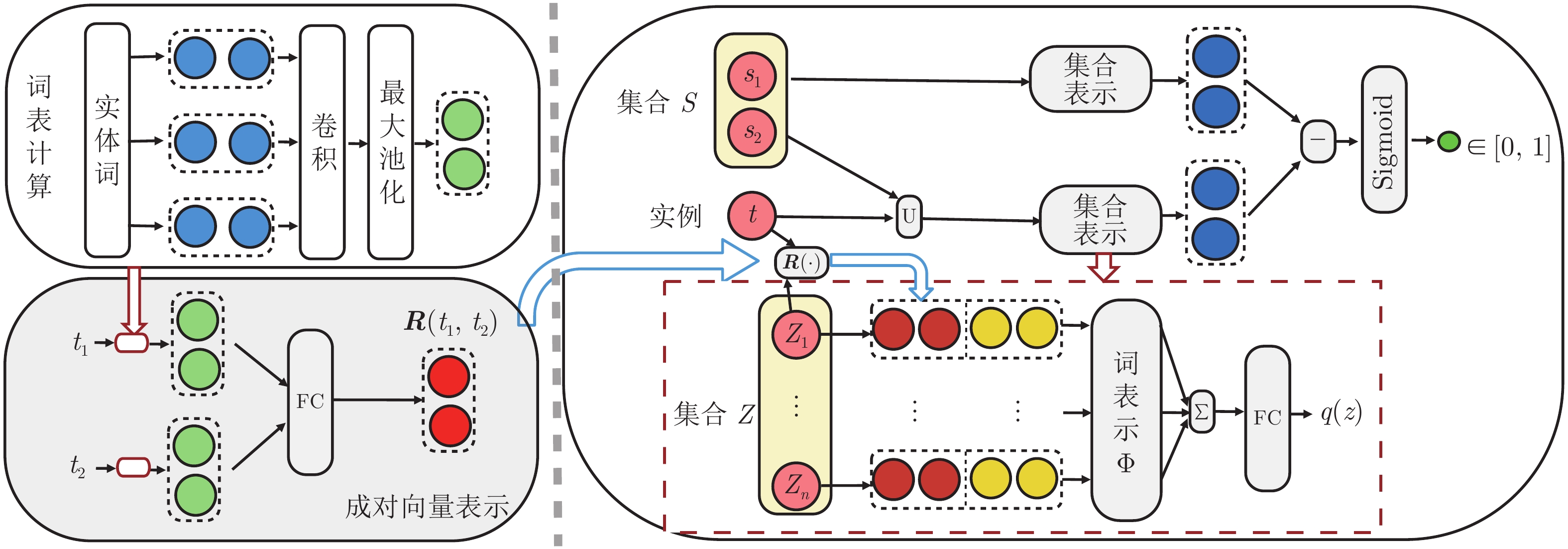
摘要: 同义词挖掘是自然语言处理中一项重要任务. 为了构建大规模训练语料, 现有研究利用远程监督、点击图筛选等方式抽取同义词种子, 而这几种方式都不可避免地引入了噪声标签, 从而影响高质量同义词挖掘模型的训练. 此外, 由于大量实体词所具有的少样本特性、领域分布差异性和预训练词向量训练目标与同义词挖掘任务的不一致性, 在同义词挖掘任务中, 词级别的预训练词向量很难产生高质量的实体语义表示. 为解决这两个问题, 提出了一种利用成对字向量和噪声鲁棒学习框架的同义词挖掘模型. 模型利用预训练的成对字向量增强实体语义表示, 并利用自动标注的噪声标签通过交替优化的方式, 估计真实标签的分布并产生伪标签, 希望通过这些改进提升模型的表示能力和鲁棒性. 最后, 使用WordNet分析和过滤带噪声数据集, 并在不同规模、不同领域的同义词数据集上进行了实验验证. 实验结果和分析表明, 该同义词挖掘模型在各种数据分布和噪声比例下, 与有竞争力的基准方法相比, 均提升了同义词判别和同义词集合生成的效果.Abstract: Synonym mining is an important task in natural language processing. In order to construct large-scale training corpus, existing studies extract synonym seeds using distant supervision and click graph filtering, which inevitably introduce noisy labels, thus affecting the training of high-quality synonym mining models. In addition, due to the few-shot and domain-distribution-shift property of most entity words, and the inconsistency between the training objective of the pre-trained word embeddings and the synonym mining task, it is difficult for the pre-trained word embeddings in the synonym mining task to produce high-quality entity semantic representations. To address these two issues, this paper proposes a synonym mining model that utilizes pair-wise character embeddings and a noise robust learning framework. The model uses pre-trained pair-wise character embeddings to enhance the entity semantic representations, estimate true label distribution and generate pseudo-labels through a joint optimization process. We want to improve the representation ability and robustness of the model through these improvements. Finally, we use WordNet to analyze and filter noisy datasets and conduct the experiments on synonym datasets of different sizes and domains. The experimental results show that the proposed synonym mining model improves the synonym set-instance classification and set generation performances compared to competitive benchmark methods under different data distribution and noise ratios.1)
1 1 数据集下载URL:http://bit.ly/SynSetMine-dataset 2 同义词词林语料URL:http://ir.hit.edu.cn/demo/ltp/Sharing_Plan.htm 2)2 2 同义词词林语料URL:http://ir.hit.edu.cn/demo/ltp/Sharing_Plan.htm 3)3 3 WordNet下载URL:https://wordnet.princeton.edu/ 4)4 4 源代码开放于:https://github.com/mickeystroller/SynSetMine-pytorch -
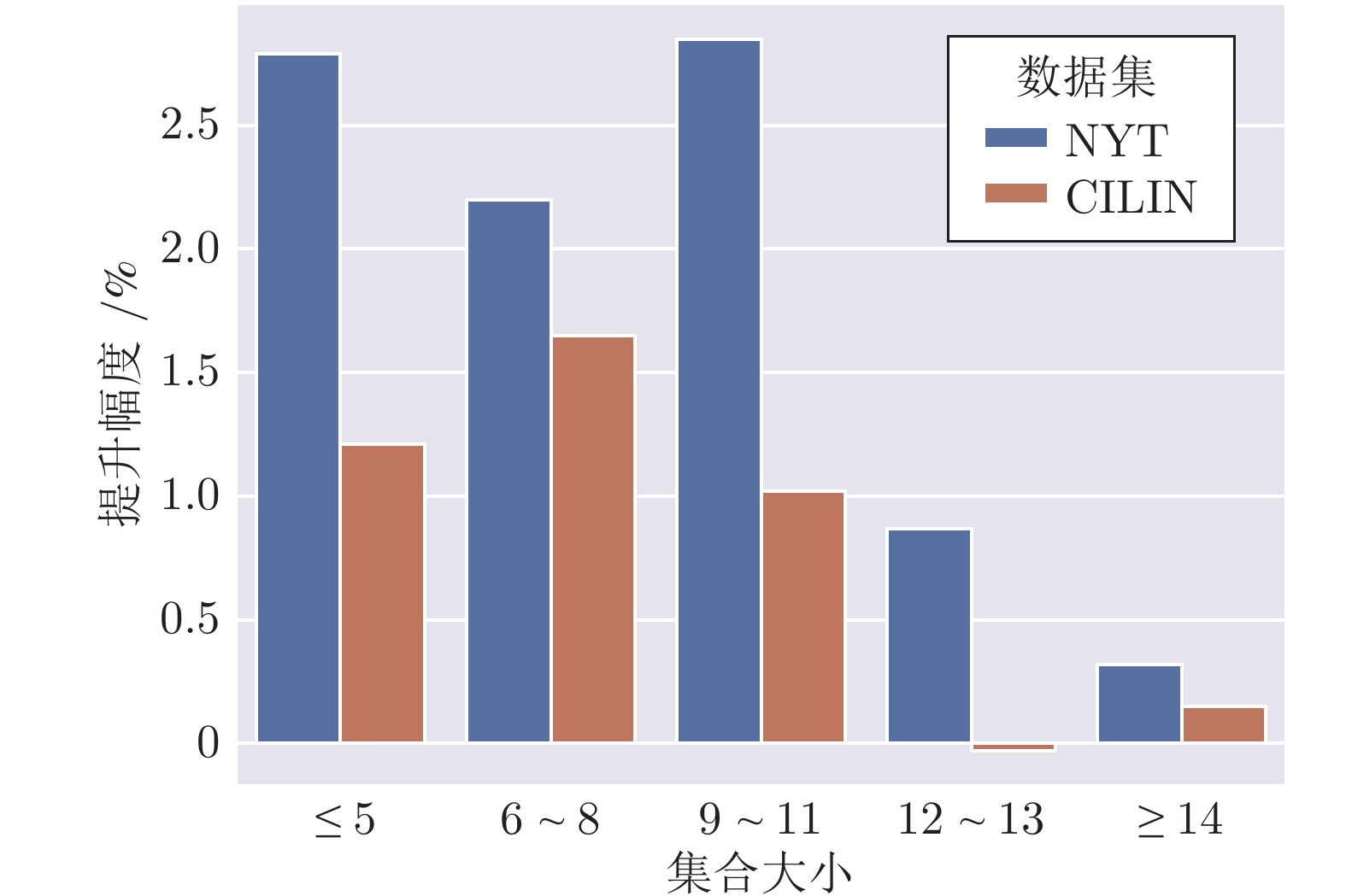
图 3 不同集合大小的中、英文数据性能效果对比
Fig. 3 Comparison of performance enhancement in Chinese and English data with different set sizes
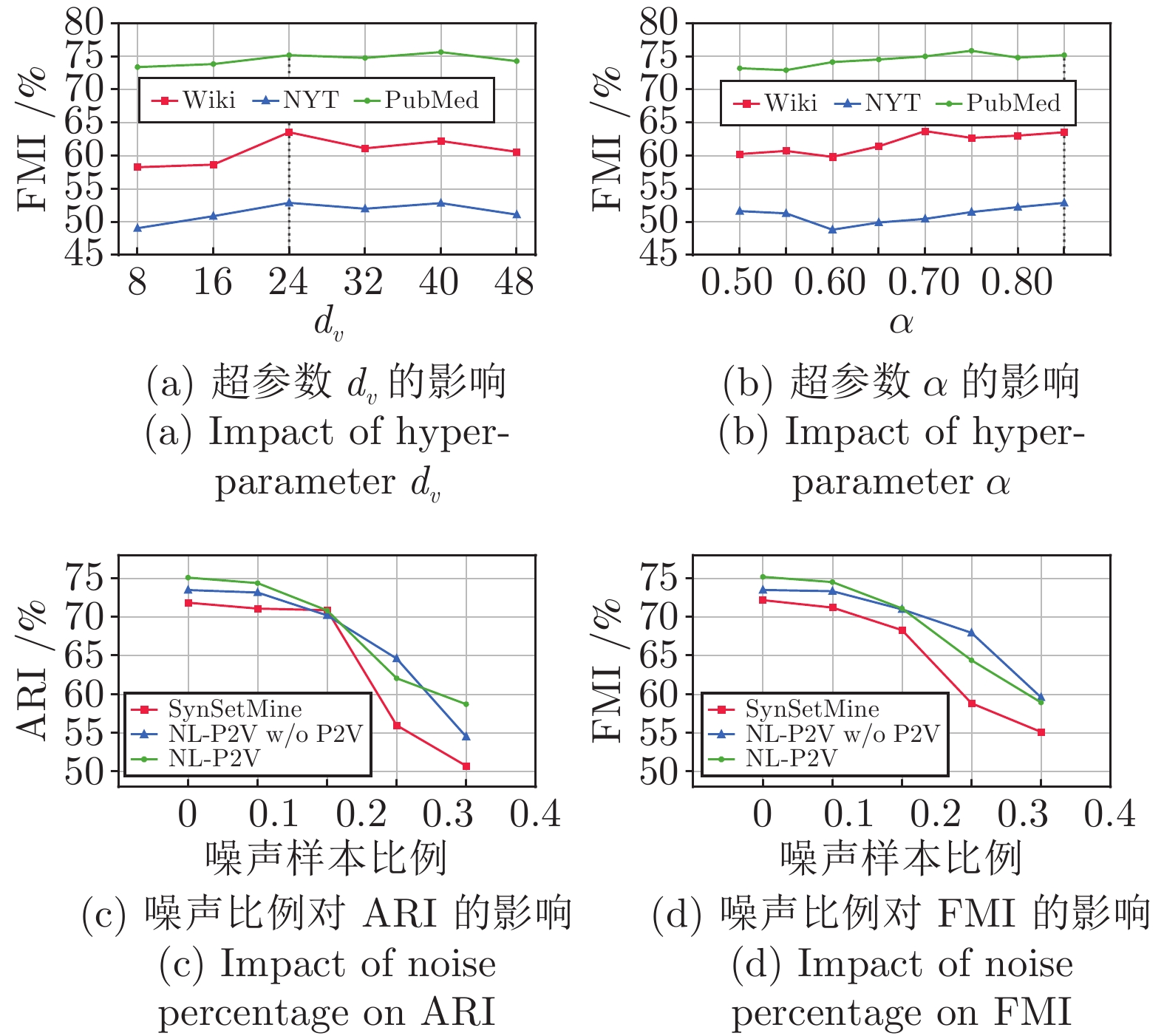
图 4 超参数以及训练集噪声比例的影响分析
Fig. 4 Analysis of the impact on hyper-parameters and training set noise percentage

图 5 不同优化器和生成策略下集合生成效果
Fig. 5 Model performances with different optimizers and set generation policy

图 6 加入成对字向量之前和之后词表示可视化对比
Fig. 6 Visualization of word distributed representations with or without pair-wise character vector embeddings
表 1 数据集统计信息
Table 1 Dataset statistics
数据集 Wiki NYT PubMed CILIN 文档 100000 118664 1554433 — 句子 6839331 3002123 15051203 — 训练集单词 8731 2600 72627 75614 训练集同义词集合 4359 1273 28600 17317 测试集单词 891 389 1743 2237 测试集同义词集合 256 117 250 500  下载: 导出CSV
下载: 导出CSV
表 2 超参数设置
Table 2 Hyper-parameter settings
数据集 Wiki NYT PubMed CILIN 词向量维度$d_w$ 50 50 50 300 词级别表示维度$d_p$ 250 250 250 250 集合表示隐单元维度$d'_s$ 500 500 500 500 学习率 0.0001 0.0001 0.0003 0.0003 训练轮数 800 500 50 50 负样本采样数量$K$ 50 20 50 70 批大小 64 32 32 32 随机失活比例 0.5 0.3 0.3 0.3 字向量维度$d_c$ 50 50 50 150 卷积窗口大小$w_c$ 5 5 5 5 字级别表示维度$d_v$ 24 24 24 50 辅助判别器损失比率$\alpha$ 0.15 0.15 0.15 0.15
下载: 导出CSV
表 3 数据集噪声比例
Table 3 Noise data percentage on datasets
统计类别 Wiki PubMed 训练集 测试集 训练集 测试集 原始词对 4372 635 44027 1493 噪声样本对 875 169 2740 70 遗漏样本对 380 182 12851 331 干净词对 3877 648 54138 1754 原始集合数量 4359 256 28600 250 干净集合数量 3327 228 25761 259
下载: 导出CSV
表 4 实验结果(%)
Table 4 Main experimental results (%)
方法 Wiki NYT PubMed ARI (± std) FMI (± std) NMI (± std) ARI (± std) FMI (± std) NMI (± std) ARI (± std) FMI (± std) NMI (± std) K-means* 34.35
(± 1.06)35.47
(± 0.96)86.98
(± 0.27)28.87
(± 1.98)30.85
(± 1.76)83.71
(± 0.57)48.68
(± 1.93)49.86
(± 1.79)88.08
(± 0.45)Louvain* 42.25 (± 0) 46.48 (± 0) 92.58 (± 0) 21.83 (± 0) 30.58 (± 0) 90.13 (± 0) 46.58 (± 0) 52.76 (± 0) 90.46 (± 0) SetExpan + Louvain* 44.78
(± 0.28)44.95
(± 0.28)92.12
(± 0.02)43.92
(± 0.90)44.31
(± 0.93)90.34
(± 0.11)58.91
(± 0.08)61.87
(± 0.07)92.23
(± 0.15)约束K-means* 38.80
(± 0.51)39.96
(± 0.49)90.31
(± 0.15)33.80
(± 1.94)34.57
(± 2.06)87.92
(± 0.30)49.12
(± 0.85)51.92
(± 0.83)89.91
(± 0.15)SVM + Louvain* 6.03
(±0.73)7.75
(± 0.81)25.43
(± 0.13)3.64
(± 0.42)5.10
(± 0.39)21.02
(± 0.27)7.76
(± 0.96)8.79
(± 1.03)31.08
(± 0.34)L2C* 12.87
(± 0.22)19.90
(± 0.24)73.47
(± 0.29)12.71
(± 0.89)16.66
(± 0.68)70.23
(± 1.20)— — — SynSetMine* 56.43
(± 1.31)57.10
(± 1.17)93.04
(± 0.23)44.91
(± 2.16)46.37
(± 1.92)90.62
(± 1.53)74.33
(± 0.66)74.45
(± 0.64)94.90
(± 0.97)SynSetMine 54.52
(± 1.23)54.87
(± 1.08)92.80
(± 0.20)47.33
(± 1.84)47.96
(± 2.07)90.16
(± 1.29)71.61
(± 0.66)72.20
(± 0.60)94.38
(± 0.60)NL-P2V 63.01
(± 1.06)63.54
(± 0.98)93.92
(± 0.12)50.72
(± 1.63)52.88
(± 2.10)91.66
(± 1.02)75.54
(± 0.88)75.65
(± 0.56)94.98
(± 0.49)NL-Word-P2V 61.31
(± 0.94)61.18
(± 0.76)93.70
(± 0.41)49.13
(± 1.07)51.69
(± 1.71)91.21
(± 0.45)74.67
(± 0.96)74.58
(± 0.50)95.02
(± 0.46)NL-P2V w/o P2V 56.09
(± 1.01)56.34
(± 0.83)93.13
(± 0.31)49.04
(± 1.43)50.02
(± 1.79)91.07
(± 0.57)73.48
(± 0.92)73.49
(± 0.47)94.47
(± 0.56)
下载: 导出CSV
表 5 CILIN实验结果(%)
Table 5 Experimental results on CILIN (%)
方法 训练噪声比例 ARI FMI NMI SynSetMine 0 17.07 17.97 71.94 NL-P2V 1 20.26 20.73 73.97 SynSetMine 2 17.02 17.57 73.34 NL-P2V 3 17.01 17.96 73.36 SynSetMine 3 14.28 15.80 75.00 NL-P2V 5 16.24 16.91 74.01
下载: 导出CSV
表 6 效率对比
Table 6 Efficiency comparison
方法 训练 集合预测 Wiki
(h)NYT PubMed
(h)Wiki
(s)NYT
(s)PubMed
(s)K-means — — — 1.82 0.88 2.95 Louvain — — — 3.94 20.59 74.60 SynSetMine 7.7 77 min 3.6 3.57 1.24 19.11 NL-P2V w/o P2V 8.2 80 min 4.9 3.60 1.18 20.58 NL-P2V 18.1 2.9 h 7.1 6.47 2.69 27.04
下载: 导出CSV
-
[1] Azad H K, Deepak A. Query expansion techniques for information retrieval: a survey. Information Processing & Management, 2019, 56(5): 1698-1735. [2] Gui T, Ye J, Zhang Q, Zhou Y, Gong Y, Huang X. Leveraging document-level label consistency for named entity recognition. In: Proceedings of the 29th International Joint Conference on Artificial Intelligence. Virtual Event: 2020. 3976−3982 [3] Zhang H, Cai J, Xu J, Wang J. Complex question decomposition for semantic parsing. In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Florence, Italy: ACL, 2019. 4477−4486 [4] 饶子昀, 张毅, 刘俊涛, 曹万华. 应用知识图谱的推荐方法与系统. 自动化学报, 2020, 46(x): 1-16.Rao Zi-Yun, Zhang Yi, Liu Jun-Tao, Cao Wan-Hua. Recommendation methods and systems using knowledge graph. Acta Automatica Sinica, 2020, 46(x): 1-16. [5] 侯丽微, 胡珀, 曹雯琳. 主题关键词信息融合的中文生成式自动摘要研究. 自动化学报, 2019, 45(3): 530-539.HOU Li-Wei, HU Po, CAO Wen-Lin. Automatic Chinese Abstractive Summarization With Topical Keywords Fusion. ACTA AUTOMATICA SINICA, 2019, 45(3): 530-539. [6] Qu M, Ren X, Han J. Automatic synonym discovery with knowledge bases. In: Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Halifax, Canada: ACM, 2017. 997−1005 [7] Wang Z, Yue X, Moosavinasab S, Huang Y, Lin S, Sun H. SurfCon: Synonym discovery on privacy-aware clinical data. In: Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. Anchorage, USA: ACM, 2019. 1578−1586 [8] Li C, Zhang M, Bendersky M, Deng H, Metzler D, Najork M. Multi-view embedding-based synonyms for email search. In: Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval. Paris, France: ACM. 575−584 [9] Shen J, Lyu R, Ren X, Vanni M, Sadler B, Han J. Mining entity synonyms with efficient neural set generation. In: Proceedings of the 33rd AAAI Conference on Artificial Intelligence. Honolulu, Hawaii, USA: AAAI, 2019. 249−256 [10] Song H, Kim M, Park D, Lee J. Learning from noisy labels with deep neural networks: A survey [Online], available: https://arxiv.org/abs/2007.08199, July 22, 2020 [11] Arazo E, Ortego D, Albert P, O'Connor N E, McGuinness K. Unsupervised label noise modeling and loss correction. In: Proceedings of the 36th International Conference on Machine Learning. Long Beach, USA: PMLR, 2019. 312−321 [12] Zhang H, Long D, Xu G, Zhu M, Xie P, Huang F, et al. Learning with noise: Improving distantly-supervised fine-grained entity typing via automatic relabeling. In: Proceedings of the 29th International Joint Conference on Artificial Intelligence. Virtual Event: IJCAI, 2020. 3808−3815 [13] Chen B, Gu X, Hu Y, Tang S, Hu G, Zhuang Y, et al. Improving distantly-supervised entity typing with compact latent space clustering. In: Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Minneapolis, USA: ACL, 2019. 2862−2872 [14] Jiang L, Huang D, Liu M, Yang W. Beyond synthetic noise: Deep learning on controlled noisy labels. In: Proceedings of the 37th International Conference on Machine Learning. Virtual Event: PMLR, 2020. 4804−4815 [15] Mikolov T, Sutskever I, Chen K, Corrado G S, Dean J. Distributed representations of words and phrases and their compositionality. In: Proceedings of the 27th Annual Conference on Neural Information Processing Systems. Lake Tahoe, USA: NIPS, 2013. 3111−3119 [16] 李小涛, 游树娟, 陈维. 一种基于词义向量模型的词语语义相似度算法. 自动化学报, 2020, 46(8): 1654-1669.Li Xiao-Tao, You Shu-Juan, Chen Wai. An algorithm of semantic similarity between words based on word single-meaning embedding model. Acta Automatica Sinica, 2020, 46(8): 1654-1669. [17] Fei H, Tan S, Li P. Hierarchical multi-task word embedding learning for synonym prediction. In: Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. Anchorage, USA: ACM, 2019. 834−842 [18] Roth M, Upadhyay S. Combining discourse markers and cross-lingual embeddings for synonym-antonym classification. In: Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Minneapolis, USA: ACL, 2019. 3899−3905 [19] Miller G. Wordnet: a lexical database for english. Communications of the ACM, 1995, 38(11): 39-41. doi: 10.1145/219717.219748 [20] Zaheer M, Kottur S, Ravanbakhsh S, Póczos B, Salakhutdinov R, Smola A J. Deep sets. In: Proceedings of the Annual Conference on Neural Information Processing Systems. Long Beach, USA: NIPS, 2017. 3391−3401 [21] Kipf T N, Welling M. Semi-supervised classification with graph convolutional networks. In: Proceedings of the 5th International Conference on Learning Representations. Toulon, France: ICLR, 2017. [22] Hazem A, Daille B. Word embedding approach for synonym extraction of multi-word terms. In: Proceedings of the 11th International Conference on Language Resources and Evaluation. Miyazaki, Japan: ELRA, 2018. 297−303 [23] Devlin J, Chang M W, Lee K, Toutanova K. Bert: Pre-training of deep bidirectional transformers for language understanding. In: Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Minneapolis, USA: ACL, 2019. 4171−4186 [24] Banar N, Daelemans W, Kestemont M. Character-level transformer-based neural machine translation. In: Proceedings of the 4th International Conference on Natural Language Processing and Information Retrieval. Seoul, South Korea: ACM, 2020. 149−156 [25] Miyamoto Y, Cho K. Gated word-character recurrent language model. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing. Austin, USA: ACL, 2016. 1992−1997 [26] Lukovnikov D, Fischer A, Lehmann J, Auer S. Neural network-based question answering over knowledge graphs on word and character level. In: Proceedings of the 26th International Conference on World Wide Web. Perth, Australia: ACM, 2017. 1211−1220 [27] Joshi M, Choi E, Levy O, Weld D S, Zettlemoyer L. Pair2Vec: Compositional word-pair embeddings for cross-sentence inference. In: Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Minneapolis, USA: ACL, 2019. 3597−3608 [28] Pereyra G, Tucker G, Chorowski J, Kaiser L, Hinton G E. Regularizing neural networks by penalizing confident output distributions. In: Proceedings of the 5th International Conference on Learning Representations. Toulon, France: ICLR, 2017. [29] Nguyen X V, Epps J, Bailey J. Information theoretic measures for clusterings comparison: Variants, properties, normalization and correction for chance. The Journal of Machine Learning Research, 2010, 11: 2837-2854. [30] Blondel V, Guillaume J, Lambiotte R, Lefebvre E. Fast unfolding of communities in large networks. Journal of Statistical Mechanics: Theory and Experiment, 2008, 2008(10): 10008. doi: 10.1088/1742-5468/2008/10/P10008 [31] Shen J, Wu Z, Lei D, Shang J, Ren X, Han J. Setexpan: Corpus-based set expansion via context feature selection and rank ensemble. Machine Learning and Knowledge Discovery in Databases, 2017. 1: 288-304. [32] Hsu Y, Lv Z, Kira Z. Learning to cluster in order to transfer across domains and tasks. In: Proceedings of the 6th International Conference on Learning Representations. Vancouver, Canada: ICLR, 2018. [33] Xu P, Barbosa D. Neural fine-grained entity type classification with hierarchy-aware loss. In: Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. New Orleans, Louisiana, USA: ACL, 2018. 16−25 [34] van der Maaten L. Accelerating t-sne using tree-based algorithms. The Journal of Machine Learning Research, 2014, 15(1): 3221-3245. [35] He Y, Chakrabarti K, Cheng T, Tylenda T. Automatic discovery of attribute synonyms using query logs and table corpora. In: Proceedings of the 25th International Conference on World Wide Web. Montreal, Canada: ACM, 2016. 1429−1439 [36] Liu X, Wang L, Zhang J, Yin J, Liu H. Global and local structure preservation for feature selection. IEEE Transactions on Neural Networks and Learning Systems, 2013, 25(6): 1083-1095. [37] Grigonyte G, Cordeiro J, Dias G, Moraliyski R, Brazdil P. Paraphrase alignment for synonym evidence discovery. In: Proceedings of the 23rd International Conference on Computational Linguistics. Beijing, China: ACL, 2010. 403−411 [38] 王亚珅, 黄河燕, 冯冲, 周强. 基于注意力机制的概念化句嵌入研究. 自动化学报, 2020, 46(7): 1390-1400.WANG Ya-Shen, HUANG He-Yan, FENG Chong, ZHOU Qiang. Conceptual Sentence Embeddings Based on Attention Mechanism. ACTA AUTOMATICA SINICA, 2020, 46(7): 1390-1400. [39] Ustalov D, Panchenko A, Biemann C. Automatic induction of synsets from a graph of synonyms. In: Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. Vancouver, Canada: ACL, 2017. 1579−1590 [40] Tang C, Liu X, Li M, Wang P, Chen J, Wang L, Li W. Robust unsupervised feature selection via dual self-representation and manifold regularization. Knowledge-based Systems, 2018. 145: 109-120. doi: 10.1016/j.knosys.2018.01.009 [41] Wang X, Hua Y, Kodirov E, Robertson N M. ProSelfLC: Progressive self label correction for training robust deep neural networks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Virtual Event: CVPR, 2021. [42] Lin Y, Shen S, Liu Z, Luan H, Sun M. Neural relation extraction with selective attention over instances. In: Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Berlin, Germany: ACL, 2016. 2124−2133 -

 下载:
下载:

计量
- 文章访问数: 659
- HTML全文浏览量: 249
- PDF下载量: 169
- 被引次数: 0
