

Design of Optimal Strategies for the Pursuit-evasion Problem Based on Differential Game
-
摘要:
本文设计了基于线性二次型微分博弈的多个攻击者、多个防御者和单个目标的追逃问题最优策略. 首先, 针对攻防双方保持聚合状态的情形, 基于攻击方内部、防御方内部以及双方之间的通信拓扑, 分别给出了目标沿固定轨迹运动和目标采取逃跑时攻防双方的最优策略. 其次, 针对攻防双方保持分散状态的情形, 利用二分图最大匹配算法分配相应的防御者与攻击者, 将多攻击者、多防御者追逃问题转化为多组两人零和微分博弈, 并求解出了攻防双方的最优策略. 最后, 数值仿真验证了所提策略的有效性.
-
关键词:
- 微分博弈 /
- 追逃问题 /
- 团队聚合 /
- 线性二次型博弈 /
- 目标–攻击者–防御者
Abstract:This paper is concerned with the design of optimal strategies for the pursuit-evasion problem with multi-attacker, multi-defender and single target based on the linear quadratic differential game. Firstly, for the case that attackers and defenders maintain their group cohesion, strategies of attackers and defenders are proposed when the target moves with a certain trajectory or the target adopts evasion policy respectively, based on communication graphs among attackers, among defenders, and between attackers and defenders. Secondly, for the case that attackers and defenders stay distributed, the maximum matching algorithm of bipartite graph is used to match attackers for defenders and the multi-attacker multi-defender pursuit-evasion problem is transformed into multi two-person zero-sum differential games, and then optimal strategies of attackers and defenders are proposed. Finally, simulation examples are provided to verify the effectiveness of the proposed strategies.
-
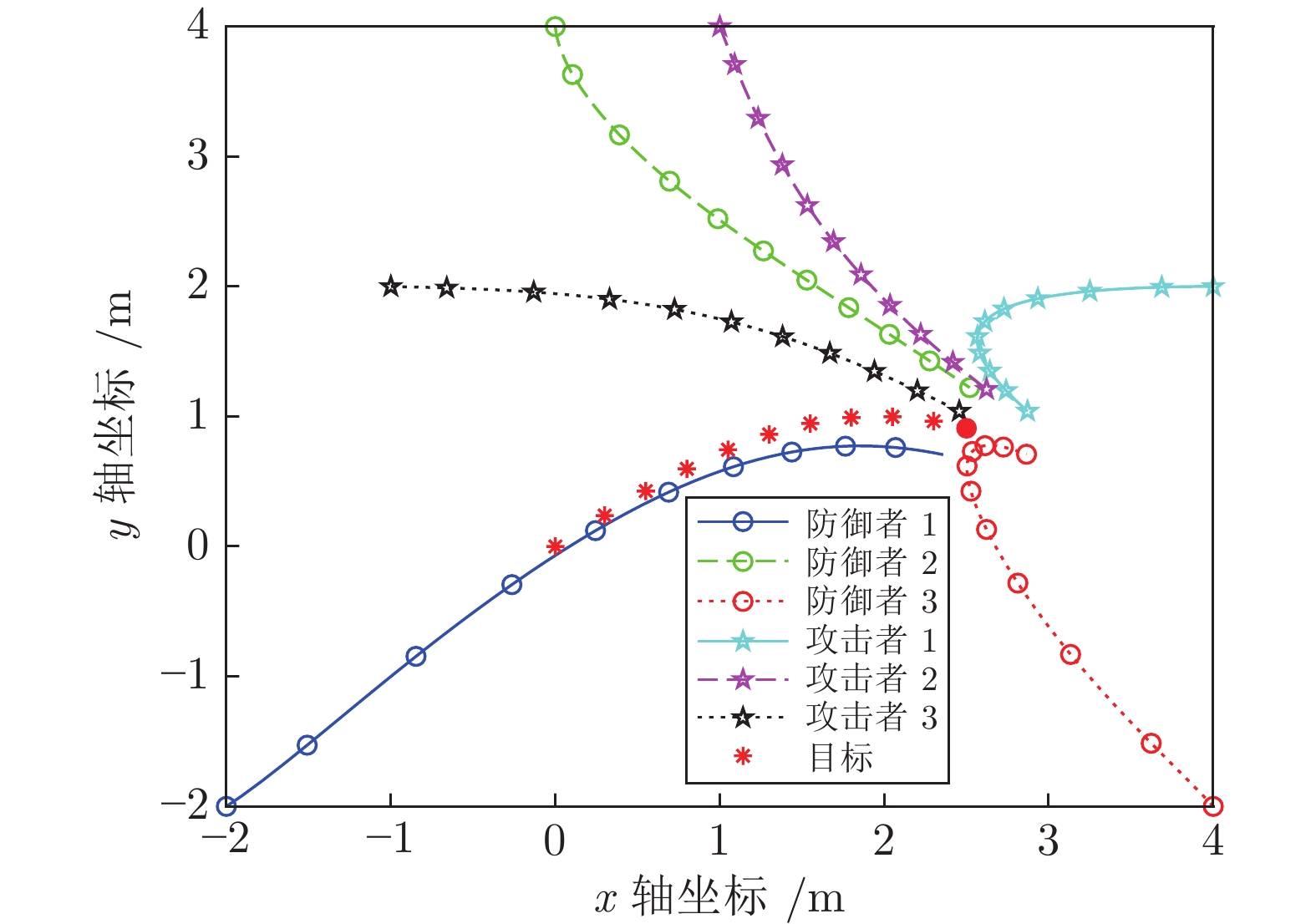
图 4 攻击者胜利时目标、攻击者、防御者的运动轨迹
Fig. 4 Trajectories of the target, attackers and defenders when attackers win
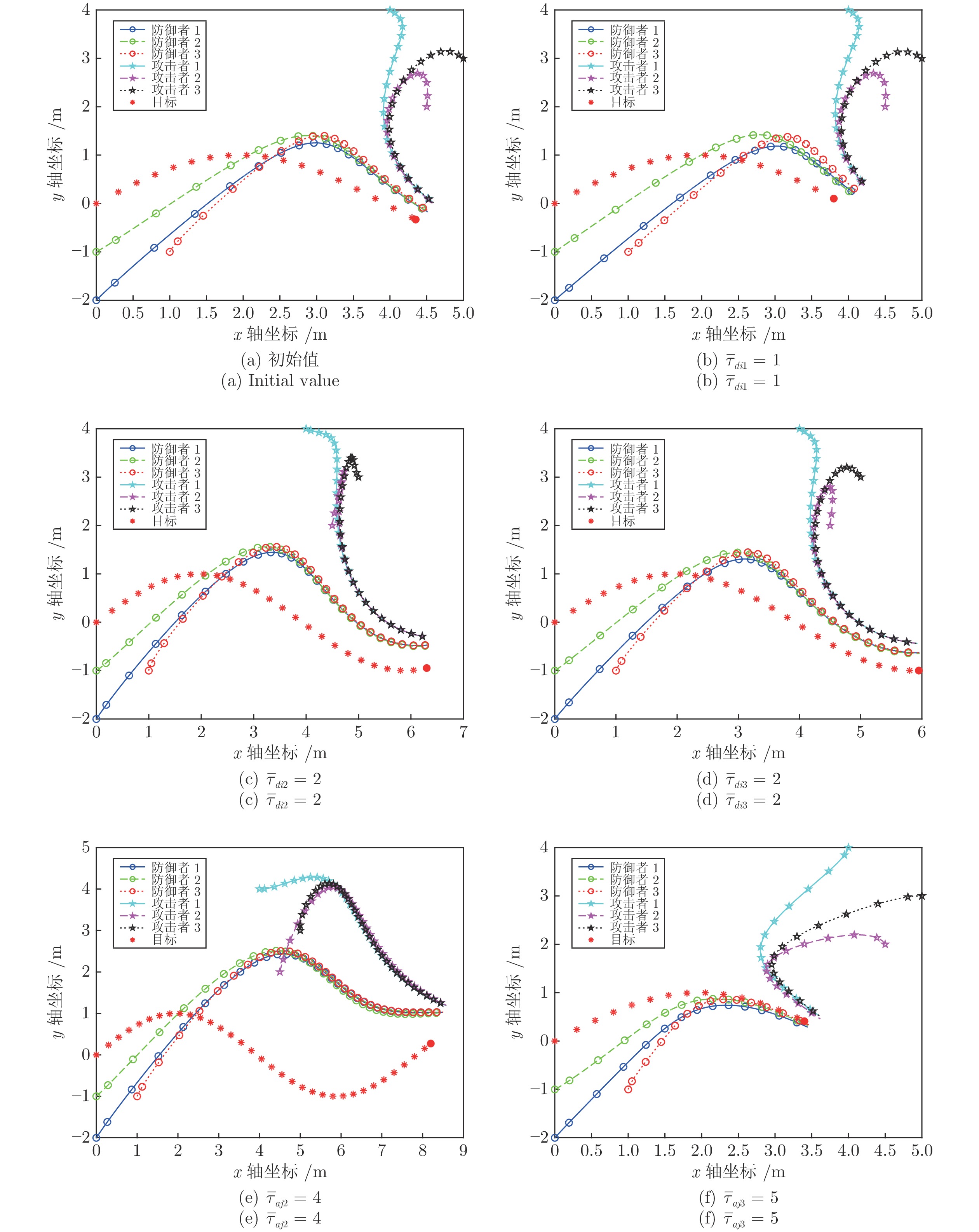
图 5 防御者胜利时权重系数调整目标、攻击者、防御者的运动轨迹
Fig. 5 Trajectories of the target, attackers and defenders with different weight coefficients when defendes win
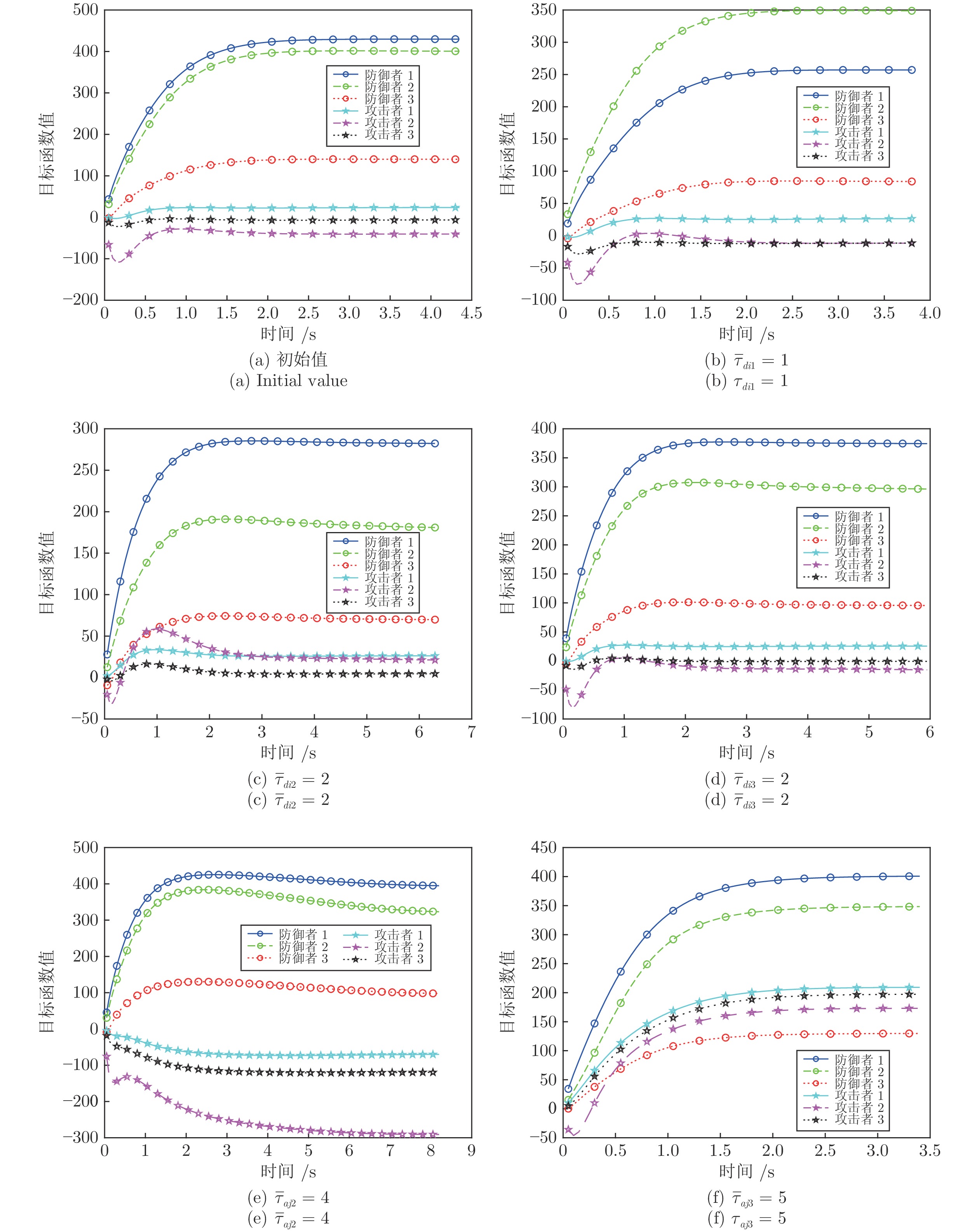
图 6 防御者胜利时权重系数调整目标、攻击者、防御者的成本函数
Fig. 6 Cost functions of the target, attackers and defenders with different weight coefficients when defendes win

图 7
$ m = 3$ ,$ l = 5$ 时目标、攻击者、防御者的运动轨迹Fig. 7 Trajectories of the target, attackers and defenders with
$ m = 3$ ,$ l = 5$ 
图 8
$m = 5,\;l = 3$ 时目标、攻击者、防御者的运动轨迹Fig. 8 Trajectories of the target, attackers and defenders with
$m = 5,\;l = 3$ 
图 9 目标采取逃跑行动时目标、攻击者、防御者的运动轨迹
Fig. 9 Trajectories of the target, attackers and defenders when the target adopts an escape strategy
-
[1] 杜永浩, 邢立宁, 蔡昭权. 无人飞行器集群智能调度技术综述. 自动化学报, 2020, 46(2): 222-241.DU Yong-Hao, XING Li-Ning, CAI Zhao-Quan. Survey on intelligent scheduling technologies for unmanned flying craft clusters. Acta Automatica Sinica, 2020, 46(2): 222-241. [2] 周宏宇, 王小刚, 单永志, 赵亚丽, 崔乃刚. 基于改进粒子群算法的飞行器协同轨迹规划. 自动化学报, DOI: 10.16383/j.aas.c190865Zhou Hong-Yu, Wang Xiao-Gang, Shan Yong-Zhi, Zhao Ya-Li, Cui Nai-Gang. Synergistic path planning for multiple vehicles based on an improved particle swarm optimization method. Acta Automatica Sinica, DOI: 10.16383/j.aas.c190865 [3] Azam M A, Ragi S. Decentralized formation shape control of UAV swarm using dynamic programming. In: Proceedings of Signal Processing, Sensor/Information Fusion, and Target Recognition XXIX. California, USA, 2020. 11423: 114230I [4] Zhou Z, Zhang W, Ding J, Huang, H, Stipanovic D M, Tomlin C J. Cooperative pursuit with voronoi partitions. Automatica, 2016, 72: 64-72. doi: 10.1016/j.automatica.2016.05.007 [5] De Simone D, Scianca N, Ferrari P, Lanari L, Oriolo G. MPC-based humanoid pursuit-evasion in the presence of obstacles. In: Proceedings of IEEE/RSJ International Conference on Intelligent Robots and Systems. 2017. 5245−5250 [6] Isaacs R. Differential Games: A Mathematical Theory With Applications to Warfare and Pursuit, Control and Optimization. Courier Corporation, 1999. [7] Fang B, Pan Q, Hong B, Lei D, Zhong Q B, Zhang Z. Research on high speed evader vs. multi lower speed pursuers in multi pursuit-evasion games. Information Technology Journal, 2012, 11(8): 989-997. doi: 10.3923/itj.2012.989.997 [8] Lin W, Qu Z, Simaan M A. Nash strategies for pursuit-evasion differential games involving limited observations. IEEE Transactions on Aerospace and Electronic Systems, 2015, 51(2): 1347-1356. doi: 10.1109/TAES.2014.130569 [9] Pachter M, Garcia E, Casbeer D W. Differential game of guarding a target. Journal of Guidance, Control, and Dynamics, 2017, 40(11): 2991-2998. doi: 10.2514/1.G002652 [10] Venkatesan R H, Sinha N K. The target guarding problem revisited: Some interesting revelations. In: Proceedings of IFAC World Congress. Cape Town, South Africa, 2014. 1556−1561 [11] Li D, Cruz J B. Defending an asset: A linear quadratic game approach. IEEE Transactions on Aerospace and Electronic Systems, 2011, 47(2): 1026-1044. doi: 10.1109/TAES.2011.5751240 [12] Garcia E, Casbeer D W, Pachter M. Design and analysis of state-feedback optimal strategies for the differential game of active defense. IEEE Transactions on Automatic Control, 2018, 64(2): 553-568. [13] Liang L, Deng F, Peng Z, Li X, Zha W. A differential game for cooperative target defense. Automatica, 2019, 102: 58-71. doi: 10.1016/j.automatica.2018.12.034 [14] Casbeer D W, Garcia E, Pachter M. The target differential game with two defenders. Journal of Intelligent & Robotic Systems, 2018, 89(1-2): 87-106. [15] Chen M, Zhou Z, Tomlin C J. Multiplayer reach-avoid games via low dimensional solutions and maximum matching. In: Proceedings of American Control Conference. Portland, USA, 2014. 1444−1449 [16] Coon M, Panagou D. Control strategies for multiplayer target-attacker-defender differential games with double integrator dynamics. In: Proceedings of IEEE Conference on Decision and Control. Melbourne, Australia, 2017. 1496−1502 [17] Chipade V S, Panagou D. Multiplayer target-attacker-defender differential game: pairing allocations and control strategies for guaranteed intercept. In: Proceedings of AIAA Scitech 2019 Forum. California, USA, 2019. 658−678 [18] Yan R, Shi Z, Zhong Y. Task assignment for multiplayer reach-avoid games in convex domains via analytical barriers. IEEE Transactions on Robotics, 2019, 36(1): 107-124. [19] Garcia E, Casbeer D W, Von Moll A, Pachter M. Multiple Pursuer Multiple Evader Differential Games. IEEE Transactions on Automatic Control, arxiv: 1911. 03806 [20] Sin E, Arcak M, Packard A, Philbrick D, Seiler P. Optimal assignment of collaborating agents in multi-body asset-guarding games. In: Proceedings of the 2020 American Control Conference (ACC). Denver, Colorado, USA, 2020. 858−864 [21] Li D X, Cruz J B. Graph-Based Strategies for Multi-Player Pursuit Evasion Games. In: Proceedings of IEEE Conference on Decision and Control. New Orleans, LA, USA, 2007. 4063−4068 [22] Mejia V G L, Lewis F L, Wan Y, Sanchez E N, Fan L. Solutions for multiagent pursuit-evasion games on communication graphs: Finite-time capture and asymptotic behaviors. IEEE Transactions on Automatic Control, 2019, 65(5): 1911-1923. [23] Engwerda J. LQ dynamic optimization and differential games. John Wiley & Sons, 2005. [24] Kuhn H. The Hungarian method for the assignment problem. Naval Research Logistics Quarterly, 1955, 2(1-2): 83-97. doi: 10.1002/nav.3800020109 [25] Amato F, Pironti A. A note on singular zero-sum linear quadratic differential games. In: Proceedings of IEEE Conference on Decision and Control. Lake Buena Vista, USA, 1994. 1533−1535 [26] 夏元清. 云控制系统及其面临的挑战. 自动化学报, 2016, 42(01): 1-12.Xia Yuan-Qing. Cloud control systems and their challenges. Acta Automatica Sinica, 2016, 42(1): 1-12. -

 下载:
下载:









计量
- 文章访问数: 5478
- HTML全文浏览量: 1713
- PDF下载量: 875
- 被引次数: 0
