

Review on the Applications and Grants of National Natural Science Foundation on Artificial Intelligence and Its Prospects
-
摘要: 针对信息学部人工智能学科(F06) 2018至2020年度基金项目的申请和资助情况, 截取面上、青年、地区和重点项目, 点−线−面相结合, 从多种客观指标角度系统分析了三年来人工智能学科的申请和资助情况. 2020年度国家自然科学基金委学科代码进行了大幅度的调整和改革, 特别是在取消三级代码、增加二级代码数目的背景下, 本文的分析可以为新版代码的科学性和未来基金项目的申请、评审和资助导向提供统计支撑. 同时, 结合最近三年人工智能学科基金项目的申请资助情况, 以及科学处对人工智能领域的若干推动和工作安排, 对未来国家自然科学基金资助架构下的人工智能学科发展进行了展望.Abstract: In this paper, the funding situations of the Artificial Intelligence of the Department of Information Science have been analyzed based on the statistical data of the 2018−2020 NSFC (National Natural Science Foundation of China) funded projects, including the general projects, the youth science foundation projects, projects for developing region and the key projects. Under the background of significant reorganization of the code-base in 2020, the analysis in this study can validate the scientific rationality of new code, and can be regarded as a support of future applications and grants. Meanwhile, according to the application and grant situations in recent three years, the future development trends and prospects in the field of artificial intelligence under the support of NSFC are further analyzed.
-
表 1 2018年信息学部F06申请资助情况[2]
Table 1 Application and funding of F06 in Department of Information Sciences 2018
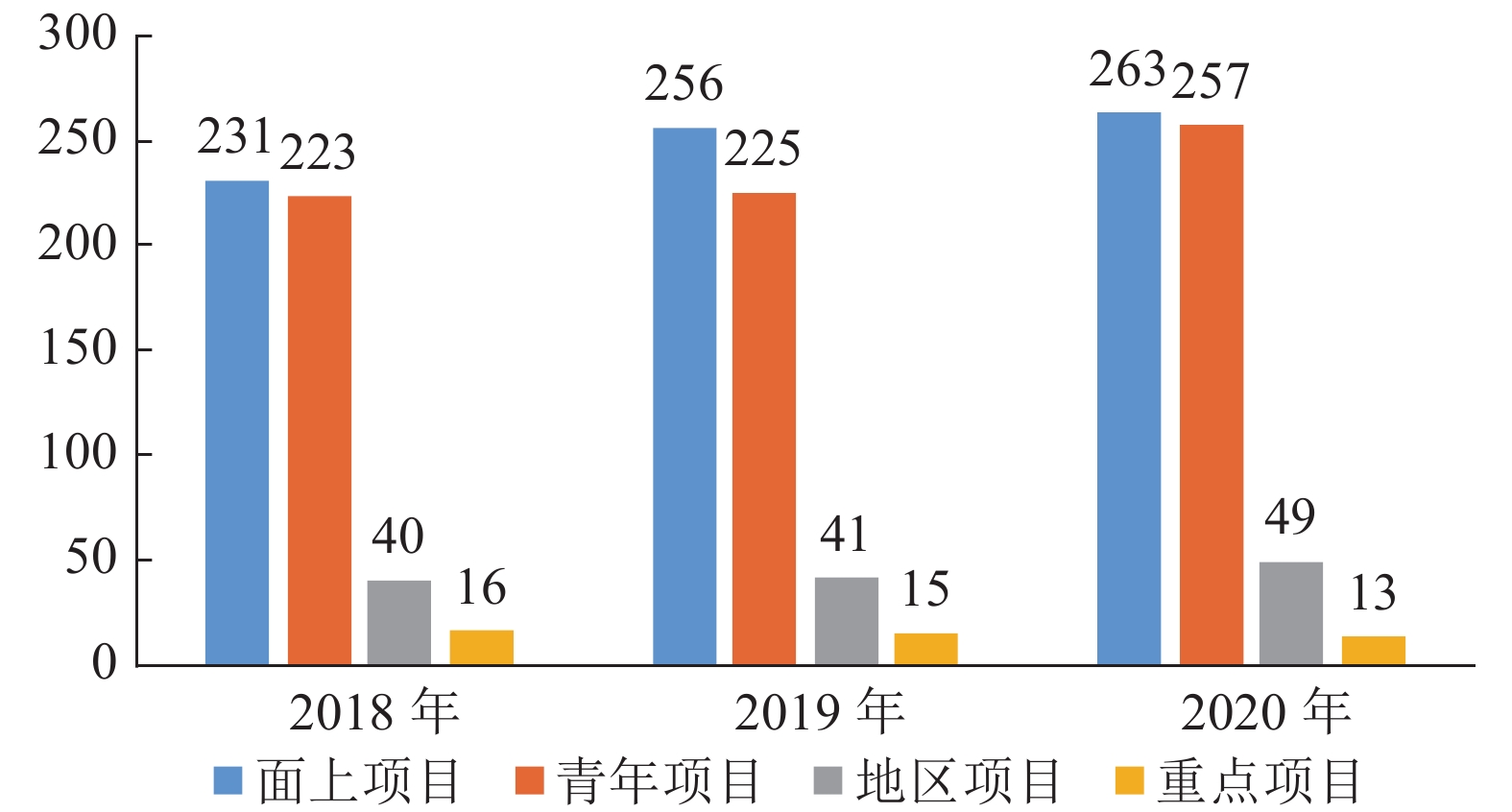
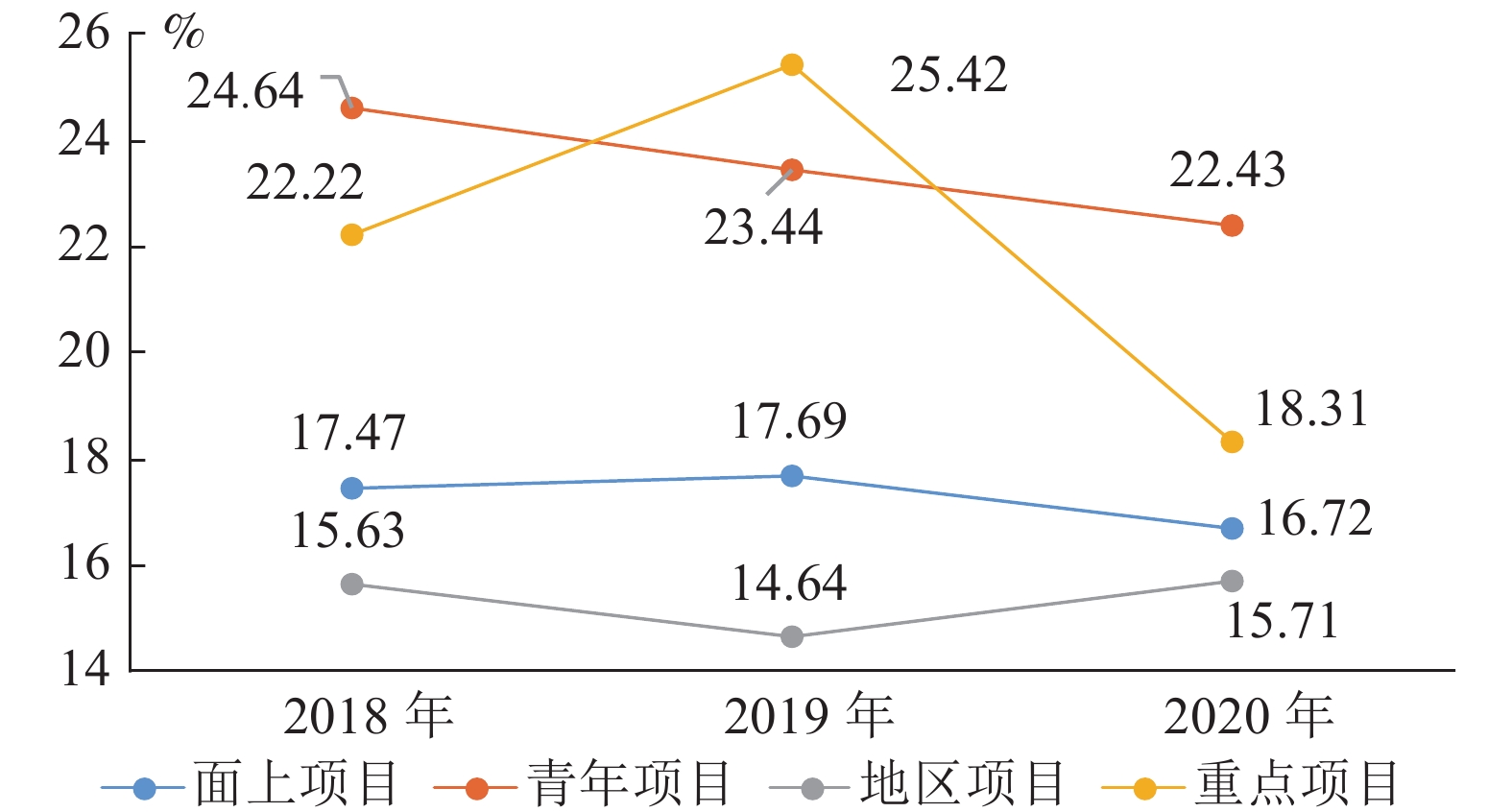
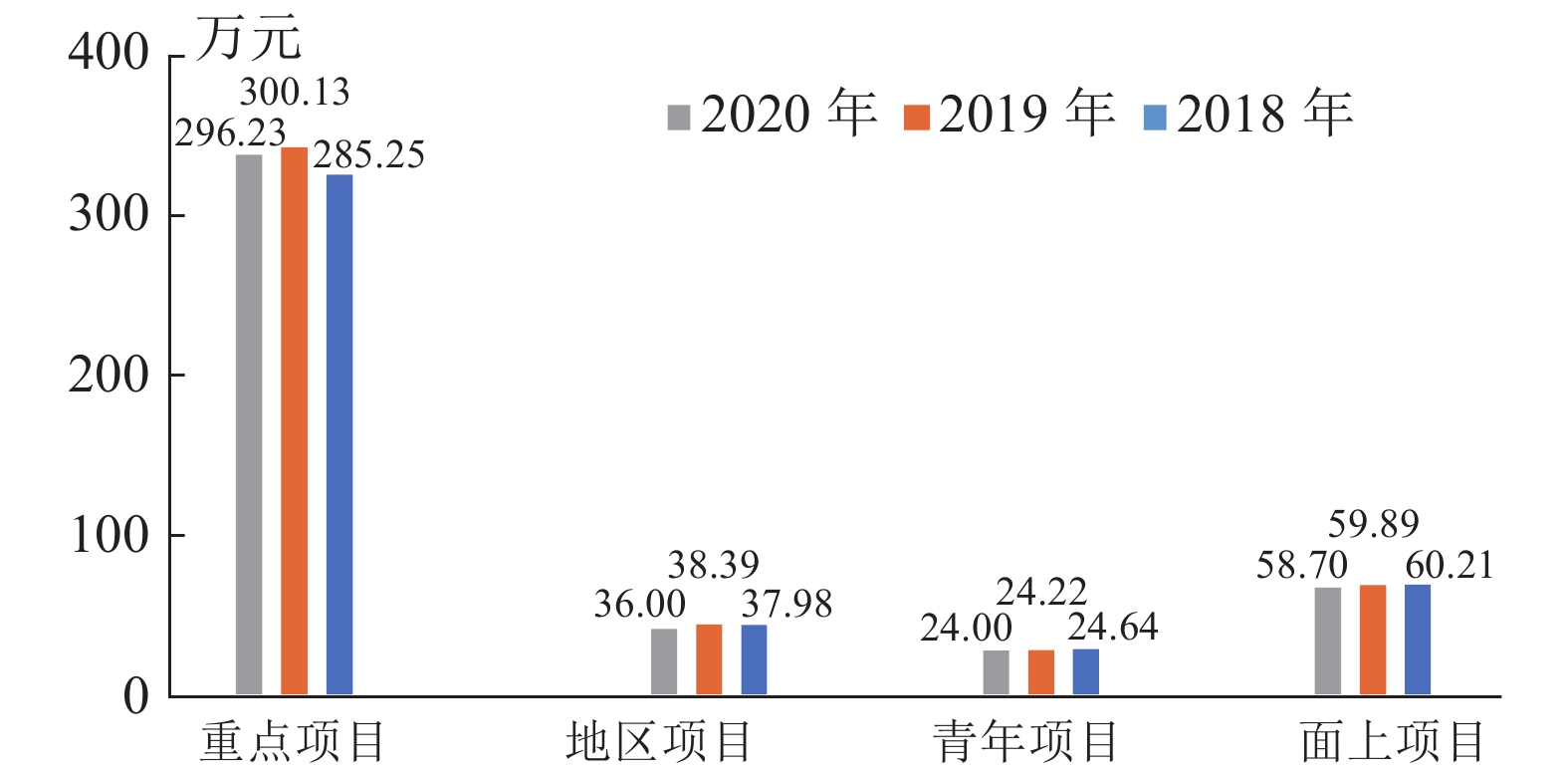
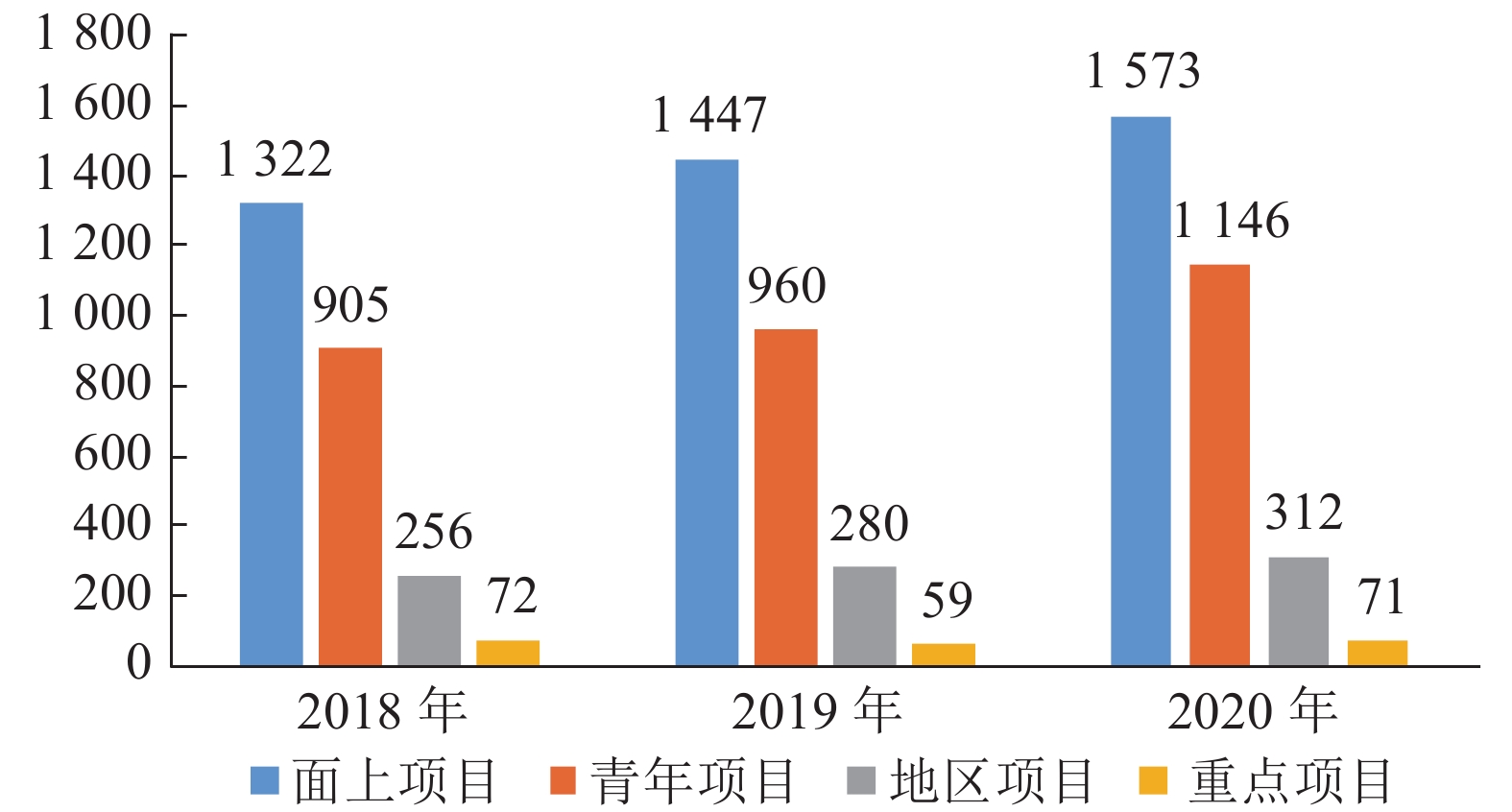
项目类型 申请数量 资助数量 资助比例 (%) 平均资助强度 (万元) 面上项目 1322 231 17.47 60.21 青年项目 905 223 24.64 24.64 地区项目 256 40 15.63 37.98 重点项目 72 16 22.22 285.25  下载: 导出CSV
下载: 导出CSV
表 2 2019年信息学部F06申请资助情况
Table 2 Application and funding of F06 in Department of Information Sciences 2019
项目类型 申请数量 资助数量 资助比例 (%) 平均资助强度 (万元) 面上项目 1447 256 17.69 59.89 青年项目 960 225 23.44 24.22 地区项目 280 41 14.64 38.39 重点项目 59 15 25.42 300.13
下载: 导出CSV
表 3 2020年信息学部F06申请资助情况
Table 3 Application and funding of F06 in Department of Information Sciences 2020
项目类型 申请数量 资助数量 资助比例 (%) 平均资助强度 (万元) 面上项目 1573 263 16.72 58.70 青年项目 1146 257 22.43 24.00 地区项目 312 49 15.71 36.00 重点项目 71 13 18.31 296.23
下载: 导出CSV
表 4 2019−2020年度信息学部F06面上项目申请量排名前五位的依托单位
Table 4 Top 5 application of F06 general projects in Department of Information Sciences 2019−2020
2019年 2020年 依托单位 项目数 占比 (%) 依托单位 项目数 占比 (%) 电子科技大学 32 2.21 电子科技大学 24 1.53 西安电子科技大学 27 1.87 华南理工大学 23 1.46 西安交通大学 24 1.66 中国科学院自
动化研究所22 1.40 广东工业大学 20 1.38 同济大学 21 1.34 中国科学院自
动化研究所19 1.31 广东工业大学 20 1.27
下载: 导出CSV
表 5 2019−2020年度信息学部F06面上项目资助量排名前五位的依托单位
Table 5 Top 5 funding of F06 general projects in Department of Information Sciences 2019−2020
2019年 2020年 依托单位 项目数 资助率 (%) 依托单位 项目数 资助率 (%) 大连理工大学 8 50.00 中国科学院自
动化研究所8 36.36 中国科学院自
动化研究所7 36.84 大连理工大学 8 53.33 哈尔滨工业大学 7 36.84 北京邮电大学 7 35.00 电子科技大学 7 21.88 复旦大学 7 43.75 中山大学 7 46.67 中山大学 6 42.86
下载: 导出CSV
表 6 2019−2020年度信息学部F06青年项目申请量排名前五位的依托单位
Table 6 Top 5 application of F06 youth science foundation projects in Department of Information Sciences 2019−2020
2019年 2020年 依托单位 项目数 占比 (%) 依托单位 项目数 占比 (%) 国防科技大学 27 2.81 中国科学院自
动化研究所22 1.92 中国科学院自
动化研究所21 2.19 国防科技大学 20 1.75 西安电子科技大学 13 1.35 深圳大学 12 1.05 北京工业大学 11 1.15 西安电子科技大学 10 0.87 中山大学 11 1.15 国防科技创
新研究院10 0.87
下载: 导出CSV
表 7 2019−2020年度信息学部F06青年项目资助量排名前五位的依托单位
Table 7 Top 5 funding of F06 youth science foundation projects in Department of Information Sciences 2019−2020
2019年 2020年 依托单位 项目数 资助率 (%) 依托单位 项目数 资助率 (%) 国防科技大学 12 44.44 中国科学院自
动化研究所9 40.91 西安电子科
技大学10 76.92 哈尔滨工业大学 6 100 中国科学院自
动化研究所10 47.62 深圳大学 5 83.33 北京工业大学 7 63.64 广东工业大学 5 55.56 合肥工业大学 6 75.00 中山大学 5 71.43
下载: 导出CSV
表 8 2019−2020年度信息学部F06地区项目申请量排名前五位的依托单位
Table 8 Top 5 application of F06 projects for developing region in Department of Information Sciences 2019−2020
2019年 2020年 依托单位 项目数 占比 (%) 依托单位 项目数 占比 (%) 新疆大学 24 8.57 新疆大学 17 5.45 昆明理工大学 15 5.36 云南大学 11 3.53 桂林电子科技大学 13 4.64 桂林电子科技大学 10 3.21 江西师范大学 12 4.29 贵州大学 10 3.21 云南大学 10 3.57 昆明理工大学 9 2.88
下载: 导出CSV
表 9 2019−2020年度信息学部F06地区项目资助量排名前五位的依托单位
Table 9 Top 5 funding of F06 projects for developing region in Department of Information Sciences 2019−2020
2019年 2020年 依托单位 项目数 资助率 (%) 依托单位 项目数 资助率 (%) 江西师范大学 4 33.33 南昌大学 5 71.43 云南大学 3 30.00 云南大学 3 27.27 内蒙古大学 3 50.00 贵州大学 3 30.00 桂林电子
科技大学3 23.08 桂林电子
科技大学2 20.00 内蒙古工业大学 2 100 内蒙古工业大学 2 50.00
下载: 导出CSV
表 10 2019−2020年度信息学部F06重点项目申请量排名前五位的依托单位
Table 10 Top 5 application of F06 key projects in Department of Information Sciences 2019−2020
2019年 2020年 依托单位 项目数 占比 (%) 依托单位 项目数 占比 (%) 西安电子科技大学 5 8.47 西安电子科技大学 6 8.45 清华大学 4 6.78 中国科学院自
动化研究所5 7.04 北京邮电大学 3 5.08 北京大学 5 7.04 北京师范大学 2 3.39 天津大学 4 5.63 西北工业大学 2 3.39 清华大学 4 5.63
下载: 导出CSV
表 11 2019−2020年度信息学部F06重点项目资助量排名前五位的依托单位
Table 11 Top 5 funding of F06 key projects in Department of Information Sciences 2019−2020
2019年 2020年 依托单位 项目数 资助率 (%) 依托单位 项目数 资助率 (%) 清华大学 3 75.00 北京大学 2 40.00 同济大学 1 100 中国科学院自
动化研究所2 40.00 大连理工大学 1 100 西安电子科技大学 2 33.33 西北工业大学 1 50.00 电子科技大学 1 100 华南理工大学 1 100 西安交通大学 1 50.00
下载: 导出CSV
表 12 2020年人工智能 (F06) 新版学科代码与旧版学科代码的迁移变化关系
Table 12 The relationship between 2020 new-version code and old-version code of artificial intelligence (F06)
旧版代码 原学科领域 变化 新版代码 现学科领域 F0601 人工智能基础 迁移 F0601 人工智能基础 新增 F0602 复杂性科学与人工智能理论 F0602 机器学习 迁移 F0603 机器学习 F0603 机器感知与模式识别 迁移 F0604 机器感知与机器视觉 新增 F0605 模式识别与数据挖掘 F0604 自然语言处理 迁移 F0606 自然语言处理 F0605 知识表示与处理 迁移 F0607 知识表示与处理 F0606 智能系统与应用 迁移 F0608 智能系统与人工智能安全 F0607 认知与神经科学启发的人工智能 迁移 F0609 认知与神经科学启发的人工智能 新增 F0610 交叉学科中的人工智能问题
下载: 导出CSV
表 13 2018−2020年度人工智能 (F06) 各学科代码的资助率 (以新版代码统计) (%)
Table 13 The funding rate of each artificial intelligence (F06) code in 2018−2020 (Based on new-version code) (%)
学科领域 代码 面上项目 青年项目 地区项目 2018年 2019年 2020年 2018年 2019年 2020年 2018年 2019年 2020年 人工智能基础 F0601 18.40 21.52 19.49 31.64 25.66 26.42 25.00 20.59 25.00 复杂性科学与人工智能理论 F0602 0.00 0.00 9.09 0.00 0.00 18.92 0.00 0.00 25.00 机器学习 F0603 14.38 9.51 16.92 26.45 23.77 24.83 21.74 17.65 7.41 机器感知与机器视觉 F0604 18.24 33.33 16.55 26.38 25.42 23.43 17.86 11.76 19.15 模式识别与数据挖掘 F0605 20.99 32.86 20.45 21.19 23.20 24.34 12.50 11.11 16.67 自然语言处理 F0606 21.28 54.17 23.08 25.42 29.31 31.94 14.29 15.56 10.20 知识表示与处理 F0607 11.76 4.24 15.49 18.18 28.57 18.87 11.76 19.05 15.38 智能系统与人工智能安全 F0608 14.63 17.78 19.72 21.98 19.81 20.63 3.70 14.29 0.00 认知与神经科学启发的人工智能 F0609 20.21 13.14 18.28 35.14 19.74 22.67 20.00 9.09 33.33 交叉学科中的人工智能问题 F0610 14.56 9.49 12.11 13.33 18.75 15.10 20.00 10.53 16.67 人工智能 F06 0.00 0.00 0.00 16.67 0.00 8.33 0.00 0.00 0.00 合计 17.47 17.69 16.72 24.64 23.44 22.43 15.63 14.64 15.71
下载: 导出CSV
表 14 2019−2020年度信息学部人工智能 (F06) 面上项目科学问题属性分布
Table 14 Scientific properties of artificial intelligence (F06) general projects in Department of Information Sciences 2019−2020
年份 科学属性 申请数 上会数 资助数 上会/申请 (%) 资助/上会 (%) 资助率 (%) 2019年 A类 145 36 21 24.83 58.33 14.48 B类 532 194 131 36.47 67.53 24.62 C类 506 125 77 24.70 61.60 15.22 D类 264 54 27 20.45 50.00 10.23 合计 1447 409 256 28.27 62.59 17.69 2020年 A类 105 14 11 13.33 78.57 10.48 B类 609 188 134 30.87 71.28 22.00 C类 540 123 87 22.78 70.73 16.11 D类 319 54 31 16.93 57.41 9.72 合计 1573 379 263 24.09 69.39 16.72
下载: 导出CSV
表 15 2019−2020年度信息学部人工智能 (F06) 青年项目科学问题属性分布
Table 15 Scientific properties of artificial intelligence (F06) youth science foundation projects in Department of Information Sciences 2019−2020
年份 科学属性 申请数 上会数 资助数 上会/申请 (%) 资助/上会 (%) 资助率 (%) 2019年 A类 83 25 13 30.12 52.00 15.66 B类 367 167 113 45.50 67.66 30.79 C类 314 112 64 35.67 57.14 20.38 D类 196 56 35 28.57 62.50 17.86 合计 960 360 225 37.50 62.50 23.44 2020年 A类 86 21 13 24.42 61.9 15.12 B类 462 176 129 38.10 73.30 27.92 C类 367 110 72 29.97 65.45 19.62 D类 231 64 43 27.71 67.19 18.61 合计 1146 371 257 32.37 69.27 22.43
下载: 导出CSV
表 16 2019−2020年度信息学部人工智能 (F06) 地区项目科学问题属性分布
Table 16 Scientific properties of artificial intelligence (F06) projects for developing region in Department of Information Sciences 2019−2020
年份 科学属性 申请数 上会数 资助数 上会/申请 (%) 资助/上会 (%) 资助率 (%) 2019年 A类 28 1 0 3.57 0.00 0.00 B类 76 18 11 23.68 61.11 14.47 C类 119 31 18 26.05 58.06 15.13 D类 57 15 12 26.32 80.00 21.05 合计 280 65 41 23.21 63.08 14.64 2020年 A类 17 5 5 29.41 100.00 29.41 B类 86 24 16 27.91 66.66 18.60 C类 141 30 20 21.28 66.66 14.18 D类 68 12 8 17.65 66.66 11.76 合计 312 71 49 22.76 69.01 15.71
下载: 导出CSV
表 17 2019−2020年度信息学部人工智能 (F06) 重点项目科学问题属性分布
Table 17 Scientific properties of artificial intelligence (F06) key projects in Department of Information Sciences 2019−2020
年份 科学属性 申请数 上会数 资助数 上会/申请 (%) 资助/上会 (%) 资助率 (%) 2019年 A类 5 1 1 20.00 100.00 20.00 B类 13 5 3 38.46 60.00 23.08 C类 28 13 8 46.43 61.54 28.57 D类 13 4 3 30.77 75.00 23.08 合计 59 23 15 38.98 65.22 25.42 2020年 A类 3 0 0 0.00 — 0.00 B类 20 3 1 15.00 33.33 5.00 C类 41 13 10 31.71 76.92 24.39 D类 7 3 2 42.86 66.66 28.57 合计 71 19 13 26.76 68.42 18.31
下载: 导出CSV
-
[1] 中国人工智能2.0发展战略研究项目组. 中国人工智能2.0发展战略研究. 杭州: 浙江大学出版社, 2019.China AI 2.0 Development Strategy Research Group. China AI 2.0 Development Strategy Research. Hangzhou: Zhejiang University Press, 2019. [2] 吴国政, 胡振涛, 潘庆, 李建军, 张兆田. 2018年度信息科学部基金评审工作综述. 中国科学基金, 2019, 31(1): 15−18Wu Guo-Zheng, Hu Zhen-Tao, Pan Qing, Li Jian-Jun, Zhang Zhao-Tian. Proposal application, peer review and funding of the Department of Information Sciences in 2018: an overview. Bulletin of National Natural Science Foundation of China, 2019, 31(1): 15−18 [3] 李静海. 全面深化科学基金改革更好发挥在国家创新体系中的基础引领作用. 中国科学基金, 2019, 33(3): 209−214Li Jing-Hai. Deepen the reform of the National Natural Science Fund to play the fundamental and leading role in the national innovation system. Bulletin of National Natural Science Foundation of China, 2019, 33(3): 209−214 [4] 李静海. 构建新时代科学基金体系, 夯实世界科技强国根基. 中国科学基金, 2018, 32(4): 345−350Li Jing-Hai. Building a science funding system for a new paradigm shift in science. Bulletin of National Natural Science Foundation of China, 2018, 32(4): 345−350 [5] 邓方, 宋苏, 刘克, 吴国政, 付俊. 国家自然科学基金自动化领域数据分析与研究热点变化. 自动化学报, 2018, 44(2): 377−384Deng Fang, Song Su, Liu Ke, Wu Guo-Zheng, Fu Jun. Data and research hotspot analyses of National Natural Science Foundation of China in automation field. Acta Automatica Sinica, 2018, 44(2): 377−384 [6] 吴飞, 阳春华, 兰旭光, 丁进良, 郑南宁, 桂卫华, 等. 人工智能的回顾与展望. 中国科学基金, 2018, 32(3): 243−250Wu Fei, Yang Chun-Hua, Lan Xu-Guang, Ding Jin-Liang, Zheng Nan-Ning, Gui Wei-Hua, et al. Artificial intelligence: review and future opportunities. Bulletin of National Natural Science Foundation of China, 2018, 32(3): 243−250 -

 下载:
下载:

计量
- 文章访问数: 3020
- HTML全文浏览量: 7022
- PDF下载量: 1084
- 被引次数: 0
