

-
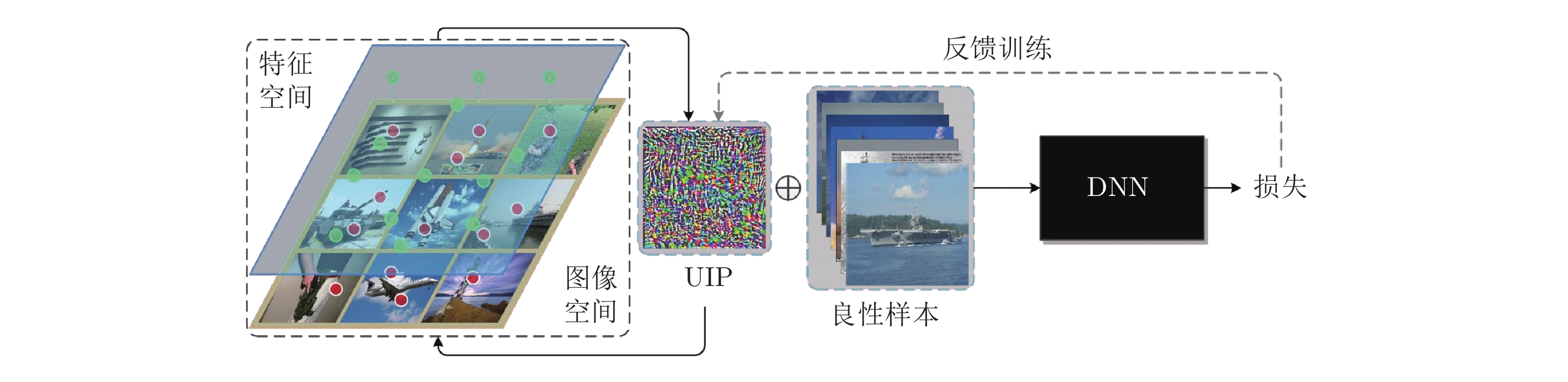
摘要: 现有研究表明深度学习模型容易受到精心设计的对抗样本攻击, 从而导致模型给出错误的推理结果, 引发潜在的安全威胁. 已有较多有效的防御方法, 其中大多数针对特定攻击方法具有较好防御效果, 但由于实际应用中无法预知攻击者可能采用的攻击策略, 因此提出不依赖攻击方法的通用防御方法是一个挑战. 为此, 提出一种基于通用逆扰动(Universal inverse perturbation, UIP)的对抗样本防御方法, 通过学习原始数据集中的类相关主要特征, 生成通用逆扰动, 且UIP对数据样本和攻击方法都具有通用性, 即一个UIP可以实现对不同攻击方法作用于整个数据集得到的所有对抗样本进行防御. 此外, UIP通过强化良性样本的类相关重要特征实现对良性样本精度的无影响, 且生成UIP无需对抗样本的先验知识. 通过大量实验验证, 表明UIP在不同数据集、不同模型中对各类攻击方法都具备显著的防御效果, 且提升了模型对正常样本的分类性能.Abstract: Existing studies have shown that deep learning models are vulnerable to carefully crafted adversarial sample, leading to wrong decision by the model, which will cause potential security threats. Many effective defense methods have been proposed, most of which have good defense effects against specific attack methods. However, since the possible strategies of attackers cannot be predicted in practical applications, it is a challenge to propose a general defense that does not rely on attack methods. This paper proposes a defense method based on universal inverse perturbation (UIP), which generates universal inverse perturbation by learning important features of classes in the original data. UIP is universal to data and attack methods, that is, one UIP can realize defense against all samples obtained by different attack methods acting on the entire data set. In addition, UIP can guarantee the accuracy of benign samples by enhancing the important characteristics of the benign samples, and the generation of UIP does not require prior knowledge of adversarial samples. Extensive experiments are carried out to testify that UIP has a significant defense effect against various attack methods in different data sets and different models, and the model's classification performance for normal samples is improved as well.
-
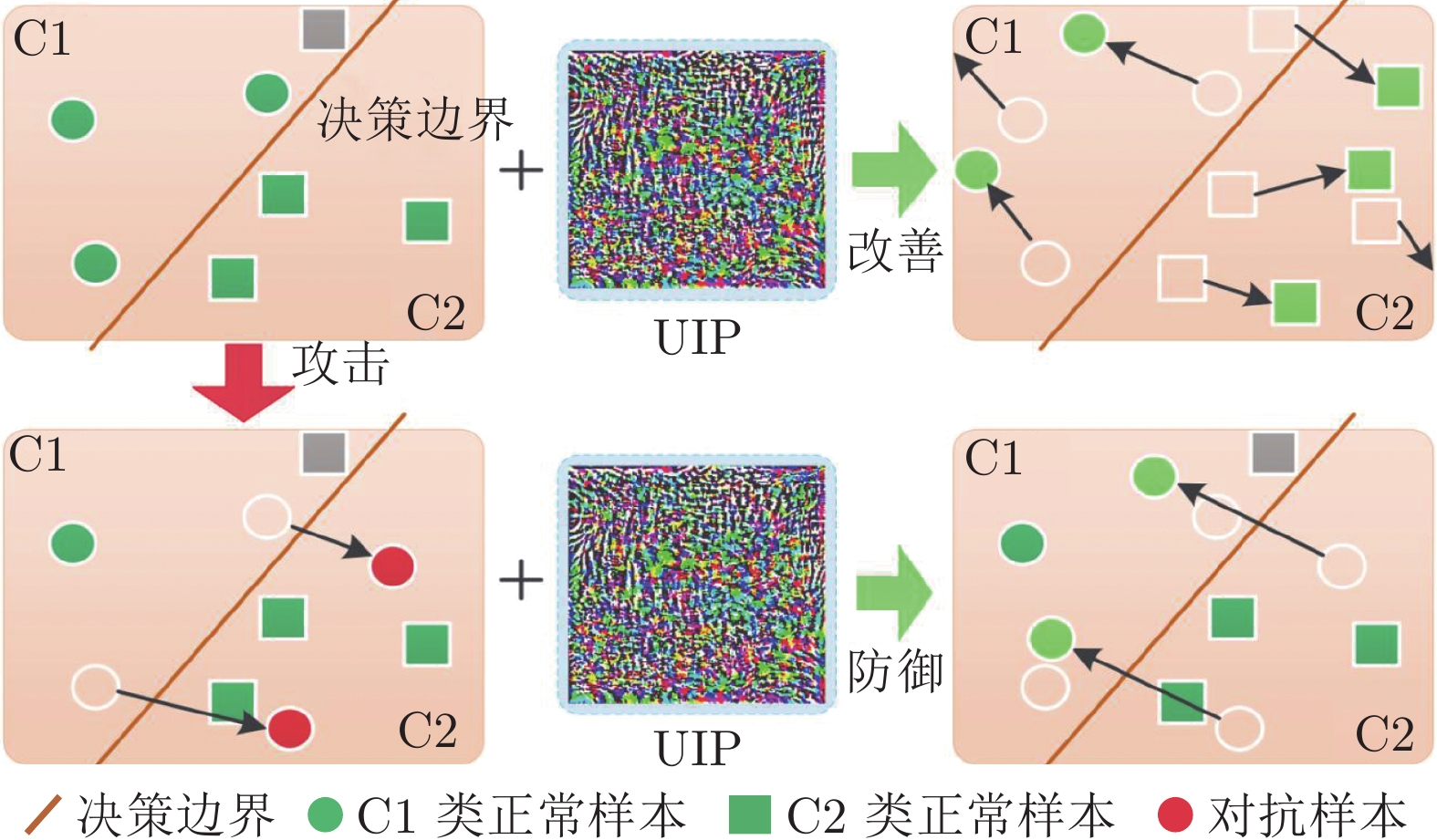
图 2 基于特征分布和决策边界的UIPD分析示意图
Fig. 2 The UIPD analysis based on feature distribution and decision boundary

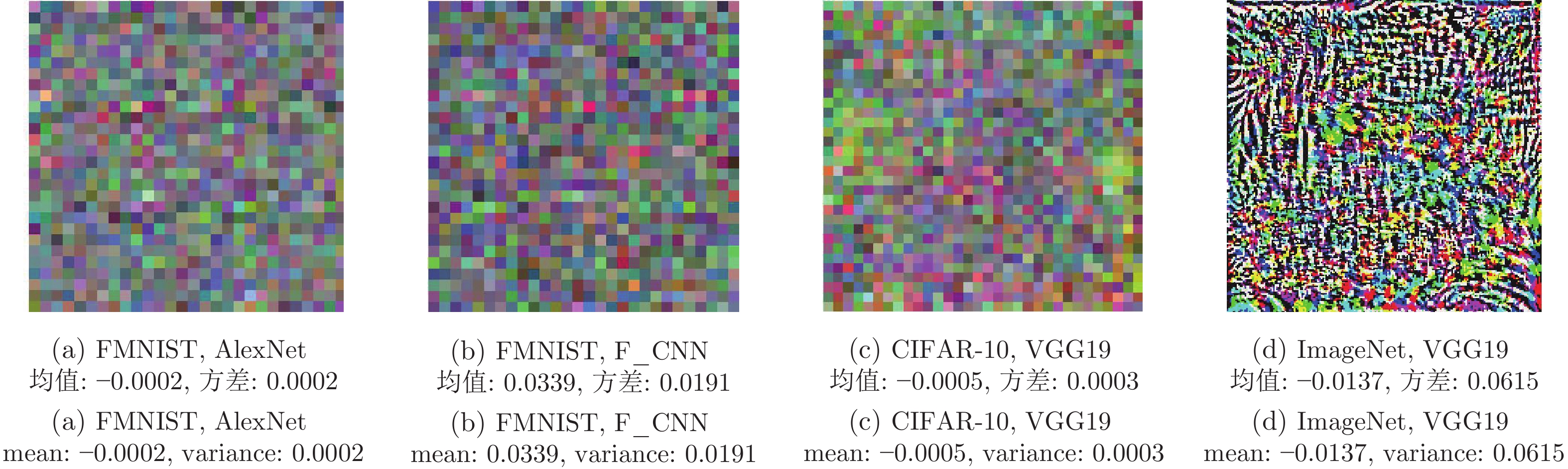
图 4 MNIST数据集中不同模型的 UIP 可视化图
Fig. 4 The UIP visualization of MNIST dataset in different models
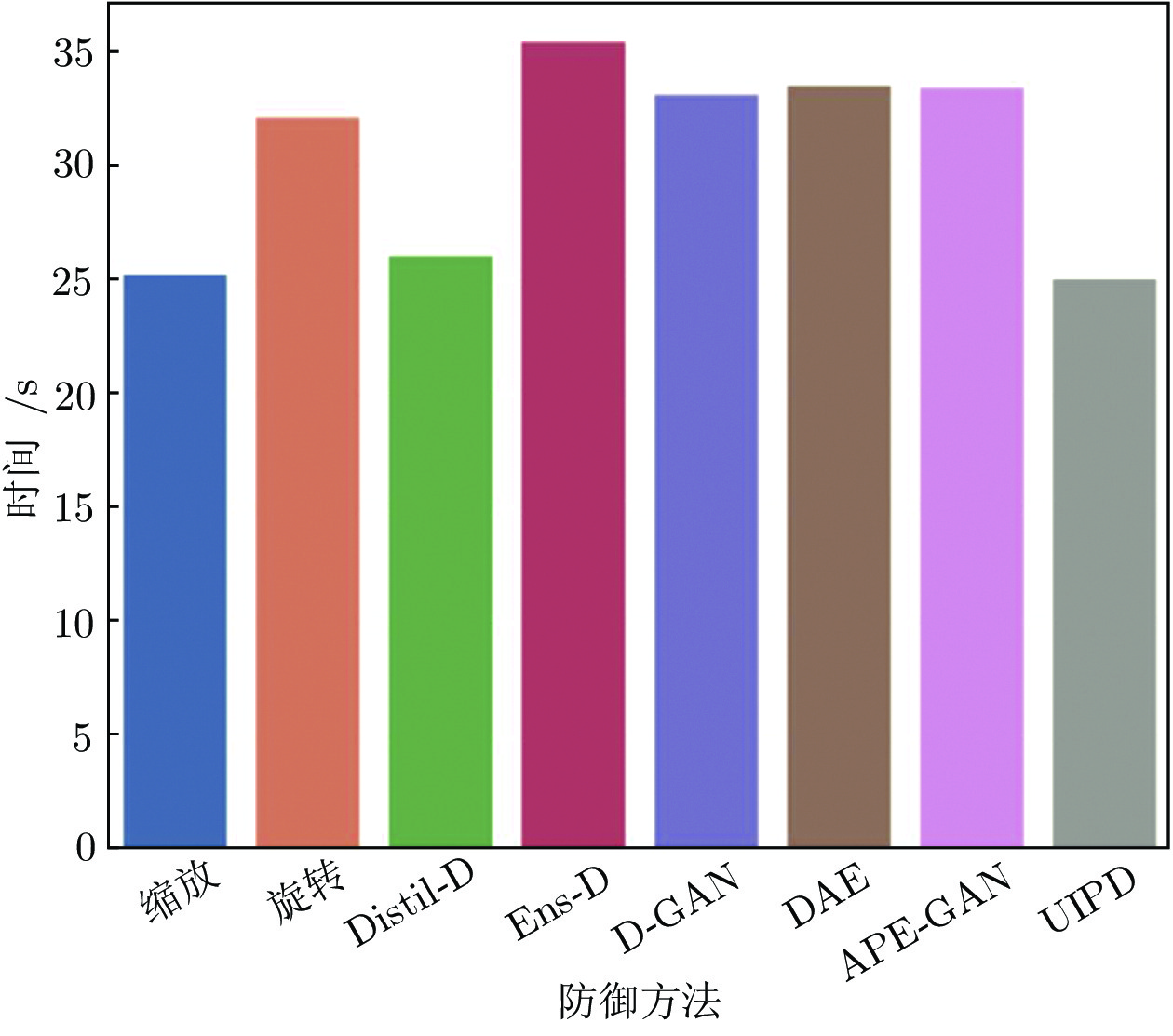
图 6 不同防御方法实施1000次防御的时间消耗
Fig. 6 The time cost in 1000 defenses of different defense methods
表 1 自行搭建的网络模型结构
Table 1 The network structure built by ourselves
网络层 M_CNN/F_CNN Conv + ReLU 5 × 5 × 5 Max pooling 2 × 2 Conv + ReLU 5 × 5 × 64 Max pooling 2 × 2 Dense (Fully connected) 1024 Dropout 0.5 Dense (Fully connected) 10 Softmax 10  下载: 导出CSV
下载: 导出CSV
表 2 UIPD针对不同攻击方法的防御成功率(%)
Table 2 The defense success rate of UIPD against different attack methods (%)
DSR MNIST FMNIST CIFAR-10 ImageNet AlexNet LeNet M_CNN AlexNet F_CNN VGG19 VGG19 良性样本识别准确率 92.34 95.71 90.45 89.01 87.42 79.55 89.00 FGSM[8] 73.31 85.21 77.35 79.15 80.05 78.13 43.61 BIM[18] 99.30 93.73 99.11 95.28 97.61 85.32 72.90 MI-FGSM[9] 69.65 90.32 98.99 88.35 85.75 56.93 44.76 PGD[17] 99.31 95.93 99.19 97.80 95.83 81.05 73.13 C&W[19] 99.34 96.04 92.10 96.44 94.44 80.67 46.67 L-BFGS[6] 98.58 70.12 67.79 66.35 71.75 68.69 31.36 JSMA[10] 64.33 55.59 76.61 72.31 69.51 60.04 37.54 DeepFool[20] 98.98 97.98 94.52 93.54 91.63 83.13 62.54 UAP[15] 97.46 97.09 99.39 97.85 96.55 83.07 72.66 Boundary[12] 93.63 94.38 95.72 92.67 91.88 76.21 68.45 ZOO[11] 77.38 75.43 76.39 68.36 65.42 61.58 54.18 AGNA[21] 75.69 76.40 81.60 64.80 72.14 62.10 55.70 AUNA[21] 74.20 73.65 78.53 65.75 62.20 62.70 52.40 SPNA[21] 92.10 88.35 89.17 77.58 74.26 72.90 60.30
下载: 导出CSV
表 3 UIPD针对不同数据样本的通用性(MNIST, M_CNN)
Table 3 The universality of UIPD for different examples (MNIST, M_CNN)
第1组 第2组 第3组 第4组 良性样本类标 置信度 (良性样本 + UIP)类标 置信度 对抗样本类标 置信度 (对抗样本 + UIP) 类标 置信度 0 1.000 0 1.000 5 0.5390 0 0.9804 1 1.000 1 1.000 8 0.4906 1 0.9848 2 1.000 2 1.000 1 0.5015 2 0.9841 3 1.000 3 1.000 7 0.5029 3 0.9549 4 1.000 4 1.000 9 0.5146 4 0.9761 5 1.000 5 1.000 3 0.5020 5 0.9442 6 1.000 6 1.000 4 0.5212 6 0.9760 7 1.000 7 1.000 3 0.5225 7 0.8960 8 1.000 8 1.000 6 0.5228 8 0.9420 9 1.000 9 1.000 7 0.5076 9 0.9796
下载: 导出CSV
表 4 不同防御方法针对基于梯度的攻击的防御效果比较
Table 4 The performance comparison of different defense methods against gradient-based attacks
MNIST FMNIST CIFAR-10 ImageNet AlexNet LeNet M_CNN AlexNet F_CNN VGG19 VGG19 平均ASR (%) 95.46 99.69 97.88 98.77 97.59 87.63 81.79 DSR (%) resize1 78.24 74.32 81.82 79.84 77.24 69.38 47.83 resize2 78.54 64.94 78.64 79.34 69.65 64.26 43.26 rotate 76.66 80.54 84.74 77.63 61.46 72.49 42.49 Distil-D 83.51 82.08 80.49 85.24 82.55 75.17 57.13 Ens-D 87.19 88.03 85.24 87.71 83.21 77.46 58.34 D-GAN 72.40 68.26 70.31 79.54 75.04 73.05 51.04 GN 22.60 30.26 27.56 27.96 22.60 23.35 13.85 DAE 84.54 85.25 85.68 86.94 80.21 75.85 59.31 APE-GAN 83.40 80.71 82.36 84.10 79.45 72.15 57.88 UIPD 88.92 86.89 87.45 87.77 83.91 78.23 59.91 Rconf resize1 0.9231 0.9631 0.9424 0.8933 0.9384 0.6742 0.4442 resize2 0.8931 0.9184 0.9642 0.9731 0.9473 0.7371 0.4341 rotate 0.9042 0.8914 0.9274 0.9535 0.8144 0.6814 0.4152 Distil-D 0.9221 0.9053 0.9162 0.9340 0.9278 0.6741 0.4528 Ens-D 0.9623 0.9173 0.9686 0.9210 0.9331 0.7994 0.5029 D-GAN 0.8739 0.8419 0.8829 0.9012 0.8981 0.7839 0.4290 GN 0.1445 0.1742 0.2452 0.1631 0.1835 0.1255 0.0759 DAE 0.9470 0.9346 0.9633 0.9420 0.9324 0.7782 0.5090 APE-GAN 0.8964 0.9270 0.9425 0.8897 0.9015 0.6301 0.4749 UIPD 0.9788 0.9463 0.9842 0.9642 0.9531 0.8141 0.5141
下载: 导出CSV
表 5 不同防御方法针对基于优化的攻击的防御效果比较
Table 5 The performance comparison of different defense methods against optimization-based attacks
MNIST FMNIST CIFAR-10 ImageNet AlexNet LeNet M_CNN AlexNet F_CNN VGG19 VGG19 平均ASR (%) 93.28 96.32 94.65 95.20 93.58 88.10 83.39 DSR (%) resize1 78.65 70.62 79.09 74.37 66.54 65.31 38.28 resize2 63.14 67.94 77.14 66.98 63.09 62.63 41.60 rotate 76.62 72.19 71.84 66.75 64.42 65.60 42.67 Distil-D 82.37 82.22 80.49 82.47 83.28 71.14 45.39 Ens-D 86.97 83.03 85.24 83.41 82.50 74.29 47.85 D-GAN 82.43 80.34 86.13 79.35 80.47 70.08 43.10 GN 20.16 21.80 25.30 19.67 18.63 21.40 13.56 DAE 83.66 84.17 86.88 82.40 83.66 74.30 51.61 APE-GAN 82.46 85.01 85.14 81.80 82.50 73.80 49.28 UIPD 87.92 85.22 87.54 83.70 83.91 75.38 52.91 Rconf resize1 0.8513 0.8614 0.8460 0.7963 0.8324 0.6010 0.3742 resize2 0.7814 0.8810 0.8655 0.8290 0.8475 0.6320 0.3800 rotate 0.8519 0.8374 0.8319 0.8100 0.8040 0.6462 0.4058 Distil-D 0.9141 0.8913 0.9033 0.9135 0.9200 0.7821 0.4528 Ens-D 0.9515 0.9280 0.8720 0.8940 0.9011 0.8155 0.4788 D-GAN 0.8539 0.8789 0.8829 0.8733 0.8820 0.7450 0.4390 GN 0.1630 0.1920 0.2152 0.1761 0.1971 0.1450 0.0619 DAE 0.9120 0.9290 0.9510 0.9420 0.9324 0.7782 0.5090 APE-GAN 0.8964 0.9270 0.9425 0.8897 0.9015 0.6301 0.4749 UIPD 0.9210 0.9340 0.9520 0.9512 0.9781 0.8051 0.5290
下载: 导出CSV
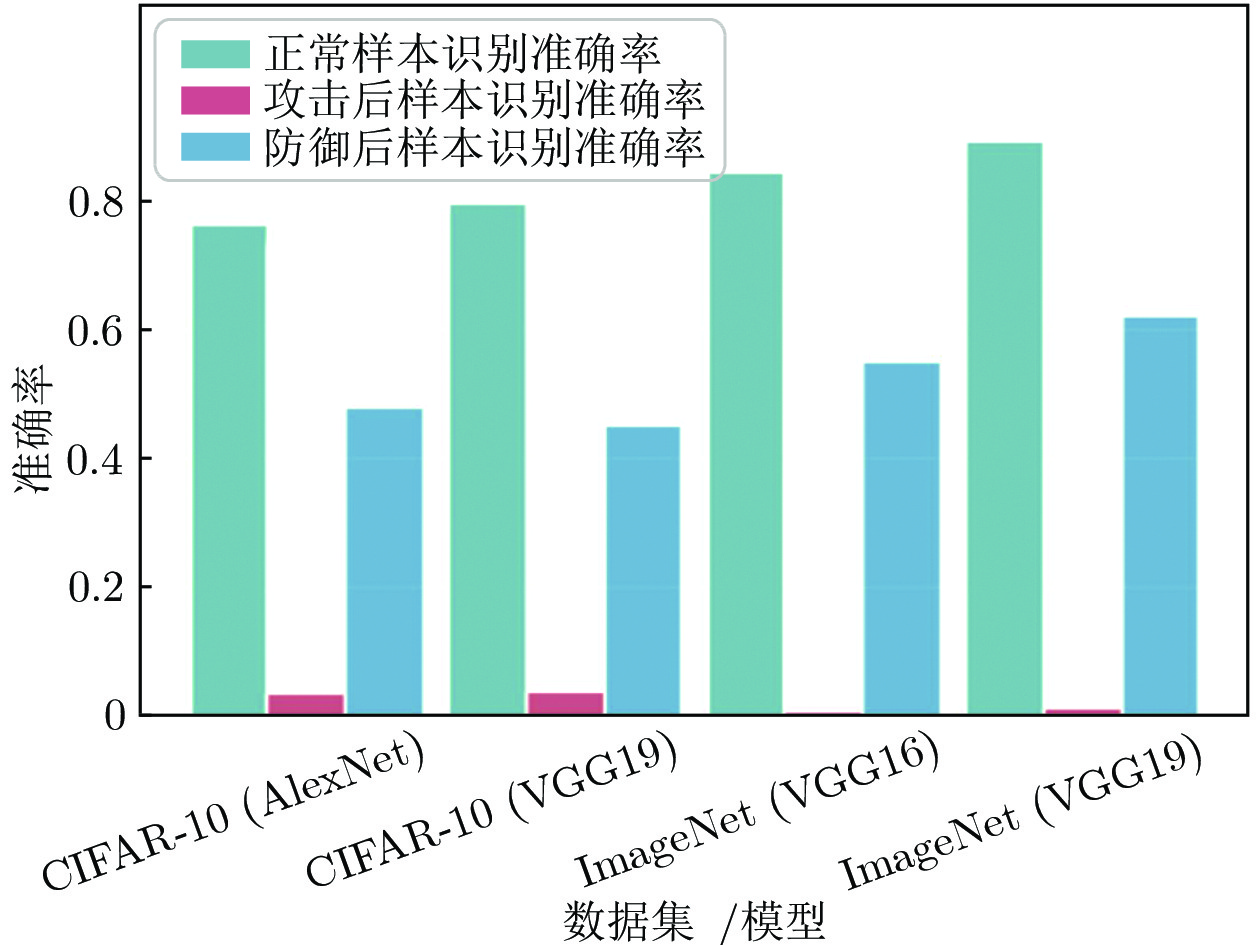
表 6 不同防御方法处理后良性样本的识别准确率 (%)
Table 6 The accuracy of benign examples after processing by different defense methods (%)
MNIST FMNIST CIFAR-10 ImageNet AlexNet LeNet M_CNN AlexNet F_CNN VGG19 VGG19 良性样本 92.34 95.71 90.45 89.01 87.42 79.55 89.00 resize1 92.27 (−0.07) 95.66 (−0.05) 90.47 (+0.02) 88.97 (−0.04) 87.38 (−0.04) 79.49 (−0.06) 88.98 (−0.02) resize2 92.26 (−0.80) 95.68 (−0.30) 90.29 (−0.16) 88.71 (−0.30) 87.38 (−0.04) 79.48 (−0.07) 87.61 (−1.39) rotate 92.31 (−0.03) 95.68 (−0.03) 90.39 (−0.06) 88.95 (−0.06) 87.40 (0.02) 79.53 (−0.02) 88.82 (−0.18) Distil-D 90.00 (−2.34) 95.70 (−0.01) 90.02 (−0.43) 88.89 (−0.12) 86.72 (−0.70) 76.97 (−2.58) 87.85 (−1.15) Ens-D 94.35 (+2.01) 96.15 (+0.44) 92.38 (+1.93) 89.13 (+0.12) 87.45 (+0.03) 80.13 (+0.58) 89.05 (+0.05) D-GAN 92.08 (−0.26) 95.18 (−0.53) 90.04 (−0.41) 88.60 (−0.41) 87.13 (−0.29) 78.80 (−0.75) 87.83 (−1.17) GN 22.54 (−69.80) 25.31 (−70.40) 33.58 (−56.87) 35.71 (−53.30) 28.92 (−58.59) 23.65 (−55.90) 17.13 (−71.87) DAE 91.57 (−0.77) 95.28 (−0.43) 89.91 (−0.54) 88.13 (−0.88) 86.80 (−0.62) 79.46 (−0.09) 87.10 (−1.90) APE-GAN 92.30 (−0.04) 95.68 (−0.03) 90.42 (−0.03) 89.00 (−0.01) 87.28 (−0.14) 79.49 (−0.06) 88.88 (−0.12) UIPD 92.37 (+0.03) 95.96 (+0.25) 90.51 (+0.06) 89.15 (+0.14) 87.48 (+0.06) 79.61 (+0.06) 89.15 (+0.15)
下载: 导出CSV
A1 UIPD针对不同数据样本的通用性(FMNIST, F_CNN)
A1 The universality of UIPD for different examples (FMNIST, F_CNN)
第1组 第2组 第3组 第4组 良性样本类标 置信度 (良性样本 + UIP)类标 置信度 对抗样本类标 置信度 (对抗样本 + UIP) 类标 置信度 0 1.000 0 1.000 6 0.4531 0 0.9415 1 1.000 1 1.000 3 0.4714 1 0.8945 2 1.000 2 1.000 6 0.5641 2 0.9131 3 1.000 3 1.000 1 0.5103 3 0.9425 4 1.000 4 1.000 2 0.4831 4 0.8773 5 1.000 5 1.000 7 0.5422 5 0.9026 6 1.000 6 1.000 5 0.4864 6 0.8787 7 1.000 7 1.000 5 0.5144 7 0.8309 8 1.000 8 1.000 4 0.4781 8 8.9424 9 1.000 9 1.000 7 0.4961 9 0.8872
下载: 导出CSV
A2 UIPD针对不同数据样本的通用性(CIFAR-10, VGG19)
A2 The universality of UIPD for different examples (CIFAR-10, VGG19)
第1组 第2组 第3组 第4组 良性样本类标 置信度 (良性样本 + UIP)类标 置信度 对抗样本类标 置信度 (对抗样本 + UIP) 类标 置信度 飞机 1.000 飞机 1.000 船 0.4914 飞机 0.9331 汽车 1.000 汽车 1.000 卡车 0.5212 汽车 0.9131 鸟 1.000 鸟 1.000 马 0.5031 鸟 0.8913 猫 1.000 猫 1.000 狗 0.5041 猫 0.9043 鹿 1.000 鹿 1.000 鸟 0.5010 鹿 0.8831 狗 1.000 狗 1.000 马 0.5347 狗 0.9141 青蛙 1.000 青蛙 1.000 猫 0.5314 青蛙 0.8863 马 1.000 马 1.000 狗 0.4814 马 0.8947 船 1.000 船 1.000 飞机 0.5142 船 0.9251 卡车 1.000 卡车 1.000 飞机 0.4761 卡车 0.9529
下载: 导出CSV
A3 UIPD针对不同数据样本的通用性(ImageNet, VGG19)
A3 The universality of UIPD for different examples (ImageNet, VGG19)
第1组 第2组 第3组 第4组 良性样本类标 置信度 (良性样本 + UIP)类标 置信度 对抗样本类标 置信度 (对抗样本 + UIP) 类标 置信度 导弹 0.9425 导弹 0.9445 军装 0.5134 导弹 0.8942 步枪 0.9475 步枪 0.9525 航空母舰 0.4981 步枪 0.7342 军装 0.9825 军装 0.9925 防弹背心 0.5014 军装 0.8245 皮套 0.9652 皮套 0.9692 军装 0.4831 皮套 0.8074 航空母舰 0.9926 航空母舰 0.9926 灯塔 0.4788 航空母舰 0.8142 航天飞机 0.9652 航天飞机 0.9652 导弹 0.5101 航天飞机 0.7912 防弹背心 0.9256 防弹背心 0.9159 步枪 0.4698 防弹背心 0.8141 灯塔 0.9413 灯塔 0.9782 客机 0.5194 灯塔 0.7861 客机 0.9515 客机 0.9634 坦克 0.4983 客机 0.7134 坦克 0.9823 坦克 0.9782 灯塔 0.5310 坦克 0.7613
下载: 导出CSV
-
[1] Goodfellow I, Bengio Y, Courville A. Deep Learning. Cambridge: The MIT Press, 2016. 24−45 [2] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks. In: Proceedings of the 25th International Conference on Neural Information Processing Systems. Lake Tahoe, Nevada, USA: ACM, 2012. 1097−1105 [3] Sutskever I, Vinyals O, Le Q V. Sequence to sequence learning with neural networks. In: Proceedings of the 27th International Conference on Neural Information Processing Systems. Montreal, Canada: ACM, 2014. 3104−3112 [4] 袁文浩, 孙文珠, 夏斌, 欧世峰. 利用深度卷积神经网络提高未知噪声下的语音增强性能. 自动化学报, 2018, 44(4): 751-759 doi: 10.16383/j.aas.2018.c170001Yuan Wen-Hao, Sun Wen-Zhu, Xia Bin, Ou Shi-Feng. Improving speech enhancement in unseen noise using deep convolutional neural network. Acta Automatica Sinica, 2018, 44(4): 751-759 doi: 10.16383/j.aas.2018.c170001 [5] 代伟, 柴天佑. 数据驱动的复杂磨矿过程运行优化控制方法. 自动化学报, 2014, 40(9): 2005-2014Dai Wei, Chai Tian-You. Data-driven optimal operational control of complex grinding processes. Acta Automatica Sinica, 2014, 40(9): 2005-2014 [6] Szegedy C, Zaremba W, Sutskever I, Bruna J, Erhan D, Goodfellow I J, et al. Intriguing properties of neural networks. In: Proceedings of the 2nd International Conference on Learning Representations. Banff, Canada: ICLR, 2014. [7] Akhtar N, Mian A. Threat of adversarial attacks on deep learning in computer vision: A survey. IEEE Access, 2018, 6: 14410-14430 doi: 10.1109/ACCESS.2018.2807385 [8] Goodfellow I J, Shlens J, Szegedy C. Explaining and harnessing adversarial examples. In: Proceedings of the 3rd International Conference on Learning Representations. San Diego, USA: ICLR, 2015. [9] Dong Y P, Liao F Z, Pang T Y, Su H, Zhu J, Hu X L, et al. Boosting adversarial attacks with momentum. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 9185−9193 [10] Papernot N, McDaniel P, Jha S, Fredrikson M, Celik Z B, Swami A. The limitations of deep learning in adversarial settings. In: Proceedings of the IEEE European Symposium on Security and Privacy (EuroS&P). Saarbruecken, Germany: IEEE, 2016. 372−387 [11] Chen P Y, Zhang H, Sharma Y, Yi J F, Hsieh C J. ZOO: Zeroth order optimization based black-box attacks to deep neural networks without training substitute models. In: Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security. Dallas, USA: ACM, 2017. 15−26 [12] Brendel W, Rauber J, Bethge M. Decision-based adversarial attacks: Reliable attacks against black-box machine learning models. In: Proceedings of the 6th International Conference on Learning Representations. Vancouver, Canada: ICLR, 2018. [13] Xiao C W, Li B, Zhu J Y, He W, Liu M Y, Song D. Generating adversarial examples with adversarial networks. In: Proceedings of the 27th International Joint Conference on Artificial Intelligence. Stockholm, Sweden: IJCAI, 2018. 3905−3911 [14] Papernot N, McDaniel P, Goodfellow I. Transferability in machine learning: From phenomena to black-box attacks using adversarial samples. arXiv preprint arXiv: 1605.07277, 2016. [15] Moosavi-Dezfooli S M, Fawzi A, Fawzi O, Frossard P. Universal adversarial perturbations. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE, 2017. 86−94 [16] Ilyas A, Santurkar S, Tsipras D, Engstrom L, Tran B, Mądry A. Adversarial examples are not bugs, they are features. In: Proceedings of the 33rd International Conference on Neural Information Processing Systems. Vancouver, Canada: ACM, 2019. Article No. 12 [17] Madry A, Makelov A, Schmidt L, Tsipras D, Vladu A. Towards deep learning models resistant to adversarial attacks. In: Proceedings of the 6th International Conference on Learning Representations. Vancouver, Canada: ICLR, 2018. [18] Kurakin A, Goodfellow I, Bengio S. Adversarial examples in the physical world. In: Proceedings of the 5th International Conference on Learning Representations.Toulon, France: ICLR, 2017. [19] Carlini N, Wagner D. Towards evaluating the robustness of neural networks. In: Proceedings of the IEEE Symposium on Security and Privacy (SP). San Jose, USA: IEEE, 2017. 39−57 [20] Moosavi-Dezfooli S M, Fawzi A, Frossard P. DeepFool: A simple and accurate method to fool deep neural networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 2574−2582 [21] Rauber J, Brendel W, Bethge M. Foolbox: A python toolbox to benchmark the robustness of machine learning models. arXiv preprint arXiv: 1707.04131, 2017. [22] Su J W, Vargas D V, Sakurai K. One pixel attack for fooling deep neural networks. IEEE Transactions on Evolutionary Computation, 2019, 23(5): 828-841 doi: 10.1109/TEVC.2019.2890858 [23] Baluja S, Fischer I. Adversarial transformation networks: Learning to generate adversarial examples. arXiv preprint arXiv: 1703.09387, 2017. [24] Cisse M, Adi Y, Neverova N, Keshet J. Houdini: Fooling deep structured prediction models. arXiv preprint arXiv: 1707.05373, 2017. [25] Sarkar S, Bansal A, Mahbub U, Chellappa R. UPSET and ANGRI: Breaking high performance image classifiers. arXiv preprint arXiv: 1707.01159, 2017. [26] Brown T B, Mané D, Roy A, Abadi M, Gilmer J. Adversarial patch. arXiv preprint arXiv: 1712.09665, 2017. [27] Karmon D, Zoran D, Goldberg Y. LaVAN: Localized and visible adversarial noise. In: Proceedings of the 35th International Conference on Machine Learning. Stockholm, Sweden: ICML, 2018. 2512−2520 [28] Liu A S, Liu X L, Fan J X, Ma Y Q, Zhang A L, Xie H Y, et al. Perceptual-sensitive GAN for generating adversarial patches. In: Proceedings of the AAAI Conference on Artificial Intelligence. Honolulu, USA: AAAI, 2019. 1028−1035 [29] Liu A S, Wang J K, Liu X L, Cao B W, Zhang C Z, Yu H. Bias-based universal adversarial patch attack for automatic check-out. In: Proceedings of the 16th European Conference on Computer Vision. Glasgow, UK: Springer, 2020. 395−410 [30] Xie C H, Wang J Y, Zhang Z S, Zhou Y Y, Xie L X, Yuille A. Adversarial examples for semantic segmentation and object detection. In: Proceedings of the International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017. 1378−1387 [31] Song C B, He K, Lin J D, Wang L W, Hopcroft J E. Robust local features for improving the generalization of adversarial training. In: Proceedings of the 8th International Conference on Learning Representations. Addis Ababa, Ethiopia: ICLR, 2020. [32] Miyato T, Dai A M, Goodfellow I J. Adversarial training methods for semi-supervised text classification. In: Proceedings of the 5th International Conference on Learning Representations. Toulon, France: ICLR, 2017. [33] Zheng S, Song Y, Leung T, Goodfellow I. Improving the robustness of deep neural networks via stability training. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 4480−4488 [34] Dziugaite G K, Ghahramani Z, Roy D M. A study of the effect of JPG compression on adversarial images. arXiv preprint arXiv: 1608.00853, 2016. [35] Das N, Shanbhogue M, Chen S T, Hohman F, Chen L, Kounavis M E, et al. Keeping the bad guys out: Protecting and vaccinating deep learning with JPEG compression. arXiv preprint arXiv: 1705.02900, 2017. [36] Luo Y, Boix X, Roig G, Poggio T, Zhao Q. Foveation-based mechanisms alleviate adversarial examples. arXiv preprint arXiv: 1511.06292, 2015. [37] Gu S X, Rigazio L. Towards deep neural network architectures robust to adversarial examples. In: Proceedings of the 3rd International Conference on Learning Representations. San Diego, USA: ICLR, 2015. [38] Rifai S, Vincent P, Muller X, Glorot X, Bengio Y. Contractive auto-encoders: Explicit invariance during feature extraction. In: Proceedings of the 28th International Conference on International Conference on Machine Learning. Bellevue, USA: ACM, 2011. 833−840 [39] Ross A S, Doshi-Velez F. Improving the adversarial robustness and interpretability of deep neural networks by regularizing their input gradients. In: Proceedings of the 32nd AAAI Conference on Artificial Intelligence. Menlo Park, CA, USA: AAAI, 2018. 1660−1669 [40] Hinton G, Vinyals O, Dean J. Distilling the knowledge in a neural network. arXiv preprintarXiv: 1503.02531, 2015. [41] Papernot N, McDaniel P, Wu X, Jha S, Swami A. Distillation as a defense to adversarial perturbations against deep neural networks. In: Proceedings of the IEEE Symposium on Security and Privacy (SP). San Jose, USA: IEEE, 2016. 582−597 [42] Nayebi A, Ganguli S. Biologically inspired protection of deep networks from adversarial attacks. arXiv preprint arXiv: 1703.09202, 2017. [43] Cisse M, Adi Y, Neverova N, Keshet J. Houdini: Fooling deep structured visual and speech recognition models with adversarial examples. In: Proceedings of Advances in Neural Information Processing Systems. 2017. [44] Gao J, Wang B L, Lin Z M, Xu W L, Qi T J. DeepCloak: Masking deep neural network models for robustness against adversarial samples. In: Proceedings of the 5th International Conference on Learning Representations. Toulon, France: ICLR, 2017. [45] Jin J, Dundar A, Culurciello E. Robust convolutional neural networks under adversarial noise. arXiv preprint arXiv: 1511.06306, 2015. [46] Sun Z, Ozay M, Okatani T. HyperNetworks with statistical filtering for defending adversarial examples. arXiv preprint arXiv: 1711.01791, 2017. [47] Akhtar N, Liu J, Mian A. Defense against universal adversarial perturbations. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 3389−3398 [48] Hlihor P, Volpi R, Malagò L. Evaluating the robustness of defense mechanisms based on autoencoder reconstructions against Carlini-Wagner adversarial attacks. In: Proceedings of the 3rd Northern Lights Deep Learning Workshop. Tromsø, Norway: NLDL, 2020. 1−6 [49] 孔锐, 蔡佳纯, 黄钢. 基于生成对抗网络的对抗攻击防御模型. 自动化学报, DOI: 10.16383/j.aas.c200033Kong Rui, Cai Jia-Chun, Huang Gang. Defense to adversarial attack with generative adversarial network. Acta Automatica Sinica, DOI: 10.16383/j.aas.c200033 [50] Samangouei P, Kabkab M, Chellappa R. Defense-GAN: Protecting classifiers against adversarial attacks using generative models. In: Proceedings of the 6th International Conference on Learning Representations. Vancouver, Canada: ICLR, 2018. [51] Lin W A, Balaji Y, Samangouei P, Chellappa R. Invert and defend: Model-based approximate inversion of generative adversarial networks for secure inference. arXiv preprintarXiv: 1911.10291, 2019. [52] Jin G Q, Shen S W, Zhang D M, Dai F, Zhang Y D. APE-GAN: Adversarial perturbation elimination with GAN. In: Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Brighton, UK: IEEE, 2019. 3842−3846 [53] Xu W L, Evans D, Qi Y J. Feature squeezing: Detecting adversarial examples in deep neural networks. In: Proceedings of the 25th Annual Network and Distributed System Security Symposium. San Diego, USA: NDSS, 2018. [54] Ju C, Bibaut A, Van Der Laan M. The relative performance of ensemble methods with deep convolutional neural networks for image classification. Journal of Applied Statistics, 2018, 45(15): 2800-2818 doi: 10.1080/02664763.2018.1441383 [55] Kim B, Rudin C, Shah J. Latent Case Model: A Generative Approach for Case-Based Reasoning and Prototype Classification, MIT-CSAIL-TR-2014-011, MIT, Cambridge, USA, 2014. -

 下载:
下载:

计量
- 文章访问数: 1811
- HTML全文浏览量: 1793
- PDF下载量: 217
- 被引次数: 0
