

Identification of Linear Time-delay Systems With Unknown Delay Distributions in Its Value Range
-
摘要: 在大多数系统辨识方法中, 通常假设时变时滞在其可能的取值范围内服从均匀分布. 但是这种假设是非常受限的且在实际过程中常常无法得到满足. 因此在时滞取值概率条件未知的情况下, 针对一类线性时变时滞系统提出有效的辨识方法. 利用期望最大化(Expectation maximization, EM)算法将拟研究的辨识问题公式化, 期望最大化算法通过不断地迭代执行期望步骤和最大化步骤得到优化的参数估计. 在期望步骤中, 将未知的时变时滞当作隐含变量来处理并且假设可能的取值范围已知. 在每一个采样时刻, 时滞的变换由一个概率向量控制, 并且该向量中的每一个元素是未知的, 将其当作待估计的未知参数处理. 在算法的每次迭代过程中, 计算时滞的后验概率密度函数(Probability density function, PDF), 并在此基础上构造代价函数(Q-函数). 在最大化步骤中, 通过不断优化(Q-函数)来估计想要的参数, 包括模型参数、噪声参数、控制概率向量中的每一个元素和未知的时滞. 最后通过一个数值例子验证提出算法的有效性.Abstract: In majority system identification methods, the varying system delay is generally assumed to be uniformly distributed in its possible value range. However this assumption is very limited and it is often not satisfied in practical settings. Hence this paper addresses the identification of linear time-delay systems with unknown delay distributions in its value range. The formulation of the above identification problem is realized by using the expectation maximization (EM) algorithm which iteratively performs the expectation step (E-step) and the maximization step (M-step) until the desired optimal parameters obtained. In the E-step, the unknown varying time-delay is processed as the latent variable and its possible value range is assumed to be known as a priori. At each sampling instant, the variant of the time-delay is governed by a probability vector which is processed as the unknown parameter. In each iteration, the posterior probability density function (PDF) of the unknown delay is calculated which facilitates the construction of the cost function (Q-function). In the M-step, the calculated Q-function is optimized in order to estimate the unknown parameters including the model parameters, the noise parameter, each element in the governmental probability vector and the unknown delay. Finally, the verification tests performed on a numerical example are provided to illustrate the effectiveness of the proposed algorithm.
-

图 5 参数${g_1}$和${g_2}$的蒙特卡洛辨识结果
Fig. 5 The identified${g_1}$and${g_2}$in Monte Carlo simulations
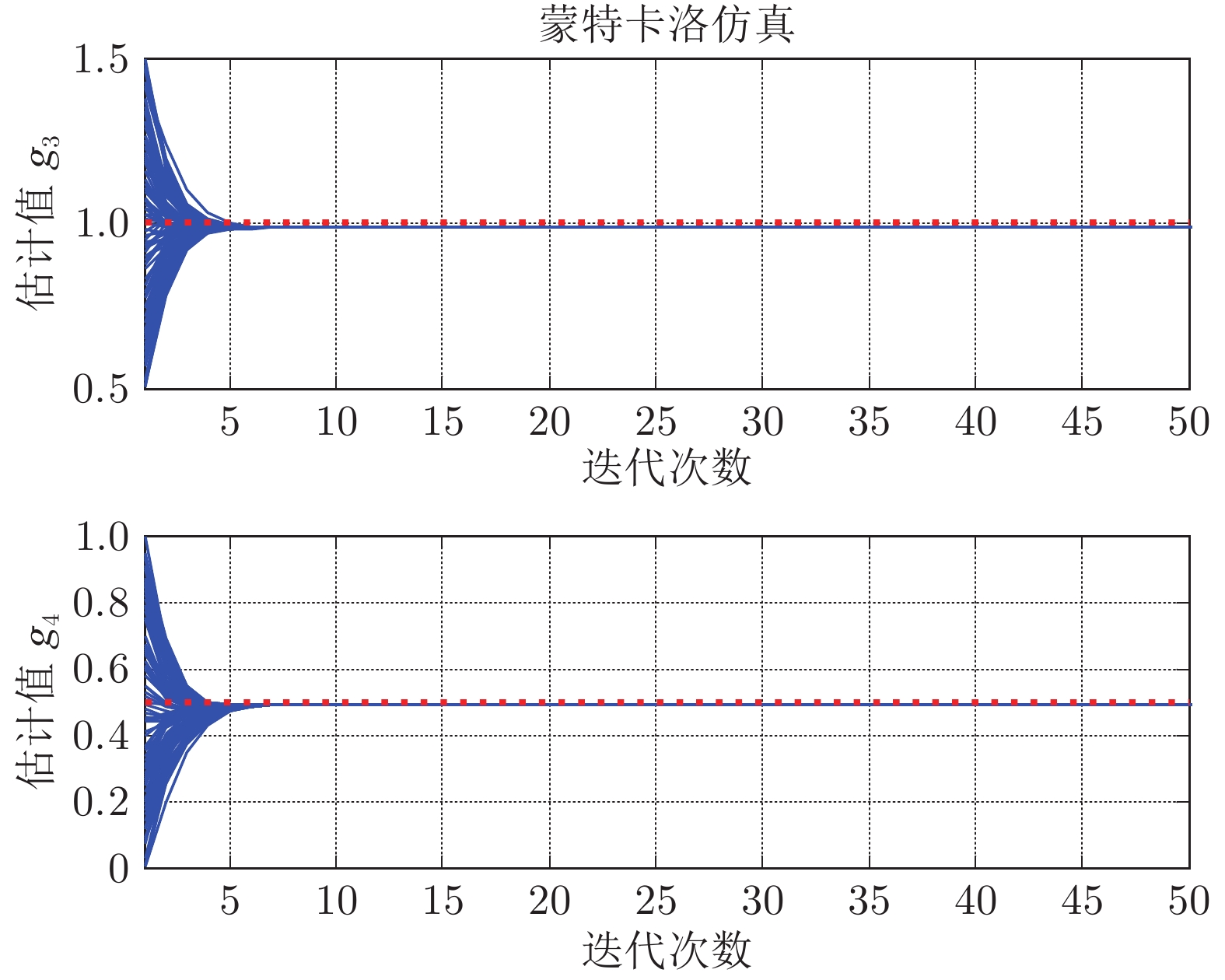
图 6 参数${g_3}$和${g_4}$的蒙特卡洛辨识结果
Fig. 6 The identified${g_3}$and${g_4}$in Monte Carlo simulations

图 8 不同噪声下的${g_1}$和${g_2}$估计结果
Fig. 8 The identified${g_1}$and${g_2}$under different noise levels
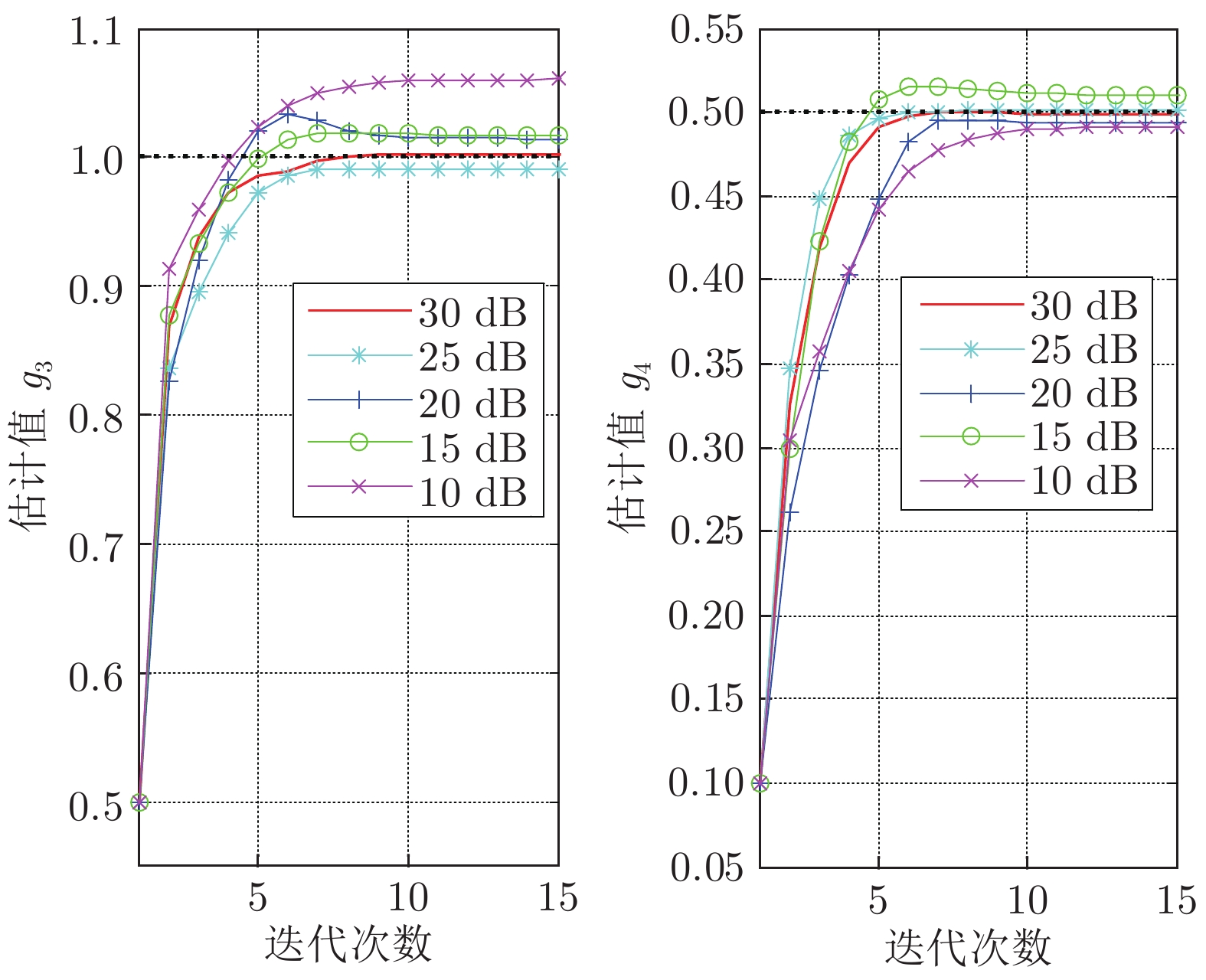
图 9 不同噪声下的${g_3}$和${g_4}$估计结果
Fig. 9 The identified${g_3}$and${g_4}$under different noise levels
表 1 不同信噪比下的未知时滞估计精度
Table 1 The estimation accuracy of the unknown delays under different SNRs
信噪比 (dB) 时滞匹配精度 (%) 10 73.00 15 81.25 20 88.75 25 93.25 30 97.50  下载: 导出CSV
下载: 导出CSV
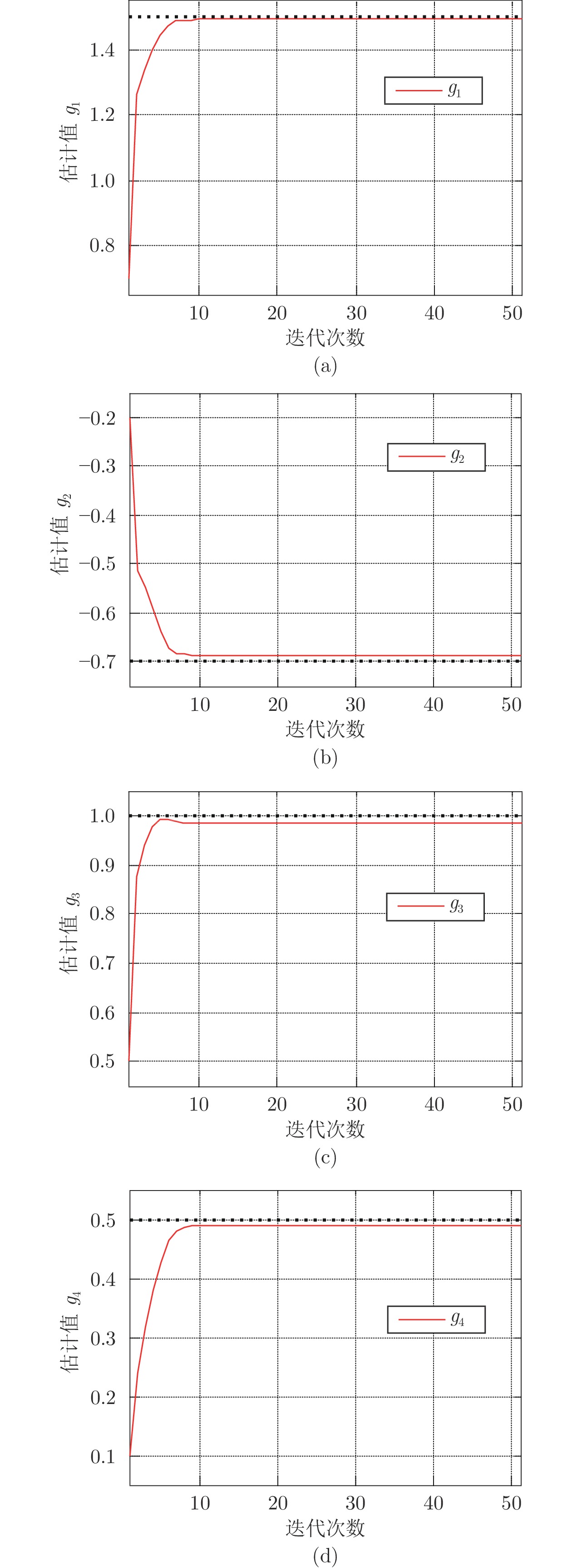
表 2 对比实验结果
Table 2 The identification results of the comparison tests
参数 真实值 RLS-accurate 算法2 RLS-ignore ${g_1}$ 1.5 1.4982 1.4861 1.1553 ${g_2}$ −0.7 −0.7025 −0.6969 −0.4136 ${g_3}$ 1.0 1.0092 1.0146 0.8348 ${g_4}$ 0.5 0.5052 0.4941 0.5256
下载: 导出CSV
-
[1] 黄玉龙, 张勇刚, 李宁, 赵琳. 一种带有色量测噪声的非线性系统辨识方法. 自动化学报, 2015, 41(11): 1877--1892.Huang Yu-Long, Zhang Yong-Gang, Li Ning, Zhao Lin. An identification method for nonlinear systems with colored measurement noise. Acta Automatica Sinica, 2015, 41(11): 1877--1892. [2] 段广全, 孙书利. 带未知模型参数和衰减观测率系统自校正分布式融合估计. 自动化学报, 2021, 47(2): 423--431.Duan Guang-Quan, Sun Shu-Li. Self-tuning distributed fusion estimation for systems with unknown model parameters and fading measurement rates. Acta Automatica Sinica, 2021, 47(2): 423--431. [3] Chen J, Huang B, Ding F, Gu Y. Variational Bayesian approach for ARX systems with missing observations and varying time-delays. Automatica, 2018, 94: 194--204. doi: 10.1016/j.automatica.2018.04.003 [4] Ding F, Liu X M, Hayat T. Hierarchical least squares identification for feedback nonlinear equation-error systems. Journal of the Franklin Institute, 2020, 357: 2958--2977. doi: 10.1016/j.jfranklin.2019.12.007 [5] 李沛, 孙书利. 阳春华, 贺建军, 桂卫华. 基于影子趋势对比的矿热炉炉况在线辨识及趋势预测. 自动化学报, 2020, 41(x): 1--12doi: 10.16383/j.aas.c190827.Li Pei, Yang Chun-Hua, He Jian-Jun, Gui Wei-Hua. Smelting Condition Identification and Prediction for Submerged Arc Furnace Based on Shadow trend comparison. Acta Automatica Sinica, 2020, 41(x): 1−12doi: 10.16383/j.aas.c190827. [6] Lindfors M, Chen T S. Regularized LTI system identification in the presence of outliers: A variational EM approach. Automatica, 2020, 121: 1--13. [7] Liu X, Liu X F. An improved identification method for a class of time-delay systems. Signal Processing, 2020, 167: 1--9. [8] Battilotti S, d’Angelo M. Stochastic output delay identification of discrete-time Gaussian systems. Automatica, 2019, 109: 1--6. [9] Sammaknejad N, Zhao Y J, Huang B. A review of the Expectation Maximization algorithm in data-driven process identification. Journal of Process Control, 2019, 73: 123--136. doi: 10.1016/j.jprocont.2018.12.010 [10] Zhao W X, Yin G, Bai E W. Sparse system identification for stochastic systems with general observation sequences. Automatica, 2020, 121: 1--13. [11] Chen J, Shen Q Y, Liu Y J, Wan L J. Expectation maximization identification algorithm for time-delay two-dimensional systems. Journal of the Franklin Institute, 2020, 37: 9992--10009. [12] Xia W F, Zheng W X, Xu S Y. Extended dissipativity analysis of digital filters with time delay and Markovian jumping parameters. Signal Processing, 2018, 152: 247--254. doi: 10.1016/j.sigpro.2018.06.004 [13] 刘青松. 基于嵌套-伪预估器反馈的时滞控制系统输入时滞补偿. 自动化学报, 2020, 45(x): 1--8doi: 10.16383/j.aas.c190830.Liu Qing-Song. Nested-pseudo predictor feedback based input delay compensation for time-delay control systems. Acta Automatica Sinica, 2020, 45(x): 1−18doi: 10.16383/j.aas.c190830. [14] Yang X Q, Yang X B. Local identification of LPV dual-rate system with random measurements delays. IEEE Transactions on Industrial Electronics, 2017, 62(2): 1499--1507. [15] Li X D, Yang X Y, Song S J. Lyapunov conditions for finite-time stability of time-varying time-delay systems. Automatica, 2019, 103: 135--140. doi: 10.1016/j.automatica.2019.01.031 [16] Ding F, Wang X H, Mao L, Xu L. Joint state and multi-innovation parameter estimation for time-delay linear systems and its convergence based on the Kalman filtering. Digital Signal Processing, 2017, 62: 211--223. doi: 10.1016/j.dsp.2016.11.010 [17] Yang X Q, Yin S. Robust global identification and output estimation for LPV dual-rate systems subjected to random output time-delays. IEEE Transactions on Industrial Informatics, 2017, 13(6): 2876--2885. doi: 10.1109/TII.2017.2702754 [18] Chen L, Han L L, Huang B, Liu F. Parameter estimation for a dual-rate system with time delay. ISA Transactions, 2014, 53(5): 1368--1376. doi: 10.1016/j.isatra.2014.01.001 [19] Ma J X, Chen J, Xiong W L, Ding Feng. Expectation maximization estimation algorithm for Hammerstein models with non-Gaussian noise and random time delay from dual-rate sampled-data. Digital Signal Processing, 2018, 73: 135--144. doi: 10.1016/j.dsp.2017.11.009 [20] Xu L, Ding F, Gu Y, Alsaedi A, Hayat T. A multi-innovation state and parameter estimation algorithm for a state space system with d-step state-delay. Signal Processing, 2017, 140: 97--103. doi: 10.1016/j.sigpro.2017.05.006 [21] Kodamana H, Huang B, Ranjan R, Zhao Y J, Tan R M, Sammaknejad N. Approaches to robust process identification: A review and tutorial of probabilistic methods. Journal of Process Control, 2018, 66: 68--83. doi: 10.1016/j.jprocont.2018.02.011 [22] Yang X Q, Karimi H R. Identification of LTI time-delay systems with missing output data using GEM algorithm. Mathematical Problems in Engineering, 2014, 15: 1−8 [23] Yang X Q, Gao H J. Multiple model approach to linear parameter varying time-delay system identification with EM algorithm. Journal of the Franklin Institute, 2014, 351(12): 5565--5581. doi: 10.1016/j.jfranklin.2014.09.015 [24] Chen J, Ma J X, Liu Y J, Ding F. Identification methods for time-delay systems based on the redundant rules. Signal Processing, 2017, 137: 192--198. doi: 10.1016/j.sigpro.2017.02.006 [25] Xie L, Yang H Z, Huang B. FIR model identification of multirate processes with random delays using EM algorithm. AIChE Journal, 2013, 59(11): 4124--4132. doi: 10.1002/aic.14147 [26] Wu C. On the convergence properties of the EM algorithm. The Annals of Statistics, 1983, 11(1): 95--103. doi: 10.1214/aos/1176346060 -

 下载:
下载:
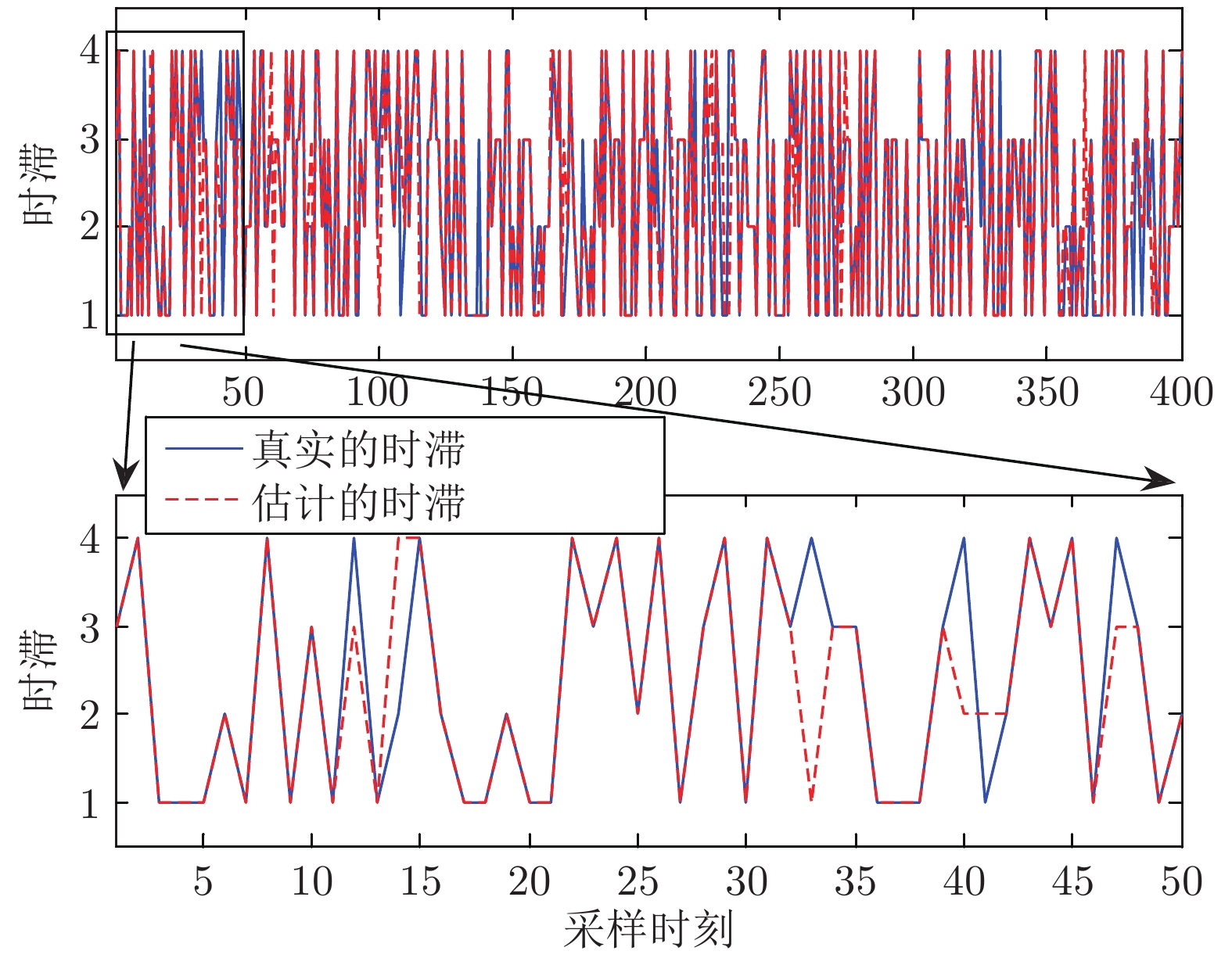
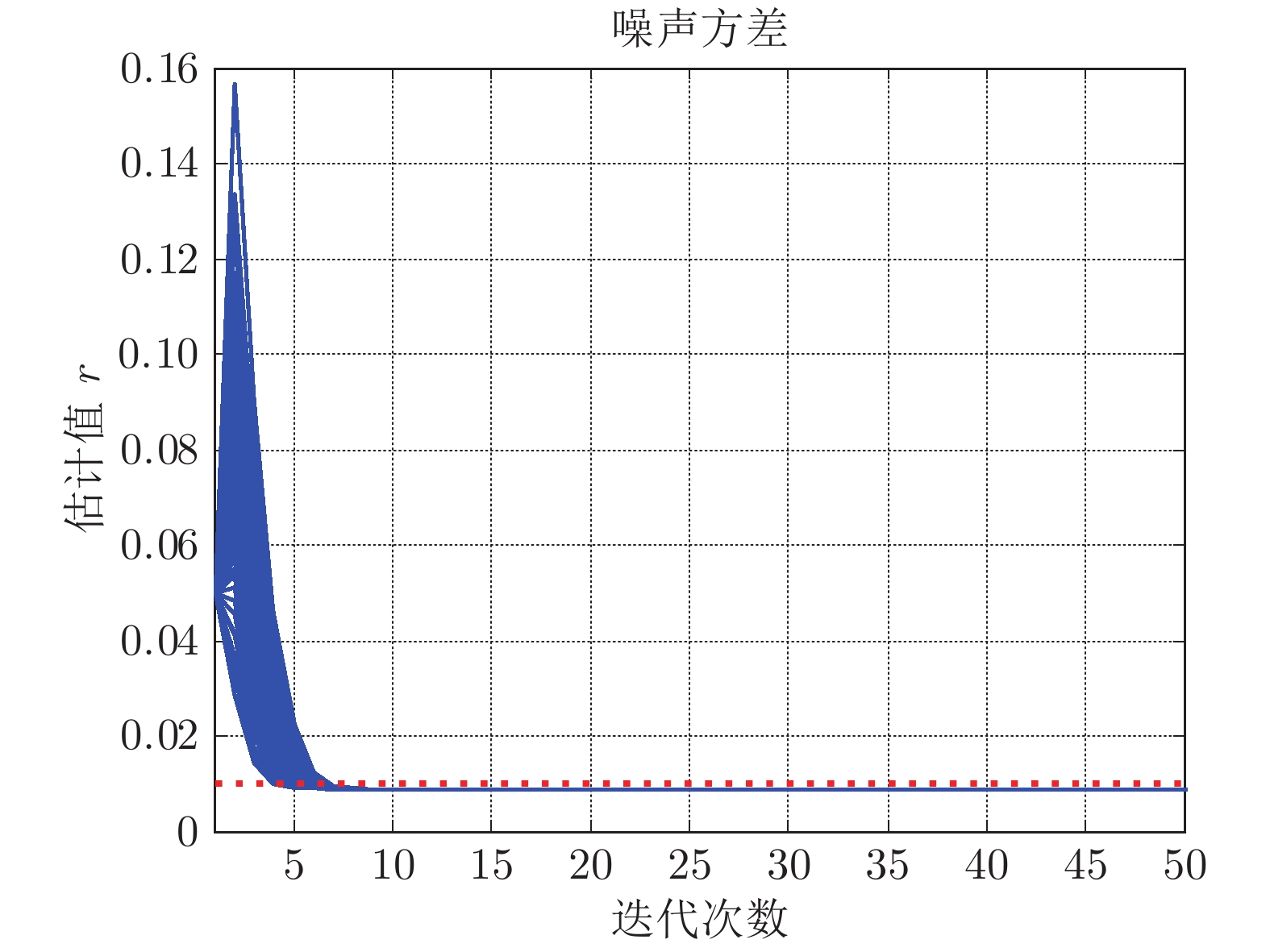

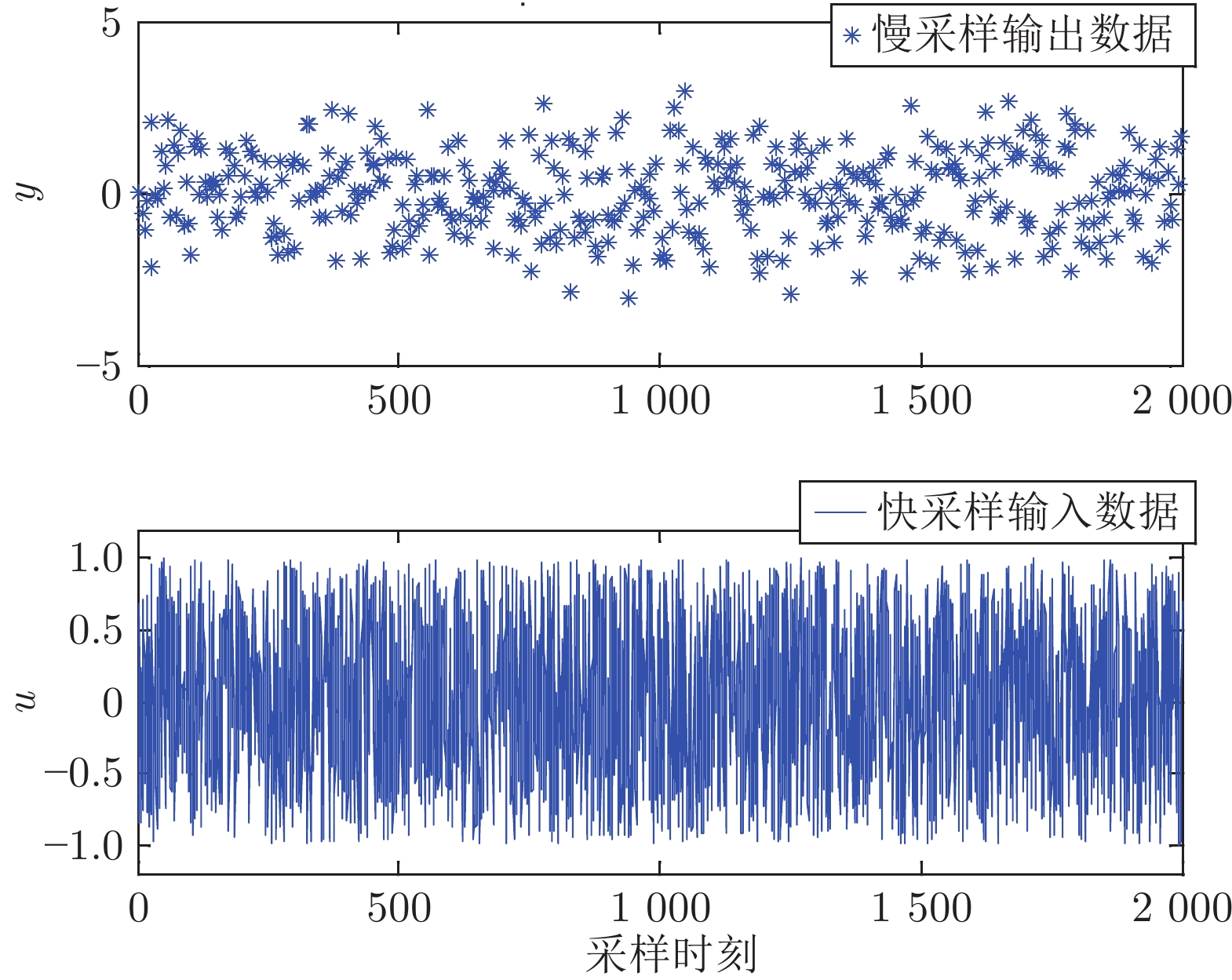
计量
- 文章访问数: 1365
- HTML全文浏览量: 404
- PDF下载量: 220
- 被引次数: 0
