

-
摘要: 针对具有外部系统扰动的线性离散时间系统的输出调节问题, 提出了可保证收敛速率的数据驱动最优输出调节方法, 包括状态可在线测量系统的基于状态反馈的算法, 与状态不可在线测量系统的基于输出反馈的算法. 首先, 该问题被分解为输出调节方程求解问题与反馈控制律设计问题, 基于输出调节方程的解, 通过引入收敛速率参数, 建立了可保证收敛速率的最优控制问题, 通过求解该问题得到具有保证收敛速率的输出调节器. 之后, 利用强化学习的方法, 设计基于值迭代的数据驱动状态反馈控制器, 学习得到基于状态反馈的最优输出调节器. 对于状态无法在线测量的被控对象, 利用历史输入输出数据对状态进行重构, 并以此为基础设计基于值迭代的数据驱动输出反馈控制器. 仿真结果验证了所提方法的有效性.Abstract: This paper investigates the output regulation problem for linear discrete-time systems with disturbances caused by exosystem and proposes data-driven optimal output regulation approaches with assured convergence rate, including the state feedback based algorithm for the system whose state can be measured online, and the output feedback based algorithm for the system whose state cannot be measured online. Firstly, this problem is decomposed into an output regulation equation solving problem and a feedback control law design problem. Based on the solutions of the output regulation equation, by introducing the convergence rate parameter, an optimal control problem with assured convergence rate is formulated and an assured convergence rate output regulator can be obtained by solving this problem. Then, by using the reinforcement learning approach, this paper designs a value iteration based data-driven state feedback controller which can learn the state feedback based optimal output regulator. For the systems whose states cannot be measured online, the state is reconstructed by using historical input and output data, and a data-driven output feedback controller based on value iteration is designed. Simulation results show the effectiveness of the proposed approaches.
-
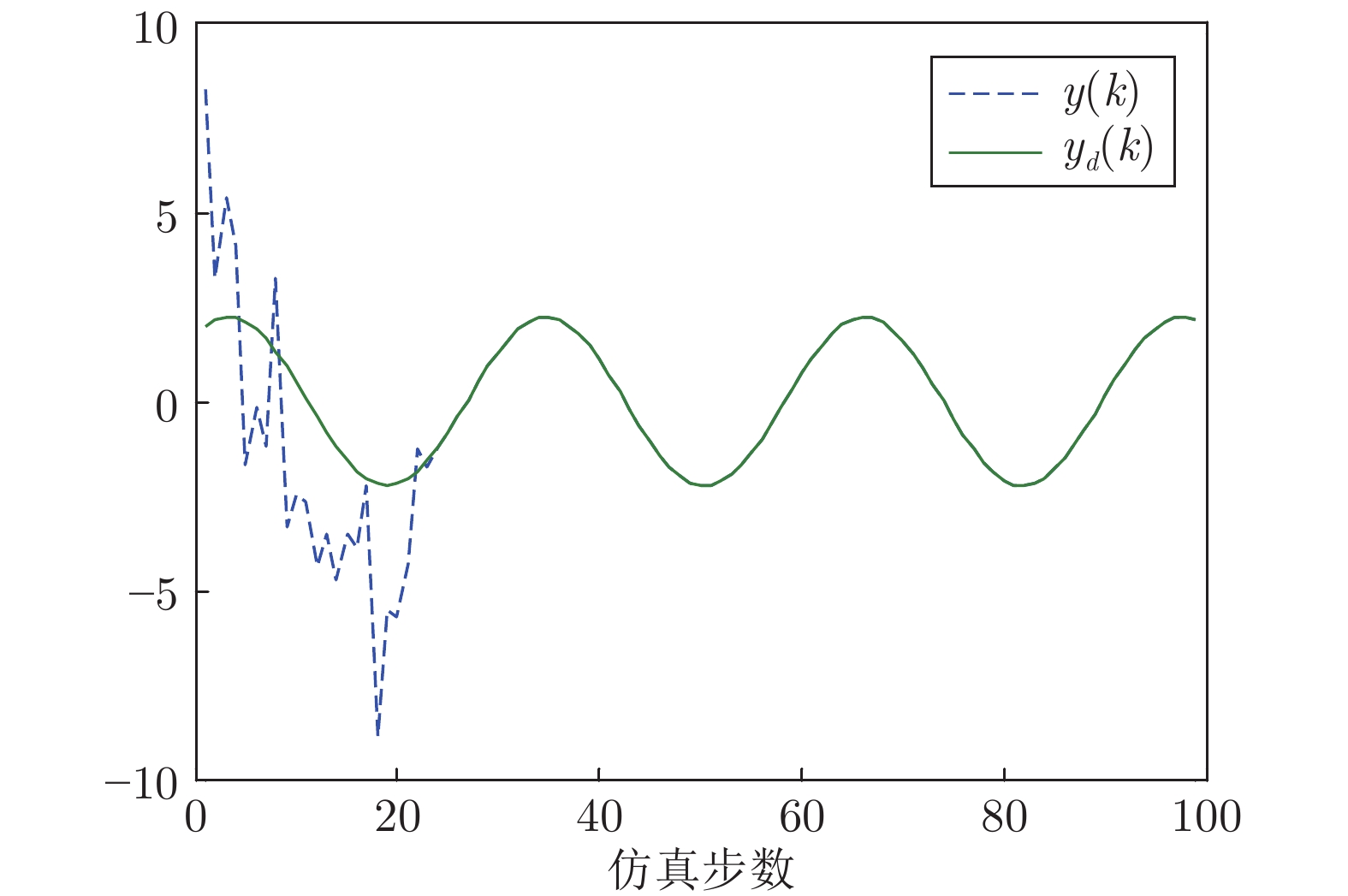
图 1 基于状态反馈的输出y(k)与参考信号yd(k)轨迹
Fig. 1 Trajectories of the output y(k) and the reference signal yd(k) via state feedback
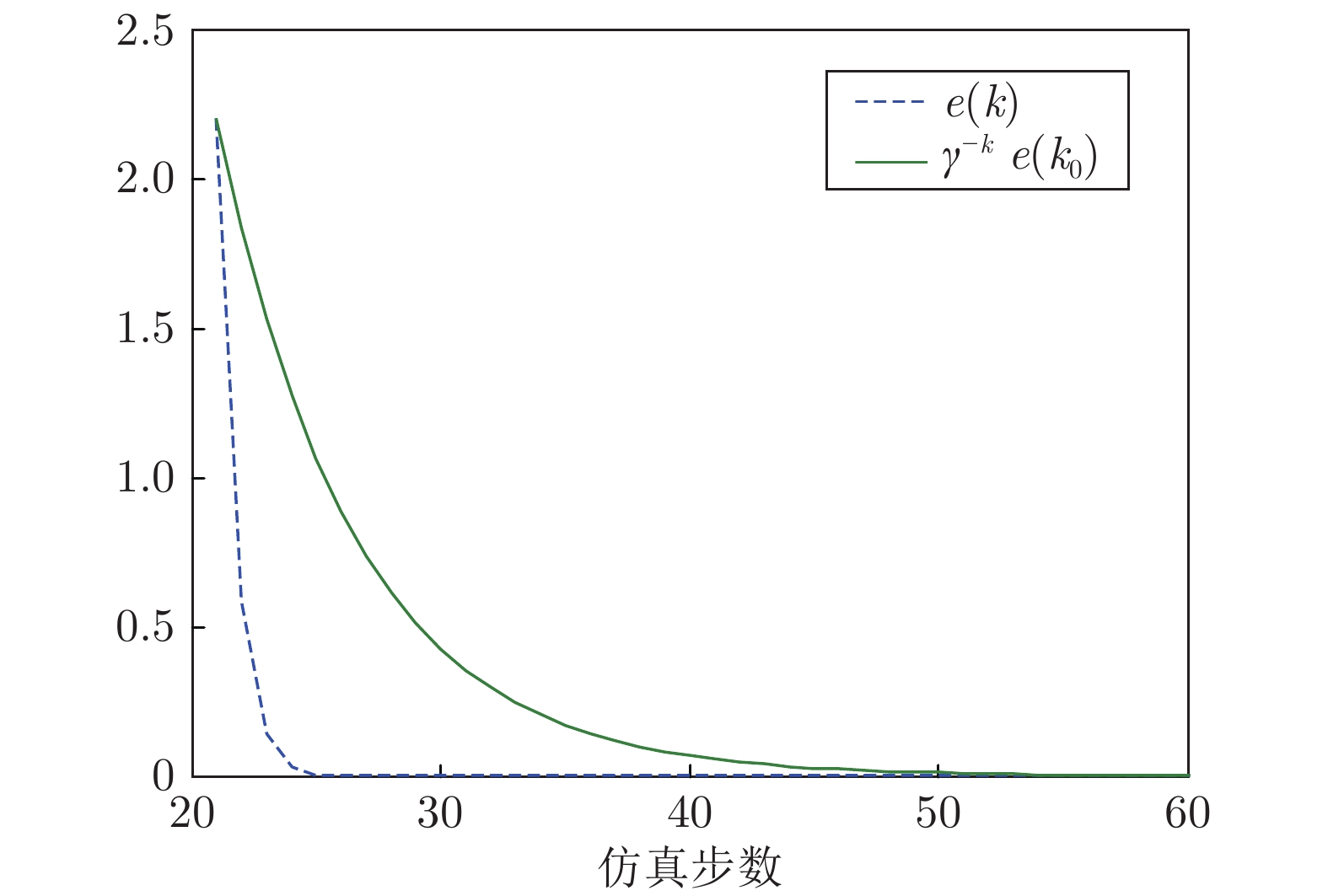
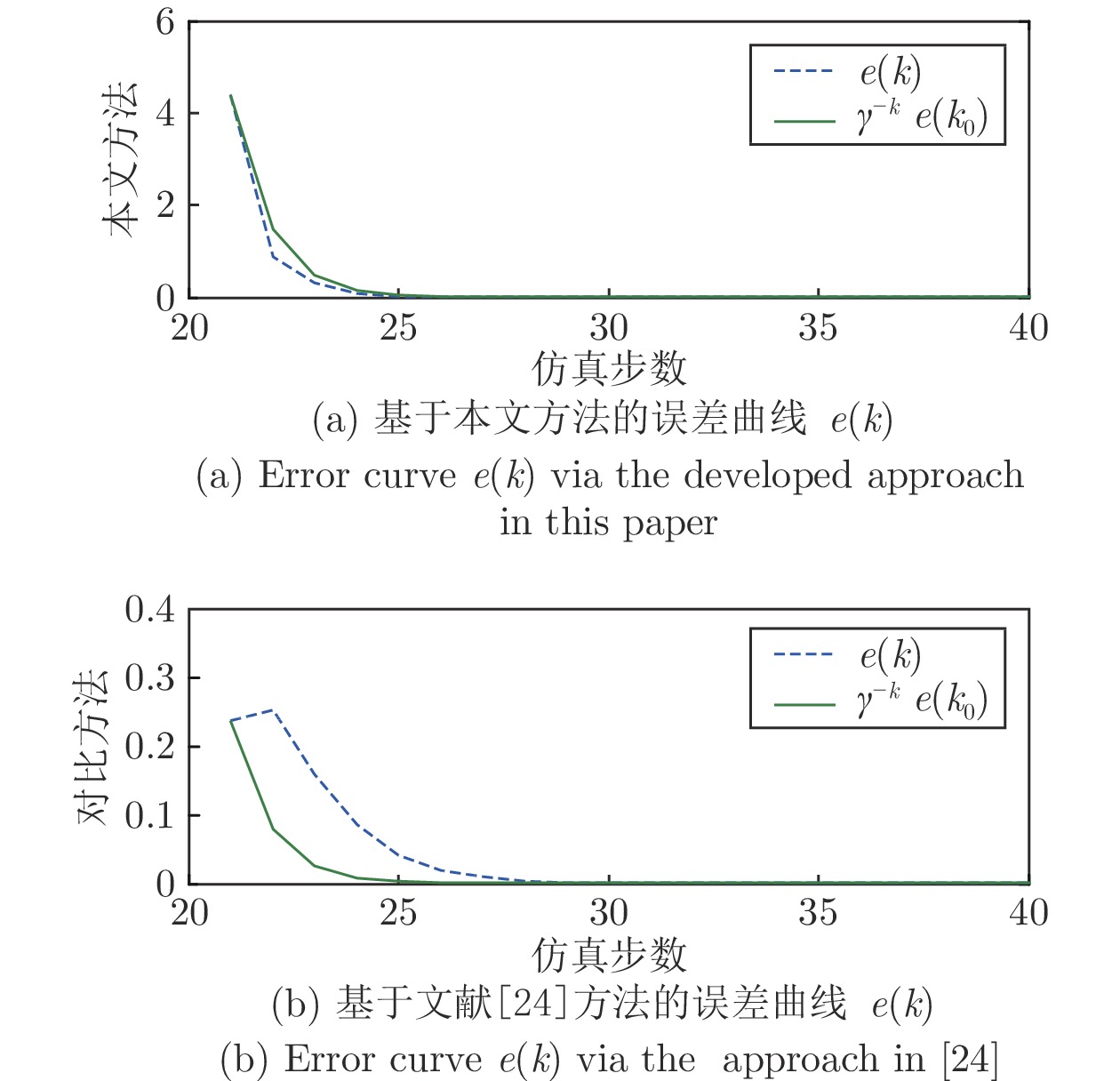
图 3 基于状态反馈的误差e(k)与
${\gamma ^{ - k}}e({k_0})$ 对比曲线Fig. 3 Comparison curve of e(k) and
${\gamma ^{ - k}}e({k_0})$ via state feedback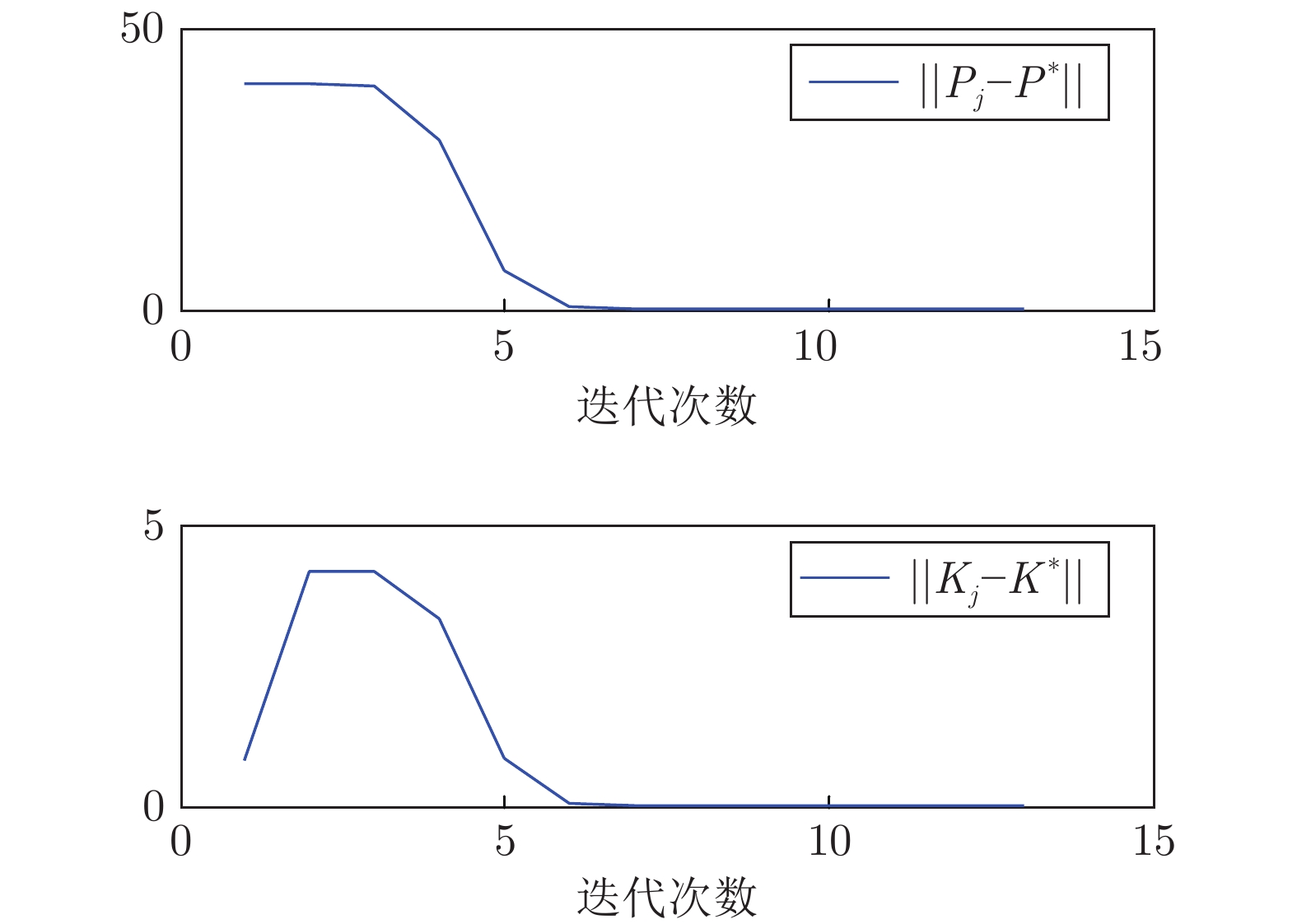
图 2 基于状态反馈的
$ \Vert {P}_{j}-{P}^{*}\Vert $ 与$ \Vert {K}_{j}-{K}^{*}\Vert $ 误差轨迹Fig. 2 Trajectory of the error between
$ \Vert {P}_{j}-{P}^{*}\Vert $ and$ \Vert {K}_{j}-{K}^{*}\Vert $ via state feedback
图 4 基于输出反馈的输出y(k)与参考信号yd(k)轨迹
Fig. 4 Trajectories of the output y(k) and the reference signal yd(k) via output feedback
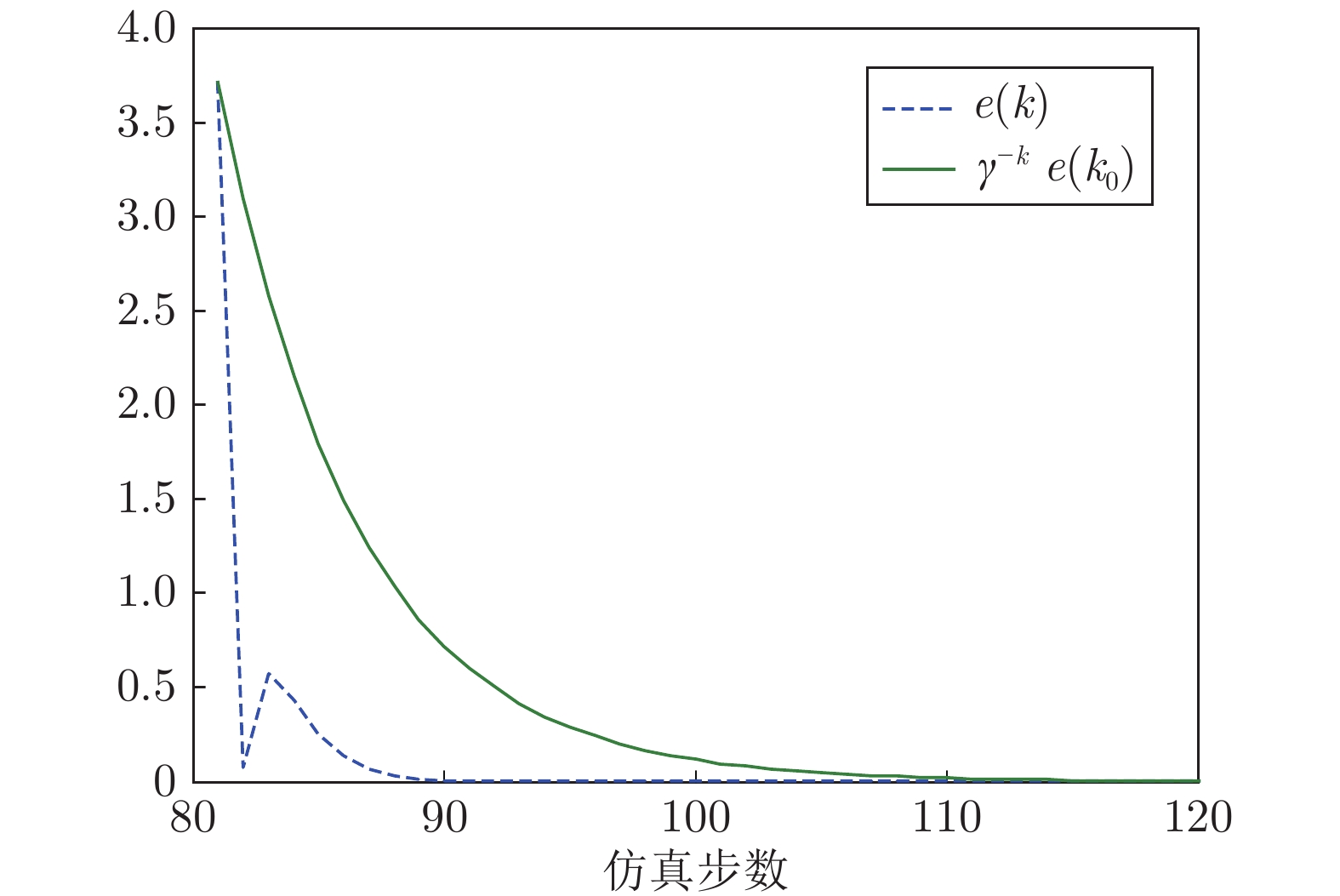
图 6 基于输出反馈的误差e(k)与
${\gamma ^{ - k}}e({k_0})$ 对比曲线Fig. 6 Comparison curve of e(k) and
${\gamma ^{ - k}}e({k_0})$ via output feedback
图 5 基于输出反馈的
$ \Vert {\overline{P}}_{j}-{\overline{P}}^{*}\Vert $ 与$ \Vert {\overline{K}}_{j}-{\overline{K}}^{*}\Vert $ 误差轨迹Fig. 5 Trajectory of the error between
$ \Vert {\overline{P}}_{j}-{\overline{P}}^{*}\Vert $ and$ \Vert {\overline{K}}_{j}-{\overline{K}}^{*}\Vert $ via output feedback -
[1] Åström K J, Tore H. PID Controllers: Theory, Design, and Tuning. Research Triangle Park, NC: Instrument Society of America, 1995. [2] Garcia C E, Prett D M, Morari M. Model predictive control: theory and practice—a survey. Automatica, 1989, 25(3): 335-348. doi: 10.1016/0005-1098(89)90002-2 [3] Francis B A. The Linear Multivariable Regulator Problem. SIAM Journal on Control and Optimization, 1977, 15(3): 486-505. doi: 10.1137/0315033 [4] Isidori A, Byrnes C I. Output regulation of nonlinear systems. IEEE Transactions on Automatic Control, 1990, 35(2): 131-140. doi: 10.1109/9.45168 [5] Ding Z T. Output regulation of uncertain nonlinear systems with nonlinear exosystems. IEEE Transactions on Automatic Control, 2006, 51(3): 498-503. doi: 10.1109/TAC.2005.864199 [6] Huang J, Chen Z. A general framework for tackling the output regulation problem. IEEE Transactions on Automatic Control, 2004, 49(12): 2203-2218. doi: 10.1109/TAC.2004.839236 [7] Parks P. Liapunov redesign of model reference adaptive control systems. IEEE Transactions on Automatic Control, 1966, 11(3): 362-367. doi: 10.1109/TAC.1966.1098361 [8] 田涛涛, 侯忠生, 刘世达, 邓志东. 基于无模型自适应控制的无人驾驶汽车横向控制方法. 自动化学报, 2017, 43(11): 1931-1940.Tian Tao-Tao, Hou Zhong-Sheng, Liu Shi-Da, Deng Zhi-Dong. Model-free Adaptive Control Based Lateral Control of Self-driving Car. Acta Automatica Sinica, 2017, 43(11): 1931-1940. [9] 于欣波, 贺威, 薛程谦, 孙永坤, 孙长银. 基于扰动观测器的机器人自适应神经网络跟踪控制研究. 自动化学报, 2019, 45(7): 1307-1324.Yu Xin-Bo, He Wei, Xue Cheng-Qian, Sun Yong-Kun, Sun Chang-Yin. Disturbance Observer-based Adaptive Neural Network Tracking Control for Robots. Acta Automatica Sinica, 2019, 45(7): 1307-1324. [10] Modares H, Lewis F L. Linear Quadratic Tracking Control of Partially-Unknown Continuous-Time Systems Using Reinforcement Learning. IEEE Transactions on Automatic Control, 2014, 59(11): 3051-3056. doi: 10.1109/TAC.2014.2317301 [11] Xue W Q, Fan J L, Lopez V G, Jiang Y, Chai T Y, Lewis F L. Off-policy reinforcement learning for tracking in continuous-time systems on two time-scales. IEEE Transactions on Neural Networks and Learning Systems, 2021, 32 (10), 4334−4346 [12] Kiumarsi B, Lewis F L, Modares H, Karimpour A, Naghibisistani M B. Reinforcement Q-learning for optimal tracking control of linear discrete-time systems with unknown dynamics. Automatica, 2014, 50(4): 1167-1175. doi: 10.1016/j.automatica.2014.02.015 [13] Jiang Y, Fan J, Chai T, Lewis F L, Li J N. Tracking Control for Linear Discrete-Time Networked Control Systems With Unknown Dynamics and Dropout. IEEE Transactions on Neural Networks and Learning System, 2018, 29(10): 4607-4620. doi: 10.1109/TNNLS.2017.2771459 [14] 吴倩, 范家璐, 姜艺, 柴天佑. 无线网络环境下数据驱动混合选别浓密过程双率控制方法. 自动化学报, 2019, 45(6): 1122-1135.Wu Qian, Fan Jia-Lu, Jiang Yi, Chai Tian-You. Data-driven Dual-rate Control for Mixed Separation Thickening Process in a Wireless Network Environment. Acta Automatica Sinica, 2019, 45(6): 1122-1135. [15] Xue W Q, Fan J L, Lopez V G, Li J N, Jiang Y, Chai T Y, Lewis F L. New Methods for Optimal Operational Control of Industrial Processes Using Reinforcement Learning on Two Time Scales. IEEE Transactions on Industrial Informatics, 2020, 16(5): 3085-3099. doi: 10.1109/TII.2019.2912018 [16] Modares H, Lewis F L. Optimal tracking control of nonlinear partially-unknown constrained-input systems using integral reinforcement learning. Automatica, 2014, 50(7): 1780-1792. doi: 10.1016/j.automatica.2014.05.011 [17] Kiumarsi B, Lewis F L. Actor–critic-based optimal tracking for partially unknown nonlinear discrete-time systems. IEEE Transactions on Neural Networks and Learning Systems, 2014, 26(1): 140-151. [18] Jiang Y, Fan J L, Chai T Y, Li J N, Lewis F L. Data-driven flotation industrial process operational optimal control based on reinforcement learning. IEEE Transactions on Industrial Informatics, 2018, 14(5): 1974-1989. doi: 10.1109/TII.2017.2761852 [19] Jiang Y, Fan J L, Chai T Y, Lewis F L. Dual-rate operational optimal control for flotation industrial process with unknown operational model. IEEE Transactions on Industrial Electronics, 2019, 66(6): 4587-4599. doi: 10.1109/TIE.2018.2856198 [20] Gao W N, Jiang Z P. Adaptive Dynamic Programming and Adaptive Optimal Output Regulation of Linear Systems. IEEE Transactions on Automatic Control, 2016, 61(12): 4164-4169. doi: 10.1109/TAC.2016.2548662 [21] Gao W N, Jiang Z P, Lewis F L, Wang Y B. Leader-to-Formation Stability of Multi-agent Systems: An Adaptive Optimal Control Approach. IEEE Transactions on Automatic Control, 2018, 63(10): 3581-3587. doi: 10.1109/TAC.2018.2799526 [22] Chen C, Modares H, Xie K, Lewis F L, Wan Y, Xie S L. Reinforcement Learning-Based Adaptive Optimal Exponential Tracking Control of Linear Systems With Unknown Dynamics. IEEE Transactions on Automatic Control, 2019, 64(11): 4423-4438. doi: 10.1109/TAC.2019.2905215 [23] Chen C, Lewis F L, Xie K, Xie S L, Liu Y L. Off-policy learning for adaptive optimal output synchronization of heterogeneous multi-agent systems. Automatica, 2020, 119: 109081. doi: 10.1016/j.automatica.2020.109081 [24] Jiang Y, Kiumarsi B, Fan J L, Chai T Y, Li J N, Lewis. Optimal Output Regulation of Linear Discrete-Time Systems with Unknown Dynamics using Reinforcement Learning. IEEE Transactions on Cybernetics, 2020, 50(7): 3147-3156. doi: 10.1109/TCYB.2018.2890046 [25] 庞文砚, 范家璐, 姜艺, 刘易斯·弗兰克. 基于强化学习的部分线性离散时间系统最优输出调节. 自动化学报, DOI: 10.16383/j.aas.c190853Pang Wen-Yan, Fan Jia-Lu, Jiang Yi, Lewis Frank Leroy. Optimal output regulation of partially linear discrete-time systems using reinforcement learning. Acta Automatica Sinica, DOI: 10.16383/j.aas.c190853 [26] Fan J L, Wu Q, Jiang Y, Chai T Y, Lewis F L. Model-Free Optimal Output Regulation for Linear Discrete-Time Lossy Networked Control Systems. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2020, 50(11): 4033-4042. doi: 10.1109/TSMC.2019.2946382 [27] Gao W N, Jiang Z P. Learning-Based Adaptive Optimal Tracking Control of Strict-Feedback Nonlinear Systems. IEEE Transactions on Neural Networks and Learning System, 2018, 29(6): 2614-2624. doi: 10.1109/TNNLS.2017.2761718 [28] Jiang Y, Fan J L, Gao W N, Chai T Y, Lewis F L. Cooperative Adaptive Optimal Output Regulation of Discrete-Time Nonlinear Multi-Agent Systems. Automatica, 2020, 121: 109149. doi: 10.1016/j.automatica.2020.109149 [29] Kiumarsi B, Lewis F L, Modares H, Karimpour A, Naghibisistani M B. Optimal Tracking Control of Unknown Discrete-Time Linear Systems Using Input-Output Measured Data. IEEE Transactions on Cybernetics, 2015, 45(12): 2770-2779. doi: 10.1109/TCYB.2014.2384016 [30] Gao W N, Jiang Z P. Adaptive optimal output regulation of time-delay systems via measurement feedback. IEEE Transactions on Neural Networks and Learning System, 2018, 30(3): 938-945. [31] 张春燕, 戚国庆, 李银伢, 盛安冬. 一种基于有限时间稳定的环绕控制器设计. 自动化学报, 2018, 44(11): 2056-2067.Zhang Chun-Yan, Qi Guo-Qing, Li Yin-Ya, Sheng An-Dong. Standoff Tracking Control With Respect to Moving Target via Finite-time Stabilization. Acta Automatica Sinica, 2018, 44(11): 2056-2067. [32] Hong Y G, Xu Y S, Huang J. Finite-time control for robot manipulators. Systems and control letters, 2002, 46(4): 243-253. doi: 10.1016/S0167-6911(02)00130-5 [33] Huang J. Nonlinear Output Regulation: Theory and Applications. SIAM, 2004. [34] Krener A J. The construction of optimal linear and nonlinear regulators. Systems, Models and Feedback: Theory and Applications. Springer, 1992. [35] Arnold W F, Laub A J. Generalized eigen problem algorithms and software for algebraic Riccati equations. Proceedings of the IEEE. 1984, 72(12): 1746-1754. doi: 10.1109/PROC.1984.13083 [36] Lewis F L, Vrabie D, Syrmos V L. Optimal Control. John Wiley & Sons, 2012. [37] Lancaster P, Rodman L. Algebraic Riccati Equations. New York: Oxford University Press, 1995. [38] Hewer G. An iterative technique for the computation of the steady state gains for the discrete optimal regulator. IEEE Transactions on Automatic Control, 1971, 16(4): 382-384. doi: 10.1109/TAC.1971.1099755 [39] Li J N, Chai T Y, Lewis F L, Ding Z T, Jiang Y. Off-Policy Interleaved Q-Learning: Optimal Control for Affine Nonlinear Discrete-Time Systems. IEEE Transactions on Neural Networks and Learning System, 2019, 30(5): 1308-1320. doi: 10.1109/TNNLS.2018.2861945 [40] Kiumarsi B, Lewis F L, Jiang Z P. H∞ control of linear discrete-time systems: Off-policy reinforcement learning. Automatica, 2017, 78: 144–152. doi: 10.1016/j.automatica.2016.12.009 [41] 李臻, 范家璐, 姜艺, 柴天佑. 一种基于Off-policy的无模型输出数据反馈H∞控制方法. 自动化学报, 2021, 47(9), 2182-2193Li Zhen, Fan Jia-Lu, Jiang Yi, Chai Tian-You. A model-free H∞ method based on off-policy with output data feedback. Acta Automatica Sinica, 2021, 47(9), 2182−21932 -

 下载:
下载:













计量
- 文章访问数: 2451
- HTML全文浏览量: 502
- PDF下载量: 548
- 被引次数: 0
