

Semi-supervised Concept Drift Detection Method by Combining Sample Output Space and Feature Space With Its Application
-
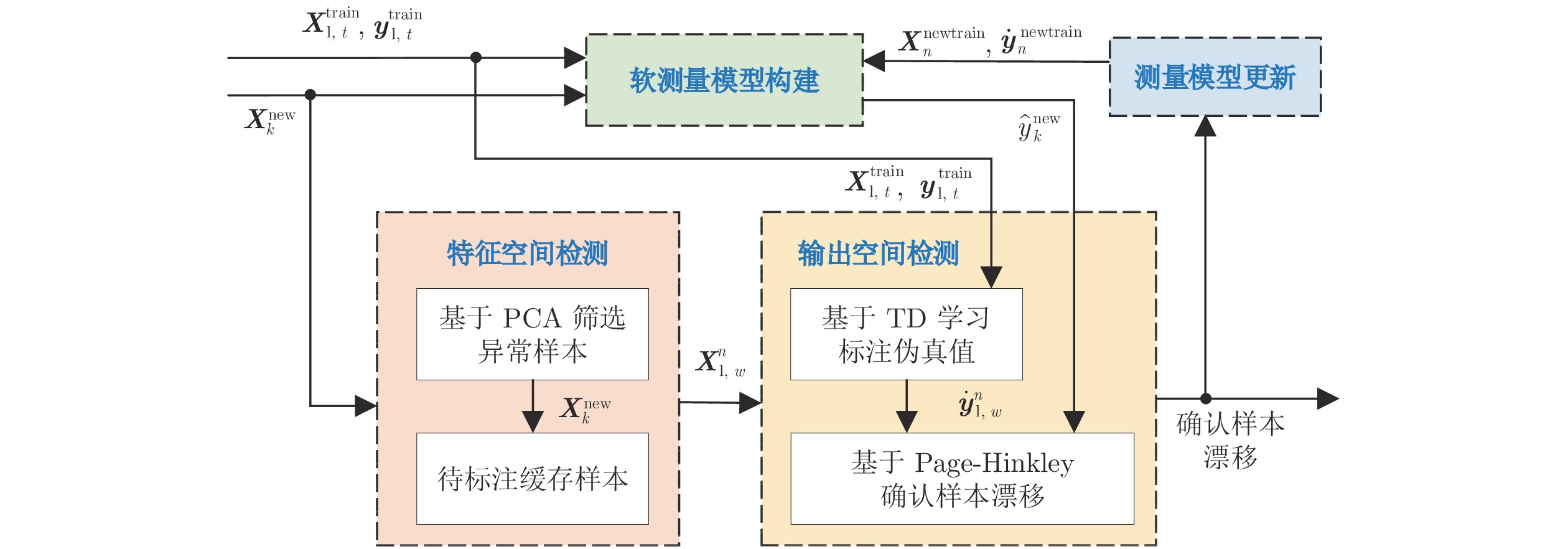
摘要: 城市固废焚烧(Municipal solid waste incineration, MSWI)过程受垃圾成分波动、设备磨损与维修、季节交替变化等因素的影响而存在概念漂移现象, 这导致用于污染物排放浓度的建模数据具有时变性. 为此, 需要识别能够表征概念漂移的新样本对污染物测量模型进行更新, 但现有漂移检测方法难以有效应用于建模样本真值获取困难的工业过程. 针对上述问题, 提出一种联合样本输出与特征空间的半监督概念漂移检测方法. 首先, 采用基于主成分分析(Principal component analysis, PCA)的无监督机制识别特征空间内的概念漂移样本; 然后, 在样本输出空间采用基于时间差分(Temporal-difference, TD)学习的半监督机制对上述概念漂移样本进行伪真值标注后, 再用Page-Hinkley检测法确认能够表征概念漂移的样本; 最后, 采用上述步骤获得的新样本结合历史样本对模型进行更新. 基于合成和真实工业过程数据集的仿真结果表明所提方法具有优于已有方法的性能, 能够在加强模型漂移适应性的同时有效缩减样本标注成本.Abstract: The modeling data used for pollutant emission concentration in the municipal solid waste incineration (MSWI) is time-varying due to the concept drift phenomenon, which is caused by factors such as fluctuations in waste composition, equipment wear and repair, and seasonal changes. Thus, it is necessary to identify new samples that can represent the concept drift for pollutant measurement model updating. However, the existing methods are limited by the modeling samples' true values, which are difficult to be effectively applied to industrial processes. Thus, a semi-supervised concept drift detection method by combining sample output space and feature space is proposed. Firstly, unsupervised mechanism based on principal component analysis (PCA) is used in the sample feature space to identify concept drift samples. Then, semi-supervised mechanism based on temporal-difference (TD) learning is used in the sample output space to label the pseudo-true value for the identified concept drift samples. Further, the Page-Hinkley detection method is used to confirm the concept drift samples. Finally, the new samples obtained by the above steps are combined with historical samples to update the measurement model. The simulation results based on synthetic and real industrial process data sets show that the proposed method has better performance than the existing methods. Moreover, the cost of sample annotation is effectively reduced and the drift adaptability of the measurement model is enhanced.
-
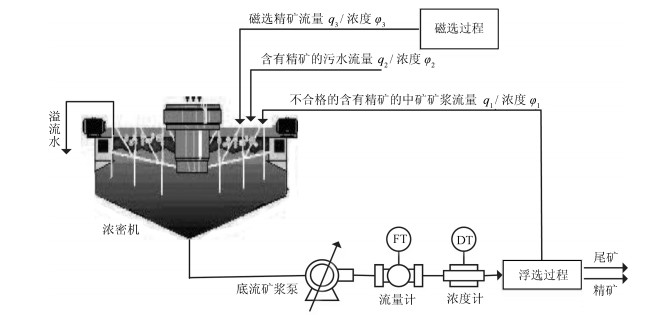
我国赤铁矿矿石品位低、杂质含量高、嵌布粒度细、可选性差, 只经过磨矿—磁选的选矿流程难以有效去除杂质获得较高的精矿品位.为获得较高的精矿品位, 故一般在磁选之后采用再磨、浓密和浮选的工艺.浮选入选最佳浓度为30 % ~ 35 %, 而经过再磨之后浓度大概为25 % ~ 30 %, 同时由于浮选过程返回的中矿矿浆的影响使浓密机的浓度波动比较大.浓密过程可将浓度偏低的矿浆通过重力沉降浓缩为合格浓度的底流矿浆[1-2].赤铁矿混合选别浓密过程是以底流矿浆泵频率为内环输入, 以矿浆流量为内环输出、外环输入, 以矿浆浓度为外环输出的串级非线性被控过程.由于底流矿浆流量与底流矿浆浓度具有强非线性, 其模型建立过程复杂, 因此实现矿浆浓度控制成为浓密过程的研究热点.
底流矿浆流量过程难以建模, 而对底流矿浆浓度过程的控制又要兼顾底流矿浆流量的控制, 致使矿浆浓度控制难度增大.增强学习方法对于解决无模型的最优控制存在优势, 但其计算量复杂, 对浓度过程在本地设备采用增强学习的方法难以达到高的计算性能.与此同时, 工业无线网迅猛发展, 流量过程比较简单, 故可在本地设备实现控制; 浓度过程因计算量大, 故可通过无线网络传输到工业云计算, 从而为浓度控制提高性能.但网络传输的过程中易受丢包等不确定性的影响[3-5], 从而影响到浓密过程的控制性能, 甚至使其不稳定.因此, 研究浓密等工业过程中的网络控制很有必要.
文献[6]针对铝土矿浓密过程, 提出一种基于规则推理的控制方法对矿浆浓度进行控制.文献[7]针对混合选别的浓密过程, 提出区间智能控制, 外环采用静态模型和模糊推理切换补偿控制方法.文献[8]在外环采用未建模动态补偿一步最优PI控制与模糊推理结合的控制方法.文献[9]考虑内外环提出将未建模动态补偿驱动的一步最优PI控制和基于模糊推理与规则推理的切换结合的控制方法.但现有对浓密过程控制都未考虑不同网络环境下数据通信对运行控制的影响.
针对传输不可靠的线性网络, 文献[4, 5, 10]利用Lyapunov函数得到一组线性不等式求解出稳定的反馈增益.文献[11-12]针对丢包将卡尔曼滤波与最优控制相结合.文献[13]针对前向通道和反馈通道都存在随机时延的情况下设计鲁棒H2/H∞ 控制方法.文献[14]针对时延采用网络预测的控制策略解决系统的跟踪控制问题.文献[15]在网络控制系统中的反馈通道和前向通道采用时延补偿的方法.以上这些方法需要知道系统的动力学模型.而增强学习[16-18] (Reinforcement learning)是一种广泛应用于寻找未知系统动力学的最优控制策略的方法.文献[19]对应用层设计了最优自适应事件触发控制器以及在数据链路层中设计了无线网络的分布式调度方案.文献[20]针对具有时变系统矩阵的未知网络系统提出采用自适应估计器和Q-学习思想的随机最优控制方法求解无限维度最优调节问题.文献[21]将此方法推广到非线性情况.但文献[19-21]都未考虑网络存在反馈丢包的问题.
本文的主要贡献如下:针对未发生丢包的底层矿浆流量过程, 提出Q-学习方法, 实现底层底流矿浆流量跟踪流量设定值.由于底流矿浆浓度过程存在状态丢包, 当前状态可能无法获得, 从而不能采用标准的Q-学习方法计算最优控制, 所以提出一种丢包Q-学习方法解决线性离散浓密过程的网络控制的跟踪问题, 首先采用史密斯预估器的思想通过历史的数据估计系统当前的状态, 当丢包发生时, 这些信息可应用到在线Q-学习方法中.论文的组织结构如下, 第1节为浓密过程的问题描述; 第2节介绍控制器设计; 第3节为整体系统的性能分析; 第4节为仿真实验, 其结果表明所提数据驱动控制方法只利用采集的数据实现浓密过程对设定值的跟踪并使系统稳定; 第5节为本文结论.
1. 控制问题描述
1.1 浓密过程描述
赤铁矿混合选别的浓密过程如图 1所示, 磁选精矿矿浆经再磨工序研磨处理后, 得到浓度相对较低的精矿矿浆, 低浓度精矿矿浆流入浓密机后, 通过浓密机耙子的搅拌作用, 矿浆颗粒在自身重力的作用下, 自然沉降, 从而在浓密机底部得到浓度较高的矿浆, 以满足浮选过程的要求.
根据参考文献[22-23], 可建立以底流矿浆泵频率$ u( t ) $为控制输入, 以底流矿浆流量$ y( t ) $为内环输出外环输入且以底流矿浆浓度$ {r}( t ) $为外环输出的动态模型:
$$ \begin{align} {\dot y}\left( t \right) = \, & -\frac{{{y}\left( t \right)}}{\tau } + \frac{1}{\tau }\sqrt {\frac{{{k_0}{u^2}\left( t \right) - \frac{{\Delta \rho \left( t \right)}}{{g\rho \left( {{r}\left( t \right)} \right)}} + D}}{\bar{K}}} \end{align} $$ (1) $$ \begin{align} {\dot r}\left( t \right) = \, & \frac{1}{{{k_2}h\left( {{y}, {r}} \right)}}\left( {\frac{{ - r^2\left( t \right){y} \left( t \right)}}{{{r}\left( t \right) + {k_3} \left( {\theta\left( t \right) + Q}\right)}}} \right.{\rm{ + }}\\& {k_1}{v_p}\left( {{y}, {r}, \theta} \right)\left( {\theta\left( t \right) + Q} \right) + \\& \left. {\frac{{{k_1}\left( {{k_i} - {k_3}} \right){v_p}\left( {{y}, {r}} \right)\left( {\theta\left( t \right) + Q} \right)}}{{{r}\left( t \right) + {k_3}\left( {\theta\left( t \right) + Q} \right)}}} \right) \end{align} $$ (2) 其中, $ {k_1} = S{k_i} $, $ {k_2} = Sp $, $ {k_3} = {k_i} - \mu ( p _s - p _l )/Sp $, $ Q = {q_3}{\varphi _3} $, $ {\varphi _3} $、$ {q_3} $是磁选精矿矿浆浓度和流量, $ {k_i} $和$ S $是与浓密机结构有关的常数, $ \theta( t ) $为干扰, 且$ \theta (t) = q_1\varphi_1+q_2\varphi_2 $.假设$ \theta( t ) $恒定.各符号及物理意义见表 1.
表 1 浓密过程符号表Table 1 Mixed separation thickening process symbol table符号 物理含义 符号 物理含义 $S$ 浓密机横截面积 $\frac{{\Delta \rho (t)}}{{g\rho (\cdot)}}$ 泵两端管路单位重量
矿浆的势能差$\mu$ 介质的粘度 $D$ 阻力损失 $p$ 平均浓度系数 $k_i$, $\bar{K}$ 与浓密机结构有关的常数 $p _s$ 矿浆内固体密度 $g$ 重力加速度 $p _l$ 矿浆内液体密度 $\theta(t)$ 干扰 $k_{0}$ 静态放大系数 $h(\cdot)$ 泥层界面高度 $\tau$ 时间常数 ${v_p}(\cdot)$ 矿浆颗粒沉降速度 ${\varphi _1}$ 浮选中矿矿浆浓度 ${q_1}$ 浮选中矿流量 ${\varphi _2}$ 污水浓度 ${q_2}$ 污水流量 ${\varphi _3}$ 磁选精矿矿浆浓度 ${q_3}$ 磁选精矿矿浆流量 底流矿浆流量过程为快过程, 采样周期为$ k $; 底流矿浆浓度过程为慢过程, 采样周期为$ T = nk $ ($ n $为整数).利用工业过程通常在工作点附近稳态运行的特点, 分别对式(1)和式(2)在工作点对其线性化并离散化得到其线性模型, 则底层底流矿浆流量过程的线性模型为
$$ \begin{align} {x_1}( {k + 1} ) = \, & {A_1}{x_1}( k ) + {B_1}u( k )\\ {y}( k ) = \, & {C_1}{x_1}( k ) \end{align} $$ (3) 其中, $ {x_1}( k ) $维数为$ 1 \times 1 $, $ u( k ) $为底流矿浆泵频率且维数为$ 1 \times 1 $, $ {y}( k ) $为底流矿浆流量且维数为$ 1 \times 1 $. $ {A_1} $, $ {B_1} $和$ {C_1} $的维数分别为$ 1 \times 1 $, $ 1 \times 1 $和$ 1 \times 1 $. 运行层底流矿浆浓度过程的线性模型为
$$ \begin{align} {x_2}( {T + 1} ) = \, & {A_2}{x_2}( T ) + {B_2}{y}( T )\\ {r}( T ) = \, & {C_2}{x_2}( T ) \end{align} $$ (4) 其中, $ {x_2}(T) $维数为$ 1 \times 1 $, $ {y}(T) $维数为$ 1 \times 1 $, $ {r}(T) $为底流矿浆流量且维数为$ 1 \times 1 $. $ {A_2} $, $ {B_2} $和$ {C_2} $的维数分别为$ 1 \times 1 $, $ 1 \times 1 $和$ 1 \times 1 $.
1.2 无线网络环境下丢包模型
系统的状态$ \eta ( T ) $通过无线网传输到控制器时可能会发生丢包, 根据参考文献[4, 5, 24], 可知状态$ \eta ( T ) $经过网络传输后可得到的状态$ \eta_f ( T ) $为
$$ \begin{align} {\eta _f}(T) = \delta (T)\eta ( T ) + \left( {1 - \delta ( T )} \right){\eta _f}( {T - 1} ) \end{align} $$ (5) 其中, $ \delta ( T ) $取值为0和1, 当$ \delta ( T ) = 0 $表示此时网络存在丢包, 反之$ \delta ( T ) = 1 $表示此时通过网络传输的信号传输成功.系统如果一直处于丢包的状态即控制系统相当于开环系统, 所以需做以下假设:
假设 1. 反馈丢包$ \delta ( T ) $的最大连续发生丢包的次数为$ \delta _{f\max} $有界, 即
$$ \begin{align} \sum\limits_{i = 0}^{{\delta _{f\max }}} {\delta ( {T - i} ) > 0} \end{align} $$ (6) 如果当最大连续发生丢包的次数$ \delta _{f\max } $是无界的, 控制系统相当于开环系统, 所以此论文认为$ \delta _{f\max } $是有界的.
1.3 控制问题描述
本文的控制问题为对于浓密过程的线性模型(3)和(4), 在网络存在丢包的情况下, 设计的控制器可完全基于采集到的数据实现系统的线性二次跟踪(Linear quadratic tracking, LQT).其中浓密过程的浓度的设定值为定值$ {r^*} $, 运行层流量设定值控制器为底层提供底流矿浆流量的设定值$ y^*( T ) $, 为解决浓密过程底层底流矿浆流量和运行层底流矿浆浓度的跟踪问题, 故设底层的性能指标为
$$ \begin{align} {J_1}&( k ) = \sum\limits_{i = k}^\infty \gamma^{i - k}\times\\&\left[ {{{\left( {{y^*}( i ) \!-\! y( i )} \right)}^{\rm T}}{Q_1}\left( {{y^*}( i ) \!-\! {y}( i )} \right) \!+\! u^{\rm T}{{( i )}}{R_1}u( i )} \right] \end{align} $$ (7) 其中, $ \gamma\; ( 0 < \gamma < 1 ) $为衰减因子, 矩阵$ {Q_1} $和$ {R_1} $为适当维数的正定矩阵, $ {y^*}( k ) $维数为$ 1 \times 1 $.
设运行层的性能指标为
$$ \begin{align} {J_2}&( T ) = \sum\limits_{i = T}^\infty \bar{\gamma}^{i - T}\times\\&\left[ {{{\left( {{r^*}\! -\! r( i )} \right)}^{\rm T}}{Q_2}\left( {{r^*} \!-\! r( i )} \right) \!+\! {y^{*{\rm T}}}( i ){R_2}{y^*}( i )} \right] \end{align} $$ (8) 其中, $ \bar{\gamma}\; ( {0 < \bar{\gamma} < 1} ) $为衰减因子, 矩阵$ {Q_2} $和$ {R_2} $为适当维数的正定矩阵, $ r^* $维数为$ 1 \times 1 $.
注1. 由于时间趋于无穷时, 底层控制输入和运行层的控制输入分别与其设定值有关, 且设定值都不为0, 故不能保证控制输入为0, 当衰减因子为1时不能保证性能指标有界, 故衰减因子取小于1.
2. 控制算法
2.1 控制策略
由浓密过程的动态模型(1)和(2)可知, 底流矿浆泵的频率$ u( k ) $首先影响底流矿浆流量$ y( k ) $, 然后影响到底流矿浆浓度$ r( T ) $, 故可先设计$ Q $-学习控制器在底层模型未知的情况下实现底层矿浆流量的跟踪得到内环底流矿浆流量闭环控制系统.因流量过程是快过程, 浓度过程是慢过程, 此为双层结构, 考虑到在外环采样周期内, 内环流量的设定值不变, 故采用提升技术[5, 9-10, 25]得到一个采样周期为外环采样周期的矿浆浓度外环动态模型, 由于系统的状态通过无线网络传输时可能会发生丢包现象, 此刻系统的状态可能无法获得, 而传统的$ Q $-学习算法需要知道此时系统的状态值, 故设计丢包$ Q $-学习流量设定值控制器, 其中, 利用史密斯预估器可根据过去时刻网络传输成功时的状态量估计此刻系统的状态值, 将过去时刻的状态、过去时刻流量过程的设定值以及浓密过程的设定值进行重组成$ z(T) $, 即基于史密斯预估器的状态重组.然后将重组后的$ z(T) $应用到$ Q $-学习流量设定值控制算法中, 从而为底流矿浆流量过程提供流量设定值.控制策略同时考虑到底层和运行层的动态, 在网络发生丢包时不需要知道系统的模型也可以实现底流矿浆流量和底流矿浆浓度的跟踪. 图 2为数据驱动的无线网络下浓密过程的控制结构图, 其控制策略包括$ Q $-学习流量控制器、提升技术和丢包$ Q $-学习流量设定值控制器.
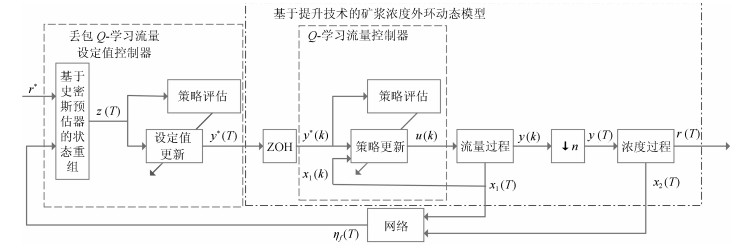 图 2 数据驱动的无线网络下浓密过程的控制结构图Fig. 2 Structure diagram of data-driven for MSTP under wireless network environment
图 2 数据驱动的无线网络下浓密过程的控制结构图Fig. 2 Structure diagram of data-driven for MSTP under wireless network environment2.2 Q-学习流量控制器设计
在每一个运行层的采样周期内丢包$ Q $-学习流量设定值控制器为底层底流矿浆流量过程提供的设定值$ {y^*}( k ) $为恒定的, 所以底流矿浆流量过程的主要目标是跟踪底层的设定值$ {y^*}( k ) $, 且
$$ \begin{align} {y^*}( k + 1 ) = {F_1}y^*(k) \end{align} $$ (9) 其中, $ F_1 $为单位矩阵.根据式(3)及式(9)得到底流矿浆流量的增广系统为
$$ \begin{align} X_d (k+1) = A_d X_d (k)+B_d u (k) \end{align} $$ (10) 其中, $ X_d(k) = \left[ \begin{matrix} x_1^{\rm T}(k)&y^{*{\rm T}}(k) \end{matrix} \right]^{\rm T} $, $ A_d = \left[ \begin{matrix} A_1&0\nonumber\\0&F_1\end{matrix} \right] $和$ B_d = \left[ B_1\; \; \; 0\right]^{\rm T} $, 且$ X_d(k) $维数为$ 2\times 1 $.
根据增广向量$ {X_d}\left( k \right) $的定义, 底流矿浆流量过程的性能指标(7)可重新写成
$$ \begin{align} {J_1}( k ) = \sum\limits_{i = k}^\infty {\gamma^{i - k}\left[ X_d^{\rm T}(i){Q_d}{X_d}(i) + u^{\rm T}( i ){R_1}u(i) \right]} \end{align} $$ (11) 其中, $ {C_d} = \left[ {\begin{matrix} C_1&{ - I} \end{matrix}} \right] $, $ {Q_d} = C_d^{\rm T}{Q_1}{C_d} $.
针对具有衰减因子的线性跟踪问题, 选取的控制器形式为
$$ \begin{align} u(k) = {K_1}{x_1}(k) + {K_2}{y^*}(k) = K{X_d}(k) \end{align} $$ (12) 根据参考文献[26], 可知针对性能指标(11)和选取的控制策略(12), 选取合适的衰减因子$ {\gamma} $使$ ({\gamma^{0.5}{F_1}}) $是稳定的, 此时性能指标(11)可表示为线性二次型的值函数:
$$ \begin{align} {J_1}(k) = {V_1}(k) = X_d^{\rm T}(k){P_d}{X_d}(k) \end{align} $$ (13) 其中, $ P_d = P_d^{\rm T}>0 $.
由式(11)可以得到如下LQT贝尔曼(Bellman)方程:
$$ \begin{align} {V_1}(k) = \, &X_d^{\rm T}(k){Q_d}{X_d}(k) + {u^{\rm T}}(k){R_1}u(k)+\\&{\gamma}{V_1}(k+1) \end{align} $$ (14) 将式(13)代入式(14)得到以值函数核矩阵$ P_d $表示的LQT贝尔曼方程:
$$ \begin{align} X_d^{\rm T}&(k){P_d}{X_d}(k) = X_d^{\rm T}(k){Q_d}{X_d}(k) + \\&{u^{\rm T}}(k){R_1}u(k) + {\gamma}X_d^{\rm T}({k + 1}){P_d}{X_d}({k + 1}) \end{align} $$ (15) 从而得到LQT哈密顿(Hamiltonian)函数:
$$ \begin{equation*} \begin{aligned} {H_1}&(k) = X_d^{\rm T}(k){Q_d}{X_d}(k) + {u^{\rm T}}(k){R_1}u(k)+\nonumber\\&{\gamma}X_d^{\rm T}({k + 1}){P_d}{X_d}({k + 1}) - X_d^{\rm T}\left( k \right){P_d}{X_d}(k) \end{aligned} \end{equation*} $$ 根据参考文献[26], 基于最优性的必要条件, 即$ {{\partial {H_1}(k)}}/{{\partial u(k)}} = 0 $, 可得
$$ \begin{align} K = - {({R_1} + {\gamma}B_d^{\rm T}{P_d}{B_d})^{ - 1}}{\gamma}B_d^{\rm T}{P_d}{A_d} \end{align} $$ (16) 且矩阵$ P_d $满足如下代数黎卡提方程(Algebraic Riccati equation, ARE):
$$ \begin{align} {Q_d}& - {P_d} + {\gamma}A_d^{\rm T}{P_d}{A_d} - \gamma^2A_d^{\rm T}{P_d}{B_d} \times \\&{({{R_1} + {\gamma}B_d^{\rm T}{P_d}{B_d}})^{ - 1}}B_d^{\rm T}{P_d}{A_d} = 0 \end{align} $$ (17) 本节设计的$ Q $-学习流量控制器不需要模型中$ A_1 $和$ B_1 $的值, 只利用输入输出的数据就能在线解决代数黎卡提方程(17).根据LQT贝尔曼方程(15), 可定义离散时间的$ Q $-函数($ Q $-function)为
$$ \begin{align} {Q_1}(k) = \, & X_d^{\rm T}(k){Q_d}{X_d}(k) + {u^{\rm T}}(k)R_1u(k)+\\&{\gamma}X_d^{\rm T}({k + 1}){P_d}{X_d}({k + 1}) \label{eq18} \end{align} $$ (18) 将式(10)代入式(18)可得
$$ \begin{align} Q_1(k) = \, & \left[ {\begin{matrix} X_d(k)\nonumber\\u(k) \end{matrix}} \right]^{\rm T} H \left[ {\begin{matrix} X_d(k)\\u(k) \end{matrix}} \right] = \\&\left[ {\begin{matrix} X_d(k)\\u(k) \end{matrix}} \right]^{\rm T} \left[ {\begin{matrix} H_{X_dX_d}&H_{X_du}\\H_{uX_d}&H_{uu}\end{matrix}}\right] \left[ {\begin{matrix} X_d(k)\\u(k) \end{matrix}} \right] \end{align} $$ (19) 其中,
$$ \begin{equation*} \begin{aligned} &H_{X_dX_d} = {Q_d} + \gamma A_d^{\rm T}{P_d}{A_d}\nonumber\\ &H_{X_du} = H_{uX_d}^{\rm T} = \gamma A_d^{\rm T}{P_d}{B_d}\nonumber\\ &H_{uu} = {R_1} + \gamma B_d^{\rm T}{P_d}{B_d} \end{aligned} \end{equation*} $$ 根据$ {{\partial {Q_1}(k)}}/{{\partial u(k)}} = 0 $得到流量过程的控制输入:
$$ \begin{align} u(k) = - H_{uu}^{ - 1}{H_{uX_d}}{X_d}(k) \end{align} $$ (20) 故$ K = - H_{uu}^{ - 1}{H_{uX_d}} $, 显然其等价于式(16).
根据定义的$ Q $-函数, 引入不依赖模型参数的$ Q $-学习算法就能得到底层底流矿浆流量过程的控制输入. $ Q $-方程满足下面贝尔曼方程:
$$ \begin{align} {Q_1}(k) = \, &X_d^{\rm T}(k){Q_d}{X_d}(k) + {u^{\rm T}}(k){R_1}u(k) + \\&\gamma{Q_1}\left( {k + 1} \right) \end{align} $$ (21) 定义$ Z_d(k) = {\left[ {\begin{matrix} {X_d^{\rm T}(k)}&u^{\rm T}(k) \end{matrix}} \right]^{\rm T}} $, 则式(19)变成
$$ \begin{align} {Q_1}(k) = Z_d^{\rm T}(k)H{Z_d}(k) \end{align} $$ (22) 其中, $ Z_d (k) $维数为$ 3\times 1 $.
将式(22)代入(21)可得到$ Q $-函数的贝尔曼方程:
$$ \begin{align} Z_d^{\rm T}(k)H{Z_d}(k) = \, & X_d^{\rm T}(k){Q_d}{X_d}(k) + {u^{\rm T}}(k){R_1}u(k)+\\& \gamma Z_d^{\rm T}({k + 1})H{Z_d}({k + 1}) \label{eq23} \end{align} $$ (23) 根据$ Q $-函数贝尔曼方程(23)以及流量过程的控制输入表达式(20), 采用策略迭代的方法可以实现底流矿浆流量的跟踪, 算法如下:
算法1. 基于策略迭代的底流矿浆流量的跟踪控制
初始化:开始于稳定的控制策略$ K^1 $, 依次重复下面两个步骤直到控制输入收敛.
1) 策略评估:
$$ \begin{equation*} \begin{aligned} &Z_d^{\rm T}(k){H^{j + 1}}{Z_d}(k) = X_d^{\rm T}(k){Q_d}{X_d}(k) + \nonumber\\&{\left( {{u^j}(k)} \right)^{\rm T}}R_1{u^j}(k)+ \gamma Z_d^{\rm T}({k + 1}){H^{j + 1}}{Z_d}({k + 1}) \end{aligned} \end{equation*} $$ 2) 策略提升:
$$ \begin{equation*} \begin{aligned} {u^{j + 1}}(k) = - {({H_{uu}^{j+1}})^{ - 1}}H_{uX_d}^{j + 1}{X_d}(k) \end{aligned} \end{equation*} $$ 注2. 算法1的收敛性在文献[27-28]中有证明.可采用最小二乘的方法计算$ H^{j+1} $, 由于$ H $是对称矩阵, 故执行最小二乘方法前应至少收集6组数据才能保证满秩的条件.
2.3 无线网络环境下浓度过程控制算法
2.3.1 基于提升技术的矿浆浓度外环动态模型
将式(12)代入式(3), 得到以矿浆流量设定值$ {y^*}(k) $为输入且以矿浆流量$ y(k) $为输出的稳定闭环方程:
$$ \begin{align} {x_1}({k + 1}) = \, & ({A_1 + B_1K_1}){x_1}(k) + {B_1}{K_2}{y^*}(k)\\ y(k) = \, & {C_1}{x_1}(k) \end{align} $$ (24) 由于运行层设定值$ Q $-学习控制给出的设定值$ {y^*}(T) $是慢信号, 而底层控制的设定值$ {y^*}(k) $是快信号, 故采用提升技术, 即流量设定值$ {y^*}(k) $利用零阶保持器, 对应下采样器的参数为$ n $, 即
$$ \begin{align} {y^*}(T) = \, & {y^*}({nk}) = {y^*}({nk + 1}) = \cdots = \\& {y^*}({nk + n - 1}) \end{align} $$ (25) 将式(24)结合式(25)得到
$$ \begin{align} {x_1}({T + 1}) = \, & {x_1}\left( {n({k + 1})} \right) = {x_1}({nk + n}) = \\& ({{A_1} + {B_1K_1}}){x_1}({nk+n-1}) +\\&{B_1}{K_2}{y^*}({nk+n-1}) = \cdots = \\& {( {{A_1} + {B_1}{K_1}} )^n}{x_1}({nk}) +\\&\sum\limits_{i = 0}^{n - 1} {{{({A_1+B_1K_1})}^i}{B_1K_2}{y^*}({nk})} = \\& {A_o}{x_1}(T) + {B_o}{y^*}(T)\\ y(T) = \, & {C_1}{x_1}(T) \label{eq26} \end{align} $$ (26) 其中, $ {A_o} = ( A_1+B_1K_1 )^n $和$ {B_o} = \sum\nolimits_{i = 0}^{n - 1} ( A_1+ $ $ B_1K_1 )^i{B_1K_2} $.
将式(26)代入式(4), 并与式(4)组成新的增广系统, 则基于提升技术的矿浆浓度外环动态模型为
$$ \begin{equation*} \begin{aligned} \left[ {\begin{matrix} x_1( {T + 1} )\\ x_2( {T + 1} )\end{matrix}} \right] = \, &\left[ {\begin{matrix} A_o&0\nonumber\\B_2C_1&A_2 \end{matrix}} \right] \left[ {\begin{matrix} x_1( {T} )\\ x_2( {T} )\end{matrix}} \right]+ \\&\left[ {\begin{matrix} B_o\nonumber\\0 \end{matrix}} \right] {y^*} \left( T\right)\nonumber\\ r\left( T\right) = \, & \left[ {\begin{matrix} 0&C_2 \end{matrix}} \right] \left[ {\begin{matrix} x_1( T )\nonumber\\ x_2( T )\end{matrix}} \right] \end{aligned} \end{equation*} $$ 令$ \tilde A = \left[ {\begin{matrix} {A_o}&0\nonumber\\ {B_2C_1}&{A_2} \end{matrix}} \right] $, $ \tilde B = \left[ {\begin{matrix} {B_o}\nonumber\\ 0 \end{matrix}} \right] $, $ \tilde C = \left[ {\begin{matrix} 0&{C_2} \end{matrix}} \right] $和$ \eta (T) = {\left[ {\begin{matrix} {x_1^{\rm T}( T )}&{x_2^{\rm T}( T )} \end{matrix}} \right]^{\rm T}} $, 则
$$ \begin{align} \eta ( {T + 1} ) = \, & \tilde A\eta (T) + \tilde B{y^*}(T)\\ r (T) = \, & \tilde C\eta (T) \end{align} $$ (27) 其中, $ \eta (T) $的维数为$ 2 \times 1 $.
底流矿浆浓度的设定值为$ r^* $, 工艺要求该浓度在一定范围内, 故设$ r^* $为满足工艺要求的常数.为解决系统的跟踪问题, 式(27)与底流矿浆浓度的设定值可重组为
$$ \begin{align} {X_h}({T + 1}) = \, & \left[ {\begin{matrix} {\tilde A}&0\nonumber\\0&{F_2} \end{matrix}} \right] \left[ {\begin{matrix} {\eta (T)}\nonumber\\ {r^*} \end{matrix}} \right] + \left[ {\begin{matrix} {\tilde B}\nonumber\\ 0 \end{matrix}} \right]{y^*}(T) = \\& {A_h}{X_h}(T) + {B_h}{y^*}(T)\\ r ( T ) = \, & \left[ {\begin{matrix} {\tilde C}&0\end{matrix}} \right]{X_h}(T) = {C_h}{X_h}(T) \label{eq28} \end{align} $$ (28) 其中, $ F_2 $为适当维数的单位矩阵, $ {X_h}( T ) $维数为$ 3 \times 1 $.
2.3.2 史密斯预估器设计
由于在无线网络下系统的状态量会发生丢包, 故利用史密斯预估器的思想, 通过过去传输成功的数据估计出此刻系统的状态$ \eta (T) $.定义在$ T $步之前发生丢包的次数为$ {\delta _{fn}}(T) $.由假设1可知, $ 0 \le {\delta _{fn}}(T) \le {\delta _{f\max }} $, 同时根据式(5)得到在$ T $时刻状态量传输成功时$ {\delta _{fn}}(T) = 0 $, 从而通过无线网络进行传输时在第$ T $步可以获得的最近的有用数据为$ {\eta _f}(T) = \eta \left( {T - {\delta _{fn}}(T)} \right) $.
根据丢包次数的定义, 可以将网络丢包现象认为是随机有界延迟现象, 所以可以用过去系统采集到的未发生丢包的数据和控制输入的信息预测出当前系统的状态:
$$ \begin{align} \eta (T) = \, & {\tilde A^{{\delta _{fn}}(T)}}\eta \left( {T - {\delta _{fn}}(T)} \right) +\\&\sum\limits_{i = 1}^{{\delta _{fn}}(T)} {{{\tilde A}^{i - 1}}\tilde B{y^*}({T - i})} \end{align} $$ (29) 其中, $ {\delta _{fn}}(T) $是已知的.
结合式(28)和(29), 利用过去时刻的数据可预测出当前的增广状态$ {X_h}(T) $:
$$ \begin{align} {X_h}(T) = Mz(T) \end{align} $$ (30) 其中,
$$ \begin{equation*} \small \begin{aligned} &M = \nonumber\\&\left[ {\begin{matrix} I&{\tilde A}& \cdots &{{\tilde A}^{\delta _{f\max }}}&{\tilde B}&{\tilde A\tilde B}& \cdots &{{{\tilde A}^{{\delta _{f\max }} - 1}}\tilde B}&0\nonumber\\ 0&0& \cdots &0&0&0& \cdots &0&{F_2} \end{matrix}} \right], \end{aligned} \end{equation*} $$ 在$ T $时刻, $ z\left( T \right) $是已知的, 且$ z\left( T \right) $维数为$ {n_z} \times 1 $, $ {n_z} = \left( {\delta _{f\max }}+1 \right) \times 2 + {\delta _{f\max}}+ 1 $.则当$ {\delta _{fn}}( T ) = 0, 1, \cdots , \delta _{f\max } $时, $ z( T ) $分别表示为
$$ \begin{equation*} \begin{aligned} z( T ) = \, &\left[ {\underbrace {\begin{matrix} {\eta _f^{\rm T}( T )}& \cdots &0 \; \end{matrix}}_{\delta _{f\max}+1}}\; \; {\underbrace {\begin{matrix} \; 0& \cdots &0 \end{matrix}}_{{\delta _{f\max }}}\;\;r^{*{\rm T}}} \right]^{\rm T}, \\ &{\delta _{fn}}( T ) = 0 \end{aligned} \end{equation*} $$ $$ \begin{equation*} \begin{aligned} \begin{array}{l} z( T ) = \left[ {\underbrace {\begin{array}{*{20}{c}} 0&{\eta _f^{\rm T}( T )}& \cdots &0 \end{array}}_{{\delta _{f\max }} + 1}} \right.\nonumber\\ \;\;\;\;\;\;\;\;\;\;\;{\left. {\underbrace {\begin{array}{*{20}{c}} {y^{*{\rm T}}( {T - 1} )}& \cdots &0 \end{array}}_{{\delta _{f\max }}}\;\;r^{*{\rm T}}} \right]^{\rm T}}, {\delta _{fn}}(T) = 1 \end{array} \end{aligned} \end{equation*} $$ $$ \begin{equation*} \vdots \end{equation*} $$ $$ \begin{equation*} \begin{aligned} \begin{array}{l} z( T ) = \left[ {\underbrace {\begin{array}{*{20}{c}} 0& \cdots &{\eta _f^{\rm T}( T )} \end{array}}_{{\delta _{f\max }} + 1}} \right.\nonumber\\ {\left. {\underbrace {\begin{array}{*{20}{c}} {y^{*{\rm T}}( {T - 1} )}& \cdots &{y^{*{\rm T}}( {T - {\delta _{f\max }}} )} \end{array}}_{{\delta _{f\max }}}\;\;r^{*{\rm T}}} \right]^{\rm T}}, \nonumber\\ {\delta _{fn}}(T) = {\delta _{f\max }} \end{array} \end{aligned} \end{equation*} $$ 2.3.3 丢包Q-学习流量设定值控制器设计
为解决运行层底流矿浆浓度的跟踪问题, 根据增广状态$ {X_h} (T) $的定义, 其性能指标(8)可写成
$$ \begin{align} {J_2}(T) = \sum\limits_{i = T}^\infty {\bar {\gamma} ^{i - T}\left[ {X_h^{\rm T}(i)\tilde Q{X_h}(i) \!+\! {y^{*{\rm T}}}{( i )} {R_2}{y^*}( i )} \right]} \end{align} $$ (31) 其中, $ \tilde Q = {\left[ {\begin{matrix}{\tilde C}&{ - I} \end{matrix}} \right]^{\rm T}}{Q_2}\left[ {\begin{matrix} {\tilde C}&{ - I} \end{matrix}} \right] $.针对发生丢包的系统, 设计底流矿浆流量的设定值形式如下
$$ \begin{align} {y^*}(T) = \, & {L_1}\eta (T) + {L_2}{r^*} = \\& L{X_h}(T) = LMz(T) = \tilde Lz(T) \end{align} $$ (32) 根据参考文献[24], 当选取稳定的控制策略(32)和合适的衰减因子$ \bar{\gamma} $使$ \left( {\bar{\gamma}^{0.5}{F_2}} \right) $是稳定的, 能够将系统的性能指标(31)写成二次型的形式:
$$ \begin{align} {J_2}(T) = X_h^{\rm T}(T){P_h}{X_h}(T) = {z^{\rm T}}( T )\tilde Pz( T ) \end{align} $$ (33) 其中, $ {P_h} = P_h^{\rm T} > 0 $和$ \tilde P = {M^{\rm T}}{P_h}M > 0 $.
由式(31)和(33), 得到如下丢包形式的LQT贝尔曼方程:
$$ \begin{align} {z^{\rm T}}&(T)\tilde Pz(T) = {z^{\rm T}}(T){M^{\rm T}}\tilde Q Mz(T)+ \\&y^{*{\rm T}}( T ){R_2}{y^*}(T)+ {\bar{\gamma}}{z^{\rm T}}( {T + 1} )\tilde Pz( {T + 1} ) \end{align} $$ (34) 从而得到如下LQT哈密顿函数:
$$ \begin{equation*} \begin{aligned} {H_2}(T) = \, & {z^{\rm T}}(T){M^{\rm T}}\tilde Q Mz(T) + y^{*{\rm T}}( T ){R_2}{y^*}(T)+\nonumber\nonumber\\&\bar{\gamma}{z^{\rm T}}({T + 1})\tilde Pz( {T + 1} ) - {z^{\rm T}}( T )\tilde Pz(T) \end{aligned} \end{equation*} $$ LQT贝尔曼方程的稳定条件为
$$ \begin{align} &\frac{{\partial {H_2}(T)}}{{\partial {y^*}(T)}} = 2{R_2}{y^*}(T) +\\& \bar {\gamma}\frac{{\partial z^{\rm T}{{( {T + 1} )}}}}{{\partial {y^*}(T)}}\frac{{\partial {J_2}( {T + 1} )}}{{\partial z( {T + 1})}} = 0 \end{align} $$ (35) 结合式(28)和(30), 可以得到
$$ \begin{align} z( {T + 1} ) = {M^*}{A_h}Mz( T ) + {M^*}{B_h}{y^*}( T ) \end{align} $$ (36) 其中, $ {M^*} = {M^{\rm T}}{( {M{M^{\rm T}}} )^{ - 1}} $为$ M $的右逆, 将其代入式(35)得到
$$ \begin{align} {y^*}( T ) = \, & - {( {{R_2} + \bar{\gamma}B_h^{\rm T}{M^{*{\rm T}}}\tilde P{M^*}{B_h}} )^{ - 1}} \times \\&\bar{\gamma}{B_h^{\rm T}}{M^{*{\rm T}}}\tilde P{M^*}{A_h}Mz( T ) = \\& -{( {{R_2} + \bar{\gamma}B_h^{\rm T}{P_h}{B_h}} )^{ - 1}}\bar{\gamma }{B_h^{\rm T}}{P_h}{A_h}Mz(T) \end{align} $$ (37) 将式(36)和(37)代入丢包形式的LQT贝尔曼方程(34)中, 从而得到丢包形式的LQT黎卡提方程
$$ \begin{align} {M^{\rm T}}\tilde QM& - \tilde P + \bar{\gamma}{M^{\rm T}}A_h^{\rm T}{M^{*{\rm T}}}\tilde P{M^*}{A_h}M -\\&\bar{\gamma}^2{M^{\rm T}}A_h^{\rm T}{M^{*{\rm T}}} \tilde P{M^*}{B_h}( {R_2} +\\& \bar{\gamma}B_h^{\rm T}{M^{*{\rm T}}}\tilde P{M^*}{B_h} )^{ - 1}\times \\&B_h^{\rm T}{M^{*{\rm T}}}\tilde P{M^*}{A_h}M = 0 \end{align} $$ (38) 因为$ M $是行满秩, 故式(38)可化为
$$ \begin{align} \tilde Q - {P_h} + \bar{\gamma}A_h^{\rm T}{P_h}{A_h} - \bar{\gamma}^2A_h^{\rm T}{P_h}{B_h} \times\\ {( {{R_2} + \bar{\gamma}B_h^{\rm T}{P_h}{B_h}} )^{ - 1}}B_h^{\rm T}{P_h}{A_h} = 0 \end{align} $$ (39) 引理1[24]. 将式(32)代入具有丢包的系统(27), 选择合适的衰减因子$ \bar{\gamma} $使$ \left( \bar \gamma^{0.5}{F_2} \right) $是稳定的, 同时参数满足
$$ \begin{equation*} \begin{aligned} 0 < ( {{P_{11}} - {{\tilde C}^{\rm T}}{Q_2}\tilde C} ){( {P_{11} + G} )^{ - 1}} < \bar{\gamma}^2I \end{aligned} \end{equation*} $$ 其中, $ P_{11} = \sum\limits_{i = 0}^\infty {{{\bar \gamma }^i}\left[ {{{( {G_c^i} )}^{\rm T}}( {{{\tilde C}^{\rm T}}{Q_2}\tilde C + L_1^{\rm T}{R_2}{L_1}} )G_c^i} \right]} $, $ G = \tilde A^{\rm T}P_{11}\tilde B{( {R_2 \!+\! {{\tilde B}^{\rm T}}P_{11}\tilde B} )^{ - 1}}{R_2} {( {R_2 \!+\! {{\tilde B}^{\rm T}}{P_{11}}\tilde B} )^{ - 1}} $
$ {\times\tilde B^{\rm T}}{P_{11}}\tilde A $和$ {G_c} = \tilde A + \tilde B{L_1} $, 从而可以得到系统(27)是稳定的, 此时控制为最优的即能最小化性能指标(31), 此部分证明放在下一节.
基于LQT贝尔曼方程的定义(34), 则可将丢包$ Q $-函数定义为
$$ \begin{align} {Q_2}(T) = \, & {z^{\rm T}}(T){M^{\rm T}}\tilde Q M z (T) + y^{*{\rm T}}(T){R_2}{y^*}(T)+\\& \bar{\gamma}{z^{\rm T}}({T + 1})\tilde P z({T + 1}) \label{eq40} \end{align} $$ (40) 将式(36)代入式(40)得到
$$ \begin{align} Q_2(T) = \chi ^{\rm T}(T)H_2\chi (T) \end{align} $$ (41) 其中, $ \chi (T) = \left[ \begin{matrix} z^{\rm T}(T)&y^{*{\rm T}}(T)\end{matrix}\right]^{\rm T} $,
$$ \begin{equation*} \begin{aligned} \begin{array}{l} H_2 = \left[ {\begin{matrix} H_{zz}&H_{zr_1}\nonumber\\ H_{r_1z}&H_{r_1r_1} \end{matrix}} \right]\nonumber\\ H_{zz} = {M^{\rm T}}\tilde QM + \bar{\gamma}{M^{\rm T}}A_h^{\rm T}{M^{*{\rm T}}}\tilde P{M^*}{A_h}M\nonumber\\ H_{zr_1} = H_{r_1z}^{\rm T} = \bar{\gamma}{M^{\rm T}}A_h^{\rm T}{M^{*{\rm T}}}\tilde P{M^*}{B_h}\nonumber\\ H_{r_1r_1} = {R_2} + \bar{\gamma}{B_h}{M^{*{\rm T}}}\tilde P{M^*}{B_h} \end{array} \end{aligned} \end{equation*} $$ 令$ {{\partial {Q_2}(T)}}/{{\partial {y^*}(T)}} = 0 $得到底流流量的最优设定值:
$$ \begin{align} {y^*}(T) = - {H^{ - 1}_{r_1r_1}}H_{r_1z}z(T) \end{align} $$ (42) 显然, 式(37)和(42)等价.
根据丢包$ Q $-函数的定义(40)结合式(34), 则$ Q $-函数满足丢包LQT贝尔曼方程:
$$ \begin{align} {Q_2}&(T) = {z^{\rm T}}(T){M^{\rm T}}\tilde Q Mz(T) +\\&y^{*{\rm T}}(T){R_2}{y^*}(T) + \bar{\gamma}{Q_2}({T + 1}) \label{eq42} \end{align} $$ (43) 将式(41)代入式(43)得到丢包$ Q $-函数贝尔曼方程:
$$ \begin{align} {\chi ^{\rm T}}&(T) H_2 \chi (T) = {z^{\rm T}}(T){M^{\rm T}}\tilde QMz(T) +\\&y^{*{\rm T}}(T){R_2}{y^*}(T) + \bar{\gamma}{\chi ^{\rm T}}({T+1}) H_2 \chi ({T+1}) \end{align} $$ (44) 定义
$ z(T) = \left[ {\begin{matrix} {z_1}( T )\nonumber\\ {z_2}( T )\nonumber\\ {r^*} \end{matrix}} \right] $, $ M = \left[ {\begin{matrix} I&{\bar M}&0\nonumber\\ 0&0&I \end{matrix}} \right] $
$ \tilde Q = \left[ {\begin{matrix} {{{\tilde C}^{\rm T}}{Q_2}\tilde C}&{ - {{\tilde C}^{\rm T}}{Q_2}}\nonumber\\ { - {Q_2}\tilde C}&{{Q_2}} \end{matrix}} \right] $
其中, $ z_1 (T) $是$ z (T) $从第一列第1个元素到第2个元素, 所以当$ \delta (T) = 0 $时$ z_1 (T) = 0 $和当$ \delta (T) = 1 $时$ z_1 (T) = \eta (T) $, 且$ z_2 (T) $是$ z (T) $去掉$ z_1 (T) $和$ r^* $元素之后剩下的元素, 从而
$$ \begin{equation*} \begin{aligned} {z^{\rm T}}&(T){M^{\rm T}}\tilde QMz(T) = {z_1^{\rm T}}(T){{\tilde C}^{\rm T}}{Q_2}\tilde C{z_1}(T) + \nonumber\\&r^{*{\rm T}}{Q_2}{r^*}+ z_2^{\rm T}(T){{\bar M}^{\rm T}}{{\tilde C}^{\rm T}}{Q_2}\tilde C\bar M{z_2}(T)-\nonumber\\&2r^{*{\rm T}}{Q_2}\tilde C{z_1}(T) - 2r^{*{\rm T}}{Q_2}\tilde C\bar M{z_2}(T) \end{aligned} \end{equation*} $$ 利用克罗内克积展开, 即$ {a^{\rm T}}Wb = ({{b^{\rm T}} \otimes {a^{\rm T}}}){\rm vec}(W) $, 定义$ {{U}}(T) = {\chi ^{\rm T}}(T) \otimes {\chi ^{\rm T}}(T) $, $ V(T) = z_2^{\rm T}(T) \otimes z_2^{\rm T}(T) $, $ W(T) = z_2^{\rm T}(T) \otimes {r^{*{\rm T}}} $和$ \varepsilon (T) = z_1^{\rm T} (T){{\tilde C}^{\rm T}}{Q_2}\tilde C{z_1}(T) + r^{*{\rm T}}{Q_2}{r^*} - 2r^{*{\rm T}}{Q_2}\tilde C{z_1}( T )+ y^{*{\rm T}} (T){R_2}{y^*}(T) $, 从而丢包$ Q $-函数贝尔曼方程(44)可表示为
$$ \begin{equation*} \begin{aligned} U&(T){\rm vec} ({H_2}) = \varepsilon (T) + V (T){\rm vec} ({{{\bar M}^{\rm T}}{{\tilde C}^{\rm T}}{Q_2}\tilde C\bar M})-\nonumber\\&2W(T){\rm vec} ( {{Q_2}\tilde C\bar M} ) + \bar{\gamma}U({T + 1}){\rm vec} ( {{H_2}} ) \end{aligned} \end{equation*} $$ 或者等价于
$$ \begin{equation*} \begin{aligned} \begin{array}{l} \left[ {\begin{matrix} {U(T) - \bar{\gamma}U({T + 1})}&{ - V(T)}&{2W (T)} \end{matrix}} \right] \times \nonumber\\ \left[ {\begin{matrix} {{\rm vec} ({{H_2}})}\nonumber\\ {{\rm vec} ({{{\bar M}^{\rm T}}{{\tilde C}^{\rm T}}{Q_2}\tilde C\bar M})}\nonumber\\ {{\rm vec} ( {{Q_2}\tilde C\bar M} )} \end{matrix}} \right] = \varepsilon (T) \end{array} \end{aligned} \end{equation*} $$ 定义
$$ \begin{equation*} \begin{aligned} \begin{array}{l} \sigma ( T ) = \nonumber\\ \left[ {\begin{matrix} {U(T) - \bar{\gamma}U ({T + 1})}&{ - V(T)}&{2W(T)}\nonumber\\ \vdots & \vdots & \vdots \nonumber\\ {U({T + s}) - \bar{\gamma}U ({T + s + 1})}&{ - V ({T + s})}&{2W ({T + s})} \end{matrix}} \right]\cong\nonumber\\ \left[ {\begin{matrix} {\bar \sigma (T)}&0 \end{matrix}} \right] = \sigma (T)N \end{array} \end{aligned} \end{equation*} $$ $$ \begin{equation*} \begin{aligned} \xi (T) = \left[ {\begin{matrix} {\varepsilon (T)}\nonumber\\ \vdots \nonumber\\ {\varepsilon ({T + s})} \end{matrix}} \right] \end{aligned} \end{equation*} $$ 其中, $ N $为列初等变换矩阵, $ s $是依赖于反馈丢包的连续最大丢包次数$ {\delta _{f\max}} $的整数.使用最小二乘的方法, 需要满足秩条件
$$ \begin{equation*} \begin{aligned} {\rm rank}\left\{ {{\sigma ^{\rm T}}(T)\sigma (T)} \right\} = {S_r} \end{aligned} \end{equation*} $$ 其中, $ {S_r} = \sum\nolimits_{i = 0}^{{\delta _{f\max }}} {({4 + i})} \times ({5 + i})/2 - 3{\delta _{f\max }}\; + ( {2 + {\delta _{f\max }}} ) \times ( {3 + {\delta _{f\max }}} )/2 + ( {2 + {\delta _{f\max }}} ) $.
丢包$ Q $-函数的贝尔曼方程变为
$$ \begin{equation*} \begin{aligned} \sigma (T)\left[ {\begin{matrix} {{\rm vec}({{H_2}})}\nonumber\\ {{\rm vec}({{{\bar M}^{\rm T}}{{\tilde C}^{\rm T}}{Q_2}\tilde C\bar M})}\nonumber\\ {{\rm vec}( {{Q_2}\tilde C\bar M} )} \end{matrix}} \right] = \xi (T) \end{aligned} \end{equation*} $$ 或者等价于
$$ \begin{equation*} \begin{aligned} \bar \sigma ( T ){\rm vec}( {{{\bar H}_2}} ) = \xi ( T ) \end{aligned} \end{equation*} $$ 其中,
$ \left[ {\begin{array}{*{20}{c}} {{\rm vec} ( {{{\bar H}_2}} )}\nonumber\\ {{\rm vec}( {{{\hat H}_2}} )} \end{array}} \right] = {N^{ - 1}}\left[ {\begin{array}{*{20}{c}} {{\rm vec}( {{H_2}} )}\nonumber\\ {{\rm vec}( {{{\bar M}^{\rm T}}{{\tilde C}^{\rm T}}{Q_2}\tilde C\bar M} )}\nonumber\\ {{\rm vec}( {{Q_2}\tilde C\bar M} )} \end{array}} \right] $
最终可得
$$ \begin{equation*} \begin{aligned} {\rm vec}({{{\bar H}_2}}) = {\left( {{{\bar \sigma }^{\rm T}}(T)\bar \sigma (T)} \right)^{ - 1}}{\bar \sigma ^{\rm T}}( T )\xi (T) \end{aligned} \end{equation*} $$ 为实现底流矿浆浓度的跟踪, 为底流流量过程提供最优设定值$ y^*(T) $.使用策略迭代的方法利用在网络环境下采集到的系统数据$ {\eta _f}(T) $在线解决$ Q $-函数, 其算法如下所示.
算法2. 底流流量过程最优设定值$ y^*(T) $的丢包$ Q $-学习算法
初始化:给定初始稳定的控制策略$ {\tilde L^1} $, 依次重复下面两个步骤直到控制输入收敛.
1) 策略评估:利用最小二乘的方法计算出$ \bar H_2^{j+1} $
$$ \begin{equation*} \begin{aligned} \begin{array}{l} \left[ {\begin{matrix} {U (T) - \bar{\gamma}U ( {T + 1} )}&{ - V(T)}&{2W(T)} \end{matrix}} \right]\nonumber\\ N{N^{ - 1}}\left[ {\begin{matrix} {{\rm vec} ({{H_2}})}\nonumber\\ {{\rm vec} ({{{\bar M}^{\rm T}}{{\tilde C}^{\rm T}}{Q_2}\tilde C\bar M})}\nonumber\\ {{\rm vec} ({{Q_2}\tilde C\bar M})} \end{matrix}} \right]^{j+1} = \nonumber\\ z_1^{\rm T} (T){{\tilde C}^{\rm T}}{Q_2}\tilde C{z_1}(T) + r^{*{\rm T}}{Q_2}{r^*}-\nonumber\\ 2r^{*{\rm T}}{Q_2}\tilde C{z_1}( T )+ (y^{*j}(T))^{\rm T}{R_2}{y^{*j}}(T) \end{array} \end{aligned} \end{equation*} $$ 2) 策略提升:
$$ \begin{equation*} \begin{aligned} {y^{*j+1}}(T) = - {({H_{{r_1}{r_1}}^{j + 1}})^{ - 1}}H_{{r_1}z}^{j + 1}z(T) \end{aligned} \end{equation*} $$ 注3. 根据参考文献[26], 选取比较大的半正定矩阵和合适的衰减因子能够得到比较小的跟踪误差.
注4. 本文为双层架构的控制算法, 首先以底层和运行层稳定的控制策略运行, 运行层为底层提供设定值, 底层通过算法1不依赖于系统的模型参数计算得到最优的控制策略; 然后在底层稳定的情况下, 再通过算法2为底层提供最优的控制设定值.此算法不需要知道系统的模型.
注5. 算法1和算法2都需要持续激励的条件, 从而对状态空间进行充分的探索得到足够充足的数据.如果状态收敛到期望位置, 持续激励的条件就不再需要.可以在控制输入中加入探测噪声从而确保持续激励的条件, 此处探测噪声选择为白噪声.
3. 控制性能分析
将控制策略(32)代入系统(27)得到闭环系统:
$$ \begin{equation*} \begin{aligned} \eta ({T + 1}) = \, & ({\tilde A + \tilde B{L_1}})\eta (T) + \tilde B{L_2}{r^*} = \nonumber\nonumber\\& {A_p}\eta (T) + {B_p}{r^*} \end{aligned} \end{equation*} $$ 如果闭环系统$ A_p $的特征值在单位圆内, 则闭环系统是稳定的.
假设$ \lambda $是闭环系统$ A_p $的一个特征值, 可知满足$ {A_p}{x_\lambda } = \lambda {x_\lambda } $ ($ {x_\lambda} $是矩阵$ A_p $对应$ \lambda $的一个特征向量).根据参考文献[26]可得$ {P_h} = \left[ {\begin{matrix} P_{11}&P_{12}\nonumber\\ P_{21}&P_{22}\end{matrix}} \right] $的具体形式, 从而LQT黎卡提方程可以化为
$$ \begin{equation*} \begin{aligned} {\tilde C^{\rm T}}{Q_2}\tilde C - {P_{11}} + {\bar \gamma}A_p^{\rm T}{P_{11}}{A_p} + L_1^{\rm T}{R_{2}}{L_1} = 0 \end{aligned} \end{equation*} $$ 其中, $ {L_1} = - {({{R_2} + {\bar \gamma}{{\tilde B}^{\rm T}}{P_{11}}\tilde B})^{ - 1}}{\bar\gamma}{\tilde B^{\rm T}}{P_{11}}\tilde A $, 对其左乘$ x_\lambda ^{\rm T} $右乘$ {x_\lambda} $可得
$$ \begin{equation*} \begin{aligned} x_\lambda& ^{\rm T} {{\tilde C}^{\rm T}}{Q_2}\tilde C{x_\lambda } - x_\lambda ^{\rm T}{P_{11}}{x_\lambda} + {\bar \gamma}{\left| \lambda \right|^2}x_\lambda ^{\rm T}{P_{11}}{x_\lambda }+\nonumber\\&{\bar \gamma}^2 x_\lambda ^{\rm T}\tilde A^{\rm T}{P_{11}}\tilde B{({{R_2} + {\bar \gamma}{{\tilde B}^{\rm T}}{P_{11}}\tilde B})^{ - 1}} \times \nonumber\\&{R_2}{({{R_2} + {\bar \gamma}{{\tilde B}^{\rm T}}{P_{11}}\tilde B})^{ - 1}}{{\tilde B}^{\rm T}}{P_{11}}\tilde A {x_\lambda } = 0 \end{aligned} \end{equation*} $$ 因为$ R_2 $和$ Q_2 $是正定的且衰减因子$ 0 < {\bar\gamma} < 1 $, 故$ {( {{R_2} + {\bar\gamma}{{\tilde B}^{\rm T}}{P_{11}}\tilde B} )^{ - 1}} > {({{R_2} + {{\tilde B}^{\rm T}}{P_{11}}\tilde B})^{ - 1}} $, 所以可得
$$ \begin{equation*} \begin{aligned} &({1 - {\bar\gamma}{{\left| \lambda \right|}^2}}){P_{11}} - {{\tilde C}^{\rm T}}{Q_2}\tilde C \ge \bar\gamma^2{\left| \lambda \right|^2}\tilde A ^{\rm T}{P_{11}}\tilde B \times \nonumber\\&{({{R_2} + {{\tilde B}^{\rm T}}{P_{11}}\tilde B})^{ - 1}}{R_2}( {R_2} +\nonumber\\& {{\tilde B}^{\rm T}}{P_{11}}\tilde B)^{ - 1}{{\tilde B}^{\rm T}}{P_{11}}\tilde A \end{aligned} \end{equation*} $$ 定义
$$ \begin{equation*} \begin{aligned} G = \, &\tilde{A}^{\rm T} {P_{11}}\tilde B{( {{R_2} \!+\! {{\tilde B}^{\rm T}}{P_{11}}\tilde B} )^{ - 1}}\times\\&{R_2}{( {{R_2}\! +\! {{\tilde B}^{\rm T}}{P_{11}}\tilde B} )^{ - 1}}{\tilde B^{\rm T}}{P_{11}}\tilde A, \end{aligned} \end{equation*} $$ 所以
$$ \begin{equation*} \begin{aligned} {P_{11}} - {\tilde C^{\rm T}}{Q_2}\tilde C > {\bar \gamma ^2}{\left| \lambda \right|^2}({{P_{11}} + G}) \end{aligned} \end{equation*} $$ 或等价于
$$ \begin{equation*} \begin{aligned} \frac{1}{{\bar \gamma }^2}({{P_{11}} - {\tilde C}^{\rm T} {Q_2}\tilde C}){({{P_{11}} + G})^{ - 1}} > {\left| \lambda \right|^2}I \end{aligned} \end{equation*} $$ 如果闭环系统$ A_p $的特征值在单位圆内, 即$ \left| \lambda \right| \le 1 $, 闭环系统是稳定的.所以当满足条件$ 0 < ( {P_{11} - {{\tilde C}^{\rm T}}{Q_2}\tilde C} ){( {P_{11} + G} )^{ - 1}} < \bar\gamma^2I $, 闭环系统的稳定性成立.采用$ Q $-学习流量控制器能保证内环稳定, 又因为外环给内环的设定值是有界的, 故双率控制结构下整体稳定.
为证明最优性, 设
$$ \begin{equation*} \begin{aligned} {U_2}(i) = {\left( {r^* \!-\! r(i)} \right)^{\rm T}}{Q_2}\left ( {r^* \!-\! r(i)} \right) \!+\! y^{*{\rm T}}(i) {R_2} {y^*} (i) \end{aligned} \end{equation*} $$ 则性能指标(8)可写成
$$ \begin{equation*} \begin{aligned} {J_2}(T) = {U_2}(T) + {\bar\gamma}{J_2}({T + 1}) \end{aligned} \end{equation*} $$ 对其左乘$ \bar\gamma^T $得到
$$ \begin{equation*} \begin{aligned} \bar \gamma^T{J_2}(T) = \bar \gamma^T{U_2}(T) + \bar \gamma ^{T + 1}{J_2}({T + 1}) \end{aligned} \end{equation*} $$ 移项可得
$$ \begin{align} \bar \gamma^{ T + 1}{J_2}({T + 1}) - \bar \gamma^T{J_2}(T) = - \bar \gamma ^T{U_2}(T) \end{align} $$ (45) 对其两边从$ T $到$ \infty $进行累加和, 得
$$ \begin{align} \bar \gamma^\infty {J_2}(\infty) - \bar \gamma^T{J_2}(T) = - \sum\limits_{i = T}^\infty {\bar \gamma^i{U_2}(i)} \end{align} $$ (46) 因为$ \bar \gamma^\infty {J_2}\left( \infty \right) = 0 $, 得到
$$ \begin{align} \bar\gamma^T{J_2}(T) = \sum\limits_{i = T}^\infty {\bar\gamma ^i{U_2}(i)} \end{align} $$ (47) 对式(45)的等号左边从$ T $到$ \infty $累加得到
$$ \begin{align} \begin{array}{l} \bar\gamma^T{J_2}(T) = \sum\limits_{i = T}^\infty {\left[ {\bar\gamma ^i{J_2}(i) - \bar \gamma^{i + 1}{J_2}({i + 1})} \right]} = \nonumber\\ \sum\limits_{i = T}^\infty {\left[ {\bar\gamma^i{z^{\rm T}}(i)\tilde Pz(i) - \bar\gamma ^{i + 1}{z^{\rm T}}( {i + 1})\tilde Pz({i + 1})} \right]} \end{array} \end{align} $$ 将丢包形式的黎卡提方程(38)代入上式, 结合式(47), 从而得到
$$ \begin{equation*} \begin{aligned} \bar \gamma^T, & {J_2}(T) = \bar \gamma ^T{z^{\rm T}}(k)\tilde P z(k)+\nonumber\\ &\sum\limits_{i = T}^\infty {\left[ {{y^*}(i) + {{({{R_2} + {\bar\gamma}B_h^{\rm T}{M^{*{\rm T}}}\tilde P{M^*}{B_h}})}^{ - 1}}} \right.} \times \nonumber\\ &{\left. {{\bar\gamma}B_h^{\rm T}{M^{*{\rm T}}}\tilde P{M^*} {A_h}Mz(i)} \right]^{\rm T}}\times\nonumber\\&( {{R_2} + {\bar\gamma}B_h^{\rm T} {M^{*{\rm T}}}\tilde P{M^*}{B_h}} )\times\nonumber\\ &\left[ {{y^*}(i) + {{({{R_2} + {\bar\gamma}B_h^{\rm T} {M^{*{\rm T}}}\tilde P{M^*}{B_h}})}^{ - 1}} \times } \right.\nonumber\\ &{\left. {{\bar\gamma}B_h^{\rm T}{M^{*{\rm T}}}\tilde P{M^*}{A_h}Mz (i)} \right]^{\rm T}} \end{aligned} \end{equation*} $$ 因为$ ({{R_2} + {\bar\gamma}B_h^{\rm T}{M^{*{\rm T}}}\tilde P{M^*}{B_h}}) $是正定的, 故为了最小化性能指标, 则最优控制输入应该满足控制策略(37).
4. 仿真实验
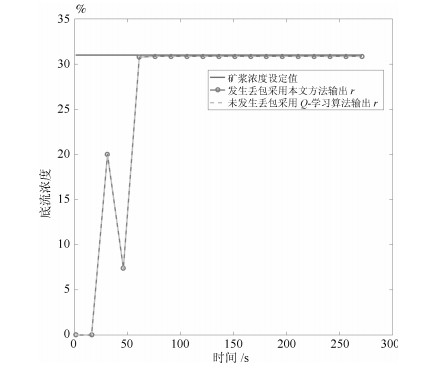
为了验证在无线网络环境下针对浓密过程本文提出数据驱动算法的有效性, 设计的对比实验为浓度过程发生丢包时将最近的有用数据作为采集的数据采用$ Q $-学习的方法, 浓度过程未发生丢包时采用$ Q $-学习的方法和对本文方法增大权重的方法.
4.1 仿真实验参数选择
针对赤铁矿混合选别的浓密过程(1)和(2), 进行本文提出的无线网络环境下增强学习控制方法的仿真实验, 根据实际混合选别过程可确定其参数如下[9], $ k_i = 0.001 $, $ k_1 = 1.9625 $, $ k_2 = 19.625 $, $ k_3 = 0.0049 $, $ k_0 = 47.97 $, $ h = 6 $, $ S = 1 962.5 \rm{m}^2 $, $ \tau = 3.25 $, $ v_p = 1.825 $, $ D = 100 000 $, $ {{\Delta \rho \left( t \right)}}/[{{g\rho \left( \cdot \right)}}] = 151.0748 $, $ \bar{K} = 1.12 $.
底流矿浆流量为快过程, 其采样周期为$ k = 1 \rm{s} $, 底流矿浆浓度为慢过程, 其采样周期为$ T = 15 \rm{s} $.在工作点处对其进行线性离散化, 则底流矿浆流量过程可以表示为
$$ \begin{equation*} \begin{aligned} {A_1}({z^{ - 1}}) y ({k + 1}) = {B_1} ({z^{ - 1}})u(k)\nonumber\\ \begin{cases} {A_1}({z^{ - 1}}) = 1 + 0.1905{z^{ - 1}}\nonumber\\ {B_1}({z^{ - 1}}) = 12.6027 \end{cases} \end{aligned} \end{equation*} $$ 底流矿浆浓度过程可以表示为
$$ \begin{equation*} \begin{aligned} {A_2}({z^{ - 1}})r ({T + 1}) = {B_2} ({z^{ - 1}}) y(T)\nonumber\\ \begin{cases} {{A_2}({z^{ - 1}}) = 1 - 0.3701{z^{ - 1}}}\nonumber\\ {{B_2}({z^{ - 1}}) = - 0.1} \end{cases} \end{aligned} \end{equation*} $$ 设底流矿浆浓度的设定值$ r^{*} $为$ 31 \% $, 运行层的最大丢包间隔为$ \delta _{f\max } = 1 $.选取底层系统的初始策略为$ {K^1} = \left[ \begin{matrix} 0.002&0.06 \end{matrix} \right] $和运行层的初始策略为$ {\tilde L^1} = \left[ {\begin{matrix} {- 0.31}&{1.3}&{ - 0.12}&{0.3}&{ - 0.35}&{ - 9.9} \end{matrix}} \right] $, 选取底层系统的权重为$ Q_1 = 10 $, $ R_1 = 1 $.选取运行层的权重为$ Q_2 = 10 000 $, $ R_2 = 1 $, 且$ \gamma = 0.95 $和$ \bar{\gamma} = 0.95 $, 计算得$ H_{u{X_d}}^* = \left[ {\begin{matrix}{ - 22.8083}&{ - 119.7113} \end{matrix}} \right] $, $ H_{uu}^* = 1 509.9 $, 从而得到底层系统的最优策略为$ K^* = \left[ {\begin{matrix} {0.0151}&{0.0793} \end{matrix}} \right] $, 计算得到丢包$ Q $-学习流量设定值控制器的$ H_{{r_1}z} = \left[ {\begin{matrix} {33.4223}\!&\!{ - 123.6960}\!&\!{12.3696}\!&\!{ - 45.7799} \!&\!{33.3456}\end{matrix}} \right.\nonumber\\ \left. {\begin{matrix} {905.2622} \end{matrix}} \right] $和$ H_{r_1r_1}^* = 91.233 5 $, 则丢包$ Q $-学习流量设定值控制器的最优策略为$ {\tilde L}^* = \left[ {\begin{matrix} { - 0.3663}&{1.3561}&{ - 0.1354}&{0.5029}&{ - 0.3661}\end{matrix}} \right.\nonumber\\ \left. {\begin{matrix} { - 9.9236} \end{matrix}} \right] $.
4.2 仿真结果
算法1经过迭代3次收敛, 得到$ Q $-学习流量控制器的$ H_{uX_d} = \left[ {\begin{matrix} { - 22.8083}&{ - 119.7113} \end{matrix}} \right] $, $ H_{uu} = 1 509.9 $, 则增益$ {K} = \left[ {\begin{matrix} {0.0151}&{0.0793} \end{matrix}} \right] $.待$ Q $-学习流量控制器收敛时, 之后算法2迭代6次就能收敛得到丢包$ Q $-学习流量设定值控制器的$ H_{{r_1}z} = \left[ {\begin{matrix} {33.4122}\!&\!{ - 123.7178}\!&\!{12.3686}\!&\!{ - 45.7484}\!&\!{33.3905}\end{matrix}} \right.\nonumber \left. {\begin{matrix} {905.1541} \end{matrix}} \right] $和$ H_{r_1r_1} \! = \!91.2114 $, 从而得到$ {\tilde L} = $ $ \left[ {\begin{matrix} { - 0.3663}&{1.3564}&{ - 0.1356}&{0.5016}& { - 0.3661}\end{matrix}} \right.\nonumber \left. {\begin{matrix}{ - 9.9237} \end{matrix}} \right] $.
由图 3可知, $ Q $-学习流量控制器能使流量$ y(k) $跟踪丢包$ Q $-学习控制器提供的设定值$ y^{*}(T) $, 并且使浓密过程的浓度输出$ r(T) $跟踪浓度的设定值$ r^* $, 同时在系统稳定时, 矿浆泵频率$ u $的输入也趋于稳定. 图 4表明流量过程控制增益$ K $在学习的过程中与最优的控制增益$ K^* $差值的2范数逐渐变小, 且趋于$ 0 $. 图 5为底流矿浆流量过程在学习的过程中$ H $收敛到最优值$ H^* $. 图 6表明浓度过程控制增益$ \tilde L $在学习的过程中与最优的控制增益$ {\tilde L}^* $差值的2范数逐渐变小, 且趋于$ 0 $. 图 7为浓度过程在学习的过程中$ {\bar H_2} $收敛到最优值$ {\bar H_2}^* $.仿真结果表明, 本文提出的算法在不知道浓密过程的模型时, 在无线网络环境下, 只利用在线采集到的输入输出的数据就能实现最优控制.
 图 3 浓密过程中浓度、流量的跟踪曲线以及底流泵转速的输入的曲线Fig. 3 The tracing result of the slurry concentration and the slurry flow-rate, and the input of the frequency of slurry pump
图 3 浓密过程中浓度、流量的跟踪曲线以及底流泵转速的输入的曲线Fig. 3 The tracing result of the slurry concentration and the slurry flow-rate, and the input of the frequency of slurry pump 图 5 流量过程Q-学习的结果Fig. 5 The result of the slurry flow-rate process during the Q-learning process
图 5 流量过程Q-学习的结果Fig. 5 The result of the slurry flow-rate process during the Q-learning process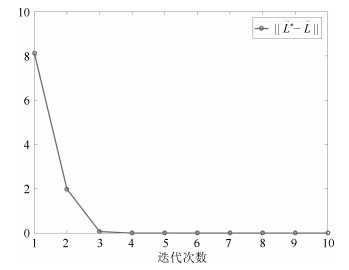 图 6 浓度过程控制增益$\tilde L$的收敛过程Fig. 6 Convergence of $\tilde L$to its optimal value $\tilde L$*
图 6 浓度过程控制增益$\tilde L$的收敛过程Fig. 6 Convergence of $\tilde L$to its optimal value $\tilde L$*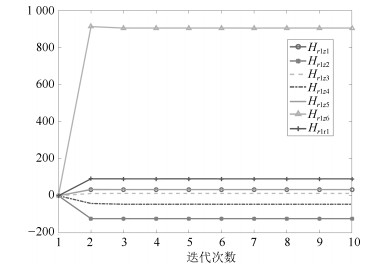 图 7 浓度过程丢包Q-学习的结果Fig. 7 The result of the slurry concentration process during the dropout Q-learning process
图 7 浓度过程丢包Q-学习的结果Fig. 7 The result of the slurry concentration process during the dropout Q-learning process4.3 对比实验
对比实验1为流量过程采取相同的控制策略, 在网络发生丢包时, 因为没有数据传输过来, 故将最近的有用数据作为这次采集的数据, 此时采用$ Q $-学习的方法计算得到流量设定值增益.选取$ Q_2 = 10 000 $和$ \bar \gamma = 0.95 $, 第一次迭代得到的增益为$ \left[ \begin{matrix} {0.0476}&{-0.7379}&{-4.9454}\end{matrix} \right] $, 第二次迭代得到的增益为$ \left[ \begin{matrix} {1.2071}&{4.8951}&{-3.5455}\end{matrix} \right] $, 第三次迭代得到的增益为$ \left[ \begin{matrix} {0.9464}&{8.6217}&{-8.5626}\end{matrix} \right] $, 三次迭代得到的增益不能收敛且变化大, 其作用到浓密过程得到仿真结果为图 8.
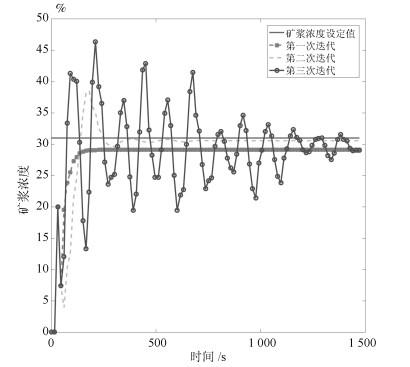 图 8 浓度过程Q-学习的结果Fig. 8 The result of the slurry concentration process during the Q-learning process
图 8 浓度过程Q-学习的结果Fig. 8 The result of the slurry concentration process during the Q-learning process从图 8可知将最近的有用数据作为这次采集的数据, 采用$ Q $-学习的方法迭代计算的三次增益分别作用到系统中不能实现对设定值的跟踪, 且随着迭代次数的增多使浓密过程越来越不稳定.
对比实验2为不考虑网络存在丢包的情况下, 流量过程采取相同的控制策略, 对浓度过程采取$ Q $-学习控制算法, 选取$ Q_2 = 10 000 $和$ \bar \gamma = 0.95 $, 经过迭代得到$ Q $-学习流量设定值增益为$ \left[ \begin{matrix} {-0.3664}&{1.3560}&{-9.9237}\end{matrix} \right] $, 其仿真结果为图 9.
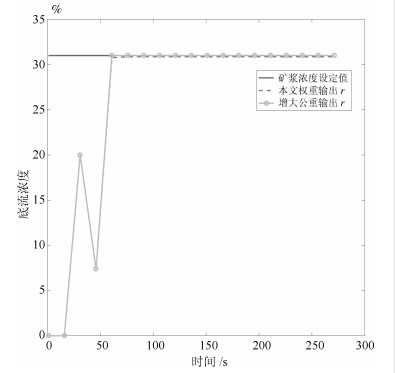
对比实验3为流量过程采取相同的控制律, 对浓度过程的性能指标增大权重$ Q_2 = 500 000 $, 得到的仿真结果如图 10所示.
为了评价本文的控制效果, 采用绝对误差积分(Integral absolute error, IAE)与误差均方差(Mean square error, MSE)[16, 29], 其公式为
$$ \begin{equation*} \begin{aligned} {\rm IAE } = \sum\limits_{T = 1}^{{T^*}} {\left| {r^* - {r}(T)} \right|} \end{aligned} \end{equation*} $$ $$ \begin{equation*} \begin{aligned} {\rm MSE} = \sqrt {{1 \over {{T^*}}}\sum\limits_{T = 1}^{{T^*}} {{{\left| {r^* - {r}(T)} \right|}^2}} } \end{aligned} \end{equation*} $$ 对比实验2和3的评价指标结果如表 2所示.
表 2 对比实验2和3评价指标Table 2 Performance index of comparison experimentIAE MSE 本文$Q_2$ 8.4224 0.0191 未丢包 8.4093 0.0190 增大$Q_2$ 0.0418 6.63$\times 10^{-7}$ 从表 2中可知, 选取相同的权重和衰减因子, 当系统发生丢包采取本文的方法得到的控制效果与未发生丢包采取$ Q $-学习的控制效果基本相同, 表明本文的方法对网络环境下浓密过程存在丢包的情况有效.对本文的方法增大$ Q_2 $时, 浓度过程的输出能很好的跟踪浓度设定值, 余差变小且性能评价指标变优, 且本文不需要系统的模型, 在丢包时利用采集到的数据也能实现跟踪.
5. 结论
本文针对在网络环境下的浓密过程设计$ Q $-学习流量控制器和丢包$ Q $-学习流量设定值控制器, 保证浓密过程存在网络丢包时, 不需要知道浓密过程的模型仅利用在线采集到的输入输出的数据实现能够很好地跟踪浓度设定值, 且仅依赖采集的数据为流量过程提供最优的设定值.其仿真结果表明该方法的有效性, 保证丢包时不依赖模型参数, 仅利用采集的数据实现对底流矿浆浓度的跟踪.
-

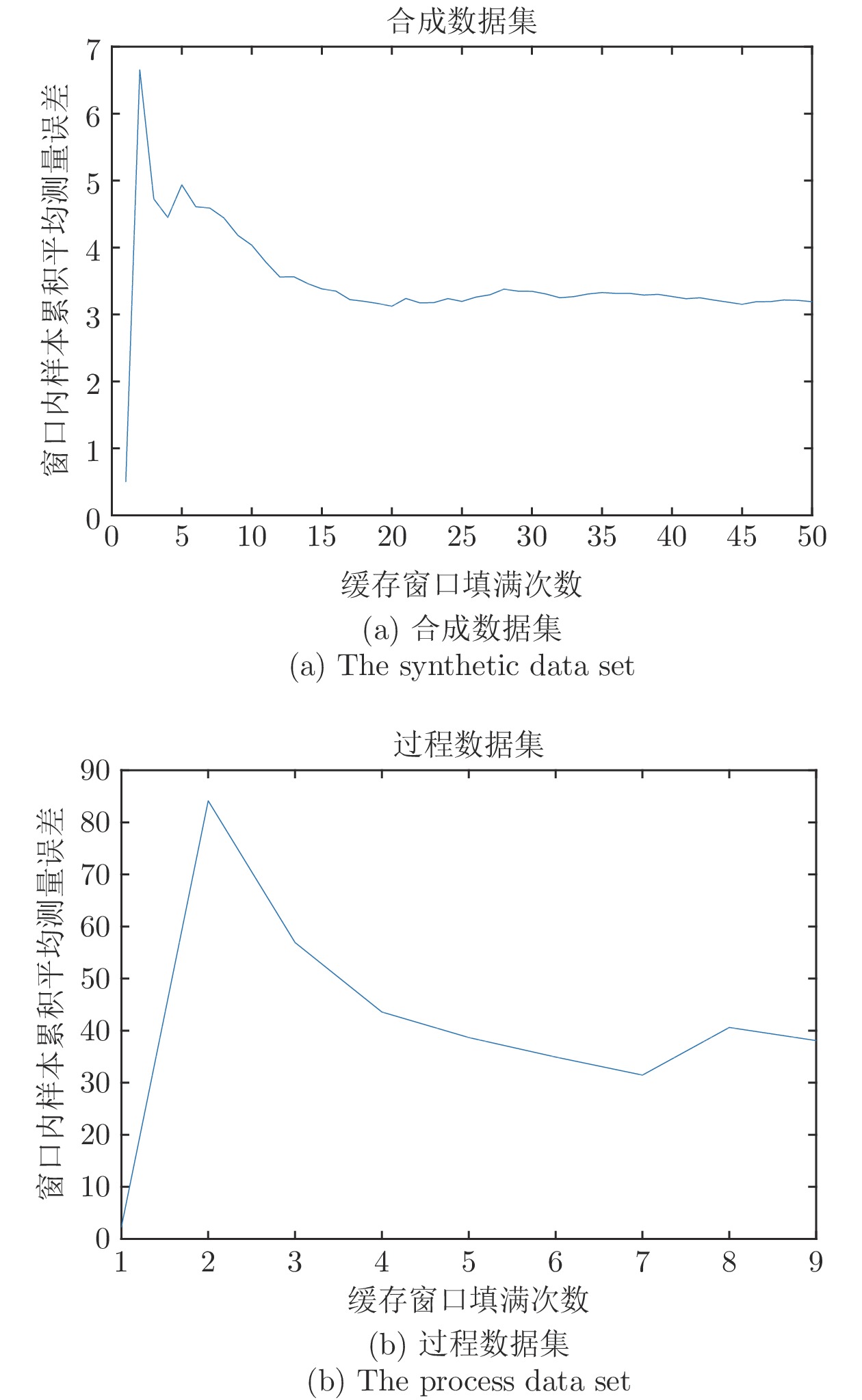
图 7 针对特征空间漂移样本的伪真值标注结果
Fig. 7 Pseudo-true value labeling results for samples with concept drift in the feature space

图 9 采用所提漂移检测算法后模型测量误差变化
Fig. 9 Changes of model measurement error after adopting the proposed drift detection algorithm

图 10 采用不同算法时模型测量误差变化
Fig. 10 Changes in model measurement errors when using different algorithms
表 1 各数据集参数介绍
Table 1 Detailed introduction of each data set
数据集 样本总数 建模样本数 验证样本数 漂移样本数 特征空间维数 合成 1500 500 500 500 5 过程 1500 500 500 500 18  下载: 导出CSV
下载: 导出CSV
表 2 仿真参数设置
Table 2 Simulation parameter setting
参数名称 数据集 合成 过程 GPR 核函数 径向基核函数 径向基核函数 核函数宽度 0.5967 1.5116 核函数特征长度 0.7939 1.4734 待标注样本窗口容量 (w) 8 50 PCA 控制限置信度 (ConfSPE, ConfT2) 0.8, 0.8 0.9, 0.9 TD 学习最近邻数量 $(\varepsilon) $ 6 5 Page-Hinkley 检测法基准累计
平均测量误差 (${\phi _0}$)2.2919 16.8846
下载: 导出CSV
表 3 所提算法检测信息
Table 3 Detection information of the proposed algorithm
合成数据集 过程数据集 缓存窗口填满次数 50 9 模型更新次数 44 8 标注漂移样本伪真值数 350 441 原始模型 RMSE 7.6478 53.0210 采用本文算法后模型 RMSE 2.5840 28.8785
下载: 导出CSV
表 4 不同算法检测性能比较
Table 4 Comparison of detection performance of different algorithms
数据集 检测算法 模型更新次数 更新所需真值数 模型测量 RMSE 其他 合成 无监督型 101 101 2.5846 需采用真值更新 有监督型 99 990 2.2943 需采用真值检测与更新 本文算法 44 50 2.5840 采用伪真值更新 过程 无监督型 463 463 35.8261 需采用真值更新 有监督型 19 450 28.4729 需采用真值检测与更新 本文算法 8 9 28.8785 采用伪真值更新
下载: 导出CSV
表 5 不同模型测量性能比较
Table 5 Comparison of measurement performance of different models
数据集 测量模型 核函数 (核宽度) 最小叶尺寸 训练 RMSE 训练 R2 测量 RMSE 合成 SVR 径向基 (0.5600) — 0.2479 0.94 3.7900 RT — 4 0.3034 0.91 3.1241 GPR 径向基 (0.5967) — 0.1899 0.96 2.5840 过程 SVR 径向基 (1.1000) — 0.1369 0.98 30.3916 RT — 4 0.1630 0.97 29.9548 GPR 径向基 (1.5116) — 0.1348 0.98 28.8785
下载: 导出CSV
表 6 不同距离函数对模型更新性能影响
Table 6 The influence of different distance functions on model updating performance
数据集 距离函数 伪真值标注平均误差 模型测量 RMSE 合成 曼哈顿距离 3.3434 3.1939 切比雪夫距离 3.2382 3.2484 欧氏距离 3.2760 2.5840 过程 曼哈顿距离 38.0043 28.9954 切比雪夫距离 37.7392 28.9947 欧氏距离 35.9429 28.8785
下载: 导出CSV
表 7 不同可变参数对应算法性能变化
Table 7 Algorithm performance changes corresponding to different variable parameters
样本窗口容量 w 最近邻数量 $\varepsilon $ PCA 控制限 ConfSPE,ConfT2 缓存窗口填满次数 标注伪真值数 更新次数 伪真值标注平均误差 模型测量 RMSE 30 3 0.85, 0.85 16 464 13 38.9005 31.0823 0.90, 0.90 16 464 15 48.2016 35.2513 0.95, 0.95 16 464 12 37.7528 28.9876 5 0.85, 0.85 16 464 15 40.0004 30.4071 0.90, 0.90 16 464 15 47.6636 34.2694 0.95, 0.95 15 435 13 39.0258 31.0078 8 0.85, 0.85 16 464 12 40.1782 28.8912 0.90, 0.90 16 464 15 46.5567 32.8323 0.95, 0.95 15 435 14 38.4400 30.5321 50 3 0.85, 0.85 9 441 8 42.9923 30.1536 0.90, 0.90 9 441 8 36.8999 29.7216 0.95, 0.95 9 441 7 31.2822 29.3330 5 0.85, 0.85 9 441 8 43.4483 29.8960 0.90, 0.90 9 441 9 35.9429 28.8785 0.95, 0.95 9 441 7 31.9674 29.9178 8 0.85, 0.85 9 441 8 42.9759 29.4615 0.90, 0.90 9 441 8 37.0338 29.2796 0.95, 0.95 9 441 6 31.4267 29.3356 70 3 0.85, 0.85 6 414 5 44.7315 33.6308 0.90, 0.90 6 414 5 46.9859 36.2573 0.95, 0.95 6 414 5 33.4711 33.1686 5 0.85, 0.85 6 414 5 41.9744 32.4663 0.90, 0.90 6 414 5 44.4580 34.3495 0.95, 0.95 6 414 5 33.6287 34.2660 8 0.85, 0.85 6 414 5 42.3929 31.0446 0.90, 0.90 6 414 5 45.8771 34.5003 0.95, 0.95 6 414 5 33.2206 33.5950
下载: 导出CSV
-
[1] Kolekar K A, Hazra T, Chakrabarty S N. A review on prediction of municipal solid waste generation models. Procedia Environmental Sciences, 2016, 35: 238-244. doi: 10.1016/j.proenv.2016.07.087 [2] Li X, Zhang C, Li Y, Zhi Q. The status of municipal solid waste incineration (MSWI) in China and its clean development. Energy Procedia, 2016, 104: 498-503. doi: 10.1016/j.egypro.2016.12.084 [3] 乔俊飞, 郭子豪, 汤健. 面向城市固废焚烧过程的二噁英排放浓度检测方法综述. 自动化学报, 2020, 46(06): 1063-1089.Qiao Jun-Fei, Guo Zi-Hao, Tang Jian. Dioxin emission concentration measurement approaches for municipal solid wastes incineration process: a survey. Acta Automatica Sinica, 2020, 46(06): 1063-1089. [4] 汤健, 乔俊飞, 徐喆, 郭子豪. 基于特征约简与选择性集成算法的城市固废焚烧过程二噁英排放浓度软测量. 控制理论与应用, 2021, 38(1), 110−120Tang Jian, Qiao Jun-Fei, Xu Zhe, Guo Zi-Hao. Soft measuring approach of dioxin emission concentration in municipal solid waste incineration process based on feature reduction and selective ensemble algorithm. Control Theory and Applications, 2021, 38(1), 110−120 [5] 汤健, 夏恒, 乔俊飞, 郭子豪. 深度集成森林回归建模方法及应用研究 [Online], available: http://kns.cnki.net/kcms/detail/11.2286.T.20200723.1048.002.html, July 23, 2020Tang Jian, Xia Heng, Qiao Jun-Fei, Guo Zi-Hao. Deep ensemble forest regression modeling method with its application research [Online], available: http://kns.cnki.net/kcms/detail/11.2286.T.20200723.1048.002.html, July 23, 2020 [6] Wang S, Schlobach S, Klein M. What is concept drift and how to measure it? In: Proceedings of the 2010 International Conference on Knowledge Engineering and Knowledge Management. Lisbon, Portugal: Springer, 2010. 241–256 [7] Widmer G, Kubat M. Learning in the presence of concept drift and hidden contexts. Machine Learning, 1996, 23(1): 69-101. [8] 汤健, 柴天佑, 刘卓, 余文, 周晓杰. 基于更新样本智能识别算法的自适应集成建模. 自动化学报, 2016, 42(7): 1040-1052.TANG Jian, CHAI Tian-You, LIU Zhuo, YU Wen, ZHOU Xiao-Jie. Adaptive ensemble modelling approach based on updating sample intelligent identification. Acta Automatica Sinica, 2016, 042(007): 1040-1052. [9] Žliobaitė I. Learning under concept drift: An overview [Online], available: http://arxiv.org/abs/1010.4784, October 22, 2010 [10] Lu J, Liu A, Dong F, Gu F, Gama J, Zhang G. Learning under concept drift: A review. IEEE Transactions on Knowledge and Data Engineering, 2018, 31(12): 2346-2363. [11] Gama J, Medas P, Castillo G, Rodrigues P. Learning with drift detection. In: Proceedings of the 17th Brazilian Symposium on Artificial Intelligence. São Luís, Brazil: Springer, 2004. 286–295 [12] Pesaranghader A, Viktor H L. Fast hoeffding drift detection method for evolving data streams. In: Proceedings of the 2016 Joint European Conference on Machine Learning and Knowledge Discovery in Databases. Riva Del Garda, Italy: Springer, 2016. 96–111 [13] Yang Z, Al-Dahidi S, Baraldi P, Zio E, Montelatici L. A novel concept drift detection method for incremental learning in nonstationary environments. IEEE Transactions on Neural Networks and Learning Systems, 2019, 31(1): 309-320. [14] Frías B I, Campo A J, Ramos J G, Morales B R, Ortiz D A, Caballero M Y. Online and non-parametric drift detection methods based on Hoeffding’s bounds. IEEE Transactions on Knowledge and Data Engineering, 2014, 27(3): 810-823. [15] Mahdi O A, Pardede E, Ali N, Cao J. Diversity measure as a new drift detection method in data streaming. Knowledge-Based Systems, 2020, 191: Article No. 105227. doi: 10.1016/j.knosys.2019.105227 [16] Korpela T, Kumpulainen P, Majanne Y, Häyrinen A, Lautala P. Indirect NOx emission monitoring in natural gas fired boilers. Control Engineering Practice, 2017, 65: 11–25 [17] Tang J, Yu W, Chai T Y, Zhao L J. Online principal component analysis with application to process modeling. Neurocomputing, 2012, 82: l67-168. [18] Han X, Tian S, Romagnoli J A, Lic H, Suna W. PCA-SDG based process monitoring and fault diagnosis: application to an industrial pyrolysis furnace. IFAC-PapersOnLine, 2018, 51(18): 482-487. doi: 10.1016/j.ifacol.2018.09.378 [19] Liu S, Feng L, Wu J, Hou G, Han G. Concept drift detection for data stream learning based on angle optimized global embedding and principal component analysis in sensor networks. Computers & Electrical Engineering, 2017, 58(2017): 327-336. [20] Toubakh H, Sayed-Mouchaweh M. Hybrid dynamic data-driven approach for drift-like fault detection in wind turbines. Evolving Systems, 2015, 6(2): 115-129. doi: 10.1007/s12530-014-9119-8 [21] Xu S, Feng L, Liu S, Qiao H. Self-adaption neighborhood density clustering method for mixed data stream with concept drift. Engineering Applications of Artificial Intelligence, 2020, 89: Article No. 103451 [22] Wang X S, Kang Q, Zhou M C, Yao S Y. A multiscale concept drift detection method for learning from data streams. In: Proceedings of the 14th International Conference on Automation Science and Engineering. Munich, Germany: IEEE, 2018. 786–790 [23] Liu A, Lu J, Liu F, Zhang G. Accumulating regional density dissimilarity for concept drift detection in data streams. Pattern Recognition, 2018, 76: 256-272. doi: 10.1016/j.patcog.2017.11.009 [24] Lughofer E, Weigl E, Heidl W, Eitzinger C, Radauer T. Recognizing input space and target concept drifts in data streams with scarcely labeled and unlabelled instances. Information Sciences, 2016, 355: 127-151. [25] Haque A, Khan L, Baron M, Thuraisingham B, Aggarwal C. Efficient handling of concept drift and concept evolution over stream data. In: Proceedings of the 32nd International Conference on Data Engineering. Helsinki, Finland: IEEE, 2016. 481–492 [26] Tan C H, Lee V, Salehi M. Online semi-supervised concept drift detection with density estimation [Online], available: https://arxiv.org/abs/1909.11251, November 11, 2019 [27] Zhou Z H, Li M. Semi-supervised regression with co-training. In: Proceedings of the 2005 International Joint Conference on Artificial Intelligence. Scotland, UK: AAAI, 2005. 908–913 [28] Miller J A. Bowman C T. Mechanism and modelling of nitrogen chemistry in combustion. Progress in Energy and Combustion Science, 1989, 15(4): 287-338. doi: 10.1016/0360-1285(89)90017-8 [29] Kadlec P, Gabrys B, Strandt S. Data-driven soft sensors in the process industry. Computers & Chemical Engineering, 2009, 33(4): 795-814. [30] Schlimmer J C, Granger R H. Incremental learning from noisy data. Machine learning, 1986, 1(3): 317-354. [31] 杨俊志. 测量准确度及相关术语辨析. 测绘科学, 2011, 36(01): 75-76.YANG Jun-Zhi. Full analysis on accuracy and related terms. Science of Surveying and Mapping, 2011, 36(01): 75-76. [32] Wang B, Mao Z. Outlier detection based on gaussian process with application to industrial processes. Applied Soft Computing, 2019, 76: 505-516. doi: 10.1016/j.asoc.2018.12.029 [33] Schulz E, Speekenbrink M, Krause A. A tutorial on gaussian process regression: modelling, exploring, and exploiting functions. Journal of Mathematical Psychology, 2018, 85(2018): 1-16. [34] Yin S, Ding S X, Xie X, Luo H. A review on basic data-driven approaches for industrial process monitoring. IEEE Transactions on Industrial Electronics, 2014, 61(11): 6418-6428. doi: 10.1109/TIE.2014.2301773 [35] Tang J, Yu W, Chai T Y, Liu Z, Zhou X. Selective ensemble modeling load parameters of ball mill based on multi-scale frequency spectral features and sphere criterion. Mechanical Systems & Signal Processing, 2016, 66: 485-504. [36] Kaneko H, Funatsu K. Classification of the degradation of soft sensor models and discussion on adaptive models. AIChE Journal, 2013, 59(7): 2339-2347. doi: 10.1002/aic.14006 [37] 袁小锋, 葛志强, 宋执环. 基于时间差分和局部加权偏最小二乘算法的过程自适应软测量建模. 化工学报, 2016, (3): 724−728Yuan Xiao-Feng, Ge Zhi-Qiang, Song Zhi-Huan. Adaptive soft sensor based on time difference model and locally weighted partial least squares regression. Journal of Chemical Industry and Engineering (China), 2016, (3): 724−728 [38] Kaneko H, Funatsu K. Maintenance-free soft sensor models with time difference of process variables. Chemometrics and Intelligent Laboratory Systems, 2011, 107(2): 312-317. doi: 10.1016/j.chemolab.2011.04.016 [39] 濮晓龙. 关于累积和 (CUSUM) 检验的改进. 应用数学学报, 2003, (2): 225−241Pu Xiao-Long, Improvement of CUSUM test. Acta Mathematicae Applicate Sinica, 2003, (2): 225−241 [40] Ikonomovska E. Algorithms for Learning Regression Trees and Ensembles on Evolving Data Streams [Ph.D. Dissertation], Jožef Stefan International Postgraduate School, The Republic of Slovenia, 2012 [41] Channoi K, Maneewongvatana S. Concept drift for CRD prediction in broiler farms. In: Proceedings of the 12th International Joint Conference on Computer Science and Software Engineering. Songkhla, Thailand: IEEE, 2015. 287–290 期刊类型引用(7)
1. 褚菲,王佩,朱安强,张海军. 面向过程控制的煤泥浮选机理建模与仿真研究. 控制工程. 2024(12): 2129-2139+2166 .  百度学术
百度学术2. 赵建国,杨春雨. 复杂工业过程非串级双速率组合分散运行优化控制. 自动化学报. 2023(01): 172-184 . 本站查看3. 姜艺,范家璐,柴天佑. 数据驱动的保证收敛速率最优输出调节. 自动化学报. 2022(04): 980-991 . 本站查看4. 庞文砚,范家璐,姜艺,LEWIS Frank Leroy. 基于强化学习的部分线性离散时间系统的最优输出调节. 自动化学报. 2022(09): 2242-2253 . 本站查看5. 牛桂强. 絮凝剂制备系统在某金矿尾矿浓缩的应用. 铜业工程. 2022(04): 37-40 . 百度学术6. 李臻,范家璐,姜艺,柴天佑. 一种基于Off-Policy的无模型输出数据反馈H_∞控制方法. 自动化学报. 2021(09): 2182-2193 . 本站查看7. 盘城. 基于数据驱动的智能个性化排版系统设计. 自动化与仪器仪表. 2020(12): 66-69+74 . 百度学术其他类型引用(11)
-

 下载:
下载:






计量
- 文章访问数: 1318
- HTML全文浏览量: 642
- PDF下载量: 200
- 被引次数: 18
