

-
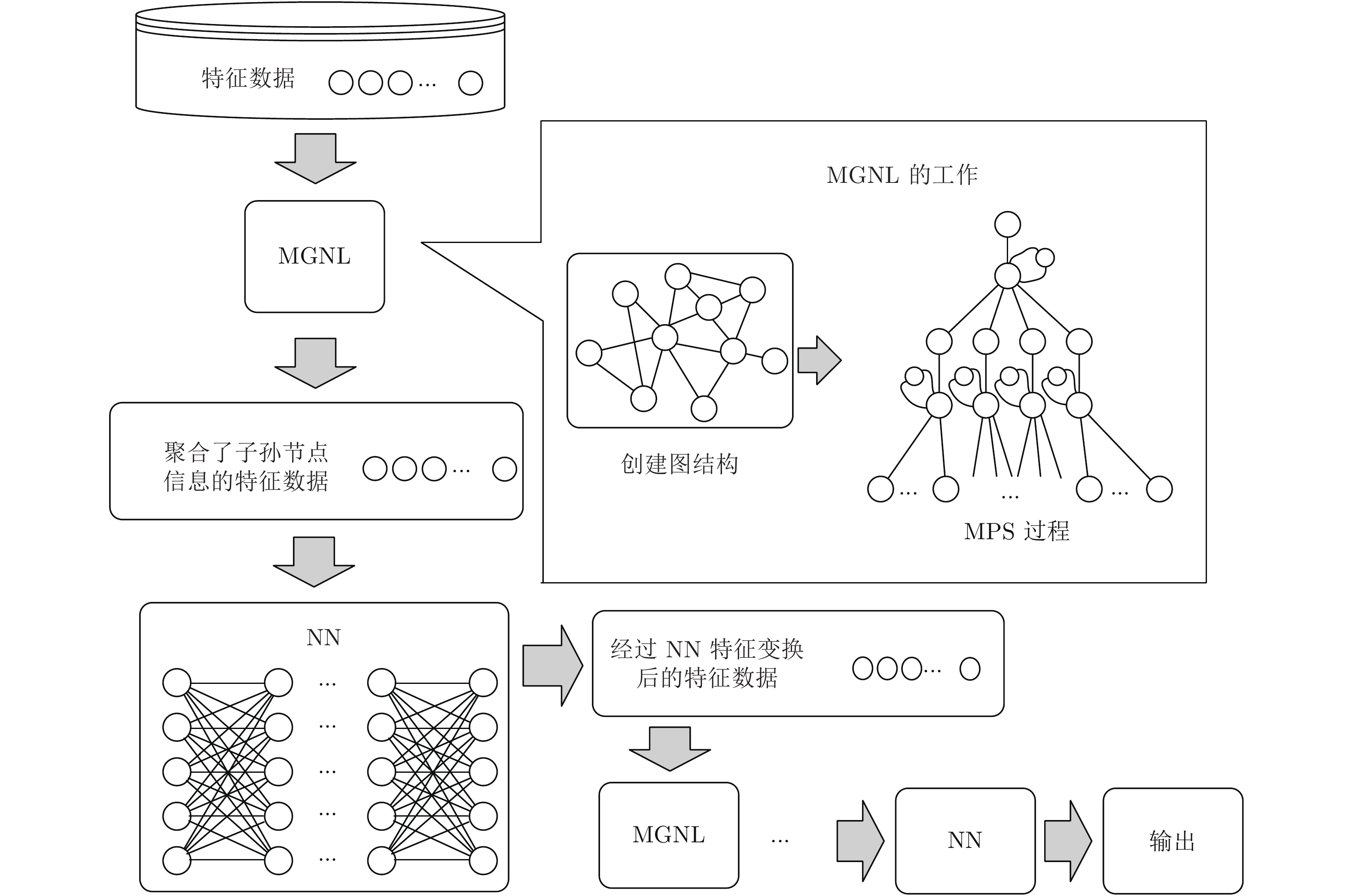
摘要: 网络入侵样本数据特征间存在未知的非欧氏空间图结构关系, 深入挖掘并利用该关系可有效提升网络入侵检测方法的检测效能. 对此, 设计一种元图神经网络(Meta graph neural network, MGNN), MGNN能够对样本数据特征内部隐藏的图结构关系进行挖掘与利用, 在应对入侵检测问题时优势明显. 首先, 设计元图网络层(Meta graph network layer, MGNL), 挖掘出样本数据特征内部隐藏的图结构关系, 并利用该关系对样本数据的原始特征进行更新; 然后, 针对MGNN存在的图信息传播过程中父代信息湮灭现象提出反信息湮灭策略, 并设计了注意力损失函数, 简化MGNN中实现注意力机制的运算过程. KDD-NSL、UNSW-NB15、CICDoS2019数据集上的实验表明, 与经典深度学习算法深度神经网络 (Deep neural network, DNN)、卷积神经网络(Convolutional neural network, CNN)、循环神经网络(Recurrent neural network, RNN)、长短期记忆(Long short-term memory, LSTM)和传统机器学习算法支持向量机(Support vector machine, SVM)、决策树(Decision tree, DT)、随机森林(Random forest, RF)、K-最近邻(K-nearest neighbor, KNN)、逻辑回归(Logistic regression, LR)相比, MGNN在准确率、F1值、精确率、召回率评价指标上均具有良好效果.Abstract: There is an unknown non-European spatial graph structure relationship among network intrusion sample data characteristics. Deeply digging and using this relationship can effectively improve the detection efficiency of network intrusion detection methods. In this regard, this paper designs a meta graph neural network (MGNN). MGNN can mine and utilize the hidden graph structure relationships within the sample data features, which has obvious advantages in dealing with intrusion detection problems. First, the meta graph network layer (MGNL) meta graph network layer (MGNL) is designed to mine the hidden graph structure relationship within the sample data features, and use this relationship to update the original features of the sample data; then, the parental information is annihilated in the process of dissemination of graph information that exists in MGNN phenomenon proposes an anti-information annihilation strategy, and designs an attention loss function to simplify the calculation process of the attention mechanism in MGNN. Experiments on the KDD-NSL, UNSW-NB15, and CICDoS2019 datasets show that compared with the classic deep learning algorithms DNN (deep neural network), CNN (convolutional neural network), RNN (recurrent neural network), LSTM (long short-term memory) and traditional machine learning algorithms SVM (support vector machine), DT (decision tree), RF (random forest), KNN (K-nearest neighbor), LR (logistic regression), MGNN has an accuracy rate, F1 value, accuracy rate, recall rate evaluation indicators have good results.
-
Key words:
- Intrusion detection /
- meta graph neural network (MGNN) /
- deep learning /
- graph structure
-
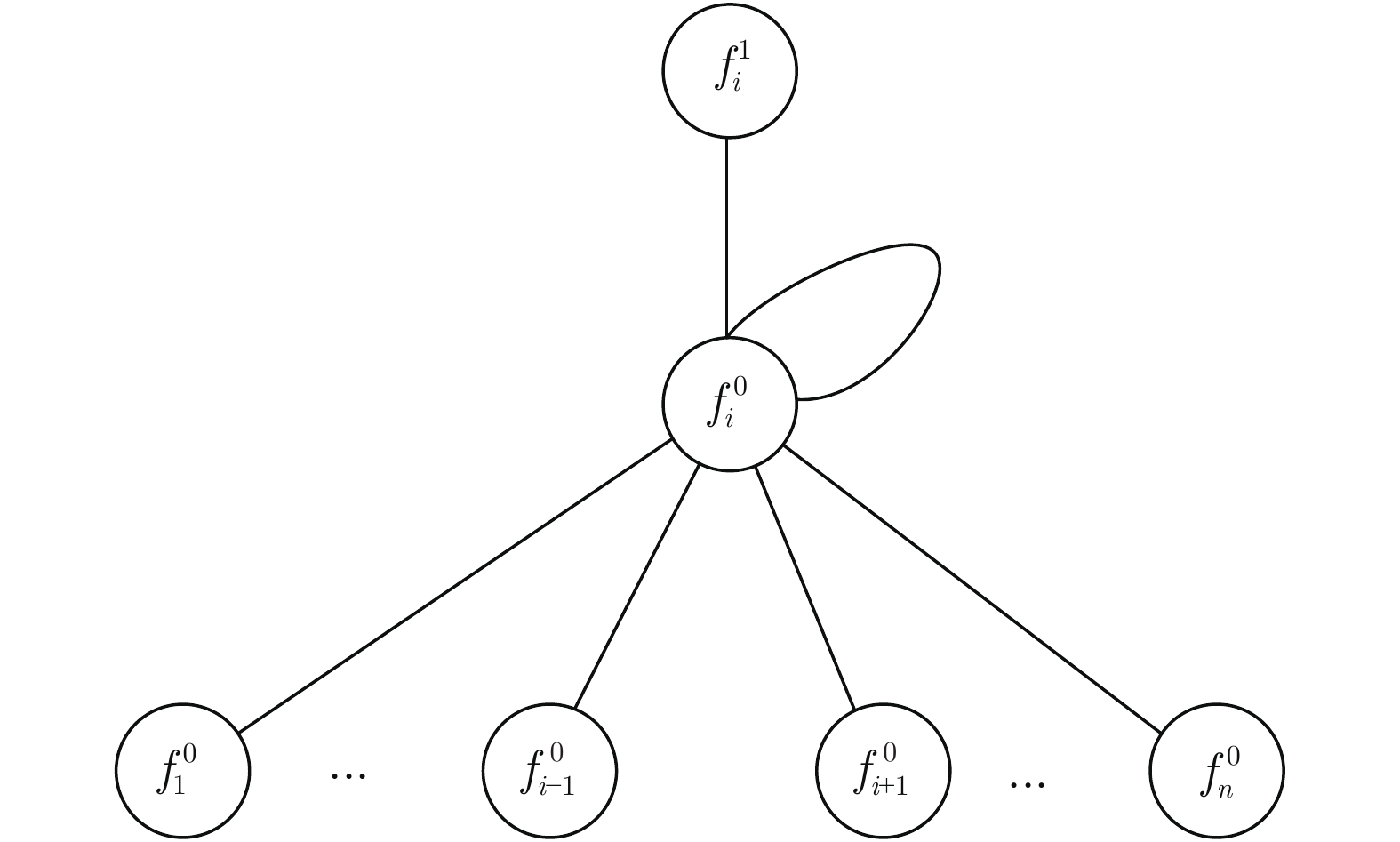
图 2 MGNL中单代父子结点间信息传递结构
Fig. 2 Information transfer process of parent-child node between single generation in MGNL
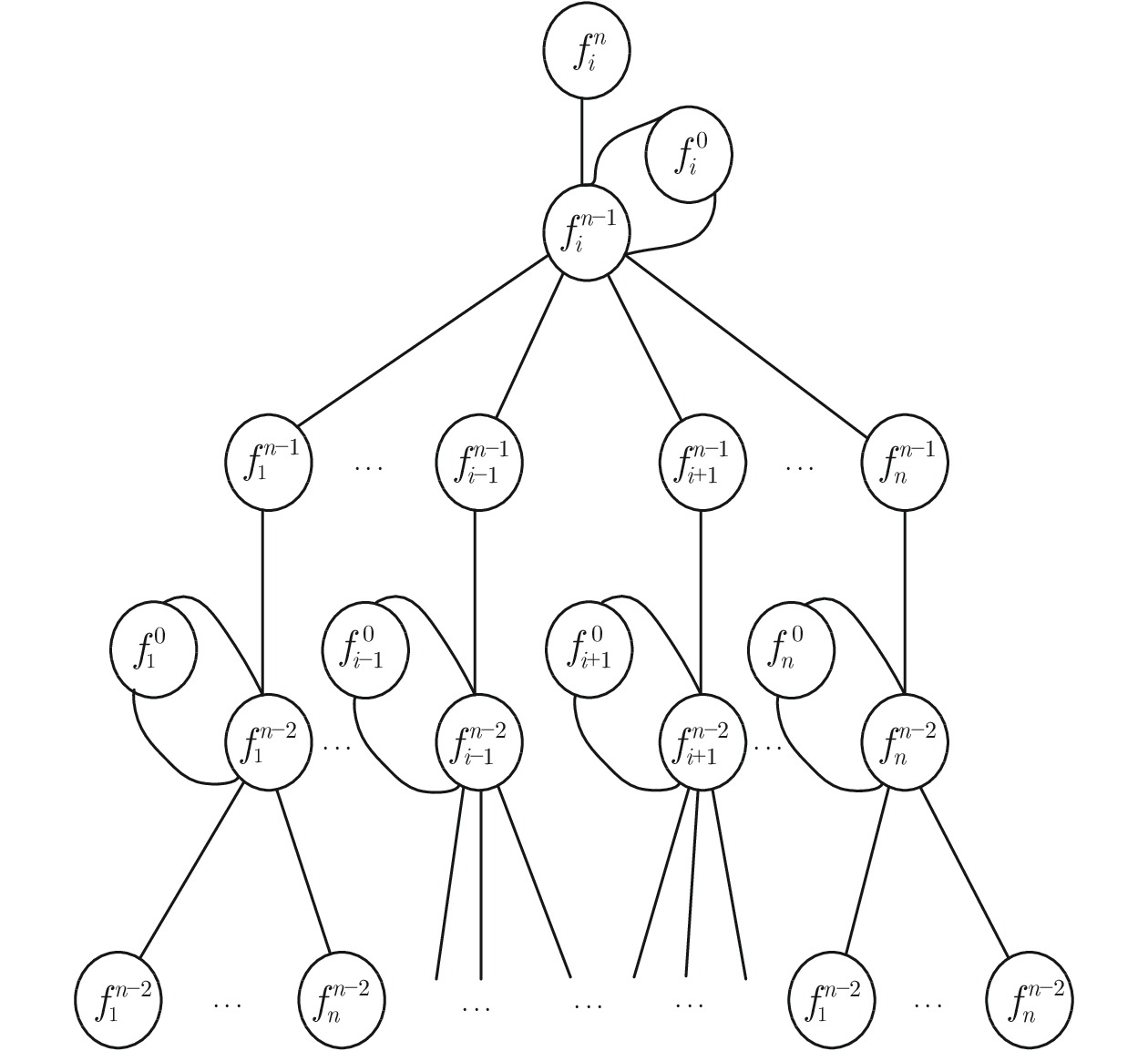
图 3 MGNN祖孙结点间信息传递结构
Fig. 3 Information transfer process between grandparents and grandchildren in MGNN
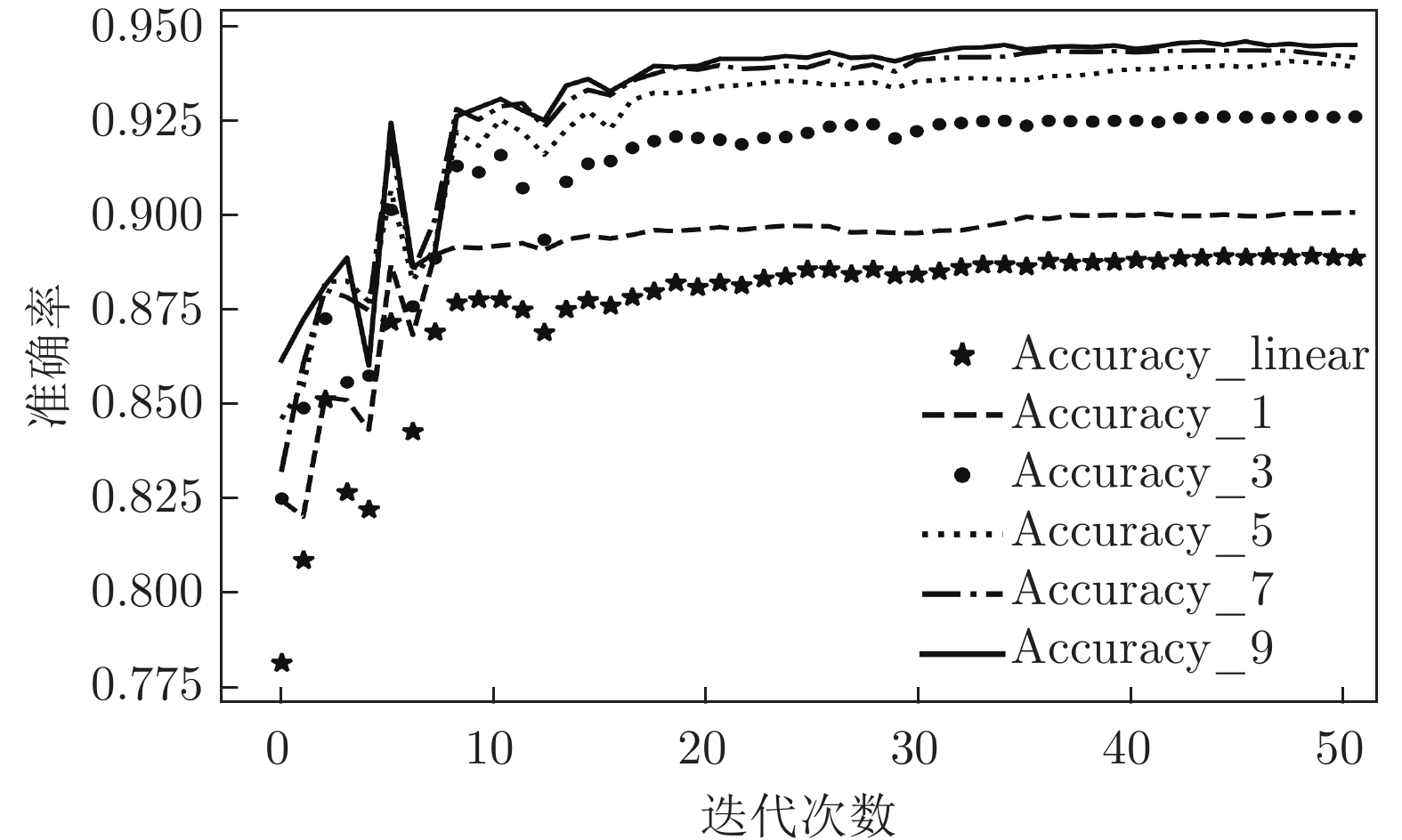
图 6 各神经网络对UNSW_NB15进行二分类
Fig. 6 Each neural network performs a binary classification experiment on the UNSW_NB15
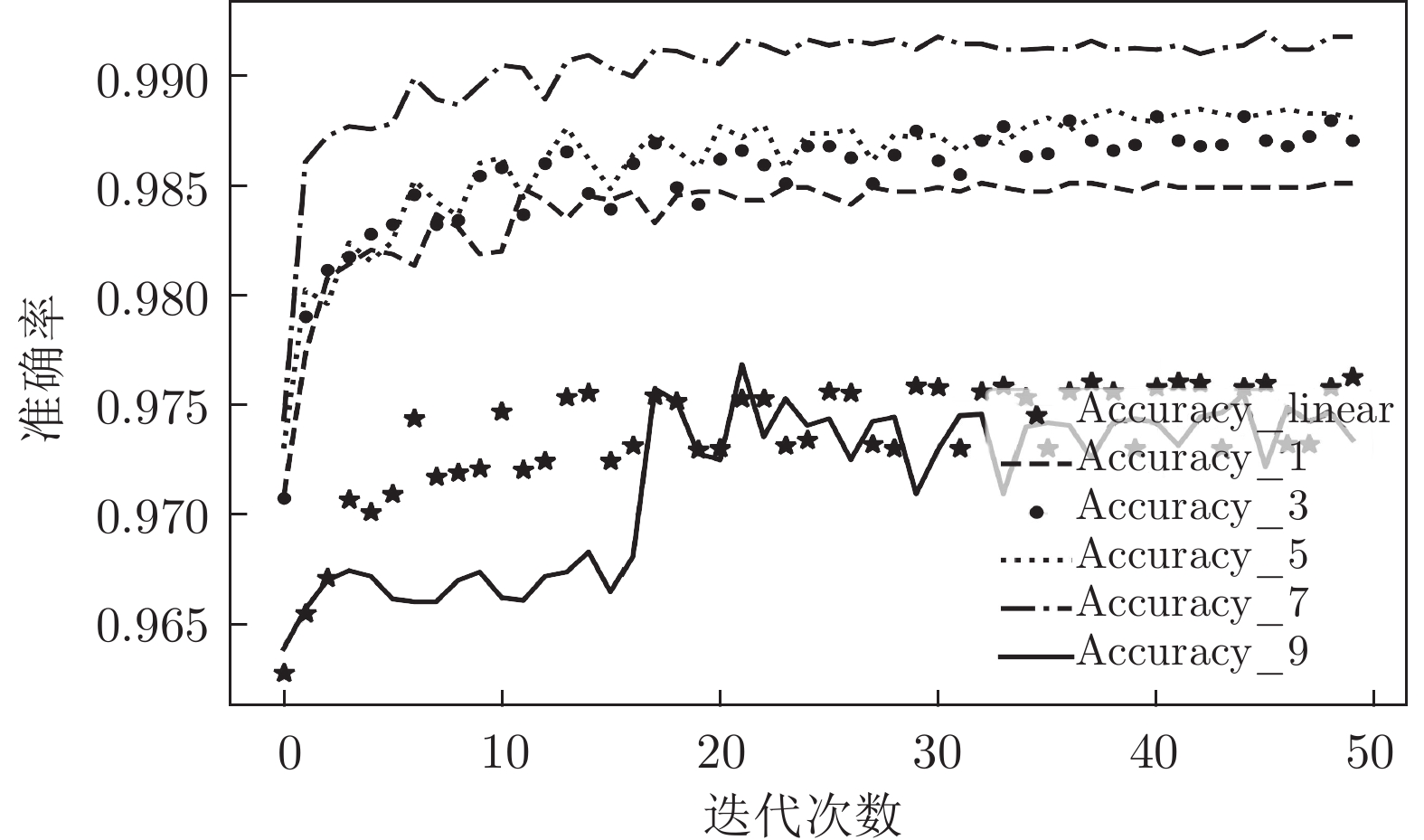
图 7 各神经网络对NSL_KDD进行二分类
Fig. 7 Each neural network performs a binary classification experiment on the NSL_KDD
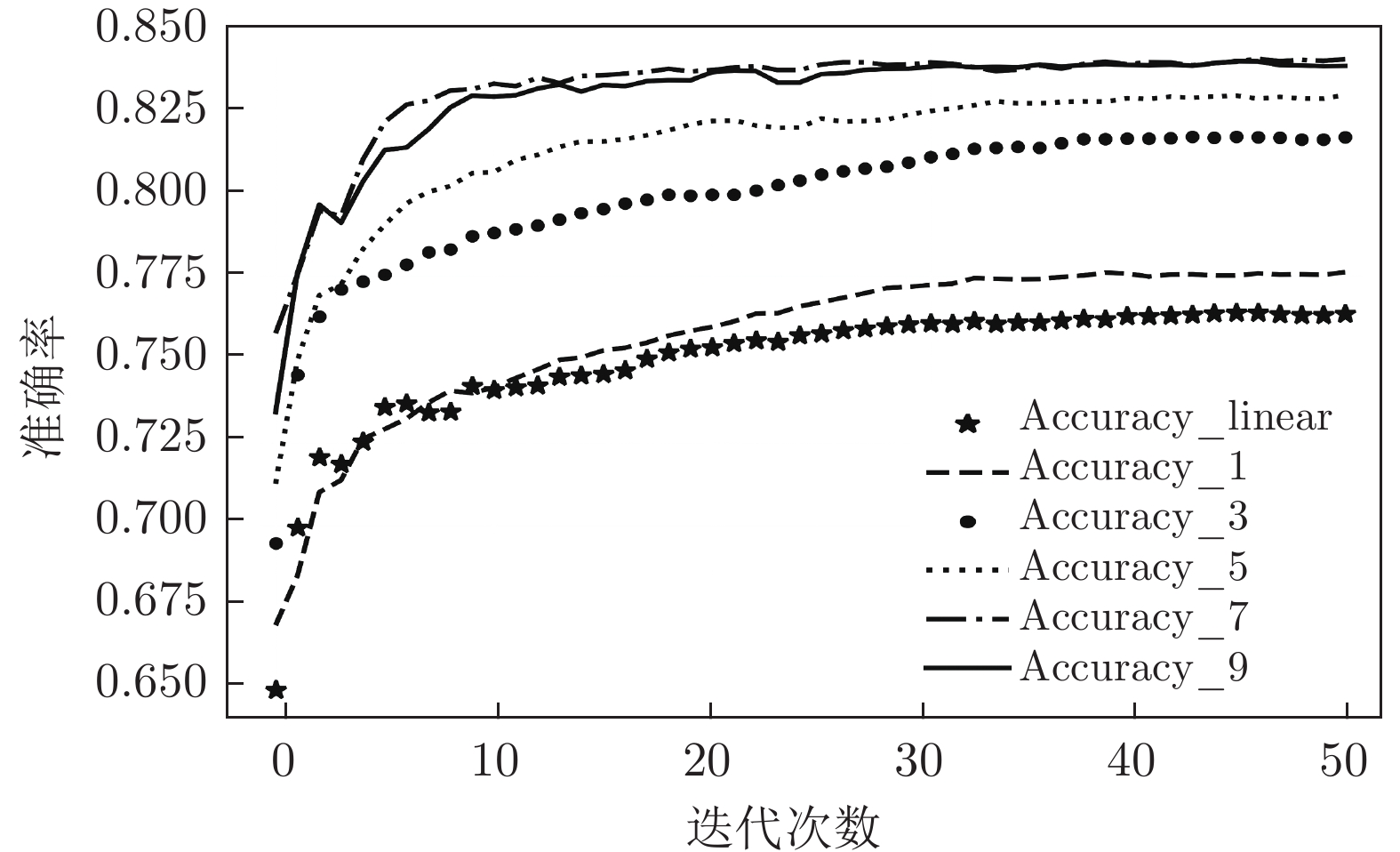
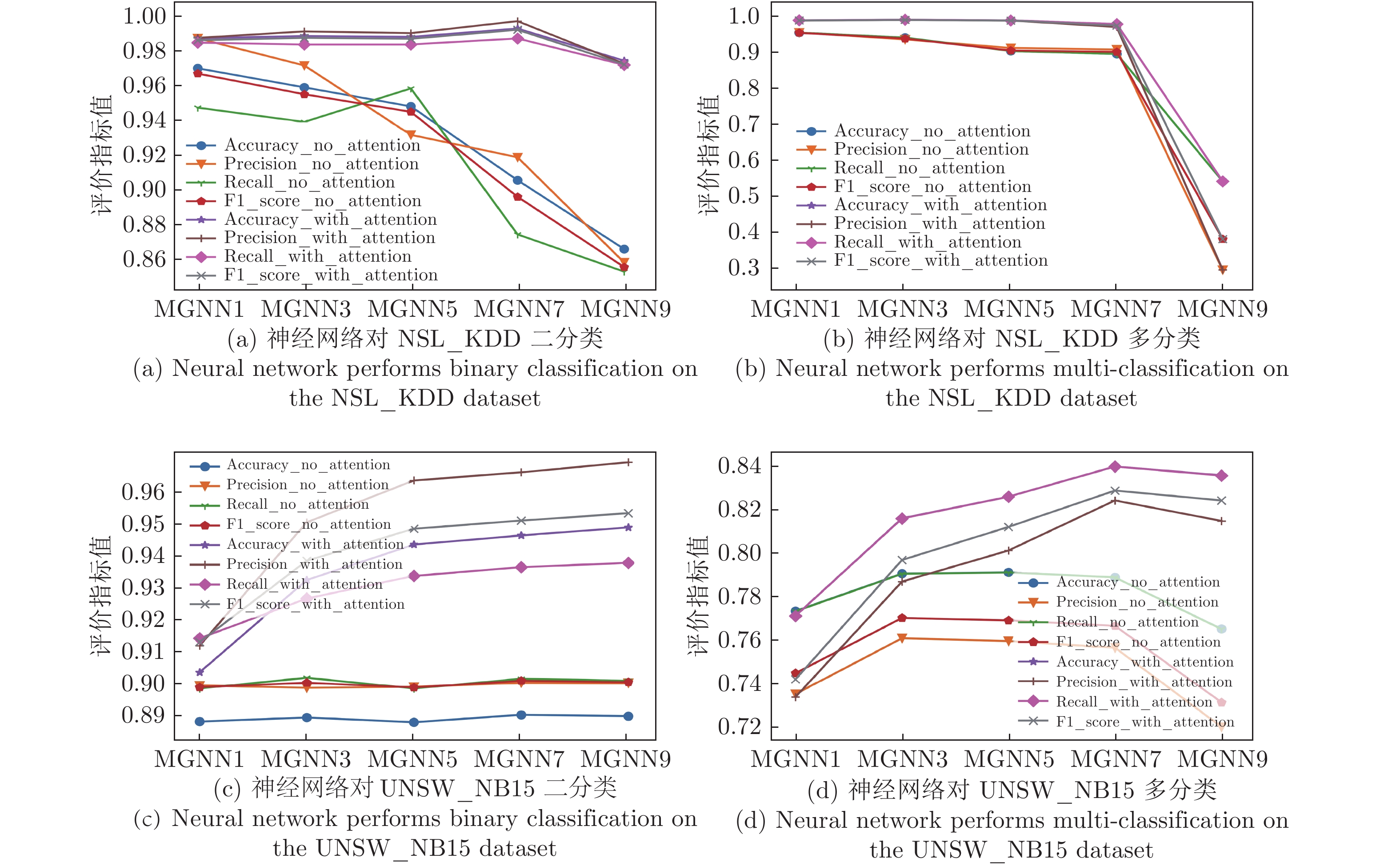
图 8 各神经网络对UNSW_NB15进行多分类
Fig. 8 Each neural network performs multi-classification experiments on the UNSW_NB15
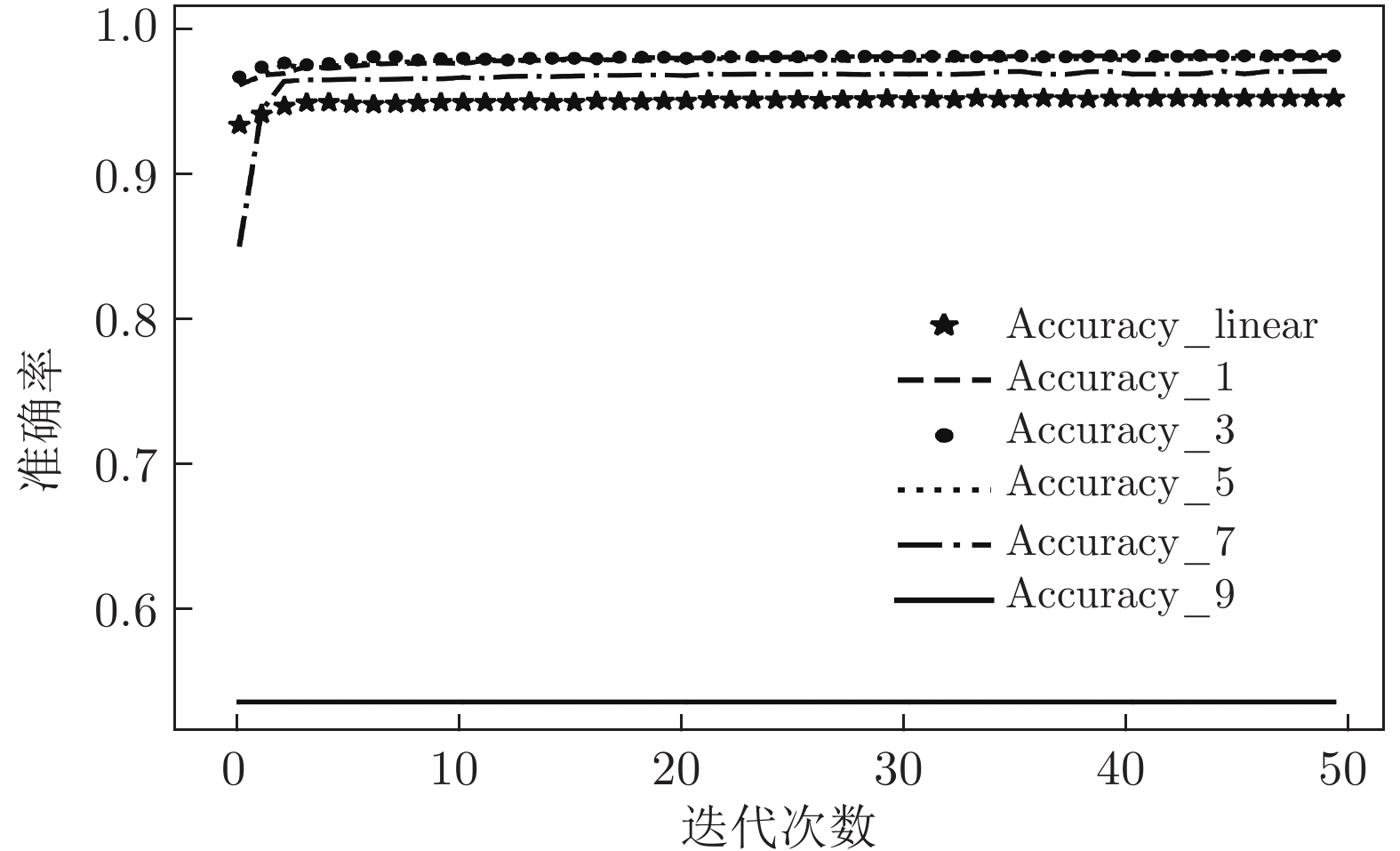
图 9 各神经网络对NSL_KDD进行多分类
Fig. 9 Each neural network performs multi-classification experiments on the NSL_KDD
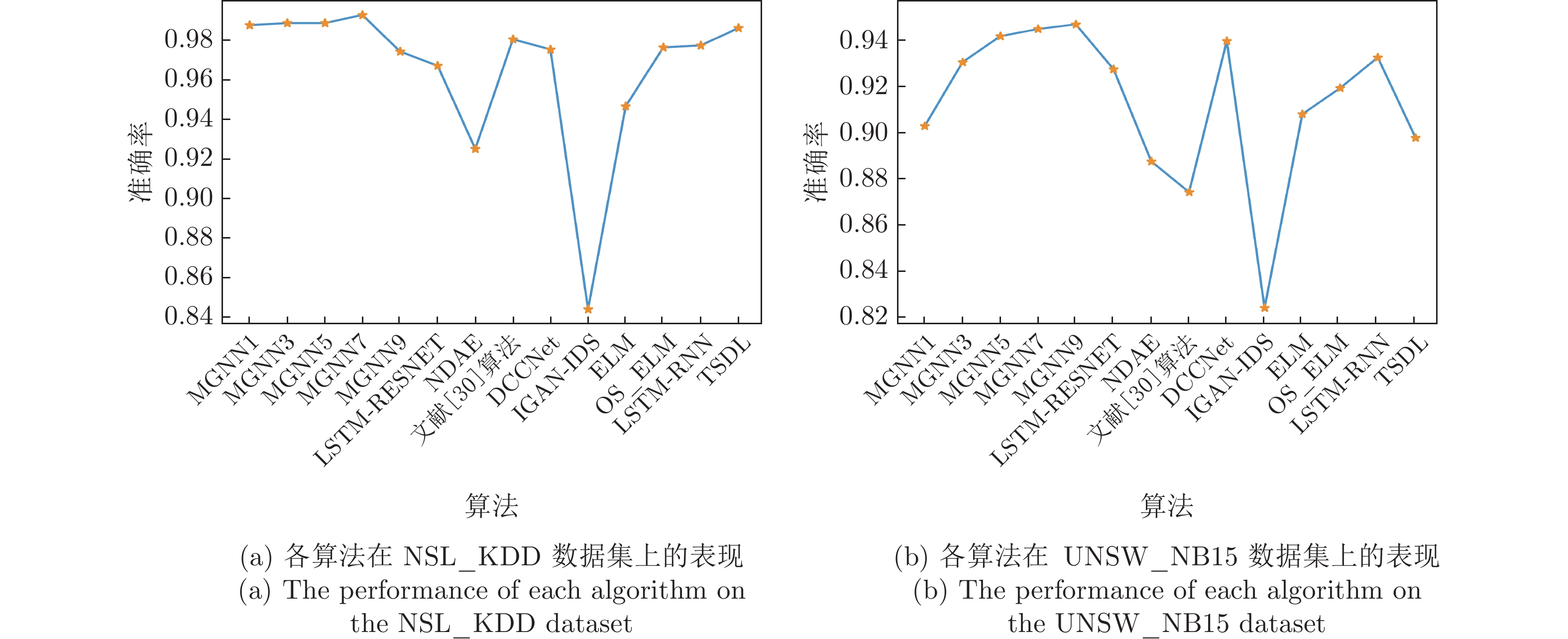
图 10 MGNN与最新入侵检测算法对比
Fig. 10 Performance comparison between MGNN and the latest intrusion detection algorithms on different datasets

图 11 各神经网络对UNSW_NB15进行二分类
Fig. 11 Each neural network performs a binary classification experiment on the UNSW_NB15
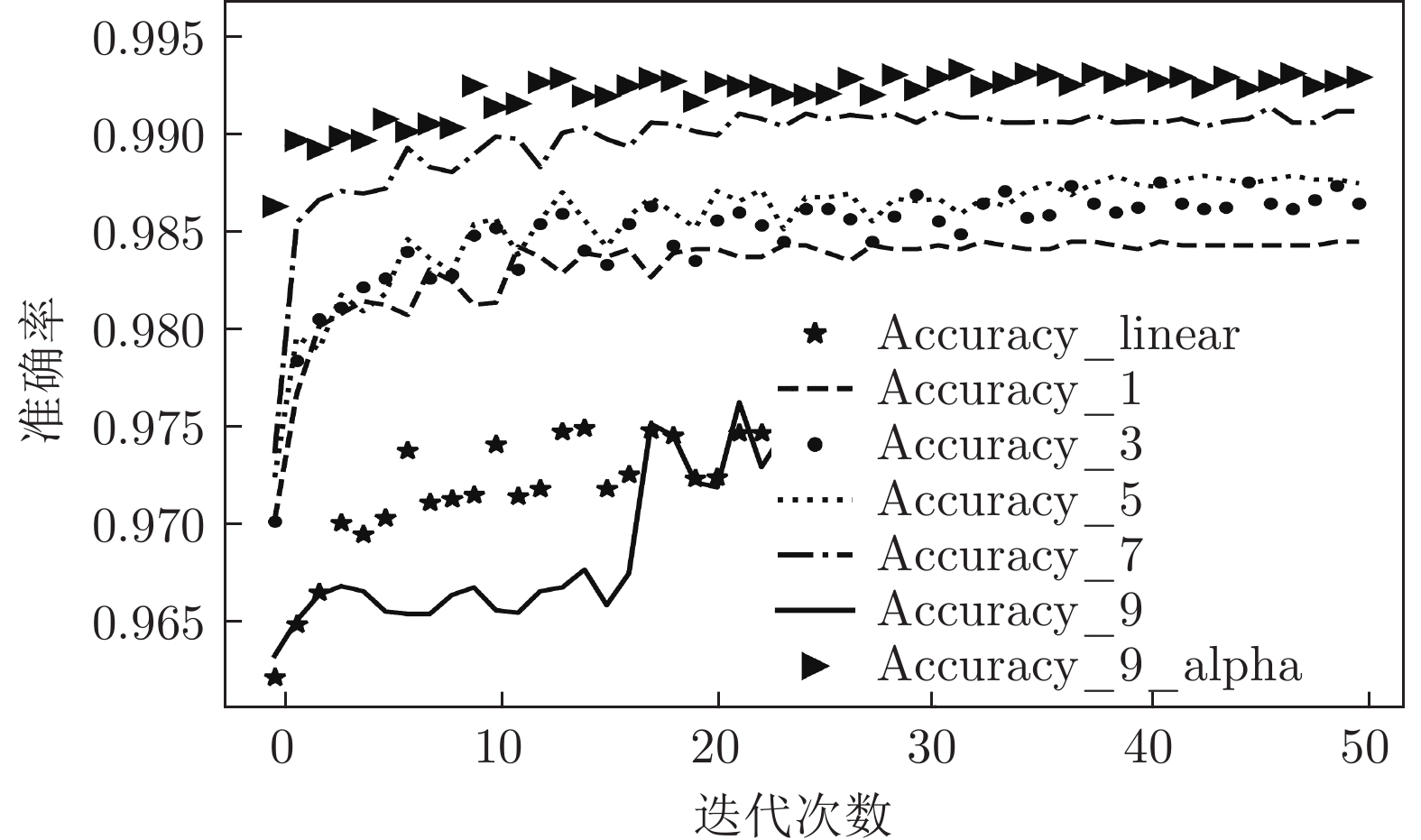
图 12 各神经网络对NSL_KDD进行二分类
Fig. 12 Each neural network performs a binary classification experiment on the NSL_KDD
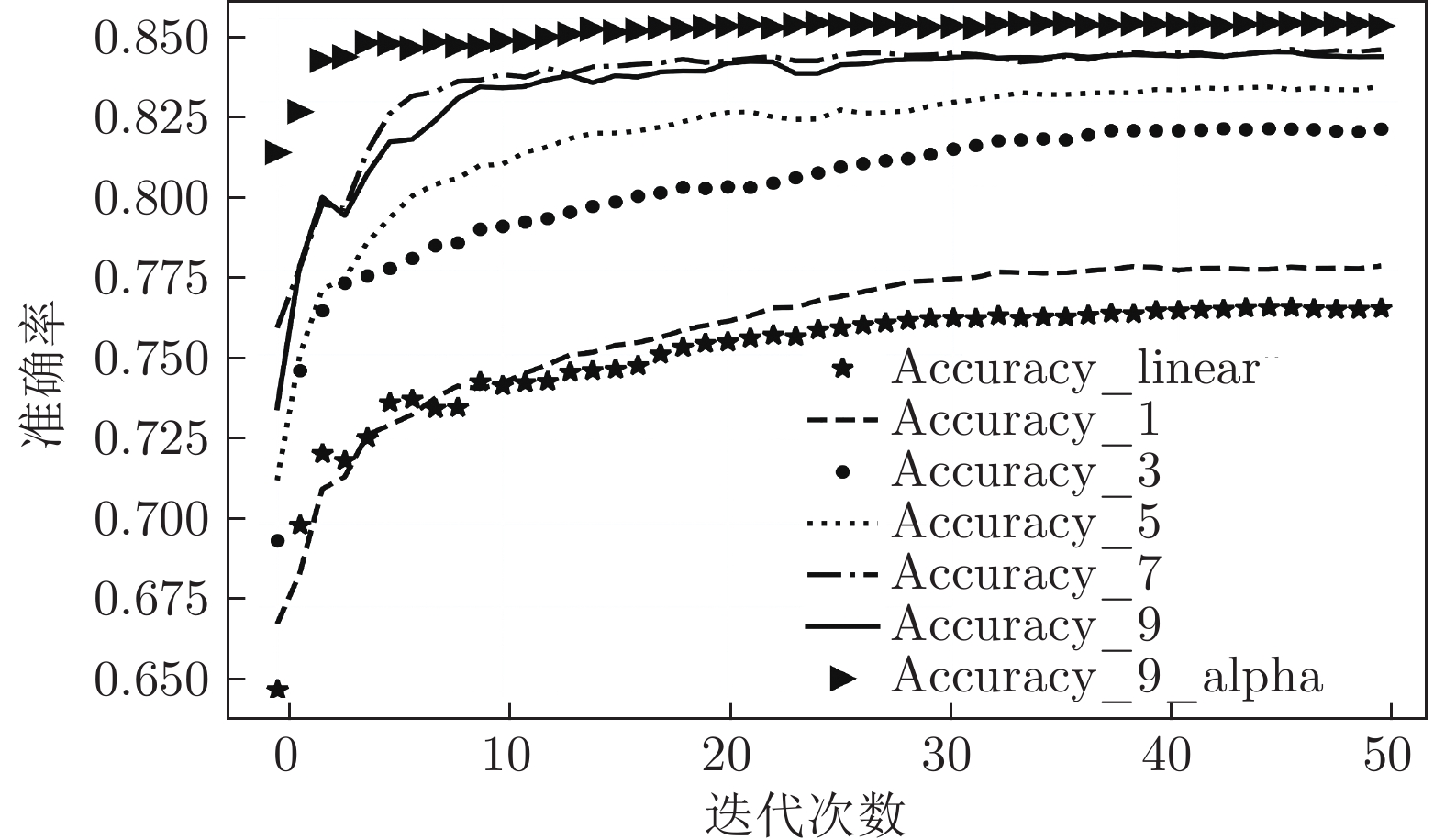
图 13 各神经网络对UNSW_NB15进行多分类
Fig. 13 Each neural network performs multi-classification experiments on the UNSW_NB15

图 14 各神经网络对NSL_KDD进行多分类
Fig. 14 Each neural network performs multi-classification experiments on the NSL_KDD
表 1 MGNN1 ~ MGNN9网络各参数设置
Table 1 Various parameter settings in the MGNN1 ~ MGNN9 networks
网络类别 MGNNSB Nn Pn Units $\alpha $ Activation 参数量 MGNN1 1 42 1 64 1 tanh 287509 2 64 1 128 1 tanh 3 128 1 268 1 tanh 4 268 1 268 1 tanh MGNN3 1 42 3 64 1 tanh 287509 2 64 3 128 1 tanh 3 128 3 268 1 tanh 4 268 3 268 1 tanh MGNN5 1 42 5 64 1 tanh 287509 2 64 5 128 1 tanh 3 128 5 268 1 tanh 4 268 5 268 1 tanh MGNN7 1 42 7 64 1 tanh 287509 2 64 7 128 1 tanh 3 128 7 268 1 tanh 4 268 7 268 1 tanh MGNN9 1 42 9 64 1 tanh 287509 2 64 9 128 1 tanh 3 128 9 268 1 tanh 4 268 9 268 1 tanh  下载: 导出CSV
下载: 导出CSV
表 2 各算法对UNSW_NB15数据集二分类测试的结果
Table 2 The experimental results of the binary classification test of each algorithm on the UNSW_NB15 dataset
算法 Accuracy Precision Recall F1-score MGNN1 0.902 0.910 0.912 0.911 MGNN3 0.929 0.947 0.924 0.935 MGNN5 0.940 0.959 0.931 0.945 MGNN7 0.943 0.961 0.933 0.947 MGNN9 0.945 0.964 0.935 0.949 DNN 0.890 0.901 0.898 0.900 CNN 0.853 0.898 0.827 0.861 RNN 0.709 0.722 0.766 0.744 LSTM 0.813 0.877 0.768 0.819 RF 0.903 0.988 0.867 0.924 LR 0.743 0.955 0.653 0.775 KNN 0.810 0.932 0.778 0.848 DT 0.897 0.982 0.864 0.919 SVM_RBF 0.653 0.998 0.492 0.659
下载: 导出CSV
表 3 各算法对UNSW_NB15数据集多分类测试的结果
Table 3 The experimental results of the multi-classification test of each algorithm on the UNSW_NB15 dataset
算法 Accuracy Precision Recall F1-score MGNN1 0.772 0.735 0.772 0.743 MGNN3 0.816 0.787 0.816 0.797 MGNN5 0.826 0.801 0.826 0.812 MGNN7 0.840 0.824 0.840 0.829 MGNN9 0.836 0.815 0.836 0.824 DNN 0.762 0.718 0.762 0.724 CNN 0.616 0.530 0.616 0.501 RNN 0.640 0.443 0.640 0.521 LSTM 0.660 0.561 0.660 0.566 RF 0.755 0.755 0.755 0.724 LR 0.538 0.414 0.538 0.397 KNN 0.622 0.578 0.622 0.576 DT 0.733 0.721 0.733 0.705 SVM_RBF 0.581 0.586 0.581 0.496
下载: 导出CSV
表 4 各算法对NSL_KDD数据集二分类测试的结果
Table 4 The experimental results of the binary classification test of each algorithm on the NSL_KDD dataset
算法 Accuracy Precision Recall F1-score MGNN1 0.985 0.985 0.982 0.984 MGNN3 0.986 0.989 0.981 0.985 MGNN5 0.986 0.988 0.981 0.985 MGNN7 0.990 0.995 0.985 0.990 MGNN9 0.972 0.971 0.970 0.970 DNN 0.979 0.975 0.980 0.978 CNN 0.979 0.988 0.967 0.977 RNN 0.927 0.925 0.919 0.922 LSTM 0.910 0.895 0.915 0.905 RF 0.929 0.946 0.919 0.933 LR 0.826 0.915 0.744 0.820 KNN 0.910 0.926 0.905 0.915 DT 0.930 0.928 0.943 0.935 SVM_RBF 0.837 0.769 0.993 0.867
下载: 导出CSV
表 5 各算法对NSL_KDD数据集多分类测试的结果
Table 5 The experimental results of the multi-classification test of each algorithm on the NSL_KDD dataset
算法 Accuracy Precision Recall F1-score MGNN1 0.986 0.985 0.986 0.985 MGNN3 0.987 0.987 0.987 0.987 MGNN5 0.986 0.985 0.986 0.985 MGNN7 0.975 0.967 0.975 0.971 MGNN9 0.533 0.284 0.533 0.371 DNN 0.957 0.955 0.957 0.955 CNN 0.970 0.969 0.970 0.968 RNN 0.893 0.884 0.893 0.887 LSTM 0.865 0.866 0.865 0.838 RF 0.753 0.814 0.753 0.715 LR 0.612 0.509 0.612 0.530 KNN 0.731 0.720 0.731 0.684 DT 0.763 0.767 0.763 0.728 SVM_RBF 0.702 0.689 0.702 0.656
下载: 导出CSV
表 6 各算法对CICDoS2019数据集测试
Table 6 Test results of each algorithm on the CICDoS2019 dataset
算法 Accuracy Precision Recall F1-score Attack Benign Attack Benign Attack Benign MGNN12 0.87 0.99 1.00 0.79 0.93 0.88 0.96 NB 0.57 1.00 0.53 0.17 1.00 0.29 0.69 DT 0.77 0.70 0.98 0.99 0.54 0.82 0.70 LR 0.95 0.93 0.99 0.99 0.91 0.96 0.95 RF 0.86 1.00 0.78 0.74 1.00 0.85 0.88 Booster 0.84 0.76 0.99 0.99 0.67 0.86 0.80 SVM 0.93 0.99 0.88 0.88 0.99 0.93 0.93 DDoSNet 0.99 0.99 1.00 0.99 0.99 0.99 0.99
下载: 导出CSV
表 7 MGNN9、MGNN9_alpha网络对UNSW_NB15数据集二分类测试的结果
Table 7 MGNN9, MGNN9_alpha networks on the UNSW_NB15 dataset binary classification test results
算法 Accuracy Precision Recall F1-score MGNN9 0.945 0.964 0.935 0.949 MGNN9_alpha 0.951 0.972 0.939 0.955
下载: 导出CSV
表 8 MGNN9、MGNN9_alpha网络对UNSW_NB15数据集多分类测试的结果
Table 8 MGNN9, MGNN9_alpha networks on the UNSW_NB15 dataset multi-classification test results
算法 Accuracy Precision Recall F1-score MGNN9 0.836 0.815 0.836 0.824 MGNN9_alpha 0.846 0.831 0.846 0.837
下载: 导出CSV
表 9 MGNN9、MGNN9_alpha网络对NSL_KDD数据集二分类测试的结果
Table 9 MGNN9, MGNN9_alpha networks on the NSL_KDD dataset binary classification test results
算法 Accuracy Precision Recall F1-score MGNN9 0.972 0.971 0.970 0.970 MGNN9_alpha 0.992 0.993 0.990 0.991
下载: 导出CSV
表 10 MGNN9、MGNN9_alpha网络对NSL_KDD数据集多分类测试的结果
Table 10 MGNN9, MGNN9_alpha networks on the NSL_KDD dataset multi-classification test results
算法 Accuracy Precision Recall F1-score MGNN9 0.533 0.284 0.533 0.371 MGNN9_alpha 0.987 0.987 0.987 0.986
下载: 导出CSV
-
[1] Tsai C F, Hsu Y F, Lin C Y, Lin W Y. Intrusion detection by machine learning: A review. Expert Systems With Applications, 2009, 36(10): 11994-12000 doi: 10.1016/j.eswa.2009.05.029 [2] 任家东, 刘新倩, 王倩, 何海涛, 赵小林. 基于KNN离群点检测和随机森林的多层入侵检测方法. 计算机研究与发展, 2019, 56(3): 566-575Ren Jia-Dong, Liu Xin-Qian, Wang Qian, He Hai-Tao, Zhao Xiao-Lin. An multi-level intrusion detection method based on KNN outlier detection and random forests. Journal of Computer Research and Development, 2019, 56(3): 566-575 [3] Ahmad I, Basheri M, Iqbal M J, Rahim A. Performance comparison of support vector machine, random forest, and extreme learning machine for intrusion detection. IEEE Access, 2018, 6: 33789-33795 doi: 10.1109/ACCESS.2018.2841987 [4] Mabu S, Gotoh S, Obayashi M, Kuremoto T. A random-forests-based classifier using class association rules and its application to an intrusion detection system. Artificial Life and Robotics, 2016, 21(3): 371-377 doi: 10.1007/s10015-016-0281-x [5] 缪祥华, 单小撤. 基于密集连接卷积神经网络的入侵检测技术研究. 电子与信息学报, 2020, 42(11): 2706-2712Miao Xiang-Hua, Shan Xiao-Che. Research on intrusion detection technology based on densely connected convolutional neural networks. Journal of Electronics & Information Technology, 2020, 42(11): 2706-2712 [6] 王振东, 刘尧迪, 杨书新, 王俊岭, 李大海. 基于天牛群优化与改进正则化极限学习机的网络入侵检测. 自动化学报, 2022, 48(12): 3024-3041Wang Zhen-Dong, Liu Yao-Di, Yang Shu-Xin, Wang Jun-Ling, Li Da-Hai. Network intrusion detection based BSO and improved RELM. Acta Automatica Sinica, 2022, 48(12): 3024-3041 [7] 张颐康, 张恒, 刘永革, 刘成林. 基于跨模态深度度量学习的甲骨文字识别. 自动化学报, 2021, 47(4): 791-800Zhang Yi-Kang, Zhang Heng, Liu Yong-Ge, Liu Cheng-Lin. Oracle character recognition based on cross-modal deep metric learning. Acta Automatica Sinica, 2021, 47(4): 791-800 [8] 徐鹏斌, 瞿安国, 王坤峰, 李大字. 全景分割研究综述. 自动化学报, 2021, 47(3): 549-568Xu Peng-Bin, Qu An-Guo, Wang Kun-Feng, Li Da-Zi. A survey of panoptic segmentation methods. Acta Automatica Sinica, 2021, 47(3): 549-568 [9] 徐聪, 李擎, 张德政, 陈鹏, 崔家瑞. 文本生成领域的深度强化学习研究进展. 工程科学学报, 2020, 42(4): 399-411Xu Cong, Li Qing, Zhang De-Zheng, Chen Peng, Cui Jia-Rui. Research progress of deep reinforcement learning applied to text generation. Chinese Journal of Engineering, 2020, 42(4): 399-411 [10] 宋勇, 侯冰楠, 蔡志平. 基于深度学习特征提取的网络入侵检测方法. 华中科技大学学报(自然科学版), 2021, 49(2): 115-120Song Yong, Hou Bing-Nan, Cai Zhi-Ping. Network intrusion detection method based on deep learning feature extraction. Journal of Huazhong University of Science and Technology (Natural Science Edition), 2021, 49(2): 115-120 [11] Gao L G, Chen P Y, Yu S M. Demonstration of convolution kernel operation on resistive cross-point array. IEEE Electron Device Letters, 2016, 37(7): 870-873 doi: 10.1109/LED.2016.2573140 [12] Li Y, Zhang B. An intrusion detection model based on multi-scale CNN. In: Proceedings of the 3rd Information Technology, Networking, Electronic and Automation Control Conference (ITNEC). Chengdu, China: IEEE, 2019. 214−218 [13] Lin W H, Lin H C, Wang P, Wu B H, Tsai J Y. Using convolutional neural networks to network intrusion detection for cyber threats. In: Proceedings of the IEEE International Conference on Applied System Invention (ICASI). Chiba, Japan: IEEE, 2018. 1107−1110 [14] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. In: Proceedings of the 3rd International Conference on Learning Representations (ICLR). San Diego, USA: ICLR, 2015. 1−14 [15] Szegedy C, Liu W, Jia Y Q, Sermanet P, Reed S, Anguelov D, et al. Going deeper with convolutions. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, USA: IEEE, 2015. 1−9 [16] He K M, Zhang X Y, Ren S Q, Sun J. Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 770−778 [17] Yang S. Research on network behavior anomaly analysis based on bidirectional LSTM. In: Proceedings of the 3rd Information Technology, Networking, Electronic and Automation Control Conference (ITNEC). Chengdu, China: IEEE, 2019. 798−802 [18] Hossain D, Ochiai H, Fall D, Kadobayashi Y. LSTM-based network attack detection: Performance comparison by hyper-parameter values tuning. In: Proceedings of the 7th IEEE International Conference on Cyber Security and Cloud Computing (CSCloud)/the 6th IEEE International Conference on Edge Computing and Scalable Cloud (EdgeCom). New York, USA: IEEE, 2020. 62−69 [19] 陈红松, 陈京九. 基于循环神经网络的无线网络入侵检测分类模型构建与优化研究. 电子与信息学报, 2019, 41(6): 1427-1433Chen Hong-Song, Chen Jing-Jiu. Recurrent neural networks based wireless network intrusion detection and classification model construction and optimization. Journal of Electronics & Information Technology, 2019, 41(6): 1427-1433 [20] Studer L, Wallau J, Ingold R, Fischer A. Effects of graph pooling layers on classification with graph neural networks. In: Proceedings of the 7th Swiss Conference on Data Science (SDS). Luzern, Switzerland: IEEE, 2020. 57−58 [21] Hamilton W L, Ying Z, Leskovec J. Inductive representation learning on large graphs. In: Proceedings of the 31st Annual Conference on Neural Information Processing Systems. Long Beach, USA: Curran Associates Inc., 2017. 1025−1035 [22] Chaudhary A, Mittal H, Arora A. Anomaly detection using graph neural networks. In: Proceedings of the International Conference on Machine Learning, Big Data, Cloud and Parallel Computing (COMITCon). Faridabad, India: IEEE, 2019. 346−350 [23] 刘颖, 雷研博, 范九伦, 王富平, 公衍超, 田奇. 基于小样本学习的图像分类技术综述. 自动化学报, 2021, 47(2): 297-315Liu Ying, Lei Yan-Bo, Fan Jiu-Lun, Wang Fu-Ping, Gong Yan-Chao, Tian Qi. Survey on image classification technology based on small sample learning. Acta Automatica Sinica, 2021, 47(2): 297-315 [24] Li Q Y, Shang Y L, Qiao X Q, Dai W. Heterogeneous dynamic graph attention network. In: Proceedings of the IEEE International Conference on Knowledge Graph (ICKG). Nanjing, China: IEEE, 2020. 404−411 [25] Shanthamallu U S, Thiagarajan J J, Spanias A. A regularized attention mechanism for graph attention networks. In: Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Barcelona, Spain: IEEE, 2020. 3372−3376 [26] Avelar P H C, Tavares A R, da Silveira T L T, Jung C R, Lamb L C. Superpixel image classification with graph attention networks. In: Proceedings of the 33rd SIBGRAPI Conference on Graphics, Patterns and Images (SIBGRAPI). Porto de Galinhas, Brazil: IEEE, 2020. 203−209 [27] Vinayakumar R, Alazab M, Soman K P, Poornachandran P, Al-Nemrat A, Venkatraman S. Deep learning approach for intelligent intrusion detection system. IEEE Access, 2019, 7: 41525-41550 doi: 10.1109/ACCESS.2019.2895334 [28] 杨印根, 王忠洋. 基于深度神经网络的入侵检测技术. 网络安全技术与应用, 2019(4): 37-41Yang Yin-Gen, Wang Zhong-Yang. Intrusion detection technology based on deep neural network. Network Security Technology & Application, 2019(4): 37-41 [29] Shone N, Ngoc T N, Phai V D, Shi Q. A deep learning approach to network intrusion detection. IEEE Transactions on Emerging Topics in Computational Intelligence, 2018, 2(1): 41-50 doi: 10.1109/TETCI.2017.2772792 [30] Liang W, Li K C, Long J, Kui X Y, Zomaya A Y. An industrial network intrusion detection algorithm based on multifeature data clustering optimization model. IEEE Transactions on Industrial Informatics, 2020, 16(3): 2063-2071 doi: 10.1109/TII.2019.2946791 [31] Huang S K, Lei K. IGAN-IDS: An imbalanced generative adversarial network towards intrusion detection system in ad-hoc networks. Ad Hoc Networks, 2020, 105: 102177 doi: 10.1016/j.adhoc.2020.102177 [32] Kozik R, Choraś M, Ficco M, Palmieri F. A scalable distributed machine learning approach for attack detection in edge computing environments. Journal of Parallel and Distributed Computing, 2018, 119: 18-26 doi: 10.1016/j.jpdc.2018.03.006 [33] Prabavathy S, Sundarakantham K, Shalinie S M. Design of cognitive fog computing for intrusion detection in Internet of Things. Journal of Communications and Networks, 2018, 20(3): 291-298 doi: 10.1109/JCN.2018.000041 [34] Fu Y S, Lou F, Meng F Z, Tian Z H, Zhang H, Jiang F. An intelligent network attack detection method based on RNN. In: Proceedings of the 3rd IEEE International Conference on Data Science in Cyberspace (DSC). Guangzhou, China: IEEE, 2018. 483−489 [35] Khan F A, Gumaei A, Derhab A, Hussain A. A novel two-stage deep learning model for efficient network intrusion detection. IEEE Access, 2019, 7: 30373-30385 doi: 10.1109/ACCESS.2019.2899721 [36] Elsayed M S, Le-Khac N A, Dev S, Jurcut A D. DDoSNet: A deep-learning model for detecting network attacks. In: Proceedings of the 21st International Symposium on a World of Wireless, Mobile and Multimedia Networks (WoWMoM). Cork, Ireland: IEEE, 2020. 391−396 [37] 陈晋音, 章燕, 王雪柯, 蔡鸿斌, 王珏, 纪守领. 深度强化学习的攻防与安全性分析综述. 自动化学报, 2022, 48(1): 21-39Chen Jin-Yin, Zhang Yan, Wang Xue-Ke, Cai Hong-Bin, Wang Jue, Ji Shou-Ling. A survey of attack, defense and related security analysis for deep reinforcement learning. Acta Automatica Sinica, 2022, 48(1): 21-39 [38] Suwannalai E, Polprasert C. Network intrusion detection systems using adversarial reinforcement learning with deep Q-network. In: Proceedings of the 18th International Conference on ICT and Knowledge Engineering (ICT&KE). Bangkok, Thailand: IEEE, 2020. 1−7 -

 下载:
下载:


计量
- 文章访问数: 2192
- HTML全文浏览量: 956
- PDF下载量: 176
- 被引次数: 0
