

Research on Machine Reading Comprehension Method Based on MHSA and Syntactic Relations Enhancement
-
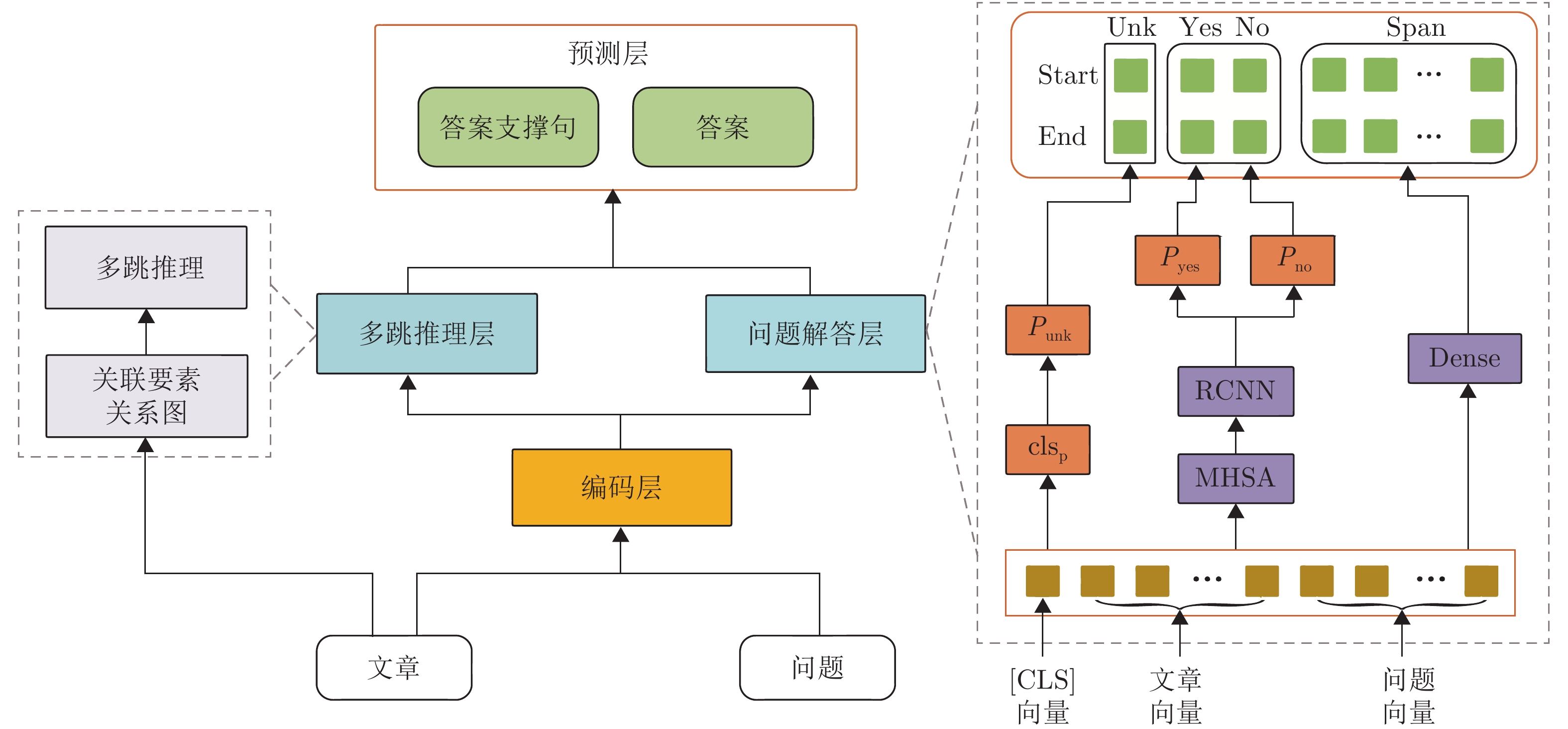
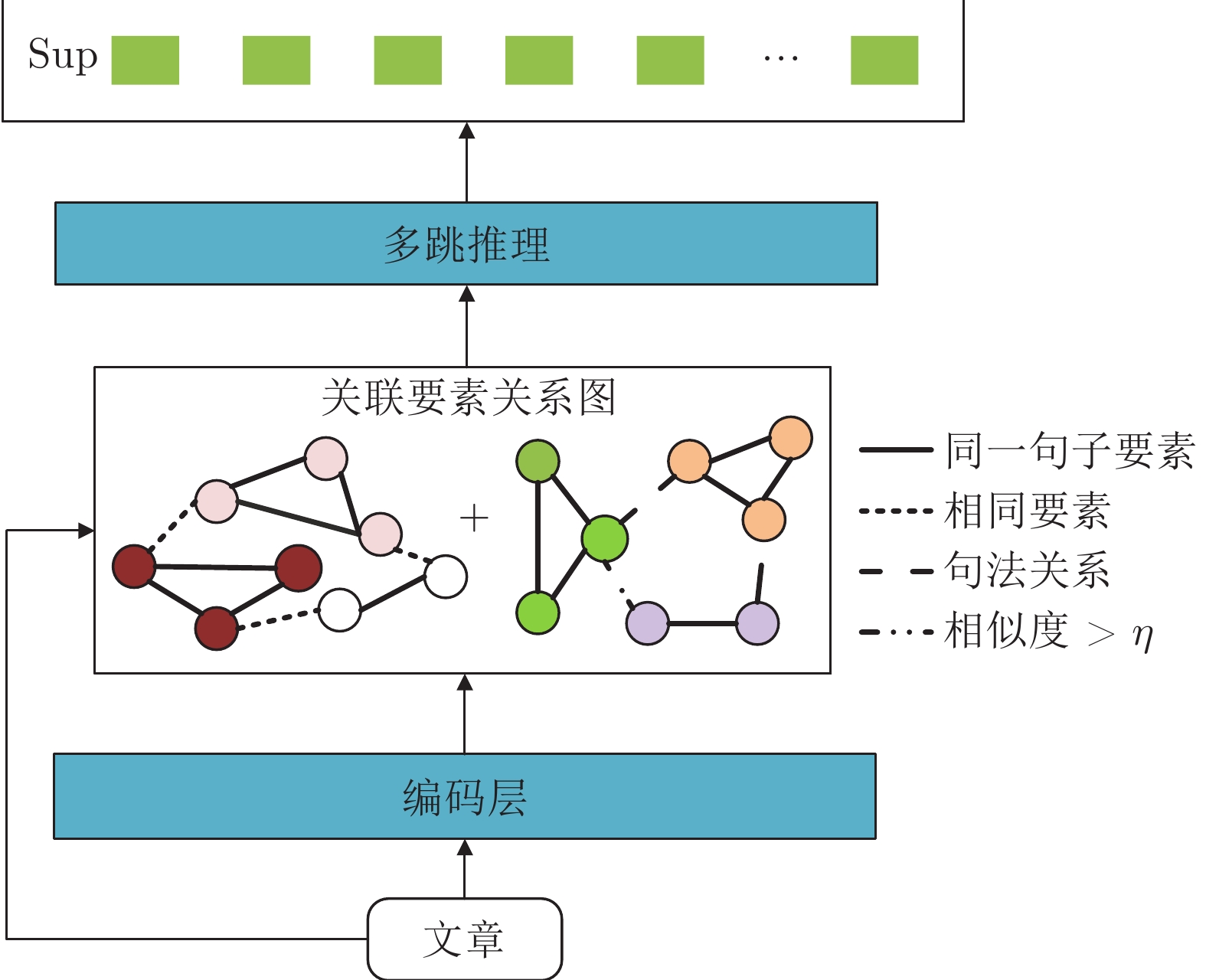
摘要: 机器阅读理解 (Machine reading comprehension, MRC)是自然语言处理领域中一项重要研究任务, 其目标是通过机器理解给定的阅读材料和问题, 最终实现自动答题. 目前联合观点类问题解答和答案依据挖掘的多任务联合学习研究在机器阅读理解应用中受到广泛关注, 它可以同时给出问题答案和支撑答案的相关证据, 然而现有观点类问题的答题方法在答案线索识别上表现还不是太好, 已有答案依据挖掘方法仍不能较好捕获段落中词语之间的依存关系. 基于此, 引入多头自注意力(Multi-head self-attention, MHSA)进一步挖掘阅读材料中观点类问题的文字线索, 改进了观点类问题的自动解答方法; 将句法关系融入到图构建过程中, 提出了基于关联要素关系图的多跳推理方法, 实现了答案支撑句挖掘; 通过联合优化两个子任务, 构建了基于多任务联合学习的阅读理解模型. 在2020中国“法研杯”司法人工智能挑战赛(China AI Law Challenge 2020, CAIL2020)和HotpotQA数据集上的实验结果表明, 本文提出的方法比已有基线模型的效果更好.Abstract: Machine reading comprehension (MRC), which aims to understand the question and the relevant article to answer questions automatically, is an important research task in natural language processing. Recently, the multi-task joint learning research combining opinion question solving and answer evidence mining has attracted much attention. Although methods proposed by such researches always provide both the answer and the relevant evidence simultaneously, neither are the existing methods handling the opinion-type questions good at identifying the clues to the answer, nor are the previous methods mining the answer evidence good at capturing the dependency relationship between words in the given paragraph. Therefore, the method to solve the opinion-type questions has been improved by further exploring the related text clues within the given reading materials through utilizing multi-head self-attention (MHSA); a multi-hop reasoning method realizing the mining of supporting sentences to the answer has been developed by integrating syntactic relation into the construction process of the element graph; a multi-task joint learning model for MRC has been constructed by optimizing the two sub-tasks jointly. Experiments on MRC datasets of CAIL2020 (China AI Law Challenge 2020) and HotpotQA show that the proposed method can provide better results than the existing baseline models.1) 1
https://github.com/baidu/lac 2) 1https://github.com/baidu/lac 2https://github.com/baidu/DDParser 3https://github.com/explosion/spaCy 3) 3https://github.com/explosion/spaCy 4) 4https://github.com/china-ai-law-challenge/CAIL2020/tree/master/ydlj 5https://github.com/neng245547874/cail2020-mrc 6https://github.com/hotpotqa/hotpot 5) 5https://github.com/neng245547874/cail2020-mrc 6) 6https://github.com/hotpotqa/hotpot -
表 1 CAIL2020数据集实验结果(%)
Table 1 Results on the CAIL2020 dataset (%)
模型 Ans_F1 Sup_F1 Joint_F1 Baseline_BERT 70.40 65.74 49.25 Baseline_RoBERTa 71.81 71.11 55.74 Baseline_DPCNN 77.43 75.07 61.80 Cola 74.63 73.68 59.62 DFGN_CAIL 68.79 72.34 53.82 MJL-model 78.83 75.51 62.72  下载: 导出CSV
下载: 导出CSV
表 2 HotpotQA实验结果(%)
Table 2 Results on the HotpotQA dataset (%)
模型 Ans_F1 Sup_F1 Joint_F1 Baseline 58.28 66.66 40.86 QFE 68.70 84.70 60.60 DFGN 69.34 82.24 59.86 SAE 74.81 85.27 66.45 MJL-Model 70.92 85.96 62.87
下载: 导出CSV
表 3 消融实验结果(%)
Table 3 Results of ablation experiments (%)
模型 Ans_F1 Sup_F1 Joint_F1 MJL-model 78.83 75.51 62.72 Question_answering 76.36 — — Answer_evidence — 73.42 — –MHSA 76.28 75.11 61.16 –RCNN 75.96 75.05 60.96 –Syntax & Similarity 77.61 74.39 60.80
下载: 导出CSV
-
[1] 曾帅, 王帅, 袁勇, 倪晓春, 欧阳永基. 面向知识自动化的自动问答研究进展. 自动化学报, 2017, 43(9): 1491-150.Zeng Shuai, Wang Shuai, Yuan Yong, Ni Xiao-Chun, Ouyang Yong-Ji. Towards knowledge automation: a survey on question answering systems. ACTA AUTOMATICA SINICA, 2017, 43(9): 1491-1508(in Chinese). [2] 奚雪峰, 周国栋. 面向自然语言处理的深度学习研究. 自动化学报, 2016, 42(10): 1445-1465.Xi Xue-Feng, Zhou Guo-Dong. A survey on deep learning for natural language processing. ACTA AUTOMATICA SINICA, 2016, 42(10): 1445-1465(in Chinese). [3] Devlin J, Chang M W, Lee K, Toutanova K. BERT: Pre-training of deep bidirectional transformers for language understanding. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Minneapolis, USA: ACL, 2019. 4171−4186 [4] Rajpurkar P, Zhang J, Lopyrev K, Liang P. SQUAD: 100 000+ questions for machine comprehension of text. In: Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. Austin, USA: ACL, 2016. 2383−2392 [5] Rajpurkar P, Jia R, Liang P. Know what you don't know: Unanswerable questions for squad. In: Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics. Melbourne, Australia: ACL, 2018.784−789 [6] Reddy S, Chen D Q, Manning C D, CoQA: A conversational question answering challenge. Transactions of the Association for Computational Linguistics, 2019, 7: 249−266 [7] Duan X Y, Wang B X, Wang Z Y, Ma W T, Cui Y M, Wu D Y, et al. CJRC: A reliable human-annotated benchmark dataset for Chinese judicial reading comprehension. In: Proceedings of the 2019 China National Conference on Chinese Computational Linguistics. Kunming, China: Springer, 2019. 439−451 [8] Yang Z L, Qi P, Zhang S Z, Bengio Y, Cohen W W, Salakhutdinov R, et al. HotpotQA: A dataset for diverse, explainable multi-hop question answering. In: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Brussels, Belgium: ACL, 2018. 2369−2380 [9] Lai S W, Xu L H, Liu K, Zhao J. Recurrent convolutional neural networks for text classification. In: Proceedings of the 2015 AAAI Conference on Artificial Intelligence. Austin, USA: AAAI, 2015. 2267−2273 [10] Xiao Y X, Qu Y R, Qiu L, Zhou H, Li L, Zhang W N, Yu Y. Dynamically fused graph network for multi-hop reasoning. In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Florence, Italy: ACL, 2019. 6140−6150 [11] Lai G K, Xie Q Z, Liu H X, Yang Y M, Hovy E. RACE: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Copenhagen, Denmark: ACL, 2017. 785−794 [12] He W, Liu K, Liu J, Lv Y J, Zhao S Q, Xiao X Y, et al. Dureader: A Chinese machine reading comprehension dataset from real-world applications. In: Proceedings of the 2018 Workshop on Machine Reading for Question Answering. Melbourne, Australia: ACL, 2018. 37−46 [13] Chen D Q, Bolton J, Manning C D. A thorough examination of the CNN/daily mail reading comprehension task. In: Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Berlin, Germany: ACL, 2016. 2358−2376 [14] Seo M, Kembhavi A, Farhadi A, Hajishirzi H. Bidirectional attention flow for machine comprehension. In: Proceedings of the 5th International Conference on Learning Representations. Toulon, France: ICLR, 2017. [15] Wang W H, Yang N, Wei F R, Chang B B, Zhou M. Gated self-matching networks for reading comprehension and question answering. In: Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. Vancouver, Canada: ACL, 2017. 189−198 [16] Yu A W, Dohan D, Luong M T. QANet: Combining local convolution with global self-attention for reading comprehension. In: Proceedings of the 6th International Conference on Learning Representations. Vancouver, Canada: ICLR, 2018. [17] Liu Y H, Ott M, Goyal N, Du J F, Joshi M, Chen D Q, et al. RoBERTa: A robustly optimized BERT pretraining approach. arXiv: 1907.11692, 2019. [18] Lan Z Z, Chen M D, Goodman S, Gimpel K, Sharma P, Soricut R. ALBERT: A lite BERT for self-supervised learning of language representations. In: Proceedings of the 8th International Conference on Learning Representations. Addis Ababa, Ethiopia: ICLR, 2020. [19] Sun Y, Wang S H, Li Y K, Feng S K, Chen X Y, Zhang H, et al. ERNIE: Enhanced representation through knowledge integration. arXiv: 1904.09223, 2019. [20] Cui Y M, Che W X, Liu T, Qin B, Yang Z Q. Pre-training with whole word masking for Chinese BERT. IEEE Transactions on Audio, Speech, and Language Processing, 2021, 29: 3504−3514 [21] Ding M, Zhou C, Chen Q B, Yang H X, Tang J. Cognitive graph for multi-hop reading comprehension at scale. In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Florence, Italy: ACL, 2019. 2694−2703 [22] Tu M, Wang G T, Huang J, Tang Y, He X D, Zhou B W. Multi-hop reading comprehension across multiple documents by reasoning over heterogeneous graphs. In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Florence, Italy: ACL, 2019. 2704−2713 [23] Nishida K, Nishida K, Nagata M, Otsuka A, Saito I, Asano H, et al. Answering while summarizing: multi-task learning for multi-hop QA with evidence extraction. In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Florence, Italy: ACL, 2019. 2335−2345 [24] Tu M, Huang K, Wang G T, Huang J, He X D, Zhou B W. Select, answer and explain: Interpretable multi-hop reading comprehension over multiple documents. In: Proceedings of the 32nd Innovative Applications of Artificial Intelligence Conference. New York, USA: AAAI, 2020. 9073−9080 [25] Johnson R, Zhang T. Deep pyramid convolutional neural networks for text categorization. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. Vancouver, Canada: ACL, 2017. 562−570 [26] Pennington J, Socher R, Manning C D. GloVe: Global vectors for word representation. In: Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Doha, Qatar: ACL, 2014. 1532−1543 [27] 刘康, 张元哲, 纪国良, 来斯惟, 赵军. 基于表示学习的知识库问答研究进展与展望. 自动化学报, 2016, 42(6): 807-818.Liu Kang, Zhang Yuan-Zhe, Ji Guo-Liang, Lai Si-Wei, Zhao Jun. Representation learning for question answering over knowledge base: An Overview. ACTA AUTOMATICA SINICA, 2016, 42(6): 807-818(in Chinese). -

 下载:
下载:





图(6) / 表(3)
计量
- 文章访问数: 1816
- HTML全文浏览量: 439
- PDF下载量: 194
- 被引次数: 0
