

Research on Multi-aircraft Cooperative Air Combat Method Based on Deep Reinforcement Learning
-
摘要:
多机协同是空中作战的关键环节, 如何处理多实体间复杂的协作关系、实现多机协同空战的智能决策是亟待解决的问题. 为此, 提出基于深度强化学习的多机协同空战决策流程框架(Deep-reinforcement-learning-based multi-aircraft cooperative air combat decision framework, DRL-MACACDF), 并针对近端策略优化(Proximal policy optimization, PPO)算法, 设计4种算法增强机制, 提高多机协同对抗场景下智能体间的协同程度. 在兵棋推演平台上进行的仿真实验, 验证了该方法的可行性和实用性, 并对对抗过程数据进行了可解释性复盘分析, 研讨了强化学习与传统兵棋推演结合的交叉研究方向.
Abstract:Multi-aircraft cooperation is the key part of air combat, and how to deal with the complex cooperation relationship between multi-entities is the essential problem to be solved urgently. In order to solve the problem of intelligent decision-making in multi-aircraft cooperative air combat, a deep-reinforcement-learning-based multi-aircraft cooperative air combat decision framework (DRL-MACACDF) is proposed in this paper. Based on proximal policy optimization (PPO), four algorithm enhancement mechanisms are designed to improve the synergistic degree of agents in multi-aircraft cooperative confrontation scenarios. The feasibility and practicability of the method are verified by the simulation on the wargame platform, and the interpretable review analysis of the antagonistic process data is carried out, and the cross research direction of the combination of reinforcement learning and traditional wargame deduction is discussed.
1) 1版本号: v1.4.1.0 -
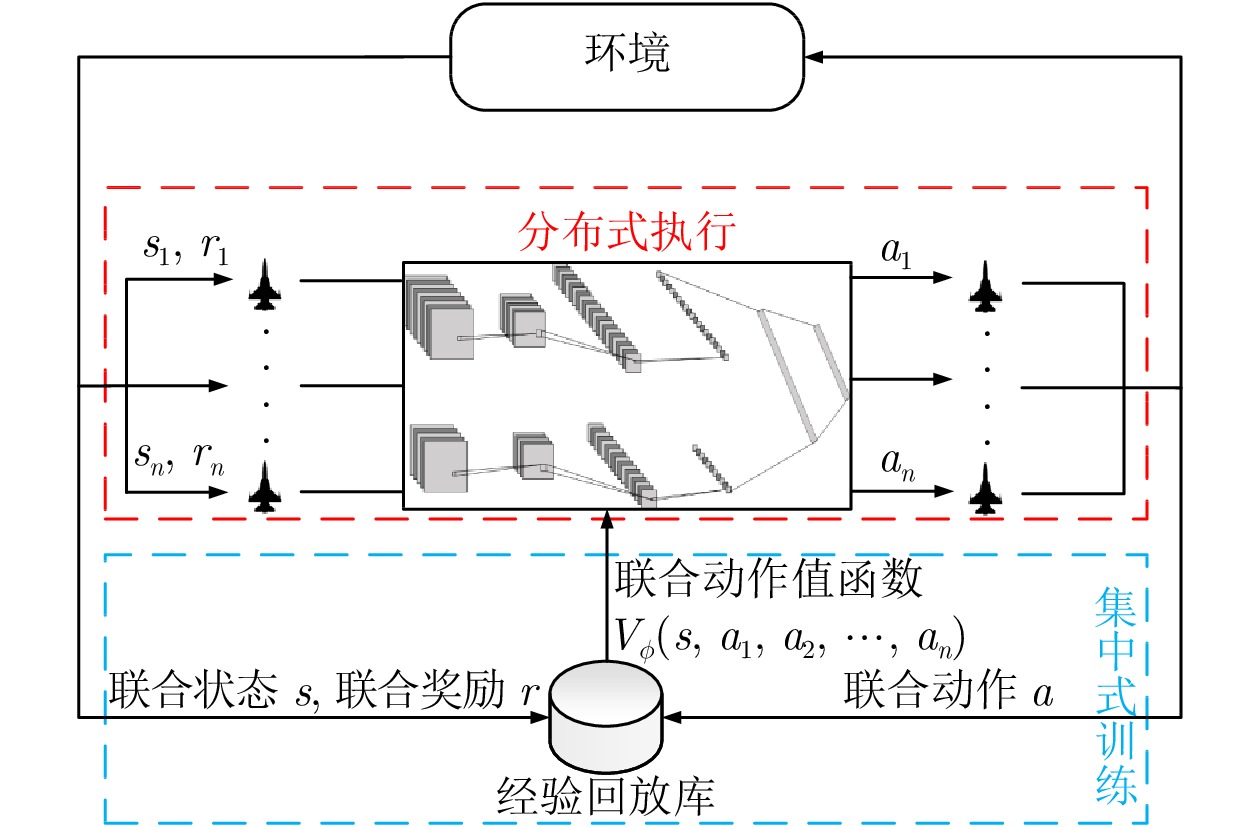
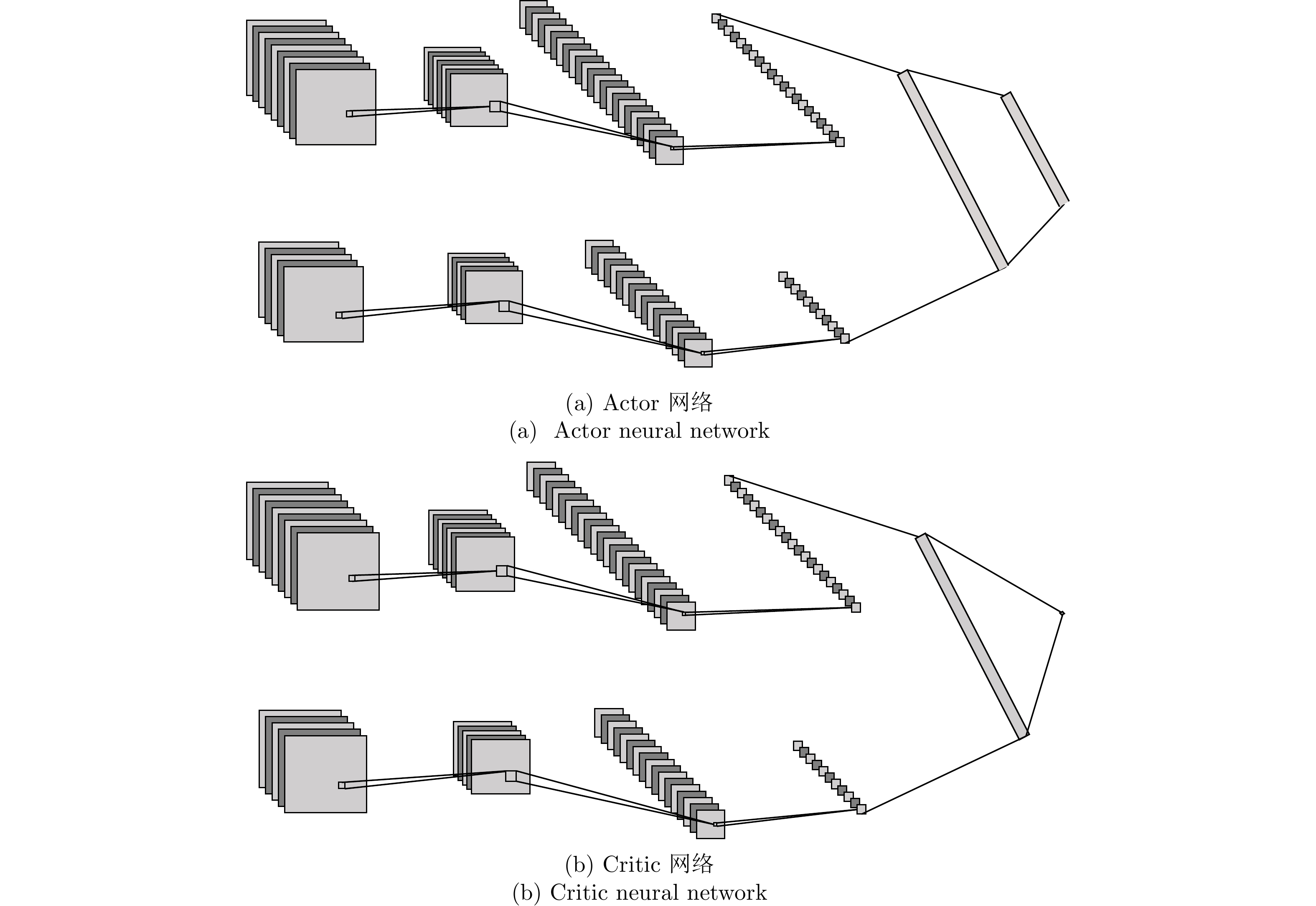
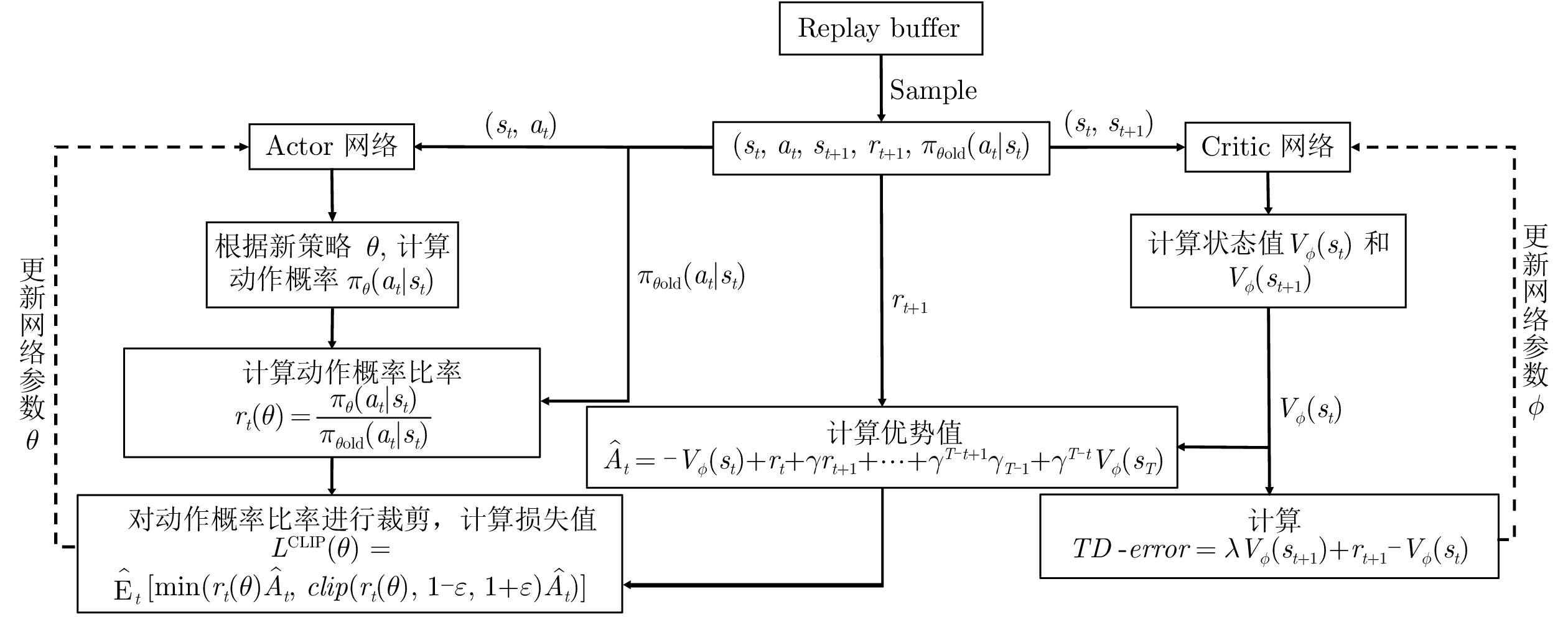
图 3 集中式训练−分布式执行架构
Fig. 3 Framework of centralized training and decentralized execution
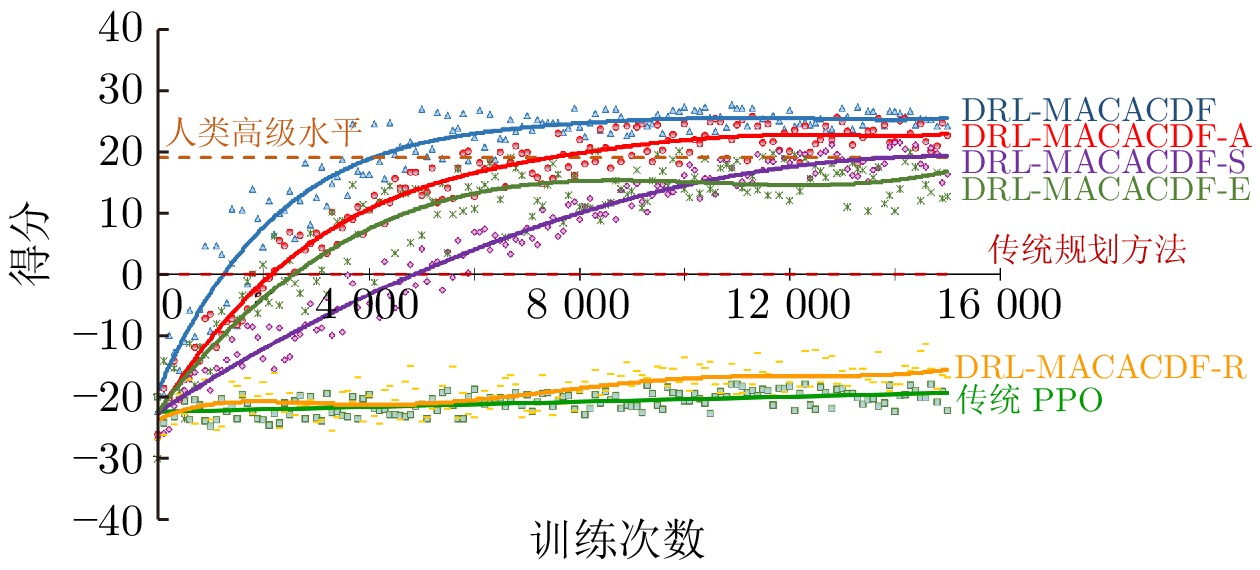
图 6 消融实验算法性能对比图
Fig. 6 Performance comparison diagram of ablation experimental algorithm
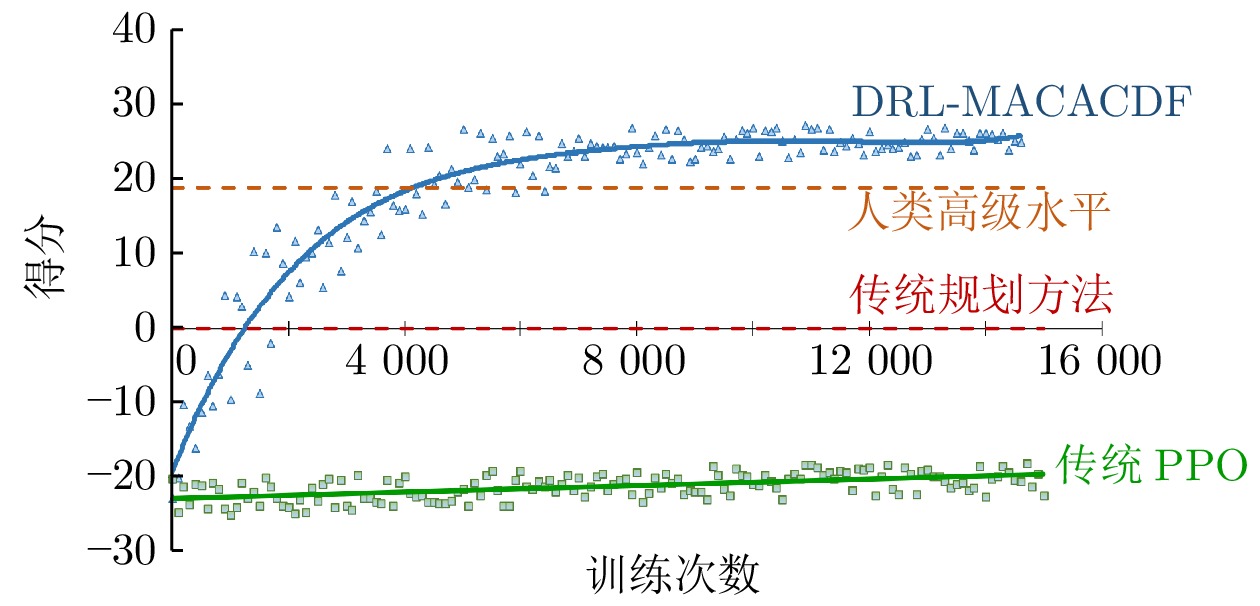
表 1 算法有效性实验数据统计
Table 1 Experimental statistics of algorithm effectiveness
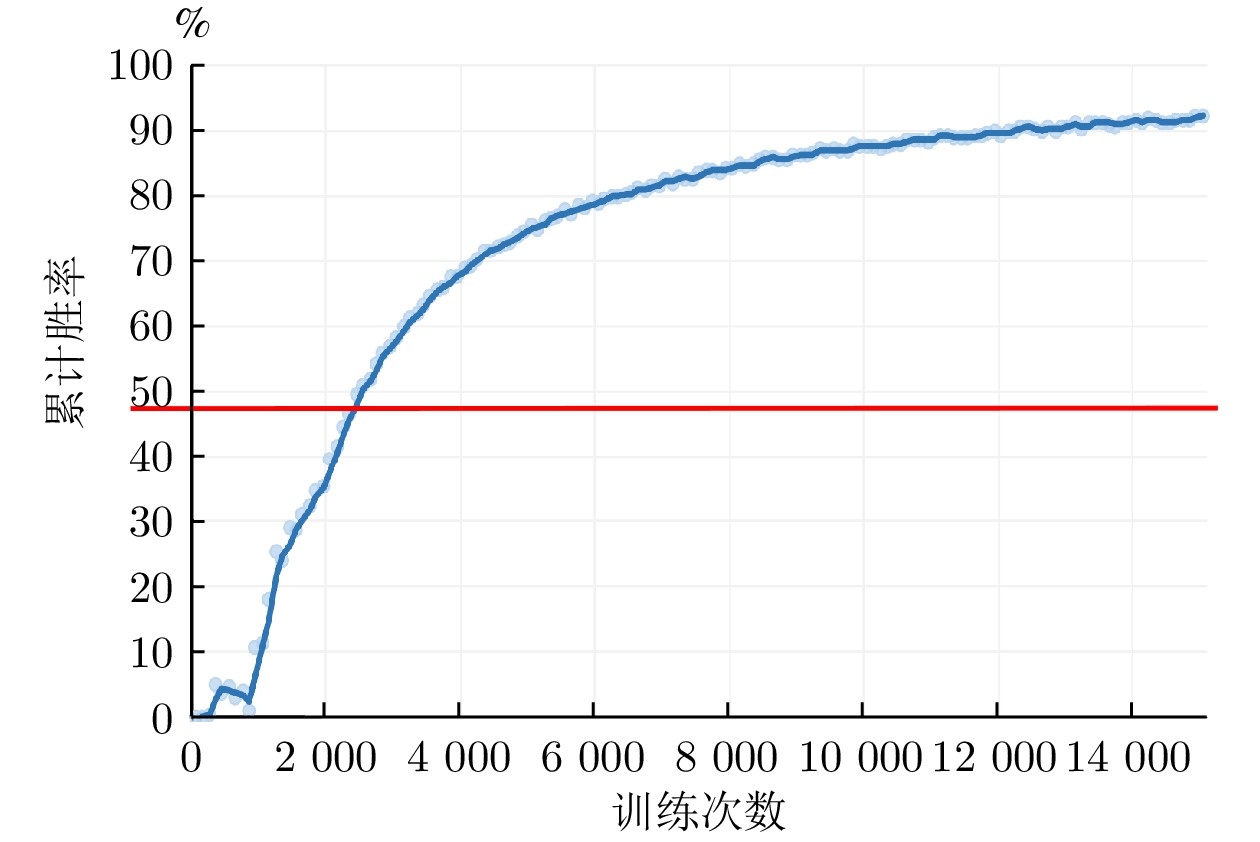
算法 平均得分 得分标准差 平均胜率 (%) DRL-MACACDF 18.929 10.835 91.472 PPO −21.179 1.698 0  下载: 导出CSV
下载: 导出CSV
表 2 消融实验设置
Table 2 The setting of ablation experiment
模型 嵌入式专家
经验奖励
机制经验共享
机制自适应权重及
优先采样机制鼓励
探索
机制DRL-MACACDF ● ● ● ● DRL-MACACDF-R ○ ● ● ● DRL-MACACDF-A ● ○ ● ● DRL-MACACDF-S ● ● ○ ● DRL-MACACDF-E ● ● ● ○ 注: ● 表示包含该机制, ○ 表示不包含
下载: 导出CSV
表 3 消融实验数据统计
Table 3 Statistics of ablation experimental results
模型 平均得分 平均得分比传统 PPO
提高百分比 (%)平均胜率
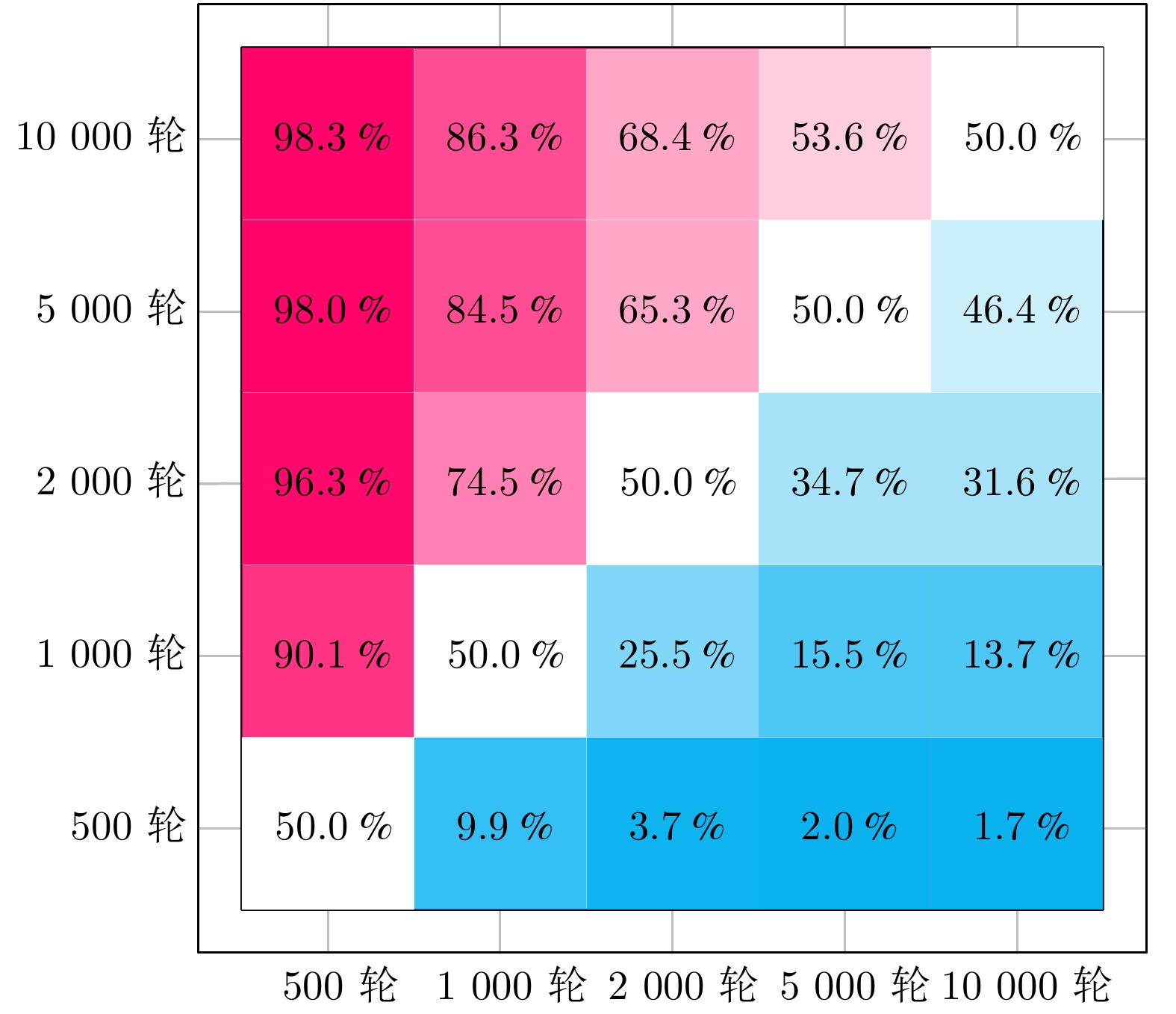
(%)RL-MACACDF-R −19.297130 8.327 0 RL-MACACDF-A 13.629237 154.019 86.774 RL-MACACDF-S 5.021890 115.934 66.673 RL-MACACDF-E 8.973194 133.417 82.361
下载: 导出CSV
A1 实验超参数设置
A1 Experimental hyperparameter setting
参数名 参数值 参数名 参数值 网络优化器 Adam 经验库容量 3000 (个) 学习率 5 × 10−5 批大小 200 (个) 折扣率 0.9 $ \tau $初始值 1.0 裁剪率 0.2 ${\tau _{{\rm{step}}} }$ 1 × 10−4 训练开始样本数 1400 (个) ${\tau _{{\rm{temp}}} }$ 50000
下载: 导出CSV
A2 想定实体类型
A2 Entity type of scenario
单元类型 数量 主要作战武器 F/A-18 型战斗机 2 4 × AIM-120D 空空导弹
2 × AGM-154C 空地导弹F-35C 型战斗机 1 6 × AGM-154C 空地导弹 基地 1 2 × F/A-18 型战斗机
1 × F-35C 型战斗机
下载: 导出CSV
A4 状态空间信息
A4 State space information
实体 信息 己方飞机 经度、纬度、速度、朝向、海拔、目标点经度、目标点纬度等 7 维信息 己方导弹 经度、纬度、速度、朝向、海拔、打击目标的经度、打击目标的纬度等 7 维信息 敌方飞机 经度、纬度、速度、朝向、海拔等 5 维信息 敌方导弹 经度、纬度、速度、朝向、海拔等 5 维信息
下载: 导出CSV
A5 动作空间信息
A5 Action space information
类别 取值范围 飞行航向 0°、60°、120°、180°、240°、300° 飞行高度 7620 米、10973 米、15240 米 飞行速度 低速、巡航、加力 自动开火距离 35 海里、40 海里、45 海里、
50 海里、60 海里、70 海里导弹齐射数量 1 枚、2 枚
下载: 导出CSV
-
[1] 李卿莹. 协同空战技术发展概况及作战模式. 科技与创新, 2020 (07): 124−126Li Qing-Ying. Overview of collaborative air combat technology development and operational mode. Science and Technology and Innovation, 2020 (07): 124−126 [2] Isaacs R. Differential Games: A Mathematical Theory With Applications to Warfare and Pursuit, Control and Optimization. North Chelmsford: Courier Dover Publications, 1999. [3] Yan T, Cai Y, Bin X U. Evasion guidance algorithms for air-breathing hypersonic vehicles in three-player pursuit-evasion games. Chinese Journal of Aeronautics, 2020, 33(12): 3423−3436 doi: 10.1016/j.cja.2020.03.026 [4] Karelahti J, Virtanen K, Raivio T. Near-optimal missile avoidance trajectories via receding horizon control. Journal of Guidance Control and Dynamics, 2015, 30(5): 1287−1298 [5] Oyler D W, Kabamba P T, Girard A R. Pursuit-evasion games in the presence of obstacles. Automatica, 2016, 65: 1−11 doi: 10.1016/j.automatica.2015.11.018 [6] Li W. The confinement-escape problem of a defender against an evader escaping from a circular region. IEEE Transactions on Cybernetics, 2016, 46(4): 1028−1039 doi: 10.1109/TCYB.2015.2503285 [7] Sun Q L, Shen M H, Gu X L, Hou K, Qi N M. Evasion-pursuit strategy against defended aircraft based on differential game theory. International Journal of Aerospace Engineering, 2019 (2019): 1−12 [8] Scott W L, Leonard N E. Optimal evasive strategies for multiple interacting agents with motion constraints. Automatica, 2018, 94: 26−34 doi: 10.1016/j.automatica.2018.04.008 [9] 邵将, 徐扬, 罗德林. 无人机多机协同对抗决策研究. 信息与控制, 2018, 47(03): 347−354Shao Jiang, Xu Yang, Luo De-Lin. Cooperative combat decision-making research for multi UAVs. Information and Control, 2018, 47(03): 347−354 [10] Virtanen K, Karelahti J, Raivio T. Modeling air combat by a moving horizon influence diagram game. Journal of Guidance Control and Dynamics, 2006, 29(5): 1080−1091 doi: 10.2514/1.17168 [11] Feng C, Yao P. On close-range air combat based on hidden markov model. In: Proceeding of the 2016 IEEE Chinese Guidance, Navigation and Control Conference. Piscataway, USA: IEEE, 2016. 687−694 [12] 冯超, 景小宁, 李秋妮, 姚鹏. 基于隐马尔科夫模型的空战决策点理论研究. 北京航空航天大学学报(自然科学版), 2017, 43(3): 615−626Feng Chao, Jing Xiao-Ning, Li Qiu-Ni, Yao Peng. Theoretical research of decision-making point in air combat based on hidden markov model. Journal of Beijing University of Aeronautics and Astronsutics (Natural Science Edition), 2017, 43(3): 615−626 [13] 何旭, 景小宁, 冯超. 基于蒙特卡洛树搜索方法的空战机动决策. 空军工程大学学报(自然科学版), 2017, 18(5): 36−41He Xu, Jing Xiao-Ning, Feng Chao. Air combat maneuver decision based on MCTS method. Journal of Air Force Engineering University (Natural Science Edition), 2017, 18(5): 36−41 [14] Nelson R L, Rafal Z. Effectiveness of autonomous decision making for unmanned combat aerial vehicles in dogfight engagements. Journal of Guidance Control and Dynamics, 2018, 41(4): 1021−1024 doi: 10.2514/1.G002937 [15] 徐光大, 吕超, 王光辉, 谢宇鹏. 基于双矩阵对策的UCAV空战自主机动决策研究. 舰船电子工程, 2017, 37(11): 24−28 doi: 10.3969/j.issn.1672-9730.2017.11.007Xu Guang-Da, Lv Chao, Wang Guang-Hui, Xie Yu-Peng. Research on UCAV autonomous air combat maneuvering decision-making based on bi-matrix game. Ship Electronic Engineering, 2017, 37(11): 24−28 doi: 10.3969/j.issn.1672-9730.2017.11.007 [16] Amnon K. Tree lookahead in air combat. Journal of Aircraft, 2015, 31(4): 970−973 [17] Ma Y F, Ma X L, Song X, Fei M R. A case study on air combat decision using approximated dynamic programming. Mathematical Problems in Engineering, 2014 (2014): 183401 [18] Chen M, Zhou Z Y, Tomlin C J. Multiplayer reach-avoid games via low dimensional solutions and maximum matching. In: Proceeding of the 2014 American Control Conference. Piscataway, USA: IEEE, 2014. 1443−1449 [19] 欧建军, 张安. 不确定环境下协同空战目标分配模型. 火力与指挥控制, 2020, 45(5): 115−118 doi: 10.3969/j.issn.1002-0640.2020.05.021Ou Jian-Jun, Zhang An. Target distribution model in cooperative air combat under uncertain environment. Fire Control and Command Control, 2020, 45(5): 115−118 doi: 10.3969/j.issn.1002-0640.2020.05.021 [20] 奚之飞, 徐安, 寇英信, 李战武, 杨爱武. 多机协同空战机动决策流程. 系统工程与电子技术, 2020, 42(2): 381−389 doi: 10.3969/j.issn.1001-506X.2020.02.17Xi Zhi-Fei, Xu An, Kou Ying-Xin, Li Zhan-Wu, Yang Ai-Wu. Decision process of multi-aircraft cooperative air combat maneuver. Systems Engineering and Electronics, 2020, 42(2): 381−389 doi: 10.3969/j.issn.1001-506X.2020.02.17 [21] 韩统, 崔明朗, 张伟, 陈国明, 王骁飞. 多无人机协同空战机动决策. 兵器装备工程学报, 2020, 41(04): 117−123 doi: 10.11809/bqzbgcxb2020.04.023Han Tong, Cui Ming-Lang, Zhang Wei, Chen Guo-Ming, Wang Xiao-Fei. Multi-UCAV cooperative air combat maneuvering decision. Journal of Ordnance Equipment Engineering, 2020, 41(04): 117−123 doi: 10.11809/bqzbgcxb2020.04.023 [22] 嵇慧明, 余敏建, 乔新航, 杨海燕, 张帅文. 改进BAS-TIMS算法在空战机动决策中的应用. 国防科技大学学报, 2020, 42(04): 123−133Ji Hui-Ming, Yu Min-Jian, Qiao Xin-Hang, Yang Hai-Yan, Zhang Shuai-Wen. Application of the improved BAS-TIMS algorithm in air combat maneuver decision. Journal of National University of Defense Technology, 2020, 42(04): 123−133 [23] 王炫, 王维嘉, 宋科璞, 王敏文. 基于进化式专家系统树的无人机空战决策技术. 兵工自动化, 2019, 38(01): 42−47Wang Xuan, Wang Wei-Jia, Song Ke-Pu, Wang Min-Wen. UAV air combat decision based on evolutionary expert system tree. Ordnance Industry Automation, 2019, 38(01): 42−47 [24] 周同乐, 陈谋, 朱荣刚, 贺建良. 基于狼群算法的多无人机协同多目标攻防满意决策方法. 指挥与控制学报, 2020, 6(03): 251−256 doi: 10.3969/j.issn.2096-0204.2020.03.0251Zhou Tong-Le, Chen Mou, Zhu Rong-Gang, He Jian-Liang. Attack-defense satisficing decision-making of multi-UAVs cooperative multiple targets based on WPS Algorithm. Journal of Command and Control, 2020, 6(03): 251−256 doi: 10.3969/j.issn.2096-0204.2020.03.0251 [25] 左家亮, 杨任农, 张滢, 李中林, 邬蒙. 基于启发式强化学习的空战机动智能决策. 航空学报, 2017, 38(10): 217−230Zuo Jia-Liang, Yang Ren-Nong, Zhang Ying, Li Zhong-Lin, Wu Meng. Intelligent decision-making in air combat maneuvering based on heuristic reinforcement learning. Acta Aeronautica et Astronautica Sinica, 2017, 38(10): 217−230 [26] 刘树林. 一种评价的新方法. 系统工程理论与实践, 1991, 11(4): 63−66Liu Shu-Lin. A new method of evaluation. Systems Engineering-Theory and Practice, 1991, 11(4): 63−66 [27] Zhang H P, Huang C Q, Zhang Z R, Wang X F, Han B, Wei Z L, et al. The trajectory generation of UCAV evading missiles based on neural networks. Journal of Physics Conference Series, 2020, 1486(2020): 022025 [28] Teng T H, Tan A H, Tan Y S, Yeo A. Self-organizing neural networks for learning air combat maneuvers. In: Proceeding of the 2012 International Joint Conference on Neural Networks. Piscataway, USA: IEEE, 2012. 2858−2866 [29] 孟光磊, 马晓玉, 刘昕, 徐一民. 基于混合动态贝叶斯网的无人机空战态势评估. 指挥控制与仿真, 2017, 39(04): 1−6, 39 doi: 10.3969/j.issn.1673-3819.2017.04.001Meng Guang-Lei, Ma Xiao-Yu, Liu Xin, Xu Yi-Min. Situation assessment for unmanned aerial vehicles air combat based on hybrid dynamic Bayesian network. Command Control and Simulation, 2017, 39(04): 1−6, 39 doi: 10.3969/j.issn.1673-3819.2017.04.001 [30] 杨爱武, 李战武, 徐安, 奚之飞, 常一哲. 基于加权动态云贝叶斯网络空战目标威胁评估. 飞行力学, 2020, 38(04): 87−94Yang Ai-Wu, Li Zhan-Wu, Xu An, Xi Zhi-Fei, Chang Yi-Zhe. Threat level assessment of the air combat target based on weighted cloud dynamic Bayesian network. Flight Dynamics, 2020, 38(04): 87−94 [31] Yang Q, Zhang J, Shi G, Wu Y. Maneuver decision of UAV in short-range air combat based on deep reinforcement learning. IEEE Access, 2019, PP(99): 1−1 [32] Liu P, Ma Y. A deep reinforcement learning based intelligent decision method for UCAV air combat. In: Proceeding of the 2017 Asian Simulation Conference. Berlin, Germany: Springer, 2017. 274−286 [33] Zhou Y N, Ma Y F, Song X, Gong G H. Hierarchical fuzzy ART for Q-learning and its application in air combat simulation. International Journal of Modeling Simulation and Scientific Computing, 2017, 8(04): 1750052 doi: 10.1142/S1793962317500520 [34] Schulman J, Wolski F, Dhariwal P, Radford A, Klimov O. Proximal policy optimization algorithms [Online], available: https://arxiv.org/abs/1707.06347v2, August 28, 2017 [35] Mnih V, Kavukcuoglu K, Silver D, Rusu A A, Veness J, Bellemare M G, et al. Human-level control through deep reinforcement learning. Nature, 2015, 518(7540): 529−533 doi: 10.1038/nature14236 [36] Silver D, Schrittwieser J, Simonyan K, Antonoglou I, Huang A, Guez A, et al. Mastering the game of go without human knowledge. Nature, 2017, 550(7676): 354−359 doi: 10.1038/nature24270 [37] Conde R, Llata J R, Torre-Ferrero C. Time-varying formation controllers for unmanned aerial vehicles using deep reinforcement learning [Online], available: https://arxiv.org/abs/1706.01384, June 5, 2017 [38] Shalev-Shwartz S, Shammah S, Shashua A. Safe, multi-agent, reinforcement learning for autonomous driving [Online], available: https://arxiv.org/abs/1610.03295, October 11, 2016 [39] Su P H, Gasic M, Mrksic N, Rojas-Barahona L, Ultes S, Vandyke D, et al. On-line active reward learning for policy optimization in spoken dialogue systems [Online], available: https://arxiv.org/abs/1605.07669v2, June 2, 2016 [40] Schulman J, Levine S, Abbeel P, Jordan M, Moritz P. Trust region policy optimization [Online], available: https://arxiv.org/abs/1502.05477, April 20, 2017 -

 下载:
下载:




计量
- 文章访问数: 6600
- HTML全文浏览量: 3133
- PDF下载量: 1771
- 被引次数: 0
